深入讲解C++基础知识(一)
目录
- 一、基本内置类型
- 1. 类型的作用
- 2. 分类
- 3. 整型
- 3.1 内存描述及查询
- 3.2 布尔类型 —— bool
- 3.3 字符类型 —— char
- 3.4 其他整型
- 4. 有符号类型和无符号类型
- 5. 浮点型
- 6. 如何选择类型
- 7. 类型转换
- 7.1 自动类型转换
- 7.2 强制类型转换
- 7.3 类型转换总结
- 8. 类型溢出
- 8.1 注意事项
- 9. 字面值常量
- 9.1 整形字面值
- 9.2 浮点型字面值
- 9.3 字符和字符串字面值
- 9.3.1 转义字符
- 二、变量
- 1. 变量的定义和初始化
- 2. 变量若未初始化的结果
- 3. 变量声明和定义的区别
- 4. 变量名的命名规则
- 5. 变量名的作用域
一、基本内置类型
1. 类型的作用
数据类型是程序的基础,它决定了该数据的意义和能对其进行的操作。如:
a = a + b;
若 a 和 b 均为 int 类型,则执行的是 int 类型的加法,若为 double 类型则执行的是 double 类型的加法,若为自定义类型则执行自定义类型的加法。
2. 分类
C++中基本数据类型分为算数类型和空类型(void)。算数类型包含布尔类型、字符类型、整型和浮点型,由于布尔和字符类型也算整型,所以算数类型实际上就是整型和浮点型。空类型不对应具体类型,只在一些特殊场合使用,最常见的是:当函数不返回任何值时,使用空类型(void)作为返回类型。
3. 整型
一般来说按照所占位数的大小,可以按如下顺序划分整形:bool(布尔)、char(字符)、short(短整型)、int(整型)、long(长整型)和 long long。
3.1 内存描述及查询
在计算机中,数据都是用一个个比特位来表示的,该值只有 0 和 1 两种。而一般把 8 个比特位称为一个字节(byte),即 1 字节 = 8 比特。一个字节可以表示 2 的8次方种变化,如果是无符号整数即 0-255 。而算数类型的尺寸(也就是该类型所占比特位数)在不同实现上面是有所差别的。我们可以通过对类型使用 sizeof 运算符来查看该类型所占内存大小(单位字节)。如:

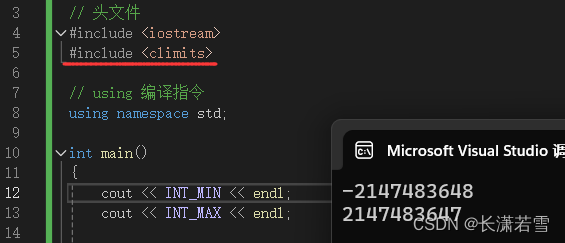
可以看到 int 类型占 4 个字节,也就是 32 位。
也可以通过包含头文件 climits ,通过符号常量来查询具体的值。如:
3.2 布尔类型 —— bool
布尔类型的值只有两种,真(true)和假(false)。true 和 false 为 bool 类型的字面值常量,分别表示真和假。布尔型一般用在条件判断语句中,判断该条件是否成立。虽然只用一个比特为就可以表示该类型,但是一般都以一个字节进行存储。如果使用 bool 类型进行算数运算,则真(true)为 1,假(false)为 0。而如果在需要使用 bool 型的地方使用整型或者浮点型,则 0 为假,非 0 为真。
3.3 字符类型 —— char
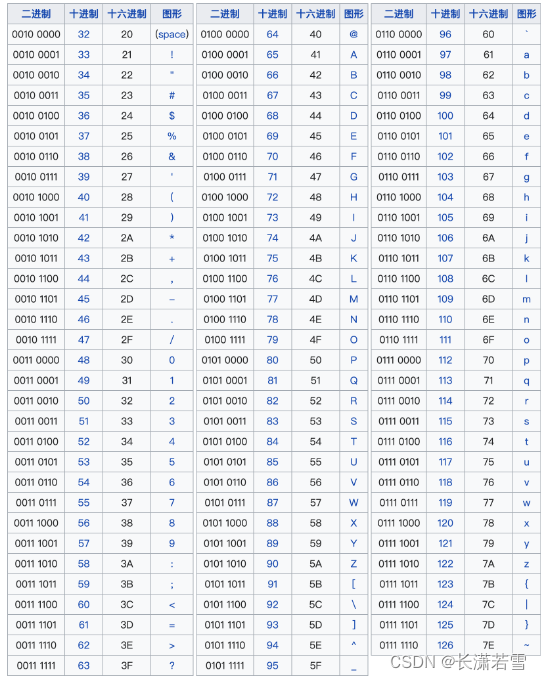
C++提供了多种字符类型,其中多数支持国际化。基本字符类型是 char,一个 char 应确保可以存放机器基本字符集中的任意字符对应的数字值。char 的大小和一个机器字节一样,一般为 8 位。而在计算机中,实际上是使用整数来存储 char 类型,如 ASCII码表,通过给每个字符对应一个数字,当需要使用字符时,就通过存储的数值找到对应的字符。如:在ASCII码中,字符’A’对应整数 65,字符’a’对应整数 97。
3.4 其他整型
除了字符和布尔类型,其他整型用于表示不同范围的整数。C++规定 int 至少和 short 一样大,long 至少和 int 一样大,long long 至少和 long 一样大。其中,long long 类型是 C++11 中新定义的。
4. 有符号类型和无符号类型
除去 bool 型之外,其他类型可以分为有符号和无符号类型两种。有符号类型(signed)就是既可以表示正数又可以表示负数,而无符号类型(unsigned)就是只能表示 0 和正数。一般情况下 short、int、long 和 long long都是有符号类型。无符号类型只需要在其前面加上 unsigned 修饰即可,如 unsigned int 。
与其他整型不同,char 被分为了三种:char、signed char 和 unsigned char。但是实际上只有两种,char 类型会被编译器转换为有符号或者无符号的一种,具体是哪一种由具体实现决定。
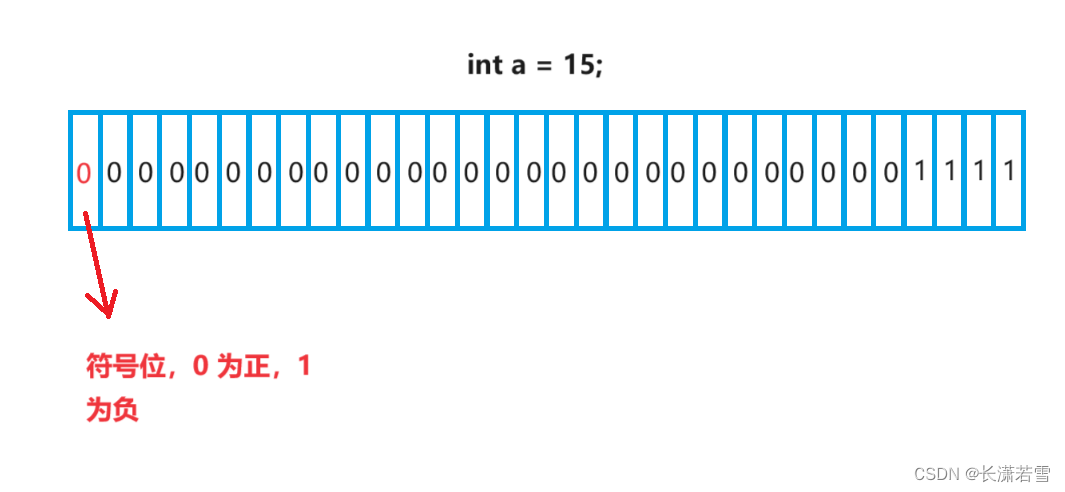
C++并没有规定带符号类型应如何表示,但是约定了表示范围内的正值和负值应平衡。所以有符号类型的最高位表示正负,最高位为 1 为负,最高位为 0 为正。如:int a = 15;
5. 浮点型
浮点型按照所占位数由低到高为:float、double 和 long double。浮点型与整型的差别在于,浮点型可以表示整数。但是浮点型有精度范围,超出该范围其值不精准。所以,上述三种类型的差别在于所表示的值的范围不同和精度不同。浮点型全是有符号类型。
6. 如何选择类型
a. 当确定数值不可能为负数时,选择无符号类型。
b. 一般选择 int 进行算数运算。short 一般显得太小,而 long 一般和 int 一样大。如果数值超出 int 一般选择 long long 类型。
c. 在算数表达式中尽量不要使用 char 或 bool,只在使用字符或者布尔值时使用它们。因为 char 类型在一些实现上面是有符号的,在另一些实现上面是无符号的。如果真的需要使用,请指明其类型是 signed char 或者 unsigned char 。
d. 执行浮点数运算选用 double,因为 float 通常精度不够,而两者计算代价相差无几。long double 提供的精度在一般情况下是没有必要的,而且其运行时消耗更大。
7. 类型转换
类型转换分为自动类型转换和强制类型转换。
7.1 自动类型转换
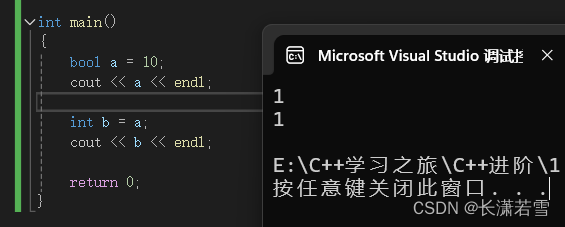
bool 值进行算数运算时,会自动类型转换为 int 类型,真(true)为 1 ,假(false)为 0 。而其他类型赋值给 bool 变量,0 为假(false),非 0 为真(true)。如下代码:
char 类型进行算数运算时,也会自动类型转换为 int 类型。而其他整型赋值给 char 类型时,只会存储该类型的后 8 位。如下代码:
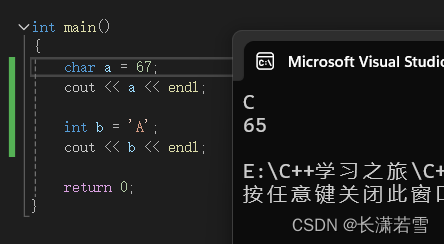
再次证明 char 类型是用整数进行存储的,当需要字符时,编译器就找到整数 67 对应的字符 ‘C’,然后输出。而当需要整数时,编译器找到字符 ‘A’ 对应的整数 65 存入变量 b 中,然后输出。
浮点数赋值给整型变量时,会发生截断,丢弃小数部分。而整数赋值给浮点型变量时,小数部分为0。如下代码:
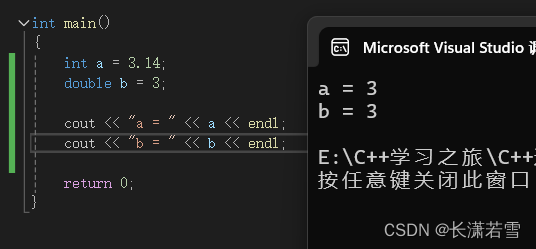
这里时编译器做了处理,实际上 b = 3.0 。
7.2 强制类型转换
强制类型转换有两种方式,一种时从 C 语言继承下来的 C 风格,另一种是 C++ 新增的 C++风格。
如下代码:
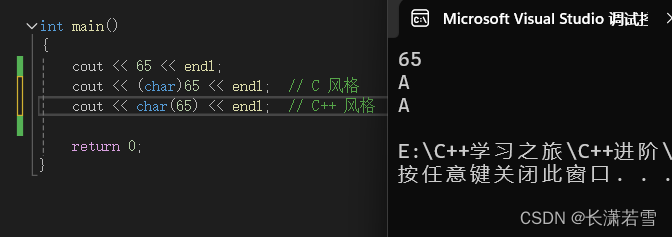
本来三行代码都应该和第一行一样输出数字 65。但是第二行和第三行进行了强制类型转换,使原本 int 类型的 65,变成了 char 类型的 65 。编译器就会按照 char 类型进行输出,找到整数 65 对应的字符 ‘A’,输出。
