流媒体学习之路(WebRTC)——音频NackTracker优化思路(8)
流媒体学习之路(WebRTC)——音频NackTracker优化思路(8)
——
我正在的github给大家开发一个用于做实验的项目 —— github.com/qw225967/Bifrost目标:可以让大家熟悉各类Qos能力、带宽估计能力,提供每个环节关键参数调节接口并实现一个json全配置,提供全面的可视化算法观察能力。欢迎大家使用
——
文章目录
- 流媒体学习之路(WebRTC)——音频NackTracker优化思路(8)
- 一、NackTracker逻辑分析
- 1.1 设计思路
- 1.2 代码
- 二、优化思路
- 三、测试
- 四、总结
在讲具体内容之前插一句嘴,从GCC分析(3)开始,我们将针对GCC的实现细节去分析它设计的原理,让我们理解这些类存在的意义,不再带大家去串具体的流程了。
一、NackTracker逻辑分析
1.1 设计思路
NackTracker是WebRTC根据NetEq逻辑设计的Nack逻辑,相比于视频的重传,音频考虑的问题相对更多一些。(本文的音频NackTracker逻辑来源于WebRTC105版本)
//
// The NackTracker class keeps track of the lost packets, an estimate of
// time-to-play for each packet is also given.
//
// Every time a packet is pushed into NetEq, LastReceivedPacket() has to be
// called to update the NACK list.
//
// Every time 10ms audio is pulled from NetEq LastDecodedPacket() should be
// called, and time-to-play is updated at that moment.
//
// If packet N is received, any packet prior to N which has not arrived is
// considered lost, and should be labeled as "missing" (the size of
// the list might be limited and older packet eliminated from the list).
//
// The NackTracker class has to know about the sample rate of the packets to
// compute time-to-play. So sample rate should be set as soon as the first
// packet is received. If there is a change in the receive codec (sender changes
// codec) then NackTracker should be reset. This is because NetEQ would flush
// its buffer and re-transmission is meaning less for old packet. Therefore, in
// that case, after reset the sampling rate has to be updated.
//
// Thread Safety
// =============
// Please note that this class in not thread safe. The class must be protected
// if different APIs are called from different threads.
//
上面是NackTracker注释的设计思路,意思是:
1.统计丢失的数据包,并给出每个数据包播放的估计时间;
2.每次数据进入NetEq时,都会调用 LastReceivedPacket() 更新 NackList;
3.每次从NetEq队列提取10ms的音频,都需要调用LastDecodedPacket(),更新播放时间记录;
4.如果接收到数据包N,则在N之前尚未到达的任何数据包都被视为丢失,并应标记为“丢失”(列表的大小可能受到限制,旧的数据包将从列表中删除——这里记录的默认值是500)。
5.NackTracker类必须知道数据包的采样率才能计算播放时间。因此,一旦接收到第一个数据包,就应该设置采样率。如果接收编解码器发生变化(发送方更改编解码器),则应重置NackTracker。这是因为NetEQ会清空其缓冲区,而重新传输对旧数据包来说意义不大。因此,在这种情况下,在重置之后,必须更新采样率。
1.2 代码
void NackTracker::UpdateLastReceivedPacket(uint16_t sequence_number,uint32_t timestamp) {// Just record the value of sequence number and timestamp if this is the// first packet.