必看!!! 2024 最新 PG 硬核干货大盘点(上)
PGConf.dev(原名PGCon,从2007年至2023年)首次在风景如画的加拿大温哥华市举办。此次重新定位的会议带来了全新的视角和多项新的内容,参会体验再次升级。尽管 PGCon 历来更侧重于开发者,吸引来自世界各地的资深开发者、贡献者和研究人员来攻克“棘手难题”,但 PGConf.dev 扩大了其范围,在强调技术讨论的同时,也注重社区贡献。
由 Jonathan Katz 和 Melanie Plageman 等主要成员组成的新会议组织委员会的引领下,PGConf.dev 2024 在保留其深厚的技术研讨历史的同时,也营造一个更加包容和以社区为导向的环境。特别新增了如“PostgreSQL 黑客入门”、“高级补丁反馈会议”和“让 PostgreSQL 黑客行为更具包容性”等会议,旨在指导和激励用户和开发者成为 PostgreSQL 社区的积极贡献者。
以下内容集结了各位大咖对 PG(PostgreSQL)的独到见解与深刻思考,由IvorySQL社区精心整理,与大家一起分享。欢迎大家积极转发分享,点亮“在看”,让更多人领略 PG 的魅力与力量!
✅PUSHING BOUNDARIES WITH EXTENSIONS, FOR EXTENSIONS
Yurii Rashkovskii
Yurii 是新创公司 Omnigres 的创办人,他致力于提供更好的 PostgreSQL 的插件(extension)开发和使用体验。Yurii 认为,Postgres 扩展生态系统在快速发展的同时也会带来一些局限性和问题。
-
Omni manifest - 依赖解析器。当一个插件依赖一个,或多个其它插件时,Omni manifest 会试着在已知的插件存储库,例如 pgxn,下载依赖的插件
-
Omni resolver - 插件以外的依赖解析器,当一个基于 C 语言的插件需要使用 OpenSSL 或是其它 shared library 的函数,他会保证所需的版本和当前加载的shared library 一致。如果是 python 语言的插件,它会确认 import 的模块的版本一致。如果 shared library 或是 python 模块在系统上被改变了,Omni resolver 会更新 pg_proc 所记载的信息判断出它们是否被改变,并及时的报错。
-
Omni migration - 处理插件版本升级产生的差异(函数,数据类型,等)
-
background worker - 如果插件需要启用一个 background worker 可以通过 omni 自动和 PostgreSQL 内核注册。ALTER EXTENSION 时,如果 background worker 要重启,Omni 也可以处理
-
atomic switchboard - Omni 避免多个 background worker 同时启动
-
hooks - 插件通常通过许多不同的钩子(hooks),来改变 PostgreSQL 内核的工作模式,这些钩子目前没有办法被查看,或管理。换句话说,我们没法查看系统目前现在到底有几个钩子被插件替换掉,哪些没被替换掉。这个只有开发者自己知道。Omni 提供了 hooks 的管理,告诉用户哪一些hooks 被哪一些插件给替换了。
-
transaction aware - hooks 的注册,可以被 transaction 保护。如果rollback 了,hooks会自动被卸载。
-
cluster scoping - omni 能做到在不重启的情况下对不同的 database 使用不同的 hooks。现在的 PostgreSQL,如果要换 hooks,需要重启,重新加载extension。
-
共享内存管理 - 插件也可以注册共享内存,但是目前没有一个很好的共享内存管理接口来告诉用户目前有多少共享内存被注册,以及被谁注册(插件还是 PostgreSQL 内核?)。Omni 提供接口查看 共享内存的注册信息以及哪些插件注册了多少共享内存。
-
整体来说,Omni 可以让插件的使用更安全和更透明。
-
Omnigres 处于开源试用状态:https://github.com/omnigres/omnigres


✅SHAVING OFF BYTES AT ANY SCALE: SPACE SAVINGS IN VARIOUS SUBSYSTEMS OF POSTGRESQL
Matthias van de Meent
Matthias 是 Neon 的资深工程师,他在此演讲中介绍 PostgreSQL 内部的子模块内,有哪些地方可以节省存储空间
-
catalogs->pg_node_tree:包含太详细但对用户没什么用的信息,不容易解析。
-
catalogs->pg_attributes:104 字节的头信息,64字节的名字,包含pg_type重复数据,4 byte flag(但用不到那么多 flag 值)。这里有许多空间的浪费
-
table 存储 - 可见性信息 - 如果 tuple 被 frozen 那它总是可见,不需要额外可见性信息,导致空间浪费。这个信息可以考虑存在别处来避免table 存储上的浪费。数据量大的时候是很可观的。
-
数据 padding - 这也是很客观的空间浪费。bool 值其实可以用 1 个 字节表示,但系统会自动padding 到 4 个字节。
-
compression - 某些数据很好压缩,例如时间,但是 PostgreSQL 没有 page-level 的压缩支持(mysql 是有的)- 包含索引。这里也有许多空间的浪费
-
WAL - 一个空的 WAL 记录也会占用 24 字节,里面的 xid 也没有人使用,无端占用了 4 个字节。里面还有2 个字节莫名的 padding
-
Full Page Insert 和 TOAST 表也可以被压缩来节省空间,但目前都不支持
-
TOAST update - 目前很“空间昂贵”,有很多数据的拷贝,需要几乎两倍的额外空间完成,容易造成 TOAST 膨胀,能不能搞一个简单的 API 直接 append 数据?


