微小目标识别研究(2)——基于K近邻的白酒杂质检测算法实现
文章目录
- 实现思路
- 配置opencv
- 位置剪裁
- 实现代码
- 自适应中值滤波
- 实现代码
- 动态范围增强
- 实现代码
- 形态学处理
- 实现代码
- 图片预处理效果
- 计算帧差
- 连续帧帧差法原理和实现代码
- 实现代码
- K近邻实现
- 基本介绍
- 实现代码
- 这部分是手动实现的,并没有直接调用相关的库
- 完整的代码——调用opencv的特定的库实现的
- 实现过程
- 参考
实现思路
- 使用C++进行实现,开发平台是clion,并没有使用深度学习,使用opencv进行开发
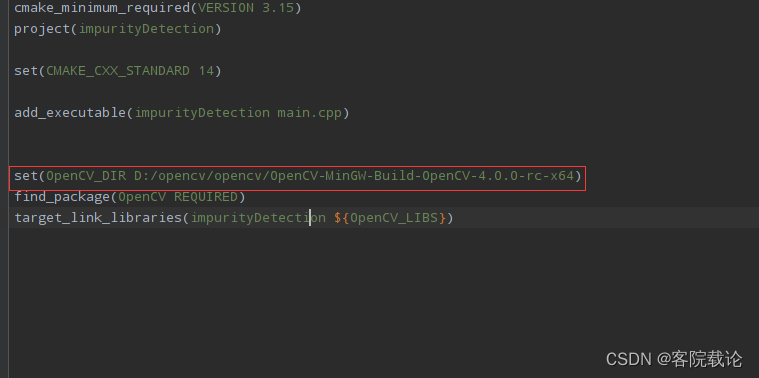
配置opencv
-
一开始就出来幺蛾子,之前装好的opencv怎么都找不到包,弄了一个小时,夹着红框后面的三句,告诉clion我安装的opencv包的具体位置,可能是因为我之前没有编译成功,直接间别人编译好的直接下载下来的,不过我为什么不用python上面的opencv那。
-
位置剪裁

