Springboot整合SpringCache+redis简化缓存开发
使用步骤:
1.引入依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-cache</artifactId>
</dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency>2.写配置,在配置文件配置使用redis作为缓存
spring.cache.type=redis
#指定缓存过期时间,单位毫秒
spring.redis.time-to-live=3600000引入的上面依赖后CacheAutoConfiguration会导入RedisCacheConfiguration,自动配置RedisCacheManager;
3.在启动类添加下面的注解开启缓存功能:
@EnableCaching
完成以上配置后,就可以使用注解为简化redis缓存管理,下面是一些常用到的注解:
@Cacheable:触发将数据保存到缓存中;
@CacheEvict:触发将数据从缓存中删除;
@CachePut:使用不影响方法执行的方式更新缓存;
@Caching:组合以上多个操作;
@CacheConfig:在类级别共享缓存的相同配置。
4.在需要缓存中的方法上添加对应的注解
@Cacheable({"category"})
@Override
public List<CategoryEntity> getLevel1Categorys() {//此处省略具体业务逻辑
}
如果使用上面的方式声明缓存,SpringCache会有以下默认行为:
- 如果缓存中已存在该数据,方法不再执行,直接查询缓存返回;
- key默认自动生成,生成的规则为缓存的名字::SimpleKey[](自主生成的key值),如下图

- 缓存的value值,默认使用jdk序列化机制,将序列化的数据存到redis;
- 默认ttl时间为-1,即永不过期。
如果要想自己定义一些规则,SpringCashe是支持的:
指定key名字,使用key属性,接受spEl表达式,spEl支持的表达式详见官方文档;
注意spEl表达式如果是普通字符串,一定要带单引才生效
普通字符串不带单引号,不生效:
@Cacheable(value = {"category"},key = "level1Categorys") ✘
普通字符串带单引号,生效:
@Cacheable(value = {"category"},key = "'level1Categorys'") ✔
指定缓存的存活时间ttl,在appliaction配置文件中配置,参见上文描述;
将数据保存为json格式,方便不同编程语言解析,如果想实现这一步,需添加自定义配置,参考如下代码:
@Configuration
@EnableCaching //将启动类的开启注解移到这方便统一管理
public class MyCacheConfig {@Beanpublic RedisCacheConfiguration cacheConfiguration(){RedisCacheConfiguration config=RedisCacheConfiguration.defaultCacheConfig();config=config.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()));config=config.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()));return config;}
}注意,如果开启了Spring Cache自定义缓存,那么Spring只会来读取自定义缓存的内容,对于自定义缓存中没有的内容,将会缺失。像上面代码只配置了key和value序列化规则,没有配置缓存过期时间,即使配置文件配置了,不会读取,为了避免这个问题,对上面的方法进行升级如下:
@Configuration
@EnableCaching
public class MyCacheConfig {@Beanpublic RedisCacheConfiguration cacheConfiguration(CacheProperties cacheProperties){RedisCacheConfiguration config=RedisCacheConfiguration.defaultCacheConfig();config=config.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()));config=config.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()));CacheProperties.Redis redisProperties= cacheProperties.getRedis();//如果配置文件配置了过期时间,则读取if(redisProperties.getTimeToLive()!=null){config=config.entryTtl(redisProperties.getTimeToLive());}if(redisProperties.getKeyPrefix()!=null){ //如果配置文件配置了key前缀,则读取config=config.prefixKeysWith(redisProperties.getKeyPrefix());}if(!redisProperties.isCacheNullValues()){// //如果配置文件配置了不缓存空值,则禁用空值缓存config=config.disableCachingNullValues();}if(!redisProperties.isUseKeyPrefix()){ //如果配置文件配置禁用禁用key,则禁用config=config.disableKeyPrefix();}return config;}
}附SpringCashce 在application.yml中的完整配置:
#上面还有spring在最左侧cache:type: redisredis:#设置缓存过期时间,单位mstime-to-live: 3600000#开启缓存null值,可防止缓存穿透cache-null-values: true#开启key前缀 不推荐,建议设置成falseuse-key-prefix: true#定义key前缀,不推荐,建议使用缓存分区#key-prefix: CACHE_如果想在修改数据时触发对缓存的删除,在方面上方添加@CacheEvict并批量缓存分区即可。
如果想在修改时对多个缓存进行批量操作,可以使用下面两种方法中任一种:
@Caching(evict = {@CacheEvict(value = {"category"},key = "'level1Categorys'"),@CacheEvict(value = {"category"},key = "'getCatelogJson'"),})value为设置缓存时指定的分区的名字,key为设置缓存时定义的方法名
方法二:
@CacheEvict(value = "category",allEntries = true)value为设置缓存时指定的分区的名字,allEntries设置为true,当标注有上面注解的方法被调用,数据修改时,指定缓存分区categorys的缓存都会被删除,当有请求再次添加缓存时,缓存分区categorys的所有数据会再次添加到缓存中。附设置缓存的方法
@Cacheable(value = {"category"},key = "'level1Categorys'")@Overridepublic List<CategoryEntity> getLevel1Categorys() {//此处省略方法具体实现,重点在缓存注解声明}@Cacheable(value = {"category"},key = "#root.methodName")@Overridepublic Map<String, List<Catelog2Vo>> getCatelogJson() {//此处省略方法具体实现,重点在缓存注解声明}PS:存储同一类型的数据,可放到到同一分区,即@Cacheable注解里value的值。如此在redis缓存分区就有层次分明的结构了,这在缓存多的情况下,非常有用,能快速找到相关缓存,方便统一管理。