✅ADAPTIVE QUERY OPTIMIZATION IN POSTGRESQL
Alena Rybakina
Alena 解释自适应查询优化 (AQO) 的机制,它有一个内置的“规划器内存”。规划器的内存通过分析查询执行树并保存实际基数来填充。如果问题情况再次重复(相同查询或具有相同查询子树的另一个查询),规划器将利用这些知识,这可能使其有机会构建正确的计划,从而加快查询执行速度
-
AQO 根据临近节点(neighbot nodes)预估执行计划最终需要扫描的行数(row number)
-
AQO 是基于 k nearest neighbors method 来对一个语句进行不断地“学习”
-
AQO 自动优化执行计划并不断地学习
-
AQO 存储所有已知查询的选择性和节点行数,设置。学习、使用和自动调整 AQO。它存储所有已知查询及其哈希值和查询文本和存储有关执行和计划时间的信息。这些信息可以帮助 AQO 做更好的优化
-
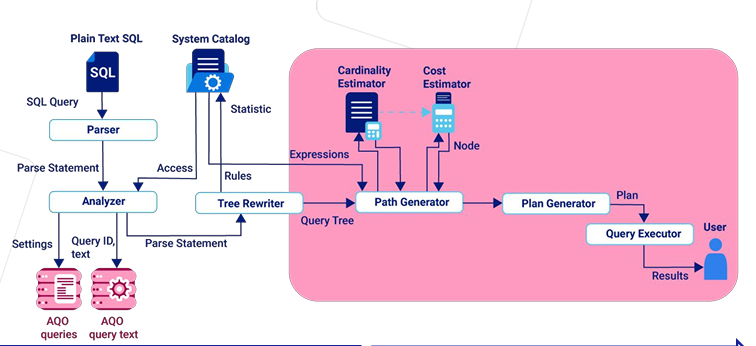
AQO 通过 Analyzer hooks 截获用户的语句
-
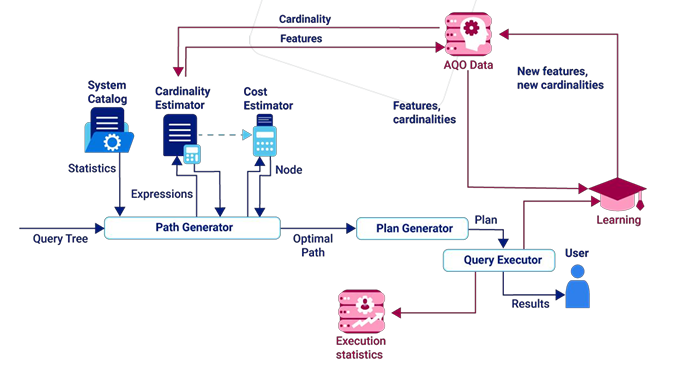
通过 query executor hooks,学习语句执行的信息,并把结果融合到 planner 选择执行方法的时候,选择最优化的执行计划。
-
AQO 根据学习状态,动态改变执行计划来达到最好的执行效果
-
目前仅限于单进程的执行计划,如果planner 选择多进程来执行某个语句 AQO 需要花更多的时间来做学习,效果没有单进程来的好。
-
后续计划:实现从replica 节点学习语句,实现从temporary table 学习语句,从有限数据的语句学习。
-
AQO 处于开源状态,可以在这里找到:https://github.com/postgrespro/aqo

✅POSTGRESQL MEETS ART - USING ADAPTIVE RADIX TREE TO SPEED UP VACUUMIN
Masahiko Sawada
自适应基数树 (ART) 最初发表于 Viktor Leis、Alfons Kemper 和 Thomas Neumann 的论文“自适应基数树:用于主内存数据库的 ARTful 索引”,是一种利用垂直和水平压缩来创建紧凑索引结构的基数树变体。ART 已被众多软件采用,并于 2023 年在 PostgreSQL 中提出。该演讲不仅包括 PostgreSQL 的 ART 实现,还包括另一个名为 TidStore 的新数据结构,该结构可有效存储 TID 并与 VACUUM 集成。
-
ART 是一个,有序列的,可以重建 key 值,支持不同大小的叶子节点的树状结构。
-
有小高度大跨度的属性,会占用稍微多的空间但减少了查找(traversal)的频率
-
支持单值、多值、混合值的键值类型
-
64 位元键值大小,支持共享内存,和用户自定义键值类型
-
Radix Tree 相关的 API 已在 PG17 内引进(lib/radixtree.h)相关测试在 src/test/module/test_radixtress 内
-
新引进 tidstore 结构
-
用来存储大量的 TID 值
-
内部使用 Radix Tree 结构
-
目前支持简单的操作(tidstore.c)
-
用来提升 vacuum 的效率
-
-
以前 vacuum 怎么工作?
-
vacuum 扫描所有死掉的 tuple,然后把它们的 TID 放在一个数组里面
-
然后一个一个扫描,找到他们的 index和相应的table,做 vacuum
-
-
vacuum 问题?
-
空间和效率低下
-
数组有 1GB 大小闲置,(不管maintainence_work_mem 设置多大)
-
-
PG17 把这个数组替换成基于 Radix Tree 的 Tidstore 结构,让它使用更少量的内存,移除了 1GB 闲置,并增加vacuum 效率
-
目前处于新功能状态,测试还没有做的很到位,需要社区朋友们帮忙测试,找出潜在的问题,完善regression 测试等等

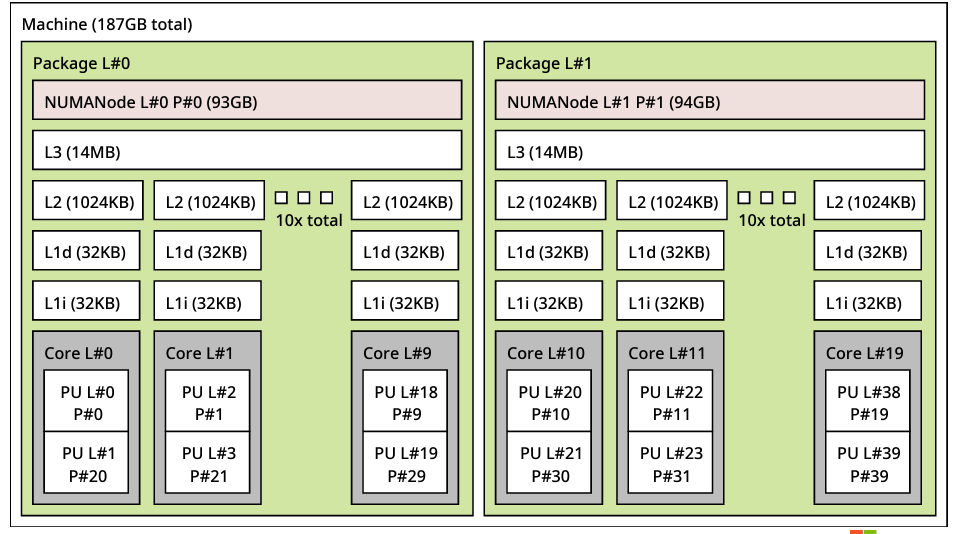
✅ANALYZING CACHELINE CONTENTION USING PERF C2C
Andres Freund
postgres 中大量的可扩展性问题是由 CPU 缓存行争用(cache line contention)引起的。一旦知道了有问题的缓存区域,通常就不难修复,例如通过减少共享、改善访问局部性或复制数据。更难的是识别争用的缓存行。
在本次演讲中,Andres 简要介绍缓存一致性、如何使用 perf c2c 查找争用的缓存行以及如何解决一些已发现的问题。
-
通常在单一 CPU,或是单一 CPU 多个 CORE 的环境下,缓存行争用这个现象并不常见,但是到了多个 CPU + 多个 CORE 的硬件环境下,缓存行争用就是一个影响读写性能的现象。这个现象可以通过像 perf c2c 这种工具发现
-
cache line 通常大小为 64 位元
-
Andres 对 CPU 缓存结构做了简单的解释
-
L1i:指令高速缓存
-
L1d:数据高速缓存
-
L2:快速缓存
-
L3:缓存,跨核心共享
-
-
当读和写的操作都落在同一个 cache line 上的时候,CPU 缓存行争用的现象就会发生,导致延迟增加和吞吐量降低。
-
当 CPU 内核必须等待另一个内核更新缓存行时,可能会导致内核停顿,从而浪费 CPU 周期并降低整体效率。
-
CPU 缓存行争用影响多大?
-
高并发性 - 影响最大
-
多个插槽 - 非常糟糕
-
一个插槽中有多个芯片组 - 非常糟糕
-
一个芯片组中有多个内核 - 有点糟糕
-
-
怎么优化?
-
将数据分散到更多的缓存行中 - 但会浪费更多内存
-
分离写入密集型数据和读取密集型数据
-
从根本上重新设计数据结构
-
重新设计锁
-
-
perf c2c 工具
-
可以用来调查 CPU 缓存行争用
-
Load Latency (加载延迟):表示加载指令的延迟。高延迟可能表明存在缓存争用。
-
L1D/L2 Cache Misses (L1D/L2 缓存未命中):高未命中率可能表明数据经常在内核之间失效和传输。
-
Cache Line Transfers (缓存行传输):显示缓存行在内核之间的传输频率,这是争用的直接指标。
-
-
通关简单的把 PostgreSQL buffer descriptor 的数据大小强行做 64 位元的对齐可以看到显著的 TPS 性能提升。这个排序强制每一次的查找都是放在独立的 cache line,而不会和其它内核共享



