目标检测 pytorch复现R-CNN目标检测项目
目标检测 pytorch复现R-CNN目标检测项目
- 1、R-CNN目标检测项目基本流程思路
- 2、项目实现
- 1 、数据集下载:
- 2、车辆数据集抽取
- 3、创建分类器数据集
- 3、微调二分类网络模型
- 4、分类器训练
- 5、边界框回归器训练
- 6、效果测试
目标检测 R-CNN论文详细讲解
1、R-CNN目标检测项目基本流程思路

2、项目实现
项目整体源码以上传至CSDN
本文档实现了R-CNN算法进行目标检测的完整过程,包括
数据集创建
卷积神经网络训练
分类器训练
边界框回归器训练
目标检测器实现

1 、数据集下载:
本次复现使用PASCAL VOC2007数据集
执行代码0_pascal_voc.py
# -*- coding: utf-8 -*-"""
@date: 2020/2/29 下午2:51
@file: pascal_voc.py
@author: zj
@description: 加载PASCAL VOC 2007数据集
"""import cv2
import numpy as np
from torchvision.datasets import VOCDetectiondef draw_box_with_text(img, object_list):"""绘制边框及其分类概率:param img::param object_list::return:"""for object_ in object_list:print(object_)xmin, ymin, xmax, ymax = [int(temp) for temp in list(object_["bndbox"].values())]name=object_["name"]cv2.rectangle(img, (xmin, ymin), (xmax, ymax), (0, 0, 255), 3)cv2.putText(img,name, (xmin-10, ymin-5), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 2)return imgif __name__ == '__main__':"""下载PASCAL VOC数据集"""dataset = VOCDetection('../../data', year='2007', image_set='trainval', download=False)print(len(dataset))img, target = dataset.__getitem__(500) # 利用迭代器的方式获取到第1000张图片,返回图像数据与标注信息img = np.array(img)print(target)print("^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^")print(target["annotation"].keys())print("****************************************")print(target["annotation"]["object"])print("---------------------------------------")# 进行数据可视化操作img_copy = img.copy()draw_img=draw_box_with_text(img_copy,target["annotation"]["object"])print(img.shape)cv2.imshow('draw_img', draw_img)cv2.imshow('img', img)cv2.waitKey(0)cv2.destroyAllWindows()

2、车辆数据集抽取
本文列举训练车辆检测流程,所以需要利用VOCdevkit-VOC2007-ImageSets-Main目录下的文件抽取出包含有car标签的对应数据:
执行代码2_pascal_voc_car.py
# -*- coding: utf-8 -*-"""
@date: 2020/2/29 下午2:43
@file: pascal_voc_car.py
@author: zj
@description: 从PASCAL VOC 2007数据集中抽取类别Car。保留1/10的数目
"""import os
import shutil
import random
import numpy as np
import xmltodict
from util import check_dirsuffix_xml = '.xml'
suffix_jpeg = '.jpg'car_train_path = '../../data/VOCdevkit/VOC2007/ImageSets/Main/car_train.txt'
car_val_path = '../../data/VOCdevkit/VOC2007/ImageSets/Main/car_val.txt'voc_annotation_dir = '../../data/VOCdevkit/VOC2007/Annotations/'
voc_jpeg_dir = '../../data/VOCdevkit/VOC2007/JPEGImages/'car_root_dir = '../../data/voc_car/'def parse_train_val(data_path):"""提取指定类别图像"""samples = []with open(data_path, 'r') as file:lines = file.readlines()for line in lines:res = line.strip().split(' ')if len(res) == 3 and int(res[2]) == 1:samples.append(res[0])return np.array(samples)def sample_train_val(samples):"""随机采样样本,减少数据集个数(留下1/10)"""for name in ['train', 'val']:dataset = samples[name]length = len(dataset)random_samples = random.sample(range(length), int(length / 10))# print(random_samples)new_dataset = dataset[random_samples]samples[name] = new_datasetreturn samples# def parse_car(sample_list):
# """
# 遍历所有的标注文件,筛选包含car的样本
# """
#
# car_samples = list()
# for sample_name in sample_list:
# annotation_path = os.path.join(voc_annotation_dir, sample_name + suffix_xml)
# with open(annotation_path, 'rb') as f:
# xml_dict = xmltodict.parse(f)
# # print(xml_dict)
#
# bndboxs = list()
# objects = xml_dict['annotation']['object']
# if isinstance(objects, list):
# for obj in objects:
# obj_name = obj['name']
# difficult = int(obj['difficult'])
# if 'car'.__eq__(obj_name) and difficult != 1:
# car_samples.append(sample_name)
# elif isinstance(objects, dict):
# obj_name = objects['name']
# difficult = int(objects['difficult'])
# if 'car'.__eq__(obj_name) and difficult != 1:
# car_samples.append(sample_name)
# else:
# pass
#
# return car_samplesdef save_car(car_samples, data_root_dir, data_annotation_dir, data_jpeg_dir):"""保存类别Car的样本图片和标注文件"""for sample_name in car_samples:src_annotation_path = os.path.join(voc_annotation_dir, sample_name + suffix_xml)dst_annotation_path = os.path.join(data_annotation_dir, sample_name + suffix_xml)shutil.copyfile(src_annotation_path, dst_annotation_path)src_jpeg_path = os.path.join(voc_jpeg_dir, sample_name + suffix_jpeg)dst_jpeg_path = os.path.join(data_jpeg_dir, sample_name + suffix_jpeg)shutil.copyfile(src_jpeg_path, dst_jpeg_path)csv_path = os.path.join(data_root_dir, 'car.csv')np.savetxt(csv_path, np.array(car_samples), fmt='%s')if __name__ == '__main__':samples = {'train': parse_train_val(car_train_path), 'val': parse_train_val(car_val_path)}print(samples)# samples = sample_train_val(samples)# print(samples)check_dir(car_root_dir)for name in ['train', 'val']:data_root_dir = os.path.join(car_root_dir, name)data_annotation_dir = os.path.join(data_root_dir, 'Annotations')data_jpeg_dir = os.path.join(data_root_dir, 'JPEGImages')check_dir(data_root_dir)check_dir(data_annotation_dir)check_dir(data_jpeg_dir)save_car(samples[name], data_root_dir, data_annotation_dir, data_jpeg_dir)print('done')得到文件如下:

3、创建分类器数据集
通过选择性搜索算法的质量模式获取候选建议,然后计算候选建议与标注边界框的IoU,当建议框的IoU大于0,且小于0.3,并且大于最大标注框的1/5时,才为负样本
正样本为标注边界框
执行代码:3_create_classifier_data.py
# -*- coding: utf-8 -*-"""
@date: 2020/3/1 下午7:17
@file: create_classifier_data.py
@author: zj
@description: 创建分类器数据集
"""import random
import numpy as np
import shutil
import time
import cv2
import os
import xmltodict
import selectivesearch
from util import check_dir
from util import parse_car_csv
from util import parse_xml
from util import iou
from util import compute_ious# train
# positive num: 625
# negative num: 366028
# val
# positive num: 625
# negative num: 321474def parse_annotation_jpeg(annotation_path, jpeg_path, gs):"""获取正负样本(注:忽略属性difficult为True的标注边界框)正样本:标注边界框负样本:IoU大于0,小于等于0.3为负样本。为了进一步限制负样本数目,其大小必须大于标注框的1/5"""img = cv2.imread(jpeg_path)selectivesearch.config(gs, img, strategy='q')# 计算候选建议rects = selectivesearch.get_rects(gs)# 获取标注边界框bndboxs = parse_xml(annotation_path)print("bndboxs:",bndboxs) #((),())# 标注框大小# 获得当前标注文件中面积最大的标注框面积maximum_bndbox_size = 0for bndbox in bndboxs:xmin, ymin, xmax, ymax = bndboxbndbox_size = (ymax - ymin) * (xmax - xmin)if bndbox_size > maximum_bndbox_size:maximum_bndbox_size = bndbox_size# 获取候选建议和标注边界框的IoUiou_list = compute_ious(rects, bndboxs)positive_list = list()negative_list = list()for i in range(len(iou_list)):xmin, ymin, xmax, ymax = rects[i]rect_size = (ymax - ymin) * (xmax - xmin)iou_score = iou_list[i]if 0 < iou_score <= 0.3 and rect_size > maximum_bndbox_size / 5.0:# 负样本negative_list.append(rects[i])else:passreturn bndboxs, negative_listif __name__ == '__main__':car_root_dir = '../../data/voc_car/'classifier_root_dir = '../../data/classifier_car/'check_dir(classifier_root_dir)gs = selectivesearch.get_selective_search()for name in ['train', 'val']:src_root_dir = os.path.join(car_root_dir, name)src_annotation_dir = os.path.join(src_root_dir, 'Annotations')src_jpeg_dir = os.path.join(src_root_dir, 'JPEGImages')dst_root_dir = os.path.join(classifier_root_dir, name)dst_annotation_dir = os.path.join(dst_root_dir, 'Annotations')dst_jpeg_dir = os.path.join(dst_root_dir, 'JPEGImages')check_dir(dst_root_dir)check_dir(dst_annotation_dir)check_dir(dst_jpeg_dir)total_num_positive = 0total_num_negative = 0samples = parse_car_csv(src_root_dir)# 复制csv文件src_csv_path = os.path.join(src_root_dir, 'car.csv')dst_csv_path = os.path.join(dst_root_dir, 'car.csv')shutil.copyfile(src_csv_path, dst_csv_path)for sample_name in samples:print("在处理--------:",sample_name)since = time.time()src_annotation_path = os.path.join(src_annotation_dir, sample_name + '.xml')src_jpeg_path = os.path.join(src_jpeg_dir, sample_name + '.jpg')# 获取正负样本positive_list, negative_list = parse_annotation_jpeg(src_annotation_path, src_jpeg_path, gs) # positive_list:标注框列表,negative_list:经过ioc分析后的推荐框列表total_num_positive += len(positive_list)total_num_negative += len(negative_list)# 拼接csv文件的本地保存路径dst_annotation_positive_path = os.path.join(dst_annotation_dir, sample_name + '_1' + '.csv')dst_annotation_negative_path = os.path.join(dst_annotation_dir, sample_name + '_0' + '.csv')dst_jpeg_path = os.path.join(dst_jpeg_dir, sample_name + '.jpg')# 保存图片shutil.copyfile(src_jpeg_path, dst_jpeg_path)# 保存正负样本标注np.savetxt(dst_annotation_positive_path, np.array(positive_list), fmt='%d', delimiter=' ')np.savetxt(dst_annotation_negative_path, np.array(negative_list), fmt='%d', delimiter=' ')time_elapsed = time.time() - sinceprint('parse {}.png in {:.0f}m {:.0f}s'.format(sample_name, time_elapsed // 60, time_elapsed % 60))print('%s positive num: %d' % (name, total_num_positive))print('%s negative num: %d' % (name, total_num_negative))print('done')3、微调二分类网络模型
PyTorch提供了AlexNet的预训练模型
二分类模型:即1:代表car;0:代表背景
训练参数:
批量处理:每次训练128个图像,其中32个正样本,96个负样本
输入模型图像:缩放到(227, 227),随机水平翻转,进行归一化操作
优化器:使用SGD:学习率为1e-3,动量大小为0.9
随步长衰减:每隔7轮衰减一次,衰减因子为0.1
迭代次数:25轮
模型在训练过程中呈现过拟合现象,可考虑调整学习率、添加权重衰减以及更换优化器的方式:
学习率从1e-3调整为1e-4
添加L2权重衰减,衰减因子为1e-4
使用Adam替换SGD
微调实现:finetune.py
自定义微调数据集类:py/utils/data/custom_finetune_dataset.py
自定义批量采样器类:py/utils/data/custom_batch_sampler.py
执行代码:finetune.py
# -*- coding: utf-8 -*-"""
@date: 2020/3/1 上午9:54
@file: finetune.py
@author: zj
@description:
"""import os,cv2
import copy
import time
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import torchvision.models as models
import numpy as np
from py.utils.data.custom_finetune_dataset import CustomFinetuneDataset
from py.utils.data.custom_batch_sampler import CustomBatchSampler
from py.utils.data.util import check_dir
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
print("------------------")def load_data(data_root_dir):transform = transforms.Compose([transforms.ToPILImage(),transforms.Resize((227, 227)),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])data_loaders = {}data_sizes = {}for name in ['train', 'val']:data_dir = os.path.join(data_root_dir, name)data_set = CustomFinetuneDataset(data_dir, transform=transform) # 加载数据集,改写相应的迭代器方法data_sampler = CustomBatchSampler(data_set.get_positive_num(), data_set.get_negative_num(), 32, 96) # 此处表示是将32张正例图像与96张负例图像组成128张混合数据data_loader = DataLoader(data_set, batch_size=128, sampler=data_sampler, num_workers=8, drop_last=True)data_loaders[name] = data_loader # 迭代器data_sizes[name] = data_sampler.__len__() # 得到的是正例框体与负例框体的汇总数量return data_loaders, data_sizesdef train_model(data_loaders, model, criterion, optimizer, lr_scheduler, num_epochs=25, device=None):since = time.time()best_model_weights = copy.deepcopy(model.state_dict())best_acc = 0.0for epoch in range(num_epochs):print('Epoch {}/{}'.format(epoch, num_epochs - 1))print('-' * 10)# Each epoch has a training and validation phasefor phase in ['train', 'val']:if phase == 'train':model.train() # Set model to training modeelse:model.eval() # Set model to evaluate moderunning_loss = 0.0running_corrects = 0# Iterate over data.for inputs, labels in data_loaders[phase]:inputs = inputs.to(device)labels = labels.to(device)# zero the parameter gradientsoptimizer.zero_grad() # 进行梯度清零操作# forward# track history if only in trainwith torch.set_grad_enabled(phase == 'train'):outputs = model(inputs)_, preds = torch.max(outputs, 1)loss = criterion(outputs, labels)# backward + optimize only if in training phaseif phase == 'train':loss.backward()optimizer.step()# statisticsrunning_loss += loss.item() * inputs.size(0)running_corrects += torch.sum(preds == labels.data)if phase == 'train':lr_scheduler.step()epoch_loss = running_loss / data_sizes[phase]epoch_acc = running_corrects.double() / data_sizes[phase]print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))# deep copy the modelif phase == 'val' and epoch_acc > best_acc:best_acc = epoch_accbest_model_weights = copy.deepcopy(model.state_dict())print()time_elapsed = time.time() - sinceprint('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))print('Best val Acc: {:4f}'.format(best_acc))# load best model weightsmodel.load_state_dict(best_model_weights)return modelif __name__ == '__main__':device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")data_loaders, data_sizes = load_data('./data/classifier_car') # 返回迭代器,样本量# AlexNet预训练模型model = models.alexnet(pretrained=True)print(model)data_loader = data_loaders["train"]num_features = model.classifier[6].in_featuresmodel.classifier[6] = nn.Linear(num_features, 2)print(model)model = model.to(device)inputs,targets = next(data_loader.__iter__())print(inputs[0].size(),type(inputs[0]))trans=transforms.ToPILImage()print(type(trans(inputs[0])))print(targets)print(inputs.shape)titles = ["True" if i.item() else "False" for i in targets[0:60]]images = [np.array(trans(im)) for im in inputs[0:60]]from images_handle import show_imageshow_image(images,titles=titles,num_cols=12)# temp_=inputs.numpy()# for temp__ in temp_:# temp__=temp__.transpose(1,2,0)# cv2.imshow(" ",temp__)# cv2.waitKey(0)# cv2.destroyAllWindows()criterion = nn.CrossEntropyLoss()optimizer = optim.SGD(model.parameters(), lr=1e-3, momentum=0.9)lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)best_model = train_model(data_loaders, model, criterion, optimizer, lr_scheduler, device=device, num_epochs=25)# 保存最好的模型参数check_dir('./models')torch.save(best_model.state_dict(), 'models/alexnet_car.pth')4、分类器训练
R-CNN在完成卷积模型的微调后,额外使用了线性SVM分类器,采用负样本挖掘方法进行训练,参考Hard Negative Mining,即针对正样本较少,负样本过多问题,在训练过程中,测试阶段中识别错误的负样本放置到训练集中用于训练
SVM损失函数设置为折页损失:
def hinge_loss(outputs, labels):"""折页损失计算:param outputs: 大小为(N, num_classes):param labels: 大小为(N):return: 损失值"""num_labels = len(labels)corrects = outputs[range(num_labels), labels].unsqueeze(0).T# 最大间隔margin = 1.0margins = outputs - corrects + marginloss = torch.sum(torch.max(margins, 1)[0]) / len(labels)# # 正则化强度# reg = 1e-3# loss += reg * torch.sum(weight ** 2)return loss
负样本挖掘
实现流程如下:
设置初始训练集,正负样本数比值为1:1(以正样本数目为基准)
每轮训练完成后,使用分类器对剩余负样本进行检测,如果检测为正,则加入到训练集中
重新训练分类器,重复第二步,直到检测精度开始收敛
训练参数
学习率:1e-4
动量:0.9
随步长衰减:每隔4轮衰减一次,参数因子α=0.1
迭代次数:10
批量处理:每次训练128个图像,其中32个正样本,96个负样本
执行代码:linear_svm.py
# -*- coding: utf-8 -*-"""
@date: 2020/3/1 下午2:38
@file: linear_svm.py
@author: zj
@description:
"""import time
import copy
import os
import random
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torchvision.models import alexnetfrom py.utils.data.custom_classifier_dataset import CustomClassifierDataset
from py.utils.data.custom_hard_negative_mining_dataset import CustomHardNegativeMiningDataset
