006 CentOS 7.9 elasticsearch7.10.0安装及配置
文章目录
- 一、安装Elasticsearch 7.10.0
- 二、安装Logstash 7.10.0
- 三、配置防火墙和网络访问
- 可能出现的错误
- 配置
Elasticsearch官方网址: https://www.elastic.co
Elasticsearch中文官网地址:https://www.elastic.co/cn/products/elasticsearch
https://www.elastic.co/cn/downloads/logstash
https://www.elastic.co/cn/downloads/kibana
https://dev.mysql.com/downloads/connector/j/
Logstash与Java 8适配的版本取决于你所使用的Elasticsearch(ES)版本。根据Elastic Stack的兼容性建议:
对于ES 6.7.x之前的版本,推荐Java 8。
对于ES 6.7.x到7.17.x的版本,Java 8或Java 11都是推荐的。但请注意,虽然这些版本的ES支持Java 8,但Elasticsearch 7.10是官方支持Java 8的最后一个版本。
对于ES 8.x及之后的版本,推荐使用Oracle/OpenJava 11或Oracle/OpenJava 17。
至于Logstash,从7.8.0版本开始,它支持Azul Zulu JDK,这对于使用M1 Mac的用户是一个好的选择。但是,对于Java 8的适配,你应该选择与你的Elasticsearch版本兼容的Logstash版本。
在CentOS 7.9上安装Elasticsearch 7.10.0和Logstash 7.10.0,并确保远程可以访问,你可以按照以下步骤进行:
一、安装Elasticsearch 7.10.0
下载RPM包:
从Elasticsearch官网下载Elasticsearch 7.10.0的RPM包(elasticsearch-7.10.0-x86_64.rpm)。
安装Elasticsearch:
使用rpm命令安装下载的RPM包。
sudo rpm -ivh elasticsearch-7.10.0-x86_64.rpm
配置Elasticsearch:
编辑Elasticsearch的配置文件/etc/elasticsearch/elasticsearch.yml
cluster.name: "my-cluster-name"
node.name: "my-node-name"
network.host: 0.0.0.0
http.port: 9200
cluster.initial_master_nodes: ["my-node-name"]
# 如果启用了X-Pack安全功能,请确保设置了正确的xpack配置
# # xpack.security.enabled: true
# # xpack.license.self_generated.type: basic
# # ... 其他xpack相关配置 ...# 集群和节点名称一定要设置吗?# 集群名称(cluster.name):推荐设置。它有助于标识和管理Elasticsearch集群,特别是当您有多个集群时。
# 节点名称(node.name):不是必须设置,但推荐设置。如果不设置,Elasticsearch将自动为节点生成一个名称。但自定义节点名称可以使管理更加容易,特别是在大型集群中。sudo vi /etc/elasticsearch/jvm.options
-Xms128m
-Xmx128m
启动Elasticsearch服务:
使用systemctl命令启动Elasticsearch服务,并设置为开机自启。
sudo systemctl daemon-reload # 重新加载 systemd 配置文件
sudo systemctl start elasticsearch
sudo systemctl enable elasticsearch
二、安装Logstash 7.10.0
下载RPM包:
从Logstash官网下载Logstash 7.10.0的RPM包(logstash-7.10.0-x86_64.rpm)。
安装Logstash:
使用rpm命令安装下载的RPM包。
sudo rpm -ivh logstash-7.10.0-x86_64.rpm
配置Logstash:
创建或编辑Logstash的配置文件(例如logstash.conf),配置输入(input)、过滤(filter)和输出(output)。对于从MySQL读取数据并发送到Elasticsearch的场景,你需要使用jdbc插件作为输入,并使用elasticsearch插件作为输出。
以下是一个简单的配置示例:
input { jdbc { jdbc_driver_library => "/path/to/mysql-connector-java.jar" jdbc_driver_class => "com.mysql.cj.jdbc.Driver" jdbc_connection_string => "jdbc:mysql://localhost:3306/your_database" jdbc_user => "your_username" jdbc_password => "your_password" statement => "SELECT * FROM your_table" }
} output { elasticsearch { hosts => ["localhost:9200"] index => "your_index_name" document_id => "%{some_field}" }
}
请根据你的实际情况替换数据库连接字符串、用户名、密码等。
sudo vi /etc/logstash/jvm.options
-Xms123m
-Xmx128m
使用命令行参数:
当启动Logstash时,你可以使用-w标志来指定工作线程的数量。例如,要设置工作线程数为2,你可以使用以下命令启动Logstash:
bin/logstash -f <config-file> -w 2
其中<config-file>是你的Logstash配置文件的路径。
修改配置文件:
在某些情况下,你可能需要在Logstash的配置文件中直接指定工作线程的数量。这通常涉及到修改pipeline的配置。然而,请注意,直接在配置文件中设置工作线程数量可能不是所有Logstash版本都支持的功能。在这种情况下,使用命令行参数可能是更可靠的方法。
确认Logstash是否安装成功
sudo rpm -qa | grep logstash
检查服务单元文件是否存在
ls /usr/lib/systemd/system/logstash.service
sudo rpm -ivh logstash-7.10.0-x86_64.rpm
检查Logstash安装目录
sudo find / -name logstash.service 2>/dev/null
创建一个新的 logstash.service 文件在 /usr/lib/systemd/system/ 目录下,并填入适当的配置。例如:
[Unit]
Description=Logstash
After=network.target [Service]
Type=simple
User=logstash
Group=logstash
Environment=JAVA_HOME=/usr/share/logstash/jdk
ExecStart=/usr/share/logstash/bin/logstash "-f" "/etc/logstash/conf.d/"
Restart=always [Install]
WantedBy=multi-user.target
sudo systemctl daemon-reload