@注意@CacheEvict采用的是缓存一致性里的失效模式,@CachePut属于双写模式。
SpringCache有其优越之处,但存在一定的不足。
如SpringCache默认是不加锁的,要想解决缓存击穿问题,在使用时只有@Cacheable注解可配置sync属性的值为true加锁,其他注解不支持配置加锁,示例:
@Cacheable(value = {"category"},key = "'level1Categorys'",sync = true)@Overridepublic List<CategoryEntity> getLevel1Categorys() {}因此,要结合具体业务情况来看是否采用。
SpringCache适用场景:常规数据(读多写少,即时性、一致性要求不高的数据)
而对于即时性和数据一致性要求高的场景需要进行特殊设计,如引入读写锁,引入canal。
相关文章:
Springboot整合SpringCache+redis简化缓存开发
使用步骤: 1.引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-cache</artifactId> </dependency><dependency><groupId>org.springframework.boot</groupI…...

关于EOF标识符
EOF的概念 EOF是C语言中表示文件结束的标志符号,通常被定义为-1,它用于指示已到达文件的末尾或输入流的末尾。 EOF的使用 在输入操作中,EOF常常用于判断是否到达了文件末尾或输入流末尾,以便终止读取操作。例如,在使…...

家用洗地机排行榜前十名:2024十大王牌机型精准种草
最近很多人都在问我洗地机相关的问题,不愧是改善家庭生活品质的“三神器”之一。洗地机依靠其清洁力和清洁效率吸引了越来越多的平时需要做家务人群的兴趣,为了解答大家关于洗地机的各种疑问,我把市面上目前非常火爆的洗地机型号和参数都进行…...

