【动手学深度学习】使用块的网络(VGG)的研究详情



目录
🌊1. 研究目的
🌊2. 研究准备
🌊3. 研究内容
🌍3.1 多层感知机模型选择、欠拟合和过拟合
🌍3.2 练习
🌊4. 研究体会
🌊1. 研究目的
- 理解块的网络结构;
- 比较块的网络与传统浅层网络的性能差异;
- 探究块的网络深度与性能之间的关系;
- 研究块的网络在不同任务上的适用性。
🌊2. 研究准备
- 根据GPU安装pytorch版本实现GPU运行研究代码;
- 配置环境用来运行 Python、Jupyter Notebook和相关库等相关库。
🌊3. 研究内容
启动jupyter notebook,使用新增的pytorch环境新建ipynb文件,为了检查环境配置是否合理,输入import torch以及torch.cuda.is_available() ,若返回TRUE则说明研究环境配置正确,若返回False但可以正确导入torch则说明pytorch配置成功,但研究运行是在CPU进行的,结果如下:

🌍3.1 使用块的网络(VGG)
(1)使用jupyter notebook新增的pytorch环境新建ipynb文件,完成基本数据操作的研究代码与练习结果如下:
VGG块
import torch
from torch import nn
from d2l import torch as d2ldef vgg_block(num_convs, in_channels, out_channels):layers = []for _ in range(num_convs):layers.append(nn.Conv2d(in_channels, out_channels,kernel_size=3, padding=1))layers.append(nn.ReLU())in_channels = out_channelslayers.append(nn.MaxPool2d(kernel_size=2,stride=2))return nn.Sequential(*layers)VGG网络
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))def vgg(conv_arch):conv_blks = []in_channels = 1# 卷积层部分for (num_convs, out_channels) in conv_arch:conv_blks.append(vgg_block(num_convs, in_channels, out_channels))in_channels = out_channelsreturn nn.Sequential(*conv_blks, nn.Flatten(),# 全连接层部分nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),nn.Linear(4096, 10))net = vgg(conv_arch)X = torch.randn(size=(1, 1, 224, 224))
for blk in net:X = blk(X)print(blk.__class__.__name__,'output shape:\t',X.shape)
训练模型
ratio = 4
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]
net = vgg(small_conv_arch)lr, num_epochs, batch_size = 0.05, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())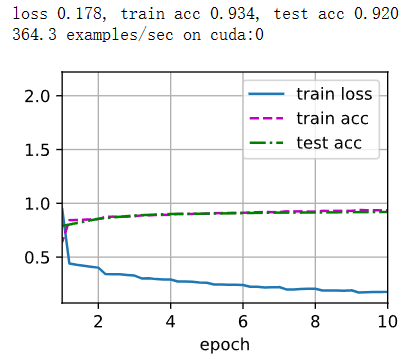
🌍3.2 练习
1.打印层的尺寸时,我们只看到8个结果,而不是11个结果。剩余的3层信息去哪了?
在VGG网络中,最后三个全连接层(nn.Linear)的输出尺寸没有被打印出来。这是因为在for循环中,只遍历了卷积层部分的模块,而没有遍历全连接层部分的模块。
为了打印出全连接层的输出尺寸,可以将全连接层的模块添加到一个列表中,然后在遍历网络的时候也打印出这些模块的输出尺寸。以下是修改后的代码:
import torch
import torch.nn as nn# 定义 VGG 模型
def vgg(conv_arch):layers = []in_channels = 1for c, num_convs in conv_arch:layers.append(nn.Sequential(nn.Conv2d(in_channels, c, kernel_size=3, padding=1),nn.ReLU()))in_channels = cfor _ in range(num_convs - 1):layers.append(nn.Sequential(nn.Conv2d(c, c, kernel_size=3, padding=1),nn.ReLU()))layers.append(nn.MaxPool2d(kernel_size=2, stride=2))return nn.Sequential(*layers)conv_arch = ((1, 1), (2, 2), (4, 2), (8, 2), (16, 2))net = vgg(conv_arch)X = torch.randn(size=(1, 1, 224, 224))
for blk in net:X = blk(X)print(blk.__class__.__name__, 'output shape:\t', X.shape)# 获取卷积层的输出尺寸
_, channels, height, width = X.shape# 添加全连接层模块到列表中
fc_layers = [nn.Flatten(),nn.Linear(channels * height * width, 4096),nn.ReLU(),nn.Dropout(0.5),nn.Linear(4096, 4096),nn.ReLU(),nn.Dropout(0.5),nn.Linear(4096, 10)
]net = nn.Sequential(*net, *fc_layers)# 打印全连接层的输出尺寸
for blk in fc_layers:X = blk(X)print(blk.__class__.__name__, 'output shape:\t', X.shape)

