Android源码分析 - Parcel 与 Parcelable
0. 相关分享
Android-全面理解Binder原理
Android特别的数据结构(二)ArrayMap源码解析
1. 序列化 - Parcelable和Serializable的关系
如果我们需要传递一个Java对象,通常需要对其进行序列化,通过内核进行数据转发,可能转发到本地文件,也可能转发到其他进程。序列化的方式很多,只要定好序列化和反序列化的规则,就可以进行Java对象的传输。常见的就是通过Serializable接口进行序列化。
Serializable序列化
Serializable序列化接口,将Java对象转换为字节序列写入文件中,实现了持久化存储。下一次需要使用该Java对象时,可以直接通过Serializable的反序列化规范,将文件中的数据提取出来,转换回Java对象。
Serializable序列化不仅可以让Java对象在本地持久化存储,还可以将此对象数据二进制用于网络传输、进程之间传输。在Android中,为什么还需要设计一个Parcelable来进行序列化呢?对Java对象的序列化方式远不止Serializable、Parcelable,序列化与反序列化的本质目的就是让Java对象能够在不同程序(可能不在一个主机上)进行传输,其实现可能关注在编码,也可能关注在性能,也可能关注在多平台可用。Android中如果要进行进程间通信,使用Serializable并不会表现出良好的性能优势。Serializable序列化过程中会出现反射和IO操作,这对性能要求高的程序来说是不合适的。为针对性能,Android推出了Parcelable序列化接口:
Parcelable序列化
简而言之,Parcelable将Java对象序列化到内存中,其他进程可以通过内核访问到Parcelable序列化后的Java对象的数据,和Serializable不同的是,Parcelable不需要通过内核去进行IO、反射来反序列化,而是直接将序列化的数据写入到内存中。
Parcelable翻译也是“可打包的”,把Java对象的实例数据打包到一块连续的内存空间中(写到Parcel这个native层的对象中,它的大小是可变的,填充数据过程可能会发生扩容,但一定是连续空间)。我们本文主要探讨Parcelable的实现原理,及其在跨进程通信中的表现。
2. Parcelable和Parcel的关系
Parcelable是Android特有的序列化接口,序列化的数据需要存放到内存中,那么再内存中就需要一个Parcel对象来保存这些数据。Parcel对象的结构设计,就表现出了Parcelable序列化的原理。
3. Parcel的结构设计
Parcel是一个C++对象。当我们需要通过Parcelable接口序列化一个Java对象时,需要先通过JNI创建一个Parcel对象,创建Parcel对象时会在内存开辟一块连续的内存空间,Java对象的数据可以按顺序填充到这段内存空间,这样一来,只要知道这段内存空间的地址,就可以按同样的顺序取出数据,填充给另一个Java对象。它的结构大致如下,在内存空间开辟一个Parcel对象,会得到一个首地址。position指针用来表示下一个数据可以存放的位置,也可以表示下一个要读取数据的起始位置。
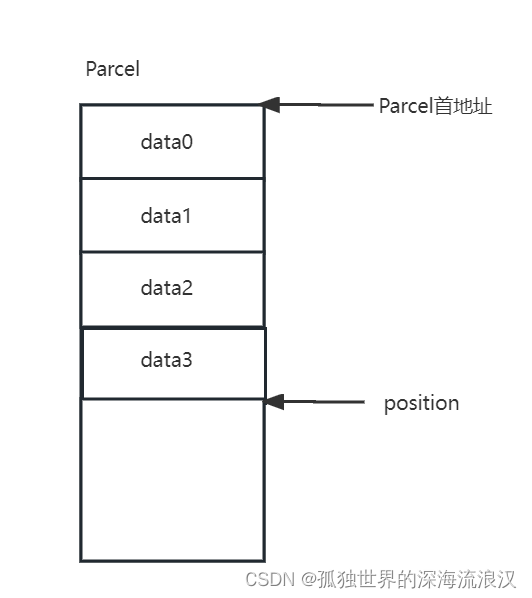
我们知道,不同数据占用的内存空间是不同的,例如Int类型需要占据 4 字节,而double类型则需要占据 8 字节。填入一个数据后,下一个数据可以填充的位置position就需要在原有基础上跨过刚填充数据的字节占用数量。例如上图,position指向了下一个可以插入数据的位置,接下来我要插入一个 int a = 3,将int类型的 3 写入后,将position后移 4 Byte,使之指向未来可以插入数据的位置。
我们来看一下其具体使用:
4. Parcel的使用方法
首先要进行序列化,就要对Java对象实现Parcelable接口,假设我们需要序列化一个User对象,且它的iconUrl属性不参与序列化。代码大致如下:
import android.os.Parcel;
import android.os.Parcelable;public class User implements Parcelable {long id;String username;String password;String iconUrl;//不参与序列化int age;boolean sex;//生成一个User对象,其实例数据,通过Parcel获取protected User(Parcel in) {id = in.readLong();username = in.readString();password = in.readString();
// iconUrl = in.readString();//不参与序列化age = in.readInt();sex = in.readByte() != 0;}//将User对象数据序列化存放到Parcel对象中@Overridepublic void writeToParcel(Parcel dest, int flags) {dest.writeLong(id);dest.writeString(username);dest.writeString(password);
// dest.writeString(iconUrl);//不参与序列化dest.writeInt(age);dest.writeByte((byte) (sex ? 1 : 0));}@Overridepublic int describeContents() {return 0;}public static final Creator<User> CREATOR = new Creator<User>() {@Overridepublic User createFromParcel(Parcel in) {return new User(in);}@Overridepublic User[] newArray(int size) {return new User[size];}};
}
writeToParcel()方法是序列化的核心,将需要序列化的属性通过 writeLong()、writeString() 等方法写入 Parcel 对象中。未来反序列化时,也需要与序列化时相同顺序进行 readLong()、readString() 进行数据提取。到这里我们只能在上层感受到Parcel对象数据的写入和读取是有序的,而且是有类型要求的,那么具体是如何实现的?我们还需要看到 write() 相关的代码:
5. Parcel实现原理
Parcel实现原理主要关注到它的写入和读出,是如何写入到一个连续内存空间的,以及如何从连续内存空间有序地提取数据出来的。写入Java对象时,通过writeToParcel()方法将Java对象的实例数据写入到Parcel对象中。先来关注一下Parcel是何时被调用writeToParcel()的。如果我们通过AIDL实现一个跨进程通信,会生成一个Binder实体类和代理类,代理类中,就调用了writeToParcel()。如下是定义的一个AIDL:
//IFyService.aidl
import com.company.binderstudy.javabean.User;interface IFyService{int addUser(in User user);
}
我们可以通过Binder代理来调用这个addUser:
//IFyService.java
private static class Proxy implements com.company.binderstudy.IFyService{@Override public int addUser(com.company.binderstudy.javabean.User user) throws android.os.RemoteException{//复用或者创建一个Parcel对象用于序列化发送数据android.os.Parcel _data = android.os.Parcel.obtain();//复用或者创建一个Parcel对象用于接收返回数据android.os.Parcel _reply = android.os.Parcel.obtain();int _result;try {//往parcel中写入token_data.writeInterfaceToken(DESCRIPTOR);if ((user!=null)) {//如果传入参数user不为空,就开始对其序列化//写入一个标志,表示对象不为null_data.writeInt(1);//调用其writeToParcel方法,进行序列化,将数据写入parceluser.writeToParcel(_data, 0);}else {//如果传入参数为null,写入一个标志位0,表示对象为null_data.writeInt(0);}//调用远程服务的addUser方法boolean _status = mRemote.transact(Stub.TRANSACTION_addUser, _data, _reply, 0);if (!_status && getDefaultImpl() != null) {return getDefaultImpl().addUser(user);}_reply.readException();_result = _reply.readInt();}finally {_reply.recycle();_data.recycle();}return _result;}
}
可以看到,通过Proxy进行远程通信的时候,需要做几件事:
- 复用或者创建一个Parcel对象_data用于序列化发送数据
- 复用或者创建一个Parcel对象_reply用于接收返回数据
- 往 _data 中写入token,标识着这个parcel来自哪个服务(服务的全路径)
- 将方法的若干个传入参数序列化到_data中
- 将_data 发送给远程服务,发起事务。
我们主要关注Parcel对象的复用或创建,与序列化。
5.1 Parcel对象的复用与创建
Parcel.obtain()方法,进行Parcel对象的复用与创建。Parcel对象的实例化过程,除了C++层的Parcel对象创建,还包括了其Java层外壳Parcel对象的创建。Java层的Parcel对象主要用于对Java应用提供接口,以及提供复用池设计:
//Parcel.java
private static final Object sPoolSync = new Object();
//单链表形式的复用池
private Parcel mPoolNext;
