MYSQL 三、mysql基础知识 7(MySQL8其它新特性)
一、mysql8新特性概述
MySQL从5.7版本直接跳跃发布了8.0版本 ,可见这是一个令人兴奋的里程碑版本。MySQL 8版本在功能上 做了显著的改进与增强,开发者对MySQL的源代码进行了重构,最突出的一点是多MySQL Optimizer优化器进行了改进。不仅在速度上得到了改善,还为用户带来了更好的性能和更棒的体验。
1.1 MySQL8.0 新增特性
1. 更简便的NoSQL支持 NoSQL泛指非关系型数据库和数据存储。随着互联网平台的规模飞速发展,传统的关系型数据库已经越来越不能满足需求。从5.6版本开始,MySQL就开始支持简单的NoSQL存储功能。MySQL 8对这一功能做了优化,以更灵活的方式实现NoSQL功能,不再依赖模式(schema)。
2. 更好的索引 在查询中,正确地使用索引可以提高查询的效率。MySQL 8中新增了 隐藏索引 和 降序索引 。隐藏索引可以用来测试去掉索引对查询性能的影响。在查询中混合存在多列索引时,使用降序索引可以提高查询的性能。
3.更完善的JSON支持 MySQL从5.7开始支持原生JSON数据的存储,MySQL 8对这一功能做了优化,增加了聚合函数 JSON_ARRAYAGG() 和 JSON_OBJECTAGG() ,将参数聚合为JSON数组或对象,新增了行内操作符 ->>,是列路径运算符 ->的增强,对JSON排序做了提升,并优化了JSON的更新操作。
4.安全和账户管理 MySQL 8中新增了 caching_sha2_password 授权插件、角色、密码历史记录和FIPS模式支持,这些特性提高了数据库的安全性和性能,使数据库管理员能够更灵活地进行账户管理工作。
5.InnoDB的变化 InnoDB是MySQL默认的存储引擎 ,是事务型数据库的首选引擎,支持事务安全表(ACID),支持行锁定和外键。在MySQL 8 版本中,InnoDB在自增、索引、加密、死锁、共享锁等方面做了大量的 改进和优化 ,并且支持原子数据定义语言(DDL),提高了数据安全性,对事务提供更好的支持。
6.数据字典 在之前的MySQL版本中,字典数据都存储在元数据文件和非事务表中。从MySQL 8开始新增了事务数据字典,在这个字典里存储着数据库对象信息,这些数据字典存储在内部事务表中。
7. 原子数据定义语句 MySQL 8开始支持原子数据定义语句(Automic DDL),即 原子DDL 。目前,只有InnoDB存储引擎支持原子DDL。原子数据定义语句(DDL)将与DDL操作相关的数据字典更新、存储引擎操作、二进制日志写入结合到一个单独的原子事务中,这使得即使服务器崩溃,事务也会提交或回滚。 使用支持原子操作的存储引擎所创建的表,在执行DROP TABLE、CREATE TABLE、ALTER TABLE、RENAME TABLE、TRUNCATE TABLE、CREATE TABLESPACE、DROP TABLESPACE等操作时,都支持原子操 作,即事务要么完全操作成功,要么失败后回滚,不再进行部分提交。 对于从MySQL 5.7复制到MySQL 8版本中的语句,可以添加 IF EXISTS 或 IF NOT EXISTS 语句来避免发生错误。
8.资源管理 MySQL 8开始支持创建和管理资源组,允许将服务器内运行的线程分配给特定的分组,以便 线程根据组内可用资源执行。组属性能够控制组内资源,启用或限制组内资源消耗。数据库管理员能够 根据不同的工作负载适当地更改这些属性。 目前,CPU时间是可控资源,由“虚拟CPU”这个概念来表 示,此术语包含CPU的核心数,超线程,硬件线程等等。服务器在启动时确定可用的虚拟CPU数量。拥有 对应权限的数据库管理员可以将这些CPU与资源组关联,并为资源组分配线程。 资源组组件为MySQL中的资源组管理提供了SQL接口。资源组的属性用于定义资源组。MySQL中存在两个默认组,系统组和用户 组,默认的组不能被删除,其属性也不能被更改。对于用户自定义的组,资源组创建时可初始化所有的属性,除去名字和类型,其他属性都可在创建之后进行更改。 在一些平台下,或进行了某些MySQL的配置时,资源管理的功能将受到限制,甚至不可用。例如,如果安装了线程池插件,或者使用的是macOS系统,资源管理将处于不可用状态。在FreeBSD和Solaris系统中,资源线程优先级将失效。在Linux系统中,只有配置了CAP_SYS_NICE属性,资源管理优先级才能发挥作用。
9.字符集支持 MySQL 8中默认的字符集由 latin1 更改为 utf8mb4 ,并首次增加了日语所特定使用的集 合,utf8mb4_ja_0900_as_cs。
10.优化器增强 MySQL优化器开始支持隐藏索引和降序索引。隐藏索引不会被优化器使用,验证索引的必 要性时不需要删除索引,先将索引隐藏,如果优化器性能无影响就可以真正地删除索引。降序索引允许优化器对多个列进行排序,并且允许排序顺序不一致。
11.公用表表达式 公用表表达式(Common Table Expressions)简称为CTE,MySQL现在支持递归和非递 归两种形式的CTE。CTE通过在SELECT语句或其他特定语句前 使用WITH语句对临时结果集 进行命名。
基础语法如下:
WITH cte_name (col_name1,col_name2 ...) AS (Subquery)SELECT * FROM cte_name;

