Apache Pulsar 从入门到精通
一、快速入门
Pulsar 是一个分布式发布-订阅消息平台,具有非常灵活的消息模型和直观的客户端 API。
最初由 Yahoo 开发,在 2016 年开源,并于2018年9月毕业成为 Apache 基金会的顶级项目。Pulsar 已经在 Yahoo 的生产环境使用了三年多,主要服务于Mail、Finance、Sports、 Flickr、 the Gemini Ads platform、 Sherpa (Yahoo 的 KV 存储)。
号称:云原生消息队列之王
主要特征:
- 水平扩展
- 低延迟持久存储
- 多租户、认证、授权、配额
- 跨地域复制
- 主题的多种订阅模式(独占,共享和故障转移)。
官网:GitHub - apache/pulsar: Apache Pulsar - distributed pub-sub messaging system
B站入门视频: 01-Apache Pulsar 课程介绍_哔哩哔哩_bilibili
SpringBoot使用starter:GitHub - majusko/pulsar-java-spring-boot-starter: Simple pulsar spring boot starter with annotation based consumer/producer registration.
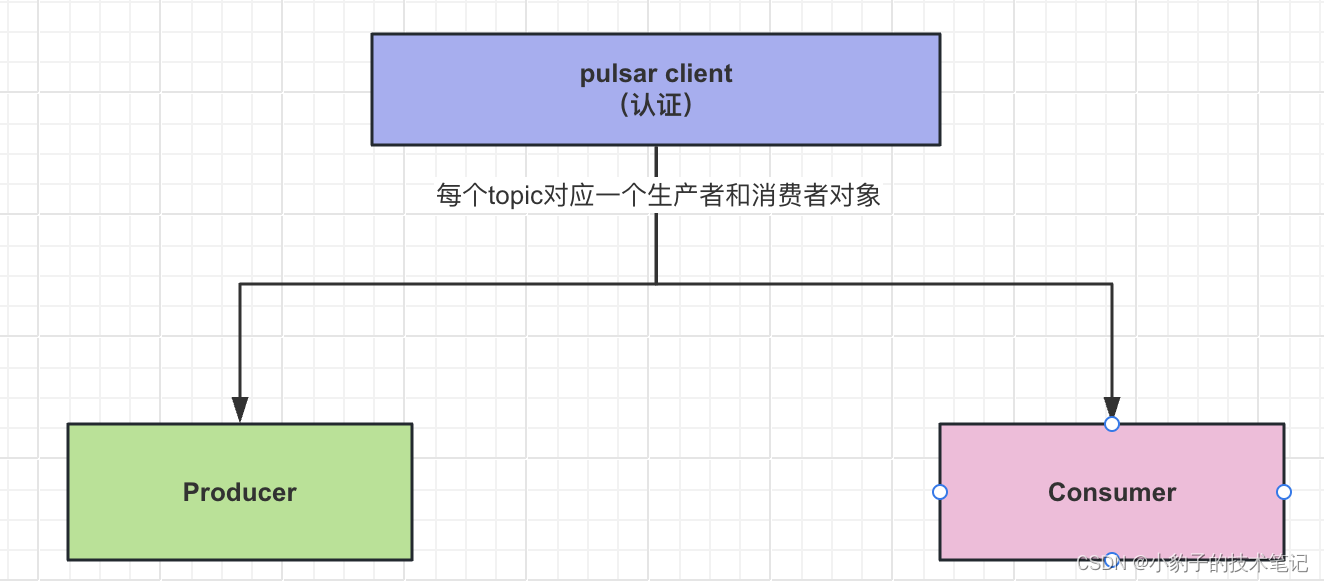
注意:全局一个pulsar Client对象,每一个topic生成对应的一个生产者和消费者对象,因为不同topic可以灵活设置不同的特性。
消息传递
Pulsar基于publish-subscribe(pub-sub)生产订阅模式,生产者将消息发布到Topic,消费者可以订阅这些主题来处理消息,并在处理完成后发送确认消息

消息生产者
发送模式
生产者将消息发布到Topic上,发送消息分可为同步发送和异步发送两种模式:

消息压缩
生产者发布消息在传输过程中会对数据进行压缩,目前Pulsar支持的压缩方式有LZ4,ZLIB, ZSTD, SNAPPY。如果启用了批处理,生产者将在单个请求中累积一批消息进行发送,批处理大小可以由最大消息数和最大发布延迟定义
批处理发送(Batching)
如果批处理开启,producer将会累积一批消息,然后通过一次请求发送出去。批处理的大小取决于最大的消息数量及最大的发布延迟。
消息消费者
消费者从Topic上接收消息进行数据处理,同样,消息接收也分为同步接收和异步接收两种模式:
 消费确认(ack)
消费确认(ack)
1)消费者成功接收到消息时:
当消费者成功处理完一条消息后,会发送一个确认请求给broker,告诉broker可以删除这条消息了,否则broker会一直存储这条消息。消息可以逐个确认也可以累积确认,消费者只需要确认收到的最后一条消息,这个流中所涉及到的所有消息都不会再重新传递给这个消费者。
2)消费者不成功消费时
当消费者处理消息失败时,会给broker发送一个失败确认,这个时候broker就会给消费者重新发送这条消息,失败确认可以逐条发送,也可以累积发送,这取决于消费订阅模式。在exclusive和failover订阅模式中,消费者只会对收到的最后一条消息进行失败确认。在Pulsar客户端可以通过设置timeout的方式触发broker自动重新传递消息,如果在timeout范围内消费者都没有发送确认请求,那么broker就会自动重新发送这条消息给消费者。
3)确认超时
如果某条消息一直处理失败就会触发broker一直重发这条消息给消费者,使消费者无法处理其他消息,Dead letter topic机制可以让消费者在无法成功消费某些消息时接收新的消息进行消费,在这种机制下,无法消费的消息存储在一个单独的topic中(Dead letter topic),用户可以决定如何处理这个topic中的消息。
消息的持久化
消息的持久化是通过BookKeeper实现的,一旦创建了订阅关系,Pulsar将保留所有的消息(即使消费者断开了链接),只有当消费者确认已经成功处理保留的消息时,才会将这些消息丢弃消息。
消息的保留分为两种:
1.在保留策略内的消息即使消费者已发送了确认也可以持久地存储在Pulsar中,保留策略未涵盖的已确认消息将被删除,如果没有保留策略所有已确认的消息都将被删除;
2.设置消息到期时间,会根据应用于namespace的TTL过期时间,如果到期了,即使消息没有被确认也会被删除
当有某条消息被重复发送时,可以选择两种持久化策略:
1.是将重复的消息也持久化到BookKeeper中
2.是判断如果是重复消息,则不再进行持久化操作
租户(tenant)
Pulsar 从一开始就支持多租户,topic 的名称是层级化的,最上层是租户(tenant)
命名空间(namespace)
命名空间是租户内部逻辑上的命名术语。一个租户可以通过admin API创建多个命名空间。例如,一个对接多个应用的租户,可以为每个应用创建不同的namespace。

Topic
与其他pub-sub系统一样,Pulsar中的topic被命名为从生产者向消费者传输消息的通道:
{persistent|non-persistent}://tenant/namespace/topic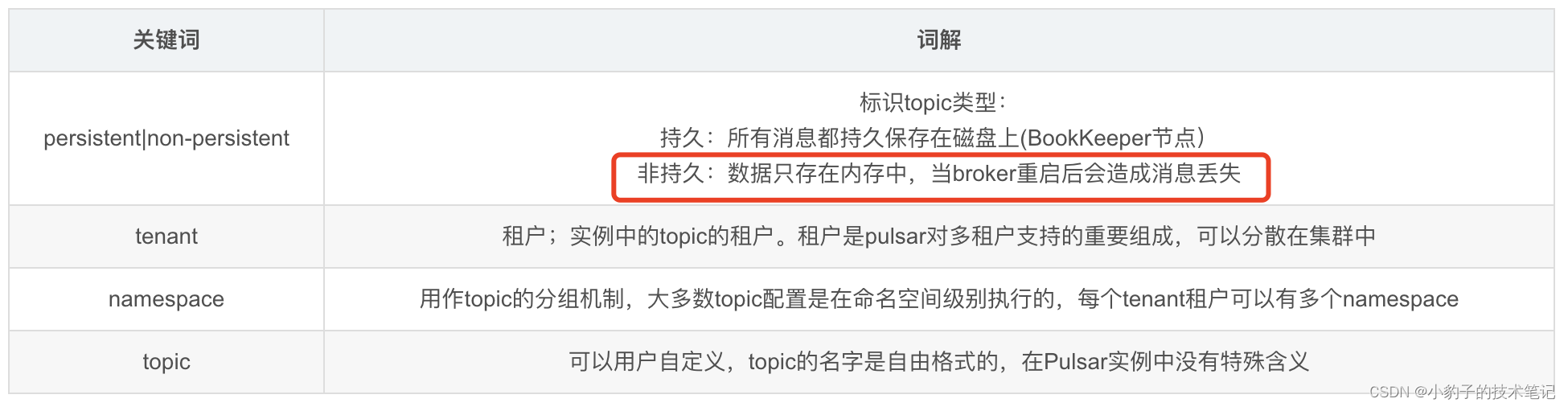
producer写入不存在的主题时 了会在提供的命名空间下自动创建该主题。
常规topic只能由单个broker提供,这限制了topic的最大吞吐量,分区topic是由多个broker处理的一种特殊类型的topic,它允许更高的吞吐量。分区topic和普通topic在订阅模式的工作方式上没有区别,在创建主题时可以指定分区数。
消息路由模式
发布到分布分区topic主题时,必须指定路由模式。默认三个路由模式,默认轮询-和Kafka类似。

消息订阅模式(subscription)
Pulsar具有exclusive,shared,failover,Key_Shared 4种订阅模式

独占(exclusive)
exclusive模式:一个topic只允许一个消费者订阅,否则会报错
在 exclusive 模式下,一个 subscription 只允许被一个 consumer 用于订阅 topic ,如果多个 consumer 使用相同的 subscription 去订阅同一个 topic,则会发生错误。exclusive 是默认的订阅模式。如下图所示,Consumer A-0 和 Consumer A-1 都使用了相同的 subscription(相同的消费组),只有 Consumer A-0 被允许消费消息。

故障转移|灾备(failover)
failover模式:多个消费者订阅同一个topic,按照消费者名称进行排序,第一个消费者时唯一接收到消息的消费者(主消费者),当主消费者断开连接时,所有的后续消息都将发给下一个消费者
在 failover 模式下,多个 consumer 允许使用同一个 subscription 去订阅 topic。但是对于给定的 topic,broker 将选择⼀个 consumer 作为该 topic 的主 consumer ,其他 consumer 将被指定为故障转移 consumer 。当主 consumer 失去连接时,topic 将被重新分配给其中⼀个故障转移 consumer ,⽽新分配的 consumer 将成为新的主 consumer 。发⽣这种情况时,所有未确认的消息都将传递给新的主 consumer ,这个过程类似于 Kafka 中的 consumer 组重平衡(rebalance)。
如下图所示,Consumer B-0 是 topic 的主 consumer ,当 Consumer B-0 失去连接时,Consumer B-1 才能成为新的主 consumer 去消费 topic。

