Sqoop学习详细介绍!!
一、Sqoop介绍
Sqoop是一款开源的工具,主要用于在Hadoop(HDFS/Hive/HBase)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
Sqoop项目开始于2009年,最早是作为Hadoop的一个第三方模块存在,后来为了让使用者能够快速部署,也为了让开发人员能够更快速的迭代开发,Sqoop独立成为一个Apache项目。
二、安装
1).解压
tar -zxf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /opt/installs
2).重命名
mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha sqoop1.4.6
3).修改配置文件
cd /opt/installs/sqoop1.4.6/conf
mv sqoop-env-template.sh sqoop-env.sh
vi sqoop-env.sh
#增加配置,注意修改路径
export HADOOP_COMMON_HOME=/opt/installs/hadoop3.1.4
export HADOOP_MAPRED_HOME=/opt/installs/hadoop3.1.4
export ZOOCFGDIR=/opt/installs/zookeeper3.4.6
export HIVE_HOME=/opt/installs/hive3.1.24).将mysql的驱动jar复制到sqoop的lib目录下 (底层需要用JDBC操作MySQL数据库)
cp /opt/installs/hive3.1.2/lib/mysql-connector-java-8.0.26.jar /opt/installs/sqoop1.4.6/lib/5).配置sqoop环境变量
export PATH=$PATH:/opt/installs/sqoop1.4.6/bin三、sqoop-import
在Sqoop中,“导入”概念指:从非大数据集群(RDBMS)向大数据集群(HDFS,HIVE,HBASE)中传输数据,叫做:导入,即使用import关键字。
-- 测试数据库的表是否可以连接,显示库中的所有表
sqoop list-tables --connect jdbc:mysql://hadoop10:3306/test1 --username root --password 1234561). RDBMS(mysql) -> HDFS
sqoop import \
--driver com.mysql.jdbc.Driver \
--connect jdbc:mysql://hadoop10:3306/test1?characterEncoding=UTF-8 \
--username root \
--password 123456 \
--table t_sex \
--num-mappers 4 \
--fields-terminated-by '\t' \
--target-dir /mysql/t_user \
--delete-target-dir参数 作业
--driver mysql驱动
--connect 数据库连接url jdbc:mysql://ip:3306/数据库
