C++ GPU编程(英伟达CUDA)
安装编译环境
https://developer.download.nvidia.com/compute/cuda/12.5.0/local_installers/cuda_12.5.0_555.85_windows.exe
CMakeLists.txt
cmake_minimum_required(VERSION 3.10)set(CMAKE_CXX_STANDARD 17)
set(CMAKE_BUILD_TYPE Release)
#set(CMAKE_CUDA_ARCHITECTURES 52;70;75;86)
set(CMAKE_CUDA_SEPARABLE_COMPILATION ON)project(hellocuda LANGUAGES CXX CUDA)add_executable(main main.cu hello.cu)target_include_directories(main PUBLIC ../../include)
target_compile_options(main PUBLIC $<$<COMPILE_LANGUAGE:CUDA>:--extended-lambda>)
target_compile_options(main PUBLIC $<$<COMPILE_LANGUAGE:CUDA>:--expt-relaxed-constexpr>)
# --use_fast_math sinf 替换成 __sinf
# --ftz=true 会把极小数(denormal)退化为0
# --prec-div=false 降低除法的精度换取速度。
# --prec-sqrt=false 降低开方的精度换取速度。
# --fmad 因为非常重要,所以默认就是开启的,会自动把 a * b + c 优化成乘加(FMA)指令。
# 开启 --use_fast_math 后会自动开启上述所有CudaAllocator.h
template <class T>
struct CudaAllocator {using value_type = T;T* allocate(size_t size) {T* ptr = nullptr;checkCudaErrors(cudaMallocManaged(&ptr, size * sizeof(T)));return ptr;}void deallocate(T* ptr, size_t size = 0) {checkCudaErrors(cudaFree(ptr));}template <class ...Args>void construct(T* p, Args &&...args) {if constexpr (!(sizeof...(Args) == 0 && std::is_pod_v<T>))::new((void*)p) T(std::forward<Args>(args)...);}
};hello.cu
#include <cstdio>
#include <cuda_runtime.h>__device__ void say_hello3() { // 定义printf("Hello, world!\n");
}
main.cu
#include <cstdio>
#include <cuda_runtime.h>
#include "helper_cuda.h"
#include <vector>
#include "CudaAllocator.h"
#include <thrust/universal_vector.h>
#include <thrust/device_vector.h>
#include <thrust/host_vector.h>
#include <thrust/generate.h>
#include <thrust/for_each.h>__device__ void say_hello3(); // 声明__device__ __inline__ void say_hello() {printf("Hello, world, world from GPU!\n");
}__host__ void say_hello_host() {printf("Hello, world from CPU!\n");
}__host__ __device__ void say_hello2() {
#ifdef __CUDA_ARCH__printf("Hello, world from GPU architecture %d!\n", __CUDA_ARCH__);
#elseprintf("Hello, world from CPU!\n");
#endif
}__global__ void another() {int localVal = 1;printf("another: Thread %d of %d\n", threadIdx.x, blockDim.x);
}__global__ void kernel() {unsigned int tid = blockDim.x * blockIdx.x + threadIdx.x;unsigned int tnum = blockDim.x * gridDim.x;printf("Flattened Thread %d of %d\n", tid, tnum);say_hello2();say_hello3();another << <1, tnum >> > (); // 核函数调用核函数printf("kernel: called another with %d threads\n", tnum);
}__global__ void kernel2() {printf("Block (%d,%d,%d) of (%d,%d,%d), Thread (%d,%d,%d) of (%d,%d,%d)\n",blockIdx.x, blockIdx.y, blockIdx.z,gridDim.x, gridDim.y, gridDim.z,threadIdx.x, threadIdx.y, threadIdx.z,blockDim.x, blockDim.y, blockDim.z);
}// 默认host
constexpr const char* cuthead(const char* p) {return p + 1;
}// 内存访问
__global__ void kernel_memory(int* pret) {*pret = 42;
}// 数组并行处理
__global__ void kernel_array(int* arr, int n) {for (int i = blockDim.x * blockIdx.x + threadIdx.x;i < n; i += blockDim.x * gridDim.x) {arr[i] = i;}
}// 并行处理模板
template <class Func>
__global__ void parallel_for(int n, Func func) {for (int i = blockDim.x * blockIdx.x + threadIdx.x;i < n; i += blockDim.x * gridDim.x) {func(i);}
}// 自定义加减乘除
__device__ __inline__ int float_atomic_add(float* dst, float src) {int old = __float_as_int(*dst), expect;do {expect = old;old = atomicCAS((int*)dst, expect,__float_as_int(__int_as_float(expect) + src));} while (expect != old);return old;
}// map
template <int blockSize, class T>
__global__ void parallel_sum_kernel(T* sum, T const* arr, int n) {__shared__ volatile int local_sum[blockSize];int j = threadIdx.x;int i = blockIdx.x;T temp_sum = 0;for (int t = i * blockSize + j; t < n; t += blockSize * gridDim.x) {temp_sum += arr[t];}local_sum[j] = temp_sum;__syncthreads();if constexpr (blockSize >= 1024) {if (j < 512)local_sum[j] += local_sum[j + 512];__syncthreads();}if constexpr (blockSize >= 512) {if (j < 256)local_sum[j] += local_sum[j + 256];__syncthreads();}if constexpr (blockSize >= 256) {if (j < 128)local_sum[j] += local_sum[j + 128];__syncthreads();}if constexpr (blockSize >= 128) {if (j < 64)local_sum[j] += local_sum[j + 64];__syncthreads();}if (j < 32) {if constexpr (blockSize >= 64)local_sum[j] += local_sum[j + 32];if constexpr (blockSize >= 32)local_sum[j] += local_sum[j + 16];if constexpr (blockSize >= 16)local_sum[j] += local_sum[j + 8];if constexpr (blockSize >= 8)local_sum[j] += local_sum[j + 4];if constexpr (blockSize >= 4)local_sum[j] += local_sum[j + 2];if (j == 0) {sum[i] = local_sum[0] + local_sum[1];}}
}// reduce