from py.utils.data.custom_batch_sampler import CustomBatchSampler
from py.utils.data.util import check_dir
from py.utils.data.util import save_modelbatch_positive = 32
batch_negative = 96
batch_total = 128def load_data(data_root_dir):transform = transforms.Compose([transforms.ToPILImage(),transforms.Resize((227, 227)),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])data_loaders = {}data_sizes = {}remain_negative_list = list()for name in ['train', 'val']:data_dir = os.path.join(data_root_dir, name)data_set = CustomClassifierDataset(data_dir, transform=transform)if name is 'train':"""使用hard negative mining方式初始正负样本比例为1:1。由于正样本数远小于负样本,所以以正样本数为基准,在负样本集中随机提取同样数目负样本作为初始负样本集"""positive_list = data_set.get_positives() # 返回正例样本数据 形如 [{"rect":[12,25,227,96],"image_id":1},{"rect":[12,25,227,96],"image_id":1},...]negative_list = data_set.get_negatives() # 返回负总例样本数据 形如 [{"rect":[12,25,227,96],"image_id":0},{"rect":[12,25,227,96],"image_id":0},...]init_negative_idxs = random.sample(range(len(negative_list)), len(positive_list)) # 从负总样本集中随机抽取一定的数量的样本,用于当做负样本,训练模型(数据索引)init_negative_list = [negative_list[idx] for idx in range(len(negative_list)) if idx in init_negative_idxs] # 表示从负总样本中挑选出来的与正样本数量一样的负样本remain_negative_list = [negative_list[idx] for idx in range(len(negative_list))if idx not in init_negative_idxs] # 负总样本中剔除了挑选的负样本剩余的负样本data_set.set_negative_list(init_negative_list) # 重新定义负样本data_loaders['remain'] = remain_negative_listsampler = CustomBatchSampler(data_set.get_positive_num(), data_set.get_negative_num(),batch_positive, batch_negative) # 传入的第一个参数是正样本的总量,第二个参数是负样本的总量# 创建迭代器data_loader = DataLoader(data_set, batch_size=batch_total, sampler=sampler, num_workers=8, drop_last=True)data_loaders[name] = data_loaderdata_sizes[name] = len(sampler) # 得到训练集样本的总量return data_loaders, data_sizesdef hinge_loss(outputs, labels):"""折页损失计算1、针对每个样本上对不同分类的分数,选择不是该样本真实分类的分数与该样本真实分类的分数进行比较,如果该分数大于1,小于真实分类上的分数,则loss为02、反之,该样本的loss为该分数加1再减去该样本在真实分类上的分数3、对所有的样本都按照此方法进行计算得到每个样本的loss,然后将它们加在一起凑成总loss值,并除以样本数以求平均:param outputs: 大小为(N, num_classes):param labels: 大小为(N) 样本真实分类标签:return: 损失值Li="""num_labels = len(labels)corrects = outputs[range(num_labels), labels].unsqueeze(0).T# 最大间隔margin = 1.0margins = outputs - corrects + marginloss = torch.sum(torch.max(margins, 1)[0]) / len(labels)# # 正则化强度# reg = 1e-3# loss += reg * torch.sum(weight ** 2)return lossdef add_hard_negatives(hard_negative_list, negative_list, add_negative_list):for item in hard_negative_list:if len(add_negative_list) == 0:# 第一次添加负样本negative_list.append(item)add_negative_list.append(list(item['rect']))if list(item['rect']) not in add_negative_list:negative_list.append(item)add_negative_list.append(list(item['rect']))def get_hard_negatives(preds, cache_dicts):"""困难样本挖掘函数:param preds::param cache_dicts::return:"""fp_mask = preds == 1 # 找寻到苦难样本,,,,得到掩码tn_mask = preds == 0fp_rects = cache_dicts['rect'][fp_mask].numpy()fp_image_ids = cache_dicts['image_id'][fp_mask].numpy()tn_rects = cache_dicts['rect'][tn_mask].numpy()tn_image_ids = cache_dicts['image_id'][tn_mask].numpy()hard_negative_list = [{'rect': fp_rects[idx], 'image_id': fp_image_ids[idx]} for idx in range(len(fp_rects))]easy_negatie_list = [{'rect': tn_rects[idx], 'image_id': tn_image_ids[idx]} for idx in range(len(tn_rects))]return hard_negative_list, easy_negatie_listdef train_model(data_loaders, model, criterion, optimizer, lr_scheduler, num_epochs=25, device=None):since = time.time()best_model_weights = copy.deepcopy(model.state_dict())best_acc = 0.0for epoch in range(num_epochs):print('Epoch {}/{}'.format(epoch, num_epochs - 1))print('-' * 10)# Each epoch has a training and validation phasefor phase in ['train', 'val']:if phase == 'train':model.train() # Set model to training modeelse:model.eval() # Set model to evaluate moderunning_loss = 0.0running_corrects = 0# 输出正负样本数data_set = data_loaders[phase].datasetprint('{} - positive_num: {} - negative_num: {} - data size: {}'.format(phase, data_set.get_positive_num(), data_set.get_negative_num(), data_sizes[phase]))# Iterate over data.for inputs, labels, cache_dicts in data_loaders[phase]: # for循环,其会调用迭代器 cache_dicts:形如:[{"rect":[12,25,227,96],"image_id":1},{"rect":[12,25,227,96],"image_id":1},...]inputs = inputs.to(device)labels = labels.to(device)# zero the parameter gradientsoptimizer.zero_grad()# forward# track history if only in trainwith torch.set_grad_enabled(phase == 'train'):outputs = model(inputs)# print(outputs.shape)_, preds = torch.max(outputs, 1) # 返回最大项的索引值loss = criterion(outputs, labels) # 计算损失函数# backward + optimize only if in training phaseif phase == 'train':loss.backward()optimizer.step()# statisticsrunning_loss += loss.item() * inputs.size(0) # inputs.size(0):为图像的批次数running_corrects += torch.sum(preds == labels.data)if phase == 'train':lr_scheduler.step()epoch_loss = running_loss / data_sizes[phase] # data_sizes[phase] 训练集或者样本集样本总数epoch_acc = running_corrects.double() / data_sizes[phase]print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))# deep copy the modelif phase == 'val' and epoch_acc > best_acc:best_acc = epoch_accbest_model_weights = copy.deepcopy(model.state_dict())"""# 每一轮训练完成后,测试剩余负样本集,进行hard negative mining 难分辨负样本挖掘"""train_dataset = data_loaders['train'].datasetremain_negative_list = data_loaders['remain'] # 获取到负总样本数据集中除去训练集中负样本的剩余负样本jpeg_images = train_dataset.get_jpeg_images() # 返回加载的图像数据列表transform = train_dataset.get_transform() # 返回数据图像处理方式列表with torch.set_grad_enabled(False):remain_dataset = CustomHardNegativeMiningDataset(remain_negative_list, jpeg_images, transform=transform) # 初始化艰难搜索对象,改写迭代器remain_data_loader = DataLoader(remain_dataset, batch_size=batch_total, num_workers=8, drop_last=True)# 获取训练数据集的负样本集negative_list = train_dataset.get_negatives() # 训练样本集数据# 记录后续增加的负样本add_negative_list = data_loaders.get('add_negative', []) # 创建一个键为“add_negative”的列表,用于存放负样本数据running_corrects = 0# Iterate over data.for inputs, labels, cache_dicts in remain_data_loader:inputs = inputs.to(device)labels = labels.to(device)# zero the parameter gradientsoptimizer.zero_grad()outputs = model(inputs)# print(outputs.shape)_, preds = torch.max(outputs, 1)running_corrects += torch.sum(preds == labels.data)hard_negative_list, easy_neagtive_list = get_hard_negatives(preds.cpu().numpy(), cache_dicts) # 困难样本挖掘函数add_hard_negatives(hard_negative_list, negative_list, add_negative_list)remain_acc = running_corrects.double() / len(remain_negative_list)print('remiam negative size: {}, acc: {:.4f}'.format(len(remain_negative_list), remain_acc))# 训练完成后,重置负样本,进行hard negatives miningtrain_dataset.set_negative_list(negative_list) # 将训练集负样本进行更新tmp_sampler = CustomBatchSampler(train_dataset.get_positive_num(), train_dataset.get_negative_num(),batch_positive, batch_negative)data_loaders['train'] = DataLoader(train_dataset, batch_size=batch_total, sampler=tmp_sampler,num_workers=8, drop_last=True)data_loaders['add_negative'] = add_negative_list# 重置数据集大小data_sizes['train'] = len(tmp_sampler)# 每训练一轮就保存save_model(model, 'models/linear_svm_alexnet_car_%d.pth' % epoch)time_elapsed = time.time() - sinceprint('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))print('Best val Acc: {:4f}'.format(best_acc))# load best model weightsmodel.load_state_dict(best_model_weights)return modelif __name__ == '__main__':device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')# device = 'cpu'data_loaders, data_sizes = load_data('./data/classifier_car')# 加载CNN模型model_path = './models/alexnet_car.pth'model = alexnet() # 因为此处不是进行预训练,而是加载模型,所以没有参数pretrained=Truenum_classes = 2num_features = model.classifier[6].in_featuresmodel.classifier[6] = nn.Linear(num_features, num_classes) # 将模型结构调整成二分类# model.load_state_dict(torch.load(model_path))model.load_state_dict(torch.load(model_path, map_location='cpu'))model.eval() # 表示进入估算模式下# 固定特征提取for param in model.parameters():param.requires_grad = False # 冻结各层模型参数# 创建SVM分类器(即再重新定义最后一层,重新训练该层,采用的损失函数是折页损失)model.classifier[6] = nn.Linear(num_features, num_classes)# print(model)model = model.to(device)criterion = hinge_loss # 损失函数# 由于初始训练集数量很少,所以降低学习率optimizer = optim.SGD(model.parameters(), lr=1e-4, momentum=0.9)# 共训练10轮,每隔4论减少一次学习率lr_schduler = optim.lr_scheduler.StepLR(optimizer, step_size=4, gamma=0.1)best_model = train_model(data_loaders, model, criterion, optimizer, lr_schduler, num_epochs=10, device=device)# 保存最好的模型参数save_model(best_model, 'models/best_linear_svm_alexnet_car.pth')
5、边界框回归器训练
使用SVM分类器对候选建议进行分类后,使用对应类别的边界框回归器(bounding-box regression)预测其坐标偏移值,这一操作能够进一步提高检测精度
执行代码4_create_bbox_regression_data.py
# -*- coding: utf-8 -*-"""
@date: 2020/4/3 下午7:19
@file: create_bbox_regression_data.py
@author: zj
@description: 创建边界框回归数据集
"""import os
import shutil
import numpy as np