--username 连接mysql数据库用户名
--password 连接mysql数据库密码
--table mysql中test1数据库中表名
--num-mappers sqoop底层是mapreduce, 指定启动的maptask个数,海量数据可以并 行抽取
解释:sqoop抽取任务会转换成mr作业,该mr作业由于不需要对数据进行聚合,所有只需要保留maptask阶段,没有reduceTasksqoop,需要依赖hadoop的HDFS和Yarn
--fields-terminated-by 数据写入HDFS存储到文件中,列与列之间的分隔符
--target-dir 存储到HDFS的目标路径,配置的是目录,并且该目录应该不存在
--delete-target-dir 如果存在,则提前删除
mysql中的表:
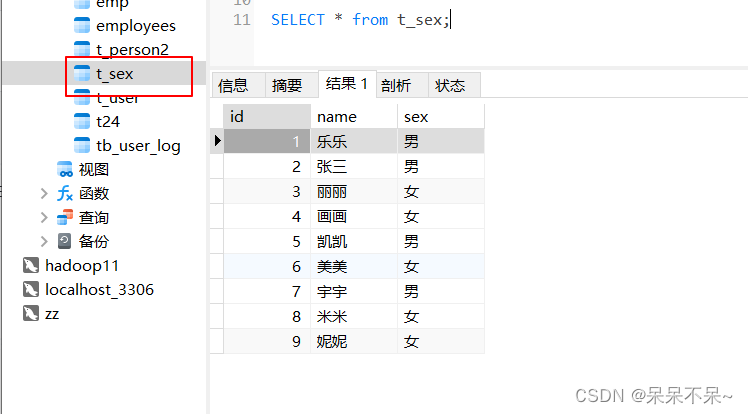
运行1:
 查看:
查看:
yarn:
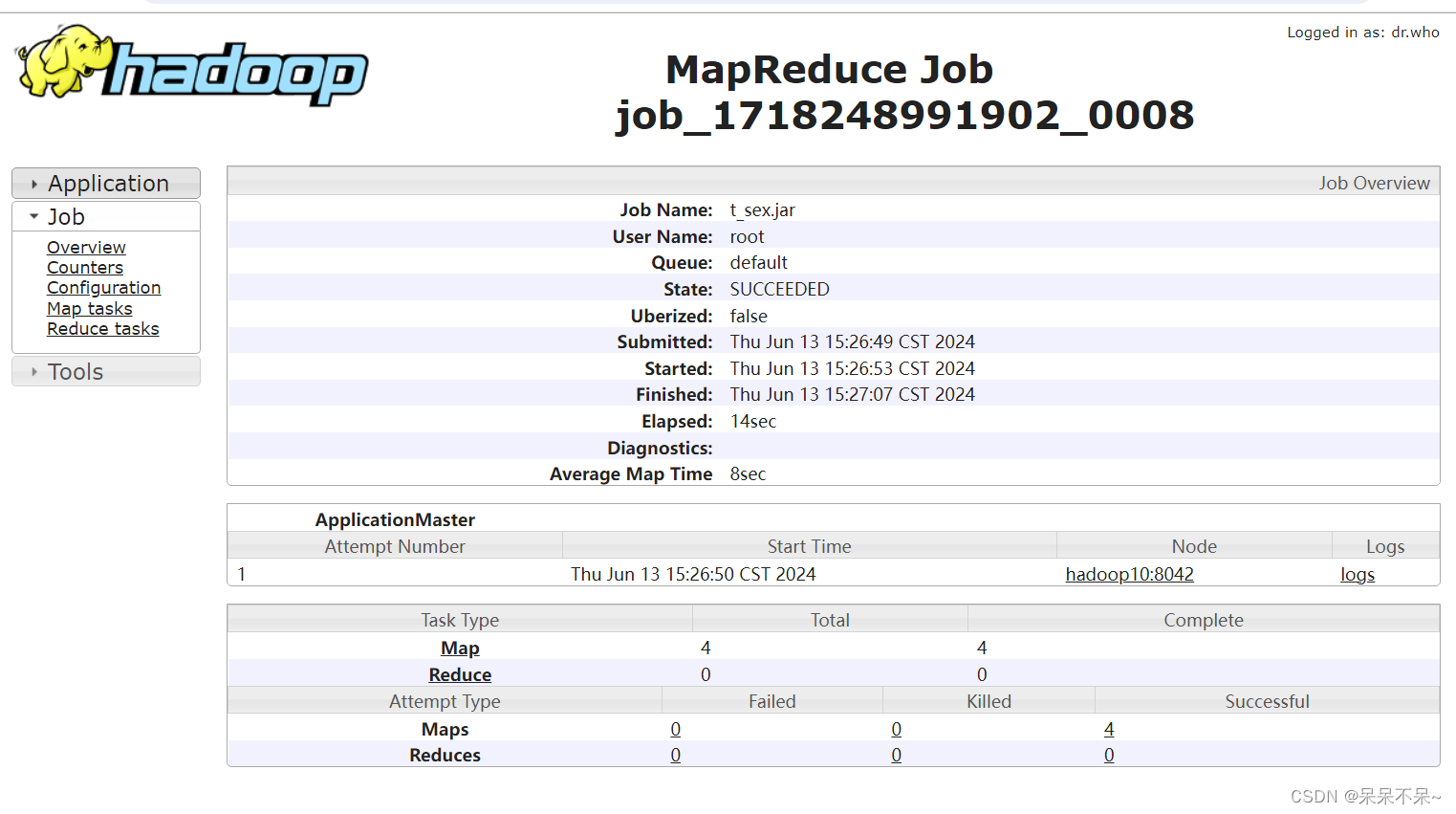
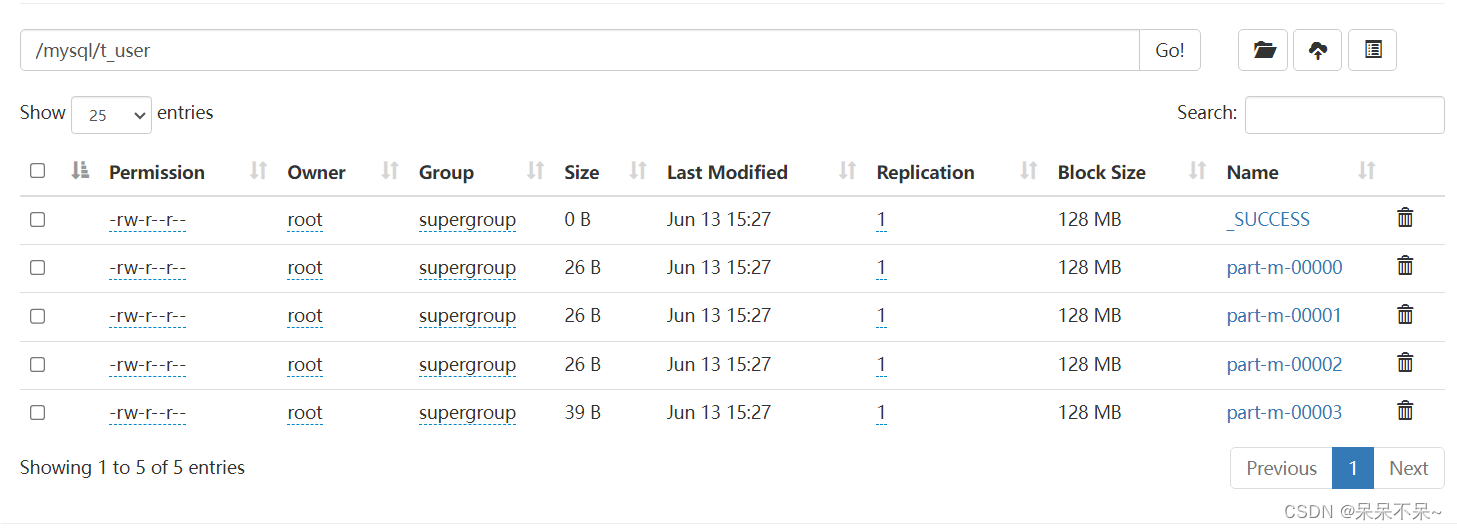
hdfs:
运行2:
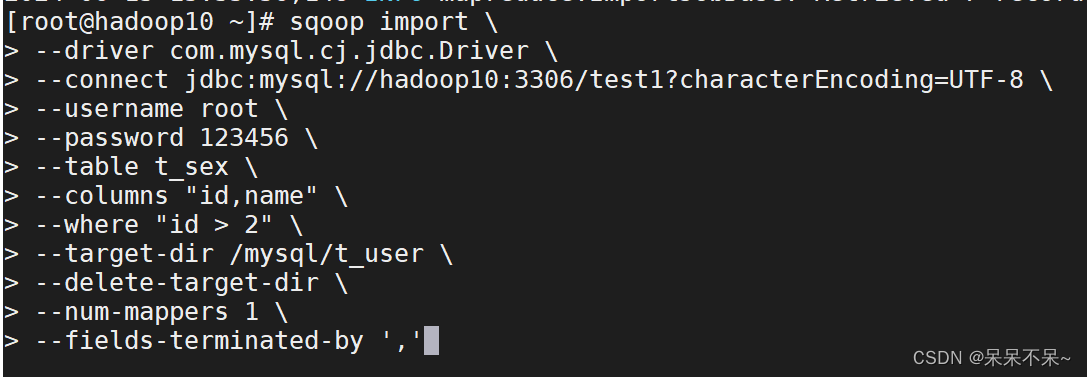
sqoop import \
--driver com.mysql.cj.jdbc.Driver \
--connect jdbc:mysql://hadoop10:3306/test1?characterEncoding=UTF-8 \
--username root \
--password 123456 \
--table t_sex \
--columns "id,name" \
--where "id > 2" \
--target-dir /mysql/t_user \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by ','参数
--columns 指定列名
--where 指定查询条件
查看hdfs:
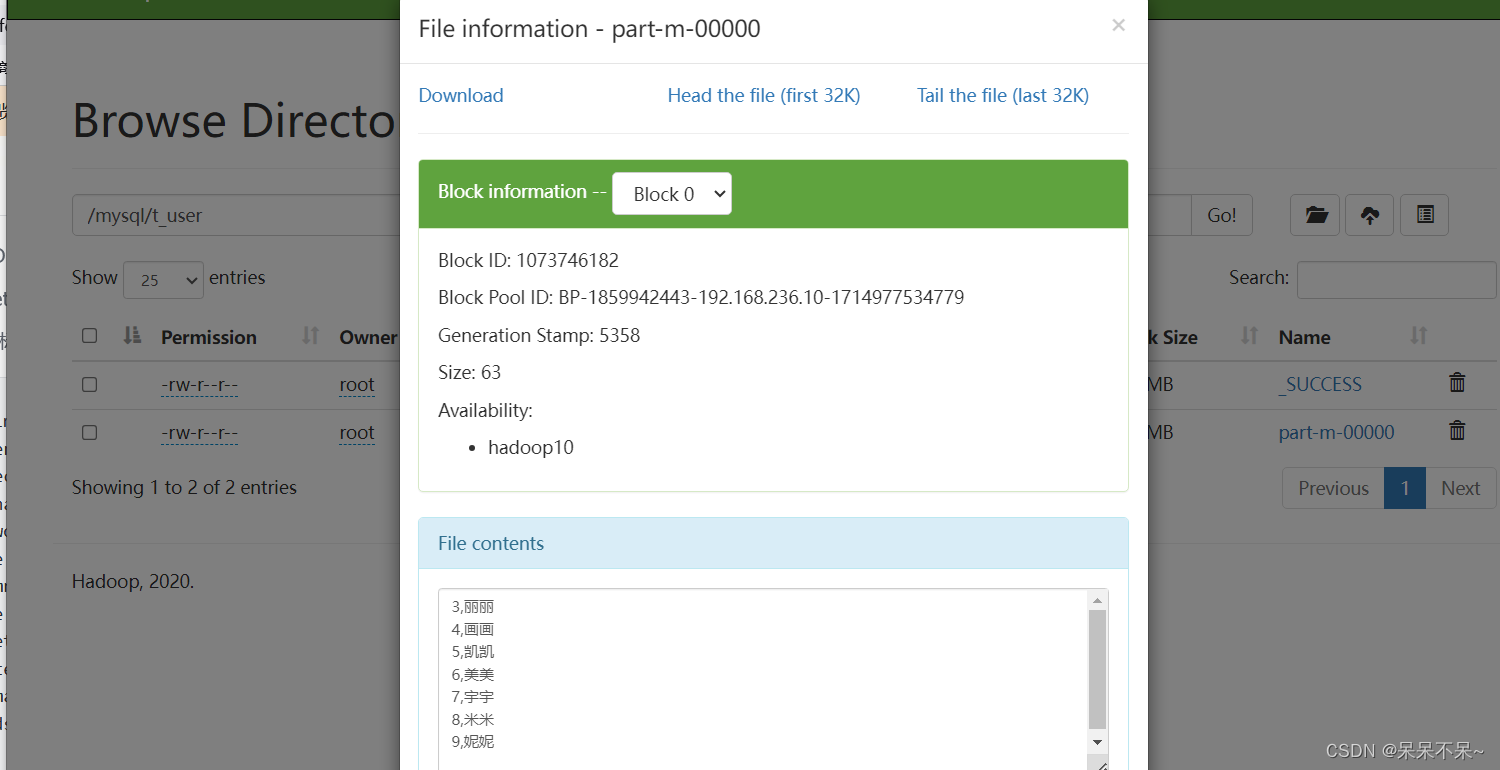
运行3:
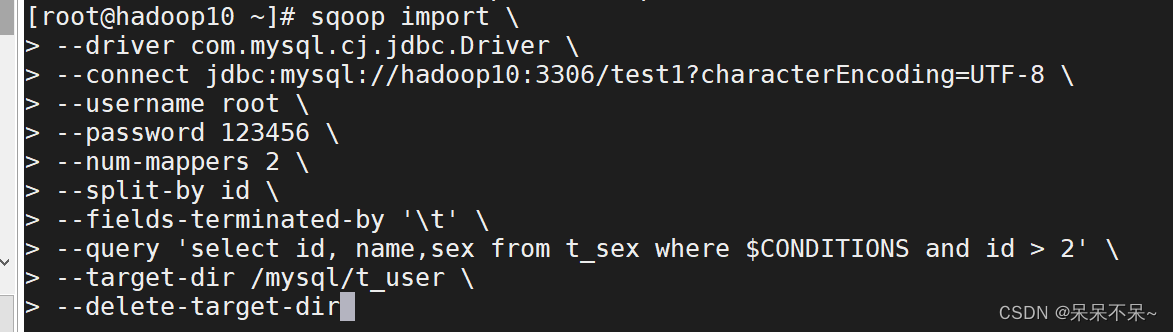
sqoop import \
--driver com.mysql.cj.jdbc.Driver \
--connect jdbc:mysql://hadoop10:3306/test1?characterEncoding=UTF-8 \
--username root \
--password 123456 \
--num-mappers 2 \
--split-by id \
--fields-terminated-by '\t' \
--query 'select id, name,sex from t_sex where $CONDITIONS and id > 2' \
--target-dir /mysql/t_user \
--delete-target-dir参数 作用
--split-by 根据指定字段进行拆分,相当于datax的splitPK。根据这一列的值把数据分成几部分
--num-mappers 指定并行度,简写-m
--query 查询语句。$CONDITIONS相当于占位符,写where条件必须有写这个
查看hdfs:

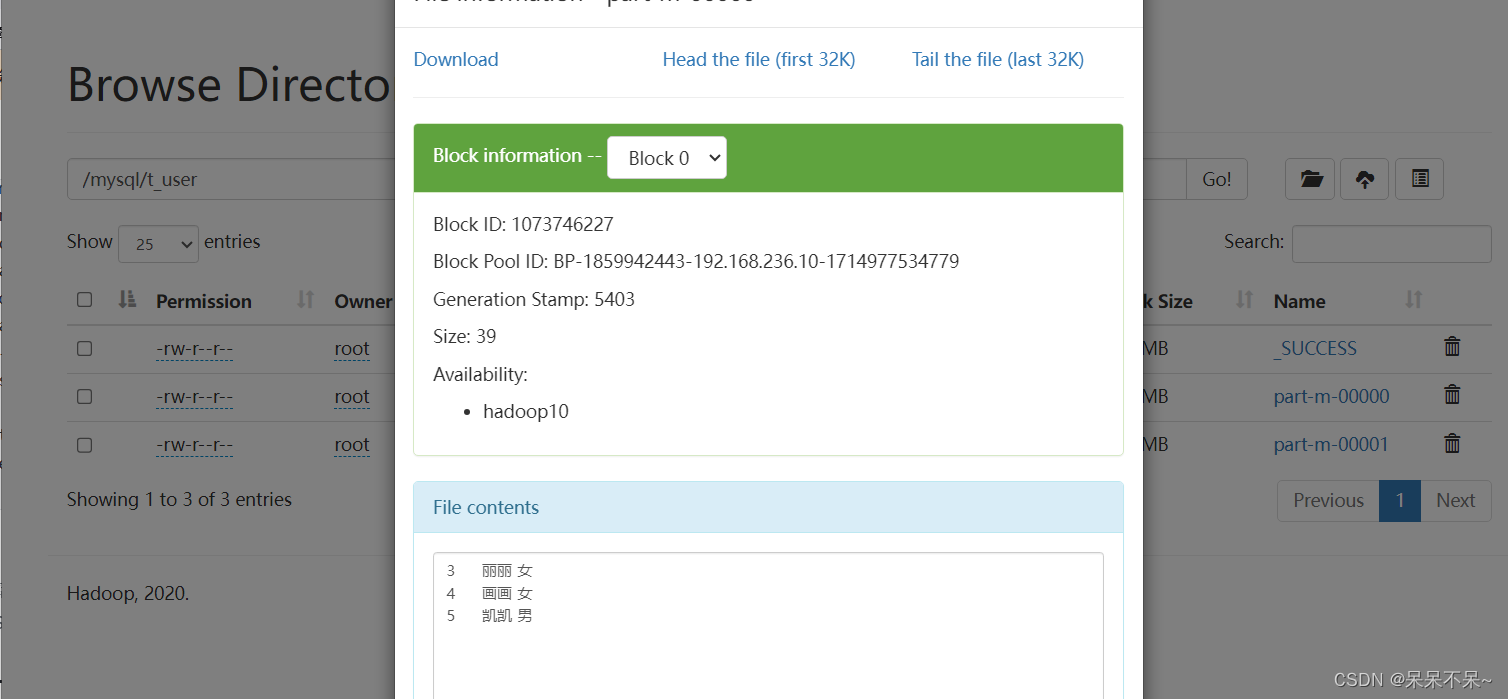
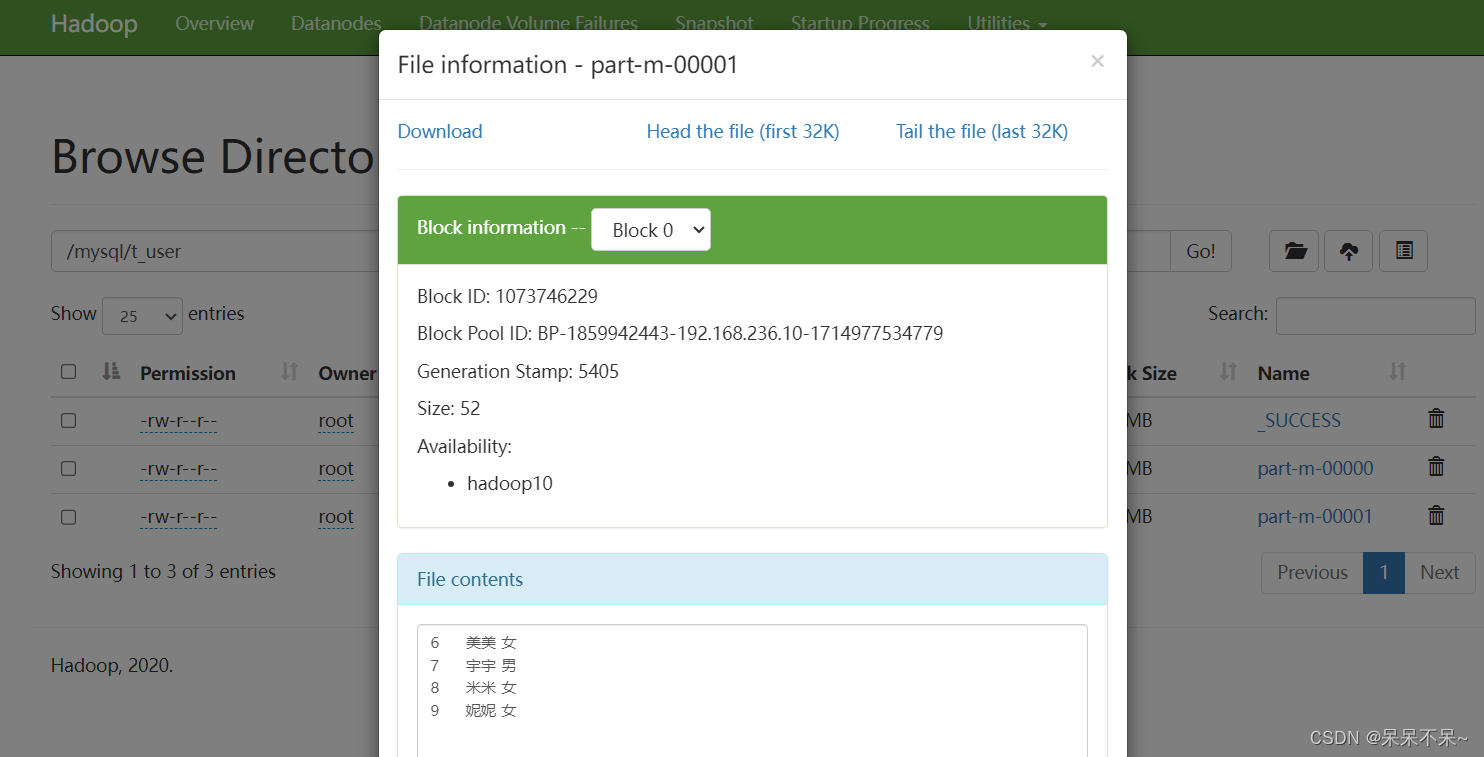
2). RDBMS -> Hive
运行:
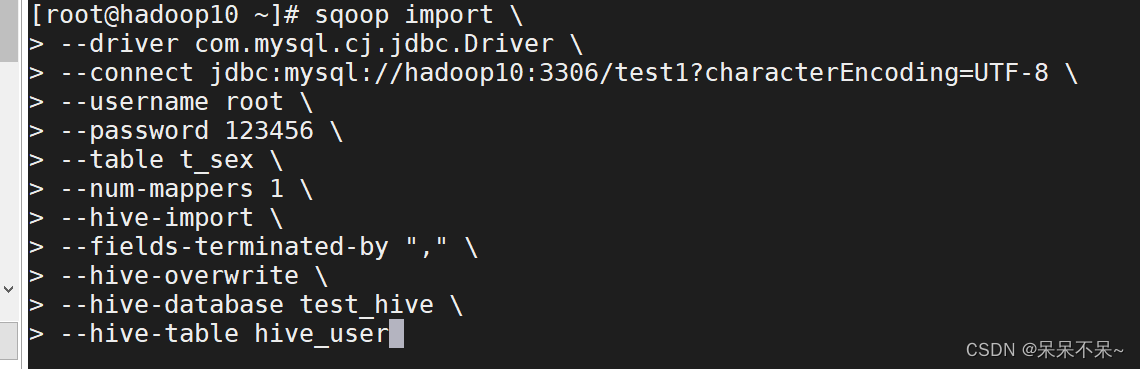
sqoop import \
--driver com.mysql.cj.jdbc.Driver \
--connect jdbc:mysql://hadoop10:3306/test1?characterEncoding=UTF-8 \
--username root \
--password 123456 \
--table t_sex \
--num-mappers 1 \
--hive-import \
--fields-terminated-by "," \
--hive-overwrite \
--hive-database test_hive \
--hive-table hive_user--hive-import 代表将数据导入hive
--fields-terminated-by 导入hive后,存储在HDFS上文件的分隔符
--hive-database hive的数据库
--hive-table 上边指定库下的表,可以不存在,会自动创建
--hive-overwrite 将表中数据覆盖
查看hive:
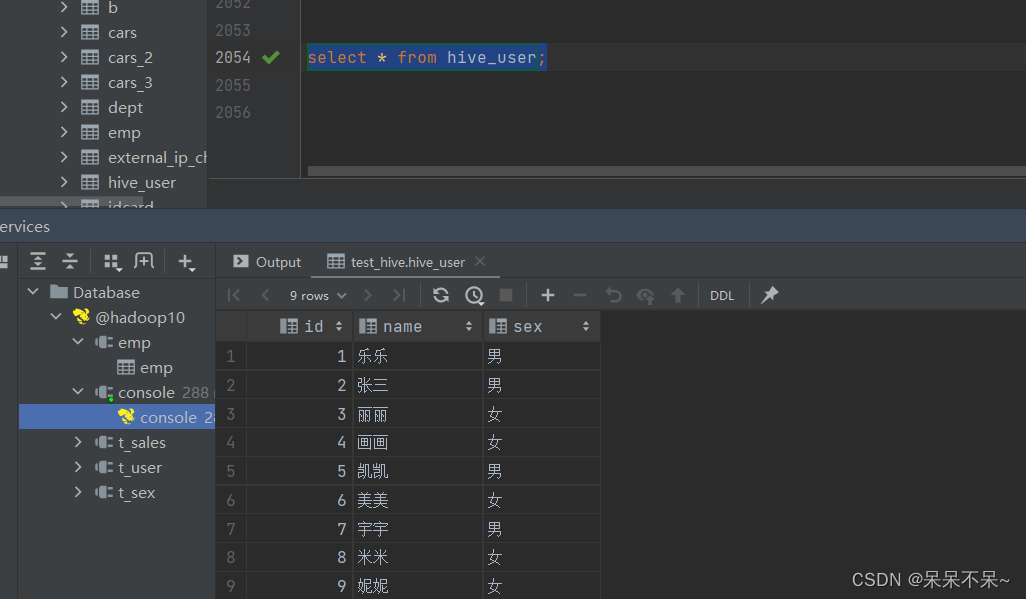
四、sqoop-export
在Sqoop中,“导出”概念指:从大数据集群(HDFS,HIVE,HBASE)向非大数据集群(RDBMS关系型数据库)中传输数据,叫做:导出,即使用export关键字。
1). HDFS|hive -> RDBMS
① 准备数据,上传hdfs的sqoop目录下
vi a.txt
# 在文件中添加如下内容
1 zhangsan true 20 2020-01-11
2 lisi false 25 2020-01-10
3 wangwu true 36 2020-01-17
4 zhaoliu false 50 1990-02-08
5 win7 true 20 1991-02-08#在hdfs上创建sqoop目录(目录名称随意,不过需要和后边对应),将文件上传到sqoop目录下
