Es 索引查询排序分析
文章目录
- 概要
- 一、Es数据存储
- 1.1、_source
- 1.2、stored fields
- 二、Doc values
- 2.1、FieldCache
- 2.2、DocValues
- 三、Fielddata
- 四、Index sorting
- 五、小结
- 六、参考
概要
倒排索引 优势在于快速的查找到包含特定关键词的所有文档,但是排序,过滤、聚合等操作并不是倒排索引所擅长的。
假设文档有两个字段,一个被分词的字段name,一个日期date。现在要查出包含
花朵的所有文档中的按日期正序的前10个,如果仅仅有倒排索引该如何实现的呢?
答:在name字段的倒排索引上找到包含关键词花朵的所有文档ID,然后获取date排序字段的值,根据date值实时排序,取前10个。
这种办法数据量少的时候还可以,如果索引有百万级以上的数据,就很低效了。显然,MySQL、MongoDB等数据库按字段建立索引进行预排序更高效。
可以看到只有倒排索引的话,排序是非常耗时的。Es维护组投入了大量时间和精力来优化排序查询,随着版本更新,在Es6基本完善了这一块工作,分三部分:
- Docvalues
- Fielddata
- index sorting
Es对搜索与排序的区别解释很到位:
Search needs to answer the question “Which documents contain this term?”, while sorting and aggregations need to answer a different question: “What is the value of this field for this document?”.
一、Es数据存储
Es是基于Lucene引擎的,在Lucene中索引文档时,原始字段信息经过分词、转换处理后形成倒排索引,而原始内容本身并不直接保留。因此,Lucene为了检索时能够获取到字段的原始值而设计了stored fields。另外Es自己追了一个_source字段,保存了用户插入文档的字段值。
1.1、_source
Es将文档内容以json形式存储在一个叫_source的字段中,其默认是开启的。在Lucene层面,_source仅仅是一个普通字段,当开启时,我们插入一个文档,Es会自动把文档内容序列化,赋值给_source字段,组成新的文档结构,再交由Lucene处理,大致流程如下:

可以看到,在Lucene层面_source字段和其他字段并无特别之处。我们一般按如下方式调整_source字段:
PUT my-index
{"mappings": {"_source": {"enabled": true, #是否开启_source字段,默认开启"includes": [ #开启_source字段是包含哪些字段,支持正则"*.count","meta.*"],"excludes": [ #开启_source字段是排除哪些字段,支持正则"meta.description","meta.other.*"]}}
}
PS:一般情况下我们都是开启_source字段的,因为关闭_source后update、update_by_query、reindex等API将无法正常使用。
1.2、stored fields
stored fields是Lucene引擎自带的特性,在Es层面可通过store属性来控制,默认不开启。
PUT my-index
{"mappings": {"properties": {"name": { "type": "text" #默认关闭name字段的stored field},"age": { "type": "long","store": true #开启age字段的stored field}}}
}
那么如果即开启_source字段,某个字段的stored fields也开启,那么这个字段值会被存储两次,所以字段stored fields属性一般不开启,如果开启最好通过_source的excludes属性排除该字段即可。
演示如下:
[root@test ~]# curl -XPUT http://127.0.0.1:9200/test -H 'Content-Type: application/json' -d '{"mappings":{"properties":{"status_code":{"type":"text"},"session_id":{"type":"keyword","store":true}}}}'
{"acknowledged":true,"shards_acknowledged":true,"index":"test"}
[root@test ~]# curl -XGET http://127.0.0.1:9200/test/_doc/1?pretty
{"_index" : "test","_id" : "1","_version" : 1,"_seq_no" : 0,"_primary_term" : 1,"found" : true,"_source" : {"status_code" : "xxx bob","session_id" : "999"}
}
[root@test ~]# curl -XGET http://127.0.0.1:9200/test/_doc/1?pretty\&stored_fields=status_code
{"_index" : "test","_id" : "1","_version" : 1,"_seq_no" : 0,"_primary_term" : 1,"found" : true
}
[root@test ~]# curl -XGET http://127.0.0.1:9200/test/_doc/1?pretty\&stored_fields=status_code,session_id
{"_index" : "test","_id" : "1","_version" : 1,"_seq_no" : 0,"_primary_term" : 1,"found" : true,"fields" : {"session_id" : ["999"]}
}Lucene的stored fields属于正排索引,由于字段值经过分词转换为倒排索引后,原始值并未保存,为了根据doc id快速获取字段原始值而设计的。在Lucene下的应用场景是当需要返回原始字段值时,就需要对对应字段设置stored fields; 在Es下由于设计了_source字段,一般不需开启,根据实际场景二者结合使用即可。
值得注意的是,如果 _source 为不开启,并且字段 store 属性也为 false ,字段值就无法返回了,但是如果字段index属性为true的话,还是可以通过该字段查询文档的,如果字段index属性为false的话,该字段既不能查询,也不会被返回,是无效字段。
二、Doc values
默认情况下,大多数字段都会被建立倒排索引,这使得它们可以进行搜索。但是排序、聚合和脚本操作中的字段值需要获取文档某个字段的具体值。Doc values就是专为这种场景而诞生的,简单来说就是实现根据doc id快速获取doc中某个字段值的目标。
doc values是列式存储,主要包含doc id和字段具体值(可能被压缩),属于正排索引。Es默认每个字段的 doc values 都是开启的(不支持
text和annotated_text类型字段)。
Doc values是Lucene引擎自带的特性,从Lucene V4.0开始引入的,在4.0之前都是依赖fieldCache机制,用于缓存字段值。
2.1、FieldCache
FieldCache,即字段缓存,作用是加载所有文档中某个特定字段的值到内存,便于随机获取某些文档中该字段的值。在FieldCache出现之前,当用户需要访问各文档中某个字段的值时,IndexSearcher.doc(docId)获得Document的所有字段值,但访问速度比较慢,而且只能获得被stored字段的值。
于是Lucene 在 3.0 提出了字段缓存(FieldCache)的概念,这个 API 主要是在内部使用,但开发者也可以外部调用,在自定义排序或者自定义评分的时候都涉及到相关的接口。准确的说,就是将相关的字段的值加载到内存中,形成一维数组。加载字段缓存,并不要求相关字段的值必须在索引中被stored,而是要求必须 index,并且不能分词,实际上字段缓存的值是从倒排索引中转换而来。
FieldCache主要用于以下场景:
- 加速对特定字段值的访问;
- 支持脚本中对字段值进行操作;
- 用于排序、聚合等操作。
具体原理见下图:
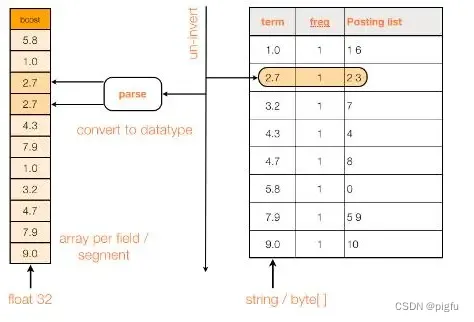
但是这种方式有很大的不足:
- 内存消耗大:常驻内存,大小是文档个数 * 字段类型大小;
- 性能开销大:初始加载过程耗时,需要遍历倒排索引及类型转换。可能导致其他请求延迟;
- 内存管理复杂:内存管理不够灵活,可能导致频繁的GC及性能问题。
