使用R语言生成CDISC SDTM.AE domain
写在前面
- 使用的是Rstudio
- 其实R已经有生成sdtm相关的package,以下代码仅作为练习R语言的语法,不是高效生成sdtm的方法
- 代码中没有解决的问题包括:EPOCH相关的逻辑没有考虑partial date的情况;在使用arrange() function做-SEQ排序时,关于大小写英文字母的排序机制似乎与SAS语言的sort function有所不同,导致使用相同的排序变量,通过R和SAS排序后,record的顺序会有不同;输出xpt结果是乱码,暂时输出到csv文件中。
- 还没有写生成SUPPAE的代码
- 代码参考了以下材料
Generating .xpt files with SAS, R and Python
https://www.pharmasug.org/proceedings/2021/EP/PharmaSUG-2021-EP-057.pdf
Yotube @mycsg
mycsg TASKS-SDTMGEN
以下是R代码
setwd('C://R_software')
library(haven)
library(dplyr)
library(tidyverse)
library(sas7bdat)
library(SASxport)
library(Hmisc)
# import source data
raw_ae_001 <- read_sas('C://rawdata/ae_001.sas7bdat')
raw_meddrathsaurus <- read_sas('C://rawdata/meddrathesaurus.sas7bdat')
sdtm_dm <- read_sas('C://sdtmdata/SDTM/DM.sas7bdat')
sdtm_se <- read_sas('C://rawdata/SE.sas7bdat')
# Update the variable name to uppercase, because var name is case sensitive in R
names(raw_ae_001) <- toupper(names(raw_ae_001))
names(raw_meddrathsaurus) <- toupper(names(raw_meddrathsaurus))
# Filter ae raw data with AETERM not missing, and keep necessary variables
ae <- raw_ae_001 %>%
select(SUBJECT,RECORDPOSITION,AETERM,AESTDAT_RAW,AESTTIM,AEENDAT_RAW,AEENTIM,
AESEV_STD,AESER_STD,AEACN_STD,AEREL_STD,AEREL_WD_STD,AEPATT_STD,AEOUT_STD,AESCONG_STD,
AESDISAB_STD,AESDTH_STD,AESHOSP_STD,AESLIFE_STD,AESMIE_STD,AEONGO) %>%
filter(AETERM != "")
# Update AETERM value to uppercase in order to merge with source MedDRA coding data
ae$AETERM <- toupper(ae$AETERM)
# Filter MedDRA source data with AE pannel only
meddra <- raw_meddrathsaurus %>%
filter(PANEL=="AE")
# Merge AE and MedDRA data (left join) by AETERM, create AESTDTC/AEENDTC
ae1 <- merge (ae, meddra, by.x = c("AETERM"), by.y = c("VERBATIM"), all.x = T) %>%
# create AESTDTC
mutate(
stdayn = suppressWarnings(as.numeric(word(AESTDAT_RAW,1))), ### as.numeric>>input, word>>scan
stday = if_else(!is.na(stdayn), str_pad(stdayn, width = 2, pad = "0"), "-"), ### is.na>>not missing, !>>not, str_pad>>put xx.
stmonthc = str_to_upper(word(AESTDAT_RAW, 2)), ### str_to_upper>>uppercase
stmonth = case_when(
stmonthc == "JAN" ~ "01",
stmonthc == "FEB" ~ "02",
stmonthc == "MAR" ~ "03",
stmonthc == "APR" ~ "04",
stmonthc == "MAY" ~ "05",
stmonthc == "JUN" ~ "06",
stmonthc == "JUL" ~ "07",
stmonthc == "AUG" ~ "08",
stmonthc == "SEP" ~ "09",
stmonthc == "OCT" ~ "10",
stmonthc == "NOV" ~ "11",
stmonthc == "DEC" ~ "12",
TRUE ~ "-"
),
styear = word(AESTDAT_RAW,3),
