如何通过数据库与AI实现以图搜图?OceanBase向量功能详解
OceanBase支持向量数据库的基础能力
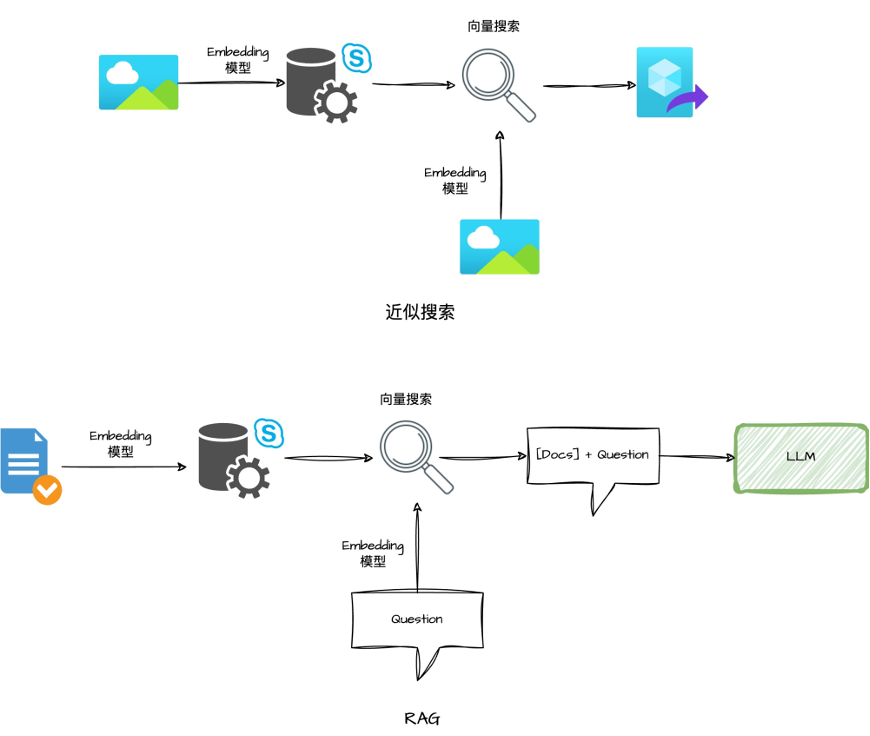
当前,数据库存储系统与人工智能技术的结合,可以体现在两个主要的应用方向上。
一、近似搜索。它利用大语言模型(LLM,简称大模型)的嵌入(embedding)技术,将非结构化数据转换为向量数据并存储于数据库系统中。通过数据库系统提供的向量运算和近似度查询功能,实现搜索推荐和非结构化数据查询的应用场景。
二、检索增强生成。大模型具备自然语言对话、文本总结、智能体Agent、辅助编码等通用能力,但限于其预训练时使用有限知识,难以有效应对互联网平台源源不断涌现的海量知识。因此,常见的做法是使用数据库存储问答等语料并为大语言模型提供语料检索,即RAG。
在OceanBase社区版的4.3版本中,率先支持了向量数据库的基本能力:
- 支持向量数据类型(VECTOR关键字)定义以及存储;
- 支持向量数据列创建向量近似邻近搜索(ANN)索引,目前支持IVFFLAT以及HNSW两种算法;
- 支持分区并行构建向量近似邻近搜索索引;
- 支持分区并行执行向量近似邻近搜索。
这些能力得以让OceanBase成为上述两种AI应用架构的存储基座,下面按照近似搜索应用架构,以一个简单的图搜图应用来展示OceanBase的向量存储能力。
OceanBase向量存储能力演示
1. 部署OceanBase向量数据库Docker镜像
通过以下命令安装OceanBase向量数据库:
docker run -p 2881:2881 --name obvec -d oceanbase/oceanbase-ce:vector等待docker容器输出“boot success!”之后,我们可以用SQL接口试玩一下OceanBase的向量处理能力:
obclient [test]> create table t1 (c1 vector(3), c2 int, c3 float, primary key (c2));
Query OK, 0 rows affected (0.128 sec)obclient [test]> insert into t1 values ('[1.1, 2.2, 3.3]', 1, 1.1), ('[ 9.1, 3.14, 2.14]', 2, 2.43), ('[7576.42, 467.23, 2913.762]', 3, 54.6), ('[3,1,2]', 4, 4.67), ('[42.4,53.1,5.23]', 5, 423.2), ('[ 3.1, 1.5, 2.12]', 6, 32.1), ('[4,6,12]', 7, 23), ('[2.3,66.77,34.35]', 8, 67), ('[0.43,8.342,0.43]', 9, 67), ('[9.99,23.2,5.88]', 10, 67),('[23.5,76.5,6.34]',11,11);
Query OK, 11 rows affected (0.011 sec)
Records: 11 Duplicates: 0 Warnings: 0obclient [test]> CREATE INDEX vidx1_c1_t1 on t1 (c1 l2) using hnsw;
Query OK, 0 rows affected (0.315 sec)obclient [test]> select * from t1;
+--------------------------------------+----+-------+
| c1 | c2 | c3 |
+--------------------------------------+----+-------+
| [1.100000,2.200000,3.300000] | 1 | 1.1 |
| [9.100000,3.140000,2.140000] | 2 | 2.43 |
| [7576.419922,467.230011,2913.761963] | 3 | 54.6 |
| [3.000000,1.000000,2.000000] | 4 | 4.67 |
| [42.400002,53.099998,5.230000] | 5 | 423.2 |
| [3.100000,1.500000,2.120000] | 6 | 32.1 |
| [4.000000,6.000000,12.000000] | 7 | 23 |
| [2.300000,66.769997,34.349998] | 8 | 67 |
| [0.430000,8.342000,0.430000] | 9 | 67 |
| [9.990000,23.200001,5.880000] | 10 | 67 |
| [23.500000,76.500000,6.340000] | 11 | 11 |
+--------------------------------------+----+-------+
11 rows in set (0.004 sec)obclient [test]> select c1,c2 from t1 order by c1 <-> '[3,1,2]' limit 2;
+------------------------------+----+
| c1 | c2 |
+------------------------------+----+
| [3.000000,1.000000,2.000000] | 4 |
| [3.100000,1.500000,2.120000] | 6 |
+------------------------------+----+
2 rows in set (0.013 sec)- 首先创建一个包含向量列
c1的向量数据表t1; - 插入向量数据,展示OceanBase向量数据常量值的定义方式;
- 在该向量数据表上创建
hnsw向量索引(也支持创建ivfflat索引); - 向量数据表全表扫描;
- 一个典型的向量近似最邻近查询(select XXX from XX order by XXX limit XX);
- <->:计算向量之间的欧式距离;
- <@>:计算向量之间的内积;
- <~>:计算向量之间的cosine距离。
2. 处理图片数据
可以选择任意的分类图片库作为数据集,本文演示资料是从如下链接下载:
极市开发者平台-计算机视觉算法开发落地平台-极市科技
这个图片库中的图片大小不一,对于传统的机器学习应用来说需要统一图片大小,不过我们使用embedding模型进行向量搜索的方式并不需要。唯一需要做的预处理操作是:图片库中的图片按照图片目录事先已做好归类,需要打散统一放到一个目录下:
import os
import shutildef copy_imgs(src, dest):if not os.path.exists(dest):os.makedirs(dest)for root, dirs, files in os.walk(src):for file in files:if file.endswith('.jpg'):src_file_path = os.path.join(root, file)dest_file_path = os.path.join(dest, file)shutil.copy2(src_file_path, dest_file_path)copy_imgs(src_dir, dest_dir)3. 使用Python连接OceanBase
