自动驾驶仿真(高速道路)LaneKeeping
前言
A high-level decision agent trained by deep reinforcement learning (DRL) performs quantitative interpretation of behavioral planning performed in an autonomous driving (AD) highway simulation. The framework relies on the calculation of SHAP values and takes into account neural architectures with attention layers. The framework is particularly dedicated to studying the relationship between attention and interpretability, and how attention and SHAP values can be represented, analyzed, and compared in a two-dimensional spatial highway environment. The framework has three main visualization areas, which are obtained by processing quantities of attention, SHAP values, vehicle observations, etc. : Episode View, which plots quantities on the timeline of the episode; Frame view, reporting measured values step by step; Aggregate view, which also displays statistics from aggregates of multiple simulated events on a 2D map.
LaneKeepingEnv环境的工作原理可以归纳如下:
- 初始化阶段:
- 环境在创建时,会调用
__init__方法进行初始化。 - 初始化过程中,会设置一些关键的属性,如
lane(当前车道)、lanes(所有车道的列表)、trajectory(车辆的轨迹)等。 - 环境的默认配置参数由
default_config方法定义,这些参数包括观测类型、动作类型、模拟频率等。
- 环境在创建时,会调用
- 配置参数:
- 观测类型设置为
"AttributesObservation",意味着环境会观察车辆的某些属性,如状态、状态导数和参考状态。 - 动作类型设置为
"ContinuousAction",并且指定了转向范围(在-π/3到π/3之间),这意味着控制输入是连续的转向角,不涉及纵向控制。 - 仿真频率和策略频率设置为10,表示每秒钟模拟10次并更新策略10次。
- 还包括了噪声水平、屏幕大小和居中位置等参数,这些参数可能与环境的渲染和可视化有关。
- 观测类型设置为
- 步进过程:
- 在每一步中,环境会调用
step方法。 step方法首先检查当前车辆是否仍在当前车道上。如果不在,它会从lanes列表中取出下一个车道,并设置为当前车道。- 然后,它会调用
store_data方法(尽管该方法在给定的代码片段中未定义),但通常用于存储或更新车辆的轨迹、状态等信息。 - 如果
lpv(可能是车辆控制器)存在,step方法会使用当前动作(控制输入)和车辆状态来设置控制器的控制参数。这里,控制器的控制输入只包括车辆状态的子集,如横向位置和速度,以及相对于车道的偏角和偏角速度。
- 在每一步中,环境会调用
- 控制和仿真:
- 车辆在
LaneKeepingEnv环境中的运动受控制器(如lpv)控制,控制器根据环境提供的观测数据和当前策略产生控制输入。 - 环境会根据控制输入和车辆当前状态更新车辆的位置和状态,并可能渲染车辆在新位置的状态以供观察或评估。
- 车辆在
- 总结:
LaneKeepingEnv环境通过模拟车辆在车道上的运动,提供了一个用于测试车道保持控制策略的平台。- 环境通过提供观测数据、处理控制输入和更新车辆状态来模拟真实世界中的车道保持场景。
- 通过与强化学习算法等结合,可以在该环境中训练和优化车道保持控制策略。
LaneKeepingEnv 环境通常包含以下几个功能模块:
- 初始化模块:
- 负责在环境创建时初始化所有必要的属性,如车道、车辆、观察空间、动作空间等。
- 调用
__init__方法进行初始化,并可能包括读取配置文件或默认配置来设置参数。
- 配置模块:
- 定义环境的默认配置参数,如仿真频率、观察类型、动作类型、噪声水平等。
- 通过
default_config方法提供默认配置,并允许用户通过配置字典来自定义参数。
- 物理模拟模块:
- 负责模拟车辆的物理行为,包括根据控制输入更新车辆状态(位置、速度、加速度等)。