// 记录第一个数据包接收信息if (!any_rtp_received_) {sequence_num_last_received_rtp_ = sequence_number;timestamp_last_received_rtp_ = timestamp;any_rtp_received_ = true;// If no packet is decoded, to have a reasonable estimate of time-to-play// use the given values.if (!any_rtp_decoded_) {sequence_num_last_decoded_rtp_ = sequence_number;timestamp_last_decoded_rtp_ = timestamp;}return;}// 序号已接到直接返回if (sequence_number == sequence_num_last_received_rtp_)return;// Received RTP should not be in the list.nack_list_.erase(sequence_number);// If this is an old sequence number, no more action is required, return.// 如果是旧数据直接返回if (IsNewerSequenceNumber(sequence_num_last_received_rtp_, sequence_number))return;// 更新丢包率估计UpdatePacketLossRate(sequence_number - sequence_num_last_received_rtp_ - 1);// 更新nack列表UpdateList(sequence_number, timestamp);sequence_num_last_received_rtp_ = sequence_number;timestamp_last_received_rtp_ = timestamp;// 尝试清除队列到当前最大限制LimitNackListSize();
}// 这里的逻辑是个指数滤波器
// 指数滤波器是个低通滤波器,主要是削弱高频信号:
// y(k) = a * y(k-1) + (1-a) * x(k)
// a就是下面的alpha_q30,这个值在:0-1之间,通常是0.8 ~ 0.99,这里配置给出0.996
void NackTracker::UpdatePacketLossRate(int packets_lost) {// 计算alpha值,用默认值换算后:1069446856const uint64_t alpha_q30 = (1 << 30) * config_.packet_loss_forget_factor;// Exponential filter.// 进行指数滤波留下丢包的低通值packet_loss_rate_ = (alpha_q30 * packet_loss_rate_) >> 30;for (int i = 0; i < packets_lost; ++i) {packet_loss_rate_ =((alpha_q30 * packet_loss_rate_) >> 30) + ((1 << 30) - alpha_q30);}
}// 这个函数根据最新的包序号更新丢包值
void NackTracker::UpdateList(uint16_t sequence_number_current_received_rtp,uint32_t timestamp_current_received_rtp) {// 序号连续直接返回if (!IsNewerSequenceNumber(sequence_number_current_received_rtp,sequence_num_last_received_rtp_ + 1)) {return;}RTC_DCHECK(!any_rtp_decoded_ ||IsNewerSequenceNumber(sequence_number_current_received_rtp,sequence_num_last_decoded_rtp_));// 更新采样的包周期absl::optional<int> samples_per_packet = GetSamplesPerPacket(sequence_number_current_received_rtp, timestamp_current_received_rtp);if (!samples_per_packet) {return;}// 更新丢包到nacklistfor (uint16_t n = sequence_num_last_received_rtp_ + 1;IsNewerSequenceNumber(sequence_number_current_received_rtp, n); ++n) {uint32_t timestamp = EstimateTimestamp(n, *samples_per_packet);NackElement nack_element(TimeToPlay(timestamp), timestamp);nack_list_.insert(nack_list_.end(), std::make_pair(n, nack_element));}
}// 需要根据采样率估计出每个包的周期
absl::optional<int> NackTracker::GetSamplesPerPacket(uint16_t sequence_number_current_received_rtp,uint32_t timestamp_current_received_rtp) const {uint32_t timestamp_increase =timestamp_current_received_rtp - timestamp_last_received_rtp_;uint16_t sequence_num_increase =sequence_number_current_received_rtp - sequence_num_last_received_rtp_;int samples_per_packet = timestamp_increase / sequence_num_increase;if (samples_per_packet == 0 ||samples_per_packet > kMaxPacketSizeMs * sample_rate_khz_) {// Not a valid samples per packet.return absl::nullopt;}return samples_per_packet;