✅IMPLEMENTING ROW PATTERN RECOGNITION
Tatsuo Ishii
自 SQL:2016 以来,行模式识别 (Row Pattern Recognition) 就已定义。RPR 是分析复杂数据(尤其是一系列数据)的强大功能。使用 RPR,您可以通过定义搜索条件和正则表达式在一系列行中找到特定趋势
-
主要目的是通过“正则表达式” 来从数据里面识别特定序列,或事件的状况,如检测股票价格模式、异常检测等。
-
支持 pettern 变量关键字,例如:
-
START
-
UP+
-
DOWN+
-
-
支持 pattern 查找,例如
-
INITIAL
-
DEFINE
-
PATTERN
-
FIRST, LAST, PREV, NEXT
-
WINDOW
-
MATCH_RECOGNIZE
-
等等
-
-
例子
SELECT *FROM table_nameMATCH_RECOGNIZE (PARTITION BY partition_columnORDER BY order_columnMEASURES measure_definitionsONE ROW PER MATCH | ALL ROWS PER MATCHAFTER MATCH SKIP TO NEXT ROW | PAST LAST ROW | FIRST ROWPATTERN (pattern)DEFINE variable AS condition); -
RPR 相关测试在 src/test/regress/sql/rpr.sql ,预计 PG18 发布
-
更多的关键字会在后续补丁提供,目前不支持的有:
-
SEEK
-
AGGREGATES
-
Subqueries
-
CLASSIFIER
-


✅MYSQL REPLICATION DEEP DIVE, AND IDEAS FOR POSTGRESQL
Jagdeep Sidhu
PostgreSQL 最初支持物理复制,在 PostgreSQL 10 中内置了对逻辑复制的支持。而 MySQL 仅支持逻辑复制。在本次演讲中,Jagdeep 介绍 MySQL 复制的实现细节 - MySQL 如何写入二进制日志,并确保它与存储引擎一致?二进制日志如何应用于副本,以及各种优化技术。
-
MySQL 为了实现逻辑复制增加了 binary log 的功能
-
MySQL 原本就指出 REDO log, UNDO log(这个 PostgreSQL 不支持(因为不需要)) MySQL 的更新都是 in-place update,所以需要 UNDO log 来往回rollback 如果事务回滚。PostgreSQL 基于 MVCC 所以不需要 UNDO
-
MySQL Binary log 里面记录着逻辑复制的每一行改动,也需要 primary key来表征哪一行被删除了
-
包含原生 SQL 语句
-
和改动的 行信息
-
-
Global Transaction ID
-
用来追踪拿一些改动已经被复制了,拿一些还没有。类似 PostgreSQL 的逻辑复制槽
-
存在于表和binary log内
-
全局唯一,基于server id 和 transaction UUID 组成
-
也可用来逻辑复制的自动定位
-
-
2 phase commit
-
每当 MySQL 改动了一行数据,这个动作会被记录在 REDO log, UNDO log 和 binary log
-
如何确保全部的文件都被写成功了是个问题
-
MySQL 使用 2 phase commit 来确保所有的文件都已被写入,这个和 PostgreSQL 的 2 phase commit 概念一致
-
缺点就是写的开销大(老是要call fsync)
-
-
Group commit
-
用来减缓 2 phase commit 的开销
-
运行批量提交,在处理大事务时还是会慢
-
-
Parellel Apply
-
MySQL 支持并行处理逻辑复制
-
重叠时间线上的提交,可以并行处理
-
只对处理顺序没有要求的情况下启用。
-
PostgreSQL 的 parallel apply 只在处理大事务的情况下才会启用。和 MySQL 的触发点不一样
-

