MySQL: 索引与事务
文章目录
- 1. 索引 (Index)
- 1.1 概念
- 1.2 作用
- 1.3 使用场景
- 1.4 索引的使用
- 1.5 索引的使用案例 (不要轻易尝试)
- 1.6 索引背后的数据结构
- 1.7 重点总结
- 2.事务
- 2.1 为什么要使用事务
- 2.2 事务的概念
- 2.3 事务的使用
- 2.4 对事务的理解
- 2.5 事务的基本特性
1. 索引 (Index)
1.1 概念
索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引,并指定索引的类型,各类索引有各自的数据结构实现。
对索引的理解
- 数据库中的索引可以理解为书目录 (跟C/Java中的下标有所区别) , 为了加快查询的速度.
- 数据库中select的查询操作, 默认是按照 “遍历” 的方式来完成查询操作的, 消耗时间很大.
- "索引"就相当于在数据库中构建一个特殊的 “目录” , 通过这种数据结构, 加快查询速度, 尽可能避免针对数据进行遍历操作, 大大加快了查询速度.
- “索引” 虽然会加快查询速度, 但是需要付出一定的代价
1)引入索引会消耗额外的存储空间
2)引入索引后确实会提高查询的效率, 但是可能会影响到增删改的效率(可能变快, 也可能变慢, 也可能不变). - 索引有利有弊, 在实际开发中, 推荐使用索引
1)硬盘往往不是主要消耗矛盾
2)对于增删改不一定都是负面影响, 也有很多正面效果, 另一方面, 很多业务场景当中, 查询的场景比增删改要高得多…
1.2 作用
- 数据库中的表、数据、索引之间的关系,类似于书架上的图书、书籍内容和书籍目录的关系。
- 索引所起的作用类似书籍目录,可用于快速定位、检索数据。
- 索引对于提高数据库的性能有很大的帮助。