共享(shared)
shared模式:多个消费者订阅同一个topic,消息在消费者之间以循环的方式发送,并且给定的某条消息只能发送给一个消费者,当消费者断开连接时,所有发送给它但没有确认的消息将重新安排发送给其他消费者
在 shared 模式下,多个 consumer 可以使用同一个 subscription 去订阅 topic。消息以轮询的方式分发给 consumer ,并且每条消费仅发送给一个 consumer 。当有 consumer 失去连接时,所有发送给该 consumer 但未被确认的消息将被重新安排,以便发送给该 subscription 上剩余的 consumer 。
但是消息不能保证有序以及不支持批量ack
如下图所示,Consumer C-1,Consumer C-2,Consumer C-3 以轮询的方式接受消息。

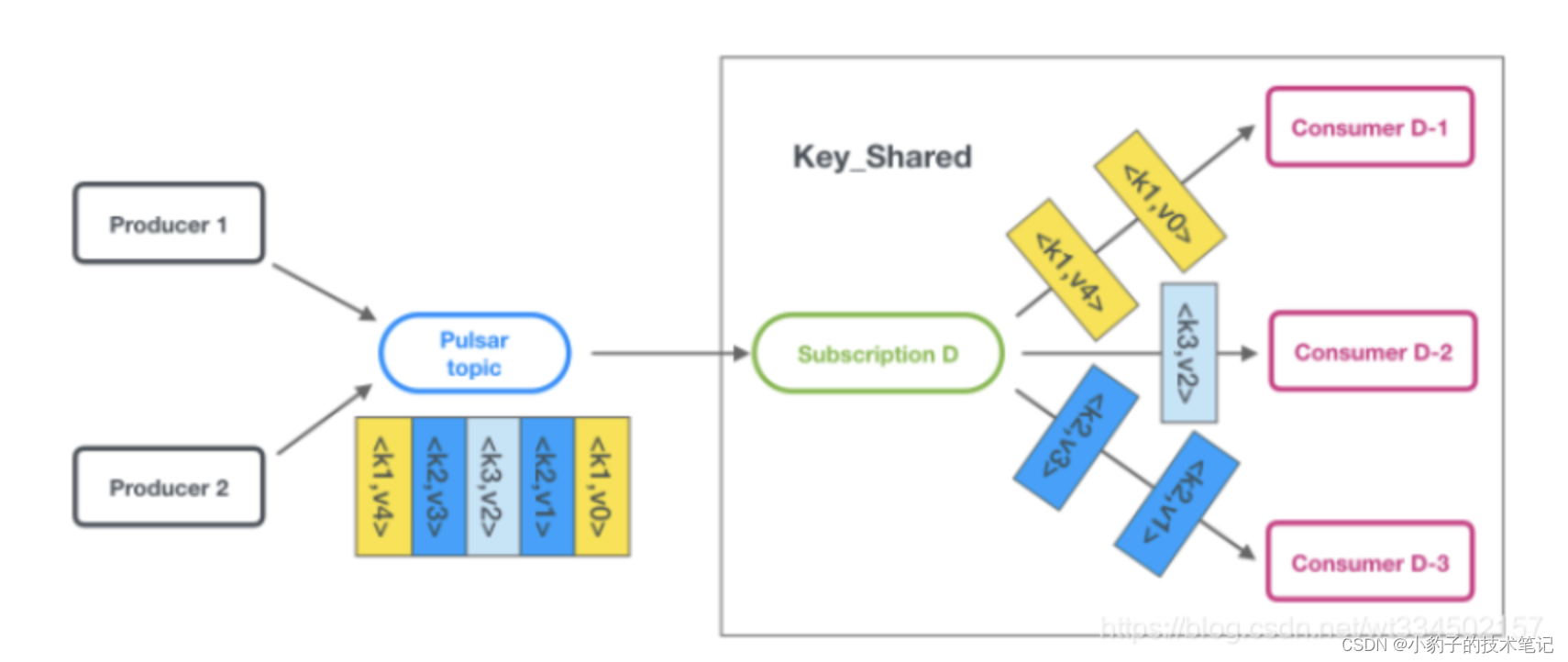
共享键(key_shared)
key_shared模式:多个消费者订阅同一个topic,消息以分布方式在消费者之间传递(<key, value>),具有相同key的消息传递给同一个消费者,当这个消费者断开连接时,将导致key对应的消费者更改
在 shared 模式下,多个 consumer 可以使用同一个 subscription 去订阅 topic。消息按照 key 分发给 consumer ,含有相同 key 的消息只被发送给同一个 consumer 。
如下图所示,不同的 consumer 只接受到对应 key 的消息。
二、Pulsar原理架构
体系结构
在最高级别中,一个Pulsar实例有一个或多个Pulsar集群组成,实例中的集群可以彼此复制数据。在Pulsar集群中,一个或多个broker处理和加载来自生产者传入的消息,将消息发送给消费者,与Pulsar配置存储通信以处理各种协调任务,Pulsar集群架构如下所示,包括一个或多个broker,用于集群级配置和协调的Zookeeper,用于持久存储消息的BookKeeper,集群可以使用地理复制在集群间进行复制
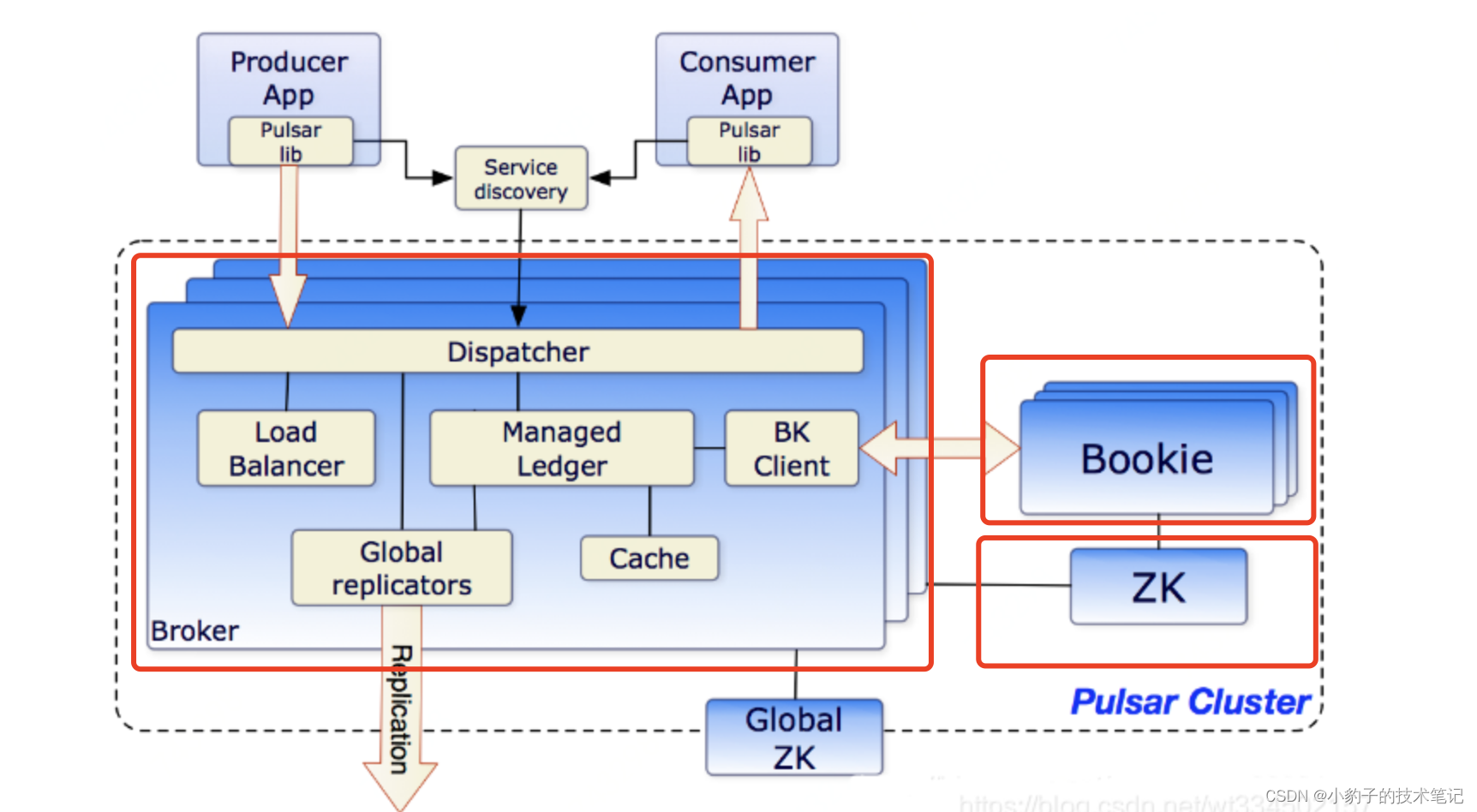
Pulsar组件
Broker
Pulsar 的 broker 是一个无状态组件,本身不存储数据。主要负责处理 producer 和 consumer 的请求,消息的复制与分发,数据的计算。可以理解成Broker 是 Pulsar 的自身实例
主要有2部分组成:
1)HTTP服务器,向生产者和消费者公开,用于管理任务和topic查找端的REST API;
2)调度程序,异步TCP服务器,通过用于所有数据传输的自定义二进制协议;
每个集群都有自己的本地Zookeeper用于存储集群特定的配置和协调,如所有权元数据、代理加载报告、簿记员分类帐元数据等等。
Pulsar使用BookKeeper进行持久消息存储,BookKeeper是一个分布式预写日志(WAL)系统。
除了消息数据外,消费者的订阅位置cursor也可以持久地存储在BookKeeper中
每个 topic 的 partition 都会分配到某一个 borker 上,producer 和 consumer 则会连接到这个 broker,从而向该 topic 的 partition 发送和消费消息。broker 主要负责消息的复制与分发,数据的计算。
zookeeper
主要用于存储元数据、集群配置,任务的协调(例如哪个 broker 负责哪个 topic),服务的发现(例如 broker 发现 bookie 的地址)。
bookkeeper
主要用于数据的持久化存储。除了消息数据,cursors(游标) 也会被持久化到 Bookeeper,cursors 是消费端订阅消费的位移。Bookeeper 中每一个存储节点叫做 bookie。
BookKeeper 是一种优化实时工作负载的存储服务,具有可扩展、高容错、低延迟的特点。企业级的实时存储平台应符合以下几项要求:
- 以极低的延迟(小于 5 毫秒)读写 entry 流
- 能够持久、一致、容错地存储数据
- 在写数据时,能够进行流式传输或追尾传输
- 有效地存储、访问历史数据与实时数据
数据存储
数据分区
写入主题的数据可能只有几个MB,也有可能是几个TB。所以,在某些情况下主题的吞吐量很低,有时候又很高,完全取决于消费者的数量。那么碰到有些主题吞吐量很高而有些又很低的情况该怎么处理?为了解决这个问题,Pulsar将一个主题的数据分布到多台机器上,也就是所谓的分区。
在处理海量数据时,为了保证高吞吐量,分区是一种很常见的手段。默认情况下,Pulsar的主题是不进行分区的,但通过命令行工具或API可以很容易地创建分区主题,并指定分区的数量。
在创建好分区主题之后,Pulsar可以自动对数据进行分区,不会影响到生产者和消费者。也就是说,一个应用程序向一个主题写入数据,对主题分区之后,不需要修改应用程序的代码。分区只是一个运维操作,应用程序不需要关心分区是如何进行的。【类似Kafka中的partition】
数据持久性
Pulsar broker在收到消息并进行确认之后,就必须确保消息在任何情况下都不会丢失。与其他消息系统不同的是,Pulsar使用Apache BookKeeper来保证持久性。BookKeeper提供了低延迟的持久化存储。Pulsar在收到消息之后,将消息发送给多个BookKeeper节点(具体由复制系数来定),节点将数据写入预写式日志(write ahead log),同时在内存里也保存一份。节点在对消息进行确认之前,强制将日志写入到持久化的存储上,因此即使出现电力故障,数据也不会丢失。因为Pulsar broker将数据发给了多个节点,所以只会在大多数节点(quorum)确认写入成功之后它才会将确认消息发给生产者。Pulsar就是通过这种方式来保证即使在出现了硬件故障、网络故障或其他故障的情况下仍然能够保证数据不丢失。
