python词云生成库-wordcloud
内容目录
- 一、模块介绍
- 二、WordCloud常用的方法
- 1. generate(self, text)
- 2. generate_from_frequencies(frequencies)
- 3. fit_words(frequencies)
- 4. generate_from_text(text)
- 三、进阶技巧
- 1. 设置蒙版
- 2. 设置过滤词
WordCloud 是一个用于生成词云的 Python 库,它可以根据提供的文本数据创建出美观的视觉化图像,其中文本的大小和频率成比例。同时也提供了丰富的绘制功能, 可以结合 matplotlib 库进行复杂的操作
关键的方法就是WordCloud方法
一、模块介绍
导入模块
from wordcloud import WordCloud
该类的定义如下:
def __init__(self, font_path=None, width=400, height=200, margin=2,ranks_only=None, prefer_horizontal=.9, mask=None, scale=1,color_func=None, max_words=200, min_font_size=4,stopwords=None, random_state=None, background_color='black',max_font_size=None, font_step=1, mode="RGB",relative_scaling='auto', regexp=None, collocations=True,colormap=None, normalize_plurals=True, contour_width=0,contour_color='black', repeat=False,include_numbers=False, min_word_length=0, collocation_threshold=30):... ...
其中各个参数和属性的说明如下:
font_path: 字符串, 词云中字体格式文件的路径
用于字体的字体路径(OTF或TTF)。默认为Linux机器上的DroidSansMono路径。如果你在其他操作系统上或没有这个字体,你需要调整这个路径。
width: 整数,默认=400, 画布的宽度。
height: 整数,默认=200, 画布的高度。
prefer_horizontal: 浮点数,默认=0.90
尝试水平适应相对于垂直适应的比例。如果 prefer_horizontal < 1,算法会在单词不适应时尝试旋转单词。(目前没有内置方法仅获取垂直单词。)
mask: 数组或None,默认=None
如果不为None,给出在何处绘制单词的二进制掩模。如果mask不为None,将忽略width和height,并使用mask的形状。所有白色(#FF或#FFFFFF)条目将被视为“屏蔽”,而其他条目则可以自由绘制。
contour_width: 浮点数,默认=0
如果mask不为None且contour_width > 0,绘制掩模轮廓。
contour_color: 颜色值,默认="black", 掩模轮廓颜色。
scale: 浮点数,默认=1
计算与绘制之间的缩放。对于大的词云图像,使用scale而不是更大的画布尺寸会显著更快,但可能导致单词的拟合更粗糙。
min_font_size: 整数,默认=4, 使用的最小字体大小。当这个大小没有更多空间时停止。
font_step: 整数,默认=1, 字体的步长。font_step > 1可能会加速计算,但可能给出较差的拟合。
max_words: 数量,默认=200, 最大单词数。
stopwords: 字符串集合或None
将被消除的单词。如果为None,将使用内置的STOPWORDS列表。如果使用generate_from_frequencies,则忽略。
background_color: 颜色值,默认="black", 词云图像的背景颜色。
max_font_size: 整数或None,默认=None
最大单词的最大字体大小。如果为None,则使用图像的高度。
mode: 字符串,默认="RGB"
当mode为"RGBA"且background_color为None时,将生成透明背景。
relative_scaling: 浮点数,默认='auto'
单词相对频率对字体大小的重要性。如果relative_scaling=0,只考虑单词排名。如果relative_scaling=1,频率是两倍的单词将有两倍的大小。如果你想同时考虑单词频率和不仅仅它们的排名,relative_scaling大约0.5通常看起来不错。如果为'auto',则除非repeat为真,否则设置为0.5,此时设置为0。版本更新:: 2.0默认现在是'auto'。
color_func: 可调用,默认=None
有参数word, font_size, position, orientation, font_path, random_state的可调用函数,为每个单词返回一个PIL颜色。覆盖"colormap"。有关指定matplotlib色谱的信息,请参见colormap。要创建单色的词云,使用
color_func=lambda *args, **kwargs: "white"。单色也可以使用RGB代码指定。例如,
color_func=lambda *args, **kwargs: (255,0,0)设置颜色为红色。
regexp: 字符串或None(可选)
在process_text中分割输入文本为标记的正则表达式。如果指定为None,则使用r"\w[\w']+"。如果使用generate_from_frequencies,则忽略。
collocations: 布尔,默认=True
是否包括两个单词的搭配(二元组)。如果使用generate_from_frequencies,则忽略。
colormap: 字符串或matplotlib色谱,默认="viridis"
从每个单词随机抽取颜色的matplotlib色谱。如果指定了"color_func",则忽略。
normalize_plurals: 布尔,默认=True
是否去除单词末尾的's'。如果为True,一个单词以's'结尾和不以's'结尾都出现时,去掉以's'结尾的单词并将它的计数加到没有's'结尾的版本上——除非单词以'ss'结尾。如果使用generate_from_frequencies,则忽略。
repeat: 布尔,默认=False
是否重复单词和短语直到达到max_words或min_font_size。
include_numbers: 布尔,默认=False, 是否将数字作为短语包含进来。
min_word_length: 整数,默认=0, 单词必须有的最少字母数才能被包含。
collocation_threshold: 整数,默认=30
大二元组必须具有高于此参数的Dunning似然性搭配分数才能被计为大二元组。默认值30是任意的。属性
words_: 字符串到浮点数的字典, 关联频率的单词令牌。2.0后words_ 是一个字典
layout_: 元组列表((字符串, 浮点数), 整数, (整数, 整数), 整数, 颜色)
编码拟合的词云。对于每个单词,它编码字符串、规范化频率、字体大小、位置、方向和颜色。频率由最常出现的单词归一化。颜色格式为'rgb(R, G, B)'。
二、WordCloud常用的方法
1. generate(self, text)
接收一个字符串作为输入,计算文本中各单词的频率,并生成相应的词云。这是最基础也是最常用的方法之一。
from wordcloud import WordCloud
import matplotlib.pyplot as plt# 示例文本
text = "This is a simple example showing how to generate a word cloud using the generate method. Generate method uses the input text directly."# 创建WordCloud对象
wordcloud = WordCloud(width=800, height=800, max_words=100, background_color='white').generate(text)# 显示词云
plt.figure(figsize=(8, 8), facecolor=None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad=0)
plt.show()