2.与AlexNet相比,VGG的计算要慢得多,而且它还需要更多的显存。分析出现这种情况的原因。
VGG相对于AlexNet而言,计算速度更慢、显存需求更高的主要原因如下:
- 更深的网络结构: VGG网络相比AlexNet更深,它使用了更多的卷积层和全连接层。VGG的网络结构包含了多个连续的卷积层,导致了参数的数量增加和计算量的增加。相对于AlexNet的8层网络,VGG网络有16或19层,这导致了更多的计算和内存消耗。
- 小尺寸的卷积核: VGG网络使用了较小的卷积核(3x3大小),而AlexNet则使用了更大的卷积核(11x11和5x5大小)。较小的卷积核意味着每个卷积层需要进行更多次的卷积运算来覆盖相同的感受野,从而增加了计算量。
- 更多的参数: VGG网络具有更多的参数量。由于每个卷积层都使用了较小的卷积核,导致了更多的卷积核参数。此外,由于网络更深,全连接层的参数数量也更多。更多的参数需要更多的内存来存储,并且在计算过程中需要更多的计算量。
- 更高的内存需求: VGG网络的深度和参数量的增加导致了更高的内存需求。在训练过程中,需要存储每一层的输出、梯度和参数,这会消耗大量的显存。较大的显存需求可能导致无法一次性加载更多的数据和模型,从而导致更多的显存读写操作和内存碎片化,进而影响计算速度。
3.尝试将Fashion-MNIST数据集图像的高度和宽度从224改为96。这对实验有什么影响?
将Fashion-MNIST数据集图像的高度和宽度从224改为96会对实验产生以下影响:
- 模型性能下降: 缩小图像尺寸会导致图像的信息丢失和细节损失。VGG网络在设计时使用了较大的输入尺寸,以便更好地捕捉图像的细节和纹理。通过将图像尺寸缩小为96x96,模型可能无法有效地捕捉到原始图像中的细微特征,从而导致性能下降。
- 空间分辨率减小: 图像尺寸从224x224缩小到96x96会导致空间分辨率的减小。较小的图像尺寸意味着每个像素代表的区域更大,图像中的细节信息被压缩。这可能会导致模型在进行物体边界检测、纹理识别等任务时表现不佳。
- 减少计算和内存需求: 缩小图像尺寸可以减少模型的计算和内存需求。较小的输入图像尺寸意味着每个卷积层的特征图大小也会减小,从而减少了参数数量和计算量。此外,由于特征图大小减小,模型所需的内存也会相应减少。
- 训练速度加快: 缩小图像尺寸可以加快训练速度。较小的输入图像尺寸意味着每个批次的数据量减少,从而减少了每个训练步骤的计算量和内存消耗。这可能导致更快的训练速度和更高的训练效率。
import torch
from torch import nn
from torchvision.transforms import ToTensor
from torchvision.datasets import FashionMNIST
from torch.utils.data import DataLoader# 定义VGG块
def vgg_block(num_convs, in_channels, out_channels):layers = []for _ in range(num_convs):layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))layers.append(nn.ReLU())in_channels = out_channelslayers.append(nn.MaxPool2d(kernel_size=2, stride=2))return nn.Sequential(*layers)# 定义VGG网络
class VGG(nn.Module):def __init__(self, conv_arch):super(VGG, self).__init__()self.conv_blocks = nn.Sequential()in_channels = 1for i, (num_convs, out_channels) in enumerate(conv_arch):self.conv_blocks.add_module(f'vgg_block{i+1}', vgg_block(num_convs, in_channels, out_channels))in_channels = out_channelsself.fc_layers = nn.Sequential(nn.Linear(out_channels * 3 * 3, 4096),nn.ReLU(),nn.Dropout(0.5),nn.Linear(4096, 4096),nn.ReLU(),nn.Dropout(0.5),nn.Linear(4096, 10))def forward(self, x):x = self.conv_blocks(x)x = torch.flatten(x, start_dim=1)x = self.fc_layers(x)return x# 将Fashion-MNIST图像尺寸缩小为96x96
transform = ToTensor()
train_dataset = FashionMNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = FashionMNIST(root='./data', train=False, download=True, transform=transform)# 创建数据加载器
batch_size = 128
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 定义VGG网络结构
conv_arch = [(1, 64), (1, 128), (2, 256), (2, 512), (2, 512)]
model = VGG(conv_arch)# 训练和测试
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.05)
criterion = nn.CrossEntropyLoss()def train(model, train_loader, optimizer, criterion, device):model.train()train_loss = 0.0train_acc = 0.0for images, labels in train_loader:images = images.to(device)labels = labels.to(device)optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()train_loss += loss.item() * images.size(0)_, preds = torch.max(outputs, 1)train_acc += torch.sum(preds == labels.data).item()train_loss /= len(train_loader.dataset)train_acc /= len(train_loader.dataset)return train_loss, train_accdef test(model, test_loader, criterion, device):model.eval()test_loss = 0.0test_acc = 0.0with torch.no_grad():for images, labels in test_loader:images = images.to(device)labels = labels.to(device)outputs = model(images)loss = criterion(outputs, labels)test_loss += loss.item() * images.size(0)_, preds = torch.max(outputs, 1)test_acc += torch.sum(preds == labels.data).item()test_loss /= len(test_loader.dataset)test_acc /= len(test_loader.dataset)return test_loss, test_acc# 训练模型
num_epochs = 10