1.3 使用场景
要考虑对数据库表的某列或某几列创建索引,需要考虑以下几点:
- 数据量较大,且经常对这些列进行条件查询。
- 该数据库表的插入操作,及对这些列的修改操作频率较低。
- 索引会占用额外的磁盘空间。
满足以上条件时,考虑对表中的这些字段创建索引,以提高查询效率。反之,如果非条件查询列,或经常做插入、修改操作,或磁盘空间不足时,不考虑创建索引。
1.4 索引的使用
创建主键约束(PRIMARY KEY)、唯一约束(UNIQUE)、外键约束(FOREIGN KEY)时,会自动创建对应列的索引。
-- 查看索引
show index from 表名;-- 案例: 查看学生表已有的索引
show index from student;
+---------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+---------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| student | 0 | PRIMARY | 1 | id | A | 8 | NULL | NULL | | BTREE | | | YES | NULL |
| student | 1 | classes_id | 1 | classes_id | A | 2 | NULL | NULL | YES | BTREE | | | YES | NULL |
+---------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
-- Key_name 这一列是索引名字, 如primary是给主键列自动生成的索引
-- 主键索引(不需要手动创建, 只需要建表的时候, 制定了主键就会自动生成主键索引)
-- column_name 这一列是索引创建的依据列名
-- 创建索引
-- 对于非主键、非唯一约束、非外键的字段,可以创建普通索引
create index 索引名 on 表名(字段名);-- 案例:创建班级表中,name字段的索引
create table classes(
id int primary key auto_increment,
name varchar(20),
`desc` varchar(100));desc classes;
+-------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-----+---------+----------------+
| id | int | NO | PRI | NULL | auto_increment |
| name | varchar(20) | YES | | NULL | |
| desc | varchar(100) | YES | | NULL | |
+-------+--------------+------+-----+---------+----------------+create index idx_classes_name on classes(name);desc classes;
+-------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-----+---------+----------------+
| id | int | NO | PRI | NULL | auto_increment |
| name | varchar(20) | YES | MUL | NULL | |
| desc | varchar(100) | YES | | NULL | |
+-------+--------------+------+-----+---------+----------------+
-- 可以看到Key这一列的变化
注意:
创建索引是一个危险操作, 如果针对空表或者表里面的数据量很少(几千, 几万…) 创建索引并无大碍, 一旦表的数据量比较大, 千万级别的数据量, 此时创建索引就可能会触发大量的硬盘IO, 直接把机器搞得卡死了…
所以, 在最初创建表的时候, 有需要哪些索引就需要提前规划好, 创建好…
解决方法: 万一某个表需要索引, 但是没有提前创建, 可以再申请一个服务器, 把表创建好, 再导入数据.
-- 删除索引(只能删除自建索引)
drop index 索引名 on 表名;-- 案例:删除班级表中name字段的索引
drop index idx_classes_name on classes;
1.5 索引的使用案例 (不要轻易尝试)
准备测试表:
-- 创建用户表
DROP TABLE IF EXISTS test_user;
CREATE TABLE test_user (id_number INT,name VARCHAR(20) comment '姓名',age INT comment '年龄',create_time timestamp comment '创建日期'
);
准备测试数据,批量插入用户数据(操作耗时较长,约在1小时+):
-- 构建一个8000000条记录的数据
-- 构建的海量表数据需要有差异性,所以使用存储过程来创建, 拷贝下面代码就可以了,暂时不用理解-- 产生名字
drop function if exists rand_name;
delimiter $$
create function rand_name(n INT, l INT)
returns varchar(255)
begindeclare return_str varchar(255) default '';declare i int default 0;while i < n do if i=0 thenset return_str = rand_string(l);elseset return_str =concat(return_str,concat(' ', rand_string(l)));end if;set i = i + 1;end while;return return_str;end $$
delimiter ;-- 产生随机字符串
drop function if exists rand_string;
delimiter $$
create function rand_string(n INT)
returns varchar(255)
begindeclare lower_str varchar(100) default'abcdefghijklmnopqrstuvwxyz';declare upper_str varchar(100) default'ABCDEFJHIJKLMNOPQRSTUVWXYZ';declare return_str varchar(255) default '';declare i int default 0;declare tmp int default 5+rand_num(n);while i < tmp do if i=0 thenset return_str
=concat(return_str,substring(upper_str,floor(1+rand()*26),1));elseset return_str
=concat(return_str,substring(lower_str,floor(1+rand()*26),1));end if;set i = i + 1;end while;return return_str;end $$
delimiter ;-- 产生随机数字
drop function if exists rand_num;
delimiter $$
create function rand_num(n int)
returns int(5)
begindeclare i int default 0;
set i = floor(rand()*n);
return i;
end $$
delimiter ;-- 向用户表批量添加数据
drop procedure if exists insert_user;
delimiter $$
create procedure insert_user(in start int(10),in max_num int(10))
begin
declare i int default 0;
set autocommit = 0; repeatset i = i + 1;insert into test_user values ((start+i) ,rand_name(2,
5),rand_num(120),CURRENT_TIMESTAMP);until i = max_numend repeat;commit;
end $$
delimiter ;-- 执行存储过程,添加8000000条用户记录
call insert_user(1, 8000000);
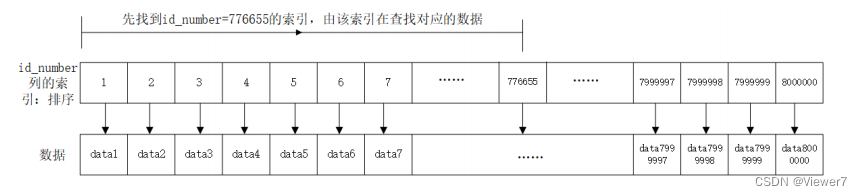
查询 id_number 为778899的用户信息:
-- 可以看到耗时4.93秒,这还是在本机一个人来操作
-- 在实际项目中,如果放在公网中,假如同时有1000
个人并发查询,那很可能就死机。
select * from test_user where id_number=556677;

