RabbitMQ-工作模式(Publish模式Routing模式)

文章目录
- 发布/订阅(Publish/Subscribe)
- 交换机
- 临时队列
- 绑定
- 总体代码示例
- 路由(Routing)
- 绑定
- 直连交换机
- 多重绑定
- 发送日志
- 订阅
- 总体代码示例
更多相关内容可查看
发布/订阅(Publish/Subscribe)
构建一个简单的日志系统
- 我们将通过构建一个简单的日志系统来说明这个模式。它将包含两个程序 – 第一个程序将发出日志消息,第二个程序将接收并打印它们。
- 在我们的日志系统中,每个运行中的接收程序都将收到这些消息。这样,我们就能够运行一个接收程序并将日志定向到磁盘;同时,我们也能够运行另一个接收程序,并在屏幕上看到日志。
基本上,发布的日志消息将被广播到所有的接收程序。
交换机
Rabbit中完整的消息模型:
- 生产者是发送消息的用户应用程序。
- 队列是存储消息的缓冲区。
- 消费者是接收消息的用户应用程序。
在RabbitMQ中消息模型的核心思想是,生产者从不直接发送任何消息到队列。实际上,很多时候生产者甚至不知道消息是否会被发送到任何队列。
相反,生产者只能将消息发送到一个交换机。交换机是一个非常简单的东西。它一边从生产者接收消息,另一边将它们推送到队列。交换机必须确切地知道如何处理收到的消息。它应该被附加到特定的队列吗?它应该被附加到多个队列吗?还是应该被丢弃。这些规则由交换机类型定义。

