集成学习概述
概述
集成学习(Ensemble learning)就是将多个机器学习模型组合起来,共同工作以达到优化算法的目的。具体来讲,集成学习可以通过多个学习器相结合,来获得比单一学习器更优越的泛化性能。集成学习的一般步骤为:1.生产一组“个体学习器(individual learner)”;2.用某种策略将他们结合起来。
个体学习器通常由一个现有的学习算法从训练数据产生。在同质集成(系统中个体学习器的类型相同)中,个体学习器又被称为“基学习器”,而在异质集成(系统中个体学习器的类型不同)中,个体学习器又被称为“组建学习(component learner)”。
集成学习的集成框架主要有:Bagging,Boosting和Stacking,其中Bagging和Boosting为同质集成,而Stacking为异质集成。
Bagging可以减少弱分类器的方差,而Boosting 可以减少弱分类器的偏差;
Bagging就是再取样 (Bootstrap) 然后在每个样本上训练出来的模型取平均,所以是降低模型的variance. Bagging 比如Random Forest 这种先天并行的算法都有这个效果。
Boosting 则是迭代算法,每一次迭代都根据上一次迭代的预测结果对样本进行加权,所以随着迭代不断进行,误差会越来越小,所以模型的 bias 会不断降低。这种算法无法并行,如Adaptive Boosting.
多样性增强的几种方法
一般的做法主要是对数据样本,输入属性,输出表示,算法参数进行扰动。
- (1)数据样本扰动
这个其实主要就是采样,比如在bagging中的自助采样法,数据样本扰动对决策树,神经网络这样对数据样本变化非常敏感的学习算法非常有效,但是对支持向量机,朴素贝叶斯,k近邻这些对样本扰动不敏感的算法没用。对此类算法作为基学习器进行集成时往往需要使用输入属性扰动等机制。 - (2)输入属性扰动
这个就是从样本的特征空间中产生不同的特征子集。这样训练出来的基学习器必然是不同的。在包含大量冗余属性的数据,在特征子集中训练基学习器不仅能产生多样性大的个体,还会因属性数的减少而大幅节省时间开销,同时,由于冗余属性多,减少一些冗余属性后训练出来的基学习器性能也不会差。若数据只包含少量属性,或者冗余属性少,则不适宜使用输入属性扰动法。 - (3)输出表示扰动
这类做法的基本思路是对输出表示进行操纵以增强多样性。比如可对训练样本的label稍作变动,比如“翻转法”随机改变一些训练样本的标记;也可以对输出表示进行转化,如“输出调制法”将分类输出转化为回归输出后构建基学习器。这一类貌似用的不多。 - (4)算法参数扰动
这个在现在深度学习比赛中很常见,主要是神经网络有很多参数可以设置,不同的参数往往可以产生差别比较大的基学习器。
Bagging
核心思想:并行地训练一系列各自独立的同类模型,然后再将各个模型的输出结果按照某种策略进行聚合。例如,分类中可以采用投票策略,回归中可以采用平均策略;Bagging主要分为两个阶段:
步骤:
- Boostrap阶段,即采用有放回的采样方式,将训练集分为n个子样本集;并用基学习器对每组样本分布进行训练,得到n个基模型;
- Aggregating阶段,将上一个阶段训练得到的n个基模型组合起来,共同做决策。在分类任务中,可采用投票法,比如相对多数投票法,将结果预测为得票最多的类别。而在回归任务中可采用平均法,即将每个基模型预测得到的结果进行简单平均或加权平均来获得最终的预测结果。
Bagging就是再取样 (Bootstrap) 然后在每个样本上训练出来的模型取平均,所以是降低模型的variance.;Bagging 比如Random Forest 这种先天并行的算法都有这个效果
随机森林(Random Forest)
1. 算法原理
随机森林(Random Forest)是一种基于决策树的集成学习方法。它通过构建多个决策树,并将它们的预测结果进行投票(分类问题)或平均(回归问题),以获得最终的预测结果。随机森林的构建过程包括两个关键步骤:自助采样(bootstrap sampling)和特征随机选择。自助采样用于生成不同的训练数据子集,每个子集用于构建一个决策树。特征随机选择则在每个决策树节点上随机选择一部分特征进行划分,以增加决策树的多样性。这两个步骤共同提高了随机森林的泛化能力和鲁棒性。
2.优缺点
优点:
a) 随机森林具有较高的预测准确性,通常比单个决策树的性能要好。
b) 能够有效地处理高维数据和大量特征。
c) 对噪声和异常值具有较强的鲁棒性。
d) 可以进行特征重要性评估,有助于特征选择。
e) 并行化能力强,易于实现并行计算。
缺点:
a) 相比单个决策树,随机森林的模型可解释性较差。
b) 训练和预测时间可能较长,尤其是在大数据集上。
c) 对于某些不平衡的数据集,随机森林的性能可能不尽如人意。
3.适用场景
随机森林适用于以下场景:
a) 需要提高预测准确性的分类和回归问题。
b) 数据集具有高维特征或特征数量较多。
c) 数据集中存在噪声和异常值。
随机森林在许多实际应用中表现出较好的性能,尤其是在提高预测准确性方面。然而,随机森林的可解释性较差,且在大数据集上训练和预测时间可能较长。在面临这些问题时,可以考虑使用其他集成方法,如梯度提升树(Gradient Boosting Trees)等。
RandomForestClassifier:分类树
RandomForestRegressor(n_estimators=100, criterion='mse', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, ccp_alpha=0.0, max_samples=None)
重要的参数:
- n_estimators:随机森林中决策树的个数,默认为 100。
- criterion:随机森林中决策树的算法,可选的有两种:1)gini:基尼系数,也就是 CART 算法,为默认值;2)entropy:信息熵,也就是 ID3 算法。
- max_depth:决策树的最大深度。
RandomForestRegressor:回归树
RandomForestRegressor(n_estimators=100, criterion='mse', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, ccp_alpha=0.0, max_samples=None)回归树中的参数与分类树中的参数基本相同,但 criterion 参数的取值不同。
在回归树中,criterion 参数有下面两种取值:
- mse:表示均方误差算法,为默认值。
- mae:表示平均误差算法。
Boosting
Boosting由于各基学习器之间存在强依赖关系,因此只能串行处理,也就是Boosting实际上是个迭代学习的过程。
Boosting的工作机制为:先从初始训练集中训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整(比如增大被误分样本的权重,减小被正确分类样本的权重),使得先前基学习器做错的样本在后续的训练过程中受到更多关注,然后基于调整后的样本分布来训练下一个基学习器,如此重复,直到基学习器数目达到事先自定的值T,然后将这T 个基学习器进行加权结合(比如错误率小的基学习器权重大,错误率大的基学习器权重小,这样做决策时,错误率小的基本学习器影响更大)
Boosting算法主要有AdaBoost(Adaptive Boost)自适应提升算法和Gradient Boosting梯度提升算法。最主要的区别在于两者如何识别和解决模型的问题。AdaBoost用错分的数据样本来识别问题,通过调整错分数据样本的权重来改进模型。Gradient Boosting主要通过负梯度来识别问题,通过计算负梯度来改进模型。


