Elasticsearch之深入聚合查询
1、正排索引
1.1 正排索引(doc values )和倒排索引
概念:从广义来说,doc values 本质上是一个序列化的 列式存储 。列式存储 适用于聚合、排序、脚本等操作,所有的数字、地理坐标、日期、IP 和不分词( not_analyzed )字符类型都会默认开启,不支持text和annotated_text类型
区别:
- 倒排:倒排索引的优势是可以快速查找包含某个词项的文档有哪些。如果用倒排来确定哪些文档中是否包含某个词项就很鸡肋。
- 正排:正排索引的优势在于可以快速的查找某个文档里包含哪些词项。同理,正排不适用于查找包含某个词项的文档有哪些。
倒排索引和正排索引均是在index-time时创建,保存在 Lucene文件中(序列化到磁盘)。
1.2 正排索引的数据结构
1.2.1 doc values
doc values是正排索引的基本数据结构之一,其存在是为了提升排序和聚合效率,默认true,如果确定不需要对字段进行排序或聚合,也不需要通过脚本访问字段值,则可以禁用doc values值以节省磁盘空间。
1.2.2 fielddata:
概念:查询时内存数据结构,在首次用当前字段聚合、排序或者在脚本中使用时,需要字段为fielddata数据结构,并且创建倒排索引保存到堆中。与 doc value 不同,当没有doc value的字段需要聚合时,需要打开fielddata,然后临时在内存中建立正排索引,fielddata 的构建和管理发生在 JVM Heap中。Fielddata默认是不启用的,因为text字段比较长,一般只做关键字分词和搜索,很少拿它来进行全文匹配和聚合还有排序。
语法:
PUT /<index>/_mapping
{"properties": {"tags": {"type": "text","fielddata": true //true:开启fielddata; false:关闭fielddata}}
}
**深层解读(独家):**doc values是文档到词项的映射 inverted是词项到文档id的映射从原理上讲 先说倒排索引为什么不适合聚合,你无法通过倒排索引确定doc的总数量,并且因为倒排索引默认会执行analysis,即使聚合,结果也可能不准确,所以你还要创建not_analyzed字段,徒增磁盘占用,举个最简单的例子:假如有一张商品表,每个商品都有若干标签,我们执行了以下查询
GET product/_search
{"query": {"match": {"tags": "性价比"}},"aggs": {"tag_terms": {"terms": {"field": "tags.keyword"}}}
}
这段聚合查询的意思 查询包含“性价比”这个标签商品的所有标签,在执行agg的时候 我们使用倒排索引,那么语义将是这样的:在倒排索引中扫描逐个term,看看这个term对用的倒排表中对应的doc的标签 是否包含“性价比”,如果包含,则记录,由于我们不确定下面一个term是否符合条件,所以我们就要一个一个的判断,所以就造成了扫表。如果使用正排索引,而正排索引的指的是,doc中包含了哪些词项,也就是当前doc_id=>当前字段所包含的所有词项的映射,我们要查找的是符合条件的doc中所有的标签,那么我们直接根据key(doc_id)去拿values(all terms)就可以了,所以就不用扫表。所以聚合查询使用正排索引效率高本质是两种数据结构的区别 和结不结合倒排索引没有关系,结合倒排索引只是预先进行了数据筛选。以上是正排索引在原理上对聚合查询友好的原因 下面我说一下关于两种数据结构在数据压缩上的不同,doc values是一种序列化的列式存储结构,其values其中也包含了词频数据。而这种结构是非常有利于数据压缩的,参考第二版VIP课程中的FOR和RBM压缩算法,因为Lucene底层读取文件的方式是基于mmap的,原理是上是从磁盘读取到OS cache里面进行解码的,使用正排索引的数据结构,由于其列式存储的数据和posting list一样可以被高效压缩,所以这种方式极大的增加了从磁盘中读取的速度,因为体积小了,然后把数据在OS Cache中进行解码
2、三角选择原则

