RAGFlow 学习笔记
RAGFlow 学习笔记
- 0. 引言
- 1. RAGFlow 支持的文档格式
- 2. 嵌入模型选择后不再允许改变
- 3. 干预文件解析
- 4. RAGFlow 与其他 RAG 产品有何不同?
- 5. RAGFlow 支持哪些语言?
- 6. 哪些嵌入模型可以本地部署?
- 7. 为什么RAGFlow解析文档的时间比LangChain要长?
- 8. 为什么RAGFlow比其他项目需要更多的资源?
- 9. RAGFlow 支持哪些架构或设备?
- 10. 可以通过URL分享对话吗?
- 11. 为什么我的 pdf 解析在接近完成时停止,而日志没有显示任何错误?
- 12. 为什么我无法将 10MB 以上的文件上传到本地部署的 RAGFlow?
- 13. 如何增加RAGFlow响应的长度?
- 14. Empty response(空响应)是什么意思?怎么设置呢?
- 15. 如何配置 RAGFlow 以 100% 匹配的结果进行响应,而不是利用 LLM?
- 16. 使用 DataGrip 连接 ElasticSearch
- 99. 功能扩展
- 99-1. 扩展支持本地 LLM 功能
- 99-2. 扩展支持 OCI Cohere Embedding 功能
- 99-3. 扩展支持 OCI Cohere Command-r 功能
- 99-4. 扩展支持 Cohere Rerank 功能
0. 引言
这篇文章记录一下学习 RAGFlow 是一些笔记,方便以后自己查看和回忆。
1. RAGFlow 支持的文档格式
RAGFlow 支持的文件格式包括文档(PDF、DOC、DOCX、TXT、MD)、表格(CSV、XLSX、XLS)、图片(JPEG、JPG、PNG、TIF、GIF)和幻灯片(PPT、PPTX)。
2. 嵌入模型选择后不再允许改变
一旦您选择了嵌入模型并使用它来解析文件,您就不再允许更改它。明显的原因是我们必须确保特定知识库中的所有文件都使用相同的嵌入模型进行解析(确保它们在相同的嵌入空间中进行比较)。
3. 干预文件解析
RAGFlow 具有可见性和可解释性,允许您查看分块结果并在必要时进行干预。
4. RAGFlow 与其他 RAG 产品有何不同?
尽管 LLMs 显着推进了自然语言处理 (NLP),但“垃圾进垃圾出”的现状仍然没有改变。为此,RAGFlow 引入了与其他检索增强生成 (RAG) 产品相比的两个独特功能。
- 细粒度文档解析:文档解析涉及图片和表格,您可以根据需要灵活干预。
- 可追踪的答案,减少幻觉:您可以信任 RAGFlow 的答案,因为您可以查看支持它们的引文和参考文献。
5. RAGFlow 支持哪些语言?
目前有英文、简体中文、繁体中文。
6. 哪些嵌入模型可以本地部署?
- BAAI/bge-large-zh-v1.5
- BAAI/bge-base-en-v1.5
- BAAI/bge-large-en-v1.5
- BAAI/bge-small-en-v1.5
- BAAI/bge-small-zh-v1.5
- jinaai/jina-embeddings-v2-base-en
- jinaai/jina-embeddings-v2-small-en
- nomic-ai/nomic-embed-text-v1.5
- sentence-transformers/all-MiniLM-L6-v2
- maidalun1020/bce-embedding-base_v1
7. 为什么RAGFlow解析文档的时间比LangChain要长?
RAGFlow 使用了视觉模型,在布局分析、表格结构识别和 OCR(光学字符识别)等文档预处理任务中投入了大量精力。这会增加所需的额外时间。
8. 为什么RAGFlow比其他项目需要更多的资源?
RAGFlow 有许多用于文档结构解析的内置模型,这些模型占用了额外的计算资源。
9. RAGFlow 支持哪些架构或设备?
目前,我们仅支持 x86 CPU 和 Nvidia GPU。
10. 可以通过URL分享对话吗?
是的,此功能现已可用。
11. 为什么我的 pdf 解析在接近完成时停止,而日志没有显示任何错误?
如果您的 RAGFlow 部署在本地,则解析进程可能会因 RAM 不足而被终止。尝试通过增加 docker/.env 中的 MEM_LIMIT 值来增加内存分配。
12. 为什么我无法将 10MB 以上的文件上传到本地部署的 RAGFlow?
您可能忘记更新 MAX_CONTENT_LENGTH 环境变量:
将环境变量 MAX_CONTENT_LENGTH 添加到 ragflow/docker/.env:
MAX_CONTENT_LENGTH=100000000
更新 docker-compose.yml:
environment:- MAX_CONTENT_LENGTH=${MAX_CONTENT_LENGTH}
重新启动 RAGFlow 服务器:
docker compose up ragflow -d
现在您应该能够上传大小小于 100MB 的文件。
13. 如何增加RAGFlow响应的长度?
右键单击所需的对话框以显示“Chat Configuration(聊天配置)”窗口。
切换到Model Setting(模型设置)选项卡并调整Max Tokens(最大令牌)滑块以获得所需的长度。
单击“确定”确认您的更改。
14. Empty response(空响应)是什么意思?怎么设置呢?
如果从您的知识库中未检索到任何内容,则您可以将系统的响应限制为您在“Empty response(空响应)”中指定的内容。如果您没有在空响应中指定任何内容,您就可以让您的 LLM 即兴创作,给它一个产生幻觉的机会。
15. 如何配置 RAGFlow 以 100% 匹配的结果进行响应,而不是利用 LLM?
单击页面中间顶部的知识库。
右键单击所需的知识库以显示配置对话框。
选择“Q&A(问答)”作为块方法,然后单击“保存”以确认您的更改。
16. 使用 DataGrip 连接 ElasticSearch
curl -X POST -u "elastic:infini_rag_flow" -k "http://localhost:1200/_license/start_trial?acknowledge=true&pretty"
99. 功能扩展
99-1. 扩展支持本地 LLM 功能
vi rag/utils/__init__.py---
# encoder = tiktoken.encoding_for_model("gpt-3.5-turbo")
encoder = tiktoken.encoding_for_model("gpt-4-128k")
---
vi api/settings.py---"Local-OpenAI": {"chat_model": "gpt-4-128k","embedding_model": "","image2text_model": "","asr_model": "",},
---
vi api/db/init_data.py---
factory_infos = [{"name": "OpenAI","logo": "","tags": "LLM,TEXT EMBEDDING,SPEECH2TEXT,MODERATION","status": "1",
}, {"name": "Local-OpenAI","logo": "","tags": "LLM","status": "1",
},
---# ---------------------- Local-OpenAI ------------------------{"fid": factory_infos[0]["name"],"llm_name": "gpt-4-128k","tags": "LLM,CHAT,128K","max_tokens": 128000,"model_type": LLMType.CHAT.value},
vi rag/llm/__init__.py---
ChatModel = {"OpenAI": GptTurbo,"Local-OpenAI": GptTurbo,
---
vi web/src/pages/user-setting/setting-model/index.tsx---
const IconMap = {'Tongyi-Qianwen': 'tongyi',Moonshot: 'moonshot',OpenAI: 'openai','Local-OpenAI': 'openai', 'ZHIPU-AI': 'zhipu',文心一言: 'wenxin',Ollama: 'ollama',Xinference: 'xinference',DeepSeek: 'deepseek',VolcEngine: 'volc_engine',BaiChuan: 'baichuan',Jina: 'jina',
};
---
vi web/src/pages/user-setting/setting-model/api-key-modal/index.tsx---{llmFactory === 'Local-OpenAI' && (<Form.Item<FieldType>label={t('baseUrl')}name="base_url"tooltip={t('baseUrlTip')}><Input placeholder="https://api.openai.com/v1" /></Form.Item>)}
---
连接 MySQL 数据库,1. 向llm_factories表插入数据
Local-OpenAI,1717812204952,2024-06-08 10:03:24,1717812204952,2024-06-08 10:03:24,"",LLM,12. 向llm表插入数据
gpt-4-128k,1717812204975,2024-06-08 10:03:24,1717812204975,2024-06-08 10:03:24,chat,Local-OpenAI,128000,"LLM,CHAT,128K",1
99-2. 扩展支持 OCI Cohere Embedding 功能
连接 MySQL 数据库,1. 向llm_factories表插入数据
OCI-Cohere,1717812204967,2024-06-08 10:03:24,1717812204967,2024-06-08 10:03:24,"",TEXT EMBEDDING,12. 向llm表插入数据
cohere.embed-multilingual-v3.0,1717812204979,2024-06-08 10:03:24,1717812204979,2024-06-08 10:03:24,embedding,OCI-Cohere,512,"TEXT EMBEDDING,",1
