python中scrapy
安装环境
pip install scrapy
发现Twisted版本不匹配
卸载pip uninstall Twisted
安装
pip install Twisted==22.10.0
新建scrapy项目
scrapy startproject 项目名
注意:项目名称不允许使用数字开头,也不能包含中文
eg: scrapy startproject scrapy_baidu_01
创建爬虫文件
要在spiders文件夹中去创建爬虫文件
切换路径:cd .\scrapy_baidu_01\scrapy_baidu_01\spiders\
scrapy genspider 爬虫文件的名字 要爬取网页
scrapy genspider baidu www.baidu.com
import scrapyclass BaiduSpider(scrapy.Spider):# 爬虫的名字 用于运行爬虫的时候 使用的值name = "baidu"# 允许访问的域名allowed_domains = ["www.baidu.com"]# 起始的url地址 指的是第一次要访问的域名start_urls = ["https://www.baidu.com"]def parse(self, response):pass
注意反爬:把这行代码注释掉settings.py
# ROBOTSTXT_OBEY = True(注释掉改行,不遵守robots协议,通常不用遵守)
运行爬虫代码
scrapy crawl baidu
项目结构

汽车之家案例
import scrapyclass CarSpider(scrapy.Spider):name = "car"allowed_domains = ["www.autohome.com.cn"]start_urls = ["https://www.autohome.com.cn/price/brandid_15"]def parse(self, response):name_list = response.xpath('//div[@class="tw-mt-1 tw-px-4"]/a/text()')price_list = response.xpath('//div[@class="tw-mt-1 tw-px-4"]/p/text()')for i in range(len(name_list)):name = name_list[i].extract()price = price_list[i].extract()print(name, price)
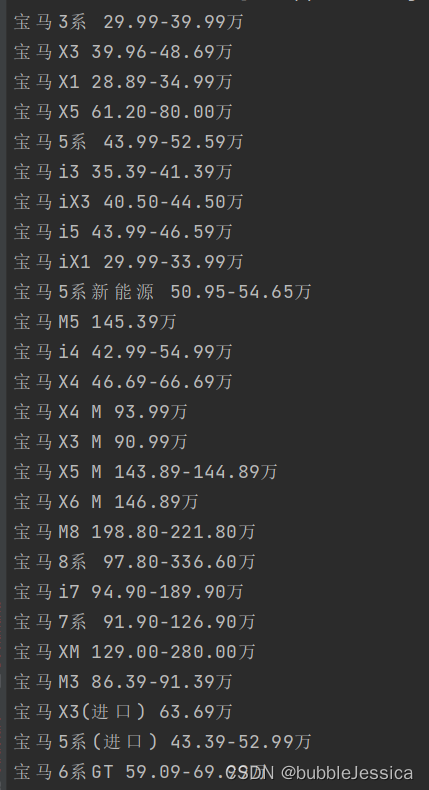
scrapy工作原理
当当网爬取数据
管道封装、开启多条管道、多页下载
items.py
import scrapyclass ScrapyDangdang04Item(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()# 图片src = scrapy.Field()# 名称name = scrapy.Field()# 价格price = scrapy.Field()# passpipelines.py
# 解决文件频繁打开的场景
# 如果想使用管道的话,就必须在settings.xml开启管道
class ScrapyDangdang04Pipeline:def open_spider(self, spider):# 使用w模式就行# 因为只打开但没关self.fp = open('book.json', 'w', encoding='utf-8')# item就是yield后面的对象bookdef process_item(self, item, spider):# (1)write方法里面需要是字符串# (2)w模式 会每一个对象都打开一次文件 覆盖之前的内容# (3)所以使用a模式追加模式,不推荐# with open('book.json', 'w', encoding='utf-8') as fp:# fp.write(str(item))self.fp.write(str(item))return itemdef close_spider(self, spider):self.fp.close()import urllib.request# 多条管道开启
# 在settings.py开启管道class DangDangDownloadPineline:def process_item(self, item, spider):url = 'http:' + item.get('src')filename = './books/' + item.get('name') + '.jpg'urllib.request.urlretrieve(url=url, filename=filename)return item
settings.py
ITEM_PIPELINES = {# 管道可以有多个 管道有优先级 值越小 优先级越高 优先级范围0~1000"scrapy_dangdang_04.pipelines.ScrapyDangdang04Pipeline": 300,"scrapy_dangdang_04.pipelines.DangDangDownloadPineline": 301,
}dang.py
import scrapy
from scrapy_dangdang_04.items import ScrapyDangdang04Itemclass DangSpider(scrapy.Spider):name = "dang"# 一般情况下,我们要调整domains范围,只写域名就可以了allowed_domains = ["category.dangdang.com"]start_urls = ["https://category.dangdang.com/cp01.01.02.00.00.00.html"]# 多页下载数据 初始化urlbase_url = 'https://category.dangdang.com/pg'page = 1def parse(self, response):# pipelines管道# items下载数据# src=//ul[@id="component_59"]//li//img/@src# alt=//ul[@id="component_59"]//li//img/@alt# price=//ul[@id="component_59"]//li//p[@class="price"]//span[1]/text()# 所有selector对象都可以再次调用xpath方法li_list = response.xpath('//ul[@id="component_59"]//li')for li in li_list:# 图片做了懒加载# 需要将src改为data-originalsrc = li.xpath('.//img/@data-original').extract_first()# 注意第一张图片和其他图片是不一样的属性# 第一张图片使用src,其他图片使用data-originalif src:src = srcelse:src = li.xpath('.//img/@src').extract_first()name = li.xpath('.//img/@alt').extract_first()price = li.xpath('.//p[@class="price"]//span[1]/text()').extract_first()# print(src, name, price)book = ScrapyDangdang04Item(src=src, name=name, price=price)# 获取一个book就将book交给pipelinesyield book# 每一页爬取的业务逻辑都是一样# 所以我们只需要将执行那个页的请求再次调用parse方法就可以了# https://category.dangdang.com/pg2-cp01.01.02.00.00.00.html 第2页# https://category.dangdang.com/pg3-cp01.01.02.00.00.00.html 第3页# https://category.dangdang.com/pg4-cp01.01.02.00.00.00.html 第4页if self.page < 6:self.page = self.page + 1url = self.base_url + str(self.page) + 'cp01.01.02.00.00.00.html'# 怎么调用parse方法# scrapy.Request就是scrapy的get请求# url就是请求地址# callback就是要执行的函数,注意不需要加括号yield scrapy.Request(url=url, callback=self.parse())
结果爬虫出60条数据
{'name': ' 那个不为人知的故事','price': '¥39.10','src': '//img3m2.ddimg.cn/46/8/29124262-1_b_5.jpg'
}{'name': ' 朝俞(全2册) 限定正面白版护封+背面黑版护封套装 原名伪装学渣 青春畅销小说实体书','price': '¥79.60','src': '//img3m9.ddimg.cn/16/20/29579929-1_b_2.jpg'
}{'name': ' 大哥(套装共2册)','price': '¥59.50','src': '//img3m8.ddimg.cn/72/12/23945598-1_b_1706687985.jpg'
}{'name': ' 偏偏宠爱','price': '¥59.80','src': '//img3m1.ddimg.cn/86/23/28523471-1_b_6.jpg'
}{'name': ' 人鱼陷落4(当当专享电子屏保,限时印特签,畅销书作者麟潜口碑代表作!)','price': '¥52.80','src': '//img3m2.ddimg.cn/92/32/29689202-1_b_1714458199.jpg'
}{'name': ' 可爱过敏原:全2册(人气作家稚楚温馨之作。随书附赠多重主题赠品)','price': '¥103.50','src': '//img3m6.ddimg.cn/5/16/29629616-1_b_1713412892.jpg'
}{'name': ' 人鱼陷落3(长佩原创人气文学,高人气作者麟潜口碑代表作!)','price': '¥51.70','src': '//img3m7.ddimg.cn/39/6/29634897-1_b_1703060622.jpg'
}{'name': ' 人鱼陷落全四册(畅销书作者麟潜口碑代表作!)','price': '¥207.00','src': '//img3m7.ddimg.cn/72/26/29689677-1_b_1708488434.jpg'
}{'name': ' 朝俞1+2套装(全2册)','price': '¥79.60','src': '//img3m1.ddimg.cn/82/1/29397241-1_b_1.jpg'
}{'name': ' 吾乡有情人(李现、周雨彤主演影视剧《春色寄情人》原著小说,桀骜遗体整容师VS霸气医疗销售,演绎熟龄男女的极致拉扯和双向救','price': '¥68.40','src': '//img3m6.ddimg.cn/18/36/29690316-1_b_1714982275.jpg'
}{'name': ' 退烧(全二册)舒虞浪漫新作','price': '¥69.80','src': '//img3m7.ddimg.cn/27/35/29299077-1_b_6.jpg'
}{'name': ' 你失信了','price': '¥39.80','src': '//img3m7.ddimg.cn/20/2/29485487-1_b_4.jpg'
}{'name': ' 偷偷藏不住(全二册) 晋江金榜 赵露思、陈哲远 主演 影视原著 桑稚VS段嘉许 言情大神竹已难哄奶油味暗恋','price': '¥59.80','src': '//img3m6.ddimg.cn/25/7/28525786-1_b_7.jpg'
}{'name': ' 人鱼陷落(高人气作者麟潜口碑代表作!)','price': '¥51.70','src': '//img3m3.ddimg.cn/2/32/29411813-1_b_5.jpg'
}{'name': ' 骄阳似我(下)','price': '¥36.00','src': '//img3m3.ddimg.cn/71/16/29687003-1_b_1713320766.jpg'
}{'name': ' 蔷薇信号(亲签版)双女主青春成长短篇故事集','price': '¥41.20','src': '//img3m8.ddimg.cn/98/8/29570408-1_b_1699842163.jpg'
}{'name': ' 人鱼陷落2(高人气作者麟潜口碑代表作!)','price': '¥51.70','src': '//img3m0.ddimg.cn/33/12/29510250-1_b_3.jpg'
}{'name': ' 他最野了(全2册)曲小蛐代表作','price': '¥68.00','src': '//img3m8.ddimg.cn/39/16/29150688-1_b_1689332684.jpg'
}{'name': ' 苍兰诀 (当当专享人气画手眠狼绘制印刷海报)九鹭非香','price': '¥37.00','src': '//img3m5.ddimg.cn/60/22/29171895-1_b_21.jpg'
