Python爬虫学习 | Scrapy框架详解
一.Scrapy框架简介
何为框架,就相当于一个封装了很多功能的结构体,它帮我们把主要的结构给搭建好了,我们只需往骨架里添加内容就行。scrapy框架是一个为了爬取网站数据,提取数据的框架,我们熟知爬虫总共有四大部分,请求、响应、解析、存储,scrapy框架都已经搭建好了。scrapy是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架,scrapy使用了一种非阻塞(又名异步)的代码实现并发的,Scrapy之所以能实现异步,得益于twisted框架。twisted有事件队列,哪一个事件有活动,就会执行!Scrapy它集成高性能异步下载,队列,分布式,解析,持久化等。
1.五大核心组件
引擎(Scrapy)
框架核心,用来处理整个系统的数据流的流动, 触发事务(判断是何种数据流,然后再调用相应的方法)。也就是负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等,所以被称为框架的核心。
调度器(Scheduler)
用来接受引擎发过来的请求,并按照一定的方式进行整理排列,放到队列中,当引擎需要时,交还给引擎。可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址。
下载器(Downloader)
负责下载引擎发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。Scrapy下载器是建立在twisted这个高效的异步模型上的。
爬虫(Spiders)
用户根据自己的需求,编写程序,用于从特定的网页中提取自己需要的信息,即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面。跟进的URL提交给引擎,再次进入Scheduler(调度器)。
项目管道(Pipeline)
负责处理爬虫提取出来的item,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。