可以使用explain来进行查看SQL的执行:
explain select * from test_user where id_number=556677;
*************************** 1. row ***************************id: 1select_type: SIMPLEtable: test_usertype: ALL
possible_keys: NULLkey: NULL <== key为null表示没有用到索引key_len: NULLref: NULLrows: 6Extra: Using where
1 row in set (0.00 sec)
为提供查询速度,创建 id_number 字段的索引:
create index idx_test_user_id_number on test_user(id_number);
换一个身份证号查询,并比较执行时间:
select * from test_user where id_number=776655;
可以使用explain来进行查看SQL的执行:
explain select * from test_user where id_number=776655;
*************************** 1. row ***************************id: 1select_type: SIMPLEtable: test_usertype: ref
possible_keys: idx_test_user_id_numberkey: idx_test_user_id_number <= key用到了idx_test_user_id_numberkey_len: NULLref: constrows: 1Extra: Using where
1 row in set (0.00 sec)
索引保存的数据结构主要为B+树,及hash的方式, 对这方面感兴趣可给个关注, 后面会持续更新.
1.6 索引背后的数据结构
"构建索引"就是引入一些数据结构, 对数据进行存储, 从而提高查找的速度.
我们在学习数据结构的时候可以知道, 二叉搜索树和哈希表都可以提高数据的查找速度, 但是并不适合给数据库做索引, 原因如下:
- 二叉搜索树, 最大的问题在于"二叉" 当保存数据的元素较多的时候, 就会使整个树的高度变得比较高, 查询时, 比较次数就会变多, 会伤硬盘.
- 哈希表, 最大问题在于只能进行"相等" 查询, 无法进行 > < 这样的"范围查询", 也无法进行like的模糊查询
B树(B- 树), 是N叉搜索树, 每个节点就能有多个子树了(树的度是N), 这样就会降低树的高度, 每个节点上会存多个key值, 保存了N个key值就可以延伸出N + 1个子树了. 此时, 当我们查询时, 针对每个节点, 都需要比较多次, 才能确定下一步走哪个区间了. 此时虽然高度降低了, 但是比较次数变多了, 但是还是会比二叉树有优势, 每次访问节点时, 一次硬盘IO就可以了, 剩下的比较在内存中进行. B树主要目的不是减少比较次数, 而是降低内存IO次数来提升效率.
B+树, 为数据库量身定制的数据结构~~针对B树又一步改进了,
1)B+树也是一个N叉搜索树, 不同于B树, B+树有N个key划分出N个区间.
2)父节点的key值会在下一个子节点再次出现, 是以子节点最大值出现的, 看是浪费空间, 实际上非常有用.
3)B+ 树把子叶结点像链表一样首尾相连了, 类似双向链表的结构, 进行范围查询时就会非常方便了. 每次查询, 经历的IO次数和比较次数都是差不多的, 查询的开销比较稳定. (稳定的优势很大, 意味着开发成本容易被预估出来…)
4)由于B+ 树叶子结点是全集, 非叶子节点上不必存储"数据行", 只需要存储索引列的key即可, 使得非叶子节点消耗的空间比较少. 甚至可以直接加载到内存中进行, 有进一步减少了硬盘IO.
1.7 重点总结
经典面试题: 谈谈对索引的理解
1.索引是什么?解决了什么问题?
索引相当于书的目录, 能够提高查询的速度…
2.索引付出了什么代价?
1)需要更多的存储空间
2)可能会影响增删改的速率(不一定全都是负面影响)
整体来说, 索引利大于弊, 日常开发还是要常用
