Python深度学习基于Tensorflow(17)基于Transformer的图像处理实例VIT和Swin-T
文章目录
- VIT 模型搭建
- Swin-T 模型搭建
- 参考
这里使用 VIT 和 Swin-T 在数据集 cifar10 上进行训练
![![[5f5e5055bc1149e4bb1fa2961cc71434.gif]]](https://img-blog.csdnimg.cn/direct/5bfa9859e5244f879337110cc6bb553a.gif)
VIT 模型搭建
导入需要的外部库
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
这里我们接着使用 cifar10 的数据,导入数据如下
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
# x_train.shape, y_train.shape
# ((50000, 32, 32, 3), (50000, 1))train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))# 图片处理
image_size = 72 # 把图片尺寸固定为 image_size
def process_data(image, label):image = tf.image.resize(image, [image_size, image_size])image = tf.image.random_flip_left_right(image)image = tf.image.random_flip_up_down(image)image = tf.image.random_brightness(image, 0.2)image = tf.cast(image, tf.float32) / 255.0return image, label# 这里batchsize定位128
train_dataset = train_dataset.map(process_data).batch(128)
test_dataset = test_dataset.map(process_data).batch(128)
图片展示
plt.figure(figsize=(5, 5))
for i in range(25):plt.subplot(5, 5, i + 1)plt.imshow(x_train[i])plt.axis('off')
plt.show()
得到图片效果
![![[Pasted image 20240611175813.png]]](https://img-blog.csdnimg.cn/direct/1f654884e01b4f5b87e5f902637722fd.png)
VIT 模型架构如图所示:
![![[Pasted image 20240605185215.png]]](https://img-blog.csdnimg.cn/direct/13027d4257f04d1e849255fe3321d3f8.png)
从中可以看到,其创新点主要是将图片进行拆分作为序列数据带入 Transformer 中,这里先实现拆分图片类 PatchExtract 和 分块编码类 PatchEmbedding
class PatchExtract(tf.keras.layers.Layer):def __init__(self, patch_size):"""patch_size 每一块图片的长宽"""super(PatchExtract, self).__init__()self.patch_size = patch_sizedef call(self, images):patches = tf.image.extract_patches(images,sizes=[1, self.patch_size, self.patch_size, 1],strides=[1, self.patch_size, self.patch_size, 1],rates=[1, 1, 1, 1],padding='VALID')patches = tf.reshape(patches, [tf.shape(patches)[0], -1, tf.shape(patches)[-1]])return patchesclass PatchEmbedding(tf.keras.layers.Layer):def __init__(self, patch_size, patch_nums, d_model):super(PatchEmbedding, self).__init__()self.patch_size = patch_sizeself.patch_nums = patch_numsself.d_model = d_modelself.patches = PatchExtract(self.patch_size)self.embedding = tf.keras.layers.Embedding(self.patch_nums + 1, self.d_model)self.dense = tf.keras.layers.Dense(self.d_model)self.learnabel_parameters = self.add_weight(shape=[1, 1, d_model])def call(self, x):# 处理 patchesx = self.patches(x)x = self.dense(x)x = tf.concat([tf.repeat(self.learnabel_parameters, tf.shape(x)[0], axis=0), x], axis=1)# 处理位置编码p = tf.range(self.patch_nums + 1)p = self.embedding(p)output = x + preturn output
可视化 Patches ,代码如下
image_size = 72
patch_size = 6# 定义图片
img = x_train[0]# 原图
plt.figure(figsize=(4, 4))
plt.imshow(img)
plt.axis("off")# 放大图片 并 切分 patches
patches = tf.image.resize(img[tf.newaxis, :], [image_size, image_size])
patches = PatchExtract(patch_size)(patches)# 由于patches的行数和列数相同,这里采取开根号的形式
n = int(np.sqrt(patches.shape[1]))# patches 图
plt.figure(figsize=(4, 4))
for i, patch in enumerate(patches[0]):ax = plt.subplot(n, n, i + 1)patch_img = tf.reshape(patch, (patch_size, patch_size, 3))plt.imshow(tf.cast(patch_img, dtype=tf.int32))plt.axis("off")
plt.show()
得到效果如下
![![[Pasted image 20240605185037.png]]](https://img-blog.csdnimg.cn/direct/ba2a65280f0346f7bbc03090afec3aed.png)
定义一个多头注意力机制类 MultiHeadAttention 如下
class MultiHeadAttention(tf.keras.layers.Layer):def __init__(self, num_heads, d_model):super(MultiHeadAttention, self).__init__()self.num_heads = num_headsself.d_model = d_model## 判断能否被整除assert self.d_model % self.num_heads == 0## 定义需要用到的 layerself.query_dense = tf.keras.layers.Dense(self.d_model)self.key_dense = tf.keras.layers.Dense(self.d_model)self.value_dense = tf.keras.layers.Dense(self.d_model)self.output_dense = tf.keras.layers.Dense(self.d_model)def call(self, x_query, x_key, x_value, use_casual_mask=False):query = self._split_heads(self.query_dense(x_query))key = self._split_heads(self.key_dense(x_key))value = self._split_heads(self.value_dense(x_value))output, attention_weights = self._scaled_dot_product_attention(query, key, value, use_casual_mask)output = tf.keras.layers.Lambda(lambda output: tf.transpose(output, perm=[0, 2, 1, 3]))(output)output = tf.keras.layers.Lambda(lambda output: tf.reshape(output, [tf.shape(output)[0], -1, self.d_model]))(output)output = self.output_dense(output)return outputdef _split_heads(self, x):# x = tf.reshape(x, [tf.shape(x)[0], -1, self.num_heads, self.d_model / self.num_heads])# x = tf.transpose(x, perm=[0, 2, 1, 3])x = tf.keras.layers.Lambda(lambda x: tf.reshape(x, [tf.shape(x)[0], -1, self.num_heads, self.d_model // self.num_heads]))(x)x = tf.keras.layers.Lambda(lambda x: tf.transpose(x, perm=[0, 2, 1, 3]))(x)return xdef _scaled_dot_product_attention(self, query, key, value, use_casual_mask):dk = tf.cast(tf.shape(key)[-1], tf.float32)scaled_attention_logits = tf.matmul(query, key, transpose_b=True) / tf.math.sqrt(dk)if use_casual_mask:casual_mask = 1 - tf.linalg.band_part(tf.ones_like(scaled_attention_logits), -1, 0)scaled_attention_logits += casual_mask * -1e9attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1)output = tf.matmul(attention_weights, value)return output, attention_weights
再定义一个 MLP 网络层如下:
class MLP(tf.keras.layers.Layer):def __init__(self, d_model, dropout_rate=0.1):super(MLP, self).__init__()self.dense_layers = [tf.keras.layers.Dense(units, activation='gelu') for units in [d_model * 2, d_model]]self.dropout = tf.keras.layers.Dropout(rate=dropout_rate)def call(self, x):for dense_layer in self.dense_layers:x = dense_layer(x)x = self.dropout(x)return x