sudo systemctl enable logstash
sudo systemctl start logstash
检查 SELinux 状态:
如果您的系统上启用了 SELinux,并且它在阻止某些操作,您可能需要调整 SELinux 策略或将其设置为 Permissive 模式进行测试。使用 getenforce 命令来检查 SELinux 的状态。
查看 Logstash 和系统的日志文件:
查看 Logstash 的日志文件(通常位于 /var/log/logstash/)以及系统的日志文件(如 /var/log/messages 或使用 journalctl 命令),以获取更多关于安装或配置问题的信息。
查看日志:
如果 Logstash 服务没有按预期运行,您可能需要查看其日志文件以获取更多信息。Logstash 的日志文件通常位于 /var/log/logstash/ 目录下。
使用 journalctl 命令也可以查看 systemd 服务的日志:
journalctl -u logstash
在 CentOS 7.9 上,您可以使用 useradd 命令来创建用户和组。以下是在 CentOS 7.9 上为 Logstash 和 Elasticsearch 创建专用用户和相关组的步骤:创建 Logstash 用户和组:
bash
# 创建 logstash 组
sudo groupadd logstash # 创建 logstash 用户,并将其添加到 logstash 组
# 同时指定 `/usr/sbin/nologin` 作为其 shell,以禁止 shell 登录
sudo useradd -r -g logstash -s /usr/sbin/nologin logstash
创建 Elasticsearch 用户和组:
bash
# 创建 elasticsearch 组
sudo groupadd elasticsearch # 创建 elasticsearch 用户,并将其添加到 elasticsearch 组
# 同时指定 `/usr/sbin/nologin` 作为其 shell,以禁止 shell 登录
sudo useradd -r -g elasticsearch -s /usr/sbin/nologin elasticsearch
设置文件和目录权限:
接下来,您需要确保 Logstash 和 Elasticsearch 用户有权访问其配置文件和数据目录。假设 Logstash 的配置文件位于 /etc/logstash/,Elasticsearch 的数据目录位于 /var/lib/elasticsearch/,您可以执行以下命令来设置权限:bash
# 设置 Logstash 配置文件目录的所有者和组为 logstash,并设置适当的权限
sudo chown -R logstash:logstash /etc/logstash/
sudo chmod -R 750 /etc/logstash/ # 设置 Elasticsearch 数据目录的所有者和组为 elasticsearch,并设置适当的权限
sudo chown -R elasticsearch:elasticsearch /var/lib/elasticsearch/
sudo chmod -R 750 /var/lib/elasticsearch/
请注意,上述路径和权限设置可能需要根据您的实际安装和配置进行调整。此外,如果您使用的是 Elasticsearch 的默认安装路径,它可能会在安装过程中自动创建必要的用户和组,并设置适当的权限。在这种情况下,您可能不需要手动执行上述步骤。最后,确保在启动 Logstash 和 Elasticsearch 服务时使用新创建的用户身份运行,这通常通过在服务的配置文件中指定用户或通过在 systemd 服务单元文件中设置 User= 和 Group= 指令来完成。
sudo groupadd logstash
sudo useradd -g logstash logstash
要删除之前创建的 logstash 用户和用户组,你可以使用 userdel 和 groupdel 命令。以下是删除步骤:删除用户:
使用 userdel 命令可以删除用户。如果你还想同时删除用户的主目录(如果有的话),可以加上 -r 选项。在你的情况下,因为 logstash 是作为系统用户(没有主目录)创建的,所以 -r 选项可能不是必需的,但加上也无妨。
bash
sudo userdel -r logstash
这里的 -r 选项会删除用户的主目录和邮件池,但因为 logstash 用户可能没有主目录(特别是如果用 -r 选项创建的话),这个命令主要会确保用户账户被删除。删除用户组:
一旦用户被删除,你可以使用 groupdel 命令来删除对应的用户组。
bash
sudo groupdel logstash
这个命令会删除名为 logstash 的用户组。请注意,在删除用户和用户组之前,请确保没有任何进程或服务正在以该用户的身份运行,否则可能会导致数据丢失或服务中断。此外,如果这些用户或用户组拥有特定的文件或目录,你可能需要先更改这些文件或目录的所有者,然后再删除用户和用户组,以避免留下无人拥有的文件或目录。
在你的具体情况下,因为 logstash 是作为系统服务账户创建的,很可能没有运行中的交互式进程,所以直接删除应该是安全的。但是,始终建议在执行此类操作之前进行充分的检查和备份。
验证配置:
在启动Logstash之前,验证您的配置文件是否正确。您可以使用Logstash的-t或–config.test_and_exit选项来测试配置文件的语法是否正确。
sudo /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/ --config.test_and_exit
运行Logstash:
使用Logstash命令行工具运行你的配置文件。
sudo /usr/share/logstash/bin/logstash -f /path/to/logstash.conf
安装Logstash:
使用rpm命令安装下载的RPM包。
bash
sudo rpm -ivh logstash-7.10.0-x86_64.rpm
二、配置Logstash
编辑Logstash配置文件:
Logstash的配置文件通常位于/etc/logstash/logstash.yml。你可能需要编辑这个文件来设置一些基本的Logstash参数,如节点名称等。但是,对于允许远程访问,主要的配置在pipeline配置文件中完成。
创建或编辑pipeline配置文件:
Logstash使用pipeline配置文件来描述数据处理的流程。你需要创建一个或多个这样的文件来定义你的数据处理逻辑。对于允许远程访问,你需要确保Logstash监听在所有接口上,以便可以从远程机器接收数据。
例如,创建一个名为logstash-sample.conf的pipeline配置文件,并在其中设置输入和输出插件。对于允许远程访问,你可能需要使用像beats这样的输入插件,它监听在特定端口上等待数据。conf
input {
beats {
port => 5044
}
}output {
elasticsearch {
hosts => [“localhost:9200”] # 这里可以替换为你的Elasticsearch实例的地址
index => “your_index_name”
}
}
在这个例子中,Logstash使用beats输入插件监听在5044端口上。确保你的防火墙允许对这个端口的访问。测试配置文件:
在启动Logstash之前,你可以使用Logstash的-f选项和–config.test_and_exit标志来测试你的配置文件是否有语法错误。
bash
sudo /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/logstash-sample.conf --config.test_and_exit