Lucene 自 4.0 起提出了一个新的概念 DocValues, 允许用户在建索引的时候将相关字段的doc id 和字段值 之间的映射直接保存在索引文件中(磁盘)。因此,在 lucene4.0 中,Lucene 在根据doc id查询字段值时,首先会根据doc id 去对应DocValues中获取字段的值。如果 DocValues 中不存在,才会从倒排索引中进行类型转换,再加载到内存中,即FieldCache机制。也就是说,默认会使用 DocValues代替FieldCache机制。
PS:事实上,查了下,在 lucene5 的 API 中,FieldCache 已经被取消了,大家了解曾经有这么个机制即可
 可以看到,Lucene 5就没有了。
可以看到,Lucene 5就没有了。
2.2、DocValues
DocValues相比FieldCache机制,大大节约内存,获取字段值快;其大概结构如下:
| doc id |field value |
| 1 | 500 |
| 2 | 900 |
| 3 | 1500 |
| 4 | 100 |
使用方式:
PUT my-index
{"mappings": {"properties": {"status_code": { "type": "keyword" #默认开启status_code字段的doc value},"session_id": { "type": "long","doc_values": false #关闭session_id字段的doc value}}}
}
- 生成时机: doc values 在文档被插入的时候与倒排索引同期生成,即Es 为了提高查询排序速度,插入文档时,同时把字段的值加入倒排索引中,也会把字段的值加入到doc values中(空间换时间)。
- 存储位置:磁盘,使用时会被加载到内存。
通过下面案例可以清晰看到text 和 annotated_text类型的字段不支持doc_vlues属性。
[root@test ~]# curl -XPUT http://127.0.0.1:9200/test -H 'Content-Type: application/json' -d '{"mappings":{"properties":{"status_code":{"type":"text","doc_vlues":true},"session_id":{"type":"keyword","doc_values":false}}}}'
{"error":{"root_cause":[{"type":"mapper_parsing_exception","reason":"unknown parameter [doc_vlues] on mapper [status_code] of type [text]"}]}}"Es 中
text和annotated_text类型的字段不支持doc_vlues属性,主要是因为Lucene中Docvalues机制保存的是字段原始值,并不支持分词后的结果;
为了更好地理解Es如何使用Lucene的DocValues机制,我们可以看一下相关API;
public class LuceneExample {public static void main(String[] args) throws Exception {// 创建一个内存目录来存储索引Directory directory = new RAMdirectory();// 使用标准分析器StandardAnalyzer analyzer = new StandardAnalyzer();// 配置IndexWriterIndexWriterConfig config = new IndexWritereConfig(analyzer);// 创建IndexWriterIndexWriter iwriter = new IndexWriter(directory, config);// 创建文档并添加字段Document doc = new Document();doc.add(new StringField("id", "1", Field.Store.YES));//字段id被建立倒排索引并存储其原始值,并且不会被分词doc.add(new TextField("title", "Lucene", Field.Store.YES));//字段title被建立倒排索引并存储其原始值,但会被分词doc.add(new TextField("content", "Hello Lucene,My is...", Field.Store.NO));//字段content被建立倒排索引但不存储其原始值,且会被分词doc.add(new LongField("createTime", 1672564789001L));//对字段createTime建立倒排索引doc.add(new StoredField("createTime", 1672564789001L));//存储字段createTime原始值doc.add(new StoredField("name", "Bob"));//只存储字段name原始值doc.add(new NumericDocValuesField(name, 1672564789001L));//对字段createTime建立docvaluesdoc.add(new SortedNumericDocValuesField("list", 3));//对字段list建立docvaluesdoc.add(new SortedNumericDocValuesField("list", 9));//对字段list建立docvalues// 将文档写入索引iwriter.addDocument(doc);// 关闭写入器iwriter.close();}
}
通过这个案例就可以想到我们就文档提交给Es后,Es也是这样调用Lucene的API来完成工作。Es会根据mapping中字段配置来组装doc:
案例中name和createTime字段的mapping配置如下:
{"name": {"type": "text","index": false,"store": true,"doc_values": false},"age": {"type": "long","index": true,"store": true,"doc_values": true}
}