- 可能使用车辆动力学模型(如
BicycleVehicle)来模拟车辆的横向和纵向运动。
- 车道模块:
- 定义和管理车道,包括直线车道和曲线车道(如
StraightLane和SineLane)。 - 提供检查车辆是否在车道内的方法(如
on_lane)。
- 定义和管理车道,包括直线车道和曲线车道(如
- 车辆模块:
- 定义和管理车辆对象,包括车辆的状态(位置、速度、加速度、偏角等)。
- 提供获取车辆状态、设置控制输入和更新车辆状态的方法。
- 观测模块:
- 根据配置的观测类型,提供从环境中获取观测数据的方法。
- 观测数据可能包括车辆的当前状态、状态导数、参考状态等。
- 动作模块:
- 定义动作空间,包括动作的类型(连续或离散)、范围和维度。
- 提供将原始动作转换为环境可以理解的格式的方法(如缩放、裁剪等)。
- 渲染模块(可选):
- 负责环境的可视化,包括渲染车辆、车道和其他相关元素。
- 提供渲染环境状态到屏幕或窗口的方法,以便用户或评估系统可以观察环境的状态。
- 数据存储模块(可选):
- 负责存储环境在仿真过程中产生的数据,如车辆的轨迹、状态、动作等。
- 提供存储和检索数据的方法,以便后续分析和评估。
- 交互模块(可选):
- 允许外部系统与环境进行交互,如接收控制输入、提供奖励信号等。
- 提供与环境交互的接口,如
step方法用于执行一步仿真并返回结果。
在LaneKeepingEnv环境中,模块之间的通讯通常通过函数调用和属性访问来实现。以下是一个简化的例子,说明这些模块如何相互通讯:
1. 初始化模块
- 功能:设置所有模块的初始状态。
- 通讯:
- 调用物理模拟模块的初始化函数,设置物理参数。
- 调用车道模块的初始化函数,创建初始车道。
- 调用车辆模块的初始化函数,设置车辆的初始状态。
2. 物理模拟模块
- 功能:模拟车辆的物理行为。
- 通讯:
- 接收来自车辆模块的车辆当前状态(如位置、速度、加速度)。
- 根据接收到的控制输入(来自动作模块)和车辆当前状态,更新车辆状态。
- 将更新后的车辆状态返回给车辆模块。
3. 车道模块
- 功能:管理车道信息。
- 通讯:
- 提供车道信息(如车道边界、车道中心线)给物理模拟模块,用于车辆状态更新。
- 提供检查车辆是否在车道内的方法给车辆模块或物理模拟模块。
4. 车辆模块
- 功能:管理车辆状态。
- 通讯:
- 提供车辆当前状态给物理模拟模块进行模拟。
- 接收物理模拟模块更新后的车辆状态,并更新自身状态。
- 提供车辆状态给观测模块,用于生成观测数据。
5. 观测模块
- 功能:根据配置生成观测数据。
- 通讯:
- 接收车辆模块提供的车辆状态。
- 根据配置(如观察类型、噪声水平等),生成对应的观测数据。
- 将观测数据提供给外部系统(如强化学习算法)。
6. 动作模块
- 功能:定义动作空间,处理原始动作。
- 通讯:
- 提供动作空间信息给外部系统(如强化学习算法),使其知道如何生成有效的控制输入。
- 接收外部系统生成的原始动作,并根据配置将其转换为环境可以理解的控制输入(如缩放、裁剪)。
- 将控制输入提供给物理模拟模块,用于更新车辆状态。
7. 渲染模块(可选)
- 功能:可视化环境状态。
- 通讯:
- 接收车辆模块提供的车辆状态。
- 接收车道模块提供的车道信息。
- 根据这些信息渲染环境状态到屏幕或窗口。
8. 数据存储模块(可选)
- 功能:存储仿真过程中产生的数据。
- 通讯:
- 接收物理模拟模块提供的车辆轨迹、状态等信息。
- 接收动作模块提供的控制输入。
- 将数据存储到文件、数据库或其他存储介质中。
9. 交互模块(可选)
- 功能:允许外部系统与环境进行交互。
- 通讯:
- 提供
step方法给外部系统,接收控制输入并返回下一步的观测数据、奖励等。 - 可能还需要提供其他接口,如重置环境、获取环境状态等。
- 提供
aneKeepingEnv类是一个用于车道保持控制任务的模拟环境,它继承自AbstractEnv类。车道保持是自动驾驶和车辆控制中的一个重要任务,它要求车辆能够保持在车道内行驶。
以下是该类的一些主要部分和功能的解释:
-
初始化 (
__init__方法):- 初始化环境时,它设置了几个关键的属性,如
lane(当前车道)、lanes(所有车道的列表)、trajectory(车辆的轨迹)、interval_trajectory(可能用于存储某个时间间隔内的轨迹)和lpv(可能是某种车辆控制器的引用,但从给出的代码片段中无法确定其完整含义)。
- 初始化环境时,它设置了几个关键的属性,如
-
默认配置 (
default_config方法):- 这个方法定义了环境的默认配置参数。这些参数包括观测类型、动作类型、模拟频率、策略频率、噪声水平、屏幕大小、缩放比例和居中位置等。
- 观测类型设置为
"AttributesObservation",并指定了要观察的属性(如车辆状态、状态导数和参考状态)。 - 动作类型设置为
"ContinuousAction",并指定了转向范围(在-π/3到π/3之间)和动作是否涉及纵向或横向控制(这里只考虑横向控制)。
-
步进 (
step方法):- 这个方法定义了环境在每一步中的行为。
