【Redis】Redis经典问题:缓存穿透、缓存击穿、缓存雪崩
目录
- 缓存的处理流程
- 缓存穿透
- 解释
- 产生原因
- 解决方案
- 1.针对不存在的数据也进行缓存
- 2.设置合适的缓存过期时间
- 3. 对缓存访问进行限流和降级
- 4. 接口层增加校验
- 5. 布隆过滤器
- 原理
- 优点
- 缺点
- 关于扩容
- 其他使用场景
- SpringBoot 整合 布隆过滤器
- 缓存击穿
- 产生原因
- 解决方案
- 1.设置热点数据永不过期
- 优点
- 缺点
- 示例
- 2.使用互斥锁
- 优点
- 缺点
- 示例
- 3. 使用分布式缓存
- 4. 设置随机过期时间
- 缓存雪崩
- 产生原因
- 解决方案
- 对于大量的缓存key同时失效
- 对于redis服务宕机
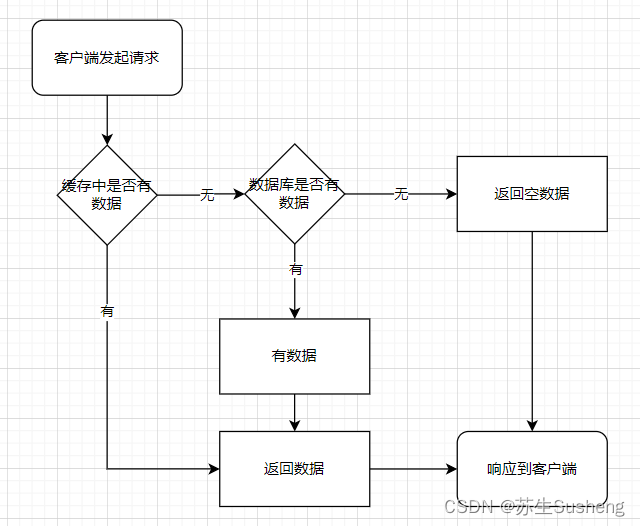
缓存的处理流程
- 客户端发起请求,服务端先尝试从缓存中取数据,若取到直接返回结果
- 若取不到,则从数据库中取,然后将取出的数据更新到缓存,并返回结果
- 若数据库也没取到,那直接返回空结果。
缓存穿透
解释
- Redis缓存穿透指的是针对一个不存在于缓存中的数据进行查询操作,由于缓存中不存在该数据,所以会直接访问数据库获取数据。
- 这种情况下,如果有大量并发查询这个不存在于缓存中的数据,就会导致大量的查询请求直接访问数据库,增加了数据库的负载,并且没有起到缓存的作用。
产生原因
- 缓存穿透的主要原因是恶意攻击或者查询频率极高的缓存击穿。
- 恶意攻击指的是有人故意请求不存在于缓存中的数据,以此来进行攻击。
- 查询频率极高的缓存击穿是指某个热点数据在缓存中过期后,大量并发访问该数据,导致缓存失效并且直接访问数据库。
解决方案
1.针对不存在的数据也进行缓存
针对不存在的数据也进行缓存:即使查询的数据不存在于数据库中,也可以将查询的结果缓存起来,标记为不存在。这样下次查询同样的数据时,就可以直接从缓存中获取结果,而不需要再查询数据库。
2.设置合适的缓存过期时间
设置合适的缓存过期时间:对于热点数据,可以设置较长的缓存过期时间,让它在过期之前不会被失效。这样可以减少缓存击穿的风险。
3. 对缓存访问进行限流和降级
对缓存访问进行限流和降级:限制并发访问缓存的请求数量,避免由于高并发访问导致缓存失效。当缓存失效时,可以选择使用备用方案,如返回默认值或者降级处理。
4. 接口层增加校验
接口层增加校验:如用户鉴权校验;查询数据的id做基础校验,id<=0的直接拦截;
5. 布隆过滤器
- 使用布隆过滤器(Bloom Filter)来过滤掉不存在的数据:布隆过滤器是一种高效的数据结构,可以用来判断一个元素是否存在于一个集合中,如果布隆过滤器判断一个元素不存在,则可以避免进行数据库查询操作。
- 它由位数组(Bit Array)和一系列哈希函数组成。
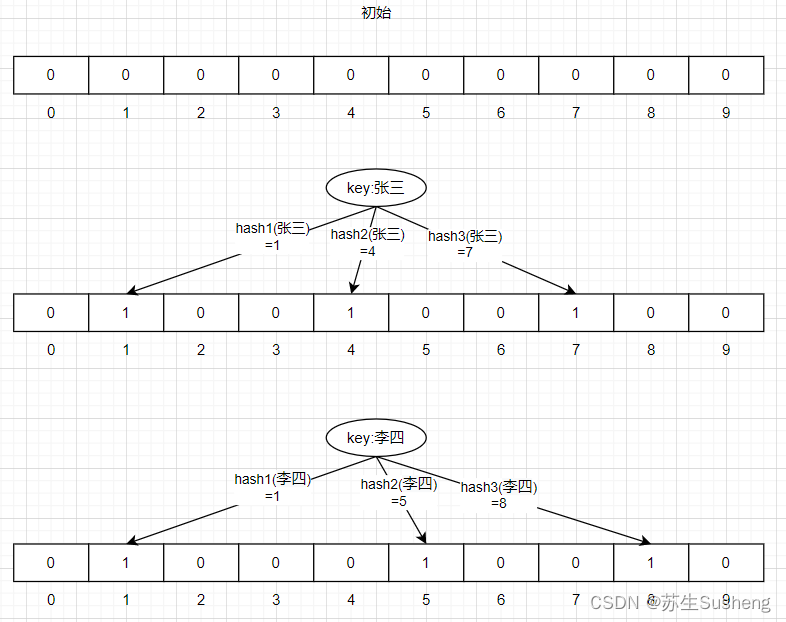
原理
- 初始化时,位数组的所有位都被设置为0。
- 当要插入一个元素时,使用预先设定好的多个独立、均匀分布的哈希函数对元素进行哈希运算,每个哈希函数都会计算出一个位数组的索引位置。
- 将通过哈希运算得到的每个索引位置的位设置为1。
- 查询一个元素是否存在时,同样用相同的哈希函数对该元素进行运算,并检查对应位数组的位置是否都是1。
- 如果所有位都为1,则认为该元素可能存在于集合中;
- 如果有任何一个位为0,则可以确定该元素肯定不在集合中。
- 由于哈希碰撞的存在,当多位同时为1时,可能出现误报(False Positive),即报告元素可能在集合中,但实际上并未被插入过。但布隆过滤器不会出现漏报(False Negative),即如果布隆过滤器说元素不在集合中,则这个结论是绝对正确的。
 - 由于哈希碰撞的存在,在实际应用中,随着更多元素被插入,相同哈希值对应的位会被多次置1,这就导致原本未出现过的元素经过哈希运算后也可能指向已经置1的位置,从而产生误报。不过,通过调整位数组大小、哈希函数的数量以及负载因子等参数,可以在误报率和存储空间之间取得平衡。
- 由于哈希碰撞的存在,在实际应用中,随着更多元素被插入,相同哈希值对应的位会被多次置1,这就导致原本未出现过的元素经过哈希运算后也可能指向已经置1的位置,从而产生误报。不过,通过调整位数组大小、哈希函数的数量以及负载因子等参数,可以在误报率和存储空间之间取得平衡。
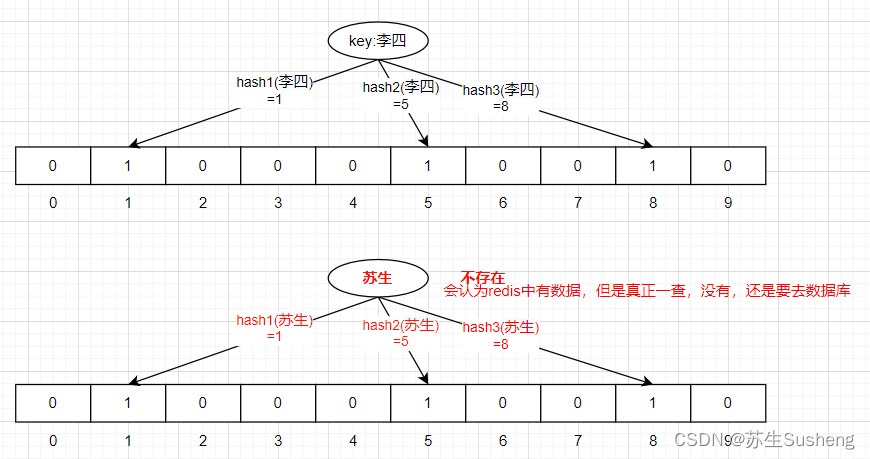
总之,布隆过滤器提供了一种空间效率极高但牺牲了精确性的解决方案,特别适合用于那些能够容忍一定误报率的大规模数据处理场景。
优点
- 布隆过滤器的主要优点是占用空间较小,查询速度快。
- 由于只需要位数组和哈希函数,不需要存储实际的元素,因此占用的空间相对较小。
- 同时,布隆过滤器查询一个元素的时间复杂度为O(k),与集合的大小无关,查询速度非常快。