1.2 MySQL8.0移除的旧特性
二、新特性1:窗口函数
2.1 使用窗口函数前后对比
# 假设我现在有这样一个数据表,它显示了某购物网站在每个城市每个区的销售额:
CREATE TABLE sales(id INT PRIMARY KEY AUTO_INCREMENT,city VARCHAR(15),county VARCHAR(15),sales_value DECIMAL
);INSERT INTO sales(city,county,sales_value)
VALUES
('北京','海淀',10.00),
('北京','朝阳',20.00),
('上海','黄埔',30.00),
('上海','长宁',10.00);# 查询:
mysql> SELECT * FROM sales;
+----+------+--------+-------------+
| id | city | county | sales_value |
+----+------+--------+-------------+
| 1 | 北京 | 海淀 | 10 |
| 2 | 北京 | 朝阳 | 20 |
| 3 | 上海 | 黄埔 | 30 |
| 4 | 上海 | 长宁 | 10 |
+----+------+--------+-------------+
4 rows in set (0.00 sec)# 需求:现在计算这个网站在每个城市的销售总额、在全国的销售总额、每个区的销售额占所在城市销售
额中的比率,以及占总销售额中的比率。# 如果用分组和聚合函数,就需要分好几步来计算。
# 第一步,计算总销售金额,并存入临时表 a:
CREATE TEMPORARY TABLE a -- 创建临时表
SELECT SUM(sales_value) AS sales_value -- 计算总计金额
FROM sales;# 查看一下临时表 a :
mysql> SELECT * FROM a;
+-------------+
| sales_value |
+-------------+
| 70 |
+-------------+
1 row in set (0.00 sec)# 第二步,计算每个城市的销售总额并存入临时表 b:
CREATE TEMPORARY TABLE b -- 创建临时表
SELECT city,SUM(sales_value) AS sales_value -- 计算城市销售合计
FROM sales
GROUP BY city;# 查看临时表 b :
mysql> SELECT * FROM b;
+------+-------------+
| city | sales_value |
+------+-------------+
| 北京 | 30 |
| 上海 | 40 |
+------+-------------+
2 rows in set (0.00 sec)# 第三步,计算各区的销售占所在城市的总计金额的比例,和占全部销售总计金额的比例。我们可以通过
下面的连接查询获得需要的结果:mysql> SELECT s.city AS 城市,s.county AS 区,s.sales_value AS 区销售额,
-> b.sales_value AS 市销售额,s.sales_value/b.sales_value AS 市比率,
-> a.sales_value AS 总销售额,s.sales_value/a.sales_value AS 总比率
-> FROM sales s
-> JOIN b ON (s.city=b.city) -- 连接市统计结果临时表
-> JOIN a -- 连接总计金额临时表
-> ORDER BY s.city,s.county;
+------+------+----------+----------+--------+----------+--------+
| 城市 | 区 | 区销售额 | 市销售额 | 市比率 | 总销售额 | 总比率 |
+------+------+----------+----------+--------+----------+--------+
| 上海 | 长宁 | 10 | 40 | 0.2500 | 70 | 0.1429 |
| 上海 | 黄埔 | 30 | 40 | 0.7500 | 70 | 0.4286 |
| 北京 | 朝阳 | 20 | 30 | 0.6667 | 70 | 0.2857 |
| 北京 | 海淀 | 10 | 30 | 0.3333 | 70 | 0.1429 |
+------+------+----------+----------+--------+----------+--------+
4 rows in set (0.00 sec)#结果显示:市销售金额、市销售占比、总销售金额、总销售占比都计算出来了。#同样的查询,如果用窗口函数,就简单多了。我们可以用下面的代码来实现:mysql> SELECT city AS 城市,county AS 区,sales_value AS 区销售额,
-> SUM(sales_value) OVER(PARTITION BY city) AS 市销售额, -- 计算市销售额
-> sales_value/SUM(sales_value) OVER(PARTITION BY city) AS 市比率,
-> SUM(sales_value) OVER() AS 总销售额, -- 计算总销售额
-> sales_value/SUM(sales_value) OVER() AS 总比率
-> FROM sales
-> ORDER BY city,county;
+------+------+----------+----------+--------+----------+--------+
| 城市 | 区 | 区销售额 | 市销售额 | 市比率 | 总销售额 | 总比率 |
+------+------+----------+----------+--------+----------+--------+
| 上海 | 长宁 | 10 | 40 | 0.2500 | 70 | 0.1429 |
| 上海 | 黄埔 | 30 | 40 | 0.7500 | 70 | 0.4286 |
| 北京 | 朝阳 | 20 | 30 | 0.6667 | 70 | 0.2857 |
| 北京 | 海淀 | 10 | 30 | 0.3333 | 70 | 0.1429 |
+------+------+----------+-----------+--------+----------+--------+
4 rows in set (0.00 sec)# 结果显示,我们得到了与上面那种查询同样的结果。
# 使用窗口函数,只用了一步就完成了查询。而且,由于没有用到临时表,执行的效率也更高了。很显
然,在这种需要用到分组统计的结果对每一条记录进行计算的场景下,使用窗口函数更好。2.2 窗口函数分类
MySQL从8.0版本开始支持窗口函数。窗口函数的作用类似于在查询中对数据进行分组,不同的是,分组操作会把分组的结果聚合成一条记录,而窗口函数是将结果置于每一条数据记录中。
- 静态窗口:函数的窗口大小是固定的,不会因为记录的不同而不同;
- 动态窗口:函数的窗口大小会随着记录的不同而变化
MySQL官方网站窗口函数的网址为https://dev.mysql.com/doc/refman/8.0/en/window-function-descriptions.html#function_row-number。
| 函数分类 | 函数 | 函数说明 |
| 序号函数 | ROW_NUMBER() | 顺序排序 |
| RANK() | 并列排序,会跳过重复的序号,比如序号1、1、3 | |
| DENSE_RANK() | 并列排序,不会跳过重复的序号,比如序号为1、1、2 | |
| 分布函数 | PERCENT_RANK() | 等值百分比 |
| CUME_DIST() | 累积分布值 | |
| 前后函数 | LAG(expr,n) | 返回当前行的前n行的expr的值 |
| LEAD(expr,n) | 返回当前行的后n行的expr的值 | |
| 首位函数 | FIRST_VALUE(expr) | 返回第一个expr的值 |
| LAST_VALUE(expr) | 返回最后一个expr的值 | |
| 其他函数 | NTH_VALUE(expr,n) | 返回第n个expr的值 |
| NTILE(n) | 将分区中的有序数据分为n个桶,记录桶编号 |
2.3 语法结构
窗口函数的语法结构是:
函数 OVER ( [ PARTITION BY 字段名 ORDER BY 字段名 ASC | DESC ] )
函数 OVER 窗口名 … WINDOW 窗口名 AS ( [ PARTITION BY 字段名 ORDER BY 字段名 ASC | DESC ] )
- OVER 关键字指定函数窗口的范围。
- 如果省略后面括号中的内容,则窗口会包含满足WHERE条件的所有记录,窗口函数会基于所有满足WHERE条件的记录进行计算。
- 如果OVER关键字后面的括号不为空,则可以使用如下语法设置窗口。
- 窗口名:为窗口设置一个别名,用来标识窗口。
- PARTITION BY子句:指定窗口函数按照哪些字段进行分组。分组后,窗口函数可以在每个分组中分别执行。
- ORDER BY子句:指定窗口函数按照哪些字段进行排序。执行排序操作使窗口函数按照排序后的数据记录的顺序进行编号。
- FRAME子句:为分区中的某个子集定义规则,可以用来作为滑动窗口使用。
2.4 分类讲解
# 创建表:
CREATE TABLE goods(id INT PRIMARY KEY AUTO_INCREMENT,category_id INT,category VARCHAR(15),NAME VARCHAR(30),price DECIMAL(10,2),stock INT,upper_time DATETIME
);# 添加数据:
INSERT INTO goods(category_id,category,NAME,price,stock,upper_time)
VALUES
(1, '女装/女士精品', 'T恤', 39.90, 1000, '2020-11-10 00:00:00'),
(1, '女装/女士精品', '连衣裙', 79.90, 2500, '2020-11-10 00:00:00'),
(1, '女装/女士精品', '卫衣', 89.90, 1500, '2020-11-10 00:00:00'),
(1, '女装/女士精品', '牛仔裤', 89.90, 3500, '2020-11-10 00:00:00'),
(1, '女装/女士精品', '百褶裙', 29.90, 500, '2020-11-10 00:00:00'),
(1, '女装/女士精品', '呢绒外套', 399.90, 1200, '2020-11-10 00:00:00'),
(2, '户外运动', '自行车', 399.90, 1000, '2020-11-10 00:00:00'),
(2, '户外运动', '山地自行车', 1399.90, 2500, '2020-11-10 00:00:00'),
(2, '户外运动', '登山杖', 59.90, 1500, '2020-11-10 00:00:00'),
(2, '户外运动', '骑行装备', 399.90, 3500, '2020-11-10 00:00:00'),
(2, '户外运动', '运动外套', 799.90, 500, '2020-11-10 00:00:00'),
(2, '户外运动', '滑板', 499.90, 1200, '2020-11-10 00:00:00');# 1. 序号函数# 1.ROW_NUMBER()函数
# ROW_NUMBER()函数能够对数据中的序号进行顺序显示。
# 举例:查询 goods 数据表中每个商品分类下价格降序排列的各个商品信息。mysql> SELECT ROW_NUMBER() OVER(PARTITION BY category_id ORDER BY price DESC) AS
row_num,
-> id, category_id, category, NAME, price, stock
-> FROM goods;
+---------+----+-------------+---------------+------------+---------+-------+
| row_num | id | category_id | category | NAME | price | stock |
+---------+----+-------------+---------------+------------+---------+-------+
| 1 | 6 | 1 | 女装/女士精品 | 呢绒外套 | 399.90 | 1200 |
| 2 | 3 | 1 | 女装/女士精品 | 卫衣 | 89.90 | 1500 |
| 3 | 4 | 1 | 女装/女士精品 | 牛仔裤 | 89.90 | 3500 |
| 4 | 2 | 1 | 女装/女士精品 | 连衣裙 | 79.90 | 2500 |
| 5 | 1 | 1 | 女装/女士精品 | T恤 | 39.90 | 1000 |
