Elasticsearch:Open Crawler 发布技术预览版
作者:来自 Elastic Navarone Feekery

多年来,Elastic 已经经历了几次 Crawler 迭代。最初是 Swiftype 的 Site Search,后来发展成为 App Search Crawler,最近又发展成为 Elastic Crawler。这些 Crawler 功能丰富,允许以稳健而细致的方式将网站数据导入 Elasticsearch。但是,如果用户想在自己的基础设施上运行这些 Crawler,他们也需要运行整个企业搜索。企业搜索代码库非常庞大,包含许多不同的工具,因此用户无法选择只运行 Crawler。由于企业搜索是私有代码,因此用户也不完全清楚他们正在运行什么。
这一切都改变了,因为我们发布了最新版本的 Crawler:Open Crawler!
Open Crawler 允许用户从他们喜欢的任何位置抓取 Web 内容并将其索引到 Elasticsearch 中。使用 Elastic Cloud 没有任何要求,也不需要运行 Kibana 或企业搜索实例。只需要一个 Elasticsearch 实例即可将抓取结果导入其中。
这次的存储库也是开放代码。用户现在可以检查代码库、提交问题和 PR 请求,或者分支存储库进行更改并运行他们自己的爬虫变体。
有什么变化?
Open Crawler 比之前的 SaaS 爬虫轻量得多。该产品本质上是现有 Elastic Crawler 的核心爬虫代码,与企业搜索服务分离。分离 Open Crawler 意味着暂时放弃一些功能。如果你想阅读我们实现功能对等的路线图,本博客末尾有一个完整的功能比较表。我们打算重新引入这些功能,并在该产品成为正式发布时达到近乎功能对等。
这个过程还使我们能够对核心产品进行改进。例如:
- 我们能够消除索引命名的限制
- 现在可以在抓取和提取内容之前对索引使用自定义映射
- 抓取结果现在也被批量索引到 Elasticsearch 中,而不是一次索引一个网页
- 这提供了显着的性能提升,我们将在下面介绍
它与 Elastic Crawler 相比如何?
如前所述,此爬虫程序可以从你喜欢的任何地方运行;你的计算机、你的个人服务器或云托管服务器。它可以将文档索引到本地、云甚至无服务器的 Elasticsearch 中。你也不再需要使用企业搜索将你的网站内容导入 Elasticsearch。
但最令人兴奋的是,Open Crawler 也比 Elastic Crawler 更快。
我们进行了性能测试,以比较 Open Crawler 和我们的下一个最新爬虫程序 Elastic Crawler 的速度。这两个爬虫程序都爬取了网站 elastic.co,没有更改默认配置。Open Crawler 设置为在两个 AWS EC2 实例上运行;m1.small 和 m1.large,而 Elastic Crawler 则从 Elastic Cloud 本地运行。所有这些都设置在北弗吉尼亚州地区。内容被索引到具有相同设置的 Elasticsearch Cloud 实例中(默认 360 GB 存储 | 8 GB RAM | 最多 2.5 个 vCPU)。
结果如下:
| Crawler Type | Server RAM | Server CPU | Crawl Duration (mins) | Docs Ingested (n) |
|---|---|---|---|---|
| Elastic Crawler | 2GB | up to 8 vCPU | 305 | 43957 |
Open Crawler (m1.small) | 1.7 GB | 1 vCPU | 160 | 56221 |
Open Crawler (m1.large) | 3.75 GB per vCPU | 2 vCPU | 100 | 56221 |