vi api/apps/llm_app.py---fac = LLMFactoriesService.get_all()return get_json_result(data=[f.to_dict() for f in fac if f.name not in ["Youdao", "FastEmbed", "BAAI"]])# return get_json_result(data=[f.to_dict() for f in fac if f.name not in ["Youdao", "FastEmbed", "BAAI", "OCI-Cohere"]])
------for m in llms:m["available"] = m["fid"] in facts or m["llm_name"].lower() == "flag-embedding" or m["fid"] in ["Youdao","FastEmbed", "BAAI"]# m["available"] = m["fid"] in facts or m["llm_name"].lower() == "flag-embedding" or m["fid"] in ["Youdao","FastEmbed", "BAAI", "OCI-Cohere"]
---
vi api/settings.py---"OCI-Cohere": {"chat_model": "","embedding_model": "cohere.embed-multilingual-v3.0","image2text_model": "","asr_model": "",},
---
vi api/db/init_data.py---
factory_infos = [{"name": "OpenAI","logo": "","tags": "LLM,TEXT EMBEDDING,SPEECH2TEXT,MODERATION","status": "1",
}, {"name": "OCI-Cohere","logo": "","tags": "TEXT EMBEDDING","status": "1",
},
---# ---------------------- OCI-Cohere ------------------------{"fid": factory_infos[0]["name"],"llm_name": "cohere.embed-multilingual-v3.0","tags": "TEXT EMBEDDING,512","max_tokens": 512,"model_type": LLMType.EMBEDDING.value},
vi rag/llm/__init__.py---
EmbeddingModel = {"OCI-Cohere": OCICohereEmbed,
---
vi rag/llm/embedding_model.py---
class OCICohereEmbed(Base):def __init__(self, key, model_name="cohere.embed-multilingual-v3.0",base_url="https://inference.generativeai.us-chicago-1.oci.oraclecloud.com"):if not base_url:base_url = "https://inference.generativeai.us-chicago-1.oci.oraclecloud.com"CONFIG_PROFILE = "DEFAULT"config = oci.config.from_file('~/.oci/config', CONFIG_PROFILE)self.client = oci.generative_ai_inference.GenerativeAiInferenceClient(config=config, service_endpoint=base_url,retry_strategy=oci.retry.NoneRetryStrategy(),timeout=(10, 240))self.model_name = model_nameself.compartment = keydef encode(self, texts: list, batch_size=1):token_count = 0texts = [truncate(t, 512) for t in texts]for t in texts:token_count += num_tokens_from_string(t)embed_text_detail = oci.generative_ai_inference.models.EmbedTextDetails()embed_text_detail.serving_mode = oci.generative_ai_inference.models.OnDemandServingMode(model_id=self.model_name)embed_text_detail.inputs = textsembed_text_detail.truncate = "NONE"embed_text_detail.compartment_id = self.compartmentres = self.client.embed_text(embed_text_detail)print(f"{res.data=}")return res.data.embeddings, token_countdef encode_queries(self, text):text = truncate(text, 512)token_count = num_tokens_from_string(text)res = self.encode(texts=[text])return res[0], token_count
在服务器上设置好 ~/.oci/config。
添加的模型时,OCI-Cohere输入使用的OCI CompartmentID。
制作图标,访问 https://brandfetch.com/oracle.com 下载 oracle svg 图标,保存到 web/src/assets/svg/llm 目录下面。
vi web/src/pages/user-setting/setting-model/index.tsx---
const IconMap = {'OCI-Cohere': 'oracle',
---
99-3. 扩展支持 OCI Cohere Command-r 功能
连接 MySQL 数据库,1. 向llm_factories表插入数据
OCI-Cohere,1717812204967,2024-06-08 10:03:24,1717812204967,2024-06-08 10:03:24,"",LLM,TEXT EMBEDDING,12. 向llm表插入数据
cohere.embed-multilingual-v3.0,1717812204979,2024-06-08 10:03:24,1717812204979,2024-06-08 10:03:24,embedding,OCI-Cohere,512,"TEXT EMBEDDING,",1
vi api/apps/llm_app.py---fac = LLMFactoriesService.get_all()return get_json_result(data=[f.to_dict() for f in fac if f.name not in ["Youdao", "FastEmbed", "BAAI"]])# return get_json_result(data=[f.to_dict() for f in fac if f.name not in ["Youdao", "FastEmbed", "BAAI", "OCI-Cohere"]])
------for m in llms:m["available"] = m["fid"] in facts or m["llm_name"].lower() == "flag-embedding" or m["fid"] in ["Youdao","FastEmbed", "BAAI"]# m["available"] = m["fid"] in facts or m["llm_name"].lower() == "flag-embedding" or m["fid"] in ["Youdao","FastEmbed", "BAAI", "OCI-Cohere"]
---
vi api/settings.py---"OCI-Cohere": {"chat_model": "cohere.command-r-16k","embedding_model": "cohere.embed-multilingual-v3.0","image2text_model": "","asr_model": "",},
---
vi api/db/init_data.py---
factory_infos = [{"name": "OpenAI","logo": "","tags": "LLM,TEXT EMBEDDING,SPEECH2TEXT,MODERATION","status": "1",
}, {"name": "OCI-Cohere","logo": "","tags": "LLM,TEXT EMBEDDING","status": "1",
},
---# ---------------------- OCI-Cohere ------------------------{"fid": factory_infos[0]["name"],"llm_name": "cohere.embed-multilingual-v3.0","tags": "TEXT EMBEDDING,512","max_tokens": 512,"model_type": LLMType.EMBEDDING.value},{"fid": factory_infos[0]["name"],"llm_name": "cohere.command-r-16k","tags": "LLM,CHAT,16K","max_tokens": 16385,"model_type": LLMType.CHAT.value},
vi rag/llm/__init__.py---
ChatModel = {"OCI-Cohere": OCICohereChat,
---
vi rag/llm/chat_model.py---