构建一个 EncoderLayer 来结合 MultiHeadAttention 和 MLP,并利用 EncoderLayer 来构建 VIT
class EncoderLayer(tf.keras.layers.Layer):def __init__(self, num_heads, d_model):super(EncoderLayer, self).__init__()self.mha = MultiHeadAttention(num_heads, d_model)self.mlp = MLP(d_model)self.layernorm_mha = tf.keras.layers.LayerNormalization(epsilon=1e-6)self.layernorm_mlp = tf.keras.layers.LayerNormalization(epsilon=1e-6)def call(self, x):# 注意力部分x = self.layernorm_mha(x)x = x + self.mha(x, x, x)# 多重感知机部分x = x + self.mlp(self.layernorm_mlp(x))return xclass VIT(tf.keras.models.Model):def __init__(self, patch_size, patch_nums, encoder_layer_nums, num_heads, d_model):super(VIT, self).__init__()self.embedding = PatchEmbedding(patch_size, patch_nums, d_model)self.encoder_layers = [EncoderLayer(num_heads, d_model) for _ in range(encoder_layer_nums)]self.final_dense = tf.keras.layers.Dense(10, activation='softmax')def call(self, x):x = self.embedding(x)for encoder_layer in self.encoder_layers:x = encoder_layer(x)x = self.final_dense(x[:, 0, :])return x
模型定义完毕后,初始化模型并开始训练
# 定义超参数
patch_size = 6
patch_nums = 144
encoder_layer_nums = 3
num_heads = 8
d_model = 256model = VIT(patch_size, patch_nums, encoder_layer_nums, num_heads, d_model)# 定义学习率
learning_rate = 1e-3model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(),optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate),metrics=[tf.keras.metrics.SparseCategoricalAccuracy(name="accuracy"),tf.keras.metrics.SparseTopKCategoricalAccuracy(5, name="top-5-accuracy"),],
)# 开始训练
history = model.fit(train_dataset, epochs=20, validation_data=test_dataset)
训练过程如下
Epoch 1/20
391/391 [==============================] - 23s 47ms/step - loss: 2.1613 - accuracy: 0.2516 - top-5-accuracy: 0.7557 - val_loss: 1.6115 - val_accuracy: 0.3989 - val_top-5-accuracy: 0.8984
Epoch 2/20
391/391 [==============================] - 18s 46ms/step - loss: 1.5517 - accuracy: 0.4297 - top-5-accuracy: 0.9031 - val_loss: 1.3938 - val_accuracy: 0.4899 - val_top-5-accuracy: 0.9331
Epoch 3/20
391/391 [==============================] - 18s 46ms/step - loss: 1.3867 - accuracy: 0.4973 - top-5-accuracy: 0.9304 - val_loss: 1.2830 - val_accuracy: 0.5353 - val_top-5-accuracy: 0.9457
Epoch 4/20
391/391 [==============================] - 18s 45ms/step - loss: 1.2876 - accuracy: 0.5326 - top-5-accuracy: 0.9437 - val_loss: 1.2664 - val_accuracy: 0.5308 - val_top-5-accuracy: 0.9513
Epoch 5/20
391/391 [==============================] - 18s 45ms/step - loss: 1.2138 - accuracy: 0.5618 - top-5-accuracy: 0.9505 - val_loss: 1.2320 - val_accuracy: 0.5522 - val_top-5-accuracy: 0.9483
Epoch 6/20
391/391 [==============================] - 18s 46ms/step - loss: 1.1558 - accuracy: 0.5821 - top-5-accuracy: 0.9567 - val_loss: 1.2069 - val_accuracy: 0.5682 - val_top-5-accuracy: 0.9536
Epoch 7/20
391/391 [==============================] - 18s 46ms/step - loss: 1.1135 - accuracy: 0.5980 - top-5-accuracy: 0.9608 - val_loss: 1.1252 - val_accuracy: 0.5982 - val_top-5-accuracy: 0.9601
Epoch 8/20
391/391 [==============================] - 18s 46ms/step - loss: 1.0649 - accuracy: 0.6175 - top-5-accuracy: 0.9645 - val_loss: 1.0961 - val_accuracy: 0.6041 - val_top-5-accuracy: 0.9625
Epoch 9/20
391/391 [==============================] - 18s 45ms/step - loss: 1.0353 - accuracy: 0.6285 - top-5-accuracy: 0.9674 - val_loss: 1.0793 - val_accuracy: 0.6174 - val_top-5-accuracy: 0.9640
Epoch 10/20
391/391 [==============================] - 18s 45ms/step - loss: 1.0059 - accuracy: 0.6390 - top-5-accuracy: 0.9689 - val_loss: 1.0667 - val_accuracy: 0.6221 - val_top-5-accuracy: 0.9638
Epoch 11/20
391/391 [==============================] - 18s 46ms/step - loss: 0.9743 - accuracy: 0.6491 - top-5-accuracy: 0.9717 - val_loss: 1.0402 - val_accuracy: 0.6284 - val_top-5-accuracy: 0.9653
Epoch 12/20
391/391 [==============================] - 23s 58ms/step - loss: 0.9518 - accuracy: 0.6601 - top-5-accuracy: 0.9735 - val_loss: 1.0703 - val_accuracy: 0.6240 - val_top-5-accuracy: 0.
Swin-T 模型搭建
Swin-T 的思想核心和 CNN 差不多,主要实现的是一个下采样的算法过程;
首先导入外部库
import tensorflow as tf
import numpy as np
import matplotlib.pylab as plt
导入数据,这里同样用 cifar10 的数据集
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
# x_train.shape, y_train.shape # ((50000, 32, 32, 3), (50000, 1))train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))def process_data(image, label):image = tf.image.random_flip_left_right(image)image = tf.image.random_flip_up_down(image)image = tf.image.random_brightness(image, 0.2)image = tf.cast(image, tf.float32) / 255.0return image, labeltrain_dataset = train_dataset.map(process_data).batch(128)
test_dataset = test_dataset.map(process_data).batch(128)
数据可视化
plt.figure(figsize=(5, 5))
for i in range(25):plt.subplot(5, 5, i + 1)plt.imshow(x_train[i])plt.axis('off')
plt.show()
得到图片效果
![![[Pasted image 20240611180840.png]]](https://img-blog.csdnimg.cn/direct/d386a88d34fb480b9ee5bb874e7d3b00.png)
在对 Patch 进行操作时我们定义三个类 PatchExtract, PatchEmbedding, PatchMerging,前面两个和 VIT 模型相似,第三个 PatchMerging 是将 PatchExtract 后的 Patch 相同位置的像素绑定到一起构成一张新的 Patch;
