LLVM Cpu0 新后端5 静态重定位 动态重定位
想好好熟悉一下llvm开发一个新后端都要干什么,于是参考了老师的系列文章:
LLVM 后端实践笔记
代码在这里(还没来得及准备,先用网盘暂存一下):
链接: https://pan.baidu.com/s/1yLAtXs9XwtyEzYSlDCSlqw?pwd=vd6s 提取码: vd6s
目录
一、准备知识
1.1 链接器与编译器
1.2 静态重定位
1.3 动态重定位
二、修改的文件
2.1 Cpu0AsmPrinter.cpp
2.2 Cpu0ISelDAGToDAG.cpp/.h
2.3 Cpu0ISelLowering.cpp/.h
2.4 Cpu0InstrInfo.td
2.5 Cpu0MCInstLower.cpp/.h
2.6 Cpu0MachineFunctionInfo.cpp/.h
2.7 Cpu0RegisterInfo.cpp
2.8 Cpu0Subtarget.cpp/.h
2.9 Cpu0TargetObjectFile.cpp/.h
2.10 MCTargetDesc/Cpu0BaseInfo.h
三、修改后的效果
3.1 static模式
3.2 static small section模式
3.3 dynamic模式
3.4 dynamic small section模式
一、准备知识
1.1 链接器与编译器
首先,显而易见链接器和编译器肯定不是一个东西。编译器的作用是中端优化以及后端转化成目标架构相关的汇编文件或者目标文件,到这里编译器就算是完成了他的工作了。之后就需要链接器了,链接器的作用是将生成的目标文件与其他的应用库和系统库一起链接成可执行文件,传统链接器在这一过程中主要做了两个工作,一是段合并,链接器会将不同文件的相似段进行合并,另一个就是符号重定位,链接器会对文件进行第二次扫描,利用第一次扫描的符号表信息,对符号引用地址的地方进行地址的更新,这个就是符号的解析以及重定位过程。
注意,这里我们说的是传统链接器,因为现在的链接器都支持LTO(链接时优化),其实相当于将编译器部分的一些中端优化和后端的工作在链接阶段做,链接阶段所需的所有文件是可见的,因此能够在一个更高的视野上做一个全局的优化,所以现代链接器的功能绝不仅仅是上述两点。
本章是做Cpu0架构重定位的适配,因此本章简单介绍一下当前linux系统上的两种重定位机制。我们用下边的这个例子:
# extern.c
int extern_aaa = 555;
int extern_func() {return 666;
}#test.c
extern int extern_aaa;
int global_bbb = 111;
static int static_ccc = 222;
extern int extern_func();
int global_func() {return 333;
}
static int static_func() {return 444;
}
int main() {int ddd1 = extern_aaa;int ddd2 = global_bbb;int ddd3 = static_ccc;int ddd4 = extern_func();int ddd5 = global_func();int ddd6 = static_func();return 0;
}1.2 静态重定位
静态重定位一般由操作系统中的重定位装入程序完成。重定位装入程序根据当前内存的分配情况,按照分配区域的起始地址逐一调整目标程序指令中的地址部分。目标程序在经过重定位装入程序加工之后,不仅进入到分配给自己的绝对地址空间中,而且程序指令中的地址部分全部进行了修正,反映出了自己正确的存储位置,保证了程序的正确运行。
特点:即在程序装入内存的过程中完成,是指在程序开始运行前,程序中的各个地址有关的项均已完成重定位,地址变换通常是在装入时一次完成的,以后不再改变,故成为静态重定位。
优点:无需硬件支持。
缺点:程序重定位之后就不能在内存中搬动了;要求程序的存储空间是连续的,不能把程序放在若干个不连续的区域中。
clang -fno-PIC -g -c extern.c -o extern.o
clang -fno-PIC -g -c test.c -o test.o
clang -no-pie -g extern.o test.o -o test.outclang默认是使用动态重定位的,因此我们使用no-pic选项来关闭PIC,同时打开-g选项方便我们看到更多的符号以及调试,我的机器的clang版本是15,不同版本的clang可能会有一些区别。
首先我们先通过objdump -d命令先看一下test.o中的内容
test.o: file format elf64-x86-64Disassembly of section .text:0000000000000000 <global_func>:0: 55 push %rbp1: 48 89 e5 mov %rsp,%rbp4: b8 4d 01 00 00 mov $0x14d,%eax9: 5d pop %rbpa: c3 retqb: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)0000000000000010 <main>:10: 55 push %rbp11: 48 89 e5 mov %rsp,%rbp14: 48 83 ec 20 sub $0x20,%rsp18: c7 45 fc 00 00 00 00 movl $0x0,-0x4(%rbp)1f: 8b 04 25 00 00 00 00 mov 0x0,%eax26: 89 45 f8 mov %eax,-0x8(%rbp)29: 8b 04 25 00 00 00 00 mov 0x0,%eax30: 89 45 f4 mov %eax,-0xc(%rbp)33: 8b 04 25 00 00 00 00 mov 0x0,%eax3a: 89 45 f0 mov %eax,-0x10(%rbp)3d: b0 00 mov $0x0,%al3f: e8 00 00 00 00 callq 44 <main+0x34>44: 89 45 ec mov %eax,-0x14(%rbp)47: e8 00 00 00 00 callq 4c <main+0x3c>4c: 89 45 e8 mov %eax,-0x18(%rbp)4f: e8 1c 00 00 00 callq 70 <static_func>54: 89 45 e4 mov %eax,-0x1c(%rbp)57: 8b 45 f8 mov -0x8(%rbp),%eax5a: 03 45 f4 add -0xc(%rbp),%eax5d: 03 45 f0 add -0x10(%rbp),%eax60: 03 45 ec add -0x14(%rbp),%eax63: 03 45 e8 add -0x18(%rbp),%eax66: 03 45 e4 add -0x1c(%rbp),%eax69: 48 83 c4 20 add $0x20,%rsp6d: 5d pop %rbp6e: c3 retq6f: 90 nop0000000000000070 <static_func>:70: 55 push %rbp71: 48 89 e5 mov %rsp,%rbp74: b8 bc 01 00 00 mov $0x1bc,%eax79: 5d pop %rbp7a: c3 retq1f、29、33三条指令就是对于extern_aaa、global_bbb、static_ccc三个变量的调用,我们能够看到当前是用0来占位的。我们能够看到他们最终都被存到了rbp寄存器一定偏移的栈中了,因此局部变量通过当前函数栈桢的基地址(rbp)就可以直接拿到,不存在重定位的问题。然后我们看3f、47、4f这三条指令,e8是callq指令的编码,我们能够看到对于extern_func和global_func这两个函数后边的地址也是通过用0来占位的,然而4f这条后边的数据是 0x1c 00 00 00,由于是小端存储,这个数据的实际大小其实是0x00 00 00 1c=28,这里28是static_func函数相对于当前rip的偏移,当执行到这一条的时候rip指向的是下一条的地址,因此static_func函数的地址是0x54+0x1c=0x70,我们能看到与下边static_func函数的地址相对应。为什么static_func函数的地址能直接算出来呢?是因为在链接过程中虽然会进行段合并,但是段内的数据也不会打乱,因此static_func函数相对main函数的位置还是一样的,我们反汇编看test.out也能够验证这一点,这条指令还是0xe8 1c 00 00 00,不会变的。
我们使用objdump -R test.o或者readelf -r test.o命令能够看到重定位表里边的内容。
RELOCATION RECORDS FOR [.text]:
OFFSET TYPE VALUE
0000000000000022 R_X86_64_32S extern_aaa
000000000000002c R_X86_64_32S global_bbb
0000000000000036 R_X86_64_32S .data+0x0000000000000004
0000000000000040 R_X86_64_PLT32 extern_func-0x0000000000000004
0000000000000048 R_X86_64_PLT32 global_func-0x0000000000000004重定位表里边能够看到几种数据:偏移、类型、哪个符号、以及最后的对齐值。我们会做简单的解释。我们先看第一条extern_aaa的,它对应的指令是1f: 8b 04 25 00 00 00 00,extern_aaa的重定位表的数据是偏移0x22处对齐0,22就是1f中25后边的位置,我们知道这里就是给extern_aaa用0占位的区域。
我们objdump -d test.out查看可执行文件的反汇编:
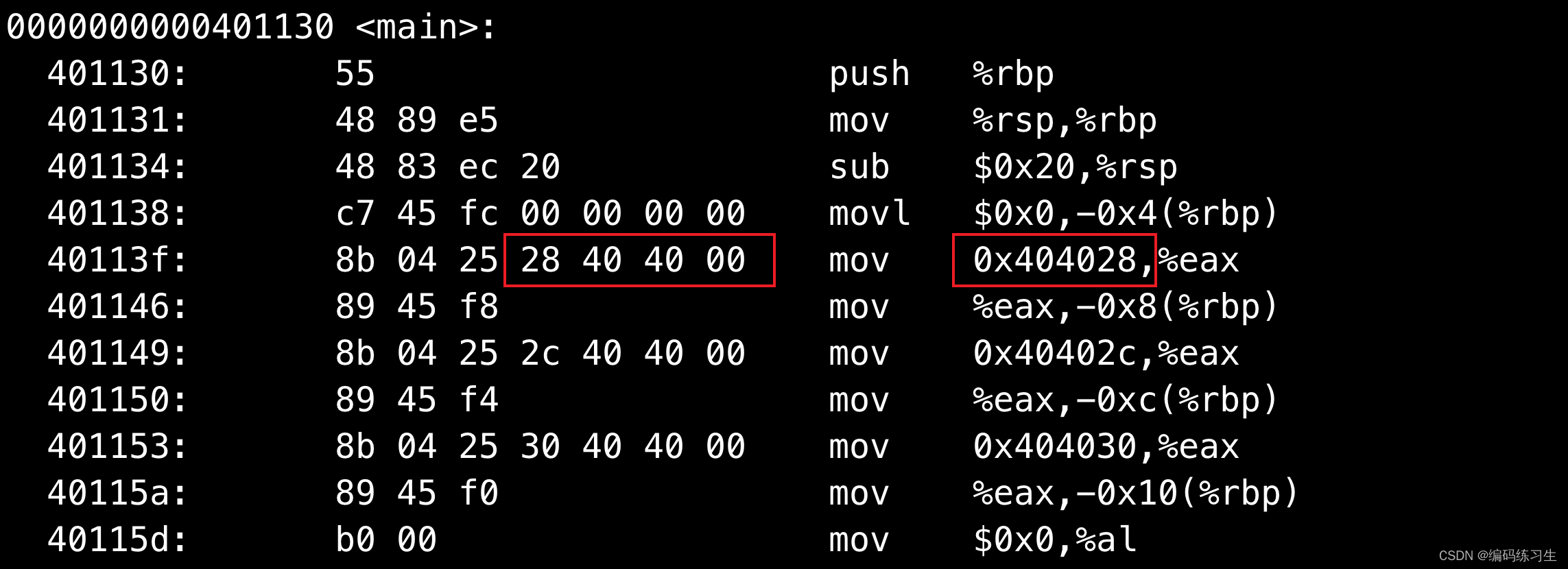
看到这个位置填了0x 28 40 40 00(也就是0x00 40 40 28的小端序列),链接器在链接的时候会将我们.rela.text记录的符号进行更新,填到记录的offset处。我们lldb调试test.out可以看到:
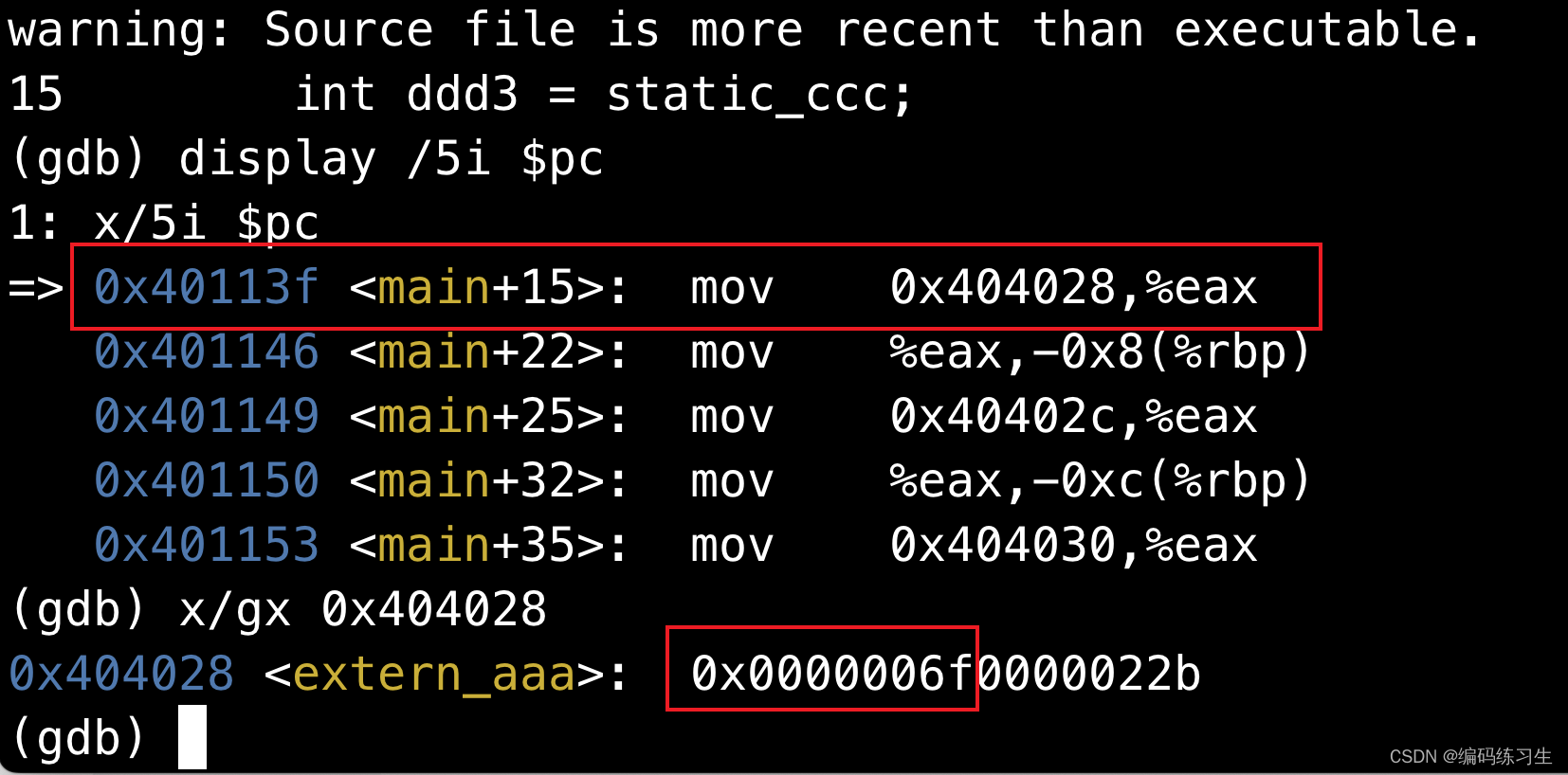
我们能够看到0x404028地址处存的数据是0x6f也就是111,与我们代码中写的相一致。
1.3 动态重定位
动态重定位在程序执行寻址时进行重定位,访问地址时,通过地址变换机构改变为内存地址。用户程序原封不动地装入内存,运行时再完成地址的定位工作。动态重定位需要硬件的支持,要求系统中配备定位寄存器和加法器
特点:不是在程序执行之前而是在程序执行过程中进行地址重定位。更确切的说,是在每次访问内存单元前才进行地址变换。动态重定位可使装配模块不加任何修改而装入内存,但是它需要硬件一定位寄存器的支持。
优点:目标模块装入内存时无需任何修改,因而装入之后再搬迁也不会影响其正确执行,这对于存储器紧缩、解决碎片问题是极其有利的;一个程序由若干个相对独立的目标模块组成时,每个目标模块各装入一个存储区域,这些存储区域可以不是顺序相邻的,只要各个模块有自己对应的定位寄存器就行。