class OCICohereChat(Base):def __init__(self, key, model_name="cohere.command-r-16k",base_url="https://inference.generativeai.us-chicago-1.oci.oraclecloud.com"):if not base_url:base_url = "https://inference.generativeai.us-chicago-1.oci.oraclecloud.com"CONFIG_PROFILE = "DEFAULT"config = oci.config.from_file('~/.oci/config', CONFIG_PROFILE)self.client = oci.generative_ai_inference.GenerativeAiInferenceClient(config=config, service_endpoint=base_url,retry_strategy=oci.retry.NoneRetryStrategy(),timeout=(10, 240))self.model_name = model_nameself.compartment = key@staticmethoddef _format_params(params):return {"max_tokens": params.get("max_tokens", 3999),"temperature": params.get("temperature", 0),"frequency_penalty": params.get("frequency_penalty", 0),"top_p": params.get("top_p", 0.75),"top_k": params.get("top_k", 0),}def chat(self, system, history, gen_conf):chat_detail = oci.generative_ai_inference.models.ChatDetails()chat_request = oci.generative_ai_inference.models.CohereChatRequest()params = self._format_params(gen_conf)chat_request.max_tokens = params.get("max_tokens")chat_request.temperature = params.get("temperature")chat_request.frequency_penalty = params.get("frequency_penalty")chat_request.top_p = params.get("top_p")chat_request.top_k = params.get("top_k")chat_detail.serving_mode = oci.generative_ai_inference.models.OnDemandServingMode(model_id=self.model_name)chat_detail.chat_request = chat_requestchat_detail.compartment_id = self.compartmentchat_request.is_stream = Falseif system:chat_request.preamble_override = systemprint(f"{history[-1]=}")chat_request.message = history[-1]['content']chat_response = self.client.chat(chat_detail)# Print resultprint("**************************Chat Result**************************")print(vars(chat_response))chat_response = vars(chat_response)chat_response_data = chat_response['data']chat_response_data_chat_response = chat_response_data.chat_responseans = chat_response_data_chat_response.texttoken_count = 0for t in history[-1]['content']:token_count += num_tokens_from_string(t)for t in ans:token_count += num_tokens_from_string(t)return ans, token_countdef chat_streamly(self, system, history, gen_conf):chat_detail = oci.generative_ai_inference.models.ChatDetails()chat_request = oci.generative_ai_inference.models.CohereChatRequest()params = self._format_params(gen_conf)chat_request.max_tokens = params.get("max_tokens")chat_request.temperature = params.get("temperature")chat_request.frequency_penalty = params.get("frequency_penalty")chat_request.top_p = params.get("top_p")chat_request.top_k = params.get("top_k")chat_detail.serving_mode = oci.generative_ai_inference.models.OnDemandServingMode(model_id=self.model_name)chat_detail.chat_request = chat_requestchat_detail.compartment_id = self.compartmentchat_request.is_stream = Trueif system:chat_request.preamble_override = systemprint(f"{history[-1]=}")token_count = 0for t in history[-1]['content']:token_count += num_tokens_from_string(t)chat_request.message = history[-1]['content']chat_response = self.client.chat(chat_detail)# Print resultprint("**************************Chat Result**************************")chat_response = vars(chat_response)chat_response_data = chat_response['data']# for msg in chat_response_data.iter_content(chunk_size=None):for event in chat_response_data.events():token_count += 1yield json.loads(event.data)["text"]yield token_count
在服务器上设置好 ~/.oci/config。
添加的模型时,OCI-Cohere输入使用的OCI CompartmentID。
99-4. 扩展支持 Cohere Rerank 功能
连接 MySQL 数据库,1. 向llm_factories表插入数据
Cohere,1717812204971,2024-06-08 10:03:24,1717812204971,2024-06-08 10:03:24,"",TEXT RE-RANK,12. 向llm表插入数据
rerank-multilingual-v3.0,1717812205057,2024-06-08 10:03:25,1717812205057,2024-06-08 10:03:25,rerank,Cohere,4096,"RE-RANK,4k",1
vi api/settings.py---"Cohere": {"chat_model": "","embedding_model": "","image2text_model": "","asr_model": "","rerank_model": "rerank-multilingual-v3.0",},
---
vi api/db/init_data.py---
factory_infos = [{"name": "OpenAI","logo": "","tags": "LLM,TEXT EMBEDDING,SPEECH2TEXT,MODERATION","status": "1",
}, {"name": "Cohere","logo": "","tags": "TEXT RE-RANK","status": "1",
}
---# ---------------------- Cohere ------------------------{"fid": factory_infos[12]["name"],"llm_name": "rerank-multilingual-v3.0","tags": "RE-RANK,4k","max_tokens": 4096,"model_type": LLMType.RERANK.value},
vi rag/llm/__init__.py---
RerankModel = {"Cohere": CohereRerank,
---
vi rag/llm/rerank_model.py---def similarity(self, query: str, texts: list):token_count = 1texts = [truncate(t, 4096) for t in texts]for t in texts:token_count += num_tokens_from_string(t)for t in query:token_count += num_tokens_from_string(t)response = self.co.rerank(model=self.model,query=query,documents=texts,top_n=len(texts),return_documents=False,)return np.array([r.relevance_score for r in response.results]), token_count
添加的模型时,Cohere输入使用的Cohere 的 API Key。
制作图标,访问 https://brandfetch.com/cohere.com 下载 cohere svg 图标,保存到 web/src/assets/svg/llm 目录下面。
vi web/src/pages/user-setting/setting-model/index.tsx---
const IconMap = {'Cohere': 'cohere',
---
未完待续!
相关文章:

RAGFlow 学习笔记
RAGFlow 学习笔记 0. 引言1. RAGFlow 支持的文档格式2. 嵌入模型选择后不再允许改变3. 干预文件解析4. RAGFlow 与其他 RAG 产品有何不同? 5. RAGFlow 支持哪些语言? 6. 哪些嵌入模型可以本地部署? 7. 为什么RAGFlow解析文档的时间比…...

使用Docker-Java监听Docker容器的信息
使用Docker-Java监听Docker容器的信息 Docker作为一种轻量级的容器化平台,极大地方便了应用的部署与管理。然而,在实际使用过程中,我们常常需要对运行中的容器进行监控,以确保其健康状态,并能及时响应各种异常情况。本…...
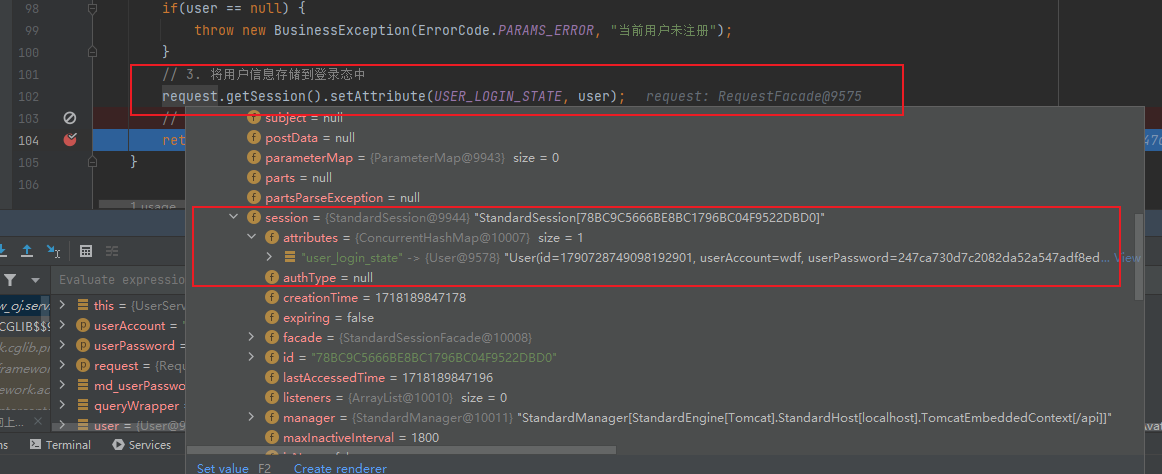
Spring Boot + Mybatis Plus实现登录注册
Spring Boot 实现登录注册 1. 注册 业务逻辑 客户端输入注册时需要的用户参数,比如:账户名、密码、确认密码、其他服务端接收到客户端的请求参数进行校验,然后判断是否有误,有误的地方就将错误信息抛出将密码进行加密之后存储到…...