3.如何使用sql操作索引, 是否有注意事项.
1)show index from 表名; -- 查看索引 (主键, 外键, unique 会自动生成索引, 不可删除)
2)create index 索引名 on 表名(列名); -- 给指定列创建索引, 可以删除
3)drop index 索引名 on 表名; -- 删除索引
注意事项
索引是针对列来创建的, 后续查询的时候, 查询条件使用的列和索引列匹配, 才能使索引生效, 才能提高查询速率
针对一个比较大的表 (有上千万条数据) , 创建或者删除索引是非常危险的, 可能会触发大量的硬盘IO, 把机器高挂了
4.索引背后的数据结构 => B+ 树特点和优势
特点:
1)N叉搜索树, 每个节点上包含N个key, 划分出N个区间
2)每个父节点中的元素, 都会下沉到子节点中, 作为孩子节点中最大的角色来存在
3)叶子结点这一层就构成了数据集合的全集
4)使用类似于链表这样的结构, 把叶子结点串起来
优势:
1)N叉搜索树, 高度比较低, 降低了硬盘IO的次数
2)范围查询非常高效且方便
3)所有的查询都落在叶子结点上, 开销非常稳定, 容易预估成本
4)叶子结点存储数据行, 非叶子节点只存储索引列的key 值, 非叶子节点占据空间小, 可以加载到内存中进一步减少查询时IO的访问次数
2.事务
2.1 为什么要使用事务
准备测试表
create table accout(id int primary key auto_increment,name varchar(20) comment '账户名称',money decimal(11,2) comment '金额'
);
insert into accout(name, money) values
('阿里巴巴', 5000),
('四十大盗', 1000);
比如说,四十大盗把从阿里巴巴的账户上偷盗了2000元
-- 阿里巴巴账户减少2000
update accout set money=money-2000 where name = '阿里巴巴';
-- 四十大盗账户增加2000
update accout set money=money+2000 where name = '四十大盗';
假如在执行以上第一句SQL时,出现网络错误,或是数据库挂掉了,阿里巴巴的账户会减少2000,但是四十大盗的账户上就没有了增加的金额。
解决方案:使用事务来控制,保证以上两句SQL要么全部执行成功,要么全部执行失败。
2.2 事务的概念
事务指逻辑上的一组操作,组成这组操作的各个单元,要么全部成功,要么全部失败。
在不同的环境中,都可以有事务。对应在数据库中,就是数据库事务。
2.3 事务的使用
(1) 开启事务: start transaction;
(2) 执行多条SQL语句
(3) 回滚或提交: rollback/commit;
说明:rollback即是全部失败,commit即是全部成功。
start transaction;
-- 阿里巴巴账户减少2000
update accout set money=money-2000 where name = '阿里巴巴';
-- 四十大盗账户增加2000
update accout set money=money+2000 where name = '四十大盗';
commit;
2.4 对事务的理解
开启事务后, 并不是一起执行语句, 还是一条一条执行的, 当执行到事物的墨条语句发生错误就会自动进行"还原操作", 相当于把前面执行过的sql给撤销, 最终的效果好像是一个都没执行的效果. 这样的机制也称为"回滚" (rollback).
同时, 也把事务支持的上述的"特性" 称为 “原子性”
数据库如何知道怎样回滚的?(前面的SQL语句对表做出了怎样的修改?)
数据库内部存在一系列的 “日志体系”, 记录到文件中
当开启事务后, 此时每一步执行的SQL语句对数据的修改情况就会记录到文件里面, 后续如果需要回滚, 就可以参考之前记录的内容进行还原了.
这样, 我们就可以应对防止回滚操作时"程序崩溃" 或者 “主机掉电” 的情况造成数据丢失.
事务的核心就是原子性, 能够解决批量执行SQL语句 (转账, 点外卖, 记录学生信息…) 时造成的错误
2.5 事务的基本特性