3、基数聚合:Cardinality
3.1 易并行算法和不易并行算法
3.1.1 易并行算法
如:Max、Min、Avg、Sum等指标函数,通常只需要在多个分片中计算一个值进行汇总计算,因此不必消耗过多内存资源。(参考深度分页原理)
3.1.2 不易并行算法
如:Cardinality函数,由于无法在不同分片中保证数据是否重合,因此将消耗更多的内存用于数据汇总进行基数聚合,尤其是高基聚合。
3.2 高基数与低基数聚合
高基数:性能低
低基数:性能高
3.3 Cardinality精度内存换算
3.3.1 precision_threshold参数
ES在执行Cardinality聚合的时候,通过precision_threshold参数以内存换精度,默认3000,最大值40000,设置再大的值,实际也最高只能是4W,当小于precision_threshold设置的时候,精度接近100%,当大于此设置的时候,即使数据量有几百万,误差也只是1-6%。
注意:precision_threshold设置较高阈值对低基数聚合时有显著效果,而对高基数聚合是并无显著效果,反而会占用大量的资源,适得其反。
3.3.2 内存精度换算单位
内存消耗 <=> precision_threshold * 8 个Byte,比如 precision_threshold = 1000,内存消耗约 8KB。
3.4 HyperLogLog++介绍
HyperLogLog++(HLL)算法是依赖于field value计算hash,在做cardinality运算的时候,ES会动态为每一个field value计算hash用于提升聚合性能。
3.5 低基聚合的优化方案:maper-murmur3
3.5.1 作用
提升低基聚合的查询性能,副作用是消耗较大磁盘空间。
3.5.2 原理
maper-murmur3提升低基聚合的原理就是通过预先为字段值计算hash,在做cardinality计算的时候,使用提前准备好的hash值参与计算,避免了动态运算从而节省性能,建议在字段基数较大并且可能会有大量重复值得时候使用,这样可能会产生显著的性能提升,不然可能不但不会带来显著的性能提升,而且会徒增磁盘消耗,得不偿失。
3.5.3 安装与使用
安装
bin/elasticsearch-plugin install mapper-murmur3
使用
PUT <index>
{"mappings": {"properties": {"type": {"type": "keyword","doc_values": true,"fields": {"hash": {"type": "murmur3"}}}}}
}
POST /index/_search?size=0
{"aggs": {"type_count": {"cardinality": {"field": "type.hash"}}}
}
4、深度优先(DFS)和广度优先(BFS)
4.1 概念和基本原理