for epoch in range(num_epochs):train_loss, train_acc = train(model, train_loader, optimizer, criterion, device)test_loss, test_acc = test(model, test_loader, criterion, device)print(f'Epoch {epoch+1}/{num_epochs}, Train Loss: {train_loss:.4f}, Train Accuracy: {train_acc:.4f}, 'f'Test Loss: {test_loss:.4f}, Test Accuracy: {test_acc:.4f}')# 输出样例
print("Sample outputs:")
model.eval()
with torch.no_grad():for images, labels in test_loader:images = images.to(device)labels = labels.to(device)outputs = model(images)_, preds = torch.max(outputs, 1)for i in range(images.size(0)):print(f"Predicted: {preds[i].item()}, Ground Truth: {labels[i].item()}")break # 只输出一个批次的样例结果
在上面的代码中,定义了VGG网络结构,并在Fashion-MNIST数据集上进行了训练和测试。通过将图像尺寸从224缩小为96,可以看到模型的训练和推理速度可能会加快,但模型的性能可能会下降,因为图像的细节被压缩。这里使用了SGD优化器和交叉熵损失函数来训练模型,并输出了训练和测试的损失和准确率。最后输出了一个样例的预测结果,以查看模型的输出效果。请注意,实际训练过程可能需要更多的迭代次数和调整超参数以获得更好的性能。
4.请参考VGG论文 (Simonyan and Zisserman, 2014)中的表1构建其他常见模型,如VGG-16或VGG-19。
VGG-16:
import torch
from torch import nn
from torchvision.transforms import ToTensor
from torchvision.datasets import FashionMNIST
from torch.utils.data import DataLoader# 定义VGG块
def vgg_block(num_convs, in_channels, out_channels):layers = []for _ in range(num_convs):layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))layers.append(nn.ReLU())in_channels = out_channelslayers.append(nn.MaxPool2d(kernel_size=2, stride=2))return nn.Sequential(*layers)# 定义VGG-16网络
class VGG16(nn.Module):def __init__(self):super(VGG16, self).__init__()self.conv_blocks = nn.Sequential(vgg_block(2, 3, 64),vgg_block(2, 64, 128),vgg_block(3, 128, 256),vgg_block(3, 256, 512),vgg_block(3, 512, 512))self.fc_layers = nn.Sequential(nn.Linear(512 * 7 * 7, 4096),nn.ReLU(True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(True),nn.Dropout(),nn.Linear(4096, 10))def forward(self, x):x = self.conv_blocks(x)x = torch.flatten(x, start_dim=1)x = self.fc_layers(x)return x# 将Fashion-MNIST图像转换为Tensor,并进行数据加载
transform = ToTensor()
train_dataset = FashionMNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = FashionMNIST(root='./data', train=False, download=True, transform=transform)# 创建数据加载器
batch_size = 128
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 创建VGG-16模型实例
model = VGG16()# 定义优化器和损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=0.05)
criterion = nn.CrossEntropyLoss()# 将模型移动到GPU(如果可用)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)# 训练模型
num_epochs = 10
for epoch in range(num_epochs):model.train()train_loss = 0.0train_acc = 0.0for images, labels in train_loader:images = images.to(device)labels = labels.to(device)optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()train_loss += loss.item() * images.size(0)_, preds = torch.max(outputs, 1)train_acc += torch.sum(preds == labels.data).item()train_loss /= len(train_loader.dataset)train_acc /= len(train_loader.dataset)# 在测试集上评估模型model.eval()test_loss = 0.0test_acc = 0.0with torch.no_grad():for images, labels in test_loader:images = images.to(device)labels = labels.to(device)outputs = model(images)loss = criterion(outputs, labels)test_loss += loss.item() * images.size(0)_, preds = torch.max(outputs, 1)test_acc += torch.sum(preds == labels.data).item()test_loss /= len(test_loader.dataset)test_acc /= len(test_loader.dataset)print(f'Epoch {epoch+1}/{num_epochs}, Train Loss: {train_loss:.4f}, Train Accuracy: {train_acc:.4f}, 'f'Test Loss: {test_loss:.4f}, Test Accuracy: {test_acc:.4f}')# 输出样例
print("Sample outputs:")
model.eval()
with torch.no_grad():for images, labels in test_loader:images = images.to(device)labels = labels.to(device)outputs = model(images)_, preds = torch.max(outputs, 1)for i in range(images.size(0)):print(f"Predicted: {preds[i].item()}, Ground Truth: {labels[i].item()}")break # 只输出一个批次的样例结果以上代码展示了包含数据加载和训练的完整代码,使用VGG-16模型对Fashion-MNIST数据集进行了训练和测试。训练过程中,模型在每个epoch中进行了训练和验证,并输出了训练和验证集上的损失和准确率。最后,展示了一个样例输出,显示了模型在测试集上的预测结果。
