MASA:匹配一切、分割一切、跟踪一切
文章目录
- 摘要
- 1、引言
- 2、相关工作
- 2.1、学习实例级关联
- 2.2、Segment and Track Anything 模型
- 3、方法
- 3.1、预备知识:SAM
- 3.2、通过分割任何事物来匹配任何事物
- 3.2.1、MASA流程
- 3.2.2、MASA适配器
- 3.2.3、推理
- 4、实验
- 4.1、实验设置
- 4.2、与最先进技术的比较
- 4.3、消融研究与分析
- 5、结论
- 附录
- A. 在其他主干网络上的有效性
- B. 在YoutubeVIS上的零次学习评估
- C. 实例嵌入的可视化
- D. 领域差异与适应
- E. 光度增强的影响
- F. 提案多样性的比较
- G. 与自监督方法的比较
- H. 与基于视频对象分割(VOS)的方法的比较
- I. 更多定性结果
- I.1. 快速候选区域生成
- I.2. 开放词汇跟踪
- I.3. 联合分割和跟踪所有内容
- J. 实现细节
- J.1. 架构细节
- J.2. 更多训练细节
- J.3. 使用给定观测的推理
- J.4. 推理细节
- K. 局限性
摘要
https://matchinganything.github.io/
在复杂场景中跨视频帧稳健地关联相同对象是许多应用的关键,特别是多目标跟踪(MOT)。当前方法主要依赖于标注的特定领域视频数据集,这限制了学习到的相似度嵌入的跨域泛化能力。我们提出了MASA,一种新颖的方法用于稳健的实例关联学习,该方法能够在不同领域内的视频中匹配任何对象,而无需跟踪标签。MASA利用Segment Anything Model(SAM)丰富的对象分割结果,通过详尽的数据变换来学习实例级别的对应关系。我们将SAM的输出视为密集的对象区域提案,并从庞大的图像集合中学习匹配这些区域。我们进一步设计了一个通用的MASA适配器,它可以与基础的分割或检测模型协同工作,并使它们能够跟踪任何检测到的对象。这些组合在复杂领域中表现出强大的零次学习跟踪能力。在多个具有挑战性的MOT和MOTS基准测试上的广泛测试表明,所提出的方法仅使用未标记的静态图像,在零次学习关联中,其性能甚至超过了使用完全标注的域内视频序列训练的最新方法。我们的代码已公开在github.com/siyuanliii/masa。
1、引言
多目标跟踪(MOT)是计算机视觉中的一个基本问题。它在许多机器人系统中扮演着关键角色,如自动驾驶。跟踪不仅需要检测视频中的感兴趣对象,还需要跨帧关联这些对象。尽管最近视觉基础模型[33,35,40,47,70,78]的进展已经展示了检测、分割和感知任何对象深度的卓越能力,但在视频中关联这些对象仍然是一个挑战。最近成功的多目标跟踪方法[36,66]已经强调了学习判别性实例嵌入以进行准确关联的重要性。一些方法[46]甚至认为,除了检测之外,它是唯一的必要跟踪组件。
然而,学习有效的对象关联通常需要大量的标注数据。虽然收集一组多样化图像的检测标签是繁琐的,但在视频上获得跟踪标签则更具挑战性。因此,当前的MOT数据集主要关注来自特定领域的对象,具有少量固定类别或有限数量的标注帧。
在这些数据集上进行训练限制了跟踪模型对不同领域和新颖概念的泛化能力。尽管最近的研究[35,40,78]已经成功地尝试解决了对象检测和分割模型的泛化问题,但学习一个能够跟踪任何对象的通用关联模型的路径仍然不明确。
我们的目标是开发一种能够匹配任何对象或区域的方法。我们旨在将这种可泛化的跟踪能力与任何检测和分割方法相结合,以帮助它们跟踪已检测到的任何对象。一个主要的挑战是在不产生大量标注成本的情况下,为不同领域的一般对象获取匹配监督。