缺点:需要硬件寄存器的支持。
这一部分参考了海枫老师的课程:聊聊Linux动态链接中的PLT和GOT,大家想更多了解的话可以过去详读。
我们先看动态链接生成的反汇编的形式:
0000000000001150 <main>:1150: 55 push %rbp1151: 48 89 e5 mov %rsp,%rbp1154: 48 83 ec 20 sub $0x20,%rsp1158: c7 45 fc 00 00 00 00 movl $0x0,-0x4(%rbp)115f: 48 8b 05 72 2e 00 00 mov 0x2e72(%rip),%rax # 3fd8 <extern_aaa>1166: 8b 00 mov (%rax),%eax1168: 89 45 f8 mov %eax,-0x8(%rbp)116b: 8b 05 bf 2e 00 00 mov 0x2ebf(%rip),%eax # 4030 <global_bbb>1171: 89 45 f4 mov %eax,-0xc(%rbp)1174: 8b 05 ba 2e 00 00 mov 0x2eba(%rip),%eax # 4034 <static_ccc>117a: 89 45 f0 mov %eax,-0x10(%rbp)117d: b0 00 mov $0x0,%al117f: e8 ac fe ff ff callq 1030 <extern_func@plt>1184: 89 45 ec mov %eax,-0x14(%rbp)1187: e8 b4 ff ff ff callq 1140 <global_func>118c: 89 45 e8 mov %eax,-0x18(%rbp)118f: e8 0c 00 00 00 callq 11a0 <static_func>1194: 89 45 e4 mov %eax,-0x1c(%rbp)1197: 31 c0 xor %eax,%eax1199: 48 83 c4 20 add $0x20,%rsp119d: 5d pop %rbp119e: c3 retq119f: 90 nop一方面我们能够看到对于外部变量和全局变量等的地址是用的rip寄存器的相对地址来表示的,然后还有一个plt的东西,不知道是什么?
首先我们考虑我们的需求,我们希望在程序运行的时候修正这个地址,那么我们直接就让运行时来修正可不可以呢?答案肯定是不可以的,因为我们的代码都在代码段,数据在数据段,运行时可以修改数据段的东西,但是我们的代码段是只读不能修改的。设想一下,如果代码段是能被运行时修改的话,所有的计算机程序都会被黑客彻底攻克了吧?他们可以按他们的意图随便修改代码段的功能。所以说运行时不能直接修正地址。
这个时候就提出了got表这个东西。got表中存储的是函数的地址。为每一个需要重定位的符号建立一个GOT表项。当动态链接器装载共享对象时查找每一个需要重定位符号的变量地址,填充GOT。当指令需要访问变量或者函数的地址时,从对应的GOT表项中读出地址,再访问即可。对应的指令可能是callq *(addr in GOT)或者movq offset(%rip) %rax(%rax就是全局变量的地址,可以用(%rax)解引用)。
但是这样有一个问题,一个动态库可能有成百上千个符号,但是我们引入该动态库可能只会使用其中某几个符号,像上面那种方式就会造成不使用的符号也会进行重定位,造成不必要的效率损失。我们知道,动态链接比静态链接慢1% ~ 5%,其中一个原因就是动态链接需要在运行时查找地址进行重定位。所以ELF采用了延迟绑定的技术,当函数第一次被用到时才进行绑定。实现方式就是使用plt。
Linux 动态链接器提供动态重位功能,所有外部函数只有调用时才做重定位,实现延迟绑定功能。下面是以调用puts函数为例画出了整个动态重定位的执行过程:(两张图用的海枫老师的,画的太形象了,再说一下,大家感兴趣的话可以去海枫老师那里学习一下)
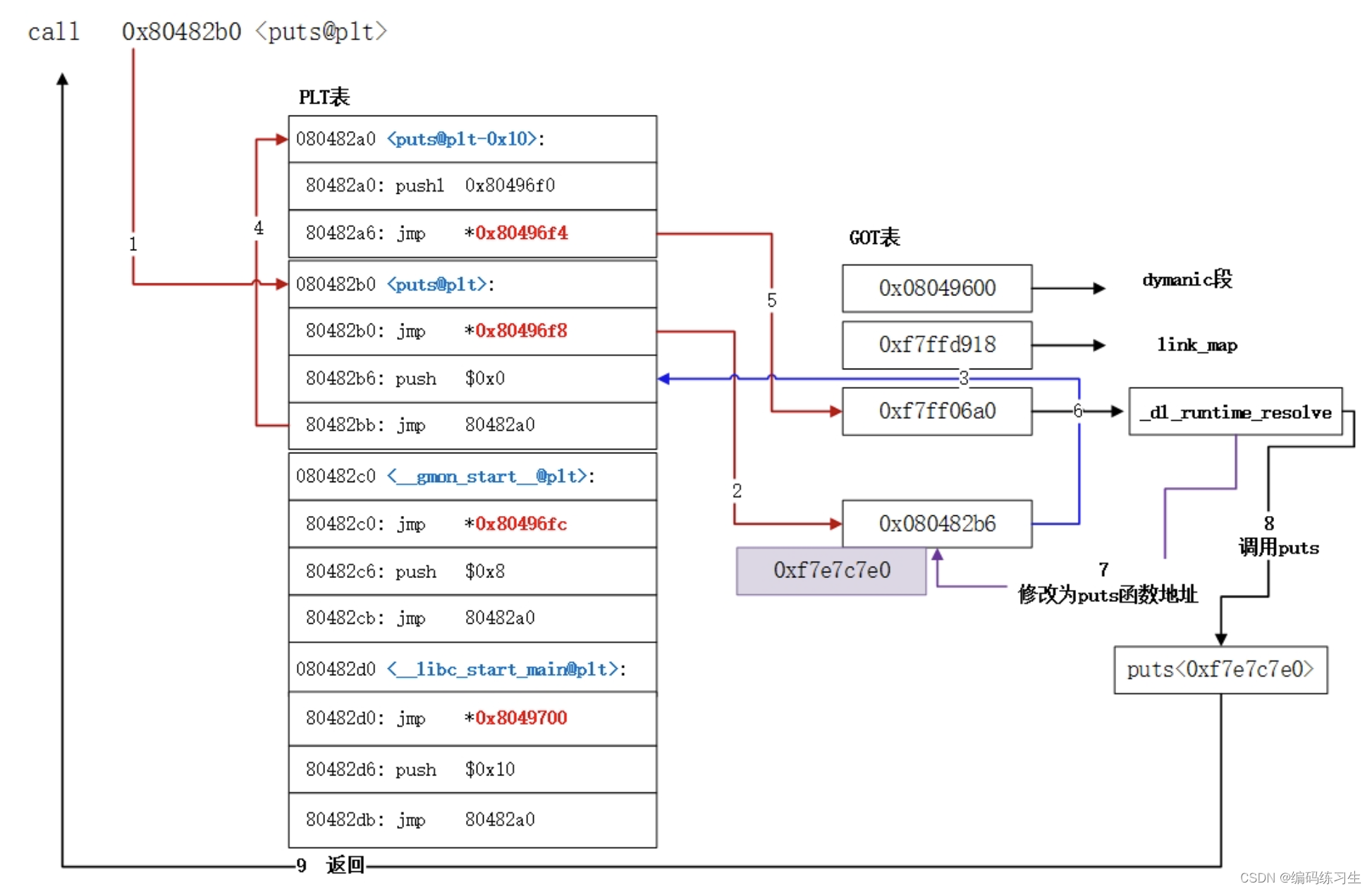
PLT属于代码段,在进程加载和运行过程都不会发生改变,PLT指向GOT表的关系在编译时已完全确定,唯一能发生变化的是GOT表。GOT表项已完成重定位的情况下,PLT利用GOT表直接调用到真实的动态库函数,下面puts函数的调用过程:
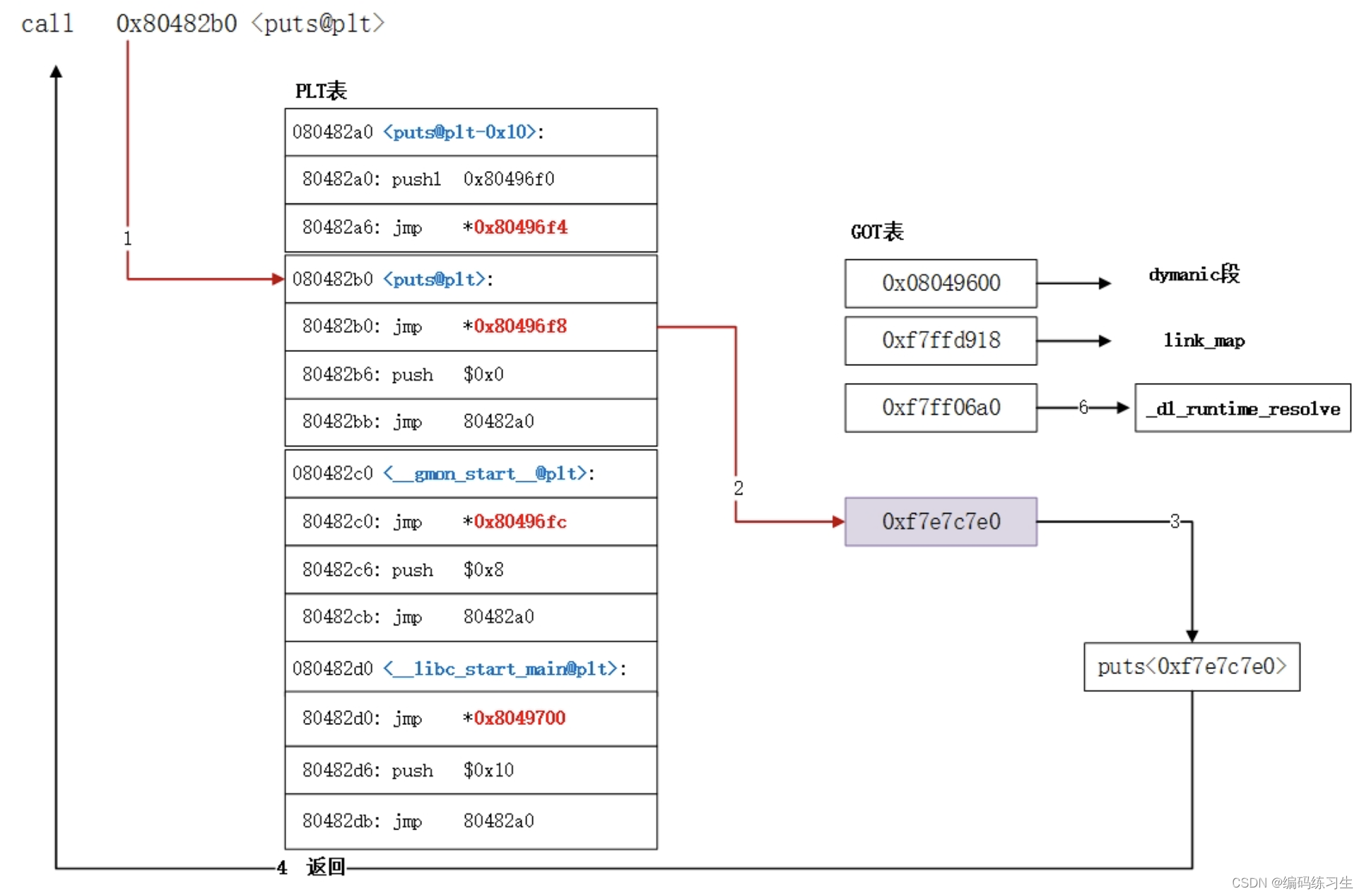
上述就是本文对于链接器、静态重定位和动态重定位的一个介绍,虽然写的内容挺多的,但是其实也不是那么详细,因为这一块涉及到的内容太多了,大家感兴趣的话可以自行查阅资料学习,之后有时间的话我也会出一篇详细介绍这方面的文章,接下来就是本章的主题了。
二、修改的文件
虽然这一章节的改动涉及到的文件可能还不少,但是增加的一些函数的逻辑和功能实现都算是相对比较简单的,多数都是一些指令的lower操作,包括DAG阶段指令lower成Cpu0架构相关的DAG,然后再lower成什么样的汇编指令,等等。LLVM中对于指令的修改算是相对比较容易的工作了,主要是你要明白为什么要这么改?其次让你设计的话你是否能想到这个解法?其实后端对于指令的优化涉及到的不像中端那么多,流程上的东西稍微多一点。
2.1 Cpu0AsmPrinter.cpp
在 EmitFunctionBodyStart() 函数中增加了对 .cpload 的输出,.cpload 是一条伪指令,它用来标记一段伪代码,将会被展开成多条指令。另外,.set nomacro 用来判断汇编器的操作生成超过一种机器语言,并输出警告信息。
.set noreorder
.cpload $6