static protected final Parcel obtain(long obj) {Parcel res = null;//1. 在复用池获取synchronized (sPoolSync) {if (sHolderPool != null) {res = sHolderPool;sHolderPool = res.mPoolNext;res.mPoolNext = null;sHolderPoolSize--;}}//2. 如果没有可复用的,就new一个Parcelif (res == null) {res = new Parcel(obj);} else {if (DEBUG_RECYCLE) {res.mStack = new RuntimeException();}res.init(obj);}return res;
}
//2. 构造函数,调用native层的方法,通过JNI在本地内存中创建一个C++层的Parcel对象
private Parcel(long nativePtr) {if (DEBUG_RECYCLE) {mStack = new RuntimeException();}init(nativePtr);
}private void init(long nativePtr) {if (nativePtr != 0) {mNativePtr = nativePtr;mOwnsNativeParcelObject = false;} else {mNativePtr = nativeCreate();mOwnsNativeParcelObject = true;}
}
//4. native层的方法,通过JNI调用
private static native long nativeCreate();
因为在本地内存中开辟一块连续内存空间是耗时的(使用过程中可能需要扩容,一开始创建Parcel对象的时候并不是确定长度的),所以尽量不要频繁地创建、删除native层的Parcel对象,通过复用池来保存复用对象。Java层的Parcel对象是如何持有native层的Parcel对象引用的?其实从nativeCreate()方法的返回值就能猜出来,将native层的Parcel的内存地址,将会交给mNativePtr。
我们来到native层看一下Parcel的创建:
//android_os_Parcel.cpp
static jlong android_os_Parcel_create(JNIEnv* env, jclass clazz)
{Parcel* parcel = new Parcel();return reinterpret_cast<jlong>(parcel);
}
//Parcel.cpp
//构造函数
Parcel::Parcel()
{LOG_ALLOC("Parcel %p: constructing", this);initState();
}
//用来释放内存
Parcel::~Parcel()
{freeDataNoInit();LOG_ALLOC("Parcel %p: destroyed", this);
}void Parcel::initState()
{LOG_ALLOC("Parcel %p: initState", this);mError = NO_ERROR;mData = nullptr;mDataSize = 0;mDataCapacity = 0;mDataPos = 0;ALOGV("initState Setting data size of %p to %zu", this, mDataSize);ALOGV("initState Setting data pos of %p to %zu", this, mDataPos);mObjects = nullptr;mObjectsSize = 0;mObjectsCapacity = 0;mNextObjectHint = 0;mHasFds = false;mFdsKnown = true;mAllowFds = true;mDeallocZero = false;mOwner = nullptr;clearCache();//...
}
至此,Java层的Parcel对象的mNativePtr就指向了native层的Parcel对象的地址。刚创建的nateive层的Parcel对象占用空间很小,只有在不断写入数据的过程中,才会发生扩容。
5.2 Parcel对象序列化数据的写入
创建好Parcel对象之后,就可以往里写入序列化数据,通过调用需要序列化的Java对象的writeToParcel()方法进行写入,仍然还是上面的 User 类的例子:
@Override
public void writeToParcel(Parcel dest, int flags) {dest.writeLong(id);dest.writeString(username);dest.writeString(password);// dest.writeString(iconUrl);//不参与序列化dest.writeInt(age);dest.writeByte((byte) (sex ? 1 : 0));
}
这些写入的方法大同小异,我们就看writeString():
//Parcel.java
public final void writeString16(@Nullable String val) {mReadWriteHelper.writeString16(this, val);
}
//最终调用到ReadWriteHelper的writeString16方法
public void writeString16(Parcel p, String s) {p.writeString16NoHelper(s);
}
//最后来到Parcel的nativeWriteString16
private static native void nativeWriteString16(long nativePtr, String val);来到native层的Parcel对象数据写入:
//android_os_parcel
static void android_os_Parcel_writeString16(JNIEnv *env, jclass clazz, jlong nativePtr,jstring val) {//根据mNativePtr反向获取到native层的Parcel对象Parcel* parcel = reinterpret_cast<Parcel*>(nativePtr);if (parcel != nullptr) {status_t err = NO_ERROR;if (val) {//获取String数据的长度(char数组的长度)const size_t len = env->GetStringLength(val);//计算需要申请的控件长度const size_t allocLen = len * sizeof(char16_t);//先写入长度再写入数据err = parcel->writeInt32(len);//先判断空间,写入对齐填充char *data = reinterpret_cast<char*>(parcel->writeInplace(allocLen + sizeof(char16_t)));if (data != nullptr) {//将数据填充到data指针指向的地址,写入val数据env->GetStringRegion(val, 0, len, reinterpret_cast<jchar*>(data));*reinterpret_cast<char16_t*>(data + allocLen) = 0;} else {err = NO_MEMORY;}} else {err = parcel->writeString16(nullptr, 0);}if (err != NO_ERROR) {signalExceptionForError(env, clazz, err);}}
}
在写入字符串之前,先写入字符串的长度(便于反序列化的时候,确认要从内存中连续读取多少内容),然后再写入数据。
首先通过 witeInt32() 写入字符串长度:
//Parcel.cpp
status_t Parcel::writeInt32(int32_t val)
{return writeAligned(val);
}template<class T>
status_t Parcel::writeAligned(T val) {static_assert(PAD_SIZE_UNSAFE(sizeof(T)) == sizeof(T));if ((mDataPos+sizeof(val)) <= mDataCapacity) {
restart_write://通过mData基地址+mDataPos偏移量,在可以写入的位置写入新的值*reinterpret_cast<T*>(mData+mDataPos) = val;//更新下一个可以写入的位置,即更新mDataPos的值return finishWrite(sizeof(val));}//如果需要扩容,先扩容,然后通过goto回到写入部分再次写入status_t err = growData(sizeof(val));if (err == NO_ERROR) goto restart_write;return err;
}//完成写入,更新mDataPos位置
status_t Parcel::finishWrite(size_t len)
{//写入长度太长就报错if (len > INT32_MAX) {return BAD_VALUE;}//更新mDataPos位置mDataPos += len;//mDataSize记录的是现有数据个数//mDataPos有可能会回撤用于重写之前填入的数据,所以还需要mDataSize来记录现有全部数据个数if (mDataPos > mDataSize) {mDataSize = mDataPos;}return NO_ERROR;
}//扩容
status_t Parcel::growData(size_t len)
{if (len > INT32_MAX) {return BAD_VALUE;}if (len > SIZE_MAX - mDataSize) return NO_MEMORY; if (mDataSize + len > SIZE_MAX / 3) return NO_MEMORY; size_t newSize = ((mDataSize+len)*3)/2;//在continueWrite()中进行了alloc申请新空间return continueWrite(newSize);
}
可以看到,在真正数据写入的时候,会进行扩容判断,如果容量不够了,会先通过 growData() 进行扩容,然后再进行写入。注意几个指针:
- mData - 表示 native层Parcel的数据的起始地址
- mDataPos - 类似于游标,可以用来表示下一个插入数据的位置,也可以用来遍历提取数据
- mDataSize - 表示当前被序列化的元素总大小