配置防火墙:
确保你的防火墙规则允许对Logstash监听的端口的访问。例如,如果你使用beats输入插件并监听在5044端口上,你需要打开这个端口。
bash
复制代码
sudo firewall-cmd --zone=public --add-port=5044/tcp --permanent
sudo firewall-cmd --reload
三、配置防火墙和网络访问
开放Elasticsearch端口:
默认情况下,Elasticsearch使用9200端口进行HTTP通信。你需要确保防火墙规则允许对该端口的入站连接。
使用firewall-cmd命令开放端口:
sudo firewall-cmd --zone=public --add-port=9200/tcp --permanent
sudo firewall-cmd --reload
配置Elasticsearch的网络访问:
确保Elasticsearch的配置文件(elasticsearch.yml)中的network.host设置为0.0.0.0,以允许任何IP地址的访问。如果你只想允许特定IP或IP范围访问,可以设置为具体的IP地址或CIDR表示法。
测试远程访问:
从远程计算机尝试访问Elasticsearch的REST API(例如,使用curl命令或浏览器访问http://your_server_ip:9200/),以验证远程访问是否成功。
完成上述步骤后,你应该能够在CentOS 7.9上成功安装和配置Elasticsearch 7.10.0和Logstash 7.10.0,并确保远程可以访问Elasticsearch。请注意,根据你的具体环境和需求,可能还需要进行其他配置和优化。务必参考官方文档以获取更详细的信息和指导。
可能出现的错误
- 解决集群发现设置问题
Elasticsearch的日志中提到:“the default discovery settings are unsuitable for production use”。这意味着默认的集群发现设置不适合生产环境使用。在单节点环境中,您可以通过编辑Elasticsearch的配置文件(通常是/etc/elasticsearch/elasticsearch.yml)来设置cluster.initial_master_nodes来避免这个警告。例如:
cluster.initial_master_nodes: ["your_node_name"]
将your_node_name替换为您在elasticsearch.yml中设置的节点名称。
如果您打算运行一个多节点的集群,您需要配置discovery.seed_hosts,它指定了Elasticsearch用于发现其他集群成员的主机列表。例如:
discovery.seed_hosts: ["host1", "host2", "host3"]
将host1、host2和host3替换为您集群中其他节点的实际主机名或IP地址。
-
查看启动引导检查失败的具体原因
日志中提到有启动引导检查失败,但是没有提供具体的失败原因。要查看这些原因,您需要检查Elasticsearch的日志文件,通常位于/var/log/elasticsearch/目录下。查看与您的集群名称相对应的日志文件(例如my-cluster-name.log),文件中应该包含启动引导检查失败的具体原因。 -
根据日志中的错误信息进行修复
一旦您查看了具体的启动引导检查错误信息,您就可以根据这些信息进行修复。一些常见的启动引导检查失败原因包括:
文件描述符限制太低。
内存锁定限制太低(vm.max_map_count)。
使用了不支持的JVM版本。
节点数据目录的权限问题。
4. 调整系统配置(如果需要)
根据启动引导检查失败的具体原因,您可能需要调整系统配置。例如,如果vm.max_map_count太低,您可以使用以下命令将其设置为一个较高的值(例如655360):
sudo sysctl -w vm.max_map_count=655360
为了使这个设置永久生效,您可以将上述行添加到/etc/sysctl.conf文件中。
根据启动引导检查失败的具体原因,您可能还需要调整系统配置。例如,增加文件描述符限制、调整内存锁定限制等。这些配置通常可以在操作系统的系统文件中设置,例如/etc/security/limits.conf和/etc/sysctl.conf。
input { beats { port => 5044 }
} filter { # 如果需要,可以在这里添加数据过滤逻辑 # ...
} output { elasticsearch { hosts => ["localhost:9200"] # 如果Elasticsearch不在同一台机器上,请替换为正确的地址 index => "fruit-%{+YYYY.MM.dd}" # 使用日期作为索引名的一部分,便于管理 document_id => "%{fruitId}" # 假设数据源中包含fruitId字段,用于设置文档ID # 如果Elasticsearch启用了安全性功能,请添加用户名和密码配置 # user => "logstash_internal" # password => "your_password" }
}配置
vim /etc/logstash/conf.d/fruit.conf
input {jdbc {jdbc_driver_library => "/installer/mysql-connector-j-8.3.0.jar"jdbc_driver_class => "com.mysql.cj.jdbc.Driver"jdbc_connection_string => "jdbc:mysql://localhost:3306/fshop_app"jdbc_user => "root"jdbc_password => "Root123_"statement => "SELECT fruit_id AS fruitId, category_id AS categoryId, fruit_name AS fruitName, fruit_origin AS fruitOrigin, fruit_price AS fruitPrice, fruit_standard AS fruitStandard, fruit_detail AS fruitDetail, fruit_image_url AS fruitImageUrl, fruit_pick_time AS fruitPickTime, fruit_quality_time AS fruitQualityTime, fruit_inventory AS fruitInventory, fruit_status AS fruitStatus, version, create_time AS createTime, update_time AS updateTime, other1, other2 FROM fruit"#statement => "select * from fruit"#schedule => "*/1 * * * *"# 是否将 sql 中 column 名称转小写lowercase_column_names => false}
}output {elasticsearch {hosts => ["localhost:9200"]index => "fruit"document_id => "%{fruitId}"}stdout {codec => json_lines}}
package com.fshop.entity;import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.fasterxml.jackson.annotation.JsonFormat;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.*;