为此,我们提出了通过分割任何事物(MASA)来学习任何领域未标记图像中的对象级关联的管道。图1展示了我们的MASA管道的概述。我们利用基础分割模型SAM编码的丰富对象外观和形状信息,结合广泛的数据变换,来建立强大的实例对应关系。
对同一张图像应用不同的几何变换可以在两个视图之间自动生成像素级的对应关系。SAM的分割能力允许自动将来自同一实例的像素进行分组,从而促进了从像素级到实例级的对应关系的转换。这一过程为学习判别性对象表示提供了自我监督信号,利用视图对之间的密集相似性学习。我们的训练策略使我们能够使用来自不同领域的丰富原始图像集合,展示了这种在多样化原始图像上的自动自我训练提供了出色的零次学习多目标跟踪性能,甚至超过了依赖于领域内视频标注进行关联学习的模型。
除了自我训练管道之外,我们进一步构建了一个通用的跟踪适配器——MASA适配器,用于为任何现有的开放世界分割和检测基础模型(如SAM[35]、Detic[78]和GroundingDINO[40])赋能,使它们能够跟踪已检测到的任何对象。为了保持它们原始的分割和检测能力,我们冻结了它们的原始主干网络,并在其顶部添加了MASA适配器。
此外,我们提出了一个多任务训练流程,该流程同时执行SAM检测知识的蒸馏和实例相似性学习。这种方法使我们能够学习SAM的对象位置、形状和外观先验知识,并在对比相似性学习中模拟真实的检测建议。这个流程进一步提高了我们跟踪特征的泛化能力。另外,我们学习的检测头将原始SAM的密集均匀点建议用于分割所有内容的速度提高了十倍以上,这对于跟踪应用至关重要。
我们在多个具有挑战性的基准测试中评估了MASA,包括TAO MOT[17]、开放词汇MOT[37]、BDD100K上的MOT和MOTS[71],以及UVO[55]。广泛的实验表明,与在完全领域内标注视频上训练的最先进对象跟踪方法相比,我们的方法使用具有相同模型参数的单一模型并在零次学习关联设置中测试,达到了相当甚至更好的关联性能。
2、相关工作
2.1、学习实例级关联
学习鲁棒的实例级对应关系对于目标跟踪至关重要。现有的方法可以分为自监督[58]和监督[9, 36, 44, 46, 57, 63, 65, 66, 72, 76]策略。具体而言,作为一种典型的自监督方法,UniTrack[58]试图直接使用现成的自监督表示[11, 64]进行关联。尽管在某些基准测试[45]上取得了具有竞争力的结果,但这些方法无法充分利用实例级训练数据,从而限制了它们在挑战性场景下的性能。相反,监督方法通过对比学习在帧对上训练具有区分性的实例嵌入。尽管这些方法在挑战性基准测试[17, 37, 41, 50, 71]上取得了优越的性能,但它们依赖于大量的领域内标注视频数据。一些方法[2, 20, 37, 77, 79]从静态图像中学习跟踪信号,但仍然需要在特定领域中进行大量的细粒度实例标注或在测试时进行后适应[53],这限制了它们的跨域泛化能力。为了解决这些问题,我们利用SAM编码的详尽对象形状和外观信息来学习通用的实例匹配,完全依赖于未标记的图像。我们学到的表示在跨不同领域时显示出卓越的零次学习关联能力。
2.2、Segment and Track Anything 模型
Deva [14]、TAM [67] 和 SAM-Track [15] 将 SAM [35] 与视频对象分割(VOS)方法(如 XMem [13] 和 DeAOT [69])相结合,以实现任何对象的交互式跟踪流程。在这些方法中,SAM 主要用于掩码的初始化和修正,而 XMem/DeAOT 负责跟踪和预测。SAM-PT [49] 将 SAM 与点跟踪方法(如 [24, 29, 54])相结合来执行跟踪。然而,所有这些方法都面临一些限制,如由于领域差异导致的掩码传播质量不佳,以及无法处理多个多样化对象或快速进入和离开场景的对象,这在自动驾驶等场景中很常见。我们的工作关注于不同的方向。我们不构建交互式跟踪流程或使用现成的 VOS 或基于点的跟踪器,而是专注于通过学习通用关联模块来利用 SAM 丰富的实例分割知识。
3、方法
3.1、预备知识:SAM
SAM [35] 由三个模块组成:(a) 图像编码器:一个基于 ViT 的重型骨干网络,用于特征提取。(b) 提示编码器:对交互式点、框或掩码提示中的位置信息进行建模。© 掩码解码器:一个基于 Transformer 的解码器,它接收提取的图像嵌入和连接的输出以及提示令牌,以进行最终的掩码预测。为了生成所有可能的掩码提议,SAM 采用密集采样的规则网格作为点锚点,并为每个点提示生成掩码预测。完整的流程包括基于贪心框的 NMS 的补丁裁剪、三步过滤和对掩码的重度后处理。关于 SAM 的“万物模式”的更多详细信息,我们参考 [35]。
3.2、通过分割任何事物来匹配任何事物
我们的方法由两个关键组件组成。首先,基于 SAM,我们开发了一个新的流程:MASA(第 3.2.1 节)。通过这个流程,我们从丰富的未标记图像集合中构建密集实例级别的对应关系的全面监督。这使得我们能够学习强大的区分性实例表示来跟踪任何对象,而无需任何视频注释。其次,我们引入了一个通用的 MASA 适配器(第 3.2.2 节),以有效地将从冻结的检测或分割骨干网络中提取的特征转换为可学习泛化实例外观表示的特征。作为副产品,MASA 适配器的蒸馏分支也可以显著提高分割所有事物的效率。此外,我们还构建了一个统一模型,以联合检测/分割和跟踪任何事物(第 3.2.3 节)。我们的完整训练流程如图 2 所示。
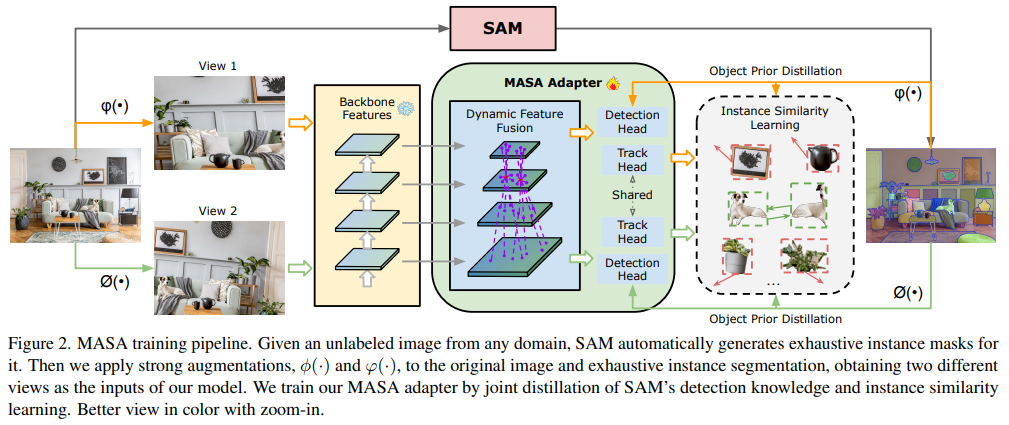
3.2.1、MASA流程
为了学习实例级别的对应关系,以前的工作[36, 46, 65, 66, 76]严重依赖于手动标记的领域内视频数据。然而,当前的视频数据集[6, 45, 71]仅包含有限范围的固定类别。数据集中的这种有限多样性导致学习到的外观嵌入是针对特定领域的,这对其通用泛化提出了挑战。
UniTrack[58]表明,可以通过对比自监督学习技术[8, 11, 64]从原始图像或视频中学习通用外观特征。这些表示利用了大量未标记图像的多样性,可以在不同的跟踪领域中泛化。然而,它们通常依赖于干净的、以对象为中心的图像,如ImageNet[52]中的图像,或DAVIS17[48]等视频,并侧重于帧级别的相似性。这种关注导致它们无法充分利用实例信息,从而在具有多个实例的复杂领域中学习有区分度的实例表示时遇到困难,如表7所示。
为了解决这些问题,我们提出了MASA训练流程。我们的核心思想是从两个角度增加多样性:训练图像多样性和实例多样性。如图1所示,我们首先从不同领域构建丰富的原始图像集合,以防止学习特定领域的特征。这些图像还包含复杂环境中的大量实例,以增强实例的多样性。给定图像 I I I,我们通过对同一图像采用不同的增强来模拟视频中的外观变化。通过应用强数据增强 φ ( I ) \varphi(I) φ(I)和 ϕ ( I ) \phi(I) ϕ(I),我们构造了 I I I的两种不同视图 V 1 V_{1} V1和 V 2 V_{2} V2,从而自动获得像素级别的对应关系。如果图像是干净的且仅包含一个实例,如ImageNet中的图像,则可以应用帧级别的相似性,如[11, 64, 74]中所述。但是,当存在多个实例时,我们需要进一步挖掘这些原始图像中包含的实例信息。基础分割模型SAM[35]为我们提供了这种能力。SAM自动将属于同一实例的像素分组,并提供检测到的实例的形状和边界信息,这对于学习有区分度的特征非常有价值。
由于我们通过选择包含多个实例的图像来构建数据集,SAM对整个图像的详尽分割自动产生了一个密集且多样的实例提议集合 Q Q Q。在建立了像素级别的对应关系后,对 Q Q Q应用相同的 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)和 φ ( ⋅ ) \varphi(\cdot) φ(⋅),将像素级别的对应关系转移到密集的实例级别对应关系。这种自监督信号使我们能够使用来自[34, 36, 46]的对比学习公式来学习一个具有区分度的对比嵌入空间:
L C = − ∑ q ∈ Q log e sim ( q , q + ) τ e sim ( q , q + ) τ + ∑ q − ∈ Q − e sim ( q , q − ) τ , \mathcal{L}_{\mathcal{C}}=-\sum_{q \in Q} \log \frac{e^{\frac{\operatorname{sim}\left(q, q^{+}\right)}{\tau}}}{e^{\frac{\operatorname{sim}\left(q, q^{+}\right)}{\tau}}+\sum_{q^{-} \in Q^{-}} e^{\frac{\operatorname{sim}\left(q, q^{-}\right)}{\tau}}}, LC=−∑q∈Qlogeτsim(q,q+)+∑q−∈Q−eτsim(q,q−)eτsim(q,q+),
在这里, q + q^{+} q+和 q − q^{-} q−分别表示 q q q的正样本和负样本。正样本是应用不同 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)和 φ ( ⋅ ) \varphi(\cdot) φ(⋅)的相同实例提议。负样本来自不同的实例。此外, sim ( ⋅ ) \operatorname{sim}(\cdot) sim(⋅)表示余弦相似度, τ \tau τ是一个温度参数,在我们的实验中设置为0.07。
这种对比学习公式将属于同一实例的对象嵌入推得更近,同时将来自不同实例的嵌入距离拉远。如现有作品[10, 46]所示,负样本对于学习有区分度的表示至关重要。在对比学习范式下,SAM生成的密集提议自然地提供了更多的负样本,从而增强了学习更好的实例表示以进行关联。
3.2.2、MASA适配器
我们引入了MASA适配器,旨在将开放世界分割和检测模型(如SAM[35]、Detic[78]和Grounding-DINO[40])扩展到跟踪任何检测到的对象。MASA适配器与这些基础模型的冻结主干特征一起工作,确保其原始的检测和分割能力得以保留。然而,由于并非所有预训练特征都天生具有跟踪区分度,因此我们首先将这些冻结的主干特征转换为更适合跟踪的新特征。
鉴于物体形状和大小的多样性,我们构建了一个多尺度特征金字塔。对于像Detic和Grounding DINO中使用的Swin Transformer[42]这样的层次化主干,我们直接采用FPN[39]。对于使用普通ViT[18]主干的SAM,我们使用转置卷积和最大池化来对步长为 16 × 16 \times 16×的单尺度特征进行上采样和下采样,以产生比例尺分别为 1 4 , 1 8 , 1 16 , 1 32 \frac{1}{4}, \frac{1}{8}, \frac{1}{16}, \frac{1}{32} 41,81,161,321的层次化特征。为了有效地学习不同实例的区分性特征,位于一个位置的物体需要了解其他位置实例的外观。因此,我们使用可变形卷积来生成动态偏移,并在空间位置和特征层级间聚合信息,如[16]所述:
F ( p ) = 1 L ∑ j = 1 L ∑ k = 1 K w k ⋅ F j ( p + p k + Δ p k j ) ⋅ Δ m k j , F(p)=\frac{1}{L} \sum_{j=1}^{L} \sum_{k=1}^{K} w_{k} \cdot F^{j}\left(p+p_{k}+\Delta p_{k}^{j}\right) \cdot \Delta m_{k}^{j}, F(p)=L1∑j=1L∑k=1Kwk⋅Fj(p+pk+Δpkj)⋅Δmkj,
其中 L L L表示特征层级, K K K是卷积核的采样位置数量, w k w_{k} wk和 p k p_{k} pk分别是第 k k k个位置的权重和预定义偏移,而 Δ p k j \Delta p_{k}^{j} Δpkj和 Δ m k j \Delta m_{k}^{j} Δmkj是第 j j j个特征层级上第 k k k个位置的可学习偏移和调制因子。对于基于SAM的模型,我们额外使用了Dyhead[16]中的任务感知注意力和尺度感知注意力,因为检测性能对于如图3(b)所示的准确自动掩码生成很重要。在获得转换后的特征图后,我们通过将RoI-Align[26]应用于视觉特征 F F F来提取实例级特征,然后通过一个包含4个卷积层和1个全连接层的轻量级跟踪头进行处理,以生成实例嵌入。
此外,我们在训练过程中引入了一个对象先验蒸馏分支作为辅助任务。该分支使用标准的RCNN[51]检测头来学习紧密包围SAM为每个实例的掩码预测的边界框。它有效地从SAM中学习详尽的对象位置和形状知识,并将这些信息蒸馏到转换后的特征表示中。这种设计不仅加强了MASA适配器的特征,提高了关联性能,还通过直接提供预测的边界框提示来加速SAM的“万物模式”。
MASA适配器使用第3.2.1节中定义的检测和对比损失的组合进行优化: L = L det + L C \mathcal{L}=\mathcal{L}_{\text {det }}+\mathcal{L}_{C} L=Ldet +LC。检测损失与[51]中的相同。
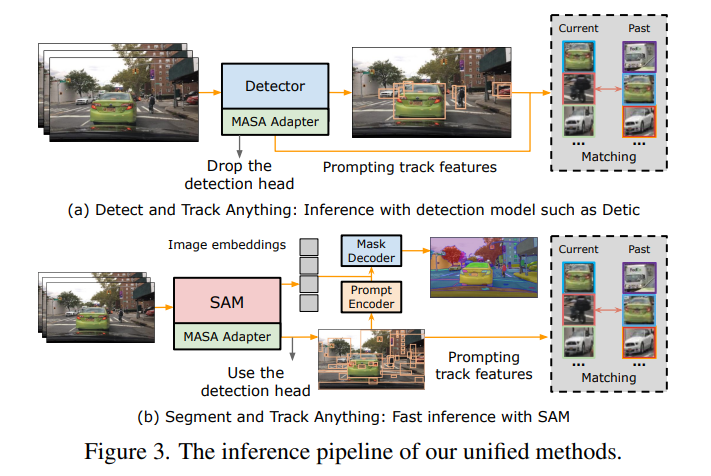
3.2.3、推理
图3展示了使用我们的统一模型的测试流程。当我们将MASA适配器与对象检测器集成时,我们在测试时移除了训练期间学习的MASA检测头。然后,MASA适配器仅作为跟踪器使用。检测器预测边界框,然后这些边界框被用来提示MASA适配器,MASA适配器检索相应的跟踪特征以进行实例匹配。我们使用一个简单的双softmax最近邻搜索来进行准确的实例匹配,如附录第J.4节所示。
使用SAM进行“Segment and Track Anything”时,我们保留了检测头。我们使用它来预测场景中的所有潜在对象,并将边界框预测作为提示转发给SAM掩码解码器和MASA适配器,以便分割和跟踪所有内容。预测的边界框提示省去了原始SAM“万物模式”中繁重的后处理步骤,因此显著加快了SAM的自动掩码生成速度。
使用给定观测结果的测试 当检测来自MASA适配器所基于的源以外的其他来源时,我们的MASA适配器作为跟踪特征提供者。我们直接使用提供的边界框作为提示,通过ROI-Align[26]操作从MASA适配器中提取跟踪特征。
4、实验
我们在多个具有不同领域的具有挑战性的MOT/MOTS基准上进行了实验。
4.1、实验设置
TAO MOT。 TAO数据集[17]旨在跟踪多种类型的对象,涵盖了超过800个类别,是目前类别收集最广泛、最多样化的MOT数据集。它包含500,988个训练视频、1,419个验证视频和测试视频,均以每秒1帧的速率进行标注。我们报告了验证集的性能。TAO包括几个基准,每个基准都强调不同的特性和要求。TAO TETA基准[36]通过奖励产生无重叠清晰轨迹的跟踪器来强调关联性。相反,TAO Track mAP基准[17]特别重视轨迹的分类,并不对重叠轨迹进行严厉惩罚。开放词汇MOT基准[37]要求跟踪器避免使用新类别的注释进行训练,专注于跟踪新类别的泛化能力。
BDD100K MOT [71] 要求跟踪器在自动驾驶场景中跟踪常见对象。该数据集以每秒5帧的速率进行标注,验证集中包含200个视频。BDD100K MOTS 与BDD100K MOT不同,BDD100K MOTS [71] 要求跟踪器同时跟踪和分割对象,在掩码上评估跟踪性能。它包含154个训练视频、32个验证视频和37个测试视频。
UVO [55] 是视频中开放世界实例分割的一个具有挑战性的基准。与之前的视频级对象分割数据集[68]相比,它标注了更多样化的实例。UVO有两个评估轨道,一个图像轨道和一个视频轨道。我们在UVOv0.5验证集上评估了所有方法。
评估指标 如先前工作[36]所分析,传统跟踪指标如mMOTA[71]和track mAP[17]可能具有误导性,特别是在长尾场景中,因为它们对分类的高度敏感性。为了解决这个问题,[36]引入了TETA这一新的跟踪指标,它分解为三个独立的部分:AssocA、LocA和ClsA,分别反映了关联、定位和分类的准确性。在标准的MOT基准测试中,为了确保公平比较跟踪器的关联能力,我们采用了领先的最先进跟踪器所使用的相同检测观测值。因此,我们的主要关注点是与关联相关的指标,如AssocA、mIDF1和IDF1。此外,在评估我们的统一模型时,我们考虑了全面的指标以捕捉它们的综合能力。特别是对于UVO上的开放世界分割,我们关注的是图像和视频级别的AR100和Track AR100指标。这是因为SAM经常分割对象的每个部分,而UVO缺乏这样的详细标注,使得传统的AP评估不够准确。
训练数据:SA-1B [35] 包含 1100 万张多样化、高分辨率的图像,这些图像涵盖了复杂环境中具有多个对象交互的多样化场景。我们从 SA-1B 的原始图像中抽样,构建了包含 500 K 500\text{ K} 500 K 张图像的训练集,即 SA-1B-500K。
实现细节:对于我们的模型,我们利用了 SAM [35]、Detic 和 Grounding-DINO 的官方权重,确保在训练阶段这些模型的所有组件都保持不变(即冻结)。具体来说,我们使用了带有 ViT-Base 和 ViT-Huge 主干的 SAM,而 Detic 和 Grounding-DINO 则使用了 SwinB 主干。我们以每个 epoch 200,000 张图像的方式进行模型训练,批次大小为 128。我们使用带有初始学习率 0.04 的 SGD(随机梯度下降)算法,并结合阶梯策略(step policy)进行学习率衰减。动量(momentum)和权重衰减(weight decay)参数分别设置为 0.9 和 1 e − 4 1e-4 1e−4。我们的训练过程跨越 12 个 epoch,并在第 8 和第 11 个 epoch 时降低学习率。在数据增强方面,除了标准的翻转、颜色抖动和随机裁剪等实践外,我们还使用了随机仿射变换、MixUp [73] 和大规模抖动 [21]。更多细节请参考附录的 J 部分。
4.2、与最先进技术的比较
我们通过两种方式评估我们的方法。首先,为了准确评估我们方法的关联能力,我们总是在标准的多目标跟踪(MOT)基准测试中提供与当前最先进技术相同的检测观测值。其次,为了评估我们统一模型的集成能力,我们遵循以下协议:对于基于SAM的模型,我们在开放世界的视频分割数据集UVO上进行评估。对于基于检测器的模型,我们在开放词汇的多目标跟踪基准[37]上进行评估。我们还报告了在TAO TETA和TAO TrackmAP基准上的得分。请注意,我们对所有变体都进行了零次学习关联测试,并在所有基准测试中都使用了相同的权重。
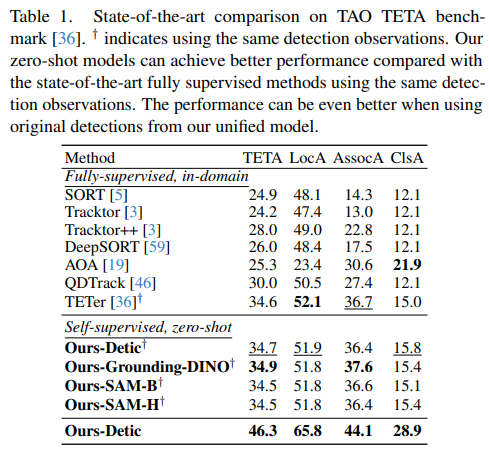
TAO TETA :我们使用了与TETerSwinT [36]相同的观测值。如表1所示,我们的方法使用Grounding-DINO的主干在零次学习设置下表现最佳,无需在任何域内标记的视频上进行训练,在AssocA和TETA两个指标上都取得了最佳成绩。我们还测试了我们的统一Detic模型,该模型同时输出检测和跟踪结果。它显著优于所有其他方法,并达到了新的最先进性能。这表明我们的方法可以很好地与当前的检测基础模型相结合,并将其强大的检测能力转移到跟踪任务中。
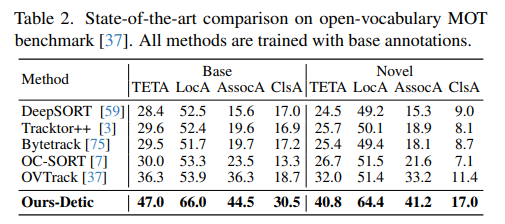
开放词汇多目标跟踪:类似于开放词汇目标检测任务[22],开放词汇多目标跟踪[37]规定方法只能使用LVIS[23]中的频繁和常见类别的注释进行训练,将稀有类别视为新类别。我们评估了我们的统一“检测和跟踪任何事物”模型Detic,该模型仅使用基本类别的注释进行训练。如表2所示,我们的统一Detic模型在基本和新颖分割的所有指标上都优于现有模型,尽管我们的跟踪器仅使用域外未标记的图像进行训练,但它仍然取得了显著的领先。
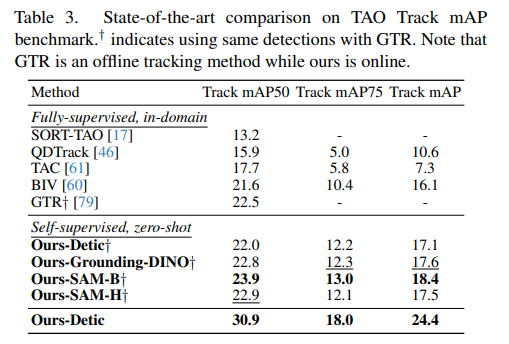
TAO Track mAP:我们使用与GTR[79]相同的观测值。如表3所示,在给定相同检测的情况下,我们的方法使用SAM-B主干取得了最佳性能(Track mAP50为23.9)。我们的大多数模型都优于当前最先进的GTR,后者是一种离线方法,利用未来信息进行关联。相比之下,我们的方法以在线方式进行跟踪,并在零次学习设置下进行测试。我们的统一Detic模型再次以较大优势超越了GTR,达到了新的最先进性能。
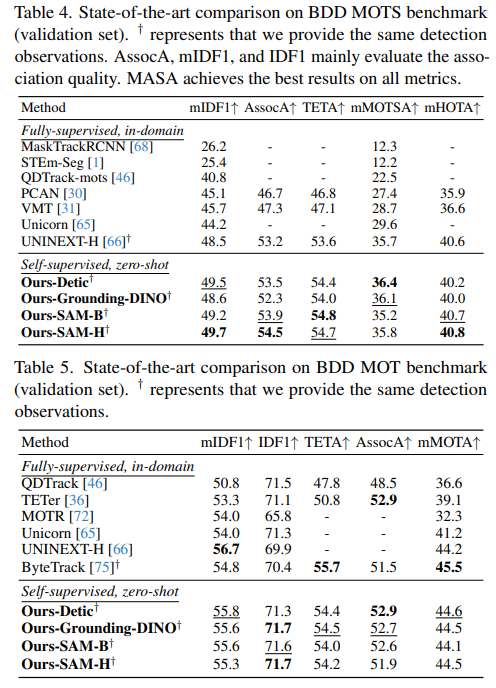
BDD100K MOTS:我们使用与最先进方法UNINEXT-H[66]相同的观测值,并在BDD100K MOTS基准上进行零次学习关联测试。如表4所示,我们的方法在所有方法中取得了最佳的关联性能(mIDF1为49.7,AssocA为54.5)。这证明了我们的方法学习到的实例嵌入的优越性。
BDD100K MOT: 如表5所示,在给定与ByteTrack[75]相同的观测值的情况下,我们的方法达到了最佳的IDF1分数71.7和AssocA分数52.9。与最先进的ByteTrack[75]相比,我们的方法也取得了更好的关联性能,IDF1和AssocA都高出约1.4%,且未使用任何BDD图像进行训练。ByteTrack额外选择了低置信度的边界框并将它们添加到轨迹中,从而获得了更好的mMOTA分数,该分数优先考虑检测性能[43]。