缺点
- 由于哈希函数的关系,布隆过滤器一旦出现误判元素存在于集合中的情况,就无法修正,也无法直接删除其中的元素。
- 此外,布隆过滤器存在一定的误判率,即有一定的概率将不存在的元素误判为存在,这取决于位数组的大小和哈希函数的个数。
关于扩容
- 布隆过滤器步进无法直接删除,而且在布隆过滤器设计时,其容量是固定的,因此不支持直接扩容。
- 传统的布隆过滤器一旦创建,它的位数组大小就无法改变,这意味着如果需要处理的数据量超过了初始化时预设的容量,将导致误报率增加,且无法通过简单地增大位数组来解决这个问题
- 在实际应用中,为了应对数据增长的需求,可以采用以下策略来进行扩容
- 并行布隆过滤器:
- 可以维护多个独立的布隆过滤器,随着数据增长,当一个过滤器填满后,新加入的数据放入新的布隆过滤器中。
- 查询时,需要对所有布隆过滤器进行查询,只有当所有的过滤器都表明元素可能不存在时,才能确定元素肯定不在集合中。
- 可扩展布隆过滤器:
- 一些变种如 Scalable Bloom Filter 或 Dynamic Bloom Filter 允许添加额外的空间,并重新哈希已有数据到更大的位数组中,从而维持较低的误报率。
- 扩容过程通常涉及构造一个新的更大容量的布隆过滤器,然后迁移旧数据到新过滤器,并从这一刻起在新过滤器中插入新数据。
- 层次结构布隆过滤器: 创建一个多层的布隆过滤器结构,新数据首先被插入到最顶层(最小容量)的过滤器中,当某个层级的过滤器接近饱和时,再启用下一个容量更大的过滤器。
- 并行布隆过滤器:
其他使用场景
- 数据库索引优化:对于大型数据库,可以利用布隆过滤器作为辅助索引结构,提前过滤掉大部分肯定不在结果集中的查询条件,减轻主索引的压力。
- 推荐系统:在个性化推荐系统中,用于快速排除用户已经浏览过或者不感兴趣的内容。
- 垃圾邮件过滤:用于电子邮件系统的垃圾邮件地址库,快速判断收到的邮件是否可能来自已知的垃圾邮件发送者。
- 数据分析与挖掘:在大规模数据清洗阶段,用来剔除重复样本或无效数据。
- 实时监控与报警系统:当大量事件流经系统时,可以用于快速识别并过滤出已知异常事件,降低报警系统误报率。
- 重复数据检测:
- 在爬虫抓取网页或者日志分析中,用于URL去重,确保不会重复抓取相同的页面或记录。
- 在大数据处理中,比如在Hadoop等框架中,用来过滤掉重复的数据块或者记录,减少计算和存储负担。
- 网络安全: 网络防火墙和入侵检测系统中,用于过滤已知恶意IP或攻击特征。
- 社交网络和互联网服务:在社交网络中,用于快速检测用户上传的内容是否存在违规信息,或是检查用户ID、账号是否存在黑名单中。
SpringBoot 整合 布隆过滤器