对于 m1.small,Open Crawler 的速度几乎是后者的两倍,而对于 m1.large,速度则是后者的三倍多!
尽管运行在 vCPU 配置较少的服务器上,Open Crawler 的速度也同样快。Open Crawler 提取了大约 13000 多个文档,但这是因为 Elastic Crawler 将具有相同主体的网站页面合并为一个文档。此功能称为重复内容处理(duplicate content handling),详细描述位于本博客末尾的功能比较矩阵中。这里的要点是,即使提取的文档数量不同,这两个爬虫在各自的抓取过程中遇到的网页数量相同。
以下是一些图表,比较了这对 Elasticsearch 的影响。这些图表比较了 Elastic Crawler 和在 m1.large 实例上运行的 Open Crawler。
CPU
当然,Open Crawler 导致 Elastic Cloud 上的 CPU 使用率显著降低,但这是因为我们删除了整个企业搜索服务器。仍然值得快速查看一下此 CPU 使用率分布在哪里。
Elastic Crawler CPU 负载(Elastic Cloud)
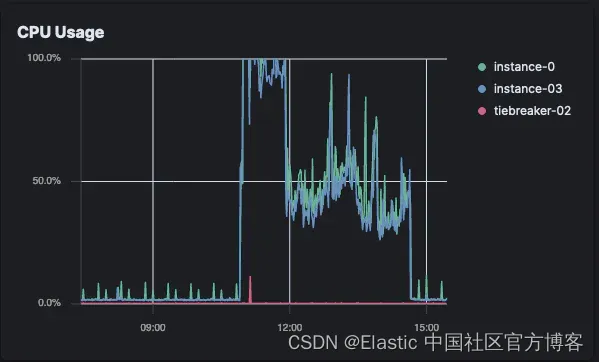
打开爬虫 CPU 负载(Elastic Cloud)
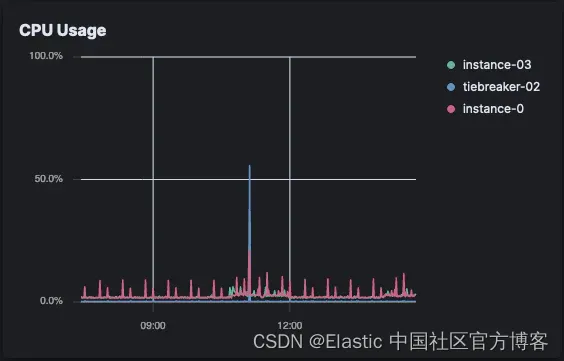
Elastic Crawler 立即达到 CPU 阈值并持续使用了一个小时。然后它下降并出现周期性峰值,直到爬取完成。
对于 Open Crawler,Elastic Cloud 上几乎没有明显的 CPI 使用情况,但 CPU 仍在某处被消耗,在我们的例子中,这是在 EC2 实例上。
EC2 CPU 负载 (m1.large)
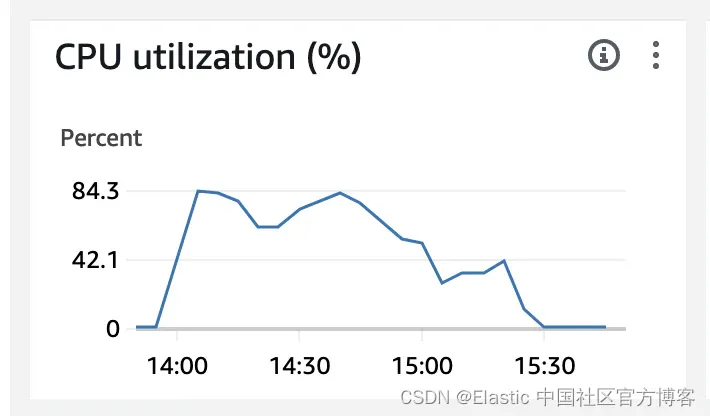
我们在这里可以看到,Open Crawler 没有达到 100% 的限制阈值。它使用的最高 CPU 为 84.3%。这意味着这里还有更多的优化空间。根据用户设置(以及我们可以添加到代码库的优化),Open Crawler 可能会更快。
请求数 (n)
通过比较抓取期间发出的请求数,我们可以看到 Elasticsearch 服务器负载的真正变化。
Elastic Crawler 请求数
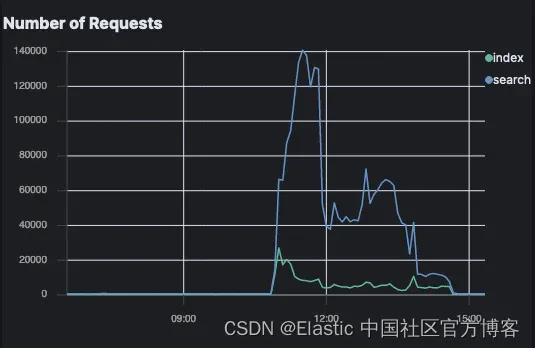
Open Crawler 请求:
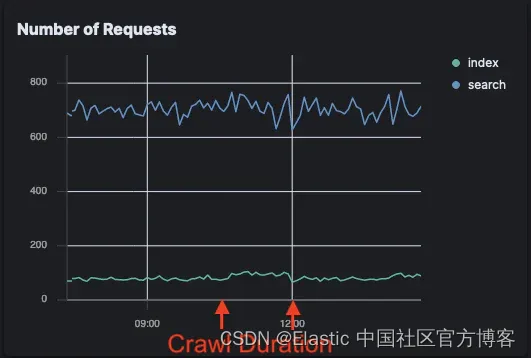
Open Crawler 对索引请求的影响非常小,与背景噪音相比,在这张图上甚至无法察觉。索引请求略有增加,搜索请求没有变化。
与此同时,Elastic Crawler 的请求激增;特别是搜索请求。
这意味着对于想要减少对其 Elasticsearch 实例的请求的用户来说,Open Crawler 是一个很好的解决方案。
那么为什么它的速度会快这么多呢?
1) Open Crawler 发出的索引请求明显更少。
Elastic Crawler 每次只对一个爬取结果进行索引。这样做是为了实现重复内容管理等功能。这意味着 Elastic Crawler 在爬取过程中执行了 43,957 个文档索引请求。它还会在遇到重复内容时更新文档,因此它还执行了超过 13,000 个单独的更新请求。
Open Crawler 反而会汇集爬取结果并批量对其进行索引。在此测试中,它仅在 604 个大小各异的批量请求中就索引了相同数量的爬取结果。这不到所发出索引请求的 1.5%,这大大降低了 Elasticsearch 的管理负载。
2)Elastic Crawler 还执行许多搜索请求,进一步降低了性能