【Chrome插件】如何在Chrome插件开发中处理复杂数据结构的存储
最近俺在接触 Chrome 插件开发,需要把一个数据存放到浏览器的存储中。这个数据结构有点复杂,它包含一个 Map 和一个数组。我使用 chrome.storage.local API来存储这个数据,然后在另一个地方获取数据。保存数据的代码并没有报错,但…...
:使用 MySQL 检索数据)
MySQL 保姆级教程(二):使用 MySQL 检索数据
使用 MySQL 3.2 选择数据库 使用数据库: 输入: USE 数据库名;输出: Database changed分析: 不返回任何结果,显示某种形式的通知 例如: 使用 crashcourse 数据库 use crashcourse; 3.3 了解数据库和表 列出所有的数据库: 输入: SHOW DATABASES;输出: --------…...
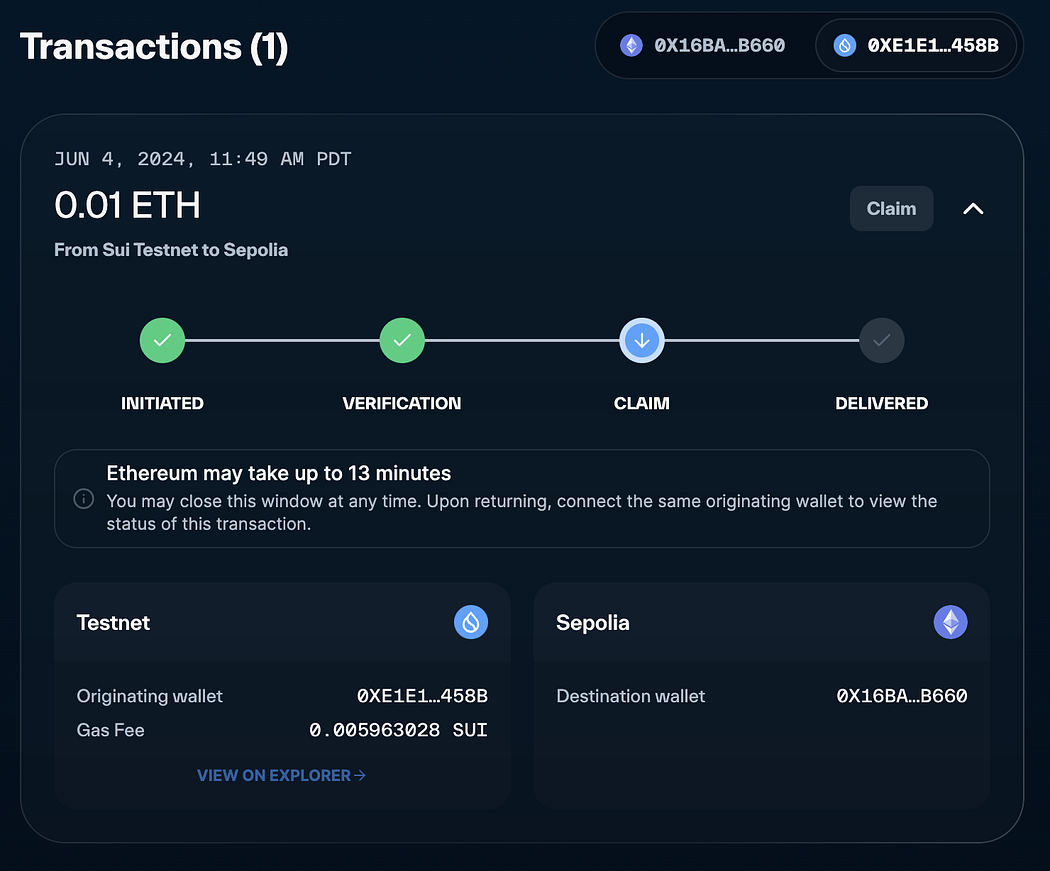
Sui Bridge在测试网上线并推出10万SUI激励计划
是一种为Sui设计的原生桥接协议,专门用于在Sui与其他网络之间桥接资产和数据。今天,Sui Bridge宣布在测试网上线。作为一种原生协议,Sui Bridge能够在Ethereum和Sui之间轻松且安全地转移ETH、wBTC、USDC和USDT,使其成为Sui基础设施…...
Spring系统学习 - Bean的作用域
bean作用域介绍 Spring框架提供了不同的作用域来管理Bean的生命周期和可见性,这对于控制不同类型的组件和处理并发请求尤其重要。 singleton(默认): 每个Spring IoC容器只有一个bean实例。当容器创建bean后,它会被缓存…...