-
依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><!-- 引入Redisson的Spring Boot启动器 --><dependency><groupId>org.redisson</groupId><artifactId>redisson-spring-boot-starter</artifactId><version>3.16.2</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.47</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency> -
配置
spring:datasource:username: xxpassword: xxxxxxdriver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/smbms?useUnicode=true&characterEncoding=utf-8&serverTimezone=CTTcache:type: redisredis:database: 0port: 6379 # Redis服务器连接端口host: localhostpassword: 123456timeout: 5000 # 超时时间 mybatis:mapper-locations: classpath:mapper/*.xmlconfiguration:log-impl: org.apache.ibatis.logging.stdout.StdOutImpl -
工具类
package com.kgc.utils; import org.redisson.api.RBloomFilter; import org.redisson.api.RedissonClient; import org.springframework.stereotype.Component; import javax.annotation.Resource; /*** @author: zjl* @datetime: 2024/6/7* @desc: 复兴Java,我辈义不容辞*/ @Component public class BloomFilterUtil {@Resourceprivate RedissonClient redissonClient;/*** 创建布隆过滤器** @param filterName 过滤器名称* @param expectedInsertions 预测插入数量* @param falsePositiveRate 误判率*/public <T> RBloomFilter<T> create(String filterName, long expectedInsertions, double falsePositiveRate) {RBloomFilter<T> bloomFilter = redissonClient.getBloomFilter(filterName);bloomFilter.tryInit(expectedInsertions, falsePositiveRate);return bloomFilter;} } -
业务示例
package com.kgc.service;import com.kgc.mapper.UserMapper; import com.kgc.pojo.User; import com.kgc.utils.BloomFilterUtil; import lombok.extern.slf4j.Slf4j; import org.redisson.api.RBloomFilter; import org.redisson.api.RedissonClient; import org.redisson.client.codec.StringCodec; import org.springframework.cache.annotation.CacheEvict; import org.springframework.cache.annotation.CachePut; import org.springframework.cache.annotation.Cacheable; import org.springframework.stereotype.Service;import javax.annotation.PostConstruct; import javax.annotation.Resource; import java.util.List; import java.util.Random; import java.util.concurrent.TimeUnit;/*** @author: zjl* @datetime: 2024/6/7* @desc: 复兴Java,我辈义不容辞*/ @Service @Slf4j public class UserService {// 预期插入数量static long expectedInsertions = 200L;// 误判率static double falseProbability = 0.01;// 非法请求所返回的JSONstatic String illegalJson = "[{\"id\":0,\"userName\":\"null\",\"userCode\":null,\"userRole\":0}]";private RBloomFilter<Long> bloomFilter = null;@Resourceprivate BloomFilterUtil bloomFilterUtil;@Resourceprivate RedissonClient redissonClient;@Resourceprivate UserMapper userMapper;@PostConstruct // 项目启动的时候执行该方法,也可以理解为在spring容器初始化的时候执行该方法public void init() {// 启动项目时初始化bloomFilterList<User> userList = userMapper.selectUserList(null,0L);bloomFilter = bloomFilterUtil.create("idWhiteList", expectedInsertions, falseProbability);for (User user : userList) {bloomFilter.add(user.getId());}}@Cacheable(cacheNames = "user", key = "#id", unless = "#result==null")public User findById(Long id) {// bloomFilter中不存在该key,为非法访问if (!bloomFilter.contains(id)) {log.info("所要查询的数据既不在缓存中,也不在数据库中,为非法key");/*** 设置unless = "#result==null"并在非法访问的时候返回null的目的是不将该次查询返回的null使用* RedissonConfig-->RedisCacheManager-->RedisCacheConfiguration-->entryTtl设置的过期时间存入缓存。** 因为那段时间太长了,在那段时间内可能该非法key又添加到bloomFilter,比如之前不存在id为1234567的用户,* 在那段时间可能刚好id为1234567的用户完成注册,使该key成为合法key。** 所以我们需要在缓存中添加一个可容忍的短期过期的null或者是其它自定义的值,使得短时间内直接读取缓存中的该值。** 因为Spring Cache本身无法缓存null,因此选择设置为一个其中所有值均为null的JSON,*/redissonClient.getBucket("user::" + id, new StringCodec()).set(illegalJson, new Random().nextInt(200) + 300, TimeUnit.SECONDS);return null;}// 不是非法访问,可以访问数据库log.info("数据库中得到数据.......");return userMapper.selectById(id);}// 先执行方法体中的代码,成功执行之后删除缓存@CacheEvict(cacheNames = "user", key = "#id")public boolean delete(Long id) {// 删除数据库中具有的数据,就算此key从此之后不再出现,也不能从布隆过滤器删除return userMapper.deleteById(id) == 1;}// 如果缓存中先前存在,则更新缓存;如果不存在,则将方法的返回值存入缓存@CachePut(cacheNames = "user", key = "#user.id")public User update(User user) {userMapper.updateById(user);// 新生成key的加入布隆过滤器,此key从此合法,因为该更新方法并不更新id,所以也不会产生新的合法的keybloomFilter.add(user.getId());return user;}@CachePut(cacheNames = "user", key = "#user.id")public User insert(User user) {userMapper.insert(user);// 新生成key的加入布隆过滤器,此key从此合法bloomFilter.add(user.getId());return user;} } -
省略实体类、mapper、测试
缓存击穿
- Redis缓存击穿是指在使用Redis作为缓存服务时,当一个缓存键失效时,大量的请求同时涌入,导致数据库负载激增,造成性能下降甚至崩溃的情况。
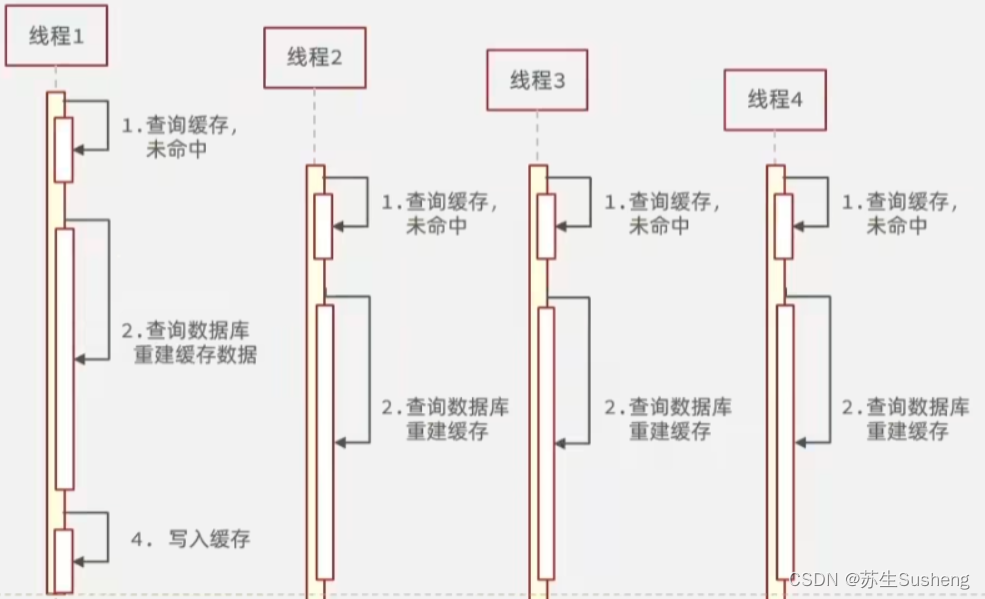
产生原因
-
热点数据失效:当一个热点数据的缓存键失效时,大量的请求会同时请求该数据,导致数据库负载过高。
-
频繁的缓存失效:如果某个应用频繁地对某个缓存键进行更新或者删除操作,那么每次失效后都会触发大量的请求同时请求该数据。
-
缓存击穿攻击:恶意用户故意请求不存在的缓存键,造成大量的请求同时涌入。
解决方案
1.设置热点数据永不过期
- 设置热点数据永不过期:对于一些热点数据,可以设置其缓存键永不过期,转为逻辑过期,以避免缓存失效时大量请求涌入。
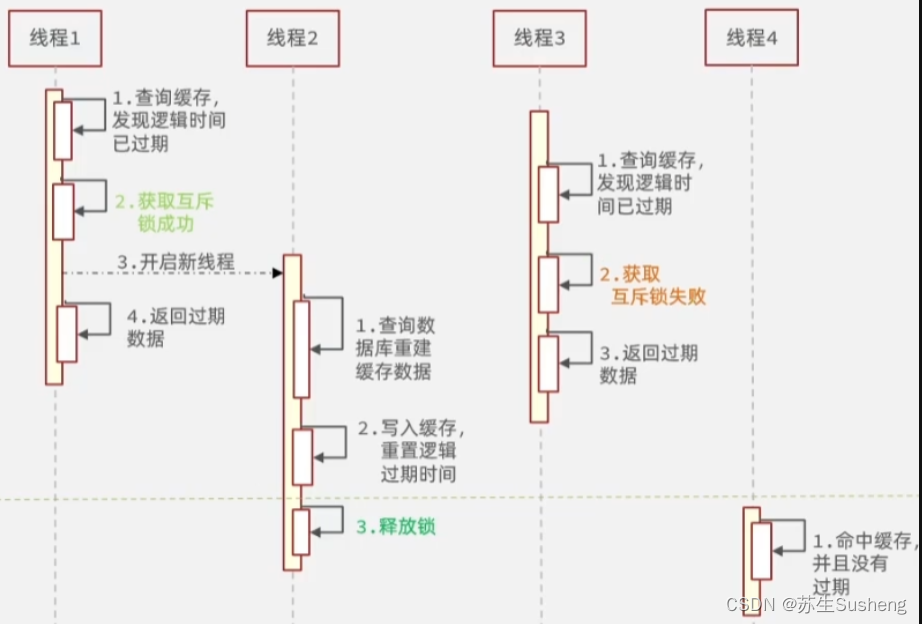
优点
- 逻辑过期的优点是可以减少缓存的更新次数,避免在没有必要的情况下过多地读取后端数据源,并且在数据本身有频繁更新的情况下可以避免缓存数据过时;
缺点
- 逻辑过期的缺点是在某些极端情况下会出现缓存为空的情况,如果此时恰巧有大量请求同时访问缓存,则可能导致缓存击穿,
- 并且无法避免大量的并发请求直接落到后端,并且实现起来也是比较复杂和数据无法保证一致性(因为可能返回旧数据)。
示例