.set nomacro伪指令展开是在 Cpu0MCInstLower.h 中完成的,LowerCPLOAD() 函数。
2.2 Cpu0ISelDAGToDAG.cpp/.h
实现获取基地址的指令,也就是通过指令将 GOT 地址加载到寄存器。填充 Select 函数,对 ISD::GLOBAL_OFFSET_TABLE 做替换,将其更改为针对我们指定寄存器作为基地址寄存器的 Node。同时还填充了 SelectAddr 函数,对 PIC 模式,返回节点的操作数。
2.3 Cpu0ISelLowering.cpp/.h
在构造函数中,使用 setOperationAction(ISD::GlobalAddress, MVT::i32, Custom) 来告诉 llc,我们实现了全局变量的自定义实现。在 LowerOperation() 函数中,新增一个 switch 分支,当处理 ISD::GlobalAddress 时,跳转到我们自定义的 lowerGlobalAddress() 方法。而后者也在这里实现,这一部分比较关键,会根据设置好的条件,选择下降成 PIC 模式还是 static 模式,small section 还是标准 section,该函数会返回一个 DAG Node。
另外还实现了一些创建地址模式 node 的函数,用来创建不同配置下的 node,比如静态模式,PIC 标准 section 模式等,这个取决于我们的指令设计,其实我们在写代码之前把要创建的指令规划好了,写起来还是比较容易的,主要是指令的设计。
函数 getTargetNodeName() 用来返回节点的名字,在其中增加了 GPRel 和 Wrapper 节点,用来实现对全局变量类型的打印功能。
2.4 Cpu0InstrInfo.td
定义了 Cpu0Hi、Cpu0Lo、Cpu0GPRel、Cpu0Wrapper 几个Cpu0架构在DAG阶段Node,被用来处理全局地址(注意与寄存器 Hi、Lo 的区分)。
实现了几个 Pat,这种 td 结构指示在 lower DAG 时,将指定的 llvm node 下降为另一种机器相关的 DAG node。这些Pat的语法我们上一节课介绍过,这里就不细说了。设计到的语法还是蛮简单的。
2.5 Cpu0MCInstLower.cpp/.h
实现对 MCInst 指令的 lower,在 LowerOperand() 函数中,针对 MO_GlobalAddress 类型的操作数做特殊处理,实现 LowerSymbolOperand() 函数,也就是对符号操作数的处理,当处理全局变量时,能够返回一个符号表达式(比如 %got_lo 这种)。
另外,实现了 LowerCPLOAD() 函数,该函数用来对伪指令 .cpload 进行展开,展开内容为:
lui $gp, %hi(_gp_disp)
addiu $gp, $gp, %lo(_gp_disp)
addu $gp, $gp, $t9_gp_disp 是一个重定位符号,它的值是函数开头到 GOT 表的偏移,加载器在加载时填充这个值。展开的指令中,我们能看到,$gp 存放的就是 sdata 段的起始地址,而将 $gp 与 $t9 相加($t9 用来保存函数调用的函数地址),就调整好了在某次函数调用时的 sdata 段数据的起始位置。$gp 是需要参与栈调整的,它是 callee saved 寄存器。
2.6 Cpu0MachineFunctionInfo.cpp/.h
实现获取全局基地址寄存器的几个辅助函数。
2.7 Cpu0RegisterInfo.cpp
保留寄存器集合中增加 $gp,但通过宏来控制是否使能对保留寄存器 $gp 的判断。
2.8 Cpu0Subtarget.cpp/.h
增加了处理编译选项的代码,提供了三个编译选项:cpu0-use-small-section、cpu0-reserve-gp、cpu0-no-cpload。第一个是控制是否使用 small section 的选项,后两个选项是将在编译器中用到的配置,分别是是否保留 $gp 作为特殊寄存器以及是否发射 .cpload 伪指令。
2.9 Cpu0TargetObjectFile.cpp/.h
声明并定义了几个判断 small section 的实现方法,属于 Cpu0TargetObjectFile 的成员方法。判断某个地址是否是合法的 small section 地址、判断是否能放到 small section 内。
2.10 MCTargetDesc/Cpu0BaseInfo.h
声明全局变量偏移表的类型枚举,增加 MO_GOT16 和 MO_GOT 两个类型。
三、修改后的效果
示例程序:
int gStart = 3;
int gI = 100;
int test_global()
{int c = 0;c = gI;return c;
}3.1 static模式
命令:
clang++ -target mips-unknown-linux-gnu -S -emit-llvm 5_1.cpp -o 5_1.ll
llc -march=cpu0 -relocation-model=static -filetype=asm 5_1.ll -o 5_1.static.s生成的汇编:
_Z11test_globalv:
...lui $2, %hi(gI)ori $2, $2, %lo(gI)ld $2, 0($2)st $2, 4($sp)ld $2, 4($sp)
....type gStart,@object # @gStart.data.globl gStart.p2align 2
gStart:.4byte 3 # 0x3.size gStart, 4.type gI,@object # @gI.globl gI.p2align 2