- 相机位置固定,拍摄的位置固定,背景干扰很少,只需要保存红框右半部分的内容即可,左半部分去除。
实现代码
#include <opencv2/opencv.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/core/core.hpp>
#include <iostream>
#include <fstream>using namespace std;
using namespace cv;struct RectPoint{int x,y;int width,height;RectPoint(int x,int y,int width,int height):x(x),y(y),width(width),height(height){}
};void ClipImage(String ImagePath,RectPoint rect,String TargetPath){// 声明Mat保存图片Mat img;Rect m_select;string line;// 判定文件存在ifstream input_file(ImagePath);if (!input_file.is_open()) {cerr << "Could not open the file - '"<< ImagePath << "'" << endl;return;}while(getline(input_file,line)){// 获取文件后缀名,并进行拼接成目标文件名string ImageName = line.substr(line.find_last_of('\\',line.size())+1);string TargetName = TargetPath;TargetName.append(ImageName);// 读取并剪裁图片到特定大小保存img = imread(line);m_select = Rect(rect.x,rect.y,rect.width,rect.height);Mat ROI = img(m_select);imwrite(TargetName,ROI);}
}int main()
{String TargetImage = R"(E:\CProject\impurityDetection\ClippedImage\)";String SourceImage = R"(E:\CProject\impurityDetection\image\path.txt)";ClipImage(SourceImage,RectPoint(600,0,1780,1480),TargetImage);return 0;
}自适应中值滤波
- 自适应中值滤波,是为了去除照相机的噪声同时,又不损坏原来的杂质信息,这里使用自适应中值滤波,具体实现如下。
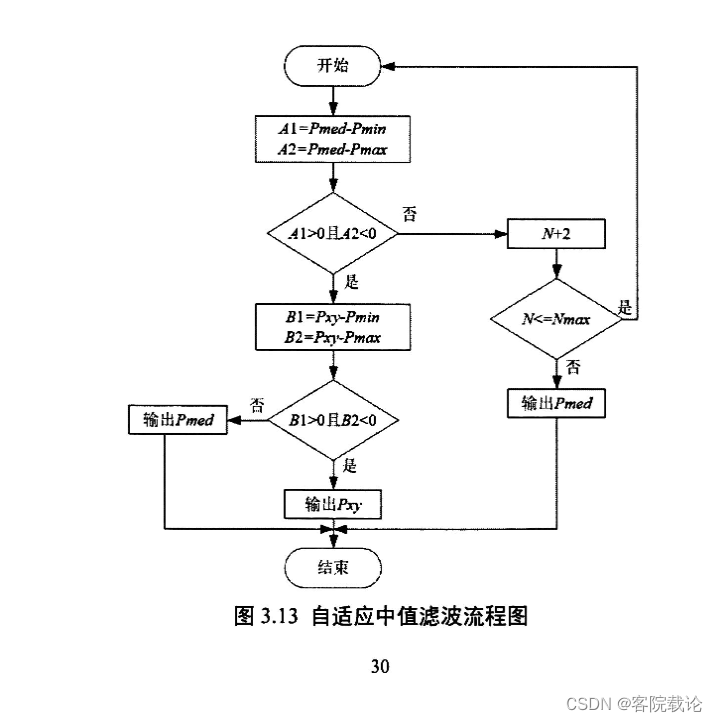
实现代码
void Convolution(Mat &SourceImage,vector<int> &pixels,int x,int y ,int border){for (int k = -border; k <= border; k++){for (int l = -border; l <= border; l++){pixels.push_back(SourceImage.at<uchar>(x+k, y+l));}}
