常用损失函数详解:广泛使用的优化约束方法
各类常用损失函数详解:广泛使用的优化约束方法
今天介绍下损失函数,先介绍下我常用的方法SmoothedL1,它是一个平滑的L1 penalty函数,用于处理约束violation。
标准的L1 penalty函数定义为:
L 1 ( x ) = { 0 , if x ≤ 0 x , if x > 0 L_1(x)=\begin{cases} 0, & \text{if } x\leq 0 \\ x, & \text{if } x>0 \end{cases} L1(x)={0,x,if x≤0if x>0
其中 x x x表示约束violation。然而,这个函数在 x = 0 x=0 x=0处不可导,会给基于梯度的优化算法带来数值问题。
为了解决这个问题,SmoothedL1使用了一个分段的、光滑的函数来近似L1 penalty。它的定义如下:
smoothedL1 ( x , μ ) = { 0 , if x < 0 1 2 μ x 2 , if 0 ≤ x < μ x − 1 2 μ , if x ≥ μ \text{smoothedL1}(x,\mu)=\begin{cases} 0, & \text{if } x<0 \\ \frac{1}{2\mu}x^2, & \text{if } 0\leq x<\mu \\ x-\frac{1}{2}\mu, & \text{if } x\geq\mu \end{cases} smoothedL1(x,μ)=⎩ ⎨ ⎧0,2μ1x2,x−21μ,if x<0if 0≤x<μif x≥μ
其中 μ > 0 \mu>0 μ>0是一个平滑参数。当 μ → 0 \mu\to 0 μ→0时,smoothedL1趋近于标准的L1 penalty;当 μ \mu μ增大时,smoothedL1变得更加平滑。
在代码中,smoothedL1的实现如下:
static inline bool smoothedL1(const double &x,const double &mu,double &f,double &df)
{if (x < 0.0){df = 0;return false;}else if (x < mu){f = x * x / (2.0 * mu);df = x / mu;return true;}else{f = x - 0.5 * mu;df = 1.0;return true;}
}
这个函数接受约束violation x和平滑参数mu,返回penalty值f和梯度df。具体来说:
- 当 x < 0 x<0 x<0时,表示没有约束violation,penalty和梯度都为0。
- 当 0 ≤ x < μ 0\leq x<\mu 0≤x<μ时,使用二次函数 1 2 μ x 2 \frac{1}{2\mu}x^2 2μ1x2来近似L1 penalty,其梯度为 x μ \frac{x}{\mu} μx。
- 当 x ≥ μ x\geq\mu x≥μ时,使用线性函数 x − 1 2 μ x-\frac{1}{2}\mu x−21μ来近似L1 penalty,其梯度为1。
通过这种分段定义,smoothedL1实现了对L1 penalty的光滑近似。在 x = 0 x=0 x=0和 x = μ x=\mu x=μ处,虽然函数本身不可导,但左右导数存在且相等,因此不会引入数值问题。
在轨迹优化中,smoothedL1被用于计算速度约束、加速度约束等的violation对应的cost和梯度。通过将这些cost项添加到目标函数中,并将梯度信息反向传播,优化算法可以在最小化能量(minimum-energy)的同时,将轨迹逐步修正为满足约束的状态,最终得到一条动力学可行(dynamically feasible)的轨迹。这就是smoothedL1在这个问题中的作用和实现原理。
具体应用
我可以给你一个通俗的例子来解释smoothedL1函数的用途。
假设你是一家披萨店的老板,你需要制定一个披萨配送的最优路线。你的目标是找到一条路线,使得配送时间尽可能短,但同时也要考虑到路上可能会遇到一些意外情况,如交通堵塞、红绿灯等。
在这个问题中,我们可以将配送时间看作是优化的目标函数。我们希望实际的配送时间与预期的配送时间尽可能接近。如果实际配送时间比预期时间长,就会有一个惩罚项。
现在,假设我们使用二次函数(即L2损失)来计算惩罚项。这意味着,如果实际配送时间比预期时间长2分钟,惩罚值为4;如果长5分钟,惩罚值为25。你可以看到,随着差异的增大,惩罚值会急剧增加。这在某些情况下可能不太合理,因为一些小的延迟是可以接受的,而大的延迟可能是由一些无法控制的因素引起的,如交通事故。
另一种选择是使用绝对值函数(即L1损失)。这意味着,无论实际配送时间比预期时间长2分钟还是5分钟,惩罚值都是一样的。这也有问题,因为它不能区分小的延迟和大的延迟。
smoothedL1函数提供了一个折衷的方案。它在小的延迟时表现得像二次函数,惩罚值随着差异的增大而平滑增加;在大的延迟时表现得像绝对值函数,惩罚值增加的速度变慢。这样,我们就可以在考虑小的延迟的同时,也对大的延迟更加宽容。
下面是一个简单的Python代码,展示了如何使用smoothedL1函数计算惩罚值:
def smoothedL1(x, mu):if x < 0:return 0elif x > mu:return x - 0.5 * muelse:return (mu - 0.5 * x) * (x / mu)**3# 预期配送时间为10分钟
expected_time = 10# 实际配送时间为12分钟
actual_time = 12# 计算延迟
delay = actual_time - expected_time# 设定平滑参数为5分钟
mu = 5# 计算惩罚值
penalty = smoothedL1(delay, mu)print(f"The penalty for a delay of {delay} minutes is {penalty}.")
如果实际配送时间比预期时间长2分钟,惩罚值为0.384;如果长5分钟,惩罚值为2.5。你可以看到,对于小的延迟,惩罚值较小;对于大的延迟,惩罚值增加的速度变慢。
