每天学一点之Stream流相关操作
StreamAPI
一、Stream特点
Stream是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。“集合讲的是数据,负责存储数据,Stream流讲的是计算,负责处理数据!”
注意:
①Stream 自己不会存储元素。
②Stream 不会改变源对象。每次处理都会返回一个持有结果的新Stream。
③Stream 操作是延迟执行的。这意味着他们会等到需要结果的时候才执行。
二、Stream操作的步骤
1- 创建 Stream:通过一个数据源(如:集合、数组),获取一个流
2- 中间操作:每次处理都会返回一个持有结果的新Stream,即中间操作的方法返回值仍然是Stream类型的对象,因此中间操作可以是个操作链(返回值类型是Stream类型的可以一直使用.方法操作),可对数据源的数据进行n次处理,但是在终结操作前,并不会真正执行。
3- 终止操作:终止操作的方法返回值类型就不再是Stream了,因此一旦执行终止操作,就结束整个Stream操作了。一旦执行终止操作,就执行中间操作链,最终产生结果并结束Stream。

案例分析:
@Testpublic void test1(){//1、创建Stream,指定数据源来创建StreamArrayList<String> list = new ArrayList<>();list.add("hello");list.add("java");list.add("hi");list.add("heihei");Stream<String> stream = list.stream();//2、加工处理//假设我要处理的要求:把里面所有的e字母,修改为a//Function<T,R> 的抽象方法 R apply(T t)stream = stream.map(s-> s.replace('e','a'));//假设我要处理的要求:筛选出包含a字母的单词//Predicate<T>接口 boolean test(T t)stream = stream.filter(s -> s.contains("a"));//处理,打印所有包含"a"字母的单词//Consumer<T> 的抽象方法 void accept(T t)stream = stream.peek( s -> System.out.println(s));//3、结束处理//统计满足条件的单词的个数
// long count = stream.count();//没有这一步,前面的加工处理不执行
// System.out.println("count = " + count);System.out.println("list = " + list);//不会修改数据源}
没有开启3、结束处理步骤时的运行结果:

开启之后的运行结果:

三、创建StreamAPI
1、创建 Stream方式一:通过集合
Java8 中的 Collection 接口被扩展,提供了两个获取流的方法:
-
public default Stream stream() : 返回一个顺序流
-
public default Stream parallelStream() : 返回一个并行流
Stream stream = list.stream();
2、创建 Stream方式二:通过数组
Java8 中的 Arrays 的静态方法 stream() 可以获取数组流:
- public static Stream stream(T[] array): 返回一个流
String[] arr = {“hello”,“world”,“java”};
Stream stream = Arrays.stream(arr);
3、创建 Stream方式三:通过Stream的of()
可以调用Stream类静态方法 of(), 通过显示值创建一个流。它可以接收任意数量的参数。
- public static Stream of(T… values) : 返回一个顺序流
Stream stringStream = Stream.of(“hello”, “world”, “java”);
4、创建 Stream方式四:创建无限流
可以使用静态方法 Stream.iterate() 和 Stream.generate(), 创建无限流。
- public static Stream iterate(final T seed, final UnaryOperator f):返回一个无限流
- public static Stream generate(Supplier s) :返回一个无限流
@Testpublic void test4(){//Supplier<T> 的抽象方法 T get()Stream<Double> stream = Stream.generate(() -> Math.random());//结束Stream//Consumer<T> 的抽象方法 void accept(T t)stream.forEach(t-> System.out.println(t));}@Testpublic void test5(){//Stream<T> iterate(final T seed, final UnaryOperator<T> f)//seed:种子//UnaryOperator<T>: T apply(T t)
// Stream<Integer> stream = Stream.iterate(1, t -> t+2);Stream<Integer> stream = Stream.iterate(1, t -> {try {Thread.sleep(10);} catch (InterruptedException e) {e.printStackTrace();}return t+2;});//结束Stream//Consumer<T> 的抽象方法 void accept(T t)stream.forEach(System.out::println);}
}
四、中间操作API
多个中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则中间操作不会执行任何的处理!而在终止操作时一次性全部处理,称为“惰性求值”。
| 序号 | 方 法 | 描 述 |
|---|---|---|
| 1 | Stream filter(Predicate p) | 接收 Lambda , 从流中排除某些元素 |
| 2 | Stream distinct() | 筛选,通过流所生成元素的equals() 去除重复元素 |
| 3 | Stream limit(long maxSize) | 截断流,使其元素不超过给定数量 |
| 4 | Stream skip(long n) | 跳过元素,返回一个扔掉了前 n 个元素的流。若流中元素不足 n 个,则返回一个空流。与 limit(n) 互补 |
| 5 | Stream peek(Consumer action) | 接收Lambda,对流中的每个数据执行Lambda体操作 |
| 6 | Stream sorted() | 产生一个新流,其中按自然顺序排序 |
| 7 | Stream sorted(Comparator com) | 产生一个新流,其中按比较器顺序排序 |
| 8 | Stream map(Function f) | 接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。 |
| 9 | Stream mapToDouble(ToDoubleFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 DoubleStream。 |
| 10 | Stream mapToInt(ToIntFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 IntStream。 |
| 11 | Stream mapToLong(ToLongFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 LongStream。 |
| 12 | Stream flatMap(Function f) | 接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流 |
/*需求:给你一组单词,统计里面使用了几个字母,并找出这些字母*//*<R> Stream<R> map(Function<? super T, ? extends R> mapper);T类型->R类型对象<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);T类型->Stream<R>流*/Set<String> set = Stream.of("hello", "java", "world", "xiaoyu") //把所有单词的每一个字母取出来.flatMap(s -> Arrays.stream(s.split("|"))).collect(Collectors.toSet());System.out.println("字母有:"+set);System.out.println("个数:" + set.size());/*字母有:[a, d, e, h, i, j, l, o, r, u, v, w, x, y]个数:14*/
案例:
@Testpublic void test10(){//找出最老的3个员工,年龄最大的3个员工ArrayList<Employee> list = new ArrayList<>();list.add(new Employee(1,"张三",23,15000));list.add(new Employee(2,"李四",24,14000));list.add(new Employee(3,"王五",25,18000));list.add(new Employee(4,"赵六",22,12000));list.add(new Employee(5,"陈前",29,12000));list.add(new Employee(6,"林上清",27,12000));list.add(new Employee(7,"昆昆",27,12000));//年龄第3名的员工,年龄值不能重复//思路:先找出年龄值是第3的值,然后再找员工//Stream mapToInt(ToIntFunction f)//ToIntFunction<T> int applyAsInt(T value);OptionalInt ageOption = list.stream().sorted((t1,t2)->t2.getAge()-t1.getAge()).mapToInt(emp -> emp.getAge()).distinct().skip(2).findFirst();System.out.println("age = " + ageOption);list.stream().filter(emp -> emp.getAge() == ageOption.getAsInt()).forEach(t-> System.out.println(t));}
五、终结操作API
终端操作会从流的流水线生成结果。其结果可以是任何不是流的值,例如:List、Integer,甚至是 void。流进行了终止操作后,不能再次使用。
| 序号 | 方法的返回值类型 | 方法 | 描述 |
|---|---|---|---|
| 1 | boolean | allMatch(Predicate p) | 检查是否匹配所有元素 |
| 2 | boolean | anyMatch(Predicate p) | 检查是否至少匹配一个元素 |
| 3 | boolean | noneMatch(Predicate p) | 检查是否没有匹配所有元素 |
| 4 | Optional | findFirst() | 返回第一个元素 |
| 5 | Optional | findAny() | 返回当前流中的任意元素 |
| 6 | long | count() | 返回流中元素总数 |
| 7 | Optional | max(Comparator c) | 返回流中最大值 |
| 8 | Optional | min(Comparator c) | 返回流中最小值 |
| 9 | void | forEach(Consumer c) | 迭代 |
| 10 | T | reduce(T iden, BinaryOperator b) | 可以将流中元素反复结合起来,得到一个值。返回 T |
| 11 | U | reduce(BinaryOperator b) | 可以将流中元素反复结合起来,得到一个值。返回 Optional |
| 12 | R | collect(Collector c) | 将流转换为其他形式。接收一个 Collector接口的实现,用于给Stream中元素做汇总的方法 |
Stream<Integer> stream = Stream.of(1, 2, 3, 5, 7, 9);//判断stream中的所有数据,是否都满足 偶数的要求//allMatch(Predicate<? super T> predicate)//Predicate<T> boolean test(T t)boolean result = stream.allMatch(num -> num % 2 == 0);//判断stream中的所有数据,是否有数字满足 偶数的要求//anyMatch(Predicate<? super T> predicate)//Predicate<T> boolean test(T t)boolean result = stream.anyMatch(num -> num % 2 == 0);}//判断stream中的所有数据,是否都不满足 偶数的要求//noneMatch(Predicate<? super T> predicate)//Predicate<T> boolean test(T t)boolean result = stream.noneMatch(num -> num % 2 == 0);//获取流中第一个元素Optional<Integer> first = stream.findFirst();//加工处理一下,筛选出所有的偶数//Stream<T> filter(Predicate<? super T> predicate);//Predicate<T> boolean test(T t)stream = stream.filter(num -> num%2==0);//统计流中的元素个数long count = stream.count();//找出流中的最大值和最小值//Comparator<T> int compare(T t1 ,T t2)Optional<Integer> max = stream.max((t1, t2) -> t1-t2);Optional<Integer> min = stream.min((t1, t2) -> t1 - t2);//遍历流中的数据// void forEach(Consumer<? super T> action);//Consumer<T> 的抽象方法 void accept(T t)stream.forEach(t-> System.out.println(t));//使用reduce方法找出最大值,不用max方法//Optional<T> reduce(BinaryOperator<T> accumulator);//BinaryOperator<T,T> T apply(T t1, T t2)Optional<Integer> max = stream.reduce((t1, t2) -> t1 > t2 ? t1 : t2);//把流中的元素值累加起来//Optional<T> reduce(BinaryOperator<T> accumulator);//BinaryOperator<T,T> T apply(T t1, T t2)final Optional<Integer> sum = stream.reduce((t1, t2) -> t1 + t2);//筛选出所有的偶数,放到一个List集合中//中间处理//Stream<T> filter(Predicate<? super T> predicate);//Predicate<T> boolean test(T t)stream = stream.filter(t->t%2==0);//收集这些元素到List中List<Integer> list = stream.collect(Collectors.toList());//筛选出所有的偶数,放到一个Set集合中//中间处理//Stream<T> filter(Predicate<? super T> predicate);//Predicate<T> boolean test(T t)stream = stream.filter(t->t%2==0);Set<Integer> set = stream.collect(Collectors.toSet());相关文章:
每天学一点之Stream流相关操作
StreamAPI 一、Stream特点 Stream是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。“集合讲的是数据,负责存储数据,Stream流讲的是计算,负责处理数据!” 注意: ①Str…...