三、集群搭建
从官网下载bin包,修改配置,组件集群搭建模式即可。
Set up a standalone Pulsar locally | Apache Pulsar
四、客户端使用
1.申请消费组【内部限制】
2.申请token
Java使用相关
依赖Pulsar官方版本 2.9.5
<!-- in your <properties> block -->
<pulsar.version>2.9.5</pulsar.version><!-- in your <dependencies> block -->
<dependency><groupId>org.apache.pulsar</groupId><artifactId>pulsar-client</artifactId><version>${pulsar.version}</version>
</dependency>完整的官方指南:
Pulsar Java client | Apache Pulsar
生产者配置
public static void main(String[] args) throws PulsarClientException {// 1.1 建立客户端PulsarClientclient =PulsarClient.builder().serviceUrl("pulsar://abc.demo.com:6651") // 集群连接地址,请勿使用pulsar://host1,host2,host3的配置.authentication(AuthenticationFactory.token("************")).build();// 1.2 默认创建的生产者,schema为byte[]Producer<byte[]> producer = client.newProducer().topic("persistent://test/test/my-topic").compressionType(LZ4).enableBatching(true) // 是否开启批量处理消息,默认true。需要注意的是enableBatching只在异步发送sendAsync生效,因此建议生产环境若想使用批处理,则需使用异步发送.batchingMaxMessages(10) // 批处理中允许的最大消息数。默认1000,建议设成10.batchingMaxBytes(4*1024*1024) // 一批消息的最大大小。建议设成4MB,因为服务端有5MB的消息大小限制.batchingMaxPublishDelay(100, TimeUnit.MILLISECONDS) // 达到该时间就将一批消息发送出去,默认10ms,建议设大点100ms。可以理解为batch就算没攒够,一旦过了这么多时间还是会发送出去.maxPendingMessages(1000).create();// 1.3 同步发送单条消息MessageId messageId = producer.send("My message".getBytes());// 1.4 同步关闭生产者producer.close();client.close();System.out.println("发送pulsar消息成功:" + new String(messageId.toByteArray()));}消费者配置
public static void main(String[] args) throws PulsarClientException {// 1.1 建立客户端PulsarClientclient =PulsarClient.builder().serviceUrl("pulsar://abc.demo.com:6651") // 集群连接地址,请勿使用pulsar://host1,host2,host3的配置.authentication(AuthenticationFactory.token("************")).build();// 1.2 创建消费者Consumer<byte[]> consumer = client.newConsumer(Schema.BYTES) // 消息schema,需要与生产者配置一致,默认是byte[].topic("persistent://test/test/my-topic").subscriptionName("my-subscription").subscriptionType(SubscriptionType.Shared) // 指定消费模式,包含:Exclusive,Failover,Shared,Key_Shared。默认的是Exclusive模式.subscriptionInitialPosition(SubscriptionInitialPosition.Earliest) // 指定创建新订阅时cursor的初始位置,默认Latest.subscribe();// 同步接收while (true) {Message msg = consumer.receive();try {System.out.println("Message received: " + new String(msg.getData()));consumer.acknowledge(msg); // 消息需要ack了,才不会再次接收} catch (Exception e) {consumer.negativeAcknowledge(msg);}}}注意:topic写上全路径名称,如 persistent://test/test/test/web-test2-topic;如果不填,就默认到这个ns下:persistent://public/default/my-topic