Elastic Crawler 的配置和元数据在 Elasticsearch 伪系统(pseudo-system)索引中进行管理。在爬取时,它会定期检查此配置并更新其中一些索引的元数据,这是通过进一步的 Elasticsearch 请求完成的。
Open Crawler 的配置完全在 yaml 文件中管理。它也不会跟踪 Elasticsearch 索引上的元数据。它对 Elasticsearch 发出的唯一请求是在抓取网站时从抓取结果中索引文档。
3)Open Crawler 对抓取结果的处理较少
在 Open Crawler 的技术预览阶段,有许多功能尚未提供。在 Elastic Crawler 中,这些功能均通过 Elasticsearch 中的伪系统索引进行管理。当我们将这些功能添加到 Open Crawler 时,我们可以确保它们以不涉及多次向 Elasticsearch 发出请求以检查配置的方式完成。这意味着即使在达到与 Elastic Crawler 几乎相同的功能后,Open Crawler 仍应保持这种速度优势。
我如何使用它?
你现在可以克隆存储库并按照此处的文档开始使用。如果你不更改源代码,我建议使用 Docker 来运行 Open Crawler,以使过程更顺畅。
如果你想将抓取结果索引到 Elasticsearch 中,你还可以试用 Elasticsearch on Cloud 的免费试用版或自行从网站下载并运行 Elasticsearch。
这是抓取网站 parksaustralia.gov.au 的快速演示。此操作的要求是 Docker、Open Crawler 存储库的克隆/分叉以及正在运行的 Elasticsearch 实例。
1. 构建 Docker 映像并运行它
这可以在一行中完成,使用 docker build -t crawler-image . && docker run -i -d --name crawler crawler-image。
docker build -t crawler-image . && docker run -i -d --name crawler crawler-image。
然后,你可以使用 CLI 命令检查版本,确认它正在运行:
docker exec -it crawler bin/crawler version
2. 配置爬虫
使用存储库中的示例,你可以创建一个配置文件。在这个例子中,我正在爬取网站 parksaustralia.org.au 并将其索引到基于云的 Elasticsearch 实例中。
这是我的配置示例,我创造性地将其命名为 example.yml。
example.yml
domain_allowlist:- https://parksaustralia.gov.au
seed_urls:- https://parksaustralia.gov.au
output_sink: elasticsearch
output_index: elastic-crawler-test-2
max_crawl_depth: 2elasticsearch:host: "https://myinstance.eu-north1.gcp.elastic-cloud.com"port: "443"username: "elastic"password: "realpassword"
可以使用以下方式将其复制到 docker 容器中:
ocker cp config/example.yml crawler:/app/config/example.yml
4. 爬取!
使用 docker exec -it crawler bin/crawler crawl config/example.yml 开始爬取。
docker exec -it crawler bin/crawler crawl config/example.yml
如果站点很大,则需要一段时间才能完成,但你会根据 shell 输出知道它已完成。