}Mat SelfAdaptMedianFilter(const Mat& SourceImage){// 复制原图Mat result = SourceImage.clone();// 掩膜大小为3int ksize = 3;int border = ksize /2 ;for (int i = border; i < SourceImage.rows - border; i++){for (int j = border; j < SourceImage.cols - border; j++){while(1){// 提取当前像素的邻域vector<int> pixels;Convolution(result, pixels, i, j, border);// 对邻域像素值进行排序sort(pixels.begin(), pixels.end());// 取中值作为当前像素的新值int median = pixels[pixels.size() / 2];int PMax = pixels[pixels.size() - 1];int PMin = pixels[0];//判定是否为异常值if (median == PMax || median == PMin) {// 掩膜再加2,重新计算ksize += 2;if (ksize + 2 > Nmax) {result.at<uchar>(i, j) = median;break;}else{// 判定传入的值,是否出现越界的情况if((i - ksize / 2 < 0 || i + ksize / 2 < SourceImage.cols) ||j - ksize / 2 < 0 || j + ksize / 2 > SourceImage.rows)result.at<uchar>(i,j) = (PMax + PMin) / 2;}} else {//中值不是极值,判定原像素点是不是极值,然后在进行输出if (result.at<uchar>(i, j) == PMax || result.at<uchar>(i, j) == PMin)result.at<uchar>(i,j) = median;break;}}}}return result;
}动态范围增强
- 这里就是图像的直方图均衡化,使得整个模型的图片颜色对比度更大,显示出更多的细节。
实现代码
//对图片进行直方图均衡化,凸显出前后差异Mat equalized;// 转成二值化,并变为直方图均衡化cvtColor(ROI, equalized, COLOR_BGR2GRAY);equalizeHist(equalized, equalized);
形态学处理
- 膨胀操作 :通过增加图像中的物体的像素数量,使得物体的大小和面积增加,边缘变得更加明显,改变了原来字体粗细

- 腐蚀操作 :在卷积核大小中对图片进行卷积。取图像中(3 * 3)区域内的最小值。可以消除图像中的毛刺和噪声。改变了原来字体粗细

- 开运算 :先腐蚀运算,在进行膨胀运算。在不损害字体信息的情况下,去除了噪声和毛刺。通过调整卷积可以进一步减少噪声

- 闭运算 :先膨胀运算,在进行腐蚀运算。在不去除任何噪声的情况下,补全了缺失的信息。
- 这里选择开运算,具体实现代码如下,别的可以参考知乎链接
实现代码
// 对图像进行开运算,Mat morphologied;int size = 3;// shape是内核的形状,size是内核的尺寸,锚点的位置,对于矩形来说,全部都是 1 ,不用调整cv::Mat element = cv::getStructuringElement(cv::MORPH_RECT,cv::Size(2*size + 1, 2*size+1),cv::Point(size, size));cout<<element<<endl;morphologyEx(equalized, morphologied, cv::MORPH_OPEN, element);
图片预处理效果