}{'name': ' 微微一笑很倾城','price': '¥36.00','src': '//img3m6.ddimg.cn/74/29/29433566-1_b_1713236624.jpg'
}{'name': ' 青:陪安东尼度过漫长岁月5','price': '¥47.00','src': '//img3m4.ddimg.cn/8/35/29381624-1_b_14.jpg'
}{'name': ' 美滋滋(全2册)','price': '¥47.50','src': '//img3m3.ddimg.cn/49/20/29291773-1_b_1704784675.jpg'
}{'name': ' 与岁长宁.下册.完结篇(超人气追光救赎古言《嫁反派》。新增未公开番外13000字。你是我的夫君,不是怪物。你只是不能像爱','price': '¥48.00','src': '//img3m7.ddimg.cn/32/14/29580737-1_b_1694066771.jpg'
}{'name': ' 元气少女缘结神:鞍马山夜话(甜蜜少女系漫画官方中文纪念版首次上市!)','price': '¥30.50','src': '//img3m5.ddimg.cn/40/5/24165445-1_b_18.jpg'
}{'name': ' 红酒绿【限量亲签版+定制十二月情话贴纸+情头贴纸】苏他','price': '¥39.80','src': '//img3m1.ddimg.cn/5/13/29526161-1_b_1702439623.jpg'
}{'name': ' 蓝:陪安东尼度过漫长岁月VI(首发加赠当当限定赠品:PET菲林胶片x2张)陪安系列的15年暖心陪伴','price': '¥47.00','src': '//img3m5.ddimg.cn/92/34/29554265-1_b_1691727485.jpg'
}{'name': ' 骄阳似我(上下 两册套装)','price': '¥72.00','src': '//img3m4.ddimg.cn/72/17/29687004-1_b_1711521722.jpg'
}{'name': ' 来我怀里躲躲【限量亲签版+定制向你靠近时钟透卡】岁见','price': '¥64.90','src': '//img3m5.ddimg.cn/77/4/29513165-1_b_1.jpg'
}{'name': ' 《尤物》新锐人气作者二喜口碑代表作!穷追不舍总裁周易vs清冷美艳公关姜迎,十年暗恋,双向救赎,势均力敌,炙热沦陷!明知道','price': '¥45.00','src': '//img3m2.ddimg.cn/29/0/29559152-1_b_1709519251.jpg'
}{'name': ' 与岁长宁.上册(追光救赎/高口碑古言《嫁反派》娇娇贵女x乖张美强惨“反派”男主,她是他心尖上的善念,是刻在他伤痕上的名字','price': '¥48.00','src': '//img3m5.ddimg.cn/20/2/29580725-1_b_1710384827.jpg'
}{'name': ' 单恋轨道(亲签版)艾鱼继《藏夏》之后再出青春暗恋之作','price': '¥42.00','src': '//img3m1.ddimg.cn/14/32/29628041-1_b_1702025455.jpg'
}{'name': ' 可爱多少钱一斤(共2册)','price': '¥42.90','src': '//img3m1.ddimg.cn/80/29/25574651-1_b_4.jpg'
}{'name': ' 我不喜欢这世界,我只喜欢你修订版 乔一 畅销百万册!由吴倩张雨剑主演的超甜电视剧我只喜欢你原著小说','price': '¥37.00','src': '//img3m6.ddimg.cn/64/10/27859456-1_b_9.jpg'
}{'name': ' 顾小姐和曲小姐【赠:双熙写真签名照*1+影后盛典镭射票*1】(晚之著优质都市娱乐圈女性互助向励志作品)','price': '¥49.80','src': '//img3m3.ddimg.cn/50/33/29496803-1_b_3.jpg'
}{'name': ' 娱乐圈是我的,我是你的 全3册 随机特签(许摘星x岑风,谢谢我的那束光,我永远爱你)','price': '¥70.00','src': '//img3m9.ddimg.cn/69/33/29161509-1_b_3.jpg'
}{'name': ' 《你是长夜,也是灯火》典藏版','price': '¥48.00','src': '//img3m3.ddimg.cn/69/1/29686803-1_b_1706770978.jpg'
}{'name': ' 橘子汽水(独家定制阿司匹林电子签名数字藏品——白城“舟渔”签名卡)','price': '¥44.10','src': '//img3m7.ddimg.cn/76/29/29619787-1_b_1693974706.jpg'
}{'name': ' 旧梦1913(当当专享刷边特签版)沈鱼藻著','price': '¥36.80','src': '//img3m9.ddimg.cn/93/8/29597529-1_b_1688546895.jpg'
}{'name': ' 草木生','price': '¥33.40','src': '//img3m8.ddimg.cn/52/33/29162878-1_b_1712107816.jpg'
}{'name': ' 一级律师 木苏里 全球高考作家木苏里又一口碑之作 纯爱都市 收录番外 强强联手','price': '¥54.80','src': '//img3m5.ddimg.cn/19/13/28554985-1_b_6.jpg'
}{'name': ' 晋江人气作者木羽愿高口碑双向奔赴代表作《纵我情深》破镜重圆vs蓄谋已久,全文高甜!新增出版番外《婚后生活》,续写“傅姜夫','price': '¥45.00','src': '//img3m5.ddimg.cn/10/21/29549035-1_b_3.jpg'
}{'name': ' 暗恋这件难过的小事','price': '¥39.80','src': '//img3m3.ddimg.cn/72/14/29502963-1_b_1.jpg'
}{'name': ' 白桃乌龙(全2册)','price': '¥64.90','src': '//img3m6.ddimg.cn/31/36/29342146-1_b_1700024542.jpg'
}{'name': ' 炽野(全2册)【定制Q版贴纸】','price': '¥55.60','src': '//img3m8.ddimg.cn/73/21/29372878-1_b_4.jpg'
}{'name': ' 逐风完结篇 (网络原名:校草太霸道了怎么破)','price': '¥46.30','src': '//img3m2.ddimg.cn/72/35/29597112-1_b_1688460724.jpg'
}{'name': ' 《别来无恙》晋江文学城畅销书作家 北南 经典虐心作品原著同名漫画 破镜重圆天花板','price': '¥45.00','src': '//img3m9.ddimg.cn/97/20/29490019-1_b_3.jpg'
}{'name': ' 冬天请与我恋爱【定制初雪海报】','price': '¥42.80','src': '//img3m7.ddimg.cn/33/22/29509557-1_b_1.jpg'
}{'name': ' 逐风 (网络原名:校草太霸道了怎么破)','price': '¥46.30','src': '//img3m4.ddimg.cn/65/16/29597204-1_b_1688460528.jpg'
}{'name': ' 《阿也(全二册)》刷边典藏版 我喜欢你的信息素 引路星 全新番外','price': '¥79.60','src': '//img3m5.ddimg.cn/23/20/29673095-1_b_1704161259.jpg'
}{'name': ' 濯枝(全2册)咬枝绿','price': '¥69.80','src': '//img3m8.ddimg.cn/42/2/29482638-1_b_1692858478.jpg'
}{'name': ' 青+蓝:陪安东尼度过漫长岁月V+VI 双册套装','price': '¥94.10','src': '//img3m9.ddimg.cn/98/7/29555459-1_b_1.jpg'
}{'name': ' 如果月亮有秘密(全2册)春风榴火作品,网络原名:反派大佬让我重生后救他','price': '¥64.90','src': '//img3m6.ddimg.cn/88/23/29361706-1_b_1709096502.jpg'
}{'name': ' 等风轻抚你(全二册)(网络原名《等风热吻你》)','price': '¥59.80','src': '//img3m2.ddimg.cn/80/20/28971242-1_b_3.jpg'
}{'name': ' 一级律师2 木苏里 纯爱都市 公理定下,正义不朽','price': '¥54.80','src': '//img3m4.ddimg.cn/21/4/28983954-1_b_1706002794.jpg'
}{'name': ' 狼行成双(一个冷漠少言,一个热情豪放,两个逗比相爱相杀,蠢萌蠢萌的兄弟情!悦读纪)','price': '¥53.00','src': '//img3m9.ddimg.cn/85/20/23691379-1_b_1701672854.jpg'
}{'name': ' 他的小仙女1+2(套装全两册)','price': '¥68.40','src': '//img3m6.ddimg.cn/73/14/26436736-1_b_2.jpg'
}{'name': ' 江海不渡【限量特签版,定制小世界贴纸+初雪拍立得】人气作家吕亦涵代表作','price': '¥39.80','src': '//img3m7.ddimg.cn/21/35/29549937-1_b_1709179306.jpg'
}{'name': ' 宁愿(全2册)','price': '¥69.80','src': '//img3m5.ddimg.cn/92/21/29246375-1_b_21.jpg'
}{'name': ' 今日晴','price': '¥39.80','src': '//img3m2.ddimg.cn/44/12/29492342-1_b_1712457271.jpg'
}{'name': ' 隐婚(艳光四射的“钓系”美人vs声名显赫的偏执少爷,高人气作家半截白菜“追妻”系列全新力作)','price': '¥68.40','src': '//img3m2.ddimg.cn/75/31/29565732-1_b_1.jpg'
}电影天堂爬取数据
items.py
import scrapyclass ScrapyMovie05Item(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()name = scrapy.Field('')src = scrapy.Field('')pass
settings,py
ITEM_PIPELINES = {"scrapy_movie_05.pipelines.ScrapyMovie05Pipeline": 300,
}pipelines.py
class ScrapyMovie05Pipeline:def open_spider(self, spider):self.fp = open('movie.json', 'w', encoding='utf-8')def process_item(self, item, spider):self.fp.write(str(item))return itemdef close_spider(self, spider):self.fp.close()mv.py
get请求使用scrapy.Request
import scrapy
from scrapy_movie_05.items import ScrapyMovie05Itemclass MvSpider(scrapy.Spider):name = "mv"allowed_domains = ["dytt8.net"]start_urls = ["https://dytt8.net/html/gndy/china/index.html"]def parse(self, response):# 要第一页的名字 和第2页的图片a_list = response.xpath('//div[@class="co_content8"]//td[2]//a[2]')for a in a_list:# 获取第一页的名字和要点击的链接name = a.xpath('./text()').extract_first()href = a.xpath('./@href').extract_first()# print(name, href)# 第二页的地址url = 'https://dytt8.net/' + href# print(url)# 对第二页的链接进行访问yield scrapy.Request(url=url, callback=self.parse_second, meta={'name': name})passdef parse_second(self, response):# 拿不到数据的情况下,需要检查xpath语法src = response.xpath('//div[@id="Zoom"]//img/@src').extract_first()# print(src)# 接受到meta请求参数的值name = response.meta['name']# print(name)movie = ScrapyMovie05Item(name=name, src=src)yield movie
