【0基础学爬虫】爬虫基础之自动化工具 DrissionPage 的使用

概述
前三期文章中已经介绍到了 Selenium 与 Playwright 、Pyppeteer 的使用方法,它们的功能都非常强大。而本期要讲的 DrissionPage 更为独特,强大,而且使用更为方便,目前检测少,强烈推荐!!!
这里推荐观看十一姐 B 站 DrissionPage 系列视频,很详细:
合集·爬虫自动化 DrissionPage 实战案例:
https://space.bilibili.com/308704191/channel/collectiondetail?sid=1947582
DrissionPage 相关资料:
官方文档:https://www.drissionpage.cn
Drissionpage “姊妹库”:https://gitee.com/haiyang0726/SaossionPage
DrissionPage 的使用
介绍
DrissionPage 是一个基于 python 的网页自动化工具。它既能控制浏览器,也能收发数据包,还能把两者合而为一。可兼顾浏览器自动化的便利性和 requests 的高效率。它功能强大,内置无数人性化设计和便捷功能。它的语法简洁而优雅,代码量少,对新手友好。
-
支持系统:Windows、Linux、Mac;
-
python 版本:3.6 及以上;
-
支持应用:Chromium 内核浏览器(如 Chrome、Edge),electron 应用;
特性
强大的自研内核
本库采用全自研的内核,内置了无数实用功能,对常用功能作了整合和优化,对比 selenium,有以下优点:
- 无 webdriver 特征;
- 无需为不同版本的浏览器下载不同的驱动;
- 运行速度更快;
- 可以跨 iframe 查找元素,无需切入切出;
- 把 iframe 看作普通元素,获取后可直接在其中查找元素,逻辑更清晰;
- 可以同时操作浏览器中的多个标签页,即使标签页为非激活状态,无需切换;
- 可以直接读取浏览器缓存来保存图片,无需用 GUI 点击另存;
- 可以对整个网页截图,包括视口外的部分(90 以上版本浏览器支持);
- 可处理非
open状态的 shadow-root。
亮点功能
除了以上优点,本库还内置了无数人性化设计。
- 极简的语法规则,集成大量常用功能,代码更优雅;
- 定位元素更加容易,功能更强大稳定;
- 无处不在的等待和自动重试功能。使不稳定的网络变得易于控制,程序更稳定,编写更省心;
- 提供强大的下载工具。操作浏览器时也能享受快捷可靠的下载功能;
- 允许反复使用已经打开的浏览器。无需每次运行从头启动浏览器,调试超方便;
- 使用 ini 文件保存常用配置,自动调用,提供便捷的设置,远离繁杂的配置项;
- 内置 lxml 作为解析引擎,解析速度成几个数量级提升;
- 使用 POM 模式封装,可直接用于测试,便于扩展;
- 高度集成的便利功能,从每个细节中体现;
- 还有很多细节,这里不一一列举,欢迎实际使用中体验。
安装升级
# 安装
pip install DrissionPage# 升级最新稳定版
pip install DrissionPage --upgrade# 指定版本升级
pip install DrissionPage==4.0.0b17
- 如何在无界面 Linux 使用:
CentOS 请参考这篇文章:
linux 部署说明:https://blog.csdn.net/sinat_39327967/article/details/132181129
Ubuntu 请参考这篇文章:
DrissionPage 在 Ubuntu Linux 的使用:https://zhuanlan.zhihu.com/p/674687748
使用
访问网页
from DrissionPage import ChromiumPage, ChromiumOptionsco = ChromiumOptions().set_paths(browser_path=r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe")
# 1、设置无头模式:co.headless(True)
# 2、设置无痕模式:co.incognito(True)
# 3、设置访客模式:co.set_argument('--guest')
# 4、设置请求头user-agent:co.set_user_agent()
# 5、设置指定端口号:co.set_local_port(7890)
# 6、设置代理:co.set_proxy('http://localhost:1080')
page = ChromiumPage(co)page.get('https://gitee.com/login', retry=3, timeout=15, interval=2)# 定位到账号文本框,获取文本框元素
ele = page.ele('#user_login')
# 输入对文本框输入账号
ele.input('您的账号')
# 定位到密码文本框并输入密码
page.ele('#user_password').input('您的密码')
# 点击登录按钮
page.ele('@value=登 录').click()
获取浏览器路径的方法:
- 这里的浏览器路径不一定是 Chrome,Edge 等 Chromium 内核的浏览器都可以;
- 打开浏览器,在地址栏输入
chrome://version(Edge 输入edge://version),回车
如图所示,红框中就是要获取的路径:
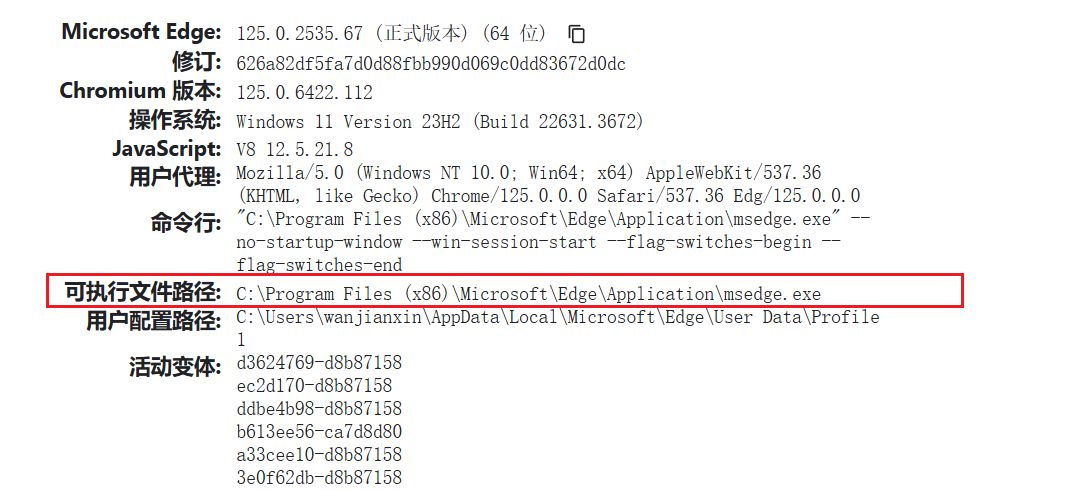
- 此法不限于 Windows,有界面的 Linux 也是这样取路径。
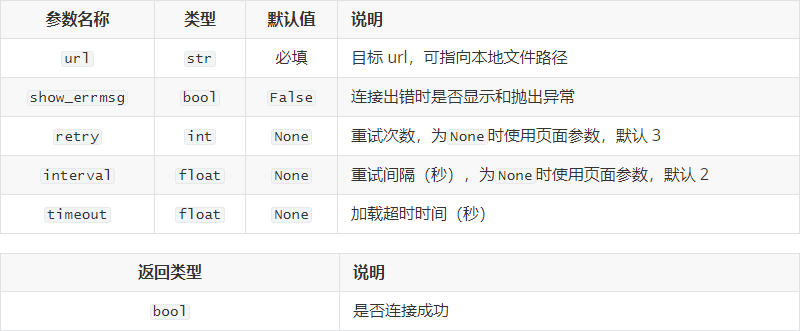
- get()
该方法用于跳转到一个网址。当连接失败时,程序会进行重试:
获取查找元素
本库提供一套简洁易用的语法,用于快速定位元素,并且内置等待功能、支持链式查找,减少了代码的复杂性。
同时也兼容 css selector、xpath、selenium 原生的 loc 元组。
定位元素大致分为三种方法:
- 在页面或元素内查找子元素;
- 根据 DOM 结构相对定位;
- 根据页面布局位置相对定位;
- xpath 方式:
# 输入
page.ele('xpath://input[@id="bindMobileFree"]').input("123456789")
# 点击
page.ele('x://span[@class="getYZM_btn"]').click()
- 其他方式:
from DrissionPage import SessionPagepage = SessionPage()
page.get('https://gitee.com/explore')# 获取包含“全部推荐项目”文本的 ul 元素
ul_ele = page.ele('tag:ul@@text():全部推荐项目') # 获取该 ul 元素下所有 a 元素
titles = ul_ele.eles('tag:a') # 遍历列表,打印每个 a 元素的文本
for i in titles: print(i.text)
foot = page.ele('#footer-left') # 用 id 查找元素
first_col = foot.ele('css:>div') # 使用 css selector 在元素的下级中查找元素(第一个)
lnk = first_col.ele('text:命令学') # 使用文本内容查找元素
text = lnk.text # 获取元素文本
href = lnk.attr('href') # 获取元素属性值print(text, href, '\n')# 简洁模式串联查找
text = page('@id:footer-left')('css:>div')('text:命令学').text
print(text)
等待
-
✅️️ 页面对象的等待方法:
-
📌
wait.load_start():此方法用于等待页面进入加载状态;-
注意
get()已内置等待加载开始,后无须跟wait.load_start();
-
-
📌
wait.doc_loaded():此方法用于等待页面文档加载完成;- 注意
- 此功能仅用于等待页面主 document 加载,不能用于等待 js 加载的变化;
- 除非
load_mode为None,get()方法已内置等待加载完成,后面无须添加等待;
- 注意
-
📌
wait.eles_loaded():此方法用于等待元素被加载到 DOM; -
📌
wait.ele_displayed():此方法用于等待一个元素变成显示状态; -
📌
wait.ele_hidden():此方法用于等待一个元素变成隐藏状态; -
📌
wait.ele_deleted():此方法用于等待一个元素被从 DOM 中删除; -
📌
wait.download_begin():此方法用于等待下载开始; -
📌
wait.upload_paths_inputted():此方法用于等待自动填写上传文件路径; -
📌
wait.new_tab():此方法用于等待新标签页出现; -
📌
wait.title_change():此方法用于等待 title 变成包含或不包含指定文本; -
📌
wait.url_change():此方法用于等待 url 变成包含或不包含指定文本。 比如有些网站登录时会进行多重跳转,url 发生多次变化,可用此功能等待到达最终需要的页面; -
📌
wait.alert_closed():此方法用于等待弹出框被关闭; -
📌
wait():此方法用于等待若干秒;
-
-
✅️️ 元素对象的等待方法
-
📌
wait.displayed():此方法用于等待元素从隐藏状态变成显示状态; -
📌
wait.hidden():此方法用于等待元素从显示状态变成隐藏状态; -
📌
wait.deleted():此方法用于等待元素被从 DOM 删除; -
📌
wait.covered():此方法用于等待元素被其它元素覆盖; -
📌
wait.not_covered():此方法用于等待元素不被其它元素覆盖; -
📌
wait.enabled():此方法用于等待元素变为可用状态; -
📌
wait.disabled():此方法用于等待元素变为不可用状态; -
📌
wait.stop_moving():此方法用于等待元素运动结束; -
📌
wait.clickable():此方法用于等待元素可被点击; -
📌
wait.disabled_or_deleted():此方法用于等待元素变为不可用或被删除; -
📌
wait():此方法用于等待若干秒。
-
监听网络数据
- 注意:要先启动监听,再执行动作,
listen.start()之前的数据包是获取不到的; - 等待并获取:
- 等待并获取:
from DrissionPage import ChromiumPagepage = ChromiumPage()
page.get('https://gitee.com/explore/all') # 访问网址,这行产生的数据包不监听page.listen.start('gitee.com/explore') # 开始监听,指定获取包含该文本的数据包(部分url)