计算帧差
- 主要有两种方法,分别是静态参考帧差分法和连续帧帧差法,下图为两个效果,很明显的可以就看到连续帧帧差法的效果更好,常见的静态帧是将多个帧进行平均,然后以平均之后的帧作为参考帧,然后后面每帧都是和当前帧作比较,没有动作的连续性。


连续帧帧差法原理和实现代码
-
实现原理如下图

-
使用absdiff函数,具体描述如下,计算frame1和frame2的帧差,然后将结果保存到framediff中
cv::Mat frameDiff;
cv::absdiff(frame1, frame2, frameDiff);
实现代码
//计算帧差,并将最终的结果进行返回
Mat DifFrame(Mat PreFrame,Mat CurFrame,Mat NextFrame){//计算帧差Mat FrameDiffPre , FrameDiffNext;absdiff(PreFrame,CurFrame,FrameDiffPre);absdiff(CurFrame,NextFrame,FrameDiffNext);// 分别进行二值化,设定二值化的阈值Mat BinImgPre , BinImgNext;threshold(FrameDiffPre,BinImgPre,128,255,cv::THRESH_BINARY);threshold(FrameDiffNext,BinImgPre,128,255,cv::THRESH_BINARY);// 将图片进行与运算,然后将结果进行输出Mat ResFrame;bitwise_and(FrameDiffPre,FrameDiffNext,ResFrame);//返回最终处理过后的帧return ResFrame;}// 计算帧差的外部函数,读取原来处理过的文件,计算所有图片的帧差
void AllDifFrame(const string& ImagePath,const string& TargetPath){// 保存文件名string line;// 判定文件存在ifstream input_file(ImagePath);if (!input_file.is_open()) {cerr << "Could not open the file - '"<< ImagePath << "'" << endl;return;}// 需要提前读取两个,然后依次往后进行迭代Mat PreFrame,CurFrame,NextFrame;getline(input_file,line);PreFrame = imread(line);// 读取下一个需要处理的帧getline(input_file,line);CurFrame = imread(line);// 逐行读取文件名while(getline(input_file,line)){// 当前需要处理的帧NextFrame = imread(line);// 获取文件后缀名,并进行拼接成目标文件名string ImageName = line.substr(line.find_last_of('\\',line.size())+1);string TargetName = TargetPath;TargetName.append(ImageName);// 三帧相邻出进行帧差运算,算出的帧差进行按位相与运算Mat TempFrame;absdiff(PreFrame,CurFrame,PreFrame);absdiff(CurFrame,NextFrame,TempFrame);bitwise_and(PreFrame,TempFrame,TempFrame);//计算计算过进行保存imwrite(TargetName,TempFrame);// 三帧往前进行迭代PreFrame = CurFrame;CurFrame = NextFrame;}}
K近邻实现
基本介绍
-
思路 : 将样本在特征空间中,根据一定的分类方法,归类于与该样本最相似的K个样本中大多数的那一类。需要一部分已经标注过的样本,然后将未标注过的样本进行分类。
-
特点 :
- 对于异常目标的容忍度比较高,因为不依靠参数直接分类,而是寻找多个近邻目标的联合分类
- 支持多分类,对于类域交叉重叠依然有较好的分类能力,因为白酒中的杂质在特征上有很强的相似性,在类域上会有很强的重叠性
- 训练过程复杂度低:实时更新样本数据集,再识别一种杂质之后,将该样本增加到样本数据中,使得分类效果更加稳定。
-
实现过程 :
- 准备数据集:需要将要分类的目标的特征向量与一些已知分类的目标的特征向量组成一个数据集。
- 特征提取:使用OpenCV库提取目标的特征向量。
- 注意 这里提取的特征是完整的一幅图片,因为我这里已经对图片进行了预处理,让特征很明显,所以不需要进行特征提取
- 训练模型:使用KNN算法对数据集进行训练,生成分类器。
- 分类:使用训练好的分类器对新的目标进行分类。
-
补充
- 针对图片进行的KNN分类,是一种高维数据,KNN算法可以使用降维技术,来提高效率和准确率,比如说主成分分析(PCA)
- KNN,适用于小数据集和低维度数据集
- 可以通过对距离加权的方式,来提升预测的准确率
实现代码
这部分是手动实现的,并没有直接调用相关的库
// 定义一个结构体,用于保存数据点和标签
struct DataPoint {vector<double> features; // 特征数据int label; // 标签
};// 计算欧氏距离
double euclideanDistance(const vector<double>& v1, const vector<double>& v2) {double dist = 0.0;for (int i = 0; i < v1.size(); i++) {dist += pow((v1[i] - v2[i]), 2);}return sqrt(dist);
}// 预测函数,返回预测标签