SpringBoot Starter使用
GitHub - majusko/pulsar-java-spring-boot-starter: Simple pulsar spring boot starter with annotation based consumer/producer registration.
1.引入依赖
<dependency><groupId>io.github.majusko</groupId><artifactId>pulsar-java-spring-boot-starter</artifactId><version>1.1.2</version></dependency>2.定义生产者对象
@Configuration
public class TestProducerConfiguration {@Beanpublic ProducerFactory producerFactory() {return new ProducerFactory().addProducer("my-topic", MyMsg.class).addProducer("other-topic", String.class);}
}在使用时可以通过模块来使用:
@Service
class MyProducer {@Autowiredprivate PulsarTemplate<MyMsg> producer;void sendHelloWorld() throws PulsarClientException {producer.send("my-topic", new MyMsg("Hello world!"));}
}3.配置消费者
@Service
class MyConsumer {@PulsarConsumer(topic="my-topic", clazz=MyMsg.class)void consume(MyMsg msg) {// TODO process your messageSystem.out.println(msg.getData());}// 批量消费@PulsarConsumer(topic = "my-topic",clazz=MyMsg.class,consumerName = "my-consumer",subscriptionName = "my-subscription",batch = true)public void consumeString(Messages<MyMsg> msgs) {msgs.forEach((msg) -> {System.out.println(msg);});}// 批量消费和自动确认@PulsarConsumer(topic = "my-topic",clazz=MyMsg.class,consumerName = "my-consumer",subscriptionName = "my-subscription",batch = true)public List<MessageId> consumeString(Messages<MyMsg> msgs) {List<MessageId> ackList = new ArrayList<>();msgs.forEach((msg) -> {System.out.println(msg);ackList.add(msg.getMessageId());});return ackList;}// 批量消费和手动确认@PulsarConsumer(topic = "my-topic",clazz=MyMsg.class,consumerName = "my-consumer",subscriptionName = "my-subscription",batch = true,batchAckMode = BatchAckMode.MANUAL)public void consumeString(Messages<MyMsg> msgs,Consumer<MyMsg> consumer) {List<MessageId> ackList = new ArrayList<>();msgs.forEach((msg) -> {try {System.out.println(msg);ackList.add(msg.getMessageId());} catch (Exception ex) {System.err.println(ex.getMessage());consumer.negativeAcknowledge(msg);}});consumer.acknowledge(ackList);}// 消费使用到元数据@PulsarConsumer(topic="my-topic", clazz=MyMsg.class)void consume(PulsarMessage<MyMsg> myMsg) { producer.send(TOPIC, msg.getValue()); }// 覆盖默认消费名称@PulsarConsumer(topic = "my-topic",clazz = MyMsg.class,consumerName = "my-consumer",subscriptionName = "my-subscription")// 支持 spel 表达式@PulsarConsumer(topic = "${my.custom.topic.name}",clazz = MyMsg.class,consumerName = "${my.custom.consumer.name}",subscriptionName = "${my.custom.subscription.name}")public void consume(MyMsg myMsg) {}