hdfs dfs -mkdir /sqoop
hdfs dfs -put a.txt /sqoop② 在mysql中创建表
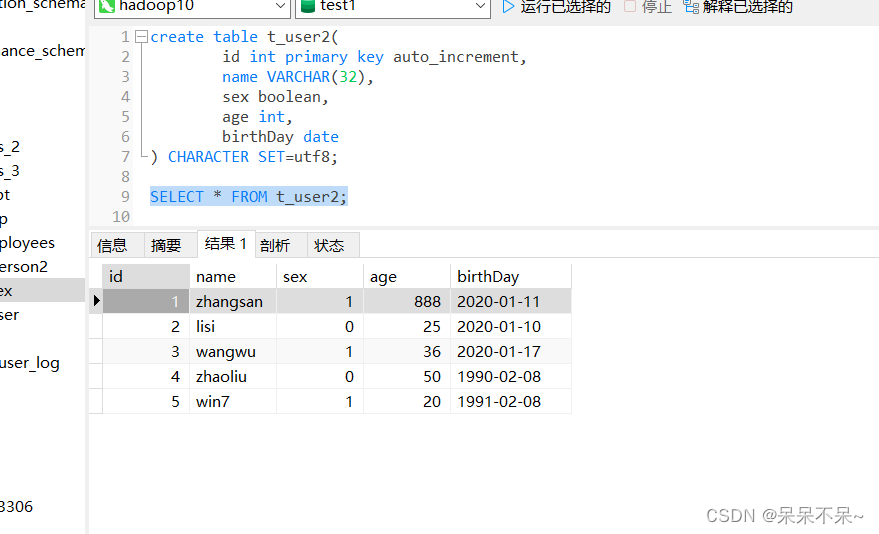
注意:导出并不会自动创建对应的表,需要提前自己创建
create table t_user2(id int primary key auto_increment,name VARCHAR(32),sex boolean,age int,birthDay date
) CHARACTER SET=utf8;③ 将hdfs上的数据导入mysql表中
sqoop export \
--connect jdbc:mysql://hadoop10:3306/test1?characterEncoding=UTF-8 \
--username root \
--password 123456 \
--export-dir /sqoop \
--input-fields-terminated-by ' ' \
--columns "id,name,sex,age,birthDay" \
--table t_user2 \
--update-key id \
--update-mode allowinsert--export-dir 指定导出数据的目录
--table mysql中的表名
--columns 字段名
--update-mode 如果是allowinsert,则允许不但能够导入新数据的时候,还可以更新之前的数据
如果是updateonly,则只会更新以前的数据,不添加新数据
--update-key 如果指定列的值已经存在,则会触发修改操作,否则添加,一般指定主键列
查看mysql:
五、sqoop应用问题汇总
1.sqoop在导入或者导出的时候,空值问题处理。
注意:不用直接通过工具界面修改表中的数据,制造空数据,需要重新添加一条
Hive 中的 Null 在底层是以“\N”来存储,而 MySQL 中的 Null 在底层就是 Null,为了保证数据两端的一致性。导入数据时采用--null-string 和--null-non-string。