C 风格强制类型转换格式:(类型)变量名
C++ 风格强制类型转换格式:类型(变量名)
C++ 风格的想法是想像使用函数一样使用使用强制类型转换。这两种就目前来说已经够用,但是一般在编写程序的过程中很少用到强制类型转换。
7.3 类型转换总结
初始化和赋值: 将值赋给取值范围更大的类型时,通常不会导致问题;将值赋给取值范围更小的类型时,可能会导致精度降低或数据丢失;将0赋给bool变量时,将被转换为false,非零值转换为true。
表达式中的转换:
整型提升: bool、char、unsigned char、signed char 和 short 值在表达式中会被转换为int。
自动类型转换: 当运算涉及两种类型时,较小的类型将被转换为较大的类型。编译器通过校验表来确定在表达式中执行的转换。
强制类型转换: 可以使用强制类型转换运算符显式地进行类型转换。
8. 类型溢出
如果赋值超出了该类型的最大值或者低于该类型的最小值,就会从另一头开始,如:unsigned char 类型的最大值是 255,最小值是 0,分别使用256 和 -1 给其赋值。代码和结果如下:
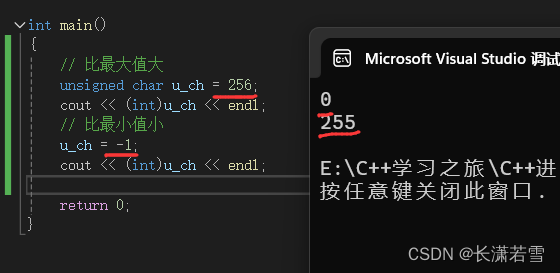
可以看出,如果超出最大值则从最小值开始,如果超出最小值就从最大值开始。但是C++只保证了无符号类型的溢出是这样处理的,而有符号类型则不一定,其造成的结果是未定义的,此时,程序可能继续工作、可能崩溃,也可能产生垃圾数据。
这是我用的计算无符号类型溢出的方法: 如果超过最大值,就用该值先减去 1,然后一直减该无符号类型的最大值,直到结果在该无符号类型范围之内。如果低于最小值,则先加 1,然后一直加该无符号类型的最大值,直到结果在该无符号类型的范围之内。这个 1 是必须加减的,最大值至少加减 1 次。如:
256 - 1 - 255 = 0;
-1 + 1 + 255 = 255;
8.1 注意事项
不要使用无符号类型进行涉及负数的算数运算。因为同类型的有符号类型遇到同类型的无符号类型,在计算过程中会转换为无符号类型。结果也是无符号类型,但是无符号类型不存在负数,就会像上面溢出这样处理。如下代码和结果:
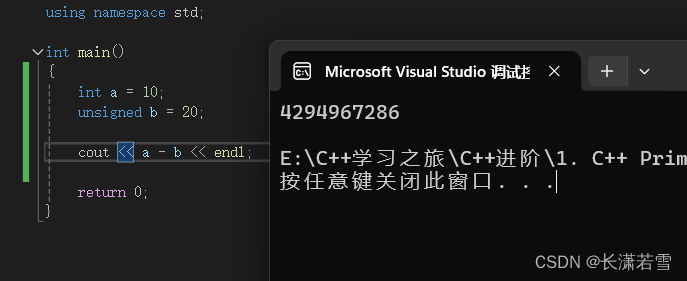
此处的计算结果本来应该是 -10,但是 int 类型的变量 a 在和 unsigned 类型的变量 b 进行运算时转换为了 unsigned 类型,-10 便成为了上述的溢出行为。
不要在循环变量中使用无符号类型的循环变量,如下代码:
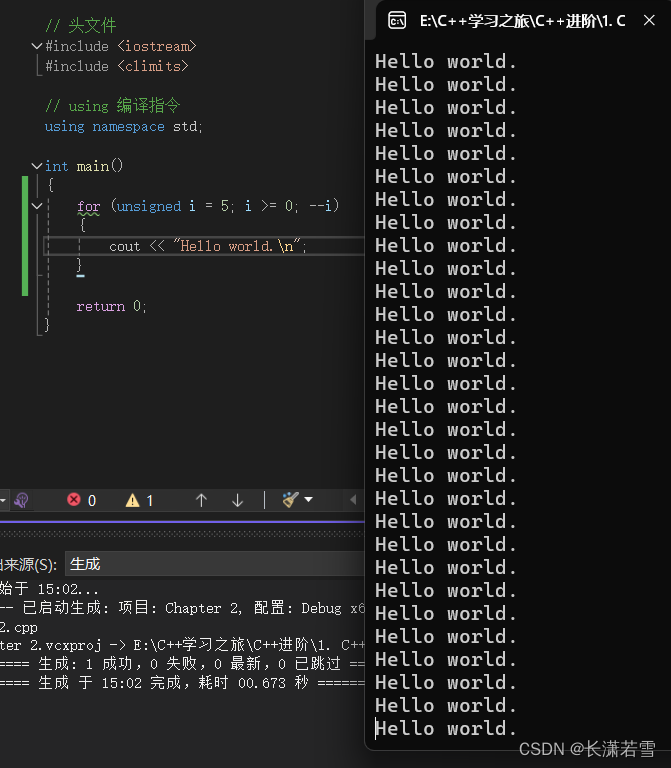
可以发现已经进入死循环了,因为当 i = 0 时,执行 --i 操作,使 i 成为了 unsigned 类型的最大值。造成了无符号类型的溢出行为。
9. 字面值常量
在C++中字面值存储在内存中的常量区。常量区是程序运行时的一个固定区域,用于存储不可修改的常量数据。
9.1 整形字面值
如:1,24,99等都是整形字面值。整形字面值还可以使用八进制和十六进制,八进制以 0 开头,而十六进制以 0x 或者 0X 开头。如下表示的都是整数 20:
20 —— 十进制
024 —— 八进制
0x14 —— 十六进制
在能容纳字面值数值的前提下,十进制字面值会从以下类型中选择尺寸最小的那个:int、long 和 long long 。而八进制和十六进制从 int 、unsigned int、long 、unsigned long、long long 和 unsigned long long 中选择尺寸最小的那个。
可以通过添加后缀来使字面值成为我们想要的类型,如:
32U / 32u —— unsigned int 类型的字面值 32
32l / 32L —— long 类型的字面值 32
32ul / 32LU —— unsigned long 类型的字面值 32
大小写可以互换,u 和 l 前后顺序可以颠倒。一般使用大写 L ,小写 l 容易 和数字 1 混淆。
9.2 浮点型字面值
浮点型字面值有两种表示方法:小数表示法和科学计数法。如:3.14,1.99,3.4E2 等均为浮点型字面值。而科学计数法中 E2 代表前面的数值乘以 10 的 2 次方,即 3.4 * 100 = 340.0 。而 -1.2E-1 中,最前面的符号表示整个浮点数是一个负数,而 E 后面的符号表示乘以 10 的 -1 次方。即 -1.2 * 0.1 = -0.12 。
9.3 字符和字符串字面值
用双引号括起来的是字符串字面值,而用单引号括起来的是字符字面值。如:‘a’,‘G’,‘1’ 等均为字符字面值。而 “abc”,“hello”,“123” 等均为字符串字面值。
字符串字面值实际上是由一组字符常量组成的数组(array)。编译器通过在其末尾添加空字符(‘\0’)来标识,所以实际上字符串字面值的实际长度比它的内容多 1 。所需要的存储空间也多了一个字节。如:字符’A’表示的就是单独的字符 A,而字符串"A"表示一个字符数组,除了字符’A’外还有一个空字符(‘\0’)。
一般来说如果两个字符串之间没有其他输出,那么第二个字符串会紧接在第一个字符串末尾。如下代码:
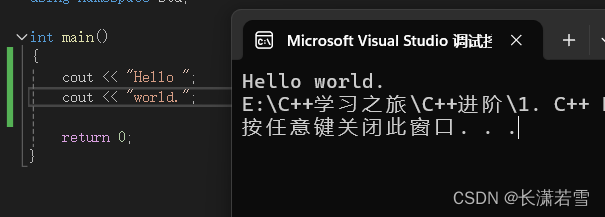
若两个字符串紧邻且中间只有空格、换行符和制表符,那么这实际上是一个字符串。如果字符串太长一行不好写,就可以分行编写,如下:

也可以通过添加前缀和后缀来指定字符字面值和字符串字面值的类型,但是我从来没用过。有兴趣的可以去了解一下。
9.3.1 转义字符
在C++中,有两类字符程序员是不能直接使用的:一类是不可打印字符,如退格或其他控制字符,因为它们看不见;另一类是在C++中有特殊含义的字符(单引号、双引号、反斜线)。所以需要使用转义字符来使用它们,转义字符均以反斜线开头(\)。如下是一些重要且经常使用的转义字符:
换行符 —— \n
横向制表符 —— \t
退格符 —— \b
双引号 —— "
单引号 —— ’
反斜线 —— \
空字符 —— \0
如:cout << “\n”; 表示换行,光标移动到下一行开头。其作用和 iostream 库中的操纵符 endl 一致,cout << endl; 。当输出字符串时需要换行使用前者比较方便,当输出数值等需要换行使用后者比较方便。
也可以使用八进制或者十六进制输出字符。八进制反斜杠后面紧跟 1-3 个八进制数,而十六进制反斜杠后面跟 1-多个十六进制数。
转以字符的使用的普通字符一样,并没有什么特别的地方,如:
cout << “Hello \x4do\115!\n”;
输出 Hi MOM! ,然后换行。
注意: 如果反斜杠后面跟着的八进制数超过 3 个,则只取前三个。如:“\1234” 表示三个字符,即八进制 123 对应的字符和字符 ‘4’,还有空字符。而十六进制 \x 后面跟着的所有数字都算,如:“\x1234” 表示两个字符,即十六进制 1234 对应的字符和空字符。但是,一般 char 只有 8 个字节,所以使用的时候需要小心。
9.4 布尔字面值和指针字面值
布尔字面值只有两个:true 和 false ,分别表示真和假。
指针字面值只有一个:nullptr,表示空指针。
二、变量
变量的实质是一块被标识符标记的内存空间。其类型决定了这块内存空间的大小和编译器如何理解这块空间。对C++程序员来说,变量和对象一般没有区别,可以互换使用,对象一般用来称呼类类型的变量。
1. 变量的定义和初始化
变量的定义形式:首先是类型说明符,其后紧跟由一个或多个变量名组成的列表,其中变量名以逗号分隔,最后以分号结束。列表中每个变量名的类型由类型说明符指定,定义时还可以为一个或多个变量赋初值,也叫初始化。如:
int a, b, c; —— 定义了三个 int 变量
double a, b, c = 0; —— 定义了三个 double 变量,并给最后一个变量 c 初始化。
上面 int 和 double 就是类型说明符,而 a,b 和 c 是变量名。
在创建对象的同时并给它赋一个初值,就叫这个对象被初始化了。用于初始化的值可以是任意复杂的表达式。当一次性定义多个变量时,先定义并初始化的变量可以用来初始化后定义的对象。如:int a = 1, b = a*2;
注意: 初始化不是赋值。初始化是在创建对象的同时赋予其一个初值。而赋值是用新的值替换当前值。
C++定义了如下几种初始化方式:
int a = 0;
int a = { 0 };
int a {0};
int a(0);
用花括号来初始化变量是C++11 新标准的一部分,这种初始化的形式被称为列表初始化。无论是初始化对象还是某些时候为对象赋新值,都可以使用花括号。
对于内置类型,列表初始化不允许出现初始值缺失的风险。如:用 double 值来初始化 int 变量,会发生截断,丢弃小数部分。若出现此类情况,编译器会报错。如下代码和结果:
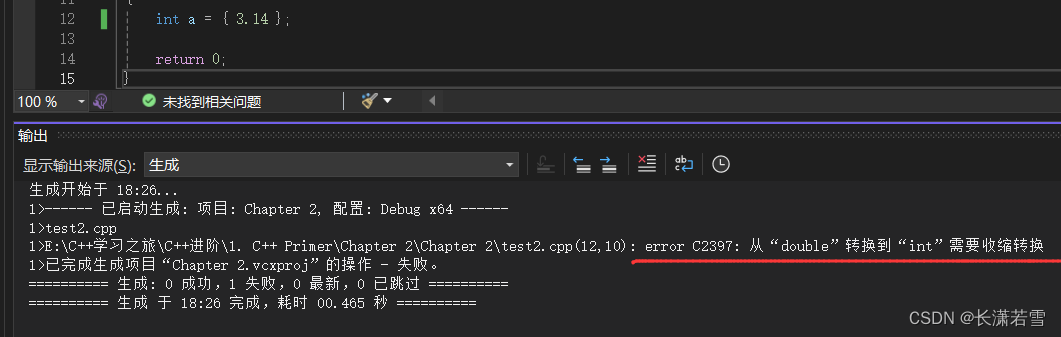
2. 变量若未初始化的结果
定义在函数之内的变量叫做局部变量,定义在函数之外的变量叫全局变量。若局部变量未初始化,则其里面存储的是之前这块空间上存储的值,也就是垃圾值。若直接使用未初始化的局部变量,会产生难以想象的错误,有的编译器会直接报错。而全局变量和静态变量若不初始化,编译器会自动把其值设置为 0 。静态变量就是生命周期为整个程序的变量。局部变量则是程序执行到其声明语句时被创建,出了其作用域时被销毁。而类类型的对象,若显式初始化,则其会自动调用其默认构造函数隐式初始化。
所以,局部变量最好在创建的同时初始化。