movie.json
{'name': '2022年剧情悬疑《源生罪》BD粤语中字','src': 'https://img9.doubanio.com/view/photo/l_ratio_poster/public/p2890623174.jpg'}{'name': '2024年剧情喜剧《摩登澡堂》HD国语中字','src': 'https://img9.doubanio.com/view/photo/l_ratio_poster/public/p2875809295.jpg'}{'name': '2024年悬疑剧情《逃逸追踪》HD国语中字','src': 'https://i.endpot.com/image/2ZVFM/36.jpg'}{'name': '2023年动作《扎职2:江湖陌路》BD国粤双语中字','src': 'https://img9.doubanio.com/view/photo/l_ratio_poster/public/p2899543296.jpg'}{'name': '2024年喜剧《前途海量》HD国语中字','src': 'https://img9.doubanio.com/view/photo/l_ratio_poster/public/p2908206665.jpg'}{'name': '2024年剧情悬疑《迅兽》HD国语中字','src': 'https://img9.doubanio.com/view/photo/l_ratio_poster/public/p2908064393.jpg'}{'name': '2024年奇幻《林都奇谭》HD国语中字','src': 'https://i.endpot.com/image/Y2ZAW/XQG5p.jpg'}{'name': '2024年爱情奇幻《金牌河东狮吼》HD国语中字','src': 'https://img9.doubanio.com/view/photo/l_ratio_poster/public/p2908011240.jpg'}{'name': '2024年动作《2024年动作《新龙门客栈之英雄觉醒》HD国语中字》HD国语中字','src': 'https://img9.doubanio.com/view/photo/l_ratio_poster/public/p2908297819.jpg'}{'name': '2024年动作《血悬棺》HD国语中字','src': 'https://i.endpot.com/image/OJPFF/LK5Hk.jpg'}{'name': '2023年爱情历史战争《天命玄女》HD国语中字','src': 'https://img9.doubanio.com/view/photo/l_ratio_poster/public/p2895950467.jpg'}{'name': '2023年动作惊悚《鳄梦岛》HD国语中字','src': 'https://img9.doubanio.com/view/photo/l_ratio_poster/public/p2896236229.jpg'}{'name': '2024年动作悬疑《借命人》HD国语中字','src': 'https://img9.doubanio.com/view/photo/l_ratio_poster/public/p2908493295.jpg'}{'name': '2024年剧情《彩虹线》HD国语中字','src': 'https://img9.doubanio.com/view/photo/l_ratio_poster/public/p2902413934.jpg'}{'name': '2024年喜剧《东北狠人沙猩猩》HD国语中字','src': 'https://img9.doubanio.com/view/photo/l_ratio_poster/public/p2908465644.jpg'}{'name': '2024年恐怖喜剧《超神经械劫案下》BD国粤双语中字','src': 'https://img9.doubanio.com/view/photo/l_ratio_poster/public/p2886145179.jpg'}{'name': '2023年喜剧《踢球吧少年》HD国语中字','src': 'https://img9.doubanio.com/view/photo/l_ratio_poster/public/p2897496282.jpg'}{'name': '2023年剧情喜剧《热烈/惊叹号》BD国语中字','src': 'https://img9.doubanio.com/view/photo/l_ratio_poster/public/p2895553074.jpg'}{'name': '2024年科幻悬疑《AR物语/莫杀我》HD国语中字','src': 'https://img9.doubanio.com/view/photo/l_ratio_poster/public/p2908432151.jpg'}{'name': '2024年科幻动作《变体》HD国语中字','src': 'https://img9.doubanio.com/view/photo/l_ratio_poster/public/p2908505824.jpg'}{'name': '2024年动作《风速极战》HD国语中字','src': 'https://img9.doubanio.com/view/photo/l_ratio_poster/public/p2877518474.jpg'}{'name': '2024年剧情《我们一起摇太阳》HD国语中字','src': 'https://img9.doubanio.com/view/photo/l_ratio_poster/public/p2904467472.jpg'}{'name': '2024年悬疑《枪不打四》HD国语中字','src': 'https://i.endpot.com/image/4V88C/beXUd.jpg'}{'name': '2024年爱情奇幻《狐王传说》HD国语中字','src': 'https://i.endpot.com/image/EXZOA/b2aau.jpg'}{'name': '2024年动作奇幻《异域狼孩》HD国语中字','src': 'https://i.endpot.com/image/JLPS1/XjYfj.jpg'}读书网爬取数据
创建爬虫文件:scrapy genspider -t crawl read https://www.dushu.com/book/1188.html
read.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy_readbook_06.items import ScrapyReadbook06Itemclass ReadSpider(CrawlSpider):name = "read"allowed_domains = ["www.dushu.com"]start_urls = ["https://www.dushu.com/book/1188_1.html"]rules = (Rule(LinkExtractor(allow=r"/book/1188_\d+\.html"),callback="parse_item",follow=False),)def parse_item(self, response):img_list = response.xpath('//div[@class="bookslist"]//img')for img in img_list:name = img.xpath('./@data-original').extract_first()src = img.xpath('./@alt').extract_first()book = ScrapyReadbook06Item(name=name, src=src)yield book
items.py
import scrapyclass ScrapyReadbook06Item(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()name = scrapy.Field()src = scrapy.Field()# passsettings.py
# Obey robots.txt rules
# 不遵守robots协议 一般情况下不用遵守
# ROBOTSTXT_OBEY = True# 打开管道
ITEM_PIPELINES = {"scrapy_readbook_06.pipelines.ScrapyReadbook06Pipeline": 300,
}pipelines.py
class ScrapyReadbook06Pipeline:def open_spider(self, spider):self.fp = open('book.json', 'w', encoding='utf-8')def process_item(self, item, spider):self.fp.write(str(item))return itemdef close_spider(self, spider):self.fp.close()
数据入库
settings.xml
# 数据库配置信息
DB_HOST = '192.168.231.130'
DB_PORT = 3306
DB_USER = 'root'
DB_PASSWORD = 'root'
DB_NAME = 'spider01'
DB_CHARSET = 'utf8'# 配置管道
ITEM_PIPELINES = {"scrapy_readbook_06.pipelines.ScrapyReadbook06Pipeline": 300,# MysqlPipeline"scrapy_readbook_06.pipelines.MysqlPipeline": 301,
}安装pymysql
pip install pymysql -i https://pypi.douban.com/simple
pipelines.py
# 加载settings配置文件
from scrapy.utils.project import get_project_settings
import pymysqlclass MysqlPipeline:def open_spider(self, spider):settings = get_project_settings()self.host = settings['DB_HOST']self.port = settings['DB_PORT']self.user = settings['DB_USER']self.password = settings['DB_PASSWORD']self.name = settings['DB_NAME']self.charset = settings['DB_CHARSET']self.connect()def connect(self):self.conn = pymysql.connect(host=self.host,port=self.port,user=self.user,password=self.password,db=self.name,charset=self.charset)self.cursor = self.conn.cursor()def process_item(self, item, spider):sql = 'insert into book(name,src) values ("{}","{}")'.format(item['name'], item['src'])# 执行sql语句self.cursor.execute(sql)# 提交self.conn.commit()return itemdef close_spider(self, spider):self.cursor.close()self.conn.close()read.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy_readbook_06.items import ScrapyReadbook06Itemclass ReadSpider(CrawlSpider):name = "read"allowed_domains = ["www.dushu.com"]start_urls = ["https://www.dushu.com/book/1188_1.html"]rules = (Rule(LinkExtractor(allow=r"/book/1188_\d+\.html"),callback="parse_item",follow=True),)def parse_item(self, response):img_list = response.xpath('//div[@class="bookslist"]//img')for img in img_list:name = img.xpath('./@data-original').extract_first()src = img.xpath('./@alt').extract_first()book = ScrapyReadbook06Item(name=name, src=src)yield book
这里的follow改为True表示不止爬取13页数据,继续跟进,按照提取连接规则进行提取
日志信息和等级