Es在调用Lucene的API时,除了我们提交的字段,Es还会预留的系统字段,用作一些特殊的目的,这些字段对于Lucene来说与用户自定义的Field无任何区别,只不过Es根据这些系统字段不同的使用目的,定制有不同的索引方式,比如_uid、_source字段等,_uid字段就设置成会被索引,不需要分词,不需要被Store,不需要Docvalues。
看到这里就有些同学会问题,Lucene除了建立倒排索引,还有Store,Docvalues,三者都会存储字段值,如果都设置了,一个字段值岂不是被存了三份?
说来确实是这样,三者各自有不同的作用,倒排索引用于快速定位哪些文档包含搜索关键词,Store是为了查询时返回文档中字段原始值;Docvalues是为了查询时便于进行排序、聚合等操作。
因为Store是正排行式存储,便于一次获取文档中所有字段的值(单行多列);Docvalues是正排列式存储,便于快速获取单个字段多个值(单列多行)。
在实际业务中,根据业务需求和性能要求,灵活选择设置这些属性即可。
三、Fielddata
Fielddata是Es自身的特性,与Lucene无关,Es之所以会维护Fielddata,就是因为Lucene的Docvalues不支持text 和 annotated_text类型的字段,本质是Docvalues只存储字段原始值,不支持存储字段值分词后的结果。
Fielddata是Es用来对
text和annotated_text类型的字段进行排序、聚合、脚本计算等操作的机制。默认关闭,此时无法对该类型字段进行排序等操作。
PUT my-index-000001/_mapping
{"properties": {"name": { "type": "text","fielddata": true, #字段name开启Fielddata特性"fielddata_frequency_filter": {"min": 0.001,"max": 0.1,"min_segment_size": 500}}}
}
只有text和annotated_text类型字段支持Fielddata特性。
- 生成时机:使用时动态生成,懒加载;
- 存储位置:JVM内存,不占用磁盘空间;
看到这里有同学会觉得Es的Fielddata和Lucene的FieldCache很相似,没错,很像,但:
- Es的Fielddata只支持text和annotated_text类型字段,Lucene的FieldCache支持所有;
- Es的Fielddata使用了更紧凑的内存表示,内存消耗更小;
- Es的Fielddata通过优化的数据结构,提高排序、聚合等操作;
- Es的Fielddata提供更灵活的内存管理方式,如用户通过fielddata_frequency_filter参数过滤掉低频词汇,节约内存。
Es通过Fielddata和Docvallues实现对所有字段排序、聚合等操作的支持。
Fielddata预加载
四、Index sorting
Index sorting属于Lucene特性。
Lucene 早期曾引入了一个离线的排序工具——IndexSorter。IndexSorter 把需要排序的索引完全复制了一份,将新的复制索引中的文档按用户指定的顺序重新排序。因为排序后的索引是一个新的索引,每次源索引中有新的数据更新,不得不重新执行一遍这个工具。IndexSorter 工具是第一次在索引写入阶段而不是查询阶段对文档进行排序的尝试。
针对索引预排序,社区提出了一个新的概念“early termination”。假设你要遍历出前N个文档,并且文档是按 date 字段排序的。如果索引存储在磁盘上时已经是有序的了,那么我们遍历出前N个文档就可以直接返回,而不需要遍历所有的文档。这就是我们所说的“early termination”。提早的返回查询结果,可以明显的缩短查询响应时间,特别是含有排序的查询。刚才介绍的离线排序的方案不能满足有大量文档更新的场景,这也是为什么最终离线排序方案会被其他方案取代。
Es排序定义如下:
单Field排序定义:
PUT events
{"settings" : {"index" : { #按timestamp倒序"sort.field" : "timestamp","sort.order" : "desc" }},"mappings": {"properties": {"timestamp": {"type": "date"}}}
}
多字段排序定义:
PUT events
{"settings" : {"index" : {"sort.field" : ["timestamp","age"],"sort.order" : ["desc","desc"] }},"mappings": {"properties": {"timestamp": {"type": "date"},"age":{"type": "integer"}}}
}
Es Settings支持 Index Sorting 4个配置:
- index.sort.field:对应排序的Field,可指定一个或者多个Field,优先按第一个排序,相同的情况下在按后续的Field排序;
- index.sort.order:对应Field的排序规则,只能时asc或者时desc;
- index.sort.mode:当对应的Field是数组时,取Max或者Min的值作为排序的基准;
- index.sort.missing:当对应的Field为null时,排第一个还是最后一个。
索引排序是一个很不错的解决方案,但是只能以单一方式进行索引排序。索引排序并不适用于具有下列特征的排序查询:
- 采用不同的排序标准,例如索引定义的是降序,你查询用的是升序;
- 所用排序字段组合不同于索引排序定义中指定的组合。
我们这里也看看Lucene中的API:
IndexWriterConfig config = new IndexWritereConfig(analyzer);
SortField sf1 = new SortField("createTime",SortField.Type.LONG)
Sort sorts = new Sort(new SortField[]{sf1}) //支持多个字段
config.setIndexSort(sorts); //设置索引排序定义
可以看到Es就是根据用户的settings.index配置,进而转换成调用Lucene的这些API来完成工作的。
由于索引排序是在索引生成阶段完成的,根据测试不可避免的降低了写入性能,此功能最多可将写入速度降低 40-50%。由于排序是一个很耗时的操作,所以如果您最关注的是索引速度,则必须谨慎考虑是否要开启索引排序功能。