背景:Terms 桶基于我们的数据动态构建桶;它并不知道到底生成了多少桶。 大多数时候对单个字段的聚合查询还是非常快的, 但是当需要同时聚合多个字段时,就可能会产生大量的分组,最终结果就是占用 es 大量内存,从而导致 OOM 的情况发生。
在Elasticsearch中,对于具有许多唯一术语和少量所需结果的字段,延迟子聚合的计算直到顶部父级聚合被修剪会更有效。通常,聚合树的所有分支都在一次深度优先传递中展开,然后才会发生任何修剪。在某些情况下,这可能非常浪费,并且可能会遇到内存限制。
基本原理即:推迟子聚合的计算
4.2 原理
4.3 适用场景及基本用法
4.3.1 用法:Collect mode
"collect_mode": "{collect_mode.value}"
4.3.2 参数
- breadth_first:广度优先模式属于最上层桶的一组文档被缓存以备后续重播,因此执行此操作时内存开销与匹配文档的数量成线性关系。即:先做第一层聚合,逐层修剪。
- depth_first:即:先构建完整的树,然后修剪无用节点。
4.4 注意
广度优先仅仅适用于每个组的聚合数量远远小于当前总组数的情况下,因为广度优先会在内存中缓存裁剪后的仅仅需要缓存的每个组的所有数据,以便于它的子聚合分组查询可以复用上级聚合的数据。
广度优先的内存使用情况与裁剪后的缓存分组数据量是成线性的。对于很多聚合来说,每个桶内的文档数量是相当大的。
相关文章:
Elasticsearch之深入聚合查询
1、正排索引 1.1 正排索引(doc values )和倒排索引 概念:从广义来说,doc values 本质上是一个序列化的 列式存储 。列式存储 适用于聚合、排序、脚本等操作,所有的数字、地理坐标、日期、IP 和不分词( no…...
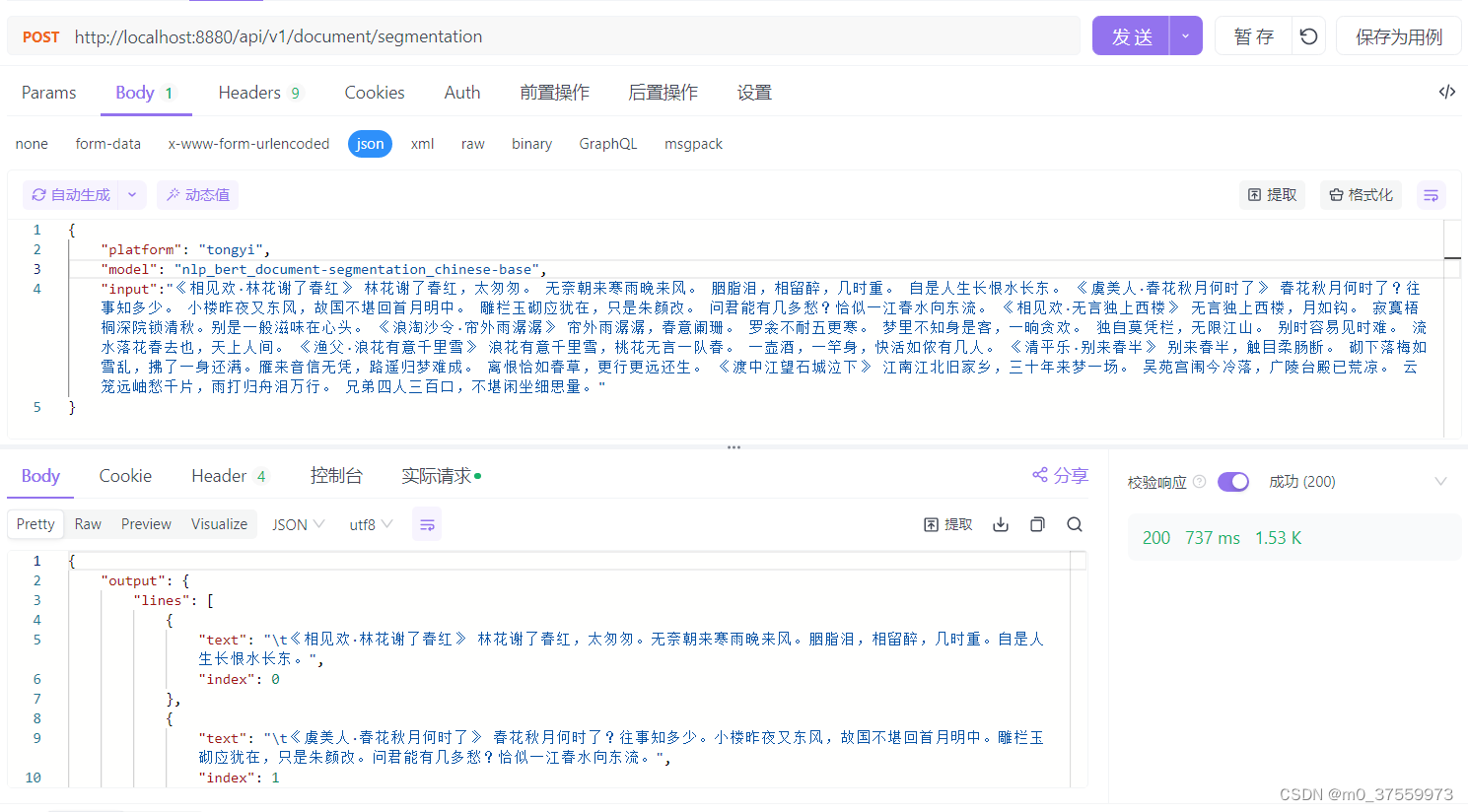
大模型:分本分割模型
目录 一、文本分割 二、BERT文本分割模型 三、部署模型 3.1 下载模型 3.2 安装依赖 3.3 部署模型 3.4 运行服务 四、测试模型 一、文本分割 文本分割是自然语言处理中的一项基础任务,目标是将连续的文本切分成有意义的片段,这些片段可以是句子、…...
数据预处理 #数据挖掘 #python
数据分析中的预处理步骤是数据分析流程中的重要环节,它的目的是清洗、转换和整理原始数据,以便后续的分析能够准确、有效。预处理通常包括以下几个关键步骤: 数据收集:确定数据来源,可能是数据库、文件、API或网络抓取…...
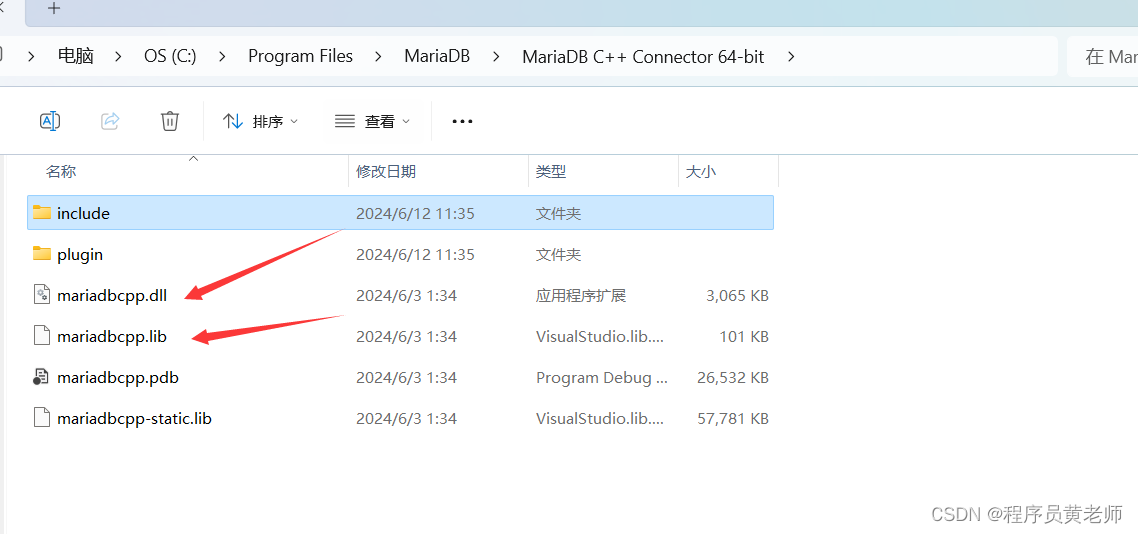
VS2022 使用C++访问 mariadb 数据库
首先,下载 MariaDB Connector/C++ 库 MariaDB Products & Tools Downloads | MariaDB 第二步,安装后 第三步,写代码 #include <iostream> #include <cstring> #include <memory> #include <windows.h>#include <mariadb/conncpp.hpp>…...