当然,在实际的路线优化问题中,情况会更加复杂。这在许多优化问题中都非常有用。
其它常用的损失函数
除了smoothedL1损失函数,还有许多其他先进的损失函数在各个领域发挥着关键作用。下面我将介绍几个常用的损失函数及其应用。
-
交叉熵损失(Cross-Entropy Loss)
交叉熵损失函数常用于分类问题。它衡量了模型预测的概率分布与真实标签的差异。对于二分类问题,交叉熵损失函数定义为:
L C E = − ∑ i = 1 N y i log ( p i ) + ( 1 − y i ) log ( 1 − p i ) L_{CE}=-\sum_{i=1}^N y_i\log(p_i)+(1-y_i)\log(1-p_i) LCE=−i=1∑Nyilog(pi)+(1−yi)log(1−pi)
其中 y i y_i yi是第 i i i个样本的真实标签(0或1), p i p_i pi是模型预测的概率。
交叉熵损失函数在图像分类、自然语言处理等领域得到广泛应用。它能够促使模型学习到正确的类别,同时抑制错误的类别。许多著名的神经网络,如AlexNet, VGG, ResNet等,都使用交叉熵损失函数进行训练。 -
对比损失(Contrastive Loss)
对比损失函数常用于学习嵌入空间(embedding space),使得相似的样本在嵌入空间中靠近,不相似的样本在嵌入空间中远离。它的定义如下:
L c o n t r a s t = ∑ ( i , j ) y i j d ( x i , x j ) + ( 1 − y i j ) max ( 0 , α − d ( x i , x j ) ) L_{contrast}=\sum_{(i,j)}y_{ij}d(x_i,x_j)+(1-y_{ij})\max(0,\alpha-d(x_i,x_j)) Lcontrast=(i,j)∑yijd(xi,xj)+(1−yij)max(0,α−d(xi,xj))
其中 y i j y_{ij} yij表示样本 i i i和 j j j是否相似(1表示相似,0表示不相似), d ( x i , x j ) d(x_i,x_j) d(xi,xj)是样本 i i i和 j j j在嵌入空间中的距离, α \alpha α是一个margin参数。
对比损失函数在人脸识别、图像检索等领域发挥了重要作用。通过最小化对比损失,模型可以学习到一个鲁棒的嵌入空间,使得相似的样本(如同一个人的不同照片)聚集在一起,不相似的样本(如不同人的照片)分散开来。 -
焦点损失(Focal Loss)
焦点损失函数是一种用于处理类别不平衡问题的损失函数。在许多实际问题中,不同类别的样本数量差异很大。这会导致模型更加关注样本量大的类别,而忽视样本量小的类别。焦点损失函数通过引入一个调制因子来缓解这个问题:
L f o c a l = − ∑ i = 1 N ( 1 − p i ) γ log ( p i ) L_{focal}=-\sum_{i=1}^N(1-p_i)^\gamma\log(p_i) Lfocal=−i=1∑N(1−pi)γlog(pi)
其中 p i p_i pi是模型预测的概率, γ \gamma γ是一个超参数。当模型预测错误时, p i p_i pi较小, ( 1 − p i ) γ (1-p_i)^\gamma (1−pi)γ较大,损失函数会给这些样本更大的权重。
焦点损失函数在目标检测领域取得了巨大成功。在著名的目标检测算法RetinaNet中,使用焦点损失函数替代交叉熵损失函数,大幅提高了对小目标的检测精度。 -
Wasserstein损失(Wasserstein Loss)
Wasserstein损失函数源于最优传输理论,它衡量了两个概率分布之间的距离。在生成对抗网络(GAN)中,Wasserstein损失函数被用于度量生成数据和真实数据的分布差异:
L W a s s e r s t e i n = sup ∣ ∣ f ∣ ∣ L ≤ 1 E x ∼ P r [ f ( x ) ] − E x ∼ P g [ f ( x ) ] L_{Wasserstein}=\sup_{||f||_L\leq1}\mathbb{E}_{x\sim P_r}[f(x)]-\mathbb{E}_{x\sim P_g}[f(x)] LWasserstein=∣∣f∣∣L≤1supEx∼Pr[f(x)]−Ex∼Pg[f(x)]
其中 P r P_r Pr是真实数据的分布, P g P_g Pg是生成数据的分布, f f f是一个Lipschitz连续函数。
相比于传统的GAN损失函数,Wasserstein损失函数提供了一个更加稳定的训练过程。它在图像生成、风格迁移等领域取得了令人印象深刻的成果。著名的WGAN和WGAN-GP都是基于Wasserstein损失函数构建的。
一个好的损失函数可以引导模型学习到正确的特征表示,加速训练过程,提高模型的泛化能力。
这几种损失函数的应用和优势
- 交叉熵损失在图像分类中的应用
假设我们要训练一个图像分类模型,用于识别图片中的物体类别。我们可以使用交叉熵损失函数来训练这个模型。交叉熵损失函数能够衡量模型预测的类别分布与真实标签的差异,引导模型学习到正确的分类边界。
以下是使用PyTorch实现交叉熵损失函数的代码示例:
import torch
import torch.nn as nn
# 定义模型
class ImageClassifier(nn.Module):def __init__(self):super(ImageClassifier, self).__init__()self.conv1 = nn.Conv2d(3, 32, 3)self.conv2 = nn.Conv2d(32, 64, 3)self.fc1 = nn.Linear(64 * 6 * 6, 128)self.fc2 = nn.Linear(128, 10)def forward(self, x):x = self.conv1(x)x = nn.functional.relu(x)x = self.conv2(x)x = nn.functional.relu(x)x = x.view(-1, 64 * 6 * 6)x = self.fc1(x)x = nn.functional.relu(x)x = self.fc2(x)return x
# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 定义优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 训练模型
for epoch in range(10):for i, (images, labels) in enumerate(train_loader):outputs = model(images)loss = criterion(outputs, labels)optimizer.zero_grad()loss.backward()optimizer.step()
这个例子中定义了一个简单的卷积神经网络ImageClassifier,使用nn.CrossEntropyLoss()作为损失函数。在训练过程中,我们将图像输入模型,计算模型的预测结果和真实标签之间的交叉熵损失,然后使用优化器更新模型参数。交叉熵损失函数能够有效地指导模型学习,使其对不同类别的图像进行准确分类。
- 对比损失在人脸识别中的应用
在人脸识别任务中,我们希望模型能够学习到一个鲁棒的人脸嵌入空间,使得同一个人的不同照片在嵌入空间中靠近,不同人的照片在嵌入空间中远离。我们可以使用对比损失函数来达到这个目的。
以下是使用TensorFlow实现对比损失函数的代码示例:
import tensorflow as tf
# 定义模型
model = tf.keras.Sequential([tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),tf.keras.layers.MaxPooling2D((2, 2)),tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),tf.keras.layers.MaxPooling2D((2, 2)),tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),tf.keras.layers.Flatten(),tf.keras.layers.Dense(64, activation='relu'),tf.keras.layers.Dense(10)
])
# 定义损失函数
def contrastive_loss(y_true, y_pred):margin = 1square_pred = tf.math.square(y_pred)margin_square = tf.math.square(tf.math.maximum(margin - y_pred, 0))return tf.math.reduce_mean(y_true * square_pred + (1 - y_true) * margin_square)
# 编译模型
model.compile(optimizer='adam',loss=contrastive_loss,metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=5)
在这个例子中定义了一个卷积神经网络作为人脸嵌入模型。我们自定义了一个contrastive_loss函数,它接收两个参数:真实标签y_true(1表示两张图片属于同一个人,0表示属于不同的人)和模型的预测值y_pred(表示两张图片在嵌入空间中的距离)。对比损失函数鼓励模型将同一个人的照片映射到相近的位置,将不同人的照片映射到相distant的位置。通过最小化对比损失,模型可以学习到一个判别性强的人脸嵌入空间,用于人脸识别和验证。
- 焦点损失在目标检测中的应用
在目标检测任务中,我们需要同时预测目标的位置和类别。然而,背景区域通常占据了图像的大部分,导致正负样本数量极度不平衡。如果直接使用交叉熵损失函数,模型可能会倾向于将大多数区域预测为背景,而忽视了真正的目标。焦点损失函数通过引入一个调制因子来缓解这个问题,使得模型更加关注难以分类的样本。
以下是使用PyTorch实现焦点损失函数的代码示例:
import torch
import torch.nn as nn
# 定义焦点损失函数
class FocalLoss(nn.Module):def __init__(self, alpha=0.25, gamma=2):super(FocalLoss, self).__init__()self.alpha = alphaself.gamma = gammadef forward(self, pred, target):ce_loss = nn.functional.cross_entropy(pred, target, reduction='none')pt = torch.exp(-ce_loss)focal_loss = self.alpha * (1 - pt) ** self.gamma * ce_lossreturn torch.mean(focal_loss)
# 定义模型
model = nn.Sequential(nn.Conv2d(3, 32, 3, padding=1),nn.ReLU(),nn.Conv2d(32, 64, 3, padding=1),nn.ReLU(),nn.Conv2d(64, 64, 3, padding=1),nn.ReLU(),nn.Conv2d(64, 2, 1)
)
# 定义优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 训练模型
for epoch in range(10):for i, (images, targets) in enumerate(train_loader):preds = model(images)loss = FocalLoss()(preds, targets)optimizer.zero_grad()loss.backward()optimizer.step()
