ElasticSearch搜索详细讲解与操作
全文检索基础
全文检索流程
流程:
创建索引:
查询索引:
相关概念
索引库
索引库就是存储索引的保存在磁盘上的一系列的文件。里面存储了建立好的索引消息以及文档对象。
** 一个索引库相当于数据库中的一张表,一个文档对象相当于数据库中的一行数据
doucument对象
获取原始内容的目的是为了索引,在索引前需要将原始内容建成文档,文档中包含一个一个的域(字段),域中存储内容。每个文档都有一个唯一的编号,就是文档id。
field对象
如果我们把document看作是数据库中的一条记录的话,field相当于是记录中的字段。field是索引库中存储数据的最小单位。field的数据类型大致可以分为数值类型和文本类型,一般需要查询的字段都是文本类型的,field还有如下属性:
是否分词:是否对域的内容进行分词处理。前提是我们对域的内容进行查询
是否索引:将Field分析后的词或整个Field值进行索引,只有索引方可搜索到
是否存储:Field值存储在文档中,存储在文档中的Field才可以从Document中获取
term对象
从文档对象中拆分出来的每个单词叫做term,不同域中拆分出来的相同的单词是不同term。term中包含两部分,一部分是文档的域名。另一部分是单词的内容。term是创建索引的关键词对象。
ElasticSearch相关概念
概述
ES是面对文档的,这意味这它可以存储整个对象或文档。然而它不仅仅是存储,还会索引每个文档的内容使之可以被搜索。在ES中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。
ES比较传统关系型数据库如下:
Relational DB -> Databases->Tables->Rows ->Columns
ES->Indices->Types->Documents->Fields
ES核心概念
索引index
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索引。
类型type
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定,通常,会为具有一组共同字段文档定义一个类型。比如说,我们假设你运营一个博客平台
字段Field
相当于是字段表的字段,对文档数据根据不同属性进行的分类标识
映射mapping
mapping是处理数据的范式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等,这些都是映射里面可以设置的,其他就是处理es里面的数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。
文档document
一个文档是一个可被索引的基础消息单元。比如,你可以拥有某一个客户的文档,某个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON格式来表示,而JSON是一个到处存在的互联网数据交互格式
在一个index/type里面,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须被索引/赋予一个索引的type
接近实时NRT
ES是一个接近实时的搜索平台,这意味这,从索引一个文档直到这个文档能够被搜索到有一个轻微的延迟
集群cluster
集群就是有一个或多个节点组织在一起,它们共同持有整个数据,并一起提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字默认就是es。这个名字是重要的,意味一个节点只能通过指定某个集群的名字来加入这个集群
节点node
一个节点是集群的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。和集群类似,一个节点也是由一个名字来标识,默认情况下,这个名字是一个随机的名字。
分片和复制 shards&replicas
一个索引可以存储超出单个节点硬件限制的大量数据。每个分片本身也是一个功能完善并且独立的索引,这个索引可以被放置到集群的任何节点上。分片很重要,主要有两方面:
1)允许你水平分割/扩展你的内容容量
2)允许你的分片(潜在地,位于多个节点上)之上进行分布式、并行的操作,进而提高性能/吞吐量
要复制的两个原因:在分片/节点失败的情况下,提高了高可用性。因为这个原因,主要到复制分片从不与原/主要分片置于同一节点上是非常重要的。扩展你的搜索量/吞吐量。因为搜索可以在所有的复制上并行运行。总之,每个索引可以被分成多个分片,一个索引也可以被复制0次或多次,一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你是不能改变分片的数量
安装
docker安装
sudo docker pull elasticsearch:5.6.8
启动
sudo docker run -id --name=zys_es -p 9200:9200 -p 9300:9300 elasticsearch:5.6.8
注意:可能因为内存不够或者进程满等原因会中断es进程
安装包安装
sudo apt-get install openjdk-8-jdk #1、安装open-jdk
#2、官网查找需要的es版本 es官网:https://www.elastic.co/cn/downloads/elasticsearch
#点击【apt-get】
#查找自己想要的版本,点击使用deb方式安装
#安装es-7.6.2
1、wgethttps://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.6.2-amd64.deb
2、wgethttps://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.6.2-amd64.deb.sha512
3、shasum -a 512 -c elasticsearch-7.6.2-amd64.deb.sha512
4、sudo dpkg -i elasticsearch-7.6.2-amd64.deb
#修改配置文件elasticsearch.yml
vi /etc/elasticsearch/elasticsearch.yml{
node.name: node-1
network.host: 0.0.0.0 #允许外网访问
http.port: 9200 #指定es端口号
clauster.initial_master_nodes: ["node-1"]
}
#修改jvm.options
{
-Xms4g
-Xms4g
}
#启动es
sudo chown -R elasticsearch:elasticsearch /usr/share/elasticsearch/ #目录的owner和group改成elasticsearch
systemctl enable elasticsearch.service #设置es开机自启动
sudo systemctl start elasticsearch.service #启动es
sudo systemctl stop elasticsearch.service #停止es#查看es运行状态
service elasticsearch status
#查看报错日志
tail -f /var/log/elasticsearch/elasticsearch.log
#检查是否运行正常