我们使用sqlalchemy库连接OceanBase,由于vector类型并不是mysql方言中支持的类型,需要定义一个Vector类,实现该类型从数据库类型转为python列表类型、列表类型转为OceanBase向量常量类型的方法:
# OceanBase Vector DataBase
import datetime
from typing import Any, Callable, Iterable, List, Optional, Sequence, Tuple, Typefrom sqlalchemy import Column, String, Table, create_engine, insert, text
from sqlalchemy.types import UserDefinedType, Float, String
from sqlalchemy.dialects.mysql import JSON, LONGTEXT, VARCHAR, INTEGERtry:from sqlalchemy.orm import declarative_base
except ImportError:from sqlalchemy.ext.declarative import declarative_baseBase = declarative_base()def from_db(value):return [float(v) for v in value[1:-1].split(',')]def to_db(value, dim=None):if value is None:return valuereturn '[' + ','.join([str(float(v)) for v in value]) + ']'class Vector(UserDefinedType):cache_ok = True_string = String()def __init__(self, dim):super(UserDefinedType, self).__init__()self.dim = dimdef get_col_spec(self, **kw):return "VECTOR(%d)" % self.dimdef bind_processor(self, dialect):def process(value):return to_db(value, self.dim)return processdef literal_processor(self, dialect):string_literal_processor = self._string._cached_literal_processor(dialect)def process(value):return string_literal_processor(to_db(value, self.dim))return processdef result_processor(self, dialect, coltype):def process(value):return from_db(value)return process# 与 OceanBase Vector DataBase 建立连接
ob_host = "127.0.0.1"
ob_port = 2881
ob_database = "test"
ob_user = "root@test"
ob_password = ""
connection_str = f"mysql+pymysql://{ob_user}:{ob_password}@{ob_host}:{ob_port}/{ob_database}?charset=utf8mb4"
ob_vector_db = create_engine(connection_str)OceanBase docker启动会自动创建一个test租户,并在本地2881端口开启MySQL服务,构造连接串后创建连接即可。
4. 定义向量处理接口
接着我们事先定义好OceanBase向量处理的Python接口:
# 创建 img2img 表
def ob_create_img2img(embedding_dim):img2img_table_query = f"""CREATE TABLE IF NOT EXISTS `img2img` (id INT NOT NULL, embedding VECTOR({embedding_dim}), path VARCHAR(1024) NOT NULL, PRIMARY KEY (id))"""with ob_vector_db.connect() as conn:with conn.begin():conn.execute(text(img2img_table_query))print(f"create table ok: {img2img_table_query}")glb_img_id = 0
# 向 img2img 表中插入向量
def ob_insert_img2img(embedding_dim, embedding_vec, path):global glb_img_idglb_img_id += 1img_id = glb_img_idimg2img_table = Table("img2img",Base.metadata,Column("id", INTEGER, primary_key=True),Column("embedding", Vector(embedding_dim)),Column("path", VARCHAR(1024), nullable=False),keep_existing=True,)data = [{"id": img_id,"embedding": embedding_vec.tolist(),"path": path,}]with ob_vector_db.connect() as conn:with conn.begin():conn.execute(insert(img2img_table).values(data))# vector_distance_op:
# <->: 欧式距离; <~>: cosine距离; <@>: 点积
# 使用 OceanBase Vector DataBase 进行 ANN 查找
def ob_ann_search(vector_distance_op, query_vector, topk):try:from sqlalchemy.engine import Rowexcept ImportError:raise ImportError("Could not import Row from sqlalchemy.engine. ""Please 'pip install sqlalchemy>=1.4'.")vector_str = to_db(query_vector)sql_query = f"""SELECT path, embedding {vector_distance_op} '{vector_str}' as distanceFROM `img2img`ORDER BY embedding {vector_distance_op} '{vector_str}'LIMIT {topk}"""sql_query_str_for_print = f"""SELECT path, embedding {vector_distance_op} '?' as distanceFROM `img2img`ORDER BY embedding {vector_distance_op} '?'LIMIT {topk}"""with ob_vector_db.connect() as conn:begin_ts = datetime.datetime.now()results: Sequence[Row] = conn.execute(text(sql_query)).fetchall()print(f"Search {sql_query_str_for_print} cost: {(datetime.datetime.now() - begin_ts).total_seconds()} s")return [res for res in results]return []ob_create_img2img:创建向量数据表。需要传入向量维度,目前OceanBase限制一个向量数据表只支持插入固定维度的向量;在图搜图这个应用中,表的schema定义为:id:每一张图片分配一个唯一的id号,用作向量数据的主键;embedding:存放图片嵌入的向量数据,用于近似查询;path:图片的路径。通过embedding字段找到近似的向量后,利用path字段来展示图片。