3. 变量声明和定义的区别
简单点来说,变量的声明不开辟空间,而变量的定义开辟空间。在中后期学习C++的时候,基本上都是分多个文件进行编程。有时一个文件需要使用另一个文件里面的变量,这个时候就只需要声明该变量,而不需要定义。意思就是告诉编译器,有这个变量,但是这个变量的定义不在该文件,需要去别的文件找。
只声明而不定义变量就是在原来定义变量的前面加上关键字 extren ,但是不能进行初始化。如果进行初始化就抵消了 extren 关键字的作用,还是定义变量。我们最开始定义变量的形式既是声明也是定义,如:int a; 。
必须在使用变量之前声明变量,因为可能存在拼写错误,这样没有声明的变量就不能使用,就可以检查出来这种低级错误。C++是一种静态类型语言,在编译阶段进行类型检查。其中检查类型的过程称为类型检查。如下代码展示了拼写错误:
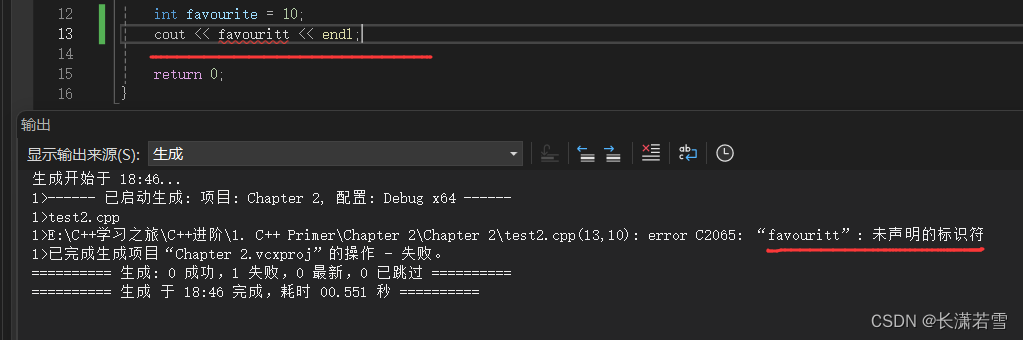
这里单词 favorite 就拼写错了一个字母,然后被编译器检查出来了,因为这个拼写错误的标识符未声明,编译器不认识。
4. 变量名的命名规则
变量名实际上就是标识符,变量名、函数名、结构名和类名等使用的都是标识符。标识符由字母、数字和下划线组成,且必须以字母或者下划线开头。标识符对长度一般没有限制,但是区分大小写。如下面定义了四个不同的 int 变量:
int ab = 1, Ab = 1, aB = 1, AB = 1;
但是标识符不能和C++关键字相同。同时C++也保留了一些名称给语言本身使用。用户自定义的标识符不能连续出现两个下划线,也不能以下划线紧连着大写字母开头。此外,定义在函数体外的标识符不能以下划线开头。
变量名的命名规范:
C++没有规定变量名的命名标准,但是下面是一些约定俗成的命名规范,可以提高代码的可读性。
(1)标识符要能体现实际含义
(2)变量名一般用小写字母,如:year
(3)用户自定义的类名一般以大写字母开头,如:Person
(4)如果标识符由多个单词组成,则单词之前应该由明显区分,用下划线分开或者使用大写字母。如:student_number 或者 studentNumber,不要使用 studentnumber 。
5. 变量名的作用域
作用域是程序的一部分,在其中名字有其特定的含义。C++中在多数作用域,以花括号分隔。
在函数内定义的变量,其作用域一般都是从声明语句到其所在最近花括号的结尾。注意: 在同一作用域内不能创建两个变量名相同的变量,否则编译器会报错。如下代码:
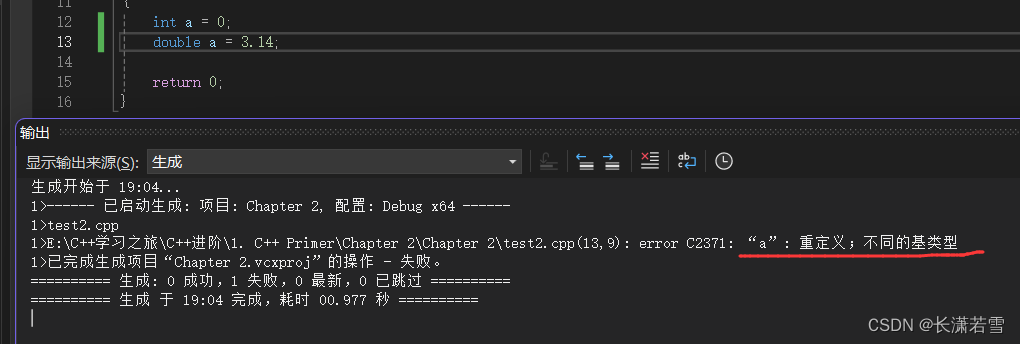
但是,不同作用域可以创建同名变量。当前作用域变量会隐藏其他同名变量。
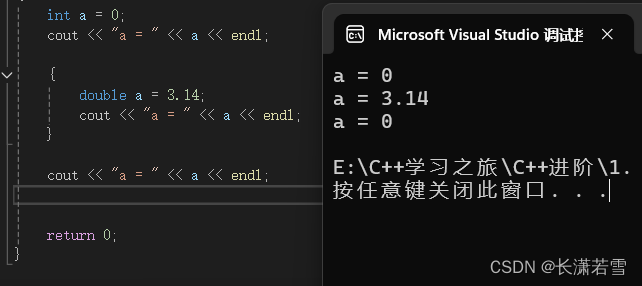
上面这种作用域中包含作用域称为嵌套作用域。外面的叫外层作用域,里面的叫内层作用域,允许在内层作用域中重新定义外层作用域中已有的名称,当执行到内层作用域时,内层作用域中的同名变量会隐藏外层作用域中的同名变量。当执行第一条输出语句时,内层中的 a 还未创建,所以输出外层中的 a。而执行第二条输出语句时,内层的 a 隐藏了外层的 a ,所以输出内层的 a 。而执行第三条语句时,已经不在第二个 a 的作用域中,且其已经被销毁,所以输出第一个 a 。
全局变量的作用域为整个程序,从声明的位置到程序结束。如果在函数中声明了与全局变量同名的变量,那么函数中的局部变量会隐藏全局变量。而通过使用作用域操作符(::)可以显式地访问全局变量。如下代码:
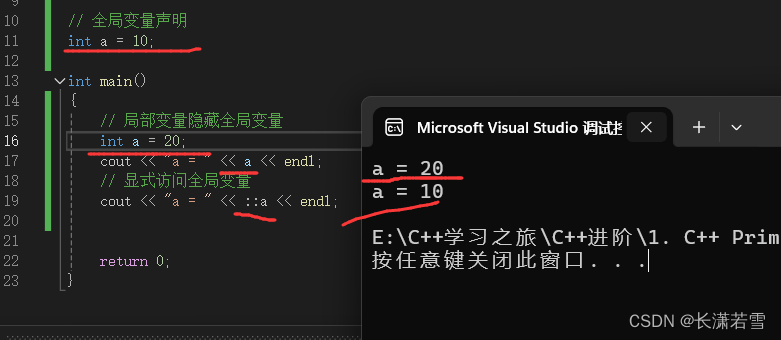
第一条输出语句,局部变量隐藏了全局变量。而第二条语句通过作用域操作符(::)显式访问全局变量。
相关文章:
深入讲解C++基础知识(一)
目录 一、基本内置类型1. 类型的作用2. 分类3. 整型3.1 内存描述及查询3.2 布尔类型 —— bool3.3 字符类型 —— char3.4 其他整型 4. 有符号类型和无符号类型5. 浮点型6. 如何选择类型7. 类型转换7.1 自动类型转换7.2 强制类型转换7.3 类型转换总结 8. 类型溢出8.1 注意事项 …...

