svm和决策树基本知识以及模型评价以及模型保存
svm和决策树基本知识以及模型评价以及模型保存
文章目录
- 一、SVM
- 1.1,常用属性函数
- 二、决策树
- 2.1,常用属性函数
- 2.2,决策树可视化
- 2.3,决策树解释
- 3,模型评价
- 3.1,方面一(评价指标)
- 3.2,方面二(不同数据规模下,模型的性能)
- 4,模型保存与读取
- 4.1,模型的保存
- 4.2,模型的读取
一、SVM
1.1,常用属性函数
predict:返回一个数组表示个测试样本的类别。
predict_probe:返回一个数组表示测试样本属于每种类型的概率。
decision_function:返回一个数组表示测试样本到对应类型的超平面距离。
get_params:获取当前svm函数的各项参数值。
score:获取预测结果准确率。
set_params:设置SVC函数的参数 clf.n_support_:各类的支持向量的个数
clf.support_:各类的支持向量在训练样本中的索引
clf.support_vectors_:全部支持向量
原文链接:
二、决策树
2.1,常用属性函数
classes_:类标签(单输出问题)或类标签数组的列表(多输出问题)。
feature_importances_:特征重要度。
max_features_:max_features的推断值。
n_classes_:类数(用于单输出问题),或包含每个输出的类数的列表(用于多输出问题)。
n_features_:执行拟合时的特征数量。
n_outputs_:执行拟合时的输出数量。
tree_:训练(拟合):fit(train_x, train_y)
预测:predict(X)返回标签、predict_log_proba(X)、predict_proba(X)返回概率,每个点的概率和为1,一般取predict_proba(X)[:,1]
评分(返回平均准确度):score(test_x, test_y)。等效于准确率accuracy_score
参数类:获取分类器的参数get_params([deep])、设置分类器的参数set_params(params)。
原文链接:
2.2,决策树可视化
from sklearn.datasets import load_iris
from sklearn import tree
import matplotlib.pyplot as plt# 加载鸢尾花数据集
iris = load_iris()# 创建决策树模型
model = tree.DecisionTreeClassifier(max_depth=2)
model.fit(iris.data, iris.target)# 可视化决策树
feature_names = iris.feature_names
plt.figure(figsize=(12,12))
_ = tree.plot_tree(model, feature_names=feature_names, class_names=iris.target_names, filled=True, rounded=True)
plt.show()
2.3,决策树解释
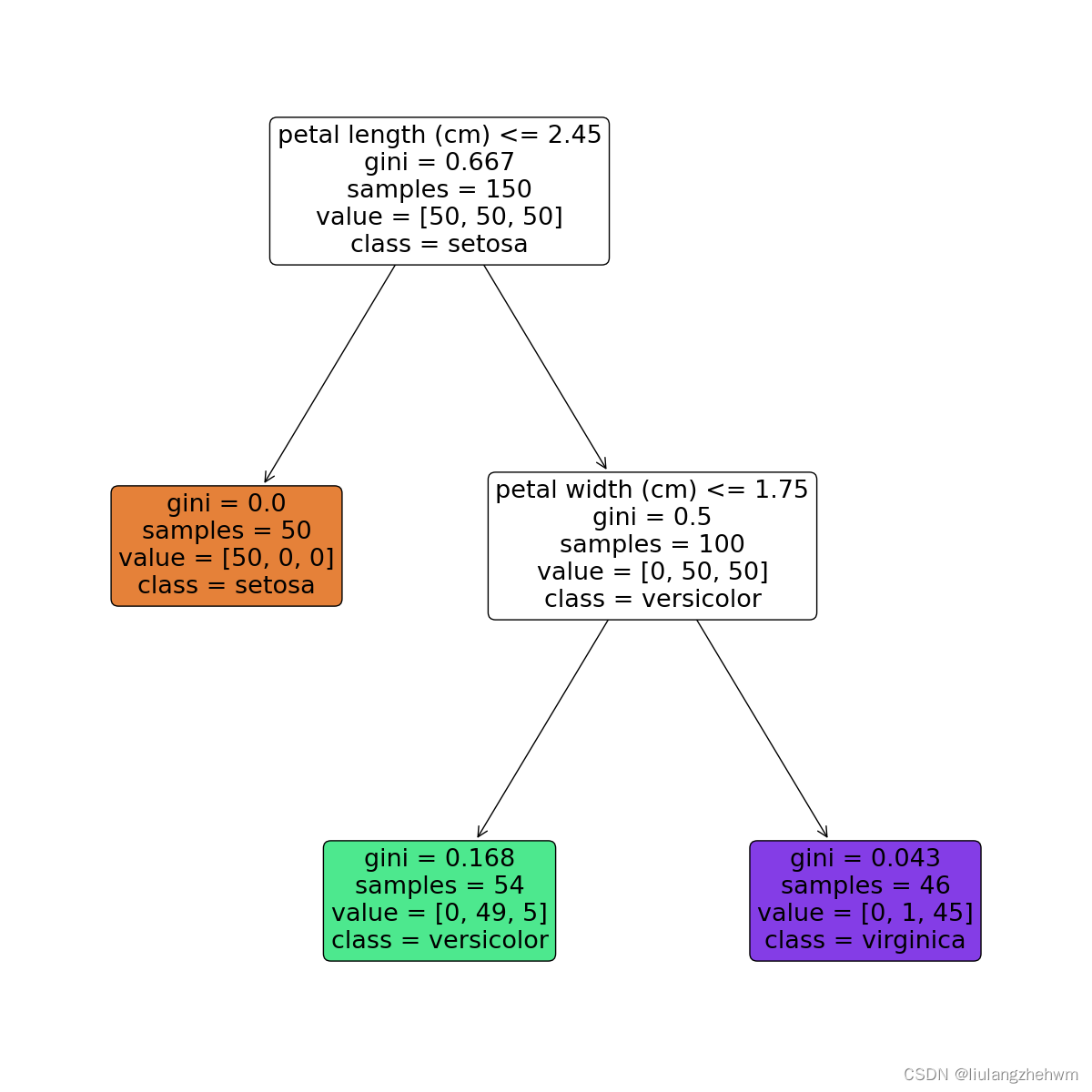
节点含义:
- petal length (cm)<=2.45表示数据特征petal width (cm)<=0.75,当petal width (cm)<=0.75,进入左边分支,否则进入右边分支;
- gini表示该节点的基尼系数;
- samples表示该节点的样本数;
- value表示各分类的样本数,例如,根节点中的[34,32,39]表示分类为Setosa的样本数为34,分类为Versicolour的样本数为32,分类为Virginica的样本数量为39;
- class表示该区块被划分为的类别,它是由value中样本数较多的类别决定的,例如,根节点中分类为Virginica的样本数最多,所以该节点的分类为Virginica,依此类推。
每一个颜色代表一个分类,随着层数的增加,颜色也会变深。
原文链接
3,模型评价
3.1,方面一(评价指标)
- 准确率
准确率是分类问题中最常用的评估指标,用于衡量模型的正确预测率。 - 精确率和召回率
精确率和召回率用于评估二分类模型的性能。精确率是指预测为正例的样本中实际为正例的比例,召回率是指实际为正例的样本中被正确预测为正例的比例。 - F1分数
F1分数是精确率和召回率的加权平均值,用于评估二分类模型的性能。
# 其他的指标
def accuracy_precision_recall_f1(y_true, y_pred):# 1.准确率accuracy = accuracy_score(y_true, y_pred)# 2.精确率和召回率precision = precision_score(y_true, y_pred)recall = recall_score(y_true, y_pred)# 3.F1分数f1 = f1_score(y_true, y_pred)return [accuracy, precision, recall, f1]print(accuracy_precision_recall_f1(test_label_shulle_scaler, test_data_predict))