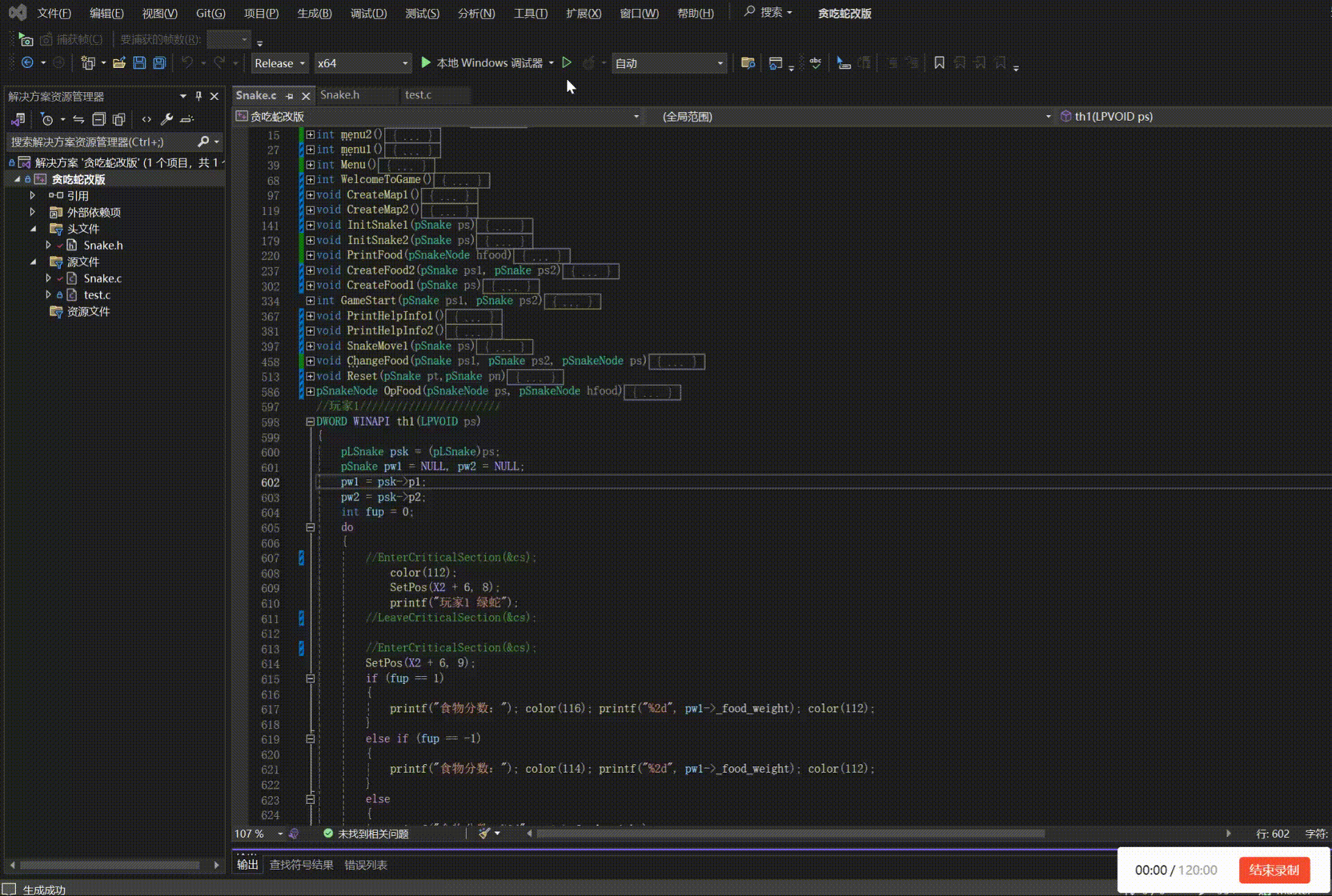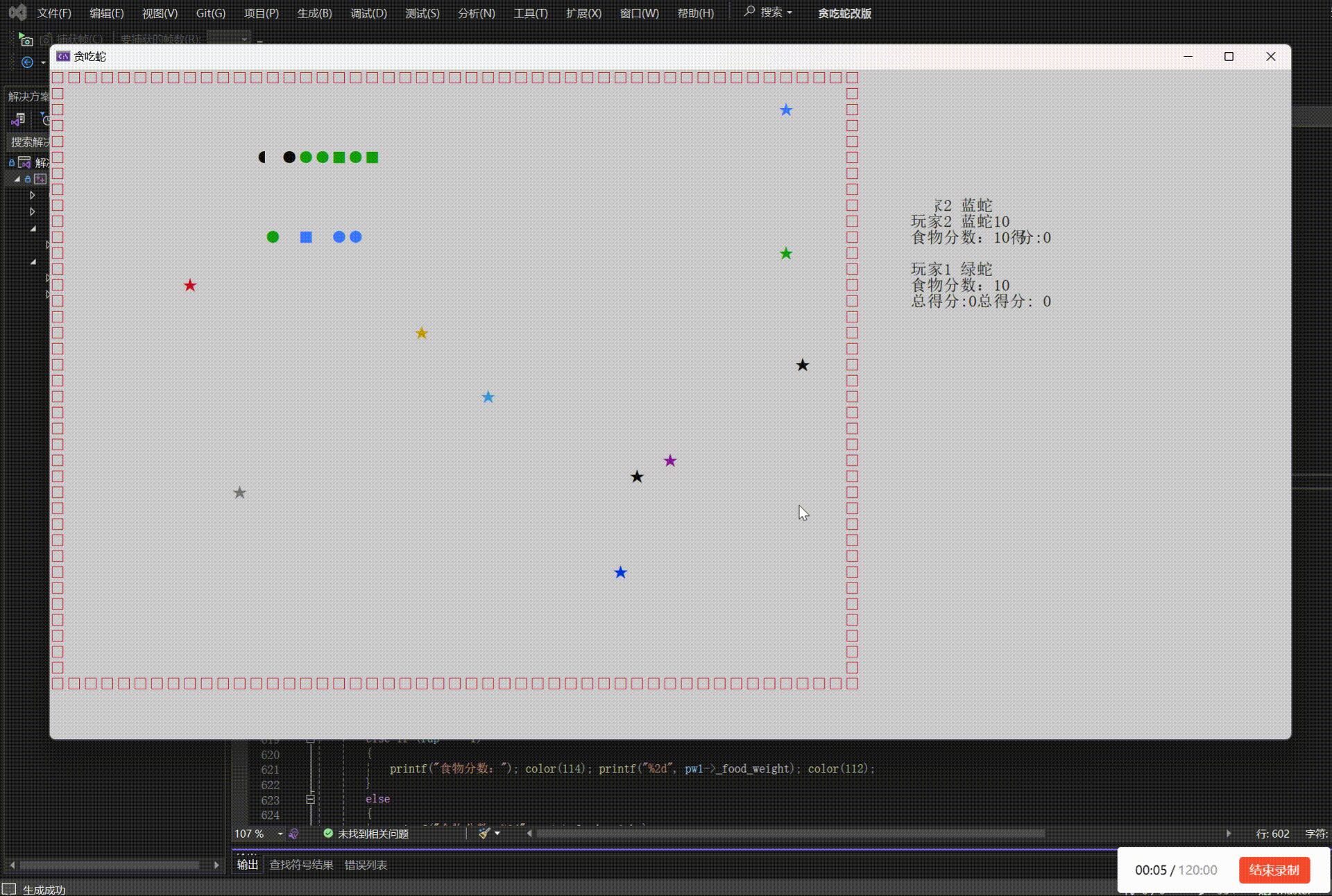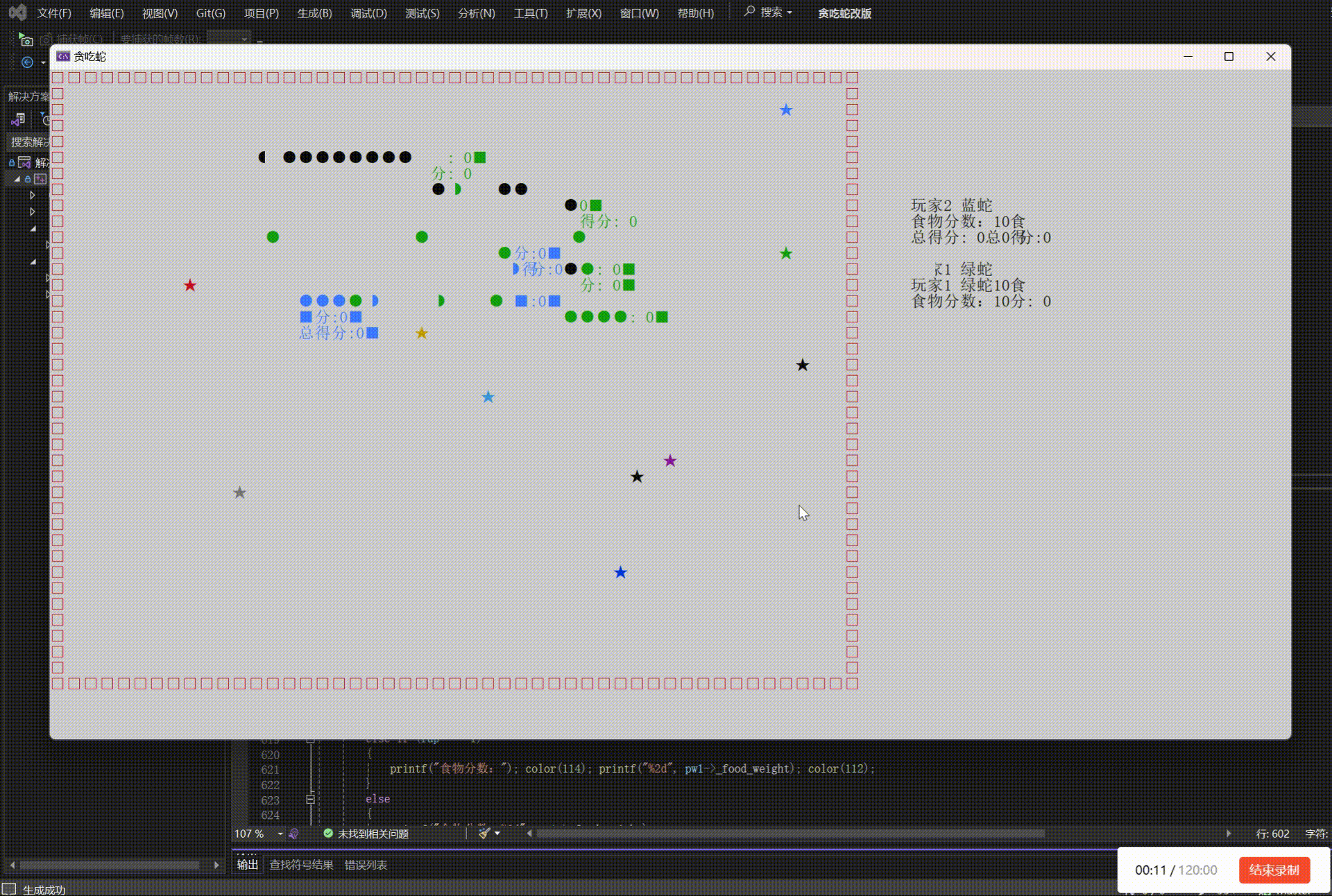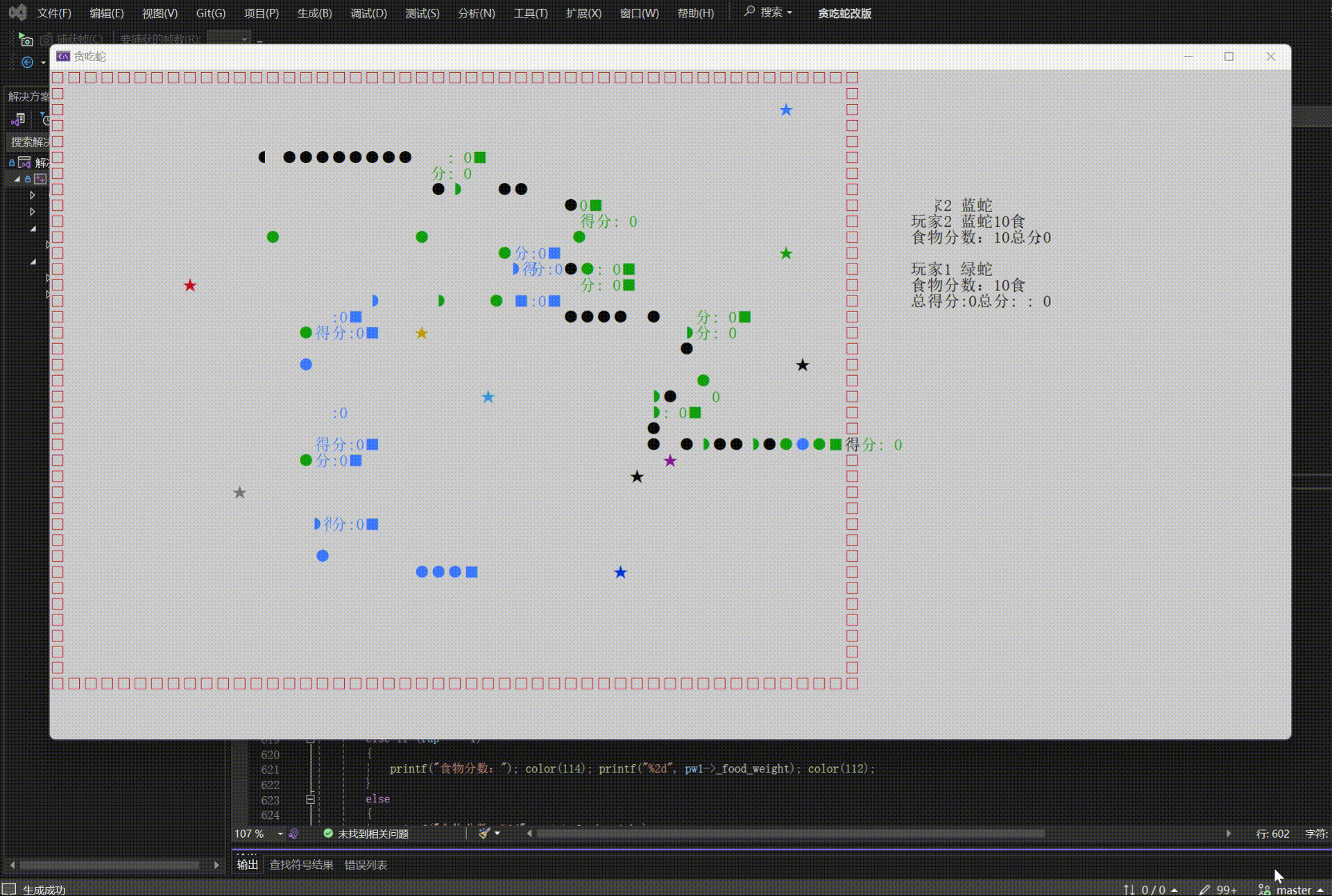
贪吃蛇双人模式设计(2)
敲上瘾-CSDN博客控制台程序设置_c语言控制程序窗口大小-CSDN博客贪吃蛇小游戏_贪吃蛇小游戏csdn-CSDN博客 一、功能实现: 玩家1使用↓ → ← ↑按键来操作蛇的方向,使用右Shift键加速,右Ctrl键减速玩家2使用W A S D按键来操作蛇的方向&am…...