settings.py
# 指定日志级别
LOG_LEVEL = 'WARNING'
# 指定日志文件
LOG_FILE = 'logdemo.log'scrapy中Post请求
注意使用FormRequest
testpost.py
import scrapyimport jsonclass TestpostSpider(scrapy.Spider):name = "testpost"allowed_domains = ["fanyi.baidu.com"]# post请求 如果没有参数 这个请求没有意义# 所以这个start_urls没有用# start_urls = ["https://fanyi.baidu.com/sug"]## def parse(self, response):# passdef start_requests(self):url = 'https://fanyi.baidu.com/sug'data = {'kw': 'final'}yield scrapy.FormRequest(url=url, formdata=data, callback=self.parse_second)def parse_second(self, response):content = response.textobj = json.loads(content, encoding='utf-8')print(obj)
相关文章:
python中scrapy
安装环境 pip install scrapy 发现Twisted版本不匹配 卸载pip uninstall Twisted 安装 pip install Twisted22.10.0 新建scrapy项目 scrapy startproject 项目名 注意:项目名称不允许使用数字开头,也不能包含中文 eg: scrapy startproject scrapy_baidu_…...

基础语法总结 —— Python篇
1、环境搭建 建议直接安装 PyCharm (Community Edition) Python3.x版本,前者是一个很好用的编译器,后者是Python的运行环境之类的,安装参考https://mp.csdn.net/mp_blog/creation/editor/139511640 2、标识符 第一个…...
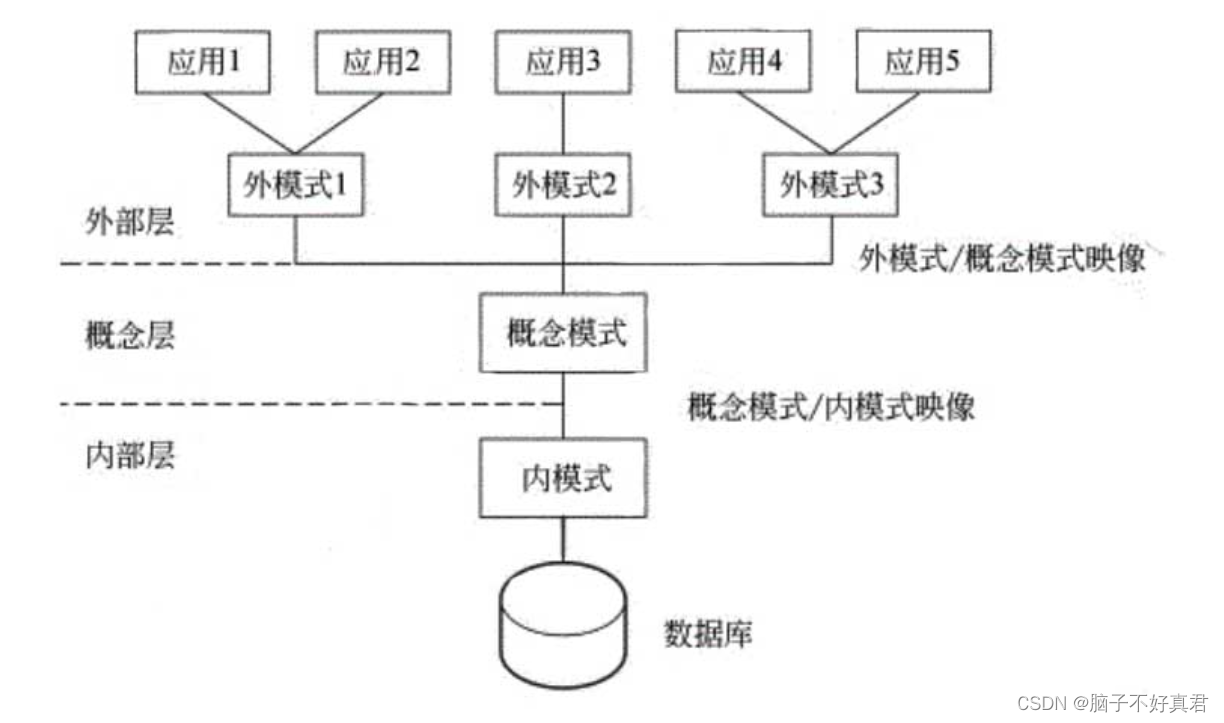
数据库系统概述选择简答概念复习
目录 一、组成数据库的三要素 二、关系数据库特点 三、三级模式、二级映像 四、视图和审计提供的安全性 审计(Auditing) 视图(Views) 五、grant、revoke GRANT REVOKE 六、三种完整性 实体完整性 参照完整性 自定义完整性 七、事务的特性ACDI 原子性(Atomicity)…...