AdaBoost
核心思想:串行地训练一系列前后依赖的同类模型,即后一个模型用来对前一个模型的输出结果进行纠正。Boosting算法是可以将弱学习器提升为强学习器的学习算法。
步骤:先从初始训练集训练出一个基学习器,再根据基学习器的表现对训练样本进行调整,使得先前基学习器做错的训练样本在后续受到更多的关注,然后基于调整后的样本分布来训练下一个基学习器;如此重复进行。直至基学习器数目达到实现指定的值n,最终将这n个基学习器进行结合。
Boosting 则是迭代算法,每一次迭代都根据上一次迭代的预测结果对样本进行加权,所以随着迭代不断进行,误差会越来越小,所以模型的 bias 会不断降低。这种算法无法并行,如Adaptive Boosting;
1. 算法原理
AdaBoost(Adaptive Boosting)是一种集成学习方法,通过多次迭代训练一系列弱学习器并加权组合,以提高分类性能。在每次迭代过程中,对错误分类的样本增加权重,使得后续的弱学习器更关注这些样本。最后,将所有弱学习器的预测结果进行加权投票,得到最终分类结果。
2.优缺点
a) 优点:
i. 可以提高模型的准确性和泛化能力。
ii. 算法简单易于实现。 iii. 不容易过拟合。
b) 缺点:
i. 对异常值和噪声敏感,可能导致性能下降。
ii. 训练过程需要依次进行,较难并行化。
3.适用场景
AdaBoost适用于以下场景:
a) 当基学习器性能较弱时,可以通过集成提高性能。
b) 适用于二分类问题,尤其是需要提高分类性能的场景。
AdaBoost在人脸检测、文本分类、客户流失预测等领域有广泛应用。
GBDT
核心思想
梯度提升决策树(Gradient Boosting Decision Tree,GBDT) 是将多个弱学习器(通常是决策树)组合成一个强大的预测模型。具体而言,GBDT的定义如下:
初始化:首先,GBDT使用一个常数(通常是目标变量的平均值)作为初始预测值。这个初始预测值代表了我们对目标变量的初始猜测。
迭代训练:GBDT是一个迭代算法,通过多轮迭代来逐步改进模型。在每一轮迭代中,GBDT都会训练一棵新的决策树,目标是减少前一轮模型的残差(或误差)。残差是实际观测值与当前模型预测值之间的差异,新的树将学习如何纠正这些残差。
集成:最终,GBDT将所有决策树的预测结果相加,得到最终的集成预测结果。这个过程使得模型能够捕捉数据中的复杂关系,从而提高了预测精度。
GBDT的核心原理在于不断迭代,每一轮迭代都尝试修正前一轮模型的错误,逐渐提高模型的预测性能。
优缺点
优点:
- 可以灵活处理各种类型的数据,包括连续值和离散值。
- 在相对少的调参时间情况下,预测的准备率也可以比较高。这个是相对SVM来说的。
3)使用一些健壮的损失函数,对异常值的鲁棒性非常强。比如 Huber损失函数和Quantile损失函数。 - 很好的利用了弱分类器进行级联。
- 充分考虑的每个分类器的权重。
6)不需要归一化。树模型都不需要,梯度下降算法才需要
6)处理非线性关系
缺点:
1)由于弱学习器之间存在依赖关系,难以并行训练数据。不过可以通过自采样的SGBT来达到部分并行。
2)不适合高维稀疏特征
适用场景
GBDT 可以适用于回归问题(线性和非线性);
GBDT 也可用于二分类问题(设定阈值,大于为正,否则为负)和多分类问题。
XGBoost
1. 算法原理
XGBoost(eXtreme Gradient Boosting)是基于梯度提升(Gradient Boosting)的决策树集成学习方法。XGBoost通过加入正则化项,降低模型复杂度,提高泛化能力。同时,XGBoost采用了并行计算和近似算法,显著提高了训练速度。
XGBoost是基于GBDT 的一种改进算法;
列抽样(column subsampling)。xgboost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性。
Shrinkage(缩减),相当于学习速率(xgboost中的eta)。xgboost在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。实际应用中,一般把eta设置得小一点,然后迭代次数设置得大一点。(传统GBDT的实现也有学习速率)
对缺失值的处理。对于特征的值有缺失的样本,xgboost可以自动学习出它的分裂方向。
2.优缺点
优点:
i. 高效的训练速度,支持并行计算。
ii. 高准确率,通过正则化降低过拟合风险。
iii. 支持自定义损失函数和评估指标。
iv. 内置特征重要性排序功能。
缺点:
i. 超参数调优较为复杂。
ii. 需要较多的计算资源。
3.适用场景
XGBoost在以下场景表现优异:
a) 大规模数据集。
b) 需要高准确率的分类和回归任务。
c) 特征选择。
XGBoost在Kaggle竞赛中广泛应用,获得了多次胜利。
LightGBM
LightGBM是一种基于梯度提升树的机器学习算法,它通过使用基于直方图的算法和带有按叶子节点分割的决策树来提高训练和预测的效率。
算法原理
基于直方图的算法:LightGBM使用了一种基于直方图的算法来处理数据。它将数据按特征值进行离散化,构建直方图并对其进行优化,从而减少了内存消耗和计算时间。
基于按叶子节点分割的决策树:传统的梯度提升树算法在每个节点上都尝试所有特征的切分点,而LightGBM在构建决策树时采用了按叶子节点分割的策略。这样可以减少计算量,并且更容易处理高维稀疏特征。
LightGBM也是基于GBDT的改进算法;
优缺点
优点:
高效性:LightGBM具有高效的训练和预测速度,尤其在处理大规模数据集时表现出色。
低内存消耗:由于使用了基于直方图的算法和按叶子节点分割的决策树,LightGBM能够减少内存消耗,适用于内存有限的环境。
高准确性:LightGBM通过优化算法和特征选择等方法提高了模型的准确性。
缺点:
对噪声敏感:LightGBM在处理噪声较大的数据时可能会过拟合,需要进行适当的正则化。
参数调优:LightGBM有一些需要调优的参数,不同的参数组合可能会导致不同的效果,需要进行合适的参数调优。
注意事项:
数据预处理:对数据进行清洗、缺失值处理和特征工程等预处理步骤,以提高模型的泛化能力。
参数调优:通过交叉验证等方法选择合适的参数组合,以获得更好的模型性能。
提前停止:在训练过程中使用早期停止法,避免模型过拟合。
特征重要性评估:通过分析模型输出的特征重要性,可以帮助理解数据和模型之间的关系,指导特征选择和特征工程。
总体而言,LightGBM是一种高效、低内存消耗且具有准确性的机器学习算法,在处理大规模数据集和高维稀疏特征方面具有优势。但需要注意参数调优和模型过拟合问题。
参数设置
AdaBoost
class sklearn.ensemble.AdaBoostClassifier(base_estimator=None, n_estimators=50, learning_rate=1.0, algorithm='SAMME.R', random_state=None)