mysql什么时候不需要建立索引
WHERE 条件,GROUP BY,ORDER BY 里用不到的字段,索引的价值是快速定位,如果起不到定位的字段通常是不需要创建索引的,因为索引是会占用物理空间的。字段中存在大量重复数据,不需要创建索引,比如性…...

热门开源项目推荐:技术与地址概览
随着开源项目的不断兴起,越来越多的优秀项目涌现出来,为开发者们提供了丰富的资源和灵感。在此,我将为大家推荐几个热门的开源项目,并附上它们的开源地址,以供大家参考和了解。 1. TensorFlow 项目简介: …...
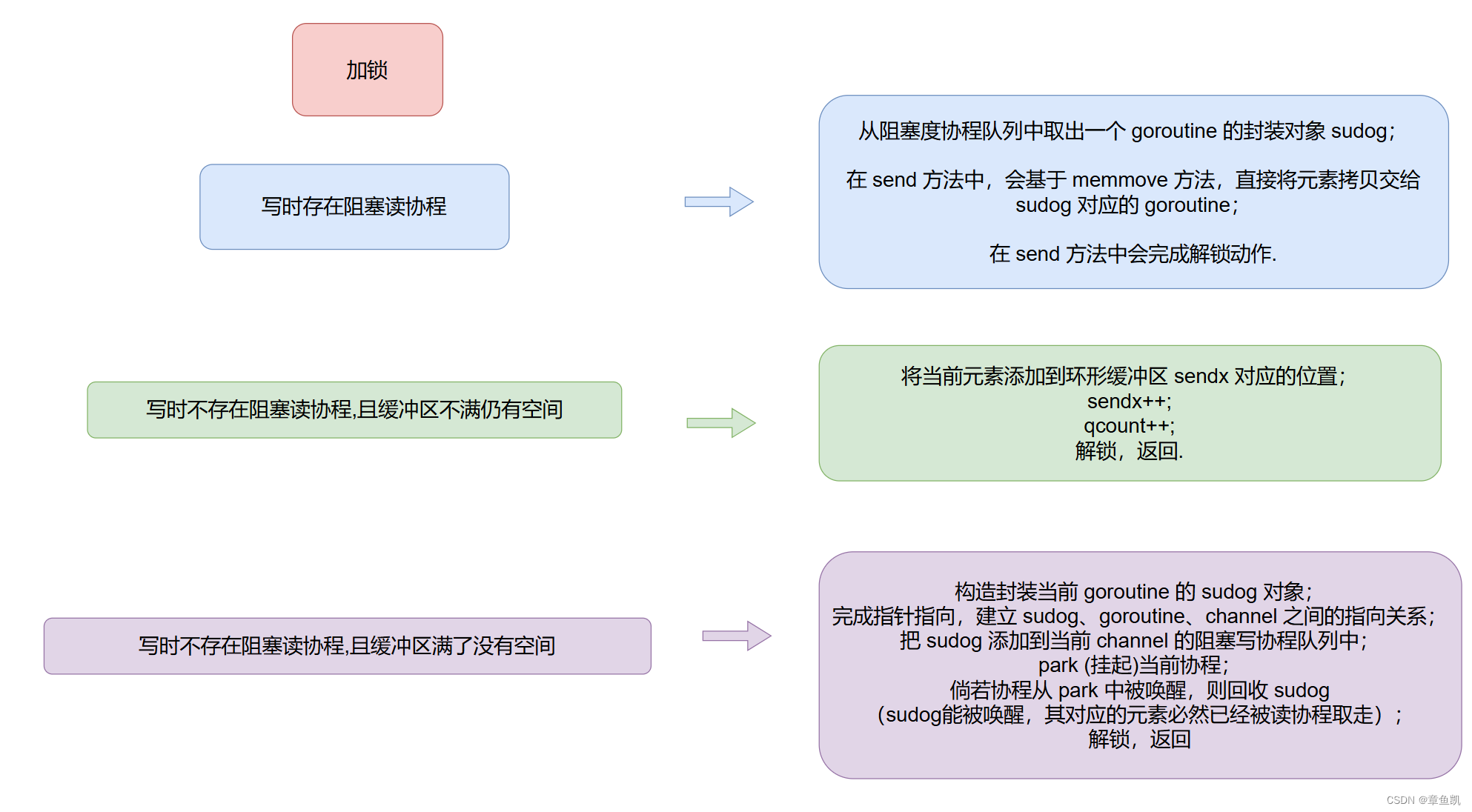
Golang的channel
目录 基本使用 channel 数据结构 阻塞的协程队列 协程节点 构建 channel 写流程 读流程 非阻塞与阻塞 closechan(关闭) 基本使用 创建无缓存 channel c : make(chan int) //创建无缓冲的通道 cc : make(chan int,0) //创建无缓冲的通道 c 创建有缓存 channel c : m…...
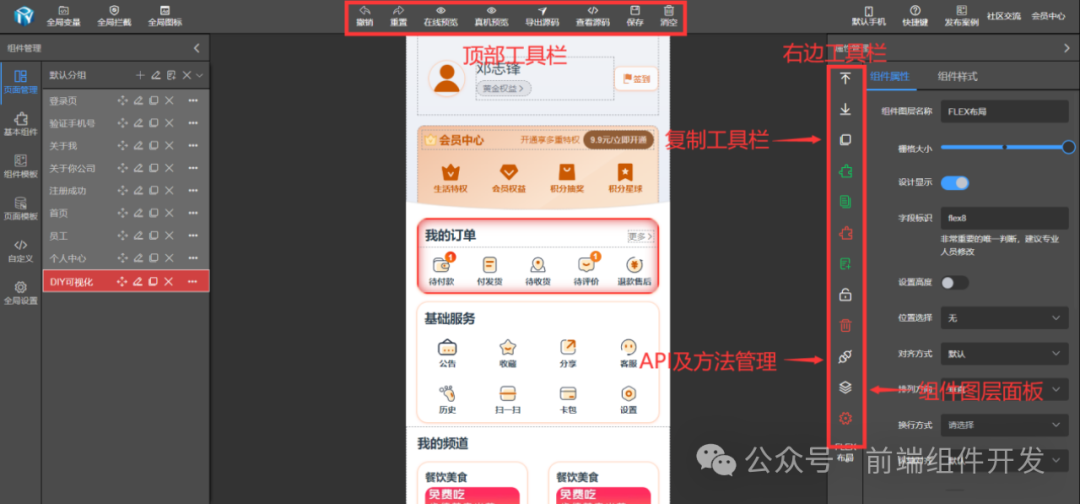
DIYGW可视化开发工具:微信小程序与多端应用开发的利器
一、引言 随着移动互联网的飞速发展,微信小程序以其轻便、易用和跨平台的特点受到了广泛关注。然而,微信小程序的开发相较于传统的H5网页开发,在UI搭建和交互设计上存在一定的挑战。为了应对这些挑战,开发者们一直在寻找更加高效…...

