NVIDIA Triton系列01-应用概论
NVIDIA Triton系列01-应用概论
推理识别是人工智能最重要的落地应用,其他与深度学习相关的数据收集、标注、模型训练等工作,都是为了得到更好的最终推理性能与效果。
几乎每一种深度学习框架都能执行个别的推理工作,包括 Tensorflow、Pytorch、MXNet 等通用型框架与 YOLO 专属的 Darknet 框架,此外还有 ONNX 开发推理平台、NVIDIA TensorRT 加速推理引擎,也提供推理相关的 C / C++ 与 Python 开发接口,这是大部分技术人员所熟悉的方法。
在垂直应用方面,NVIDIA 的 DeepStream 智能分析工具是非常适合用在种类固定且需要长期统计分析的场景,包括各种交通场景的人 / 车流量分析、工业流水线质量检测等应用,并且在早期视觉(Visualization)类推理功能之上,再添加对话(Conversation)类推理功能,让使用范围更加完整。
上述的推理方式通常适合在识别固定种类与固定输入源的使用场景,在交通、工业自动化领域、无人设备等领域的使用比较普及。
但是这种方式并不适合在网络相关的服务类应用中使用,包括在线的产品推荐、图像分类、聊天机器人等应用,因为在线服务需要同时面对未知数量与类型的数据源,并且透过 HTTP 协议进行数据传输的延迟问题,也是严重影响用户体验感的因素,这是绝大部分网路服务供应商要导入 AI 智能识别技术所面临的共同难题。
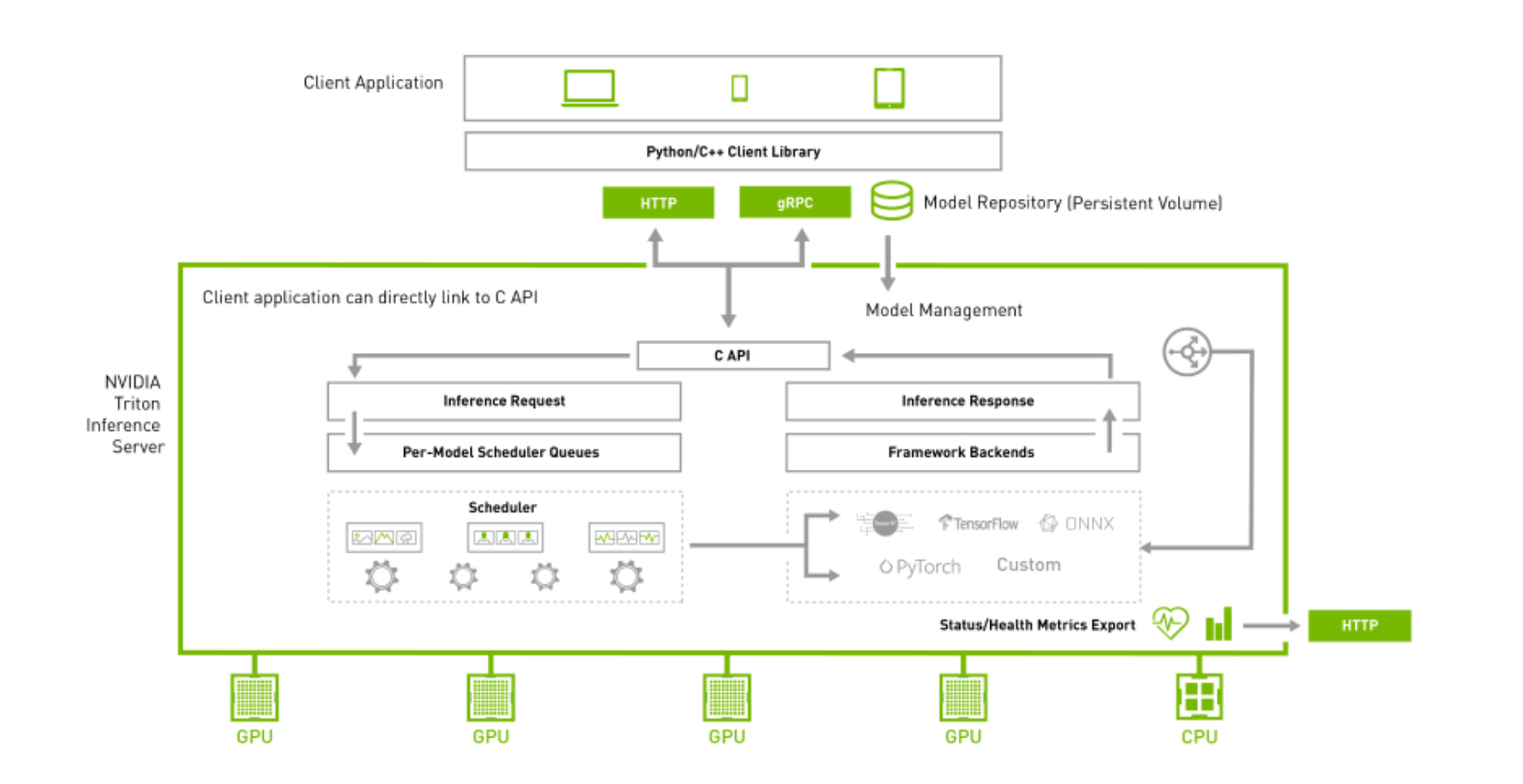
NVIDIA Triton 推理服务器的最大价值,便是为服务类智能应用提供一个完整的解决方案,因此首先需要解决以下的三大关键问题:
1. 高通用性:
(1) 广泛支持多种计算处理器:包括具备 NVIDIA GPU 的 x86 与 ARM CPU 设备,也支持纯 CPU 设备的推理计算。
(2) 广泛支持各种训练框架的文件格式:包括 TensorFlow 1.x/2.x、PyTorch、ONNX、TensorRT、RAPIDS FIL(用于 XGBoost、Scikit-learn Random Forest、LightGBM)、OpenVINO、Python 等。
(3) 广泛支持各种模型种类:包括卷积神经网络 (CNN)、循环神经网络 (RNN)、决策树、随机森林和图神经网络等算法。
2.部署便利:
(1) 可在横向扩展的云或数据中心、企业边缘,甚至 NVIDIA Jetson 等嵌入式设备上运行。
(2) 支持用于 AI 推理的裸机和虚拟化环境,包括 VMware vSphere 与基于 Docker 技术的 Kubernetes 管理机制。
(3) 可托管于多种人工智能云平台,包括 Amazon SageMaker、Azure ML、Google Vertex AI、阿里巴巴 AI、腾讯 TI-EMS 等平台。
3.性能优化:
(1)动态批量处理:推理优化的一个因素是批量大小,或者您一次处理多少个样本,GPU 以更高的批量提供高吞吐量。然而,对于实时应用程序,服务的真正限制不是批量大小甚至吞吐量,而是为最终客户提供出色体验所需的延迟。
(2)模型并发执行:GPU 是能够同时执行多个工作负载的计算设备,NVIDIA Triton 推理服务器通过在 GPU 上同时运行多个模型来最大限度地提高性能并减少端到端延迟,这些模型可以是相同的,也可以是来自不同框架的不同模型。GPU 内存大小是同时运行模型数量的唯一限制,这会影响GPU利用率和吞吐量。