✅ONLINE UPGRADE OF REPLICATION CLUSTERS WITHOUT DOWNTIME
Hayato Kuroda
目前,流式复制集群需要大量的停机时间才能升级。在 PostgreSQL 中寻找无需停机即可升级复制集群的方法一直是一个讨论点。Hayato 将讨论在不停机的情况下升级复制集群的问题并介绍新引进的工具 pg_subscriber 来减少升级流式复制集群所需的一些手动步骤。
-
目前的 PostgreSQL 流复制的架构,主备节点的版本必须相同,流复制才能进行。但如果要升级怎么办呢?
-
可以使用 pg_dump 和 pg_restore,但是这个效率不高
-
也可以使用 pg_upgrade,这个比 pg_dump 和 pg_restore 速度快了 7 倍,唯一的问题就是服务器必须先关闭。
-
Hayato 介绍了新的 逻辑复制用法来应对这个需要停机 upgrade 的问题。
-
使用新工具 pg_createsubscriber 让订阅节点可以重用已经通过物理复制来的数据基础上,在做增量的逻辑复制。这个省去了做逻辑复制开始前要做的数据同步的动作。简单来说就是重新运用了物理复制的数据来做逻辑复制。整个升级的步骤可以简化成:
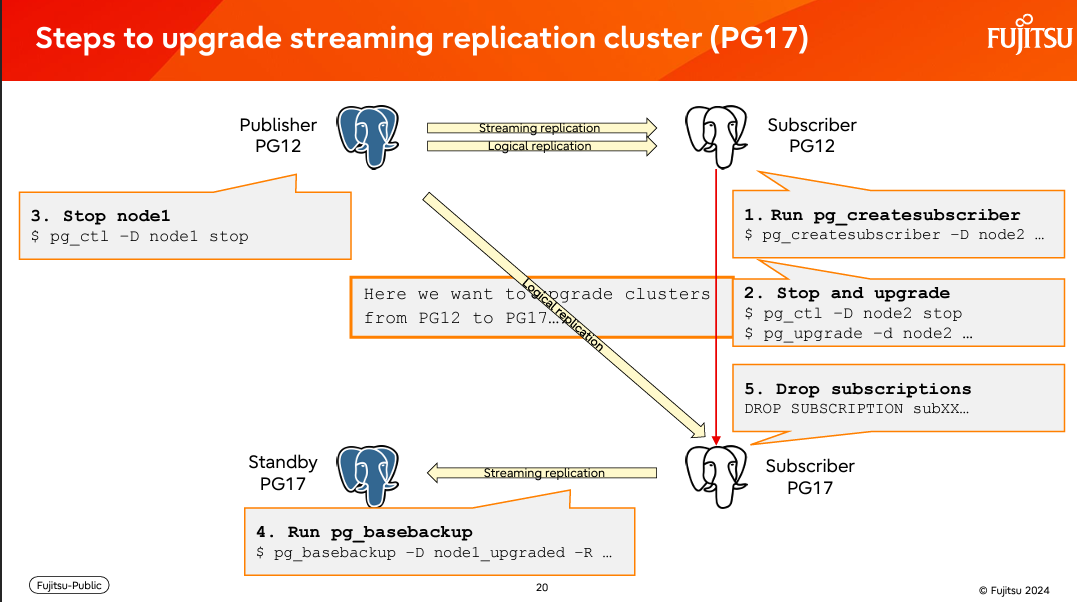
-
pg_createsubscriber 工具基本上可以把物理复制备节点转换成逻辑复制订阅端,在不需要重新拷贝数据的情况下。所以在数据量很大的时候有很大的优势。

-
逻辑复制架构的升级
-
PG16 和之前的版本,做了 pg_upgrade 了以后,逻辑复制槽的信息并不会被,它需要手动的拷贝和设置,逻辑复制才能接续。PG17 以后做的 pg_upgrade,时逻辑复制槽会被同步,所以升级完毕了以后逻辑复制可以自动接续。整个流程可以被简化成下图:
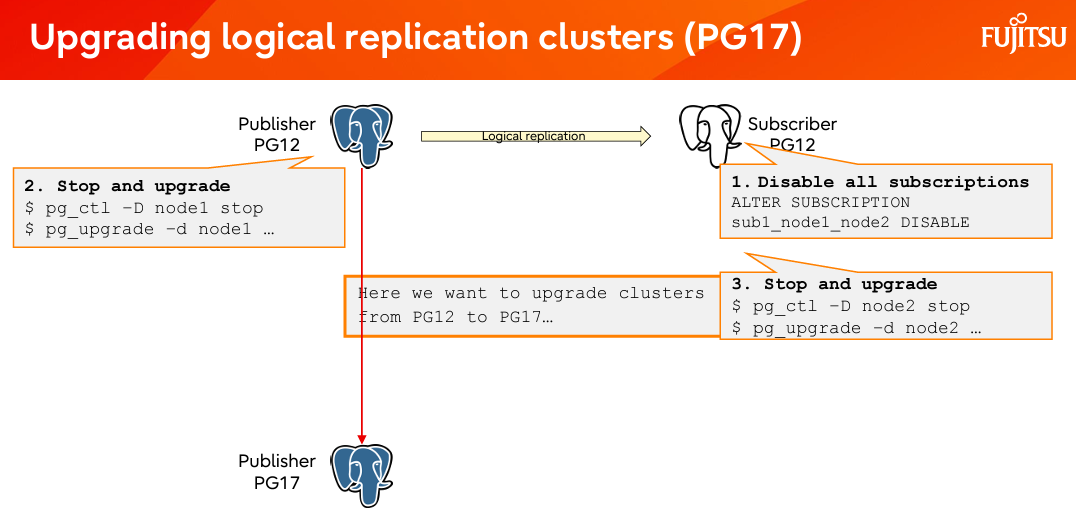
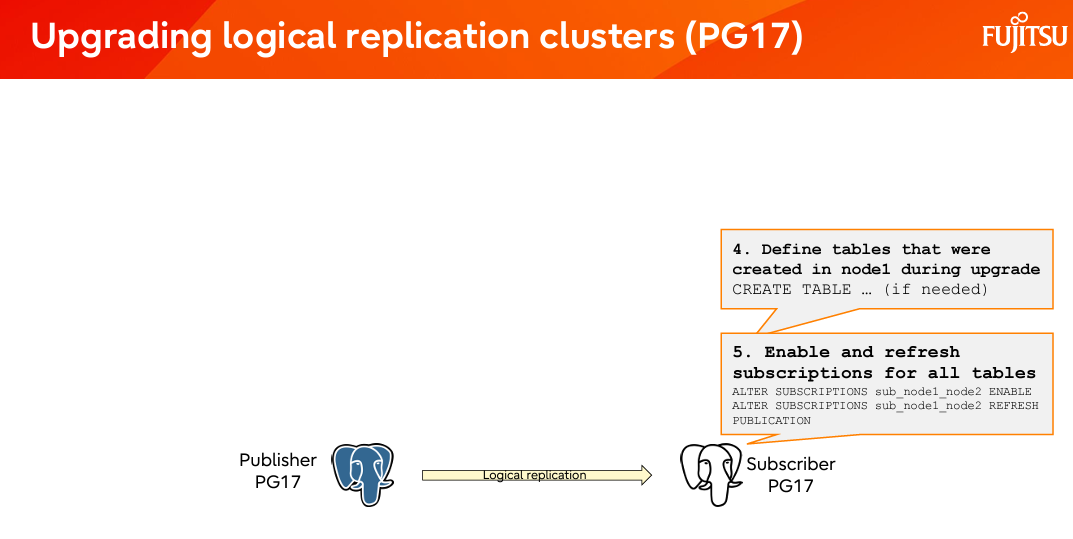
-
pg_createsubscriber 工具,和 logical replication slot 的同步消除了大部分升级造成的停机时间。这些功能已提交到 pg17版本


