LSTM 词语模型上的动态量化
原文链接
(beta) Dynamic Quantization on an LSTM Word Language Model — PyTorch Tutorials 2.3.0+cu121 documentation
引言
量化涉及将模型的权重和激活值从浮点数转换为整数,这样可以缩小模型大小,加快推理速度,但对准确性的影响很小。
在本教程中,我们将把最简单的量化形式--动态量化--应用到基于 LSTM 的下一个单词预测模型中,这与 PyTorch 示例中的单词语言模型密切相关。
# imports
import os
from io import open
import timeimport torch
import torch.nn as nn
import torch.nn.functional as F
定义模型
在此,我们按照单词语言模型示例中的模型,定义 LSTM 模型架构。
class LSTMModel(nn.Module):"""Container module with an encoder, a recurrent module, and a decoder."""def __init__(self, ntoken, ninp, nhid, nlayers, dropout=0.5):super(LSTMModel, self).__init__()self.drop = nn.Dropout(dropout)self.encoder = nn.Embedding(ntoken, ninp)self.rnn = nn.LSTM(ninp, nhid, nlayers, dropout=dropout)self.decoder = nn.Linear(nhid, ntoken)self.init_weights()self.nhid = nhidself.nlayers = nlayersdef init_weights(self):initrange = 0.1self.encoder.weight.data.uniform_(-initrange, initrange)self.decoder.bias.data.zero_()self.decoder.weight.data.uniform_(-initrange, initrange)def forward(self, input, hidden):emb = self.drop(self.encoder(input))output, hidden = self.rnn(emb, hidden)output = self.drop(output)decoded = self.decoder(output)return decoded, hiddendef init_hidden(self, bsz):weight = next(self.parameters())return (weight.new_zeros(self.nlayers, bsz, self.nhid),weight.new_zeros(self.nlayers, bsz, self.nhid))加载文本数据
接下来,我们将 Wikitext-2 数据集加载到[Corpus]{.title-ref}中,同样按照单词语言模型示例进行预处理。
class Dictionary(object):def __init__(self):self.word2idx = {}self.idx2word = []def add_word(self, word):if word not in self.word2idx:self.idx2word.append(word)self.word2idx[word] = len(self.idx2word) - 1return self.word2idx[word]def __len__(self):return len(self.idx2word)class Corpus(object):def __init__(self, path):self.dictionary = Dictionary()self.train = self.tokenize(os.path.join(path, 'train.txt'))self.valid = self.tokenize(os.path.join(path, 'valid.txt'))self.test = self.tokenize(os.path.join(path, 'test.txt'))def tokenize(self, path):"""Tokenizes a text file."""print(path)assert os.path.exists(path), f"Error: The path {path} does not exist."# Add words to the dictionarywith open(path, 'r', encoding="utf8") as f:for line in f:words = line.split() + ['<eos>']for word in words:self.dictionary.add_word(word)# Tokenize file contentwith open(path, 'r', encoding="utf8") as f:idss = []for line in f:words = line.split() + ['<eos>']ids = []for word in words:ids.append(self.dictionary.word2idx[word])idss.append(torch.tensor(ids).type(torch.int64))ids = torch.cat(idss)return idsmodel_data_filepath = ".\data\\"corpus = Corpus(model_data_filepath + 'wikitext-2')加载预训练模型
这是一个关于动态量化的教程,一种在模型训练完成后应用的量化技术。因此,我们只需将一些预先训练好的权重加载到该模型架构中;这些权重是通过使用单词语言模型示例中的默认设置进行五次历时训练获得的。
ntokens = len(corpus.dictionary)model = LSTMModel(ntoken=ntokens,ninp=512,nhid=256,nlayers=5,
)# model.load_state_dict(
# torch.load(
# model_data_filepath + 'word_language_model_quantize.pth',
# map_location=torch.device('cpu')
# )
# )model.eval()
print(model)现在让我们生成一些文本,以确保预训练模型正常工作 - 与之前类似,我们遵循此处
input_ = torch.randint(ntokens, (1, 1), dtype=torch.long)