import util as util# 正样本边界框数目:37222if __name__ == '__main__':"""从voc_car/train目录中提取标注边界框坐标从classifier_car/train目录中提取训练集正样本坐标(IoU>=0.5),进一步提取IoU>0.6的边界框数据集保存在bbox_car目录下"""voc_car_train_dir = '../../data/voc_car/train'# ground truthgt_annotation_dir = os.path.join(voc_car_train_dir, 'Annotations') # 标注xml所在文件夹jpeg_dir = os.path.join(voc_car_train_dir, 'JPEGImages') # 图像数据集所在文件夹classifier_car_train_dir = '../../data/classifier_car/train'# positivepositive_annotation_dir = os.path.join(classifier_car_train_dir, 'Annotations')dst_root_dir = '../../data/bbox_regression/'dst_jpeg_dir = os.path.join(dst_root_dir, 'JPEGImages')dst_bndbox_dir = os.path.join(dst_root_dir, 'bndboxs')dst_positive_dir = os.path.join(dst_root_dir, 'positive')util.check_dir(dst_root_dir)util.check_dir(dst_jpeg_dir)util.check_dir(dst_bndbox_dir)util.check_dir(dst_positive_dir)samples = util.parse_car_csv(voc_car_train_dir) # 读取csv文件,获取到图像名称res_samples = list()total_positive_num = 0for sample_name in samples:# 提取正样本边界框坐标(IoU>=0.5)positive_annotation_path = os.path.join(positive_annotation_dir, sample_name + '_1.csv')positive_bndboxes = np.loadtxt(positive_annotation_path, dtype=np.int, delimiter=' ')# 提取标注边界框gt_annotation_path = os.path.join(gt_annotation_dir, sample_name + '.xml')bndboxs = util.parse_xml(gt_annotation_path)# 计算符合条件(IoU>0.6)的候选建议positive_list = list()if len(positive_bndboxes.shape) == 1 and len(positive_bndboxes) != 0:scores = util.iou(positive_bndboxes, bndboxs)if np.max(scores) > 0.6:positive_list.append(positive_bndboxes)elif len(positive_bndboxes.shape) == 2:for positive_bndboxe in positive_bndboxes:scores = util.iou(positive_bndboxe, bndboxs)if np.max(scores) > 0.6:positive_list.append(positive_bndboxe)else:pass# 如果存在正样本边界框(IoU>0.6),那么保存相应的图片以及标注边界框if len(positive_list) > 0:# 保存图片jpeg_path = os.path.join(jpeg_dir, sample_name + ".jpg")dst_jpeg_path = os.path.join(dst_jpeg_dir, sample_name + ".jpg")shutil.copyfile(jpeg_path, dst_jpeg_path)# 保存标注边界框dst_bndbox_path = os.path.join(dst_bndbox_dir, sample_name + ".csv")np.savetxt(dst_bndbox_path, bndboxs, fmt='%s', delimiter=' ')# 保存正样本边界框dst_positive_path = os.path.join(dst_positive_dir, sample_name + ".csv")np.savetxt(dst_positive_path, np.array(positive_list), fmt='%s', delimiter=' ')total_positive_num += len(positive_list)res_samples.append(sample_name)print('save {} done'.format(sample_name))else:print('-------- {} 不符合条件'.format(sample_name))dst_csv_path = os.path.join(dst_root_dir, 'car.csv')np.savetxt(dst_csv_path, res_samples, fmt='%s', delimiter=' ')print('total positive num: {}'.format(total_positive_num))print('done')
训练逻辑回归模型代码:
bbox_regression.py
# -*- coding: utf-8 -*-"""
@date: 2020/4/3 下午6:55
@file: bbox_regression.py
@author: zj
@description: 边界框回归训练
"""import os
import copy
import time,cv2
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torchvision.models import AlexNetfrom py.utils.data.custom_bbox_regression_dataset import BBoxRegressionDataset
import py.utils.data.util as utildef load_data(data_root_dir):transform = transforms.Compose([transforms.ToPILImage(),transforms.Resize((227, 227)),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])data_set = BBoxRegressionDataset(data_root_dir, transform=transform)data_loader = DataLoader(data_set, batch_size=128, shuffle=True, num_workers=8)return data_loaderdef train_model(data_loader, feature_model, model, criterion, optimizer, lr_scheduler, num_epochs=25, device=None):since = time.time()model.train() # Set model to training modeloss_list = list()for epoch in range(num_epochs):print('Epoch {}/{}'.format(epoch, num_epochs - 1))print('-' * 10)running_loss = 0.0# Iterate over data.for inputs, targets in data_loader:inputs = inputs.to(device) # 标注的图像截取片段targets = targets.float().to(device) # 物体标注框# for input in inputs:# cv2.imshow("pppp",input.numpy().transpose(2,1,0))# cv2.waitKey(0)# cv2.destroyAllWindows()features = feature_model.features(inputs) # 得到经过卷积神经网络提取到的数据特征features = torch.flatten(features, 1) # 将批次的数据进行拉伸操作,由于第0维度代表数据的批次,所以从第1万维度开始拉伸# zero the parameter gradientsoptimizer.zero_grad()# forwardoutputs = model(features) # 将提取到的数据特征喂入回归模型,训练边框回归器loss = criterion(outputs, targets)loss.backward()optimizer.step()# statisticsrunning_loss += loss.item() * inputs.size(0)lr_scheduler.step()epoch_loss = running_loss / data_loader.dataset.__len__()loss_list.append(epoch_loss)print('{} Loss: {:.4f}'.format(epoch, epoch_loss))# 每训练一轮就保存util.save_model(model, './models/bbox_regression_%d.pth' % epoch)print()time_elapsed = time.time() - sinceprint('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))return loss_listdef get_model(device=None):# 加载CNN模型model = AlexNet(num_classes=2) # 设置为二分类model.load_state_dict(torch.load('./models/best_linear_svm_alexnet_car.pth',map_location='cpu')) # 加载本地的模型文件model.eval()# 取消梯度追踪for param in model.parameters():param.requires_grad = Falseif device:model = model.to(device)return modelif __name__ == '__main__':data_loader = load_data('./data/bbox_regression')device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")feature_model = get_model(device) # 加载本地的模型文件print("--------------------->\n", feature_model)# AlexNet最后一个池化层计算得到256*6*6输出in_features = 256 * 6 * 6out_features = 4model = nn.Linear(in_features, out_features)print(model)model.to(device)criterion = nn.MSELoss()optimizer = optim.Adam(model.parameters(), lr=1e-4, weight_decay=1e-4)lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)loss_list = train_model(data_loader, feature_model, model, criterion, optimizer, lr_scheduler, device=device,num_epochs=12)util.plot_loss(loss_list)
6、效果测试
# -*- coding: utf-8 -*-"""
@date: 2020/3/2 上午8:07
@file: car_detector.py
@author: zj
@description: 车辆类别检测器
"""import time
import copy
import cv2
import numpy as np
import torch
import torch.nn as nn
from torchvision.models import alexnet
import torchvision.transforms as transforms
import selectivesearchimport utils.data.util as utildef get_device():return torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')def get_transform():# 数据转换transform = transforms.Compose([transforms.ToPILImage(),transforms.Resize((227, 227)),# transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])return transformdef get_model(device=None):# 加载CNN模型model = alexnet()num_classes = 2num_features = model.classifier[6].in_featuresmodel.classifier[6] = nn.Linear(num_features, num_classes)model.load_state_dict(torch.load('./models/best_linear_svm_alexnet_car.pth',map_location='cpu'))model.eval() # 设置成推理模式print(model)# 取消梯度追踪for param in model.parameters():param.requires_grad = Falseif device:model = model.to(device)return modeldef draw_box_with_text(img, rect_list, score_list):"""绘制边框及其分类概率:param img::param rect_list::param score_list::return:"""for i in range(len(rect_list)):xmin, ymin, xmax, ymax = rect_list[i]score = score_list[i]cv2.rectangle(img, (xmin, ymin), (xmax, ymax), color=(0, 0, 255), thickness=1)cv2.putText(img, "{:.3f}".format(score), (xmin, ymin), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 1)def nms(rect_list, score_list):"""非最大抑制:param rect_list: list,大小为[N, 4]:param score_list: list,大小为[N]"""nms_rects = list()nms_scores = list()rect_array = np.array(rect_list)score_array = np.array(score_list)# 一次排序后即可# 按分类概率从大到小排序idxs = np.argsort(score_array)[::-1]rect_array = rect_array[idxs] # 即重新排序后的目标框列表score_array = score_array[idxs] # 即重新排序后的概率值列表thresh = 0.3while len(score_array) > 0:# 添加分类概率最大的边界框nms_rects.append(rect_array[0])nms_scores.append(score_array[0])rect_array = rect_array[1:]score_array = score_array[1:]length = len(score_array)if length <= 0:break# 计算IoUiou_scores = util.iou(np.array(nms_rects[len(nms_rects) - 1]), rect_array) # 即每次都使用nms_rects列表中的最后一个框体与rect_array循环进行NMS# print(iou_scores)# 去除重叠率大于等于thresh的边界框print("-------->",np.where(iou_scores < thresh))idxs = np.where(iou_scores < thresh)[0]rect_array = rect_array[idxs]score_array = score_array[idxs]return nms_rects, nms_scoresif __name__ == '__main__':device = get_device() # 设置GPU或者CPUprint(device)transform = get_transform() # 设置数据预处理方式model = get_model(device=device) # 加载模型# 创建selectivesearch对象gs = selectivesearch.get_selective_search()test_img_path = '../imgs/000007.jpg'test_xml_path = '../imgs/000007.xml'# test_img_path = '../imgs/000012.jpg'# test_xml_path = '../imgs/000012.xml'img = cv2.imread(test_img_path)dst = copy.deepcopy(img)bndboxs = util.parse_xml(test_xml_path) # 读取xml文件中的坐标框for bndbox in bndboxs:xmin, ymin, xmax, ymax = bndboxcv2.rectangle(dst, (xmin, ymin), (xmax, ymax), color=(0, 255, 0), thickness=1)# 候选区域建议selectivesearch.config(gs, img, strategy='f')rects = selectivesearch.get_rects(gs) # 传入图像,利用selective research算法生成一定数量的候选框print('候选区域建议数目: %d' % len(rects))# softmax = torch.softmax()svm_thresh = 0.60# 保存正样本边界框以及score_list = list()positive_list = list()# tmp_score_list = list()# tmp_positive_list = list()start = time.time()for rect in rects:xmin, ymin, xmax, ymax = rectrect_img = img[ymin:ymax, xmin:xmax]rect_transform = transform(rect_img).to(device) # 对数据进行预处理,传入到设备上output = model(rect_transform.unsqueeze(0))[0]if torch.argmax(output).item() == 1:"""预测为汽车"""probs = torch.softmax(output, dim=0).cpu().numpy()# tmp_score_list.append(probs[1])# tmp_positive_list.append(rect)if probs[1] >= svm_thresh: # 如果softmax求得的概率大于svm_thresh阈值,则为汽车score_list.append(probs[1]) # 将概率加入到score_list列表positive_list.append(rect) # 将框体加入到positive_list列表# cv2.rectangle(dst, (xmin, ymin), (xmax, ymax), color=(0, 0, 255), thickness=2)print(rect, output, probs)end = time.time()print('detect time: %d s' % (end - start))# tmp_img2 = copy.deepcopy(dst)# draw_box_with_text(tmp_img2, tmp_positive_list, tmp_score_list)# cv2.imshow('tmp', tmp_img2)## tmp_img = copy.deepcopy(dst)# draw_box_with_text(tmp_img, positive_list, score_list)# cv2.imshow('tmp2', tmp_img)nms_rects, nms_scores = nms(positive_list, score_list) # 进行非极大值抑制算法print(nms_rects)print(nms_scores)draw_box_with_text(dst, nms_rects, nms_scores)cv2.imshow('img', dst)cv2.waitKey(0)