Python爬虫实战:批量下载网站图片
1.获取图片的url链接 首先,打开百度图片首页,注意下图url中的index 接着,把页面切换成传统翻页版(flip),因为这样有利于我们爬取图片! 对比了几个url发现,pn参数是请求到的数量。…...

使用 JavaScript 获取电池状态
在现代的移动设备和笔记本电脑上,了解电池状态是一项非常有用的功能。使用 JavaScript 可以轻松地获取电池的充电状态、电量百分比等信息。本文将介绍如何使用 JavaScript 访问这些信息,并将其显示在网页上。 1. HTML 结构 首先,我们需要一…...
java—类反射机制
简述 反射机制允许程序在执行期间借助于Reflection API取得任何类的内部信息(如成员变量,构造器,成员方法等),并能操作对象的属性及方法。反射机制在设计模式和框架底层都能用到。 类一旦加载,在堆中会产生…...

浏览器-服务器架构 (BS架构) 详解
目录 前言1. BS架构概述1.1 BS架构的定义1.2 BS架构的基本原理 2. BS架构的优势2.1 客户端简化2.2 易于更新和维护2.3 跨平台性强2.4 扩展性高 3. BS架构的劣势3.1 网络依赖性强3.2 安全性问题3.3 用户体验局限 4. BS架构的典型应用场景4.1 企业内部应用4.2 电子商务平台4.3 在…...