curl localhost:9200# 开启跨域访问支持,默认为false
http.cors.enabled: true
# 跨域访问允许的域名地址
http.cors.allow-origin: "*"
# 通过为 cluster.initial_master_nodes 参数设置符合主节点条件的节点的 IP 地址来引导启动集群
cluster.initial_master_nodes: ["node-1"]
ElasticSearch的客户端操作
三种方式:
第一种:elasticsearch-head操作
第二种:使用elasticsearch提供的Restful接口直接访问
第三种:使用es提供的API直接访问
elasticsearch-head
下载elasticsearch-head安装包
进入目录下打开cmd
npm install -g grunt-cli
启动
npm install
grunt server
Postman
创建索引index和映射Mapping
注意:elasticsearch7默认不在支持指定索引类型,默认索引类型是_doc,如果想改变,则配置include_type_name: true 即可(这个没有测试,官方文档说的,无论是否可行,建议不要这么做,因为elasticsearch8后就不在提供该字段)。官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/removal-of-types.html
7.x之前:
{"settings":{ "number_of_shards" : 3, "number_of_replicas" : 0 }, "mappings":{ "books":{ //指定索引"properties":{ "title":{"type":"text"},"name":{"type":"text","index":false}, //有index"publish_date":{"type":"date","index":false}, "price":{"type":"double"}, "number":{"type":"object","dynamic":true}}}}
}
7.x之后:
{"settings":{"number_of_shards":3, #分片数量"number_of_replicas":2 #每个分片副本},"mappings":{//无索引"properties":{"id":{"type":"long"},"name":{"type":"text","analyzer":"standard"}, //无指定index为true或为false,standard为分词器的一种,standard一个汉字一个词"text":{"type":"text","analyzer":"ik_max_word"}}}}
创建索引后设置Mapping
http://120.78.130.50:9200/blog7/hello/mapping{"properties":{"id":{"type":"long"},"name":{"type":"text","analyzer":"ik_smart"}, //无指定index为true或为false"text":{"type":"text","analyzer":"ik_max_word"}}}
创建文档document
请求url:
post http://120.78.130.50:9200/blog1/_doc/1
请求体:
{"id":1,"name":"es是一个lucene的搜索服务器", "text":"阿萨的贺卡收到萨拉DHL收到啦收到啦实打实的拉萨机的卡拉卡斯德拉夫拉上来就"
}
修改文档
请求url:
post http://120.78.130.50:9200/blog1/_doc/1
请求体:
{"id":1,"name":"es是一个lucene的搜索服务器反对犯得上", "text":"阿萨的贺卡收到萨拉DHL收到啦收到啦实打实的拉萨机的卡拉卡斯德拉夫拉上来就"
}
文档删除document
delete http://120.78.130.50:9200/blog1/_doc/1
根据id查询文档
GET http://120.78.130.50:9200/blog1/_doc/2
结果
{"_index": "blog1", //索引名称"_type": "_doc", //索引类型"_id": "2", "_version": 1,"_seq_no": 2,"_primary_term": 1,"found": true,"_source": { //数据"id": 1,"name": "es是一个lucene的搜索服务器", //无指定index为true或为false"text": "阿萨的贺卡收到萨拉DHL收到啦收到啦实打实的拉萨机的卡拉卡斯德拉夫拉上来就"}
}
查询文档-querystring查询
url:
POST http://120.78.130.50:9200/blog1/_doc/_search
请求体:
{"query": {"query_string": {"default_field": "name","query": "搜索服务器"}}
}
钢索->“钢”,“索”,搜索是分为两个词,注意Standard标准分词器,会把汉字每个字分为一个词存到索引库中的name,也就是按照Standard进行的分词,所以搜索钢索能搜到这个document
查询文档-term查询
url:
POST http://120.78.130.50:9200/blog1/_doc/_search
body
{"query": {"term": {"name": "搜索"}}
}
query_string :搜索之前对搜索的关键词分词
term:对搜索的关键词不分词
IK分词器
安装
下载安装包 :https://github.com/medcl/elasticsearch-analysis-ik/releases
放到/ usr/share/elasticsearch/plugins
重启es
7.x之前测试:
http://120.78.130.50:9200/_analyze?analyzer=ik_smart&pretty=true&text=我是程序员
http://120.78.130.50:9200/_analyze?analyzer=ik_max_word&pretty=true&text=我是程序员
7.x之后测试:url+body
http://120.78.130.50:9200/_analyze
{
“analyzer”: “ik_smart”,
“text”: “我是傻逼”
}
注意:
ik_smart:会做最粗粒度的拆分
ik_max_word: 会将文本做最细粒度的拆分
注意出错:将ik解压成功后es可能就启动不了,可能是ik中所有文件的用户组和所有者属于root,需要改成当前的用户组和所有者,用
sudo chmod zys_ergou ./ik/*
sudo chown zys_ergou ./ik/*
还有一种情况就是es和ik的版本不兼容,需要进入plugin-descriptor.properties文件更改es的version
Kibaba
安装
第一步:去官网下载Linux版本的Kibana
https://www.elastic.co/cn/downloads/past-releases#kibana
sudo wget https://artifacts.elastic.co/downloads/kibana/kibana-7.6.2-linux-x86_64.tar.gz