## 这里可以直接使用 Conv2D 实现 `PatchExtract` 和 `PatchEmbedding`
## self.proj = Conv2D(filters=embed_dim, kernel_size=patch_size, strides=patch_size)class PatchExtract(tf.keras.layers.Layer):def __init__(self, patch_size, **kwargs):"""patch_size 每一块图片的长宽"""super(PatchExtract, self).__init__(**kwargs)self.patch_size = patch_sizedef call(self, images):patches = tf.image.extract_patches(images,sizes=[1, self.patch_size, self.patch_size, 1],strides=[1, self.patch_size, self.patch_size, 1],rates=[1, 1, 1, 1],padding='VALID')patches = tf.reshape(patches, [tf.shape(patches)[0], -1, tf.shape(patches)[-1]])return patchesclass PatchEmbedding(tf.keras.layers.Layer):def __init__(self, d_model, patch_size, patch_nums, **kwargs):super(PatchEmbedding, self).__init__(**kwargs)self.patch_nums = patch_numsself.proj = tf.keras.layers.Dense(d_model, activation='relu')self.patches = PatchExtract(patch_size)self.pos_embed = tf.keras.layers.Embedding(input_dim=patch_nums, output_dim=d_model)def call(self, x):patch = self.patches(x)pos = tf.range(start=0, limit=self.patch_nums, delta=1)return self.proj(patch) + self.pos_embed(pos)class PatchMerging(tf.keras.layers.Layer):def __init__(self, input_resolution, d_model, **kwargs):super(PatchMerging, self).__init__(**kwargs)self.d_model = d_modelself.input_resolution = input_resolutionself.dense = tf.keras.layers.Dense(self.d_model * 2, use_bias=False, activation='relu')self.norm = tf.keras.layers.LayerNormalization(epsilon=1e-6)def call(self, x):# assert tf.shape(x)[1] == self.input_resolution[0] * self.input_resolution[1]# assert tf.shape(x)[-1] == self.d_modelx = tf.reshape(x, [tf.shape(x)[0], self.input_resolution[0], self.input_resolution[1], -1])x1 = x[:, 0::2, 0::2, :]x2 = x[:, 1::2, 0::2, :]x3 = x[:, 0::2, 1::2, :]x4 = x[:, 1::2, 1::2, :]x = tf.concat([x1, x2, x3, x4], axis=-1)x = tf.reshape(x, [-1, self.input_resolution[0]*self.input_resolution[1]//4, 4 * self.d_model])# x = self.norm(x)x = self.dense(x)return x## 代码中的 https://github.com/VcampSoldiers/Swin-Transformer-Tensorflow/blob/main/models/swin_transformer.py 中并没有使用 Embedding(range) 的方式进行添加
定义窗口注意力机制,与普通的注意力机制不同,其是在各个窗口中执行注意力机制
class WindowAttention(tf.keras.layers.Layer):def __init__(self, d_model, window_size, num_heads, **kwargs):super(WindowAttention, self).__init__(**kwargs)self.d_model = d_modelself.window_size = window_sizeself.num_heads = num_headsassert self.d_model % self.num_heads == 0self.head_dim = self.d_model // self.num_headsself.scale = self.head_dim ** -0.5self.relative_position_bias_table = self.add_weight(shape=[(2*self.window_size[0]-1)*(2*self.window_size[1]-1), self.num_heads])# get pair-wise relative position index for each token inside the windowcoords_h = tf.range(self.window_size[0])coords_w = tf.range(self.window_size[1])coords = tf.stack(tf.meshgrid(coords_h, coords_w)) # 2, Wh, Wwcoords_flatten = tf.reshape(coords, [2, -1]) # 2, Wh*Wwrelative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Wwrelative_coords = tf.transpose(relative_coords, perm=[1,2,0]) # Wh*Ww, Wh*Ww, 2relative_coords = relative_coords + [self.window_size[0] - 1, self.window_size[1] - 1] # shift to start from 0relative_coords = relative_coords * [2*self.window_size[0] - 1, 1]self.relative_position_index = tf.math.reduce_sum(relative_coords,-1) # Wh*Ww, Wh*Wwself.qkv = tf.keras.layers.Dense(3 * self.d_model, activation='relu', use_bias=True)self.output_dense = tf.keras.layers.Dense(self.d_model, activation='relu', use_bias=True)def call(self, x, mask=None):qkv = self.qkv(x) # x.shape = B, L, C -> qkv.shape = B, L, 3 * Cqkv = tf.reshape(qkv, [tf.shape(x)[0], tf.shape(x)[1], 3, self.num_heads, self.head_dim]) # B, L, 3, num_heads, C // num_headsqkv = tf.transpose(qkv, perm=[2, 0, 3, 1, 4]) # 3, B, num_heads, L, C // num_headsq, k, v = tf.unstack(qkv, axis=0) # q,k,v -> B, num_heads, L, C // num_headsscaled_attention_logits = tf.matmul(q, k, transpose_b=True) * self.scale # B, num_heads, L, L# 获得 relative_position_biasrelative_position_bias = tf.reshape(tf.gather(self.relative_position_bias_table, tf.reshape(self.relative_position_index, [-1])),[self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1]) # L, L, num_headsrelative_position_bias = tf.transpose(relative_position_bias, perm=[2, 0, 1]) # num_heads, L, Lscaled_attention_logits = scaled_attention_logits + relative_position_bias[tf.newaxis, :] # B, num_heads, L, Lif mask is not None:nW = mask.shape[0] # every window has different mask [num_heads, L, L]scaled_attention_logits = tf.reshape(scaled_attention_logits, [tf.shape(x)[0] // nW, nW, self.num_heads, tf.shape(x)[1], tf.shape(x)[1]]) + mask[:, None, :, :] # add mask: make each component -inf or just leave itscaled_attention_logits = tf.reshape(scaled_attention_logits, [-1, self.num_heads, tf.shape(x)[1], tf.shape(x)[1]])# scaled_attention_logits -> B, num_heads, L, Lattention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1) # B, num_heads, L, Loutput = tf.matmul(attention_weights, v) # B, num_heads, L, L and B, num_heads, L, C // num_heads -> B, num_heads, L, C // num_headsoutput = tf.keras.layers.Lambda(lambda output: tf.transpose(output, perm=[0, 2, 1, 3]))(output)output = tf.keras.layers.Lambda(lambda output: tf.reshape(output, [tf.shape(output)[0], tf.shape(x)[1], self.d_model]))(output)output = self.output_dense(output)return output
定义一个 MLP 模块
class MLP(tf.keras.layers.Layer):def __init__(self, d_model, **kwargs):super(MLP, self).__init__(**kwargs)self.dense_1 = tf.keras.layers.Dense(4 * d_model, activation='gelu')self.dense_2 = tf.keras.layers.Dense(d_model, activation='gelu')def call(self, x):x = self.dense_1(x)x = self.dense_2(x)return x
定义一个 SwinTransformerBlock