VGG-19:
import torch
from torch import nn
from torchvision.transforms import ToTensor
from torchvision.datasets import FashionMNIST
from torch.utils.data import DataLoader# 定义VGG块
def vgg_block(num_convs, in_channels, out_channels):layers = []for _ in range(num_convs):layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))layers.append(nn.ReLU())in_channels = out_channelslayers.append(nn.MaxPool2d(kernel_size=2, stride=2))return nn.Sequential(*layers)# 定义VGG-19网络
class VGG19(nn.Module):def __init__(self):super(VGG19, self).__init__()self.conv_blocks = nn.Sequential(vgg_block(2, 3, 64),vgg_block(2, 64, 128),vgg_block(4, 128, 256),vgg_block(4, 256, 512),vgg_block(4, 512, 512))self.fc_layers = nn.Sequential(nn.Linear(512 * 7 * 7, 4096),nn.ReLU(True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(True),nn.Dropout(),nn.Linear(4096, 10))def forward(self, x):x = self.conv_blocks(x)x = torch.flatten(x, start_dim=1)x = self.fc_layers(x)return x# 将Fashion-MNIST图像转换为Tensor,并进行数据加载
transform = ToTensor()
train_dataset = FashionMNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = FashionMNIST(root='./data', train=False, download=True, transform=transform)# 创建数据加载器
batch_size = 128
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 创建VGG-19模型实例
model = VGG19()# 定义优化器和损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=0.05)
criterion = nn.CrossEntropyLoss()# 将模型移动到GPU(如果可用)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)# 训练模型
num_epochs = 10
for epoch in range(num_epochs):model.train()train_loss = 0.0train_acc = 0.0for images, labels in train_loader:images = images.to(device)labels = labels.to(device)optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()train_loss += loss.item() * images.size(0)_, preds = torch.max(outputs, 1)train_acc += torch.sum(preds == labels.data).item()train_loss /= len(train_loader.dataset)train_acc /= len(train_loader.dataset)# 在测试集上评估模型model.eval()test_loss = 0.0test_acc = 0.0with torch.no_grad():for images, labels in test_loader:images = images.to(device)labels = labels.to(device)outputs = model(images)loss = criterion(outputs, labels)test_loss += loss.item() * images.size(0)_, preds = torch.max(outputs, 1)test_acc += torch.sum(preds == labels.data).item()test_loss /= len(test_loader.dataset)test_acc /= len(test_loader.dataset)print(f'Epoch {epoch+1}/{num_epochs}, Train Loss: {train_loss:.4f}, Train Accuracy: {train_acc:.4f}, 'f'Test Loss: {test_loss:.4f}, Test Accuracy: {test_acc:.4f}')# 输出样例
print("Sample outputs:")
model.eval()
with torch.no_grad():for images, labels in test_loader:images = images.to(device)labels = labels.to(device)outputs = model(images)_, preds = torch.max(outputs, 1)for i in range(images.size(0)):print(f"Predicted: {preds[i].item()}, Ground Truth: {labels[i].item()}")break # 只输出一个批次的样例结果
🌊4. 研究体会
在本次实验中,我采用了块的网络结构,具体来说是VGG(Visual Geometry Group)网络,进行了深入的研究和分析。通过实验,我对使用块的网络的性能和优势有了更深刻的理解,并在不同任务上的适用性方面进行了探索。
首先,块的网络结构给予了深度神经网络更强大的特征提取能力。通过将多个卷积层和池化层堆叠在一起形成块的方式,块的网络能够逐层地提取出越来越抽象的特征信息。这种层次化的特征提取过程有助于网络更好地理解和表示输入数据,提高模型的分类准确率。在实验中的结果表明,相比传统的浅层网络,块的网络在处理复杂的视觉任务时表现出更好的性能。
其次,通过实验发现,块的网络的深度与性能之间存在一定的关系。逐渐增加块的数量可以增加网络的深度,但并不意味着性能一定会线性提升。实验中,我逐步增加了VGG网络的块数,并观察了模型的性能变化。结果显示,在增加块的数量初期,性能得到了显著提升,但随着深度继续增加,性能的改善趋于平缓,甚至有时会出现性能下降的情况。这表明网络深度的增加并不是无限制地提高性能的唯一因素,适当的模型复杂度和正则化方法也需要考虑。对块的网络在不同任务上的适用性进行了研究。通过在不同的数据集上进行训练和测试,我发现块的网络在图像分类、目标检测和语义分割等多个视觉任务中都表现出很好的性能。这表明块的网络具有较强的泛化能力和适应性,能够应用于多个领域和应用场景。这对于深度学习的研究和应用具有重要的启示意义,也为实际应用中的图像分析和理解提供了有力支持。
实验发现块的网络结构具有良好的模块化和复用性,使得网络的设计和调整变得更加灵活和高效。通过将相同的卷积层和池化层堆叠在一起形成块,我可以轻松地调整网络的深度和宽度,而不需要对每一层都进行单独设计和调整。这种模块化的结构使得网络的搭建和调试更加高效,节省了大量的时间和资源。