写入数据后,会更新mDataPos。写入字符串首先写入完int类型表示长度之后,就写入字符串的char[]数据,首先会根据字符串长度计算,并做对齐填充,同样的,也可能会通过growData()进行扩容,然后通过env->GetStringRegion(val, 0, len, reinterpret_cast<jchar*>(data))将val的数据写入data。
5.3 并不是所有类型都能写入Parcel
写入Parcel的类型判断在Java层的Parcel完成。我们可以看到方法列表中,都给出了可以写入的类型。
比较特别的是Map类型的数据写入,我们知道Map的Value类型是不确定的,Parcel当然也在对Map遍历写入的过程中会进行类型判断,只允许写入规范内的类型,以写入ArrayMap为例:
//Parcel.java
//写入ArrayMap
public void writeArrayMap(@Nullable ArrayMap<String, Object> val) {writeArrayMapInternal(val);
}void writeArrayMapInternal(@Nullable ArrayMap<String, Object> val) {if (val == null) {writeInt(-1);return;}final int N = val.size();writeInt(N);int startPos;for (int i=0; i<N; i++) {//先写入Key,在写入Value,Key必须是String类型writeString(val.keyAt(i));writeValue(val.valueAt(i));
}
核心看到这里的writeValue()是如何做判断的:
//Parcel.java
public final void writeValue(@Nullable Object v) {if (v instanceof LazyValue) {LazyValue value = (LazyValue) v;value.writeToParcel(this);return;}//拿到Value的类型,在这类做类型判断,如果类型不符合要求,会抛异常int type = getValueType(v);//如果没有抛异常,就继续执行下去,先写入类型writeInt(type);//如果是一个有长度的type,除了写入value,还要写入长度if (isLengthPrefixed(type)) {// Lengthint length = dataPosition();writeInt(-1); // Placeholder// Objectint start = dataPosition();writeValue(type, v);int end = dataPosition();// Backpatch lengthsetDataPosition(length);writeInt(end - start);setDataPosition(end);} else {//writeValue写入的时候只能写入确定类型的,如果不在范围内,将会报错,即无法Parcel打包//例如你写了一个Object的子类例如Student,但是没有实现Parcelable接口,或者没有符合Parcel写入规约,将会在writeValue的时候报错writeValue(type, v);}
}
写入value的时候,首先会对Value的类型进行判断,如果不是规范类型,将会抛出异常,如果是规范类型,还会分成不定长度的类型和定长类型。比如String、Map就是不定长,Integer这类的就是定长数据。
//Parcel.java
//获取Value的类型
public static int getValueType(@Nullable Object v) {if (v == null) {return VAL_NULL;} else if (v instanceof String) {return VAL_STRING;} else if (v instanceof Integer) {return VAL_INTEGER;} else if (v instanceof Map) {return VAL_MAP;} else if (v instanceof Bundle) {// Must be before Parcelablereturn VAL_BUNDLE;}//...else {Class<?> clazz = v.getClass();if (clazz.isArray() && clazz.getComponentType() == Object.class) {return VAL_OBJECTARRAY;} else if (v instanceof Serializable) {// Must be lastreturn VAL_SERIALIZABLE;} else {//如果类型不对,抛异常throw new IllegalArgumentException("Parcel: unknown type for value " + v);}}
}
至此,将Java对象的数据序列化写入native层的Parcel对象的过程以及跟通了。小小感受一下它和Serializable的区别,Serializable将序列化的数据直接写入文件,而Parcelable接口则将序列化的数据写入内存,更加适用于跨进程通信。既然Parcelable适用于跨进程通信,我们就来看一下Parcel在跨进程通信过程中的表现:
6. Parcel在Bundle中的使用
通常我们使用Intent来发起进程间通信,传递的数据可以放到Intent中,其实最终都是放到Intent的Bundle类型的mExtras中:
//Intent.java
private Bundle mExtras;public Intent putExtra(String name, Charsequence value){if (mExtras == null) {mExtras = new Bundle();}mExtras.putCharSequence(name, value);return this;
}public Intent putExtra(String name, Parcelable value){if (mExtras == null) {mExtras = new Bundle();}mExtras.putParcelable(name, value);return this;
}
//...
放到Intent中的数据将通过Bundle类型的mExtras.putXXX()存放到Bundle中,这个方法在Bundle的父类BaseBundle中实现:
//BaseBundle.java
ArrayMap<String, Object> mMap = null;
volatile Parcel mParcelledData = null;//如果mParcelledData不为空,那么mMap将为空,并且数据存储为包含Bundle的Parcel。但数据被拆封时,mParcelledData将会被设置为nullvoid putBoolean(String key, boolean value){unparcel();//数据拆封,放到mMap中mMap.put(key,value);
}void putString(String key, String value){unparcel();//数据拆封,放到mMap中mMap.put(key,value);
}
//...
其中,如果mParcelledData不为空,那么mMap将为空,并且数据存储为包含Bundle的Parcel。但数据被拆封时,mParcelledData将会被设置为null。
正常情况下,ArrayMap的存储容量只受堆大小影响。但如果将数据打包到Parcel中进行进程间通信,就需要考虑Binder的mmap映射内存空间的大小了,一般情况下,内存大小不能超过 1M - 8K。再大也不能超过 4M。
binder驱动给每个进程分配最多4M的buffer空间(一般从Zygote孵化出来的APP默认分配 1M-8K大小,servicemanager默认分配128K).
当然可以突破这个 1M-8K 的限制,可以自己手动调用open和mmap即可:
int main(int argc,char **argv){ ... bs = binder_open("/dev/binder",【自定义大小】); }但是还是无法突破 binder_mmap() 中 SM_4M 的限制
如果还要再深究,其实binder_mmap中害设置了最大值的另外设置:
static int binder_mmap(...){ proc->free_async_space = proc->buffer_size/2; }对于oneway和非oneway来说:
手写mmap初始化binder服务 ProcessState初始化Binder服务 oneway 4M/2 (1M-8K)/2 非oneway 4M 1M-8K 一般情况下,Intent传输数据的上限是1M,因为 Intent 传输数据的机制中,用到了Binder。Intent 中的数据,会被作为 Parcel被存储在 Binder的事务缓冲区(Binder transaction buffer)中的对象进行传输。而 1M 并不是安全的上限,还是推荐不要通过Intent传递太大的数据。
解决办法:
- 减少传输数据量
- Intent 通过绑定一个 Bundle 来传输,这个可以超过 1M,不过也不能过大
- 通过内存共享
- 通过文件共享,如这里说到的 binder通信中进行传输文件句柄fd
这里不做 Bundle 的知识补充
7. Parcel在Binder通信中的表现
Parcel在Binder通信中,并不只序列化Java实例数据,还存了许多其他信息,包括但不限于Binder实体/远程引用:
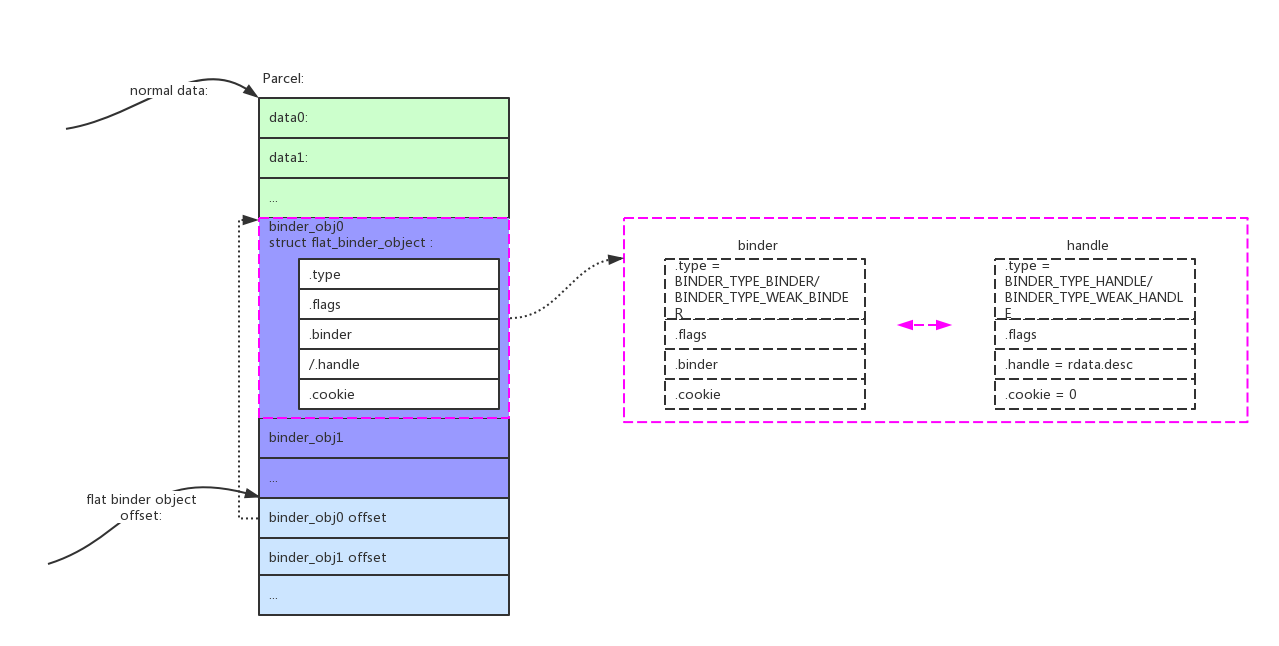
如果要传递大量数据,只能通过传递文件句柄fd,通过共享文件的方式来传递大数据:
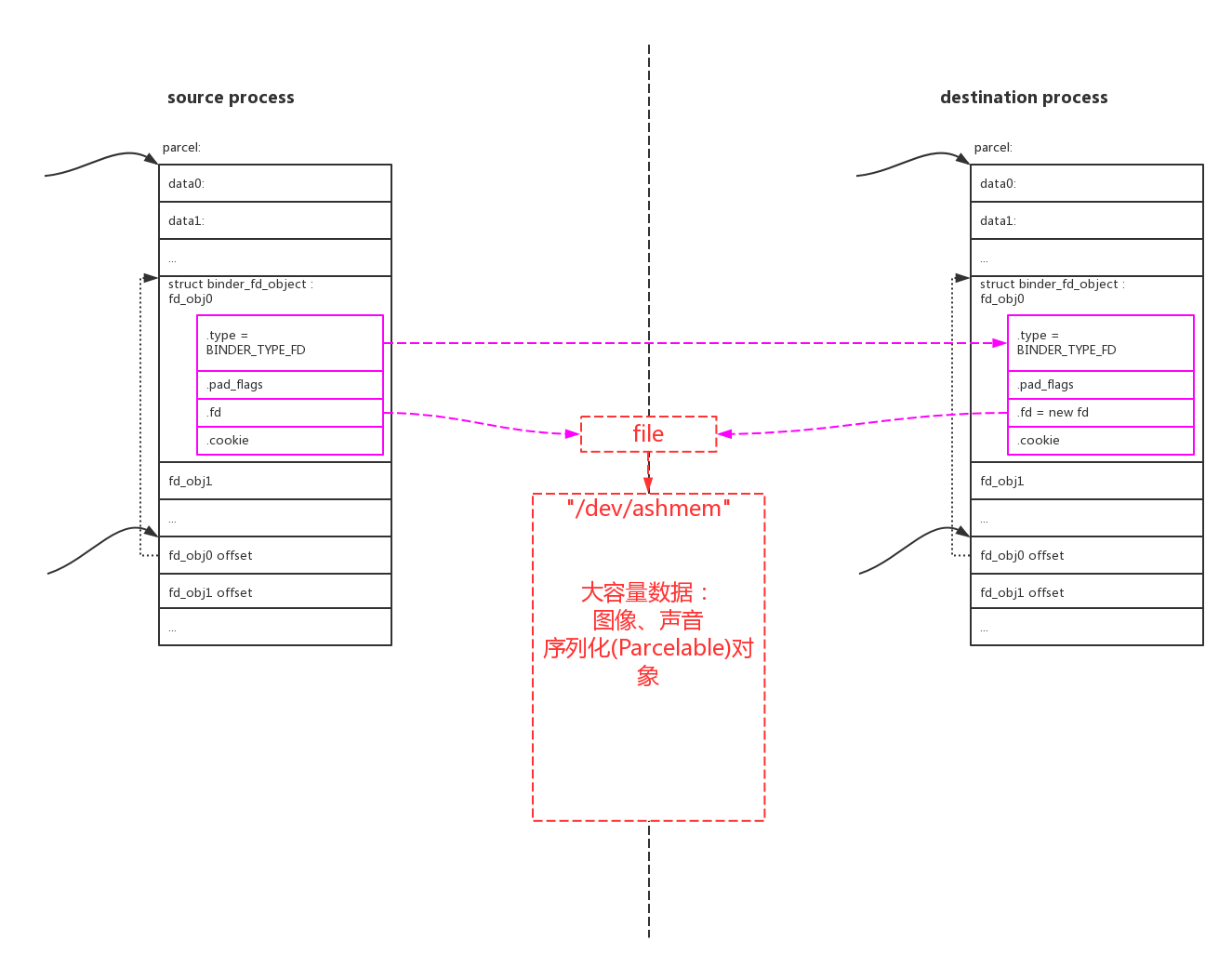
那么Parcel写入数据的时候如何写入这些内容呢?显然入口是通过Parcel.java写入binder。对应的方法是nativeWriteStrongBinder(),来到native层:
//android_os_Parcel.cpp
static void android_os_Parcel_writeStrongBinder(JNIEnv* env, jclass clazz, jlong nativePtr, jobject object)
{Parcel* parcel = reinterpret_cast<Parcel*>(nativePtr);if (parcel != NULL) {//交给Parcel对象来写入Binderconst status_t err = parcel->writeStrongBinder(ibinderForJavaObject(env, object));if (err != NO_ERROR) {signalExceptionForError(env, clazz, err);}}