以上是 NVIDIA Triton 推理服务器的基本特性说明,要满足上面所列的特性,是相对复杂的内容,这是本系列文章所要为读者逐一探索的内容,不过在讲解技术内容之前,我们可以先看看有哪些比较具有代表性成功案例,能让大家对于 Triton 推理服务器的使用场景有更进一步的了解。
案例1:微软 Teams 会议系统使用 Triton 提升生成实时字幕和转录性能
微软 Teams 是全球沟通和协作的重要工具,每月有近 2.5 亿活跃用户,其 Azure 认知服务提供 28 种语言的字幕和转录,实时字幕功能帮助与会者实时跟踪对话,转录功能方便与会者在日后回顾当时的创意或回看未能参与的会议,实时字幕对聋哑人、听力障碍者,或者异国与会者特别有用。
底层语音识别技术作为认知服务中的一个 API,开发人员可以使用它定制和运行自己的应用程序,例如客服电话转录、智能家居控制或为急救人员提供 AI 助手。认知服务会生成 Teams 的转录和字幕,将语音转换为文本,并识别说话人。同时也能够识别专业术语 、姓名和其他会议背景,提高字幕的准确性。
微软 Teams 首席项目经理 Shalendra Chhabra 表示:“这样的 AI 模型非常复杂,需要数千万个神经网络参数才能识别几十种不同的语言。但模型越大,就越难以经济高效地实时运行。”
为了提高服务质量,微软使用 NVIDIA Triton 开源推理服务软件,来帮助 Teams 使用认知服务优化语音识别模型,以及认知服务所支持的高度先进语言模型,在极低的延迟状态下提供高度准确、个性化的语音转文本结果,同时可以保证运行这些语音转文本模型的 NVIDIA GPU 充分发挥计算资源,在消耗更少计算资源的同时为客户提供更高的吞吐量,进而降低成本。
NVIDIA GPU 和 Triton 软件能够帮助微软,在不牺牲低延迟的情况下,通过强大的神经网络,实现高准确性,确保语音-文本的实时转换,当启用转录功能时,与会者可以在会议结束后轻松补上错过的内容。
Triton 推理服务器有助于简化 AI 模型部署并解锁高性能推理,用户甚至可以为自己的应用开发自定义后端。下面三种关键功能,是协助微软将 Teams 的字幕和转录功能扩展到更多会议和用户的效能:
流推理:新型流推理功能—通过跟踪语音上下语境,提高延迟、敏感性字幕的准确度,协助 Azure 认知服务合作定制语音转文本的应用程序。
动态批量处理:批量大小指神经网络同时处理的输入样本数量,通过 Triton 的动态批量处理功能,单项推理请求被自动组合成一个批次,因此能够在不影响模型延迟的情况下更好地利用 GPU 资源。
并发模型执行:实时字幕和转录需要同时运行多个深度学习模型,Triton 使开发人员能够在单个 GPU 上同时完成这些工作,包括使用不同深度学习框架的模型。
案例2:Triton 助力微信加速视觉应用,提高可靠性
本案例中,通过 NVIDIA 的 GPU 执行 Triton 推理服务器与 TensorRT 推理加速引擎, 帮助微信的二维码光学识别(OCR)计算降低 46% 时间,并将系统的失败率降低 81%,同时减少 78% 的服务器使用数量。
腾讯微信是一款跨平台的通讯工具,支持通过手机网络发送语音、图片、视频和文字等。截至 2021 年 6 月,微信在全球拥有超过 12 亿活跃用户,是国内活跃用户最多的社交软件。