}// 根据周期计算时间戳
uint32_t NackTracker::EstimateTimestamp(uint16_t sequence_num,int samples_per_packet) {uint16_t sequence_num_diff = sequence_num - sequence_num_last_received_rtp_;return sequence_num_diff * samples_per_packet + timestamp_last_received_rtp_;
}// 根据最大包限制清除包
void NackTracker::LimitNackListSize() {uint16_t limit = sequence_num_last_received_rtp_ -static_cast<uint16_t>(max_nack_list_size_) - 1;nack_list_.erase(nack_list_.begin(), nack_list_.upper_bound(limit));
}
上述逻辑中有几个点需要思考一下:
1.为什么使用指数滤波器对丢包率进行低通滤波?
2.为什么Nack队列需要记录时间戳信息?
答:首先,packet_loss_rate_是用于做最大等待时间估计的,这个最大等待时间估计用于判断是否需要请求重传的判断。
// We don't erase elements with time-to-play shorter than round-trip-time.
std::vector<uint16_t> NackTracker::GetNackList(int64_t round_trip_time_ms) {RTC_DCHECK_GE(round_trip_time_ms, 0);std::vector<uint16_t> sequence_numbers;// rtt异常兜底if (round_trip_time_ms == 0) {if (config_.require_valid_rtt) {return sequence_numbers;} else {round_trip_time_ms = config_.default_rtt_ms;}}// 丢包率异常,大于1直接返回if (packet_loss_rate_ >static_cast<uint32_t>(config_.max_loss_rate * (1 << 30))) {return sequence_numbers;}// The estimated packet loss is between 0 and 1, so we need to multiply by 100// here.// 根据丢包率计算最大等待时间int max_wait_ms =100.0 * config_.ms_per_loss_percent * packet_loss_rate_ / (1 << 30);// 重传包放入队列for (NackList::const_iterator it = nack_list_.begin(); it != nack_list_.end();++it) {// 计算当前时间戳和丢包时间戳的差值int64_t time_since_packet_ms =(timestamp_last_received_rtp_ - it->second.estimated_timestamp) /sample_rate_khz_;// 丢包数据播放时间超过rtt || 接到数据的差值 + rtt 小于最大等待时间 则进行重传请求if (it->second.time_to_play_ms > round_trip_time_ms ||time_since_packet_ms + round_trip_time_ms < max_wait_ms)sequence_numbers.push_back(it->first);}// 配置开启,仅进行单次Nack请求,则清除队列if (config_.never_nack_multiple_times) {nack_list_.clear();}return sequence_numbers;
}
从上述的代码中可以看到,音频的重传限制主要有两个:
1.播放时间大于rtt——(代表这个重传是有意义的,这个数据请求重传能在一个rtt重传回来则可以赶上播放,不增加延迟);
2.等待时间+rtt 小于最大等待时间——最大等待时间的计算:
// 每次丢包增加等待的时长:ms_per_loss_percent = 20
// 计算alpha衰减因子:packet_loss_forget_factor = 0.996
// 假设有7个丢包,那么根据上述运算逻辑:int ms_per_loss_percent = 20;uint32_t packet_loss_rate_ = 0;double packet_loss_forget_factor = 0.996;const uint64_t alpha_q30 = (1 << 30) * packet_loss_forget_factor;packet_loss_rate_ = (alpha_q30 * packet_loss_rate_) >> 30;for (int i = 0; i < 7; ++i) {packet_loss_rate_ =((alpha_q30 * packet_loss_rate_) >> 30) + ((1 << 30) - alpha_q30);}int max_wait_ms =100.0 * ms_per_loss_percent * packet_loss_rate_ / (1 << 30);// 那么 max_wait_ms 计算得到为 55ms。
随着丢包个数的增加,最大等待时间也会增长。下面画了一张最大等待时间和每次计算丢包个数的曲线图:

上面的图显示,随着丢包数不断增加,等待的时间增长也变得缓慢,即使把连续丢包数增加到199个(这个连续丢包指的是每次接到的数据跳了199个,在现实的网络环境中,随机丢包基本不可能出现这种情况,除非完全堵死)也只是增加到了1099ms。因此,音频的nack相比视频来说更注重实时性,因为很多时候丢一两个包,整体的沟通也不会有太大的影响。
二、优化思路
在实时传输中,我们需要根据应用的场景进行针对性调整。例如:我们常常看到导弹的引导画面会出现各种花屏的情况,在这种实时性要求较高,体验要求低的战场场景下,那么多重传并没有意义。相反,在延迟较大的CDN直播场景下,实时要求低,质量要求高的情况下重传来保证整体的质量就更有必要。因此,我们可以思考一下,在我们各自的使用场景中是否需要提高Nack重传的效率。
基于上面的理解,我们对NackTracker进行分析:
接收RTP:

发送Nack:

限制发送Nack的位置就是我们可以做手脚的地方:
1.调整播放时间和RTT的比,想速度变快就把RTT变为 RTT/2 或者 RTT/4,想速度变慢就把RTT变为2RTT 或者 3RTT;
2.在增加重传速度时,也可以适当的调长最大等待时间。
可以增加每多一个丢包等待的时间;也可以调整平滑值来增大丢包率的平滑值。
struct Config {Config();// The exponential decay factor used to estimate the packet loss rate.// 这个值会影响丢包率的平滑值double packet_loss_forget_factor = 0.996;// How many additional ms we are willing to wait (at most) for nacked// packets for each additional percentage of packet loss.// 这个值是每多一个丢包,多等待的时间值int ms_per_loss_percent = 20;// If true, never nack packets more than once.// 这个值影响是否第二次重传bool never_nack_multiple_times = false;// Only nack if the RTT is valid.// 这个值代表只有在RTT生效时发送Nackbool require_valid_rtt = false;// Default RTT to use unless `require_valid_rtt` is set.// 默认RTT值int default_rtt_ms = 100;// Do not nack if the loss rate is above this value.// 最大丢包率限制double max_loss_rate = 1.0;};
三、测试
本次测试中间通过了进行过上行Nack调整的Mediasoup服务器。在原先的测试中我们发现,当上行存在小丢包,下行大延迟的网络环境中,音频会产生很大的丢包,相比我们调整过的Nack视频确没有任何丢包产生,于是我们进行了以下调整,使音频与视频效果对其:
1.调整重传限制为,待播放时间差 大于 rtt/2 就进行重传;
2.调整等待时间为 2倍的最大等待(根据计算,在延迟600ms时,大部分音频的重传都超过了最大等待时间)。
进行测试:
| 环境 | 视频表现 | 音频表现 | 码率增加 |
|---|---|---|---|
| 上行 15%丢包,下行 600ms延迟 | 几乎没有丢包,偶现卡顿 | 几乎没有丢包,无明显丢字 | 约23% |
| 下行30%丢包,下行100ms延迟 | 几乎没有丢包,偶现卡顿 | 几乎没有丢包,无明显丢字 | 约34% |
四、总结
音频NackTracker的逻辑与视频NackRequest有相似的地方,但是相比多了播放时间以及丢包的等待估计,因此限制更多。在同样的模拟环境下,原NackTracker的逻辑丢包明显。这与音频的特点有关,音频可以合理的丢弃数据并不会明显的影响听感,但是视频少一个数据就无法组成完整的图像。因此WebRTC为了保证实时性,增加了播放时间对比以及丢包参考,如果想要保证Nack的效果与视频一致,那么也需要调整一下它的频率和最大限制。但这不意味着效果更好,因为测试发现它的带宽消耗相对高了不少,因此我们需要结合场景考虑。
相关文章:
流媒体学习之路(WebRTC)——音频NackTracker优化思路(8)
流媒体学习之路(WebRTC)——音频NackTracker优化思路(8) —— 我正在的github给大家开发一个用于做实验的项目 —— github.com/qw225967/Bifrost目标:可以让大家熟悉各类Qos能力、带宽估计能力,提供每个环节关键参数调节接口并实…...
Java基础面试重点-2
21. JVM是如何处理异常(大概流程)? 如果发生异常,方法会创建一个异常对象(包括:异常名称、异常描述以及异常发生时应用程序的状态),并转交给JVM。创建异常对象,并转交给…...

【活动文章】通用大模型VS垂直大模型,你更青睐哪一方
垂直大模型和通用大模型各有其特定的应用场景和优势。垂直大模型专注于特定领域,提供深度的专业知识和技能,而通用大模型则具备广泛的适用性和强大的泛化能力。以下是一些垂直大模型和通用大模型的例子: 垂直大模型 BERT-Financial…...