Lucene针对索引排序做了很多优化,在新segment生成后刷盘时对段内所有文档进行一次排序,在segment merge时对所有段的文档进行排序(此时segment内文档有序,相当于合并有序数组 O(N))。
五、小结
通过前几章节的描述可知,Es排序是一个复杂的场景,在优化过程中不断地打补丁,不像MySQL,MongoDB依赖B+tree实现。主要分为:
- 实时排序:
text类型字段依赖Fielddata机制,其他类型字段依赖Docvalues机制; - 预排序:在创建索引时定义排序规则,一个索引只能定义一个,限制较大。
六、参考
1]:Es官网_source字段
2]:Es官网store属性
3]:Es官网doc_values属性
4]:Lucene官网FIELD对像
5]:Es Fielddata知识点梳理
6]:Es 优化排序查询
7]:Es 索引排序为人不知的优势-减少索引磁盘占用
8]:Es 索引预排序分析和英文版
9]:Lucene Fieldcache机制原理
10]:Lucene源码解析——DocValue存储方式
11]:Lucene 段合并原理
相关文章:
Es 索引查询排序分析
文章目录 概要一、Es数据存储1.1、_source1.2、stored fields 二、Doc values2.1、FieldCache2.2、DocValues 三、Fielddata四、Index sorting五、小结六、参考 概要 倒排索引 优势在于快速的查找到包含特定关键词的所有文档,但是排序,过滤、聚合等操作…...