原文链接
- 混淆矩阵
混淆矩阵是一个二维矩阵,用于表示分类模型的性能。它将预测结果分为真正例(True Positive)、假正例(False Positive)、真反例(True Negative)和假反例(False Negative)四类,分别对应矩阵的四个象限。
def draw_confusion_matrix(label_true, label_pred, label_name, normlize, title="Confusion Matrix", pdf_save_path=None,dpi=100):"""@param label_true: 真实标签,比如[0,1,2,7,4,5,...]@param label_pred: 预测标签,比如[0,5,4,2,1,4,...]@param label_name: 标签名字,比如['cat','dog','flower',...]@param normlize: 是否设元素为百分比形式@param title: 图标题@param pdf_save_path: 是否保存,是则为保存路径pdf_save_path=xxx.png | xxx.pdf | ...等其他plt.savefig支持的保存格式@param dpi: 保存到文件的分辨率,论文一般要求至少300dpi@return:example:draw_confusion_matrix(label_true=y_gt,label_pred=y_pred,label_name=["Angry", "Disgust", "Fear", "Happy", "Sad", "Surprise", "Neutral"],normlize=True,title="Confusion Matrix on Fer2013",pdf_save_path="Confusion_Matrix_on_Fer2013.png",dpi=300)"""cm1 = confusion_matrix(label_true, label_pred)cm = confusion_matrix(label_true, label_pred)print(cm)if normlize:row_sums = np.sum(cm, axis=1)cm = cm / row_sums[:, np.newaxis]cm = cm.Tcm1 = cm1.Tplt.imshow(cm, cmap='Blues')plt.title(title)# plt.xlabel("Predict label")# plt.ylabel("Truth label")plt.xlabel("预测标签")plt.ylabel("真实标签")plt.yticks(range(label_name.__len__()), label_name)plt.xticks(range(label_name.__len__()), label_name, rotation=45)plt.tight_layout()plt.colorbar()for i in range(label_name.__len__()):for j in range(label_name.__len__()):color = (1, 1, 1) if i == j else (0, 0, 0) # 对角线字体白色,其他黑色value = float(format('%.1f' % (cm[i, j] * 100)))value1 = str(value) + '%\n' + str(cm1[i, j])plt.text(i, j, value1, verticalalignment='center', horizontalalignment='center', color=color)plt.show()# if not pdf_save_path is None:# plt.savefig(pdf_save_path, bbox_inches='tight', dpi=dpi)labels_name = ['健康', '故障']
test_data_predict = SVC_all.predict(test_data_shuffle_scaler)draw_confusion_matrix(label_true=test_label_shulle_scaler,label_pred=test_data_predict,label_name=labels_name,normlize=True,title="混淆矩阵",# title="Confusion Matrix",pdf_save_path="Confusion_Matrix.jpg",dpi=300)
原文链接
- AUC和ROC曲线
ROC曲线是一种评估二分类模型性能的方法,它以真正例率(TPR)为纵轴,假正例率(FPR)为横轴,绘制出模型预测结果在不同阈值下的性能。AUC是ROC曲线下面积,用于评估模型总体性能。