IDEA创建web项目
IDEA创建web项目 第一步:创建一个空项目 第二步:在刚刚创建的项目下创建一个子模块 第三步:在子模块中引入web 创建结果如下: 这里我们需要把这个目录移到main目录下,并改名为webapp,结果如下 将pom文件…...
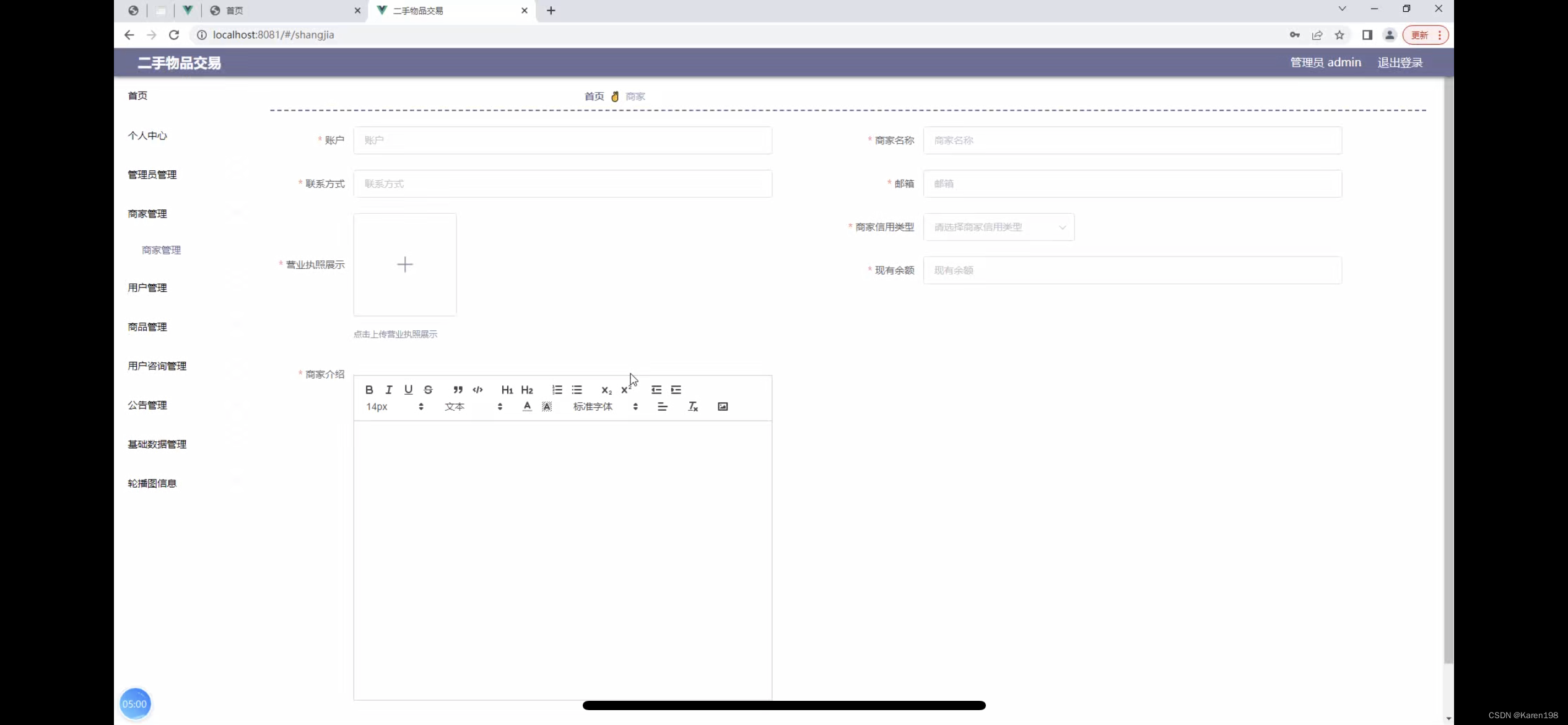
二手物品交易系统的设计
管理员账户功能包括:系统首页,个人中心,管理员管理,商家管理,用户管理,商品管理,用户咨询管理 商家账户功能包括:系统首页,个人中心,商品管理,用…...