ob_insert_img2img:向向量数据表插入向量数据;ob_ann_search:用于执行向量近似最邻近查询并计算查询耗时。
5. 图片导入OceanBase
我们使用CLIP模型来将图片转为向量。CLIP模型可以使用towhee库进行下载:
import os
import shutil
from towhee import ops,pipe,AutoPipes,AutoConfig,DataCollectionimg_pipe = AutoPipes.pipeline('text_image_embedding')然后,简单调用一下即可获取向量:
def img_embedding(path):return img_pipe(path).get()[0]最后将整个pipeline组合起来,将图片库中的所有图片转为向量,再插入OceanBase中。特殊处理一下第一次插入,需要额外执行向量数据表的创建:
# 将图片转换为 embedding 向量后导入 OceanBase Vector DataBase
def import_all_imgs(img_dir):embedding_dim = -1first_embedding = Trueimgs = os.listdir(img_dir)for i in range(len(imgs)):path = os.path.join(img_dir, imgs[i])vec = img_embedding(path)if first_embedding:embedding_dim = len(vec.tolist())ob_create_img2img(embedding_dim)first_embedding = Falseif embedding_dim != len(vec.tolist()):print(f"dim mismatch!! ---- expect: {embedding_dim} while get {len(vec.tolist())}")breakob_insert_img2img(embedding_dim, vec, path)if i % 100 == 0:print(f"{i} vectors inserted...")print("import finish")dest_dir = "/your/image/dest/dir"
import_all_imgs(dest_dir)导入完成后,开启一个MySQL连接,可以看到导入了5399条维度为512的向量:
obclient [test]> show create table img2img\G
*************************** 1. row ***************************Table: img2img
Create Table: CREATE TABLE `img2img` (`id` int(11) NOT NULL,`embedding` vector(512) DEFAULT NULL,`path` varchar(1024) NOT NULL,PRIMARY KEY (`id`),KEY `vidx` (`embedding`) BLOCK_SIZE 16384 LOCAL
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 1 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0
1 row in set (0.002 sec)obclient [test]> select count(*) from img2img;
+----------+
| count(*) |
+----------+
| 5399 |
+----------+
1 row in set (0.021 sec)6. 启动图搜图小应用
我们使用gradio库作为简易的WebUI,接受以下两个输入。
图片上传组件:待查询的图片。topK滑动组件:设定最邻近查询的topK值。
查询时,首先将传入的图片写到临时路径,再将临时图片嵌入为向量,最后调用之前定义的ob_ann_search函数获取最邻近图片路径列表。最后通过gallery组件展示图片:
# Gradio 界面
import gradio as gr
import os
import IPython.display as display
import imageio# Gradio界面的主要逻辑函数
def show_search_results(image, topk):if not os.path.exists("uploads"):os.makedirs("uploads")# 保存上传的图片到临时目录并获取其路径if image is not None:temp_image_path = os.path.join("uploads", "uploaded_image.jpg")imageio.imsave(temp_image_path, image)# 调用图搜索函数query_vec = img_embedding(temp_image_path)res = ob_ann_search("<~>", query_vec, topk)result_paths = [r.path for r in res]return result_pathsreturn []# 创建Gradio UI
iface = gr.Interface(fn=show_search_results,inputs=[gr.Image(label="上传图片"), gr.Slider(1, 10, step=1, label="Top K")],outputs=gr.Gallery(label="搜索结果图片"),examples=[])# 在Jupyter Notebook内运行Gradio应用
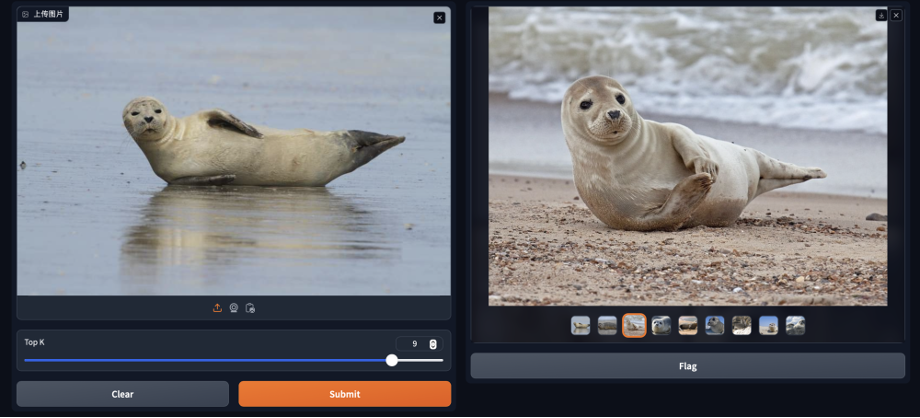
iface.launch()简单测试一下,可以发现原图被精确地查找了出来:
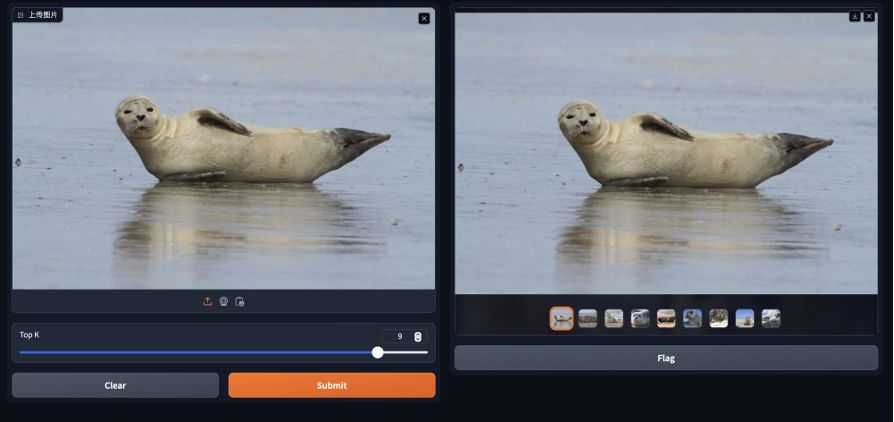
而相关图片中都是“海豹”!
7. 创建一个向量索引会如何?
开启一个MySQL连接,创建一个ivfflat索引:
obclient [test]> create index vidx on img2img (embedding l2) using ivfflat;
Query OK, 0 rows affected (11.129 sec)创建索引前耗时39ms,而在利用向量索引进行查询优化后,仅7.6ms就响应了Top 9的结果:


拥抱AI,强化向量功能
OceanBase分布式数据库-海量数据 笔笔算数
- 依靠OceanBase的分布式存储引擎,提供海量向量数据存储能力;
- 扩展OceanBase分区并行执行能力,提供高效的向量近似检索能力。
这意味着在海量存储和高效检索这两个场景下,OceanBase用户将获得更低的存储成本、更快的查询速度和更精确的查询结果。
此外,在AI应用中,相对于直接存储非结构化数据,存储非结构化数据Embedding后的向量数据具有两个优势:其一,数据更安全,非结构化数据对于数据库管理者不可见;其二,便于语义理解,向量近似搜索是一种从语义层面的检索方式,相似的文字、图片、视频信息具有距离接近的向量数值,这意味着用户在检索时更加灵活,即使使用相近的关键词也能得到精确的检索结果,节省检索成本并提高检索效率。
目前OceanBase可以初步支持近似搜索和搜索增强两个典型应用场景。
近似搜索场景包括但不限于:
- 搜索推荐;
- 数据分类、去重;
- 用于生成式模型的向量输入,如风格迁移应用;
- ……
检索增强生成场景包括但不限于:
- 私有知识库问答;
- Text2SQL;
- ……
后续OceanBase将继续强化向量功能,包括但不限于简化ANN搜索的SQL语法、支持GPU加速、支持更多向量操作函数及向量检索算法、强化标量向量混合查询能力,以及提供更多的AI接口,比如支持matrix,能够直接使用SQL接口对图片进行一些变换操作。
相关文章:
如何通过数据库与AI实现以图搜图?OceanBase向量功能详解
OceanBase支持向量数据库的基础能力 当前,数据库存储系统与人工智能技术的结合,可以体现在两个主要的应用方向上。 一、近似搜索。它利用大语言模型(LLM,简称大模型)的嵌入(embedding)技术&am…...