@Data
public class RedisData {private LocalDateTime expireTime;private Object data;
}
/*** 给热点key缓存预热* @param id* @param expireSeconds*/
private void saveShop2Redis(Long id, Long expireSeconds) {// 1.查询店铺数据Shop shop = getById(id);// 2.封装逻辑过期时间RedisData redisData = new RedisData();redisData.setData(shop);redisData.setExpireTime(LocalDateTime.now().plusSeconds(expireSeconds));// 3.写入RedisstringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id, JSONUtil.toJsonStr(redisData));
}
/*** 缓存击穿(逻辑过期)功能封装* @param id* @return*/
public Shop queryWithLogicalExpire(Long id) {String key = CACHE_SHOP_KEY + id;//1. 从Redis中查询商铺缓存String shopJson = stringRedisTemplate.opsForValue().get(key);//2. 判断是否存在if(StrUtil.isBlank(shopJson)){//3. 不存在,直接返回(这里做的事热点key预热,所以已经假定热点key已经在缓存中)return null;}//4. 存在,需要判断过期时间,需要先把json反序列化为对象RedisData redisData = JSONUtil.toBean(shopJson, RedisData.class);Shop shop = JSONUtil.toBean((JSONObject) redisData.getData(), Shop.class);LocalDateTime expireTime = redisData.getExpireTime();//5. 判断是否过期if(expireTime.isAfter(LocalDateTime.now())) {//5.1 未过期,直接返回店铺信息return shop;}//5.2 已过期,需要缓存重建//6. 缓存重建//6.1 获取互斥锁String lockKey = LOCK_SHOP_KEY + id;//6.2 判断是否获取锁成功boolean isLock = tryLock(lockKey);if(isLock) {// 二次验证是否过期,防止多线程下出现缓存重建多次String shopJson2 = stringRedisTemplate.opsForValue().get(key);// 这里假定key存在,所以不做存在校验// 存在,需要判断过期时间,需要先把json反序列化为对象RedisData redisData2 = JSONUtil.toBean(shopJson2, RedisData.class);Shop shop2 = JSONUtil.toBean((JSONObject) redisData2.getData(), Shop.class);LocalDateTime expireTime2 = redisData2.getExpireTime();if(expireTime2.isAfter(LocalDateTime.now())) {// 未过期,直接返回店铺信息return shop2;}//6.3 成功,开启独立线程,实现缓存重建CACHE_REBUILD_EXECUTOR.submit(() -> {try {// 重建缓存,这里设置的值小一点,方便观察程序执行效果,实际开发应该设为30minthis.saveShop2Redis(id, 20L);} catch (Exception e) {throw new RuntimeException(e);} finally {// 释放锁unLock(lockKey);}});}//7. 返回return shop;
}
测试
@SpringBootTest
class HmDianPingApplicationTests {@Resourceprivate ShopServiceImpl shopService;@Testvoid testSaveShop() throws InterruptedException {shopService.saveShop2Redis(1L, 10L);}
}
2.使用互斥锁
- 使用互斥锁:在缓存失效时,可以通过加锁的方式只允许一个请求去更新缓存,其他请求等待直到缓存更新完成。
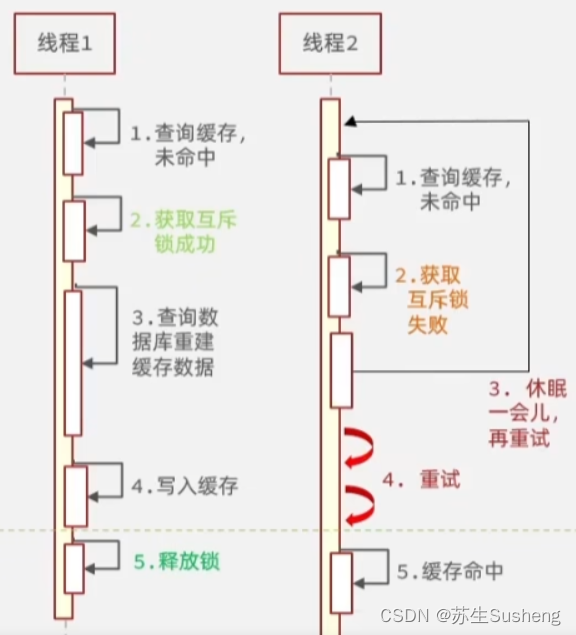
优点
- 互斥锁的优点是它可以确保只有一个线程在访问缓存内容,并且在缓存中没有命中时,只会读取一次后端数据库(或其他数据源),
- 其余线程会等待读取完毕后再次读取缓存,这避免了大量的并发请求直接落到后端,从而减少了并发压力,保证系统的稳定性,并且可以保证数据的一致性;
缺点
- 互斥锁的缺点是会增加单个请求的响应时间,因为只有一个线程能够读取缓存值,其他线程则需要等待,这可能会在高并发场景下导致线程池饱和。
示例