- base_estimator:基分类器,默认是决策树,在该分类器基础上进行boosting,理论上可以是任意一个分类器,但是如果是其他分类器时需要指明样本权重。
- n_estimators:基分类器提升(循环)次数,默认是50次,这个值过大,模型容易过拟合;值过小,模型容易欠拟合。
- learning_rate:学习率,表示梯度收敛速度,默认为1,如果过大,容易错过最优值,如果过小,则收敛速度会很慢;该值需要和n_estimators进行一个权衡,当分类器迭代次数较少时,学习率可以小一些,当迭代次数较多时,学习率可以适当放大。
- algorithm:boosting算法,也就是模型提升准则,有两种方式SAMME, 和SAMME.R两种,默认是SAMME.R,两者的区别主要是弱学习器权重的度量,前者是对样本集预测错误的概率进行划分的,后者是对样本集的预测错误的比例,即错分率进行划分的,默认是用的SAMME.R。
- random_state:随机种子设置。
GBDT
class sklearn.ensemble.GradientBoostingClassifier(*, loss='deviance', learning_rate=0.1, n_estimators=100, subsample=1.0,
criterion='friedman_mse', min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_depth=3,
min_impurity_decrease=0.0, min_impurity_split=None, init=None, random_state=None, max_features=None,
verbose=0, max_leaf_nodes=None, warm_start=False, presort='deprecated', validation_fraction=0.1,
n_iter_no_change=None, tol=0.0001, ccp_alpha=0.0)
GBDT(Gradient Boosting Decision Tree)是一种基于梯度提升的集成学习算法,它使用决策树作为弱学习器,通过迭代地拟合残差来提高预测性能。GBDT 的主要参数有:
- n_estimators:也就是弱学习器的最大迭代次数,或者说最大的弱学习器的个数。一般来说n_estimators太小,容易欠拟合,n_estimators太大,又容易过拟合,一般选择一个适中的数值。默认是100。在实际调参的过程中,我们常常将n_estimators和下面介绍的参数learning_rate一起考虑;
- learning_rate:float,认= 0.1,学习率缩小了每棵树的贡献learning_rate。在learning_rate和n_estimators之间需要权衡;推荐的候选值为:[0.01, 0.015, 0.025, 0.05, 0.1]
- subsample:子采样,取值为(0,1]。注意这里的子采样和随机森林不一样,随机森林使用的是放回抽样,而这里是不放回抽样。如果取值为1,则全部样本都使用,等于没有使用子采样。如果取值小于1,则只有一部分样本会去做GBDT的决策树拟合。选择小于1的比例可以减少方差,即防止过拟合,但是会增加样本拟合的偏差,因此取值不能太低。推荐在 [0.5, 0.8] 之间,默认是1.0,即不使用子采样;
loss:即我们GBDT算法中的损失函数。分类模型和回归模型的损失函数是不一样的。1)对于分类模型,有对数似然损失函数"deviance"和指数损失函数"exponential"两者输入选择。默认是对数似然损失函数"deviance"。2)对于回归模型,有均方差"ls", 绝对损失"lad", Huber损失"huber"和分位数损失“quantile”。默认是均方差"ls"。一般来说,如果数据的噪音点不多,用默认的均方差"ls"比较好。如果是噪音点较多,则推荐用抗噪音的损失函数"huber"。而如果我们需要对训练集进行分段预测的时候,则采用“quantile”。- init:计量或“零”,默认=无,一个估计器对象,用于计算初始预测。 init必须提供fit和predict_proba。如果为“零”,则初始原始预测设置为零。默认情况下,使用 DummyEstimator预测类优先级;
- max_depth:int,默认= 3,各个回归估计量的最大深度。最大深度限制了树中节点的数量。调整此参数以获得最佳性能;最佳值取决于输入变量的相互作用。也就是那个树有多少层(一般越多越容易过拟合);
- min_samples_split:int或float,默认为2,拆分内部节点所需的最少样本数:如果为int,则认为min_samples_split是最小值。如果为float,min_samples_split则为分数, 是每个拆分的最小样本数。ceil(min_samples_split * n_samples)
- min_samples_leaf: int或float,默认值= 1,在叶节点处所需的最小样本数。仅在任何深度的分裂点在min_samples_leaf左分支和右分支中的每个分支上至少留下训练样本时,才考虑。这可能具有平滑模型的效果,尤其是在回归中。如果为int,则认为min_samples_leaf是最小值。如果为float,min_samples_leaf则为分数, 是每个节点的最小样本数。ceil(min_samples_leaf * n_samples)
- min_weight_fraction_leaf:float,默认值= 0.0,在所有叶节点处(所有输入样本)的权重总和中的最小加权分数。如果未提供sample_weight,则样本的权重相等。
- min_impurity_decrease:浮动,默认值= 0.0,如果节点分裂会导致杂质的减少大于或等于该值,则该节点将被分裂;
- min_impurity_split :float,默认=无提前停止树木生长的阈值。如果节点的杂质高于阈值,则该节点将分裂,否则为叶
- subsample:用于训练每个弱学习器的样本比例。减小该参数可以降低方差,但也可能增加偏差。
- max_features:节点分裂时参与判断的最大特征数,用于分裂每个决策树节点的特征数量。减小该参数可以降低过拟合的风险,但也可能降低模型的表达能力。int:个数;float:占所有特征的百分比;auto:所有特征数的开方;sqrt:所有特征数的开方;log2:所有特征数的log2值;None:等于所有特征数。
XGBoost
XGBoost(Extreme Gradient Boosting)是一种优化的 GBDT 实现,它使用了更高效的数据结构和并行计算,同时引入了正则化项和剪枝策略来防止过拟合。XGBoost 的主要参数有:
- n_estimators:同 GBDT。
- learning_rate:同 GBDT。
- max_depth:同 GBDT。
- min_child_weight:决策树叶节点的最小权重和,相当于 GBDT 中的 min_samples_leaf 乘以样本权重。增加该参数可以防止过拟合,但也可能导致欠拟合。