2.工作流程
Scrapy中的数据流由引擎控制,其过程如下:
(1)用户编写爬虫主程序将需要下载的页面请求requests递交给引擎,引擎将请求转发给调度器;
(2)调度实现了优先级、去重等策略,调度从队列中取出一个请求,交给引擎转发给下载器(引擎和下载器中间有中间件,作用是对请求加工如:对requests添加代理、ua、cookie,response进行过滤等);
(3)下载器下载页面,将生成的响应通过下载器中间件发送到引擎;
(4) 爬虫主程序进行解析,这个时候解析函数将产生两类数据,一种是items、一种是链接(URL),其中requests按上面步骤交给调度器;items交给数据管道(数据管道实现数据的最终处理);
官方文档
英文版:https://docs.scrapy.org/en/latest/
http://doc.scrapy.org/en/master/
中文版:https://scrapy-chs.readthedocs.io/zh_CN/latest/intro/overview.html
https://www.osgeo.cn/scrapy/topics/architecture.html
二、安装及常用命令介绍
1. 安装
Linux:pip3 install scrapy
Windows:
a. pip3 install wheelb. 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twistedc. shift右击进入下载目录,执行 pip3 install typed\_ast-1.4.0-cp36-cp36m-win32.whld. pip3 install pywin32e. pip3 install scrapy
2.scrapy基本命令行
(1)创建一个新的项目
scrapy startproject ProjectName(2)生成爬虫
scrapy genspider +SpiderName+website(3)运行(crawl) # -o output
scrapy crawl +SpiderName
scrapy crawl SpiderName \-o file.json
scrapy crawl SpiderName\-o file.csv(4)检查spider文件是否有语法错误
scrapy check(5)list返回项目所有spider名称
scrapy list(6)测试电脑当前爬取速度性能:
scrapy bench(7)scrapy runspider
scrapy runspider zufang\_spider.py(8)编辑spider文件:
scrapy edit <spider>
相当于打开vim模式,实际并不好用,在IDE中编辑更为合适。(9)将网页内容下载下来,然后在终端打印当前返回的内容,相当于 request 和 urllib 方法:
scrapy fetch <url>(10)将网页内容保存下来,并在浏览器中打开当前网页内容,直观呈现要爬取网页的内容:
scrapy view <url>(11)进入终端。打开 scrapy 显示台,类似ipython,可以用来做测试:
scrapy shell \[url\](12)输出格式化内容:
scrapy parse <url> \[options\](13)返回系统设置信息:
scrapy settings \[options\]
如:
$ scrapy settings \--get BOT\_NAME
scrapybot(14)显示scrapy版本:
scrapy version \[\-v\]
后面加 \-v 可以显示scrapy依赖库的版本
三、简单实例
以麦田租房信息爬取为例,网站http://bj.maitian.cn/zfall/PG1
**1.**创建项目
scrapy startproject houseinfo
生成项目结构:
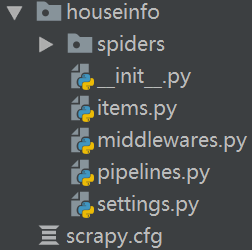
scrapy.cfg 项目的主配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py 设置数据存储模板,用于结构化数据,如:Django的Model
pipelines 数据持久化处理
settings.py 配置文件
spiders 爬虫目录
2.创建爬虫应用程序
cd houseinfo
scrapy genspider maitian maitian.com
然后就可以在spiders目录下看到我们的爬虫主程序
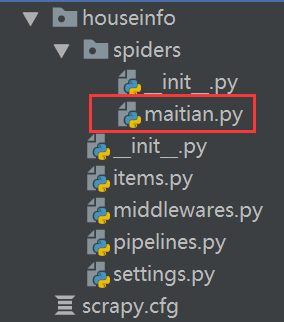
3.编写爬虫文件
步骤2执行完毕后,会在项目的spiders中生成一个应用名的py爬虫文件,文件源码如下:
1 # -\*- coding: utf-8 -\*-2 import scrapy3 4 5 class MaitianSpider(scrapy.Spider): 6 name = 'maitian' **# 应用名称** 7 allowed\_domains = \['maitian.com'\] **#一般注释掉,允许爬取的域名(如果遇到非该域名的url则爬取不到数据)**8 start\_urls = \['http://maitian.com/'\] **#起始爬取的url列表,该列表中存在的url,都会被parse进行请求的发送**9
10 #解析函数
11 def parse(self, response):
12 pass
我们可以在此基础上,根据需求进行编写
1 # -\*- coding: utf-8 -\*-2 import scrapy3 4 class MaitianSpider(scrapy.Spider): 5 name = 'maitian'6 start\_urls = \['http://bj.maitian.cn/zfall/PG100'\]7 8 9 #解析函数
10 def parse(self, response):
11
12 li\_list = response.xpath('//div\[@class="list\_wrap"\]/ul/li')
13 results = \[\]
14 for li in li\_list:
15 title = li.xpath('./div\[2\]/h1/a/text()').extract\_first().strip()
16 price = li.xpath('./div\[2\]/div/ol/strong/span/text()').extract\_first().strip()
17 square = li.xpath('./div\[2\]/p\[1\]/span\[1\]/text()').extract\_first().replace('㎡','') # 将面积的单位去掉
18 area = li.xpath('./div\[2\]/p\[2\]/span/text()\[2\]').extract\_first().strip().**split('\\xa0')\[0\] # 以空格分隔**
19 adress = li.xpath('./div\[2\]/p\[2\]/span/text()\[2\]').extract\_first().strip().split('\\xa0')\[2\]
20
21 dict = {
22 "标题":title,
23 "月租金":price,
24 "面积":square,
25 "区域":area,
26 "地址":adress
27 }
28 results.append(dict)
29
30 print(title,price,square,area,adress)
31 return results
须知:
- xpath为scrapy中的解析方式
- xpath函数返回的为列表,列表中存放的数据为Selector类型数据。解析到的内容被封装在Selector对象中,需要调用extract()函数将解析的内容从Selector中取出。
- 如果可以保证xpath返回的列表中只有一个列表元素,则可以使用extract_first(), 否则必须使用extract()
两者等同,都是将列表中的内容提取出来
title = li.xpath(‘./div[2]/h1/a/text()’).extract_first().strip()
title = li.xpath(‘./div[2]/h1/a/text()’)[0].extract()****.strip()
4. 设置修改settings.py配置文件相关配置:
1 #伪装请求载体身份
2 USER\_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10\_12\_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
3
4 #可以忽略或者不遵守robots协议
5 ROBOTSTXT\_OBEY = False
5.执行爬虫程序:scrapy crawl maitain
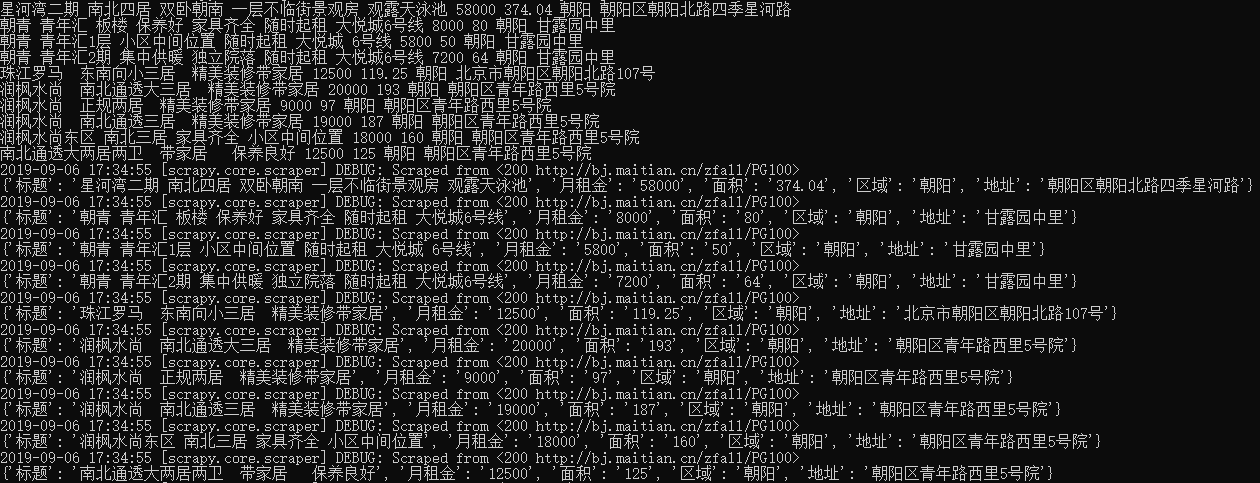
**爬取全站数据,也就是全部页码数据。**本例中,总共100页,观察页面之间的共性,构造通用url
方式一:通过占位符,构造通用url
1 import scrapy 2 3 class MaitianSpider(scrapy.Spider): 4 name = 'maitian'5 start\_urls = \['http://bj.maitian.cn/zfall/PG{}'.**format(page) for page in range(1,4**)\] **#注意写法**6 7 8 #解析函数9 def parse(self, response):
10
11 li\_list = response.xpath('//div\[@class="list\_wrap"\]/ul/li')
12 results = \[\]
13 for li in li\_list:
14 title = li.xpath('./div\[2\]/h1/a/text()').extract\_first().strip()
15 price = li.xpath('./div\[2\]/div/ol/strong/span/text()').extract\_first().strip()
16 square = li.xpath('./div\[2\]/p\[1\]/span\[1\]/text()').extract\_first().replace('㎡','')
17 ** # 也可以通过正则匹配提取出来**
18 area = li.xpath('./div\[2\]/p\[2\]/span/text()\[2\]')..re(r'昌平|朝阳|东城|大兴|丰台|海淀|石景山|顺义|通州|西城')\[0\]