| 6 | 5 | 1 | 女装/女士精品 | 百褶裙 | 29.90 | 500 |
| 1 | 8 | 2 | 户外运动 | 山地自行车 | 1399.90 | 2500 |
| 2 | 11 | 2 | 户外运动 | 运动外套 | 799.90 | 500 |
| 3 | 12 | 2 | 户外运动 | 滑板 | 499.90 | 1200 |
| 4 | 7 | 2 | 户外运动 | 自行车 | 399.90 | 1000 |
| 5 | 10 | 2 | 户外运动 | 骑行装备 | 399.90 | 3500 |
| 6 | 9 | 2 | 户外运动 | 登山杖 | 59.90 | 1500 |
+---------+----+-------------+---------------+------------+---------+-------+
12 rows in set (0.00 sec)# 举例:查询 goods 数据表中每个商品分类下价格最高的3种商品信息。mysql> SELECT *
-> FROM (
-> SELECT ROW_NUMBER() OVER(PARTITION BY category_id ORDER BY price DESC) AS
row_num,
-> id, category_id, category, NAME, price, stock
-> FROM goods) t
-> WHERE row_num <= 3;
+---------+----+-------------+---------------+------------+---------+-------+
| row_num | id | category_id | category | NAME | price | stock |
+---------+----+-------------+---------------+------------+---------+-------+
| 1 | 6 | 1 | 女装/女士精品 | 呢绒外套 | 399.90 | 1200 |
| 2 | 3 | 1 | 女装/女士精品 | 卫衣 | 89.90 | 1500 |
| 3 | 4 | 1 | 女装/女士精品 | 牛仔裤 | 89.90 | 3500 |
| 1 | 8 | 2 | 户外运动 | 山地自行车 | 1399.90 | 2500 |
| 2 | 11 | 2 | 户外运动 | 运动外套 | 799.90 | 500 |
| 3 | 12 | 2 | 户外运动 | 滑板 | 499.90 | 1200 |
+---------+----+-------------+---------------+------------+----------+-------+
6 rows in set (0.00 sec)# 在名称为“女装/女士精品”的商品类别中,有两款商品的价格为89.90元,分别是卫衣和牛仔裤。两款商品
的序号都应该为2,而不是一个为2,另一个为3。此时,可以使用RANK()函数和DENSE_RANK()函数解
决。# 2.RANK()函数
# 使用RANK()函数能够对序号进行并列排序,并且会跳过重复的序号,比如序号为1、1、3。
# 举例:使用RANK()函数获取 goods 数据表中各类别的价格从高到低排序的各商品信息。mysql> SELECT RANK() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num,
-> id, category_id, category, NAME, price, stock
-> FROM goods;
+---------+----+-------------+---------------+------------+---------+-------+
| row_num | id | category_id | category | NAME | price | stock |
+---------+----+-------------+---------------+------------+---------+-------+
| 1 | 6 | 1 | 女装/女士精品 | 呢绒外套 | 399.90 | 1200 |
| 2 | 3 | 1 | 女装/女士精品 | 卫衣 | 89.90 | 1500 |
| 2 | 4 | 1 | 女装/女士精品 | 牛仔裤 | 89.90 | 3500 |
| 4 | 2 | 1 | 女装/女士精品 | 连衣裙 | 79.90 | 2500 |
| 5 | 1 | 1 | 女装/女士精品 | T恤 | 39.90 | 1000 |
| 6 | 5 | 1 | 女装/女士精品 | 百褶裙 | 29.90 | 500 |
| 1 | 8 | 2 | 户外运动 | 山地自行车 | 1399.90 | 2500 |
| 2 | 11 | 2 | 户外运动 | 运动外套 | 799.90 | 500 |
| 3 | 12 | 2 | 户外运动 | 滑板 | 499.90 | 1200 |
| 4 | 7 | 2 | 户外运动 | 自行车 | 399.90 | 1000 |
| 4 | 10 | 2 | 户外运动 | 骑行装备 | 399.90 | 3500 |
| 6 | 9 | 2 | 户外运动 | 登山杖 | 59.90 | 1500 |
+---------+----+-------------+---------------+------------+---------+-------+
12 rows in set (0.00 sec)# 举例:使用RANK()函数获取 goods 数据表中类别为“女装/女士精品”的价格最高的4款商品信息。mysql> SELECT *
-> FROM(
-> SELECT RANK() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num,
-> id, category_id, category, NAME, price, stock
-> FROM goods) t
-> WHERE category_id = 1 AND row_num <= 4;
+---------+----+-------------+---------------+----------+--------+-------+
| row_num | id | category_id | category | NAME | price | stock |
+---------+----+-------------+---------------+----------+--------+-------+
| 1 | 6 | 1 | 女装/女士精品 | 呢绒外套 | 399.90 | 1200 |
| 2 | 3 | 1 | 女装/女士精品 | 卫衣 | 89.90 | 1500 |
| 2 | 4 | 1 | 女装/女士精品 | 牛仔裤 | 89.90 | 3500 |
| 4 | 2 | 1 | 女装/女士精品 | 连衣裙 | 79.90 | 2500 |
+---------+----+-------------+---------------+----------+--------+-------+
4 rows in set (0.00 sec)# 可以看到,使用RANK()函数得出的序号为1、2、2、4,相同价格的商品序号相同,后面的商品序号是不
连续的,跳过了重复的序号。# 3.DENSE_RANK()函数
DENSE_RANK()函数对序号进行并列排序,并且不会跳过重复的序号,比如序号为1、1、2。
举例:使用DENSE_RANK()函数获取 goods 数据表中各类别的价格从高到低排序的各商品信息。
mysql> SELECT DENSE_RANK() OVER(PARTITION BY category_id ORDER BY price DESC) AS
row_num,
-> id, category_id, category, NAME, price, stock
-> FROM goods;
+---------+----+-------------+---------------+------------+---------+-------+
| row_num | id | category_id | category | NAME | price | stock |
+---------+----+-------------+---------------+------------+---------+-------+
| 1 | 6 | 1 | 女装/女士精品 | 呢绒外套 | 399.90 | 1200 |
| 2 | 3 | 1 | 女装/女士精品 | 卫衣 | 89.90 | 1500 |
| 2 | 4 | 1 | 女装/女士精品 | 牛仔裤 | 89.90 | 3500 |
| 3 | 2 | 1 | 女装/女士精品 | 连衣裙 | 79.90 | 2500 |
| 4 | 1 | 1 | 女装/女士精品 | T恤 | 39.90 | 1000 |
| 5 | 5 | 1 | 女装/女士精品 | 百褶裙 | 29.90 | 500 |
| 1 | 8 | 2 | 户外运动 | 山地自行车 | 1399.90 | 2500 |
| 2 | 11 | 2 | 户外运动 | 运动外套 | 799.90 | 500 |
| 3 | 12 | 2 | 户外运动 | 滑板 | 499.90 | 1200 |
| 4 | 7 | 2 | 户外运动 | 自行车 | 399.90 | 1000 |
| 4 | 10 | 2 | 户外运动 | 骑行装备 | 399.90 | 3500 |
| 5 | 9 | 2 | 户外运动 | 登山杖 | 59.90 | 1500 |
+---------+----+-------------+---------------+------------+---------+-------+
12 rows in set (0.00 sec)# 举例:使用DENSE_RANK()函数获取 goods 数据表中类别为“女装/女士精品”的价格最高的4款商品信息。mysql> SELECT *
-> FROM(
-> SELECT DENSE_RANK() OVER(PARTITION BY category_id ORDER BY price DESC) AS
row_num,
-> id, category_id, category, NAME, price, stock
-> FROM goods) t
-> WHERE category_id = 1 AND row_num <= 3;
+---------+----+-------------+---------------+----------+--------+-------+
| row_num | id | category_id | category | NAME | price | stock |
+---------+----+-------------+---------------+----------+--------+-------+
| 1 | 6 | 1 | 女装/女士精品 | 呢绒外套 | 399.90 | 1200 |
| 2 | 3 | 1 | 女装/女士精品 | 卫衣 | 89.90 | 1500 |
| 2 | 4 | 1 | 女装/女士精品 | 牛仔裤 | 89.90 | 3500 |
| 3 | 2 | 1 | 女装/女士精品 | 连衣裙 | 79.90 | 2500 |
+---------+----+-------------+---------------+----------+--------+-------+
4 rows in set (0.00 sec)# 可以看到,使用DENSE_RANK()函数得出的行号为1、2、2、3,相同价格的商品序号相同,后面的商品序
号是连续的,并且没有跳过重复的序号。2. 分布函数
# 1.PERCENT_RANK()函数
# PERCENT_RANK()函数是等级值百分比函数。按照如下方式进行计算。
(rank - 1) / (rows - 1)
# 其中,rank的值为使用RANK()函数产生的序号,rows的值为当前窗口的总记录数。
# 举例:计算 goods 数据表中名称为“女装/女士精品”的类别下的商品的PERCENT_RANK值。#写法一:
SELECT RANK() OVER (PARTITION BY category_id ORDER BY price DESC) AS r,
PERCENT_RANK() OVER (PARTITION BY category_id ORDER BY price DESC) AS pr,
id, category_id, category, NAME, price, stock
FROM goods
WHERE category_id = 1;
#写法二:
mysql> SELECT RANK() OVER w AS r,
-> PERCENT_RANK() OVER w AS pr,
-> id, category_id, category, NAME, price, stock
-> FROM goods
-> WHERE category_id = 1 WINDOW w AS (PARTITION BY category_id ORDER BY price