相关文章:
【动手学深度学习】使用块的网络(VGG)的研究详情
目录 🌊1. 研究目的 🌊2. 研究准备 🌊3. 研究内容 🌍3.1 多层感知机模型选择、欠拟合和过拟合 🌍3.2 练习 🌊4. 研究体会 🌊1. 研究目的 理解块的网络结构;比较块的网络与传统…...

JFinal学习07 控制器——接收数据之getBean()和getModel()
JFinal学习07 控制器——接收数据之getBean()和getModel() 视频来源https://www.bilibili.com/video/BV1Bt411H7J9/?spm_id_from333.337.search-card.all.click 文章目录 JFinal学习07 控制器——接收数据之getBean()和getModel()一、接收数据的类型二、getBean()和getModel()…...

二百三十九、Hive——Hive函数全篇
--创建测试数据库test show databases ; create database if not exists test; use test;一、关系运算 1、等值比较: select 1 where 1 1; --1 select 1 where 0 1; --NULL 2、不等值比较:<> select 1 where 1 <> 2; --1 sele…...
视频去水印电脑版,视频去水印软件
视频去水印怎么去,一直是视频编辑者们的热门话题。那么,如何去除频水印呢?接下来,我们将为您详细介绍视频去水印方法。 第一种方法: 首先通过浏览器打开 “ 51视频处理官网” 的网站。打开网站后,我们上传…...

北邮21硕后端开发笔记
blog 整理北邮21渣硕Java后端开发知识网络,阅读笔记以及技术博客,持续更新!欢迎Star! GitHub: https://github.com/WeiXiao-Hyy/blog Java 基础篇 一文带你搞懂final关键字 Java并发编程 fucking-java-concurrency解读你真…...

【Linux】系统优化:一键切换软件源与安装Docker
引言 在Linux系统安装完成后,进行一些必要的初始化设置是提升系统性能和用户体验的关键。本文将重点介绍两个实用的一键脚本:LinuxMirrors提供的软件源切换脚本和Docker安装脚本。这两个脚本将帮助我们简化配置安装过程。 一键切换软件源脚本 在Linux…...

【集装箱调度】基于粒子群算法实现考虑重量限制和时间约束的集装箱码头满载AGV自动化调度附matlab代码
% 交叉定位 - 最小二乘法定位算法模拟 % 参数设置 numIterations 1000; % 模拟迭代次数 maxDistance 1000; % 最远定位距离(设定范围) speedOfSound 343; % 声速(单位:m/s) % 预警机坐标 source [0, 0]; % 初始…...
使用 ESP32 和 PlatformIO (arduino框架)实现 Over-the-Air(OTA)固件更新
使用 ESP32 和 PlatformIO 实现 Over-the-Air(OTA)固件更新 摘要: 本文将介绍如何在 ESP32 上使用 PlatformIO 环境实现 OTA(Over-the-Air)固件更新。OTA 更新使得在设备部署在远程位置时,无需物理接触设…...

学习笔记——路由网络基础——汇总静态路由
4、汇总静态路由 (1)定义 静态路由汇总:多条静态路由都使用相同的送出接口或下一跳 IP 地址。(将多条路由汇总成一条路由表示) (2)目的 1.减少路由条目数量,减小路由表,加快查表速度 2.增加网络稳定性 (3)路由黑洞以及路由环路的产生…...

这10个python库,下载都超过5亿
python的库数不胜数。哪些库使用得最多呢。今天分享10个下载都超过5亿的python库。从高到低排序 第一名:Urllib3 下载次数:8.93亿次 介绍:Urllib3是一个功能强大且用户友好的HTTP客户端库,提供了许多Python标准库中没有的特性&…...
Vue3【十一】08使用toRefs和toRef
08使用toRefs和toRef toRefs()函数将person对象中的name和age属性转换为响应式引用,并返回一个对象,对象中的name和age属性都是响应式引用,具有响应式功能。 toRef()函数将person对象中的name属性转换为响应式引用,并返回一个响应…...

离散数学---树
目录 1.基本概念及其相关运用 2.生成树 3.有向树 4.最优树 5.前缀码 1.基本概念及其相关运用 (1)无向树:连通而且没有回路的无向图就是无向树; 森林就是有多个连通分支,每个连通分支都是树的无连通的无向图&…...