1.原子性 (最重要)
2.一致性 描述的是事务执行前和执行后, 数据库中的数据都是 “合法状态” , 不会出现非法的临时结果状态. (类似于 “对账” 的过程)
3.持久性 事务执行完毕之后, 就会修改硬盘上的数据, 事务是持久生效的.
4.隔离性(最难)
隔离性, 描述了多个实物并发执行的时候, 相互之间产生影响是怎样的.
并发执行, MySQL是一个 “客户端-服务器” 结构的程序, 一个服务器, 通常会给多个客户端同时提供服务, 因此, 多个客户端就同时给这个服务器提交事务来执行, 与之相对, 服务器就需要同时执行这多个事务, 此时就是 “并发” 执行的.
如果这些同事执行的事务对同一张表进行增删改查, 就会引入一些问题, 问题如下
1)脏读
有两个事务A和B并发执行, A在对数据修改的过程中, B去读取这个表的数据, B读取完成后, A又把数据给改了, 就导致B读取的数据不是一个正确的想要的数据, 而是读到了A执行过程中的一个临时数据, 这个临时数据就称作"脏数据". (数据过期了, 过时了)
如何去解决这个问题呢?
我们可以在执行事务A时进行加锁, 让事务B在事务A执行时不能读表中的数据, 具体如何加锁会在后面的博客更新, 希望大家持续关注…
2)不可重复读
有三个事务, 事务A, B, C.当事务A执行修改操作完成后, 提交数据. 事务B开始执行, 读取事务A修改后的数据, 在执行过程中, 事务C执行, 修改事务A修改后的数据, 完成后并提交数据(此时事务B并未结束), 这时, 事务B在执行时读到的数据就会和之前的不一样, 这个过程叫做"不可重复读". (事务B多次读取到的结果不一样, 如果是多个事务读到的结果不一样属于正常情况)
如何解决这个问题?
给读操作加锁, 当一个事物读取数据时, 其他事务不能对这个数据进行修改
3)幻读
相当于不可重复读的特殊情况
有一个事务A在读取数据的时候, 事务B对当前数据进行增加或者删除, 这就造成事务A在多次读取的时候, 得到的结果不一样, 就称作幻读. (相对于不可重复读没那么严重)
如何解决这个问题?
规定当一个事物读取数据时, 其他事务不进行任何操作, 这样的操作就成为"串行化" (如: 当多个客户端同时提交多个事务过来, 我们一个一个执行事务)
MySQL中提供了四个隔离级别, 通过配置文件可以来设置当前服务器的隔离级别, 根据实际需要来选择
设置不同的隔离级别, 就会使事物之间的并发执行的影响产生不同的差别, 从而影响到上述的三个情况
并发程度越高, 执行速度越快; 并发程度越低, 执行速度越慢
1)read uncommitted (读未提交)
这种情况下, 一个事物可能读取另一个事务未提交的数据, 此时就可能产生脏读, 不可重复读, 幻读 三种问题, 但是此时, 多个事务并发执行程度是最高的, 执行速度也是最快的.
2)read committed (读已提交)
这个情况下, 一个事务只能读另一个事务提交之后的数据 (给写操作加锁了), 此时, 可能会产生不可重复读, 幻读问题 (脏读问题解决了), 此时并发程度会降低, 执行速度相对减慢. 事物之间的隔离性相对提高了.
3)repeatable read (可重复读)
这个情况下, 相当于给写操作和读操作都加锁了, 此时可能产生幻读问题, 解决了脏读和不可重复读问题, 并发程度进一步降低, 执行速度进一步变慢, 事物之间的隔离性进一步提高了
4)serializable (串行化)
此时所有事务都是在服务器上一个一个执行的, 事务之间的隔离性进一步提高了, 解决了脏读, 不可重复读, 幻读问题, 并发程度最低, 执行速度最慢, 隔离性最高.
MySQL默认隔离级别为第三个…
啥时候需要准?
算钱…
啥时候需要快, 对于准不要求?
短视频的点赞数, 转发数, 评论数… 这些数据要快, 但是不要求准, 用户才能使用流畅…
相关文章:
MySQL: 索引与事务
文章目录 1. 索引 (Index)1.1 概念1.2 作用1.3 使用场景1.4 索引的使用1.5 索引的使用案例 (不要轻易尝试)1.6 索引背后的数据结构1.7 重点总结 2.事务2.1 为什么要使用事务2.2 事务的概念2.3 事务的使用2.4 对事务的理解2.5 事务的基本特性 1. 索引 (Index) 1.1 概念 索引是…...