Kafka内外网分流配置listeners和advertised.listeners
问题背景: Kafka部署在内网,内网Java服务会使用Kafka收发消息,另外,Java服务会与其他第三方系统使用kafka实现数据同步,也就是外网也会发送消息到kafka,外网IP做了端口映射到了内网,advertised…...
Linux系统编程——网络编程
目录 一、对于Socket、TCP/UDP、端口号的认知: 1.1 什么是Socket: 1.2 TCP/UDP对比: 1.3 端口号的作用: 二、字节序 2.1 字节序相关概念: 2.2 为什么会有字节序: 2.3 主机字节序转换成网络字节序函数…...

信息安全技术基础知识-经典题目
【第1题】 1.在信息安全领域,基本的安全性原则包括机密性(Confidentiality)、完整性(Integrity)和 可用性(Availability)。机密性指保护信息在使用、传输和存储时 (1) 。信息加密是保证系统机密性的常用手段。使用哈希校验是保证数据完整性的常用方法。可用性指保证…...

nextjs(持续学习中)
return ( <p className{${lusitana.className} text-xl text-gray-800 md:text-3xl md:leading-normal}> Welcome to Acme. This is the example for the{’ } Next.js Learn Course , brought to you by Vercel. ); } 在顶级 /public 文件夹下提供静态资产 **默认 /…...

数据预处理与特征工程、过拟合与欠拟合
数据预处理与特征工程 常用的数据预处理步骤 向量化:将数据转换成pytorch张量值归一化:将特定特征的数据表示成均值为0,标准差为1的数据的过程;取较小的值:通常在0和1之间;相同值域处理缺失值特征工程&am…...

甲辰年五月十四风雨思
甲辰年五月十四风雨思 夜雨消暑气,远光归家心。 只待万窗明,朝夕千家勤。 苦乐言行得,酸甜日常品。 宫商角徵羽,仁义礼智信。...

java分别使用 iText 7 库和iText 5 库 将excel转成PDF导出,以及如何对excel转PDF合并单元格
第一种 package com.junfun.pms.report.util;import com.itextpdf.kernel.font.PdfFontFactory; import com.itextpdf.layout.Document; import com.itextpdf.layout.element.Paragraph; import com.itextpdf.layout.property.TextAlignment; import com.itextpdf.layout.prop…...

Java特性之设计模式【访问者模式】
一、访问者模式 概述 在访问者模式(Visitor Pattern)中,我们使用了一个访问者类,它改变了元素类的执行算法。通过这种方式,元素的执行算法可以随着访问者改变而改变。这种类型的设计模式属于行为型模式。根据模式&…...

【教师资格证考试综合素质——法律专项】未成年人保护法笔记以及练习题
《中华人民共和国未成年人保护法》 目录 第一章 总 则 第二章 家庭保护 第三章 学校保护 第四章 社会保护 第五章 网络保护 第六章 政府保护 第七章 司法保护 第八章 法律责任 第九章 附 则 介一.首次颁布:第一部《中华人民共和国未成年人保护法…...