UVO VIS: 我们对我们的基于SAM的统一“分割和跟踪任何事物”模型进行了零次学习测试。我们直接使用MASA检测头中的框提示来快速分割所有内容。如图4a所示,我们的方法在图像和视频轨迹上都取得了最佳性能,大幅超越了其竞争对手。此外,我们还将我们的方法与SAM的默认自动掩码分割进行了比较。如图4b所示,随着推理时间的增加,由于蒸馏检测分支的存在,我们的方法的AR100增长速度远快于SAM。使用ViT-Base主干的我们的方法的AR100上限甚至超过了SAM的10%。此外,当达到相同的AR100时,我们的方法比SAM快约10倍。这源于我们的方法学习了一个强大的对象先验,通过少量的稀疏提案来捕获潜在对象。然而,为了分割所有内容,SAM必须均匀地采样约1k个点,这种方法既不灵活也不高效,同时还依赖于复杂的手工后处理方法。
与VOS方法比较:我们评估了基于VOS的方法Deva[14],该方法集成了XMem[13]用于跟踪多个对象,以及使用点跟踪的SAM-PT[49]。为了确保公平比较,我们在BDD MOTS、TAO TETA和UVO基准上提供了相同的观测值。对于UVO,我们首先使用SAM的自动掩码生成来生成掩码,然后按照Deva[14]中的启发式方法解决重叠掩码问题,并使用Deva生成每帧观测值。
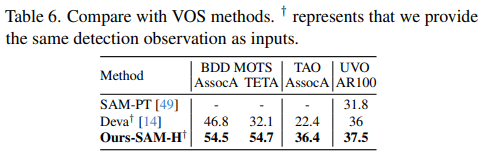
表6显示,我们的方法在所有基准上都优于Deva。值得注意的是,在自动驾驶BDD100K基准上,由于物体频繁进出场景,基于VOS的方法(如Deva)容易导致误报显著增加。这反映在TETA分数上,此类错误会受到严厉惩罚。此外,Deva在处理重叠预测时遇到困难,这是当前检测模型的常见问题。我们在附录的H节中提供了更深入的分析。
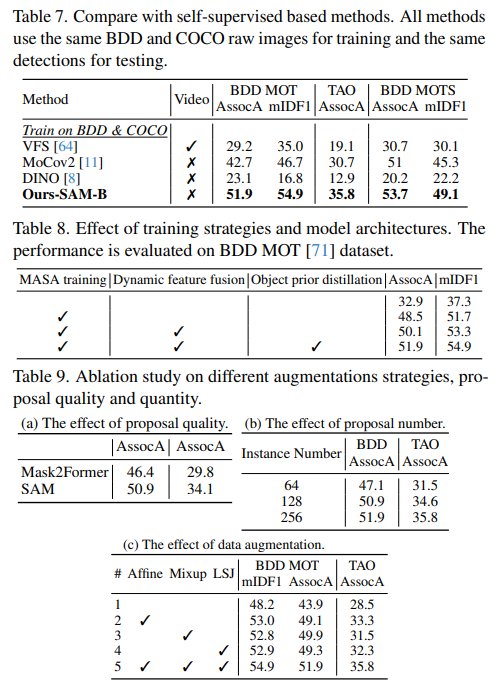
与自监督方法比较:我们进一步将我们的方法与旨在从原始图像或视频中学习通用外观特征的自监督方法进行了比较。为了确保公平比较,我们使用BDD和COCO原始图像的混合数据来训练所有方法。具体来说,对于VFS,我们使用了来自BDD的原始视频。我们为VFS[64]和MoCov2[11]采用了ResNet-50模型,为DINO[8]采用了ViTB模型,并遵循UniTrack[58]中概述的关联跟踪策略。此外,我们确保所有模型的检测观测值都是相同的。表7表明,我们的方法明显优于其他自监督方法。这种优势源于传统的自监督学习主要关注帧级相似性,这限制了它们在利用实例信息方面的有效性,并在训练包含多个对象的图像时导致困难。附录的G节提供了对此的进一步分析。
4.3、消融研究与分析
为了降低训练成本,我们在消融实验中使用了较少的原始图像( 40 K 40 \mathrm{~K} 40 K)进行训练。除非特别说明,否则我们使用包含来自[71]的 70 k 70 \mathrm{k} 70k原始图像和来自[38]训练集的 110 k 110 \mathrm{k} 110k图像的图像集合来训练模型。我们采用Ours-SAM-B模型,并在BDD MOT和TAO TETA基准上进行测试。
训练策略和模型架构的影响:表8表明,直接使用现成的SAM特征(第1行)进行关联会产生较差的结果。主要原因是SAM的原始特征是为分割而优化的,而不是为了实例级别的区分。然而,通过整合我们的MASA训练方法和添加一个轻量级的跟踪头,可以显著提高性能,在BDD MOT上AssocA提高了 15.6 % 15.6\% 15.6%,mIDF1提高了 14.4 % 14.4\% 14.4%。这突出了我们训练策略的有效性。融入动态特征融合块进一步将性能提高了 1.6 % 1.6\% 1.6%。此外,与对象先验蒸馏分支的联合训练使AssocA提高了 1.8 % 1.8\% 1.8%,mIDF1提高了 1.6 % 1.6\% 1.6%,显示了这些架构设计的效果。
提案多样性的影响:我们评估了关联学习中不同的提案生成机制。我们使用BDD检测任务训练集的原始图像进行训练。通过在我们的MASA管道中将SAM替换为在COCO上预训练的Mask2former-SwinL[12]。如表9a所示,我们发现使用SAM提案训练的模型显著提高了BDD上的域内性能和TAO上的零次学习跟踪性能。这强调了SAM的密集、多样化的对象提案对于出色的对比相似性学习的重要性。