DESC);
+---+-----+----+-------------+---------------+----------+--------+-------+
| r | pr | id | category_id | category | NAME | price | stock |
+---+-----+----+-------------+---------------+----------+--------+-------+
| 1 | 0 | 6 | 1 | 女装/女士精品 | 呢绒外套 | 399.90 | 1200 |
| 2 | 0.2 | 3 | 1 | 女装/女士精品 | 卫衣 | 89.90 | 1500 |
| 2 | 0.2 | 4 | 1 | 女装/女士精品 | 牛仔裤 | 89.90 | 3500 |
| 4 | 0.6 | 2 | 1 | 女装/女士精品 | 连衣裙 | 79.90 | 2500 |
| 5 | 0.8 | 1 | 1 | 女装/女士精品 | T恤 | 39.90 | 1000 |
| 6 | 1 | 5 | 1 | 女装/女士精品 | 百褶裙 | 29.90 | 500 |
+---+-----+----+-------------+---------------+----------+--------+-------+
6 rows in set (0.00 sec)# 2.CUME_DIST()函数
CUME_DIST()函数主要用于查询小于或等于某个值的比例。
举例:查询goods数据表中小于或等于当前价格的比例。mysql> SELECT CUME_DIST() OVER(PARTITION BY category_id ORDER BY price ASC) AS cd,
-> id, category, NAME, price
-> FROM goods;
+---------------------+----+---------------+------------+---------+
| cd | id | category | NAME | price |
+---------------------+----+---------------+------------+---------+
| 0.16666666666666666 | 5 | 女装/女士精品 | 百褶裙 | 29.90 |
| 0.3333333333333333 | 1 | 女装/女士精品 | T恤 | 39.90 |
| 0.5 | 2 | 女装/女士精品 | 连衣裙 | 79.90 |
| 0.8333333333333334 | 3 | 女装/女士精品 | 卫衣 | 89.90 |
| 0.8333333333333334 | 4 | 女装/女士精品 | 牛仔裤 | 89.90 |
| 1 | 6 | 女装/女士精品 | 呢绒外套 | 399.90 |
| 0.16666666666666666 | 9 | 户外运动 | 登山杖 | 59.90 |
| 0.5 | 7 | 户外运动 | 自行车 | 399.90 |
| 0.5 | 10 | 户外运动 | 骑行装备 | 399.90 |
| 0.6666666666666666 | 12 | 户外运动 | 滑板 | 499.90 |
| 0.8333333333333334 | 11 | 户外运动 | 运动外套 | 799.90 |
| 1 | 8 | 户外运动 | 山地自行车 | 1399.90 |
+---------------------+----+---------------+------------+---------+
12 rows in set (0.00 sec)
3. 前后函数
# 1.LAG(expr,n)函数
LAG(expr,n)函数返回当前行的前n行的expr的值。
举例:查询goods数据表中前一个商品价格与当前商品价格的差值。mysql> SELECT id, category, NAME, price, pre_price, price - pre_price AS diff_price
-> FROM (
-> SELECT id, category, NAME, price,LAG(price,1) OVER w AS pre_price
-> FROM goods
-> WINDOW w AS (PARTITION BY category_id ORDER BY price)) t;
+----+---------------+------------+---------+-----------+------------+
| id | category | NAME | price | pre_price | diff_price |
+----+---------------+------------+---------+-----------+------------+
| 5 | 女装/女士精品 | 百褶裙 | 29.90 | NULL | NULL |
| 1 | 女装/女士精品 | T恤 | 39.90 | 29.90 | 10.00 |
| 2 | 女装/女士精品 | 连衣裙 | 79.90 | 39.90 | 40.00 |
| 3 | 女装/女士精品 | 卫衣 | 89.90 | 79.90 | 10.00 |
| 4 | 女装/女士精品 | 牛仔裤 | 89.90 | 89.90 | 0.00 |
| 6 | 女装/女士精品 | 呢绒外套 | 399.90 | 89.90 | 310.00 |
| 9 | 户外运动 | 登山杖 | 59.90 | NULL | NULL |
| 7 | 户外运动 | 自行车 | 399.90 | 59.90 | 340.00 |
| 10 | 户外运动 | 骑行装备 | 399.90 | 399.90 | 0.00 |
| 12 | 户外运动 | 滑板 | 499.90 | 399.90 | 100.00 |
| 11 | 户外运动 | 运动外套 | 799.90 | 499.90 | 300.00 |
| 8 | 户外运动 | 山地自行车 | 1399.90 | 799.90 | 600.00 |
+----+---------------+------------+---------+-----------+------------+
12 rows in set (0.00 sec)# 2.LEAD(expr,n)函数
LEAD(expr,n)函数返回当前行的后n行的expr的值。
举例:查询goods数据表中后一个商品价格与当前商品价格的差值。mysql> SELECT id, category, NAME, behind_price, price,behind_price - price AS
diff_price
-> FROM(
-> SELECT id, category, NAME, price,LEAD(price, 1) OVER w AS behind_price
-> FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price)) t;
+----+---------------+------------+--------------+---------+------------+
| id | category | NAME | behind_price | price | diff_price |
+----+---------------+------------+--------------+---------+------------+
| 5 | 女装/女士精品 | 百褶裙 | 39.90 | 29.90 | 10.00 |
| 1 | 女装/女士精品 | T恤 | 79.90 | 39.90 | 40.00 |
| 2 | 女装/女士精品 | 连衣裙 | 89.90 | 79.90 | 10.00 |
| 3 | 女装/女士精品 | 卫衣 | 89.90 | 89.90 | 0.00 |
| 4 | 女装/女士精品 | 牛仔裤 | 399.90 | 89.90 | 310.00 |
| 6 | 女装/女士精品 | 呢绒外套 | NULL | 399.90 | NULL |
| 9 | 户外运动 | 登山杖 | 399.90 | 59.90 | 340.00 |
| 7 | 户外运动 | 自行车 | 399.90 | 399.90 | 0.00 |
| 10 | 户外运动 | 骑行装备 | 499.90 | 399.90 | 100.00 |
| 12 | 户外运动 | 滑板 | 799.90 | 499.90 | 300.00 |
| 11 | 户外运动 | 运动外套 | 1399.90 | 799.90 | 600.00 |
| 8 | 户外运动 | 山地自行车 | NULL | 1399.90 | NULL |
+----+---------------+------------+--------------+---------+------------+
12 rows in set (0.00 sec)4. 首尾函数
# 1.FIRST_VALUE(expr)函数
FIRST_VALUE(expr)函数返回第一个expr的值。
举例:按照价格排序,查询第1个商品的价格信息。mysql> SELECT id, category, NAME, price, stock,FIRST_VALUE(price) OVER w AS
first_price
-> FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price);
+----+---------------+------------+---------+-------+-------------+
| id | category | NAME | price | stock | first_price |
+----+---------------+------------+---------+-------+-------------+
| 5 | 女装/女士精品 | 百褶裙 | 29.90 | 500 | 29.90 |
| 1 | 女装/女士精品 | T恤 | 39.90 | 1000 | 29.90 |
| 2 | 女装/女士精品 | 连衣裙 | 79.90 | 2500 | 29.90 |
| 3 | 女装/女士精品 | 卫衣 | 89.90 | 1500 | 29.90 |
| 4 | 女装/女士精品 | 牛仔裤 | 89.90 | 3500 | 29.90 |
| 6 | 女装/女士精品 | 呢绒外套 | 399.90 | 1200 | 29.90 |
| 9 | 户外运动 | 登山杖 | 59.90 | 1500 | 59.90 |
| 7 | 户外运动 | 自行车 | 399.90 | 1000 | 59.90 |
| 10 | 户外运动 | 骑行装备 | 399.90 | 3500 | 59.90 |
| 12 | 户外运动 | 滑板 | 499.90 | 1200 | 59.90 |
| 11 | 户外运动 | 运动外套 | 799.90 | 500 | 59.90 |
| 8 | 户外运动 | 山地自行车 | 1399.90 | 2500 | 59.90 |
+----+---------------+------------+---------+-------+-------------+
12 rows in set (0.00 sec)# 2.LAST_VALUE(expr)函数
LAST_VALUE(expr)函数返回最后一个expr的值。
举例:按照价格排序,查询最后一个商品的价格信息。mysql> SELECT id, category, NAME, price, stock,LAST_VALUE(price) OVER w AS last_price
-> FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price);
+----+---------------+------------+---------+-------+------------+
| id | category | NAME | price | stock | last_price |
+----+---------------+------------+---------+-------+------------+
| 5 | 女装/女士精品 | 百褶裙 | 29.90 | 500 | 29.90 |
| 1 | 女装/女士精品 | T恤 | 39.90 | 1000 | 39.90 |
| 2 | 女装/女士精品 | 连衣裙 | 79.90 | 2500 | 79.90 |
| 3 | 女装/女士精品 | 卫衣 | 89.90 | 1500 | 89.90 |
| 4 | 女装/女士精品 | 牛仔裤 | 89.90 | 3500 | 89.90 |
| 6 | 女装/女士精品 | 呢绒外套 | 399.90 | 1200 | 399.90 |
| 9 | 户外运动 | 登山杖 | 59.90 | 1500 | 59.90 |
| 7 | 户外运动 | 自行车 | 399.90 | 1000 | 399.90 |
| 10 | 户外运动 | 骑行装备 | 399.90 | 3500 | 399.90 |