int predict(const vector<DataPoint>& trainData, const vector<double>& testData, const int k) {// 对于测试集,计算每一个测试样本和数据集中的,所有样本的欧式距离vector<pair<int, double>> distances; // 存储距离和标签for (const auto & i : trainData) {double distance = euclideanDistance(i.features, testData);distances.emplace_back(i.label, distance);}// 根据结果进行排序,指定排序函数,仅仅对距离进行比较sort(distances.begin(), distances.end(), [](pair<int, double> a, pair<int, double> b) {return a.second < b.second;});// 获取最后k个样本最高的分类类别vector<int> kLabels(k);for (int i = 0; i < k; i++) {kLabels.push_back(distances[i].first);}// 获取数量类别最大的分类int maxLabel = 0;int maxCount = 0;for (auto iter = kLabels.begin();iter != kLabels.end();iter ++){int times = count(kLabels.begin(),kLabels.end(),*(iter));if(times > maxCount){maxCount = times;maxLabel = *(iter);}}return maxLabel;}完整的代码——调用opencv的特定的库实现的
#include<opencv2/opencv.hpp>
#include<iostream>
#include <fstream>using namespace std;
using namespace cv;
using namespace cv::ml;// 读取图片并形成数据集
void KNNTraning(const string& ImagePath, Mat& Images, Mat& Labels) {/** 将图片转成一维数据,并保存在MAT中* path: 读取文件需要使用的路径* images:保存所有图片的数据集* labels:对应每一张图片的标签*/// 声明Mat保存图片Mat img;string line;string ImgLabel;int flag = 0;// 判定文件存在ifstream input_file(ImagePath);if (!input_file.is_open()) {cerr << "Could not open the file - '"<< ImagePath << "'" << endl;return;}while(getline(input_file,line)) {// 获取文件后缀名,并进行拼接成目标文件名string ImageName = line.substr(line.find_last_of('\\',line.size())+1);if(ImageName != ImgLabel)flag ++;// 将图片转成一维的数据,并合并到一个大的mat中img = imread(line, cv::IMREAD_GRAYSCALE);Images.push_back(img.reshape(0,1));Labels.push_back(flag);}// 将Mat转变成数据集Images.convertTo(Images,CV_32F);Images = Images / 255;int nImgCount = Images.rows;int nTrainCount = nImgCount / 4 * 3;Mat trainData,trainLabels;trainData = Images(Range(0,nTrainCount),Range::all());trainLabels = Labels(Range(0,nTrainCount),Range::all());Ptr<TrainData> tData = TrainData::create(trainData, ROW_SAMPLE, trainLabels);// 训练KNN模型Ptr<KNearest> model = KNearest::create();// 设定k值,最终选取是哪个类别model->setDefaultK(5);// 设置分类还是回归,true为分类,false为回归model->setIsClassifier(true);// 设置训练数据,进行训练。就相当于将前面的标注数据和测试数据进行了一个训练绑定model->train(tData);model->save("model.xml");
}float predict(string ImgPath,string modelPath){// 加载模型cv::Ptr<cv::ml::KNearest> knn = cv::ml::StatModel::load<cv::ml::KNearest>(modelPath);//读取图片Mat imgTest = imread(ImgPath);imgTest.convertTo(imgTest,CV_32F);imgTest = imgTest / 255;imgTest = imgTest.reshape(0,1);//输出预测结果float ret = knn->predict(imgTest);return ret;
}
实现过程
参考
- Opencv 图像处理之膨胀与腐蚀 【https://zhuanlan.zhihu.com/p/110330329】
相关文章:
微小目标识别研究(2)——基于K近邻的白酒杂质检测算法实现
文章目录实现思路配置opencv位置剪裁实现代码自适应中值滤波实现代码动态范围增强实现代码形态学处理实现代码图片预处理效果计算帧差连续帧帧差法原理和实现代码实现代码K近邻实现基本介绍实现代码这部分是手动实现的,并没有直接调用相关的库完整的代码——调用ope…...