提案数量的影响:为了研究SAM提案数量对学习的影响,我们尝试了每批64、128和256个提案的不同上限。如表9b所示,随着提案数量的增加,BDD和TAO上的AssocA指标均有一致的改进,这表明丰富的实例集合有助于培养更具辨别力的跟踪特征。
数据增强的影响:如表9c所示,随机仿射变换、Mixup[73]和LSJ[21]的组合给出了最佳性能。方法1表示包括翻转、调整大小、颜色抖动和随机裁剪在内的基础数据增强。如果没有强烈的数据增强(方法1),其在BDD MOT上的mIDF1下降了 6.7 % 6.7\% 6.7%,远差于方法5的结果。这些结果说明了仅在静态图像上进行训练时强烈增强的必要性。
定性结果:在图14中,我们展示了我们的统一方法Grounding-DINO和SAM-H的定性结果。我们的方法能够准确检测、分割和跟踪多个对象,甚至是它们在不同领域的部分。这包括包含许多相似外观角色的动画电影场景和复杂环境内的驾驶场景。
5、结论
我们提出了MASA,一种新颖的方法,该方法利用SAM提供的广泛实例级别的形状和外观信息,从未标记的图像中学习可泛化的实例关联。MASA在各种基准测试中展示了卓越的零次学习关联性能,消除了对昂贵特定领域标签的需求。此外,我们的通用MASA适配器可以添加到任何现有的检测和分割模型中,使它们能够在不同领域有效地跟踪任何对象。
附录
在本补充材料中,我们提供了关于我们快速提案生成和关联的额外消融研究和定性结果。同时,我们也详细阐述了我们的实验设置、方法细节以及训练和推理的超参数。
补充材料的结构如下:
-
A节:在其他主干网络上的有效性
-
B节:在YoutubeVIS上的零次学习评估
-
C节:实例嵌入的可视化
-
D节:领域差异和适应性
-
E节:额外光度增强的影响
-
F节:提案多样性的更详细比较
-
G节:与自监督方法的比较
-
H节:与基于VOS方法的比较
-
I节:更多定性结果
-
J节:更多实现细节
-
K节:限制
A. 在其他主干网络上的有效性
在我们的主论文中,我们介绍了四种方法变体,每种方法都是基于基础检测和分割模型构建的:SAM-ViT-B、SAM-ViT-H、Grounding-DINO和Detic。值得注意的是,后两种变体利用了Swin-B主干网络。我们的MASA训练流程和适配器展现出了对多种变量的高度适应性,这些变量包括主干结构的差异、预训练方法(如检测或分割)以及用于训练这些基础模型的多样化数据集。
我们研究中的一个关键观察是这些变体对大型、复杂主干网络的依赖,以及它们在广泛数据集上的预训练。这种依赖提出了一个关于可扩展性和效率的重要问题:当应用于更小、更精简的主干网络(如ResNet-50),特别是使用标准的ImageNet预训练时,我们的方法能否保持其有效性?为了探索这一点,我们设计了一个新的变体“Ours-R50”,它集成了在ImageNet分类任务(IN-Sup R50)上预训练的ResNet-50主干网络。这个新变体保持了我们主要研究中MASA适配器的架构,并遵循我们最初四个变体所建立的相同训练协议。
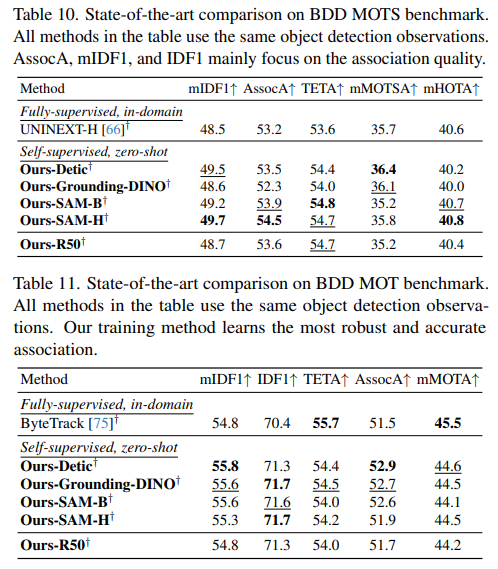
我们已经评估了Ours-R50在各种基准测试上的性能,包括BDD MOTS、BDD MOT和TAO TETA。表10、11和12中详细列出了定量结果,这些结果证明了Ours-R50的有效性。这些发现具有重要意义,因为它们表明我们的方法可以有效地适应更小的主干网络,为检测和分割任务提供了更高效和可扩展的解决方案的潜力。
BDD MOTS:在BDD MOTS(表10)中,配备ResNet-50主干网络的Ours-R50,结合我们的MASA训练方法,不仅在mIDF1上比UNINEXT-H模型高出 + 0.2 +0.2 +0.2,在AssocA上也高出 + 0.4 +0.4 +0.4,而且与表现最强的变体Ours-SAM-H相比,性能下降微乎其微(mIDF1降低 − 1 -1 −1,AssocA降低 − 0.9 -0.9 −0.9)。这突出了我们方法即使在没有大型、专业模型提供的先进特征的情况下,也能产生具有竞争力的实例嵌入的能力。
BDD MOT:在BDD MOT基准测试(表11)中,Ours-R50在IDF1(+0.9)和AssocA(+0.2)得分方面超越了ByteTrack。其性能与其他变体相当,与OursDetic相比仅有轻微下降(mIDF1降低 − 1 -1 −1,AssocA降低 − 1.2 -1.2 −1.2)。这些结果再次证明了我们方法在各种主干架构和预训练环境下的适应性。
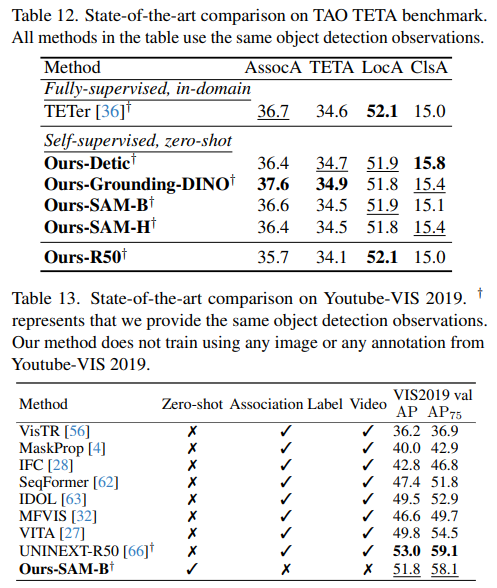
TAO TETA:在TAO TETA(表12)上进行评估时,配备标准ResNet-50主干网络的Ours-R50继续表现出稳健的性能。它与完全监督的TETer模型相差无几,仅在AssolcA上略有下降( − 1 -1 −1)。这一性能与我们其他变体一致,进一步验证了我们MASA方法在不同主干和预训练方法之间的泛化能力。
B. 在YoutubeVIS上的零次学习评估
在本节中,我们在Youtube-VIS 2019[68]基准测试中评估了我们的关联方法在零次学习设置下的性能。具体来说,我们直接在Youtube-VIS 2019上测试了我们的MASA适配器,其中SAM-ViT-B作为基础模型用于关联。
我们的方法使用了与最先进的VIS方法UNINEXT-R50[66]相同的对象检测观测结果。如表13所示,我们的方法与使用域内YoutubeVIS数据训练的SOTA UNINEXT方法性能相当,同时显著优于所有其他方法。这一结果强调了我们的方法具有稳健的零次学习关联能力,凸显了其在没有特定领域训练的场景下的有效性。
C. 实例嵌入的可视化
在图6中,我们使用t-SNE来可视化以不同方式学习的实例嵌入。我们比较了自监督方法,如MoCo-v2[11]、VFS[64]和DINO[8],以及两个基础模型:SAM ViT-B[35],最初在SA-1B上针对分割任务进行预训练,以及IN-Sup R50[25],最初在ImageNet上进行图像分类的预训练。此外,我们还展示了来自完全监督的域内视频模型[36]的嵌入,以及使用我们的MASA适配器增强的相同基础模型的嵌入。在这些可视化中,具有相同真实ID的实例用相同的颜色表示。我们使用BDD 100K序列作为数据源。