class SwinTransformerBlock(tf.keras.layers.Layer):r""" Swin Transformer Block.Args:d_model (int): Number of input channels.input_resolution (tuple[int]): Input resulotion.num_heads (int): Number of attention heads.window_size (int): Window size.shift_size (int): Shift size for SW-MSA.drop_path (float, optional): Stochastic depth rate. Default: 0.0"""def __init__(self, d_model, input_resolution, num_heads, window_size=7, shift_size=0):super().__init__()self.d_model = d_modelself.input_resolution = input_resolutionself.num_heads = num_headsself.window_size = window_sizeself.shift_size = shift_size# if window size is larger than input resolution, we don't partition windowsif min(self.input_resolution) <= self.window_size:self.shift_size = 0self.window_size = min(self.input_resolution)assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"self.norm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)self.attn = WindowAttention(self.d_model, window_size=[self.window_size, self.window_size], num_heads=num_heads)# 来一个drop_path# self.drop_path = DropPath(drop_path)self.norm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)self.mlp = MLP(d_model=self.d_model)# calculate attention mask for SW-MSAif self.shift_size > 0:self.attn_mask = self.calculate_attention_mask(self.window_size, self.shift_size)else:self.attn_mask = Nonedef call(self, x):H, W = self.input_resolutionB, L, C = tf.shape(x)[0], tf.shape(x)[1], tf.shape(x)[2]# assert L == H * W, "input feature has wrong size"shortcut = xx = self.norm1(x)x = tf.reshape(x, [B, H, W, C])# cyclic shiftif self.shift_size > 0:shifted_x = tf.roll(x, shift=[-self.shift_size, -self.shift_size], axis=(1, 2))else:shifted_x = x# partition windowsx_windows = self.window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, Cx_windows = tf.reshape(x_windows, [-1, self.window_size * self.window_size, C]) # nW*B, window_size*window_size, C# W-MSA/SW-MSAattn_windows = self.attn(x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C# merge windowsattn_windows = tf.reshape(attn_windows, [-1, self.window_size, self.window_size, C])shifted_x = self.window_reverse(attn_windows, self.window_size, H, W) # B H' W' C# reverse cyclic shiftif self.shift_size > 0:x = tf.roll(shifted_x, shift=[self.shift_size, self.shift_size], axis=(1, 2))else:x = shifted_xx = tf.reshape(x, [B, H * W, C])x = shortcut + x# FFNx = x + self.mlp(self.norm2(x))return xdef calculate_attention_mask(self, window_size, shift_size):H, W = self.input_resolutionimg_mask = np.zeros([1, H, W, 1]) # 1 H W 1h_slices = (slice(0, -window_size),slice(-window_size, -shift_size),slice(-shift_size, None))w_slices = (slice(0, -window_size),slice(-window_size, -shift_size),slice(-shift_size, None))cnt = 0for h in h_slices:for w in w_slices:img_mask[:, h, w, :] = cntcnt += 1img_mask = tf.convert_to_tensor(img_mask)mask_windows = self.window_partition(img_mask, window_size) # nW, window_size, window_size, 1mask_windows = tf.reshape(mask_windows, [-1, window_size * window_size])attn_mask = mask_windows[:, None, :] - mask_windows[:, :, None]attn_mask = tf.where(attn_mask==0, -100., 0.)return attn_maskdef window_partition(self, x, window_size):"""Args:x: (B, H, W, C)window_size (int): window sizeReturns:windows: (num_windows*B, window_size, window_size, C)"""B, H, W, C = tf.shape(x)[0], tf.shape(x)[1], tf.shape(x)[2], tf.shape(x)[3]x = tf.reshape(x, [B, H // window_size, window_size, W // window_size, window_size, C]) # TODO contiguous memory access?windows = tf.reshape(tf.transpose(x, perm=[0, 1, 3, 2, 4, 5]), [-1, window_size, window_size, C])return windows@tf.functiondef window_reverse(self, windows, window_size, H, W):"""Args:windows: (num_windows*B, window_size, window_size, C)window_size (int): Window sizeH (int): Height of imageW (int): Width of imageReturns:x: (B, H, W, C)"""B = tf.shape(windows)[0] * window_size ** 2 // (H * W)x = tf.reshape(windows, [B, H // window_size, W // window_size, window_size, window_size, -1])x = tf.reshape(tf.transpose(x, perm=[0, 1, 3, 2, 4, 5]), [B, H, W, -1])return x
由于层之间重复性出现,可以定义一个 BasicLayer 简化模型定义操作
![![[Pasted image 20240611182658.png]]](https://img-blog.csdnimg.cn/direct/081c01d04ab940f19e8e75e0213a2381.png)
class BasicLayer(tf.keras.layers.Layer):""" A basic Swin Transformer layer for one stage.Args:d_model (int): Number of input channels.input_resolution (tuple[int]): Input resolution.depth (int): Number of blocks.num_heads (int): Number of attention heads.window_size (int): Local window size.downsample (tf.keras.layers.Layer | None, optional): Downsample layer at the end of the layer. Default: None"""def __init__(self, d_model, input_resolution, depth, num_heads, window_size, downsample=None, **kwargs):super().__init__(**kwargs)self.d_model = d_modelself.input_resolution = input_resolutionself.depth = depth# build blocksself.blocks = [SwinTransformerBlock(d_model=d_model, input_resolution=input_resolution,num_heads=num_heads, window_size=window_size,shift_size=0 if (i % 2 == 0) else window_size // 2) for i in range(depth)]# patch merging layerif downsample is not None:self.downsample = downsample(input_resolution=input_resolution, d_model=d_model)else:self.downsample = Nonedef call(self, x):for blk in self.blocks:x = blk(x)if self.downsample is not None:x = self.downsample(x)return x
利用 BasicLayer 定义最后的模型结构 SwinTransformer