/*** 获取锁* @param key* @return
*/
private boolean tryLock(String key) {// setnx 就是 setIfAbsent 如果存在Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.MINUTES);// 装箱是将值类型装换成引用类型的过程;拆箱就是将引用类型转换成值类型的过程// 不要直接返回flag,可能为nullreturn BooleanUtil.isTrue(flag);
}/*** 释放锁* @param key*/
private void unLock(String key) {stringRedisTemplate.delete(key);
}
/*** 互斥锁解决缓存击穿 queryWithMutex()* @param id* @return*/
public Shop queryWithMutex(Long id) {// 1.从redis查询商铺缓存String key = CACHE_SHOP_KEY + id;String shopJson = stringRedisTemplate.opsForValue().get(key);// 2.判断是否存在if (StrUtil.isNotBlank(shopJson)) {return JSONUtil.toBean(shopJson, Shop.class);}// 判断空值if (shopJson != null) {// 返回一个错误信息return null;}String lockKey = "lock:shop:" + id;Shop shop = null;try {// 4.实现缓存重建// 4.1获取互斥锁boolean isLock = tryLock(lockKey);// 4.2判断是否成功if (!isLock) {// 4.3失败,则休眠并重试Thread.sleep(50);// 递归return queryWithMutex(id);}// 4.4成功,根据id查询数据库shop = getById(id);// 模拟延迟Thread.sleep(200);// 5.不存在,返回错误if (shop == null) {stringRedisTemplate.opsForValue().set(key,"",CACHE_NULL_TTL,TimeUnit.MINUTES);return null;}// 6.存在,写入redisstringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL,TimeUnit.MINUTES);} catch (InterruptedException ex) {throw new RuntimeException(ex);} finally {// 7.释放锁unLock(lockKey);}// 8.返回return shop;
}
合并
/*** 缓存击穿和缓存穿透功能合并封装* @param id* @return*/
public Shop queryWithMutex(Long id) {String key = CACHE_SHOP_KEY + id;//1. 从Redis中查询商铺缓存String shopJson = stringRedisTemplate.opsForValue().get(key);//2. 判断是否存在if(StrUtil.isNotBlank(shopJson)){//3. 存在,直接返回return JSONUtil.toBean(shopJson, Shop.class);}// 这里要先判断命中的是否是null,因为是null的话也是被上面逻辑判断为不存在// 这里要做缓存穿透处理,所以要对null多做一次判断,如果命中的是null则shopJson为""if("".equals(shopJson)){return null;}//4. 实现缓存重建//4.1 获取互斥锁String lockKey = LOCK_SHOP_KEY + id;Shop shop = null;try {boolean isLock = tryLock(lockKey);//4.2 判断获取是否成功if(!isLock) {//4.3 失败,则休眠并重试Thread.sleep(50);// 递归重试return queryWithMutex(id);}//4.4 成功,根据id查询数据库shop = getById(id);if(shop == null) {//5. 不存在,将null写入redis,以便下次继续查询缓存时,如果还是查询空值可以直接返回false信息stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);return null;}//6. 存在,写入RedisstringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), CACHE_SHOP_TTL, TimeUnit.MINUTES);} catch (InterruptedException e) {throw new RuntimeException(e);} finally {//7. 释放互斥锁unLock(lockKey);}//8. 返回return shop;
}
3. 使用分布式缓存
- 使用分布式缓存:将缓存分散到多个Redis实例中,以减轻单个Redis实例的负载压力。
4. 设置随机过期时间
- 设置随机过期时间:在设置缓存键的过期时间时,可以增加一个随机的过期时间,以避免大量的缓存同时失效。
缓存雪崩
- Redis缓存雪崩是指在使用Redis作为缓存服务时,当缓存的大量键同时失效或者Redis服务发生故障时,导致大量请求直接访问数据库,造成数据库负载过高,甚至导致数据库崩溃的情况。
产生原因
-
缓存键过期时间一致:如果大量的缓存键设置了相同的过期时间,同时失效,那么所有请求都会直接访问数据库,导致数据库压力过大。
-
Redis服务宕机:当Redis服务发生故障无法提供缓存服务时,所有的请求都会直接访问数据库,造成数据库负载过高。
-
大规模数据更新:在进行大规模数据更新时,如果更新操作直接修改数据库,而不是通过更新缓存,那么所有请求都会直接访问数据库,导致数据库负载过高。
解决方案
对于大量的缓存key同时失效
 - 给不同的Key的TTL添加随机值,比如将缓存失效时间分散开,可以在原有的失效时间基础上增加一个随机值
- 给不同的Key的TTL添加随机值,比如将缓存失效时间分散开,可以在原有的失效时间基础上增加一个随机值
比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
对于redis服务宕机

- 利用Redis集群提高服务的可用性,比如哨兵模式、集群模式;
- 给缓存业务添加降级限流策略,比如可以在ngxin或spring cloud gateway中处理;
- 降级也可以做为系统的保底策略,适用于穿透、击穿、雪崩
- 给业务添加多级缓存,比如使用Guava或Caffeine作为一级缓存,redis作为二级缓存等;
相关文章:
【Redis】Redis经典问题:缓存穿透、缓存击穿、缓存雪崩
目录 缓存的处理流程缓存穿透解释产生原因解决方案1.针对不存在的数据也进行缓存2.设置合适的缓存过期时间3. 对缓存访问进行限流和降级4. 接口层增加校验5. 布隆过滤器原理优点缺点关于扩容其他使用场景SpringBoot 整合 布隆过滤器 缓存击穿产生原因解决方案1.设置热点数据永不…...