5. 检查内容
然后我们可以针对索引执行 _search 查询。如果你有一个正在运行的实例,也可以在 Kibana Dev Tools 中执行此操作。
curl -X GET "https://myinstance.eu-north1.gcp.elastic-cloud.com:443/elastic-crawler-test-2/_search" \
-H 'Content-Type: application/json' \
-u elastic:realpassword \
-d'
{"_source": ["url", "title", "body_content"],"size": 1,"query": {"match": {"title": "Uluru"}}
}
' | jq '.hits.hits[]._source'
还有结果!
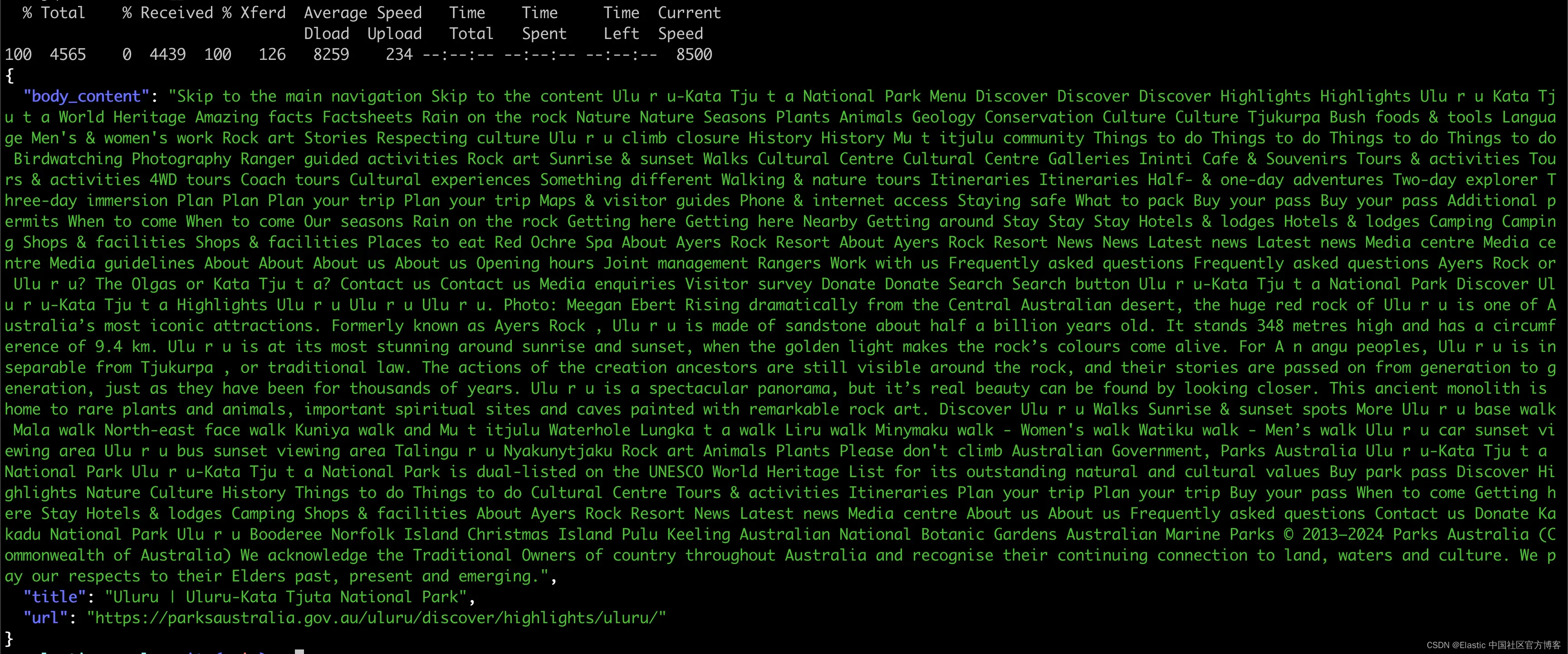
你甚至可以将这些结果与语义搜索联系起来,并进行一些很酷的真实语言查询,例如澳大利亚中心的公园是什么?你只需将你创建的管道的名称添加到 Crawler 配置 yaml 文件的 elasticsearch.pipeline 字段下。
功能比较细分
以下是截至 v8.13 的 Elastic Crawler 功能的完整列表,以及我们打算将它们添加到 Open Crawler 的时间。技术预览中提供的功能已经可用。
这些与任何特定的堆栈版本无关,但我们为每个版本设定了一个大致的时间。
- 技术预览:今天(2024 年 6 月)
- 测试版:2024 年秋季
- GA:2025 年夏季
| Feature | Open Crawler | Elastic Crawler |
|---|---|---|
| Index content into Elasticsearch | tech-preview | ✔ |
| No index name restrictions | tech-preview | ✖ |
| Run anywhere, without Enterprise Search or Kibana | tech-preview | ✖ |
| Bulk index results | tech-preview | ✖ |
| Ingest pipelines | tech-preview | ✔ |
| Seed URLs | tech-preview | ✔ |
robots.txt and sitemap.xml adherence | tech-preview | ✔ |
| Crawl through proxy | tech-preview | ✔ |
| Crawl sites with authorization | tech-preview | ✔ |
| Data attributes for inclusion/exclusion | tech-preview | ✔ |
| Limit crawl depth | tech-preview | ✔ |