class SwinTransformer(tf.keras.models.Model):r""" Swin TransformerA Tensorflow impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` -https://arxiv.org/pdf/2103.14030Args:img_size (int | tuple(int)): Input image size. Default 224patch_size (int | tuple(int)): Patch size. Default: 4in_chans (int): Number of input image channels. Default: 3num_classes (int): Number of classes for classification head. Default: 1000embed_dim (int): Patch embedding dimension. Default: 96depths (tuple(int)): Depth of each Swin Transformer layer.num_heads (tuple(int)): Number of attention heads in different layers.window_size (int): Window size. Default: 7"""def __init__(self, img_size=32, patch_size=2, num_classes=10, d_model=256,depths=[2, 2], num_heads=[4, 8], window_size=4, **kwargs):super().__init__(**kwargs)self.num_layers = len(depths)self.d_model = d_modelself.patches_resolution = [img_size // patch_size, img_size // patch_size]self.patch_nums = self.patches_resolution[0] ** 2# split image into non-overlapping patchesself.embedding = PatchEmbedding(d_model=d_model, patch_size=patch_size, patch_nums=self.patch_nums)# build layersself.sequence = tf.keras.models.Sequential(name="basic_layers_seq")for i_layer in range(self.num_layers):self.sequence.add(BasicLayer(d_model=int(self.d_model * 2 ** i_layer),input_resolution=(self.patches_resolution[0] // (2 ** i_layer),self.patches_resolution[1] // (2 ** i_layer)),depth=depths[i_layer],num_heads=num_heads[i_layer],window_size=window_size,downsample=PatchMerging if (i_layer < self.num_layers - 1) else None))self.norm = tf.keras.layers.LayerNormalization(epsilon=1e-6)self.avgpool = tf.keras.layers.GlobalAveragePooling1D()self.head = tf.keras.layers.Dense(num_classes, activation='softmax')def forward_features(self, x):x = self.embedding(x)x = self.sequence(x)x = self.norm(x) # B L Cx = self.avgpool(x)return xdef call(self, x):x = self.forward_features(x)x = self.head(x)return x
初始化模型
model = SwinTransformer(img_size=32, patch_size=2, num_classes=10, d_model=256,depths=[2, 2], num_heads=[4, 8], window_size=4)# 定义学习率
learning_rate = 1e-3model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(),optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate),metrics=[tf.keras.metrics.SparseCategoricalAccuracy(name="accuracy"),tf.keras.metrics.SparseTopKCategoricalAccuracy(5, name="top-5-accuracy"),],
)history = model.fit(train_dataset, epochs=20, validation_data=test_dataset)
得到训练过程
Epoch 1/20
391/391 [==============================] - 40s 83ms/step - loss: 2.1053 - accuracy: 0.2078 - top-5-accuracy: 0.7266 - val_loss: 1.8410 - val_accuracy: 0.2724 - val_top-5-accuracy: 0.8481
Epoch 2/20
391/391 [==============================] - 31s 80ms/step - loss: 1.6857 - accuracy: 0.3554 - top-5-accuracy: 0.8823 - val_loss: 1.5863 - val_accuracy: 0.4000 - val_top-5-accuracy: 0.9075
Epoch 3/20
391/391 [==============================] - 31s 80ms/step - loss: 1.5168 - accuracy: 0.4359 - top-5-accuracy: 0.9137 - val_loss: 1.4614 - val_accuracy: 0.4630 - val_top-5-accuracy: 0.9228
Epoch 4/20
391/391 [==============================] - 31s 79ms/step - loss: 1.4073 - accuracy: 0.4840 - top-5-accuracy: 0.9285 - val_loss: 1.3463 - val_accuracy: 0.5183 - val_top-5-accuracy: 0.9394
Epoch 5/20
391/391 [==============================] - 31s 79ms/step - loss: 1.3172 - accuracy: 0.5221 - top-5-accuracy: 0.9390 - val_loss: 1.2881 - val_accuracy: 0.5345 - val_top-5-accuracy: 0.9431
Epoch 6/20
391/391 [==============================] - 31s 79ms/step - loss: 1.2394 - accuracy: 0.5539 - top-5-accuracy: 0.9474 - val_loss: 1.2543 - val_accuracy: 0.5536 - val_top-5-accuracy: 0.9410
Epoch 7/20
391/391 [==============================] - 31s 80ms/step - loss: 1.1807 - accuracy: 0.5765 - top-5-accuracy: 0.9522 - val_loss: 1.1820 - val_accuracy: 0.5759 - val_top-5-accuracy: 0.9536
Epoch 8/20
391/391 [==============================] - 31s 79ms/step - loss: 1.1309 - accuracy: 0.5942 - top-5-accuracy: 0.9583 - val_loss: 1.1263 - val_accuracy: 0.5941 - val_top-5-accuracy: 0.9560
Epoch 9/20
391/391 [==============================] - 31s 78ms/step - loss: 1.0864 - accuracy: 0.6095 - top-5-accuracy: 0.9606 - val_loss: 1.0998 - val_accuracy: 0.6105 - val_top-5-accuracy: 0.9589
Epoch 10/20
391/391 [==============================] - 31s 80ms/step - loss: 1.0537 - accuracy: 0.6250 - top-5-accuracy: 0.9638 - val_loss: 1.0706 - val_accuracy: 0.6213 - val_top-5-accuracy: 0.9638
Epoch 11/20
391/391 [==============================] - 31s 78ms/step - loss: 1.0157 - accuracy: 0.6360 - top-5-accuracy: 0.9660 - val_loss: 1.0507 - val_accuracy: 0.6303 - val_top-5-accuracy: 0.9630
Epoch 12/20
391/391 [==============================] - 31s 78ms/step - loss: 0.9869 - accuracy: 0.6457 - top-5-accuracy: 0.9685 - val_loss: 1.0682 - val_accuracy: 0.6241 - val_top-5-accuracy: 0.9623
Epoch 13/20
391/391 [==============================] - 31s 78ms/step - loss: 0.9490 - accuracy: 0.6589 - top-5-accuracy: 0.9714 - val_loss: 1.0055 - val_accuracy: 0.6473 - val_top-5-accuracy: 0.9681
Epoch 14/20
391/391 [==============================] - 31s 78ms/step - loss: 0.9187 - accuracy: 0.6729 - top-5-accuracy: 0.9741 - val_loss: 1.0054 - val_accuracy: 0.6504 - val_top-5-accuracy: 0.9677
Epoch 15/20
391/391 [==============================] - 31s 79ms/step - loss: 0.8934 - accuracy: 0.6836 - top-5-accuracy: 0.9765 - val_loss: 0.9728 - val_accuracy: 0.6575 - val_top-5-accuracy: 0.9696
参考
Swin-Transformer网络结构详解_swin transformer-CSDN博客
相关文章:
Python深度学习基于Tensorflow(17)基于Transformer的图像处理实例VIT和Swin-T
文章目录 VIT 模型搭建Swin-T 模型搭建参考 这里使用 VIT 和 Swin-T 在数据集 cifar10 上进行训练 VIT 模型搭建 导入需要的外部库 import numpy as np import tensorflow as tf import matplotlib.pyplot as plt import matplotlib.gridspec as gridspec这里我们接着使用 ci…...
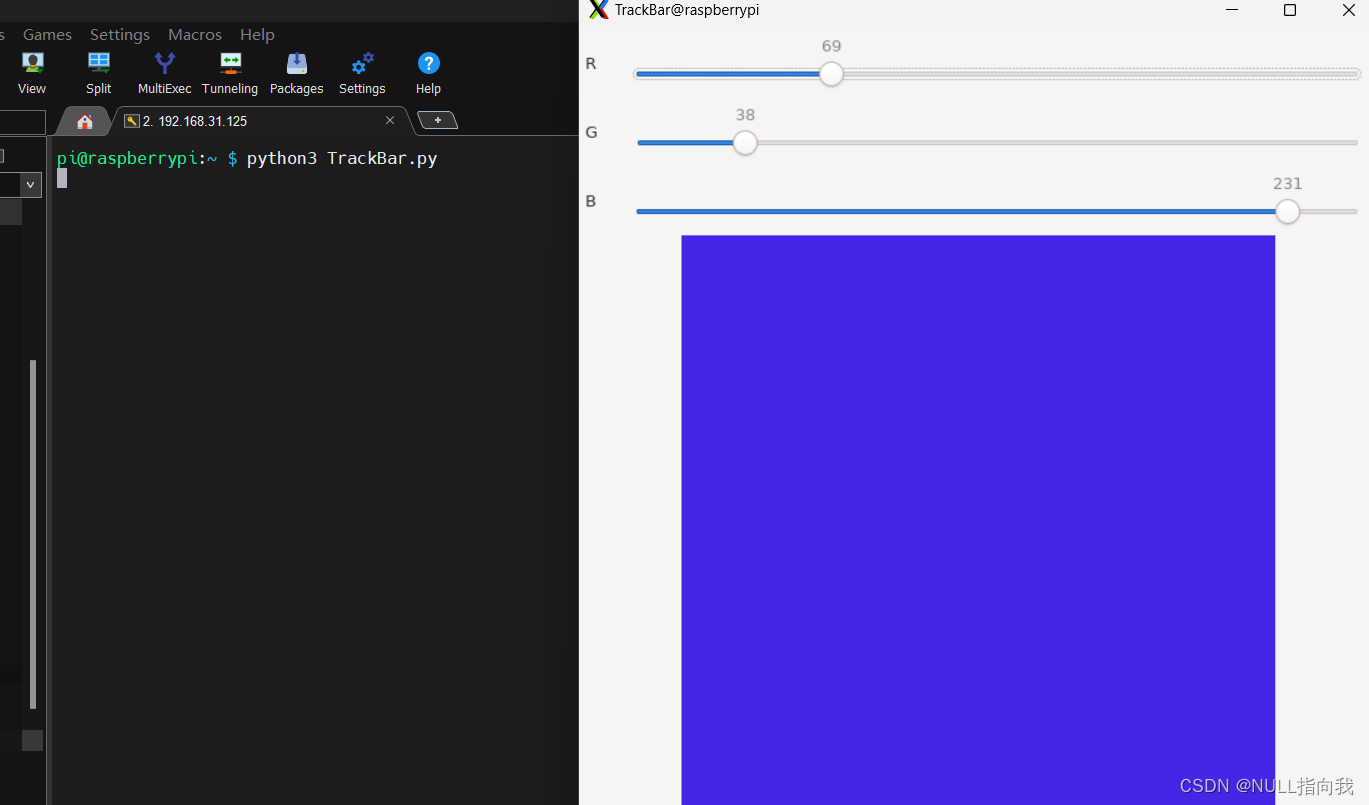
树莓派4B_OpenCv学习笔记5:读取窗口鼠标状态坐标_TrackBar滑动条控件的使用
今日继续学习树莓派4B 4G:(Raspberry Pi,简称RPi或RasPi) 本人所用树莓派4B 装载的系统与版本如下: 版本可用命令 (lsb_release -a) 查询: Opencv 版本是4.5.1: 今日学习:读取窗口鼠标状态坐标_TrackBar滑动条控件的使…...