gI:.4byte 100 # 0x64.size gI, 4首先使用lui指令加载 gI 的高 16 位部分,放到 $2 中高 16 位,低 16 位填 0;然后将 $2 与 gI 的低 16 位做或运算,将低16位的内容也填上,最后,通过 ld 指令,将 $2 指向的内容(此时 $2 保存的是指向 gI 的地址)取出来,放到 $2 中。gStart 和 gI 都存放在 .data 段。
3.2 static small section模式
命令:
clang++ -target mips-unknown-linux-gnu -S -emit-llvm 5_1.cpp -o 5_1.ll
llc -march=cpu0 -relocation-model=static -cpu0-use-small-section -filetype=asm 5_1.ll -o 5_1.static.small.s_Z11test_globalv:
...st $2, 4($sp)ori $2, $gp, %gp_rel(gI)ld $2, 0($2)st $2, 4($sp)ld $2, 4($sp)
....type gStart,@object # @gStart.section .sdata,"aw",@progbits.globl gStart.p2align 2
gStart:.4byte 3 # 0x3.size gStart, 4.type gI,@object # @gI.globl gI.p2align 2
gI:.4byte 100 # 0x64.size gI, 4其中 $gp 寄存器保存了 .sdata 的起始绝对地址,在加载时赋值(此时 $gp不能被当做普通寄存器分配),gp_rel(gI) 是计算 gI 相对于段起始的相对偏移,在链接时会计算,所以第一条指令结束时,$2 中就保存了 gI 的绝对地址。第二条指令做 gI 的取值操作。gStart 和 gI 都存放在 .sdata 段。因为 sdata 是自定义段,所以汇编选用了 .section 伪指令来描述。
这种模式下,$gp 的内容是在链接阶段被赋值的, gI 相对于 .sdata 段的相对地址也能在链接时计算,并替换在 %gp_rel(gI) 的位置,所以整个重定位过程是静态完成的(运行开始时地址都已经固定好了)。
3.3 dynamic模式
命令:
clang++ -target mips-unknown-linux-gnu -S -emit-llvm 5_1.cpp -o 5_1.ll
llc -march=cpu0 -relocation-model=pic -filetype=asm 5_1.ll -o 5_1.pic.s_Z11test_globalv:
...st $2, 4($sp)lui $2, %got_hi(gI)addu $2, $2, $gpld $2, %got_lo(gI)($2)ld $2, 0($2)st $2, 4($sp)ld $2, 4($sp)
....type gStart,@object # @gStart.data.globl gStart.p2align 2
gStart:
$gStart$local:.4byte 3 # 0x3.size gStart, 4.type gI,@object # @gI.globl gI.p2align 2
gI:
$gI$local:.4byte 100 # 0x64.size gI, 4由于全局数据放到了 data 段,所以 $gp 中保存了在这个函数中全局变量在 data 段的起始地址。通过 %got_hi(gI) 和 %got_lo(gI) 就可以获得全局变量的 GOT 偏移,分别做与 $gp 的高16位的偏移和低16位的偏移的结果,其实就是与 $gp 的偏移,进而得到它在运行时的地址。值得一提的是,这些汇编代码,都是在 td 文件中被定义如何展开的。
3.4 dynamic small section模式
命令:
clang++ -target mips-unknown-linux-gnu -S -emit-llvm 5_1.cpp -o 5_1.ll
llc -march=cpu0 -relocation-model=pic -cpu0-use-small-section -filetype=asm 5_1.ll -o 5_1.pic.small.s_Z11test_globalv:
...st $2, 4($sp)ld $2, %got(gI)($gp)ld $2, 0($2)st $2, 4($sp)ld $2, 4($sp)
....type gStart,@object # @gStart.section .sdata,"aw",@progbits.globl gStart.p2align 2
gStart:
$gStart$local:.4byte 3 # 0x3.size gStart, 4.type gI,@object # @gI.globl gI.p2align 2
gI:
$gI$local:.4byte 100 # 0x64.size gI, 4数据存放在 sdata 段, $gp寄存器指向sdata 段的开头,%got(gI)计算gI全局变量的 GOT 偏移。
相关文章:
LLVM Cpu0 新后端5 静态重定位 动态重定位
想好好熟悉一下llvm开发一个新后端都要干什么,于是参考了老师的系列文章: LLVM 后端实践笔记 代码在这里(还没来得及准备,先用网盘暂存一下): 链接: https://pan.baidu.com/s/1yLAtXs9XwtyEzYSlDCSlqw?…...