hidden = model.init_hidden(1)
temperature = 1.0
num_words = 1000with open(model_data_filepath + 'out.txt', 'w') as outf:with torch.no_grad(): # no tracking historyfor i in range(num_words):output, hidden = model(input_, hidden)word_weights = output.squeeze().div(temperature).exp().cpu()word_idx = torch.multinomial(word_weights, 1)[0]input_.fill_(word_idx)word = corpus.dictionary.idx2word[word_idx]outf.write(str(word.encode('utf-8')) + ('\n' if i % 20 == 19 else ' '))if i % 100 == 0:print('| Generated {}/{} words'.format(i, 1000))with open(model_data_filepath + 'out.txt', 'r') as outf:all_output = outf.read()print(all_output)虽然不是 GPT-2,但看起来模型已经开始学习语言结构了!
我们差不多可以演示动态量化了。我们只需要再定义几个辅助函数:
bptt = 25
criterion = nn.CrossEntropyLoss()
eval_batch_size = 1# create test data set
def batchify(data, bsz):# Work out how cleanly we can divide the dataset into ``bsz`` parts.nbatch = data.size(0) // bsz# Trim off any extra elements that wouldn't cleanly fit (remainders).data = data.narrow(0, 0, nbatch * bsz)# Evenly divide the data across the ``bsz`` batches.return data.view(bsz, -1).t().contiguous()test_data = batchify(corpus.test, eval_batch_size)# Evaluation functions
def get_batch(source, i):seq_len = min(bptt, len(source) - 1 - i)data = source[i:i + seq_len]target = source[i + 1:i + 1 + seq_len].reshape(-1)return data, targetdef repackage_hidden(h):"""Wraps hidden states in new Tensors, to detach them from their history."""if isinstance(h, torch.Tensor):return h.detach()else:return tuple(repackage_hidden(v) for v in h)def evaluate(model_, data_source):# Turn on evaluation mode which disables dropout.model_.eval()total_loss = 0.hidden = model_.init_hidden(eval_batch_size)with torch.no_grad():for i in range(0, data_source.size(0) - 1, bptt):data, targets = get_batch(data_source, i)output, hidden = model_(data, hidden)hidden = repackage_hidden(hidden)output_flat = output.view(-1, ntokens)total_loss += len(data) * criterion(output_flat, targets).item()return total_loss / (len(data_source) - 1)
测试动态量化
最后,我们可以在模型上调用 torch.quantization.quantize_dynamic!具体来说就是
我们指定要对模型中的 nn.LSTM 和 nn.Linear 模块进行量化
我们指定要将权重转换为 int8 值
import torch.quantizationquantized_model = torch.quantization.quantize_dynamic(model, {nn.LSTM, nn.Linear}, dtype=torch.qint8
)
print(quantized_model)# 模型看起来没有变化,这对我们有什么好处呢?首先,我们看到模型的尺寸大幅缩小:
def print_size_of_model(model):torch.save(model.state_dict(), "temp.p")print('Size (MB):', os.path.getsize("temp.p") / 1e6)os.remove('temp.p')print_size_of_model(model)
print_size_of_model(quantized_model)其次,我们看到推理时间更快,而评估损失没有区别:
注:我们将单线程比较的线程数设为一个,因为量化模型是单线程运行的。
torch.set_num_threads(1)def time_model_evaluation(model, test_data):s = time.time()loss = evaluate(model, test_data)elapsed = time.time() - sprint('''loss: {0:.3f}\nelapsed time (seconds): {1:.1f}'''.format(loss, elapsed))time_model_evaluation(model, test_data)
time_model_evaluation(quantized_model, test_data)
在本地 MacBook Pro 上运行这个程序,在不进行量化的情况下,推理时间约为 200 秒,而在进行量化的情况下,推理时间仅为 100 秒左右。
结论
动态量化是减少模型大小的一种简单方法,但对准确性的影响有限。
感谢您的阅读!我们一如既往地欢迎任何反馈,如果您有任何问题,请在此创建一个问题。
相关文章:

LSTM 词语模型上的动态量化
原文链接 (beta) Dynamic Quantization on an LSTM Word Language Model — PyTorch Tutorials 2.3.0cu121 documentation 引言 量化涉及将模型的权重和激活值从浮点数转换为整数,这样可以缩小模型大小,加快推理速度,但对准确性的影响很小…...
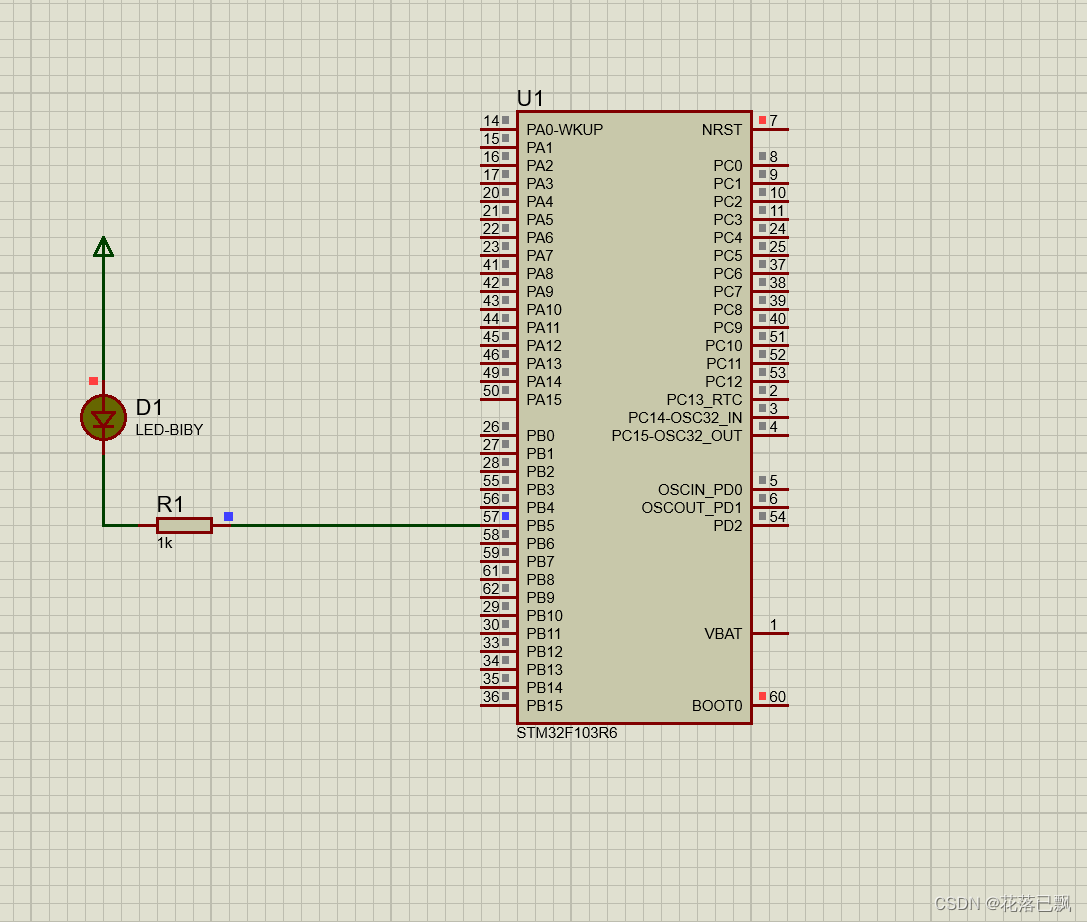
STM32 proteus + STM32Cubemx仿真教程(第一课LED教程)
文章目录 前言一、STM32点亮LED灯的原理1.1GPIO是什么1.2点亮LED灯的原理 二、STM32Cubemx创建工程三、proteus仿真电路图四、程序代码编写1.LED灯操作函数介绍HAL_GPIO_WritePin函数原型参数说明示例代码 HAL_GPIO_TogglePin函数原型参数说明示例代码 2.代码编写3.烧写程序 总…...