c、c#、c++嵌入式比较?
嵌入式系统是专门设计用于特定用途的计算机系统,通常用于控制、监视或执行特定任务。这些系统通常具有严格的资源限制,如内存、处理器速度和能耗。因此,在选择编程语言时,需要考虑到这些限制以及系统的特性。 对于嵌入式系统&…...

如何使用ai人工智能作诗?7个软件帮你快速作诗
如何使用ai人工智能作诗?7个软件帮你快速作诗 使用AI人工智能作诗是一种创新的写作方式,以下是一些可以帮助您快速作诗的AI人工智能软件: 1.AI创作云: 这是一个AI诗歌助手应用程序,可以根据您提供的主题或关键词生成…...

调用华为API实现语音合成
目录 1.作者介绍2.华为云语音合成2.1 语音合成介绍2.2 华为语音合成服务2.3 应用场景 3. 实验过程以及结果3.1 获取API密钥3.2 调用语音合成算法API3.3 实验代码3.4 运行结果 1.作者介绍 袁斌,男,西安工程大学电子信息学院,2023级研究生 研究…...
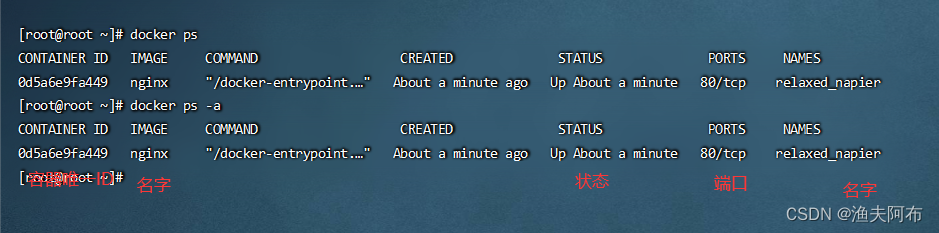
docker实战命令大全
文章目录 1 环境准备1.1 移除旧版本Docker1.2安装工具包1.3配置docker yum源 2 安装最新docker2.1 设置开机自启docker2.2配置加速器 3 实操-镜像3.1搜索镜像3.2下载镜像3.3查看镜像3.4 删除镜像 4 实操-容器4.1运行nginx容器4.2 查看容器4.3启动容器4.5关闭容器4.6查看容器日志…...