相关文章:
目标检测 pytorch复现R-CNN目标检测项目
目标检测 pytorch复现R-CNN目标检测项目1、R-CNN目标检测项目基本流程思路2、项目实现1 、数据集下载:2、车辆数据集抽取3、创建分类器数据集3、微调二分类网络模型4、分类器训练5、边界框回归器训练6、效果测试目标检测 R-CNN论文详细讲解1、R-CNN目标检测项目基本…...
荧光染料IR-825 NHS,IR825 NHS ester,IR825 SE,IR-825 活性酯
IR825 NHS理论分析:中文名:新吲哚菁绿-琥珀酰亚胺酯,IR-825 琥珀酰亚胺酯,IR-825 活性酯英文名:IR825 NHS,IR-825 NHS,IR825 NHS ester,IR825 SECAS号:N/AIR825 NHS产品详…...
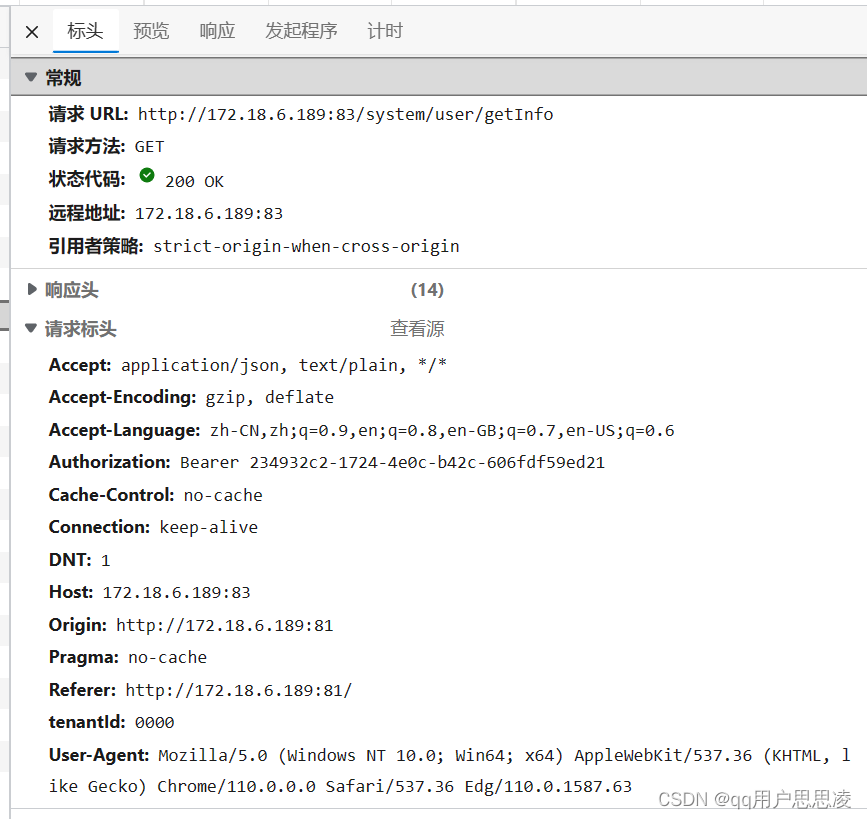
利用Postman的简单运用解决小问题的过程
这几天在修改一个前后端分离的商城项目。项目前端向后端发出数据请求之后,收到的却是504网关超时错误。 但是控制台却不止报错了网关超时,还有跨域请求的问题: 根本搞不清是哪个问题导致了另外一个问题还是独立的两个问题。 直接点击网址访…...
【C语言】8道经典指针笔试题(深度解剖)
上一篇我们也介绍了指针的笔试题,这一篇我们趁热打铁继续讲解8道指针更有趣的笔试题,,让大家更加深刻了解指针,从而也拿下【C语言】指针这个难点! 本次解析是在x86(32位)平台下进行 文章目录所需储备知识笔…...
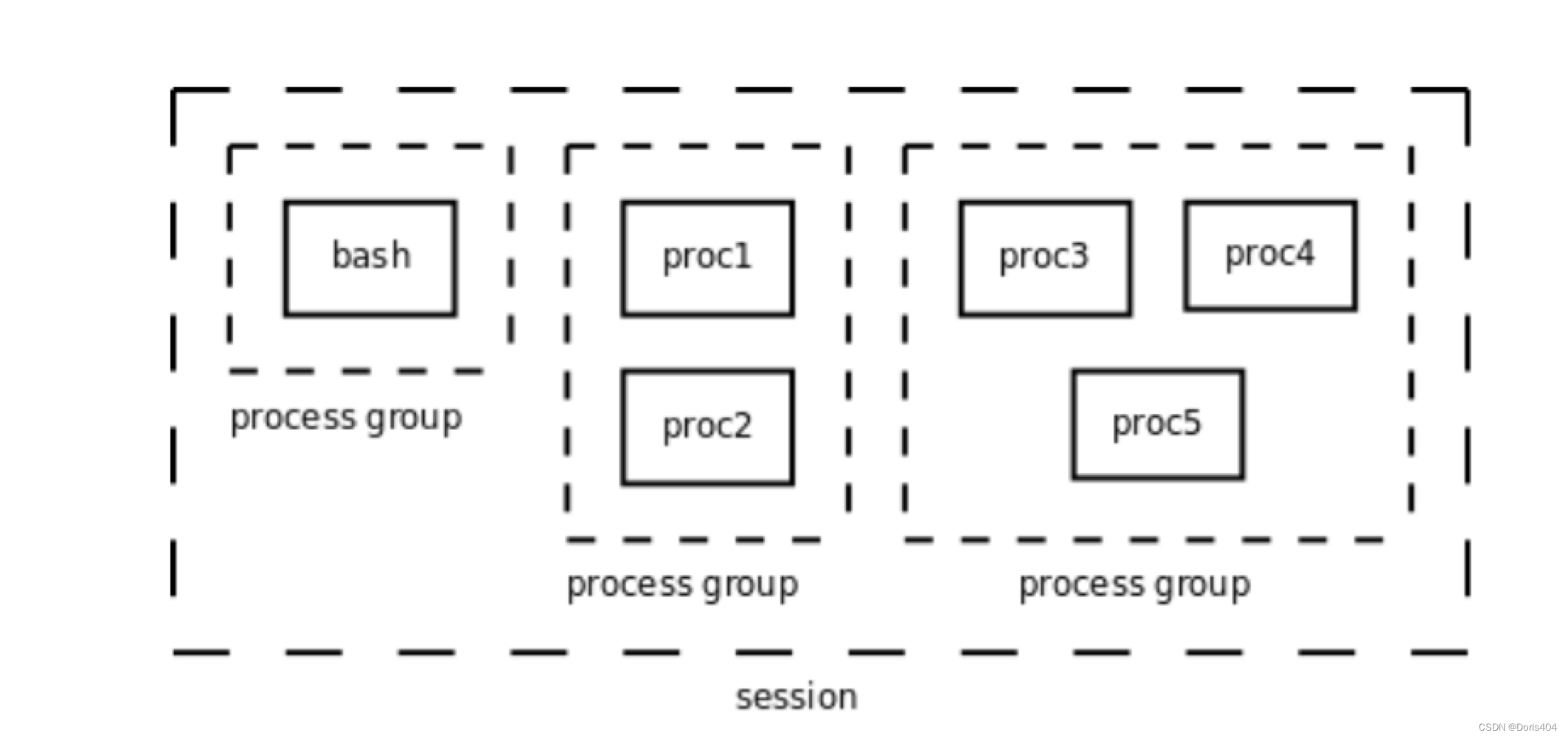
操作系统内核与安全分析课程笔记【2】进程管理与调度
文章目录基本概念与关键数据结构进程管理进程生命周期进程的关系进程家族树线程组进程组与会话进程的创建与终止Linux中的线程基本概念与关键数据结构 进程:静态的,存储在磁盘上的代码与数据。 程序:动态的,执行程序的动态过程&am…...