19 adress = li.xpath('./div\[2\]/p\[2\]/span/text()\[2\]').extract\_first().strip().split('\\xa0')\[2\]
20
21 dict = {
22 "标题":title,
23 "月租金":price,
24 "面积":square,
25 "区域":area,
26 "地址":adress
27 }
28 results.append(dict)
29
30 return results
如果碰到一个表达式不能包含所有情况的项目,解决方式是先分别写表达式,最后通过列表相加,将所有url合并成一个url列表,例如
start\_urls = \['http://www.guokr.com/ask/hottest/?page={}'.format(n) for n in range(1, 8)\] **+** \['http://www.guokr.com/ask/highlight/?page={}'.format(m) for m in range(1, 101)\]
方式二:通过重写start_requests方法,获取所有的起始url。(不用写start_urls)
1 import scrapy 2 3 class MaitianSpider(scrapy.Spider): 4 name = 'maitian'5 **6 def start\_requests(self): 7 pages=\[\]8 for page in range(90,100):9 url='http://bj.maitian.cn/zfall/PG{}'.format(page)
10 page=scrapy.Request(url)
11 pages.append(page)
12 return pages**
13
14 #解析函数
15 def parse(self, response):
16
17 li\_list = response.xpath('//div\[@class="list\_wrap"\]/ul/li')
18
19 results = \[\]
20 for li in li\_list:
21 title = li.xpath('./div\[2\]/h1/a/text()').extract\_first().strip(),
22 price = li.xpath('./div\[2\]/div/ol/strong/span/text()').extract\_first().strip(),
23 square = li.xpath('./div\[2\]/p\[1\]/span\[1\]/text()').extract\_first().replace('㎡',''),
24 area = li.xpath('./div\[2\]/p\[2\]/span/text()\[2\]').re(r'昌平|朝阳|东城|大兴|丰台|海淀|石景山|顺义|通州|西城')\[0\],
25 adress = li.xpath('./div\[2\]/p\[2\]/span/text()\[2\]').extract\_first().strip().split('\\xa0')\[2\]
26
27 dict = {
28 "标题":title,
29 "月租金":price,
30 "面积":square,
31 "区域":area,
32 "地址":adress
33 }
34 results.append(dict)
35
36 return results
四、数据****持久化存储
- 基于终端指令的持久化存储
- 基于管道的持久化存储
只要是数据持久化存储,parse方法必须有返回值(也就是return后的内容)
1. 基于终端指令的持久化存储
执行输出指定格式进行存储:将爬取到的数据写入不同格式的文件中进行存储,windows终端不能使用txt格式
-
scrapy crawl 爬虫名称 -o xxx.json -
scrapy crawl 爬虫名称 -o xxx.xml - scrapy crawl 爬虫名称 -o xxx.csv
以麦田为例,spider中的代码不变,将返回值写到qiubai.csv中。本地没有,就会自己创建一个。本地有就会追加
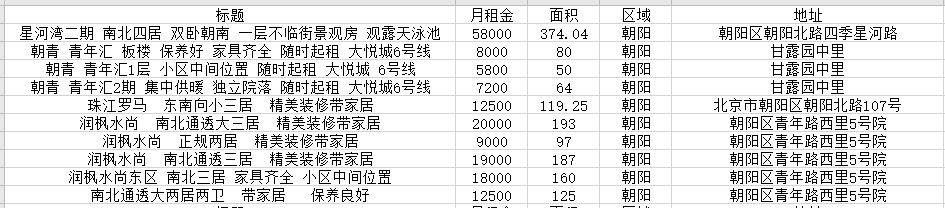
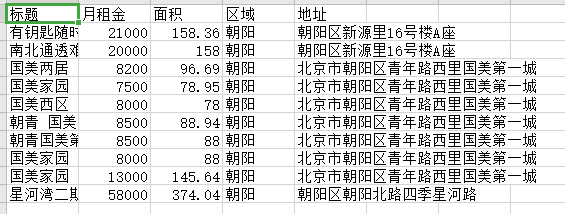
scrapy crawl maitian -o maitian.csv
就会在项目目录下看到,生成的文件
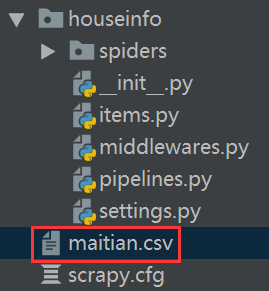
查看文件内容
**2.**基于管道的持久化存储
scrapy框架中已经为我们专门集成好了高效、便捷的持久化操作功能,我们直接使用即可。要想使用scrapy的持久化操作功能,我们首先来认识如下两个文件:
- items.py:数据结构模板文件。定义数据属性。
- pipelines.py:管道文件。接收数据(items),进行持久化操作。
持久化流程:
① 爬虫文件爬取到数据解析后,需要将数据封装到items对象中。
② **使用yield关键字将items对象提交给pipelines管道,**进行持久化操作。
③ 在管道文件中的process_item方法中接收爬虫文件提交过来的item对象,然后编写持久化存储的代码**,将item对象中存储的数据进行持久化存储(在管道的process_item方法中执行io操作,进行持久化存储)**
④ settings.py配置文件中开启管道
2.1****保存到本地的持久化存储
爬虫文件**:maitian.py**
1 import scrapy2 from houseinfo.items import HouseinfoItem **# 将item导入** 3 4 class MaitianSpider(scrapy.Spider): 5 name = 'maitian'6 start\_urls = \['http://bj.maitian.cn/zfall/PG100'\]7 8 #解析函数9 def parse(self, response):
10
11 li\_list = response.xpath('//div\[@class="list\_wrap"\]/ul/li')
12
13 for li in li\_list:
14 **item = HouseinfoItem(**
15 title = li.xpath('./div\[2\]/h1/a/text()').extract\_first().strip(),
16 price = li.xpath('./div\[2\]/div/ol/strong/span/text()').extract\_first().strip(),
17 square = li.xpath('./div\[2\]/p\[1\]/span\[1\]/text()').extract\_first().replace('㎡',''),
18 area = li.xpath('./div\[2\]/p\[2\]/span/text()\[2\]').extract\_first().strip().split('\\xa0')\[0\],
19 adress = li.xpath('./div\[2\]/p\[2\]/span/text()\[2\]').extract\_first().strip().split('\\xa0')\[2\]
20 )
21
22 yield item ** # 提交给管道,然后管道定义存储方式**
items文件:items.py
1 import scrapy
2
3 class HouseinfoItem(scrapy.Item):
4 title = scrapy.Field() #存储标题,里面可以存储任意类型的数据
5 price = scrapy.Field()
6 square = scrapy.Field()
7 area = scrapy.Field()
8 adress = scrapy.Field()
管道文件:pipelines.py
1 class HouseinfoPipeline(object):2 def \_\_init\_\_(self):3 self.file = None 4 5 #开始爬虫时,执行一次6 def open\_spider(self,**spider**):7 self.file = open('maitian.csv',**'a'**,encoding='utf-8') # 选用了追加模式8 self.file.write(",".join(\["标题","月租金","面积","区域","地址","\\n"\]))9 print("开始爬虫")
10
11 # 因为该方法会被执行调用多次,所以文件的开启和关闭操作写在了另外两个只会各自执行一次的方法中。
12 def process\_item(self, item, spider):
13 content = \[item\["title"\], item\["price"\], item\["square"\], item\["area"\], item\["adress"\], "\\n"\]
14 self.file.write(",".join(content))
15 return item
16
17 # 结束爬虫时,执行一次
18 def close\_spider(self,**spider**):
19 self.file.close()
20 print("结束爬虫")
配置文件:settings.py
1 #伪装请求载体身份2 USER\_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10\_12\_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36' 3 4 #可以忽略或者不遵守robots协议5 ROBOTSTXT\_OBEY = False 6 7 **#开启管道
** 8 ITEM\_PIPELINES = { 9 'houseinfo.pipelines.HouseinfoPipeline': 300, #数值300表示为优先级,值越小优先级越高
10 }
五、爬取多级页面
爬取多级页面,会遇到2个问题:
问题1:如何对下一层级页面发送请求?
答:在每一个解析函数的末尾,通过Request方法对下一层级的页面手动发起请求
**# 先提取二级页面url,再对二级页面发送请求。多级页面以此类推**
def parse(self, response):next\_url \= response.xpath('//div\[2\]/h2/a/@href').extract()\[0\] # 提取二级页面urlyield scrapy.Request(url=next\_url, callback=self.next\_parse) **# 对二级页面发送请求,注意要用yield,回调函数不带括号**