D. 领域差异与适应
除了之前提到的应用之外,MASA还可以作为实例关联的有用领域适应方法。具体来说,由于领域差异,如对象类别、场景和光照条件,在领域A上训练的跟踪器在领域B上评估时可能会遇到性能下降。例如,与BDD[71]相比,TAO[17]涵盖了更多样化的场景和对象类别。因此,我们选择BDD100K[71]作为源领域,TAO[17]作为目标领域。然后,我们使用BDD和LVIS+TAO[17,23]的标记数据分别训练了两个具有与TETer[36]相同架构的单独模型。这两个模型在图7中用蓝色和绿色条表示。请注意,当在TAO上评估它们的关联能力时,它们使用了相同的对象检测观测结果。
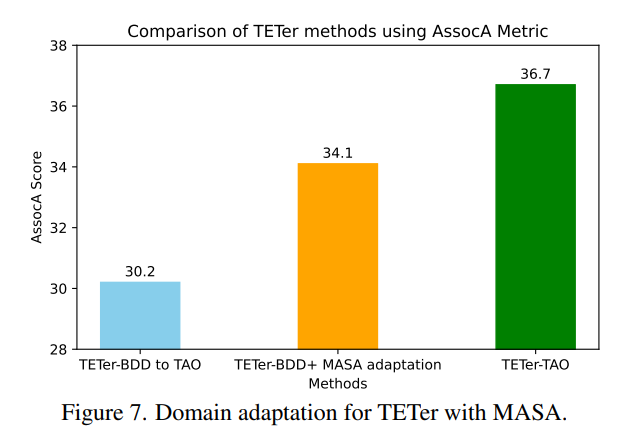
如图7所示,直接将在BDD上训练的嵌入应用于TAO(蓝色条)会导致较差的AssocA,比直接在TAO领域内训练的模型(绿色条)低 6.5 % 6.5\% 6.5%。为了缓解这种性能差距,我们使用MASA训练流程对蓝色条表示的原始TETer模型的跟踪头进行微调,同时冻结所有其他参数(橙色条)。具体来说,我们只使用LVIS和TAO的无标签图像对模型进行微调,而不使用任何原始TAO标注。如图7所示,与蓝色条相比,橙色条在AssocA上实现了 3.9 % 3.9\% 3.9%的改进,将领域差距减少了 60 % 60\% 60%。这表明MASA能够有效地提高在领域外场景中的关联性能,仅需要来自目标领域的无标签图像。
E. 光度增强的影响
在我们的主论文的第4.3节中,我们专注于各种几何增强,包括随机仿射变换和大规模抖动。我们还使用MixUp来增强实例的多样性并模拟遮挡效果。本节深入探讨了额外光度增强的影响。我们特别检查了运动模糊、高斯噪声、雪、雾和亮度调整的效果。光度增强以修改图像中像素值的能力为特点。这些改变通常模拟了如光照和天气等环境因素的变化,影响了相机如何捕获场景。与通过旋转、缩放或裁剪来改变像素空间排列的几何增强不同,光度增强不会改变图像中物体的结构完整性。图8直观地展示了这些增强。

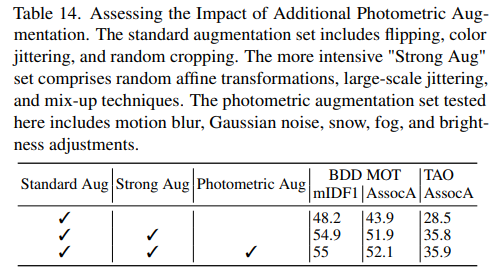
我们保持了与主论文中消融研究相同的训练方案,并使用SAM-ViT-B作为我们实验的基础模型。表14展示了结果,表明包含光度增强仅带来了适度的改进。我们在BDD数据集上观察到mIDF1和AssocA分别增加了 + 0.1 +0.1 +0.1和 + 0.2 +0.2 +0.2,在TAO数据集上AssocA增加了 + 0.1 +0.1 +0.1。因此,为了在性能提升和可能增加的计算复杂性之间实现更好的平衡,这些方法并没有作为我们方法的默认选项。
F. 提案多样性的比较
在我们的主论文中,我们评估了关联学习背景下不同的提案生成机制。具体来说,我们关注于使用BDD数据集的原始图像进行训练。我们尝试将MASA流程中的SAM替换为在COCO数据集上预训练的Mask2former-SwinL(参见[12])。如主论文表9c所示,使用SAM提案的模型展示了增强的性能。无论是在BDD数据集上的领域内跟踪,还是在TAO数据集上的零次学习跟踪场景中,这一点都显而易见。这些发现强调了SAM的密集且多样化的对象提案在促进有效的对比相似性学习中发挥的关键作用。
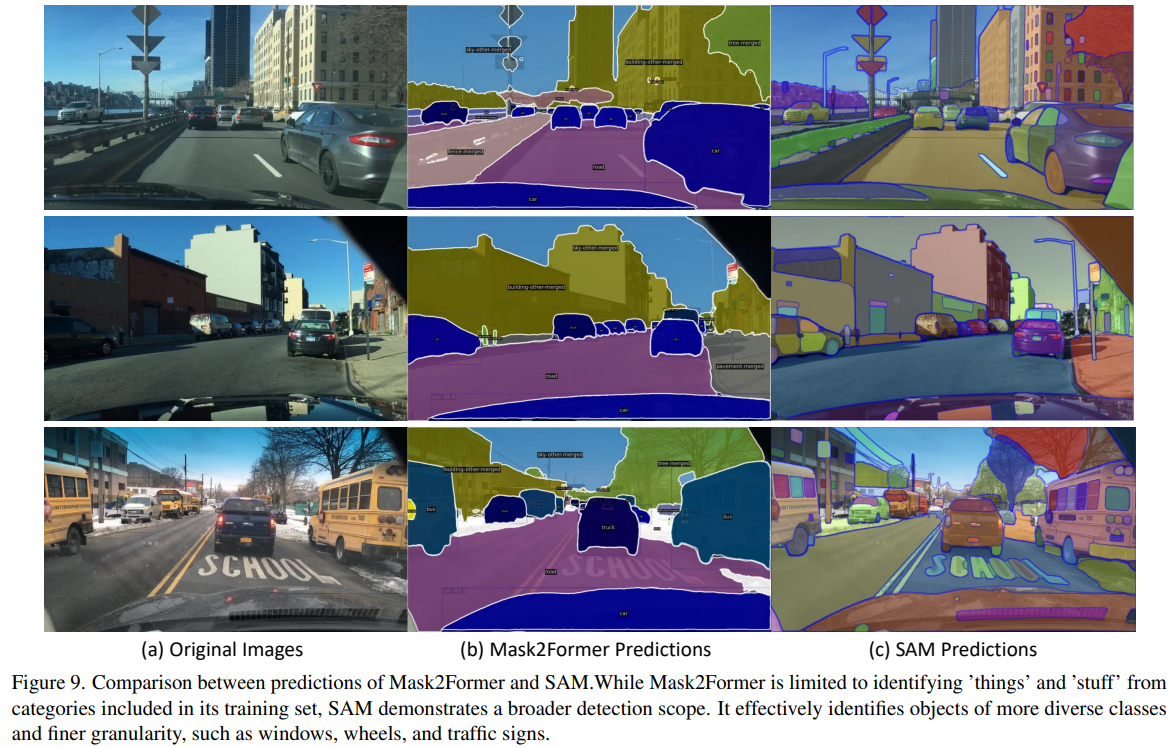
此外,我们在图9中展示了Mask2former和SAM生成的提案的视觉比较。这些比较可视化清晰地展示了SAM提案相对于Mask2former生成的提案具有更高的多样性。SAM显示出在原始图像中识别更广泛实例的增强能力,提供了具有更大多样性的提案。这种多样性在实例相似性学习中至关重要,并对学习到的实例表示的跨领域泛化能力做出了重大贡献。
G. 与自监督方法的比较
从纯无标签图像中提取有意义的信息是一项非常具有挑战性的任务。UniTrack [58] 已经展示了自监督训练表示(如MoCo [11] 和 VFS [64])在跨不同域的各种跟踪任务中泛化的潜力。然而,如图10所示,当前的自监督方法主要使用清洁的、以对象为中心的图像或视频进行对比训练。特别是,VFS在Kinetics数据集上进行训练,而MoCo和DINO则利用ImageNet。
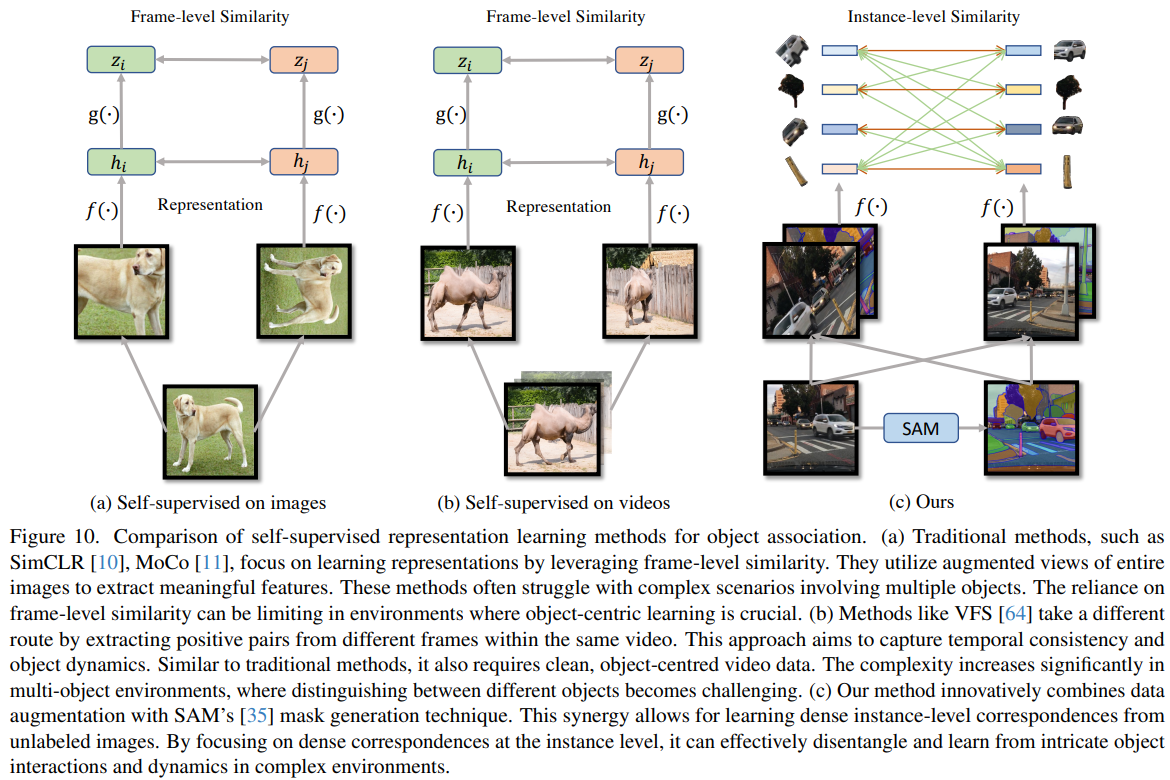
然而,这些方法主要关注帧级别的相似性,未能有效地利用实例信息。因此,在多个实例同时出现的复杂域中学习准确的实例表示时,它们显得力不从心,表现出在提取鲁棒和泛化表示方面的明显弱点。
对象中心训练数据的可视化 我们将VFS [64] 的训练数据——Kinetics数据集——进行了可视化,并将其与BDD100K中的驾驶视频进行了比较,如图11所示。作为动作识别数据集,Kinetics通过关注包含的动作来确保在整个视频中实例的存在。Kinetics视频中的中心实体通常在时间上保持一致,这使得VFS的采样策略适用于Kinetics。相比之下,BDD100K的驾驶视频呈现了一个更加动态和不可预测的环境。这些视频经常包含进入和退出帧的对象,导致不同帧中实例的存在发生显著变化。BDD 100K的这一特性构成了一个挑战,因为从同一视频中抽取的两帧可能不包含相同的实例,突显了这两个数据集训练数据的本质区别。