| 12 | 户外运动 | 滑板 | 499.90 | 1200 | 499.90 |
| 11 | 户外运动 | 运动外套 | 799.90 | 500 | 799.90 |
| 8 | 户外运动 | 山地自行车 | 1399.90 | 2500 | 1399.90 |
+----+---------------+------------+---------+-------+------------+
12 rows in set (0.00 sec)# 1.NTH_VALUE(expr,n)函数
NTH_VALUE(expr,n)函数返回第n个expr的值。
举例:查询goods数据表中排名第2和第3的价格信息。mysql> SELECT id, category, NAME, price,NTH_VALUE(price,2) OVER w AS second_price,
-> NTH_VALUE(price,3) OVER w AS third_price
-> FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price);
+----+---------------+------------+---------+--------------+-------------+
| id | category | NAME | price | second_price | third_price |
+----+---------------+------------+---------+--------------+-------------+
| 5 | 女装/女士精品 | 百褶裙 | 29.90 | NULL | NULL |
| 1 | 女装/女士精品 | T恤 | 39.90 | 39.90 | NULL |
| 2 | 女装/女士精品 | 连衣裙 | 79.90 | 39.90 | 79.90 |
| 3 | 女装/女士精品 | 卫衣 | 89.90 | 39.90 | 79.90 |
| 4 | 女装/女士精品 | 牛仔裤 | 89.90 | 39.90 | 79.90 |
| 6 | 女装/女士精品 | 呢绒外套 | 399.90 | 39.90 | 79.90 |
| 9 | 户外运动 | 登山杖 | 59.90 | NULL | NULL |
| 7 | 户外运动 | 自行车 | 399.90 | 399.90 | 399.90 |
| 10 | 户外运动 | 骑行装备 | 399.90 | 399.90 | 399.90 |
| 12 | 户外运动 | 滑板 | 499.90 | 399.90 | 399.90 |
| 11 | 户外运动 | 运动外套 | 799.90 | 399.90 | 399.90 |
| 8 | 户外运动 | 山地自行车 | 1399.90 | 399.90 | 399.90 |
+----+---------------+------------+---------+--------------+-------------+
12 rows in set (0.00 sec)# 2.NTILE(n)函数
NTILE(n)函数将分区中的有序数据分为n个桶,记录桶编号。
举例:将goods表中的商品按照价格分为3组。mysql> SELECT NTILE(3) OVER w AS nt,id, category, NAME, price
-> FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price);
+----+----+---------------+------------+---------+
| nt | id | category | NAME | price |
+----+----+---------------+------------+---------+
| 1 | 5 | 女装/女士精品 | 百褶裙 | 29.90 |
| 1 | 1 | 女装/女士精品 | T恤 | 39.90 |
| 2 | 2 | 女装/女士精品 | 连衣裙 | 79.90 |
| 2 | 3 | 女装/女士精品 | 卫衣 | 89.90 |
| 3 | 4 | 女装/女士精品 | 牛仔裤 | 89.90 |
| 3 | 6 | 女装/女士精品 | 呢绒外套 | 399.90 |
| 1 | 9 | 户外运动 | 登山杖 | 59.90 |
| 1 | 7 | 户外运动 | 自行车 | 399.90 |
| 2 | 10 | 户外运动 | 骑行装备 | 399.90 |
| 2 | 12 | 户外运动 | 滑板 | 499.90 |
| 3 | 11 | 户外运动 | 运动外套 | 799.90 |
| 3 | 8 | 户外运动 | 山地自行车 | 1399.90 |
+----+----+---------------+------------+---------+
12 rows in set (0.00 sec)2.5 小 结
三、新特性2:公用表表达式
公用表表达式(或通用表表达式)简称为CTE(Common Table Expressions)。CTE是一个命名的临时结 果集,作用范围是当前语句。CTE可以理解成一个可以复用的子查询,当然跟子查询还是有点区别的,CTE可以引用其他CTE,但子查询不能引用其他子查询。所以,可以考虑代替子查询。
依据语法结构和执行方式的不同,公用表表达式分为 普通公用表表达式 和 递归公用表表达式 2 种。
3.1 普通公用表表达式
普通公用表表达式的语法结构是:
WITH CTE 名称AS (子查询)SELECT | DELETE | UPDATE 语句 ;
# 举例:查询员工所在的部门的详细信息。mysql> SELECT * FROM departments
-> WHERE department_id IN (
-> SELECT DISTINCT department_id
-> FROM employees
-> );
+---------------+------------------+------------+-------------+
| department_id | department_name | manager_id | location_id |
+---------------+------------------+------------+-------------+
| 10 | Administration | 200 | 1700 |
| 20 | Marketing | 201 | 1800 |
| 30 | Purchasing | 114 | 1700 |
| 40 | Human Resources | 203 | 2400 |
| 50 | Shipping | 121 | 1500 |
| 60 | IT | 103 | 1400 |
| 70 | Public Relations | 204 | 2700 |
| 80 | Sales | 145 | 2500 |
| 90 | Executive | 100 | 1700 |
| 100 | Finance | 108 | 1700 |
| 110 | Accounting | 205 | 1700 |
+---------------+------------------+------------+-------------+
11 rows in set (0.00 sec)# 这个查询也可以用普通公用表表达式的方式完成:mysql> WITH emp_dept_id
-> AS (SELECT DISTINCT department_id FROM employees)
-> SELECT *
-> FROM departments d JOIN emp_dept_id e
-> ON d.department_id = e.department_id;
+---------------+------------------+------------+-------------+---------------+
| department_id | department_name | manager_id | location_id | department_id |
+---------------+------------------+------------+-------------+---------------+
| 90 | Executive | 100 | 1700 | 90 |
| 60 | IT | 103 | 1400 | 60 |
| 100 | Finance | 108 | 1700 | 100 |
| 30 | Purchasing | 114 | 1700 | 30 |
| 50 | Shipping | 121 | 1500 | 50 |
| 80 | Sales | 145 | 2500 | 80 |
| 10 | Administration | 200 | 1700 | 10 |
| 20 | Marketing | 201 | 1800 | 20 |
| 40 | Human Resources | 203 | 2400 | 40 |
| 70 | Public Relations | 204 | 2700 | 70 |
| 110 | Accounting | 205 | 1700 | 110 |
+---------------+------------------+------------+-------------+---------------+
11 rows in set (0.00 sec)# 例子说明,公用表表达式可以起到子查询的作用。以后如果遇到需要使用子查询的场景,你可以在查询
之前,先定义公用表表达式,然后在查询中用它来代替子查询。而且,跟子查询相比,公用表表达式有
一个优点,就是定义过公用表表达式之后的查询,可以像一个表一样多次引用公用表表达式,而子查询
则不能。
3.2 递归公用表表达式
WITH RECURSIVECTE 名称 AS (子查询)SELECT | DELETE | UPDATE 语句 ;
递归公用表表达式由 2 部分组成,分别是种子查询和递归查询,中间通过关键字 UNION [ALL]进行连接。 这里的种子查询,意思就是获得递归的初始值。这个查询只会运行一次,以创建初始数据集,之后递归 查询会一直执行,直到没有任何新的查询数据产生,递归返回。
递归公用表表达式由 2 部分组成,分别是种子查询和递归查询,中间通过关键字 UNION [ALL]进行连接。这里的种子查询,意思就是获得递归的初始值。这个查询只会运行一次,以创建初始数据集,之后递归查询会一直执行,直到没有任何新的查询数据产生,递归返回。
案例:针对于我们常用的employees表,包含employee_id,last_name和manager_id三个字段。如果a是b 的管理者,那么,我们可以把b叫做a的下属,如果同时b又是c的管理者,那么c就是b的下属,是a的下下属。
下面我们尝试用查询语句列出所有具有下下属身份的人员信息。
如果用我们之前学过的知识来解决,会比较复杂,至少要进行 4 次查询才能搞定:
- 第一步,先找出初代管理者,就是不以任何别人为管理者的人,把结果存入临时表;
- 第二步,找出所有以初代管理者为管理者的人,得到一个下属集,把结果存入临时表;
- 第三步,找出所有以下属为管理者的人,得到一个下下属集,把结果存入临时表。
- 第四步,找出所有以下下属为管理者的人,得到一个结果集。
- 用递归公用表表达式中的种子查询,找出初代管理者。字段 n 表示代次,初始值为 1,表示是第一代管理者。
- 用递归公用表表达式中的递归查询,查出以这个递归公用表表达式中的人为管理者的人,并且代次 的值加 1。直到没有人以这个递归公用表表达式中的人为管理者了,递归返回。
- 在最后的查询中,选出所有代次大于等于 3 的人,他们肯定是第三代及以上代次的下属了,也就是 下下属了。这样就得到了我们需要的结果集。
# 代码实现:
WITH RECURSIVE cte
AS
(
SELECT employee_id,last_name,manager_id,1 AS n FROM employees WHERE employee_id = 100
-- 种子查询,找到第一代领导
UNION ALL
SELECT a.employee_id,a.last_name,a.manager_id,n+1 FROM employees AS a JOIN cte
ON (a.manager_id = cte.employee_id) -- 递归查询,找出以递归公用表表达式的人为领导的人
)
SELECT employee_id,last_name FROM cte WHERE n >= 3;# 总之,递归公用表表达式对于查询一个有共同的根节点的树形结构数据,非常有用。它可以不受层级的
限制,轻松查出所有节点的数据。如果用其他的查询方式,就比较复杂了。
3.3 小 结
相关文章:
MYSQL 三、mysql基础知识 7(MySQL8其它新特性)
一、mysql8新特性概述 MySQL从5.7版本直接跳跃发布了8.0版本 ,可见这是一个令人兴奋的里程碑版本。MySQL 8版本在功能上 做了显著的改进与增强,开发者对MySQL的源代码进行了重构,最突出的一点是多MySQL Optimizer优化器进行了改进。不仅在速度…...