}
native层的Parcel写入Binder,会将Binder“压扁打平”写入Parcel,这部分解析可以参考上图结构:
//Parcel.cpp
status_t Parcel::writeStrongBinder(const sp<IBinder>& val)
{return flatten_binder(ProcessState::self(), val, this);
}status_t flatten_binder(const sp<ProcessState>& /*proc*/,const sp<IBinder>& binder, Parcel* out)
{//Binder数据被拆分放入flat_binder_object对象中flat_binder_object obj = {};if (binder != nullptr) {BHwBinder *local = binder->localBinder();if (!local) {//会进行一个判断,如果这个IBinder是远程服务,则会转换为Binder远程引用,也就是handle,存入Parcel中BpHwBinder *proxy = binder->remoteBinder();if (proxy == nullptr) {ALOGE("null proxy");}//生成一个int类型的handle句柄- binder远程引用句柄const int32_t handle = proxy ? proxy->handle() : 0;//设置类型为handleobj.hdr.type = BINDER_TYPE_HANDLE;//给出标记obj.flags = FLAT_BINDER_FLAG_ACCEPTS_FDS;obj.binder = 0; //由于是handle,只设置handle的值obj.handle = handle;obj.cookie = 0;} else {//如果这个IBinder是本地服务,将会转换为Binder实体,存入Parcel中int policy = local->getMinSchedulingPolicy();int priority = local->getMinSchedulingPriority();//标志设置为本地服务obj.flags = priority & FLAT_BINDER_FLAG_PRIORITY_MASK;obj.flags |= FLAT_BINDER_FLAG_ACCEPTS_FDS | FLAT_BINDER_FLAG_INHERIT_RT;obj.flags |= (policy & 3) << FLAT_BINDER_FLAG_SCHED_POLICY_SHIFT;if (local->isRequestingSid()) {obj.flags |= FLAT_BINDER_FLAG_TXN_SECURITY_CTX;}//类型设为Binder实体obj.hdr.type = BINDER_TYPE_BINDER;//设置实体的引用,根据名字可以猜到使用弱引用obj.binder = reinterpret_cast<uintptr_t>(local->getWeakRefs());obj.cookie = reinterpret_cast<uintptr_t>(local);}} else {//如果根本就没有传递binder,我猜测传递的是ServiceManager这个handle为0的服务obj.hdr.type = BINDER_TYPE_BINDER;obj.binder = 0;obj.cookie = 0;}//将obj写入out这个Parcel中return finish_flatten_binder(binder, obj, out);
}
可以看到,flatten_binder的任务主要根据IBinder是本地服务还是远程引用,拼接 flat_binder_object。最后写入到Parcel中则是通过 finish_flatten_binder() 将这个 flat_binder_object 写入。
template <typename T>
status_t Parcel::writeObject(const T& val)
{const bool enoughData = (mDataPos+sizeof(val)) <= mDataCapacity;const bool enoughObjects = mObjectsSize < mObjectsCapacity;if (enoughData && enoughObjects) {//如果需要扩容,扩容后会根据这个标记goto到这里开始执行
restart_write://写入数据到mData+mDataPos,也就是下一个可以写入的位置*reinterpret_cast<T*>(mData+mDataPos) = val;//根据接入的对象,强转成 binder_object_header对象const binder_object_header* hdr = reinterpret_cast<binder_object_header*>(mData+mDataPos);//根据头部中的type信息来判断接下来需要写入什么内容switch (hdr->type) {//如果类型是Binder类型case BINDER_TYPE_BINDER:case BINDER_TYPE_WEAK_BINDER:case BINDER_TYPE_HANDLE:case BINDER_TYPE_WEAK_HANDLE: {//强转回 flat_binder_object 类(就是刚传入的val)const flat_binder_object *fbo = reinterpret_cast<const flat_binder_object*>(hdr);//如果这是binder的实体if (fbo->binder != 0) {//将偏移量记录mObjects[mObjectsSize++] = mDataPos;//将这个 flat_binder_object 记录到 ProcessState中acquire_binder_object(ProcessState::self(), *fbo, this);}break;}//如果类型是文件描述符(共享文件)case BINDER_TYPE_FD: {// remember if it's a file descriptorif (!mAllowFds) {// fail before modifying our object indexreturn FDS_NOT_ALLOWED;}mHasFds = mFdsKnown = true;mObjects[mObjectsSize++] = mDataPos;break;}case BINDER_TYPE_FDA:mObjects[mObjectsSize++] = mDataPos;break;case BINDER_TYPE_PTR: {const binder_buffer_object *buffer_obj = reinterpret_cast<const binder_buffer_object*>(hdr);if ((void *)buffer_obj->buffer != nullptr) {mObjects[mObjectsSize++] = mDataPos;}break;}default: {ALOGE("writeObject: unknown type %d", hdr->type);break;}}//完成写入,更新mDataPosreturn finishWrite(sizeof(val));}//如果空间不够,就进行扩容,最后通过 goto 回到写入数据的部分。if (!enoughData) {const status_t err = growData(sizeof(val));if (err != NO_ERROR) return err;}if (!enoughObjects) {if (mObjectsSize > SIZE_MAX - 2) return NO_MEMORY; // overflowif (mObjectsSize + 2 > SIZE_MAX / 3) return NO_MEMORY; // overflowsize_t newSize = ((mObjectsSize+2)*3)/2;if (newSize > SIZE_MAX / sizeof(binder_size_t)) return NO_MEMORY; // overflowbinder_size_t* objects = (binder_size_t*)realloc(mObjects, newSize*sizeof(binder_size_t));if (objects == nullptr) return NO_MEMORY;mObjects = objects;mObjectsCapacity = newSize;}goto restart_write;
}
8. 总结
Android为了实现进程间通信,传递Java对象数据,需要对数据进行序列化。现有许多序列化工具,常用的就是Serializable接口,Serializable序列化的优点就是适用范围广,不仅可以持久化存储对象到本地,也可以进行网络传输,但最大的缺点就是使用了反射和IO,性能不高。进场间通信是一个聚焦的功能,使用Parcelable接口直接将对象序列化到内存中,相比之下减少了反射和IO的时间损耗。当然,我们也知道Zygote的通信是通过socket的,如果在socket场景下要进行进程间通信,仍然需要使用Serializable进行序列化。
此外,虽然说Parcelable接口将对象序列化到内存中,这个“内存”仍然是进程私有的,不是共享内存。一个APP进程除了有JVM虚拟机的内存空间,还有本地内存(包含了元空间、直接内存)。JNI创建的C++对象是在本地内存的,它将数据直接写在内存块中。通过Binder通信,Binder驱动将这个内存块的数据直接拷贝到接收方进程的映射内存空间中,接收方访问这部分内存可以直接根据Parcelable的约定来反序列化出数据,实现了跨进程数据通信。
注:JNI创建的C++对象到底在JVM堆内存还是本地内存的哪个位置笔者还没探究清除。
相关文章:
Android源码分析 - Parcel 与 Parcelable
0. 相关分享 Android-全面理解Binder原理 Android特别的数据结构(二)ArrayMap源码解析 1. 序列化 - Parcelable和Serializable的关系 如果我们需要传递一个Java对象,通常需要对其进行序列化,通过内核进行数据转发,…...