看完书上的栈不过瘾,为什么不动手试试呢?
一.栈的基本概念1.栈的定义栈(Stack):是只允许在一端进行插入或删除的线性表。首先栈是一种线性表,但限定这种线性表只能在某一端进行插入和删除操作。其中注意几点:栈顶(Top):线性表…...
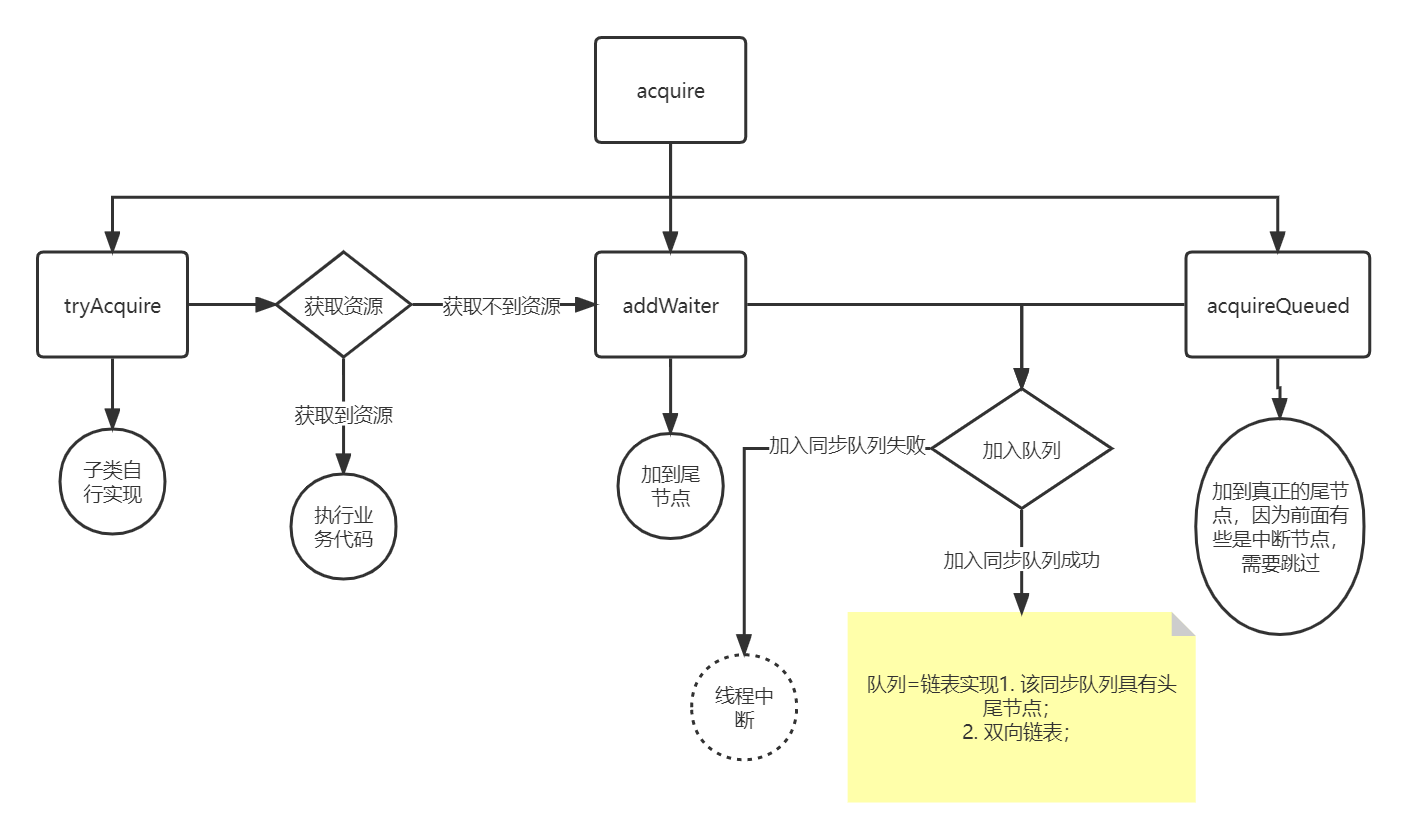
AbstractQueuedSynchronizer从入门到踹门
概念设计初衷:该类利用 状态队列 实现了一个同步器,更多的是提供一些模板方法(子类必须重写,不然会抛错)。 设计功能:独占、共享模式两个核心,state、Queue2.1 statesetState、compareAndSetSta…...