import org.springframework.format.annotation.DateTimeFormat;import java.io.Serializable;
import java.math.BigDecimal;
import java.time.LocalDateTime;/*** <p>* 水果表* </p>** @author dev* @since 2024-04-23*/
@Data
@NoArgsConstructor
@AllArgsConstructor
@Document(indexName = "fruit")
public class Fruit implements Serializable {private static final long serialVersionUID = 1L;/*** 水果ID*/@TableId(value = "fruit_id", type = IdType.AUTO)@Idprivate Integer fruitId;/*** 分类ID,外键(关联水果分类表)*/private Integer categoryId;/*** 水果名称*/@Field(type = FieldType.Keyword)private String fruitName;/*** 水果产地*/private String fruitOrigin;/*** 水果价格(元/箱)*/private BigDecimal fruitPrice;/*** 水果规格:小0、中1、大2*/private Integer fruitStandard;/*** 水果特征详细描述*/
// @Field(type = FieldType.Text,analyzer = "ik_smart",searchAnalyzer = "ik_max_word")
// private String fruitDetail;@CompletionField(analyzer = "ik_smart", searchAnalyzer = "ik_max_word")private String fruitDetail;/*** 水果主图片URL*/private String fruitImageUrl;/*** 采摘时间*/@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")@Field( type = FieldType.Date,name = "fruit_pick_time",format = {},pattern = "yyyy-MM-dd HH:mm:ss || yyyy-MM-dd'T'HH:mm:ss'+08:00' || strict_date_opotional_time || epoch_millis")private LocalDateTime fruitPickTime;/*** 保存时间(天)*/private Integer fruitQualityTime;/*** 库存(箱)*/private Integer fruitInventory;/*** 水果状态:已下架0、秒杀中1、售卖中2*/private Integer fruitStatus;/*** 版本*/private Integer version;/*** 创建时间*/@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")@Field( type = FieldType.Date,name = "create_time",format = {},pattern = "yyyy-MM-dd HH:mm:ss || yyyy-MM-dd'T'HH:mm:ss'+08:00' || strict_date_opotional_time || epoch_millis")private LocalDateTime createTime;/*** 最近更新时间*/@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")@Field( type = FieldType.Date,name = "update_time",format = {},pattern = "yyyy-MM-dd HH:mm:ss || yyyy-MM-dd'T'HH:mm:ss'+08:00' || strict_date_opotional_time || epoch_millis")private LocalDateTime updateTime;private String other1;private String other2;}
-- fshop_app.fruit definitionCREATE TABLE `fruit` (`fruit_id` int unsigned NOT NULL AUTO_INCREMENT COMMENT '水果ID',`category_id` int unsigned DEFAULT NULL COMMENT '分类ID,外键(关联水果分类表)',`fruit_name` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '水果名称',`fruit_origin` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '水果产地',`fruit_price` decimal(10,2) NOT NULL COMMENT '水果价格(元/箱)',`fruit_standard` tinyint unsigned NOT NULL COMMENT '水果规格:小0、中1、大2',`fruit_detail` text CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '水果特征详细描述',`fruit_image_url` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '水果主图片URL',`fruit_pick_time` datetime NOT NULL COMMENT '采摘时间',`fruit_quality_time` int unsigned NOT NULL COMMENT '保存时间(天)',`fruit_inventory` int unsigned NOT NULL COMMENT '库存(箱)',`fruit_status` tinyint unsigned NOT NULL COMMENT '水果状态:已下架0、秒杀中1、售卖中2',`version` int unsigned NOT NULL DEFAULT '1' COMMENT '版本',`create_time` datetime NOT NULL COMMENT '创建时间',`update_time` datetime NOT NULL COMMENT '最近更新时间',`other1` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,`other2` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,PRIMARY KEY (`fruit_id`) USING BTREE,KEY `fk_fruit_category` (`category_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=137 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ROW_FORMAT=DYNAMIC COMMENT='水果表';相关文章:

006 CentOS 7.9 elasticsearch7.10.0安装及配置
文章目录 一、安装Elasticsearch 7.10.0二、安装Logstash 7.10.0三、配置防火墙和网络访问可能出现的错误配置 Elasticsearch官方网址: https://www.elastic.co Elasticsearch中文官网地址:https://www.elastic.co/cn/products/elasticsearch https://…...
蚂蚁分类信息系统二开仿么么街货源客模板微商货源网源码(带手机版)
源码介绍 网站采用蚂蚁分类信息系统二次开发,模板仿么么街货源客模板,微商货源网定制版。 模板设计风格简洁,分类信息采用列表形式发布,这种设计方式非常符合度娘 SEO 规则。收录效果是杠杠的。 这个网站风格目前是用来做货源推…...

综合数据分析及可视化实战
【实验目的】 1、掌握数据分析常用的几种扩展库: numpy、pandas、matplotlib。 2、理解数据分析的几种方法,即描述性数据分析,探索性数据分析 和验证性数据分析。 3、理解数据分析的基本步骤:数据准备、数据导入、数据预处理、数 据分析和数据可视化…...

N32G45XVL-STB之移植LVGL(8.4.0)
目录 概述 1 系统软硬件 1.1 软件版本信息 1.2 ST7796-LCD 1.3 MCU IO与LCD PIN对应关系 2 认识LVGL 2.1 LVGL官网 2.2 下载V8.4.0 3 移植LVGL 3.1 硬件驱动实现 3.2 添加LVGL库文件 3.3 移植和硬件相关的代码 3.3.1 驱动接口相关文件介绍 3.3.2 重新接口函数 3…...
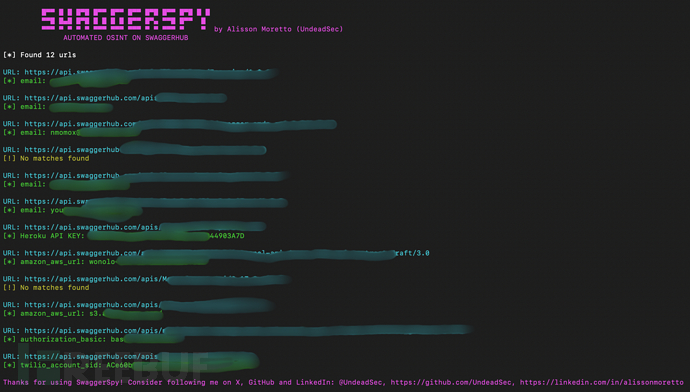
SwaggerSpy:一款针对SwaggerHub的自动化OSINT安全工具