为了公平比较,在主论文的表6中,当将我们的方法与其他自监督方法进行比较时,我们使用相同的原始训练图像(BDD和COCO)对所有方法进行了训练。这些图像不是以对象为中心的,并且通常在复杂环境中包含多个实例。在本节中,我们还展示了使用原始以对象为中心的训练数据的自监督方法的跟踪性能。如下表所示,在BDD和COCO图像上训练的MoCo的AssocA(Association Accuracy)相对于其在ImageNet上训练的原始版本相对稳定,仅在BDD MOT数据集上略有下降。然而,对于VFS,使用包含多个实例的图像进行训练会导致在BDD MOT上AssocA显著下降15.9个百分点,在TAO上下降12.7个百分点。原因如下:
VFS将来自同一视频的帧视为正样本,将来自不同视频的帧视为负样本。这种策略对于Kinetics数据集是合理的,但对于BDD数据集则不然,如图11所示。具体来说,Kinetics视频中的中心实体通常不会随时间变化,但在BDD视频中,对象经常进出帧。来自同一BDD视频的两帧可能根本不包含相同的实例。

最后,在DINO的训练过程中,它强制要求来自同一图像的两个增强视图的表示相似,而没有明确使用负样本。然而,对于BDD和COCO中的图像,考虑到这两个数据集的复杂场景,两个增强视图可能包含许多不同的实例。这种训练策略可能导致学习到的嵌入表示不太具有区分性。
我们的方法通过利用预训练SAM中的实例级别知识,超越了帧级别的相似性,采纳了更加微妙的实例级别相似性。所获得的显著结果突显了我们提出的方法在学习用于跟踪目的的鲁棒表示方面的有效性。
H. 与基于视频对象分割(VOS)的方法的比较
最近的分割基础模型SAM已显示出对任何对象进行分割的非凡能力。然而,在视频中同时跟踪SAM生成的所有实例仍然是一项具有挑战性的任务。当前的方法通常将SAM用作视频第一帧的掩码生成器,然后应用现成的视频对象分割(VOS)方法将初始化的掩码传播到后续帧[13-15, 69]。一种显著的方法,Deva[14],利用XMem[13]进行掩码传播以同时跟踪多个实例。然而,这些方法遇到了几个关键的缺点。
掩码传播质量不足:这些方法在相对较小规模的视频分割数据集上进行训练,当被要求在任何域中跟踪任何对象时,会遇到较大的域差距,导致掩码传播质量不足。我们的主要论文表明,我们的方法在零次学习测试中,在各种多目标跟踪基准测试中,特别是在Deva和我们的方法都未知的驾驶场景中,显著优于Deva[14]。我们还在图12中提供了定性比较。在提供的视频文件中可以找到更多的视频比较。在驾驶域中测试Deva,这与它的训练数据存在显著差异,导致掩码质量较差且随时间累积误差。此外,没有有效的机制来处理场景中对象的快速进入和退出,这在自动驾驶等现实世界应用中很常见。相比之下,我们的方法在此类场景中表现出稳定的性能。

管理像素的多粒度难题:此外,这些方法主要是为视频对象分割(VOS)任务开发的,这些任务通常涉及单个而非多个多样化对象的视频和标注。因此,大多数基于VOS的方法设计用于一次只跟踪一个实例。虽然最近的一些进展,如[14,69]中的方法,允许同时跟踪多个实例,但它们通常基于每个像素都属于单个实例的前提工作。这忽略了像素粒度的复杂性,即一个像素可能根据粒度级别属于多个实例——这是SAM输出中的常见情况,如图13所示。这个问题在UVO数据集中得到了进一步说明,该数据集仅包含粗略的对象级别标注,经常省略对象部分的更细节信息。
我们应用SAM为UVO数据集中的每一帧生成掩码预测,对于两种方法都是如此。为了跟踪SAM分割出的对象,基于VOS的方法(如Deva)必须解决重叠问题,将每个像素分配给唯一的实例。例如,如果一组像素属于对象的一部分,它必须决定是跟踪部分还是整个对象。将像素分配给部分意味着相应的对象部分被排除在外,如图13中的汽车所示。相反,将像素分配给对象会导致部分掩码的移除。我们在表16中展示了UVO数据集中这些场景的定量结果。跟踪部分会导致UVO上对象掩码的不完整表示,从而对性能产生负面影响。相比之下,我们的方法能够处理多粒度,同时跟踪整个对象及其部分,而不影响UVO数据集上的性能。

I. 更多定性结果
我们提供了一个视频文件,其中包含我们在多个领域上的定性跟踪结果。这里我们提供关于快速候选区域生成和密集对象关联的可视化结果。
I.1. 快速候选区域生成
在图14中,我们将我们的快速候选区域生成与SAM的原始everything模式在COCO验证集的原始图像上的分割质量进行了比较。默认情况下,我们每张图像输出300个边界框,并在推理期间仅使用0.5阈值的边界框非极大值抑制(NMS)作为后处理。结果显示,尽管我们的快速候选区域生成使用了更少的时间,但它仍然可以达到与SAM的everything模式相似的分割质量。

I.2. 开放词汇跟踪
我们在图15中展示了开放词汇跟踪的定性结果。我们观察到我们的方法在跟踪方面表现良好,并且能够泛化到非常特殊的类别,如小黄人(minions)。更多结果可以在提供的视频中找到。

I.3. 联合分割和跟踪所有内容
我们提供了关于我们的联合分割和跟踪模型的定性结果。由于我们以联合的方式学习候选区域生成和关联,这使得我们的模型能够分割和关联视频中的任何内容。图16展示了使用我们自生成的候选区域的定性关联性能。我们注意到,尽管我们可以使用MASA学习强大的关联,但在不同帧之间生成一致的候选区域是非常困难的。例如,在第二行的左侧建筑物上,我们可以看到缺失的分割。这些不一致的检测在视频上可视化结果时会导致严重的闪烁效果。这表明我们仍需要在一致的候选区域生成方面付出更多努力,以实现视频中对象的稳健检测。