有几种可用的交换机类型:direct、topic、headers和fanout。我们将专注于最后一种类型 – fanout。让我们创建一个这种类型的交换机,并称其为logs:
channel.exchangeDeclare("logs", "fanout");
fanout交换机非常简单。正如你可能从名称中猜到的那样,它只是将接收到的所有消息广播到它所知道的所有队列。这正是我们的日志记录器所需要的。
列出交换机
要列出服务器上的交换机,您可以运行非常有用的rabbitmqctl命令:
sudo rabbitmqctl list_exchanges
在这个列表中会有一些amq.*交换机和默认(未命名)交换机。这些是默认创建的,无需考虑
之前对交换机一无所知,但仍然能够将消息发送到队列。这是因为我们使用的是默认交换,通过空字符串("")来标识它。
回想一下之前发布消息的方式:
channel.basicPublish("", "hello", null, message.getBytes());
第一个参数是交换机的名称。空字符串表示默认或无名交换机:如果存在指定 routingKey 的队列,则消息会被路由到该队列。
现在,我们可以将消息发布到我们命名的交换机:
channel.basicPublish("logs", "", null, message.getBytes());
这样,我们将消息发布到名为 logs 的交换机中,而不是默认的无名交换机。
临时队列
在之前,我们使用的队列都有特定的名称。能够给队列命名对我们来说非常重要 - 我们需要将工作者指向同一个队列。在想要在生产者和消费者之间共享队列时,给队列命名非常重要。
但是对于我们的日志记录器来说情况并非如此。我们希望收到所有日志消息,而不仅仅是其中的一部分。我们也只对当前正在流动的消息感兴趣,而不是旧消息。为了解决这个问题,我们需要两件事情。
- 首先,每当我们连接到 Rabbit 时,我们都需要一个全新的空队列。为此,我们可以创建一个具有随机名称的队列,或者更好的是让服务器为我们选择一个随机的队列名称。
- 其次,一旦我们断开消费者连接,队列应该自动删除。
在 Java 中,当我们向 queueDeclare() 方法提供没有参数时,我们创建一个非持久化、独占、自动删除的队列,并且由服务器生成一个名称:
String queueName = channel.queueDeclare().getQueue();
在这一点上,queueName 包含一个随机的队列名称。例如,它可能看起来像amq.gen-JzTY20BRgKO-HjmUJj0wLg
绑定
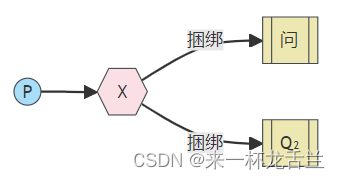
我们已经创建了一个fanout 交换机和一个队列。现在我们需要告诉交换机将消息发送到我们的队列。交换机和队列之间的这种关系称为绑定
channel.queueBind(queueName, "logs", "");
从现在开始,logs 交换机将会将消息追加到我们的队列中。
列出绑定
您可以使用以下命令列出现有的绑定:
rabbitmqctl list_bindings
总体代码示例
发出日志消息的 producer 程序:logsroutingKeyfanoutEmitLog.java
public class EmitLog {private static final String EXCHANGE_NAME = "logs";public static void main(String[] argv) throws Exception {ConnectionFactory factory = new ConnectionFactory();factory.setHost("localhost");try (Connection connection = factory.newConnection();Channel channel = connection.createChannel()) {//指定交换机类型-fanoutchannel.exchangeDeclare(EXCHANGE_NAME, "fanout");String message = argv.length < 1 ? "info: Hello World!" :String.join(" ", argv);//绑定交换机 发送消息到交换机EXCHANGE_NAME中channel.basicPublish(EXCHANGE_NAME, "", null, message.getBytes("UTF-8"));System.out.println(" [x] Sent '" + message + "'");}}
}
如果还没有队列绑定到交换机,则消息将丢失, 但这对我们来说没关系,如果还没有消费者在获取,我们可以安全地丢弃该消息。
代码为:ReceiveLogs.java
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import com.rabbitmq.client.DeliverCallback;public class ReceiveLogs {private static final String EXCHANGE_NAME = "logs";public static void main(String[] argv) throws Exception {ConnectionFactory factory = new ConnectionFactory();factory.setHost("localhost");Connection connection = factory.newConnection();Channel channel = connection.createChannel();//指定交换机类型-fanoutchannel.exchangeDeclare(EXCHANGE_NAME, "fanout");String queueName = channel.queueDeclare().getQueue();//绑定交换机跟队列channel.queueBind(queueName, EXCHANGE_NAME, "");System.out.println(" [*] Waiting for messages. To exit press CTRL+C");DeliverCallback deliverCallback = (consumerTag, delivery) -> {String message = new String(delivery.getBody(), "UTF-8");System.out.println(" [x] Received '" + message + "'");};channel.basicConsume(queueName, true, deliverCallback, consumerTag -> { });}
}
如果你想将日志保存到文件中,只需打开控制台并输入以下命令:
java -cp $CP ReceiveLogs > logs_from_rabbit.log
如果你希望在屏幕上看到日志,开启一个新的终端并运行:
java -cp $CP ReceiveLogs
当然,要发出日志,只需输入:
java -cp $CP EmitLog
使用 rabbitmqctl list_bindings 命令,你可以验证代码实际上是否按我们想要的方式创建了绑定和队列。如果有两个 ReceiveLogs.java 程序正在运行,你应该会看到类似如下的输出:
sudo rabbitmqctl list_bindings
# => Listing bindings ...
# => logs exchange amq.gen-JzTY20BRgKO-HjmUJj0wLg queue []
# => logs exchange amq.gen-vso0PVvyiRIL2WoV3i48Yg queue []
# => ...done.
结果的解释很简单:来自 exchange logs 的数据发送到两个带有服务器分配名称的队列中。这正是我们想要的。
路由(Routing)
绑定
在前面的示例中,我们已经创建了绑定。你可能还记得 代码如下:
channel.queueBind(queueName, EXCHANGE_NAME, "");
绑定是交换机和队列之间的关系。这可以简单地理解为:队列对来自该交换机的消息感兴趣。
绑定可以接受一个额外的routingKey 参数。为了避免与basic_publish参数混淆,我们将其称为绑定键。以下是我们如何使用键创建绑定的示例:
channel.queueBind(queueName, EXCHANGE_NAME, "black");
绑定键的含义取决于交换机类型。我们先前使用的fanout 交换机简单地忽略了它的值。
直连交换机
在我们之前的教程中,我们的日志系统将所有消息广播给所有消费者。我们希望扩展其功能,以允许根据消息的严重性进行过滤。例如,我们可能希望一个将日志消息写入磁盘的程序只接收关键错误,而不浪费磁盘空间来记录警告或信息日志消息。
我们之前使用的是fanout 交换机,它并没有提供太多的灵活性 - 它只能进行无脑广播。
相反,我们将使用直连交换机。直连交换机背后的路由算法很简单 - 消息将被发送到绑定键与消息的路由键完全匹配的队列中。
为了说明这一点,考虑以下设置:

在这个设置中,我们可以看到直连交换机 X 与两个绑定到它的队列。第一个队列绑定的绑定键是 orange,而第二个队列有两个绑定,一个绑定键为 black,另一个为 green。
在这样的设置中,使用路由键 orange发布到交换机的消息将被路由到队列 Q1。具有路由键 black 或 green的消息将发送到 Q2。所有其他消息将被丢弃。
多重绑定
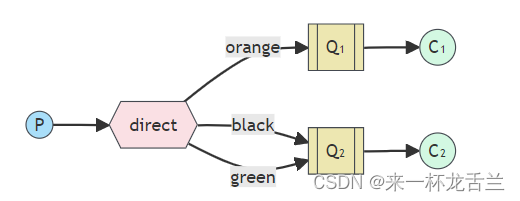
将多个队列与相同的绑定键绑定是完全合法的。在我们的示例中,我们可以添加一个在交换机 X 和队列 Q1 之间的绑定,绑定键为black。在这种情况下,直连交换机将像fanout 交换机一样行为,将消息广播到所有匹配的队列。具有路由键 black 的消息将被传递到 Q1 和 Q2。
发送日志
我们将使用这个模型来构建我们的日志系统。与使用fanout 交换机不同,我们将消息发送到一个直连交换机。我们将日志严重程度作为路由键提供。这样,接收程序就能够选择它想要接收的严重程度。让我们先专注于发送日志。
和往常一样,我们首先需要创建一个交换机:
channel.exchangeDeclare(EXCHANGE_NAME, "direct");
接下来,我们准备发送一条消息:
channel.basicPublish(EXCHANGE_NAME, severity, null, message.getBytes());
我们假设 ‘severity’ 可以是 'info'、'warning' 或 'error' 中的一个。
订阅
接收消息的方式与之前的教程类似,只有一个例外 - 我们将为每个我们感兴趣的严重程度创建一个新的绑定。
String queueName = channel.queueDeclare().getQueue();for(String severity : argv){channel.queueBind(queueName, EXCHANGE_NAME, severity);
}
总体代码示例
生产者类的代码:EmitLogDirect.java
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;public class EmitLogDirect {private static final String EXCHANGE_NAME = "direct_logs";public static void main(String[] argv) throws Exception {ConnectionFactory factory = new ConnectionFactory();factory.setHost("localhost");try (Connection connection = factory.newConnection();Channel channel = connection.createChannel()) {//指定交换机类型channel.exchangeDeclare(EXCHANGE_NAME, "direct");//指定日志类型String severity = getSeverity(argv);String message = getMessage(argv);//发送日志channel.basicPublish(EXCHANGE_NAME, severity, null, message.getBytes("UTF-8"));System.out.println(" [x] Sent '" + severity + "':'" + message + "'");}}//..
}
消费者代码为:ReceiveLogsDirect.java
import com.rabbitmq.client.*;public class ReceiveLogsDirect {private static final String EXCHANGE_NAME = "direct_logs";public static void main(String[] argv) throws Exception {ConnectionFactory factory = new ConnectionFactory();factory.setHost("localhost");Connection connection = factory.newConnection();Channel channel = connection.createChannel();//指定交换机类型channel.exchangeDeclare(EXCHANGE_NAME, "direct");//获取交换机随机名字String queueName = channel.queueDeclare().getQueue();if (argv.length < 1) {System.err.println("Usage: ReceiveLogsDirect [info] [warning] [error]");System.exit(1);}for (String severity : argv) {//指定日志类型channel.queueBind(queueName, EXCHANGE_NAME, severity);}System.out.println(" [*] Waiting for messages. To exit press CTRL+C");DeliverCallback deliverCallback = (consumerTag, delivery) -> {String message = new String(delivery.getBody(), "UTF-8");System.out.println(" [x] Received '" +delivery.getEnvelope().getRoutingKey() + "':'" + message + "'");};channel.basicConsume(queueName, true, deliverCallback, consumerTag -> { });}
}
如果你只想将 ‘warning’ 和 ‘error’(而不是 ‘info’)日志消息保存到文件中,只需打开控制台并输入以下命令:
java -cp $CP ReceiveLogsDirect warning error > logs_from_rabbit.log
如果你想在屏幕上看到所有的日志消息,打开一个新的终端并执行以下命令:
java -cp $CP ReceiveLogsDirect info warning error
# => [*] Waiting for logs. To exit press CTRL+C
例如,要发出一个错误日志消息,只需输入以下命令:
java -cp $CP EmitLogDirect error "Run. Run. Or it will explode."
# => [x] Sent 'error':'Run. Run. Or it will explode.'
相关文章:
RabbitMQ-工作模式(Publish模式Routing模式)
文章目录 发布/订阅(Publish/Subscribe)交换机临时队列绑定总体代码示例 路由(Routing)绑定直连交换机多重绑定发送日志订阅总体代码示例 更多相关内容可查看 发布/订阅(Publish/Subscribe) 构建一个简单的…...
算法概述)
【机器学习算法】期望最大化(EM)算法概述
期望最大化(EM)算法是一种迭代算法,用于在有未观测变量的情况下,求解概率模型参数的最大似然估计或最大后验估计。以下是对EM算法的原理与应用进行详细地剖析: EM算法原理 E步 - 期望计算:根据当前估计的模…...