# 画ROC曲线函数
def plot_roc_curve(y_true, y_score):"""y_true:真实值y_score:预测概率。注意:不要传入预测label!!!"""from sklearn.metrics import roc_curveimport matplotlib.pyplot as pltfpr, tpr, threshold = roc_curve(y_true, y_score)# plt.xlabel('False Positive Rate')# plt.ylabel('Ture Positive Rate')plt.xlabel('特异度')plt.ylabel('灵敏度')plt.title('ROC曲线')# plt.title('roc curve')plt.plot(fpr, tpr, color='b', linewidth=0.8)plt.plot([0, 1], [0, 1], 'r--')plt.show()# print(np.sum(SVC_all.predict(test_data_shuffle_scaler)))
test_data_score = SVC_all.decision_function(test_data_shuffle_scaler)
plot_roc_curve(test_label_shulle_scaler, SVC_all.predict_proba(test_data_shuffle_scaler)[:,1])
plot_roc_curve(test_label_shulle_scaler, test_data_score)# 计算AUC
from sklearn.metrics import roc_auc_score
print(roc_auc_score(test_label_shulle_scaler, SVC_all.predict_proba(test_data_shuffle_scaler)[:,1]))
原文链接
3.2,方面二(不同数据规模下,模型的性能)
def plot_learning_curve(estimator, title, X, y,ax, # 选择子图ylim=None, # 设置纵坐标的取值范围cv=None, # 交叉验证n_jobs=None # 设定索要使用的线程):train_sizes, train_scores, test_scores = learning_curve(estimator, X, y, cv=cv, n_jobs=n_jobs)# learning_curve() 是一个可视化工具,用于评估机器学习模型的性能和训练集大小之间的关系。它可以帮助我们理解模型在不同数据规模下的训练表现,# 进而判断模型是否出现了欠拟合或过拟合的情况。该函数会生成一条曲线,横轴表示不同大小的训练集,纵轴表示训练集和交叉验证集上的评估指标(例如# 准确率、损失等)。通过观察曲线,我们可以得出以下结论:# 1,训练集误差和交叉验证集误差之间的关系:当训练集规模较小时,模型可能过度拟合,训练集误差较低,交叉验证集误差较高;当训练集规模逐渐增大时,# 模型可能更好地泛化,两者的误差逐渐趋于稳定。# 2,训练集误差和交叉验证集误差对训练集规模的响应:通过观察曲线的斜率,我们可以判断模型是否存在高方差(过拟合)或高偏差(欠拟合)的问题。如果# 训练集和交叉验证集的误差都很高,且二者之间的间隔较大,说明模型存在高偏差;如果训练集误差很低而交叉验证集误差较高,且二者的间隔也较大,说# 明模型存在高方差。# cv : int:交叉验证生成器或可迭代的可选项,确定交叉验证拆分策略。v的可能输入是:# - 无,使用默认的3倍交叉验证,# - 整数,指定折叠数。# - 要用作交叉验证生成器的对象。# - 可迭代的yielding训练/测试分裂。# ShuffleSplit:我们这里设置cv,交叉验证使用ShuffleSplit方法,一共取得100组训练集与测试集,# 每次的测试集为20%,它返回的是每组训练集与测试集的下标索引,由此可以知道哪些是train,那些是test。# n_jobs : 整数,可选并行运行的作业数(默认值为1)。windows开多线程需要ax.set_title(title)if ylim is not None:ax.set_ylim(*ylim)# *是可以接受任意数量的参数# 而 ** 可以接受任意数量的指定键值的参数# def m(*args,**kwargs):# print(args)# print(kwargs)# m(1,2,a=1,b=2)# #args:(1,2),kwargs:{'b': 2, 'a': 1}ax.set_xlabel("Training examples")ax.set_ylabel("Score")ax.grid() # 显示网格作为背景,不是必须ax.plot(train_sizes, np.mean(train_scores, axis=1), 'o-', color="r", label="Training score")ax.plot(train_sizes, np.mean(test_scores, axis=1), 'o-', color="g", label="Test score")ax.legend(loc="best")return ax#
# y = y.astype(np.int)
print(X.shape)