数字孪生与 UWB 技术创新融合:从单点测量到全局智能化
人员定位是指利用各种定位技术对人员在特定场所的位置进行准确定位的技术。人员定位技术主要应用于需要实时监控、管理和保障人员安全的场所,如大型厂区、仓库、医院、学校、商场等。人员定位技术的应用范围非常广泛,例如:-在工厂生产线上&am…...
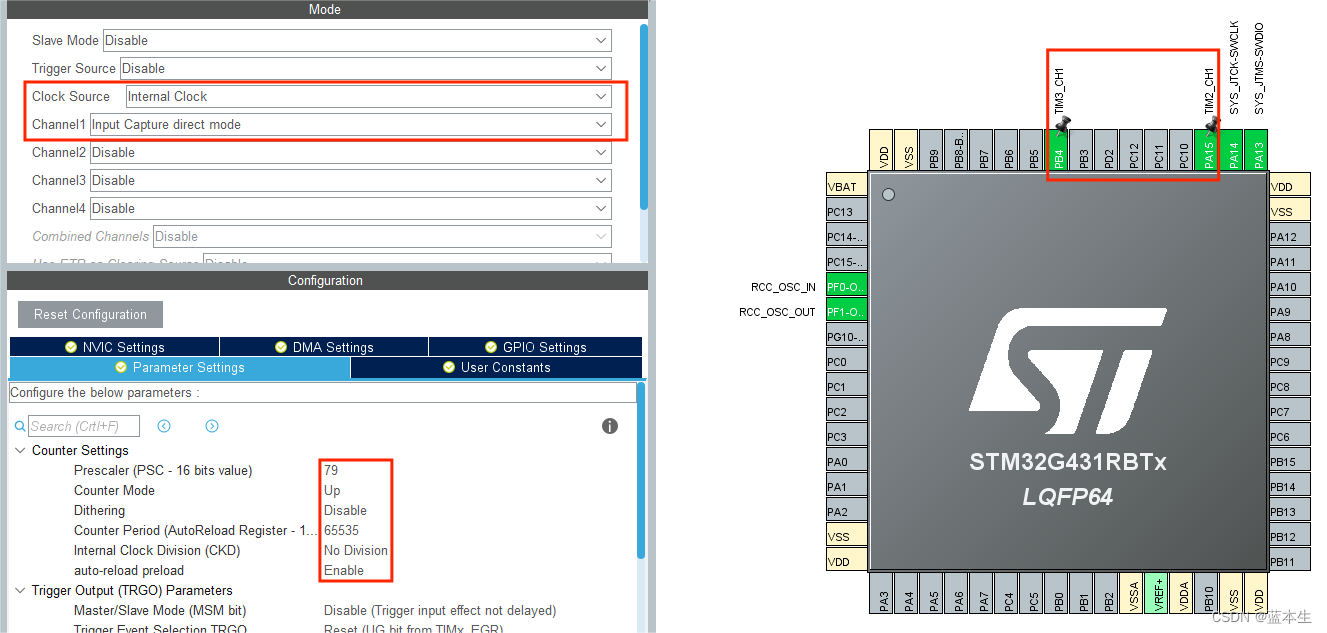
蓝桥杯嵌入式PWM_IN(打开中断)
1.原理图 2.配置 3.代码 关键函数 HAL_TIM_IC_Start_IT(&htim3,TIM_CHANNEL_1) HAL_TIM_IC_CaptureCallback(TIM_HandTypeDef *htim)//回调函数 HAL_TIM_GET_COUNTER(&htim3) __HAL_TIM_SetCounter(&htim3,0)void HAL_TIM_IC_CaptureCallback(TIM_HandleTypeDef …...