旅游卡是项目还是骗局?还是实实在在的旅游项目?
旅游卡是一个实实在在的旅游项目,而非骗局。以下是我对旅游卡项目的几点分析: 项目实质: 旅游卡项目是由国内外多条旅游线路整合而成的卡片,为旅游者提供方便、实惠的旅游方式。持有旅游卡,可以完全抵销跟团游线路中的…...

大模型+RAG,全面介绍!
1 、介绍 大型语言模型(LLMs)在处理特定领域或高度专业化的查询时存在局限性,如生成不正确信息或“幻觉”。缓解这些限制的一种有前途的方法是检索增强生成(RAG),RAG就像是一个外挂,将外部数据…...

智能合约中存储和计算效率漏洞
存储和计算效率 不当的存储结构或计算密集型操作可能导致高Gas费用和性能瓶颈。示例场景:频繁读取和写入大数组 假设你正在构建一个投票系统,其中每个提案都有一个独立的计票器。为了实现这一点,你可能最初会考虑使用一个映射(m…...

软件测试基础知识总结
🍅 视频学习:文末有免费的配套视频可观看 🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 一、软件测试概述 1、什么是软件 定义:计算机系统中与硬件相互依存的一部分&#x…...
C语言 | Leetcode C语言题解之第143题重排链表
题目: 题解: struct ListNode* middleNode(struct ListNode* head) {struct ListNode* slow head;struct ListNode* fast head;while (fast->next ! NULL && fast->next->next ! NULL) {slow slow->next;fast fast->next-&g…...
探寻性能优化:如何衡量?如何决策?
目录 一、衡量指标说明 (一)响应时间(Response Time) 平均响应时间(Average Response Time) 百分位数响应时间(Percentile Response Time) (二)吞吐量&a…...