print(y.shape)title = ["Naive_Bayes", "DecisionTree", "SVM_RBF_kernel", "RandomForest", "Logistic"]
# model = [GaussianNB(), DTC(), SVC(gamma=0.001)
# , RFC(n_estimators=50), LR(C=0.1, solver="lbfgs")]
model = [GaussianNB(), DTC(), SVC(kernel="rbf"), RFC(n_estimators=50), LR(C=0.1, solver="liblinear")]
cv = ShuffleSplit(n_splits=10, test_size=0.5, random_state=0)
# n_splits:
# 划分数据集的份数,类似于KFlod的折数,默认为10份
# test_size:
# 测试集所占总样本的比例,如test_size=0.2即将划分后的数据集中20%作为测试集
# random_state:
# 随机数种子,使每次划分的数据集不变
# train_sizes: 随着训练集的增大,选择在10%,25%,50%,75%,100%的训练集大小上进行采样。
# 比如(CV= 5)10%的意思是先在训练集上选取10%的数据进行五折交叉验证。
# train_sizes:数组类,形状(n_ticks),dtype float或int
# 训练示例的相对或绝对数量,将用于生成学习曲线。如果dtype为float,则视为训练集最大尺寸的一部分
# (由所选的验证方法确定),即,它必须在(0,1]之内,否则将被解释为绝对大小注意,为了进行分类,
# 样本的数量通常必须足够大,以包含每个类中的至少一个样本(默认值:np.linspace(0.1,1.0,5))
# 输出:
# train_sizes_abs:
# 返回生成的训练的样本数,如[ 10 , 100 , 1000 ]
# train_scores:
# 返回训练集分数,该矩阵为( len ( train_sizes_abs ) , cv分割数 )维的分数,
# 每行数据代表该样本数对应不同折的分数
# test_scores:
# 同train_scores,只不过是这个对应的是测试集分数
print("===" * 25)
fig, axes = plt.subplots(1, 5, figsize=(30, 6))
for ind, title_, estimator in zip(range(len(title)), title, model):times = time()plot_learning_curve(estimator, title_, X_scaler, y,ax=axes[ind], ylim=[0, 1.05], n_jobs=4, cv=cv)print("{}:{}".format(title_, datetime.datetime.fromtimestamp(time() - times).strftime(" %M:%S:%f")))
plt.show()
print("===" * 25)
for i in [*zip(range(len(title)), title, model)]:print(i)
原文链接
4,模型保存与读取
4.1,模型的保存
title = ["Naive_Bayes", "DecisionTree", "SVM_RBF_kernel", "RandomForest", "Logistic"]
model = [GaussianNB(), DTC(), SVC(gamma=0.001), RFC(n_estimators=50), LR(C=0.1, solver="liblinear")]import joblibfor i_index, i in enumerate(model):i.fit(X, y)joblib_file = "model_save/" + title[i_index] + "_model.pkl"with open(joblib_file, 'wb') as file:joblib.dump(i, joblib_file)print(i.score(X, y))
4.2,模型的读取
title = ["Naive_Bayes", "DecisionTree", "SVM_RBF_kernel", "RandomForest", "Logistic"]for i in title:joblib_file = "model_save/" + i + "_model.pkl"with open(joblib_file, "rb") as file:model = joblib.load(file)print(i, ": ", model.score(X, y))
相关文章:
svm和决策树基本知识以及模型评价以及模型保存
svm和决策树基本知识以及模型评价以及模型保存 文章目录 一、SVM1.1,常用属性函数 二、决策树2.1,常用属性函数2.2,决策树可视化2.3,决策树解释 3,模型评价3.1,方面一(评价指标)3.2&…...