docker——基础知识
简介 一、什么是虚拟化和容器化 实体计算机叫做物理机,有时也称为寄主机; 虚拟化:将一台计算机虚拟化为多台逻辑计算机; 容器化:一种虚拟化技术,操作系统的虚拟化;将用户空间软件实…...

SAP MMRV/MMPV 物料账期月结月底月初开关
公告:周一至周五每日一更,周六日存稿,请您点“关注”和“在看”,后续推送的时候不至于看不到每日更新内容,感谢。 这是一条刮刮乐,按住全部选中:点关注的人最帅最美,欢迎࿱…...

五分钟看懂如何解决FP独立站的广告投放问题
在数字化时代的浪潮中,跨境电商的独立站成为了商家们的新宠。与传统的电商平台相比,独立站在品牌建设、市场定位以及客户体验上提供了更多的自由度和创新空间。然而,这些独立站尤其是销售FP产品的站点,在广告投放上遇到了重重障碍…...

学习分享-FutureTask
前言 今天再改简历的时候回顾了之前实习用到的FutureTask,借此来回顾一下相关知识。 FutureTask 介绍 FutureTask 是 Java 并发包(java.util.concurrent)中的一个类,用于封装异步任务。它实现了 RunnableFuture 接口࿰…...

Javaweb02-XML概述
第一章 XML概述 1.XML基本概念 什么是xml? **a.**引入的原因:为了解决不同不同语言之间的数据传输的格式不同 **b.**概念:XML是一种可扩展标记语言,适用于不同数据之间的数据交换 **c.**XML文档:通过元素的嵌套&a…...