探索大数据在信用评估中的独特价值
随着我国的信用体系越来越完善,信用将影响越来越多的人。现在新兴的大数据信用和传统信用,形成了互补的优势,大数据信用变得越来越重要,那大数据信用风险检测的重要性主要体现在什么地方呢?本文将详细为大家介绍一下,…...

MFC基础学习应用
MFC基础学习应用 1.基于对话框的使用 左上角为菜单键(其下的关于MFC主要功能由IDD_ABOUTBOX决定) 附图 右下角为按钮(基本功能由IDD_DIALOG决定,添加按钮使用由左上角的工具箱完成) 附图 2.自行添加功能与按钮//功能代码 void CMFCApplication4Dlg:…...
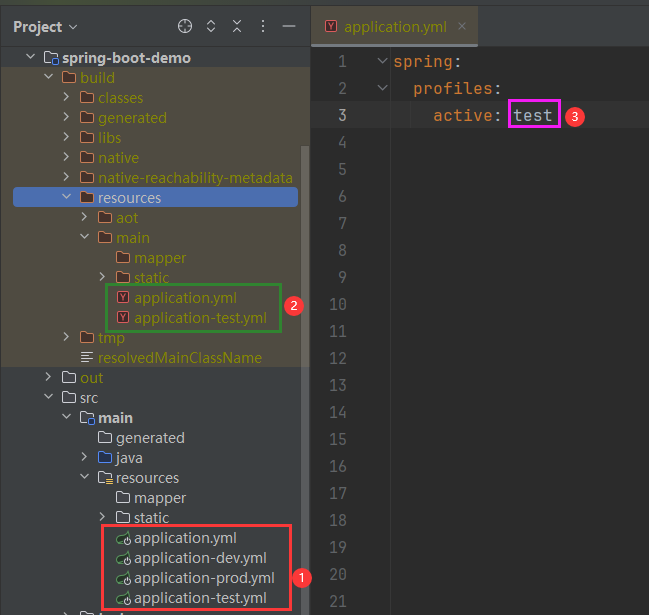
Gradle实现类似Maven的profiles功能
版本说明 GraalVM JDK 21.0.3Gradle 8.7Spring Boot 3.2.5 目录结构 指定环境打包 application.yml/yaml/properties 执行 bootJar 打包命令前要先执行 clean【其它和 processResources 相关的命令也要先执行 clean】,否则 active 值不会变! spring…...
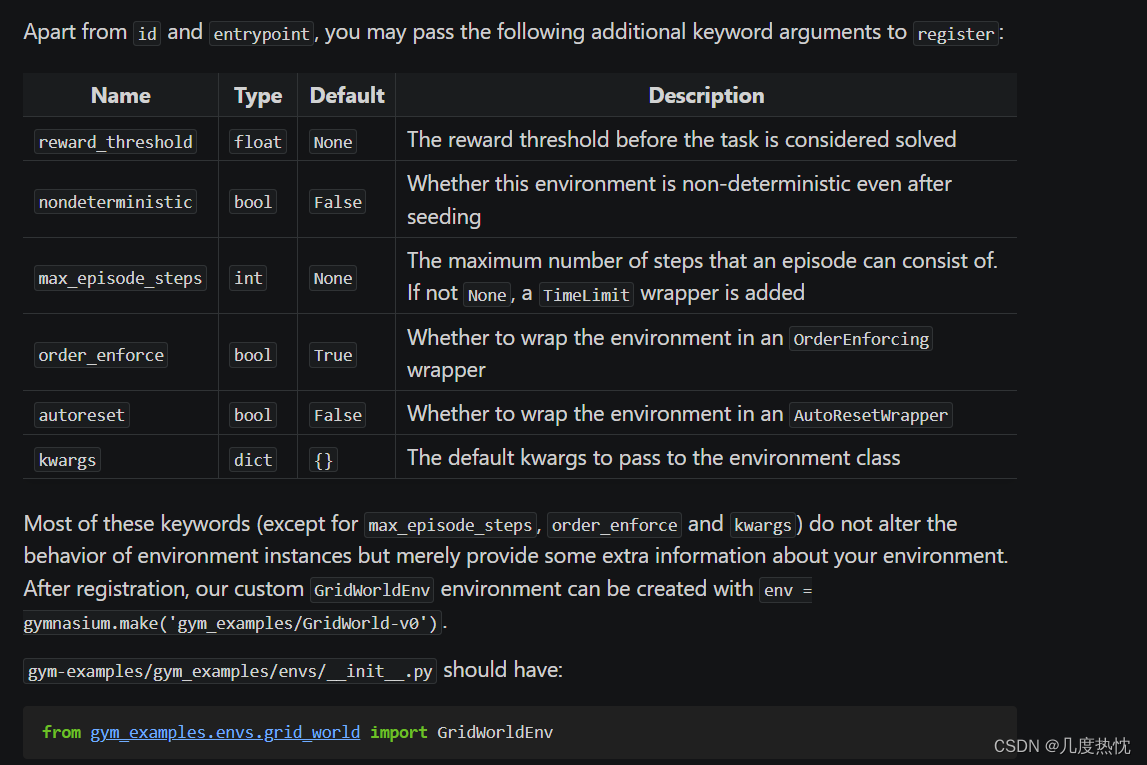
【强化学习】gymnasium自定义环境并封装学习笔记
【强化学习】gymnasium自定义环境并封装学习笔记 gym与gymnasium简介gymgymnasium gymnasium的基本使用方法使用gymnasium封装自定义环境官方示例及代码编写环境文件__init__()方法reset()方法step()方法render()方法close()方法 注册环境创建包 Package(最后一步&a…...
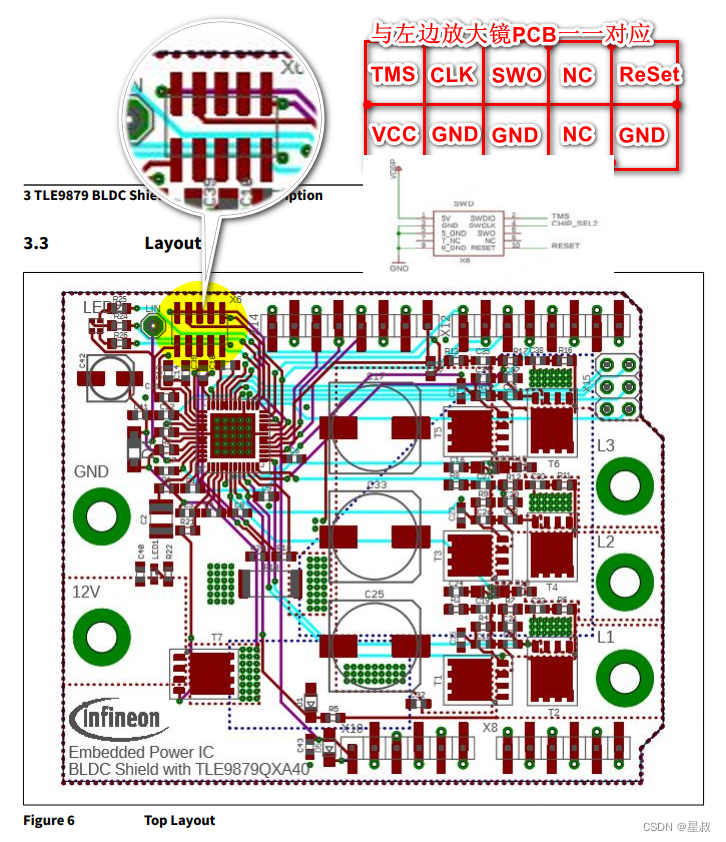
TLE9879的基于Arduino调试板SWD刷写接口
官方的Arduino评估板,如下图所示: 如果你有官方的调试器,应该不用关注本文章,如下图连接就是: 如果,您和博主一样需要自己飞线的话,如下图所示:PCB的名称在右边整理,SWD的…...