2022-06-14至2022-08-11 关于复现MKP算法的总结与反思
Prerequisite 自2022年6月14日至2022年8月11日的时间内,我致力于完成A Hybrid Approach for the 0–1 Multidimensional Knapsack problem 论文的复现工作,此次是我第一次进行组合优化方向的学习工作,下面介绍该工作内容发展过程以及该工作结…...

IBMMQ教程二(window版安装)
下载下载地址:https://public.dhe.ibm.com/ibmdl/export/pub/software/websphere/messaging/mqadv/我这里选择的是9.1.0.0版本安装将下载完成的压缩包解压双击Setup.exe直接运行点击软件需求查看系统配置是否满足,右边绿色的对号说明满足需求,…...

Java | HashSet 语法
HashSet 基于 HashMap 来实现的,是一个不允许有重复元素的集合。 HashSet 允许有 null 值。 HashSet 是无序的,即不会记录插入的顺序。 HashSet 不是线程安全的, 如果多个线程尝试同时修改 HashSet,则最终结果是不确定的。 您必须…...
)
js学习4(运算符)
### 1.算数运算符: 、-、*、\、%(取余)、**(幂方) ## 优先级 同数学课程,可以加括号 ### 2.自增和自减 、--(即数值变量加一或减一) ### 3.赋值运算符 、、-、*、/、... ### 4.比较运…...

2月更新 | Visual Studio Code Python
我们很高兴地宣布,2023年2月版 Visual Studio Code Python 和 Jupyter 扩展现已推出!此版本包括以下改进:从激活的终端启动 VS Code 时的自动选择环境 使用命令 Python: Create Environmen 时可选择需求文件或可选依赖项 预发布:改…...

C++回顾(十八)—— 文件操作
18.1 I/O流概念和流类库结构 1 概念 程序的输入指的是从输入文件将数据传送给程序,程序的输出指的是从程序将数据传送给输出文件。 C输入输出包含以下三个方面的内容: (1)对系统指定的标准设备的输入和输出。即从键盘输入数据&am…...

以java编写员工管理系统(测试过 无问题)
一、系统结果的部分展示 二、题目以及相关要求 三、组成 1.该系统由 Employee 类 、commonEmployee类、Testemd类和managerEmployee类组成 2.Employee实现的代码 public class Employee {private String id;private String name;private String job;private int holiday…...
单例模式之懒汉式
在上篇文章中,我们讲了单例模式中的饿汉式,今天接着来讲懒汉式。 1.懒汉式单例模式的实现 public class LazySingleton {private static LazySingleton instance null;// 让构造函数为private,这样该类就不会被实例化private LazySingleto…...

1638_chdir函数的功能
全部学习汇总:GreyZhang/g_unix: some basic learning about unix operating system. (github.com) 今天看一个半生不熟的小函数,chdir。说半生不熟,是因为这个接口一看就知道是什么功能。然而,这个接口如何用可真就没啥想法了。 …...

使用CEF 获得某头条请求,并生成本地文件的方法
目录 一、获得网站请求响应信息 1、响应过滤 2、匹配过滤URL的函数 3、获得请求响应后的处理...

二十、Django-restframework之视图集和路由器
一、视图集和路由器 REST框架包含了一个处理视图集的抽象,它允许开发人员集中精力建模API的状态和交互,并根据通用约定自动处理URL构造。 视图集类与视图类几乎相同,不同之处在于它们提供的是retrieve或update等操作,而不是get或…...