template标签
在HTML中,<template> 标签是一个用于封装可重用内容的非显式元素。它不直接显示在网页上,而是作为一个模板,用来定义一组HTML结构和样式,可以在JavaScript中实例化多次,动态地插入到文档的不同位置。这在创建复杂…...
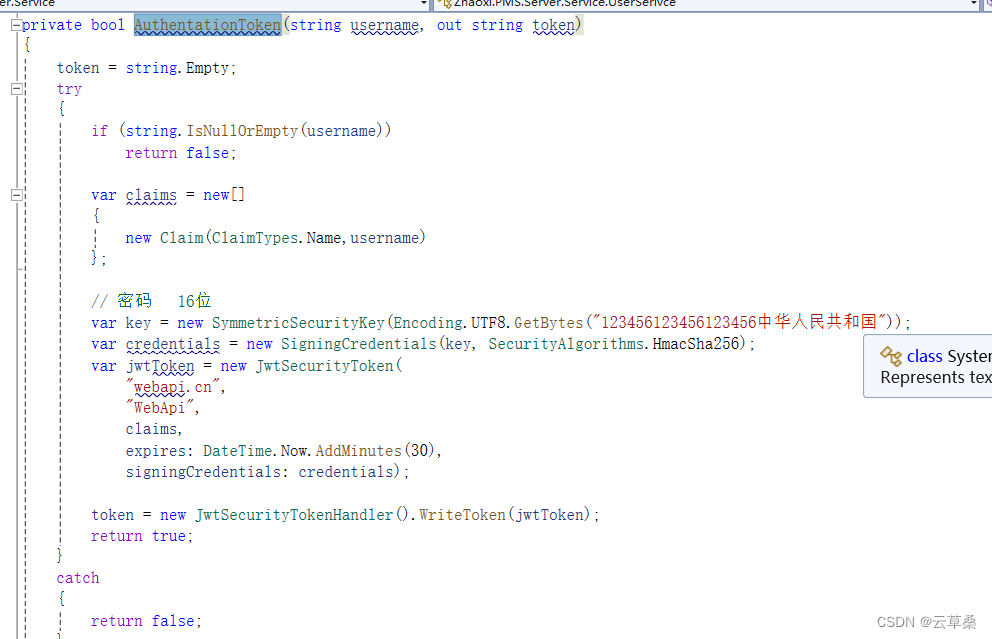
WPF 程序 分布式 自动更新 登录 打包
服务器server端 core api 客户端WPF // 检查应用更新 //1、获取最新文件列表 // var files fileService.GetUpgradeFiles(); // 2、文件判断,新增的直接下载;更新的直接下载;删除的直接删除 // 客户端本地需要一个记录…...
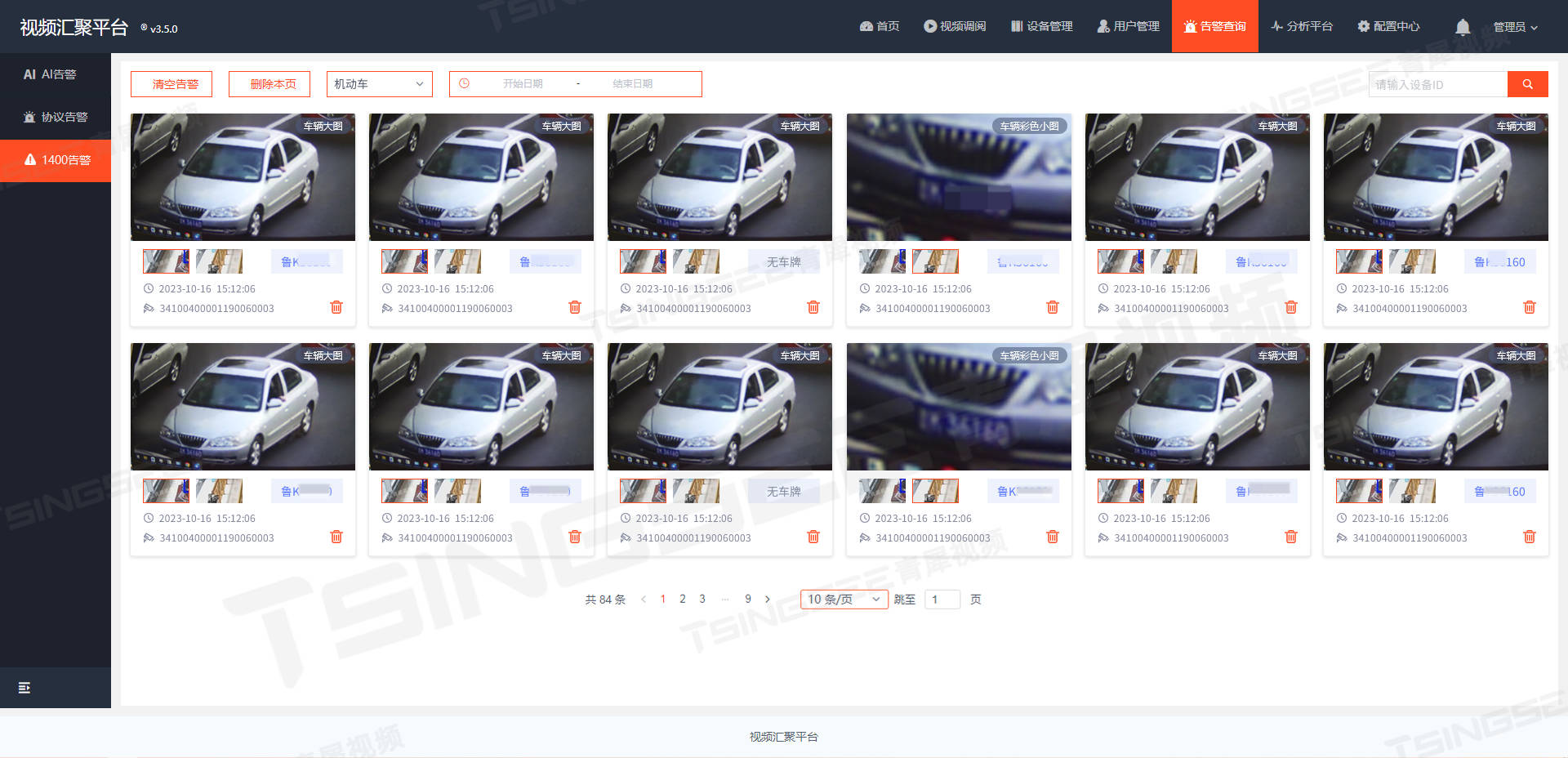
视频汇聚安防综合管理平台EasyCVR支持GA/T 1400视图库标准及设备接入配置
一、概述 视频汇聚安防综合管理平台EasyCVR视频监控系统已经与公安部GA/T 1400视图库标准协议实现了对接,即《公安视频图像信息应用系统》。 安防监控系统EasyCVR支持采用GA/T 1400进行对接,可实现人脸数据使用的标准化、合规化。其采用统一接口对接雪…...