【深度学习】数竹签演示软件系统
往期文章列表: 【YOLO深度学习系列】图像分类、物体检测、实例分割、物体追踪、姿态估计、定向边框检测演示系统【含源码】 【深度学习】物体检测/实例分割/物体追踪/姿态估计/定向边框/图像分类检测演示系统【含源码】 【深度学习】YOLOV8数据标注及模型训练方法整…...

Halcon 多相机统一坐标系
小杨说事-基于Halcon的多相机坐标系统一原理个人理解_多相机标定统一坐标系-CSDN博客 一、概述 最近在搞多相机标定等的相关问题,对于很大的场景,单个相机的视野是不够的,就必须要统一到一个坐标系下,因此我也用了4个相机&#…...

Apache Kylin:大数据分析从入门到精通
一、Kylin简介 Apache Kylin是一个分布式数据分析引擎,专为处理海量数据设计,能够在极短时间内对超大规模数据集进行OLAP(Online Analytical Processing)分析。Kylin通过预计算和高效的查询机制,为用户提供秒级的查询响应时间,支持与Hadoop、Hive、HBase等大数据平台无缝…...
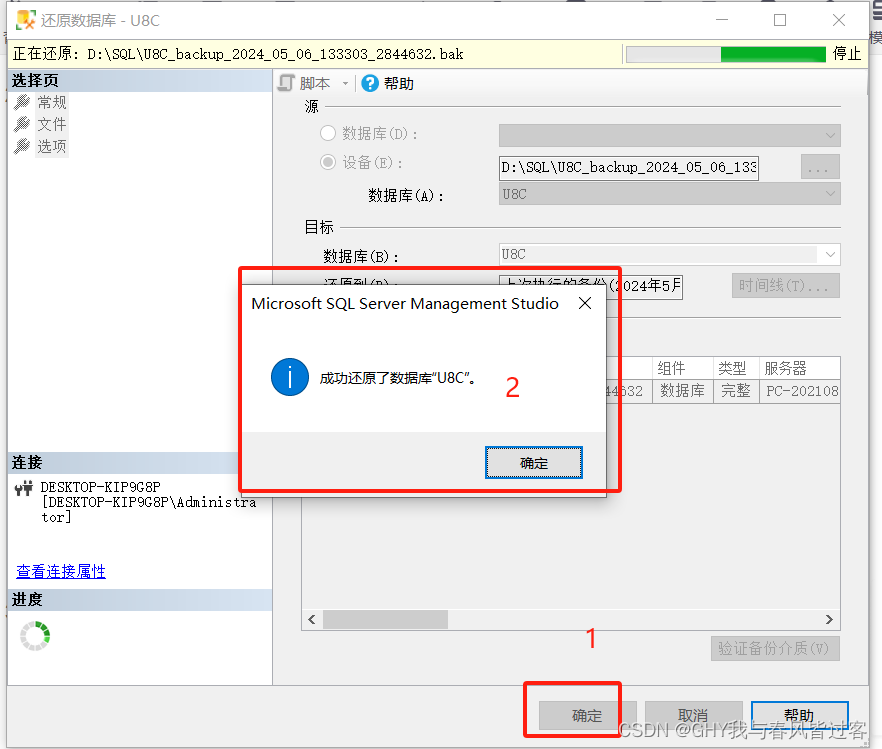
SQL Server 2016导入.bak文件到数据库里面步骤
1、打开SSMS管理器 选择数据库 右键 然后点击还原数据库。 2、选择设备 然后点击三个点 找到本地bak文件,然后点击确定 3、点击确定,会自动弹出来一个成功的提示。...