微信识物是一款主打物品识别的 AI 产品,通过相机拍摄物品,更高效、更智能地获取信息。2020 年微信识物拓展了更多识别场景,上线了微信版的图片搜索,打开微信扫一扫,左滑切换到 “识物” 功能,对准想要了解的物品正面,可以获取对应的物品信息,包括物品百科、相关资讯、相关商品。
2021 年 1 月,微信发布的 8.0 版本更新支持图片文字提取的功能,用户在聊天界面和朋友圈中长按图片就可以提取图片中文字,然后一键转发、复制或收藏。
在识物的过程包含检测、图像召回、信息提炼等环节,其中二维码扫描的使用频率也是非常高,主要包括识别和检测,这两种应用都有非常大的计算量。但原本使用 Pytorch 进行模型的推理时,遇到以下三大问题:
请求的延迟很大,影响用户体验感;
显存占用很大,单张 NVIDIA T4 GPU 卡能部署的模型数比较少,导致推理请求的并发数上不去,请求失败的概率太高,只能通过增加机器的方式来提高并发能力,业务部署成本较高。
使用的模型经常变化,而业务需要更换后的模型需要能够快速地加速和上线部署。
为了解决上述问题,微信团队使用 Triton 推理服务器结合 TensorRT 加速推理器的综合方案,主要技术内容如下:
通过使用 TensorRT 对微信识物和 OCR 的模型进行加速,在都使用 FP32 的情况下,比 Pytorch 的延迟降低 50% 左右;
在 OCR 的识别和检测阶段,使用 TensorRT 结合 NVIDIA T4 GPU 的 FP16 Tensor Core,在保证精度的前提下,识别的延迟降低 50%、检测的延迟降低 20%;
在微信识物的分类和检测任务中,通过使用 NVIDIA T4 GPU 的 int8 Tensor Core 并结合 QAT,在满足精度要求的前提下,进一步大幅提升了性能;
通过使用 FP16 和 int8 低精度模式,在大幅降低推理延迟的同时,大大减少了显存的占用,在 FP16 模式下,单模型显存占用仅占 FP32 模式的 40%–50%, 而在 int8 模式下,单模型显存占用仅占 FP32 模式的 30% 左右。在提高单张 T4 卡上部署的模型数量的同时,大幅提高了单 GPU 的推理请求并发能力;
Triton 的动态批量处理(dynamic batch)和多实例等特性,帮助微信将在满足延迟要求的同时,提高了系统整体的并发能力,将系统失败降低了 81%;
TensorRT 对个别模型得到推理的加速,Triton 则对加速后的模型进行快速的部署,满足了业务对修改后的模型进行快速部署的需求,也大大减少工程人员的工作量。
通过使用 NVIDIA 的 TensorRT 对微信识物和 OCR 的模型进行加速,在降低单次推理延迟 50% 以上的同时**,节约了多达 64% 的显存**。结合 Triton 的动态批量处理和多实例的功能,OCR 的整体时延降低了 46%,系统失败率降低了 81%。大大提高了用户的体验,并且服务器的数量减少了多达 78%,极大降低了服务的成本。
案例3:腾讯 PCG 使用 Triton 加速在线推理,提高设备效能
腾讯平台与内容事业群(简称 腾讯 PCG)负责公司互联网平台和内容文化生态融合发展,整合 QQ 软件、QQ 空间等社交平台,和应用宝、浏览器等流量平台,以及新闻资讯、视频、体育、直播、动漫、影业等内容业务,推动 IP 跨平台、多形态发展,为更多用户创造海量的优质数字内容体验。
腾讯 PCG 机器学习平台部旨在构建和持续优化符合 PCG 技术中台战略的机器学习平台和系统,提升 PCG 机器学习技术应用效率和价值,建设业务领先的模型训练系统和算法框架,提供涵盖数据标注、模型训练、评测、上线的全流程平台服务,实现高效率迭代,在内容理解和处理领域,输出业界领先的元能力和智能策略库。