导出数据时采用--input-null-string 和--input-null-non-string 两个参数。--null-string含义是 string类型的字段,当Value是NULL,替换成指定的字符
--null-string '\\N' 替换为 \N导入(mysql-->hive):
sqoop import \
--driver com.mysql.cj.jdbc.Driver \
--connect jdbc:mysql://hadoop10:3306/test1?characterEncoding=UTF-8 \
--username root \
--password 123456 \
--table t_user \
--num-mappers 1 \
--hive-import \
--fields-terminated-by "," \
--hive-overwrite \
--hive-database test_hive \
--hive-table hive_user \
--null-non-string '\\N' \
--null-string '\\N'mysql表中有空数据:
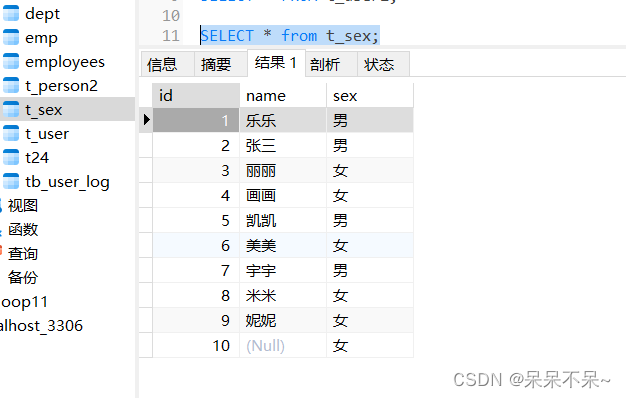
查看hive表:
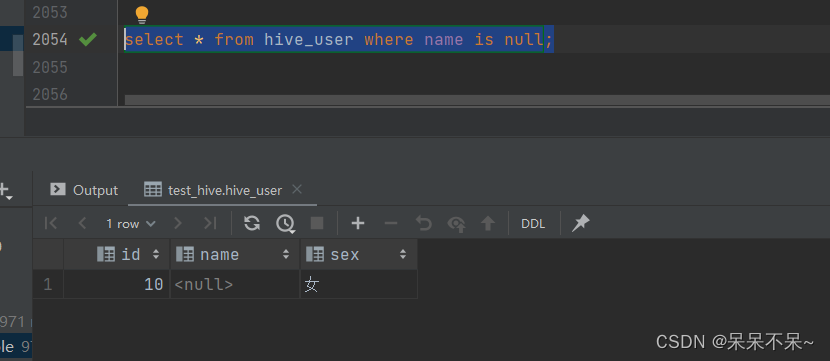
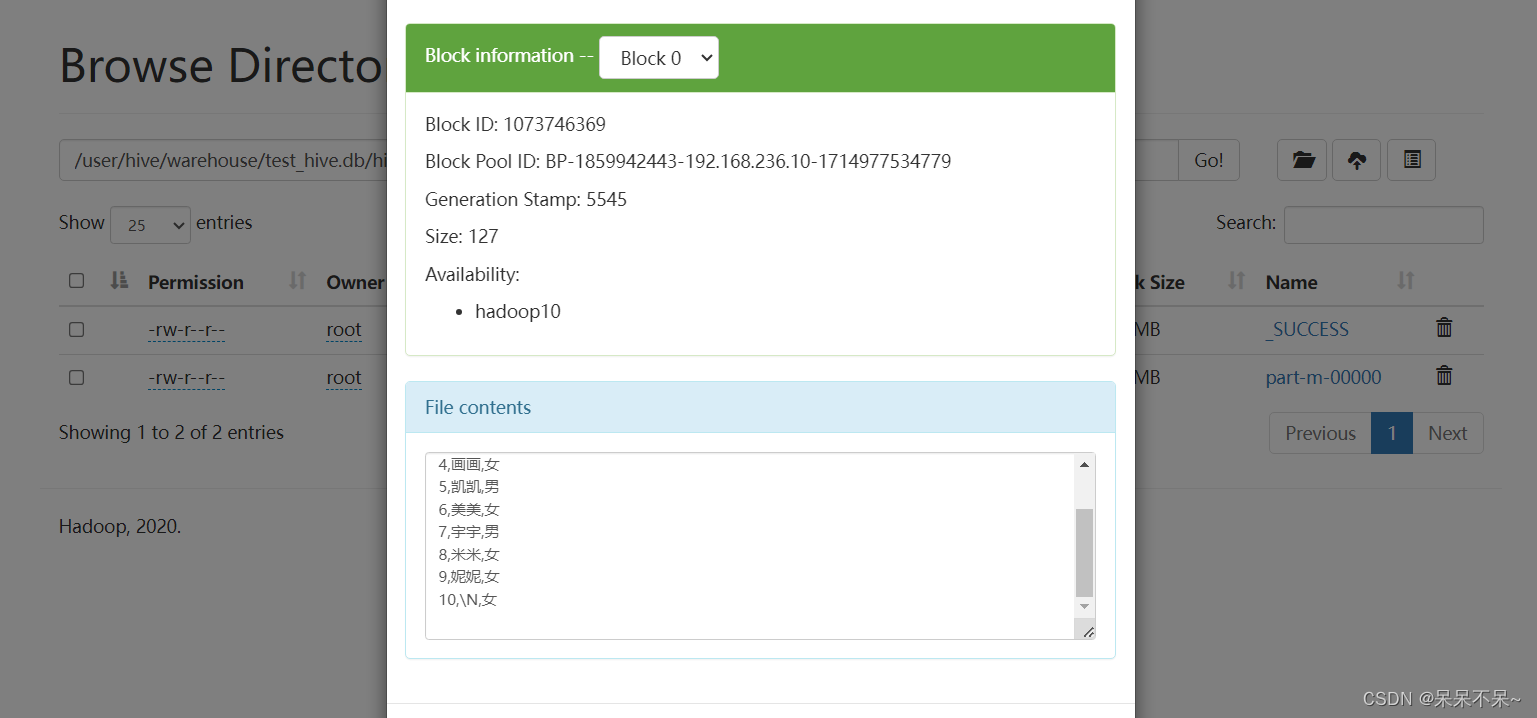
导出(hive-->mysql):
sqoop export \
--connect jdbc:mysql://hadoop10:3306/test1?characterEncoding=UTF-8 \
--username root \
--password 123456 \
--export-dir /user/hive/warehouse/test_hive.db/dept \
--input-fields-terminated-by '\t' \
--columns "deptno,dname,loc" \
--table dept \
--update-key deptno \
--update-mode allowinsert \
--input-null-non-string '\\N' \
--input-null-string '\\N'在hive表中插入空值数据:

在mysql查看表:
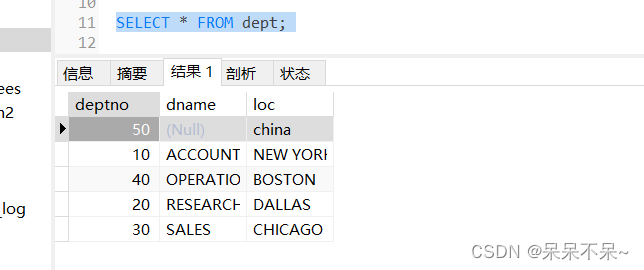
2.将mysql数据导入到hive分区表中
sqoop import \
--driver com.mysql.cj.jdbc.Driver \
--connect jdbc:mysql://hadoop10:3306/test1?characterEncoding=UTF-8 \
--username root \
--password 123456 \
--table t_person2 \
--num-mappers 1 \
--hive-import \
--fields-terminated-by "," \
--hive-overwrite \
--hive-database test_hive \
--hive-table t_person2 \
--null-non-string '\\N' \
--null-string '\\N' \
--hive-partition-key dt \
--hive-partition-value 20231220查看mysql表:

查看hive表:

3.将hive分区表导出到mysql
在mysql建表:

sqoop export \
--connect jdbc:mysql://hadoop10:3306/test1?characterEncoding=UTF-8 \
--username root \
--password 123456 \
--export-dir /user/hive/warehouse/test_hive.db/t_person2/dt=20231220 \
--input-fields-terminated-by ',' \
--table t_person2 \
--update-key dt \
--update-mode allowinsert \
--input-null-non-string '\\N' \
--input-null-string '\\N'查看表:
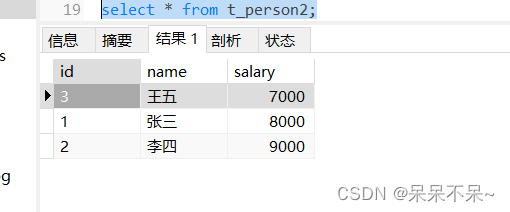
相关文章:
Sqoop学习详细介绍!!
一、Sqoop介绍 Sqoop是一款开源的工具,主要用于在Hadoop(HDFS/Hive/HBase)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的H…...
【2024最新华为OD-C/D卷试题汇总】[支持在线评测] 生成哈夫曼树(100分) - 三语言AC题解(Python/Java/Cpp)
🍭 大家好这里是清隆学长 ,一枚热爱算法的程序员 ✨ 本系列打算持续跟新华为OD-C/D卷的三语言AC题解 💻 ACM银牌🥈| 多次AK大厂笔试 | 编程一对一辅导 👏 感谢大家的订阅➕ 和 喜欢💗 📎在线评测链接 生成哈夫曼树(100分) 🌍 评测功能需要订阅专栏后私信联系清…...
ctfshow web 单身杯
web签到 <?phperror_reporting(0); highlight_file(__FILE__);$file $_POST[file];if(isset($file)){if(strrev($file)$file){ //翻转函数include $file;}}要进行反转并且包含文件用data协议 自己写不好写可以用函数帮你翻转 <?php $adata:text/plain,<?eval(…...