✅THE FUTURE OF THE EXTENSION ECOSYSTEM
David E. Wheeler
PGXN 可能是最早的 Postgres 扩展注册表,但绝非最后一个!过去一年,包括 database.dev、trunk 等在内的新成员纷纷加入,共同表明人们对扩展的兴趣日益浓厚,并渴望扩展和改进发现、打包和分发。其他社区也为包管理创建了新的模式和实践,包括 JavaScript 的 npm、Go 的 pkg.go.dev 和 Rust 的 crates.io 等。现在是时候重新审视 Postgres 扩展生态系统,找出哪些行得通,哪些行不通,David 也借此演讲介绍 pgxn 2.0
-
插件很方便,可以在不改变和重新编译PG内核的情况下,改变pg内核的工作模式。但也引进了许多问题。现在没有一个统一的插件的 repository,除了 pgxn 以外还有好几个不同的 repo,有些插件要在 github 自己编译,有些插件在某个网站上。这些插件的分配生态存在诸多问题,例如
-
无处不在
-
难以发现
-
文档较少
-
难以理解
-
难以安装
-
无二进制分发
-
-
今年在 Tembo 的赞助下,开始了 pgxn v2的开发
-
更注重在插件的作者
-
文档和指南
-
自动化的测试
-
二进制包的发布
-
-
新的 pgxn 插件开发工具 (pgxn develop)。帮助开发这更有规范的去开发新插件
-
自动生成插件源代码框架
-
测试框架
-
github workflow 框架
-
github CI 脚本
-
文档框架
-
control 文件
-
meta data
-
makefile
-
等等
-
# 创建新插件pgxn develop new --extension --langauge c --vcs github myproject# 升级插件pgxn develop add-upgrade 0.0.2
新的 pgxn 打包工具
-
自动编译及打包插件
-
管理所有已安装的插件和版本
-
升级某个插件
-
或删除插件
pgxn package buildpgxn package lspgxn package installpgxn upgradepgxn delete
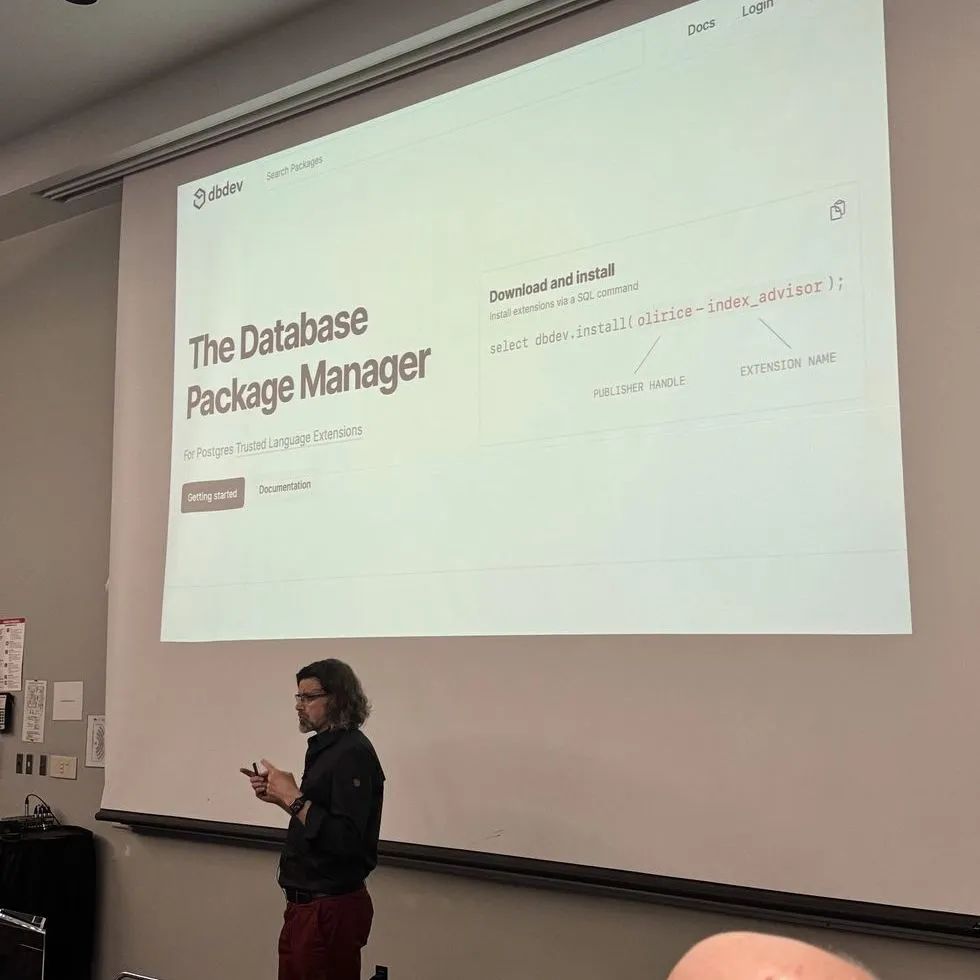

✅TRICKS FROM IN-MEMORY DATABASES
Andrey Borodin
内存数据库具有一些有趣的性能技术。但是,其中一些技术在 Postgres 中的用途也有限。将讨论以下主题。
-
指针调换。主键查找需要经过很长的路,从 B 树页面到 IndexTuple,再到 tid,再到缓冲区,再到行指针,再到元组,再到数据。我们可以试着缩短这个障碍。
-
更缓存友好的页面布局。二分搜索可以触及更少的缓存行,页面可以按列组织 (PAX)。
-
乐观缓冲区锁定。无需锁定即可读取,如果有任何更改,则丢弃结果。
-
为何需要内存数据库?用 unlogged table 不就完了?- PostgreSQL 用户的一个玩笑话
-
微秒级的读和写速度?in-memory 数据库研发人员的玩笑话
-
如果数据库真的可以从内存数据库达到微秒及的读写速度,那么新一轮的使用场景将会大量的出现
-
Andrey 基于 UMBRA 的内存数据库论文,想要在 PostgreSQL内核里去验证是否会有显著的性能提升。
-
为了应对广大的用,PostgreSQL 需要支持许多不同的数据类型,结构,等等,这导致 PostgreSQL 的内核设计的非常的笼统(general)。例如 Datum 这个数据类型往往会被当成 SQL 函数的argument,但如果直接一点,直接用它应该使用的数据类型(例如 int),这往往会有一些性能提升。
-
可变尺寸页面 – 如果 buffer manager 可以支持可变大小的 page,那么我们完全可以摒弃 TOAST 表,进而达到性能提升
-
当前的 buffer manager 依赖许多 hash 表和3 个buffer 数组来管理一个buffer 数据快,这里面有很多查找的动作,如果使用一个树结构(例如 Radix Tree)来管理 buffer manager 的数据块也可以达到性能的提升
-
但这些性能的提升幅度都很小,1% ~2% 左右,数据量大的时候,超出内存范围时也会有性能降低的问题。
-
UMBRA 的论文里还提到了不上锁的读,这个Andrey 没办法在 PostgreSQL 验证,但是它肯定会有性能的提升。但是又会产生数据正不正确的问题(因为没上锁)
-
这些都只是 UMBRA 的学术研究提出的观点,短时间内还不能对 PostgreSQL 造成实质的改变。