这个机器学习平台服务于 PCG 所有业务产品,面对上述所提到的综合需求,有以下三大挑战:
1. 业务繁多,场景复杂**:**
(1) 业务开发语言包括 C++ 与 Python;
(2)模型格式繁多,包括 ONNX、Pytorch、TensorFlow、TensorRT 等;
(3)模型预处理涉及图片下载等网络 io;
(4)多模型融合流程比教复杂,涉及循环调用;
(5)支持异构推理;
2.模型推理结果异常时,难以便利地调试定位问题;
3.需要与公司内现有协议 / 框架 / 平台进行融合。
基于以上挑战,腾讯 PCG 选择了采用 NVIDIA 的 Triton 推理服务器,以解决新场景下模型推理引擎面临的挑战,在提升用户研效的同时,也大幅降低了服务成本。
NVIDIA 的 Triton 推理服务器是一款开源软件,对于所有推理模式都可以简化在任一框架中以及任何 GPU 或 CPU 上的运行方式,从而在生产环境中使用推理计算,并且支持多模型 ensemble,以及 TensorFlow、PyTorch、ONNX 等多种深度学习模型框架,可以很好的支持多模型联合推理的场景,构建起视频、图片、语音、文本整个推理服务过程,大大降低多个模型服务的开发和维护成本。
通过将 Triton 编译为动态链接库,可以方便地链入公司内部框架,对接公司的平台治理体系,符合 C 语言规范的 API 也极大降低了用户的接入成本,借助 Python 后端和自定义后端,用户可以自由选择使用 C++ 或 Python 语言进行二次开发。
NVIDIA DALI 是 GPU 加速的数据增强和图像加载库,使用 Triton 的 DALI 后端可以替换掉原来的图片解码、缩放等操作,Triton 的 FIL 后端可以替代 Python XGBoost 模型推理,进一步提升服务端推理性能。
借助 NVIDIA Triton 推理框架,配合 DALI / FIL / Python 等后端与 TensorRT,整体推理服务的吞吐能力最大提升 6 倍,延迟最大降低 40%。帮助腾讯 PCG 各业务场景中,以更低的成本构建了高性能的推理服务,同时更低的延迟降低了整条系统链路的响应时间,优化了用户体验,也降低了 20%-66% 总成本。
透过以上三个成功案例,就能很明显看出,Triton 推理服务器在面对复杂的智能识别应用场景时,能发挥非常有效的整合功能,特别是模型来自不同训练平台时,以及面对不同前端开发语言时,更能体现其便利性。
在后面的文章会带着大家,先从宏观的角度来了解 Triton 推理服务器的应用架构以及所需要的配套资源,接着搭建 Triton 的使用环境,包括建立模型仓、安装服务端/用户端软件,然后执行一些实用性强的基础范例,以及结合 NVIDIA 的 TensorRT 与 DeepStream 等推理工具,让更多开发人员能利用 Triton 整合更多 AI 推理资源。
出处:NVIDIA Triton系列文章(1):应用概论 - 最新资讯 - 英伟达AI计算专区 - 智东西 (zhidx.com)
相关文章:
NVIDIA Triton系列01-应用概论
NVIDIA Triton系列01-应用概论 推理识别是人工智能最重要的落地应用,其他与深度学习相关的数据收集、标注、模型训练等工作,都是为了得到更好的最终推理性能与效果。 几乎每一种深度学习框架都能执行个别的推理工作,包括 Tensorflow、Pytorc…...