在这个例子中,我们定义了一个FocalLoss类,它继承自nn.Module。在forward方法中,我们首先计算交叉熵损失,然后根据预测的准确性计算一个调制因子 ( 1 − p t ) γ (1 - p_t)^\gamma (1−pt)γ。这个调制因子可以减少easy example的损失贡献,同时增大hard example的损失贡献。最后将调制后的损失取平均作为最终的焦点损失。在训练过程中,使用焦点损失函数可以使模型更加关注那些难以分类的目标,提高检测精度。
- Wasserstein损失在图像生成中的应用
在图像生成任务中,一般希望生成的图像能够尽可能逼真,同时具有丰富的多样性。传统的GAN使用Jensen-Shannon散度作为损失函数,但这会导致训练过程不稳定,生成质量难以提升。Wasserstein损失函数源于最优传输理论,它衡量了真实图像分布和生成图像分布之间的Wasserstein距离。使用Wasserstein损失函数可以缓解GAN训练中的模式崩溃问题,生成更加逼真和多样的图像。
以下是使用TensorFlow实现Wasserstein损失函数的代码示例:
import tensorflow as tf
# 定义生成器
generator = tf.keras.Sequential([tf.keras.layers.Dense(7 * 7 * 256, input_shape=(100,)),tf.keras.layers.BatchNormalization(),tf.keras.layers.LeakyReLU(),tf.keras.layers.Reshape((7, 7, 256)),tf.keras.layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same'),tf.keras.layers.BatchNormalization(),tf.keras.layers.LeakyReLU(),tf.keras.layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same'),tf.keras.layers.BatchNormalization(),tf.keras.layers.LeakyReLU(),tf.keras.layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', activation='tanh')
])
# 定义判别器
discriminator = tf.keras.Sequential([tf.keras.layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same', input_shape=(28, 28, 1)),tf.keras.layers.LeakyReLU(),tf.keras.layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'),tf.keras.layers.LeakyReLU(),tf.keras.layers.Flatten(),tf.keras.layers.Dense(1)
])
# 定义Wasserstein损失函数
def wasserstein_loss(y_true, y_pred):return tf.math.reduce_mean(y_true * y_pred)
# 编译模型
discriminator.compile(optimizer=tf.keras.optimizers.RMSprop(lr=0.00005), loss=wasserstein_loss,metrics=['accuracy'])
generator.compile(optimizer=tf.keras.optimizers.RMSprop(lr=0.00005), loss=wasserstein_loss)
# 训练模型
for epoch in range(100):for i in range(num_batches):noise = tf.random.normal([batch_size, 100])generated_images = generator(noise)real_images = next(iter(train_dataset))[0]x = tf.concat([real_images, generated_images], axis=0)y_dis = tf.concat([tf.ones((batch_size, 1)), tf.ones((batch_size, 1)) * -1], axis=0)discriminator.trainable = Truediscriminator.train_on_batch(x, y_dis)noise = tf.random.normal([batch_size, 100])y_gen = tf.ones((batch_size, 1))discriminator.trainable = Falsegenerator.train_on_batch(noise, y_gen)
在这个例子中定义了一个生成器网络和一个判别器网络。生成器接收一个随机噪声作为输入,输出一张生成的图像。判别器接收一张图像作为输入,输出一个标量值,表示输入图像是真实的还是生成的。我们使用wasserstein_loss作为损失函数,它计算了判别器的预测值和真实标签的乘积的平均值。在训练过程中,我们交替训练判别器和生成器。对于判别器,我们希望它能够正确区分真实图像(标签为1)和生成图像(标签为-1)。对于生成器,我们希望它能够生成更加逼真的图像,使得判别器将其预测为真实图像(标签为1)。通过最小化Wasserstein损失,生成器可以学习到真实图像的分布,生成高质量的图像。
选择合适的损失函数可以帮助模型更好地学习到数据的内在模式,提高任务的性能。同时,损失函数的设计也需要考虑问题的特点和模型的结构,根据实际情况进行进一步的调整和优化。
相关文章:

常用损失函数详解:广泛使用的优化约束方法
各类常用损失函数详解:广泛使用的优化约束方法 今天介绍下损失函数,先介绍下我常用的方法SmoothedL1,它是一个平滑的L1 penalty函数,用于处理约束violation。 标准的L1 penalty函数定义为: L 1 ( x ) { 0 , if x ≤ 0 x , if x > 0 …...

鸿蒙开发组件:【创建DataAbility】
创建DataAbility 实现DataAbility中Insert、Query、Update、Delete接口的业务内容。保证能够满足数据库存储业务的基本需求。BatchInsert与ExecuteBatch接口已经在系统中实现遍历逻辑,依赖Insert、Query、Update、Delete接口逻辑,来实现数据的批量处理。…...
配电室数据中心巡检3d可视化搭建的详细步骤
要搭建配电室巡检的3D可视化系统,可以按照以下步骤进行: 收集配电室数据: 首先,需要收集配电室的相关数据,包括配电室的布局、设备信息、传感器数据等。可以通过实地调查、测量和设备手册等方式获取数据。 创建3D模型…...
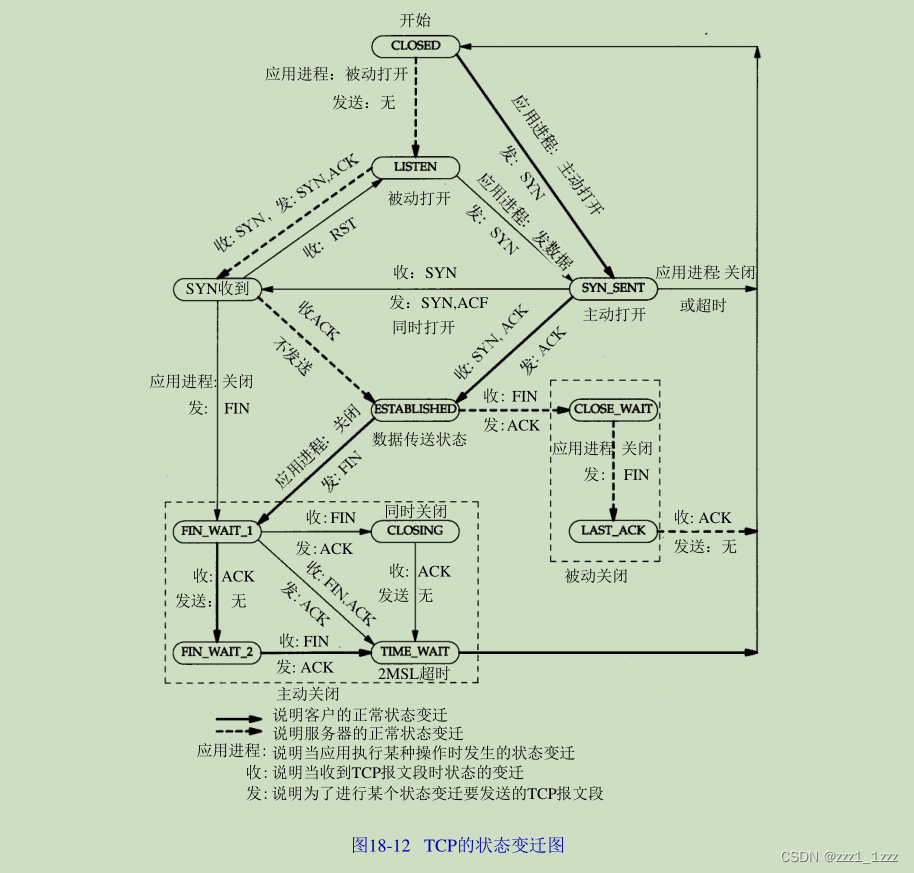
TIME_WAIT的危害
前言 该文章主要讨论下TIME_WAIT的存在意义和潜在危害,以及解决措施。 具体内容 首先看一下下面这幅图 这幅图来自《TCP IP详解卷1:协议 原书第2版中文》TCP状态变迁图。 TIME_WAIT存在意义 可靠的终止TCP连接。 保证让迟来的TCP报文有足够的时间被…...