for _ in range(5):page('@rel=next').click() # 点击下一页res = page.listen.wait() # 等待并获取一个数据包print(res.url) # 输出数据包urlprint(res.response.headers) # 输出响应头print(res.response.statusText) # 输出响应状态码print(res.response.body) # 输出响应内容
- 实时获取:
from DrissionPage import ChromiumPagepage = ChromiumPage()
page.listen.start('gitee.com/explore') # 开始监听,指定获取包含该文本的数据包
page.get('https://gitee.com/explore/all') # 访问网址i = 0
for packet in page.listen.steps():print(packet.url) # 打印数据包urlpage('@rel=next').click() # 点击下一页i += 1if i == 5:break
动作链
- ✅️ 使用方法
* 📌 使用内置actions属性
```python
from DrissionPage import ChromiumPagepage = ChromiumPage()
page.get('https://www.baidu.com')
page.actions.move_to('#kw').click().type('DrissionPage')
page.actions.move_to('#su').click()
```* 📌 使用新对象```python
from DrissionPage import ChromiumPage
from DrissionPage.common import Actionspage = ChromiumPage()
ac = Actions(page)
page.get('https://www.baidu.com')
ac.move_to('#kw').click().type('DrissionPage')
ac.move_to('#su').click()
```* 📌 操作方式```python
ac.move_to(ele).click().type('some text')
```
-
✅️ 移动鼠标
- 📌
move_to():此方法用于移动鼠标到元素中点,或页面上的某个绝对坐标; - 📌
move():此方法用于使鼠标相对当前位置移动若干距离; - 📌
up():此方法用于使鼠标相对当前位置向上移动若干距离; - 📌
down():此方法用于使鼠标相对当前位置向下移动若干距离; - 📌
left():此方法用于使鼠标相对当前位置向左移动若干距离; - 📌
right():此方法用于使鼠标相对当前位置向右移动若干距离。
- 📌
-
✅️ 鼠标按键
- 📌
click():此方法用于单击鼠标左键,单击前可先移动到元素上; - 📌
r_click():此方法用于单击鼠标右键,单击前可先移动到元素上; - 📌
m_click():此方法用于单击鼠标中键,单击前可先移动到元素上; - 📌
db_click():此方法用于双击鼠标左键,双击前可先移动到元素上; - 📌
hold():此方法用于按住鼠标左键不放,按住前可先移动到元素上; - 📌
release():此方法用于释放鼠标左键,释放前可先移动到元素上; - 📌
r_hold():此方法用于按住鼠标右键不放,按住前可先移动到元素上; - 📌
r_release():此方法用于释放鼠标右键,释放前可先移动到元素上; - 📌
m_hold():此方法用于按住鼠标中键不放,按住前可先移动到元素上; - 📌
m_release():此方法用于释放鼠标中键,释放前可先移动到元素上。
- 📌
-
✅️ 滚动滚轮
- 📌
scroll():此方法用于滚动鼠标滚轮,滚动前可先移动到元素上;
- 📌
-
✅️ 键盘按键和文本输入
- 📌
key_down():此方法用于按下键盘按键。非字符串按键(如 ENTER)可输入其名称,也可以用 Keys 类获取; - 📌
key_up():此方法用于提起键盘按键。非字符串按键(如 ENTER)可输入其名称,也可以用 Keys 类获取; - 📌
input():此方法用于输入一段文本或多段文本,也可输入组合键。多段文本或组合键用列表传入; - 📌
type():此方法用于以按键盘的方式输入一段或多段文本。也可输入组合键。type()与input()区别在于前者模拟按键输入,逐个字符按下和提起,后者直接输入一整段文本。
- 📌
-
✅️ 等待
- 📌
wait():此方法用于等待若干秒;
- 📌
-
✅️ 属性
- 📌
owner:此属性返回使用此动作链的页面对象; - 📌
curr_x:此属性返回当前光标位置的 x 坐标; - 📌
curr_y:此属性返回当前光标位置的 y 坐标。
- 📌
-
✅️ 示例
- 📌 模拟输入 ctrl+a
from DrissionPage import ChromiumPage from DrissionPage.common import Keys, Actions# 创建页面 page = ChromiumPage() # 创建动作链对象 ac = Actions(page)# 鼠标移动到<input>元素上 ac.move_to('tag:input') # 点击鼠标,使光标落到元素中 ac.click() # 按下 ctrl 键 ac.key_down(Keys.CTRL) # 输入 a ac.type('a') # 提起 ctrl 键 ac.key_up(Keys.CTRL)链式写法:
ac.click('tag:input').key_down(Keys.CTRL).type('a').key_up(Keys.CTRL)更简单的写法:
ac.click('tag:input').type(Keys.CTRL_A)- 📌 拖拽元素
把一个元素向右拖拽 300 像素:
from DrissionPage import ChromiumPage from DrissionPage.common import Actions# 创建页面 page = ChromiumPage() # 创建动作链对象 ac = Actions(page)# 左键按住元素 ac.hold('#div1') # 向右移动鼠标300像素 ac.right(300) # 释放左键 ac.release()把一个元素拖拽到另一个元素上:
ac.hold('#div1').release('#div2') -
✅️ 页面对象内置动作链
from DrissionPage import ChromiumPagepage = ChromiumPage()
page.actions.move_to((300, 500)).hold().move(300).release()
标签页操作
📌 注意:可以对多标签页操作, 即可实现并发自动化。
-
✅️️ 标签页总览
- 📌
tabs_count:此属性返回标签页数量。 - 📌
tab_ids:此属性以list方式返回所有标签页 id。
- 📌
-
✅️️ 新建标签页
- 📌
new_tab():该方法用于新建一个标签页,该标签页在最后面。只有 Page 对象拥有此方法。
- 📌
-
✅️️ 获取标签页对象
- 📌
get_tab():此方法用于获取一个标签页对象。可指定标签页序号、id、标题、url、类型等条件用于检索。当id_or_num不为None时,其它参数无效。当所有参数都为None时,获取 Page 对象控制的标签页的 Tab 对象。title、url和tab_type三个参数是与关系。只有 Page 对象拥有此方法。 - 📌
get_tabs():此方法用于查找符合条件的 tab 对象
- 📌
-
✅️️ 使用多例
from DrissionPage import ChromiumPage from DrissionPage.common import Settingspage = ChromiumPage() page.new_tab() page.new_tab()# 未启用多例: tab1 = page.get_tab(1) tab2 = page.get_tab(1) print(id(tab1), id(tab2))# 启用多例: Settings.singleton_tab_obj = False tab1 = page.get_tab(1) tab2 = page.get_tab(1) print(id(tab1), id(tab2))
-
✅️️ 关闭和重连
- 📌
close() - 📌
disconnect() - 📌
reconnect() - 📌
close_tabs()
- 📌
-
✅️️ 激活标签页
- 📌
set.tab_to_front() - 📌
set.activate()
- 📌
-
✅️️ 多标签页协同
截图和录像
✅️️ 页面截图
# 对整页截图并保存
page.get_screenshot(path='tmp', name='pic.jpg', full_page=True)
✅️️ 元素截图
img = page('tag:img')
img.get_screenshot()
bytes_str = img.get_screenshot(as_bytes='png') # 返回截图二进制文本
✅️️ 页面录像
from DrissionPage import ChromiumPagepage = ChromiumPage()
page.screencast.set_save_path('video') # 设置视频存放路径
page.screencast.set_mode.video_mode() # 设置录制
page.screencast.start() # 开始录制
page.wait(3)
page.screencast.stop() # 停止录制
执行 JS 语句
page.run_js(f'localStorage.setItem("__user_token.v3",`{token}`)')page.run_js(f'localStorage.setItem("__user_info",`{token}`)')cookies_set = ""
cookies_set += f'document.cookie=`__user_token.v3={token}; path=/;domain=i.shengcaiyoushu.com;`;'page.run_js(cookies_set)
反检测
在 Selenium、Playwright 、Playwright 的使用中,我们讲到了自动化工具容易被网站检测,也提供了一些绕过检测的方案。这里我们介绍一下 DrissionPage 的反检测方案。
以 https://bot.sannysoft.com 为例,我们分别测试正常模式与无头模式下的检测结果:
- 正常模式:

- 无头模式:
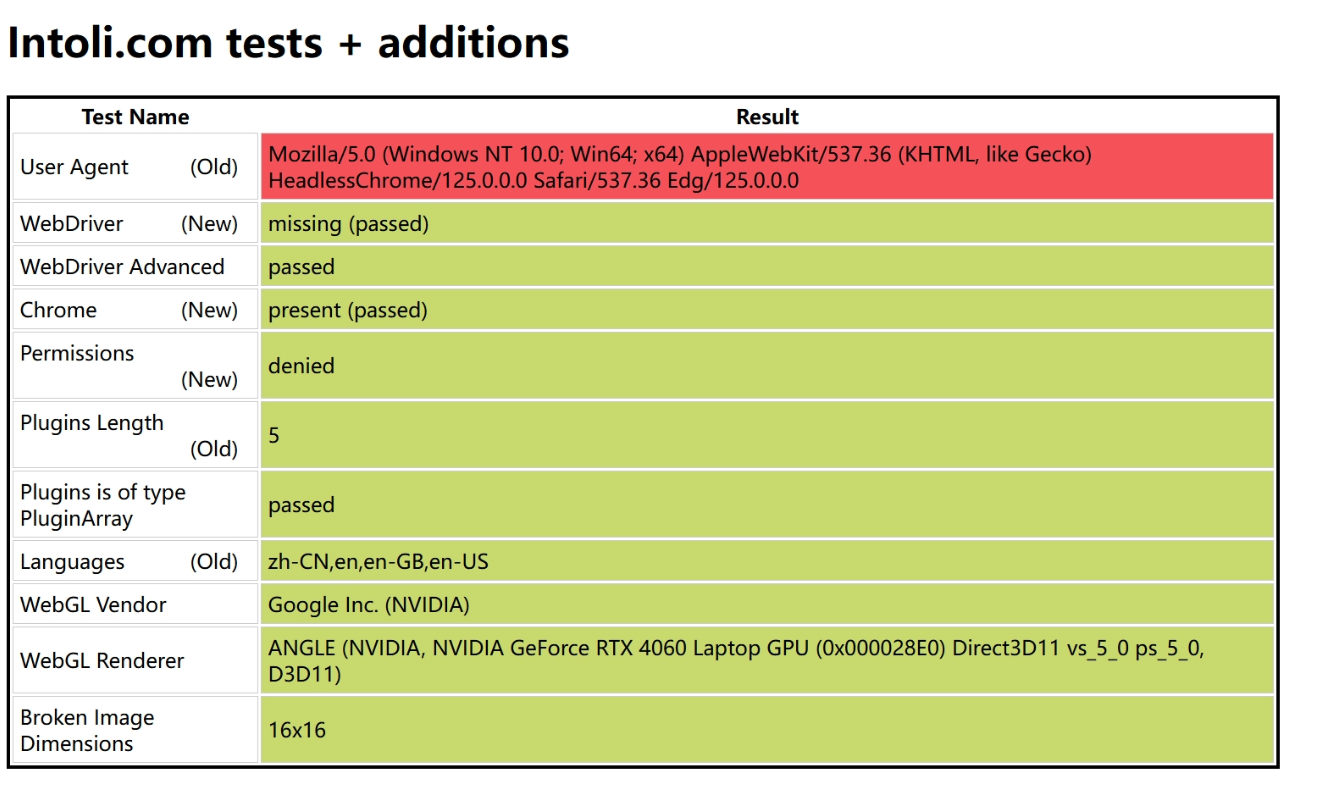
可以发现,我们没有做任何反检测的操作,都不会被检测到,就连使用无头模式也只有 userAgent 有问题,不过我们 co.set_user_agent() 设置一下就可以了,虽然这些只是最基本的检测机制,但也够用了。
总结
DrissionPage 语法简洁,使用方便,底层基于 CDP 协议,拥有较强的反检测机制,目前不需要做任何反检测的操作就可以绕过国内外绝大多数的网站自动化检测,包含但不限于 (xx 验证码、某数、5s)。 还有很多强大的功能这里没法一一展示,强烈推荐!
相关文章:
【0基础学爬虫】爬虫基础之自动化工具 DrissionPage 的使用
概述 前三期文章中已经介绍到了 Selenium 与 Playwright 、Pyppeteer 的使用方法,它们的功能都非常强大。而本期要讲的 DrissionPage 更为独特,强大,而且使用更为方便,目前检测少,强烈推荐!!&a…...
c++_0基础_讲解7 练习
这一讲我为大家准备了几道题目,大家试着独自做一下(可能来自不同网站) 整数大小比较 - 洛谷 题目描述 输入两个整数,比较它们的大小。若 x>yx>y ,输出 > ;若 xyxy ,输出 ÿ…...