template <int reduceScale = 4096, int blockSize = 256, int cutoffSize = reduceScale * 2, class T>
int parallel_sum(T const* arr, int n) {if (n > cutoffSize) {std::vector<int, CudaAllocator<int>> sum(n / reduceScale);parallel_sum_kernel<blockSize> << <n / reduceScale, blockSize >> > (sum.data(), arr, n);return parallel_sum(sum.data(), n / reduceScale);}else {checkCudaErrors(cudaDeviceSynchronize());T final_sum = 0;for (int i = 0; i < n; i++) {final_sum += arr[i];}return final_sum;}
}// 共享内存
template <int blockSize, class T>
__global__ void parallel_transpose(T* out, T const* in, int nx, int ny) {int x = blockIdx.x * blockSize + threadIdx.x;int y = blockIdx.y * blockSize + threadIdx.y;if (x >= nx || y >= ny) return;__shared__ T tmp[blockSize * blockSize];int rx = blockIdx.y * blockSize + threadIdx.x;int ry = blockIdx.x * blockSize + threadIdx.y;tmp[threadIdx.y * blockSize + threadIdx.x] = in[ry * nx + rx];__syncthreads();out[y * nx + x] = tmp[threadIdx.x * blockSize + threadIdx.y];
}void testArray() {int n = 65535;int* arr;checkCudaErrors(cudaMallocManaged(&arr, n * sizeof(int)));int nthreads = 128;int nblocks = (n + nthreads + 1) / nthreads;kernel_array << <nblocks, nthreads >> > (arr, n);checkCudaErrors(cudaDeviceSynchronize());for (int i = 0; i < n; i++) {printf("arr[%d]: %d\n", i, arr[i]);}cudaFree(arr);
}void testVector() {int n = 65536;std::vector<int, CudaAllocator<int>> arr(n);parallel_for << <32, 128 >> > (n, [arr = arr.data()] __device__(int i) {arr[i] = i;});checkCudaErrors(cudaDeviceSynchronize());for (int i = 0; i < n; i++) {printf("arr[%d] = %d\n", i, arr[i]);}}void testMath() {int n = 1 << 25;std::vector<float, CudaAllocator<float>> gpu(n);std::vector<float> cpu(n);for (int i = 0; i < n; i++) {cpu[i] = sinf(i);}parallel_for << <n / 512, 128 >> > (n, [gpu = gpu.data()] __device__(int i) {gpu[i] = __sinf(i);});checkCudaErrors(cudaDeviceSynchronize());//for (int i = 0; i < n; i++) {//printf("diff %d = %f\n", i, gpu[i] - cpu[i]);//}
}void testTrust() {int n = 65536;thrust::universal_vector<float> x(n); // CPU或GPUthrust::host_vector<float> x_host(n); // CPUthrust::device_vector<float> x_dev = x_host; // GPUthrust::for_each(x_dev.begin(), x_dev.end(), [] __device__(float& x) {x += 100.f;});
}void testAtomic() {// atomicAdd(dst, src) // atomicSub// atomicOr// atomicAnd// atomicXor// atomicMax// atomicMin// atomicExch old = *dst; *dst = src// atomicCAS automic::exchange
}void test_share() {int nx = 1 << 14, ny = 1 << 14;std::vector<int, CudaAllocator<int>> in(nx * ny);std::vector<int, CudaAllocator<int>> out(nx * ny);parallel_transpose<32> << <dim3(nx / 32, ny / 32, 1), dim3(32, 32, 1) >> >(out.data(), in.data(), nx, ny);
}// host 可以调用 global;global 可以调用 device;device 可以调用 device
// 实际上 GPU 的板块相当于 CPU 的线程,GPU 的线程相当于 CPU 的SIMD
// 数学函数sqrtf,rsqrtf,cbrtf,rcbrtf,powf,sinf,cosf,sinpif,cospif,sincosf,sincospif,logf,log2f,log10f,expf,exp2f,exp10f,tanf,atanf,asinf,acosf,fmodf,fabsf,fminf,fmaxf
// 低精度,高性能 __sinf,__expf、__logf、__cosf、__powf, __fdividef(x, y)
// old = atomicAdd(dst, src) 相当于 old = *dst; *dst += src
int main() {// 三重尖括号里的,第一个参数表示板块数量,第二个参数决定着启动 kernel 时所用 GPU 的线程数量kernel<<<1, 1>>>(); // CPU调用GPU函数异步执行kernel2<<<dim3(2, 1, 1), dim3(2, 2, 2)>>>();cudaDeviceSynchronize(); // CPU等待GPU完成say_hello_host();int* pret;checkCudaErrors(cudaMallocManaged(&pret, sizeof(int)));kernel_memory << <1, 1 >> > (pret);checkCudaErrors(cudaDeviceSynchronize());printf("result: %d\n", *pret);cudaFree(pret);testArray();float sin10 = sinf(10.f);/// map-reduceint n = 1 << 24;std::vector<int, CudaAllocator<int>> arr(n);int final_sum = parallel_sum(arr.data(), n);return 0;
}
参考
cuda-samples/Common/helper_string.h at 5f97d7d0dff880bc6567faa4c5e62e389a6d6999 · NVIDIA/cuda-samples · GitHub
https://github.com/NVIDIA/cuda-samples/blob/5f97d7d0dff880bc6567faa4c5e62e389a6d6999/Common/helper_cuda.h#L31
https://www.nvidia.cn/docs/IO/51635/NVIDIA_CUDA_Programming_Guide_1.1_chs.pdf
https://developer.download.nvidia.cn/CUDA/training/StreamsAndConcurrencyWebinar.pdf
CUDA Pro Tip: Write Flexible Kernels with Grid-Stride Loops | NVIDIA Technical Blog
创作不易,小小的支持一下吧!