git error: does not have a commit checked out fatal: adding files failed
git add net error: net/ does not have a commit checked out fatal: adding files failed这个错误是因为尝试将一个尚未被提交的文件夹添加到Git中。解决这个问题的方法是先将文件夹中的文件提交到Git仓库中,然后再将文件夹添加到Git中。 首先,需要进…...

Java Websocket分片发送
一、分片发送和接收(复杂) 如果数据量太大,需要分多次发送, 需要考虑数据划分和重组的问题。 二、具体思路 每次发送和接收用一个布尔值变量指定是否为最后一个分片。 三、具体使用 (一)字符串分片发送: sendText(文本, 布尔值)…...
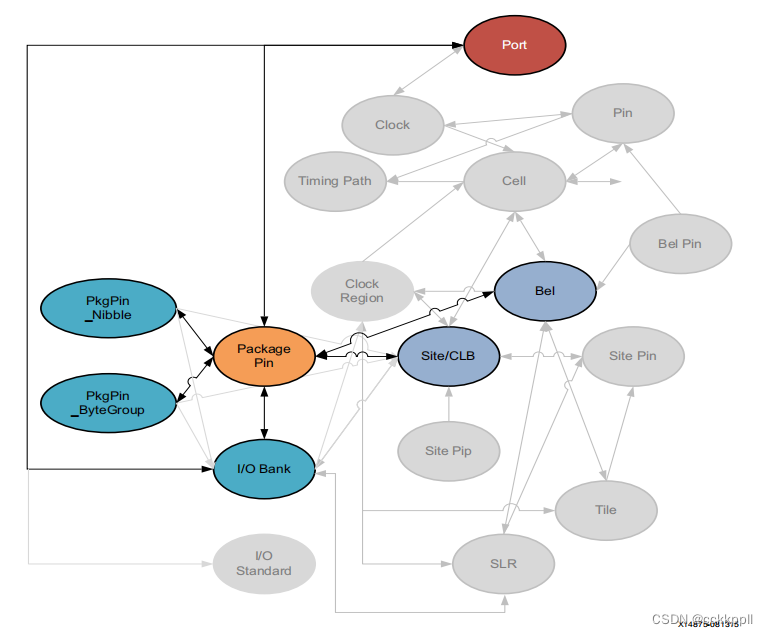
vivado NODE、PACKAGE_PIN
节点是Xilinx部件上用于路由连接或网络的设备对象。它是一个 WIRE集合,跨越多个瓦片,物理和电气 连接在一起。节点可以连接到单个SITE_, 而是简单地将NETs携带进、携带出或携带穿过站点。节点可以连接到 任何数量的PIP,并且也可以…...
JavaEE、SSM基础框架、JavaWeb、MVC(认识)
目录 一、引言 (0)简要介绍 (1)主要涉及的学习内容 (2)学习的必要性 (3)适用学习的人群(最好有这个部分的知识基础) (4)这个基础…...