记录一个Qt调用插件的问题
问题背景 使用Qt主程序插件的方式开发,即主程序做成一个框,定义好插件接口,然后主程序上通过插件接口与插件进行交互。调试过程中遇到了两个问题,在这里记录一下。 问题1(信号槽定义) 插件与主程序之间&am…...

9.1 Go 接口的定义
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「stormsha的主页」…...

易于上手的requests
Python中的requests库主要用于发送HTTP请求并获取响应结果。在现代网络编程中,HTTP请求是构建客户端与服务器之间通信的基础。Python作为一种高级编程语言,其丰富的库支持使得它在网络数据处理领域尤为突出。其中,requests库以其简洁、易用的…...
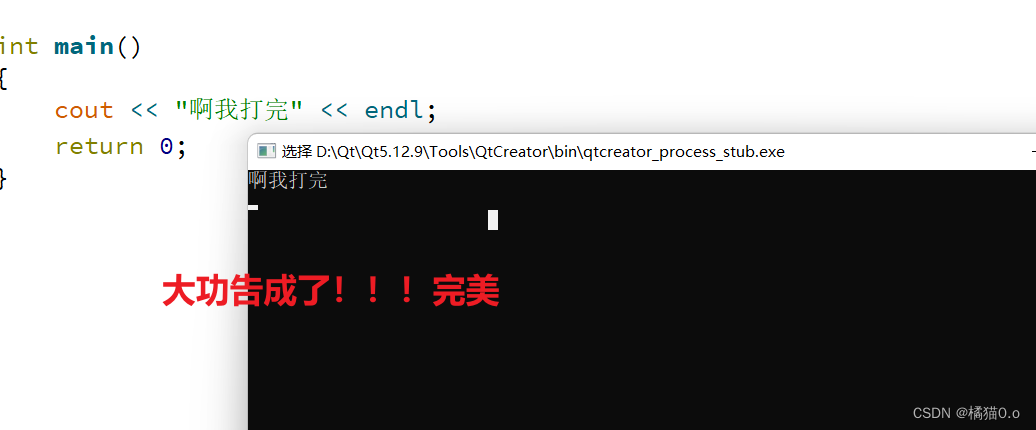
【QT Creator软件】解决中文乱码问题
QT Creator软件解决中文乱码问题 问题描述:Qtcreator安装好后打印中文在控制台输出乱码 在网上也查找了修改编辑器的默认编码为UTF-8,但是仍然没有任何作用,于是有了以下的解决方案 原因剖析:因为项目的编码与控制台的编码不一致…...
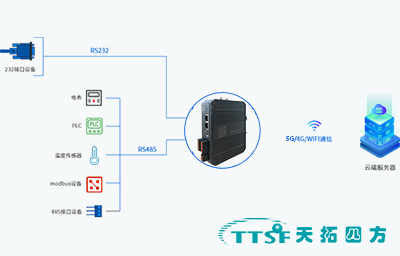
边缘网关在智能制造工厂中的创新应用及效果-天拓四方
在数字化浪潮席卷之下,智能制造工厂正面临着前所未有的数据挑战与机遇。边缘网关,作为数据处理与传输的关键节点,在提升工厂运营效率、确保数据安全方面发挥着日益重要的作用。本文将通过一个具体案例,详细阐述边缘网关在智能制造…...

Django-filter
准备工作 首先,确保你已经安装了django-filter包。如果没有,请使用以下命令安装: pip install django-filter然后,在你的settings.py文件中添加django_filters到INSTALLED_APPS列表中: INSTALLED_APPS [# ...djang…...