MatCap模拟光照效果实现
大家好,我是阿赵 之前介绍过各种光照模型的实现方法。那些光照模型的实现虽然有算法上的不同,但基本上都是灯光方向和法线方向的计算得出的明暗结果。 下面介绍一种叫做MatCap的模拟光照效果,这种方式计算非常简单,脱离灯光的计算…...

二十一、PG管理
一、 PG异常状态说明 1、 PG状态介绍 可以通过ceph pg stat命令查看PG当前状态,健康状态为“active clean” [rootrbd01 ~]# ceph pg stat 192 pgs: 192 activeclean; 1.3 KiB data, 64 MiB used, 114 GiB / 120 GiB avail; 85 B/s rd, 0 op/s2、pg常见状态 状…...

SAPUI5开发01_01-Installing Eclipse
1.0 简要要求概述: 本节您将安装SAPUI 5,以及如何在Eclipse Juno中集成SAPUI 5工具。 1.1 安装JDK JDK 是一种用于构建在 Java 平台上发布的应用程序、Applet 和组件的开发环境,即编写 Java 程序必须使用 JDK,它提供了编译和运行 Java 程序的环境。 在安装 JDK 之前,首…...
Qt之高仿QQ系统设置界面
QQ或360安全卫士的设置界面都是非常有特点的,所有的配置项都在一个垂直的ScrollArea中,但是又能通过左侧的导航栏点击定位。这样做的好处是既方便查看指定配置项,又方便查看所有配置项。 一.效果 下面左边是当前最新版QQ的系统设置界面,右边是我的高仿版本,几乎一毛一样…...