【C语言】解决C语言报错:Format String Vulnerability
文章目录 简介什么是Format String VulnerabilityFormat String Vulnerability的常见原因如何检测和调试Format String Vulnerability解决Format String Vulnerability的最佳实践详细实例解析示例1:直接使用不受信任的输入作为格式化字符串示例2:未验证格…...

Python深度学习:Bi-LSTM和LSTM在网络上有什么区别,对比来看
文章目录 LSTM代码解释类定义和构造函数前向传播方法 (`forward`)总结Bi-LSTMLSTM 代码 class BaseLSTMModel(nn.Module):def __init__(self, input_dim, hidden_dim, layer_dim, class_num):super().__init__...
Keepalived LVS群集
一、Keepalived案例分析 企业应用中,单台服务器承担应用存在单点故障的危险 单点故障一旦发生,企业服务将发生中断,造成极大的危害 二、Keepalived工具介绍 专为LVS和HA设计的一款健康检查工具 支持故障自动切换(Failover&#…...

harbor问题总结
1. http协议的仓库docker login不上,更改/etc/docker/daemon.json,加一个镜像仓库地址 http: server gave HTTP response to HTTPS client 分析一下这个问题如何解决中文告诉我详细的解决方案-CSDN博客 2. Error response from daemon: login attempt t…...
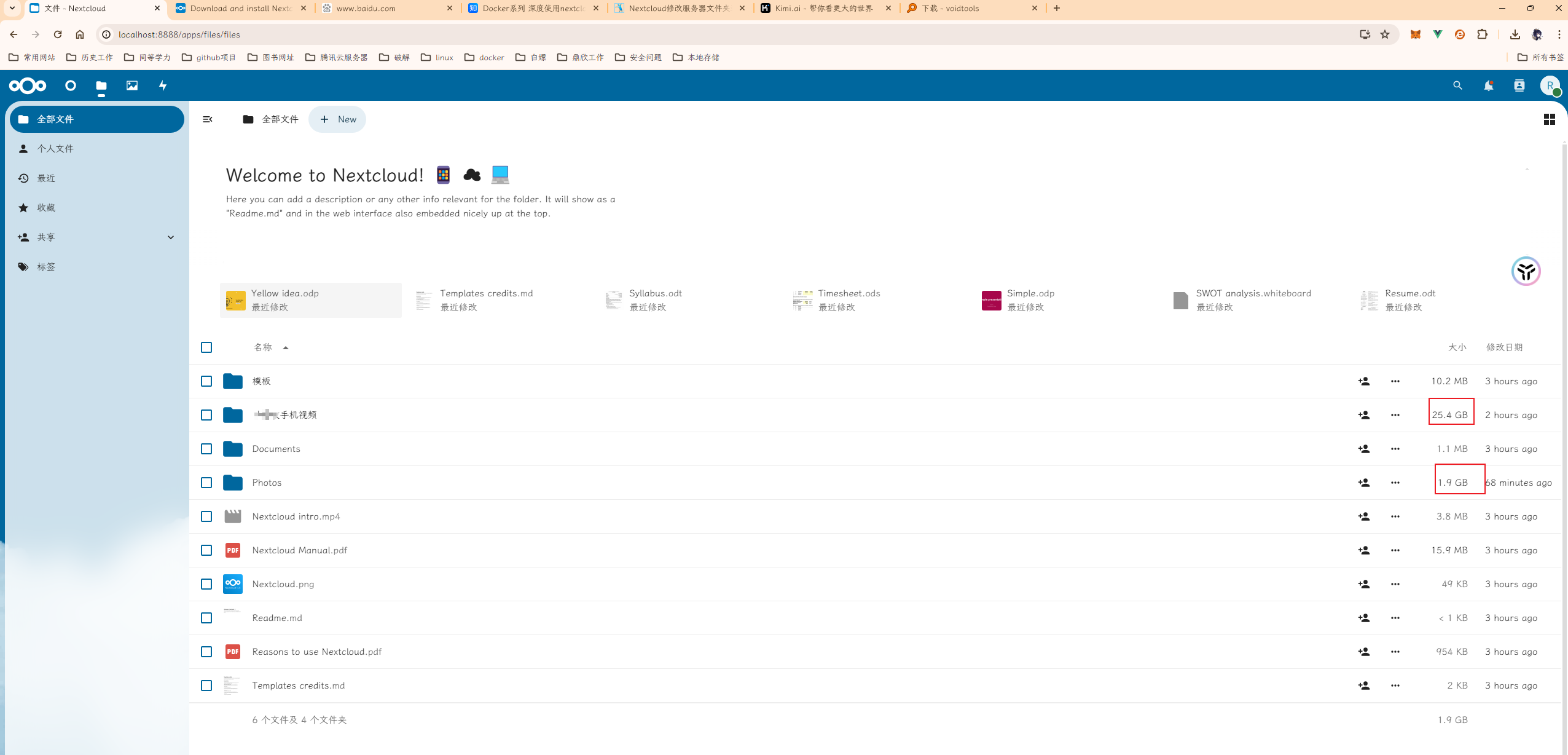
windows系统,家庭自用NAS。本地局域网 Docker安装nextcloud
windows系统,家庭自用NAS。本地局域网 Docker安装nextcloud 1、docker安装 太简单了,直接去搜一搜。 docker-compose 相关命令 docker-compose down docker compose up -d2、还是使用老的 在你需要挂载的目录下,新建一个文件,…...
迅狐跨境商城系统|全平台兼容|前端采用uni-app跨端框架,后端采用ThinkPHP5框架
高效实现全平台兼容的迅狐跨境商城系统 迅狐跨境商城系统是一款专为跨境电商企业设计的全平台兼容系统。其前端采用uni-app跨端框架,后端采用ThinkPHP5框架,旨在实现高效的开发和运营管理。 1. 全平台兼容的前端设计 迅狐跨境商城系统的前端采用uni-a…...

Elixir学习笔记——进程(Processes)
在 Elixir 中,所有代码都在进程内运行。进程彼此隔离,彼此并发运行并通过消息传递进行通信。进程不仅是 Elixir 中并发的基础,而且还提供了构建分布式和容错程序的方法。 Elixir 的进程不应与操作系统进程混淆。Elixir 中的进程在内存和 CPU…...

困惑度作为nlp指标的理解示例
为了更清晰地说明困惑度的计算过程以及如何通过困惑度判断模型的优劣,我们可以通过一个简单的例子来演示。假设我们有一个非常简单的文本语料库和两个基础的语言模型进行比较。 示例文本 假设我们的文本数据包括以下两个句子: “cat sits on the mat”…...