相关文章:
C++ GPU编程(英伟达CUDA)
安装编译环境 https://developer.download.nvidia.com/compute/cuda/12.5.0/local_installers/cuda_12.5.0_555.85_windows.exe CMakeLists.txt cmake_minimum_required(VERSION 3.10)set(CMAKE_CXX_STANDARD 17) set(CMAKE_BUILD_TYPE Release) #set(CMAKE_CUDA_ARCHITECTUR…...
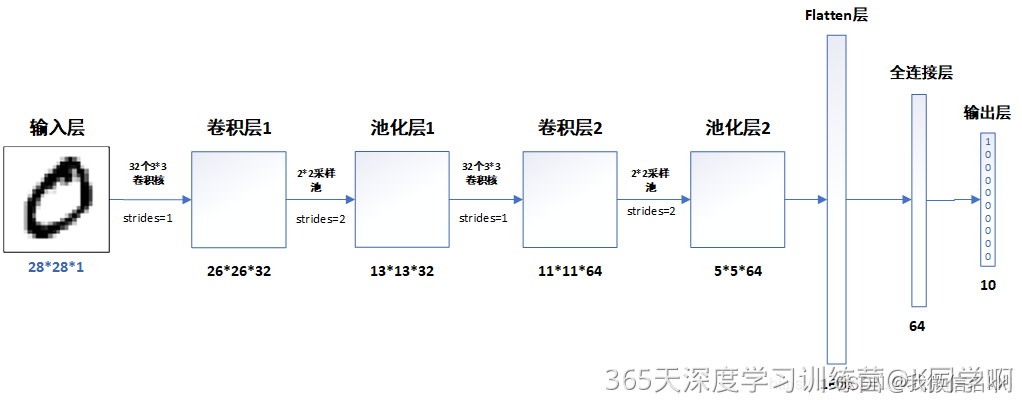
肾虚学习实验第T1周:实现mnist手写数字识别
>- **🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/0dvHCaOoFnW8SCp3JpzKxg) 中的学习记录博客** >- **🍖 原作者:[K同学啊](https://mtyjkh.blog.csdn.net/)** 目录 一、前言 作为一名研究牲࿰…...