WPF Frame 简单页面切换示例
原理比较简单,但是有个坑,为了使界面能够正确更新,记得使用 INotifyPropertyChanged 接口来实现属性更改通知。 <Window x:Class"PageTest.MainWindow"xmlns"http://schemas.microsoft.com/winfx/2006/xaml/presentation&…...

kafka-生产者监听器(SpringBoot整合Kafka)
文章目录 1、生产者监听器1.1、创建生产者监听器1.2、创建生产者拦截器1.3、发送消息测试1.4、使用Java代码创建主题分区副本1.5、application.yml配置----v1版1.6、屏蔽 kafka debug 日志 logback.xml1.7、引入spring-kafka依赖1.8、控制台日志 1、生产者监听器 1.1、创建生产…...
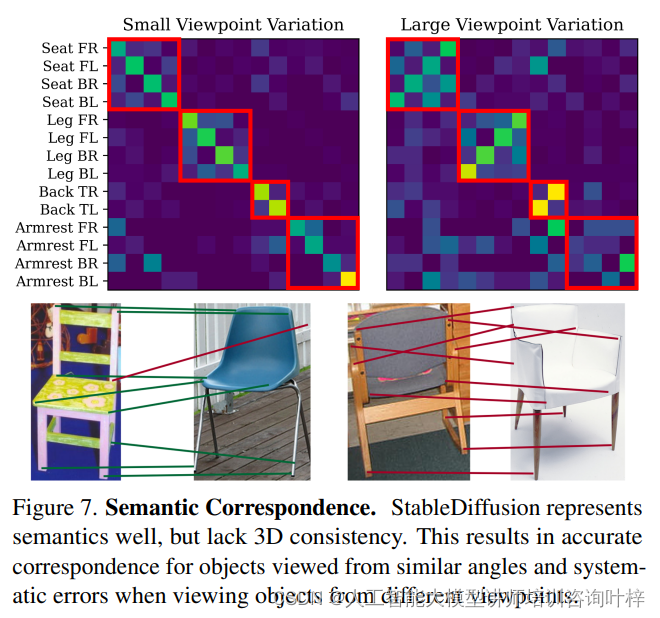
3D感知视觉表示与模型分析:深入探究视觉基础模型的三维意识
在深度学习与大规模预训练的推动下,视觉基础模型展现出了令人印象深刻的泛化能力。这些模型不仅能够对任意图像进行分类、分割和生成,而且它们的中间表示对于其他视觉任务,如检测和分割,同样具有强大的零样本能力。然而࿰…...

VS2019+QT5.15调用动态库dll带有命名空间
VS2019QT5.15调用动态库dll带有命名空间 vs创建动态库 参考: QT调用vs2019生成的c动态库-CSDN博客 demo的dll头文件: // 下列 ifdef 块是创建使从 DLL 导出更简单的 // 宏的标准方法。此 DLL 中的所有文件都是用命令行上定义的 DLL3_EXPORTS // 符号…...
助力草莓智能自动化采摘,基于YOLOv5全系列【n/s/m/l/x】参数模型开发构建果园种植采摘场景下草莓成熟度智能检测识别系统
随着科技的飞速发展,人工智能(AI)技术已经渗透到我们生活的方方面面,从智能家居到自动驾驶,再到医疗健康,其影响力无处不在。然而,当我们把目光转向中国的农业领域时,一个令人惊讶的…...

C++中的生成器模式
目录 生成器模式(Builder Pattern) 实际应用 构建一辆汽车 构建一台计算机 构建一个房子 总结 生成器模式(Builder Pattern) 生成器模式是一种创建型设计模式,它允许你分步骤创建复杂对象。与其他创建型模式不同…...

基于python的PDF文件解析器汇总
基于python的PDF文件解析器汇总 大多数已发表的科学文献目前以 PDF 格式存在,这是一种轻量级、普遍的文件格式,能够保持一致的文本布局和格式。对于人类读者而言, PDF格式的文件内容展示整洁且一致的布局有助于阅读,可以很容易地…...
C++多线程同步总结
C多线程同步总结 关于C多线程同步 一、C11规范下的线程库 1、C11 线程库的基本用法:创建线程、分离线程 #include<iostream> #include<thread> #include<windows.h> using namespace std; void threadProc() {cout<<"this is in t…...

【机器学习】基于CNN-RNN模型的验证码图片识别
1. 引言 1.1. OCR技术研究的背景 1.1.1. OCR技术能够提升互联网体验 随着互联网应用的广泛普及,用户在日常操作中频繁遇到需要输入验证码的场景,无论是在登录、注册、支付还是其他敏感操作中,验证码都扮演着重要角色来确保安全性。然而&am…...

