Elasticsearch 数据提取 - 最适合这项工作的工具是什么?
作者:来自 Elastic Josh Asres
了解在 Elasticsearch 中为你的搜索用例提取数据的所有不同方式。
对于搜索用例,高效采集和处理来自各种来源的数据的能力至关重要。无论你处理的是 SQL 数据库、CRM 还是任何自定义数据源,选择正确的数据采集工具都会对你的 Elasticsearch 体验产生重大影响。在本博客中,我们将探索 Elastic Stack 的三种搜索数据采集工具:Logstash、客户端 API 以及我们的 Elastic Native Connectors + Elastic Connector Framework。我们将深入探讨它们的优势、理想用例以及它们最擅长处理的数据类型。
Logstash,集中、转换和存储你的数据

概述
Logstash 是一个功能强大的开源数据处理管道,可采集、转换数据并将数据发送到各种输出。Logstash 是 Elastic Stack 的瑞士军刀,被广泛用于日志和事件数据处理,为数据采集提供了多功能的 ETL 工具。
主要功能和优势
Logstash 的突出功能之一是其丰富的插件生态系统,支持各种输入、过滤和输出插件。这个广泛的插件库允许在数据处理中实现显著的自定义和灵活性。用户可以使用管道配置文件定义复杂的数据转换和丰富管道,使其成为原始数据需要大量预处理的场景的理想选择。
请参阅下面的 Logstash 管道示例,该管道从文件中提取访问日志,使用过滤器丰富数据,并将其发送到 Elasticsearch。
input {file {path => "/tmp/access_log"start_position => "beginning"}
}filter {if [path] => "access" {mutate { replace => { "type" = "apache_access" } }grok {match => { "message" = "${ COMBINEDAPACHELOG}" }}}date {match => [ "timestamp", "dd/MMM/yyyy: HH: mm:ss Z" ]}
}output {elasticsearch {{cloud id => "<cloud id›" cloud_auth => "<cloud auth>"}}
}一个常见的用例是从数据库中提取数据。让我们以前面的示例为例,并对其进行修改以使用 Logstash 的 JDBC 输入插件,该插件允许你从任何具有 JDBC 接口的数据库(例如 Oracle DB)中提取数据。使用 SQL 查询,你可以定义要提取的数据。
input {jdbc {jdbc_driver_library => "mysql-connector-java-5.1.36-bin.jar"jdbc_driver_class => "com.mysql.jdbc.Driver"jdbc_connection_string => "jdbc:mysql://localhost:3306/mydb"jdbc_user => "mysql"parameters => { "favorite_artist" => "Beethoven" }schedule => "* * * * *"statement => "SELECT * from songs where artist = :favorite_artist"}
}output {elasticsearch {{cloud id => "<cloud id›" cloud_auth => "<cloud auth>"}}
}Logstash 的另一个用例是结合使用 Elasticsearch 输入和输出插件,这允许你将数据从一个 Elasticsearch 集群提取和迁移到另一个 Elasticsearch 集群。
input {elasticsearch {# Specify the host information of the source ES cluster. hosts => ["http://localhost:9200"]# Specify auth for the source ES cluster. user => "xxxxxx"password => "xxxxxx"index = "«source_index_name>"scroll = "5m"size = 1000}
}
output {elasticsearch {# Specify the host information of the destination ES cluster. hosts => ["http://destination.cluster:9200"]# Specify auth for the destination ES cluster. user => "xxxxxx"password => "xxxxxx"index => "<destination_index_name>"action => "index"scroll = "5m"size = 1000}
}最适合
Logstash 最适合在将数据索引到集群之前需要大量丰富数据或希望集中从各种来源获取数据的用例。但需要记住的一点是,Logstash 确实需要你在基础设施中的某个 VM 中托管和管理它(无论是本地还是云提供商)。如果你正在为你的用例寻找更轻量级的东西,请继续阅读以了解有关我们的语言客户端和连接器的更多信息!
Elasticsearch 客户端