享元模式
前言 享元模式:运用共享技术有效地支持大量细粒度的对象。 在享元对象内部并且不会随环境改变而改变的共享部分,可以称为是享元对象的内部状态,而随环境改变而改变的、不可以共享的状态就是外部状态了。事实上,享元模式可以避免大…...

R语言数据分析16-针对芬兰污染指数的分析与考察
1. 研究背景及意义 近年来,随着我国科技和经济高速发展,人们生活质量也随之显著提高。但是, 环境污染问题也日趋严重,给人们的生活质量和社会生产的各个方面都造成了许多不 利的影响。空气污染作为环境污染主要方面,更…...

Search用法Python:深入探索搜索功能的应用与技巧
Search用法Python:深入探索搜索功能的应用与技巧 在Python编程中,搜索功能是一项至关重要的技能,它能够帮助我们快速定位并处理数据。然而,对于初学者来说,如何高效地使用搜索功能可能会带来一些困惑。本文将从四个方…...
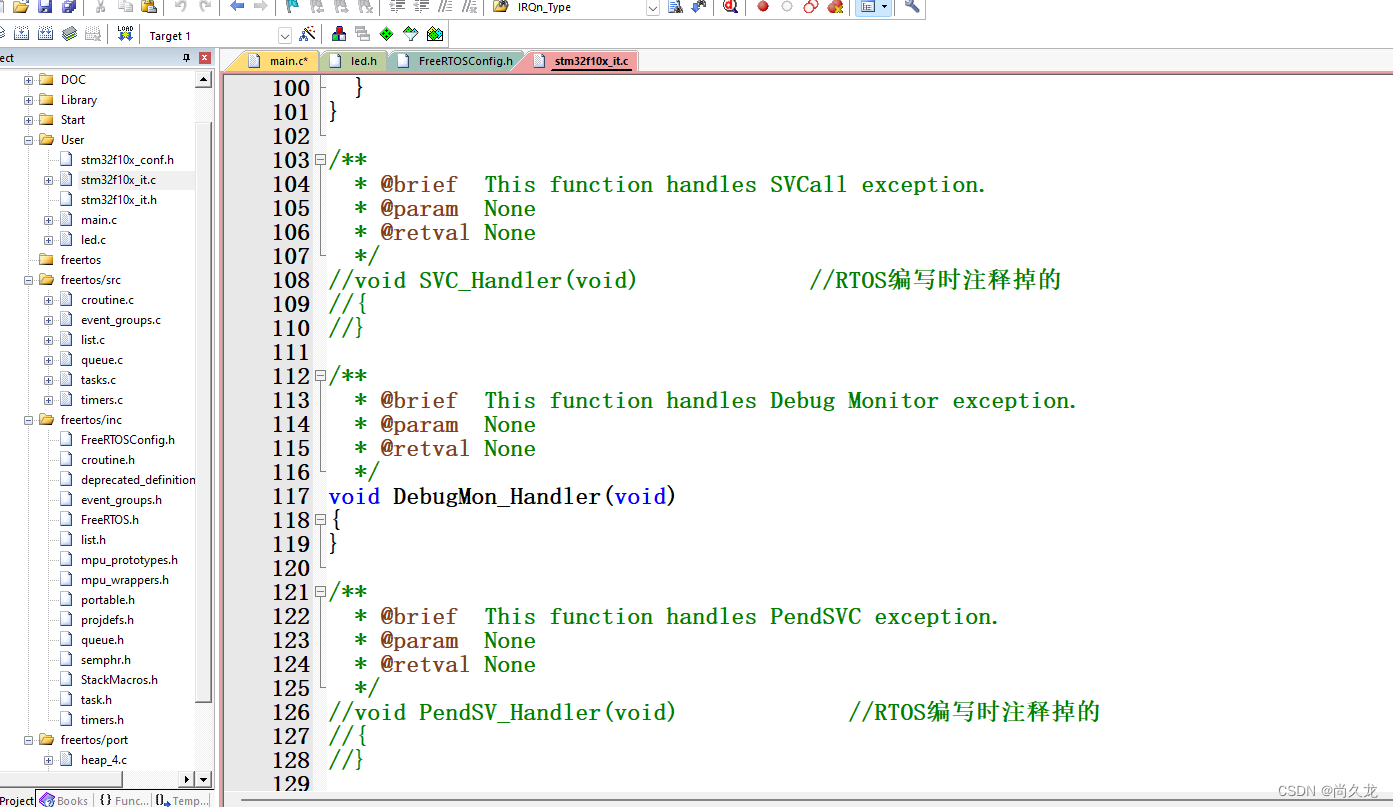
STM32的FreeRtos的学习
首先就是去官网下载一个源文件:FreeRtos官网 下载下来的是一个zip文件,解压缩了。 然后再工程文件夹中创建个文件夹: 在这个文件夹中创建3个文件夹: 然后开始把下载下来的文件夹中的文件挑选出来放到我们的工程文件夹中࿱…...