styear1 = if_else((styear == "UNK") | (is.na(styear)), "-", styear), ### | >> or
aestdate = str_c(styear1, stmonth, stday, sep = "-"), ### str_c >> catx
AESTDTC = if_else(AESTTIM != "", str_c(aestdate, str_pad(AESTTIM, width = 5, pad = "0"), sep = "T"), aestdate),
AESTDTC = if_else(str_sub(AESTDTC, -5) == "-----", "", AESTDTC),
AESTDTC = if_else(str_sub(AESTDTC, -4) == "----", str_sub(AESTDTC,end=-5), AESTDTC),
AESTDTC = if_else(str_sub(AESTDTC, -2) == "--", str_sub(AESTDTC,end=-3), AESTDTC)
) %>%
# create AEENDTC
mutate(
endayn = suppressWarnings(as.numeric(word(AEENDAT_RAW,1))), ### as.numeric>>input, word>>scan
enday = if_else(!is.na(endayn), str_pad(endayn, width = 2, pad = "0"), "-"), ### is.na>>not missing, !>>not, str_pad>>put xx.
enmonthc = str_to_upper(word(AEENDAT_RAW, 2)), ### str_to_upper>>uppercase
enmonth = case_when(
enmonthc == "JAN" ~ "01",
enmonthc == "FEB" ~ "02",
enmonthc == "MAR" ~ "03",
enmonthc == "APR" ~ "04",
enmonthc == "MAY" ~ "05",
enmonthc == "JUN" ~ "06",
enmonthc == "JUL" ~ "07",
enmonthc == "AUG" ~ "08",
enmonthc == "SEP" ~ "09",
enmonthc == "OCT" ~ "10",
enmonthc == "NOV" ~ "11",
enmonthc == "DEC" ~ "12",
TRUE ~ "-"
),
enyear = word(AEENDAT_RAW,3),
enyear1 = if_else((enyear == "UNK") | (is.na(enyear)), "-", enyear), ### | >> or
aeendate = str_c(enyear1, enmonth, enday, sep = "-"), ### str_c >> catx
AEENDTC = if_else(AEENTIM != "", str_c(aeendate, str_pad(AEENTIM, width = 5, pad = "0"), sep = "T"), aeendate),
AEENDTC = if_else(str_sub(AEENDTC, -5) == "-----", "", AEENDTC),
AEENDTC = if_else(str_sub(AEENDTC, -4) == "----", str_sub(AEENDTC,end=-5), AEENDTC),
AEENDTC = if_else(str_sub(AEENDTC, -2) == "--", str_sub(AEENDTC,end=-3), AEENDTC)
)
# Create AE domain vars
ae2 <- ae1 %>%
cbind(
STUDYID=c("PROTOCOLID"),
DOMAIN=c("AE"),
USUBJID=str_c(c("PROTOCOLID-0"),substr(ae1$SUBJECT,4,6),c("-00"),substr(ae1$SUBJECT,7,9)), # str_c() is catx() in SAS
SUBJID=ae1$SUBJECT,
AESPID=str_c(c("AE_001-"),ae1$RECORDPOSITION),
AELLT=ae1$LLT_NAME,
AELLTCD=ae1$LLT_CODE,
AEDECOD=ae1$PT_NAME,
AEPTCD=ae1$PT_CODE,
AEHLT=ae1$HLT_NAME,
AEHLTCD=ae1$HLT_CODE,
AEHLGT=ae1$HGT_NAME,
AEHLGTCD=ae1$HGT_CODE,
AEBODSYS=ae1$SOC_NAME,
AEBDSYCD=ae1$SOC_CODE,
AESOC=ae1$SOC_NAME,
AESOCCD=ae1$SOC_CODE,
AESEV=ae1$AESEV_STD,
AESER=ae1$AESER_STD,
AEACN=ae1$AEACN_STD,
AEREL=ae1$AEREL_STD,
AERELNST=ae1$AEREL_WD_STD,
AEPATT=ae1$AEPATT_STD,
AEOUT=ae1$AEOUT_STD,
AESCONG=ae1$AESCONG_STD,
AESDISAB=ae1$AESDISAB_STD,
AESDTH=ae1$AESDTH_STD,