天锐绿盾加密软件,它的适用范围是什么?
天锐绿盾数据防泄密软件的适用范围广泛,主要可以归纳为以下几点: 行业适用性: 适用于各个行业,包括但不限于制造业、设计行业、软件开发、金融服务等,特别是对数据安全性要求较高的行业。企业规模与类型: 适…...

mysql面试题 Day2
1 长文本如何存储? 可以使用Text存储 TINYTEXT(255长度) TEXT(65535) MEDIUMTEXT(int最大值16M) LONGTEXT(long最大值4G) 2 大段文本存储如何设计表结构? 分表存储 分表后多段存储 3 大段文本查找时如何建立索引࿱…...
Excel加密怎么设置?这5个方法不容错过!(2024总结)
Excel加密怎么设置?如何不让别人未经允许查看我的excel文件?如果您也有这些疑问,那么千万不要错过本篇文章了。今天小编将向大家分享excel加密的5个简单方法,保证任何人都可以轻松掌握!毫无疑问的是,为Exce…...

2024年下一个风口是什么?萤领优选 轻资产创业项目全国诚招合伙人
2024年,全球经济与科技发展的步伐不断加快,各行各业都在探寻新的增长点与风口。在这样的时代背景下,萤领优选作为一个轻资产创业项目,正以其独特的商业模式和前瞻的市场洞察力,吸引着众多创业者的目光。(领取ÿ…...

Redis 网络模型
一、用户空间和内核空间 1.1 linux 简介 服务器大多采用 Linux 系统,这里我们以 Linux 为例来讲解,下面有两个不同的 linux 发行版,分别位 ubuntu 和 centos,其实发行版就是在 Linux 系统上包了一层壳。 任何 Linux 发行版&#…...

【设计模式之组合模式 -- C++】
组合模式 – 树状结构,递归遍历 组合模式(Composite Pattern)是一种结构型设计模式,它可以让你将对象组合成树形结构,并且能像使用独立对象一样使用它们。这种模式定义了包含人和组的类,每个类都有可以在树形结构中显示的方法。这…...
C# 通过Win32API设置客户端系统时间
在日常工作中,有时可能会需要获取或修改客户端电脑的系统时间,比如软件设置了Licence有效期,预计2024-06-01 00:00:00到期,如果客户手动修改了客户端电脑时间,往前调整了一年,则软件就可以继续使用一年&…...
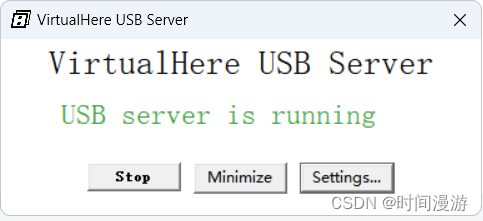
VirtualHere 允许通过网络远程使用 USB 设备,就像本地连接一样!
传统上,USB 设备需要直接插入计算机才能使用。有了 VirtualHere,就不再需要这样做,网络本身就变成了传输 USB 信号的电缆(也称为 USB over IP、USB/IP、USB over WiFi、USB over Ethernet、USB 设备服务器)。 此 USB …...
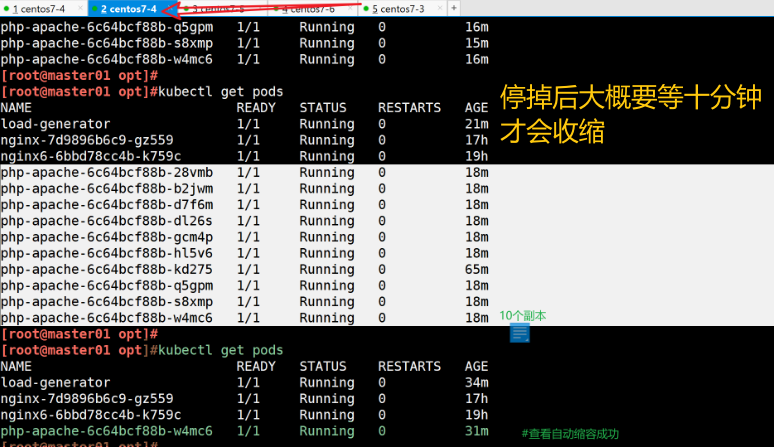
【Kubernetes】k8s 自动伸缩机制—— HPA 部署
一、在K8s中扩缩容分为两种: ●Node层面:对K8s物理节点扩容和缩容,根据业务规模实现物理节点自动扩缩容 ●Pod层面:我们一般会使用Deployment中的Replicas参数,设置多个副本集来保证服务的高可用,但是这是…...