文字悬停效果
文字悬停效果 效果展示 CSS 知识点 CSS 变量使用回顾-webkit-text-stroke 属性的运用与回顾 页面整体结构实现 <ul><li style"--clr: #e6444f"><a href"#" class"text">First</a></li><li style"--cl…...
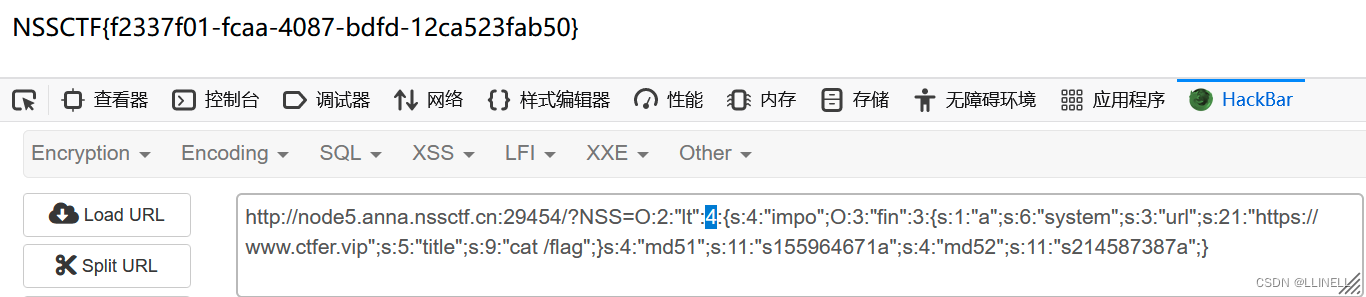
[SWPUCTF 2022 新生赛]ez_1zpop(php反序列化之pop链构造)
[SWPUCTF 2022 新生赛]ez_ez_unserialize <?php class X {public $x __FILE__;function __construct($x){$this->x $x; }function __wakeup(){if ($this->x ! __FILE__) {$this->x __FILE__; }}function __destruct(){highlight_file($this->x);//flag is…...

2-1基于matlab的拉普拉斯金字塔图像融合算法
基于matlab的拉普拉斯金字塔图像融合算法,可以使部分图像模糊的图片清楚,也可以使图像增强。程序已调通,可直接运行。 2-1 图像融合 拉普拉斯金字塔图像融合 - 小红书 (xiaohongshu.com)...

Android基础-进程间通信
在Android系统中,跨进程通信(IPC,Inter-Process Communication)是实现不同应用程序或同一应用程序中不同进程间数据共享和交互的关键技术。Android提供了多种IPC机制,每种机制都有其特定的使用场景和优缺点。下面将详细…...

【微信小程序】uni-app 配置网络请求
原因 由于平台的限制,小程序项目中 不支持axios,而且原生的,wx.request()API功能较为简单,不支持拦截器等全局定制的功能。因此,建议在uni-app项目中使用 escook/request-miniprogram 第三方包发起网络数据请求。 步…...

SpringCash
文章目录 简介引入依赖常用注解application.yml使用1. 启动类添加注解使用方法上添加注解 简介 Spring Cache是一个框架,实现了基于注解的缓存功能底层可以使用EHCache、Caffeine、Redis实现缓存。 注解一般放在Controller的方法上,CachePut 注解一般有…...

小红书的文案是怎么写的?有啥套路么!
小红书文案是有自己的调性的,为什么别人的笔记轻轻松松就是爆款,而自己写的笔记却没有人看呢,小红书文案写作有啥套路? 接下来伯乐网络传媒给大家讲一讲,小红书文案写作揭秘:抄作业、拆解产品到种草笔记结…...

开放平台接口安全验证
文章目录 开放平台接口安全验证I 加签方式说明1.1 签名生成的通用步骤1.2 生成随机数算法1.3 举例1.4 签名校验工具II Header参数说明III 业务接口返回结构说明开放平台接口安全验证 统一使用sign签名验证,签名规则也会在本文档中,详细说明。请大家认真阅读。 向平台申请密码…...

【AI原理解析】— GPT-4o模型
目录 1. 统一架构设计 2. 端到端训练 3. 模态间的信息融合 4. 语音处理 5. 视频处理 6. 性能特点 7. 模型特点 8. 服务和免费政策 9. 实时推理能力 10. 高效的编码方式 11. 输出与反馈 1. 统一架构设计 GPT-4o采用单一的Transformer架构进行设计,将文本…...