Elasticsearch 客户端是 Elastic 提供的官方库,允许开发人员从他们喜欢的编程环境与 Elasticsearch 集群进行交互。这些客户端支持 Java、JavaScript、Python、Ruby、PHP 等语言,提供一致且简化的 API 来与 Elasticsearch 进行通信。
我们的客户端提供众多优势,可简化和增强你与 Elasticsearch 集群的交互。简化的 API、特定于语言的库、性能优化和全面支持使它们成为开发人员不可或缺的工具。这使开发人员能够根据你的特定需求构建强大、高效且可靠的搜索应用程序。
我们目前提供以下编程语言的语言客户端:
-
Java Client
-
Java Low Level REST Client
-
JavaScript Client
-
Ruby Client
-
Go Client
-
.NET Client
-
PHP Client
-
Perl Client
-
Python Clients
-
Rust Client
-
Eland Client
原生连接器和连接器框架
https://www.elastic.co/guide/en/enterprise-search/current/connectors-apis.html
概述
Elastic Native Connectors 是 Elasticsearch 中的内置集成,可帮助将数据从各种来源直接无缝传输到 Elasticsearch 索引中。这些连接器设计为开箱即用,只需极少的设置和配置,并针对 Elastic Stack 中的性能进行了优化。
除了我们的 Native Connectors,我们还有 Elastic Connector Framework,它使开发人员能够自定义现有的 Elastic 连接器客户端或使用我们基于 Python 的框架为不受支持的第三方数据源构建全新的连接器。
主要功能和优势
Elastic Native Connectors 最显著的优势之一是易于使用。你需要做的就是进入 Kibana 并使用我们简单的配置 UI 连接数据源(或者如果你更喜欢配置为代码,你可以使用我们的 Connector APIs)。
我们的连接器的另一个强大优势是支持各种第三方的连接器数量,例如:
- MongoDB
- 各种 SQL DBMS,例如 MySQL、PostgreSQL、MSSQL 和 OracleDB
- Sharepoint Online
- Amazon S3
- 还有更多。完整列表可在此处查看
我们的原生连接器支持完整和增量同步以及同步调度,并且能够通过同步规则过滤要导入 Elastic 的数据。另一个强大的功能是能够将我们的导入管道与原生连接器结合使用,这允许你在导入数据时对数据执行各种转换。这还包括使用推理管道,供那些想要将这些文档中的文本向量化以执行语义搜索的人使用。
最适合
Elastic Native Connectors 为数据采集提供了许多好处,包括与 Elastic Stack 的无缝集成、简化的设置、广泛的受支持数据源、优化的性能和强大的安全功能。这些优势使其成为希望简化数据采集流程和增强搜索功能的组织的绝佳选择。使用我们的连接器框架,你还可以进一步定制现有的连接器或构建新的连接器。尽管如上所述,该框架是基于 Python 的,因此如果你想使用更熟悉的语言来采集数据,我们建议你查看语言客户端。
总结
选择正确的数据采集工具取决于你的用例的具体需求以及数据所在的位置。Logstash 在需要通过集中采集进行复杂数据转换的场景中表现出色,但确实带来了管理开销,并且其配置文件也有些复杂。我们的 Elasticsearch 客户端让你可以最大程度地自由地使用你最熟悉的编程语言构建自己的采集功能。最后,Elastic Native Connectors 为第三方数据源提供了简化的集成和管理,而我们的 Connector Framework 允许与尚未支持的数据源进行自定义集成。
通过了解每种工具的优势和最佳用例,你可以做出明智的决策,确保你的数据得到有效采集、索引并准备好进行搜索,从而能够更快、更准确地洞察以解决你的用例。
有关更深入的信息,请查看 Logstash、Elastic Native Connectors + Connector Framework 和我们的官方语言客户端的官方文档。
你可以使用来自任何来源的数据构建搜索。查看此网络研讨会以了解 Elasticsearch 支持的不同连接器和来源。
准备好亲自尝试一下了吗?开始免费试用。
原文:Elasticsearch Data Ingestion - What's the Best Tool for the Job? — Elastic Search Labs
相关文章:
Elasticsearch 数据提取 - 最适合这项工作的工具是什么?
作者:来自 Elastic Josh Asres 了解在 Elasticsearch 中为你的搜索用例提取数据的所有不同方式。 对于搜索用例,高效采集和处理来自各种来源的数据的能力至关重要。无论你处理的是 SQL 数据库、CRM 还是任何自定义数据源,选择正确的数据采集…...