✅UNCONFERENCE - IMPROVE EXTENSION IN CORE
这个 unconference 主要讨论目前插件架构的可能优化点,以及探讨插件的头疼之处:
-
API 稳定性
-
当 PostgreSQL 有小版本升级(例如15.1 到 15.2),如果有一些 API 的参数结构发生了变化(例如增加了新变量),如果插件没有重新编译会导致插件损坏。主要原因插件对某个结构的认知和 PG 内核不同(alignment 问题)
-
小版本改动尽量不要改 API
-
有没有什么工具可以检测插件 API 毁损?Omni 的 Yuri 说可能可以在插件的 MAGIC 块里包含小版本信息,让后它的 Omni 可以判断有没有版本冲突。
-
插件开发者应该多用文档描述插件,例如它具体用了那些核心 API
-
-
新增插件管理后台模块?
-
有人提议在PG 后台新增插件管理器,专门来管理插件的版本和兼容性。保证读取插件的顺序,解决依赖关系等等。类似 Omni 在做的东西,但是做到 PG 内核里。
-
插件管理器也应当检测插件对共享内存的调用,管理钩子函数等等
-
pgxn 可以在这个插件管理器之上再多增加测试的功能。
-
显示所有插件信息,版本号,提供的新SQL函数等等
-
-
如果想参与未来的插件优化讨论,可以去到 github.com/pgedc 去参与讨论。EDC 是 Extension Development Coalition 的简称


UNCONFERENCE - OBSERVABILIT
这个 unconference 主要讨论能不能把 pg_exporter 的统计信息输出直接做到 PostgreSQL 内核里,让pg 的统计信息集成更方便,更有效率。
-
可观察性很重要,因为在生产环境没办法直接上 GDB 调试。只能通过 log,或是统计信息来找问题
-
统计信息像是:
-
stack 深度,锁的请求,使用,用时,语句处理频率,负载率,autovacuum 信息等
-
-
统计模块也可以做到一定的自我修复,还可以更好的和 open-telemetry 和 prometheus 集成
-
pg_exporter 很好,但它毕竟是插件,有更多的开销,有些系统级别的统计信息它获取不到。如果 PostgreSQL 崩溃,pg_exporter 没法得知这些严重事件。只能把此功能做成核心的一部分才能真正的完整的截获这些信息


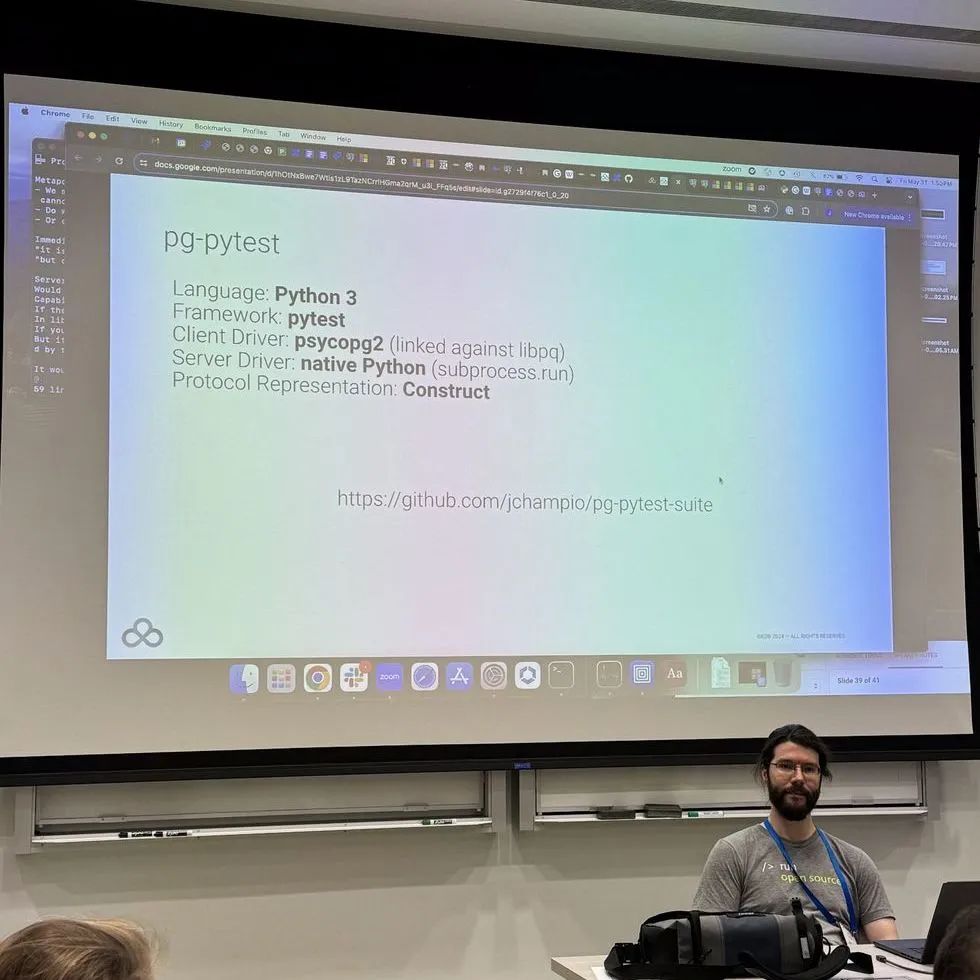
UNCONFERENCE - TEST ENHANCEMENT这个 unconference 主要讨论能不能把当前 PG 基于 perl 的测试框架升级成 python 的 pytest
-
pytest 可以测试更多复杂的测试,比当前的 tap test 架构还更强大。
-
在做安全功能的 Jacob Champion说,他用 pytest 可以动态生成证书,做复杂测试,还可以仿真黑客在连接上模拟恶意的包,测试系统的反应
-
但用了python 又会有 python 库的依赖问题,需要一个 dependency manager 管理,或是详细描述python的需求
-
pytest 还可以输出 pcap capture 文件,对安全开发者来说很有帮助。
-
其它人们对测试的优化包含:
-
能不能不要让 regression test case 依赖前一个测试,让每一个测试都独立出来
-
能否只重新跑失败的regression test?而非全部?
-
tap test 的文档描述不清楚,很难加新测试
-