AESHOSP=ae1$AESHOSP_STD,
AESLIFE=ae1$AESLIFE_STD,
AESMIE=ae1$AESMIE_STD
)
# Merge AE and SDTM.DM by USUBJID, create AESTDY/AEENDY
sdtm_dm <- select(sdtm_dm,USUBJID,RFSTDTC,RFENDTC)
ae3 <- merge (ae2, sdtm_dm, by = c("USUBJID"), all.x = T) %>%
mutate(
aestdt=as.Date(AESTDTC),
rfstdt=as.Date(RFSTDTC),
rfstdate=str_sub(RFSTDTC,1,10),
rfst_year=str_sub(RFSTDTC,1,4),
rfst_month=str_sub(RFSTDTC,6,7),
rfst_day=str_sub(RFSTDTC,9,10),
AESTDY=ifelse(!is.na(aestdt) & !is.na(rfstdt),
ifelse((aestdt>=rfstdt),aestdt-rfstdt+1,aestdt-rfstdt), ""
)
) %>%
mutate(
aeendt=as.Date(AEENDTC),
rfstdt=as.Date(RFSTDTC),
AEENDY=ifelse(!is.na(aeendt) & !is.na(rfstdt),
ifelse((aeendt>=rfstdt),aeendt-rfstdt+1,aeendt-rfstdt), ""
)
) %>%
# create AEENRTPT, AEENTPT
mutate(
AEENRTPT=ifelse(AEONGO==1,"ONGOING",""),
AEENTPT=ifelse(AEONGO==1,
ifelse(is.na(rfstdt)==T,"SCREENING","END OF STUDY"),""
)
)
# prepare SE dataset for creating EPOCH
sdtm_se <- select(sdtm_se,USUBJID,ETCD,SESTDTC,SEENDTC)
sest <- sdtm_se %>%
select(USUBJID,ETCD,SESTDTC) %>%
pivot_wider(names_from=ETCD, values_from=SESTDTC)
colnames(sest) <- c("USUBJID","st1","st2","st3")
seen <- sdtm_se %>%
select(USUBJID,ETCD,SEENDTC) %>%
pivot_wider(names_from=ETCD, values_from=SEENDTC)
colnames(seen) <- c("USUBJID","en1","en2","en3")
sesten <- merge (sest, seen, by = c("USUBJID"))
ae4 <- merge (ae3, sesten, by = c("USUBJID"), all.x = T)
ae5 <- ae4 %>%
mutate(EPOCH=NA) %>%
mutate(
EPOCH=ifelse((st1<=aestdt & aestdt<en1) | (aestdt<=en1 & is.na(st2)==T), "SCREENING",ifelse(st2<=aestdt & aestdt<=en2, "TREATMENT", "FOLLOW-UP"))
) %>%
#mutate(
# EPOCH=ifelse(!is.na(EPOCH)==T & !is.na(stday)==T, EPOCH, ifelse())
#) %>%
arrange(STUDYID,USUBJID,AEDECOD,AESTDTC,AEENDTC,AESPID) %>%
group_by(USUBJID) %>%
mutate(AESEQ=row_number())
# select target vars in AE
sdtm_ae <- select(ae5,STUDYID,DOMAIN,USUBJID,SUBJID,AESEQ,AESPID,
AETERM,AELLT,AELLTCD,AEDECOD,AEPTCD,AEHLT,AEHLTCD,AEHLGT,AEHLGTCD,AEBODSYS,AEBDSYCD,AESOC,AESOCCD,
AESEV,AESER,AEACN,AEREL,AERELNST,AEPATT,AEOUT,AESCONG,AESDISAB,AESDTH,AESHOSP,AESLIFE,AESMIE,
EPOCH,AESTDTC,AEENDTC,AESTDY,AEENDY,AEENRTPT,AEENTPT)
# convert following vars to numeric per CDSIC definition
sdtm_ae$AELLTCD <- as.numeric(sdtm_ae$AELLTCD)
sdtm_ae$AEPTCD <- as.numeric(sdtm_ae$AEPTCD)
sdtm_ae$AEHLTCD <- as.numeric(sdtm_ae$AEHLTCD)
sdtm_ae$AEHLGTCD <- as.numeric(sdtm_ae$AEHLGTCD)
sdtm_ae$AEBDSYCD <- as.numeric(sdtm_ae$AEBDSYCD)
sdtm_ae$AESOCCD <- as.numeric(sdtm_ae$AESOCCD)