蓝桥杯集训·每日一题Week1
前缀和(Monday) AcWing 3956. 截断数组(每日一题) 思路: 首先可以预处理出前缀和。判断数组长度如果小于 333 或者前 nnn 项不是 333 的倍数,则可以直接输出 000。 否则就枚举所有 s[i]s[n]3s[i] \cfrac…...

25k的Java开发常问的ThreadLocal问题有哪些?
前言:ThreadLocal问的比较多的是和Synchronized的区别、ThreadLocal被设计弱引用、存储元素的过程、实现线程隔离的原理。 文章目录 ThreadLocalThreadLocal定义ThreadLocal与Synchronized的区别ThreadLocal底层实现ThreadLocalMap存储元素的过程ThreadLocal实现线程隔离的原理…...

R语言基础(四):数据类型
R语言基础(一):注释、变量 R语言基础(二):常用函数 R语言基础(三):运算 5.数据类型 5.1 基本数据类型 R语言基本数据类型大致有六种: 整数Integer、浮点数Numeric、文本(字符串)Character、逻辑(布尔)Logical、复合类型Complex、…...

批处理命令--总结备忘「建议收藏」
批处理命令--总结备忘「建议收藏」 前言1、基础语法:2、批处理基本命令3、实例3.1 打开虚拟目录3.2 以当前时间为文件名,建文件夹3.3 备份postgresql数据库前言 最近用批处理命令做了一些postgresql数据库的备份,打开虚拟环境。。。发现批处理处理一些常用重复工作时真的很…...