Python | Leetcode Python题解之第162题寻找峰值
题目: 题解: class Solution:def findPeakElement(self, nums: List[int]) -> int:n len(nums)# 辅助函数,输入下标 i,返回 nums[i] 的值# 方便处理 nums[-1] 以及 nums[n] 的边界情况def get(i: int) -> int:if i -1 or…...
定个小目标之刷LeetCode热题(26)
这道题属于一道简单题,可以使用辅助栈法,代码如下所示 class Solution {public boolean isValid(String s) {if (s.isEmpty())return false;// 创建字符栈Stack<Character> stack new Stack<Character>();// 遍历字符串数组for (char c : …...
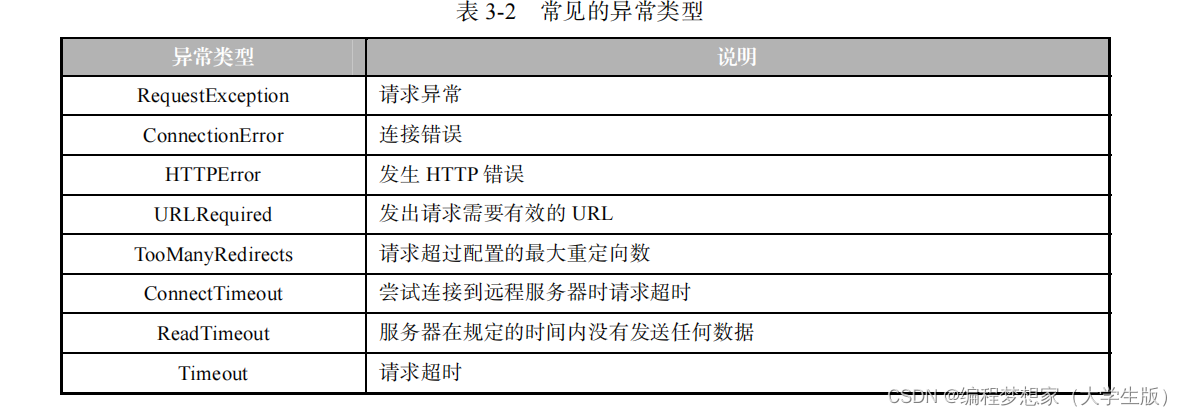
网络爬虫设置代理服务器
目录 1.获取代理 IP 2.设置代理 IP 3. 检测代理 IP 的有效性 4. 处理异常 如果希望在网络爬虫程序中使用代理服务器,就需要为网络爬虫程序设置代理服务器。 设置代理服务器一般分为获取代理 IP 、设置代理 IP 两步。接下来,分…...