2. generate_from_frequencies(frequencies)
直接接收一个字典,其中键是单词,值是该单词的频率,用来生成词云。这适用于已经计算好词频的情况。
from wordcloud import WordCloud
import matplotlib.pyplot as plt# 示例文本
dic = {'This': 120, 'example': 90, 'showing': 80, 'word': 70, 'cloud': 60, 'Generate': 50, 'method': 40, 'text': 30, 'input': 20, 'directly': 10}
# 创建WordCloud对象
wordcloud = WordCloud(width=800, height=800, max_words=100, background_color='white').generate_from_frequencies(dic)# 显示词云
plt.figure(figsize=(8, 8), facecolor=None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad=0)
plt.show()

3. fit_words(frequencies)
这个方法接收一个字典,其中键是单词,值是对应的频率,然后根据这些频率生成词云。类似于generate_from_frequencies
from wordcloud import WordCloud
import matplotlib.pyplot as plt# 示例文本
dic = {'This': 120, 'example': 90, 'showing': 80, 'word': 70, 'cloud': 60, 'Generate': 50, 'method': 40, 'text': 30, 'input': 20, 'directly': 10}
# 创建WordCloud对象
wordcloud = WordCloud(width=800, height=800, max_words=100, background_color='white').fit_words(dic)# 显示词云
plt.figure(figsize=(8, 8), facecolor=None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad=0)
plt.show()

4. generate_from_text(text)
接收一个字符串作为输入,计算文本中各单词的频率,并生成相应的词云。类似于generate。
from wordcloud import WordCloud
import matplotlib.pyplot as plt# 示例文本
text = "This is a simple example showing how to generate a word cloud using the generate method. Generate method uses the input text directly."# 创建WordCloud对象
wordcloud = WordCloud(width=800, height=800, max_words=100, background_color='white').generate_from_text(text)# 显示词云
plt.figure(figsize=(8, 8), facecolor=None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad=0)
plt.show()