从零入手人工智能(2)——搭建开发环境
1.前言 作为一名单片机工程师,想要转型到人工智能开发领域的道路确实充满了挑战与未知。记得当我刚开始这段旅程时,心中充满了迷茫和困惑。面对全新的领域,我既不清楚如何入手,也不知道能用人工智能干什么。正是这些迷茫和困惑&a…...

Web前端指南
前言 前端开发员主要负责网站的设计、外观和感觉。他们设计引人入胜的在线用户体验,激发用户兴趣,鼓励用户重复访问。他们与设计师密切合作,使网站美观、实用、快捷。 如果您喜欢创造性思维、打造更好的体验并对视觉设计感兴趣,这将是您的理想职业道路。 探讨前端、后端以…...
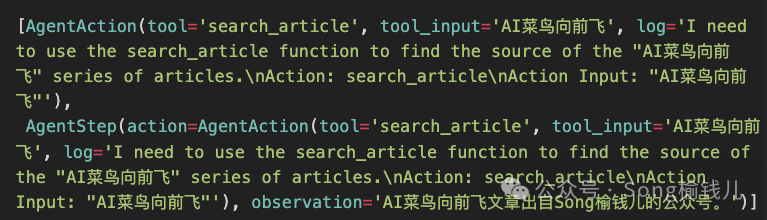
AI菜鸟向前飞 — LangChain系列之十七 - 剖析AgentExecutor
AgentExecutor 顾名思义,Agent执行器,本篇先简单看看LangChain是如何实现的。 先回顾 AI菜鸟向前飞 — LangChain系列之十四 - Agent系列:从现象看机制(上篇) AI菜鸟向前飞 — LangChain系列之十五 - Agent系列&#…...

nodejs 第三方库 exiftool-vendored
exiftool-vendored 是一款可以帮助你快捷修改图片信息的第三方库。如果你想要批量修改图片信息的话,那么它是一个不错的选择。 1.导入第三方库 在控制台中执行下面代码即可。 npm install exiftool-vendored --save2.获取信息 这里给出例子。 const { exiftool …...
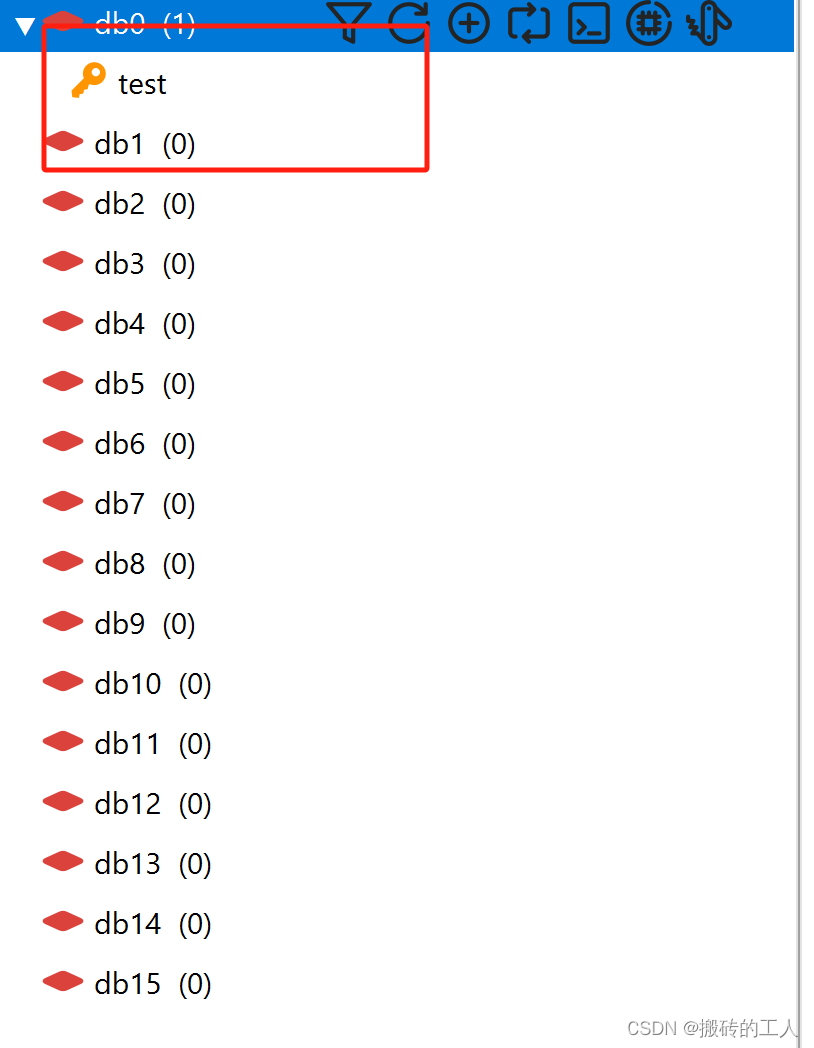
docker部署redis实践
1.拉取redis镜像 # 拉取镜像 sudo docker pull redis2.创建映射持久化目录 # 创建目录 sudo mkdir -p $PWD/redis/{conf,data}3. 运行redis 容器,查看当前redis 版本号 # 运行 sudo docker run --name redis -d -p 6379:6379 redis # 查看版本号 sudo docker ex…...