}4.配置必要参数
#PulsarClient
pulsar.service-url=pulsar://localhost:6650
pulsar.io-threads=10
pulsar.listener-threads=10
pulsar.enable-tcp-no-delay=false
pulsar.keep-alive-interval-sec=20
pulsar.connection-timeout-sec=10
pulsar.operation-timeout-sec=15
pulsar.starting-backoff-interval-ms=100
pulsar.max-backoff-interval-sec=10
pulsar.consumer-name-delimiter=
pulsar.namespace=default
pulsar.tenant=public
pulsar.auto-start=true
pulsar.allow-interceptor=false#Token based
pulsar.token-auth-value=43th4398gh340gf34gj349gh304ghryj34fh#Consumer
pulsar.consumer.default.dead-letter-policy-max-redeliver-count=-1
pulsar.consumer.default.ack-timeout-ms=30005.错误处理
@Service
public class PulsarErrorHandler {@Autowiredprivate ConsumerAggregator aggregator;@EventListener(ApplicationReadyEvent.class)public void pulsarErrorHandler() {aggregator.onError(failedMessage ->failedMessage.getException().printStackTrace());}
}6.自定义拦截器
pulsar.allow-interceptor=true
Consumer Interceptor Example:
@Component
public class PulsarConsumerInterceptor extends DefaultConsumerInterceptor<Object> {@Overridepublic Message beforeConsume(Consumer<Object> consumer, Message message) {System.out.println("do something");return super.beforeConsume(consumer, message);}
}Producer Interceptor Example:
@Component
public class PulsarProducerInterceptor extends DefaultProducerInterceptor {@Overridepublic Message beforeSend(Producer producer, Message message) {super.beforeSend(producer, message);System.out.println("do something");return message;}@Overridepublic void onSendAcknowledgement(Producer producer, Message message, MessageId msgId, Throwable exception) {super.onSendAcknowledgement(producer, message, msgId, exception);}
}五、常见Q&A
1. 消费者消费不了消息,抛的异常和schema相关
检查消费者的schema和topic生产者的schema是否一致,如果不配置schema默认是byte[]字节流
Schema在new生产者或消费者的时候配置,例如下列demo
Producer<byte[]> producer = pulsarClient.newProducer() // 默认byte[]
Consumer<byte[]> consumer = client.newConsumer(Schema.BYTES) Producer<User> producer = client.newProducer(JSONSchema.of(User.class)) // schema为json
Consumer<User> consumer = client.newConsumer(JSONSchema.of(User.class))2. 怎么确定pulsar消息生产成功
用消费者尝试从earliest开始消费,看是否能消费出消息
相关文章:
Apache Pulsar 从入门到精通
一、快速入门 Pulsar 是一个分布式发布-订阅消息平台,具有非常灵活的消息模型和直观的客户端 API。 最初由 Yahoo 开发,在 2016 年开源,并于2018年9月毕业成为 Apache 基金会的顶级项目。Pulsar 已经在 Yahoo 的生产环境使用了三年多&#…...