第二步:上传到Linux服务器(可能导致文件不完整,最好用wget下载)
第三步:解压该Kibana压缩包。
sudo tar -zxvf kibana-7.6.2-linux-x86_64.tar.gz //注意文件名称
第四步:去kibana目录下的config/kibana.yml配置相关参数。
- server.port: 5601
- server.host: “0.0.0.0”
- i18n.locale: “zh-CN”
第五步:启动Kibana。进入bin目录下
- #root账号启动
- ./kibana --allow-root
- #root账号后台启动
- nohup ./kibana --allow-root &
- #其他账号启动
- ./kibana
- #其他账号后台启动
- nohup ./kibana &
第六步:访问Kibana
http://192.168.120.157:5601/
第七步:访问Elasticsearch地址
快捷键:
ctrl + i 自动缩进
ctrl + enter 提交请求
down 打开自动补全菜单
enter 或tab 选中项自动补全
esc 关闭补全菜单
DSL语句使用
SQL查询语句
操作
(1)查询所有索引
GET /_cat/indices?v
(2)删除某个索引
DELETE /blog
(3)新增索引
PUT /user
(4)创建映射
注意:如果不设置include_type_name=true,就会报错"Types cannot be provided in put mapping requests, unless the include_type_name parameter is set to true."
PUT /user/uesrinfo/_mapping?include_type_name=true
{"properties": {"name":{"type": "text","analyzer": "ik_smart","search_analyzer": "ik_smart"},"city":{"type": "text","analyzer": "ik_smart","search_analyzer": "ik_smart"},"age":{"type": "long"},"description":{"type": "text","analyzer": "ik_smart","search_analyzer": "ik_smart"}}
}
(5)新增文档数据
PUT /user/_doc/{id}
{"name":"王五","age":21,"city":"广州","description":"王五来自湖北武汉"
}
(6)替换操作
PUT /user/_doc/3
{"name":"王五","age":21,"city":"广州","description":"王五来自湖北武汉"
}
(7)根据id查询
GET /user/_doc/2
(8)查询所有
GET /user/_search
(9)Sort排序
GET /user/_search
{"query": {"match_all": {}},"sort": [{"age": {"order": "desc"}}]
}
(10)分页
GET /user/_search
{"query": {"match_all": {}},"sort": [{"age": {"order": "desc"}}],"from": 0, "size": 2
}(11)term查询
term主要用于分词精确匹配,如字符串、数值、日期等(不适合情况:1、列中除英文字符外有其他值2、字符串值中有冒号或中文3、系统自带属性如_version)
GET _search
{"query": {"term": {//term不分词"city": "深圳武汉"}}}
}GET _search
{"query": {"match": {//match分词"city": "深圳武汉"}}
}
(12)terms查询
terms查询允许指定多个匹配条件。如果某个字段指定了多个值,那么文档需要一起做匹配
GET _search
{"query": {"terms": {"city": ["武汉","广州"]}}
}
(13)query_string查询
GET _search
{"query": {"query_string": {"default_field": "city","query": "广州武汉"}}
}
(14)range查询
GET _search
{"query": {"range": {"age": {"gte": 20,"lte": 22}}}
}
(15)exists
exists过滤可以用于查找拥有某个域的数据
GET _search
{"query": {"exists": {"field": "address"}}
}
(16)bool查询
bool可以用来合并多个条件查询结果的布尔逻辑,它包含以下操作符:
must:多个查询条件的完全匹配,相当于and
must_not:多个查询条件的相反匹配,相当于not
should:至少有一个查询条件匹配,相当于or
这些参数可以分别继承一个过滤条件或者一个过滤条件的数组:
GET _search
{"query": {"bool": {"must": [{"term": {"city": {"value": "广州"}}},{"range": {"age": {"gte": 20,"lte": 22}}}]}}
}
(17)match_all查询
可以查询到所有文档,是没有查询条件下的默认句
GET /user/_search
{"query": {"match_all": {}}
}
(18)match查询
match查询是一个标准查询,不管你需要全文查询还是精确查询基本上都要用到它。如果你使用match查询一个全文本字段,它会在真正查询之前用飞行器先分析match一下查询字符:
GET _search
{"query": {"match": {"city": "广州"}}
}
(19)prefix查询
以什么字符开头的,可以更简单地用prefix,例如查询所有以张开始的用户描述
GET _search
{"query": {"prefix": {"name": {"value": "王"}}}
}
(20)multi_match
multi_match查询允许你做match查询的基础上同时搜索多个字段,在多个字段中同时查一个
GET _search
{"query": {"multi_match": {"query": "深圳","fields": ["city","description"]}}
}
ElasticSearch编程操作
添加依赖
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.zys</groupId><artifactId>es_demon</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version><scope>test</scope></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-simple</artifactId><version>1.7.21</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-to-slf4j</artifactId><version>2.9.1</version></dependency><dependency><groupId>org.elasticsearch.client</groupId><artifactId>transport</artifactId><version>7.6.2</version></dependency><dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>7.6.2</version></dependency></dependencies> </project>