Web前端学习之路:深入探索学习时长与技能进阶的奥秘
Web前端学习之路:深入探索学习时长与技能进阶的奥秘 在数字化时代,Web前端技术成为了连接用户与互联网世界的桥梁。对于初学者来说,学习Web前端究竟需要多久,以及如何高效掌握相关技能,一直是困扰他们的难题。本文将从…...

如何不用命令创建用户
都有哪些操作: 1、在/etc/passwd添加一行 2、在/etc/shadow添加一行 3、在/etc/group添加一行 4、创建用户家目录 5、创建用户邮件文件 例如: 创建用户jerry 要求: uid:777 主组:hadoop(800)…...

基于Python实现可视化分析中国500强排行榜数据的设计与实现
基于Python实现可视化分析中国500强排行榜数据的设计与实现 “Design and Implementation of Visual Analysis for China’s Top 500 Companies Ranking Data using Python” 完整下载链接:基于Python实现可视化分析中国500强排行榜数据的设计与实现 文章目录 基于Python实现…...

VUE3 学习笔记(13):VUE3 下的Element-Plus基本使用
UI是页面的门面,一个好的UI自然令人赏心悦目;国人团队开发的ElementUI在众多UI中较为常见,因此通过介绍它的使用让大家更好的了解第三方UI的使用。 安装 Npm install element-plus --save 或 Cnpm install element-plus --save 配置 全局配置…...

MySql数据库安全加固
设置密码复杂度策略 查看密码策略 SHOW VARIABLES LIKE validate_password%; 设置密码策略 INSTALL PLUGIN validate_password SONAME validate_password.so; 设置登陆失败策略 安装插件(谨慎操作,可能会导致数据库卡死) install plug…...
Nginx(title小图标)修改方法
本章主要讲述Nginx如何上传网站图标。 操作系统: CentOS Stream 9 首先我们bing搜索ico网站图标在线设计,找到喜欢的设计分格并下载。 是一个压缩包 然后我们上传到nginx解压 [rootlocalhost html]# rz[rootlocalhost html]# unzip favicon_logosc.z…...

iOS 17.5中的一个漏洞
i0S 17.5中的一个漏洞 iOS 17.5中的一个漏洞会使已刚除的照片重新出现,并目此问题似乎会影响甚至已擦除并出售给他人的 iPhone 和 iPad. 在2023年9月,一位Reddit用户根据Apple的指南擦除了他的iPad,并将其卖给了一位朋友。然而,这…...

如何在 iPhone 上恢复已删除的短信
本文介绍如何检索已删除的短信和 iMessage 以及恢复丢失的消息。说明适用于 iOS 17 及更高版本。 如何在 iOS 17及更高版本中恢复文本 恢复已删除短信的最简单方法是使用 iOS 17。从删除短信到恢复它有 30 到 40 天的时间。 在“信息”的对话屏幕中,选择“过滤器”…...