微型操作系统内核源码详解系列五(四):cm3下svc启动任务
系列一:微型操作系统内核源码详解系列一:rtos内核源码概论篇(以freertos为例)-CSDN博客 系列二:微型操作系统内核源码详解系列二:数据结构和对象篇(以freertos为例)-CSDN博客 系列…...
)
筛质数(暴力法、埃氏筛、欧拉筛)
筛质数(暴力法、埃氏筛、欧拉筛) 暴力法 思路分析: 直接双for循环来求解质数 如果不设置标记只是简单地执行了break会导致内部循环(由j控制)而不是立即打印i或者跳过它。如果打印语句写到内部循环中,也会导致每个 非素数也被打…...

使用USI作为主SPI接口
代码; lcd_drive.c //***************************************************************************** // // File........: LCD_driver.c // // Author(s)...: ATMEL Norway // // Target(s)...: ATmega169 // // Compiler....: AVR-GCC 3.3.1; avr-libc 1.0 // // D…...

AI播客下载:Eye on AI(AI深度洞察)
"Eye on A.I." 是一档双周播客节目,由长期担任《纽约时报》记者的 Craig S. Smith 主持。在每一集中,Craig 都会与在人工智能领域产生影响的人们交谈。该播客的目的是将渐进的进步置于更广阔的背景中,并考虑发展中的技术的全球影响…...

Flink 窗口触发器
参考: NoteWarehouse/05_BigData/09_Flink(1).md at main FGL12321/NoteWarehouse GitHub Flink系列 9. 介绍 Flink 窗口触发器、移除器和延迟数据等 | hnbian https://github.com/kinoxyz1/bigdata-learning-notes/blob/master/note/flink/Window%26%E6%97%B6…...

Java面试题:解释线程间如何通过wait、notify和notifyAll方法进行通信
在 Java 中,线程间的通信可以通过 wait()、notify() 和 notifyAll() 这三个方法实现。这些方法是 Java 线程 Thread 类的一部分,它们与 synchronized 关键字一起使用,以实现线程间的协调。 基本概念 wait():当一个线程执行到 wa…...
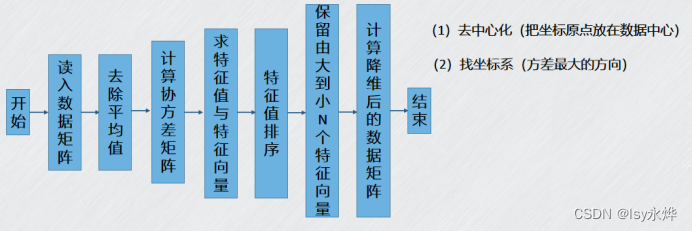
【机器学习 复习】第9章 降维算法——PCA降维
一、概念 1.PCA (1)主成分分析(Principal ComponentAnalysis,PCA)一种经典的线性降维分析算法。 (2)原理,这里以二维转一维为例,原来的平面变成了一条直线 这是三维变二…...

Ubuntu系统docker gpu环境搭建
Ubuntu系统dockergpu环境搭建 安装步骤前置安装安装指定版本的依赖包用docker官方脚本安装Docker-ce添加稳定仓库和GPG秘钥更新源 安装docker安装nvidia-docker2重启docker服务阿里云镜像加速 相关命令网络 docker常用命令镜像容器 docker相关问题解决方案使用wsl时docker的容器…...
网络安全-如何设计一个安全的API(安全角度)
目录 API安全概述设计一个安全的API一个基本的API主要代码调用API的一些问题 BasicAuth认证流程主要代码问题 API Key流程主要代码问题 Bearer auth/Token auth流程 Digest Auth流程主要代码问题 JWT Token流程代码问题 Hmac流程主要代码问题 OAuth比较自定义请求签名身份认证&…...
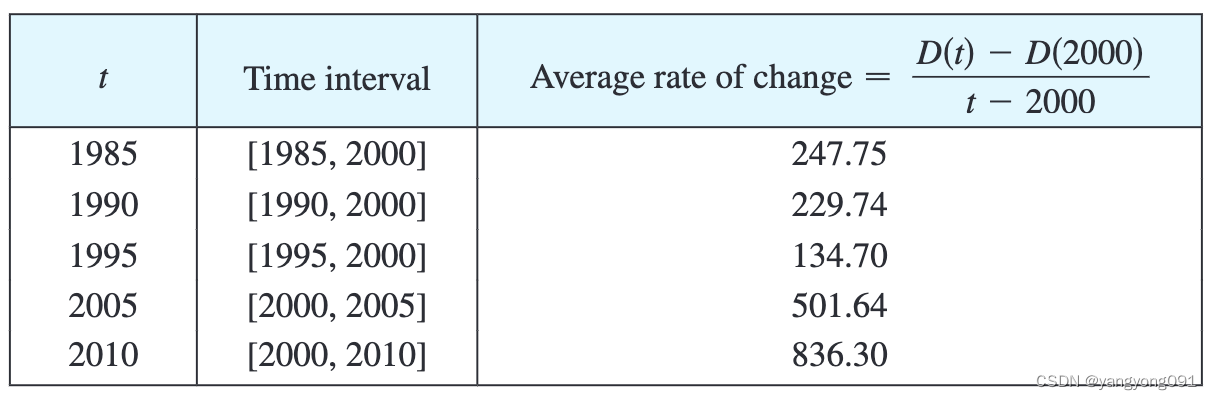
微积分-导数1(导数与变化率)
切线 要求与曲线 C C C相切于 P ( a , f ( a ) ) P(a, f(a)) P(a,f(a))点的切线,我们可以在曲线上找到与之相近的一点 Q ( x , f ( x ) ) Q(x, f(x)) Q(x,f(x)),然后求出割线 P Q PQ PQ的斜率: m P Q f ( x ) − f ( a ) x − a m_{PQ} \…...