J. 实现细节
我们提供了有关模型架构、训练和推理的更多细节。
J.1. 架构细节
MASA适配器 MASA适配器包括两个主要部分。第一部分涉及特征金字塔的构建和动态特征融合。第二部分是用于对象蒸馏前的FasterRCNN基础检测头和用于产生跟踪特征的跟踪头。特征金字塔的构建过程取决于所使用的骨干网络。这些变化在各模型的相应部分中有详细说明。动态特征融合采用[80]中概述的标准可变形卷积,以聚合跨空间位置和特征级别的信息。此外,对于基于SAM的模型,还利用了来自[16]的任务感知注意力和尺度感知注意力。总共为特征融合过程建立了三个融合块。
基于FasterRCNN的检测头包括一个区域建议网络和一个与类别无关的框回归头。跟踪头包括四个卷积层和一个全连接层,用于生成实例嵌入。
Ours-Detic 我们使用预训练的Detic[78]模型,并以Swin-B[42]为骨干网络。预训练模型遵循[22]中描述的开放词汇对象检测设置,其中LVIS中的稀有类别被排除在训练之外。我们冻结了Detic Swin-B骨干网络,并采用标准FPN来构建特征金字塔。具体来说,我们从Swin-B骨干网络的第 4 th 4^{\text {th }} 4th 、 2 2 nd 22^{\text {nd }} 22nd 和 2 4 th 24^{\text {th }} 24th 块中提取特征。随后,我们在特征金字塔之上集成了动态特征融合,以通过学习检测蒸馏和实例对比来学习跟踪特征。
Ours-Grounding-DINO 我们采用预训练的Grounding-DINO[40]模型,并以Swin-B[42]为骨干网络。Swin-B骨干网络被冻结,我们使用标准的FPN(特征金字塔网络)来构建特征金字塔。除了Swin骨干网络的预训练方式和窗口大小不同外,所有可学习的组件与Ours-Detic模型相同。
Ours-SAM-B 该模型基于SAM(Scale-Aware Model)构建,所有原始的SAM组件都被冻结。为了从SAM的纯ViT(Vision Transformer)骨干网络中获取多层次的层次化特征,我们从第 3 rd 3^{\text {rd }} 3rd 、 6 th 6^{\text {th }} 6th 、 9 th 9^{\text {th }} 9th 和 1 2 th 12^{\text {th }} 12th 个块的输出中提取特征图。我们使用转置卷积将第 3 rd 3^{\text {rd }} 3rd 个块的特征图放大 4 × 4 \times 4×,将第 6 th 6^{\text {th }} 6th 个块的特征图放大 2 × 2 \times 2×。我们保持第 9 th 9^{\text {th }} 9th 个特征图不变,并使用MaxPooling将第 1 2 th 12^{\text {th }} 12th 个块的特征图缩小 1 / 2 1/2 1/2。这种方法产生了具有 1 4 \frac{1}{4} 41、 1 8 \frac{1}{8} 81、 1 16 \frac{1}{16} 161、 1 32 \frac{1}{32} 321比例尺的层次化特征。模型的其余部分与上述两个模型相似。
Ours-SAM-H 可学习的部分在很大程度上与Ours-SAM-B相似。唯一的区别在于,我们从第 8 th 8^{\text {th }} 8th 、 1 6 th 16^{\text {th }} 16th 、 2 4 th 24^{\text {th }} 24th 和 3 2 nd 32^{\text {nd }} 32nd 个块的输出来提取特征以构建特征金字塔。
J.2. 更多训练细节
对于基于SAM的模型,我们在最后两个epoch中关闭MixUp增强。之后,我们冻结了除跟踪头以外的所有部分,并对所有增强进行了6个epoch的微调,以调整基于SAM的模型的跟踪头。
对于使用任何原始图像集合训练我们的模型,采用了以下流程。首先,使用SAM的“everything”模式在原始图像上离线生成训练数据,使用SAM-ViTH模型以确保更高的质量。我们遵循默认的SAM设置,这包括在图像的每一侧使用32个采样点。此外,应用了一个交并比(Intersection over Union,IoU)预测阈值0.88来过滤掉低质量的预测。随后,移除了小的不连通区域和掩码中的空洞。还使用了边界框非极大值抑制(Non-Maximum Suppression,NMS)来消除阈值为0.7的重叠预测。在我们的消融研究中,这一流程被应用于在原始的COCO和BDD100K图像上生成数据。
J.3. 使用给定观测的推理
值得注意的是,在UVO上进行测试时,除了使用我们快速分割的“everything”模式生成的候选框外,我们还纳入了与[14]中相同的每帧掩码观测。这一纳入旨在最小化SAM在视频上的掩码预测中的时间不一致性。
J.4. 推理细节
总体来说,我们的推理方案如算法1所示。在相似度计算方面,我们提供了所使用的公式:
s 1 ( τ , r ) = 1 2 [ exp ( q r ⋅ q τ ) ∑ r ′ ∈ P exp ( q r ′ ⋅ q τ ) + exp ( q r ⋅ q τ ) ∑ τ ′ ∈ T exp ( q r ⋅ q τ ′ ) ] s 2 ( τ , r ) = q r ⋅ q τ ∥ q r ∥ ∥ q τ ∥ s ( τ , r ) = 1 2 ( s 1 ( τ , r ) + s 2 ( τ , r ) ) \begin{array}{c} s_{1}(\tau, r)=\frac{1}{2}\left[\frac{\exp \left(\mathbf{q}_{r} \cdot \mathbf{q}_{\tau}\right)}{\sum_{r^{\prime} \in P} \exp \left(\mathbf{q}_{r^{\prime}} \cdot \mathbf{q}_{\tau}\right)}+\frac{\exp \left(\mathbf{q}_{r} \cdot \mathbf{q}_{\tau}\right)}{\sum_{\tau^{\prime} \in \mathcal{T}} \exp \left(\mathbf{q}_{r} \cdot \mathbf{q}_{\tau^{\prime}}\right)}\right] \\ s_{2}(\tau, r)=\frac{\mathbf{q}_{r} \cdot \mathbf{q}_{\tau}}{\left\|\mathbf{q}_{r}\right\|\left\|\mathbf{q}_{\tau}\right\|} \\ s(\tau, r)=\frac{1}{2}\left(s_{1}(\tau, r)+s_{2}(\tau, r)\right) \end{array} s1(τ,r)=21[∑r′∈Pexp(qr′⋅qτ)exp(qr⋅qτ)+∑τ′∈Texp(qr⋅qτ′)exp(qr⋅qτ)]s2(τ,r)=∥qr∥∥qτ∥qr⋅qτs(τ,r)=21(s1(τ,r)+s2(τ,r))
其中, s ( τ , r ) s(\tau, r) s(τ,r) 表示轨迹 τ \tau τ 和目标候选 r r r 之间的相似度分数。在这里, q r \mathbf{q}_{r} qr 表示目标候选 r r r 的检测嵌入,包含了其外观特征,而 q τ \mathbf{q}_{\tau} qτ 表示轨迹 τ \tau τ 的轨迹嵌入,捕获了被跟踪对象的特征。 s 1 ( τ , r ) s_{1}(\tau, r) s1(τ,r) 使用指数函数计算这两个嵌入的点积,反映了目标候选与轨迹之间的相似程度。这个相似度分数被双重归一化:首先,对于给定的轨迹 τ \tau τ,在集合 P P P 中的所有目标候选 r ′ r^{\prime} r′ 之间进行归一化;其次,对于给定的目标候选 r r r,在集合 T \mathcal{T} T 中的所有轨迹 τ ′ \tau^{\prime} τ′ 之间进行归一化。这种双重归一化确保了相似度的平衡和全面评估,有助于在动态视频序列中准确地进行对象关联。 s 2 ( τ , r ) s_{2}(\tau, r) s2(τ,r) 计算了余弦相似度。最终的 s ( τ , r ) s(\tau, r) s(τ,r) 分数是 s 1 ( τ , r ) s_{1}(\tau, r) s1(τ,r) 和 s 2 ( τ , r ) s_{2}(\tau, r) s2(τ,r) 的平均值。

K. 局限性
我们方法的一个关键局限性在于处理视频帧之间检测或分割结果的时间不一致性。这个问题在像SAM这样的开放世界对象检测和分割模型中很常见,当一帧中检测到的对象在下一帧中丢失时,就会在视频可视化中出现闪烁效果,这在我们的演示中可以观察到。虽然我们的MASA适配器在学习关联方面表现出色,但它无法纠正基础模型的检测或分割错误。跨帧生成一致性的提议的挑战突显了未来研究的一个重要方向,即增强动态视频环境中对象检测的鲁棒性和稳定性。
另一个局限性是缺乏长期记忆系统,这对于处理遮挡至关重要。我们仅学习了一个通用的实例外观模型,可以直接被不同的检测器使用。然而,跟踪策略和内存管理仍然依赖于双softmax匹配和一个队列来存储每个实例的外观嵌入。这种简单的策略在严重遮挡的情况下容易失败。开发一个更复杂的长期记忆系统和改进的跟踪策略将是解决这一局限性的关键。
相关文章:
MASA:匹配一切、分割一切、跟踪一切
文章目录 摘要1、引言2、相关工作2.1、学习实例级关联2.2、Segment and Track Anything 模型 3、方法3.1、预备知识:SAM3.2、通过分割任何事物来匹配任何事物3.2.1、MASA流程3.2.2、MASA适配器3.2.3、推理 4、实验4.1、实验设置4.2、与最先进技术的比较4.3、消融研究…...

Websocket前端传参:深度解析与实战应用
Websocket前端传参:深度解析与实战应用 在现代Web开发中,Websocket作为一种双向通信协议,已经广泛应用于实时数据传输场景。前端传参作为Websocket通信的重要组成部分,其正确性和高效性直接影响到应用的性能和用户体验。本文将深…...

造假高手——faker
在测试写好的代码时通常需要用到一些测试数据,大量的真实数据有时候很难获取,如果手动制造测试数据又过于繁重无聊,显得不够优雅,今天我们介绍的faker这个轮子可以完美的解决这个问题。faker是一个用于生成各种类型假数据的库&…...
—— PostCSS(v8.4.38):CSS 转换工具)
前端工程化工具系列(十二)—— PostCSS(v8.4.38):CSS 转换工具
PostCSS 是转换 CSS 语法的工具。它提供 API 来对 CSS 文件进行分析和修改它的规则。 PostCSS 本身并不能直接使用,主要是使用基于 PostCSS 编写的插件。 1 安装 pnpm add -D postcss-import postcss-nested postcss-preset-env cssnano2 配置 在项目根目录下创…...

Scanpy(3)单细胞数据分析常规流程
单细胞数据分析常规流程 面对高效快速的要求上,使用R分析数据越来越困难,转战Python分析,我们通过scanpy官网去学习如何分析单细胞下游常规分析。 数据3k PBMC来自健康的志愿者,可从10x Genomics免费获得。在linux系统上,可以取消注释并运行以下操作来下载和解压缩数据。…...

【Stable Diffusion】(基础篇二)—— Stable Diffusion图形界面介绍和基本使用流程
本系列笔记主要参考B站nenly同学的视频教程,传送门:B站第一套系统的AI绘画课!零基础学会Stable Diffusion,这绝对是你看过的最容易上手的AI绘画教程 | SD WebUI 保姆级攻略_哔哩哔哩_bilibili 在上一篇博客中,我们成功…...
OpenCv之简单的人脸识别项目(动态处理页面)
人脸识别 准备九、动态处理页面1.导入所需的包2.设置窗口2.1定义窗口外观和大小2.2设置窗口背景2.2.1设置背景图片2.2.2创建label控件 3.定义视频处理脚本4.定义相机抓取脚本5.定义关闭窗口的函数6.按钮设计6.1视频处理按钮6.2相机抓取按钮6.3返回按钮 7.定义关键函数8.动态处理…...
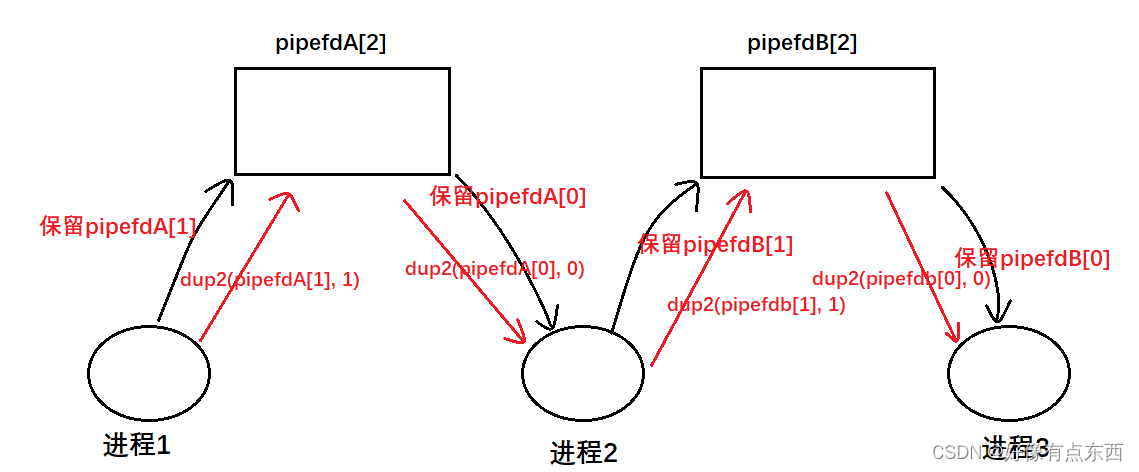
【Linux】进程间通信
目录 一、进程间通信概念 二、进程间通信的发展 三、进程间通信的分类 四、管道 4.1 什么是管道 4.2 匿名管道 4.2 基于匿名管道设计进程池 4.3 命名管道 4.4 用命名管道实现server&client通信 五、system V共享内存 5.1 system V共享内存的引入 5.2 共享内存的…...