创建索引
//1、配置
Settings settings = Settings.builder().put("cluster.name", "elasticsearch").build();//2、客户端TransportClient client = new PreBuiltTransportClient(settings);client.addTransportAddress(new TransportAddress(InetAddress.getByName("120.78.130.50"), 9300));//3、使用api创建索引client.admin().indices().prepareCreate("index_hello").get();//4、关闭clientclient.close();
添加映射
//1、配置Settings settings = Settings.builder().put("cluster.name", "elasticsearch").build();//2、客户端TransportClient client = new PreBuiltTransportClient(settings);client.addTransportAddress(new TransportAddress(InetAddress.getByName("120.78.130.50"), 9300));XContentBuilder xContentBuilder = XContentFactory.jsonBuilder().startObject().startObject("article").startObject("properties").startObject("id").field("type", "long").endObject().startObject("title").field("type", "text").field("analyzer", "ik_smart").endObject().startObject("content").field("type", "text").field("analyzer", "ik_smart").endObject().endObject().endObject().endObject();//3、使用api创建索引client.admin().indices().preparePutMapping("index_hello").setType("article").setSource(xContentBuilder).get();//4、关闭clientclient.close();
创建文档
1、使用XContenBuilder构建Document对象
XContentBuilder builder = XContentFactory.jsonBuilder().startObject().field("id", 2l).field("title", "少大金欧涉及到山东哈收到拉萨DHL撒鲁大师鲁大师劳动力").field("content", "啥的拉升阶段拉萨伦敦苏富比老大就是领导破碎了就爱上了大家来打死你电脑来合肥把程序内存,整理骄傲我觉得阿拉善的距离撒娇的了就").endObject();client.prepareIndex()//设置索引名称.setIndex("index_hello")//设置type.setType("article")//设置文档的id,如果不设置的话自动生成一个id.setId("1")//设置文档信息.setSource(builder)//执行操作.get();
2、实体对象
依赖:
<dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-core</artifactId><version>2.8.1</version></dependency><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId><version>2.8.1</version></dependency><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-annotations</artifactId><version>2.8.1</version></dependency>
实体类:
private Integer id;private String title;private String content;
添加:
Article article = new Article();article.setId(3l);article.setTitle("撒娇多久啊老师的就爱上了你发到你爱丽丝的你拉车的你");article.setContent("jdaosdnasdnlddawhlcncsnskndaskndasldnslnslkdsal;dasmd;");ObjectMapper objectMapper = new ObjectMapper();
String s = objectMapper.writeValueAsString(article);client.prepareIndex().setIndex("index_hello").setType("article").setSource(objectMapper, XContentType.JSON).get();}
查询文档
TermQuery
//创建QueryBuilder对象
// QueryBuilder queryBuilder = QueryBuilders.termQuery("title", "你");//term查询QueryStringQueryBuilder queryBuilder = QueryBuilders.queryStringQuery("你的宝贝").defaultField("title");//match查询
// MatchQueryBuilder queryBuilder = QueryBuilders.matchQuery("title", "你的宝贝");//match查询
// IdsQueryBuilder queryBuilder = QueryBuilders.idsQuery().addIds("3", "4");//根据id查询//执行查询得到一个结果SearchResponse searchResponse = client.prepareSearch("index_hello").setTypes("article").setQuery(queryBuilder).get();//处理结果SearchHits hits = searchResponse.getHits();System.out.println("总行数" + hits.getTotalHits());Iterator<SearchHit> iterator = hits.iterator();while (iterator.hasNext()) {SearchHit next = iterator.next();//文档的json输入System.out.println(next.getSourceAsString());}