JVM概览:内存空间与数据存储
核心的五个部分虚拟机栈:局部变量中基础类型数据、对象的引用存储的位置,线程独立的。堆:大量运行时对象都在这个区域存储,线程共享的。方法区:存储运行时代码、类变量、常量池、构造器等信息,线程共享。程…...
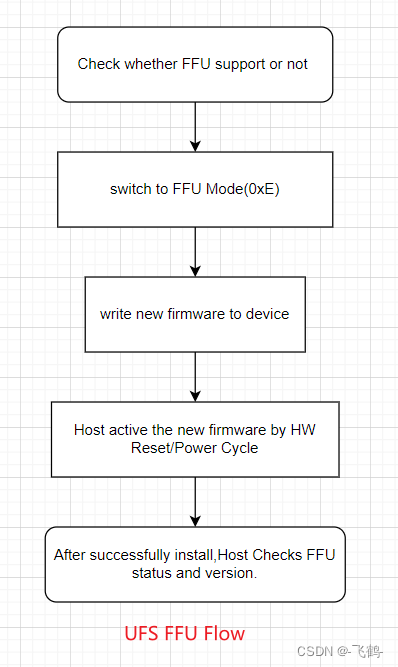
固态存储设备固件升级方案
1. 前言 随着数字化时代的发展,数字数据的量越来越大,相应的数据存储的需求也越来越大,存储设备产业也是蓬勃发展。存储设备产业中,发展最为迅猛的则是固态存储(Solid State Storage,SSS)。数字化时代,海量…...
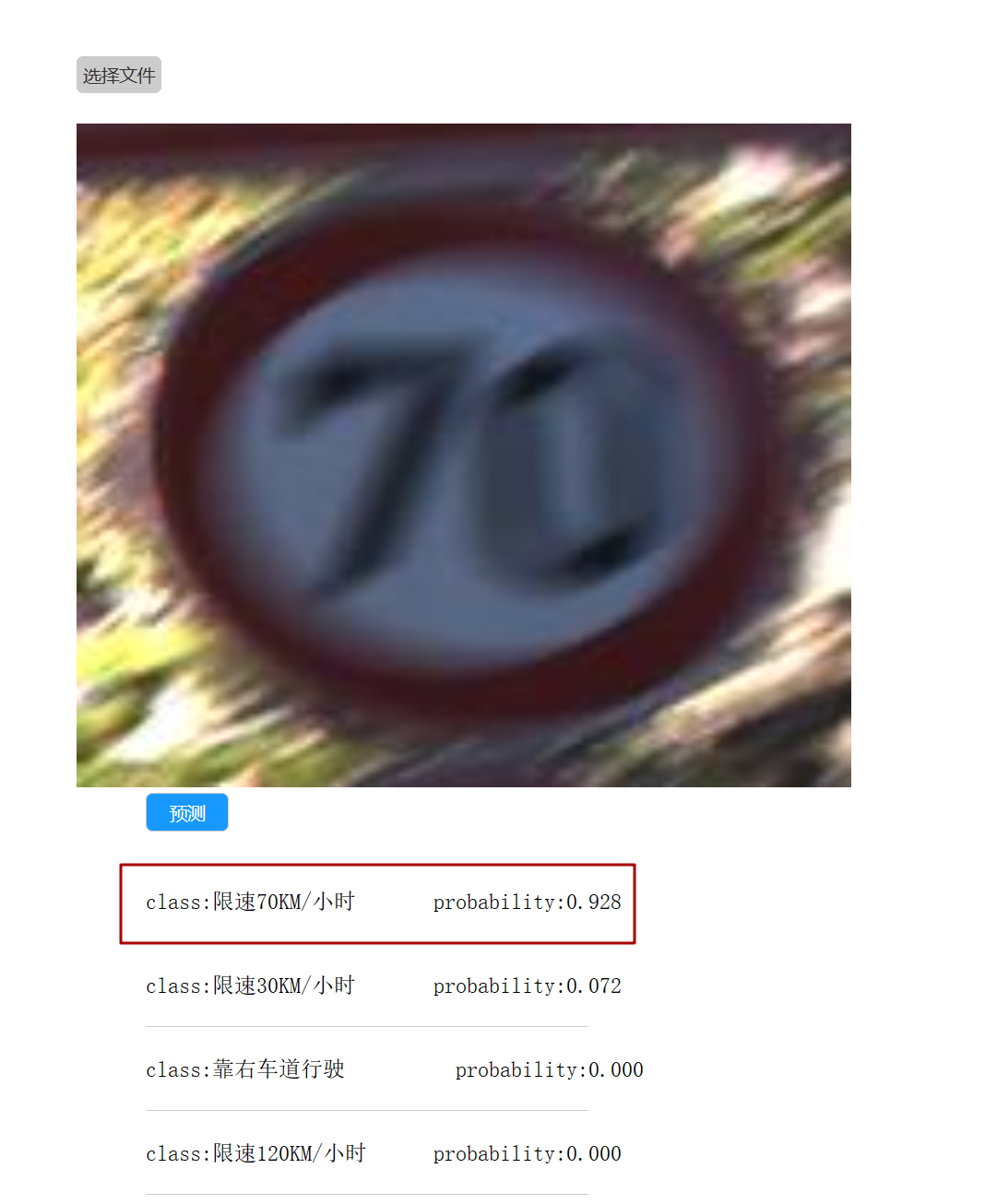
Python交通标志识别基于卷积神经网络的保姆级教程(Tensorflow)
项目介绍 TensorFlow2.X 搭建卷积神经网络(CNN),实现交通标志识别。搭建的卷积神经网络是类似VGG的结构(卷积层与池化层反复堆叠,然后经过全连接层,最后用softmax映射为每个类别的概率,概率最大的即为识别…...