C++ 79 之 自己写异常类
#include <iostream> #include <string> using namespace std;class MyOutOfRange : public exception{ // 选中exception右键 转到定义 复制一份 virtual const char* what() const _GLIBCXX_TXN_SAFE_DYN _GLIBCXX_NOTHROW 进行函数重写 public: string m_msg;M…...

如何搭建一个成功的短剧制作平台
要搭建一个成功的短剧制作平台,需要考虑多个方面,包括目标定位、技术选择、内容管理、用户体验等。 1、明确目标和定位: 确定你的目标受众是谁,他们的年龄、兴趣、消费习惯等。 明确短剧制作平台的主要定位,是提供原创…...
kotlin类
一、定义 1、kotlin中使用关键字class 声明类,如果一个类没有类体,也可以省略花括号, 默认为public 类型的: // 这段代码定义了一个公开的、不可被继承的Test类 class Test{} // 没有类体,可以省略花括号 class Test 底层代码&…...
android | studio的UI布局和代码调试 | UI调试 (用于找到项目源码)
网上找到一个项目,想快速的搞懂是怎么实现的,搞了半天发现原来android都升级到Jetpack Compose了,然后去找源码挺不容易的,摸索中发现了这个调试的方法,还可以。 https://developer.android.com/studio/debug/layout-i…...
——ConfigurableField)
LangChain实战技巧之六:一起玩转config(上篇)——ConfigurableField
简介 Config 包含两大类内容, ConfigurableField 可配置的字段 configurable_alternatives 可配置的替代方案 分别使用两篇文章来给大家介绍,本篇先介绍ConfigurableField 常规介绍 一些资料会这样介绍 model_spec model.configurable_fields(model…...