分页查询
//创建QueryBuilder对象MatchQueryBuilder queryBuilder = QueryBuilders.matchQuery("title", "你的宝贝");//match查询//执行查询得到一个结果SearchResponse searchResponse = client.prepareSearch("index_hello").setTypes("article").setQuery(queryBuilder).setFrom(0)///.setSize(5)///.get();//处理结果SearchHits hits = searchResponse.getHits();System.out.println("总行数" + hits.getTotalHits());Iterator<SearchHit> iterator = hits.iterator();while (iterator.hasNext()) {SearchHit next = iterator.next();//文档的json输入System.out.println(next.getSourceAsString());}
查询结果高亮显示
MultiMatchQueryBuilder queryBuilder = QueryBuilders.multiMatchQuery("少啥", "title", "content");//multi_match查询
//HighlightBuilder highlightBuilder = new HighlightBuilder();highlightBuilder.field("title");highlightBuilder.preTags("<em>");highlightBuilder.preTags("</em>");
///执行查询得到一个结果SearchResponse searchResponse = client.prepareSearch("index_hello").setTypes("article").setQuery(queryBuilder).highlighter(highlightBuilder)//.get();//处理结果SearchHits hits = searchResponse.getHits();System.out.println("总行数" + hits.getTotalHits());Iterator<SearchHit> iterator = hits.iterator();while (iterator.hasNext()) {SearchHit next = iterator.next();//文档的json输入System.out.println(next.getSourceAsString()); System.out.println("==============highlight==============");Map<String, HighlightField> highlightFieldMap = next.getHighlightFields();for (Map.Entry<String, HighlightField> entry : highlightFieldMap.entrySet()) {System.out.println(entry.getKey() + "\t" + Arrays.toString( entry.getValue().getFragments()));}}
Spring Data ElasticSearch
1、搭建spring boot项目
| Spring Data Release Train | Spring Data Elasticsearch | Elasticsearch | Spring Framework | Spring Boot |
|---|---|---|---|---|
| 2022.0 (Turing) | 5.0.x | 8.5.0 | 6.0.x | 3.0.x |
| 2021.2 (Raj) | 4.4.x | 7.17.3 | 5.3.x | 2.7.x |
| 2021.1 (Q) | 4.3.x | 7.15.2 | 5.3.x | 2.6.x |
| 2021.0 (Pascal) | 4.2.x[1] | 7.12.0 | 5.3.x | 2.5.x |
| 2020.0 (Ockham)[1] | 4.1.x[1] | 7.9.3 | 5.3.2 | 2.4.x |
| Neumann[1] | 4.0.x[1] | 7.6.2 | 5.2.12 | 2.3.x |
| Moore[1] | 3.2.x[1] | 6.8.12 | 5.2.12 | 2.2.x |
| Lovelace[1] | 3.1.x[1] | 6.2.2 | 5.1.19 | 2.1.x |
| Kay[1] | 3.0.x[1] | 5.5.0 | 5.0.13 | 2.0.x |
| Ingalls[1] | 2.1.x[1] | 2.4.0 | 4.3.25 | 1.5.x |
2、编写yml文件
spring:elasticsearch:rest:uris: 120.78.130.50:9300
3、编写实体类
//type在2.3.x版本不写即可,实体类名字即是type
@Document(indexName = "zys_blog", type = "article")
public class Article {@Id@Field(type = FieldType.Long, store = true)private Long id;@Field(type = FieldType.Text, store = true, analyzer = "ik_smart")private String title;@Field(type = FieldType.Text, store = true, analyzer = "ik_smart")private String content;
}4、编写Dao
方法命名规则查询的基本语法findBy+属性+关键词+连接符
关键词:and,or,is,not,between,lessThanEqual
public interface ArticleDao extends ElasticsearchRepository<Article, Long> {
}
5、使用
@Autowiredprivate ElasticsearchRestTemplate template ;RestHighLevelClient
引入依赖
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.47</version></dependency>
private RestHighLevelClient client;