6.19作业
TCP服务器 #include <stdio.h> #include <sys/types.h> #include <sys/socket.h> #include <unistd.h> #include <arpa/inet.h> #include <netinet/in.h> #include <string.h>#define PORT 8888 #define IP "192.168.124.39&q…...
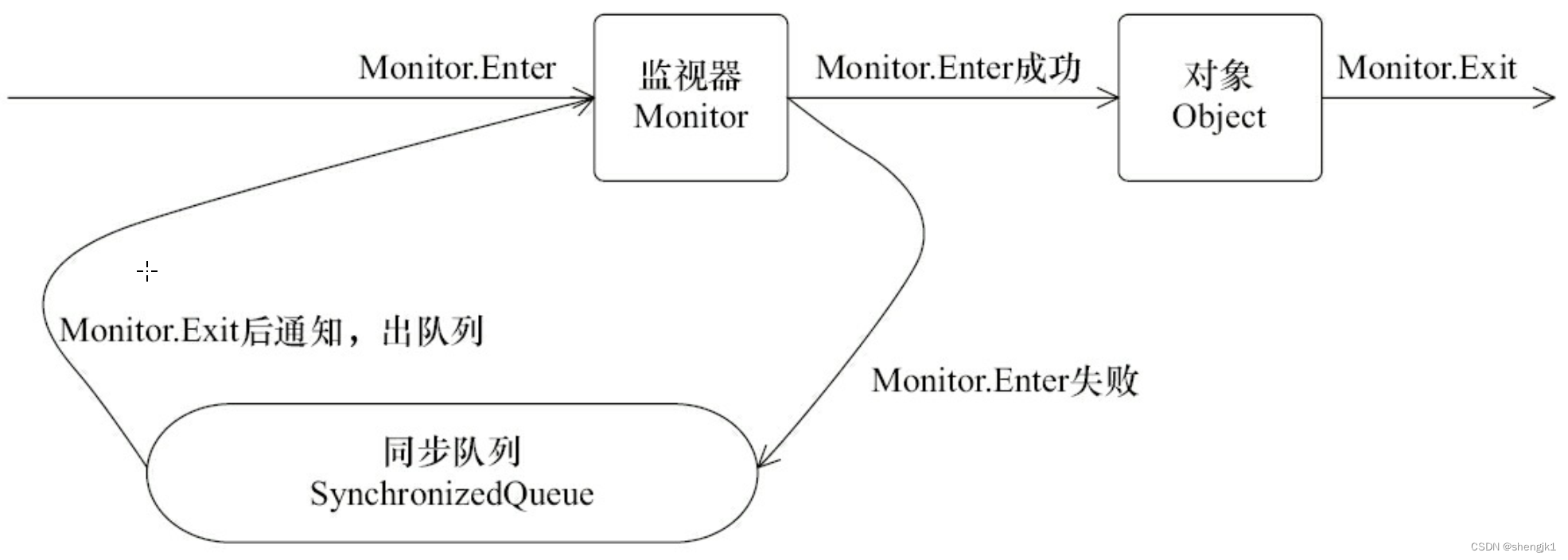
java 线程之间通信-volatile 和 synchronized
你好,我是 shengjk1,多年大厂经验,努力构建 通俗易懂的、好玩的编程语言教程。 欢迎关注!你会有如下收益: 了解大厂经验拥有和大厂相匹配的技术等 希望看什么,评论或者私信告诉我! 文章目录 一…...

资源宝库网站!人人必备的神器!
面对网络中海量的内容,一个高效、便捷的网络导航工具,可以帮助我们快速查找使用网络资源。无论是职场精英还是学生党,使用导航网站都可以帮助我们提升效率。下面小编就来和大家分享一款资源宝库网站-办公人导航-实用的办公生活导航网站&#…...
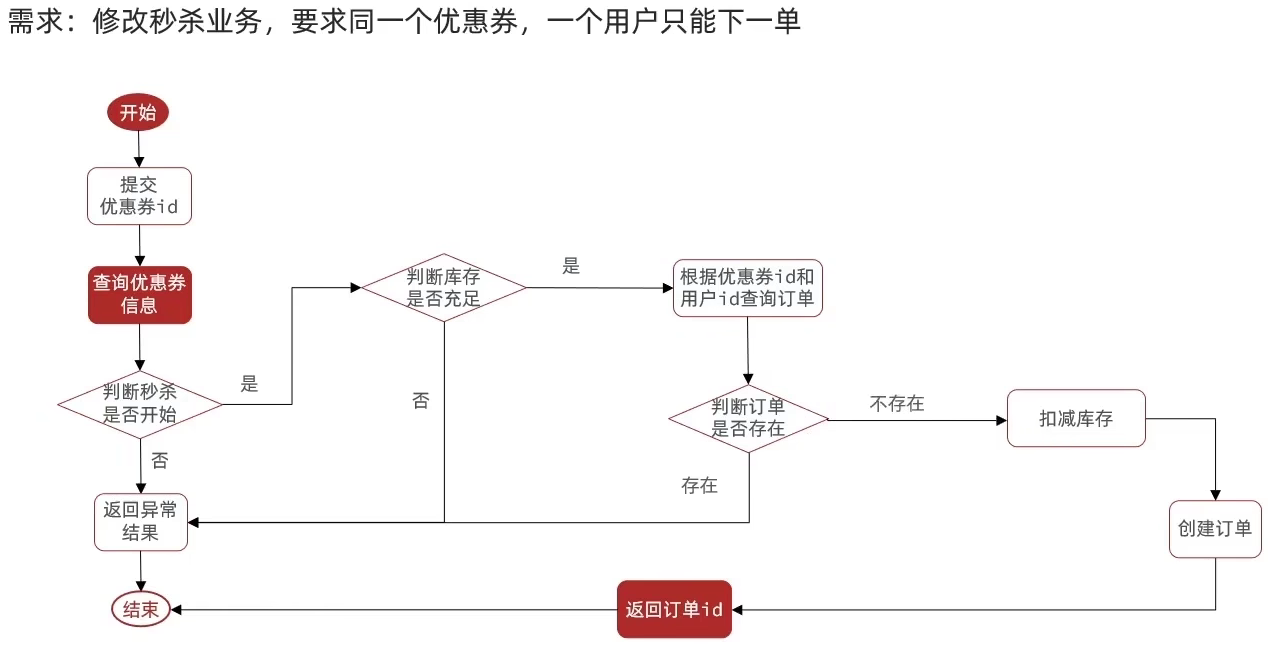
Redis实战—优惠卷秒杀(锁/事务/代理对象的应用)
本博客为个人学习笔记,学习网站与详细见:黑马程序员Redis入门到实战 P50 - P54 目录 优惠卷秒杀下单功能实现 超卖问题 悲观锁与乐观锁 实现CAS法乐观锁 一人一单功能实现 代码优化 代码细节分析 优惠卷秒杀下单功能实现 Controller层…...