关于SwaggerSpy SwaggerSpy是一款针对SwaggerHub的自动化公开资源情报(OSINT)安全工具,该工具专为网络安全研究人员设计,旨在简化广大红队研究人员从SwaggerHub上收集已归档API信息的过程,而这些OSINT信息可以为安全人…...
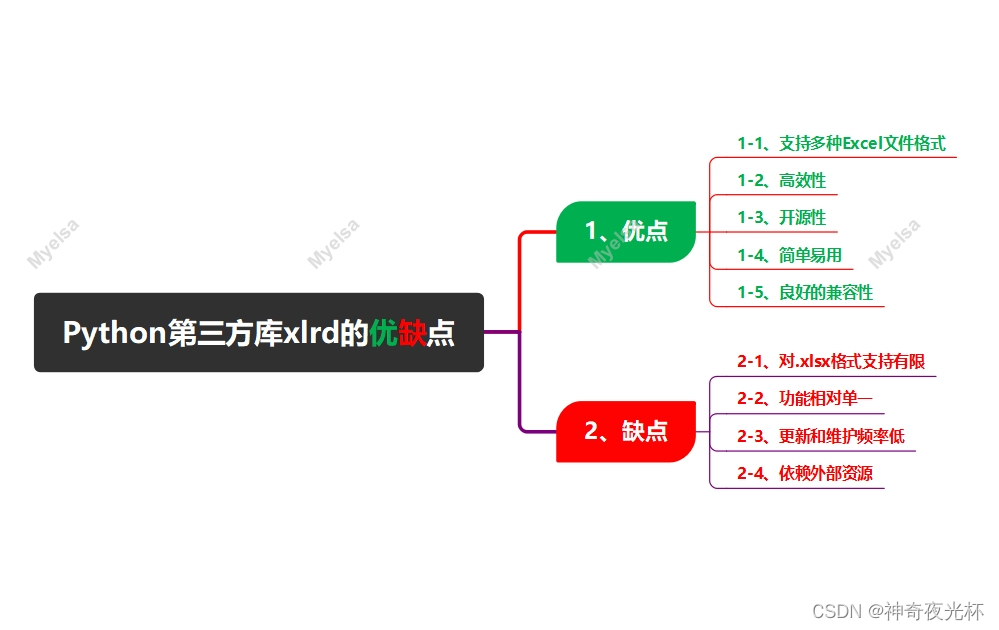
Python酷库之旅-比翼双飞情侣库(05)
目录 一、xlrd库的由来 二、xlrd库优缺点 1、优点 1-1、支持多种Excel文件格式 1-2、高效性 1-3、开源性 1-4、简单易用 1-5、良好的兼容性 2、缺点 2-1、对.xlsx格式支持有限 2-2、功能相对单一 2-3、更新和维护频率低 2-4、依赖外部资源 三、xlrd库的版本说明 …...
numpy数组transpose方法的基本原理
背景:记录一下numpy数组维度顺序操作 一、具体示例 transpose方法用于交换数组的轴,改变数组的维度顺序。方法的参数是一个代表新轴顺序的元组。 假设你有一个三维数组,其形状是 (a, b, c),即有 a 个块,每个块中有 b…...
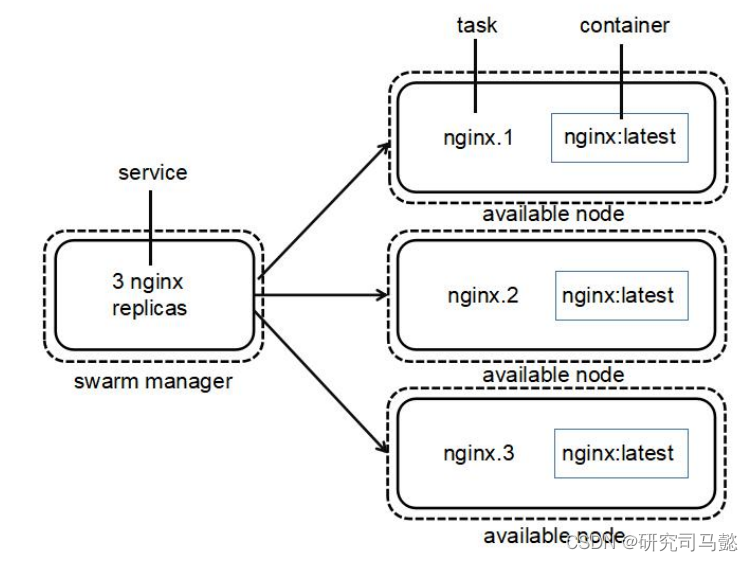
Docker Swarm集群部署管理
Docker Swarm集群管理 文章目录 Docker Swarm集群管理资源列表基础环境一、安装Docker二、部署Docker Swarm集群2.1、创建Docker Swarm集群2.2、添加Worker节点到Swarm集群2.3、查看Swarm集群中Node节点的详细状态信息 三、Docker Swarm管理3.1、案例概述3.2、Docker Swarm中的…...
碎片化知识如何被系统性地吸收?
一、方法论 碎片化知识指的是通过各种渠道快速获取的零散信息和知识点,这些信息由于其不完整性和孤立性,不易于记忆和应用。为了系统性地吸收碎片化知识,可以采用以下策略: 1. **构建知识框架**: - 在开始吸收之前&am…...