| Robots meta tags | tech-preview | ✔ |
| Canonical URL link tags | tech-preview | ✔ |
| No-follow links | tech-preview | ✔ |
| CSS selectors | beta | ✔ |
| XPath selectors | beta | ✔ |
| Custom data attributes | beta | ✔ |
| Binary content extraction | beta | ✔ |
| URL pattern extraction (extraction directly from URLs using regex) | beta | ✔ |
| URL filters (extraction rules for specific endpoints) | beta | ✔ |
| Purge crawls | beta | ✔ |
| Crawler results history and metadata | GA | ✔ |
| Duplicate content handling | TBD | ✔ |
| Schedule crawls | TBD | ✔ |
| Manage crawler through Kibana UI | TBD | ✔ |
由于我们正在评估 Open Crawler 的未来,因此 TBD 功能仍未确定。其中一些功能(如计划抓取)已经可以使用 cron 作业或类似的自动化功能完成。根据用户反馈以及 Open Crawler 项目的发展情况,我们可能会决定在以后的版本中正确实现这些功能。如果你需要其中之一,请联系我们!你可以在论坛和社区 Slack 中找到我们,也可以直接在存储库中创建问题。
下一步是什么?
我们希望在 v9.0 中及时将其发布为正式版。Open Crawler 的设计考虑到了 Elastic Cloud Serverless,我们打算让它成为该版本的主要 Web 内容提取方法。
我们还计划支持 Elastic 数据提取服务,因此可以使用 Open Crawler 提取更大的二进制内容文件。
与此同时,我们需要引入许多功能,以获得与 Elastic Crawler 目前相同的功能丰富的体验。
你可以使用来自任何来源的数据构建搜索。查看此网络研讨会,了解 Elasticsearch 支持的不同连接器和来源。
准备好自己尝试一下了吗?开始免费试用。
原文:Open Crawler released for tech-preview — Elastic Search Labs
相关文章:
Elasticsearch:Open Crawler 发布技术预览版
作者:来自 Elastic Navarone Feekery 多年来,Elastic 已经经历了几次 Crawler 迭代。最初是 Swiftype 的 Site Search,后来发展成为 App Search Crawler,最近又发展成为 Elastic Crawler。这些 Crawler 功能丰富,允许以…...