sdtm_ae$AESTDY <- as.numeric(sdtm_ae$AESTDY)
sdtm_ae$AEENDY <- as.numeric(sdtm_ae$AEENDY)
# convert NA to null
sdtm_ae$AESTDY[is.na(sdtm_ae$AESTDY)] <- ""
sdtm_ae$AEENDY[is.na(sdtm_ae$AEENDY)] <- ""
# add label
label(sdtm_ae) <- "Adverse Events"
label(sdtm_ae$STUDYID) <- "Study Identifier"
label(sdtm_ae$DOMAIN) <- "Domain Abbreviation"
label(sdtm_ae$USUBJID) <- "Unique Subject Identifier"
label(sdtm_ae$SUBJID) <- "Subject Identifier for the Study"
label(sdtm_ae$AESEQ) <- "Sequence Number"
label(sdtm_ae$AESPID) <- "Sponsor-Defined Identifier"
label(sdtm_ae$AETERM) <- "Reported Term for the Adverse Event"
label(sdtm_ae$AELLT) <- "Lowest Level Term"
label(sdtm_ae$AELLTCD) <- "Lowest Level Term Code"
label(sdtm_ae$AEDECOD) <- "Dictionary-Derived Term"
label(sdtm_ae$AEPTCD) <- "Preferred Term Code"
label(sdtm_ae$AEHLT) <- "High Level Term"
label(sdtm_ae$AEHLTCD) <- "High Level Term Code"
label(sdtm_ae$AEHLGT) <- "High Level Group Term"
label(sdtm_ae$AEHLGTCD) <- "High Level Group Term Code"
label(sdtm_ae$AEBODSYS) <- "Body System or Organ Class"
label(sdtm_ae$AEBDSYCD) <- "Body System or Organ Class Code"
label(sdtm_ae$AESOC) <- "Primary System Organ Class"
label(sdtm_ae$AESOCCD) <- "Primary System Organ Class Code"
label(sdtm_ae$AESEV) <- "Severity/Intensity"
label(sdtm_ae$AESER) <- "Serious Event"
label(sdtm_ae$AEACN) <- "Action Taken with Study Treatment"
label(sdtm_ae$AEREL) <- "Causality"
label(sdtm_ae$AERELNST) <- "Relationship to Non-Study Treatment"
label(sdtm_ae$AEPATT) <- "Pattern of Adverse Event"
label(sdtm_ae$AEOUT) <- "Outcome of Adverse Event"
label(sdtm_ae$AESCONG) <- "Congenital Anomaly or Birth Defect"
label(sdtm_ae$AESDISAB) <- "Persist or Signif Disability/Incapacity"
label(sdtm_ae$AESDTH) <- "Results in Death"
label(sdtm_ae$AESHOSP) <- "Requires or Prolongs Hospitalization"
label(sdtm_ae$AESLIFE) <- "Is Life Threatening"
label(sdtm_ae$AESMIE) <- "Other Medically Important Serious Event"
label(sdtm_ae$EPOCH) <- "Epoch"
label(sdtm_ae$AESTDTC) <- "Start Date/Time of Adverse Event"
label(sdtm_ae$AEENDTC) <- "End Date/Time of Adverse Event"
label(sdtm_ae$AESTDY) <- "Study Day of Start of Adverse Event"
label(sdtm_ae$AEENDY) <- "Study Day of End of Adverse Event"
label(sdtm_ae$AEENRTPT) <- "End Relative to Reference Time Point"
label(sdtm_ae$AEENTPT) <- "End Reference Time Point"
#export to xpt
write.xport(sdtm_ae, file="C://R_software/ae_R.xpt")
# export to CSV
write.csv(sdtm_ae, file="C://R_software/ae.csv")
相关文章:

使用R语言生成CDISC SDTM.AE domain
写在前面 - 使用的是Rstudio - 其实R已经有生成sdtm相关的package,以下代码仅作为练习R语言的语法,不是高效生成sdtm的方法 - 代码中没有解决的问题包括:EPOCH相关的逻辑没有考虑partial date的情况;在使用arrange() function做…...

怎么防止源代码泄露?9种方法教会你!
怎么防止源代码泄露?首先要了解员工可以通过哪些方式将源代码传输出去! 物理方法: — 网线直连,即把网线从墙上插头拔下来,然后和一个非受控电脑直连; — winPE启动,通过光盘或U盘的winPE启动,甚…...

原生JS如何实现可配置DM码
原生JS如何实现可配置DM码 一、 DM码简介 1、 Data Matrix码 Data Matrix码是一种二维条形码,简称DM码,由美国公司International Data Matrix, Inc.(I.D. Matrix)在1994年发明,Data Matrix码中的行数和列数随二维码中存储的信息量而增加,信息限值是2335个字母数字字符…...

【Python】Python开发面试题库:综合考察面试者能力
文章目录 Python开发面试题库:综合考察面试者能力1. 基础语法与数据类型问题1:变量与数据类型问题2:列表与字典操作问题3:字符串操作问题4:元组解包问题5:集合操作问题6:基本运算问题7ÿ…...
大语言模型的sft
https://zhuanlan.zhihu.com/p/692892489https://zhuanlan.zhihu.com/p/692892489https://zhuanlan.zhihu.com/p/679450872https://zhuanlan.zhihu.com/p/6794508721.常...
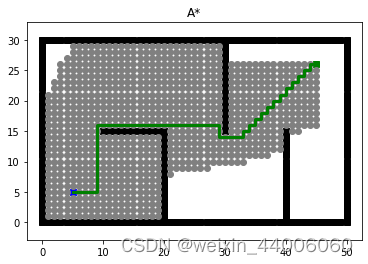
Astar路径规划算法复现-python实现
# -*- coding: utf-8 -*- """ Created on Fri May 24 09:04:23 2024"""import os import sys import math import heapq import matplotlib.pyplot as plt import time 传统A*算法 class Astar:AStar set the cost heuristics as the priorityA…...

低-零功率技术在军事中的应用
“低-零功率”概念最先由美国国防部提出,主要是针对诸如俄罗斯等大国的远程传感器,帮助美军破除“灰色地带挑衅”的威胁。由于“灰色地带”冲突仅依托小规模军事力量,其强度维持在不足以引发美国及其盟国进行直接干预的程度,因此&…...

【培训】企业档案管理专题(私货)
导读:通过该专题培训,可以系统了解企业档案管理是什么、为什么、怎么做。尤其是对档案的价值认知,如何构建与新质生产力发展相适应的企业档案工作体系将有力支撑企业新质生产力的发展,为企业高质量发展贡献档案力量,提…...
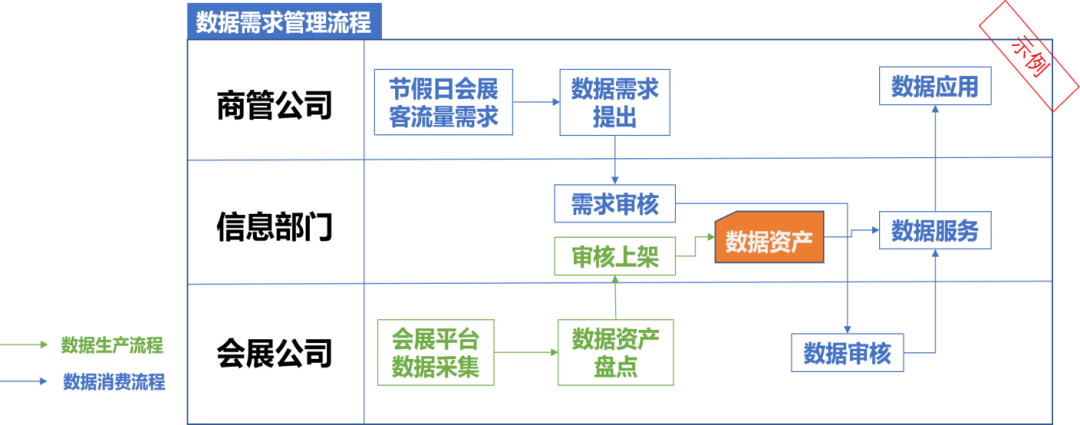
某国资集团数据治理落地,点燃高质量发展“数字引擎”
某国有资产经营控股集团为快速提升集团的内控管理能力和业务经营能力,以数字化促进企业转型的信息化建设势在必行。集团携手亿信华辰开启数据治理项目,在数据方面成功解决“哪里来、怎么盘、怎么管、怎么用”的问题,不断推动企业数字化转型…...
【AI测试版】)
2024.06.12【读书笔记】丨生物信息学与功能基因组学(第十四章 细菌和古细菌基因组 第二部分)【AI测试版】
读书笔记:《生物信息学与功能基因组学》第十四章 - 第二部分 摘要 第二部分深入讨论了基于不同标准的细菌和古细菌的分类方法,包括形态学、基因组大小和排列、生活方式以及与人类疾病的关系。此外,还探讨了基于核糖体RNA序列的分类方法&…...