- 首先,它检查当前车辆是否仍在当前车道上。如果不在,它会从
lanes列表中取出下一个车道,并设置为当前车道。 - 然后,它调用
store_data方法(该方法在给定的代码片段中未定义,但可能用于存储或更新车辆的轨迹、状态等信息)。 - 最后,如果
lpv(可能是车辆控制器)存在,它会使用当前动作(控制输入)和车辆状态来设置控制器的控制参数。这里,控制器的控制输入似乎只包括车辆状态的子集(从给定的代码来看,它只考虑了车辆的横向位置和速度,以及相对于车道的偏角和偏角速度)。
自动驾驶任务环境
- 公路驾驶:代理在包含多车道和其他车辆的高速公路上行驶,目标是保持高速并避免碰撞。
- 合并:代理在主干道上行驶时,需要为从入口匝道驶入的车辆腾出空间,确保安全合并。
- 环形交叉:代理需要快速通过环形交叉路口,同时处理变道和纵向控制以避免碰撞。
- 停车:代理需要停在指定区域内,同时确保适当的航向。
- 路口:在交通密集的交叉口进行协商。
- 跑道:涉及车道保持和避障的连续控制任务。
代理类型
- 深度Q网络(DQN):使用神经网络表示状态-动作值函数Q,并通过Q学习进行训练。
- 深度确定性策略梯度(DDPG):基于策略的无模型强化学习代理,通过梯度上升进行优化,并使用经验回放来提高学习效率。
- 值迭代:与有限离散马尔可夫决策过程(MDP)兼容,通过简化状态表示和过渡模型来计算最佳状态-值函数。
- 蒙特卡洛方法:利用过渡和奖励模型执行最佳轨迹的随机树搜索。
框架特点
- 可视化:提供三种可视化区域(Episode View、Frame View、Aggregate View),用于展示注意力、SHAP值、车辆观测等信息的处理结果。
- 注意力与可解释性:研究注意力机制在提高代理决策可解释性中的作用,并通过SHAP值分析代理的决策过程。
- 环境多样性:支持多种自动驾驶任务环境,包括公路、合并、环形交叉等,以评估代理在各种场景下的性能。
深度Q网络(DQN)
深度Q网络(Deep Q-Network, DQN)结合了深度学习的感知能力和Q-learning的决策能力。DQN使用一个深度神经网络来近似Q值函数,从而能够在高维状态空间中学习有效的策略。
原理
- 神经网络:DQN使用一个深度神经网络来估计Q值,即给定一个状态s和一个动作a,网络输出一个Q值Q(s, a)。
- 经验回放(Experience Replay):DQN使用一个经验回放缓冲区来存储智能体的经验(状态、动作、奖励、下一个状态),然后从缓冲区中随机采样一批经验来训练网络。这有助于打破数据之间的相关性,使训练更加稳定。
- 目标网络(Target Network):DQN使用两个结构相同的网络,一个用于估计当前的Q值(当前网络),另一个用于估计目标Q值(目标网络)。目标网络使用旧的网络参数进行更新,而不是直接复制当前网络的参数,这有助于稳定训练。
import torch
import torch.nn as nn
import torch.optim as optim class DQN(nn.Module): def __init__(self, state_size, action_size): super(DQN, self).__init__() self.fc1 = nn.Linear(state_size, 24) self.fc2 = nn.Linear(24, 24) self.fc3 = nn.Linear(24, action_size) def forward(self, x): x = torch.relu(self.fc1(x)) x = torch.relu(self.fc2(x)) return self.fc3(x) # 实例化网络、优化器等
dqn = DQN(state_size, action_size)
optimizer = optim.RMSprop(dqn.parameters())
criterion = nn.MSELoss() # 训练步骤(此处省略)值迭代
值迭代是一种经典的强化学习算法,用于求解有限马尔可夫决策过程(MDP)的最优策略。然而,值迭代通常不直接使用深度神经网络,因为它基于表格形式的状态和动作值函数。但这里可以描述如何在简化后的状态空间中应用值迭代。
原理
- 状态表示:在自动驾驶中,状态可能包括车辆的位置、速度、周围车辆的位置和速度等。为了应用值迭代,需要将这些连续的状态空间离散化或简化为有限的状态集合。
- 值迭代更新:对于每个状态s,值迭代通过迭代地更新状态值函数V(s)来找到最优策略。更新公式通常基于Bellman方程。
# 假设已经定义了一个有限的状态集合states、动作集合actions、转移模型P和奖励函数R V = {s: 0 for s in states} # 初始化状态值函数为0 for _ in range(num_iterations): V_new = V.copy() for s in states: V_new[s] = max(sum(P[s][a][s_prime] * (R[s][a][s_prime]自动驾驶和战术决策任务环境的集合开发和维护.