docker一些常用命令以及镜像构建完后部署到K8s上
docker一些常用命令以及镜像构建完后部署到K8s上 1.创建文件夹2.删除文件3.复制现有文件内容到新建文件4.打开某个文件5.查看文件列表6.解压文件(tar格式)7.解压镜像8.查看镜像9.删除镜像10.查看容器11.删除容器12.停止运行容器13.构建镜像14.启动容器15…...

在typora中利用正则表达式,批量处理图片
一,png格式 在 Typora 中批量将 HTML 图片标签转换为简化的 Markdown 图片链接,且忽略 alt 和 style 属性,可以按照以下步骤操作: 打开 Typora 并加载你的文档。按下 Ctrl H(在 Windows/Linux 上)或 Cmd…...

构建LangChain应用程序的示例代码:33、如何在LangChain框架中使用HumanInputChatModel来模拟人工输入的聊天模型教程
除了HumanInputLLM,LangChain还提供了一个伪聊天模型类,可以用于测试、调试或教育目的。这允许您模拟对聊天模型的调用,并模拟如果人类接收到这些消息会如何响应。 在这篇笔记中,我们将介绍如何使用这个模型。 我们首先在代理中…...

虚拟机使用桥接模式网络配置
1、获取本机的网络详细信息 windowr 输入cmd 使用ipconfig -all 一样即可 在自己的虚拟机中设置网络 虚拟机中的ip ---------192.168.36.*,不要跟自己的本机ip冲突 网关-----------192.168.36.254 一样即可 dns -----------一样即可,我多写了几个&am…...

韩顺平0基础学java——第24天
p484-508 System类 常见方法 System.arrycopy(src,0,dest,1,2); 表示从scr的第0个位置拷贝2个,放到目标数组索引为1的地方。 BigInteger和BigDecimal类 保存大整数和高精度浮点数 BigInte…...

leecode N皇后
深度优先遍历,然后回溯 思考得到的技巧: 1.先思考怎么用学过的数据结构解题 2.回溯不只需要知道最后一步,还需要知道之前所走的每一步 3. 棋盘的生成,.join([]),可以变列表为字符串 看题解得到的技巧: 1.妙啊…...
2024050802-重学 Java 设计模式《实战模板模式》
重学 Java 设计模式:实战模版模式「模拟爬虫各类电商商品,生成营销推广海报场景」 一、前言 黎明前的坚守,的住吗? 有人举过这样一个例子,先给你张北大的录取通知书,但要求你每天5点起床,12点…...
UNIAPP-ADB无线调试
ADB下载 SDK 平台工具版本说明 | Android Studio | Android Developers (google.cn) 环境变量配置 ADB版本查看 adb version 手机使用数据线连接到电脑 手机需要授权adb调试(开发人员选项里面) CMD输入命令 adb tcpip 5555 到了这一步你手机已经启动了adb服务了&…...
【stm32-新建工程】
stm32-新建工程 ■ 下载相关STM32Cube官方固件包(F1,F4,F7,H7)■ 1. ST官方搜索STM32Cube■ 2. 搜索 STM32Cube■ 3. 点击获取软件■ 4. 选择对应的版本下载■ 5. 输入账号信息■ 6. 出现下载弹框,等待下载…...

写点什么吧,作为STM32系列的开篇……
自从本科毕业后,就再也没碰过单片机…… 自从研究生毕业后,就再也没碰过硬件…… 自以为以前单片机玩的熟得很,特别是ATMEGA系列的AVR单片机,由于老师的推荐,本科时花了好多精力在这个系列单片机上面…… 本科时STM…...