问题2:解析的数据不在同一张页面中,最终如何将数据传递
答:涉及到请求传参,可以在对下一层级页面发送请求的时候,通过meta参数进行数据传递,meta字典就会传递给回调函数的response参数。下一级的解析函数通过response获取item(先通过 response.meta返回接收到的meta字典,再获得item字典)
# 通过meta参数进行Request的数据传递,meta字典就会传递给回调函数的response参数
def parse(self, response):item \= Item() # 实例化item对象Item\["field1"\] = response.xpath('expression1').extract()\[0\] # 列表中只有一个元素Item\["field2"\] = response.xpath('expression2').extract() # 列表next\_url = response.xpath('expression3').extract()\[0\] # 提取二级页面url# meta参数:请求传参.通过meta参数进行Request的数据传递,meta字典就会传递给回调函数的response参数yield scrapy.Request(url=next\_url, callback=self.next\_parse,**meta={'item':item}**) # 对二级页面发送请求def next\_parse(self,response):# 通过response获取item. 先通过 response.meta返回接收到的meta字典,再获得item字典item = **response.meta\['item'****\]**item\['field'\] = response.xpath('expression').extract\_first()yield item #提交给管道
案例1:麦田,对所有页码发送请求。不推荐将每一个页码对应的url存放到爬虫文件的起始url列表(start_urls)中。这里我们使用Request方法手动发起请求。
# -\*- coding: utf-8 -\*-
import scrapy
from houseinfo.items import HouseinfoItem # 将item导入class MaitianSpider(scrapy.Spider):name \= 'maitian'start\_urls \= \['http://bj.maitian.cn/zfall/PG1'\]#爬取多页page = 1url \= 'http://bj.maitian.cn/zfall/PG%d'#解析函数def parse(self, response):li\_list \= response.xpath('//div\[@class="list\_wrap"\]/ul/li')for li in li\_list:item \= HouseinfoItem(title \= li.xpath('./div\[2\]/h1/a/text()').extract\_first().strip(),price \= li.xpath('./div\[2\]/div/ol/strong/span/text()').extract\_first().strip(),square \= li.xpath('./div\[2\]/p\[1\]/span\[1\]/text()').extract\_first().replace('㎡',''),area \= li.xpath('./div\[2\]/p\[2\]/span/text()\[2\]').re(r'昌平|朝阳|东城|大兴|丰台|海淀|石景山|顺义|通州|西城')\[0\], # 也可以通过正则匹配提取出来adress = li.xpath('./div\[2\]/p\[2\]/span/text()\[2\]').extract\_first().strip().split('\\xa0')\[2\])\['http://bj.maitian.cn/zfall/PG{}'.format(page) for page in range(1, 4)\]yield item # 提交给管道,然后管道定义存储方式if self.page < 4:self.page += 1new\_url \= format(self.url%self.page) # 这里的%是拼接的意思yield scrapy.Request(url=new\_url,callback=self.parse) # 手动发起一个请求,注意一定要写yield
案例2:这个案例比较好的一点是,parse函数,既有对下一页的回调,又有对详情页的回调
import scrapyclass QuotesSpider(scrapy.Spider):name \= 'quotes\_2\_3'start\_urls \= \['http://quotes.toscrape.com',\]allowed\_domains \= \['toscrape.com',\]def parse(self,response):for quote in response.css('div.quote'):yield{'quote': quote.css('span.text::text').extract\_first(),'author': quote.css('small.author::text').extract\_first(),'tags': quote.css('div.tags a.tag::text').extract(),}author\_page \= response.css('small.author+a::attr(href)').extract\_first()authro\_full\_url \= response.urljoin(author\_page)yield scrapy.Request(**authro\_full\_url, callback=self.parse\_author**) ** # 对详情页发送请求,回调详情页的解析函数**next\_page \= response.css(**'li.next a::attr("href")'**).extract\_first() **# 通过css选择器定位到下一页**if next\_page is not None:next\_full\_url \= response.urljoin(next\_page)yield scrapy.Request(**next\_full\_url, callback=self.pars**e) **# 对下一页发送请求,回调自己的解析函数**def parse\_author(self,response):yield{'author': response.css('.author-title::text').extract\_first(),'author\_born\_date': response.css('.author-born-date::text').extract\_first(),'author\_born\_location': response.css('.author-born-location::text').extract\_first(),'authro\_description': response.css('.author-born-location::text').extract\_first(),
**案例3:**爬取www.id97.com电影网,将一级页面中的电影名称,类型,评分,二级页面中的上映时间,导演,片长进行爬取。(多级页面+传参)
# -\*- coding: utf-8 -\*-
import scrapy
from moviePro.items import MovieproItem
class MovieSpider(scrapy.Spider):name \= 'movie'allowed\_domains \= \['www.id97.com'\]start\_urls \= \['http://www.id97.com/'\]def parse(self, response):div\_list \= response.xpath('//div\[@class="col-xs-1-5 movie-item"\]')for div in div\_list:item \= MovieproItem() item\['name'\] = div.xpath('.//h1/a/text()').extract\_first()item\['score'\] = div.xpath('.//h1/em/text()').extract\_first()item\['kind'\] = div.xpath('.//div\[@class="otherinfo"\]').xpath('string(.)').extract\_first()item\['detail\_url'\] = div.xpath('./div/a/@href').extract\_first()#meta参数:请求传参.通过meta参数进行Request的数据传递,meta字典就会传递给回调函数的response参数yield scrapy.Request(url=item\['detail\_url'\],callback=self.parse\_detail,meta={'item':item}) def parse\_detail(self,response):#通过response获取item. 先通过 response.meta返回接收到的meta字典,再获得item字典item = response.meta\['item'\]item\['actor'\] = response.xpath('//div\[@class="row"\]//table/tr\[1\]/a/text()').extract\_first()item\['time'\] = response.xpath('//div\[@class="row"\]//table/tr\[7\]/td\[2\]/text()').extract\_first()item\['long'\] = response.xpath('//div\[@class="row"\]//table/tr\[8\]/td\[2\]/text()').extract\_first()yield item #提交item到管道
**案例4:稍复杂,可参考链接进行理解:**https://github.com/makcyun/web_scraping_with_python/tree/master/,https://www.cnblogs.com/sanduzxcvbnm/p/10277414.html