环境
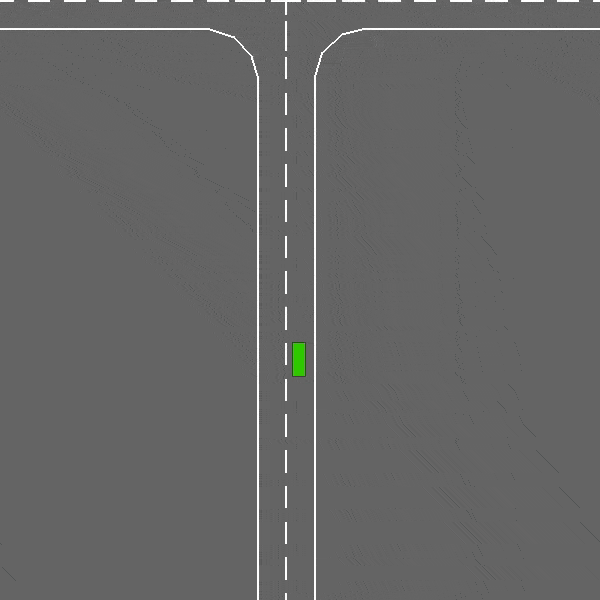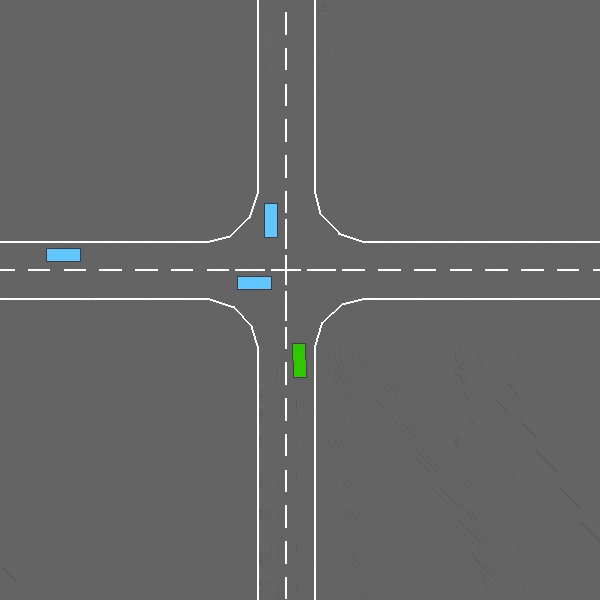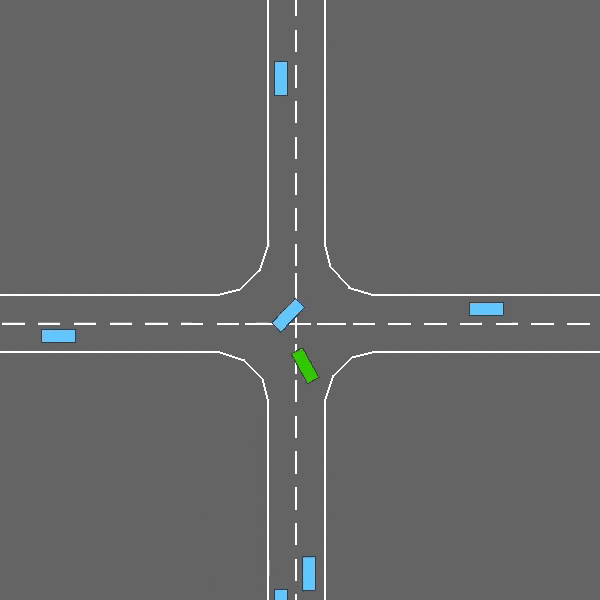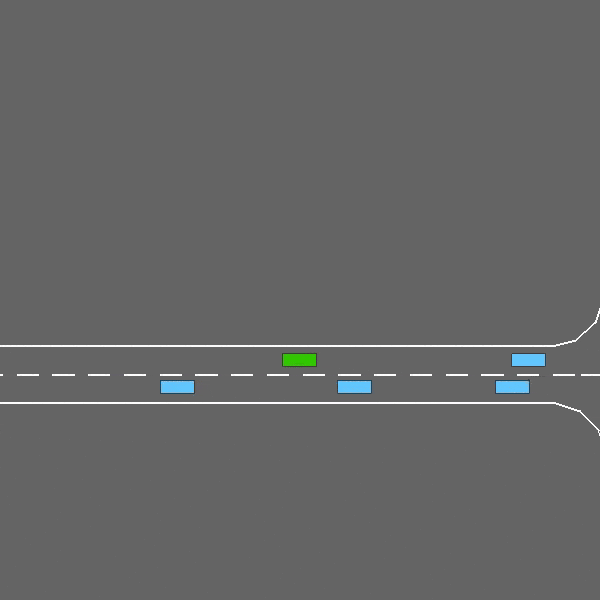
公路
在这项任务中,自我车辆在充满其他车辆的多车道高速公路上行驶。智能体的目标是达到高速,同时避免与相邻车辆发生碰撞。在道路右侧行驶也会触发。