扫码称重上位机
目录 一 设计原型 二 后台代码 一 设计原型 模拟工具: 二 后台代码 主程序: using System.IO.Ports; using System.Net; using System.Net.Sockets; using System.Text;namespace 扫码称重上位机 {public partial class Form1 : Form{public Form1(){Initialize…...

操作系统入门 -- 进程的通信方式
操作系统入门 – 进程的通信方式 1.什么是进程通信 1.1 定义 进程通信就是在不同进程之间交换信息。在之前文章中可以了解到,进程之间相互独立,一般不可能互相访问。因此进程之间若需要通信,则需要一个所有进程都认可的共享空间࿰…...
Python读取wps中的DISPIMG图片格式
需求: 读出excel的图片内容,这放在微软三件套是很容易的,但是由于wps的固有格式,会出现奇怪的问题,只能读出:类似于 DISPIMG(“ID_2B83F9717AE1XXXX920xxxx644C80DB1”,1) 【该DISPIMG函数只有wps才拥有】 …...

elasticsearch的入门与实践
Elasticsearch是一个基于Lucene构建的开源搜索引擎。它提供了一个分布式、多租户能力的全文搜索引擎,具有HTTP web接口和无模式的JSON文档。以下是Elasticsearch的入门与实践的基本步骤: 入门 安装Elasticsearch: 从Elasticsearch官网下载对…...
神经网络学习6-线性层
归一化用的较少 正则化用来解决过拟合,处理最优化问题,批量归一化加快速度 正则化(Regularization): 作用:正则化是一种用来防止过拟合的技术,通过向模型的损失函数中添加惩罚项,使…...

PHP框架详解 - CodeIgniter 框架
CodeIgniter 是一个成熟的轻量级 PHP 框架,专为小到中型的 Web 应用开发设计。它以其简洁、灵活和易于学习的特点而受到开发者的喜爱。 CodeIgniter 框架的特点包括: 轻量级:CodeIgniter 的核心非常小,加载速度快,适…...

奔驰EQS SUV升级原厂主动式氛围灯效果展示
以下是一篇关于奔驰 EQs 升级原厂主动氛围灯案例的宣传文案: 在汽车科技不断演进的今天,我们自豪地为您呈现奔驰 EQs 升级原厂主动氛围灯的精彩案例。 奔驰 EQs,作为豪华电动汽车的典范,其卓越品质与高端性能有目共睹。而此次升…...
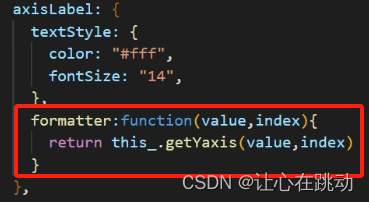
echarts Y轴展示时间片段,series data数据 也是时间片段,鼠标放上去 提示框显示对应的时间片段
功能要求 1、折线图,展示每天对应的一个时间片段 2、echarts Y轴展示时间片段,如:[00:00,03:00,05:15] 3、X轴展示日期,如:[xx年xx月xx日] 后端返回的数据结构,如 [{xAdate:"2024-06-15",data:…...

20. mediasoup服务器的布署与使用
Mediasoup Demo部署 架构服务分析 服务端提供3个服务: 1.www服务,浏览器通过访问服务器目录获取客户端代码,通过V8引擎,启动底层WebRTC 2.nodejs提供websocket服务和http服务,用于信令交互 3.Mediasoup C提供的流媒体…...