搜维尔科技邀您共赴2024第四届轨道车辆工业设计国际研讨会
会议内容 聚焦“创新、设计、突破”,围绕“面向生命健康、可持续发展的轨道交通系统” 为主题,从数字化、智能化、人性化、绿色发展等方面,探索轨道交通行业的设计新趋势及发展新机遇。 举办时间 2024年7月10日-12日 举办地点 星光岛-青岛融…...

智能中人类造成的风险、机器造成的风险、环境造成的风险
在使用智能技术时,可能会面临各种类型的风险。以下是一些可能的风险情况: 1、人类造成的风险 错误判断和决策:人类在使用智能系统时可能会因为各种原因做出错误的判断和决策,导致不良后果。人为错误:技术操作人员、维护…...

MYSQL基础查询
示例:user_profile iddevice_idgenderageuniversityprovince12138male21北京大学Beijing23214male复旦大学Shanghai36543female20北京大学Beijing42315female23浙江大学Zhejiang55432male25山东大学Shandong 查询所有列 select * from user_profile;查询…...

【Golang】Go 中的生产者-消费者模式
Go 中的生产者-消费者模式 来源:https://medium.com/@mm.nikfarjam/the-producer-consumer-pattern-in-go-cf97299a0320 文章目录 Go 中的生产者-消费者模式介绍关键组件在 Go 中的实现结论Go 中的生产者-消费者模式 介绍 生产者-消费者模式是处理大数据的最常见设计模式之一…...

【通过新能源汽车的智慧数字底盘技术看计算机的相关技术堆栈?以后是软硬结合的全能程序员的天下,取代全栈(前后端都会的全栈程序员)】
汽车的“智慧数字底盘”是一个综合性的技术平台,旨在提升车辆的性能、安全性和驾驶体验。它集成了多种先进的技术和系统,是全能程序员的必杀技! 1. 传感器技术 a. 激光雷达(LiDAR) 用于生成高分辨率的3D地图&#…...

Python网络爬虫4-实战爬取pdf
1.需求背景 爬取松产品中心网站下的家电说明书。这里以冰箱为例:松下电器-冰箱网址 网站分析: 第一步: 点击一个具体的冰箱型号,点击了解更多,会打开此型号电器的详情页面。 第二步:在新打开的详情页面中…...
超神级!Markdown最详细教程,程序员的福音
超神级!Markdown最详细教程,程序员的福音Markdown最详细教程,关于Markdown的语法和使用就先讲到这里,如果喜欢,请关注“IT技术馆”。馆长会更新最实用的技术!https://mp.weixin.qq.com/s/fNzhLFyYRd3skG-…...
Android OTA 升级基础知识详解+源码分析
前言: 本文仅仅对OTA升级的几种方式的概念和运用进行总结,仅在使用层面对其解释。需要更详细的内容我推荐大神做的全网最详细的讲解: https://blog.csdn.net/guyongqiangx/article/details/129019303?spm1001.2014.3001.5502 三种升级方式…...