C 语言连接MySQL 数据库
前提条件 本机安装MySQL 8 数据库 整体步骤 第一步:开启Windows 子系统安装Ubuntu 22.04.4,安装MySQL 数据库第三方库执行 如下命令: sudo aptitude install libmysqlclient-dev wz2012LAPTOP-8R0KHL88:/mnt/e/vsCode/cpro$ sudo aptit…...

【探索Linux】P.34(HTTPS协议)
阅读导航 引言一、HTTPS是什么1. 什么是"加密"2. 为什么要加密3. 常见的加密方式(1)对称加密(2)非对称加密 二、证书认证1. CA认证 三、HTTPS的加密底层原理✅非对称加密对称加密证书认证 温馨提示 引言 在上一篇文章中…...

Python 踩坑记 -- 调优
前言 继续解决问题 慢 一个服务运行有点慢,当然 Python 本身不快,如果再编码不当那这个可能就是量级上的劣化。 整个 Code 主线逻辑 1700,各依赖封装 3000,主线逻辑也是很久远的痕迹,长函数都很难看清楚一个 if els…...

英特尔澄清:Core i9处理器崩溃问题根本原因仍在调查,eTVB非主因
英特尔否认了有关已找到导致Core i9崩溃问题根本原因的报道,强调调查仍在继续。此前,德国媒体Igors Lab曾报道,英特尔已经发现了影响第13代猛禽湖(Raptor Lake)和第14代猛禽湖Refresh Core i9处理器稳定性的根源问题&a…...
python实战根据excel的文件名称这一列的内容,找到电脑D盘的下所对应的文件位置,要求用程序实现
今天客户需要 根据excel的文件名称这一列的内容,找到电脑D盘的下所对应的文件位置,要求用程序实现 数据样例:记录.xlsx 解决代码: 1、安装必要的库: pip install pandas openpyxl2、编写Python脚本: im…...
)
LVS ipvsadm命令的使用(二)
目录 上篇:负载均衡集群(一)-CSDN博客 命令参数概述 调度算法 基本命令 1. 添加虚拟服务器 2. 添加真实服务器 3. 删除虚拟服务器 4. 删除真实服务器 5. 列出当前配置 6. 修改服务器权重 7.保存规则 8. 清除所有配置 进行增加虚拟…...

Java面向对象-接口
Java面向对象-接口 一、JDK1.8之前二、接口的作用三、JDK1.8之后,新增非抽象方法四、静态方法 一、JDK1.8之前 1、类是类,接口是接口,它们是同一层次的概念 2、接口中没有构造器 3、接口如何声明:interface 4、在jdk1.8之前&…...