@Testpublic void createIndex() throws IOException {HttpHost httpHost = HttpHost.create("120.78.130.50:9200");RestClientBuilder builder = RestClient.builder(httpHost);client = new RestHighLevelClient(builder);//创建连接CreateIndexRequest request = new CreateIndexRequest("book_index");String json = "{\n" +" \"mappings\": {\n" +" \"properties\": {\n" +" \"id\":{\n" +" \"type\":\"keyword\"\n" +" },\n" +" \"name\":{\n" +" \"type\":\"text\",\n" +" \"analyzer\":\"ik_max_word\"\n" +" },\n" +" \"type\":{\n" +" \"type\":\"keyword\"\n" +" },\n" +" \"description\":{\n" +" \"type\":\"text\",\n" +" \"analyzer\": \"ik_max_word\"\n" +" }\n" +" }\n" +" }\n" +"}";request.source(json, XContentType.JSON);client.indices().create(request, RequestOptions.DEFAULT);//创建索引库client.close();}
添加文档
@Testpublic void addDoc() throws Exception{Book book = bookDao.selectById(1);//从数据库中查询一个对象IndexRequest request = new IndexRequest("book_index").id(book.getId().toString());String json = JSON.toJSONString(book);//对象转为jsonrequest.source(json, XContentType.JSON);client.index(request, RequestOptions.DEFAULT);}//批处理添加文档//
@Testpublic void addallDoc() throws Exception{List<Book> bookList = bookDao.selectList(null);//从数据库中查询所有对象BulkRequest bulk = new BulkRequest();//创建一个批处理对象for (Book book : bookList) {IndexRequest request = new IndexRequest("book_index").id(book.getId().toString());String json = JSON.toJSONString(book);//对象转为jsonrequest.source(json, XContentType.JSON);bulk.add(request);}client.bulk(bulk, RequestOptions.DEFAULT);}
查询文档
///根据id查询
@Testvoid testQuery() throws IOException {GetRequest request = new GetRequest("book_index","1");GetResponse res = client.get(request, RequestOptions.DEFAULT);String sourceAsString = res.getSourceAsString();System.out.println(sourceAsString);}///条件查询/@Testvoid Query() throws IOException {SearchRequest request = new SearchRequest("book_index");//设置条件SearchSourceBuilder buider = new SearchSourceBuilder();buider.query(QueryBuilders.termQuery("name", "java"));request.source(buider);SearchResponse search = client.search(request, RequestOptions.DEFAULT);//处理结果SearchHits hits = search.getHits();for (SearchHit hit : hits) {String sourceAsString = hit.getSourceAsString();JSON.parseObject(sourceAsString, Book.class);//json对为对象System.out.println(Book);}}
聚合查询
划分桶:把不同标题分开
GET /car_index/car/_search
{"query": { //查询所有"bool": {"should": [{"match_all": {}}]}},"aggs": {"group_by_bland": { //group_by_bland为桶名字"terms": { //"field": "color", //把各颜色分开,比如白色为一组(一个容器aggregations),黄色为一组}}}
}桶内度量
GET /car_index/car/_search
{"query": {"bool": {"should": [{"match_all": {}}]}},"aggs": {"group_by_bland": {"terms": {"field": "color" //分开各颜色},"aggs": {"avg_price": {"avg": {"field": "price" //求各颜色里面的价格平均值}}}}}
}
相关文章:

ElasticSearch搜索详细讲解与操作
全文检索基础 全文检索流程 流程: #mermaid-svg-7Eg2qFEl06PIEAxZ {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-7Eg2qFEl06PIEAxZ .error-icon{fill:#552222;}#mermaid-svg-7Eg2qFEl06PIEAxZ .error…...

web实现太极八卦图、旋转动画、定位、角度、坐标、html、css、JavaScript、animation
文章目录前言1、html部分2、css部分3、JavaScript部分4、微信小程序演示前言 哈哈 1、html部分 <div class"great_ultimate_eight_diagrams_box"><div class"eight_diagrams_box"><div class"eight_diagrams"><div class&…...
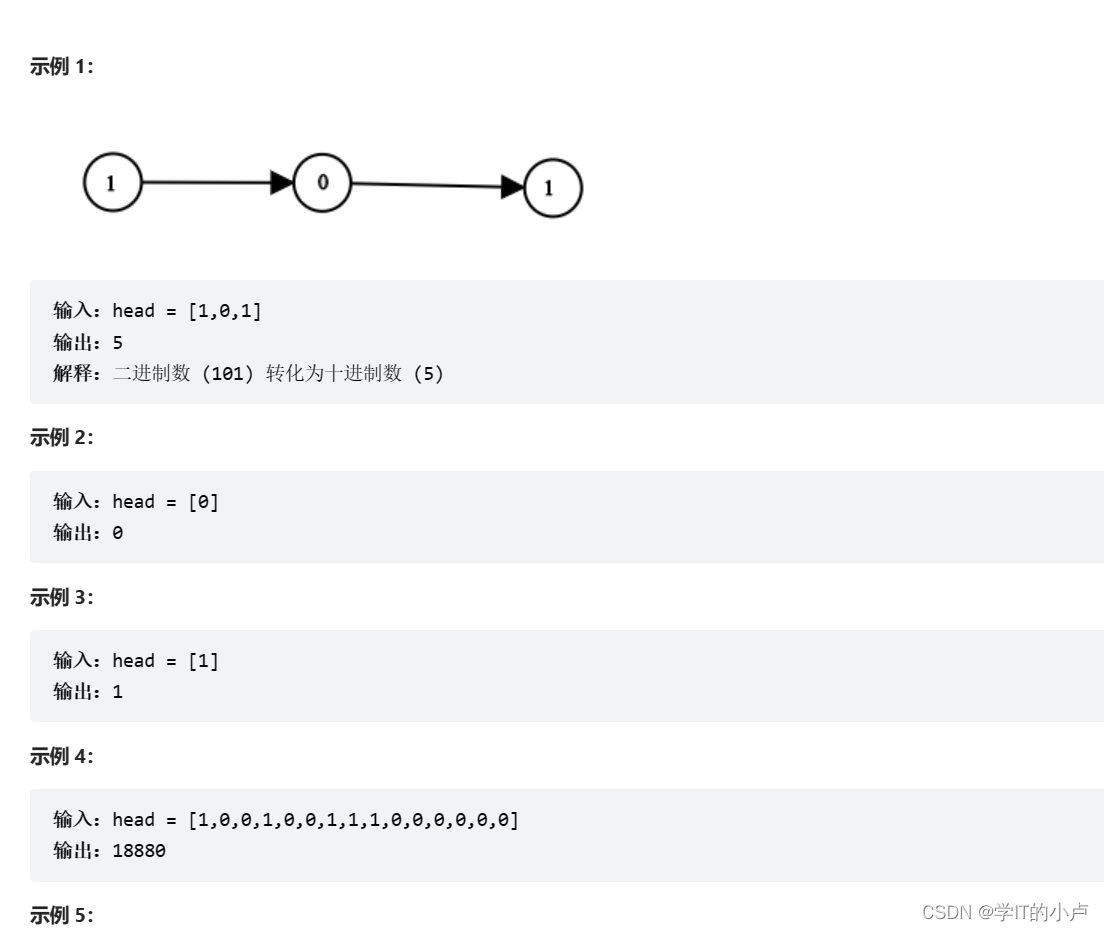
【LeetCode】33. 搜索旋转排序数组、1290. 二进制链表转整数
作者:小卢 专栏:《Leetcode》 喜欢的话:世间因为少年的挺身而出,而更加瑰丽。 ——《人民日报》 目录 33. 搜索旋转排序数组 1290. 二进制链表转整数 33. 搜索旋转排序数组 33. 搜索旋转排序…...