此外,还提供更快的变体 ,其模拟精度降低,可提高大规模训练的速度。
合并
在这项任务中,自我车辆在主干道上起步,但很快接近入口匝道上驶入车辆的路口。代理商现在的目标是保持高速,同时为车辆腾出空间,以便它们可以安全地并入交通。

环形交叉
在这项任务中,自我车辆如果接近交通畅通的环形交叉路口。它将自动遵循其计划的路线,但必须处理变道和纵向控制,以尽可能快地通过环形交叉路口,同时避免碰撞。
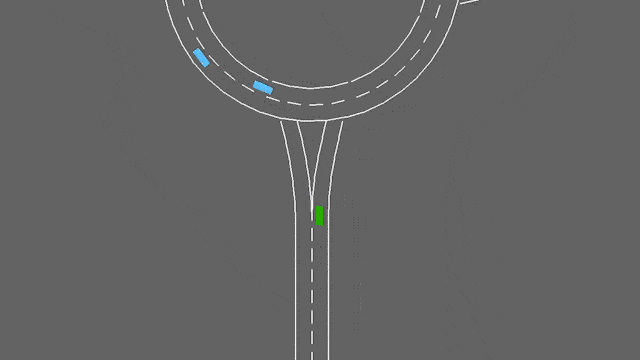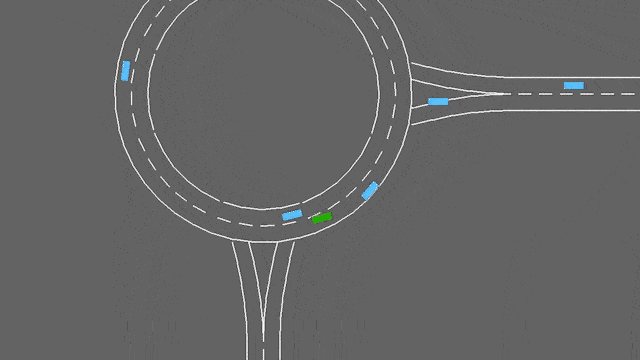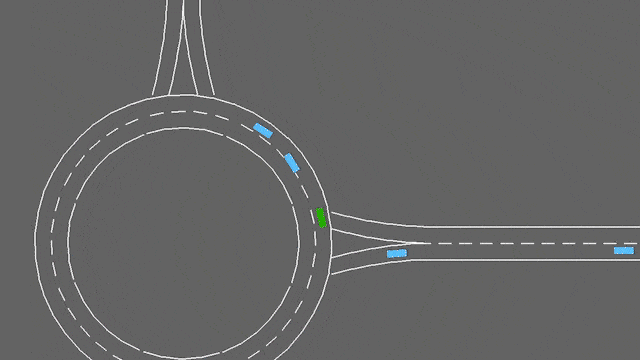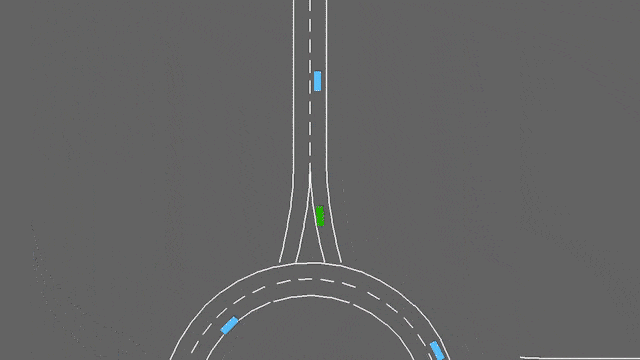
停车
一项以目标为条件的连续控制任务,其中自我车辆必须以适当的航向停在给定的空间内。
路口
交通密集的交叉口协商任务。
跑道
涉及车道保持和避障的连续控制任务。
示例
深度Q
DQN
这种基于无模型值的强化学习代理使用神经网络来表示状态动作值函数 Q,通过函数近似执行 Q 学习。
深度确定性梯度