kotlin 语法糖
Use of “when” Expression Instead of “switch” fun getDayOfWeek(day: Int): String {return when (day) {1 -> "Monday"2 -> "Tuesday"3 -> "Wednesday"4 -> "Thursday"5 -> "Friday"6 -> "Sa…...
.NET MAUI Sqlite数据库操作(一)
一、安装 NuGet 包 安装 sqlite-net-pcl 安装 SQLitePCLRawEx.bundle_green 二、配置数据库(数据库文件名和路径) namespace TodoSQLite; public static class Constants {public const string DatabaseFilename "TodoSQLite.db3";//数据库…...
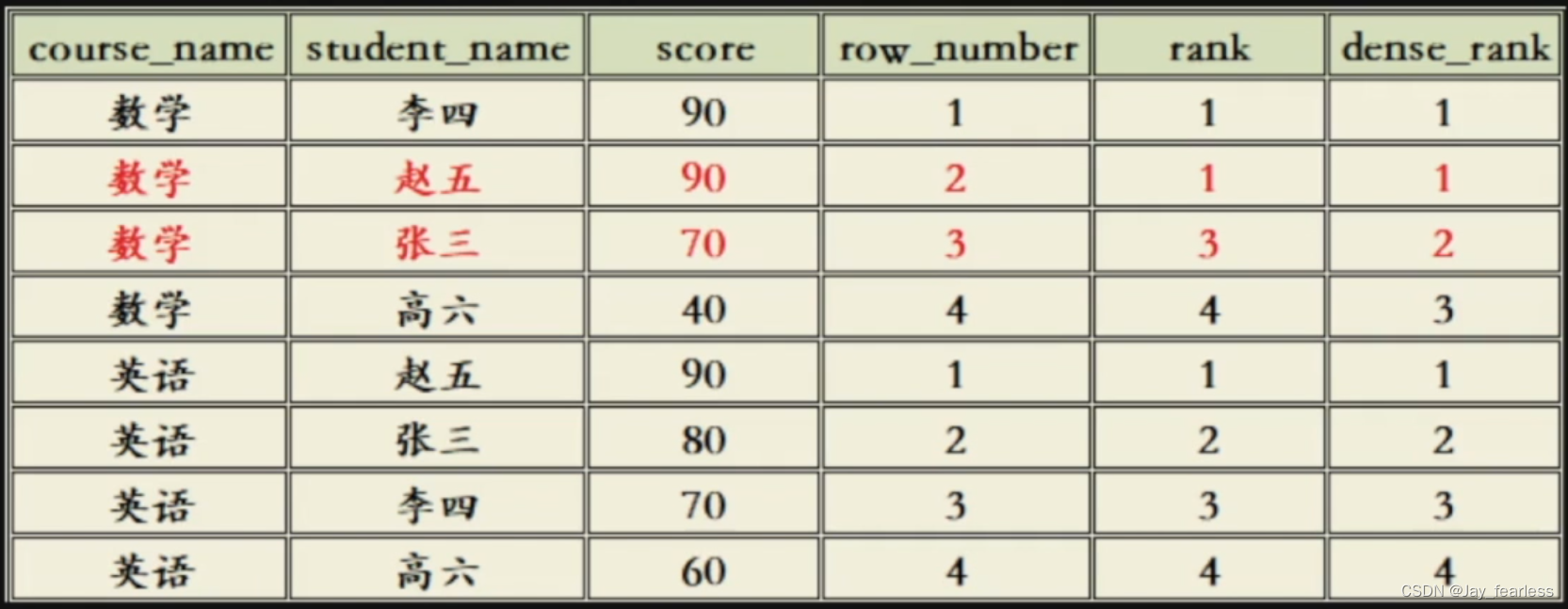
SQL 窗口函数
1.窗口函数之排序函数 RANK, DENSE_RANK, ROW_NUMBER RANK函数 计算排序时,如果存在相同位次的记录,则会跳过之后的位次 有 3 条记录排在第 1 位时: 1 位、1 位、1 位、4 位…DENSE_RANK函数 同样是计算排序,即使存在相同位次的记录,也不会跳过之后的位次 有 3 条记录排在…...
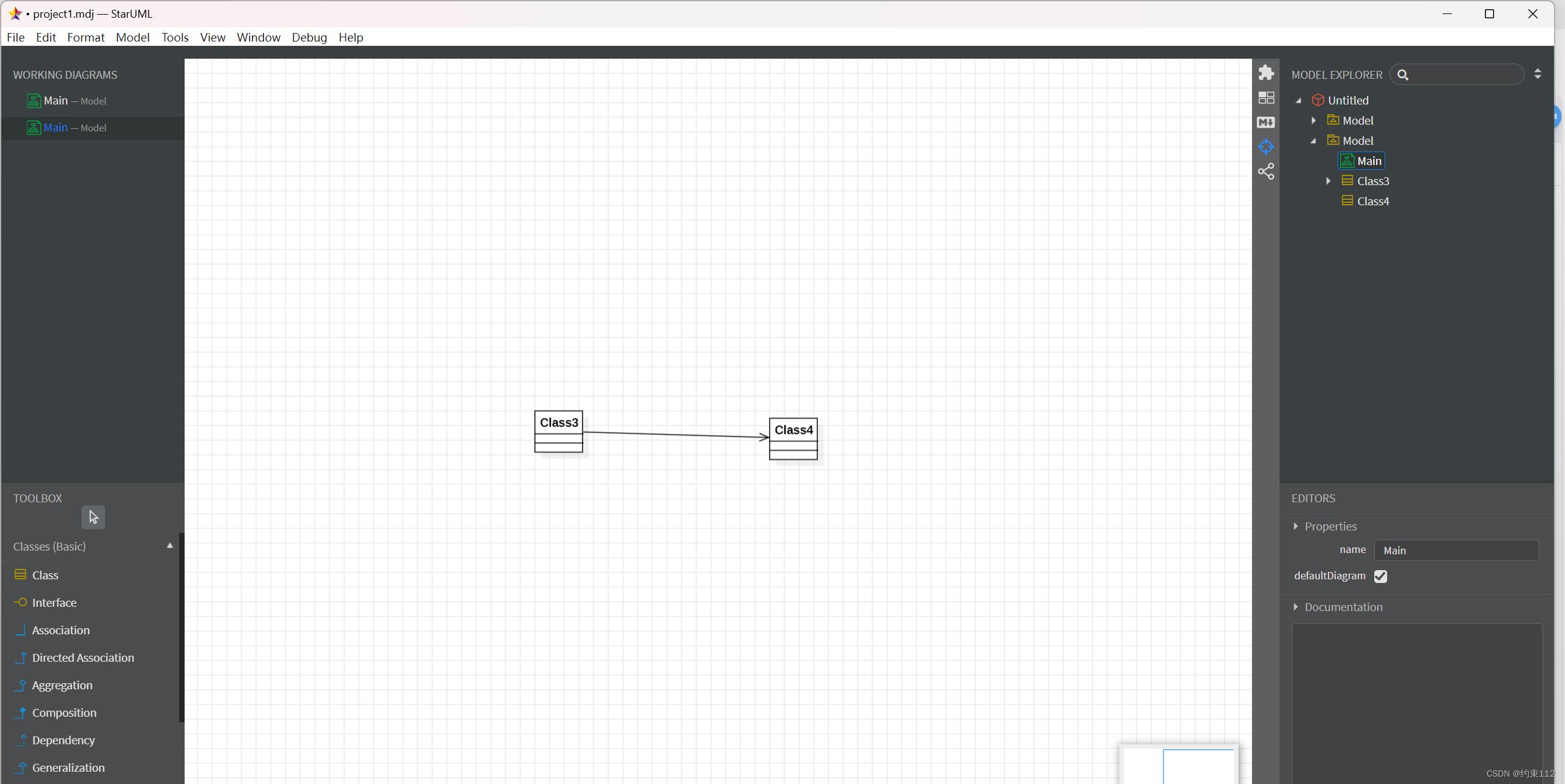
staruml怎么合并多个Project工程文件
如图现在有两个staruml文件 现在我想要把project2合并到project1里面 步骤如下: 1、首先打开project2 2、如图选择导出Fragment 3、选中自己想导出的模块(可以不止一个) 4、将其保存在桌面 5、打开project1 6、选择导入 7、选中刚刚…...