代码随想录算法训练营第十天| 232.用栈实现队列|225. 用队列实现栈|20. 有效的括号|1047. 删除字符串中的所有相邻重复项
232.用栈实现队列 文档讲解:代码随想录 视频讲解:栈的基本操作! | LeetCode:232.用栈实现队列_哔哩哔哩_bilibili 知道要用两个栈实现,具体咋做忘了。队列的特性是先进先出,栈是先进后出,入队操…...
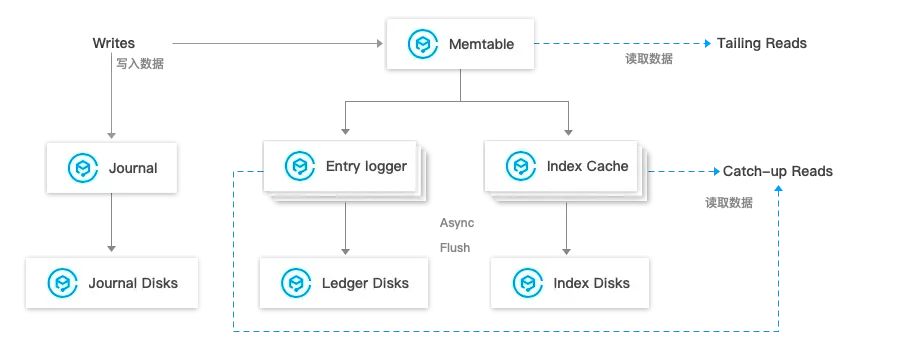
Pulsar 社区周报 | No.2024-06-07 | Apache Pulsar 新分支 3.3 版本发布
“ 各位热爱 Pulsar 的小伙伴们,Pulsar 社区周报更新啦!这里将记录 Pulsar 社区每周的重要更新,每周发布。 ” 本期主题:Apache Pulsar 新分支 3.3 版本发布 Apache Pulsar 新分支 3.3 版本发布:Apache Pulsar 3.3.0[1…...
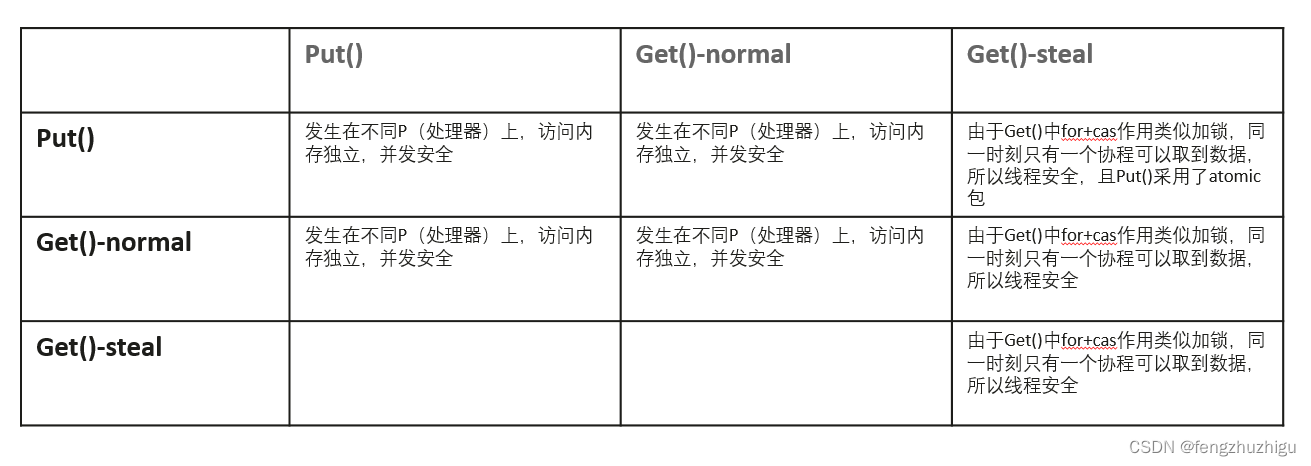
Go源码--sync库(3):sync.Pool(2)
回收 回收其实就是将 pool.local 置为空 可以让垃圾回收器回收 我们来看下 源码 func init() {// 将 poolCleanup 注册到 gc开始前的准备工作处理器中在 STW时执行runtime_registerPoolCleanup(poolCleanup) }这里注册了清理程序到GC前准备工作 也就是发生GC前需要执行这段代…...
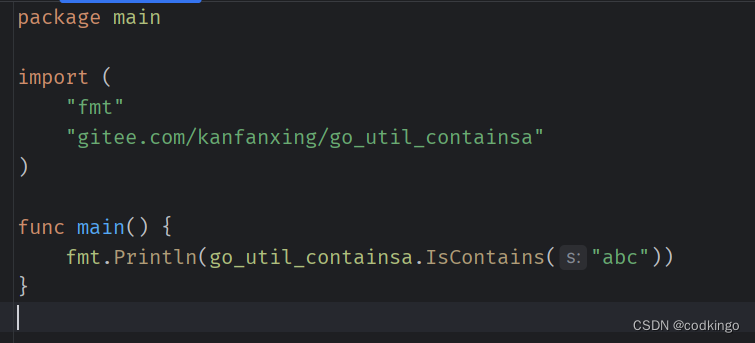
Go如何在本地引用以及发布并引用自定义工具包
如何引用本地自定义工具包 我们首先要准备两个项目,分别为需要引入的工具包和当前项目。 myutils、myproject1. myutils为我们的项目1-工具包 package mypakgeimport "strings"func IsContains(s string) bool {if strings.Contains(s, "a")…...

使用了代理IP怎么还会被封?代理IP到底有没有效果
代理IP作为一种网络工具,被广泛应用于各种场景,例如网络爬虫、海外购物、规避地区限制等。然而,很多用户在使用代理IP的过程中却发现自己的账号被封禁,这让他们不禁产生疑问:使用了代理IP怎么还会被封?代理…...