DDPG
这种基于策略的无模型强化学习代理直接通过梯度上升进行优化。它使用事后诸葛亮体验回放来有效地学习如何解决目标条件。
值迭代
值迭代
值迭代仅与有限离散 MDP 兼容,因此环境首先由 env_mdp() 的有限 MDP 环境近似。这种简化的状态表示根据道路每条车道上的预测碰撞时间 (TTC) 来描述附近的交通。过渡模型很简单,假设每辆车在不改变车道的情况下保持恒定速度行驶。这种模型偏差可能是错误的根源。
然后,代理执行值迭代以计算相应的最佳状态-值函数。
蒙特卡洛
该智能体利用过渡和奖励模型来执行最佳轨迹的随机树搜索。对状态表示或转换模型不需要特定的假设。

if self.speed_range:(self.controlled_vehicle.MIN_SPEED,self.controlled_vehicle.MAX_SPEED,) = self.speed_rangeif self.longitudinal and self.lateral:return {"acceleration": utils.lmap(action[0], [-1, 1], self.acceleration_range),"steering": utils.lmap(action[1], [-1, 1], self.steering_range),}elif self.longitudinal:return {"acceleration": utils.lmap(action[0], [-1, 1], self.acceleration_range),"steering": 0,}elif self.lateral:return {"acceleration": 0,"steering": utils.lmap(action[0], [-1, 1], self.steering_range),}
相关文章:
自动驾驶仿真(高速道路)LaneKeeping
前言 A high-level decision agent trained by deep reinforcement learning (DRL) performs quantitative interpretation of behavioral planning performed in an autonomous driving (AD) highway simulation. The framework relies on the calculation of SHAP values an…...

数据挖掘实战-基于Catboost算法的艾滋病数据可视化与建模分析
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...

分水岭算法分割和霍夫变换识别图像中的硬币
首先解释一下第一种分水岭算法: 一、分水岭算法 分水岭算法是一种基于拓扑学的图像分割技术,广泛应用于图像处理和计算机视觉领域。它将图像视为一个拓扑表面,其中亮度值代表高度。算法的目标是通过模拟雨水从山顶流到山谷的过程࿰…...

什么是AVIEXP提前发货通知?
EDI(电子数据交换)报文是一种用于电子商务和供应链管理的标准化信息传输格式。AVIEXP 是一种特定类型的 EDI 报文,用于传输提前发货通知信息。 AVIEXP 报文简介 AVIEXP 是指 Advanced Shipping Notification提前发货通知报文,用…...
Python 之SQLAlchemy使用详细说明
目录 1、SQLAlchemy 1.1、ORM概述 1.2、SQLAlchemy概述 1.3、SQLAlchemy的组成部分 1.4、SQLAlchemy的使用 1.4.1、安装 1.4.2、创建数据库连接 1.4.3、执行原生SQL语句 1.4.4、映射已存在的表 1.4.5、创建表 1.4.5.1、创建表的两种方式 1、使用 Table 类直接创建表…...
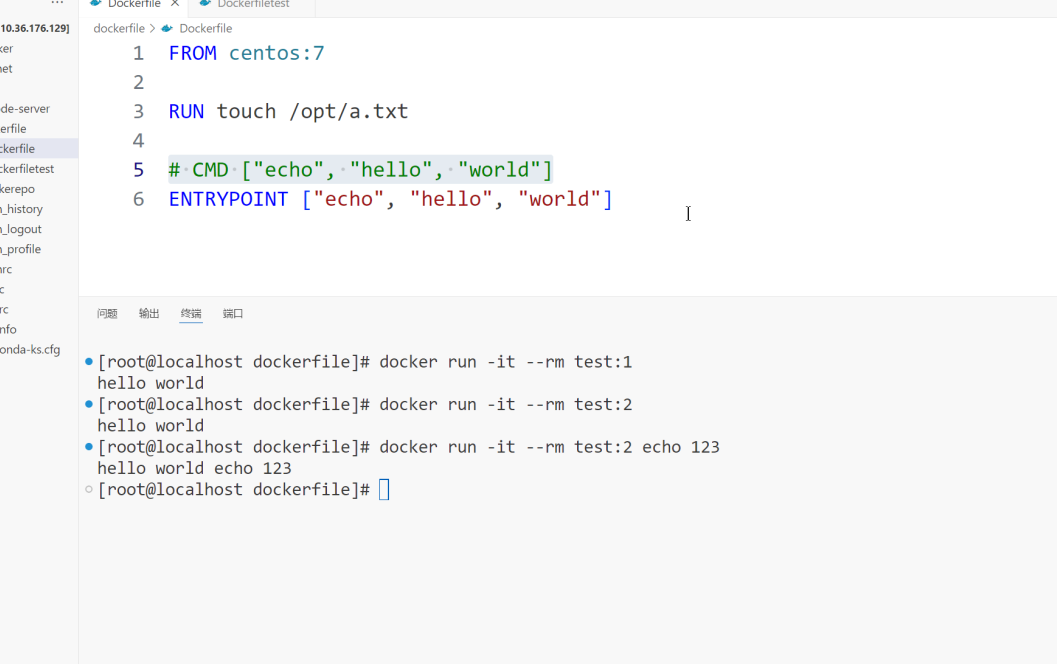
就业班 第四阶段(docker) 2401--5.29 day3 Dockerfile+前后段项目若依ruoyi
通过Dockerfile创建镜像 Docker 提供了一种更便捷的方式,叫作 Dockerfile docker build命令用于根据给定的Dockerfile构建Docker镜像。docker build语法: # docker build [OPTIONS] <PATH | URL | ->1. 常用选项说明 --build-arg,设…...