基于 Delphi 的前后端分离:之五,使用 HTMX 让页面元素组件化之面向对象的Delphi代码封装
前情提要 本博客上一篇文章,描述了使用 Delphi 作为后端的 Web Server,前端使用 HTMX 框架,把一个开源的前端图表 JS 库,进行了组件化。 上一篇文章仅仅是描述了简单的前端代码组件化的可能性,依然是基于前端库的 JS…...
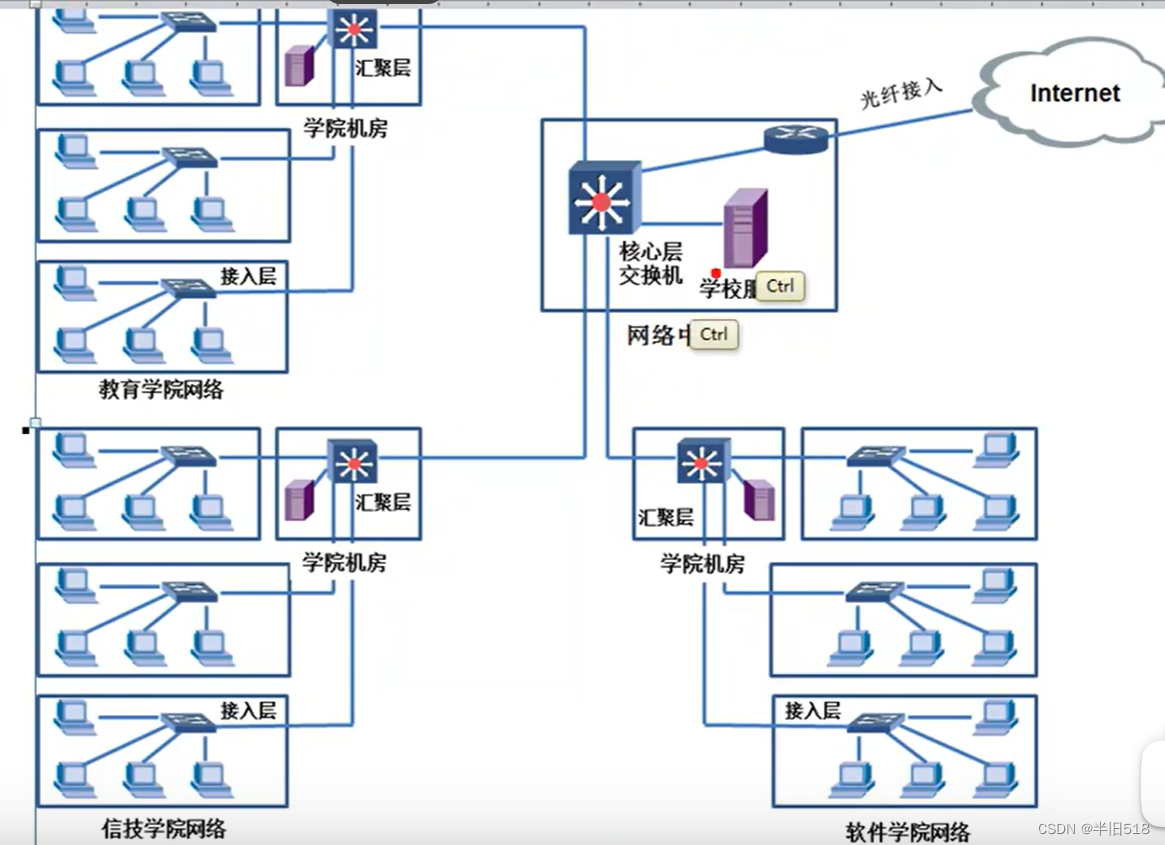
讲透计算机网络知识(实战篇)01——计算机网络和协议
一、计算机网络和协议 1、网络和互联网络 1.1 网络、互联网、Internet 用交换机、集线器连接在一起的计算机构成一个网络。 用路由器连接多个网络,形成互联网。 全球最大的互联网:Internet。 1.2 网络举例 家庭互联网 图中的无线拨号路由器既是路由…...