最新PHP仿猪八戒任务威客网整站源码/在线接任务网站源码
资源介绍 老规矩,截图为亲测,前后台显示正常,细节功能未测,有兴趣的自己下载。 PHP仿猪八戒整站源码下载,phpmysql环境。威客开源建站系统,其主要交易对象是以用户为主的技能、经验、时间和智慧型商品。经…...
Windows安装配置jdk和maven
他妈的远程连接不上公司电脑,只能在家重新配置一遍,在此记录一下后端环境全部配置 Windows安装配置JDK 1.8一、下载 JDK 1.8二、配置环境变量三、验证安装 Windows安装配置Maven 3.8.8一、下载安装 Maven并配置环境变量二、设置仓库镜像及本地仓库三、测…...

电子SOP实施(MQTT协议)
架构图 服务与程序 用docker启动mqtt broker(服务器) 访问:http://192.168.88.173:18083/#/dashboard/overview 用户名:admin 密码:*** 消息发布者(查找sop的url地址,发布出去) 修改url,重新发布消息 import ran…...

【Unity导航系统】Navigation组件的概念及其使用示例
Unity中的NavMeshObstacle组件是一个用于动态障碍物的组件,它可以实时地影响导航网格(NavMesh)。当游戏对象附加了NavMeshObstacle组件时,它可以在AI进行路径规划时被识别为障碍物,从而让AI避开这些动态变化的障碍。 …...
vue-cli 根据文字生成pdf格式文件 jsPDF
1.安装jspdf npm install jspdf --save 2.下载ttf格式文件 也可以用C:\Windows\Fonts下的字体文件,反正调一个需要的ttf字体文件就行,但有的字体存在部分字体乱码现象 微软雅黑ttf下载地址: FontsMarket.com - Download Microsoft YaHei …...

Python入门项目:调用Lingbot-Dretrain-ViTL-14 API制作你的第一张AI深度图
Python入门项目:调用Lingbot-Depth-ViTL-14 API制作你的第一张AI深度图 想用Python做点有趣又酷炫的东西吗?今天咱们不写“Hello World”,也不做计算器,而是直接上手,用几行代码让AI帮你分析图片的深度信息࿰…...

紧急!MCP v3.6升级后Sampling调用流中断?2小时内恢复方案:5步回滚检查清单 + 4个兼容性补丁 + 1份经CNCF SIG-Observability认证的验证脚本
第一章:MCP v3.6采样调用流中断的紧急现象与根因定位在生产环境大规模部署MCP v3.6后,多个集群节点出现周期性采样调用流中断(Sampling Call Flow Interruption, SCFI),表现为指标上报延迟突增、TraceID链路断裂率超过…...

cv_resnet50_face-reconstruction模型在Linux系统下的部署与调优
cv_resnet50_face-reconstruction模型在Linux系统下的部署与调优 1. 引言 想不想用一张普通的自拍照,就能生成精细的3D人脸模型?cv_resnet50_face-reconstruction这个模型就能做到。它基于阿里云团队开发的HRN技术,是CVPR2023收录的论文成果…...

[C/C++开发工具]:RedPanda-CPP调试功能的架构设计与实现解析
[C/C开发工具]:RedPanda-CPP调试功能的架构设计与实现解析 【免费下载链接】RedPanda-CPP A light-weight C/C IDE based on Qt 项目地址: https://gitcode.com/gh_mirrors/re/RedPanda-CPP RedPanda-CPP作为一款基于Qt开发的轻量级C/C集成开发环境ÿ…...

医学影像分割与AI辅助诊断:TotalSegmentator全方位技术指南
医学影像分割与AI辅助诊断:TotalSegmentator全方位技术指南 【免费下载链接】TotalSegmentator Tool for robust segmentation of >100 important anatomical structures in CT images 项目地址: https://gitcode.com/gh_mirrors/to/TotalSegmentator 在现…...

6英寸磷化铟晶圆厂在埃因霍温开始建设
获得高达1.5亿欧元的欧洲芯片法案投资,此项目被视作“欧洲未来数字经济的发射台”。荷兰应用科学研究组织(TNO)与埃因霍温高科技园(High Tech Campus Eindhoven)已着手建设一座工厂,该工厂将用于以6英寸晶圆…...

OpenClaw Skill 编写规范 与示例
OpenClaw Skill 编写规范 与示例 完整的 Skill 开发指南,从基础结构到高级实践 📁 一、目录结构 标准结构 ~/.openclaw/workspace/skills/<skill-name>/ ├── SKILL.md # 必需:技能定义文件 ├── scripts/ …...

2026年玩具喷涂废气治理优质厂家推荐榜
随着全球玩具产业向绿色制造转型,喷涂工序产生的VOCs(挥发性有机物)治理已成为企业合规生产的核心关卡。玩具喷涂废气具有“大风量、低浓度、含漆雾”的典型特征,同时苯系物、酯类等组分复杂,对治理设备的适配性与稳定…...

Agent-Browser 简明教程
您的AI代理需要在网站上填写表单。使用传统的浏览器自动化工具,这个简单的任务仅为了描述页面结构就会消耗超过15,000个token。当您浏览三个页面时,上下文窗口会以比您使用它们更快的速度消耗token。 Agent-browser 来自 Vercel Labs 用根本不同的方法解…...

Vector人工智能研究院:传统AI解释方法难以适应智能体时代需求
这项由Vector人工智能研究院等机构联合完成的研究发表于2026年2月,论文编号为arXiv:2602.06841v2,专门探讨了人工智能解释性在传统模型和智能体系统中的根本性差异。有兴趣深入了解的读者可以通过该编号查询完整论文。当我们使用智能手机的语音助手时&am…...