【运维项目经历|026】Redis智能集群构建与性能优化工程
🍁博主简介: 🏅云计算领域优质创作者 🏅2022年CSDN新星计划python赛道第一名 🏅2022年CSDN原力计划优质作者 🏅阿里云ACE认证高级工程师 🏅阿里云开发者社区专家博主 💊交流社区:CSDN云计算交流社区欢迎您的加入! 目…...

Linux编程for、while循环if判断以及case语句用法
简介 语法描述if条件语句if else条件判断语句if else-if else多条件判断语句for循环执行命令while循环执行命令until直到条件为真时停止循环case ... esac多选择语句break跳出循环continue跳出当前循环 1. for 循环 for语句,定量循环,可以遍历一个列表…...

docker命令 docker ps -l (latest)命令在 Docker 中用于列出最近一次创建的容器
文章目录 12345 1 docker ps -l 命令在 Docker 中用于列出最近一次创建的容器。具体来说: docker ps:这个命令用于列出当前正在运行的容器。-l 或 --latest:这个选项告诉 docker ps 命令只显示最近一次创建的容器,不论该容器当前…...

inflight 守恒和带宽资源守恒的有效性
接着昨天的问题,inflight 守恒的模型一定存在稳定点吗?并不是。如果相互抑制强度大于自我抑制强度,系统也会跑飞: 模拟结果如下: 所以一定要记得 a < b。 比对前两个图和后两个图的 a,b 参数关系&am…...
短视频直播教学课程小程序的作用是什么
只要短视频/直播做的好,营收通常都不在话下,近些年,线上自媒体行业热度非常高,每条细分赛道都有着博主/账号,其各种优势条件下也吸引着其他普通人冲入。 然无论老玩家还是新玩家,面对平台不断变化的规则和…...

Open AI又出王炸GPT-4,目测一大波人的饭碗要碎了...
前言 在科技的惊涛骇浪中,每一次技术的飞跃都预示着新时代的曙光。近日,Open AI公司再次震撼业界,推出了其最新力作——GPT-4,这款被誉为“王炸”的语言模型,以其前所未有的智能水平和创造力,不仅在技术圈…...
:转移指令的原理)
8086 汇编笔记(八):转移指令的原理
一、操作符 offset 操作符offset在汇编语言中是由编译器处理的符号,它的功能是取得标号的偏移地址 codesg segmentstart: mov ax,offset start ;相当于 mv ax,0s: mov ax,offset s ;相当于 mv ax,3codesg endsend start 二、jmp 指令 jmp为无条件…...

win 系统 cmd 命令从私库上传,下载jar包
1. 确保maven环境变量或者maven安装无误; 2.私库下载 命令 mvn dependency:get -DgroupId<your_group_id> -DartifactId<your_artifact_id> -Dversion<your_version> -Dpackagingjar -Dfile<path_to_your_jar_file> -Durl<your_privat…...

dots_image 增强图像中的圆点特征
dots_image 增强图像中的圆点特征 1. dot_image 有什么用途?2. 点状字符的特征增强3. Halcon代码 1. dot_image 有什么用途? Enhance circular dots in an image. 这个算子可以增强图像中的圆点特征,例如下面的例子。 2. 点状字符的特征增强…...

代码随想录算法训练营第十五天| 110.平衡二叉树、 257. 二叉树的所有路径、404.左叶子之和
110.平衡二叉树 题目链接:110.平衡二叉树 文档讲讲:代码随想录 状态:还可以 思路:计算左右子树的深度差,递归判断左右子树是否符合平衡条件 题解: public boolean isBalanced(TreeNode root) {if (root n…...