企业数据API接口大全
一、工商信息 (1)精确获取企业唯一标识 根据企业名称、注册号或统一社会信用代码,获取企业唯一标识 (2)企业模糊查询 关键字名称模糊搜索匹配企业 (3)企业详情 根据企业唯一标识、企业名称…...

【HTML】格式化文本 pre 标签
文章目录 <pre> 元素中的文本以等宽字体显示,文本保留空格和换行符。 <pre> 元素支持 HTML 中的全局属性和事件属性。 示例: <pre> pre 元素中的文本 以等宽字体显示, 并且同时保留 空格 和 换行符。 </pre&…...
2813. 子序列最大优雅度)
力扣每日一题(2024-06-13)2813. 子序列最大优雅度
基于官方题解,进行补充说明 给你一个长度为 n 的二维整数数组 items 和一个整数 k 。 items[i] [profiti, categoryi],其中 profiti 和 categoryi 分别表示第 i 个项目的利润和类别。 现定义 items 的 子序列 的 优雅度 可以用 total_profit distinct_…...

MySQL -- 优化
1. 查询优化 使用索引 示例:有一个包含数百万用户的表,名为 users,常见的查询是通过 email 字段查找用户。 CREATE INDEX idx_email ON users(email);通过创建索引 idx_email,SELECT * FROM users WHERE email exampleexample…...

学会python——密码校验(python实例三)
目录 1、认识Python 2、环境与工具 2.1 python环境 2.2 pycharm编译 3、纠正密码输入的格式问题 3.1 代码构思 3.2 代码示例 3.3 运行结果 4、总结 1、认识Python Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。 Python 的设计具有很强的可…...

【Python】中的X[:,0]、X[0,:]、X[:,:,0]、X[:,:,1]、X[:,m:n]、X[:,:,m:n]和X[: : -1]
Python中 x[m,n]是通过numpy库引用数组或矩阵中的某一段数据集的一种写法,m代表第m维,n代表m维中取第几段特征数据。 通常用法: x[:,n]或者x[n,:] X[:,0]表示对一个二维数组,取该二维数组第一维中的所有数据,第二维中取第0个数据。 X[0,:]使用类比前者。 举例说明: x[:,0…...

【Java基础】OkHttp 超时设置详解
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

巴西:海外媒体投放,大舍传媒实现企业与巴西媒体间的交流
引言 随着全球化的进程,海外市场的开拓对于企业的发展至关重要。巴西作为南美洲最大的经济体和人口大国,具有巨大的商机。在与巴西媒体的交流中,大舍传媒的投放成为了一种高效的宣传和合作途径。 巴西媒体的多样性 巴西媒体以其丰富多样的…...

MT7981B+MT7976C+MT7531A RF定频测试方法
1、从下面网址下载QA软件包,然后在WIN系统下安装QA环境。 https://download.csdn.net/download/zhouwu_linux/89428691?spm1001.2014.3001.5501 在WINDOWS 7系统下先安装WinPcap_4_1_3.exe。 2、搭建硬件环境,电脑先连接仪器,主板网络与电…...