- subsample:同 GBDT。
- colsample_bytree:相当于 GBDT 中的 max_features,表示用于训练每棵树的特征比例。减小该参数可以降低过拟合的风险,但也可能降低模型的表达能力。
- reg_alpha:L1 正则化项的系数,用于惩罚模型的复杂度。增加该参数可以使模型更稀疏,但也可能损失一些信息。推荐的候选值为:[0, 0.01~0.1, 1]
- reg_lambda:L2 正则化项的系数,用于惩罚模型的复杂度。增加该参数可以防止过拟合,但也可能降低模型的灵活性。推荐的候选值为:[0, 0.1, 0.5, 1]
LightGBM
LightGBM(Light Gradient Boosting Machine)是一种基于梯度提升的高效的分布式机器学习框架,它使用了基于直方图的算法和基于叶子的生长策略,可以大大提高训练速度和减少内存消耗。LightGBM 的主要参数有:
- n_estimators:同 GBDT。
- learning_rate:同 GBDT。
- num_leaves:决策树的最大叶子数,相当于 GBDT 中的 max_depth 的指数倍。增加该参数可以增加模型的复杂度和拟合程度,但也可能导致过拟合。
- min_child_samples:同 GBDT 中的 min_samples_leaf。
- subsample:同 GBDT。
- colsample_bytree:同 XGBoost。
- reg_alpha:同 XGBoost。
- reg_lambda:同 XGBoost。
Stacking
Stacking的核性思想是并行地训练一系列各自独立的不同类模型,然后通过训练一个元模型(meta-model)来将各个模型输出结果进行结合。Stacking也可以分为两个阶段:
分别采用全部的训练样本来训练n个组件模型,要求这些个体学习器必须异构的,比如可以分别是线性学习器,SVM,决策树模型和深度学习模型。
训练一个元模型(meta-model)来将各个组件模型的输出结果进行结合,具体过程就是将各个学习器在训练集上得到的预测结果作为训练特征和训练集的真实结果组成新的训练集;然后用这个新组成的训练集来训练一个元模型。这个元模型可以是线性模型或者树模型。
特征选择
RF、GBDT、XGboost都可以做特征选择,属于特征选择中的嵌入式方法;在用sklearn的时候经常用到feature_importances_ 来做特征筛选,分析gbdt的源码发现来源于每个base_estimator的决策树的
feature_importances_;
决策树的feature_importances_:impurity就是gini值,weighted_n_node_samples 就是各个节点的加权样本数,最后除以根节点nodes[0].weighted_n_node_samples的总样本数。最后还要归一化处理。
from sklearn import ensemble
#grd = ensemble.GradientBoostingClassifier(n_estimators=30)
grd = ensemble.RandomForestClassifier(n_estimators=30)
grd.fit(X_train,y_train)
grd.feature_importances_
计算特征重要性方法
首先,目前计算特征重要性计算方法主要有两个方面:
1)训练过程中计算
训练过程中通过记录特征的分裂总次数、总/平均信息增益来对特征重要性进行量化。例如实际工程中我们会用特征在整个GBDT、XGBoost里面被使用的次数或者带来的总/平均信息增益来给特征重要度打分,最后进行排序。由于本身Ensemble模型在选择特征分裂时带有一定随机性,一般会跑多个模型然后把特征重要性求平均后排序。
作为单个决策树模型,在模型建立时实际上是寻找到某个特征合适的分割点。这个信息可以作为衡量所有特征重要性的一个指标。
基本思路如下:
如果一个特征被选为分割点的次数越多,那么这个特征的重要性就越强。这个理念可以被推广到集成算法中,只要将每棵树的特征重要性进行简单的平均即可。
分别根据特征1和特征4进行分割,显然x1出现的次数最多,这里不考虑先分割和后分割的情况,只考虑每次分割属性出现的次数。
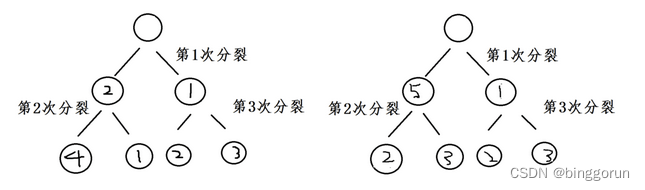
计算得:
x1的特征重要度:出现在2棵树上,两棵树一共分裂了6次,x1出现了3次。
x1特征重要度 = 3/6 = 1/2
x2的特征重要度= 4/6 = 2/3
x3的特征重要度= 3/6 = 1/2
x4的特征重要度: 出现在1棵树上,一个树分裂了3次,x4出现了1次。
x4的特征重要度= 1/3
根据特征重要度进行特征选择。
2)训练后使用OOB(Out of Bag)数据计算
第二种方式是训练好模型之后,用Out of Bag(或称Test)数据进行特征重要性的量化计算。具体来说,先用训练好的模型对OOB数据进行打分,计算出AUC或其他业务定义的评估指标;接着对OOB数据中的每个特征:
- (1)随机shuffle当前特征的取值;
- (2)重新对当前数据进行打分,计算评估指标;
- (3)计算指标变化率
按照上面方式,对每个特征都会得到一个变化率,最后按照变化率排序来量化特征重要性。
延伸到 DNN 对特征重要性判定:
DNN不像Boosting这类模型那样存在所谓的分裂次数与信息增益,就需要使用第二种方式,对每个特征进行随机shuffle,观察模型指标的变化,最后按照变化率进行排序。比如AUC下滑率,下滑的越多说明当前这个指标越重要。当然,实际操作中需要结合业务经验先指定一个候选变量池,对这部分变量计算重要度,不然计算开销太大。
随机森林(Random Forest)
-
袋外数据错误率(可参考OOB特征选择方法)
RF的数据是boostrap的有放回采样,形成了袋外数据。因此可以采用袋外数据(OOB)错误率进行特征重要性的评估。
袋外数据错误率定义为:袋外数据自变量值发生轻微扰动后的分类正确率与扰动前分类正确率的平均减少量。
(1)对于每棵决策树,利用袋外数据进行预测,将袋外数据的预测误差记录下来,其每棵树的误差为vote1,vote2,…,voteb
(2)随机变换每个预测变量,从而形成新的袋外数据,再利用袋外数据进行验证,其每个变量的误差是votel1,votel2,…votelb -
基尼指数(和GBDT的方法相同)
梯度提升树(GBDT)
基尼指数
在sklearn中,GBDT和RF的特征重要性计算方法是相同的,都是基于单棵树计算每个特征的重要性,探究每个特征在每棵树上做了多少的贡献,再取个平均值。
XGboost
根据结构分数的增益情况计算出来选择哪个特征作为分割点,而某个特征的重要性就是它在所有树中出现的次数之和。也就是说一个属性越多的被用来在模型中构建决策树,它的重要性就相对越高
xgboost实现中Booster类get_score方法输出特征重要性,其中importance_type参数支持三种特征重要性的计算方法:
- importance_type=weight(默认):the number of times a feature is used to split the data across all trees. 特征重要性使用特征在所有树中作为划分属性的次数。简单来说,就是在子树模型分裂时,用到的特征次数。这里计算的是所有的树
- importance_type=gain:is the average gain of splits which use the feature. 特征重要性使用特征在作为划分属性带来的平均增益。特征重要性使用特征在作为划分属性时loss平均的降低量。
- importance_type=cover:is the average coverage of splits which use the feature where coverage is defined as the number of samples affected by the split. 使用该特作为分割影响的平均样本数。——可以理解为被分到该节点的样本的二阶导数之和,而特征度量的标准就是平均的coverage值。 特征重要性使用特征在作为划分属性时对样本的覆盖度。
importance_type=total_gain: the total gain across all splits the feature is used in.
importance_type=total_cover: the total coverage across all splits the feature is used in
weight 将给予数值特征更高的值,因为它的变数越多,树分裂时可切割的空间越大。所以这个指标,会掩盖掉重要的枚举特征。
gain 用到了熵增的概念,它可以方便的找出最直接的特征。即如果某个特征的下的0,在label下全是0,则这个特征一定会排得靠前。
cover 对于枚举特征,会更友好。同时,它也没有过度拟合目标函数,不受目标函数的量纲影响。
Lightgbm
split: 特征重要性使用特征在所有树种作为划分属性的次数
gain: 使用该特征作为分割带来的总增益
各种算法区别
GBDT和Xgboost的区别
- ① 基分类器的选择: 传统GBDT以CART作为基分类器,XGBoost还支持线性分类器,这个时候XGBoost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。
- ② 梯度信息: 传统GBDT只引入了一阶导数信息,Xgboost引入了一阶导数和二阶导数信息,其对目标函数引入了二阶近似,求得解析解, 用解析解作为Gain来建立决策树, 使得目标函数最优(Gain求到的是解析解),相比于 GBDT,其拟合方向更准、速度更快。另外,XGBoost工具支持自定义损失函数,只要函数可一阶和二阶求导。
- ③ 正则项: Xgboost引入了正则项部分,这是传统GBDT中没有的。加入正则项可以控制模型的复杂度,防止过拟合。
- ④ 特征采样: Xgboost引入了特征子采样,像随机森林那样,既可以降低过拟合,也可以减少计算。
- ⑤ 节点分裂方式:GBDT是用的基尼系数,XGBoost是经过优化推导后的。
- ⑥ 并行化: 传统GBDT由于树之间的强依赖关系是无法实现并行处理的,但是Xgboost支持并行处理,XGBoost的并行不是在模型上的并行,而是在特征上的并行,将特征列排序后以block的形式存储在内存中,在后面的迭代中重复使用这个结构。这个block也使得并行化成为了可能,其次在进行节点分裂时,计算每个特征的增益,最终选择增益最大的那个特征去做分割,那么各个特征的增益计算就可以开多线程进行。
- ⑦ 除此之外,Xgboost实现了分裂点寻找近似算法、缺失值处理、列抽样(降低过拟合,还能减少计算)等包括一些工程上的优化,LightGBM是Xgboost的更高效实现。
Random Forest和GBDT区别
- ① RF的基分类器可以是分类树也可以是回归树,GBDT只能是回归树。
- ② RF不同基分类器可以并行,GBDT只能串行。
- ③ RF最终结果采用的策略是多数投票、一票否则、加权投票等,而GBDT是将所有结果(加权)累加起来。
- ④ RF对异常值不敏感,GBDT对异常值敏感
- ⑤ RF对训练集一视同仁,GBDT基于Boosting思想,基于权值,分类器越弱,权值越小
- ⑥ RF主要减少模型方差,所以在噪声较大的数据上容易过拟合,而GBDT主要较少模型偏差。
- ⑦ RF随机选择样本,GBDT使用所有样本。
lightGBM与XGboost区别
- 1)速度和性能
训练速度:LightGBM通常比XGBoost更快。这是因为LightGBM采用了基于直方图的算法,减少了数据扫描次数,提高了效率。
内存使用:LightGBM的内存占用通常较低,因为它通过直方图方法和特征捆绑技术减少了内存使用。 - 2)算法实现
XGBoost:采用按层生长的决策树(level-wise),即每次分裂所有节点。这种方法可以更好地控制树的结构,但在大数据集上效率较低。
LightGBM:采用按叶子生长的决策树(leaf-wise),即每次选择增益最大的叶子节点进行分裂。这种方法可以生成更深的树,提高模型的准确性,但可能导致过拟合,需要通过设置最大深度或叶子节点数来控制。 - 3)特征处理
类别特征:LightGBM能够直接处理类别特征,而XGBoost需要对类别特征进行预处理,如one-hot编码。
缺失值处理:XGBoost和LightGBM都能够自动处理缺失值,但LightGBM在处理大规模数据时表现更好。 - 4)并行和分布式计算
并行计算:XGBoost和LightGBM都支持并行计算,但LightGBM在大规模数据集上的分布式计算能力更强。
分布式训练:LightGBM能够更好地支持分布式训练,适用于超大规模数据集。
GBDT和Adaboost区别
1)GBDT与Adboost最主要的区别在于两者如何识别模型的问题。Adaboost用错分数据点来识别问题,通过调整错分数据点的权重来改进模型。GBDT通过负梯度来识别问题,通过计算负梯度来改进模型。
2)AdaBoost 是通过加权的方式来提高模型的准确率,即每棵树的权重(Amount of say)不一样;而 GBDT 是通过加法的方式来提高模型的准确率,即每棵树的权重(Amount of say)都是一样的;
3)AdaBoost 拟合的是原始数据;而 GBDT 和 XGBoost 拟合的是 Psuedo Residuals,当损失函数是平方损失函数时,Psuedo Residuals 就是残差;
4)AdaBoost 的损失函数是指数损失函数,而 GBDT 和 XGBoost 的损失函数可以是自定义的。
相关文章:
集成学习概述
概述 集成学习(Ensemble learning)就是将多个机器学习模型组合起来,共同工作以达到优化算法的目的。具体来讲,集成学习可以通过多个学习器相结合,来获得比单一学习器更优越的泛化性能。集成学习的一般步骤为:1.生产一组“个体学习…...