Java线程死锁
在Java中,线程死锁通常发生在两个或更多个线程相互等待对方释放资源的情况下。以下是一个简单的Java示例,展示了如何创建线程死锁: public class DeadlockDemo {// 定义两个资源private static Object resource1 new Object();private stat…...

virtual box安装invalid installation directory
问题原因 看官方文档Chapter 2. Installation Details 第2.1.2所示,安装目录需要满足两个条件: 一是:需要安装目录的所有父目录都要满足以下访问控制条件 Users S-1-5-32-545:(OI)(CI)(RX) Users S-1-5-32-545…...

概率分析和随机算法
目录 雇佣问题 概率分析 随机算法 生日悖论 随机算法 概率分析 球与箱子 总结 雇佣问题 有n个候选人面试,如果面试者比目前雇佣者的分数高,评价更好,那么就辞掉当前雇佣者,而去聘用面试者,否则继续面试新的候…...

15_2 Linux Shell基础
15_2 Linux Shell基础 文章目录 15_2 Linux Shell基础[toc]1. shell基本介绍1.1 什么是shell1.2 shell使用方式1.3 脚本的执行方式1.4 脚本练习 2. 变量的种类2.1 自定义变量2.2 环境变量,由系统提前定义好,使用时直接调用2.3 位置变量与预定变量2.4 变量…...
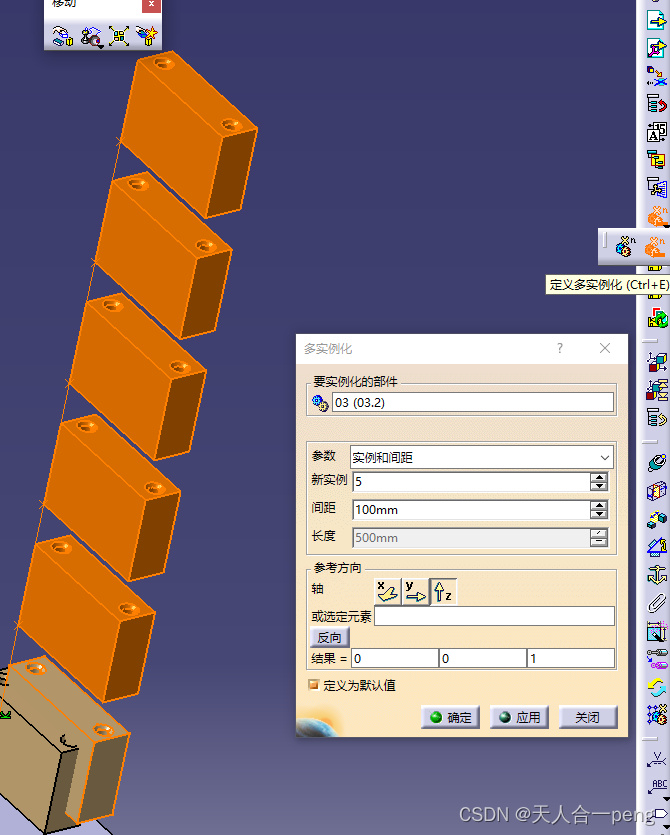
Catia装配体零件复制
先选中要复制的零件 然后选中复制到的父节点才可以。 否则 另外一种方法是多实例化...

实用小工具-python esmre库实现word查找
python esmre库实现word查找 前言: 在文本中匹配特定的字符串,一般可以用普通的字符串匹配算法,KMP算法; python中提供了一个库,esmre, 通过预先将字符串存到esm对象中,利用这些字符串从候选的字符串中进行…...
SSM框架整合,内嵌Tomcat。基于注解的方式集成
介绍: SSM相信大家都不陌生,在spring boot出现之前,SSM一直是Java在web开发中的老大哥。现在虽说有了spring boot能自动整合第三方框架了,但是现在市面上任然有很多老项目是基于SSM技术的。因此,能熟练掌握SSM进行开发…...
)
系统架构设计师【论文-2016年 试题4】: 论微服务架构及其应用(包括写作要点和经典范文)
论微服务架构及其应用(2016年 试题4) 近年来,随着互联网行业的迅猛发展,公司或组织业务的不断扩张,需求的快速变化以及用户量的不断增加,传统的单块(Monolithic)软件架构面临着越来越多的挑战,…...