UI与前端:揭秘两者的微妙差异
UI与前端:揭秘两者的微妙差异 在数字化时代的浪潮中,UI设计和前端开发已成为塑造用户体验的两大核心力量。然而,这两者之间究竟有何区别?本文将深入剖析UI设计与前端开发的四个方面、五个方面、六个方面和七个方面的差异…...
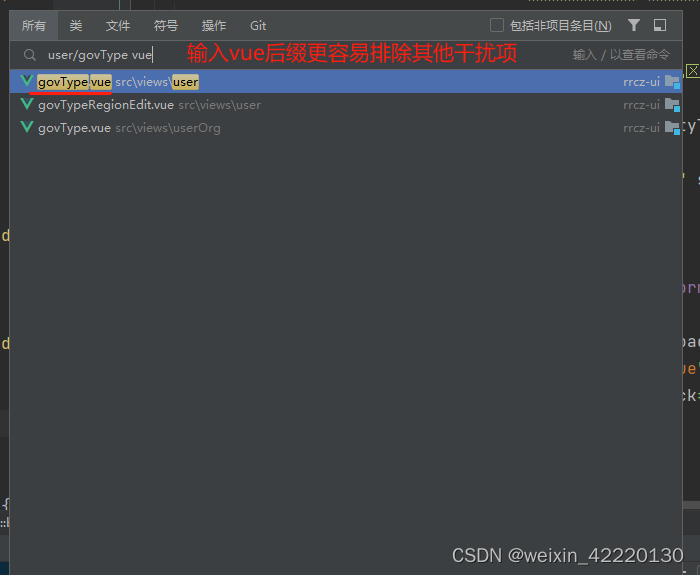
idea如何根据路径快速在项目中快速打卡该页面
在idea项目中使用快捷键shift根据路径快速找到该文件并打卡 双击shift(连续按两下shift) -粘贴文件路径-鼠标左键点击选中跳转的路径 自动进入该路径页面 例如:我的实例路径为src/views/user/govType.vue 输入src/views/user/govType或加vue后缀src/views/user/go…...

探索成功者的特质——俞敏洪的观点启示
在人生的舞台上,我们常常对成功者充满好奇与敬仰,试图探寻他们成功的奥秘。俞敏洪指出,成功者都具备七个特质,而这些特质与家庭背景和大学的好坏并无直接关系。让我们深入剖析这七个特质,或许能从中获得对我们自身成长…...

MCU的环形FIFO
fifo.h #ifndef __FIFO_H #define __FIFO_H#include "main.h"#define RINGBUFF_LEN (500) //定义最大接收字节数 500typedef struct {uint16_t Head; // 头指针 指向可读起始地址 每读一个,数字1uint16_t Tail; // 尾指针 指…...
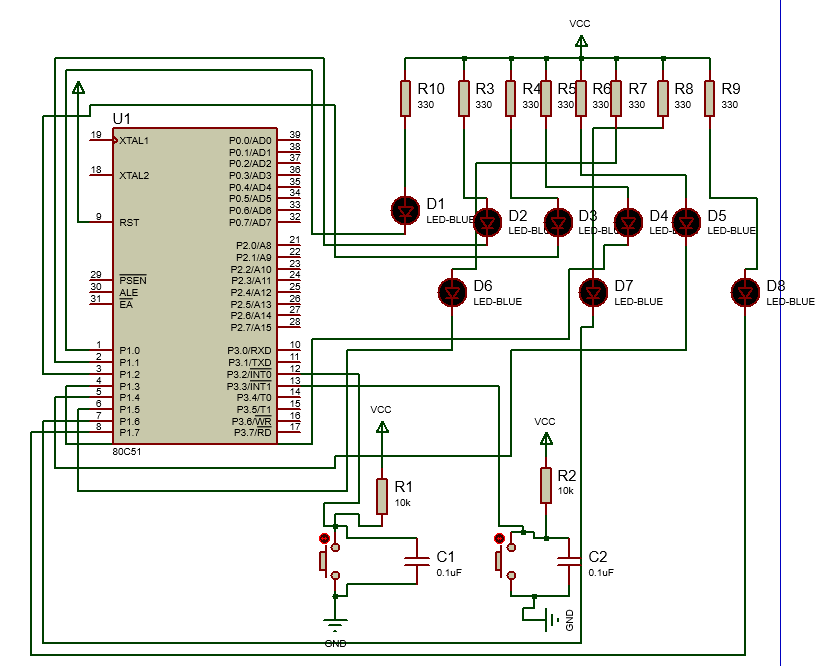
使用proteus仿真51单片机的流水灯实现
proteus介绍: proteus是一个十分便捷的用于电路仿真的软件,可以用于实现电路的设计、仿真、调试等。并且可以在对应的代码编辑区域,使用代码实现电路功能的仿真。 汇编语言介绍: 百度百科介绍如下: 汇编语言是培养…...

【漏洞复现】Apache OFBiz 路径遍历导致RCE漏洞(CVE-2024-36104)
0x01 产品简介 Apache OFBiz是一个电子商务平台,用于构建大中型企业级、跨平台、跨数据库、跨应用服务器的多层、分布式电子商务类应用系统。是美国阿帕奇(Apache)基金会的一套企业资源计划(ERP)系统。该系统提供了一整套基于Java的Web应用程序组件和工具。 0x02 …...

数据库表中创建字段查询出来却为NULL?
起因: 今天新创建了一张表,其中一个字段命名为"word_num"带下划线,我在前端页面怎么也查询不出来word_num的值,后来在后端接口处打印了一下数据库查询出来的数据,发现这个字段一直为NULL,然后我就想到是不是…...

缓存方法返回值
1. 业务需求 前端用户查询数据时,数据查询缓慢耗费时间; 基于缓存中间件实现缓存方法返回值:实现流程用户第一次查询时在数据库查询,并将查询的返回值存储在缓存中间件中,在缓存有效期内前端用户再次查询时,从缓存中间件缓存获取 2. 基于Redis实现 参考1 2.1 简单实现 引入…...
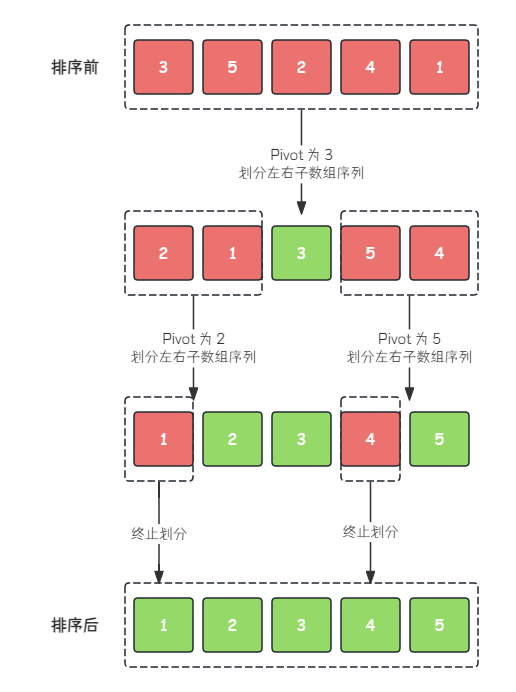
【十大排序算法】快速排序
在乱序的世界中,快速排序如同一位智慧的园丁, 以轻盈的手法,将无序的花朵们重新安排, 在每一次比较中,沐浴着理性的阳光, 终使它们在有序的花园里,开出绚烂的芬芳。 文章目录 一、快速排序二、…...

linux系统ubuntu中在命令行中打开图形界面的文件夹
在命令行中打开当前路径,以文件管理器的形式打开: 命令 # 打开文件管理器 当前的路径 nautilus .nautilus 是一个与 GNOME 桌面环境集成的文件管理器的命令行启动程序。在 Linux 系统中,特别是使用 GNOME 作为桌面环境时,用户经…...
【C++11数据结构与算法】C++ 栈
C 栈(stack) 文章目录 C 栈(stack)栈的基本介绍栈的算法运用单调栈实战题LC例题:[321. 拼接最大数](https://leetcode.cn/problems/create-maximum-number/)LC例题:[316. 去除重复字母](https://leetcode.cn/problems/remove-duplicate-letters/) 栈的基…...
pdf文件如何防篡改内容
PDF文件防篡改内容的方法有多种,以下是一些常见且有效的方法,它们可以帮助确保PDF文件的完整性和真实性: 加密PDF文档: 原理:通过设置密码来保护PDF文档,防止未经授权的访问和修改。注意事项:密…...

告别机械应答:Fay数字人语音识别上下文感知技术全解析
告别机械应答:Fay数字人语音识别上下文感知技术全解析 【免费下载链接】Fay Fay is an open-source digital human framework integrating language models and digital characters. It offers retail, assistant, and agent versions for diverse applications lik…...

django-flask基于python高校学生实习管理系统
目录高校学生实习管理系统摘要项目技术支持可定制开发之功能亮点源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作高校学生实习管理系统摘要 基于Python的Django-Flask高校学生实习管理系统旨在优化实习流程管理,提升学校、学生与…...

HY-Motion 1.0免配置环境:预装PyTorch3D/diffusers/SMPLH的容器镜像
HY-Motion 1.0免配置环境:预装PyTorch3D/diffusers/SMPLH的容器镜像 想体验用一句话生成专业3D动画,但被复杂的PyTorch3D、diffusers、SMPLH环境配置劝退?今天,我们为你带来了一个开箱即用的解决方案——一个预装了所有必需依赖的…...

Operaton入门到精通22-Operaton 2.0 升级指南:Spring Boot 4 核心变更详解
摘要:Operaton 2.0升级摘要:基于SpringBoot4的重大更新,强制要求升级Spring依赖至SpringBoot4/SpringFramework71,兼容JakartaEE11。开发环境需Java17/JUnit6,改用GraalVM引擎。仅REST/DB集成用户无需操作。1.x版本维护至2026年&a…...
✅)
计算机毕业设计源码:Python贝壳租房数据可视化分析平台 Django框架 Requests爬虫 可视化 房子 房源 大数据 大模型(建议收藏)✅
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌ > 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与…...
SFAFBR:一种自监督的人工特征偏置校正框架)
(论文速读)SFAFBR:一种自监督的人工特征偏置校正框架
论文题目:Artificial Feature Bias Rectified by Self-Supervised Learning for Rolling Bearings Fault Diagnosis Under Limited Labeled Vibration Signals(有限标记振动信号下滚动轴承故障诊断的自监督学习修正人工特征偏差)期刊…...

MedGemma X-RayGPU算力方案:单卡部署+多并发请求性能压测
MedGemma X-RayGPU算力方案:单卡部署多并发请求性能压测 1. 项目概述 MedGemma X-Ray 是一款基于前沿大模型技术开发的医疗影像智能分析平台,专门用于胸部X光片的智能解读。这个系统将人工智能的强大理解能力应用于放射科影像,能够协助用户…...
)
Minio+Nginx配置HTTPS访问的完整避坑指南(附腾讯云SSL证书实战)
MinioNginx配置HTTPS访问的完整避坑指南(附腾讯云SSL证书实战) 在企业级文件存储解决方案中,Minio作为高性能的对象存储服务越来越受到开发者青睐。而将Minio服务通过Nginx配置HTTPS访问,不仅能提升数据传输安全性,还能…...

C++ vector性能优化:从reserve到emplace_back的7个实战技巧
C vector性能优化:从reserve到emplace_back的7个实战技巧 在游戏引擎开发中,我们曾遇到一个令人头疼的场景:当角色技能系统需要实时加载上千个特效参数时,使用默认方式的vector存储导致帧率骤降。通过一系列性能调优后,…...

智谱开源视觉大模型GLM-4.6V-Flash-WEB体验:部署简单,响应快,效果惊艳
智谱开源视觉大模型GLM-4.6V-Flash-WEB体验:部署简单,响应快,效果惊艳 你是否遇到过这样的场景?想在自己的项目中加入一个能“看懂”图片的AI助手,比如让用户上传一张商品图,AI就能自动描述它的特点。听起…...