从GPU到ASIC,博通和Marvell成赢家
ASIC市场上,博通预计今年AI收入将达到110亿美元以上,主要来自与Google和Meta的合作;Marvell预计2028年AI收入将达到70亿至80亿美元,主要来自与Amazon和Google的合作。 随着芯片设计和系统复杂性的增加,科技大厂将更多地…...

【java问答小知识6】一些Java基础的知识,用于想学习Java的小伙伴们建立一些简单的认知以及已经有经验的小伙伴的复习知识点
请解释Java中的双亲委派模型是什么? 回答:双亲委派模型是Java类加载机制的核心原则,它确保所有类加载器在尝试加载一个类之前,都会委托给它的父类加载器。 Java中的类路径(Classpath)是什么? 回…...

数学建模笔记
数学建模 定义角度 数学模型是针对参照某种事物系统的特征或数量依存关系,采用数学语言,概括地或近似地表述出的一种数学结构,这种数学结构是借助于数学符号刻画出来的某种系统的纯关系结构。从广义理解,数学模型包括数学中的各…...

shell编程(三)—— 控制语句
程序的运行除了顺序运行外,还可以通过控制语句来改变执行顺序。本文介绍bash的控制语句用法。 一、条件语句 Bash 中的条件语句让我们可以决定一个操作是否被执行。结果取决于一个包在[[ ]]里的表达式。 bash中的检测命令由[[]]包起来,用于检测一个条…...

反射学习记
Java 中的反射是什么意思?有哪些应用场景? 每个类都有⼀个 Class 对象,包含了与类有关的信息。当编译⼀个新类时,会产生一个同名的 .class 文件,该⽂件 内容保存着 Class 对象。类加载相当于 Class 对象的加载&a…...

使用Python操作Redis
大家好,在当今的互联网时代,随着数据量和用户量的爆发式增长,对于数据存储和处理的需求也日益增加。Redis作为一种高性能的键值存储数据库,以其快速的读写速度、丰富的数据结构支持和灵活的应用场景而备受青睐。本文将介绍Redis数…...

Vue-CountUp-V2 数字滚动动画库
安装: $ npm install --save countup.js vue-countup-v2示例如下: <template><div class"iCountUp"><ICountUp:delay"delay":endVal"endVal":options"options"ready"onReady"/>&…...
C语言详解(文件操作)1
Hi~!这里是奋斗的小羊,很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~~ 💥💥个人主页:奋斗的小羊 💥💥所属专栏:C语言 🚀本系列文章为个人学习…...

Python Requests库详解
大家好,在现代网络开发中,与Web服务器进行通信是一项至关重要的任务。Python作为一种多才多艺的编程语言,提供了各种工具和库来简化这一过程。其中,Requests库作为Python中最受欢迎的HTTP库之一,为开发人员提供了简单而…...

Kafka 详解:全面解析分布式流处理平台
Kafka 详解:全面解析分布式流处理平台 Apache Kafka 是一个分布式流处理平台,主要用于构建实时数据管道和流式应用。它具有高吞吐量、低延迟、高可用性和高可靠性的特点,广泛应用于日志收集、数据流处理、消息系统、实时分析等场景。 &…...
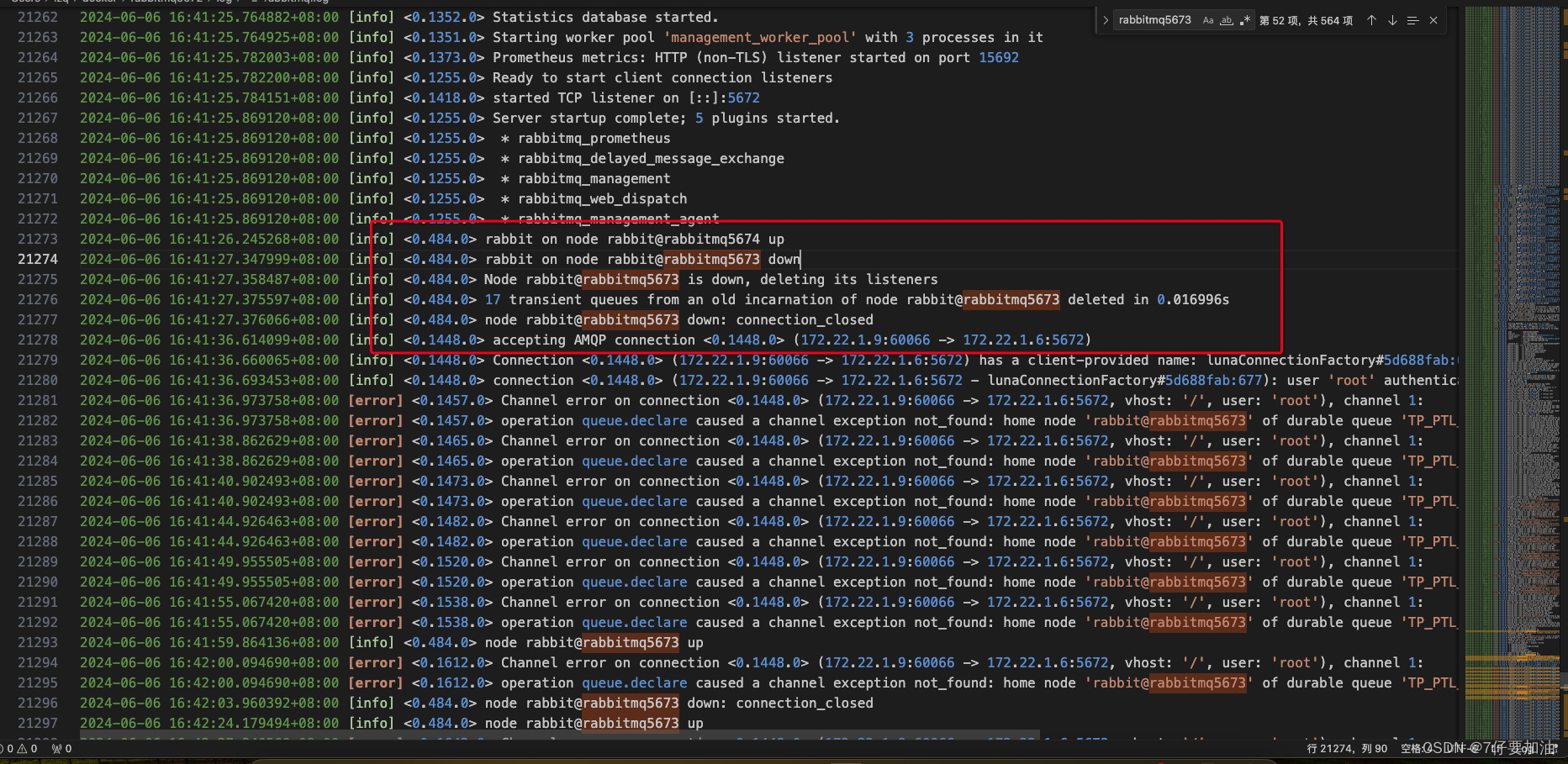
RabbitMQ系列-rabbitmq无法重新加入集群,启动失败的问题
当前存在3个节点:rabbitmq5672、rabbitmq5673、rabbitmq5674 当rabbitmq5673节点掉线之后,重启失败 重启的时候5672节点报错如下: 解决方案 在集群中取消失败节点 rabbitmqctl forget_cluster_node rabbitrabbitmq5673删除失败节点5673的…...