Qt中图表图形绘制类介绍
接上篇介绍QChart 相关的类,本片主要在QChart 载体上进行图表图形绘制使用各种形状的图类。 一.QXYSeries类 QXYSeries类是QLineSeries折线图,QSplineSeries样条曲线图,QScatterSeries散点图的基类; QXYSeries类的使用都可以参考…...
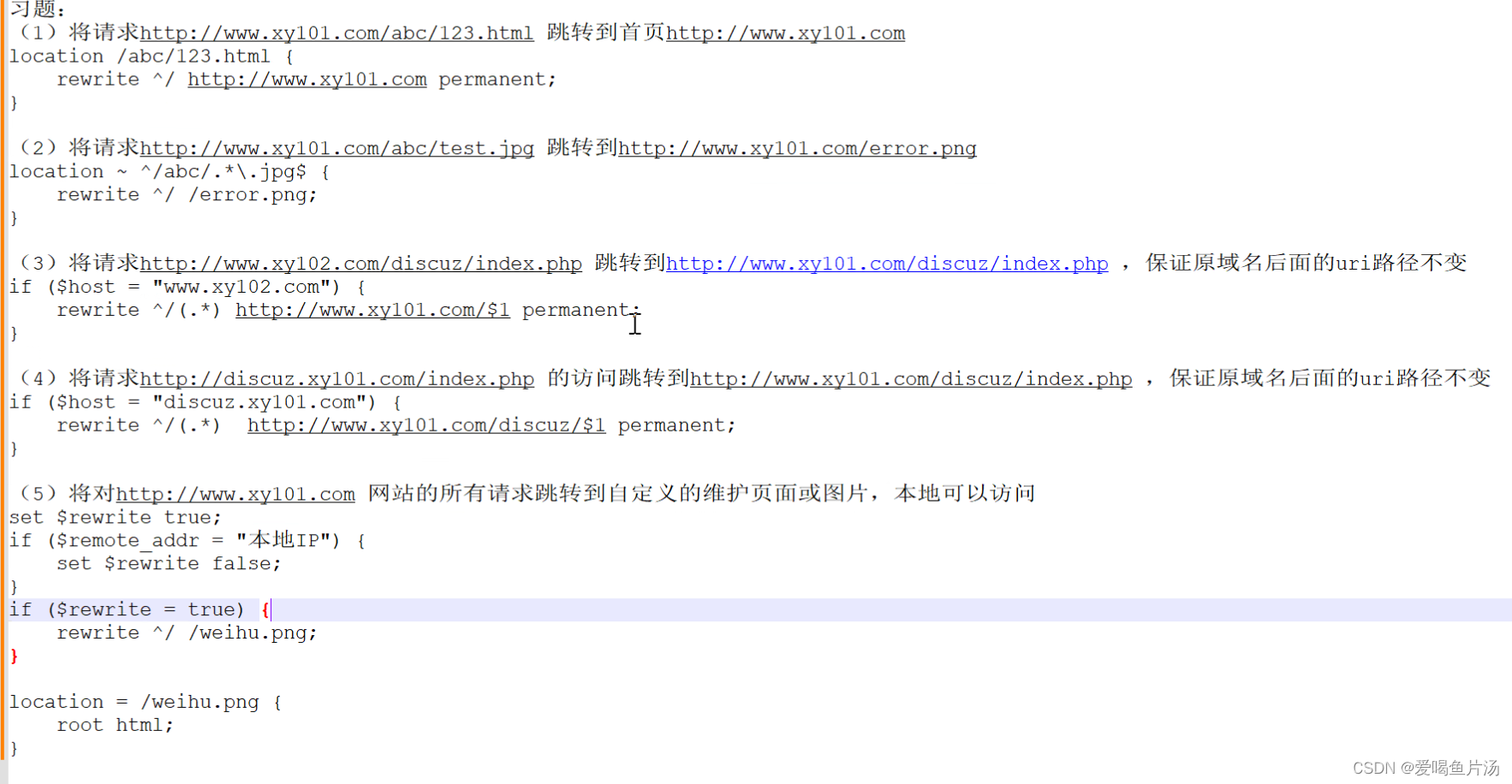
nginx rewrite地址重写
常用的nginx正则表达式 ^匹配以...开头的字符串$匹配以...结尾的字符串^$^$表示空行*匹配前面的字符0次或者多次(通配符*表示任意数量的任意字符)匹配前面的字符1次或多次?匹配前面的字符0次或1次.匹配除了“\n”之外的任意单个字符,[.\n]表…...