【漏洞复现】飞企互联-FE企业运营管理平台 treeXml.jsp SQL注入漏洞
0x01 产品简介 飞企互联-FE企业运营管理平台是一个基于云计算、智能化、大数据、物联网、移动互联网等技术支撑的云工作台。这个平台可以连接人、链接端、联通内外,支持企业B2B、C2B与020等核心需求,为不同行业客户的互联网转型提供支持。其特色在于提供…...

Android基础-运行时权限
一、引言 随着智能手机和移动互联网的普及,Android操作系统作为其中的佼佼者,其安全性问题日益受到关注。为了保障用户数据的安全和隐私,Android系统引入了权限机制来管理和控制应用程序对系统资源和用户数据的访问。特别是在Android 6.0&am…...

postman断言及变量及参数化
1:postman断言 断言:判断接口是否执行成功的过程 针对接口请求完成之后,针对他的响应状态码及响应信息进行判断,代码如下: //判断响应信息状态码是否正确 pm.test("Status code is 200", function () { pm.response.…...

安装和使用TrinityCore NPCBot
安装TrinityCore NPCBot 官网:GitHub - trickerer/Trinity-Bots: NPCBots for TrinityCore and AzerothCore 3.3.5 基本安装方法 Follow TrinityCore Installation Guide (https://TrinityCore.info/) to install the server firstDownload NPCBots.patch and put …...
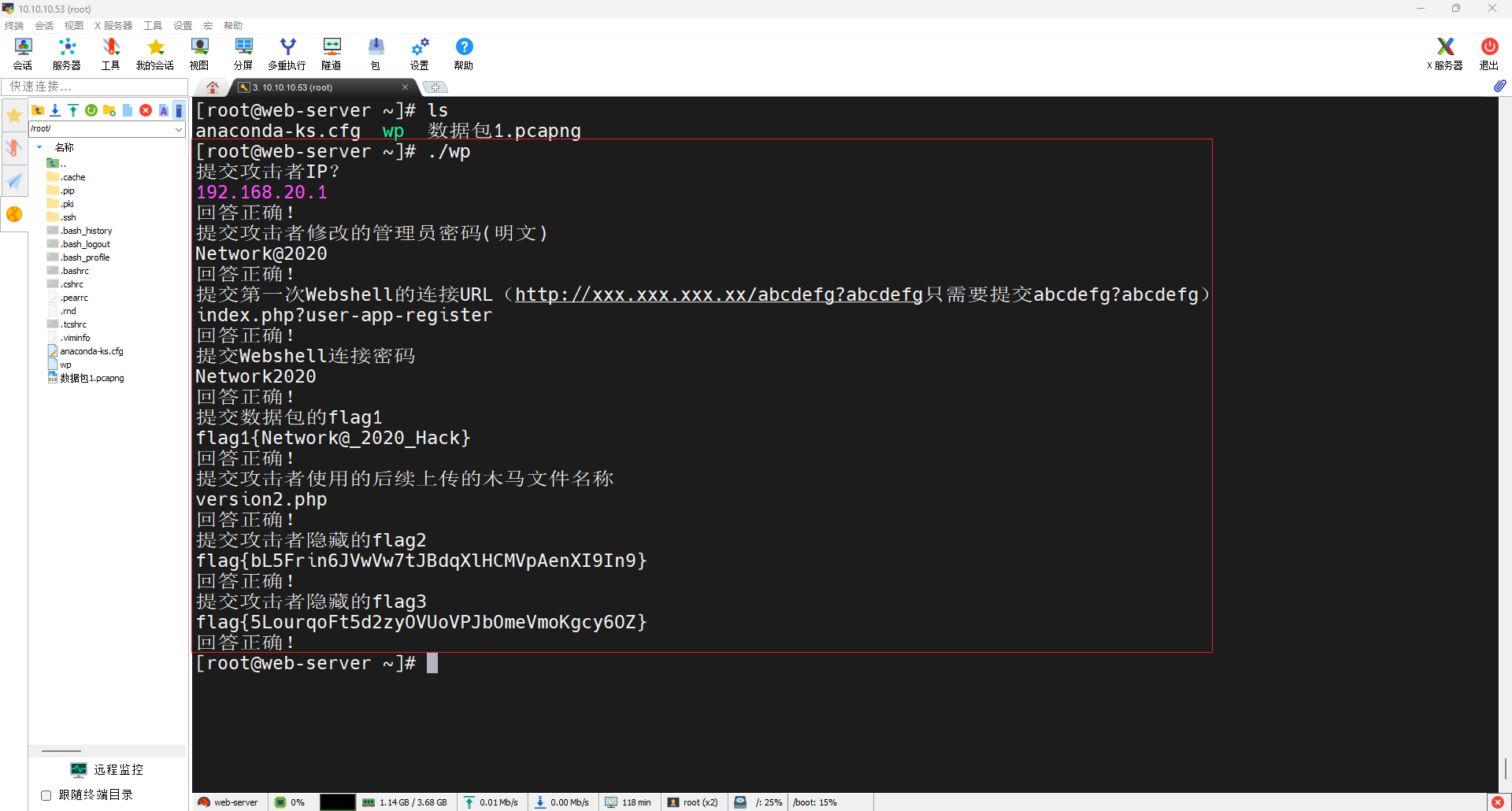
Hvv--知攻善防应急响应靶机--Linux2
HW–应急响应靶机–Linux2 所有靶机均来自 知攻善防实验室 靶机整理: 夸克网盘:https://pan.quark.cn/s/4b6dffd0c51a#/list/share百度云盘:https://pan.baidu.com/s/1NnrS5asrS1Pw6LUbexewuA?pwdtxmy 官方WP:https://mp.weixin.…...

replaceAll is not a function 详解
先说说原因: 在chrome 浏览器中使用 replaceAll 报这个错误,是因为chrome 版本过低, 在chrome 85 以上版本才支持 用法 replaceAll(pattern, replacement)const paragraph "I think Ruths dog is cuter than your dog!"; console…...

如何设置天锐绿盾的数据防泄密系统
设置天锐绿盾的数据防泄密系统,可以按照以下步骤进行: 一、系统安装与初始化 在线或离线安装天锐绿盾数据防泄密系统,确保以管理员身份运行安装包,并按照安装向导的提示完成安装。输入序列号进行注册,激活系统。 二…...
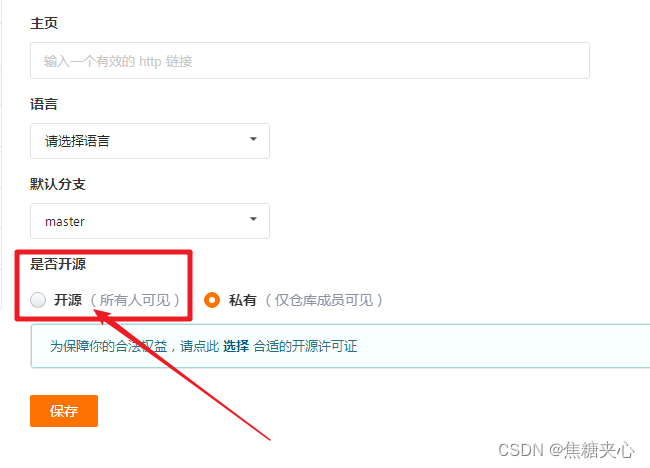
003 gitee怎样将默认的私有仓库变成公开仓库
先点击“管理”, 再点击“基本信息” 在“是否开源”里, 选择:开源...
详解)
Spring框架中的IOC(控制反转)详解
Spring框架中的IOC(控制反转)详解 一、引言 在软件开发中,设计模式与框架的应用极大地提高了开发效率和软件质量。其中,Spring框架因其强大的功能和灵活的扩展性,成为了Java企业级应用开发的首选。而Spring框架中的核…...
)
Score Matching(得分匹配)
Score Matching(得分匹配)是一种统计学习方法,用于估计概率密度函数的梯度(即得分函数),而无需知道密度函数的归一化常数。这种方法由Hyvrinen在2005年提出,主要用于无监督学习,特别…...