[深入理解SSD系列 闪存实战2.1.2] SLC、MLC、TLC、QLC、PLC NAND_固态硬盘闪存颗粒类型
闪存最小物理单位是 Cell, 一个Cell 是一个晶体管。 闪存是通过晶体管储存电子来表示信息的。在晶体管上加入了浮动栅贮存电子。数据是0或1取决于在硅底板上形成的浮动栅中是否有电子。有电子为0,无电子为1. SSD 根据闪存颗粒区分,固态硬盘有SLC、MLC、TLC、QLC、PLC 五种类型…...
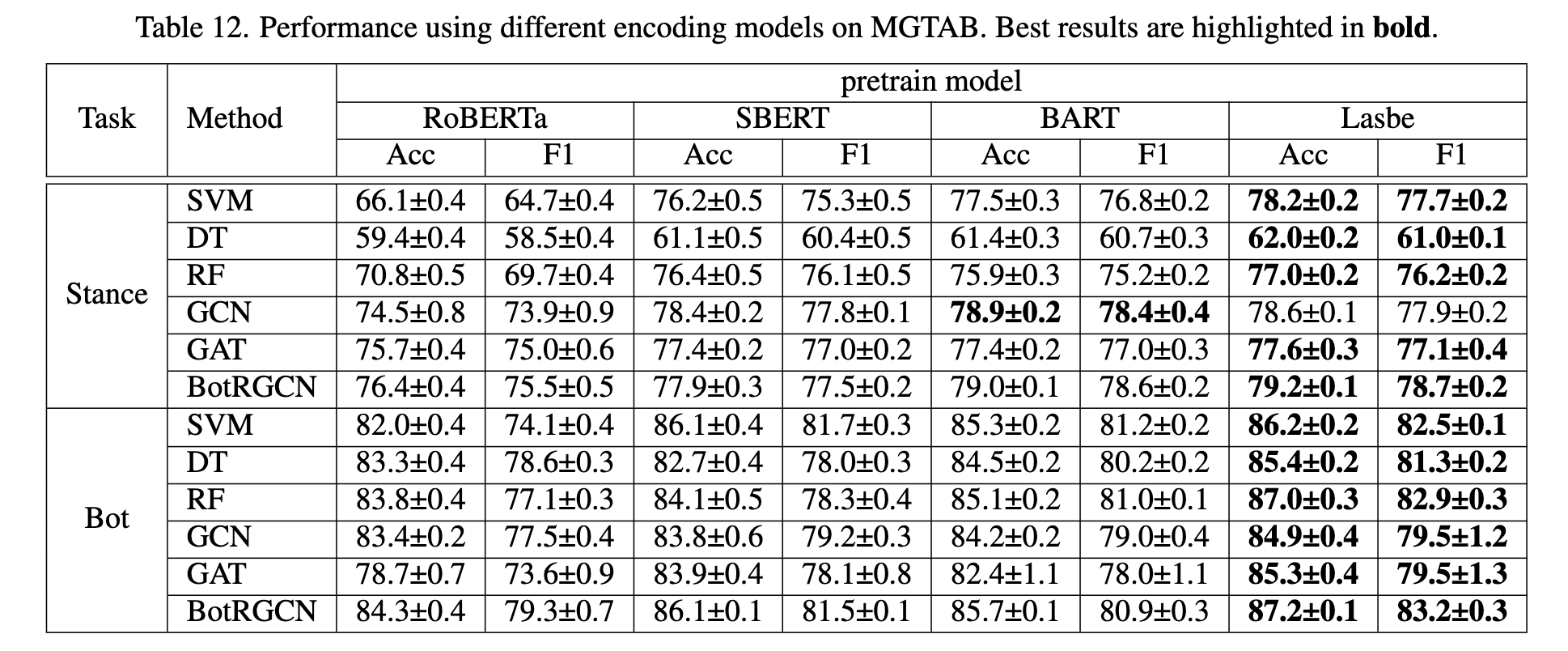
论文阅读-MGTAB: A Multi-Relational Graph-Based Twitter Account DetectionBenchmark
目录 摘要 1. 引言 2. 相关工作 2.1. 立场检测 2.2.机器人检测 3.数据集预处理 3.1.数据收集和清理 3.2.专家注释 3.3. 质量评估 3.4.特征分析 4. 数据集构建 4.1.特征表示构造 4.2.关系图构建 5. 实验 5.1.实验设置 5.2.基准性能 5.3训练集大小的研究 5.4 社…...
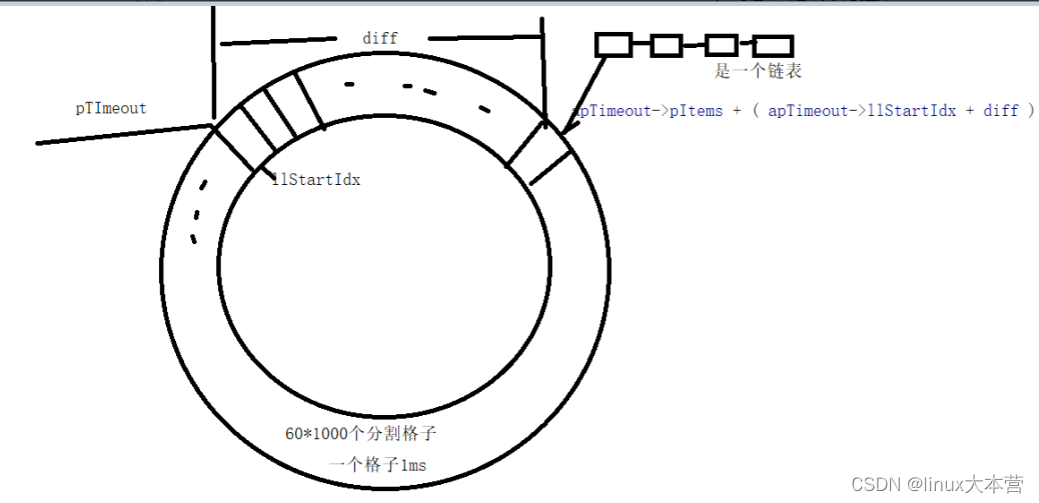
基于libco的c++协程实现(时间轮定时器)
在后端的开发中,定时器有很广泛的应用。 比如: 心跳检测 倒计时 游戏开发的技能冷却 redis的键值的有效期等等,都会使用到定时器。 定时器的实现数据结构选择 红黑树 对于增删查,时间复杂度为O(logn),对于红黑…...