支持微信支付宝账单,极空间Docker部署一个开箱即用的私人账本『cashbook』
支持微信支付宝账单,Docker部署一个开箱即用的私人账本『cashbook』 哈喽小伙伴好,我是Stark-C~ 不知道屏幕前的各位富哥富姐们有没有请一个专业的私人财务助理管理自己的巨额资产,我不是给大家炫耀,我在月薪300的时候就已经有了…...

golang循环变量捕获问题
在 Go 语言中,当在循环中启动协程(goroutine)时,如果在协程闭包中直接引用循环变量,可能会遇到一个常见的陷阱 - 循环变量捕获问题。让我详细解释一下: 问题背景 看这个代码片段: fo…...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...

FFmpeg 低延迟同屏方案
引言 在实时互动需求激增的当下,无论是在线教育中的师生同屏演示、远程办公的屏幕共享协作,还是游戏直播的画面实时传输,低延迟同屏已成为保障用户体验的核心指标。FFmpeg 作为一款功能强大的多媒体框架,凭借其灵活的编解码、数据…...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...
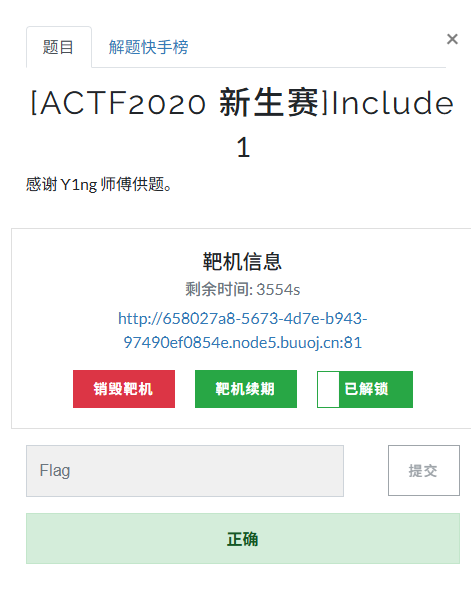
[ACTF2020 新生赛]Include 1(php://filter伪协议)
题目 做法 启动靶机,点进去 点进去 查看URL,有 ?fileflag.php说明存在文件包含,原理是php://filter 协议 当它与包含函数结合时,php://filter流会被当作php文件执行。 用php://filter加编码,能让PHP把文件内容…...

破解路内监管盲区:免布线低位视频桩重塑停车管理新标准
城市路内停车管理常因行道树遮挡、高位设备盲区等问题,导致车牌识别率低、逃费率高,传统模式在复杂路段束手无策。免布线低位视频桩凭借超低视角部署与智能算法,正成为破局关键。该设备安装于车位侧方0.5-0.7米高度,直接规避树枝遮…...

离线语音识别方案分析
随着人工智能技术的不断发展,语音识别技术也得到了广泛的应用,从智能家居到车载系统,语音识别正在改变我们与设备的交互方式。尤其是离线语音识别,由于其在没有网络连接的情况下仍然能提供稳定、准确的语音处理能力,广…...

算术操作符与类型转换:从基础到精通
目录 前言:从基础到实践——探索运算符与类型转换的奥秘 算术操作符超级详解 算术操作符:、-、*、/、% 赋值操作符:和复合赋值 单⽬操作符:、--、、- 前言:从基础到实践——探索运算符与类型转换的奥秘 在先前的文…...

图解JavaScript原型:原型链及其分析 | JavaScript图解
忽略该图的细节(如内存地址值没有用二进制) 以下是对该图进一步的理解和总结 1. JS 对象概念的辨析 对象是什么:保存在堆中一块区域,同时在栈中有一块区域保存其在堆中的地址(也就是我们通常说的该变量指向谁&…...

React核心概念:State是什么?如何用useState管理组件自己的数据?
系列回顾: 在上一篇《React入门第一步》中,我们已经成功创建并运行了第一个React项目。我们学会了用Vite初始化项目,并修改了App.jsx组件,让页面显示出我们想要的文字。但是,那个页面是“死”的,它只是静态…...