设计模式——外观模式
外观模式(Facade) 为系统中的一组接口提供一个一致的界面,此模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。 #include <iostream>using namespace std;// 四个系统子类 class SubSystemOne { public:void MethodOne(){cout <&l…...

开源-Docker部署Cook菜谱工具
开源-Docker部署Cook菜谱工具 文章目录 开源-Docker部署Cook菜谱工具介绍资源列表基础环境一、安装Docker二、配置加速器三、查看Docker版本四、拉取cook镜像五、部署cook菜谱工具5.1、创建cook容器5.2、查看容器运行状态5.3、查看cook容器日志 六、访问cook菜谱服务6.1、访问c…...

使用PHP对接企业微信审批接口的问题与解决办法(二)
在现代企业中,审批流程是非常重要的一环,它涉及到企业内部各种业务流程的规范和高效运转。而随着企业微信的流行,许多企业希望将审批流程整合到企业微信中,以实现更便捷的审批操作。本文将介绍如何使用PHP对接企业微信审批接口&am…...
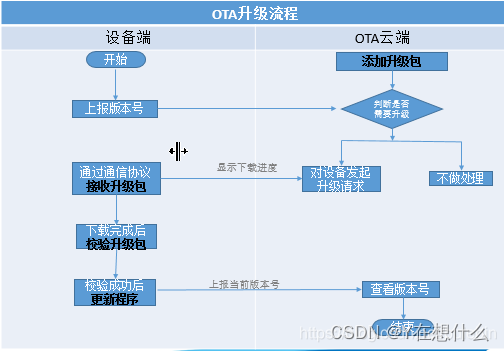
RK3288 android7.1 实现ota升级时清除用户数据
一,OTA简介(整包,差分包) OTA全称为Over-The-Air technology(空中下载技术),通过移动通信的接口实现对软件进行远程管理。 1. 用途: OTA两种类型最大的区别莫过于他们的”出发点“(我们对两种不同升级包的创建&…...