三、进阶技巧
1. 设置蒙版
蒙版设置, 设置蒙版之后, 词云的形状就会显示为设置的蒙版形状
from wordcloud import WordCloud, ImageColorGenerator
import matplotlib.pyplot as plt
import numpy as np
from PIL import Imagemask_image = np.array(Image.open('./static/img.png'))# 示例文本
text = "This is a simple example showing how to generate a word cloud using the generate method. Generate method uses the input text directly."# 创建WordCloud对象
wordcloud = WordCloud(width=800, height=800, mask=mask_image, max_words=100, background_color='white')wordcloud.generate_from_text(text)# 显示词云
plt.figure(figsize=(8, 8), facecolor=None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad=0)
plt.show()

2. 设置过滤词
对于一些不希望出现的词, 可以通过设置stopword过滤, 实现方法有两种
- 在切词阶段, 将过滤词剔除, 过滤词要求是一个集合{}
- 在生成词云阶段, 使用stopword参数添加过滤词数组, 注意, 此时如果通过generate_from_frequencies方法生成, 此参数则忽略
方式一:
stop_words = {'?', ',', '有', '其', '非常', '的', '为', '所', ':', '和', '”', "'", '\\u3000', '乎', '?', '这', '不', '在', '比', '“', '"', '而', '很', '被', '我', '那'}
datas = [... ...] # 词云数据
cloud_data = []
for data in datas:qdatas = jieba.lcut(data)qdata_filter = [word for word in qdatas if word not in excludes]cloud_data.extend(qdata_filter)wordcloud = WordCloud(font_path='./static/msyh.ttc',background_color='white',colormap='magma',max_font_size=40,random_state=42,max_words=300,# 宽width=1000,# 高height=880,mask = mask_image
).generate(' '.join(cloud_data))
方式二:
stop_words = {'?', ',', '有', '其', '非常', '的', '为', '所', ':', '和', '”', "'", '\\u3000', '乎', '?', '这', '不', '在', '比', '“', '"', '而', '很', '被', '我', '那'}
datas = [... ...] # 词云数据wordcloud = WordCloud(font_path='./static/msyh.ttc',background_color='white',colormap='magma',max_font_size=40,random_state=42,max_words=300,# 宽width=1000,# 高height=880,mask = mask_image,-- 设置过滤词stopwords=stop_words
).generate(datas)
相关文章:
python词云生成库-wordcloud
内容目录 一、模块介绍二、WordCloud常用的方法1. generate(self, text)2. generate_from_frequencies(frequencies)3. fit_words(frequencies)4. generate_from_text(text) 三、进阶技巧1. 设置蒙版2. 设置过滤词 WordCloud 是一个用于生成词云的 Python 库,它可以…...
】)
鸿蒙开发接口数据管理:【@ohos.data.rdb (关系型数据库)】
关系型数据库 关系型数据库(Relational Database,RDB)是一种基于关系模型来管理数据的数据库。关系型数据库基于SQLite组件提供了一套完整的对本地数据库进行管理的机制,对外提供了一系列的增、删、改、查等接口,也可…...

Java返回前端Bigdecimal类型数据时“0E-8“及小数点多余0的问题
目录 问题描述: 解决方法: 重要代码: 问题描述: 项目中oracle数据库需要转换为mysql,Oracle中的表字段定义为number(36,16)类型的工具自动转换为mysql的decimal(36,16)。在Oracle数据库中,number(36,16)类型的字段,使用BigDeci…...

标题:深入探索Linux中的`ausyscall`
标题:深入探索Linux中的ausyscall(注意:ausyscall并非Linux内核标准命令,但我们可以探讨类似的概念) 在Linux系统中,系统调用(syscall)是用户空间程序与内核空间进行交互的一种重要…...