[Bug]使用duckduckgo的duckduckgo_search API搜索图片出现了错误
现在在kaggle上学习一个课程,第一课主要是识别图片里面是不是鸟🐦。其中一步是使用duckduckgo 搜索图片,源码: from duckduckgo_search import ddg_images from fastcore.all import * from fastbook import search_images_ddgde…...

线程池若干问题
线程池中线程异常后,销毁还是复用? 线程池在提交任务前,可以提前创建线程吗? 线程池中线程异常后,销毁还是复用? 直接说结论,需要分两种情况: 使用execute()提交任务:…...
k8s+RabbitMQ单机部署
1 k8s 配置文件yaml: apiVersion: apps/v1 kind: Deployment metadata:name: rabbitmq-deploynamespace: rz-dt spec:replicas: 1selector:matchLabels:app: rabbitmqtemplate:metadata:labels:app: rabbitmqspec:containers:- name: rabbitmqimage: "rz-dt-image-server…...

github.com/therecipe/qt windows中安装
github.com/therecipe/qt windows中安装 a.准备好源码,解压到go/src/github.com/therecipe/qtwin下 b.设置cmd环境变量: set QT_DIRM:\work\tool\Qt5.14.2\5.14.2\mingw73_64 set QT_VERSION5.14.2 set QT_API5.13.0 set QT_QMAKE_DIRM:\work\tool\Qt5.14.2\5.14.2\mingw73_64\…...

LogicFlow 学习笔记——11. 对齐线 和 键盘快捷键
对齐线 Snapline 对齐线能够在节点移动过程中,将移动节点的位置与画布中其他节点位置进行对比,辅助位置调整。位置对比有如下两个方面。 节点中心位置节点的边框 对齐线使用 普通编辑模式下,默认开启对齐线,也可通过配置进行关…...
FastWeb - Lua开源跨平台网站开发服务
在网站开发领域,大家都熟知PHPStudy和宝塔这两款广受欢迎的工具,但今天我要介绍的是一款功能强大、支持跨平台的开源Lua网站开发服务——Fast Web,以及与之配套的网站管理器。 Fast Web简介 Fast Web是一款基于Lua编写的网站开发框架&#…...

原子阿波罗STM32F767程序的控制器改为STM32F407驱动LCD屏
由于手里没有原子大神的F429开发板,又还想学习原子大神的F429开发板程序,前几天,经过更换控制器,成功把原子大神的F429开发板程序用到了F407开发板上,驱动LCD屏显示成功,目的,就是熟悉原子大神的…...

04-jQuery工具函数及 jQuery 插件
1. jQuery工具函数 在jQuery中,工具函数是指直接依附于jQuery对象,针对jQuery对象本身定义的方法,即全局性的,我们统称为工具函数,或Utilites函数。 主要作用于:字符串、数组、对象。 调用格式: $.函数名()或jQuery.函数名() 1.1 $.get() 通过远程 HTTP GET 请…...

基于Python的花卉识别分类系统【W9】
简介: 基于Python的花卉识别分类系统利用深度学习和计算机视觉技术,能够准确识别和分类各种花卉,如玫瑰、郁金香和向日葵等。这种系统不仅有助于植物学研究和园艺管理,还在生态保护、智能农业和市场销售等领域展现广泛应用前景。随…...

Visual Studio Code 配置教程,手把手教你如何配置
文章目录 引言1. 安装 VS Code1.1 下载和安装1.2 初次启动 2. 基本配置2.1 设置用户和工作区配置2.2 常用配置项 3. 安装和配置扩展插件3.1 安装扩展3.2 推荐扩展3.3 配置扩展 4. 主题和配色方案4.1 安装主题4.2 切换主题4.3 自定义配色方案 5. 版本控制集成5.1 配置 Git5.2 Gi…...

教案:Horovod v0.2 介绍与使用
课程目标 了解Horovod的主要功能和优势。学习如何安装和配置Horovod。掌握Horovod在分布式训练中的应用。 教学内容 Horovod的简介和动机 动机 使单GPU训练脚本轻松扩展到多GPU训练。尽量减少代码修改以实现分布式训练。内部采用MPI模型,代码变动较少,…...

深入探索Spring Boot:原理与实践
Spring Boot作为一个简化Spring应用开发的框架,近年来在Java开发者中备受推崇。它通过提供默认配置、自动化配置和一系列开箱即用的功能,极大地简化了应用程序的开发和部署过程。在本篇文章中,我们将深入探讨Spring Boot的工作原理࿰…...
基于SSM框架的电影院售票网站
开头语: 你好呀,我是计算机学长猫哥!如果您对我们的电影院售票网站感兴趣或者有相关需求,欢迎通过文末的联系方式与我联系。 开发语言:Java 数据库:MySQL 技术:SSM框架 工具:ID…...

oracle发送http请求
UTL_HTTP包让SQL和PLSQL能够调用超文本传输协议(HTTP),也就是说可以使用它在Internet上访问数据。 当包用HTTPS从Web site获取数据时,要使用Oracle Wallet,它是由Oracle Wallet Manager或者orapki utility创建。非HTT…...