【leetcode--同构字符串】
要求:判断两个字符串的形式是不是一致,即是不是AABC或者ABBBCC这种。 trick:使用set()结合zip()。 set()用法:用于创建一个不包含重复元素的集合 zip&#…...

shell expr功能详解
expr命令可以实现数值运算、数值或字符串比较、字符串匹配、字符串提取、字符串长度计算等功能。它还具个特殊功能,判断变量或参数是否为整数、是否为空、是否为0等。 1.字符串表达式 ------------------------- expr支持模式匹配和字符串操作。字符串表达式的优先…...

java继承Thead类和实现Runnable接口创建线程的区别
一、继承Thread类创建多线程 public class Demo{public static void main(String[] args) {MyThread thread new MyThread();thread.start();}} class MyThread extends Thread{Overridepublic void run() {//子线程执行的操作} }注意:开启子线程要调用start()方法…...

interface Ref<T = any> 这是什么写法?为什么写接口还需要加上<T = any>
问: export interface Ref<T any> { value: T [RefSymbol]: true } 这里既然是interface接口,为什么还有<T any>这是什么意思? 回答: <T any> 中的 <T> 表示这是一个泛型参数,它可以在接口中作为类型的占位符,在实际…...

深入探索 MongoDB GridFS:高效大文件存储与管理的全面指南
GridFS 是 MongoDB 的一个规范,用于存储和检索超过 BSON 文档大小限制(16MB)的文件。与传统的文件系统不同,GridFS 可以将一个大文件分割成多个小块,并存储在 MongoDB 的两个集合中:fs.files 和 fs.chunks。…...

RestClient
什么是RestClient RestClient 是 Elasticsearch 官方提供的 Java 低级 REST 客户端,它允许HTTP与Elasticsearch 集群通信,而无需处理 JSON 序列化/反序列化等底层细节。它是 Elasticsearch Java API 客户端的基础。 RestClient 主要特点 轻量级ÿ…...

深入剖析AI大模型:大模型时代的 Prompt 工程全解析
今天聊的内容,我认为是AI开发里面非常重要的内容。它在AI开发里无处不在,当你对 AI 助手说 "用李白的风格写一首关于人工智能的诗",或者让翻译模型 "将这段合同翻译成商务日语" 时,输入的这句话就是 Prompt。…...

C++:std::is_convertible
C++标志库中提供is_convertible,可以测试一种类型是否可以转换为另一只类型: template <class From, class To> struct is_convertible; 使用举例: #include <iostream> #include <string>using namespace std;struct A { }; struct B : A { };int main…...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...
)
IGP(Interior Gateway Protocol,内部网关协议)
IGP(Interior Gateway Protocol,内部网关协议) 是一种用于在一个自治系统(AS)内部传递路由信息的路由协议,主要用于在一个组织或机构的内部网络中决定数据包的最佳路径。与用于自治系统之间通信的 EGP&…...

Linux相关概念和易错知识点(42)(TCP的连接管理、可靠性、面临复杂网络的处理)
目录 1.TCP的连接管理机制(1)三次握手①握手过程②对握手过程的理解 (2)四次挥手(3)握手和挥手的触发(4)状态切换①挥手过程中状态的切换②握手过程中状态的切换 2.TCP的可靠性&…...

Auto-Coder使用GPT-4o完成:在用TabPFN这个模型构建一个预测未来3天涨跌的分类任务
通过akshare库,获取股票数据,并生成TabPFN这个模型 可以识别、处理的格式,写一个完整的预处理示例,并构建一个预测未来 3 天股价涨跌的分类任务 用TabPFN这个模型构建一个预测未来 3 天股价涨跌的分类任务,进行预测并输…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...

SpringCloudGateway 自定义局部过滤器
场景: 将所有请求转化为同一路径请求(方便穿网配置)在请求头内标识原来路径,然后在将请求分发给不同服务 AllToOneGatewayFilterFactory import lombok.Getter; import lombok.Setter; import lombok.extern.slf4j.Slf4j; impor…...