okHttp的https请求忽略ssl证书认证
使用okhttp请求第三方https接口返回异常 sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target意思就是非安全的调用&#…...

在Java中使用Spring Boot设置全局的BusinessException
在线工具站 推荐一个程序员在线工具站:程序员常用工具(http://cxytools.com),有时间戳、JSON格式化、文本对比、HASH生成、UUID生成等常用工具,效率加倍嘎嘎好用。 程序员资料站 推荐一个程序员编程资料站:…...

Java 异常处理 -- Java 语言的异常、异常链与断言
大家好,我是栗筝i,这篇文章是我的 “栗筝i 的 Java 技术栈” 专栏的第 009 篇文章,在 “栗筝i 的 Java 技术栈” 这个专栏中我会持续为大家更新 Java 技术相关全套技术栈内容。专栏的主要目标是已经有一定 Java 开发经验,并希望进一步完善自己对整个 Java 技术体系来充实自…...

Spring Cloud Nacos 详解:服务注册与发现及配置管理平台
Spring Cloud Nacos 详解:服务注册与发现及配置管理平台 Spring Cloud Nacos 是 Spring Cloud 生态系统中的一个子项目,提供了服务注册与发现、配置管理等功能,基于 Alibaba 开源的 Nacos 项目。Nacos 是一个易于使用的动态服务发现、配置管…...

java多线程临界区介绍
在Java多线程编程中,"临界区"是指一段必须互斥执行的代码区域。当多个线程访问共享资源时,为了防止数据不一致或逻辑错误,需要确保同一时刻只有一个线程可以进入临界区。Java提供了多种机制来实现这一点,例如synchroniz…...
基于JSP的超市管理系统
你好呀,我是计算机学长猫哥!如果有相关需求,文末可以找到我的联系方式。 开发语言:Java 数据库:MySQL 技术:JSP MyBatis 工具:IDEA/Eclipse、Navicat、Maven 系统展示 员工管理界面图 管…...
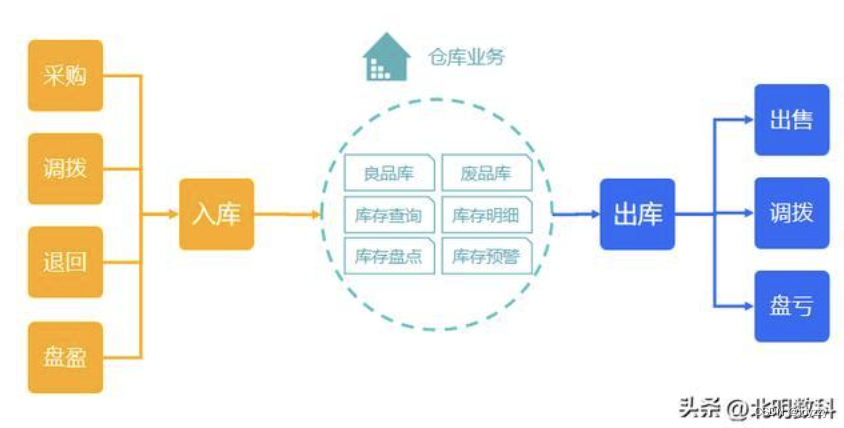
一文讲清:生产报工系统的功能、报价以及如何选择
最近这几年,企业越来越注重生产的速度和成本,尤其是“性价比”,生产报工系统已经变成了制造业里不可或缺的一部分。不过,市场上生产报工系统的选择太多,价格也都不一样,这就给很多企业出了个难题࿱…...