【栈】1106. 解析布尔表达式
本文涉及知识点 栈 LeetCode 1106. 解析布尔表达式 布尔表达式 是计算结果不是 true 就是 false 的表达式。有效的表达式需遵循以下约定: ‘t’,运算结果为 true ‘f’,运算结果为 false ‘!(subExpr)’,运算过程为对内部表达式…...
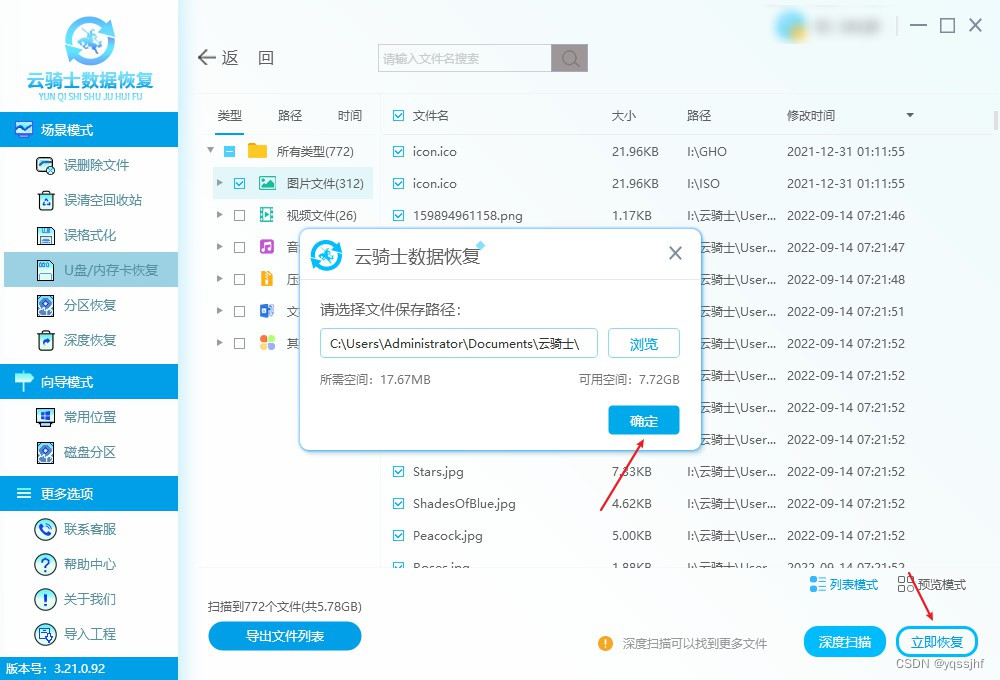
u盘内容无故消失了是什么原因?u盘部分内容无故消失了怎么恢复
在数字化时代,U盘作为便携存储设备,承载着许多重要的数据。然而,有时我们可能会遭遇U盘部分内容无故消失的情况,这无疑给我们的工作和生活带来了不小的困扰。本文将为您解析U盘内容消失的可能原因,并分享几招实用的数据…...
glm-4v-9b 部署
glm-4v-9b 模型文件地址 GLM-4 仓库文件地址 官方测试 硬件配置和系统要求 官方测试硬件信息: OS: Ubuntu 22.04Memory: 512G…...

Ansible——unarchive模块
目录 参数总结 基础语法 常见的命令行示例 示例1:解压缩文件到指定目录 示例2:解压缩文件并设置权限 示例3:远程URL解压缩 示例4:强制覆盖现有文件 具体步骤和示例 示例5:只要文件解压后,如果存在…...

Ansible——get_url模块
目录 主要用途 参数总结 基本语法示例 使用示例 示例1:下载文件 示例2:使用校验和验证文件 示例3:使用 HTTP 基本认证 示例4:通过代理服务器下载文件 示例5:设置文件权限、所有者和组 示例6:强制…...

macbook本地部署 pyhive环境连接 hive用例
前言 公司的测试和生产环境中尚未提供基于Hive的客户端。若希望尝试操作Hive表,目前一个可行的方案是使用Python语言,通过借助pyhive库,您可以对Hive表进行各种操作。以下是一些示例记录供您参考。 一、pyhive是什么? PyHive是一…...