Python Django 5 Web应用开发实战
Django 是一个高级 Python Web 框架,它鼓励快速开发和简洁、务实的设计。下面是一个关于如何使用 Django 开发一个包含五个基本页面的 Web 应用的实战指南。请注意,这里仅提供一个概述,实际开发中会有更多细节和步骤。 1. 安装 Django 首先,你需要安装 Django。你可以使用…...

H.264官方文档下载
H.264是ITU(International Telecommunication Union,国际通信联盟)和MPEG(Motion Picture Experts Group,运动图像专家组)联合制定的视频编码标准。其官方文档可以在ITU官网上下载:https://www.…...

minio多节点部署
MinIO 是一个高性能的分布式对象存储服务,它可以配置为多节点(或多服务器)模式以提供高可用性和数据冗余。以下是一个基本的多节点MinIO部署示例: 确保你有多个服务器或虚拟机。在每个节点上安装MinIO。使用minio server命令启动多…...

2024年工业设计与制造工程国际会议(ICIDME 2024)
2024年工业设计与制造工程国际会议 2024 International Conference on Industrial Design and Manufacturing Engineering 会议简介 2024年工业设计与制造工程国际会议是一个集结全球工业设计与制造工程领域精英的盛会。本次会议旨在为业界专家、学者、工程技术人员提供一个分享…...
一次曝 9 个大模型,「字节 AI」这一年都在做什么?
字节跳动的大模型家族,会长出下一个抖音吗? 整个 2023 年,字节并没有对外官宣其内部自研的大模型。外界一度认为,大模型这一技术变革,字节入场晚了。梁汝波在去年底的年会上也提到了这一点,他表示「字节对…...