3、matlab单目相机标定原理、流程及实验
1、单目相机标定流程及步骤 单目相机标定是通过确定相机的内部和外部参数,以便准确地在图像空间和物体空间之间建立映射关系。下面是单目相机标定的流程及步骤: 搜集标定图像:使用不同角度、距离和姿态拍摄一组标定图像,并确保标…...

【gdb 如何生成并查看core dump】
生成core dump 使用ulimit命令来设置core dump文件的大小。 ulimit -c unlimitedcore dump位置 如果程序崩溃,系统会生成一个名为core的文件。可以通过以下命令查看core文件位置, cat /proc/sys/kernel/core_pattern查看core dump gdb /path/to/you…...

极简短视频查看、删除应用
本地短视频服务器 背景:我的NAS中存放了很多短视频,多到很多没看过,于是写了这个程序来随机查看并删除短视频 运行: 安装依赖后运行main.py 直接使用docker: docker pull realwang/short_video docker run -d -p 3000:…...

【秋招刷题打卡】Day01-自定义排序
Day01-自定排序 前言 给大家推荐一下咱们的 陪伴打卡小屋 知识星球啦,详细介绍 >笔试刷题陪伴小屋-打卡赢价值丰厚奖励 < ⏰小屋将在每日上午发放打卡题目,包括: 一道该算法的模版题 (主要以力扣,牛客,acwin…...

API低代码平台介绍6-数据库记录删除功能
数据库记录删除功能 在前续文章中我们介绍了如何插入和修改数据库记录,本篇文章会沿用之前的测试数据,介绍如何使用ADI平台定义一个删除目标数据库记录的接口,包括 单主键单表删除、复合主键单表删除、多表删除(整合前两者&#x…...

计算机基础之:硬件系统的性能评估标准
服务器时钟的性能通常涉及多个方面,主要包括准确性、稳定性、以及对系统性能的影响。以下是一些关键指标和衡量方法: 准确性: 时间偏移:测量服务器时钟与一个可靠时间源(如GPS时间、原子钟或NTP服务器)之间…...
高互动UI设计揭秘:动画效果如何提升用户体验
动画,由于其酷的视觉冲击,往往会产生极好的用户体验。UI设计中的动态效果可以使用户界面看起来更酷,特别是界面的功能动画,是UX设计的重要组成部分,不容忽视。为什么UI设计的动态效果如此重要?接下来&#…...

探索Java异常处理的奥秘:源码解析与高级实践
1. 引言 在Java编程的广阔天地中,异常处理是确保程序健壮性、稳定性和可维护性的重要基石。对于Java工程师而言,深入理解Java异常处理的机制,并能够在实践中灵活运用,是迈向卓越的重要一步。 2. 基本概念 在Java中,异常(Exception)是程序执行期间出现的不正常或错误情况…...

深入了解python函数与函数内存使用
函数的定义 函数作为代码复用的基本单元,可以帮助我们组织代码、减少重复、提高可读性和可维护性。 在 Python 中,函数本质上是对象,可以赋值给变量、存储在数据结构中、作为参数传递和返回。 函数与内存 函数的加载和调用过程中ÿ…...

Java面试----MySQL面试题
1.索引有哪些优缺点? MySQL索引作为一种提升数据库查询效率的重要机制,具有以下主要优点和缺点: 优点: 提高查询速度: 索引能够显著加速数据的检索过程,类似于书籍的目录,让数据库引擎能够快速…...

python从入门到精通2:缩进
在Python中,缩进(Indentation)是一个非常重要的语法元素,它用于表示代码块的结构。与其他许多编程语言使用大括号 {} 来定义代码块不同,Python使用缩进来确定代码块的开始和结束。这种简洁的语法使得Python代码更加清晰…...
了解CDN:提升网络性能和安全性的利器
在当今的数字时代,网站性能和安全性是每一个网站管理员必须关注的核心问题。内容分发网络(CDN,Content Delivery Network)作为解决这一问题的重要工具,逐渐成为主流。本文将详细介绍CDN的定义、作用及其工作原理&#…...

ChatGPT的工作原理
ChatGPT的工作原理可以详细分为以下几个步骤,下面将结合相关信息进行清晰、详细的介绍: 数据收集: ChatGPT首先会从大量的文本数据中收集信息,这些数据可能包括网页、新闻、书籍等多样化的来源。它还会特别关注和分析网络上的热点…...