怎么不使用springboot Helper或Spring Initializr来创建spring项目
1. 创建项目目录结构 首先,创建项目的基本目录结构。一个典型的 Maven 项目结构如下: my-spring-project ├── src │ ├── main │ │ ├── java │ │ │ └── com │ │ │ └── example │ │ │ └…...
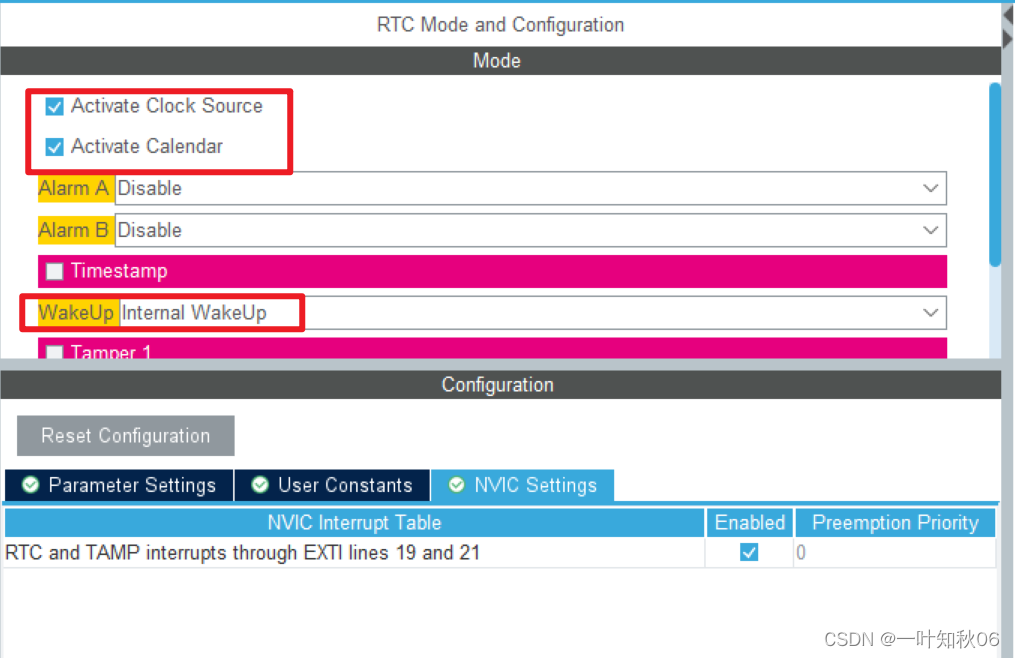
STM32CubeMX配置-RTC周期唤醒
一、简介 MCU为STM32G070,采用内部时钟32KHZ,配置为周期6s唤醒,调用回调函数,进行喂狗操作。 二、配置 初始时间、日期、周期唤醒时间配置。 开启周期唤醒中断 三、生成代码 调用回调函数,进行喂狗操作。 //RTC唤醒回…...

js如何添加新元素到数组中
1.push方法 push() 方法可向数组的末尾添加一个或多个元素,并返回新的长度。这是向数组添加元素的最常用方法。 let arr [1, 2, 3]; arr.push(4); // 向数组末尾添加元素4 console.log(arr); // 输出: [1, 2, 3, 4] 2.unshift方法 unshift() 方法可向数组的…...

Python变量和基本数据类型
变量和基本数据类型 变量是什么? 变量是存储在内存中的值,这就意味着在创建变量时会在内存中开辟一个空间。 基于变量的数据类型,解释器会分配指定内存,并决定什么数据可以被存储在内存中。 因此,变量可以指定不同…...

嵌入式数据库_1.嵌入式数据库的定义及特点和分类
1.嵌入式数据库的定义及特点 1.1定义 嵌入式数据库的名称来自其独特的运行模式。这种数据库嵌入到了应用程序进程中,消除了与客户机服务器配置相关的开销。嵌入式数据库实际上是轻量级的,在运行时,它们需要较少的内存。它们是使用精…...
)
新人学习笔记之(变量)
一、什么是变量 1.变量是存储数据的小盒子,不是里面的数据 2.经常发生改变的数据 二、变量的定义格式 1.数据类型 变量名; 数据类型:为盒子中存储的数据,加入类型【限制】 变量名:为盒子起的名字 分号:语句的结束 三…...