记录一次root过程
设备: Redmi k40s 第一步, 解锁BL(会重置手机系统!!!所有数据都会没有!!!) 由于更新了澎湃OS系统, 解锁BL很麻烦, 需要社区5级以上还要答题。 但是,这个手机…...

函数(上)(C语言)
函数(上) 一. 函数的概念二. 函数的使用1. 库函数和自定义函数(1) 库函数(2) 自定义函数的形式 2. 形参和实参3. return语句4. 数组做函数参数 一. 函数的概念 数学中我们其实就见过函数的概念,比如:一次函数ykxb,k和b都是常数&a…...
系统架构之系统安全能力的侧信道抵御)
ARM-V9 RME(Realm Management Extension)系统架构之系统安全能力的侧信道抵御
安全之安全(security)博客目录导读 目录 一、系统PMU计数器 二、使用信号和功耗操作进行的故障攻击 一、系统PMU计数器 性能监测单元 (PMU) 计数器可能成为泄露机密信息的侧信道,如访问模式或受RME安全保障保护的安全状态下的执行控制流。以下规则补充了《Arm CoreSight™…...
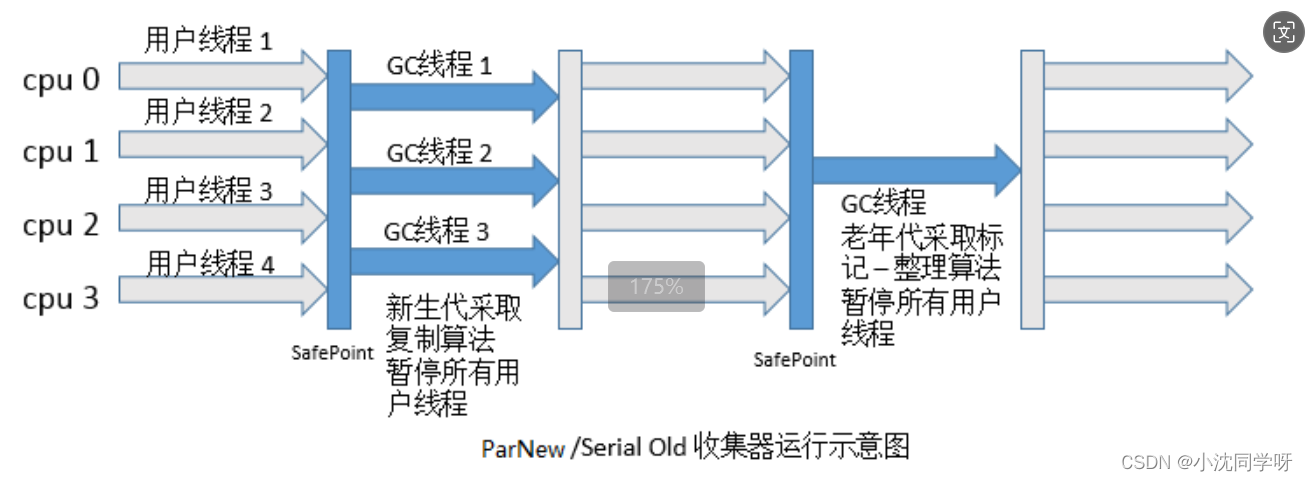
Java高级技术探索:深入理解JVM内存分区与GC机制
文章目录 引言JVM内存分区概览垃圾回收机制(GC)GC算法基础常见垃圾回收器ParNew /Serial old 收集器运行示意图 优化实践结语 引言 Java作为一门广泛应用于企业级开发的编程语言,其背后的Java虚拟机(JVM)扮演着至关重…...