01 Pytorch 基础
paddle不需要放数据到gpu! 区别:1.batch_norlization 不同 2. 1.数据处理 1.取一个数据,以及计算大小 (剩下的工作,取batch,pytorch会自动做好了) 2.模型相关 如何得到结果 3.模型训练/模型…...
STL——set、map、multiset、multimap的介绍及使用
文章目录 关联式容器键值对树形结构与哈希结构setset的介绍set的使用set的模板参数列表set的构造set的使用set的迭代器使用演示 multisetmultiset演示 mapmap的定义方式map的插入map的查找map的[ ]运算符重载map的迭代器遍历multimapmultimap的介绍multimap的使用 在OJ中的使用…...

使用C语言,写一个类似Linux中执行cat命令的类似功能
一、详细的代码案例 #include <stdio.h> #include <stdlib.h> #include <string.h>// 函数声明 void cat_file(const char *filename);int main(int argc, char *argv[]) {if (argc < 2) {fprintf(stderr, "Usage: %s filename1 [filename2 ...]\n&…...

【Android】Android系统性学习——Android系统架构
前言 部分内容参考《Android进阶解密》 – 刘望舒 1. Android版本 官方链接:https://developer.android.com/studio/releases/platforms 里面有各个版本的官方文档,有些新功能的用法在这里面。 现在做安卓11,有时候需要向下兼容 2. AOSP …...

鸿蒙应用开发
学习视频: 00.课程介绍_哔哩哔哩_bilibili 官网:开发者文档中心 | 华为开发者联盟 (huawei.com) 开发工具 :DevEcoStudio , 类似Jetbrains 全家桶 ArkTS开发语言 :(基于TS,集成了前端语言…...

索引失效有效的11种情况
1全职匹配我最爱 是指 where 条件里 都是 ,不是范围(比如>,<),不是 不等于,不是 is not null,然后 这几个字段 建立了联合索引 ,而且符合最左原则。 那么就要比 只建…...
字符数组基础知识及题目
死识。。。 字符该如何存储呢?这一点我们在以前就接触过了。用char来存储。 如何输入一个单词呢? char a[10002]; scanf("%s",a); 就不用地址符了。 如何输入句子呢? char a[100002]; gets(a); gets是读入句子的,…...

一个简单的玩具机器人代码
编写一个玩具机器人脚本通常取决于机器人的硬件、接口和具体功能。然而,由于我们不能直接控制一个真实的硬件机器人,所以只是写一个模拟的C语言脚本示例,该脚本描述了一个简单的玩具机器人可能执行的一些基本操作。 假设我们的“玩具机器人”…...
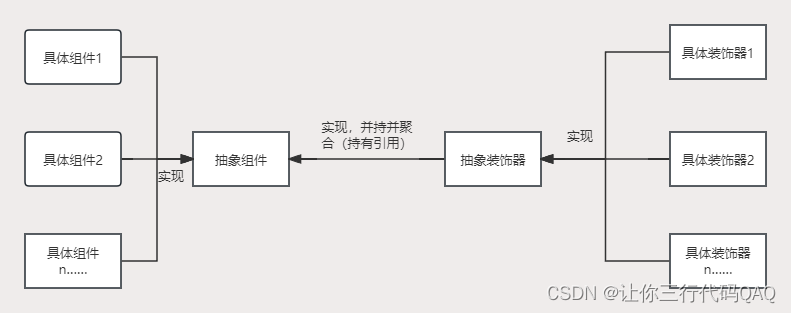
设计模式-装饰器模式Decorator(结构型)
装饰器模式(Decorator) 装饰器模式是一种结构模式,通过装饰器模式可以在不改变原有类结构的情况下向一个新对象添加新功能,是现有类的包装。 图解 角色 抽象组件:定义组件的抽象方法具体组件:实现组件的抽象方法抽象装饰器&…...