安鸾学院靶场——安全基础
文章目录 1、Burp抓包2、指纹识别3、压缩包解密4、Nginx整数溢出漏洞5、PHP代码基础6、linux基础命令7、Mysql数据库基础8、目录扫描9、端口扫描10、docker容器基础11、文件类型 1、Burp抓包 抓取http://47.100.220.113:8007/的返回包,可以拿到包含flag的txt文件。…...

ChatGPT:自然语言处理的新纪元与OpenAI的深度融合
随着人工智能技术的蓬勃发展,自然语言处理(NLP)领域取得了显著的进步。OpenAI作为这一领域的领军者,以其卓越的技术实力和创新能力,不断推动着NLP领域向前发展。其中ChatGPT作为OpenAI的重要成果更是在全球范围内引起了…...

AI引领项目管理新时代:效率与智能并驾齐驱
在数字化浪潮的推动下,项目管理领域正迎来一场由AI技术引领的革新。从自动化任务执行到智能决策支持,AI技术的应用正让项目管理变得更加高效、精准和智能化。本文将探讨项目管理人员及其实施团队如何运用AI技术,以及这些技术如何助力项目管理…...
)
AUTOSAR汽车电子嵌入式编程精讲300篇-电池管理系统中 CAN 通信模块的设计与应用(中)
目录 2.3 BMS 中 CAN 通信模块软硬件设计 2.3.1 CAN 通信模块硬件电路设计 2.3.2 CAN 通信模块软件设计 2.3.2.1 CAN 底层程序设计 2.3.2.2 CAN 底层初始化 2.3.2.3 CAN 底层接收 3.3.1.3 CAN 底层发送 2.4 通信协议的实现 2.4.1 整车通信协议的实现 2.4.2 充电机通信协议的实现…...
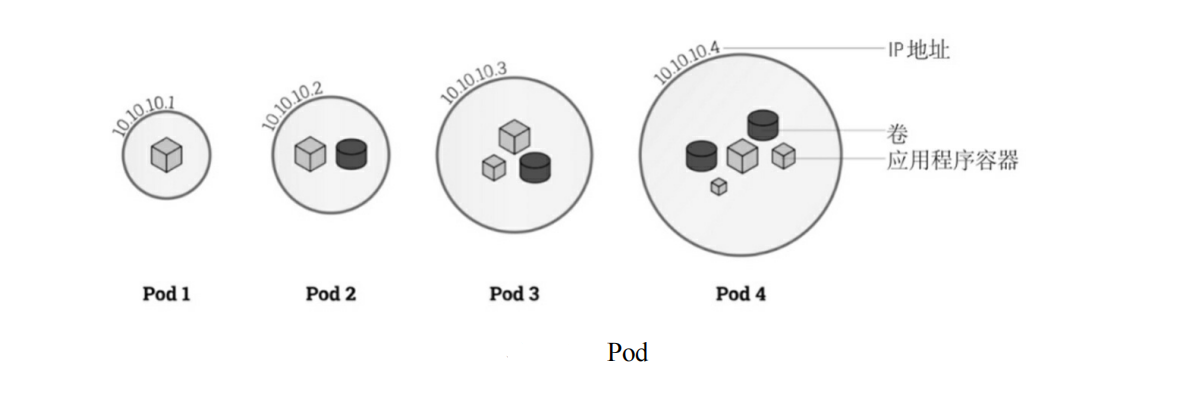
k8s概述
文章目录 一、什么是Kubernetes1、官网链接2、概述3、特点4、功能 二、Kubernetes架构1、架构图2、核心组件2.1、控制平面组件(Control Plane Components)2.1.1、kube-apiserver2.1.2、etcd2.1.3、kube-scheduler2.1.4、kube-controller-manager 2.2、No…...

多线程的运用
在现代软件开发中,多线程编程是一个非常重要的技能。多线程编程不仅可以提高应用程序的性能,还可以提升用户体验,特别是在需要处理大量数据或执行复杂计算的情况下。本文将详细介绍Java中的多线程编程,包括其基本概念、实现方法、…...
算法)
TF-IDF(Term Frequency-Inverse Document Frequency)算法
TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于文本挖掘和信息检索的统计方法,主要用于评估一个单词在一个文档或一组文档中的重要性。它结合了词频(TF)和逆文档频率(IDF)两个指…...

富格林:细心发现虚假确保安全
富格林指出,现货黄金市场内蕴藏着丰富的盈利机会,然而并非所有人都能够抓住这些机会。要想从市场中获取丰厚的利润并且保障交易的安全,必须要求我们掌握一些交易技巧利用此去发现虚假陷阱。当我们不断汲取技巧过后,才可利用此来发…...