五大维度大比拼:ChatGPT比较文心一言,你的AI助手选择指南
文章目录 一、评估AI助手的五个关键维度二、ChatGPT和文心一言的比较 评估AI助手的五个关键维度,以及ChatGPT和文心一言的比较如下: 一、评估AI助手的五个关键维度 界面友好性 : 评估标准:用户界面是否直观易用,是否…...
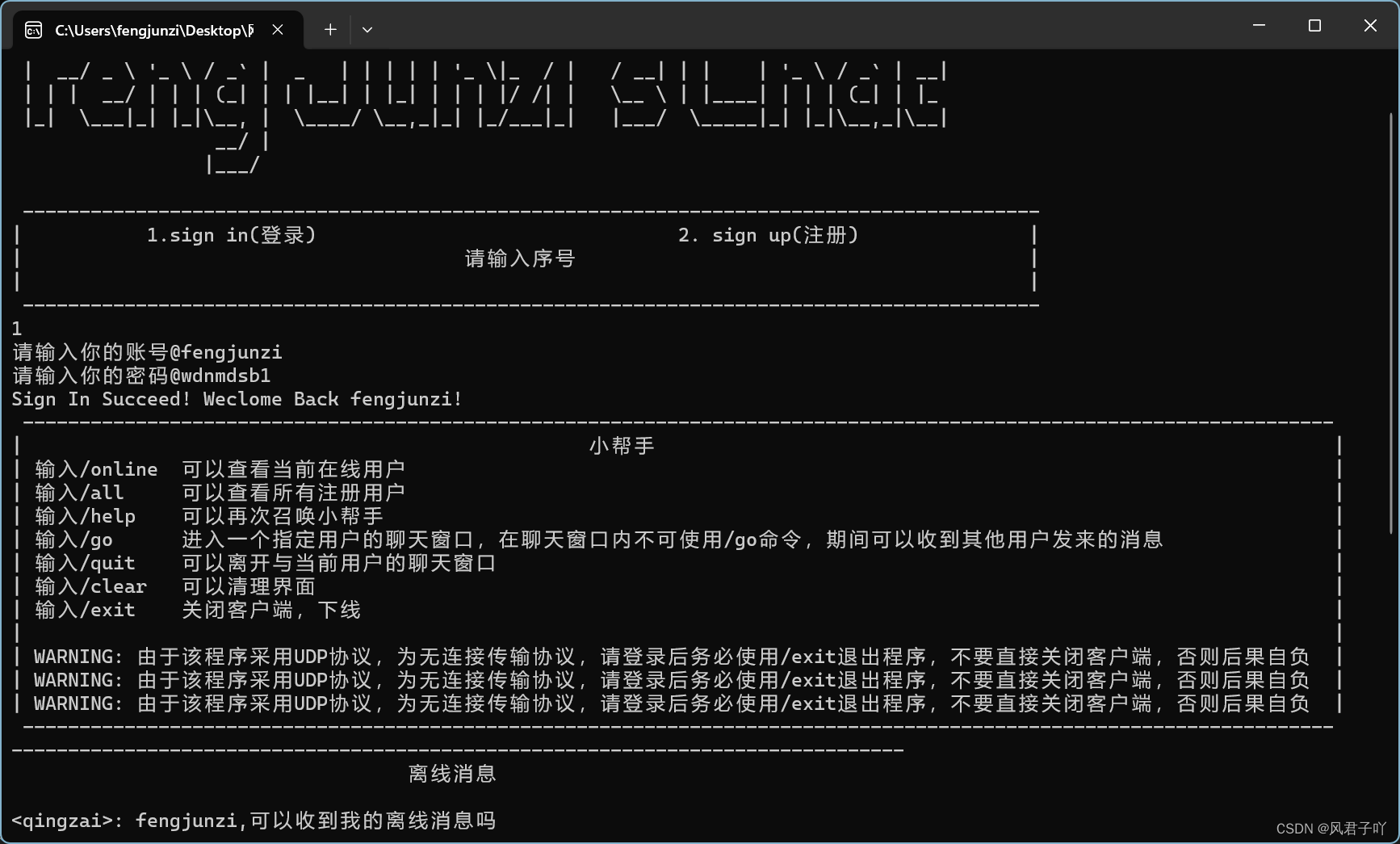
大学课设项目,Windows端基于UDP的网络聊天程序的服务端和客户端
文章目录 前言项目需求介绍一、服务端1.对Udp套接字进行一个封装2. UdpServer的编写3. Task.h4.protocol.h的编写5.线程池的编写6.main.cc 二、客户端1. Socket.h2.protocol.h3.UdpClient4.menu.h5.main.cpp 三、运行图 前言 本次项目可以作为之前内容的一个扩展,学…...

【5.x】ELK日志分析、集群部署
ELK日志分析 一、ELK概述 1、ELK简介 ELK平台是一套完整的日志集中处理解决方案,将ElasticSearch、Logstash和Kiabana三个开源工具配合使用,完成更强大的用户对日志的查询、排序、统计需求。 一个完整的集中式日志系统,需要包含以下几个主…...

揭秘创业加盟:豫腾助力,发掘商机,共赢未来
在我们生活的这个充满活力与机遇的世界里,商业活动如繁星点点,照亮着每个人的创业梦想。 在这个过程中,创业加盟作为一种独特且吸引人的模式,逐渐受到广大创业者的关注。 本文将深入解析创业加盟的精髓,以及如何在其…...
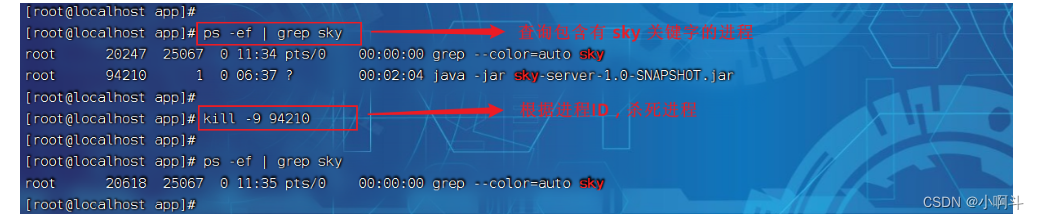
Linux操作系统以及一些操作命令、安装教程
Web课程完结啦,这是Web第一天的课程大家有兴趣可以传送过去学习 http://t.csdnimg.cn/K547r Linux-Day01 课程内容 Linux简介 Linux安装 Linux常用命令 1. 前言 1.1 什么是Linux Linux是一套免费使用和自由传播的操作系统。说到操作系统,大家比…...

Docker 离线安装指南
参考文章 1、确认操作系统类型及内核版本 Docker依赖于Linux内核的一些特性,不同版本的Docker对内核版本有不同要求。例如,Docker 17.06及之后的版本通常需要Linux内核3.10及以上版本,Docker17.09及更高版本对应Linux内核4.9.x及更高版本。…...

Linux 文件类型,目录与路径,文件与目录管理
文件类型 后面的字符表示文件类型标志 普通文件:-(纯文本文件,二进制文件,数据格式文件) 如文本文件、图片、程序文件等。 目录文件:d(directory) 用来存放其他文件或子目录。 设备…...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

SciencePlots——绘制论文中的图片
文章目录 安装一、风格二、1 资源 安装 # 安装最新版 pip install githttps://github.com/garrettj403/SciencePlots.git# 安装稳定版 pip install SciencePlots一、风格 简单好用的深度学习论文绘图专用工具包–Science Plot 二、 1 资源 论文绘图神器来了:一行…...

React第五十七节 Router中RouterProvider使用详解及注意事项
前言 在 React Router v6.4 中,RouterProvider 是一个核心组件,用于提供基于数据路由(data routers)的新型路由方案。 它替代了传统的 <BrowserRouter>,支持更强大的数据加载和操作功能(如 loader 和…...

解锁数据库简洁之道:FastAPI与SQLModel实战指南
在构建现代Web应用程序时,与数据库的交互无疑是核心环节。虽然传统的数据库操作方式(如直接编写SQL语句与psycopg2交互)赋予了我们精细的控制权,但在面对日益复杂的业务逻辑和快速迭代的需求时,这种方式的开发效率和可…...

LeetCode - 394. 字符串解码
题目 394. 字符串解码 - 力扣(LeetCode) 思路 使用两个栈:一个存储重复次数,一个存储字符串 遍历输入字符串: 数字处理:遇到数字时,累积计算重复次数左括号处理:保存当前状态&a…...

【快手拥抱开源】通过快手团队开源的 KwaiCoder-AutoThink-preview 解锁大语言模型的潜力
引言: 在人工智能快速发展的浪潮中,快手Kwaipilot团队推出的 KwaiCoder-AutoThink-preview 具有里程碑意义——这是首个公开的AutoThink大语言模型(LLM)。该模型代表着该领域的重大突破,通过独特方式融合思考与非思考…...

【项目实战】通过多模态+LangGraph实现PPT生成助手
PPT自动生成系统 基于LangGraph的PPT自动生成系统,可以将Markdown文档自动转换为PPT演示文稿。 功能特点 Markdown解析:自动解析Markdown文档结构PPT模板分析:分析PPT模板的布局和风格智能布局决策:匹配内容与合适的PPT布局自动…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...