基于DPU的云原生裸金属服务快速部署及存储解决方案
1. 背景介绍 1.1. 业务背景 在云原生技术迅速发展的当下,容器技术因其轻量级、可移植性和快速部署的特性而成为应用部署的主流选择,但裸金属服务器依然有其独特的价值和应用场景,是云原生架构中不可或缺的一部分。 裸金属服务器是一种高级…...

论文学习_Large Language Models Based Fuzzing Techniques: A Survey
论文名称发表时间发表期刊期刊等级研究单位Large Language Models Based Fuzzing Techniques: A Survey 2024年arXiv-悉尼大学 0.摘要 研究背景在软件发挥举足轻重作用的现代社会,软件安全和漏洞分析对软件开发至关重要,模糊测试作为一种高效的软件测试方法,并广泛应用于各个…...

华为云AI开发平台ModelArts
华为云ModelArts:重塑AI开发流程的“智能引擎”与“创新加速器”! 在人工智能浪潮席卷全球的2025年,企业拥抱AI的意愿空前高涨,但技术门槛高、流程复杂、资源投入巨大的现实,却让许多创新构想止步于实验室。数据科学家…...

SkyWalking 10.2.0 SWCK 配置过程
SkyWalking 10.2.0 & SWCK 配置过程 skywalking oap-server & ui 使用Docker安装在K8S集群以外,K8S集群中的微服务使用initContainer按命名空间将skywalking-java-agent注入到业务容器中。 SWCK有整套的解决方案,全安装在K8S群集中。 具体可参…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

HTML 列表、表格、表单
1 列表标签 作用:布局内容排列整齐的区域 列表分类:无序列表、有序列表、定义列表。 例如: 1.1 无序列表 标签:ul 嵌套 li,ul是无序列表,li是列表条目。 注意事项: ul 标签里面只能包裹 li…...

浅谈不同二分算法的查找情况
二分算法原理比较简单,但是实际的算法模板却有很多,这一切都源于二分查找问题中的复杂情况和二分算法的边界处理,以下是博主对一些二分算法查找的情况分析。 需要说明的是,以下二分算法都是基于有序序列为升序有序的情况…...

云原生玩法三问:构建自定义开发环境
云原生玩法三问:构建自定义开发环境 引言 临时运维一个古董项目,无文档,无环境,无交接人,俗称三无。 运行设备的环境老,本地环境版本高,ssh不过去。正好最近对 腾讯出品的云原生 cnb 感兴趣&…...

【把数组变成一棵树】有序数组秒变平衡BST,原来可以这么优雅!
【把数组变成一棵树】有序数组秒变平衡BST,原来可以这么优雅! 🌱 前言:一棵树的浪漫,从数组开始说起 程序员的世界里,数组是最常见的基本结构之一,几乎每种语言、每种算法都少不了它。可你有没有想过,一组看似“线性排列”的有序数组,竟然可以**“长”成一棵平衡的二…...

车载诊断架构 --- ZEVonUDS(J1979-3)简介第一篇
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 做到欲望极简,了解自己的真实欲望,不受外在潮流的影响,不盲从,不跟风。把自己的精力全部用在自己。一是去掉多余,凡事找规律,基础是诚信;二是…...

基于开源AI智能名片链动2 + 1模式S2B2C商城小程序的沉浸式体验营销研究
摘要:在消费市场竞争日益激烈的当下,传统体验营销方式存在诸多局限。本文聚焦开源AI智能名片链动2 1模式S2B2C商城小程序,探讨其在沉浸式体验营销中的应用。通过对比传统品鉴、工厂参观等初级体验方式,分析沉浸式体验的优势与价值…...
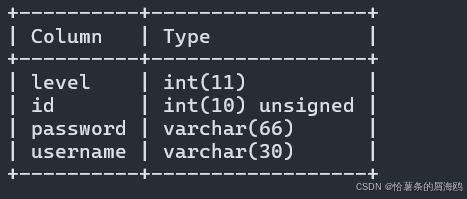
SQL注入篇-sqlmap的配置和使用
在之前的皮卡丘靶场第五期SQL注入的内容中我们谈到了sqlmap,但是由于很多朋友看不了解命令行格式,所以是纯手动获取数据库信息的 接下来我们就用sqlmap来进行皮卡丘靶场的sql注入学习,链接:https://wwhc.lanzoue.com/ifJY32ybh6vc…...