基于Selenium+Python的web自动化测试框架(附框架源码+项目实战)
目录 一、什么是Selenium? 二、自动化测试框架 三、自动化框架的设计和实现 四、需要改进的模块 五、总结 总结感谢每一个认真阅读我文章的人!!! 重点:配套学习资料和视频教学 一、什么是Selenium? …...

Python进阶-----高阶函数zip() 函数
目录 前言: zip() 函数简介 运作过程: 应用实例 1.有序序列结合 2.无序序列结合 3.长度不统一的情况 前言: 家人们,看到标题应该都不陌生了吧,我们都知道压缩包文件的后缀就是zip的,当然还有r…...

win10打印机拒绝访问解决方法
一直以来,在安装使用共享打印机打印一些文件的时候,会遇到错误提示:“无法访问.你可能没有权限使用网络资源。请与这台服务器的管理员联系”的问题,那为什么共享打印机拒绝访问呢?别着急,下面为大家带来相关的解决方法…...

深度学习训练营之数据增强
深度学习训练营学习内容原文链接环境介绍前置工作设置GPU加载数据创建测试集数据类型查看以及数据归一化数据增强操作使用嵌入model的方法进行数据增强模型训练结果可视化自定义数据增强查看数据增强后的图片学习内容 在深度学习当中,由于准备数据集本身是一件十分复杂的过程,…...
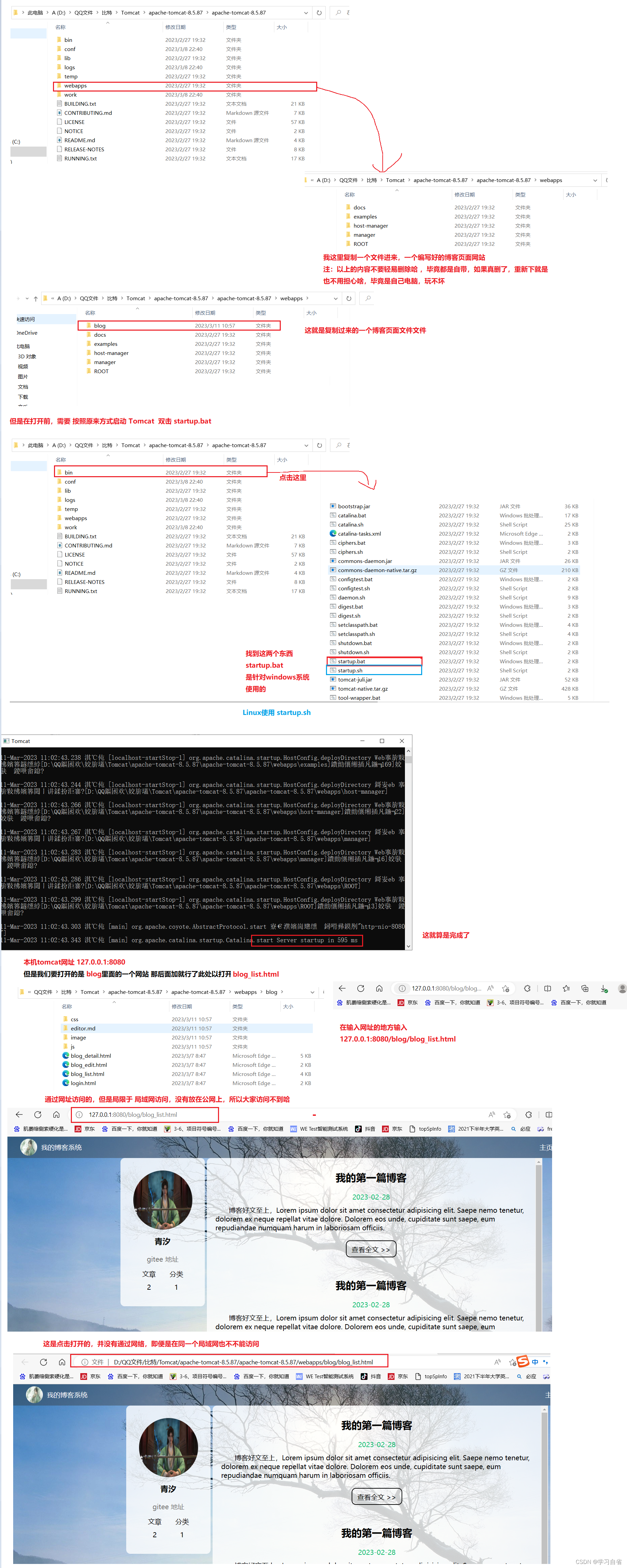
Tomcat安装及启动
日升时奋斗,日落时自省 目录 1、Tomcat下载 2、JDK安装及配置环境 3、Tomcat配置环境 4、启动Tomcat 5、部署演示 1、Tomcat下载 直接入主题,下载Tomcat 首先就是别下错了,直接找官方如何看是不是广告,或者造假 搜索Tomc…...

【专项训练】排序算法
排序算法 非比较类的排序,基本上就是放在一个数组里面,统计每个数出现的次序 最重要的排序是比较类排序! O(nlogn)的3个排序,必须要会!即:堆排序、快速排序、归并排序! 快速排序:分治 经典快排 def quickSort1(arr...

Android压测测试事件行为参数对照表
执行参数参数说明颗粒度指标基础参数--throttle <ms> 用于指定用户操作间的时延。 -s 随机数种子,用于指定伪随机数生成器的seed值,如果seed值相同,则产生的时间序列也相同。多用于重测、复现问题。 -v 指定输出日志的级别,…...

【观察】亚信科技:“飞轮效应”背后的数智化创新“延长线”
著名管理学家吉姆柯林斯在《从优秀到卓越》一书中提出“飞轮效应”,它指的是为了使静止的飞轮转动起来,一开始必须使很大的力气,每转一圈都很费力,但达到某一临界点后,飞轮的重力和冲力就会成为推动力的一部分…...