OpenLayers 可视化之热力图
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 热力图(Heatmap)又叫热点图,是一种通过特殊高亮显示事物密度分布、变化趋势的数据可视化技术。采用颜色的深浅来显示…...
。】2022-5-15)
【根据当天日期输出明天的日期(需对闰年做判定)。】2022-5-15
缘由根据当天日期输出明天的日期(需对闰年做判定)。日期类型结构体如下: struct data{ int year; int month; int day;};-编程语言-CSDN问答 struct mdata{ int year; int month; int day; }mdata; int 天数(int year, int month) {switch (month){case 1: case 3:…...

Qt Widget类解析与代码注释
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this); }Widget::~Widget() {delete ui; }//解释这串代码,写上注释 当然可以!这段代码是 Qt …...

ESP32 I2S音频总线学习笔记(四): INMP441采集音频并实时播放
简介 前面两期文章我们介绍了I2S的读取和写入,一个是通过INMP441麦克风模块采集音频,一个是通过PCM5102A模块播放音频,那如果我们将两者结合起来,将麦克风采集到的音频通过PCM5102A播放,是不是就可以做一个扩音器了呢…...

从零实现STL哈希容器:unordered_map/unordered_set封装详解
本篇文章是对C学习的STL哈希容器自主实现部分的学习分享 希望也能为你带来些帮助~ 那咱们废话不多说,直接开始吧! 一、源码结构分析 1. SGISTL30实现剖析 // hash_set核心结构 template <class Value, class HashFcn, ...> class hash_set {ty…...

uniapp中使用aixos 报错
问题: 在uniapp中使用aixos,运行后报如下错误: AxiosError: There is no suitable adapter to dispatch the request since : - adapter xhr is not supported by the environment - adapter http is not available in the build 解决方案&…...
)
OpenLayers 分屏对比(地图联动)
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 地图分屏对比在WebGIS开发中是很常见的功能,和卷帘图层不一样的是,分屏对比是在各个地图中添加相同或者不同的图层进行对比查看。…...

今日学习:Spring线程池|并发修改异常|链路丢失|登录续期|VIP过期策略|数值类缓存
文章目录 优雅版线程池ThreadPoolTaskExecutor和ThreadPoolTaskExecutor的装饰器并发修改异常并发修改异常简介实现机制设计原因及意义 使用线程池造成的链路丢失问题线程池导致的链路丢失问题发生原因 常见解决方法更好的解决方法设计精妙之处 登录续期登录续期常见实现方式特…...

在QWebEngineView上实现鼠标、触摸等事件捕获的解决方案
这个问题我看其他博主也写了,要么要会员、要么写的乱七八糟。这里我整理一下,把问题说清楚并且给出代码,拿去用就行,照着葫芦画瓢。 问题 在继承QWebEngineView后,重写mousePressEvent或event函数无法捕获鼠标按下事…...

uniapp 开发ios, xcode 提交app store connect 和 testflight内测
uniapp 中配置 配置manifest 文档:manifest.json 应用配置 | uni-app官网 hbuilderx中本地打包 下载IOS最新SDK 开发环境 | uni小程序SDK hbulderx 版本号:4.66 对应的sdk版本 4.66 两者必须一致 本地打包的资源导入到SDK 导入资源 | uni小程序SDK …...