软件回归测试:策略及案例分析
软件回归测试:策略及案例分析 回归测试的定义回归测试的执行阶段回归测试的种类回归测试的策略结论 回归测试的定义 回归测试是一种质量保障措施,其主要目的是验证在进行修改、增加新功能或修复错误后,系统的原有功能仍然能够正常工作&#…...

openstack搭建
openstack搭建 1、虚拟机部署规划 主机主机名IP规划实例通讯内部通讯控制节点controller192.168.10.144192.168.1.144实例节点compute192.168.10.145192.168.1.145 2、硬件配置 主机名内存逻辑CPU数量硬盘容量controller4G480Gcompute4G480G20G 3、安装centos7,…...

HIVE及SparkSQL优化经验
简介 针对高耗跑批时间长的作业,在公司近3个月做过一个优化专项;优化成效:综合cpu、内存、跑批耗时减少均在65%以上; cpu和内存消耗指的是:vcoreseconds和memoryseconds 这里简单说下优化的一些思路,至于…...

Django 5 Web应用开发实战
文章目录 一、内容简介二、目录内容三、值得一读四、适读人群 一、内容简介 《Django 5 Web应用开发实战》集Django架站基础、项目实践、开发经验于一体,是一本从零基础到精通Django Web企业级开发技术的实战指南。《Django 5 Web应用开发实战》内容以Python 3.x和…...
)
互联网摸鱼日报(2024-06-17)
互联网摸鱼日报(2024-06-17) 36氪新闻 本周双碳大事:历年最大规模SNEC人气火热;首批CCER审定与核查机构名单出炉;特斯拉储能业务年增长率将达200%至300% 烧光百亿,离奇破产!顶级天才,让广东损失惨重 奥特…...

Docker部署Ollama模型
技术背景 前面写过几篇关于DeepSeek大模型的本地部署以及本地Docker部署OpenClaw的教程。但是这里边的Ollama都是直接部署在裸机上的,图个方便,想来还是不妥,于是补充本文,基于Ubuntu Linux的Docker环境中部署Ollama模型的方法。 …...

comsol18650圆柱形电池组流体直冷热管理仿真 采用电化学-热-流场耦合/集总电池-流场...
comsol18650圆柱形电池组流体直冷热管理仿真 采用电化学-热-流场耦合/集总电池-流场耦合仿真模型 模拟电池组在充放电工况下,湍流流体介质直冷的散热模式下电池的电性能,热参数变化「这年头搞电池热管理,谁还没被18650的散热问题卡过脖子&…...

技术经理必修管理知识:从管理到领导——高阶技术管理者的自我修养
08-技术经理必修管理知识:从管理到领导——高阶技术管理者的自我修养管理者正确地做事,领导者做正确的事。管理的终点是效率,领导的起点是方向。当你开始思考"我们该往哪里走"而不是"我们该怎么走快一点",你就…...

AI画家助手:OpenClaw+GLM-4.7-Flash自动生成Midjourney提示词并管理作品
AI画家助手:OpenClawGLM-4.7-Flash自动生成Midjourney提示词并管理作品 1. 为什么需要AI画家助手? 去年我开始尝试用Midjourney进行艺术创作时,遇到了两个头疼的问题:一是提示词(prompt)优化需要反复调试…...
)
OpenBMC开发环境搭建:从VirtualBox到QEMU的完整流程(Romulus平台实测)
OpenBMC开发环境搭建:从VirtualBox到QEMU的完整流程(Romulus平台实测) 在服务器管理和数据中心运维领域,OpenBMC作为开源基板管理控制器解决方案,正逐渐成为企业级硬件管理的首选。本文将手把手带你完成从零开始搭建Op…...

Android密钥认证踩坑实录:GtsGoogleAttestationHostTestCases模块fail排查指南
Android密钥认证深度排错指南:从GtsGoogleAttestationHostTestCases失败到系统级修复 当你深夜盯着CI系统里那片刺眼的红色——GtsGoogleAttestationHostTestCases模块测试失败时,作为Android系统工程师的你是否感到一阵窒息?这不仅仅是又一个…...

NE555定时器电路设计:从LED闪烁到电机调速的5个实用项目
NE555定时器电路设计:从LED闪烁到电机调速的5个实用项目 在电子设计的世界里,NE555就像是一把瑞士军刀——小巧、多功能且无处不在。这款诞生于1971年的定时器芯片,至今仍然是电子爱好者和工程师们的最爱。它价格低廉、使用简单,却…...

避开这3个坑!Zynq PS与PL通过BRAM通信时,你的AXI配置可能错了
Zynq PS与PL通过BRAM通信的三大AXI配置陷阱与实战解决方案 在嵌入式系统开发中,Zynq系列芯片的PS(Processing System)与PL(Programmable Logic)之间的高效数据交互是许多项目的核心需求。BRAM(Block RAM&am…...

微搭低代码MBA 培训管理系统实战 19——教务管理:从订单到课时卡的自动转化
目录前情回顾一、 数据源设计1.1 学员档案表 (MBA_StudentProfiles)1.2 课时卡表 (MBA_LearningCards)二 创建管理页面2.1 搭建财务布局2.2 搭建待支付列表页面2.3 搭建确认支付弹窗2.4 自动化开课三 配置门户数据最终效果总结前情回顾 上一篇中我们讲解了销售在订单成交后&am…...

接口频繁变化时,Flutter 项目如何保证稳定性?
子玥酱 (掘金 / 知乎 / CSDN / 简书 同名) 大家好,我是 子玥酱,一名长期深耕在一线的前端程序媛 👩💻。曾就职于多家知名互联网大厂,目前在某国企负责前端软件研发相关工作,主要聚…...