QT编程从入门到精通之十四:“第五章:Qt GUI应用程序设计”之“5.1 UI文件设计与运行机制”之“5.1.1 项目文件组成”
目录 第五章:Qt GUI应用程序设计 5.1 UI文件设计与运行机制 5.1.1 项目文件组成 第五章:Qt GUI应用程序设计...
730. 机器人跳跃问题)
(二分)730. 机器人跳跃问题
目录 题目链接 一些话 切入点 流程 套路 ac代码 题目链接 AcWing 730. 机器人跳跃问题 - AcWing 一些话 // 向上取整 mid的表示要写成l r 1 >> 1即可,向下取整 mid l r >> 1 // 这里我用了浮点二分,mid (l r) / 2,最…...
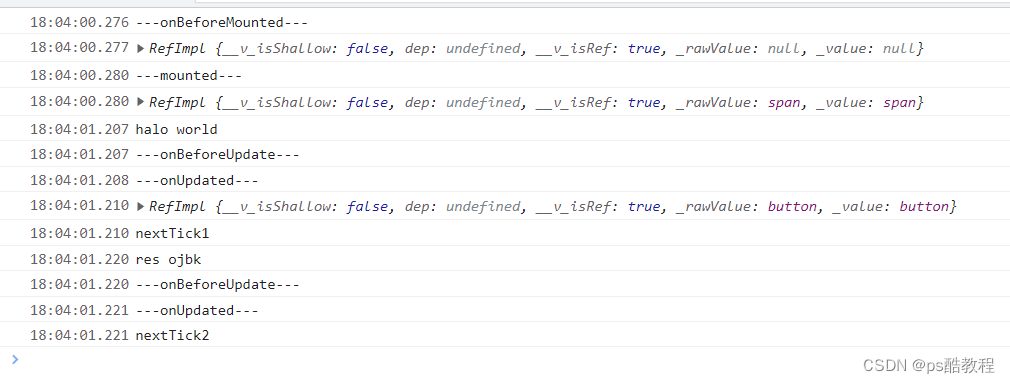
vue3使用nextTick
发现nextTick必须放在修改一个响应式数据之后,才会在onUpdated之后被调用,如果nextTick是放在所有对响应式数据修改之前,则nextTick里面的回调函数会在onBeforeUpdate方法执行前就被调用了。可是nextTick必须等到onUpdated执行完成之后执行&a…...

传统图像处理之颜色特征
博主简介 博主是一名大二学生,主攻人工智能研究。感谢让我们在CSDN相遇,博主致力于在这里分享关于人工智能,c,Python,爬虫等方面知识的分享。 如果有需要的小伙伴可以关注博主,博主会继续更新的,…...

接口测试中缓存处理策略
在接口测试中,缓存处理策略是一个关键环节,直接影响测试结果的准确性和可靠性。合理的缓存处理策略能够确保测试环境的一致性,避免因缓存数据导致的测试偏差。以下是接口测试中常见的缓存处理策略及其详细说明: 一、缓存处理的核…...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

linux 错误码总结
1,错误码的概念与作用 在Linux系统中,错误码是系统调用或库函数在执行失败时返回的特定数值,用于指示具体的错误类型。这些错误码通过全局变量errno来存储和传递,errno由操作系统维护,保存最近一次发生的错误信息。值得注意的是,errno的值在每次系统调用或函数调用失败时…...

镜像里切换为普通用户
如果你登录远程虚拟机默认就是 root 用户,但你不希望用 root 权限运行 ns-3(这是对的,ns3 工具会拒绝 root),你可以按以下方法创建一个 非 root 用户账号 并切换到它运行 ns-3。 一次性解决方案:创建非 roo…...

LeetCode - 199. 二叉树的右视图
题目 199. 二叉树的右视图 - 力扣(LeetCode) 思路 右视图是指从树的右侧看,对于每一层,只能看到该层最右边的节点。实现思路是: 使用深度优先搜索(DFS)按照"根-右-左"的顺序遍历树记录每个节点的深度对于…...

算法:模拟
1.替换所有的问号 1576. 替换所有的问号 - 力扣(LeetCode) 遍历字符串:通过外层循环逐一检查每个字符。遇到 ? 时处理: 内层循环遍历小写字母(a 到 z)。对每个字母检查是否满足: 与…...

Java编程之桥接模式
定义 桥接模式(Bridge Pattern)属于结构型设计模式,它的核心意图是将抽象部分与实现部分分离,使它们可以独立地变化。这种模式通过组合关系来替代继承关系,从而降低了抽象和实现这两个可变维度之间的耦合度。 用例子…...
echarts使用graphic强行给图增加一个边框(边框根据自己的图形大小设置)- 适用于无法使用dom的样式
pdf-lib https://blog.csdn.net/Shi_haoliu/article/details/148157624?spm1001.2014.3001.5501 为了完成在pdf中导出echarts图,如果边框加在dom上面,pdf-lib导出svg的时候并不会导出边框,所以只能在echarts图上面加边框 grid的边框是在图里…...