2024年最新Microsoft Edge关闭自动更新的方法分享
这里写自定义目录标题 打开【服务】 打开【服务】 windows中搜索服务,如下图: 打开服务界面,找到“Microsoft Edge Update Service (edgeupdate)” 及 “Microsoft Edge Update Service (edgeupdatem)” 两个服务,设置为禁用...

Unity3D TextMeshPro组件使用及优化详解
在Unity3D游戏开发中,文本渲染是一个不可或缺的部分。而TextMeshPro作为Unity的一个插件,提供了更高质量、更灵活的文本渲染功能,为开发者带来了极大的便利。本文将详细介绍TextMeshPro组件的使用技巧以及优化方法,并通过代码实例…...

react 0至1 【jsx】
1.函数调用 // 项目的根组件 // App -> index.js -> public/index.html(root)const count 100function getName () {return test }function App () {return (<div className"App">this is App{/* 使用引号传递字符串 */}{this is message}{/* 识别js变…...

算法训练营day58
题目1:392. 判断子序列 - 力扣(LeetCode) 暴力解法 class Solution { public:bool isSubsequence(string s, string t) {if(s.size() > t.size()) return false;if(s.size() < t.size()) {swap(s, t);}bool reslut false;int flag …...

JAVA面试中,面试官最爱问的问题。
解释Java中的抽象类和接口的区别。 在Java中,抽象类和接口都是用来定义类的抽象行为和特性的,但它们有一些关键区别: ### 抽象类 1. **定义**:抽象类是使用abstract关键字修饰的类,不能被实例化,只能被继…...
分类算法与逻辑回归分类算法的差异与特性?)
【机器学习300问】115、对比K近邻(KNN)分类算法与逻辑回归分类算法的差异与特性?
在学习了K近邻(KNN)和逻辑回归(Logistic Regression)这两种分类算法后,对它们进行总结和对比很有必要。尽管两者都能有效地执行分类任务,但它们在原理、应用场景和性能特点上存在着显著的差异。本文就是想详…...

Selenium IDE 工具
官网 ## https://blog.csdn.net/weixin_49770443/article/details/129366721## https://www.selenium.dev/selenium-ide/是什么? Selenium IDE是 Selenium Suite 下的开源 Web 自动化测试工具。 Selenium IDE 一个用于火狐 (firefox) 浏览器的插件,打开…...

python的open函数
1.open() 1.1 参数11.2 参数21.3 参数32.with open() as 3.open函数常用的方法 3.1 读3.2 写3.3 获取文件读写类型3.4 指针移动3.5 当前指针位置3.6 truncate在python中使用open函数对文件进行处理。 1.open() python打开文件使用open()函数,返回一个指向文件的指针。该函数常…...

德克萨斯大学奥斯汀分校自然语言处理硕士课程汉化版(第六周) - 预训练模型
预训练模型 1. 预训练模型介绍 1.1. ELMo1.2. GPT1.3. BERT 2. Seq2Seq 2.1. T52.2. BART 3. Tokenization 1. 预训练模型介绍 在预训练语言模型出现之前,统计语言模型(如N-gram模型)是主流方法。这些模型利用统计方法来预测文本中的下一个…...
【Redis】Redis常见问题——缓存更新/内存淘汰机制/缓存一致性
目录 回顾数据库的问题如何提高 mysql 能承担的并发量?缓存解决方案应对的场景 缓存更新问题定期生成如何定期统计定期生成的优缺点 实时生成maxmemory 设置成多少合适呢?项目类型上来说 新的问题 内存淘汰策略Redis淘汰策略为什么redis要内存淘汰内存淘…...
【redis】redis事务
目录 Redis事务四个命令redis事务特性redis事务执行原理 Redis 事务的使用基本使用watch 监控watch 实现原理补充 Redis事务 Redis事务是一种将多个命令打包成一个单独操作的机制,它保证了在执行这些命令期间,其他命令无法插入。 四个命令 Redis事务通…...

编程入门费用:揭开学习成本的神秘面纱
编程入门费用:揭开学习成本的神秘面纱 编程,这一曾被视为专业领域的技能,如今已逐渐走入大众视野。越来越多的人开始尝试学习编程,然而,对于初学者来说,编程入门费用无疑是一个重要的考虑因素。那么&#…...

js/javascript获取时间戳的5种方法
1.获取时间戳精确到秒,13位 const timestamp Date.parse(new Date()); console.log(timestamp);//输出 1591669256000 13位 2.获取时间戳精确到毫秒,13位 const timestamp Math.round(new Date()); console.log(timestamp);//输出 1591669961203 13位 3.获取时间戳精…...

window系统下为django自动绘制模型类关系图
Django 提供第三方包 django-extensions,可以用来将 Django 中的 Models 生成 E-R 图。 1 安装包 pip install django-extensions 2 配置 在 Django settings.py 文件, INSTALLED_APPS 中添加 django_extensions INSTALLED_APPS (django_extension…...

Redis的数据淘汰策略和集群部署
05- Redis的数据淘汰策略有哪些 ? Redis 提供 8 种数据淘汰策略: 淘汰易失数据(具有过期时间的数据) volatile-lru(least recently used):从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少…...
解决CentOS 7无法识别ntfs的问题
解决CentOS 7无法识别ntfs的问题 方式一: Centos默认不支持ntfs文件格式,直接在Centos7上插U盘或移动硬盘无法识别,安装 ntfs-3g即可: # yum install epel-release -y # yum install ntfs-3g -y[rootbogon ~]# rpm -qa | grep nt…...
排名前五的 Android 数据恢复软件
正在寻找数据恢复软件来从 Android 设备恢复数据?本指南将为您提供 5 款最佳 Android 数据恢复软件。浏览这些软件,然后选择您喜欢的一款来恢复 Android 数据。 ndroid 设备上的数据丢失可能是一种令人沮丧的经历,无论是由于意外删除、系统崩…...