6.2 文件的缓存位置
1. 文件的缓冲 1.1 缓冲说明 将文件内容写入到硬件设备时, 则需要进行系统调用, 这类I/O操作的耗时很长, 为了减少I/O操作的次数, 文件通常使用缓冲区. 当需要写入的字节数不足一个块时, 将数据放入缓冲区, 当数据凑够一个块的大小后才进行系统调用(即I/O操作).系统调用: 向…...
是用于数据筛选的一种机制)
在Elasticsearch中,过滤器(Filter)是用于数据筛选的一种机制
在Elasticsearch中,过滤器(Filter)是用于数据筛选的一种机制,它通常用于结构化数据的精确匹配,如数字范围、日期范围、布尔值、前缀匹配等。过滤器不计算相关性评分,因此比查询(Query࿰…...

MySQL----主键、唯一、普通索引的创建与删除
创建索引 CREATE INDEX index_name ON table_name (column1 [ASC|DESC], column2 [ASC|DESC], ...);CREATE INDEX: 用于创建普通索引的关键字。index_name: 指定要创建的索引的名称。索引名称在表中必须是唯一的。table_name: 指定要在哪个表上创建索引。(column1, column2, ……...

OpenClaw成本优化方案:ollama GLM-4.7-Flash自建模型接口实践
OpenClaw成本优化方案:ollama GLM-4.7-Flash自建模型接口实践 1. 为什么需要关注OpenClaw的token消耗问题 第一次用OpenClaw完成自动化周报任务时,我盯着账单倒吸一口凉气——生成三份周报竟然消耗了接近15万token。这让我意识到,如果不解决…...

矩阵按键的硬件设计与软件扫描实战
1. 矩阵按键的硬件设计要点 第一次接触矩阵按键时,我完全被它节省IO口的设计惊艳到了。想象一下,16个独立按键原本需要16个IO口,而4x4矩阵按键只需要8个IO口就能搞定。这种设计在资源受限的单片机项目中简直就是救命稻草。 硬件连接上有个容易…...

精益生产方式的核心功能拆解:精益生产方式如何解决多品种小批量场景下的库存积压难题
在当前制造业从“少品种大批量”向“多品种小批量”急剧转型的背景下,精益生产方式已成为企业打破库存僵局的唯一出路,它通过准时化拉动和消除浪费的核心逻辑,精准解决了传统模式下因预测失效导致的严重库存积压问题;面对多变的订…...

Qwen3.5-4B-Claude-Opus实际作品:正则表达式语法树构建与匹配逻辑推演
Qwen3.5-4B-Claude-Opus实际作品:正则表达式语法树构建与匹配逻辑推演 1. 模型能力概述 Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF是一个专注于逻辑推理和结构化分析的轻量级AI模型。作为Qwen3.5-4B的蒸馏版本,它在处理代码解释、算法分析…...

Project Sistine核心代码剖析:从图像分割到鼠标事件模拟
Project Sistine核心代码剖析:从图像分割到鼠标事件模拟 【免费下载链接】sistine Turn a MacBook into a Touchscreen with $1 of Hardware 项目地址: https://gitcode.com/gh_mirrors/si/sistine Project Sistine是一个创新的开源项目,它能让普…...

如何用torchtext快速构建文本分类模型?5分钟上手RoBERTa与T5实战教程
如何用torchtext快速构建文本分类模型?5分钟上手RoBERTa与T5实战教程 【免费下载链接】text Models, data loaders and abstractions for language processing, powered by PyTorch 项目地址: https://gitcode.com/gh_mirrors/te/text 想要在PyTorch生态中快…...

StructBERT-Large中文相似度工具一文详解:三级匹配等级判定逻辑与业务适配建议
StructBERT-Large中文相似度工具一文详解:三级匹配等级判定逻辑与业务适配建议 本文深度解析StructBERT-Large中文相似度工具的核心匹配逻辑,提供实际业务场景中的适配建议和优化方案 1. 工具核心价值与适用场景 StructBERT-Large中文相似度工具是一个基…...

iMeta入选新锐期刊分区表生物学1区Top
2026年3月24日,2026年新锐期刊分区表正式发布。iMeta被评选为生物学1区Top期刊,标志着iMeta期刊学术声誉与影响力持续提升。自创刊以来,iMeta的每一步成长都离不开期刊编委、审稿专家及广大同行的鼎力支持。未来,iMeta将再接再厉&…...

2026Agent元年!手把手教你从0到1搭建高能智能体,小白也能秒变大神!
逼自己练完这些,你的Agent搭建就很牛了!!2026年可谓是Agent元年,智能体(AI Agent)正以惊人的速度重塑我们的工作方式,从简单的被动响应工具,进化为能自主规划、执行、协作的"数…...

GNU Parallel进阶指南:解决管道传参的5个常见坑
GNU Parallel进阶指南:解决管道传参的5个常见坑 在数据处理和批量任务处理领域,GNU Parallel堪称瑞士军刀般的存在。这个看似简单的命令行工具,却能让你的工作效率提升数倍。但就像任何强大的工具一样,掌握其精髓需要跨越一些技术…...