物理安全防护如何创新强化信息安全体系?
物理安全防护是信息安全体系的重要组成部分,它通过保护实体设施、设备和介质等,防止未授权访问、破坏、盗窃等行为,从而为信息系统提供基础的安全保障。要创新强化信息安全体系中的物理安全防护,可以从以下几个方面着手࿱…...
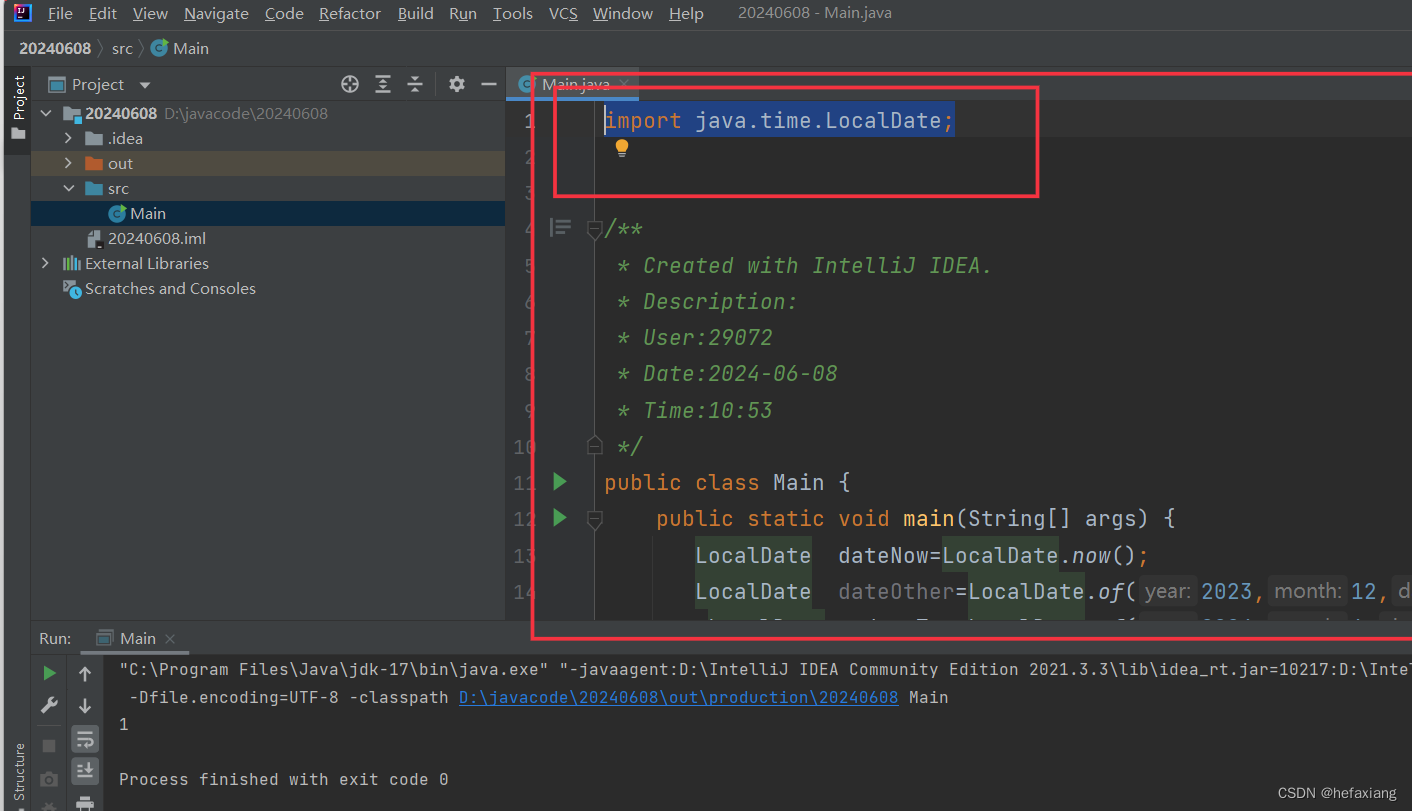
【JAVASE】日期与时间类(上)
一:概述 从JAVA SE 8开始提供了java.time包,该包中有专门处理日期和时间的类。 LocalDate LocalDateTime 和LocalTime 类的对象封装和日期、时间有关的数据,这三个类都是final类,而且不提供修改数据的方法,即这…...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...
)
【HarmonyOS 5 开发速记】如何获取用户信息(头像/昵称/手机号)
1.获取 authorizationCode: 2.利用 authorizationCode 获取 accessToken:文档中心 3.获取手机:文档中心 4.获取昵称头像:文档中心 首先创建 request 若要获取手机号,scope必填 phone,permissions 必填 …...

基于Java+MySQL实现(GUI)客户管理系统
客户资料管理系统的设计与实现 第一章 需求分析 1.1 需求总体介绍 本项目为了方便维护客户信息为了方便维护客户信息,对客户进行统一管理,可以把所有客户信息录入系统,进行维护和统计功能。可通过文件的方式保存相关录入数据,对…...

NPOI Excel用OLE对象的形式插入文件附件以及插入图片
static void Main(string[] args) {XlsWithObjData();Console.WriteLine("输出完成"); }static void XlsWithObjData() {// 创建工作簿和单元格,只有HSSFWorkbook,XSSFWorkbook不可以HSSFWorkbook workbook new HSSFWorkbook();HSSFSheet sheet (HSSFSheet)workboo…...

android RelativeLayout布局
<?xml version"1.0" encoding"utf-8"?> <RelativeLayout xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width"match_parent"android:layout_height"match_parent"android:gravity&…...