CorelDRAW2024发布更新啦!设计师们的得力助手
在数字化的今天,视觉设计已经成为我们生活中不可或缺的一部分。从手机界面到广告海报,从网页布局到包装设计,每一个细节都离不开设计师们的专业与创意。然而,面对日益增长的设计需求和不断提升的审美标准,许多设计师开…...
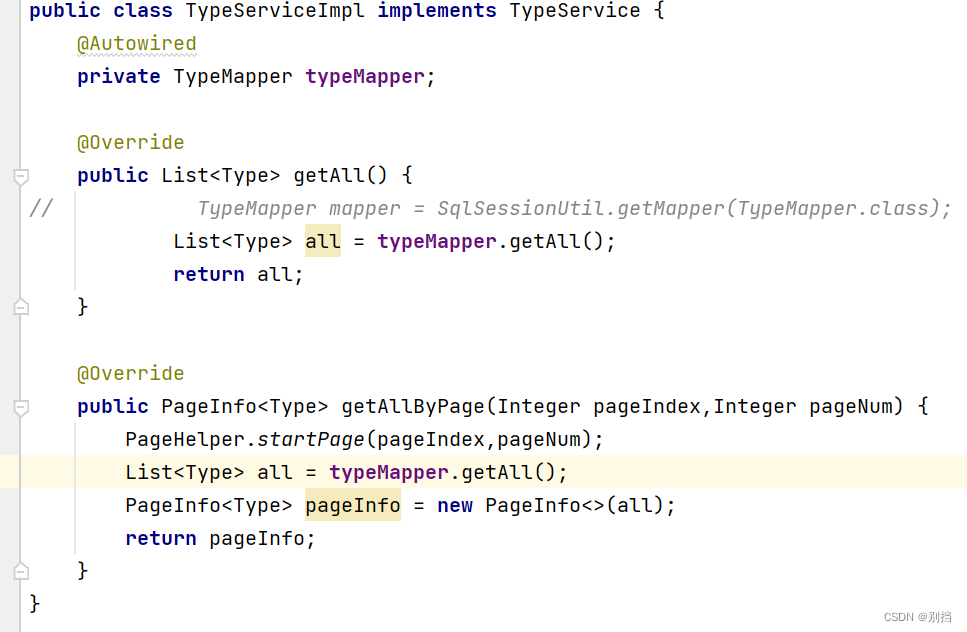
SpringMVC日期格式处理 分页条件查询
实现日期格式处理: springmvc能实现String类型和基本数据类型及包装类的自动格式转换,但是不能识别String和 日期类格式的自动转换。 实现方式: 1是在实体类上加上注解DateTimeFormat,识别String格式为“yyyy-MM-dd” 2使用自定义…...

蓝桥云课第12届强者挑战赛
第一题:字符串加法 其实本质上就是一个高精度问题,可以使用同余定理的推论 (ab)%n((a%n)(b%n))%n; #include <iostream> using namespace std; const int mod1e97; int main() {string a,b;cin>>a>>b;ab;int …...

LabVIEW储油罐监控系统
LabVIEW储油罐监控系统 介绍了基于LabVIEW的储油罐监控系统的设计与实施。系统通过集成传感器技术和虚拟仪器技术,实现对储油罐内液位和温度的实时监控,提高了油罐监管的数字化和智能化水平,有效增强了油库安全管理的能力。 项目背景 随着…...

局域网、城域网、广域网的ip
一、 广域网ip: 全球共享同一个广域网,所以广域网也被称为公网,所以广域网的ip也称为公网ip,全球公网ip必须是都是唯一的,不能冲突。 二、城域网、局域网ip: 可以有无数个局域网、城域网,虽然在…...
【全开源】Java共享茶室棋牌室无人系统支持微信小程序+微信公众号
打造智能化休闲新体验 一、引言:智能化休闲时代的来临 随着科技的飞速发展,智能化、无人化服务逐渐渗透到我们生活的各个领域。在休闲娱乐行业,共享茶室棋牌室无人系统源码的出现,不仅革新了传统的休闲方式,更为消费…...

echarts数据更新没反应解决方案
数据处理逻辑问题: 确保data数组在传入函数时确实发生了变化,并且这些变化对于生成newData1和newData2是有效的。您可以增加一些日志输出来验证处理后的数据是否如预期那样被更新了。 ECharts实例未正确更新: 虽然使用了myChart.setOption…...