Java 程序结构 -- Java 语言的变量、方法、运算符与注释
大家好,我是栗筝i,这篇文章是我的 “栗筝i 的 Java 技术栈” 专栏的第 003 篇文章,在 “栗筝i 的 Java 技术栈” 这个专栏中我会持续为大家更新 Java 技术相关全套技术栈内容。专栏的主要目标是已经有一定 Java 开发经验,并希望进…...

淘宝/天猫商品详情优惠券获取API 接口
天猫商品优惠券数据API接口是一种用于获取天猫商品优惠券信息的接口。通过该接口,商家或开发者可以获取到商品的优惠券信息,包括优惠券的名称、金额、使用条件等。 该接口的主要参数包括商品ID、优惠券ID等,通过传入这些参数,可以…...

web vue 项目 Docker化部署
Web 项目 Docker 化部署详细教程 目录 Web 项目 Docker 化部署概述Dockerfile 详解 构建阶段生产阶段 构建和运行 Docker 镜像 1. Web 项目 Docker 化部署概述 Docker 化部署的主要步骤分为以下几个阶段: 构建阶段(Build Stage):…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

设计模式和设计原则回顾
设计模式和设计原则回顾 23种设计模式是设计原则的完美体现,设计原则设计原则是设计模式的理论基石, 设计模式 在经典的设计模式分类中(如《设计模式:可复用面向对象软件的基础》一书中),总共有23种设计模式,分为三大类: 一、创建型模式(5种) 1. 单例模式(Sing…...

利用ngx_stream_return_module构建简易 TCP/UDP 响应网关
一、模块概述 ngx_stream_return_module 提供了一个极简的指令: return <value>;在收到客户端连接后,立即将 <value> 写回并关闭连接。<value> 支持内嵌文本和内置变量(如 $time_iso8601、$remote_addr 等)&a…...
)
椭圆曲线密码学(ECC)
一、ECC算法概述 椭圆曲线密码学(Elliptic Curve Cryptography)是基于椭圆曲线数学理论的公钥密码系统,由Neal Koblitz和Victor Miller在1985年独立提出。相比RSA,ECC在相同安全强度下密钥更短(256位ECC ≈ 3072位RSA…...

Qt Widget类解析与代码注释
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this); }Widget::~Widget() {delete ui; }//解释这串代码,写上注释 当然可以!这段代码是 Qt …...

2024年赣州旅游投资集团社会招聘笔试真
2024年赣州旅游投资集团社会招聘笔试真 题 ( 满 分 1 0 0 分 时 间 1 2 0 分 钟 ) 一、单选题(每题只有一个正确答案,答错、不答或多答均不得分) 1.纪要的特点不包括()。 A.概括重点 B.指导传达 C. 客观纪实 D.有言必录 【答案】: D 2.1864年,()预言了电磁波的存在,并指出…...

【OSG学习笔记】Day 16: 骨骼动画与蒙皮(osgAnimation)
骨骼动画基础 骨骼动画是 3D 计算机图形中常用的技术,它通过以下两个主要组件实现角色动画。 骨骼系统 (Skeleton):由层级结构的骨头组成,类似于人体骨骼蒙皮 (Mesh Skinning):将模型网格顶点绑定到骨骼上,使骨骼移动…...

html-<abbr> 缩写或首字母缩略词
定义与作用 <abbr> 标签用于表示缩写或首字母缩略词,它可以帮助用户更好地理解缩写的含义,尤其是对于那些不熟悉该缩写的用户。 title 属性的内容提供了缩写的详细说明。当用户将鼠标悬停在缩写上时,会显示一个提示框。 示例&#x…...
Mobile ALOHA全身模仿学习
一、题目 Mobile ALOHA:通过低成本全身远程操作学习双手移动操作 传统模仿学习(Imitation Learning)缺点:聚焦与桌面操作,缺乏通用任务所需的移动性和灵活性 本论文优点:(1)在ALOHA…...