postgresql之翻页优化
列表和翻页是所有应用系统里面必不可少的需求,但是当深度翻页的时候,越深越慢。下面是几种常用方式 准备工作 CREATE UNLOGGED TABLE data (id bigint GENERATED ALWAYS AS IDENTITY,value double precision NOT NULL,created timestamp with time zon…...
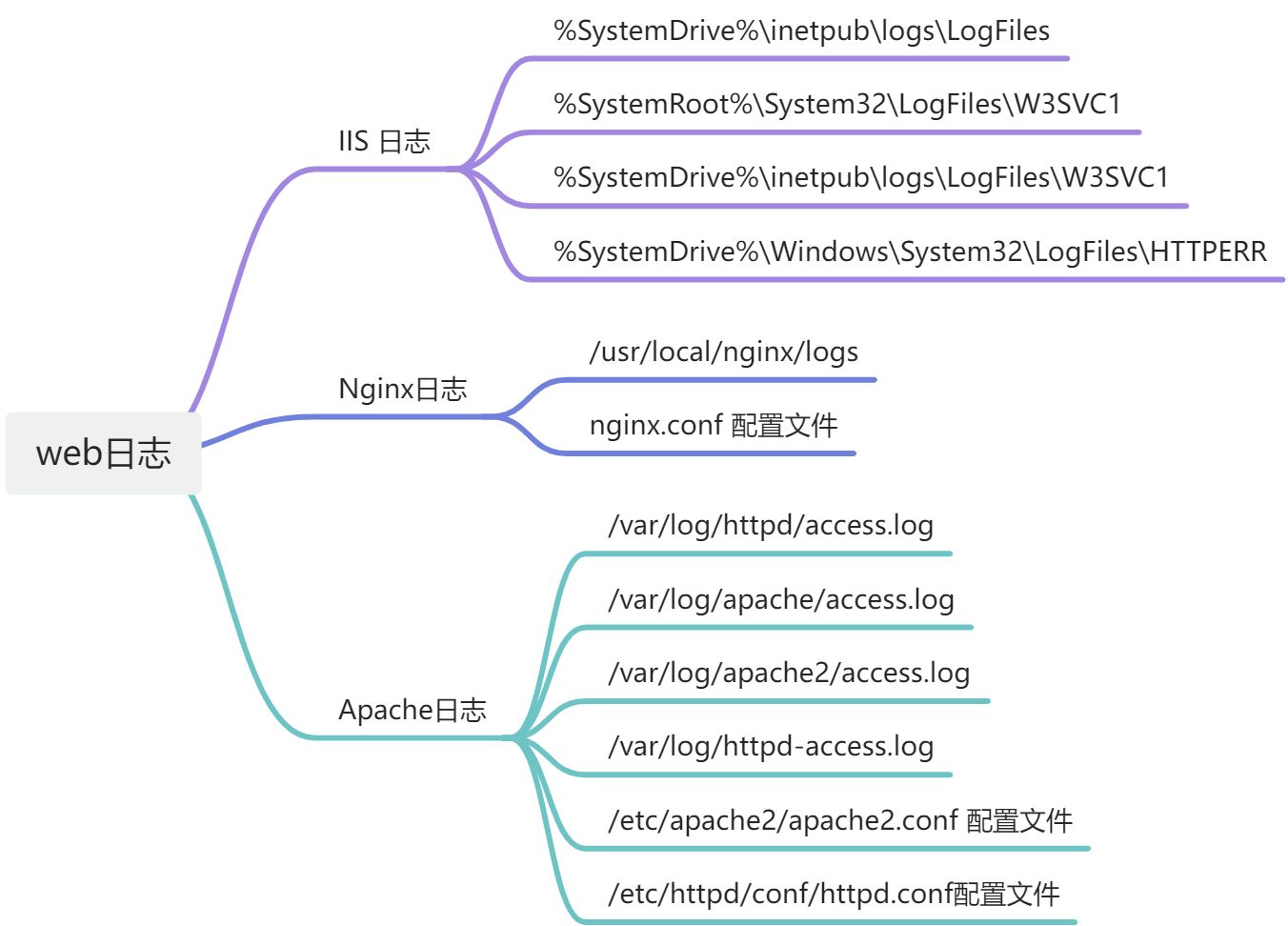
小白学Linux | 日志排查
一、windows日志分析 在【运行】对话框中输入【eventvwr】命令,打开【事件查看器】窗 口,查看相关的日志 管理员权限进入PowerShell 使用Get-EventLog Security -InstanceId 4625命令,可获取安全性日志下事 件 ID 为 4625(失败登…...