pgsql给单独数据库制定账号权限
登录到PostgreSQL: 使用psql或其他PostgreSQL客户端,以具有足够权限的账号(如postgres或superuser)登录。 2. 创建新账号: sql复制代码 CREATE USER new_user WITH PASSWORD your_secure_password; 注意:将your_secure_passwor…...

【Docker安装】Ubuntu系统下部署Docker环境
【Docker安装】Ubuntu系统下部署Docker环境 前言一、本次实践介绍1.1 本次实践规划1.2 本次实践简介二、检查本地环境2.1 检查操作系统版本2.2 检查内核版本2.3 更新软件源三、卸载Docker四、部署Docker环境4.1 安装Docker4.2 检查Docker版本4.3 配置Docker镜像加速4.4 启动Doc…...

Flink Kafka获取数据写入到MongoDB中 样例
简述 Apache Flink 是一个流处理和批处理的开源框架,它允许从各种数据源(如 Kafka)读取数据,处理数据,然后将数据写入到不同的目标系统(如 MongoDB)。以下是一个简化的流程,描述如何…...

Android Jetpack Compose入门教程(二)
一、列表和动画 列表和动画在应用内随处可见。在本课中,您将学习如何利用 Compose 轻松创建列表并添加有趣的动画效果。 1、创建消息列表 只包含一条消息的聊天略显孤单,因此我们将更改对话,使其包含多条消息。您需要创建一个可显示多条消…...
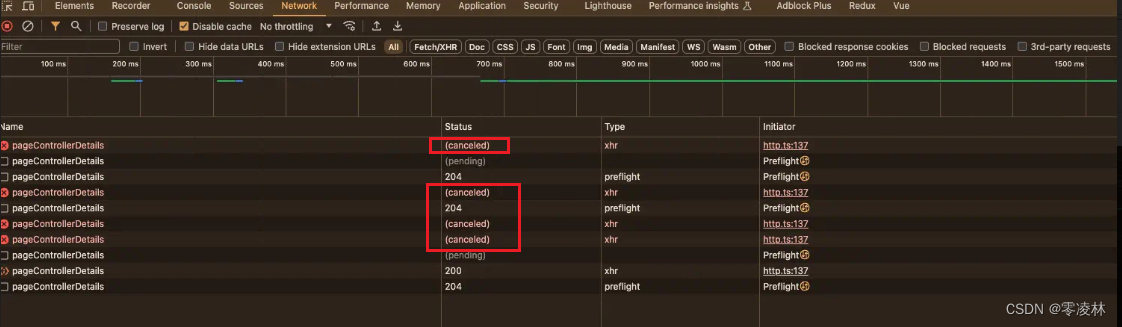
如何避免接口重复请求(axios推荐使用AbortController)
前言: 我们日常开发中,经常会遇到点击一个按钮或者进行搜索时,请求接口的需求。 如果我们不做优化,连续点击按钮或者进行搜索,接口会重复请求。 以axios为例,我们一般以以下几种方法为主: 1…...