【吊打面试官系列-Mysql面试题】SQL 语言包括哪几部分?每部分都有哪些操作关键字?
大家好,我是锋哥。今天分享关于 【SQL 语言包括哪几部分?每部分都有哪些操作关键字?】面试题,希望对大家有帮助; SQL 语言包括哪几部分?每部分都有哪些操作关键字? SQL 语言包括数据定义(DDL)、…...
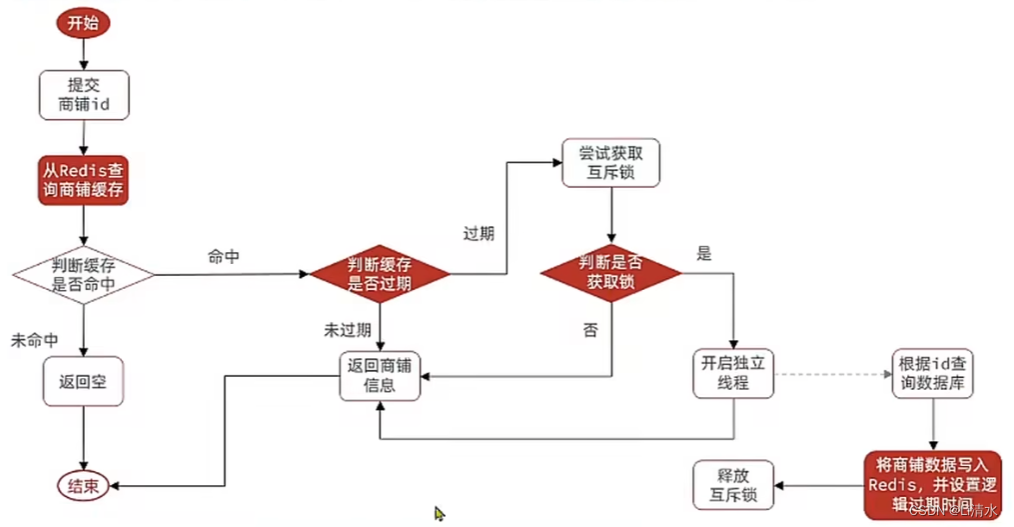
Redis的缓存击穿与解决
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的Key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。 Redis实战篇 | Kyles Blog (cyborg2077.github.io) 目录 解决方案 互斥锁 实现 逻辑过期 实现 解决方案…...
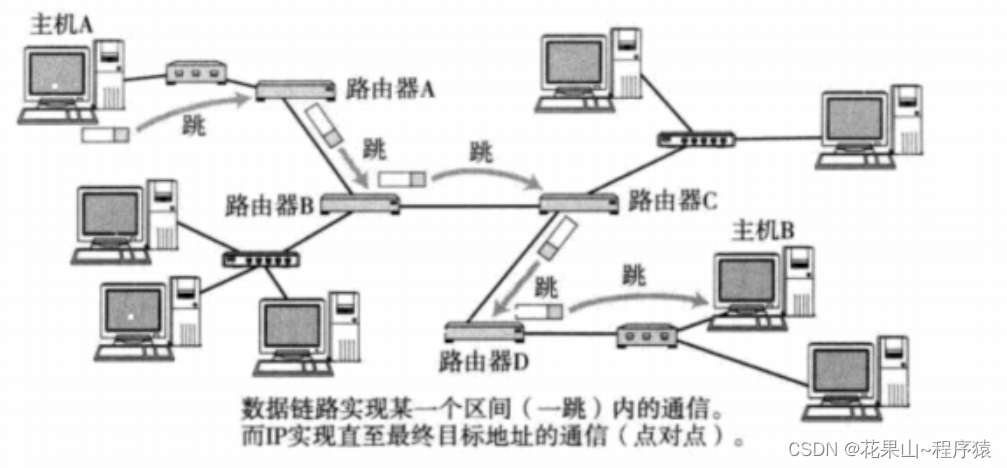
网络层 IP协议【计算机网络】【协议格式 || 分片 || 网段划分 || 子网掩码】
博客主页:花果山~程序猿-CSDN博客 文章分栏:Linux_花果山~程序猿的博客-CSDN博客 关注我一起学习,一起进步,一起探索编程的无限可能吧!让我们一起努力,一起成长! 目录 一,前提 二&…...
Python学习笔记14:进阶篇(三)。类的终结篇,类的导入和模块的导入。
前言 这篇文章属于类知识的最后一篇,带一点点其他知识,学习内容来自于Python crash course。 关注我私信发送Python crash course,分享一份中文版PDF。 类的导入 在学习的时候,包括之前,我都是在一个文件中把所有代…...