java多线程与线程池-04线程池与AQS
第7章 线程池与AQS java.util.concurrent包中的绝大多数同步工具,如锁(locks)和屏障(barriers)等,都基于AbstractQueuedSynchronizer(简称AQS)构建而成。这个框架提供了一套同步管理的通用机制,如同步状态的原子性管理、线程阻塞与解除阻塞,还有线程排队等。 在JD…...

优化模型验证关键代码25:样本均值近似技术处理两阶段随机旅行商问题及Gurobipy代码验证
大多数数学规划模型都会考虑到研究问题中存在的不确定性,针对这些不确定性,两种常用的处理方法是鲁棒优化和随机规划。这篇论文我们关注后者,也就是两阶段随机旅行商问题;利用套期保值算法计算不同规模TSP的可行解,同时比较了样本均值近似技术的解的情况,并计算了该问题的…...

老爸:“你做的什么游戏测试简直是不务正业!”——我上去就是一顿猛如虎的解释。
经常有人问我:游戏测试到底是干什么呢?是游戏代练?每天玩游戏?装备随便造,怪物随便秒,线上GM指令随便用?可以每天玩玩游戏,不用忙工作,太爽了?有时朋友不理解…...

JVM垃圾回收调优知识点整理
目录 1、JVM内存模型 1.2、堆及垃圾回收 1.3、JVM参数设置经验: 1.4、对象逃逸分析:...
linux安装mysql-8.0.31
1)、下载mysql-8.0.31压缩包两种方式 a.本地下载后上传服务器解压,下载地址:https://downloads.mysql.com/archives/community/ b.服务器使用命令下载,注意:路径在那,就下载到那个位置。 wget https://dev.mysql.com/…...
)
【OpenClaw 保姆级教程】第五篇:前端可视化面板 + 日志监控 + 权限管理(最终篇)
哈喽宝子们!一路跟着教程走到现在,我们已经完成了 OpenClaw 本地部署、多渠道接入、自定义技能、服务器私有化、多技能联动、定时任务与 API 接口化,今天迎来系列最终篇—— 直接给你的 OpenClaw 装上可视化前端面板,搭配实时日志监控、多人权限控制,从命令行工具升级成一…...

RexUniNLU在电商场景实战:精准抽取订单信息,自动处理用户投诉
RexUniNLU在电商场景实战:精准抽取订单信息,自动处理用户投诉 你有没有遇到过这种情况?作为电商客服,每天面对海量用户消息,其中夹杂着各种投诉:“我买的衣服尺码不对,订单号是20240515XXXX&am…...

基于ESP32与多传感器融合的立创空气质量检测净化器DIY全攻略
基于ESP32与多传感器融合的立创空气质量检测净化器DIY全攻略 最近想给工作室弄个能实时监测空气质量的设备,市面上成品要么功能单一,要么价格不菲。正好看到立创开源平台上有位大佬分享了一个完整的空气质量检测净化器项目,功能非常全面&…...

AudioSeal效果展示:支持中英文混合语音、带背景音乐的复杂音频检测
AudioSeal效果展示:支持中英文混合语音、带背景音乐的复杂音频检测 1. 音频水印技术新标杆 在数字内容爆炸式增长的今天,音频内容的真实性和版权保护变得尤为重要。AudioSeal作为Meta开源的语音水印系统,为AI生成音频的检测和溯源提供了专业…...

CLIP ViT-H-14效果展示:植物病害图与标准图谱的细粒度相似匹配
CLIP ViT-H-14效果展示:植物病害图与标准图谱的细粒度相似匹配 1. 项目概述 在农业病虫害防治领域,快速准确地识别植物病害一直是重要挑战。传统方法依赖专家人工比对,效率低且成本高。基于CLIP ViT-H-14模型的图像特征提取服务为解决这一问…...

Alpamayo-R1-10B真实案例:学校区域‘注意儿童’标识触发限速+扫描行为
Alpamayo-R1-10B真实案例:学校区域注意儿童标识触发限速扫描行为 1. 项目背景与技术概览 Alpamayo-R1-10B是NVIDIA开发的自动驾驶专用视觉-语言-动作(VLA)模型,其核心为100亿参数的大规模多模态模型。该模型通过整合AlpaSim模拟…...

NB-IoT模组QS100开发环境搭建与SDK实战指南
1. 从零开始:认识你的QS100 NB-IoT模组 大家好,我是老张,在物联网这行摸爬滚打十来年了,从早期的2G模块玩到现在各种NB-IoT、Cat.1,踩过的坑比走过的路还多。今天咱们不聊虚的,就手把手带你搞定QS100这个模…...

【C++】MSYS2进阶:从零到一打造现代化C++工作流
1. 为什么你的C开发环境需要一个“瑞士军刀”? 如果你在Windows上折腾过C开发环境,大概率经历过一场噩梦:去MinGW官网下载编译器,手动配置环境变量,再单独安装CMake、Ninja、GDB……每个工具都有自己的安装包和路径&am…...

【MCP安全SDK开发避坑清单】:12个被87%团队忽略的跨语言类型转换陷阱,导致JWT签名绕过的真实攻防复现
第一章:MCP安全SDK开发避坑总览与攻防启示MCP(Managed Control Plane)安全SDK是构建零信任架构下可信控制面的核心组件,其开发过程极易因权限误设、密钥硬编码、信道未加密等低级错误引发高危漏洞。开发者常将“功能可用”优先于“…...

神经符号集成方法在可解释推理中的应用
神经符号集成方法在可解释推理中的应用关键词:神经符号集成、可解释AI、符号推理、神经网络、知识表示、推理系统、人工智能摘要:本文深入探讨神经符号集成方法在构建可解释推理系统中的应用。我们将分析神经网络的感知能力与符号系统的推理能力如何互补…...