8个宝藏APP,个个都牛逼哈拉!
AI视频生成:小说文案智能分镜智能识别角色和场景批量Ai绘图自动配音添加音乐一键合成视频https://aitools.jurilu.com/ 目前win7已经逐渐淡出人们的视野,大部分人都开始使用win10,在日常工作和使用中,创客们下载神奇的软件能大幅提…...

使用docker构建java应用
1、docker简介 Docker是一个开源的容器化平台,可以帮助开发人员将应用程序及其依赖项打包成一个可移植的容器。容器化是一种轻量级的虚拟化技术,可以使应用程序在不同的操作系统和环境中具有一致的运行方式。 使用Docker带来的好处包括: 简…...

Oracle 存储过程
Oracle存储过程 创建存储过程 CREATE OR REPLACE PROCEDURE UPDATE_EMPLOYEE_SALARY(p_employee_id IN NUMBER,p_employee_salary IN NUMBER )AS BEGINUPDATE employeesSET salary p_employee_salaryWHERE employee_id p_employee_id;COMMIT;EXCEPTIONWHEN NO_DATA_FOUND T…...

下载站名文件
自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm1001.2014.3001.5501 得到了请求地址与请求参数后,可以发现请求参数中的出发地与目的地均为车站名的英文缩写。而这个英文缩写的字母是通过输入中文车站名转换…...

345453
38744...
Java操作redis
目录 一:Jedis 二:使用Spring Data Redis Redis 的 Java 客户端很多,官方推荐的有三种: 1.Jedis 2.Lettuce 3.Redisson 同时,Spring 对 Redis 客户端进行了整合,提供了 Spring Data Redis,在S…...

【数据结构(邓俊辉)学习笔记】图03——拓扑排序
文章目录 0. 概述1. 零入度算法1. 1 拓扑排序1. 2 算法 2. 零出度算法2.1 算法2.2 实现2.3. 复杂度 0. 概述 学习下拓扑排序 1. 零入度算法 1. 1 拓扑排序 首先理解下拓扑排序 其实老师经常干这事,如编讲义,将已经知道的知识点串起来变成讲课序列。那…...

C#参数使用场景简要说明
C#参数使用场景简要说明 1、传值参数 方法、类成员的初始化 2、输出参数 方法返回值不能满足,需要多个返回值时; 3、引用参数 方法需要修改变量需带回原变量时; 4、具名参数 代码可读性高,参数可交换位置 5、方法扩展(…...

RestClient
什么是RestClient RestClient 是 Elasticsearch 官方提供的 Java 低级 REST 客户端,它允许HTTP与Elasticsearch 集群通信,而无需处理 JSON 序列化/反序列化等底层细节。它是 Elasticsearch Java API 客户端的基础。 RestClient 主要特点 轻量级ÿ…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...

【JVM】- 内存结构
引言 JVM:Java Virtual Machine 定义:Java虚拟机,Java二进制字节码的运行环境好处: 一次编写,到处运行自动内存管理,垃圾回收的功能数组下标越界检查(会抛异常,不会覆盖到其他代码…...

【论文笔记】若干矿井粉尘检测算法概述
总的来说,传统机器学习、传统机器学习与深度学习的结合、LSTM等算法所需要的数据集来源于矿井传感器测量的粉尘浓度,通过建立回归模型来预测未来矿井的粉尘浓度。传统机器学习算法性能易受数据中极端值的影响。YOLO等计算机视觉算法所需要的数据集来源于…...

JDK 17 新特性
#JDK 17 新特性 /**************** 文本块 *****************/ python/scala中早就支持,不稀奇 String json “”" { “name”: “Java”, “version”: 17 } “”"; /**************** Switch 语句 -> 表达式 *****************/ 挺好的ÿ…...

k8s业务程序联调工具-KtConnect
概述 原理 工具作用是建立了一个从本地到集群的单向VPN,根据VPN原理,打通两个内网必然需要借助一个公共中继节点,ktconnect工具巧妙的利用k8s原生的portforward能力,简化了建立连接的过程,apiserver间接起到了中继节…...

[Java恶补day16] 238.除自身以外数组的乘积
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 不要使用除法,且在 O(n) 时间复杂度…...

智能分布式爬虫的数据处理流水线优化:基于深度强化学习的数据质量控制
在数字化浪潮席卷全球的今天,数据已成为企业和研究机构的核心资产。智能分布式爬虫作为高效的数据采集工具,在大规模数据获取中发挥着关键作用。然而,传统的数据处理流水线在面对复杂多变的网络环境和海量异构数据时,常出现数据质…...