PR基本概念数学知识
1、2基本概念 监督学习与非监督学习期望风险与经验风险结构风险最小化(SRM)与经验风险最小化(ERM)期望风险的上界过拟合数据预处理模型评价方法分类与聚类 数学知识 矩阵求逆、矩阵乘法协方差矩阵的计算特征值、特征向量的计算…...

信驰达蓝牙数字钥匙方案持续创新,助推智慧汽车生态发展
随着汽车智能化的加速发展,数字钥匙正成为全球化的新趋势,它通过数字化的手段连接人、车以及更广泛的生态,引领着出行方式的革命和用户体验的转变。数字钥匙不仅仅是一个简单的访问工具,它重新定义了人与车的互动方式,…...
校园生活服务平台的设计
管理员账户功能包括:系统首页,个人中心,管理员管理,用户管理,跑腿管理,文娱活动管理,活动申请管理,备忘录管理 前台账户功能包括:系统首页,个人中心ÿ…...
gerrit 使用
添加ssh 点击 蓝色方框 复制ssh 添加即可...
【GD32F303红枫派使用手册】第十二节 ADC-双轴按键摇杆多通道循环采样实验
12.1 实验内容 本实验是通过ADC规则组多通道循环采样方式实现双轴按键摇杆传感器x和y轴电压值的读取,通过本实验主要学习以下内容: 双轴按键摇杆传感器工作原理 DMA原理 规则组多通道循环采样 12.2 实验原理 12.2.1 双轴按键摇杆传感器工作原理 摇…...

Rust-03-数据类型
在 Rust 中,每一个值都属于某一个 数据类型,这告诉 Rust 它被指定为何种数据,以便明确数据处理方式。Rust 是 静态类型语言,也就是说在编译时就必须知道所有变量的类型。根据值及其使用方式,编译器通常可以推断出我们想…...

代理IP使用api接
代理IP使用API接口,通常是指通过API接口获取代理IP地址,并将其应用于爬虫、数据采集、反爬虫等场景中,以提高数据采集效率和保护数据采集安全。 一般来说,代理IP提供商会提供API接口文档和SDK供开发者使用。你需要先注册并登录代…...

C++中的适配器模式
目录 适配器模式(Adapter Pattern) 实际应用 图形渲染库适配器 日志系统适配器 支付系统适配器 总结 适配器模式(Adapter Pattern) 适配器模式是一种结构型设计模式,它使得原本由于接口不兼容而不能一起工作的类…...

ERNIE-4.5-0.3B-PT智能合约分析:区块链安全检测系统
ERNIE-4.5-0.3B-PT智能合约分析:区块链安全检测系统 1. 引言 区块链开发者们经常面临一个头疼的问题:智能合约部署后才发现存在安全漏洞,导致资产损失。传统的安全审计需要专业团队花费数天甚至数周时间,成本高昂且效率低下。现…...

解锁开源工具QMK Toolbox:完全掌握机械键盘个性化定制
解锁开源工具QMK Toolbox:完全掌握机械键盘个性化定制 【免费下载链接】qmk_toolbox A Toolbox companion for QMK Firmware 项目地址: https://gitcode.com/gh_mirrors/qm/qmk_toolbox QMK Toolbox是一款开源的设备管理工具,专为QMK固件设计&…...

Dan Koe: 如果你有多重兴趣,请不要浪费接下来的2-3年
本文整理自 Dan Koe 原文。Dan Koe 是 YouTube、X 等平台拥有数百万粉丝的个人成长领域创作者,以"一人公司"理念、深度内容创作和高效 AI 工作流著称。你是否曾因为无法只专注一件事而感到自责? 你学设计,又想学编程;读…...

CVPR 2025新秀OverLoCK上手实测:在COCO数据集上跑目标检测,比MogaNet-B高1% AP是怎么做到的?
OverLoCK实战指南:如何在COCO目标检测任务中超越MogaNet-B 1% AP 计算机视觉领域的主干网络架构正在经历一场静默革命。2025年CVPR最新收录的OverLoCK网络以其创新的"先概览再聚焦"设计理念,在多个视觉任务中展现出惊人的性能突破。本文将带您…...

3步实现视频硬字幕精准提取:本地化多语言解决方案如何解决你的字幕难题
3步实现视频硬字幕精准提取:本地化多语言解决方案如何解决你的字幕难题 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含字幕区…...

基于 LlamaFactory 与 LoRA 微调开源大模型:构建高效文本分类系统的实践指南
1. 为什么选择LlamaFactoryLoRA做文本分类? 最近在做一个政务工单分类项目时,我发现传统BERT模型遇到三个头疼问题:标注成本高(需要上万条数据)、领域迁移难(换个场景就失效)、小样本表现差&…...
教程)
C语言调用Omni-Vision Sanctuary轻量级推理接口(C API)教程
C语言调用Omni-Vision Sanctuary轻量级推理接口(C API)教程 1. 引言:为什么选择C API? 在嵌入式设备和资源受限的环境中,Python运行时往往显得过于臃肿。Omni-Vision Sanctuary提供的C语言接口(C API&…...

保姆级教程:用Python脚本一键将Labelme标注数据喂给YOLOv5/v8训练
从Labelme到YOLO:全流程数据转换与训练实战指南 当你完成数百张图像的Labelme标注后,面对满屏的JSON文件,是否曾为如何高效转换为YOLO格式而头疼?本文将以工业级解决方案,带你打通从标注到训练的全链路。不同于简单的格…...

Qt跨平台即时通讯实战:从界面设计到TCP通信的完整实现
1. Qt跨平台即时通讯开发概述 用Qt框架开发即时通讯软件最大的优势就是"一次编写,到处运行"。我去年接手过一个项目,需要在Windows和Linux双平台上部署聊天工具,当时尝试过多种技术方案,最终Qt以绝对优势胜出。想象一下…...

当知识有了‘关系网‘:LightRAG如何让大模型‘秒懂‘你的文档?
想象一下,你有一座藏书万卷的图书馆,但你找书的方式只有一种——记住每本书某个页面的关键词,然后靠"猜"来定位。 这,就是传统RAG系统的尴尬处境。 今天要介绍的这个开源项目LightRAG,被顶会EMNLP 2025接收…...