MSP430单片机控制流水灯,Proteus仿真
作品功能 本项目利用MSP430单片机控制一个简单的流水灯,通过按键切换流水灯的模式。用户可以通过按键控制LED灯的方向,从左向右或从右向左依次点亮。 作品的硬件材料 MSP430单片机 具体型号:MSP430G2553 LED灯 数量:8个类型&…...

出售iPhone前的必做步骤:完全擦除个人数据的方法
当您准备在闲鱼上转售旧 iPhone、将其捐赠、送给朋友或通过 Apple 回收之前,您可能会选择执行“恢复”操作来擦除您的数据。但请注意,这一操作并不能真正删除设备中的数据。被“删除”或“格式化”的数据实际上仍存在于 iPhone 中,只是被系统…...

npm yarn 更换国内源以及node历史版本下载地址
npm 更换国内源 npm config set registryhttps://registry.npmmirror.com npm config set electron_mirrorhttps://registry.npmmirror.com/electron/yarn 更换国内源 yarn config set registry https://registry.npmmirror.comnode历史版本下载地址 https://nodejs.org/dow…...

微信小程序手机号码授权登录
文章目录 一、微信小程序开发二、使用步骤1.前端代码2.后台配置3.后台代码 总结 一、微信小程序开发 目前个人的小程序无法使用手机号码授权登录,可以使用测试号进行开发 二、使用步骤 1.前端代码 代码如下(示例): <butto…...

线程与协程
1. 线程与协程 1.1. “函数调用级别”的切换、上下文切换 1. 函数调用级别的切换 “函数调用级别的切换”是指:像函数调用/返回一样轻量地完成任务切换。 举例说明: 当你在程序中写一个函数调用: funcA() 然后 funcA 执行完后返回&…...

pam_env.so模块配置解析
在PAM(Pluggable Authentication Modules)配置中, /etc/pam.d/su 文件相关配置含义如下: 配置解析 auth required pam_env.so1. 字段分解 字段值说明模块类型auth认证类模块,负责验证用户身份&am…...
)
postgresql|数据库|只读用户的创建和删除(备忘)
CREATE USER read_only WITH PASSWORD 密码 -- 连接到xxx数据库 \c xxx -- 授予对xxx数据库的只读权限 GRANT CONNECT ON DATABASE xxx TO read_only; GRANT USAGE ON SCHEMA public TO read_only; GRANT SELECT ON ALL TABLES IN SCHEMA public TO read_only; GRANT EXECUTE O…...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...

三体问题详解
从物理学角度,三体问题之所以不稳定,是因为三个天体在万有引力作用下相互作用,形成一个非线性耦合系统。我们可以从牛顿经典力学出发,列出具体的运动方程,并说明为何这个系统本质上是混沌的,无法得到一般解…...

NFT模式:数字资产确权与链游经济系统构建
NFT模式:数字资产确权与链游经济系统构建 ——从技术架构到可持续生态的范式革命 一、确权技术革新:构建可信数字资产基石 1. 区块链底层架构的进化 跨链互操作协议:基于LayerZero协议实现以太坊、Solana等公链资产互通,通过零知…...

第 86 场周赛:矩阵中的幻方、钥匙和房间、将数组拆分成斐波那契序列、猜猜这个单词
Q1、[中等] 矩阵中的幻方 1、题目描述 3 x 3 的幻方是一个填充有 从 1 到 9 的不同数字的 3 x 3 矩阵,其中每行,每列以及两条对角线上的各数之和都相等。 给定一个由整数组成的row x col 的 grid,其中有多少个 3 3 的 “幻方” 子矩阵&am…...

C/C++ 中附加包含目录、附加库目录与附加依赖项详解
在 C/C 编程的编译和链接过程中,附加包含目录、附加库目录和附加依赖项是三个至关重要的设置,它们相互配合,确保程序能够正确引用外部资源并顺利构建。虽然在学习过程中,这些概念容易让人混淆,但深入理解它们的作用和联…...

NPOI Excel用OLE对象的形式插入文件附件以及插入图片
static void Main(string[] args) {XlsWithObjData();Console.WriteLine("输出完成"); }static void XlsWithObjData() {// 创建工作簿和单元格,只有HSSFWorkbook,XSSFWorkbook不可以HSSFWorkbook workbook new HSSFWorkbook();HSSFSheet sheet (HSSFSheet)workboo…...

MacOS下Homebrew国内镜像加速指南(2025最新国内镜像加速)
macos brew国内镜像加速方法 brew install 加速formula.jws.json下载慢加速 🍺 最新版brew安装慢到怀疑人生?别怕,教你轻松起飞! 最近Homebrew更新至最新版,每次执行 brew 命令时都会自动从官方地址 https://formulae.…...