LIMS(实验室)信息管理系统源码、有哪些应用领域?采用C# ASP.NET dotnet 3.5 开发的一套实验室信息系统源码
LIMS(实验室)信息管理系统源码、有哪些应用领域?采用C# ASP.NET dotnet 3.5 开发的一套实验室信息系统源码 LIMS实验室信息管理系统,是一种基于计算机硬件和数据库技术,集多个功能模块为一体的信息管理系统。该系统主…...

Web前端进国企:挑战与机遇并存
Web前端进国企:挑战与机遇并存 随着互联网的飞速发展,Web前端技术已经成为企业信息化建设的重要组成部分。对于许多热衷于前端技术的年轻人来说,进入国企工作既是一种挑战,也是一种机遇。本文将从四个方面、五个方面、六个方面和…...
快速上手SpringBoot
黑马程序员Spring Boot2 文章目录 1、SpringBoot 入门程序开发1.1 创建一个新的项目 2、浅谈入门程序工作原理2.1 parent2.2 starter2.3 引导类2.4 内嵌tomcat 1、SpringBoot 入门程序开发 1.1 创建一个新的项目 file > new > project > empty Project 创建新模块&a…...

SQL 快速参考
SQL 快速参考 SQL(Structured Query Language)是一种用于管理关系数据库管理系统(RDBMS)的标准编程语言。它用于执行各种操作,如查询、更新、插入和删除数据库中的数据。本快速参考将提供SQL的基本语法和常用命令&…...