新视野大学英语2 词组 6.15
do you feel as confused and manipulated as i do with this question 你是否和我一样,对这个问题感到困惑和被操控 manipulated:被操控 defy common sense and contradict each other 违背常识且相互矛盾 defy:违背 contradict…...

【JavaScript】MDN
一、初识 1.1 基础 1.1.1 语言速成课 1.1.1.1 变量 变量是存储值的容器。首先用let关键字声明一个变量,后面跟着你给变量的名字 变量命名区分大小写 分号在JavaScript中是用来分隔语句的,但是如果语句后面有一个换行符(或者在{block}中只…...

Qt/C++中的异步编程
Qt/C++中的异步编程 1 介绍2 含义2.1 QtConcurrent2.2 std::future2.3 Qml中的Promise3 使用场景4 代码示例5 注意事项5.1异常处理5.2 线程安全5.3 性能优化5.4 线程间通信5.5 避免死锁1 介绍 异步编程是现代应用程序开发中不可或缺的一部分。它允许程序在执行耗时任务时保持响…...

解决javadoc一直找不到路径的问题
解决javadoc一直找不到路径的问题 出现以上问题就是我们在下载jdk的时候一些运行程序安装在C:\Program Files\Common Files\Oracle\Java\javapath下: 一开始是没有javadoc.exe文件的,我们只需要从jdk的bin目录下找到复制到这个里面,就可以使用…...

存储器的性能指标以及层次化存储器
存储器的性能指标 存储器有三个性能指标:速度、容量和位价(每位价格) 1.存储速度 (1)存取时间 想衡量存储速度,最直观的指标就是完成一次存储器读写操作所需要的时间,这叫做存取时间&#x…...

【C++】C++入门的杂碎知识点
思维导图大纲: namespac命名空间 什么是namespace命名空间namespace命名空间有什么用 什么是命名空间 namespace命名空间是一种域,它可以将内部的成员隔绝起来。举个例子,我们都知道有全局变量和局部变量,全局变量存在于全局域…...

springboot 整合redis问题,缓存击穿,穿透,雪崩,分布式锁
boot整合redis 压力测试出现失败 解决方案 排除lettuce 使用jedis <!-- 引入redis --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId><exclusions><exclus…...
免费个人站 独立站 wordpress 自建网站
制作免费网站 | 免费网站构建器 | WordPress.com https://bioinformatics7.wordpress.com WordPress.com...

散列函数的基本概念
散列函数 算法不能设计太过复杂 太复杂的散列函数,势必会消耗很多计算时间 散列函数生成的值要尽可能随机并且均匀分布 这样才能避免或者最小化散列冲突而且即便出现来冲突,散列到每个槽里的数据也会比较平均,不会出现某个槽内数据特别多…...

【C++拷贝构造函数深浅拷贝】
拷贝构造函数 注意:访问权限是public 拷贝构造函数:类名(const 类名& 对象名){} 可以有多个参数 。 没有常引用就是普通构造函数 如果不写,编译器自己会给一个(作用仅仅是赋值,默认拷…...