Ubuntu系统复制(U盘-电脑硬盘)
所需环境 电脑自带硬盘:1块 (1T) U盘1:Ubuntu系统引导盘(用于“U盘2”复制到“电脑自带硬盘”) U盘2:Ubuntu系统盘(1T,用于被复制) !!!建议“电脑…...
 Module Federation:Webpack.config.js文件中每个属性的含义解释)
MFE(微前端) Module Federation:Webpack.config.js文件中每个属性的含义解释
以Module Federation 插件详为例,Webpack.config.js它可能的配置和含义如下: 前言 Module Federation 的Webpack.config.js核心配置包括: name filename(定义应用标识) remotes(引用远程模块࿰…...

API网关Kong的鉴权与限流:高并发场景下的核心实践
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 引言 在微服务架构中,API网关承担着流量调度、安全防护和协议转换的核心职责。作为云原生时代的代表性网关,Kong凭借其插件化架构…...
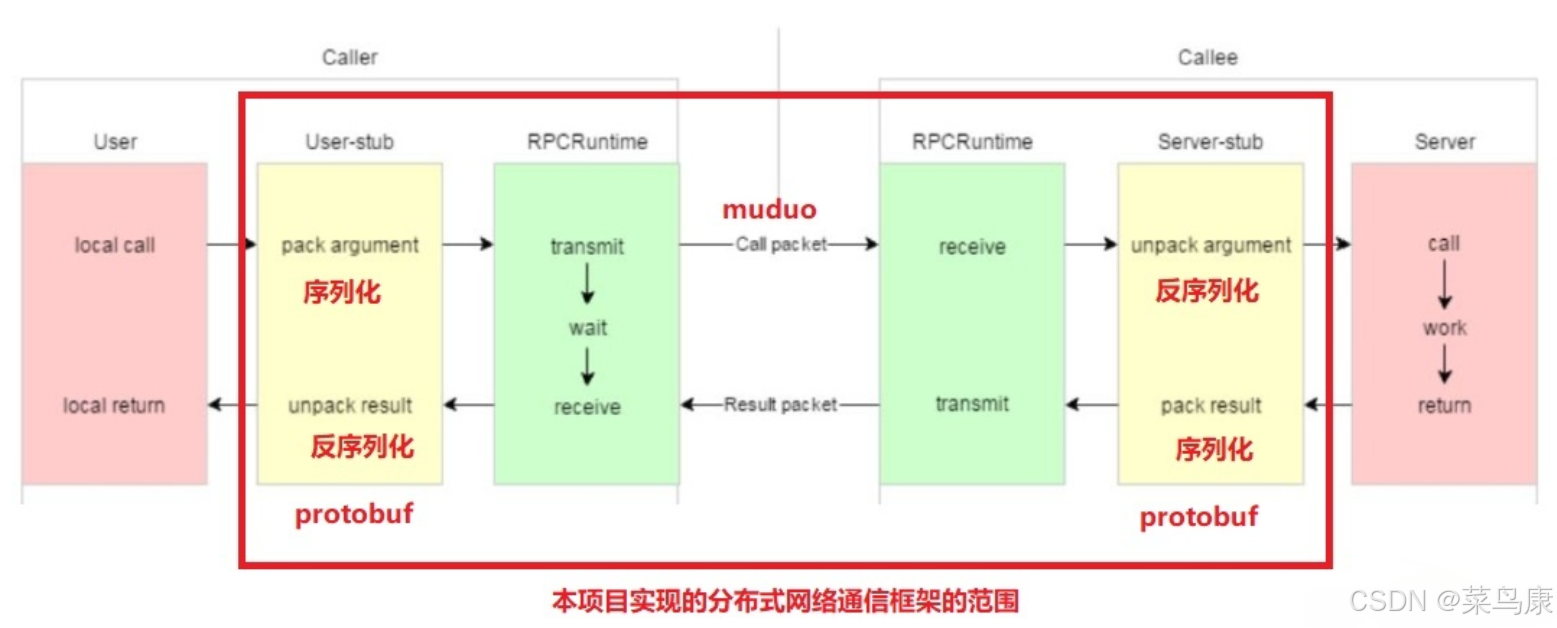
C++实现分布式网络通信框架RPC(2)——rpc发布端
有了上篇文章的项目的基本知识的了解,现在我们就开始构建项目。 目录 一、构建工程目录 二、本地服务发布成RPC服务 2.1理解RPC发布 2.2实现 三、Mprpc框架的基础类设计 3.1框架的初始化类 MprpcApplication 代码实现 3.2读取配置文件类 MprpcConfig 代码实现…...

LangChain【6】之输出解析器:结构化LLM响应的关键工具
文章目录 一 LangChain输出解析器概述1.1 什么是输出解析器?1.2 主要功能与工作原理1.3 常用解析器类型 二 主要输出解析器类型2.1 Pydantic/Json输出解析器2.2 结构化输出解析器2.3 列表解析器2.4 日期解析器2.5 Json输出解析器2.6 xml输出解析器 三 高级使用技巧3…...