MT1415 大小相同
题目 给定一个由N(<10)个正整数组成的数组A,生成一些最小元素和最大元素相同的子数组数(可以仅包含1个元素),统计这些子数组的数量并输出。 注:最大元素和最小元素相同就是数组中的元素全部为同一个值。如数组&am…...

使用python库moviepy完成视频剪辑
1.关于moviepy和原理 moviepy事github上面的一个开源项目,地址是:GitHub - Zulko/moviepy: Video editing with Python 官方文档地址: User Guide — MoviePy 1.0.2 documentation 中文版文档可参考: MoviePy中文手册 — mov…...

Java高手的30k之路|面试宝典|精通泛型
泛型 知识点 在Java高级开发中,掌握泛型(Generics)是非常重要的,它是Java语言中的一项重要特性,提供了编译时类型安全检查机制,使得代码更加灵活和可重用。以下是Java高级开发需要掌握的泛型知识点&#…...

清理Linux操作系统buff/cache缓存
清理Linux操作系统buff/cache缓存 清理页缓存 echo 1 > /proc/sys/vm/drop_caches 或者 sysctl -w vm.drop_caches1 清理目录项和inode缓存 echo 2 > /proc/sys/vm/drop_caches 或者 sysctl -w vm.drop_caches2 同时清理页缓存、目录项和inode缓存 echo 3 > /pr…...

接口测试的几种方法
其实无论用那种测试方法,接口测试的原理是通过测试程序模拟客户端向服务器发送请求报文,服务器接收请求报文后对相应的报文做出处理然后再把应答报文发送给客户端,客户端接收应答报文这一个过程。 方法一、用LoadRunner实现接口测试 大家都…...
OpenGL3.3_C++_Windows(3)
GLSL Shader基础 Shader(把输入转化为输出,运行在GPU上):首先要声明版本,有各自的入口点main()顶点数据上限:16个包含4分量:16 * 4 64个分量向量:容器vec。使用.x、.y、.z和.w&am…...

24执业药师报名时间汇总及报名流程!
24执业药师报名时间汇总!报名流程! 🕛️各省市报名时间汇总(共9地) 西藏:6月29日-7月8日 新疆:6月25日10:30-7月9日19:00 内蒙古:6月20日9:00-7月3日24:00 新疆兵团:6月2…...

成都跃享未来教育咨询解锁新篇章
在快节奏的现代社会中,每个人都在追求着属于自己的非凡人生。而成都跃享未来教育咨询,正是那个能够智慧引领你走向成功、成就非凡人生的灯塔。 跃享未来教育咨询,位于历史悠久的文化名城成都,这里不仅有丰富的文化底蕴,…...
——平稳性检验实战指南)
时间序列分析(二)——平稳性检验实战指南
1. 为什么需要平稳性检验? 当你第一次接触时间序列分析时,可能会疑惑:为什么我们要大费周章地检验数据的平稳性?这个问题困扰了我很久,直到在实际项目中踩过几次坑才真正理解。想象一下,你正在用ARIMA模型…...

遗忘因子调参指南:FFRLS算法在电池SOC估计中的5个关键陷阱
遗忘因子调参实战:FFRLS算法在电池SOC估计中的5个高阶避坑指南 当你在凌晨三点盯着屏幕上飘忽不定的SOC曲线时,是否怀疑过那个看似简单的遗忘因子参数?作为电池管理系统中最关键的"记忆调节器",遗忘因子的选择往往决定了…...
的吗?——双边滤波·保边去噪·OpenCL源码全拆解)
bilateralFilter写了一万遍,你知道OpenCV怎么用两张查找表干掉exp()的吗?——双边滤波·保边去噪·OpenCL源码全拆解
你一定写过这行代码: cv::bilateralFilter(src, dst, 9, 75, 75);一行调用搞定磨皮。但你有没有想过,这行代码背后到底藏了多少东西? 我翻了OpenCV 4.x的modules/imgproc/src/目录——bilateral_filter.dispatch.cpp有472行,bilateral_filter.simd.hpp有782行,opencl/bi…...
)
Kimi和豆包提示词实战:5个让大模型秒变聪明的指令模板(附避坑指南)
Kimi和豆包提示词实战:5个让大模型秒变聪明的指令模板(附避坑指南) 当你对着AI助手输入问题,却得到一堆无关信息时,是否也想过"这AI怎么这么笨"?其实问题可能出在你的提问方式上。就像用老式收音…...

fio 磁盘I/O测试工具:从安装到实战性能调优
1. 为什么你需要一个靠谱的磁盘性能“体检医生” 如果你刚接手一台服务器,或者自己攒了一台NAS,第一件事你会做什么?装系统?配服务?我的习惯是,先给磁盘做个全面的“体检”。为什么?因为磁盘是整…...

从在线翻译到本地引擎:Hunyuan-MT 7B如何帮你节省每年数万元API费用?
从在线翻译到本地引擎:Hunyuan-MT 7B如何帮你节省每年数万元API费用? 还在为每月高昂的翻译API账单发愁吗?或者,你是否经历过这样的场景:深夜处理紧急的跨境客户咨询,却因为在线翻译服务限频或网络波动&am…...

什么是 OpenClaw
OpenClaw(曾用名 Clawdbot、Moltbot)是一款开源的个人 AI 助手平台,于 2026 年初在GitHub 上迅速走红,成为近年来增长最快的开源项目之一。它能够在用户自己的设备上本地运行,通过 WhatsApp、Telegram、Discord、飞书、…...

基于单片机的超声波水塔液位测量系统protues仿真 本设计基于单片机的超声波水塔液位测量和智...
基于单片机的超声波水塔液位测量系统protues仿真 本设计基于单片机的超声波水塔液位测量和智能控制系统主要由硬件与软件两部分组成,硬件是基于AT89C51芯片为核心的超声波水塔液位测量,采用AT89C51单片机进行控制及数据处理,给出了超声波发射…...

update-desktop-database命令用法与技巧总结
update-desktop-database 是一个用于构建桌面文件 MIME 类型缓存数据库的命令行工具。它主要扫描指定目录下的 .desktop 文件,提取它们所能处理的 MIME 类型,并创建一个缓存文件(mimeinfo.cache)。这个缓存极大地提升了系统或应用…...

基于yolov26的多光谱成像的焊缝质量实时检测系统
目录 系统架构设计 数据预处理 网络架构 实时推理优化涉及模型压缩 脚本1:多模态数据预处理与图像配准 脚本2:双分支YOLOv26主干网络架构 脚本3:跨模态特征融合与注意力机制实现 脚本4:训练流程与多模态损失函数 脚本5:实时推理与部署优化 基于多光谱成像的焊缝质…...