【项目实战】手把手教你Dubbo微服务架构中整合熔断限流组件Sentinel
一、背景 项目中需要引入Sentinel来实现限流,但是项目是基于Dubbo的微服务架构,我们都知道Sentinel是属于SpringCloudAlibaba组件下的限流中间件,基于Dubbo的微服务架构真的能够引入 Sentinel吗?带着疑惑的心情,实践了一把~ 二、使用说明 2.1 引入依赖文件 <!-- Se…...
图像主题颜色提取(Median cut)
前言 之前想对图片素材进行分类管理,除了打标签,还有一样是通过主题色进行分类。于是开始寻找能提取主主题色的工具,最后找到了大名鼎鼎的 Leptonica 库,其中就有中位切割算法的实现。下面附上中位切割算法的其它语言版本的实现。…...

Python 分支结构
Python 分支结构 应用场景 迄今为止,我们写的Python代码都是一条一条语句顺序执行,这种代码结构通常称之为顺序结构。然而仅有顺序结构并不能解决所有的问题,比如我们设计一个游戏,游戏第一关的通关条件是玩家获得1000分&#x…...

【C++知识点】文件操作
✍个人博客:https://blog.csdn.net/Newin2020?spm1011.2415.3001.5343 📚专栏地址:C/C知识点 📣专栏定位:整理一下 C 相关的知识点,供大家学习参考~ ❤️如果有收获的话,欢迎点赞👍…...
VBA小模板,跨表统计的2种写法
目标 1 统计一个excel 文件里,多个sheet里的内容2 有的统计需求是,每个表只单表统计,只是进行批量操作3 有的需求是,多个表得某些行列累加等造出来得文件 2 实现方法1 (可能只适合VBAEXCEL,不太干净的写法…...