RK3588+FPGA+算能BM1684X:高性能AI边缘计算盒子,应用于视频分析、图像视觉等
搭载RK3588(四核 A76四核 A55),CPU主频高达 2.4GHz ,提供1MB L2 Cache 和 3MB L3 ,Cache提供更强的 CPU运算能力,具备6T AI算力,可扩展至38T算力。 产品规格 系统主控CPURK3588,四核…...

Mysql学习(三)——SQL通用语法之DML
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 DML添加数据修改数据删除数据 总结 DML DML用来对数据库中表的数据记录进行增删改操作。 添加数据 -- 给指定字段添加数据 insert into 表名(字段1,字…...

java static 如何理解
在Java中,static关键字是一个重要的概念,它用于定义类的静态成员,包括静态变量(也称作类变量)、静态方法和静态代码块。static关键字的主要作用是创建独立于对象的成员,这些成员属于类本身,而不…...

算法金 | 不愧是腾讯,问基础巨细节 。。。
大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」 最近,有读者参加了腾讯算法岗位的面试,面试着重考察了基础知识,并且提问非常详细。 特别是关于Ada…...
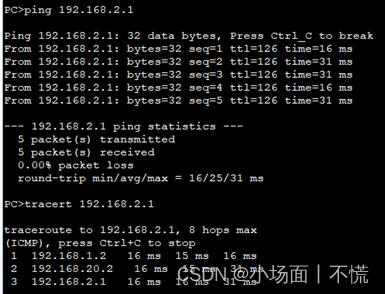
实验9 浮动静态路由配置
--名称-- 一、 原理描述二、 实验目的三、 实验内容四、 实验配置五、 实验步骤 一、 原理描述 浮动静态路由也是一种特殊的静态路由,主要考虑链路冗余。浮动静态路由通过配置一条比主路由优先级低的静态路由,用于保证在主路由失效的情况下,…...
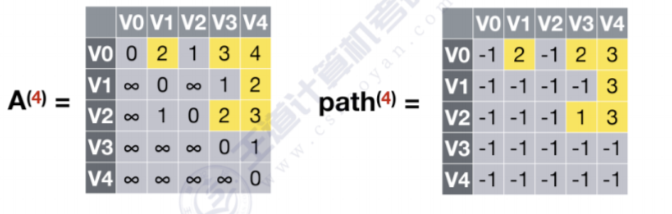
多源最短路径算法–Floyd算法
多源最短路径算法–Floyd算法 Floyd算法是为了求出每一对顶点之间的最短路径 它使用了动态规划的思想,将问题的求解分为了多个阶段 先来个例子,这是个有向图 Floyd算法的运行需要两个矩阵 最短路径矩阵 从当前这个状态看各顶点间的最短路径长度 例…...
使用Redis缓存实现短信登录逻辑,手机验证码缓存,用户信息缓存
引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency> 加配置 spring:redis:host: 127.0.0.1 #redis地址port: 6379 #端口password: 123456 #密码…...

探索未来制造,BFT Robotics引领潮流
“买机器人,上BFT” 在这个快速变化的时代,创新和效率是企业发展的关键。BFT Robotics,作为您值得信赖的合作伙伴,专注于为您提供一站式的机器人采购和自动化解决方案。 产品系列: 协作机器人:安全、灵活、…...
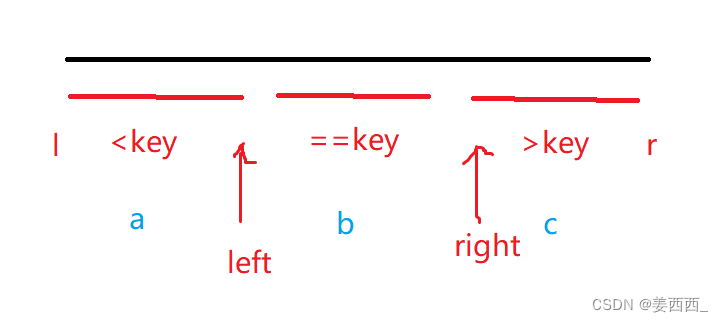
数组中的第K个最大元素 ---- 分治-快排
题目链接 题目: 分析: 这道题很明显是一个top-K问题, 我们很容易想到用堆排序来解决, 堆排序的时间复杂度是O(N*logN), 不符合题意, 所以我们可以用另一种方法:快速选择算法, 他的时间复杂度为O(N)快速选择算法, 其实是基于快排, 进行修改而成, 我们还是使用将"将数组分…...