blender bpy将顶点颜色转换为UV纹理vertex color to texture
一、关于环境 安装blender的bpy,不需要额外再安装blender软件。在python控制台中直接输入pip install bpy即可。 二、关于代码 本文所给出代码仅为参考,禁止转载和引用,仅供个人学习。 本文所给出的例子是https://download.csdn.net/downl…...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

九天毕昇深度学习平台 | 如何安装库?
pip install 库名 -i https://pypi.tuna.tsinghua.edu.cn/simple --user 举个例子: 报错 ModuleNotFoundError: No module named torch 那么我需要安装 torch pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple --user pip install 库名&#x…...

莫兰迪高级灰总结计划简约商务通用PPT模版
莫兰迪高级灰总结计划简约商务通用PPT模版,莫兰迪调色板清新简约工作汇报PPT模版,莫兰迪时尚风极简设计PPT模版,大学生毕业论文答辩PPT模版,莫兰迪配色总结计划简约商务通用PPT模版,莫兰迪商务汇报PPT模版,…...
宇树科技,改名了!
提到国内具身智能和机器人领域的代表企业,那宇树科技(Unitree)必须名列其榜。 最近,宇树科技的一项新变动消息在业界引发了不少关注和讨论,即: 宇树向其合作伙伴发布了一封公司名称变更函称,因…...

go 里面的指针
指针 在 Go 中,指针(pointer)是一个变量的内存地址,就像 C 语言那样: a : 10 p : &a // p 是一个指向 a 的指针 fmt.Println(*p) // 输出 10,通过指针解引用• &a 表示获取变量 a 的地址 p 表示…...
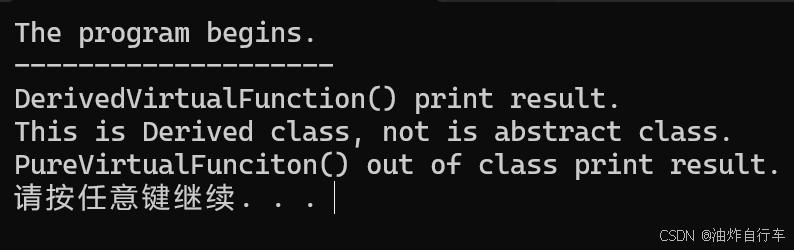
【C++】纯虚函数类外可以写实现吗?
1. 答案 先说答案,可以。 2.代码测试 .h头文件 #include <iostream> #include <string>// 抽象基类 class AbstractBase { public:AbstractBase() default;virtual ~AbstractBase() default; // 默认析构函数public:virtual int PureVirtualFunct…...

DBLP数据库是什么?
DBLP(Digital Bibliography & Library Project)Computer Science Bibliography是全球著名的计算机科学出版物的开放书目数据库。DBLP所收录的期刊和会议论文质量较高,数据库文献更新速度很快,很好地反映了国际计算机科学学术研…...

xmind转换为markdown
文章目录 解锁思维导图新姿势:将XMind转为结构化Markdown 一、认识Xmind结构二、核心转换流程详解1.解压XMind文件(ZIP处理)2.解析JSON数据结构3:递归转换树形结构4:Markdown层级生成逻辑 三、完整代码 解锁思维导图新…...

【Linux】Linux安装并配置RabbitMQ
目录 1. 安装 Erlang 2. 安装 RabbitMQ 2.1.添加 RabbitMQ 仓库 2.2.安装 RabbitMQ 3.配置 3.1.启动和管理服务 4. 访问管理界面 5.安装问题 6.修改密码 7.修改端口 7.1.找到文件 7.2.修改文件 1. 安装 Erlang 由于 RabbitMQ 是用 Erlang 编写的,需要先安…...

【实施指南】Android客户端HTTPS双向认证实施指南
🔐 一、所需准备材料 证书文件(6类核心文件) 类型 格式 作用 Android端要求 CA根证书 .crt/.pem 验证服务器/客户端证书合法性 需预置到Android信任库 服务器证书 .crt 服务器身份证明 客户端需持有以验证服务器 客户端证书 .crt 客户端身份…...