1 #!/user/bin/env python2 3 """4 爬取豌豆荚网站所有分类下的全部 app5 数据爬取包括两个部分:6 一:数据指标7 1 爬取首页8 2 爬取第2页开始的 ajax 页9 二:图标10 使用class方法下载首页和 ajax 页11 分页循环两种爬取思路,12 指定页数进行for 循环,和不指定页数一直往下爬直到爬不到内容为止13 1 for 循环14 """15 16 import scrapy 17 from wandoujia.items import WandoujiaItem 18 19 import requests 20 from pyquery import PyQuery as pq 21 import re 22 import csv 23 import pandas as pd 24 import numpy as np 25 import time 26 import pymongo 27 import json 28 import os 29 from urllib.parse import urlencode 30 import random 31 import logging 32 33 logging.basicConfig(filename='wandoujia.log',filemode='w',level=logging.DEBUG,format='%(asctime)s %(message)s',datefmt='%Y/%m/%d %I:%M:%S %p')34 # https://juejin.im/post/5aee70105188256712786b7f35 logging.warning("warn message")36 logging.error("error message")37 38 39 class WandouSpider(scrapy.Spider): 40 name = 'wandou'41 allowed\_domains = \['www.wandoujia.com'\]42 start\_urls = \['http://www.wandoujia.com/'\]43 44 def \_\_init\_\_(self):45 self.cate\_url = 'https://www.wandoujia.com/category/app'46 # 首页url47 self.url = 'https://www.wandoujia.com/category/'48 # ajax 请求url49 self.ajax\_url = 'https://www.wandoujia.com/wdjweb/api/category/more?'50 # 实例化分类标签51 self.wandou\_category = Get\_category() 52 53 def start\_requests(self): 54 yield scrapy.Request(self.cate\_url,callback=self.get\_category)55 56 def get\_category(self,response): 57 # # num = 058 cate\_content = self.wandou\_category.parse\_category(response) 59 for item in cate\_content: 60 child\_cate = item\['child\_cate\_codes'\]61 for cate in child\_cate: 62 cate\_code = item\['cate\_code'\]63 cate\_name = item\['cate\_name'\]64 child\_cate\_code = cate\['child\_cate\_code'\]65 child\_cate\_name = cate\['child\_cate\_name'\]66 67 68 # # 单类别下载69 # cate\_code = 502970 # child\_cate\_code = 83771 # cate\_name = '通讯社交'72 # child\_cate\_name = '收音机'73 74 # while循环75 page = 1 # 设置爬取起始页数76 print('\*' \* 50)77 78 # # for 循环下一页79 # pages = \[\]80 # for page in range(1,3):81 # print('正在爬取:%s-%s 第 %s 页 ' %82 # (cate\_name, child\_cate\_name, page))83 logging.debug('正在爬取:%s-%s 第 %s 页 ' %84 (cate\_name, child\_cate\_name, page))85 86 if page == 1:87 # 构造首页url88 category\_url = '{}{}\_{}' .format(self.url, cate\_code, child\_cate\_code) 89 else:90 params = { 91 'catId': cate\_code, # 大类别92 'subCatId': child\_cate\_code, # 小类别93 'page': page,94 }95 category\_url = self.ajax\_url + urlencode(params) 96 97 dict = {'page':page,'cate\_name':cate\_name,'cate\_code':cate\_code,'child\_cate\_name':child\_cate\_name,'child\_cate\_code':child\_cate\_code}98 99 yield scrapy.Request(category\_url,callback=self.parse,meta=dict)
100
101 # # for 循环方法
102 # pa = yield scrapy.Request(category\_url,callback=self.parse,meta=dict)
103 # pages.append(pa)
104 # return pages
105
106 def parse(self, response):
107 if len(response.body) >= 100: # 判断该页是否爬完,数值定为100是因为无内容时长度是87
108 page = response.meta\['page'\]
109 cate\_name = response.meta\['cate\_name'\]
110 cate\_code = response.meta\['cate\_code'\]
111 child\_cate\_name = response.meta\['child\_cate\_name'\]
112 child\_cate\_code = response.meta\['child\_cate\_code'\]
113
114 if page == 1:
115 contents = response
116 else:
117 jsonresponse = json.loads(response.body\_as\_unicode())
118 contents = jsonresponse\['data'\]\['content'\]
119 # response 是json,json内容是html,html 为文本不能直接使用.css 提取,要先转换
120 contents = scrapy.Selector(text=contents, type="html")
121
122 contents = contents.css('.card')
123 for content in contents:
124 # num += 1
125 item = WandoujiaItem()
126 item\['cate\_name'\] = cate\_name
127 item\['child\_cate\_name'\] = child\_cate\_name
128 item\['app\_name'\] = self.clean\_name(content.css('.name::text').extract\_first())
129 item\['install'\] = content.css('.install-count::text').extract\_first()
130 item\['volume'\] = content.css('.meta span:last-child::text').extract\_first()
131 item\['comment'\] = content.css('.comment::text').extract\_first().strip()
132 item\['icon\_url'\] = self.get\_icon\_url(content.css('.icon-wrap a img'),page)
133 yield item
134
135 # 递归爬下一页
136 page += 1
137 params = {
138 'catId': cate\_code, # 大类别
139 'subCatId': child\_cate\_code, # 小类别
140 'page': page,
141 }
142 ajax\_url = self.ajax\_url + urlencode(params)
143
144 dict = {'page':page,'cate\_name':cate\_name,'cate\_code':cate\_code,'child\_cate\_name':child\_cate\_name,'child\_cate\_code':child\_cate\_code}
145 yield scrapy.Request(ajax\_url,callback=self.parse,meta=dict)
146
147
148
149 # 名称清除方法1 去除不能用于文件命名的特殊字符
150 def clean\_name(self, name):
151 rule = re.compile(r"\[\\/\\\\\\:\\\*\\?\\"\\<\\>\\|\]") # '/ \\ : \* ? " < > |')
152 name = re.sub(rule, '', name)
153 return name
154
155 def get\_icon\_url(self,item,page):
156 if page == 1:
157 if item.css('::attr("src")').extract\_first().startswith('https'):
158 url = item.css('::attr("src")').extract\_first()
159 else:
160 url = item.css('::attr("data-original")').extract\_first()
161 # ajax页url提取
162 else:
163 url = item.css('::attr("data-original")').extract\_first()
164
165 # if url: # 不要在这里添加url存在判断,否则空url 被过滤掉 导致编号对不上
166 return url
167
168
169 # 首先获取主分类和子分类的数值代码 # # # # # # # # # # # # # # # #
170 class Get\_category():
171 def parse\_category(self, response):
172 category = response.css('.parent-cate')
173 data = \[{
174 'cate\_name': item.css('.cate-link::text').extract\_first(),
175 'cate\_code': self.get\_category\_code(item),
176 'child\_cate\_codes': self.get\_child\_category(item),
177 } for item in category\]
178 return data
179
180 # 获取所有主分类标签数值代码
181 def get\_category\_code(self, item):
182 cate\_url = item.css('.cate-link::attr("href")').extract\_first()
183
184 pattern = re.compile(r'.\*/(\\d+)') # 提取主类标签代码
185 cate\_code = re.search(pattern, cate\_url)
186 return cate\_code.group(1)
187
188 # 获取所有子分类标签数值代码
189 def get\_child\_category(self, item):
190 child\_cate = item.css('.child-cate a')
191 child\_cate\_url = \[{
192 'child\_cate\_name': child.css('::text').extract\_first(),
193 'child\_cate\_code': self.get\_child\_category\_code(child)
194 } for child in child\_cate\]
195
196 return child\_cate\_url
197
198 # 正则提取子分类
199 def get\_child\_category\_code(self, child):
200 child\_cate\_url = child.css('::attr("href")').extract\_first()
201 pattern = re.compile(r'.\*\_(\\d+)') # 提取小类标签编号
202 child\_cate\_code = re.search(pattern, child\_cate\_url)
203 return child\_cate\_code.group(1)
204
205 # # 可以选择保存到txt 文件
206 # def write\_category(self,category):
207 # with open('category.txt','a',encoding='utf\_8\_sig',newline='') as f:
208 # w = csv.writer(f)
209 # w.writerow(category.values())
View Code
以上4个案例都只贴出了爬虫主程序脚本,因篇幅原因,所以item、pipeline和settings等脚本未贴出,可参考上面案例进行编写。
六**、Scrapy发送post请求**
**问题:**在之前代码中,我们从来没有手动的对start_urls列表中存储的起始url进行过请求的发送,但是起始url的确是进行了请求的发送,那这是如何实现的呢?
**解答:**其实是因为爬虫文件中的爬虫类继承到了Spider父类中的start_requests(self)这个方法,该方法就可以对start_urls列表中的url发起请求:
def start\_requests(self):for u in self.start\_urls:yield scrapy.Request(url=u,callback=self.parse)**注意:****该方法默认的实现,是对起始的url发起get请求,如果想发起post请求,则需要子类重写该方法。不过,**一般情况下不用scrapy发post请求,用request模块。
例:爬取百度翻译
# -\*- coding: utf-8 -\*-
import scrapyclass PostSpider(scrapy.Spider):name \= 'post'# allowed\_domains = \['www.xxx.com'\]start\_urls = \['https://fanyi.baidu.com/sug'\]def start\_requests(self):data \= { # post请求参数'kw':'dog'}for url in self.start\_urls:yield **scrapy.FormRequest**(url=url,formdata=data,callback=self.parse) # 发送post请求def parse(self, response):print(response.text)
七、设置日志等级
- 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是scrapy的日志信息。
- 日志信息的种类:
ERROR : 一般错误
WARNING : 警告
INFO : 一般的信息
DEBUG : 调试信息
- 设置日志信息指定输出:
在settings.py配置文件中,加入
LOG\_LEVEL = ‘指定日志信息种类’即可。LOG\_FILE = 'log.txt'则表示将日志信息写入到指定文件中进行存储。
其他常用设置:
BOT\_NAME
默认:“scrapybot”,使用startproject命令创建项目时,其被自动赋值CONCURRENT\_ITEMS
默认为100,Item Process(即Item Pipeline)同时处理(每个response的)item时最大值CONCURRENT\_REQUEST
默认为16,scrapy downloader并发请求(concurrent requests)的最大值LOG\_ENABLED
默认为True,是否启用loggingDEFAULT\_REQUEST\_HEADERS
默认如下:{'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,\*/\*;q=0.8', 'Accept-Language': 'en',}
scrapy http request使用的默认headerLOG\_ENCODING
默认utt\-8,logging中使用的编码LOG\_LEVEL
默认“DEBUG”,log中最低级别,可选级别有:CRITICAL,ERROR,WARNING,DEBUGUSER\_AGENT
默认:“Scrapy/VERSION(....)”,爬取的默认User-Agent,除非被覆盖
COOKIES\_ENABLED\=False,禁用cookies
八、同时运行多个爬虫
实际开发中,通常在同一个项目里会有多个爬虫,多个爬虫的时候是怎么将他们运行起来呢?
运行单个爬虫
import sys
from scrapy.cmdline import executeif \_\_name\_\_ == '\_\_main\_\_':execute(\["scrapy","crawl","maitian","\--nolog"\])
然后运行py文件即可运行名为‘maitian‘的爬虫
同时运行多个爬虫
步骤如下:
\- 在spiders同级创建任意目录,如:commands
\- 在其中创建 crawlall.py 文件 (此处文件名就是自定义的命令)
\- 在settings.py 中添加配置 COMMANDS\_MODULE = '项目名称.目录名称'
\- 在项目目录执行命令:scrapy crawlall crawlall.py代码
1 from scrapy.commands import ScrapyCommand2 from scrapy.utils.project import get\_project\_settings3 4 class Command(ScrapyCommand):5 6 requires\_project = True7 8 def syntax(self):9 return '\[options\]'
10
11 def short\_desc(self):
12 return 'Runs all of the spiders'
13
14 def run(self, args, opts):
15 spider\_list = self.crawler\_process.spiders.list()
16 for name in spider\_list:
17 self.crawler\_process.crawl(name, \*\*opts.\_\_dict\_\_)
18 self.crawler\_process.start()
如有侵权,请联系删除。
相关文章:
Python爬虫学习 | Scrapy框架详解
一.Scrapy框架简介 何为框架,就相当于一个封装了很多功能的结构体,它帮我们把主要的结构给搭建好了,我们只需往骨架里添加内容就行。scrapy框架是一个为了爬取网站数据,提取数据的框架,我们熟知爬虫总共有四大部分&am…...
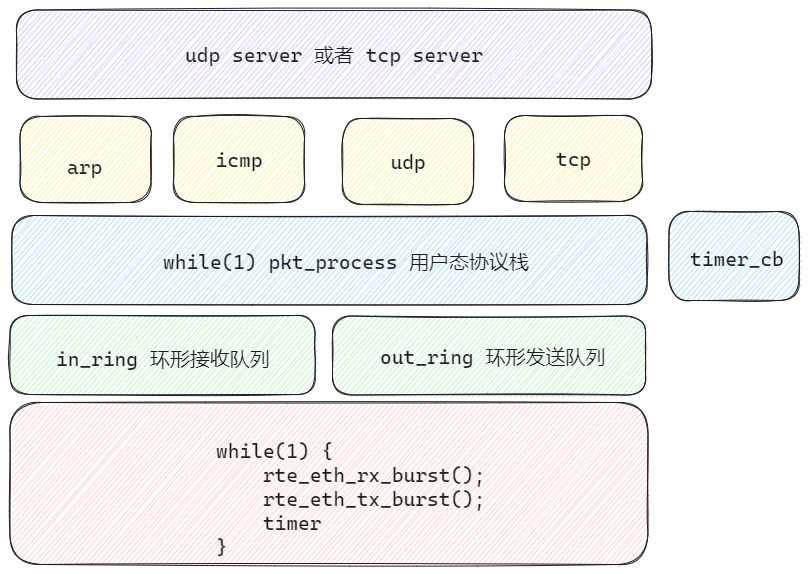
用户态协议栈05—架构优化
优化部分 添加了in和out两个环形缓冲区,收到数据包后添加到in队列;经过消费者线程处理之后,将需要发送的数据包添加到out队列。添加数据包解析线程(消费者线程),架构分层 #include <rte_eal.h> #inc…...