Windows修改CMD窗口编码为UTF-8
windows下的cmd的默认编码是GBK编码,有时可能造成乱码问题,下面是我找到的两种更换编码方式为UTF-8的方法。 1、临时修改 (1)先进入cmd命令窗口(快捷键win键R) (2)直接输入“chcp…...
)
os实训课程模拟考试(1~7)
操作系统的基本功能和设计目标 1、 操作系统是一组 ____(单选) A、 文件管理程序 B、 资源管理程序 C、 中断处理程序 D、 设备管理程序 2、 以下哪项不是操作系统关心的主要问题?(单选) A、 管理计算机裸机 B、 设计…...

yolov10 学习笔记
目录 推理代码,source可以是文件名,路径, 预测可视化: 预测可视化加nms 训练自己的数据集, 训练一段时间报错:dill库 解决方法: 推理代码,source可以是文件名,路径…...

NAT概述
NAT概念 NAT(Network Address Translation,网络地址转换)是一种用于修改网络地址信息的技术,主要用于在路由器或防火墙上进行地址转换,以解决 IPv4 地址短缺问题、提高网络安全性以及实现私有网络与公有网络之间的通信…...
Ansys Mechanical|学习方法
Ansys Mechanical是Ansys的旗舰产品之一,涉及的学科体系全面丰富,包括的力学分支主要有理论力学,振动理论,连续介质力学,固态力学,物理力学,爆炸力学及应用力学等。 在自媒体及数字经济飞速发展…...

热门开源项目ChatTTS: 国内语音技术突破,实现弯道超车
✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨ 🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。 我是Srlua小谢,在这里我会分享我的知识和经验。&am…...

基于FPGA的PID算法学习———实现PID比例控制算法
基于FPGA的PID算法学习 前言一、PID算法分析二、PID仿真分析1. PID代码2.PI代码3.P代码4.顶层5.测试文件6.仿真波形 总结 前言 学习内容:参考网站: PID算法控制 PID即:Proportional(比例)、Integral(积分&…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

如何在看板中体现优先级变化
在看板中有效体现优先级变化的关键措施包括:采用颜色或标签标识优先级、设置任务排序规则、使用独立的优先级列或泳道、结合自动化规则同步优先级变化、建立定期的优先级审查流程。其中,设置任务排序规则尤其重要,因为它让看板视觉上直观地体…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

今日学习:Spring线程池|并发修改异常|链路丢失|登录续期|VIP过期策略|数值类缓存
文章目录 优雅版线程池ThreadPoolTaskExecutor和ThreadPoolTaskExecutor的装饰器并发修改异常并发修改异常简介实现机制设计原因及意义 使用线程池造成的链路丢失问题线程池导致的链路丢失问题发生原因 常见解决方法更好的解决方法设计精妙之处 登录续期登录续期常见实现方式特…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...

使用Spring AI和MCP协议构建图片搜索服务
目录 使用Spring AI和MCP协议构建图片搜索服务 引言 技术栈概览 项目架构设计 架构图 服务端开发 1. 创建Spring Boot项目 2. 实现图片搜索工具 3. 配置传输模式 Stdio模式(本地调用) SSE模式(远程调用) 4. 注册工具提…...

手机平板能效生态设计指令EU 2023/1670标准解读
手机平板能效生态设计指令EU 2023/1670标准解读 以下是针对欧盟《手机和平板电脑生态设计法规》(EU) 2023/1670 的核心解读,综合法规核心要求、最新修正及企业合规要点: 一、法规背景与目标 生效与强制时间 发布于2023年8月31日(OJ公报&…...

LOOI机器人的技术实现解析:从手势识别到边缘检测
LOOI机器人作为一款创新的AI硬件产品,通过将智能手机转变为具有情感交互能力的桌面机器人,展示了前沿AI技术与传统硬件设计的完美结合。作为AI与玩具领域的专家,我将全面解析LOOI的技术实现架构,特别是其手势识别、物体识别和环境…...

【安全篇】金刚不坏之身:整合 Spring Security + JWT 实现无状态认证与授权
摘要 本文是《Spring Boot 实战派》系列的第四篇。我们将直面所有 Web 应用都无法回避的核心问题:安全。文章将详细阐述认证(Authentication) 与授权(Authorization的核心概念,对比传统 Session-Cookie 与现代 JWT(JS…...