C++ lambda表达式举例
C lambda表达式 Lambda表达式是一种简洁的方式来创建匿名函数,可以直接在函数调用的地方定义,主要用于简化代码。 Lambda表达式的基本语法如下: [capture](parameters) -> return_type {// function body };示例1:基本用法 …...
)
持续总结中!2024年面试必问 20 道设计模式面试题(五)
上一篇地址:持续总结中!2024年面试必问 20 道设计模式面试题(四)-CSDN博客 九、请解释代理模式(Proxy Pattern)及其类型。 代理模式(Proxy Pattern)是一种结构设计模式,…...

嵌入式面经111题答案汇总(含技术答疑)_嵌入式项目源码分享
111道嵌入式面试题答案汇总专栏链接(承诺免费技术答疑) --> 《嵌入式/C面试题解析大全》 1、简介 本人是2020年毕业于广东工业大学研究生:许乔丹,有国内大厂CVTE和世界500强企业工作经验,整理超全面111道嵌入式面试…...
鸿蒙开发通信与连接:【@ohos.connectedTag (有源标签)】
有源标签 说明: 本模块首批接口从API version 8开始支持。后续版本的新增接口,采用上角标单独标记接口的起始版本。 导入模块 import connectedTag from ohos.connectedTag;connectedTag.init init(): boolean 初始化有源标签芯片。 需要权限&#…...

统信UOS桌面系统高效运维:从入门到精通的命令行指南
1. 为什么你需要掌握统信UOS命令行? 第一次接触统信UOS桌面系统时,很多人都会被它精美的图形界面吸引。但真正用过一段时间后,你会发现图形界面虽然友好,但在处理批量操作、远程管理、自动化任务时效率远不如命令行。我刚开始用U…...

2026届必备的降AI率助手横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 若想切实有效地降低内容的AIGC检测相似度,那就非得从文本生成的起始源头开始着手…...

FLUX.1-dev FP8技术指南:AI绘画优化与低配置运行解决方案
FLUX.1-dev FP8技术指南:AI绘画优化与低配置运行解决方案 【免费下载链接】flux1-dev 项目地址: https://ai.gitcode.com/hf_mirrors/Comfy-Org/flux1-dev ⚠️ 问题篇:AI绘画的硬件门槛挑战 显存瓶颈:普通设备的最大障碍 当你尝试…...

EdgeDeflector:守护浏览器自由的系统工具
EdgeDeflector:守护浏览器自由的系统工具 【免费下载链接】EdgeDeflector A tiny helper application to force Windows 10 to use your preferred web browser instead of ignoring the setting to promote Microsoft Edge. Only runs for a microsecond when need…...

3步突破平台壁垒:跨平台资源工具的效率革命
3步突破平台壁垒:跨平台资源工具的效率革命 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 在数字化内容爆炸的时…...

【计算】漫谈Google三驾马车之 Bigtable
我们将从背景动机、系统架构、核心设计思想、使用方式四个维度,全面深入地解析 Google 的 Bigtable —— 这一支撑了 Google 多数核心服务(如 Search、Gmail、Google Maps)的分布式结构化存储系统。 一、为什么要做 Bigtable?——…...

OpCore-Simplify:从8小时到30分钟,智能OpenCore EFI配置的终极指南
OpCore-Simplify:从8小时到30分钟,智能OpenCore EFI配置的终极指南 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 在开源系统…...

DeepAnalyze舆情分析:社交媒体数据挖掘
DeepAnalyze舆情分析:社交媒体数据挖掘实战指南 1. 引言:社交媒体时代的舆情挑战 每天,社交媒体平台产生着海量的用户内容——从微博的热点讨论到小红书的消费分享,从抖音的短视频评论到专业论坛的技术交流。这些数据中蕴含着宝…...

基于DP_MPC算法的氢能源动力无人机复合电源能量管理策略研究
基于DP_MPC算法的氢能源动力无人机能量管理 背景:随着氢燃料的开发,氢能源被应用到许多领域,但是由于其不能储能,所以通常与储能元件搭配使用,复合电源就涉及到能源分配问题,于是需要一个合适的能量管理算法…...

快速原型验证:如何用快马AI一键生成50台云桌面的基础管理脚本
快速原型验证:如何用快马AI一键生成50台云桌面的基础管理脚本 最近在研究虚拟化技术,想验证一个想法:一台主机能否支撑50台云桌面的运行?传统方式搭建测试环境太费时,手动配置KVM或Docker既复杂又容易出错。好在发现了…...