HTML星空特效
目录 写在前面 完整代码 代码分析 运行效果 系列文章 写在后面 写在前面 100行代码实现HTML星空特效。 完整代码 全部代码如下。 <!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"&g…...
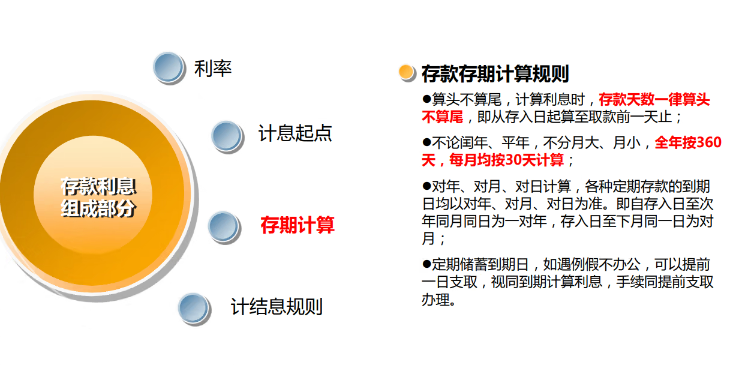
银行数仓项目实战(四)--了解银行业务(存款)
文章目录 项目准备存款活期定期整存整取零存整取存本取息教育储蓄定活两便通知存款 对公存款对公账户协议存款 利率 项目准备 (贴源层不必写到项目文档,因为没啥操作没啥技术,只是数据。) 可以看到,银行的贴源层并不紧…...
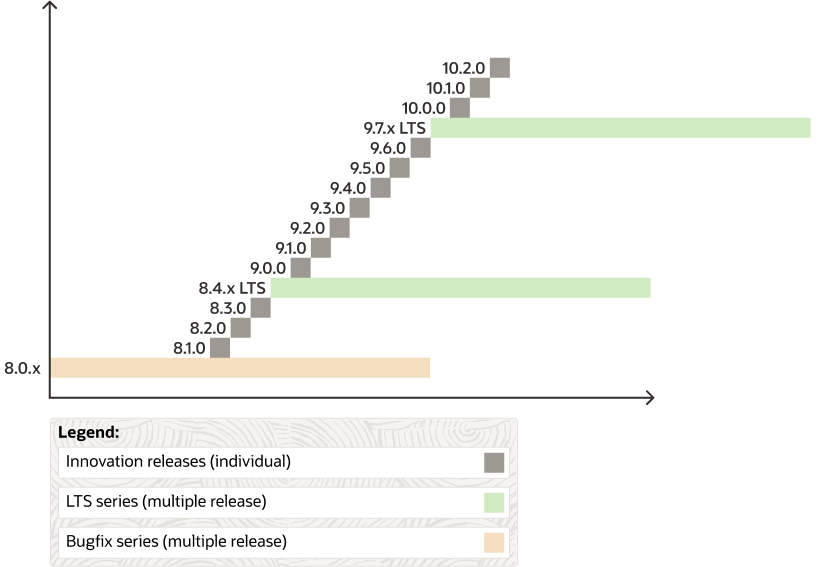
MySQL版本发布模型
MySQL 8.0 之后使用了新的版本控制和发布模型,分为两个主线:长期支持版(LTS)以及创新版。这两种版本都包含了缺陷修复和安全修复,都可以用于生产环境。 下图是 MySQL 的版本发布计划: 长期支持版 MySQL…...

java: 不兼容的类型: org.apache.xmlbeans.XmlObject无法转换为x2006.main.CTRow
我使用的xmlbeans版本是5.0,使用xmlbeans包做转换时,报错,正如标题显示得那样 解决办法 额外再引入下面的jar包 <dependency><groupId>org.apache.xmlbeans</groupId><artifactId>xmlbeans</artifactId><…...