使用VSCode开发Django指南
使用VSCode开发Django指南 一、概述 Django 是一个高级 Python 框架,专为快速、安全和可扩展的 Web 开发而设计。Django 包含对 URL 路由、页面模板和数据处理的丰富支持。 本文将创建一个简单的 Django 应用,其中包含三个使用通用基本模板的页面。在此…...

51c自动驾驶~合集58
我自己的原文哦~ https://blog.51cto.com/whaosoft/13967107 #CCA-Attention 全局池化局部保留,CCA-Attention为LLM长文本建模带来突破性进展 琶洲实验室、华南理工大学联合推出关键上下文感知注意力机制(CCA-Attention),…...

React第五十七节 Router中RouterProvider使用详解及注意事项
前言 在 React Router v6.4 中,RouterProvider 是一个核心组件,用于提供基于数据路由(data routers)的新型路由方案。 它替代了传统的 <BrowserRouter>,支持更强大的数据加载和操作功能(如 loader 和…...

Cesium1.95中高性能加载1500个点
一、基本方式: 图标使用.png比.svg性能要好 <template><div id"cesiumContainer"></div><div class"toolbar"><button id"resetButton">重新生成点</button><span id"countDisplay&qu…...

Opencv中的addweighted函数
一.addweighted函数作用 addweighted()是OpenCV库中用于图像处理的函数,主要功能是将两个输入图像(尺寸和类型相同)按照指定的权重进行加权叠加(图像融合),并添加一个标量值&#x…...

【论文笔记】若干矿井粉尘检测算法概述
总的来说,传统机器学习、传统机器学习与深度学习的结合、LSTM等算法所需要的数据集来源于矿井传感器测量的粉尘浓度,通过建立回归模型来预测未来矿井的粉尘浓度。传统机器学习算法性能易受数据中极端值的影响。YOLO等计算机视觉算法所需要的数据集来源于…...

论文浅尝 | 基于判别指令微调生成式大语言模型的知识图谱补全方法(ISWC2024)
笔记整理:刘治强,浙江大学硕士生,研究方向为知识图谱表示学习,大语言模型 论文链接:http://arxiv.org/abs/2407.16127 发表会议:ISWC 2024 1. 动机 传统的知识图谱补全(KGC)模型通过…...
)
Java入门学习详细版(一)
大家好,Java 学习是一个系统学习的过程,核心原则就是“理论 实践 坚持”,并且需循序渐进,不可过于着急,本篇文章推出的这份详细入门学习资料将带大家从零基础开始,逐步掌握 Java 的核心概念和编程技能。 …...

selenium学习实战【Python爬虫】
selenium学习实战【Python爬虫】 文章目录 selenium学习实战【Python爬虫】一、声明二、学习目标三、安装依赖3.1 安装selenium库3.2 安装浏览器驱动3.2.1 查看Edge版本3.2.2 驱动安装 四、代码讲解4.1 配置浏览器4.2 加载更多4.3 寻找内容4.4 完整代码 五、报告文件爬取5.1 提…...
:邮件营销与用户参与度的关键指标优化指南)
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南 在数字化营销时代,邮件列表效度、用户参与度和网站性能等指标往往决定着创业公司的增长成败。今天,我们将深入解析邮件打开率、网站可用性、页面参与时…...