算法设计与分析:网络流求解棒球赛淘汰问题C++
目录 一、实验目的 二、问题描述 三、实验要求 四、算法思想 1、明显的:win[i]+remain[i][j]<> 2、不明显的:最大流 3、操作 3.1 先读入相关信息(邻接矩阵**k),进行一遍“明显的”判断。 3.2 对剩下的“不明显的”的每个球队构建流网络(邻接表vector< ve…...

Linux Ubuntu 24.04 C语言gcc编译过程详解
下面是Hello World程序源代码文件hello.c的内容,我们将以它为例来说明源文件到可执行文件的形成过程,主要分4步:预处理、汇编、机器码、链接。 #include <stdio.h> int main () {printf ( "hello, world \n " );return 0; }…...

Python自动化办公篇—pandas操作Excel:读取+查看+选择+清洗+排序+筛选+函数+写入
目录 专栏导读库的介绍库的安装1、读取数据2、查看数据3、选择数据4、数据清洗5、数据排序6、数据筛选7、数据操作8、数据写入总结 专栏导读 文章名称链接Python自动化办公—pyautogui图像定位\点击功能,实现自动截取当前屏幕并检索点击(可制作为游戏点击脚本)点我进行跳转Pyt…...
数据库大作业——音乐平台数据库管理系统
W...Y的主页😊 代码仓库分享💕 《数据库系统》课程设计 :流行音乐管理平台数据库系统(本数据库大作业使用软件sql server、dreamweaver、power designer) 目录 系统需求设计 数据库概念结构设计 实体分析 属性分…...
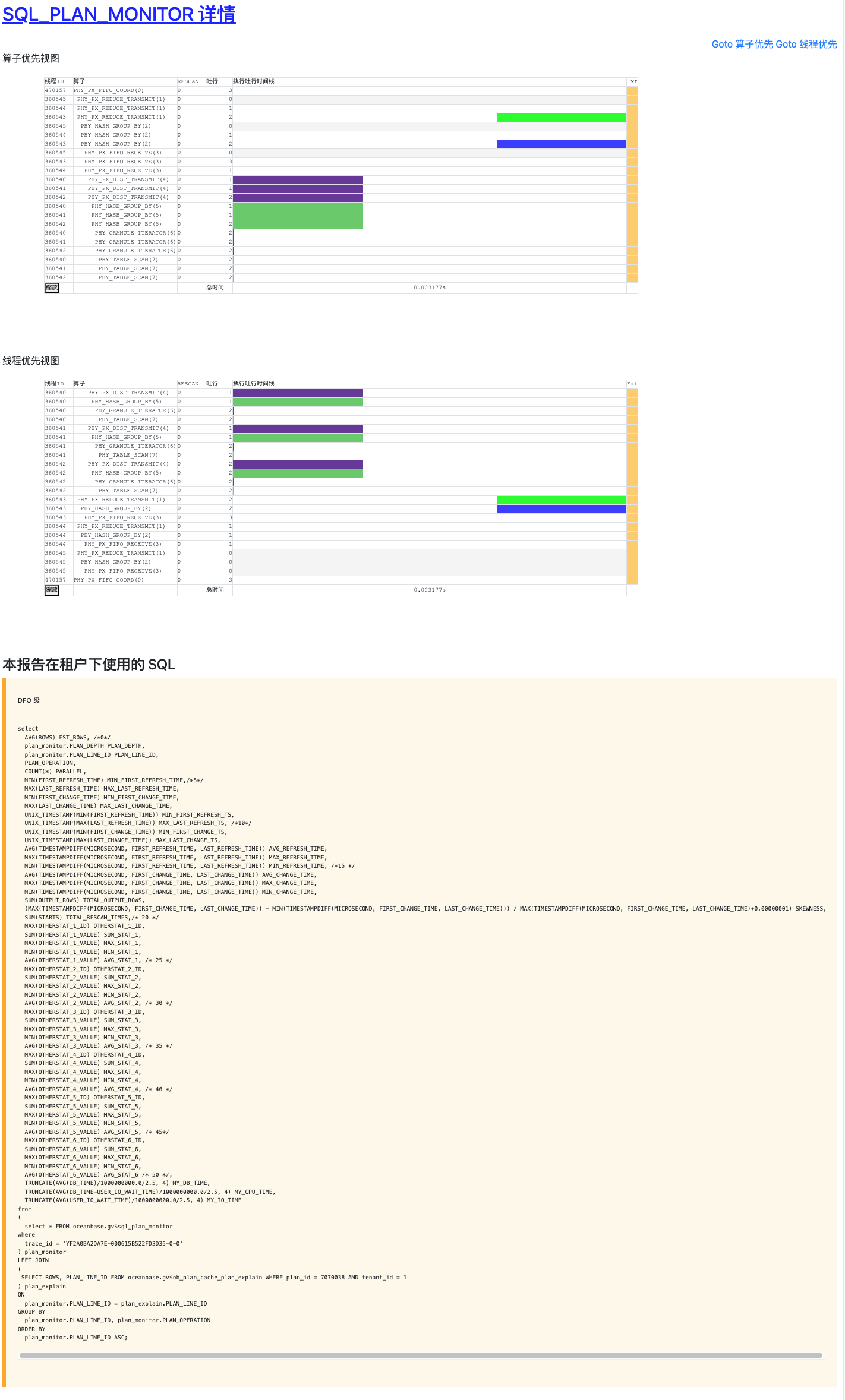
【DBA早下班系列】—— 并行SQL/慢SQL 问题该如何高效收集诊断信息
1. 前言 OceanBase论坛问答区或者提交工单支持的时候大部分时间都浪费在了诊断信息的获取交互上,今天我就其中大家比较头疼的SQL问题,给大家讲解一下如何一键收集并行SQL/慢SQL所需要的诊断信息,减少沟通成本,让大家早下班。 2. …...

用python实现多文件多文本替换功能
用python实现多文件多文本替换功能 今天修改单位项目代码时由于改变了一个数据结构名称,结果有几十个文件都要修改,一个个改实在太麻烦,又没有搜到比较靠谱的工具软件,于是干脆用python手撸了一个小工具,发现python在…...