面试知识点梳理及相关面试题(十一)-- docker
1. Docker和虚拟机的区别 容器不需要捆绑一整套操作系统,它只需要满足软件运行的最小内核就行了。 传统虚拟机技术是虚拟出一整套硬件后,在其上运行一个完成操作系统,在该系统上再运行所需应用进程容器内的应用进程直接运行于宿主的内核&am…...
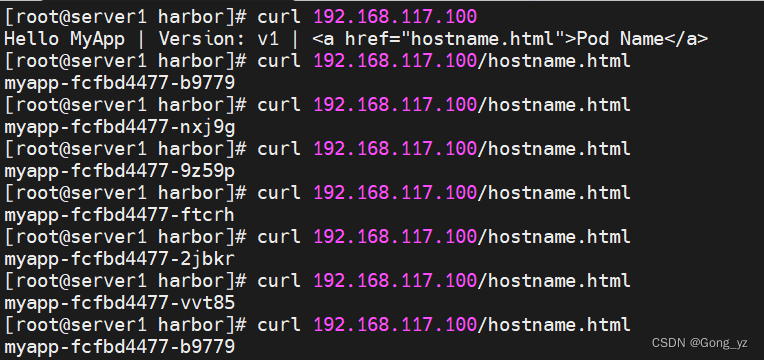
k8s--services(微服务)
文章目录一、k8s网络通信service和iptables的关系二、services1.简介2.默认3.IPVS模式的service4.clusterip5.headless6.从外部访问service的三种方式(1)nodeport(2)loadbalancer7.metallb一、k8s网络通信 k8s通过CNI接口接入其他…...

【Java开发】设计模式 01:单例模式
1 单例模式介绍单例模式(Singleton Pattern)是Java中最为基础的设计模式。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。这种模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对…...
10、go工程化与标准库
目录一、用go mod管理工程二、包引入规则三、init调用链四、可见性五、标准库1 - 时间函数2 - 数学计算3 - I/O操作4 - 编码一、用go mod管理工程 初始化项目:go mod init $module_name,$module_name和目录名可以不一样。上述命令会生成go.mod文件 mod…...

【Selenium自动化测试】鼠标与键盘操作
在 WebDriver 中,与鼠标操作相关的方法都封装在ActionChains 类中,与键盘操作相关的方法都封装在Keys类中。下面介绍下这两个类中的常用方法。 鼠标操作 ActionChains类鼠标操作常用方法: context_click():右击double_click()&…...

自定义javax.validation校验枚举类
枚举类单一情况 package com.archermind.cloud.phone.dto.portal.external.validation.validator;import com.archermind.cloud.phone.dto.portal.external.validation.constraints.EnumValidation; import lombok.extern.slf4j.Slf4j;import javax.validation.ConstraintVali…...
[Java·算法·中等]LeetCode39. 组合总和
每天一题,防止痴呆题目示例分析思路1题解1分析思路2题解2👉️ 力扣原文 题目 给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以列表形…...
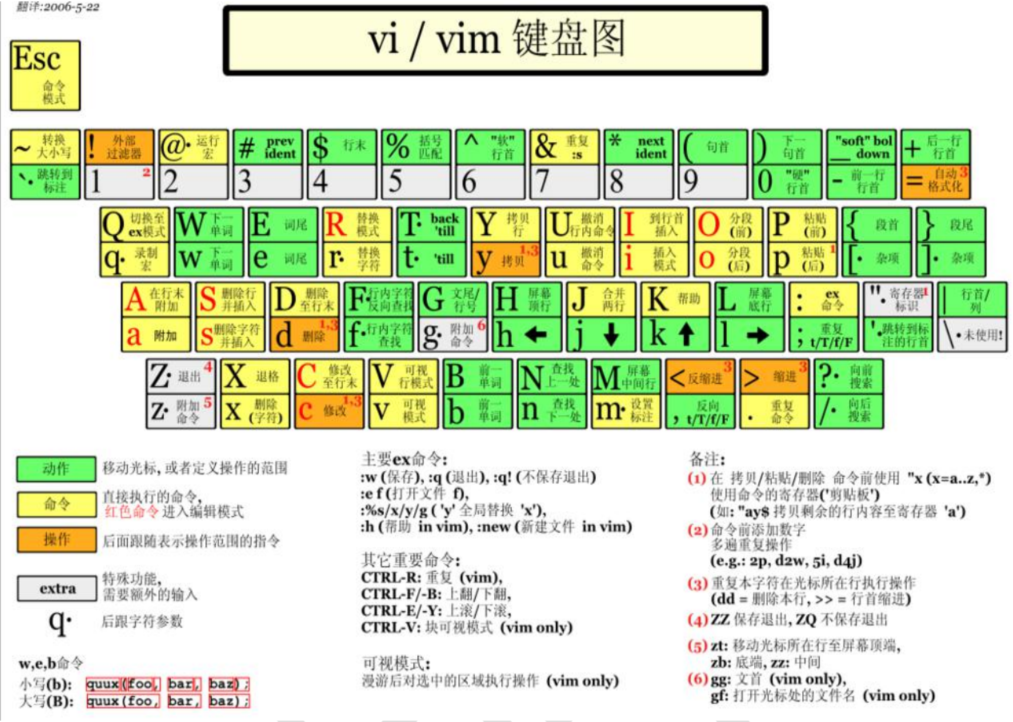
【Linux】vi和vim编辑器
目录主题主题 三种常见模式: 正常模式 以vim 打开一个档案就直接进入一般模式了(这是默认的模式)。在这个模式中,你可以使用[上下左右]按键来移动光标,你可以使用『删除字符』或『删除整行』来处理档案内容,也可以使用「复制、…...