模拟退火算法
模拟退火算法(Simulated Annealing, SA)是一种用于全局优化问题的概率搜索算法,其灵感来自于金属退火过程。在金属退火中,材料被加热到高温,然后缓慢冷却,以减少其晶格中的缺陷并达到最小能量状态。模拟退火…...

Java匿名类
Java 匿名类是一种特殊的内部类,它没有名字,并且通常用来简化代码实现,尤其是在实现接口或者抽象类的实例时。匿名类可以在实例化时定义其行为,而不需要创建单独的类文件。 匿名类的特点 没有名字:匿名类是没有名字的…...

G7易流赋能化工物流,实现安全、环保与效率的共赢
近日,中国物流与采购联合会在古都西安举办了备受瞩目的第七届化工物流安全环保发展论坛。以"坚守安全底线,追求绿色发展,智能规划化工物流未来"为主题,该论坛吸引了众多政府部门、行业专家和企业代表的参与。G7易流作为…...
)
y=sin(2x)
函数 \( y \sin(2x) \) 是一个正弦函数,其中 \( x \) 是自变量,\( y \) 是因变量。这个函数描述了一个周期性波动的波形,其特点是: 1. **振幅**:正弦函数的振幅是 1,这意味着波形在 \( y \) 轴上的最大值…...

快捷方式(lnk)--加载HTA-CS上线
免责声明:本文仅做技术交流与学习... 目录 CS: HTA文档 文件托管 借助mshta.exe突破 本地生成lnk快捷方式: 非系统图标路径不同问题: 关于lnk的上线问题: CS: HTA文档 配置监听器 有效载荷---->HTA文档--->选择监听器--->选择powershell模式----> 默认生成一…...