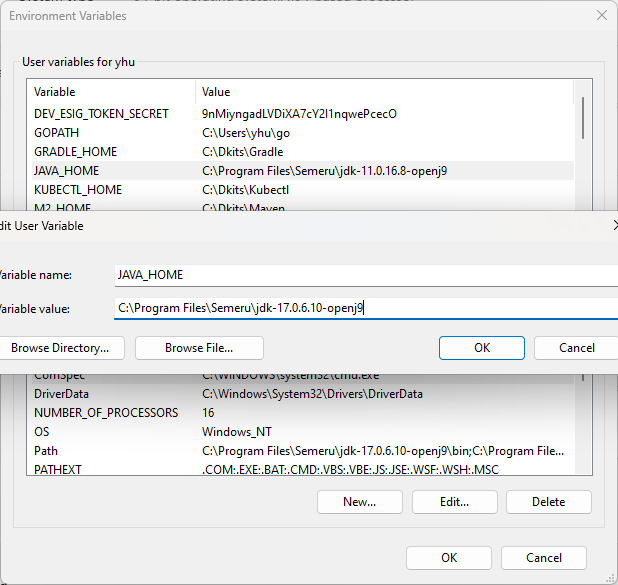
IBM Semeru Windows 下的安装 JDK 17
要搞清楚下载那个版本,请参考文章:来聊聊 OpenJDK 和 JVM 虚拟机下载地址semeru 有认证版和非认证版,主要是因为和 OpenJ9 的关系和操作系统的关系而使用不同的许可证罢了,本质代码是一样的。在 Windows 下没有认证版,…...
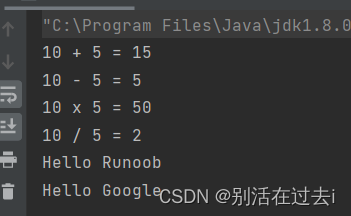
Lambda表达式和steram流
目录 引言: 语法: Lambda 表达式实例: demo演示: Stream流: 引言: Lambda 表达式,也可称为闭包,它是推动 Java 8 发布的最重要新特性。 Lambda 允许把函数作为一个方法的参数(函…...
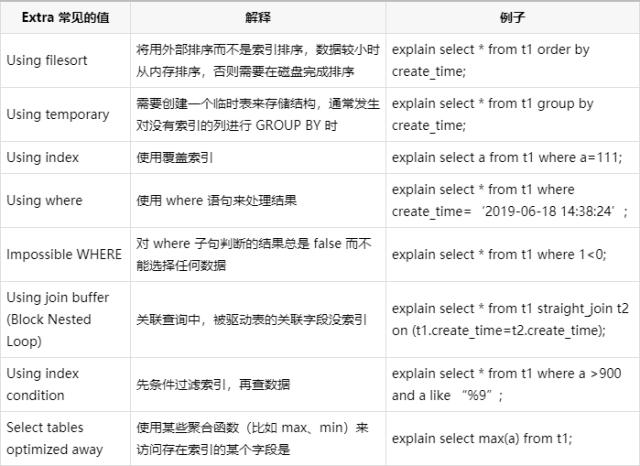
面试必会-MySQL篇
1. Mysql查询语句的书写顺序Select [distinct ] <字段名称>from 表1 [ <join类型> join 表2 on <join条件> ]where <where条件>group by <字段>having <having条件>order by <排序字段>limit <起始偏移量,行数>2. Mysql查询语…...
Hadoop入门常见面试题与集群时间同步操作
目录 一,常用端口号 Hadoop3.x : Hadoop2.x: 二,常用配置文件: Hadoop3.x: Hadoop2.x: 集群时间同步: 时间服务器配置(必须root用户): (1)…...

JS 数组去重的方法
// 数组去重 const arr ["1", "1", "2", "3", "5", "3", "1", "5", "4"] console.log(this.deduplicate(arr)) // [1, 2, 3, 5, 4] // 数组对象去重 const arr [ { id: 1, nam…...