BIO,NIO,AIO
IO模型 用什么样的通道进行数据传输和接收,java支持3种io网络编程模式 BIO NIO AIO BIO 同步阻塞 一个客户端连接对应一个处理线程 BIO示例代码(客户端和服务端) package com.tuling.bio;import java.io.IOException; import java.net.So…...

代码随想录刷题-数组-有序数组的平方
文章目录有序数组的平方习题暴力排序双指针有序数组的平方 本节对应代码随想录中:代码随想录,讲解视频:有序数组的平方_哔哩哔哩_bilibili 习题 题目链接:977. 有序数组的平方 - 力扣(LeetCode) 给你一…...
【玩转c++】stack和queue的介绍和模拟实现
本期主题:list的讲解和模拟实现博客主页: 小峰同学分享小编的在Linux中学习到的知识和遇到的问题小编的能力有限,出现错误希望大家不吝赐stack的介绍和使用1.1.stack的介绍1. stack是一种容器适配器,专门用在具有后进先出操作的上…...
Linux order(文件、磁盘、网络、系统管理、备份压缩)
1. Linux 文件命令 -rwxrwxrwx chmod:change mode,用于(文件所有者或 root )变更用户(u:owner g:group o:other a:all)的权限 chmod [OPTION]… MODE[,MODE]… FILE… OPTION -R:递归修改more option:chmod…...
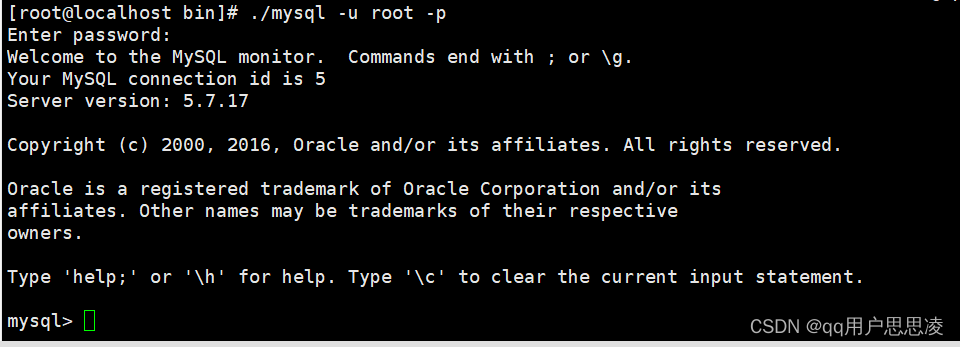
最详细的CentOS7安装Mysql数据库服务
1.查看是否安装mysql: rpm -qa | grep mysql如果有查出来东西,使用命令删除: rpm -e xxx2.检查是否有mysql用户组和mysql用户,没有就添加有就忽略: groups mysql 添加用户组和用户 groupadd mysql && useradd -r -g mysql mysql&a…...

在软件开发中正确使用MySQL日期时间类型的深度解析
在日常软件开发场景中,时间信息的存储是底层且核心的需求。从金融交易的精确记账时间、用户操作的行为日志,到供应链系统的物流节点时间戳,时间数据的准确性直接决定业务逻辑的可靠性。MySQL作为主流关系型数据库,其日期时间类型的…...

【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述 Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通…...

第一篇:Agent2Agent (A2A) 协议——协作式人工智能的黎明
AI 领域的快速发展正在催生一个新时代,智能代理(agents)不再是孤立的个体,而是能够像一个数字团队一样协作。然而,当前 AI 生态系统的碎片化阻碍了这一愿景的实现,导致了“AI 巴别塔问题”——不同代理之间…...

三体问题详解
从物理学角度,三体问题之所以不稳定,是因为三个天体在万有引力作用下相互作用,形成一个非线性耦合系统。我们可以从牛顿经典力学出发,列出具体的运动方程,并说明为何这个系统本质上是混沌的,无法得到一般解…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...

什么?连接服务器也能可视化显示界面?:基于X11 Forwarding + CentOS + MobaXterm实战指南
文章目录 什么是X11?环境准备实战步骤1️⃣ 服务器端配置(CentOS)2️⃣ 客户端配置(MobaXterm)3️⃣ 验证X11 Forwarding4️⃣ 运行自定义GUI程序(Python示例)5️⃣ 成功效果
【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...

管理学院权限管理系统开发总结
文章目录 🎓 管理学院权限管理系统开发总结 - 现代化Web应用实践之路📝 项目概述🏗️ 技术架构设计后端技术栈前端技术栈 💡 核心功能特性1. 用户管理模块2. 权限管理系统3. 统计报表功能4. 用户体验优化 🗄️ 数据库设…...

AI病理诊断七剑下天山,医疗未来触手可及
一、病理诊断困局:刀尖上的医学艺术 1.1 金标准背后的隐痛 病理诊断被誉为"诊断的诊断",医生需通过显微镜观察组织切片,在细胞迷宫中捕捉癌变信号。某省病理质控报告显示,基层医院误诊率达12%-15%,专家会诊…...

使用Spring AI和MCP协议构建图片搜索服务
目录 使用Spring AI和MCP协议构建图片搜索服务 引言 技术栈概览 项目架构设计 架构图 服务端开发 1. 创建Spring Boot项目 2. 实现图片搜索工具 3. 配置传输模式 Stdio模式(本地调用) SSE模式(远程调用) 4. 注册工具提…...