【DevOps】深入探索Ubuntu操作系统:全面了解
引言 在开源软件的世界里,Ubuntu是一个闪耀的明星。它不仅是一个操作系统,更是一种社区精神、一种共享和协作的文化。Ubuntu操作系统基于强大的Linux内核,由世界各地的开发者共同维护和改进。在这篇博文中,我们将深入探索Ubuntu操…...
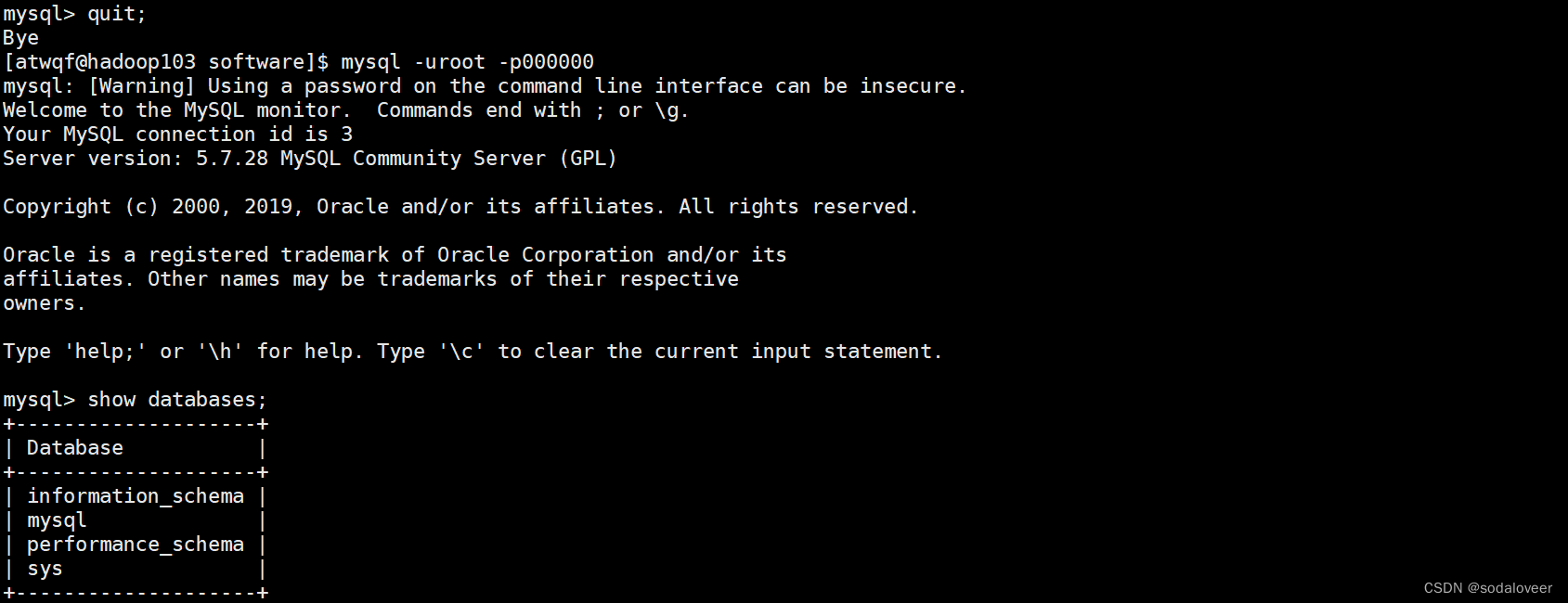
【Linux】—MySQL安装
文章目录 前言一、下载官方MySQL包二、下载完成后,通过xftp6上传到Linux服务器上三、解压MySQL安装包四、在安装目录下执行rpm安装,请按顺序依次执行。五、配置MySQL六、启动MySQL数据库七、退出,重新登录数据库 前言 本文主要介绍在Linux环境…...

【vue】form表单提交validate验证不进valid原因
目录 1. 原因 1. 原因 1.<el-form>是否写了ref“form”。2.是否有其它标签写了ref“form”。3.<el-form>中要写成:model,不能使用v-model。4.自定义的validate要各个路径均能返回callback()。 const validatePass (rule, value, callback) > {if (…...

NCP5623 RGB LED驱动库深度解析与低功耗实践
1. RAKwireless NCP5623 RGB LED库技术解析1.1 芯片级硬件架构与驱动原理NCP5623是安森美(ON Semiconductor)推出的专用IC接口RGB LED驱动芯片,采用紧凑型TSOT-23-6封装,集成三路独立PWM通道、内置电流源及IC从机控制器。其核心设…...

CYBER-VISION零号协议Java集成实战:构建企业级AI微服务应用
CYBER-VISION零号协议Java集成实战:构建企业级AI微服务应用 最近和不少做企业级应用开发的朋友聊天,发现大家有个共同的痛点:好不容易找到一个效果不错的AI模型,比如最近挺火的CYBER-VISION零号协议,但怎么把它顺滑地…...

Qwen-Image企业实操:金融文档图像+文字联合推理的合规审查应用
Qwen-Image企业实操:金融文档图像文字联合推理的合规审查应用 1. 金融合规审查的痛点与解决方案 在金融行业,合规审查是一项耗时耗力的重要工作。传统的人工审查方式面临三大挑战: 效率低下:一份50页的合同需要2-3小时人工审核…...

我的第一个Markmap
我的第一个Markmap 【免费下载链接】markmap 项目地址: https://gitcode.com/gh_mirrors/mar/markmap 核心功能 Markdown解析交互式思维导图自定义样式 应用场景 学习笔记项目规划会议记录 安装方式 npm安装源码编译 ### 2. 生成思维导图在终端中执行以下命令&…...

SmallThinker-3B-Preview惊艳效果展示:超75%样本输出超8K token实录
SmallThinker-3B-Preview惊艳效果展示:超75%样本输出超8K token实录 1. 模型能力概览 SmallThinker-3B-Preview是一个基于Qwen2.5-3b-Instruct精心微调而来的高性能模型,专门针对长文本生成和复杂推理任务进行了深度优化。这个模型最令人印象深刻的特点…...
)
论文全红怎么救?2026最新降重王炸组合:DeepSeek四大免费降AI指令与3款工具深度测评(90%→10%)
知网AIGC检测又升级了,现在除了查重复率,AIGC检测更是必须要过的硬指标。 我之前的一篇内容AI率测出59.2%,后来我花了一周时间研究,发现想降低ai,不能只是简单的替换词汇,必须要改变文本的生成逻辑&#x…...

XMLView:高效驾驭XML文档的智能工具
XMLView:高效驾驭XML文档的智能工具 【免费下载链接】xmlview Powerful XML viewer for Google Chrome and Safari 项目地址: https://gitcode.com/gh_mirrors/xm/xmlview XMLView作为一款专注于浏览器端的XML查看工具,为开发人员、数据分析师及各…...

Qwen3.5-9B效果展示:Qwen3-VL全面超越者——图文推理与代码生成惊艳案例集
Qwen3.5-9B效果展示:Qwen3-VL全面超越者——图文推理与代码生成惊艳案例集 1. 开篇:新一代多模态大模型登场 Qwen3.5-9B作为Qwen系列的最新力作,在多模态理解和代码生成领域实现了质的飞跃。这款模型不仅在图文推理能力上全面超越前代Qwen3…...

Hot100中的:图论专题
图模板 图分为有向图和无向图,入度是指向当前节点的边数,出度是当前节点指向其他节点的边数200.岛屿数量 关键信息一句话总结:遍历网格,遇到陆地就用 DFS / BFS 把整块连通陆地淹掉,并计数方法1:BFS class …...

VMware macOS解锁器终极指南:5分钟轻松在Windows/Linux上运行苹果系统
VMware macOS解锁器终极指南:5分钟轻松在Windows/Linux上运行苹果系统 【免费下载链接】unlocker 项目地址: https://gitcode.com/gh_mirrors/unloc/unlocker 想要在VMware虚拟机中体验macOS的流畅操作,却总是遇到兼容性障碍?VMware …...