一文读懂Samtec分离式线缆组件选型 | 快速攻略
【摘要/前言】 2023年,全球线缆组件市场规模大致在2100多亿美元。汽车和电信行业是线缆组件最大的两个市场,中国和北美是最大的两个制造地区。有趣的是,特定应用(即定制)和矩形组件是两个最大的产品组。 【Samtec产品…...

批量申请SSL证书如何做到既方便成本又最低
假如您手头拥有1千个域名,并且打算为每一个域名搭建网站,那么在当前的网络环境下,您必须确保这些网站通过https的方式提供服务。这意味着,您将为每一个域名申请SSL证书,以确保网站数据传输的安全性和可信度。那么&…...
)
Python 设计模式(创建型)
文章目录 抽象工厂模式场景示例 单例模式场景实现方式 工厂方法模式场景示例 简单工厂模式场景示例 建造者模式场景示例 原型模式场景示例 抽象工厂模式 抽象工厂模式(Abstract Factory Pattern)是一种创建型设计模式,它提供了一种将一组相关…...

PyTorch 索引与切片-Tensor基本操作
以如下 tensor a 为例,展示常用的 indxing, slicing 及其他高阶操作 >>> a torch.rand(4,3,28,28) >>> a.shape torch.Size([4, 3, 28, 28])Indexing: 使用索引获取目标对象,[x,x,x,....] >>> a[0].shape torch.Size([3, 2…...

深入浅出 LangChain 与智能 Agent:构建下一代 AI 助手
我们小时候都玩过乐高积木。通过堆砌各种颜色和形状的积木,我们可以构建出城堡、飞机、甚至整个城市。现在,想象一下如果有一个数字世界的乐高,我们可以用这样的“积木”来构建智能程序,这些程序能够阅读、理解和撰写文本…...

【OSG学习笔记】Day 18: 碰撞检测与物理交互
物理引擎(Physics Engine) 物理引擎 是一种通过计算机模拟物理规律(如力学、碰撞、重力、流体动力学等)的软件工具或库。 它的核心目标是在虚拟环境中逼真地模拟物体的运动和交互,广泛应用于 游戏开发、动画制作、虚…...

反向工程与模型迁移:打造未来商品详情API的可持续创新体系
在电商行业蓬勃发展的当下,商品详情API作为连接电商平台与开发者、商家及用户的关键纽带,其重要性日益凸显。传统商品详情API主要聚焦于商品基本信息(如名称、价格、库存等)的获取与展示,已难以满足市场对个性化、智能…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

ESP32读取DHT11温湿度数据
芯片:ESP32 环境:Arduino 一、安装DHT11传感器库 红框的库,别安装错了 二、代码 注意,DATA口要连接在D15上 #include "DHT.h" // 包含DHT库#define DHTPIN 15 // 定义DHT11数据引脚连接到ESP32的GPIO15 #define D…...

定时器任务——若依源码分析
分析util包下面的工具类schedule utils: ScheduleUtils 是若依中用于与 Quartz 框架交互的工具类,封装了定时任务的 创建、更新、暂停、删除等核心逻辑。 createScheduleJob createScheduleJob 用于将任务注册到 Quartz,先构建任务的 JobD…...

[ICLR 2022]How Much Can CLIP Benefit Vision-and-Language Tasks?
论文网址:pdf 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用 目录 1. 心得 2. 论文逐段精读 2.1. Abstract 2…...

P3 QT项目----记事本(3.8)
3.8 记事本项目总结 项目源码 1.main.cpp #include "widget.h" #include <QApplication> int main(int argc, char *argv[]) {QApplication a(argc, argv);Widget w;w.show();return a.exec(); } 2.widget.cpp #include "widget.h" #include &q…...

sqlserver 根据指定字符 解析拼接字符串
DECLARE LotNo NVARCHAR(50)A,B,C DECLARE xml XML ( SELECT <x> REPLACE(LotNo, ,, </x><x>) </x> ) DECLARE ErrorCode NVARCHAR(50) -- 提取 XML 中的值 SELECT value x.value(., VARCHAR(MAX))…...

Unit 1 深度强化学习简介
Deep RL Course ——Unit 1 Introduction 从理论和实践层面深入学习深度强化学习。学会使用知名的深度强化学习库,例如 Stable Baselines3、RL Baselines3 Zoo、Sample Factory 和 CleanRL。在独特的环境中训练智能体,比如 SnowballFight、Huggy the Do…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...