Spring6
一 概述 1.1、Spring是什么? Spring 是一款主流的 Java EE 轻量级开源框架 ,Spring 由“Spring 之父”Rod Johnson 提出并创立,其目的是用于简化 Java 企业级应用的开发难度和开发周期。Spring的用途不仅限于服务器端的开发。从简单性、可测…...
数字孪生概念、数字孪生技术架构、数字孪生应用场景,深度长文学习
一、数字孪生起源与发展 1.1 数字孪生产生背景 数字孪生的概念最初由Grieves教授于2003年在美国密歇根大学的产品全生命周期管理课程上提出,并被定义为三维模型,包括实体产品、虚拟产品以及二者间的连接,如下图所示: 2011年&…...

云服务对比:阿里云国际站和阿里云国内站有什么区别
阿里云国际站(Alibaba Cloud International)和阿里云国内站(Alibaba Cloud China)在许多方面存在明显区别,这些区别主要体现在服务范围、合规性、定价和支付方式、语言和客服支持、以及备案要求等方面。 首先…...

如何在npm上发布自己的包
如何在npm上发布自己的包 npm创建自己的包 一、一个简单的创建 1、创建npm账号 官网:https://www.npmjs.com/创建账号入口:https://www.npmjs.com/signup 注意:需要进入邮箱验证 2、创建目录及初始化 $ mkdir ufrontend-test $ cd ufron…...
SQL Chat:从SQL到SPEAKL的数据库操作新纪元
引言 SQL Chat是一款创新的、对话式的SQL客户端工具。 它采用自然语言处理技术,让你能够像与人交流一样,通过日常对话的形式对数据库执行查询、修改、创建及删除操作 极大地简化了数据库管理流程,提升了数据交互的直观性和效率。 在这个框…...
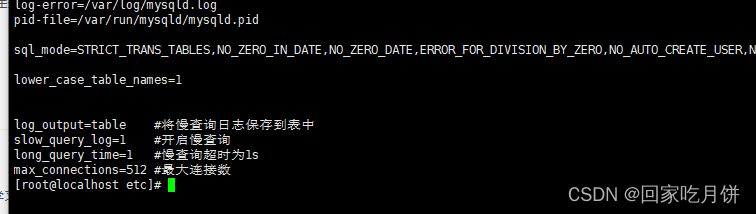
jmeter性能优化之mysql配置
一、连接数据库和grafana 准备:连接好数据库和启动grafana并导入mysql模板 大批量注册、登录、下单等,还有过节像618,双11和数据库交互非常庞大,都会存在数据库的某一张表里面,当用户在登录或者查询某一个界面时&…...

基于Matlab的智能停车场车牌识别计时计费管理系统设计与实现:集成GUI界面与先进图像处理技术
基于Matlab的车牌识别停车场出入库计时计费管理系统(含GUI界面) 【车牌识别】基于计算机视觉,数字图像处理常见实战项目:蓝色车牌识别语音播报GUI显示出入库管理计时计费时间显示空位显示库内判断车辆信息导出。 停车场管理系统是…...

从20英镑纸币到你的电路板:聊聊法拉第和他‘命名’的电容器发展简史
从20英镑纸币到你的电路板:法拉第与电容器技术演进的百年对话 伦敦皇家学院的地下实验室里,迈克尔法拉第正用自制的莱顿瓶进行着一项危险实验。这位装订工出身的科学家不会想到,一个半世纪后,他名字命名的电子元件会以毫米级尺寸存…...
)
嵌入式开发避坑指南:U-Boot命令行那些新手最容易踩的5个坑(附解决方案)
嵌入式开发避坑指南:U-Boot命令行那些新手最容易踩的5个坑(附解决方案) 在嵌入式Linux开发中,U-Boot作为系统启动的关键环节,其命令行操作往往是新手工程师的第一道门槛。许多从MCU开发转向Linux嵌入式领域的工程师&am…...

LoRA训练助手应用场景:AI艺术策展人LoRA风格档案库构建工具
LoRA训练助手应用场景:AI艺术策展人LoRA风格档案库构建工具 1. 项目背景与价值 在AI绘画创作领域,风格一致性是专业作品的重要标志。无论是个人艺术创作、商业设计项目还是内容生产,都需要保持统一的视觉风格。传统方法中,艺术家…...

西门子S7 - 200PLC与组态王构建自动化搬运机械手组态系统
西门子S7-200PLC和组态王自动化搬运机械手的组态系统在自动化控制领域,西门子S7 - 200PLC与组态王相结合来打造自动化搬运机械手的组态系统,是实现高效生产流程的关键一步。今天咱就唠唠这其中的门道。 西门子S7 - 200PLC基础 西门子S7 - 200PLC作为一款…...

OpenClaw+Qwen3.5-9B组合教学:5个新手常见问题解答
OpenClawQwen3.5-9B组合教学:5个新手常见问题解答 1. 为什么我的OpenClaw网关服务启动失败? 这个问题通常出现在首次安装后尝试启动网关时。我自己在macOS上部署时就遇到了这个坑——输入openclaw gateway start后,终端直接报错退出。 经过…...

Z-Image Turbo与LSTM结合:实现时序连贯的动画生成教程
Z-Image Turbo与LSTM结合:实现时序连贯的动画生成教程 1. 引言 你是不是曾经遇到过这样的困扰:用AI生成的单张图片效果很棒,但想要做成连续动画时,画面却跳来跳去,完全没有连贯性?这个问题困扰着很多想要…...

YOLOv8-seg道路裂缝检测实战:如何将训练好的模型部署到树莓派或Jetson Nano上
YOLOv8-seg道路裂缝检测实战:从模型优化到边缘设备部署全流程解析 在计算机视觉领域,道路裂缝检测一直是基础设施维护的重要课题。随着YOLOv8-seg这类实时实例分割模型的成熟,如何将实验室训练的模型真正部署到资源受限的边缘设备࿰…...
)
BurpSuite+SqlMap联动实战:5分钟搞定SQL注入自动化检测(附避坑指南)
BurpSuite与SqlMap高效联动:自动化SQL注入检测实战精要 从零开始的联动环境搭建 对于刚接触渗透测试的新手来说,BurpSuite和SqlMap的组合堪称SQL注入检测的"黄金搭档"。但要让这两个工具真正协同工作,光靠简单的插件安装是远远不够…...

比迪丽WebUI实战:用负向提示词精准去除多余肢体与背景干扰
比迪丽WebUI实战:用负向提示词精准去除多余肢体与背景干扰 1. 引言:当AI画图“画蛇添足”时 如果你用过AI绘画工具,一定遇到过这样的烦恼:明明只想画一个角色,结果AI给你画出了三只手;想要一个干净的背景…...