Cask ‘oraclexxx‘ is unavailable: No Cask with this name exists.
brew search oracle-jdk或brew search --cask oracle-jdk 原因:Homebrew官方仓库不再维护多个旧版本的OracleJDK 不推荐使用Homebrew环境安装JDK //指定版本安装 brew install --cask temurin17 //设置 JAVA_HOME 环境变量 //找到安装的JDK 版本的路径 /usr/lib…...

2024年武汉市中级、高级职称水测考试开卷方法分享
2024年武汉市(除开东湖高新区外)职称首次组织全员水测,先考水测后报名,水测报名在5月16号截止。 武汉市水测组织形式: 武汉市2024年专业技术职务水平能力测试分为笔试和面试,面试答辩有关事项另行通知&…...
 ICMP协议)
计算机网络(6) ICMP协议
ICMP(Internet Control Message Protocol,互联网控制消息协议)是一种用于在IP网络中传递控制消息和错误报告的协议。ICMP是IP协议族的一部分,尽管它并不用于传输用户数据,但它在网络诊断和管理中起着关键作用。以下是关…...

FuTalk设计周刊-Vol.036
🔥AI漫谈 热点捕手 1、Stable Zero123:从单张图像生成高质量 3D 对象 Stable Zero123 可以生成物体的新颖视图,展示从各个角度对物体外观的 3D 理解,由于训练数据集和高程条件的改进,其质量比 Zero1-to-3 或 Zero123-XL 显著提高…...

Java——面向对象进阶(三)
前言: 抽象类,接口,内部类 文章目录 一、抽象类1.1 抽象方法1.2 抽象类1.3 抽象类的使用 二、 接口2.1 接口的定义和实现2.2 default 关键字2.3 实现接口时遇到的问题 三、内部类3.1 成员内部类3.2 静态内部类3.3 成员内部类3.4 匿名内部类&a…...
】)
鸿蒙开发电话服务:【@ohos.telephony.observer (observer)】
observer 说明: 本模块首批接口从API version 6开始支持。后续版本的新增接口,采用上角标单独标记接口的起始版本。 导入模块 import observer from ohos.telephony.observerobserver.on(‘networkStateChange’) on(type: ‘networkStateChange’, ca…...

希亦、追觅、云鲸洗地机:究竟有何不同?选择哪款更合适
最近收到很多私信里,要求洗地机测评的呼声特别高,作为宠粉的测评博主,当然是马上安排起来,满足大家对想看洗地机的愿望。这次洗地机测评,我挑选了三款热门的品牌型号,并从多个维度对它们进行使用测评&#…...

代码随想录算法训练营第二十六天
题目:455. 分发饼干 贪心第一题 这里的局部最优就是大饼干喂给胃口大的,充分利用饼干尺寸喂饱一个,全局最优就是喂饱尽可能多的小孩。或者小饼干先喂饱小胃口 首先要对 g 和 s进行排序这样才能知道最大的胃口和最大的饼干然后进行遍历即可…...

[面试题]Java【并发】
[面试题]Java【基础】[面试题]Java【虚拟机】[面试题]Java【并发】[面试题]Java【集合】[面试题]MySQL 因为 Java 并发涉及到的内容会非常多,本面试题可能很难覆盖到所有的知识点,所以推荐 《Java并发编程的艺术》 。 Java 线程 线程 通知 等待 线…...

基于VSCode和MinGW-w64搭建LVGL模拟开发环境
目录 概述 1 运行环境 1.1 版本信息 1.2 软件安装 1.2.1 下载安装VS Code 1.2.1.1 下载软件 1.2.1.1 安装软件 1.2.2 下载安装MinGW-w64 1.2.2.1 下载软件 1.2.2.2 安装软件 1.2.3 下载安装SDL 1.2.3.1 下载软件 1.2.3.2 安装软件 1.2.4 下载安装CMake 1.2.4.…...