‘浔川画板v5.1’即将上线!——浔川python社
1 简介: 浔川画板是一款专业的数字绘画和漫画创作软件,它为艺术家和设计师提供了丰富的绘画工具、色彩管理功能以及易于使用的界面。用户可以使用浔川画板进行手绘风格的绘画、精细的素描、漫画分格、UI设计等多种创作。该软件支持多种笔刷和特效&#…...
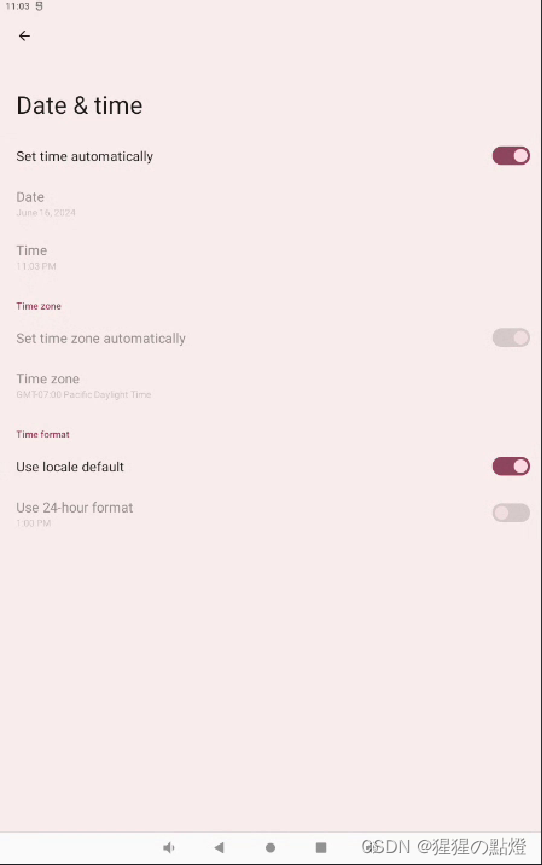
RockChip Android12 System之Datetime
一:概述 本文将针对Android12 Settings二级菜单System中Date&time的UI修改进行说明。 二:Date&Time 1、Activity packages/apps/Settings/AndroidManifest.xml <activityandroid:name="Settings$DateTimeSettingsActivity"android:label="@stri…...

详解 ClickHouse 的副本机制
一、简介 副本功能只支持 MergeTree Family 的表引擎,参考文档:https://clickhouse.tech/docs/en/engines/table-engines/mergetree-family/replication/ ClickHouse 副本的目的主要是保障数据的高可用性,即使一台 ClickHouse 节点宕机&#…...

速卖通测评成本低见效快,自养号测评的实操指南,快速积累销量和好评
对于初入速卖通的新卖家而言,销量和评价的积累显得尤为关键。由于新店铺往往难以获得平台活动的青睐,因此流量的获取成为了一大挑战。在这样的背景下,进行产品测评以积累正面的用户反馈和销售记录,成为了提升店铺信誉和吸引潜在顾…...
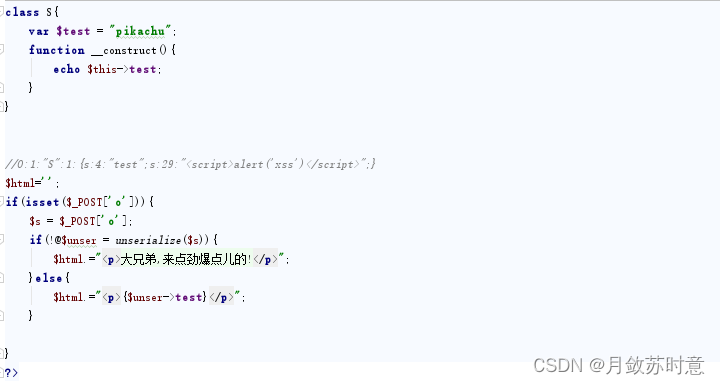
php反序列化漏洞简介
目录 php序列化和反序列化简介 序列化 反序列化 类中定义的属性 序列化实例 反序列化实例 反序列化漏洞 序列化返回的字符串格式 魔术方法和反序列化利用 绕过wakeup 靶场实战 修复方法 php序列化和反序列化简介 序列化 将对象状态转换为可保持或可传输的格式的…...