RK3588开发板中使用Qt对zip文件进行解压
操作步骤: 下载源码quazip-0.7.3.zip ,在网上找找下载地址上传源码进行解压,然后使用命令 cd quazip-0.7.3 qmake make主要用的是quazip-0.7.3/quazip这个里面的源码,然后把源码加入到自己创建的qt项目pro中,导入方式…...
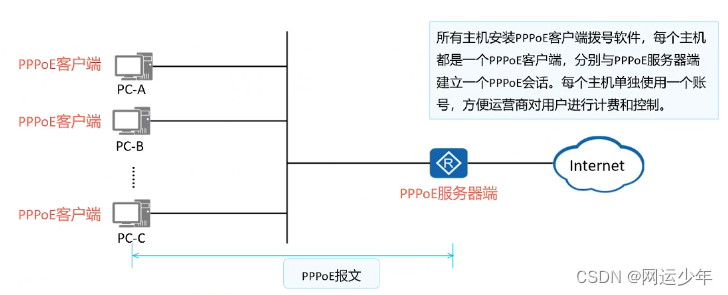
三、网络服务协议
目录 一、FTP:文件传输协议 二、Telnet:远程登录协议 三、AAA认证 四、DHCP 五、DNS 六、PPP协议 七、ISIS协议 一、FTP:文件传输协议 C/S架构,现多用于企业内部的资料共享和网络设备的文件传输,企业内部搭建一…...

Cesium1.95中高性能加载1500个点
一、基本方式: 图标使用.png比.svg性能要好 <template><div id"cesiumContainer"></div><div class"toolbar"><button id"resetButton">重新生成点</button><span id"countDisplay&qu…...

iPhone密码忘记了办?iPhoneUnlocker,iPhone解锁工具Aiseesoft iPhone Unlocker 高级注册版分享
平时用 iPhone 的时候,难免会碰到解锁的麻烦事。比如密码忘了、人脸识别 / 指纹识别突然不灵,或者买了二手 iPhone 却被原来的 iCloud 账号锁住,这时候就需要靠谱的解锁工具来帮忙了。Aiseesoft iPhone Unlocker 就是专门解决这些问题的软件&…...

MVC 数据库
MVC 数据库 引言 在软件开发领域,Model-View-Controller(MVC)是一种流行的软件架构模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种模式有助于提高代码的可维护性和可扩展性。本文将深入探讨MVC架构与数据库之间的关系,以…...

sqlserver 根据指定字符 解析拼接字符串
DECLARE LotNo NVARCHAR(50)A,B,C DECLARE xml XML ( SELECT <x> REPLACE(LotNo, ,, </x><x>) </x> ) DECLARE ErrorCode NVARCHAR(50) -- 提取 XML 中的值 SELECT value x.value(., VARCHAR(MAX))…...
)
GitHub 趋势日报 (2025年06月08日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 884 cognee 566 dify 414 HumanSystemOptimization 414 omni-tools 321 note-gen …...

什么?连接服务器也能可视化显示界面?:基于X11 Forwarding + CentOS + MobaXterm实战指南
文章目录 什么是X11?环境准备实战步骤1️⃣ 服务器端配置(CentOS)2️⃣ 客户端配置(MobaXterm)3️⃣ 验证X11 Forwarding4️⃣ 运行自定义GUI程序(Python示例)5️⃣ 成功效果
Springboot社区养老保险系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,社区养老保险系统小程序被用户普遍使用,为方…...
django blank 与 null的区别
1.blank blank控制表单验证时是否允许字段为空 2.null null控制数据库层面是否为空 但是,要注意以下几点: Django的表单验证与null无关:null参数控制的是数据库层面字段是否可以为NULL,而blank参数控制的是Django表单验证时字…...
零知开源——STM32F103RBT6驱动 ICM20948 九轴传感器及 vofa + 上位机可视化教程
STM32F1 本教程使用零知标准板(STM32F103RBT6)通过I2C驱动ICM20948九轴传感器,实现姿态解算,并通过串口将数据实时发送至VOFA上位机进行3D可视化。代码基于开源库修改优化,适合嵌入式及物联网开发者。在基础驱动上新增…...

MySQL 主从同步异常处理
阅读原文:https://www.xiaozaoshu.top/articles/mysql-m-s-update-pk MySQL 做双主,遇到的这个错误: Could not execute Update_rows event on table ... Error_code: 1032是 MySQL 主从复制时的经典错误之一,通常表示ÿ…...