在WSL2的Ubuntu中安装和使用Docker/Podman
在WSL2的Ubuntu中安装和使用Docker/Podman 0. 目的 当网络环境良好(例如在公司,能直接访问Google等)时, Docker/Podman 安装和使用不是问题。 当网络环境不佳(例如在家里),要把 WSL2 的 Ubun…...

【WEEK16】Learning Objectives and Summaries【Spring Boot】【English Version】
Learning Objectives: Learning SpringBoot Learning Content: Reference video tutorials【狂神说Java】SpringBoot最新教程IDEA版通俗易懂Dubbo and Zookeeper Integration Learning time and outputs: Week16 TUE~FRI 2024.6.11【WEEK16】 【DAY2】Dubbo和Zookeeper集成第…...

AI大模型会让搜索引擎成为历史吗?
AI大模型会让搜索引擎成为历史吗? 随着人工智能技术的不断发展,AI大模型已经在许多领域展现出了强大的能力。从自然语言处理到图像识别,AI大模型的应用越来越广泛。在这种背景下,有人开始提出一个问题:AI大模型是否可…...

springboot-vue+nodejs的电子产品商城销售平台
目录技术栈选择系统架构设计核心功能模块开发环境搭建数据库设计接口规范定义安全防护措施性能优化策略测试与部署项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作技术栈选择 后端采用Spring Boot框架,提供RESTful …...

从ResNet到mHC:DeepSeek重构残差连接,额外开销仅6.7%,附复现代码
2015年,由微软亚洲研究院的何恺明团队提出ResNet,ResNet引入残差连接的概念,用以解决深层神经网络训练中的梯度消失/爆炸和网络退化问题,使得训练极深的网络成为可能。 ��1��&#x…...

Homebrew安装后zsh补全报权限警告?深入聊聊macOS下/usr/local的目录权限管理
Homebrew安装后zsh补全报权限警告?深入聊聊macOS下/usr/local的目录权限管理 每次打开终端都看到那个烦人的zsh警告:"insecure directories, run compaudit for list",确实让人头疼。但这个问题背后隐藏着macOS系统权限管理的深层逻…...

华为无线网络配置实战:从零搭建企业级Wi-Fi环境
1. 企业级Wi-Fi环境搭建前的准备 第一次接触华为无线网络设备时,我被那一堆专业术语搞得头晕眼花。AC控制器、AP接入点、核心交换机...这些设备到底该怎么连接?经过多次实战,我发现只要掌握几个关键点,搭建企业Wi-Fi其实没那么复杂…...

告别字符串截取!用正则表达式re模块精准提取HTML表格数据的避坑指南
告别字符串截取!用正则表达式re模块精准提取HTML表格数据的避坑指南 在数据抓取的世界里,HTML解析就像一场永无止境的猫鼠游戏。每当开发者费尽心思用字符串截取搞定一个网站,前端工程师稍微调整下标签结构,整个爬虫就崩溃了。这种…...

3个超简单步骤:零门槛制作专业级AI视频
3个超简单步骤:零门槛制作专业级AI视频 【免费下载链接】Open-Sora Open-Sora:为所有人实现高效视频制作 项目地址: https://gitcode.com/GitHub_Trending/op/Open-Sora 在数字内容创作领域,AI视频生成技术正以前所未有的速度改变着创…...
)
VisionPro多模板匹配实战:CogPMAlignMultiTool从入门到精通(附完整代码)
VisionPro多模板匹配实战:CogPMAlignMultiTool从入门到精通 在工业视觉检测领域,多模板匹配技术正成为复杂场景下的关键解决方案。当单一模板无法覆盖产品多变的形态时,CogPMAlignMultiTool展现出强大的适应性。本文将带您深入掌握这一工具的…...

使用LingBot-Depth优化Git版本控制中的3D模型管理
使用LingBot-Depth优化Git版本控制中的3D模型管理 1. 引言 在3D设计和游戏开发领域,版本控制一直是个头疼的问题。传统的Git系统擅长处理代码和文本文件,但面对3D模型这种二进制文件就显得力不从心了。每次修改模型后,你只能看到"文件…...

SmolVLA长序列建模效果剖析:对比LSTM在时序预测任务中的表现
SmolVLA长序列建模效果剖析:对比LSTM在时序预测任务中的表现 最近在时间序列预测这个老生常谈的领域里,总有人问我:现在各种基于Transformer的新模型层出不穷,它们真的比LSTM这种“老将”强很多吗?尤其是在处理长序列…...

CasRel在教育AI中的应用:试题解析中‘知识点-考查方式-难度等级’三元组标注
CasRel在教育AI中的应用:试题解析中‘知识点-考查方式-难度等级’三元组标注 1. 引言:从海量试题到结构化知识 如果你是教育行业的从业者,无论是老师、教研员还是在线教育平台的产品经理,一定都面临过这样的困扰:手头…...