UNCONFERENCE - FUTURE OF BUILD FAR这个 unconference 主要讨论能不能把当前的 CI 架构 (github cirrus CI)做的更好
-
有人提议使用 pull request 来做补丁提交,然后让 CI 直接泡在一个 pull request 上,如果测试通过再 merge
-
但也有人说你可以自己 fork 一个 PostgreSQL,然后自己setup cirrusCI,然后自己跑测试,通过了以后再把 patch 发出来。cirrusCI 跑在 public repo 是免费的
-
各有好坏,大家都在提自己的观点,但大家还是倾向于现有的 CI 架构。
-
之后可能还是会接着用 cirrusCI,且再三强调所有补丁一定要在 CI 上跑成功后才能提交

相关文章:
必看!!! 2024 最新 PG 硬核干货大盘点(上)
PGConf.dev(原名PGCon,从2007年至2023年)首次在风景如画的加拿大温哥华市举办。此次重新定位的会议带来了全新的视角和多项新的内容,参会体验再次升级。尽管 PGCon 历来更侧重于开发者,吸引来自世界各地的资深开发者、…...
Redis 高可用 sentinel
简介 Sentinel提供了一种高可用方案来抵抗节点故障,当故障发生时Redis集群可以自动进行主从切换,程序可以不用重启。 Redis Sentinel集群可以看成是一个Zookeeper集群,他是Redis集群高可用的心脏,一般由3-5个节点组成࿰…...

【数据结构】练习集
数据的逻辑结构说明数据元素之间的顺序关系,它依赖于计算机的存储结构。(F) 在顺序表中逻辑上相邻的元素,其对应的物理位置也是相邻的。(T) 若一个栈的输入序列为{1, 2, 3, 4, 5},则不可能得到…...

驱动开发(四):Linux内核中断
驱动开发系列文章: 驱动开发(一):驱动代码的基本框架 驱动开发(二):创建字符设备驱动 驱动开发(三):内核层控制硬件层 驱动开发(四…...

btrace:binder_transaction+eBPF+Golang实现通用的Android APP动态行为追踪工具
一、简介: 在进行Android恶意APP检测时,需要进行自动化的行为分析,一般至少包括行为采集和行为分析两个模块。其中,行为分析有基于规则、基于机器学习、基于深度学习甚至基于大模型的方案,各有各的优缺点,不…...

C# OCCT Winform 界面搭建
目录 1.创建一个WInform项目 2.代码总览 代码解析 3.添加模型到场景 4.鼠标交互 1.创建一个WInform项目 2.代码总览 using Macad.Occt.Helper; using Macad.Occt; using System; using System.Collections.Generic; using System.Linq; using System.Runtime.Remoting.Co…...
System.Dynamic.ExpandoObject的使用说明
官方文档 ExpandoObject 类 (System.Dynamic) | Microsoft Learn https://learn.microsoft.com/zh-cn/dotnet/api/system.dynamic.expandoobject?viewnet-8.0 System.Dynamic.ExpandoObject 类 - .NET | Microsoft Learn https://learn.microsoft.com/zh-cn/dotnet/fundame…...

adb之ps命令用法
目录 前言一、命令参数二、输出结果含义 前言 在adb shell终端,输入 ps,可查看手机当前所有的进程状态,其中ps的英文全称是Process Status。 ps命令对于分析系统异常情况时都是必备的技能,需要通过这个简单命令来查看系统真实的状…...
Ubuntu-24.04-live-server-amd64安装界面中文版
系列文章目录 Ubuntu安装qemu-guest-agent Ubuntu-24.04-live-server-amd64启用ssh Ubuntu乌班图安装VIM文本编辑器工具 文章目录 系列文章目录前言一、准备工作二、开始安装三、测试效果总结 前言 Centos结束,转战Ubuntu。我之所以写这篇文章,是因为我…...
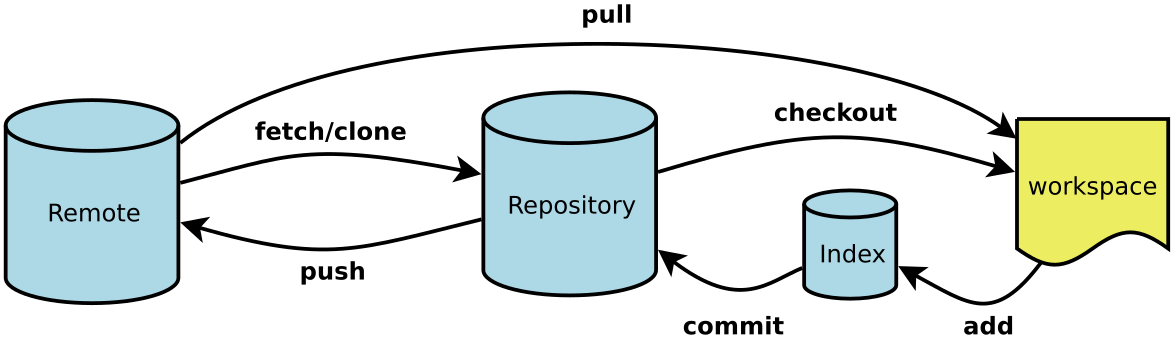
Git的3个主要区域
一般来说,日常使用只要记住下图6个命令,就可以了。但是熟练使用,恐怕要记住60~100个命令。 下面是我整理的常用 Git 命令清单。几个专用名词的译名如下。 Workspace:工作区 Index / Stage:暂存区 Reposito…...
【操作系统】操作系统实验02-生产者消费者程序改进
1. 说明文档中原有程序实现的功能、实现方法。(用语言、程序流程图、为原有程序添加注释等方式均可) 1.//const.h 2.//定义宏变量 3.#ifndef CONST_H 4.#define CONST_H 5. 6.#define TRUE 1 7.#define FALSE 0 8.#define ERROR 0 9.#define OVERFLOW -…...