部署问题 | 百度LAC安装部署清单
本项目实现基于LAC提供RESTAPI服务的最小化方案。 依赖: python-3.9.9 百度lac2.X fastAPI uvicorn 首先下载并安装python,本人选择3.9版本。 依次安装: 安装 vc vc_redist.x64.exe 64位:https://download.microsoft.com/…...

提高办公效率的免费网站有哪些
收藏一些免费好用的网站,在我们工作中需要用到的时候可以直接使用,提高我们的工作效率。小编就和大家分享10个可以提高我们办公效率的免费网站。 1.羽兔网软件下载-以设计类软件为主的免费软件下载网站 很多小白都不知道怎么下载软件,往往搜…...

前端开发者需要掌握的具体内容和步骤
第一部分:前端开发实践 前端的工作职称 下面是一个前端开发者在职业发展中各种职称的描述列表. 对于前端开发者最普遍的职称是 "前端开发者" 或者 "前端工程师", 可以根据任何包含 "前端", "客户端", "web UI", "CS…...

杨校老师课堂之基于File类的文件管理器
在日常工作中,经常会遇到批量操作系统文件的事情,通常情况下,只能手动重复的完成批量文件的操作,这样很是费时费力。 本案例要求编写一个文件管理器,实现文件的批量操作。 文件管理器具体功能要求如下: 用…...

java面试算法汇总-数组
数组 [程序一] 两数之和 :给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 class Solution {public int[] twoSum(int[] nums, int target) {Map<Integer,…...

Docker-Mysql主从复制
步骤 1、新建主服务器容器实例3307 docker run -d -p 3307:3306 --privileged=true -v /tmp/mysql_master/log:/var/log/mysql -v /tmp/mysql_master/data:/var/lib/mysql -v /tmp/mysql_master/conf:/etc/mysql/conf.d -e MYSQL_ROOT_PASSWORD=root --name mysql-master mys…...
1241. 外卖店优先级)
(模拟)1241. 外卖店优先级
目录 题目链接 一些话 流程 套路 ac代码 题目链接 1241. 外卖店优先级 - AcWing题库 一些话 流程 // // 每经过 1 // 个时间单位,如果外卖店没有订单,则优先级会减少 1 // ,最低减到 0 // ;而如果外卖店有订单,则…...

Linux进程学习【进程地址】
✨个人主页: Yohifo 🎉所属专栏: Linux学习之旅 🎊每篇一句: 图片来源 🎃操作环境: CentOS 7.6 阿里云远程服务器 Perseverance is not a long race; it is many short races one after another…...

Steer3D技术:自然语言驱动的3D模型智能编辑
1. 技术背景与核心价值在数字内容创作领域,3D资产编辑一直存在专业门槛高、操作复杂的问题。传统3D建模软件需要艺术家手动调整网格、贴图和材质参数,一个简单的外观修改可能耗费数小时。而Steer3D技术的出现,让使用者只需输入自然语言描述&a…...

秘语盾安全课堂:Ledger 助记词必须手写备份的原因
对于中国加密货币投资者而言,在复杂的网络环境与多变的监管政策下,“私钥主权离线化”已不再是进阶选项,而是保护资产的生存底线。 针对大中华区用户面临的 App Store 区域限制、网络同步卡顿及硬件供应链安全等痛点,本指南将为您…...

水下群体机器人:生物启发算法与分布式协作技术解析
1. 水下群体机器人概述:从生物启发到工程实践水下群体机器人技术正逐渐成为海洋探索和资源开发的关键工具。想象一下,一群小型自主水下机器人(AUVs)像鱼群一样协同工作,无需中央控制就能完成复杂任务——这正是水下群体…...

ComfyUI-AnimateDiff-Evolved终极指南:无限动画生成与高级采样技术
ComfyUI-AnimateDiff-Evolved终极指南:无限动画生成与高级采样技术 【免费下载链接】ComfyUI-AnimateDiff-Evolved Improved AnimateDiff for ComfyUI and Advanced Sampling Support 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-AnimateDiff-Evolved …...

保姆级教程:用dSPACE ModelDesk的Road模块,5分钟搭建一条带坑洼和交通标志的仿真道路
从零到一:用dSPACE ModelDesk Road模块高效构建复杂仿真道路 在汽车电子系统开发领域,仿真测试已成为验证ADAS和自动驾驶功能的黄金标准。作为行业标杆工具链的核心组件,dSPACE ModelDesk的Road模块让工程师能够快速构建包含复杂地形、动态交…...

压缩机灰铁液压油泵ACF 080K4 IVFE
ACF定做螺杆泵 进口润滑油泵维修附带对轮螺杆泵,以其独特的结构和工作原理,在工业领域有着广泛的应用。而ACF进口螺杆泵,则在此基础上更进一步,根据客户的具体工况、介质特性、流量压力等要求,进行精准的设计和制造。无…...

Cursor-Flow:AI编程工作流引擎的设计原理与工程实践
1. 项目概述:当AI编程助手遇上“工作流引擎”最近在GitHub上看到一个挺有意思的项目,叫cursor-flow。光看名字,你可能觉得它又是一个基于Cursor AI编辑器的插件或者脚本。但如果你像我一样,真正深入去用Cursor写代码,特…...

【Docker 27工业集群部署终极指南】:20年运维专家亲授高可用、零宕机落地五步法
更多请点击: https://intelliparadigm.com 第一章:Docker 27工业集群部署的演进逻辑与核心价值 Docker 27并非官方版本号,而是工业界对基于Docker Engine v24.0、配合Docker Compose V2.25与Swarm Mode增强套件所构建的高可靠集群范式的代称…...

2024新版HDD Regenerator硬盘坏道修复工具|专业级硬盘再生软件
温馨提示:文末有联系方式什么是HDD Regenerator 2024? HDD Regenerator 2024是专为现代机械硬盘(HDD)设计的智能坏道修复工具,采用独有磁道重映射与电磁再生技术,可针对性处理早期物理坏道,避免…...

如何通过Obsidian Style Settings插件打造个性化笔记体验:终极视觉定制指南
如何通过Obsidian Style Settings插件打造个性化笔记体验:终极视觉定制指南 【免费下载链接】obsidian-style-settings A dynamic user interface for adjusting theme, plugin, and snippet CSS variables within Obsidian 项目地址: https://gitcode.com/gh_mir…...