快速编译安装tensorrt_yolo
快速编译安装 安装 tensorrt_yolo 通过 PyPI 安装 tensorrt_yolo 模块,您只需执行以下命令即可: pip install -U tensorrt_yolo 如果您希望获取最新的开发版本或者为项目做出贡献,可以按照以下步骤从 GitHub 克隆代码库并安装: …...

外盘黄金期货需要注意什么?
为大家整理了关于黄金做单的五大原则,相信对于新手投资者来说肯定会产生一定的帮助。 1、看多空:主要有两种方法,基本面判断和技术面判断,基本面判断,主要是借助基本信息面,如政策。供需,产量…...

Allegro光绘Gerber文件、IPC网表、坐标文件、装配PDF文件导出打包
Allegro光绘Gerber文件、IPC网表、坐标文件、装配PDF文件导出打包 一、Gerber文件层叠与参数设置二、装配图文件设置导出三、光绘参数设置四、Gerber孔符图、钻孔表及钻孔文件输出五、输出Gerber文件六、输出IPC网表七、导出坐标文件八、文件打包 一、Gerber文件层叠与参数设置…...

mysql的索引可以分为哪些类型
MySQL的索引是用于提高查询性能的重要数据结构。不同类型的索引在不同的使用场景中具有不同的优势和适用性。 1. 主键索引(Primary Key Index) 特点:唯一且不允许 NULL 值。用途:唯一标识表中的每一行。自动创建:定义…...
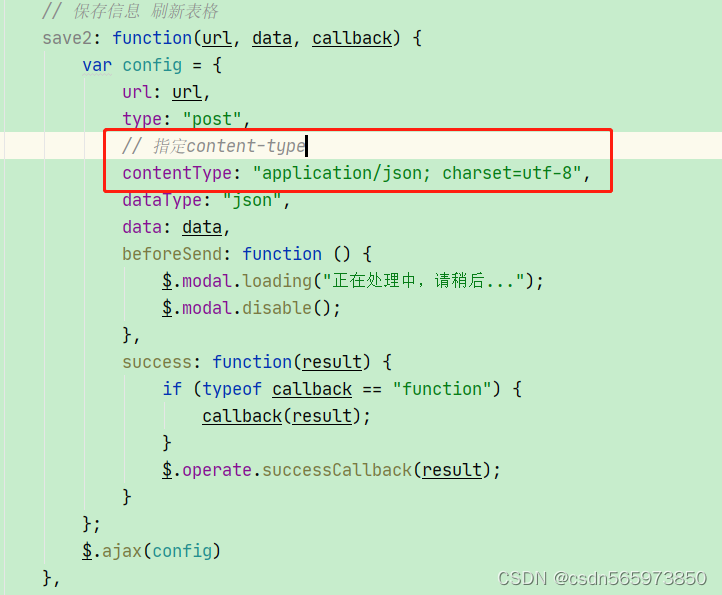
Content type ‘application/x-www-form-urlencoded;charset=UTF-8‘ not supported
Content type application/x-www-form-urlencoded;charsetUTF-8 not supported 问题背景新增页面代码改造 问题背景 这里有一个需求,前端页面需要往后端传参,参数包括主表数据字段以及子表数据字段,由于主表与子表为一对多关系,在…...

XCTF-web-easyupload
试了试php,php7,pht,phtml等,都没有用 尝试.user.ini 抓包修改将.user.ini修改为jpg图片 在上传一个123.jpg 用蚁剑连接,得到flag...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...

Ascend NPU上适配Step-Audio模型
1 概述 1.1 简述 Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤)&#x…...

微信小程序云开发平台MySQL的连接方式
注:微信小程序云开发平台指的是腾讯云开发 先给结论:微信小程序云开发平台的MySQL,无法通过获取数据库连接信息的方式进行连接,连接只能通过云开发的SDK连接,具体要参考官方文档: 为什么? 因为…...
)
OpenLayers 分屏对比(地图联动)
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 地图分屏对比在WebGIS开发中是很常见的功能,和卷帘图层不一样的是,分屏对比是在各个地图中添加相同或者不同的图层进行对比查看。…...

蓝桥杯3498 01串的熵
问题描述 对于一个长度为 23333333的 01 串, 如果其信息熵为 11625907.5798, 且 0 出现次数比 1 少, 那么这个 01 串中 0 出现了多少次? #include<iostream> #include<cmath> using namespace std;int n 23333333;int main() {//枚举 0 出现的次数//因…...

佰力博科技与您探讨热释电测量的几种方法
热释电的测量主要涉及热释电系数的测定,这是表征热释电材料性能的重要参数。热释电系数的测量方法主要包括静态法、动态法和积分电荷法。其中,积分电荷法最为常用,其原理是通过测量在电容器上积累的热释电电荷,从而确定热释电系数…...

LangChain知识库管理后端接口:数据库操作详解—— 构建本地知识库系统的基础《二》
这段 Python 代码是一个完整的 知识库数据库操作模块,用于对本地知识库系统中的知识库进行增删改查(CRUD)操作。它基于 SQLAlchemy ORM 框架 和一个自定义的装饰器 with_session 实现数据库会话管理。 📘 一、整体功能概述 该模块…...

深入浅出深度学习基础:从感知机到全连接神经网络的核心原理与应用
文章目录 前言一、感知机 (Perceptron)1.1 基础介绍1.1.1 感知机是什么?1.1.2 感知机的工作原理 1.2 感知机的简单应用:基本逻辑门1.2.1 逻辑与 (Logic AND)1.2.2 逻辑或 (Logic OR)1.2.3 逻辑与非 (Logic NAND) 1.3 感知机的实现1.3.1 简单实现 (基于阈…...