矩阵练习1
73.矩阵置零 这道题相对简单。 首先我们需要标记需要置零的行和列,可以在遍历矩阵中的元素遇到0,则将其行首和列首元素置为0。在此过程中首行、首列会受影响,因此先用两个变量记录首行、首列是否需要被置0,接着遍历非首行、非首…...
)
从单周期到五级流水:手把手教你用Verilog搭建一个最简单的LoongArch CPU(附完整代码)
从单周期到五级流水:手把手教你用Verilog搭建一个最简单的LoongArch CPU 第一次接触CPU设计时,看着那些复杂的流水线结构图,我完全摸不着头脑。直到自己动手用Verilog从零开始实现一个单周期CPU,再逐步演进到五级流水线࿰…...

新政下的绿电直连项目经济性分析:模式创新与价值重构
目录 一、绿电直连的政策背景与核心机制 (一)政策演进与落地动因 (二)核心政策框架 二、绿电直连项目的经济性影响因素分析 (一)自发自用比例:决定度电成本的核心指标 (二)负荷率与接网容量:影响输配电费的核心参数 (三)综合投资决策:超越度电成本的全面评估…...

同济线代第七版笔记:从期末突击到AI应用,我的矩阵恐惧症治愈之路
同济线代第七版笔记:从期末突击到AI应用,我的矩阵恐惧症治愈之路 第一次翻开同济版《线性代数》时,那些密密麻麻的矩阵和行列式就像天书符号。直到在机器学习课程中看到反向传播算法的推导过程,我才突然意识到——原来这些"吓…...

OpenClaw技能开发:集成德国NINA预警API的轻量级命令行工具
1. 项目概述:一个为OpenClaw定制的德国公共预警信息查询技能 如果你和我一样,是一个喜欢折腾自动化工具,并且对获取本地关键信息(比如灾害预警)有需求的开发者,那么你很可能听说过或者正在使用OpenClaw。它…...

Excel批量导入图片避坑指南:为什么你的图片和名字总对不上?从排序到对齐的完整解决方案
Excel批量导入图片避坑指南:从排序到对齐的完整解决方案 你是否曾经遇到过这样的场景:精心准备了上百张产品图片,按照教程一步步操作,结果导入Excel后发现图片和名称完全对不上号?这种令人抓狂的体验,往往源…...
)
Unity对话系统实战:用Dialogue System插件从零搭建一个RPG剧情(含Lua脚本交互与任务系统)
Unity对话系统实战:用Dialogue System构建RPG剧情框架 在独立游戏开发领域,剧情驱动型游戏始终占据重要地位。无论是经典的JRPG还是现代叙事冒险游戏,对话系统都是连接玩家与虚拟世界的核心纽带。本文将带你从零开始,使用Unity的…...

智能考勤自动化:跨设备远程打卡系统架构解析
智能考勤自动化:跨设备远程打卡系统架构解析 【免费下载链接】AutoDingding 钉钉自动打卡 项目地址: https://gitcode.com/gh_mirrors/au/AutoDingding 在数字化转型浪潮中,企业考勤管理面临着异地办公、多设备协同、数据安全等多重挑战。AutoDin…...

SkillNet:AI驱动的技能评估与人才发展系统
1. 项目概述:当经验遇上系统化AI在职业发展领域,我们常遇到一个经典困境:个人经验如何有效转化为可复用的能力体系?传统的能力评估方式往往依赖主观判断或碎片化的证书认证,而SkillNet的出现彻底改变了这一局面。这个基…...

突破性文件元数据管理革命:让Windows文件标签编辑变得简单高效
突破性文件元数据管理革命:让Windows文件标签编辑变得简单高效 【免费下载链接】FileMeta Enable Explorer in Vista, Windows 7 and later to see, edit and search on tags and other metadata for any file type 项目地址: https://gitcode.com/gh_mirrors/fi/…...

Taotoken API Key 的精细化权限管理与访问审计实践
Taotoken API Key 的精细化权限管理与访问审计实践 1. 权限管理的基本概念 在团队协作使用大模型API的场景中,合理的权限分配是保障安全与成本可控的基础。Taotoken平台提供了细粒度的API Key管理功能,允许管理员为不同成员或应用场景创建具备特定权限…...