力扣随机一题 模拟+字符串
博客主页:誓则盟约系列专栏:IT竞赛 专栏关注博主,后期持续更新系列文章如果有错误感谢请大家批评指出,及时修改感谢大家点赞👍收藏⭐评论✍ 1910.删除一个字符串中所有出现的给定子字符串【中等】 题目: …...

java-正则表达式 1
Java中的正则表达式 1. 正则表达式的基本概念 正则表达式(Regular Expression, regex)是一种用于匹配字符串中字符组合的模式。正则表达式广泛应用于字符串搜索、替换和解析。Java通过java.util.regex包提供了对正则表达式的支持,该包包含两…...

Python xlrd库:读excel表格
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「stormsha的主页」…...

开发中遇到的一个bug
遇到的报错信息是这样的: java: Annotation processing is not supported for module cycles. Please ensure that all modules from cycle [hm-api,hm-common,hm-service] are excluded from annotation processing 翻译过来就是存在循环引用的情况,导…...
及其适用场景)
Java面试题:对比不同的垃圾收集器(如Serial、Parallel、CMS、G1)及其适用场景
Java虚拟机(JVM)提供了多种垃圾收集器,每种垃圾收集器在性能和适用场景上各有不同。以下是对几种常见垃圾收集器(Serial、Parallel、CMS、G1)的对比及其适用场景的详细介绍: 1. Serial 垃圾收集器 Serial…...

每日一题——冒泡排序
C语言——冒泡排序 冒泡排序练习 前言:CSDN的小伙伴们,大家好!今天我来给大家分享一种解题思想——冒泡排序。 冒泡排序 冒泡法的核心思想:两两相邻的元素进行比较 2.冒泡排序的算法描述如下。 (1)比较相邻的元素。如果第一 个比…...

javascript浏览器对象模型
BOM对象: BOM 是浏览器对象模型的简称。JavaScript 将整个浏览器窗口按照实现的功能不同拆分成若干个对象; 包含:window 对象、history 对象、location 对象和 document 对象等 window对象: 常用方法: 1.prompt();…...

C语言之链表以及单链表的实现
一:链表的引入 1:从数组的缺陷说起 (1)数组有两个缺陷。一个是数组中所有元素类型必须一致,第二是数组的元素个数必须事先指定并且一旦指定后不能更改 (2)如何解决数组的两个缺陷:数…...
AI在线免费视频工具2:视频配声音;图片说话hedra
1、视频配声音 https://deepmind.google/discover/blog/generating-audio-for-video/ https://www.videotosoundeffects.com/ (免费在线使用) 2、图片说话在线图片生成播报hedra hedra 上传音频与图片即可合成 https://www.hedra.com/ https://www.…...
)
Elastic字段映射(_source,doc_value,fileddata,index,store)
Elastic字段映射(_source,doc_value,filed_data,index,store) _source: source 字段用于存储 post 到 ES 的原始 json 文档。为什么要存储原始文档呢?因为 ES 采用倒排索引对文本进行搜索,而倒排索引无法存储原始输入…...

kotlin空类型安全 !! ?. ?:
1、定义可空类型 fun main(){// 定义可空类型var x:String? "hello"x null } 2、!! 强转类型 定义可空类型之后,如果使用其内置方法,编译不会通过,因为值有可能为null,可以使用 !! 把类型强转为不可空:…...

通过 WireGuard 组建虚拟局域网 实现多个局域网全互联
本文后半部分代码框较多,欢迎点击原文链接获得更佳的阅读体验。 前言 上一篇关于 WireGuard 的文章通过 Docker 安装 wg-easy 的形式来使用 WireGuard,但 wg-easy 的功能比较有限,并不能发挥出 WireGuard 的全部功力。 如果只是想要出门在外连随时随地的连回家里的局域网,…...

qmt量化交易策略小白学习笔记第47期【qmt编程之期货仓单】
qmt编程之获取期货数据 qmt更加详细的教程方法,会持续慢慢梳理。 也可找寻博主的历史文章,搜索关键词查看解决方案 ! 感谢关注,咨询免费开通量化回测与获取实盘权限,欢迎和博主联系! 期货仓单 提示 1…...