面试题:String 、StringBuffer 、StringBuilder的区别
String、StringBuffer、和StringBuilder都是用于处理字符串的操作类,但它们之间存在一些关键性的差异: 1.不可变性与可变性: String:字符串常量,是不可变的。一旦创建,其内容就不能被改变。对字符串的任何…...

TLS指纹跟踪网络安全实践(C/C++代码实现)
TLS指纹识别是网络安全领域的重要技术,它涉及通过分析TLS握手过程中的信息来识别和验证通信实体的技术手段。TLS(传输层安全)协议是用于保护网络数据传输的一种加密协议,而TLS指纹则是该协议在实际应用中产生的独特标识࿰…...
小白学RAG:大模型 RAG 技术实践总结
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。 针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备面试攻略、面试常考点等热门话题进行了深入的讨论。 汇总合集…...
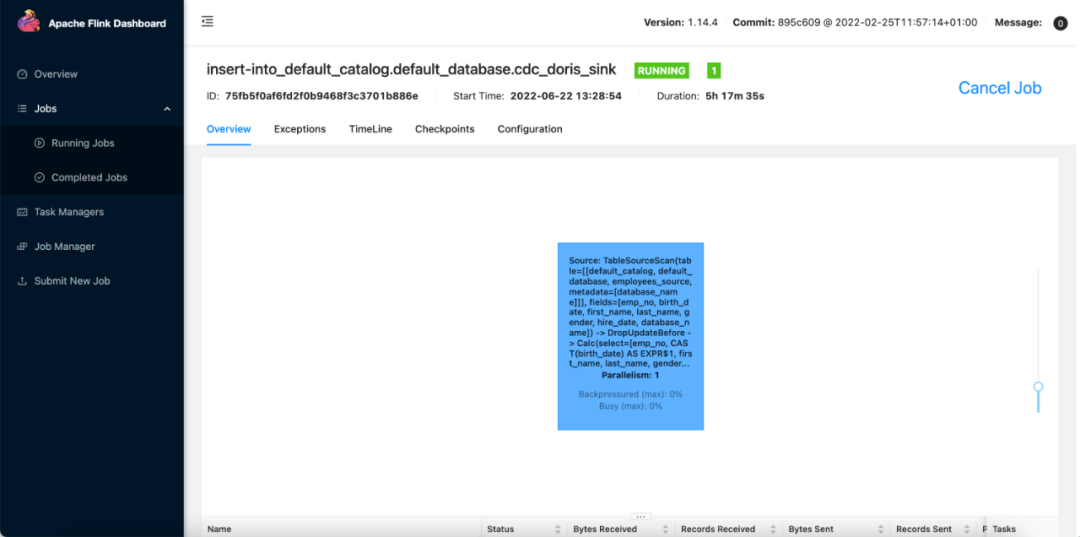
Doris Connector 结合 Flink CDC 实现 MySQL 分库分表
1. 概述 在实际业务系统中为了解决单表数据量大带来的各种问题,我们通常采用分库分表的方式对库表进行拆分,以达到提高系统的吞吐量。 但是这样给后面数据分析带来了麻烦,这个时候我们通常试将业务数据库的分库分表同步到数据仓库时&#x…...

ModbusTCP、TCP/IP都走网线,一样吗?
在现代通信技术中,Modbus/TCP和TCP/IP协议是两种广泛应用于工业自动化和网络通信领域的协议。尽管它们都运行在网线上,但它们在设计、结构和应用场景上有着明显的区别。 Modbus/TCP协议是什么 Modbus/TCP是一种基于TCP/IP的应用层协议,它是Mo…...
|Spring Boot中获取HTTP请求头(Header)内容的详细解析)
网络学习(13)|Spring Boot中获取HTTP请求头(Header)内容的详细解析
文章目录 方法一:使用HttpServletRequest实现原理代码示例优点缺点适用场景 方法二:使用RequestContextHolder实现原理代码示例优点缺点适用场景 方法三:使用RequestHeader注解实现原理代码示例优点缺点适用场景 总结 在Spring Boot应用中&am…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

XCTF-web-easyupload
试了试php,php7,pht,phtml等,都没有用 尝试.user.ini 抓包修改将.user.ini修改为jpg图片 在上传一个123.jpg 用蚁剑连接,得到flag...

【JavaEE】-- HTTP
1. HTTP是什么? HTTP(全称为"超文本传输协议")是一种应用非常广泛的应用层协议,HTTP是基于TCP协议的一种应用层协议。 应用层协议:是计算机网络协议栈中最高层的协议,它定义了运行在不同主机上…...

黑马Mybatis
Mybatis 表现层:页面展示 业务层:逻辑处理 持久层:持久数据化保存 在这里插入图片描述 Mybatis快速入门 
Admin.Net中的消息通信SignalR解释
定义集线器接口 IOnlineUserHub public interface IOnlineUserHub {/// 在线用户列表Task OnlineUserList(OnlineUserList context);/// 强制下线Task ForceOffline(object context);/// 发布站内消息Task PublicNotice(SysNotice context);/// 接收消息Task ReceiveMessage(…...

定时器任务——若依源码分析
分析util包下面的工具类schedule utils: ScheduleUtils 是若依中用于与 Quartz 框架交互的工具类,封装了定时任务的 创建、更新、暂停、删除等核心逻辑。 createScheduleJob createScheduleJob 用于将任务注册到 Quartz,先构建任务的 JobD…...

质量体系的重要
质量体系是为确保产品、服务或过程质量满足规定要求,由相互关联的要素构成的有机整体。其核心内容可归纳为以下五个方面: 🏛️ 一、组织架构与职责 质量体系明确组织内各部门、岗位的职责与权限,形成层级清晰的管理网络…...
指令的指南)
在Ubuntu中设置开机自动运行(sudo)指令的指南
在Ubuntu系统中,有时需要在系统启动时自动执行某些命令,特别是需要 sudo权限的指令。为了实现这一功能,可以使用多种方法,包括编写Systemd服务、配置 rc.local文件或使用 cron任务计划。本文将详细介绍这些方法,并提供…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...