Linux shell编程基础
Shell 是一个用 C 语言编写的程序,它是用户使用 Linux 的桥梁。Shell 既是一种命令语言,又是一种程序设计语言。Shell 是指一种应用程序,这个应用程序提供了一个界面,用户通过这个界面访问 Linux 内核的服务。 Shell 脚本&#x…...
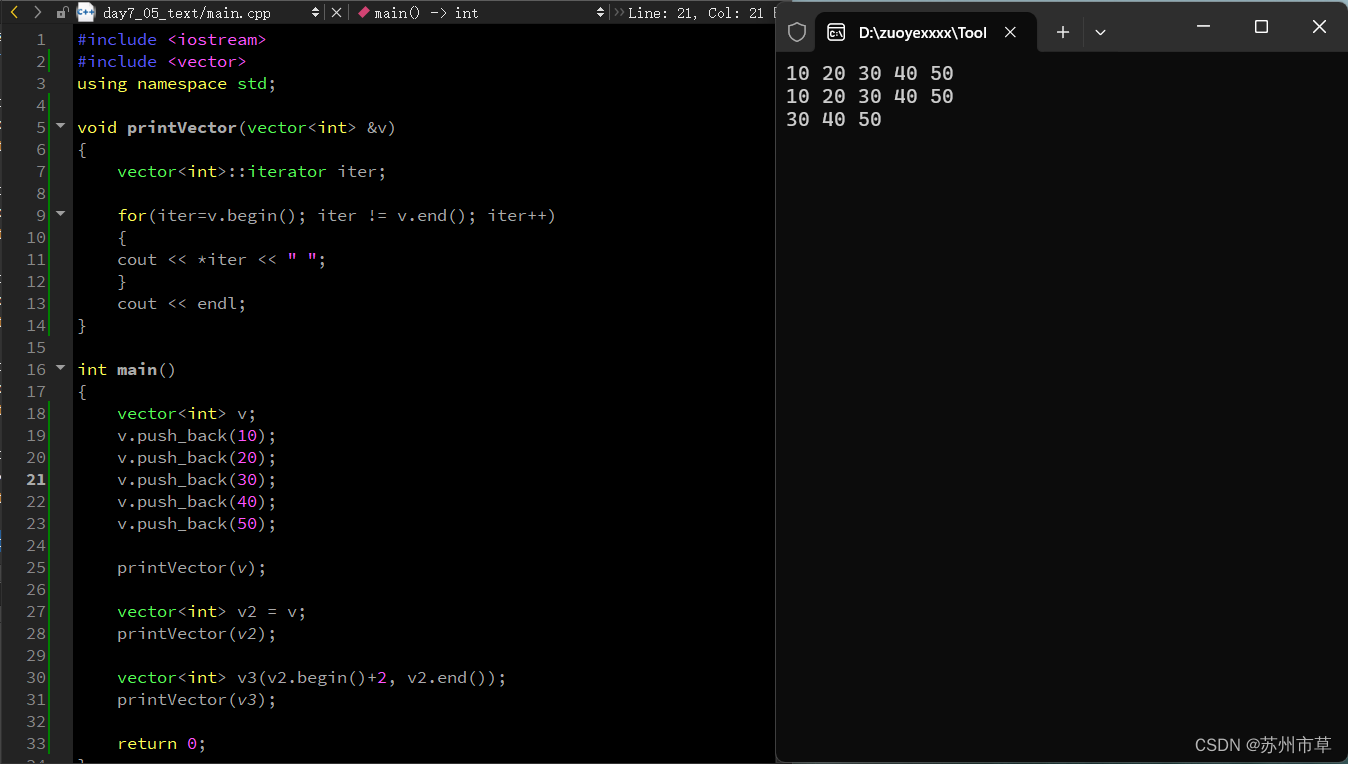
2024.6.12 作业 xyt
今日课堂练习:vector构造函数 #include <iostream> #include <vector> using namespace std;void printVector(vector<int> &v) {vector<int>::iterator iter;for(iterv.begin(); iter ! v.end(); iter){cout << *iter <<…...

QTTabBar在重置Internet Explorer后失效
网上常见的办法是: 打开IE浏览器>>设置>>Internet选项>>高级。勾选启用第三方浏览器扩展,重启后生效。 打开IE浏览器-设置–管理加载项,启用QTTabBar。 实际在Win10上使用的时候会遇到点开IE自动跳转到Edge的问题。这时…...

浅谈 React Hooks
React Hooks 是 React 16.8 引入的一组 API,用于在函数组件中使用 state 和其他 React 特性(例如生命周期方法、context 等)。Hooks 通过简洁的函数接口,解决了状态与 UI 的高度解耦,通过函数式编程范式实现更灵活 Rea…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...

(十)学生端搭建
本次旨在将之前的已完成的部分功能进行拼装到学生端,同时完善学生端的构建。本次工作主要包括: 1.学生端整体界面布局 2.模拟考场与部分个人画像流程的串联 3.整体学生端逻辑 一、学生端 在主界面可以选择自己的用户角色 选择学生则进入学生登录界面…...

黑马Mybatis
Mybatis 表现层:页面展示 业务层:逻辑处理 持久层:持久数据化保存 在这里插入图片描述 Mybatis快速入门 
Vue3 + Element Plus + TypeScript中el-transfer穿梭框组件使用详解及示例
使用详解 Element Plus 的 el-transfer 组件是一个强大的穿梭框组件,常用于在两个集合之间进行数据转移,如权限分配、数据选择等场景。下面我将详细介绍其用法并提供一个完整示例。 核心特性与用法 基本属性 v-model:绑定右侧列表的值&…...

MMaDA: Multimodal Large Diffusion Language Models
CODE : https://github.com/Gen-Verse/MMaDA Abstract 我们介绍了一种新型的多模态扩散基础模型MMaDA,它被设计用于在文本推理、多模态理解和文本到图像生成等不同领域实现卓越的性能。该方法的特点是三个关键创新:(i) MMaDA采用统一的扩散架构…...

跨链模式:多链互操作架构与性能扩展方案
跨链模式:多链互操作架构与性能扩展方案 ——构建下一代区块链互联网的技术基石 一、跨链架构的核心范式演进 1. 分层协议栈:模块化解耦设计 现代跨链系统采用分层协议栈实现灵活扩展(H2Cross架构): 适配层…...

镜像里切换为普通用户
如果你登录远程虚拟机默认就是 root 用户,但你不希望用 root 权限运行 ns-3(这是对的,ns3 工具会拒绝 root),你可以按以下方法创建一个 非 root 用户账号 并切换到它运行 ns-3。 一次性解决方案:创建非 roo…...

【git】把本地更改提交远程新分支feature_g
创建并切换新分支 git checkout -b feature_g 添加并提交更改 git add . git commit -m “实现图片上传功能” 推送到远程 git push -u origin feature_g...
)
.Net Framework 4/C# 关键字(非常用,持续更新...)
一、is 关键字 is 关键字用于检查对象是否于给定类型兼容,如果兼容将返回 true,如果不兼容则返回 false,在进行类型转换前,可以先使用 is 关键字判断对象是否与指定类型兼容,如果兼容才进行转换,这样的转换是安全的。 例如有:首先创建一个字符串对象,然后将字符串对象隐…...