点云处理中阶 Sampling
目录 一、什么是点云Sampling 二、示例代码 1、下采样 Downsampling 2、均匀采样 3、上采样 4、表面重建 一、什么是点云Sampling 点云处理中的采样(sampling)是指从大量点云数据中选取一部分代表性的数据点,以减少计算复杂度和内存使用,同时保留点云的几何特征和重…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

大型活动交通拥堵治理的视觉算法应用
大型活动下智慧交通的视觉分析应用 一、背景与挑战 大型活动(如演唱会、马拉松赛事、高考中考等)期间,城市交通面临瞬时人流车流激增、传统摄像头模糊、交通拥堵识别滞后等问题。以演唱会为例,暖城商圈曾因观众集中离场导致周边…...

PPT|230页| 制造集团企业供应链端到端的数字化解决方案:从需求到结算的全链路业务闭环构建
制造业采购供应链管理是企业运营的核心环节,供应链协同管理在供应链上下游企业之间建立紧密的合作关系,通过信息共享、资源整合、业务协同等方式,实现供应链的全面管理和优化,提高供应链的效率和透明度,降低供应链的成…...

Leetcode 3577. Count the Number of Computer Unlocking Permutations
Leetcode 3577. Count the Number of Computer Unlocking Permutations 1. 解题思路2. 代码实现 题目链接:3577. Count the Number of Computer Unlocking Permutations 1. 解题思路 这一题其实就是一个脑筋急转弯,要想要能够将所有的电脑解锁&#x…...

ServerTrust 并非唯一
NSURLAuthenticationMethodServerTrust 只是 authenticationMethod 的冰山一角 要理解 NSURLAuthenticationMethodServerTrust, 首先要明白它只是 authenticationMethod 的选项之一, 并非唯一 1 先厘清概念 点说明authenticationMethodURLAuthenticationChallenge.protectionS…...
)
Java入门学习详细版(一)
大家好,Java 学习是一个系统学习的过程,核心原则就是“理论 实践 坚持”,并且需循序渐进,不可过于着急,本篇文章推出的这份详细入门学习资料将带大家从零基础开始,逐步掌握 Java 的核心概念和编程技能。 …...
 自用)
css3笔记 (1) 自用
outline: none 用于移除元素获得焦点时默认的轮廓线 broder:0 用于移除边框 font-size:0 用于设置字体不显示 list-style: none 消除<li> 标签默认样式 margin: xx auto 版心居中 width:100% 通栏 vertical-align 作用于行内元素 / 表格单元格ÿ…...

day36-多路IO复用
一、基本概念 (服务器多客户端模型) 定义:单线程或单进程同时监测若干个文件描述符是否可以执行IO操作的能力 作用:应用程序通常需要处理来自多条事件流中的事件,比如我现在用的电脑,需要同时处理键盘鼠标…...

Elastic 获得 AWS 教育 ISV 合作伙伴资质,进一步增强教育解决方案产品组合
作者:来自 Elastic Udayasimha Theepireddy (Uday), Brian Bergholm, Marianna Jonsdottir 通过搜索 AI 和云创新推动教育领域的数字化转型。 我们非常高兴地宣布,Elastic 已获得 AWS 教育 ISV 合作伙伴资质。这一重要认证表明,Elastic 作为 …...
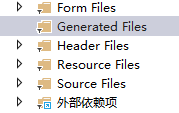
qt+vs Generated File下的moc_和ui_文件丢失导致 error LNK2001
qt 5.9.7 vs2013 qt add-in 2.3.2 起因是添加一个新的控件类,直接把源文件拖进VS的项目里,然后VS卡住十秒,然后编译就报一堆 error LNK2001 一看项目的Generated Files下的moc_和ui_文件丢失了一部分,导致编译的时候找不到了。因…...