H5112B 降压恒流芯片12V24V36V48V60V72V100V 1.2ALED 调光无频闪光滑细腻
H5112B多功能LED恒流驱动器是一款具有良好性能与高度集成度的驱动芯片。以下是该产品的主要优点及应用领域的详细分析: 产品优点: 宽电压输入范围:H5112B支持5V至90V的宽电压输入范围,使其能够适应多种不同的电源环境࿰…...

真心建议大家冲一冲新兴领域,工资高前景好【大模型NLP开发篇】
前言 从ChatGPT到新近的GPT-4,GPT模型的发展表明,AI正在向着“类⼈化”⽅向迅速发展。 GPT-4具备深度阅读和识图能⼒,能够出⾊地通过专业考试并完成复杂指令,向⼈类引以为傲的“创造⼒”发起挑战。 现有的就业结构即将发⽣重⼤变…...
深度剖析淘宝扭蛋机源码:打造趣味性电商活动的秘诀
在当今电商市场中,如何吸引用户的注意力、提升用户的参与度成为了各大电商平台竞相追求的目标。淘宝扭蛋机作为一种新型的电商活动形式,以其趣味性和互动性深受用户喜爱。本文将深度剖析淘宝扭蛋机源码,探讨其如何打造趣味性与互动性并存的电…...

vue3+优化vue-baidu-map中marker点过多导致的页面卡顿问题
场景: 移动端h5中,当我们需要在地图中展示很多marker点坐标的时候,通常会使用 bm-marker ,去循环生成marker点,在数量不多的情况下是没问题的,但是随着数据量的增加,地图就会变得卡顿,以及渲染延…...

PMS助力制造企业高效运营︱PMO大会
全国PMO专业人士年度盛会 北京易贝恩项目管理科技有限公司副总经理朱洪泽女士受邀为PMO评论主办的2024第十三届中国PMO大会演讲嘉宾,演讲议题为“PMS助力制造企业高效运营”。大会将于6月29-30日在北京举办,敬请关注! 议题简要: …...
结构体的进阶应用)
基于算法竞赛的c++编程(28)结构体的进阶应用
结构体的嵌套与复杂数据组织 在C中,结构体可以嵌套使用,形成更复杂的数据结构。例如,可以通过嵌套结构体描述多层级数据关系: struct Address {string city;string street;int zipCode; };struct Employee {string name;int id;…...

idea大量爆红问题解决
问题描述 在学习和工作中,idea是程序员不可缺少的一个工具,但是突然在有些时候就会出现大量爆红的问题,发现无法跳转,无论是关机重启或者是替换root都无法解决 就是如上所展示的问题,但是程序依然可以启动。 问题解决…...
。】2022-5-15)
【根据当天日期输出明天的日期(需对闰年做判定)。】2022-5-15
缘由根据当天日期输出明天的日期(需对闰年做判定)。日期类型结构体如下: struct data{ int year; int month; int day;};-编程语言-CSDN问答 struct mdata{ int year; int month; int day; }mdata; int 天数(int year, int month) {switch (month){case 1: case 3:…...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...

盘古信息PCB行业解决方案:以全域场景重构,激活智造新未来
一、破局:PCB行业的时代之问 在数字经济蓬勃发展的浪潮中,PCB(印制电路板)作为 “电子产品之母”,其重要性愈发凸显。随着 5G、人工智能等新兴技术的加速渗透,PCB行业面临着前所未有的挑战与机遇。产品迭代…...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...

屋顶变身“发电站” ,中天合创屋面分布式光伏发电项目顺利并网!
5月28日,中天合创屋面分布式光伏发电项目顺利并网发电,该项目位于内蒙古自治区鄂尔多斯市乌审旗,项目利用中天合创聚乙烯、聚丙烯仓库屋面作为场地建设光伏电站,总装机容量为9.96MWp。 项目投运后,每年可节约标煤3670…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

【数据分析】R版IntelliGenes用于生物标志物发现的可解释机器学习
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍流程步骤1. 输入数据2. 特征选择3. 模型训练4. I-Genes 评分计算5. 输出结果 IntelliGenesR 安装包1. 特征选择2. 模型训练和评估3. I-Genes 评分计…...