从同—视角理解扩散模型(Understanding Diffusion Models A Unified Perspective)
从同—视角理解扩散模型 Understanding Diffusion Models A Unified Perspective【全公式推导】【免费视频讲解】 B站视频讲解 视频的论文笔记 从同一视角理解扩散模型【视频讲解笔记】 配合视频讲解的同步笔记。 整个系列完整的论文笔记内容如下,仅为了不用—一回复…...
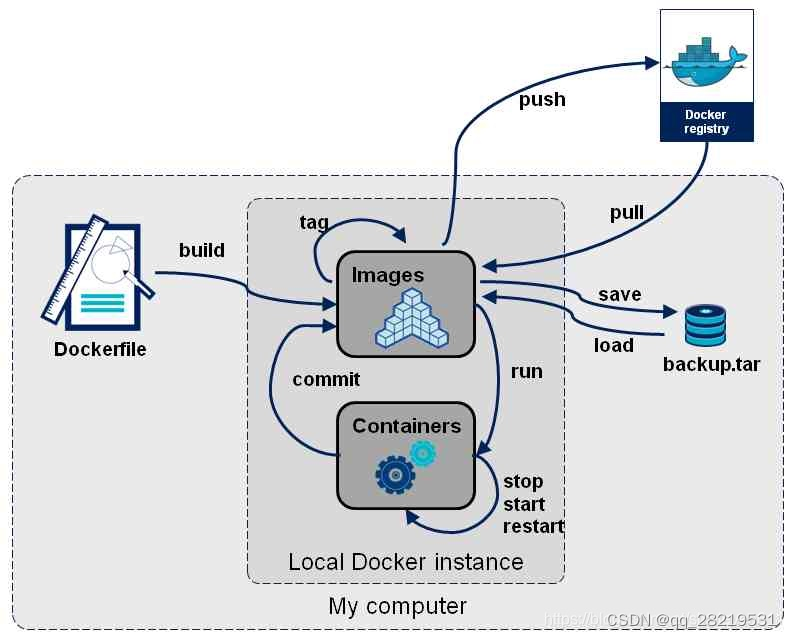
docker 基本用法及跨平台使用
一、Docker的优点 docker 主要解决的问题就是程序开发过程中编译和部署中遇到的环境配置的问题。 1.1 Docker与其他虚拟机层次结构的区别** 运行程序重点关注点在于环境。 VM虚拟机是基于Hypervisor虚拟化服务运行的。 Docker是基于内核的虚拟化技术实现的。 1.2 Docker的技…...
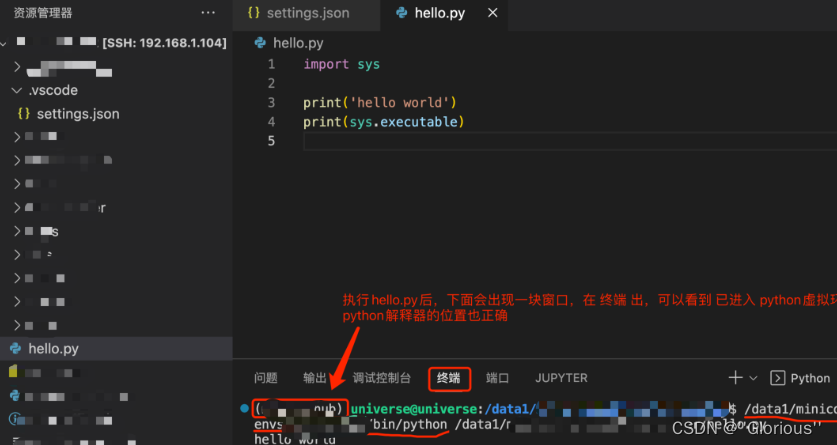
Vscode远程ubuntu
远程连接 到这里vscode远程到ubuntu和关闭远程连接,已完成 配置python环境 在远程目录下新建.vscode隐藏文件夹,文件夹里新建一个 settings.json 文件, 先远程服务器看下conda下的python虚拟环境位置 settings.json位置及内容如下 测试pyt…...
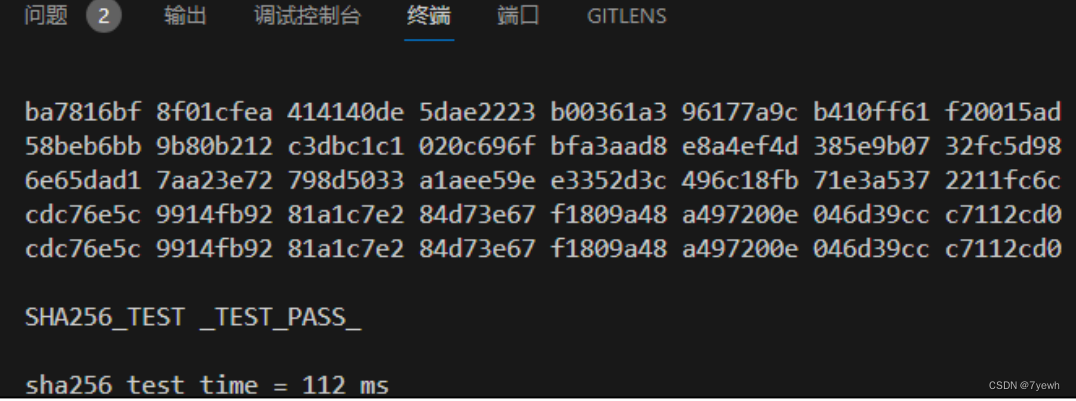
SHA256 安全散列算法加速器实验
1、SHA256 介绍 SHA256 加速器是用来计算 SHA-256 的计算单元, SHA256 是 SHA-2 下细分出的一种算法。 SHA-2 名称来自于安全散列算法 2 (英语: Secure Hash Algorithm 2 )的缩写,一种密码散列函 数算法标准…...

Elasticsearch-ES查询单字段去重
ES 语句 整体数据 GET wkl_test/_search {"query": {"match_all": {}} }结果: {"took" : 123,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0…...

【Apache Doris】周FAQ集锦:第 7 期
【Apache Doris】周FAQ集锦:第 7 期 SQL问题数据操作问题运维常见问题其它问题关于社区 欢迎查阅本周的 Apache Doris 社区 FAQ 栏目! 在这个栏目中,每周将筛选社区反馈的热门问题和话题,重点回答并进行深入探讨。旨在为广大用户和…...