内容时代:品牌如何利用社交平台精准触达用户
还记得学生时代老师教写作文的时候常说的一句话就是“开头质量决定了阅卷老师想不想花精力去读,而内容质量决定了她愿不愿意给你判高分”这个世界仿若一个巨大的圆,同样的逻辑放在任何地方好像都能适用。在品牌营销中,内容已成为品牌与消费者…...

推荐4款PC端黑科技工具,快来看看,建议收藏
Thunderbird Thunderbird 是由 Mozilla 基金会开发的一款免费且开源的电子邮件客户端,支持 Windows、macOS、Linux 等多种操作系统。它不仅可以用于发送和接收电子邮件,还可以作为新闻阅读器、聊天工具以及日历应用。 Thunderbird 提供了丰富的功能&…...
)
告别Vi和Emacs:在树莓派上用GNU nano轻松编辑代码(含语法高亮配置)
告别Vi和Emacs:在树莓派上用GNU nano轻松编辑代码(含语法高亮配置) 树莓派作为一款小巧而强大的单板计算机,已经成为开发者、教育工作者和DIY爱好者的首选工具。然而,对于许多初次接触Linux环境的用户来说,…...

Qwen3.5-9B快速上手:Python API封装+FastAPI服务化改造的完整代码实例
Qwen3.5-9B快速上手:Python API封装FastAPI服务化改造的完整代码实例 1. 引言 Qwen3.5-9B作为新一代多模态大模型,在实际业务场景中展现出强大的应用潜力。本文将带您从零开始,完成从基础API调用到完整服务化部署的全流程实践。 学习目标&…...
)
【限时公开】某军工级RTOS移植内参文档(含S32K144+SafeRTOS双核隔离移植实录,含ASIL-B级栈溢出防护设计)
第一章:RTOS移植工程全景与安全合规基线RTOS移植并非单纯替换内核代码,而是一项横跨硬件抽象层、中间件集成、运行时验证与全生命周期合规治理的系统工程。其核心目标是在资源受限的嵌入式环境中,同时达成确定性调度、内存安全边界可控、实时…...

国密算法C实现必须避开的7个隐性陷阱,第4个让国密SSL握手延迟飙升200ms!
第一章:国密算法C实现的性能瓶颈全景图国密算法(如SM2、SM3、SM4)在嵌入式设备、金融终端及政务系统中广泛部署,其C语言实现虽具备跨平台优势,但在实际运行中常遭遇多维度性能制约。深入剖析这些瓶颈,是优化…...

FlowState Lab环境配置详解:Linux系统依赖与Docker容器化部署
FlowState Lab环境配置详解:Linux系统依赖与Docker容器化部署 1. 环境配置概述 FlowState Lab作为一款高性能AI开发环境,对系统配置有特定要求。本文将带你完成从裸机到完整环境的搭建过程,特别针对Linux系统下的GPU加速和容器化部署场景。…...

Nanbeige 4.1-3B保姆级教程:添加用户反馈机制持续优化大贤者表现
Nanbeige 4.1-3B保姆级教程:添加用户反馈机制持续优化大贤者表现 1. 项目背景与目标 Nanbeige 4.1-3B是一款具有独特像素游戏风格的AI对话模型,其"大贤者"角色设定和复古JRPG界面设计为用户带来了全新的交互体验。但在实际使用中,…...

XPath 语法完全指南:从基础语法到 SQL 注入中的应用
爬虫、处理过配置文件、或者接触过 MySQL 的 XML 函数的一定都见过 XPath 这个名词。它是一种专门用来在 XML 文档中“寻址”的语言,语法像文件路径一样直观。同时,XPath 是 Web 安全领域中 SQL 报错盲注中的关键角色。一、XPath 是什么?XPat…...

六年沉浮:上汽大众在贾健旭的“局”里,寻找陶海龙的“增程”解
【文/深度评车&财经三剑客】在新能源汽车风起云涌、技术日新月异的今天,上汽大众,这家曾经在中国汽车市场叱咤风云的合资巨头,却似乎陷入了前所未有的困境与迷茫之中。从昔日的辉煌到如今的步履维艰,上汽大众的每一步都显得那…...

【GitHub项目推荐--Zoxide:智能化的终端目录导航工具】⭐⭐⭐⭐⭐
简介 Zoxide 是一款基于 Rust 语言开发的跨平台命令行工具,旨在彻底改变用户在终端中切换目录的方式。它被设计为传统 cd命令的智能化替代品,灵感来源于经典的 z和 autojump工具。Zoxide 通过持续学习用户的目录访问习惯,构建一个基于“频率…...

【GitHub项目推荐--CashClaw:Moltlaunch 生态的自主工作代理】
简介 CashClaw 是由 Moltlaunch 团队开发的一款开源自主 AI 代理(Agent)。它不仅仅是一个对话助手,而是一个具备“接单-干活-收款-学习”完整闭环的商业化智能体。该项目的核心目标是构建一个能够自主在 Moltlaunch 链上工作市场中生存的 AI…...