TCP协议是安全的吗?
不安全 虽然 TCP 提供了一种可靠且高效的数据传输方式,但它不提供任何加密或身份验证机制来保护数据。因此,传输的数据可能会被未经授权的用户拦截和读取,而且其真实性无法验证。 因此,为了确保 TCP 通信的安全,必须…...

c语言回顾-结构体(2)
前言 前面讲了结构体的概念,定义,赋值,访问等知识,本节内容小编将讲解结构体的内存大小的计算以及通过结构体实现位段,话不多说,直接上干货!!! 1.结构体内存对齐 说到计…...
Prometheus常见exporter安装部署
Prometheus常见exporter安装部署 在稳定性环境的监控当中需要收集各种各样的数据,这样的数据收集是通过各种exporter进行的,在这里我们进行最常用稳定性数据的收集exporter安装部署介绍。 node_exporter安装部署 node_exporter主要监控服务器本身的一…...
DGit的使用
将Remix连接到远程Git仓库 1.指定克隆的分支和深度 2.清理,如果您不在工作区上工作,请将其删除或推送至 GitHub 或 IPFS 以确保安全。 为了进行推送和拉取,你需要一个 PAT — 个人访问令牌 当使用 dGIT 插件在 GitHub 上推送、拉取、访问私…...
ElasticSearch学习篇13_《检索技术核心20讲》进阶篇之LSM树
背景 学习极客实践课程《检索技术核心20讲》https://time.geekbang.org/column/article/215243,文档形式记录笔记。 内容 磁盘和内存数据读取特点 工业界中数据量往往很庞大,比如数据无法全部加载进内存,无法支持索引的高效实时更新&…...
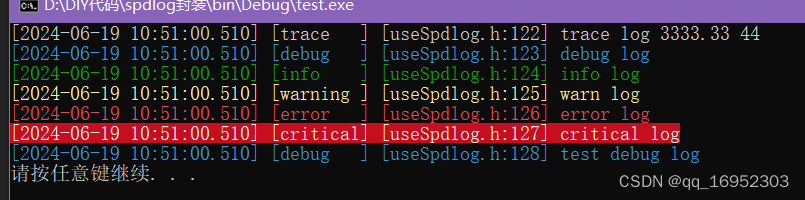
简单好用的C++日志库spdlog使用示例
文章目录 前言一、spdlog的日志风格fmt风格printf风格 二、日志格式pattern三、sink,多端写入四、异步写入五、注意事项六、自己封装了的代码usespdlog.h封装代码解释使用示例 前言 C日志库有很多,glog,log4cpp,easylogging, eas…...

python 方法运行计时装饰模式实现
在代码开发过程中,需要记录方法的执行时间,每个方法都硬代码也可以实现,但是不是最好的方式,考虑到设计模式和模版代码,通过装饰模式实现方法运行计时 在Python中,装饰器可以接受参数,这样可以…...

【权威出版/投稿优惠】2024年水利水电与能源环境科学国际会议(WRHEES 2024)
2024 International Conference on Water Resources, Hydropower, Energy and Environmental Science 2024年水利水电与能源环境科学国际会议 【会议信息】 会议简称:WRHEES 2024 大会时间:点击查看 截稿时间:点击查看 大会地点:…...

阿赵UE引擎C++编程学习笔记——场景加载和切换
大家好,我是阿赵。 继续学习UE引擎,这次来学习一下切换和加载场景的各种做法。 一、 蓝图实现 1、 切换关卡 所谓切换关卡,就是从当前关卡进入到一个新的关卡, 旧关卡的数据将会被放弃。进入新的关卡后,将会执行…...
。】2022-5-15)
【根据当天日期输出明天的日期(需对闰年做判定)。】2022-5-15
缘由根据当天日期输出明天的日期(需对闰年做判定)。日期类型结构体如下: struct data{ int year; int month; int day;};-编程语言-CSDN问答 struct mdata{ int year; int month; int day; }mdata; int 天数(int year, int month) {switch (month){case 1: case 3:…...

Flask RESTful 示例
目录 1. 环境准备2. 安装依赖3. 修改main.py4. 运行应用5. API使用示例获取所有任务获取单个任务创建新任务更新任务删除任务 中文乱码问题: 下面创建一个简单的Flask RESTful API示例。首先,我们需要创建环境,安装必要的依赖,然后…...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...

论文笔记——相干体技术在裂缝预测中的应用研究
目录 相关地震知识补充地震数据的认识地震几何属性 相干体算法定义基本原理第一代相干体技术:基于互相关的相干体技术(Correlation)第二代相干体技术:基于相似的相干体技术(Semblance)基于多道相似的相干体…...

MySQL 知识小结(一)
一、my.cnf配置详解 我们知道安装MySQL有两种方式来安装咱们的MySQL数据库,分别是二进制安装编译数据库或者使用三方yum来进行安装,第三方yum的安装相对于二进制压缩包的安装更快捷,但是文件存放起来数据比较冗余,用二进制能够更好管理咱们M…...
CSS | transition 和 transform的用处和区别
省流总结: transform用于变换/变形,transition是动画控制器 transform 用来对元素进行变形,常见的操作如下,它是立即生效的样式变形属性。 旋转 rotate(角度deg)、平移 translateX(像素px)、缩放 scale(倍数)、倾斜 skewX(角度…...

通过MicroSip配置自己的freeswitch服务器进行调试记录
之前用docker安装的freeswitch的,启动是正常的, 但用下面的Microsip连接不上 主要原因有可能一下几个 1、通过下面命令可以看 [rootlocalhost default]# docker exec -it freeswitch fs_cli -x "sofia status profile internal"Name …...

绕过 Xcode?使用 Appuploader和主流工具实现 iOS 上架自动化
iOS 应用的发布流程一直是开发链路中最“苹果味”的环节:强依赖 Xcode、必须使用 macOS、各种证书和描述文件配置……对很多跨平台开发者来说,这一套流程并不友好。 特别是当你的项目主要在 Windows 或 Linux 下开发(例如 Flutter、React Na…...

图解JavaScript原型:原型链及其分析 | JavaScript图解
忽略该图的细节(如内存地址值没有用二进制) 以下是对该图进一步的理解和总结 1. JS 对象概念的辨析 对象是什么:保存在堆中一块区域,同时在栈中有一块区域保存其在堆中的地址(也就是我们通常说的该变量指向谁&…...
解析“道作为序位生成器”的核心原理
解析“道作为序位生成器”的核心原理 以下完整展开道函数的零点调控机制,重点解析"道作为序位生成器"的核心原理与实现框架: 一、道函数的零点调控机制 1. 道作为序位生成器 道在认知坐标系$(x_{\text{物}}, y_{\text{意}}, z_{\text{文}}…...