EE trade:炒伦敦金的注意事项及交易指南
在贵金属市场中,伦敦金因其高流动性和全球认可度,成为广大投资者的首选。然而,在炒伦敦金的过程中,投资者需要注意一些关键点。南华金业小编带您一起来看看。 国际黄金报价 一般国际黄金报价会提供三个价格: 买价(B…...
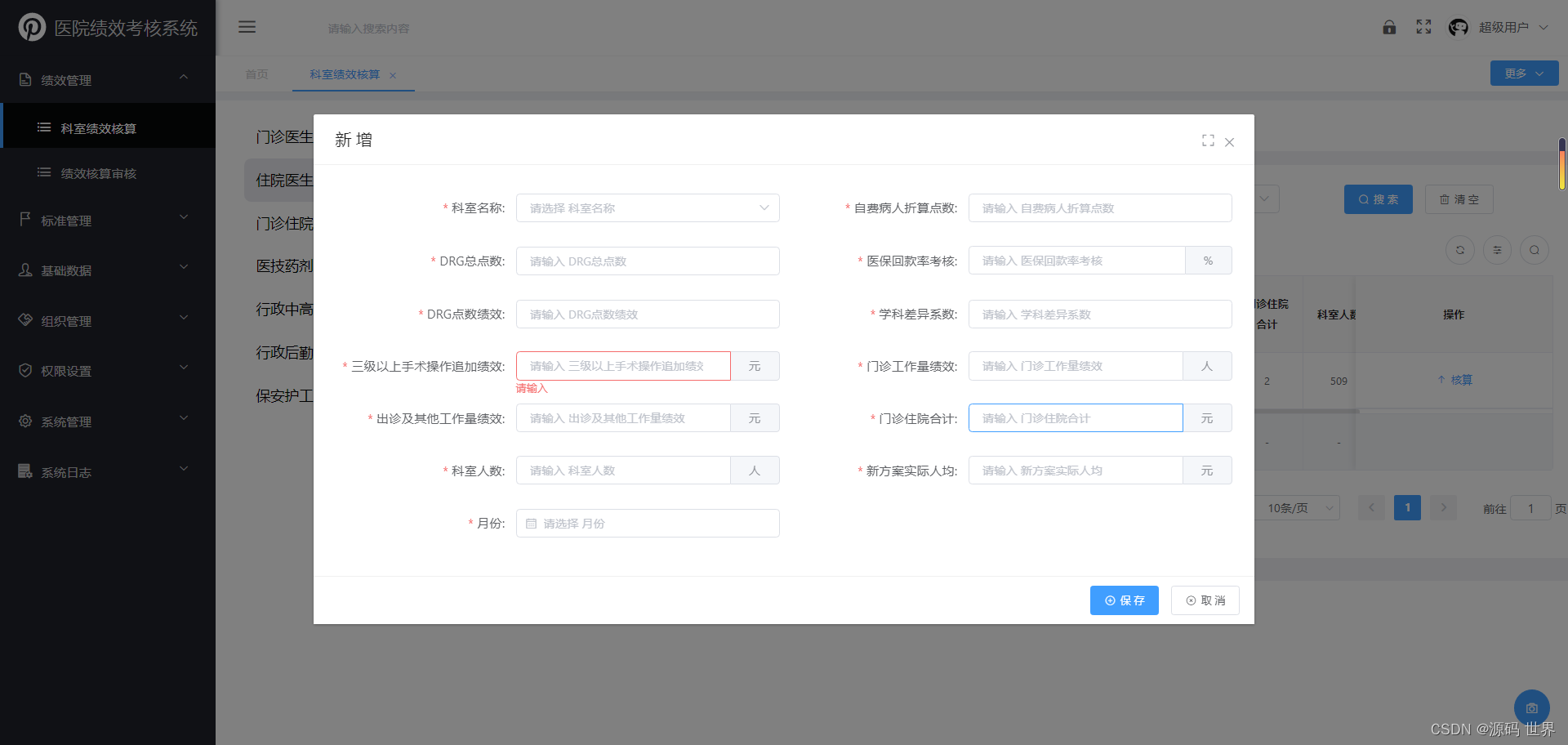
JAVA医院绩效考核系统源码 功能特点:大型医院绩效考核系统源码
JAVA医院绩效考核系统源码 功能特点:大型医院绩效考核系统源码 医院绩效管理系统主要用于对科室和岗位的工作量、工作质量、服务质量进行全面考核,并对科室绩效工资和岗位绩效工资进行核算的系统。医院绩效管理系统开发主要用到的管理工具有RBRVS、DRGS…...

Python神经影像数据的处理和分析库之nipy使用详解
概要 神经影像学(Neuroimaging)是神经科学中一个重要的分支,主要研究通过影像技术获取和分析大脑结构和功能的信息。nipy(Neuroimaging in Python)是一个强大的 Python 库,专门用于神经影像数据的处理和分析。nipy 提供了一系列工具和方法,帮助研究人员高效地处理神经影…...

非关系型数据库NoSQL数据层解决方案 之 Mongodb 简介 下载安装 springboot整合与读写操作
MongoDB 简介 MongoDB是一个开源的面向文档的NoSQL数据库,它采用了分布式文件存储的数据结构,是当前非常流行的数据库之一。 以下是MongoDB的主要特点和优势: 面向文档的存储: MongoDB是一个面向文档的数据库管理系统࿰…...

使用Redis优化Java应用的性能
使用Redis优化Java应用的性能 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们来探讨如何使用Redis优化Java应用的性能。Redis是一种开源的内存数据结构…...

基于Python的数据可视化大屏的设计与实现
基于Python的数据可视化大屏的设计与实现 Design and Implementation of Python-based Data Visualization Dashboard 完整下载链接:基于Python的数据可视化大屏的设计与实现 文章目录 基于Python的数据可视化大屏的设计与实现摘要第一章 导论1.1 研究背景1.2 研究目的1.3 研…...

什么是N卡和A卡?有什么区别?
名人说:莫听穿林打叶声,何妨吟啸且徐行。—— 苏轼《定风波莫听穿林打叶声》 本篇笔记整理:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、什么是N卡和A卡?有什么区别?…...
)
uniapp 对接腾讯云IM群组成员管理(增删改查)
UniApp 实战:腾讯云IM群组成员管理(增删改查) 一、前言 在社交类App开发中,群组成员管理是核心功能之一。本文将基于UniApp框架,结合腾讯云IM SDK,详细讲解如何实现群组成员的增删改查全流程。 权限校验…...

OpenLayers 可视化之热力图
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 热力图(Heatmap)又叫热点图,是一种通过特殊高亮显示事物密度分布、变化趋势的数据可视化技术。采用颜色的深浅来显示…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

mongodb源码分析session执行handleRequest命令find过程
mongo/transport/service_state_machine.cpp已经分析startSession创建ASIOSession过程,并且验证connection是否超过限制ASIOSession和connection是循环接受客户端命令,把数据流转换成Message,状态转变流程是:State::Created 》 St…...

Objective-C常用命名规范总结
【OC】常用命名规范总结 文章目录 【OC】常用命名规范总结1.类名(Class Name)2.协议名(Protocol Name)3.方法名(Method Name)4.属性名(Property Name)5.局部变量/实例变量(Local / Instance Variables&…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

React---day11
14.4 react-redux第三方库 提供connect、thunk之类的函数 以获取一个banner数据为例子 store: 我们在使用异步的时候理应是要使用中间件的,但是configureStore 已经自动集成了 redux-thunk,注意action里面要返回函数 import { configureS…...

Kubernetes 网络模型深度解析:Pod IP 与 Service 的负载均衡机制,Service到底是什么?
Pod IP 的本质与特性 Pod IP 的定位 纯端点地址:Pod IP 是分配给 Pod 网络命名空间的真实 IP 地址(如 10.244.1.2)无特殊名称:在 Kubernetes 中,它通常被称为 “Pod IP” 或 “容器 IP”生命周期:与 Pod …...

数据结构:泰勒展开式:霍纳法则(Horner‘s Rule)
目录 🔍 若用递归计算每一项,会发生什么? Horners Rule(霍纳法则) 第一步:我们从最原始的泰勒公式出发 第二步:从形式上重新观察展开式 🌟 第三步:引出霍纳法则&…...