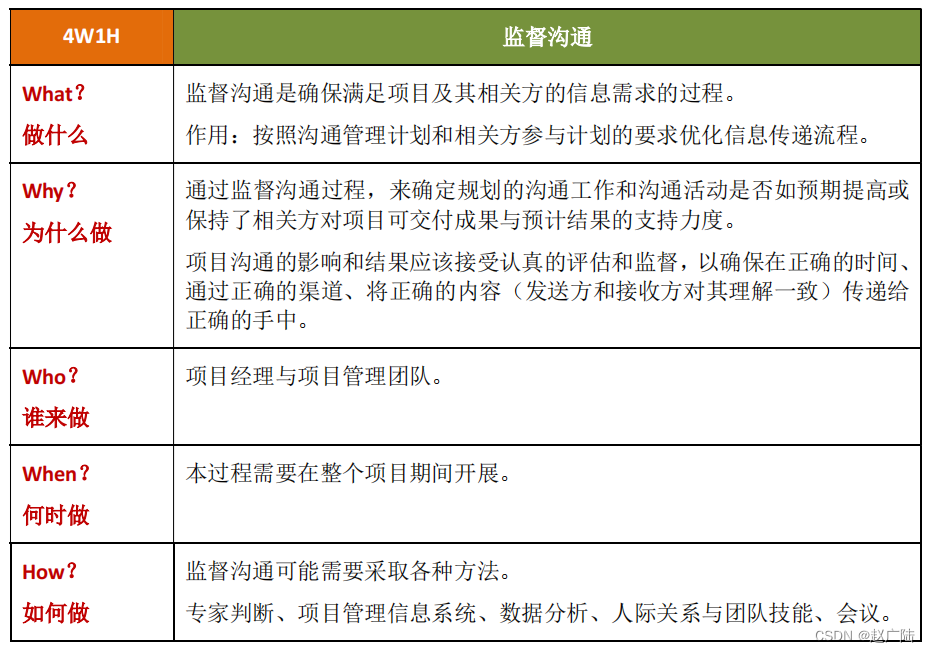
PMP项目管理项目沟通管理
目录1 项目沟通管理2 规划沟通管理3 管理沟通4 监督沟通1 项目沟通管理 项目沟通管理包括通过开发工件,以及执行用于有效交换信息的各种活动,来确保项目及其相关方的信息需求得以满足的各个过程。项目沟通管理由两个部分组成:第一部分是制定…...
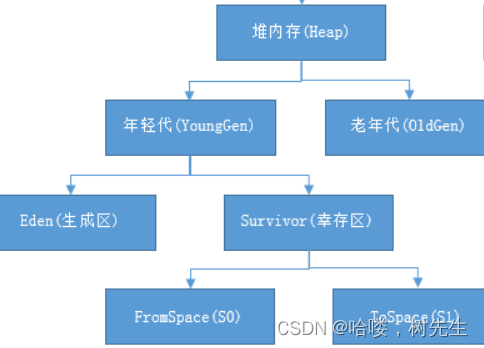
2.JVM常识之 运行时数据区
1.JVM核心组成 2.JVM 运行时数据区(jdk8) 程序计数器:线程私有,当前线程所执行字节码的行号指示器 jvm栈:线程私有,Java 虚拟机栈为 JVM 执行 Java 方法服务 本地方法栈:线程私有,本…...

你的游戏帐号是如何被盗的
据报道,2022上半年,中国游戏市场用户规模达到了5.54亿人,游戏市场销售收入1163.1亿元,相较去年均为同比增长的情况。如此庞大的市场规模,黑色产业链是绕不开的话题。 但相较于游戏中大家常见的玩家与玩家、玩家与官方…...
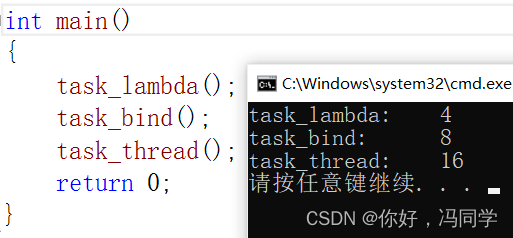
C++11异步编程
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录前言1、std::future和std::shared_future1.1 std:future1.2 std::shared_future2、std::async3、std::promise4、std::packaged_task前言 C11提供了异步操作相关的类…...

20230310----重返学习-DOM元素的操作-时间对象-定时器
day-024-twenty-four-20230310-DOM元素的操作-时间对象-定时器 复习 获取元素 id document.getElementById() 类名 document.getElementsByClassName() 标签名 document.getElementsByTagName() name属性 document.getElementsByName() 选择器 document.querySelector()docum…...
江苏专转本转本人后悔排行榜
江苏专转本转本人后悔排行榜 一、复习的太迟: 后悔指数:五颗星。 复习越到最后,时间一天天变少,要复习的内容还有很多,很多人都后悔没有早早开始,总想着多给我两月一定会考上的。 担心时间不够用,那就努力利…...
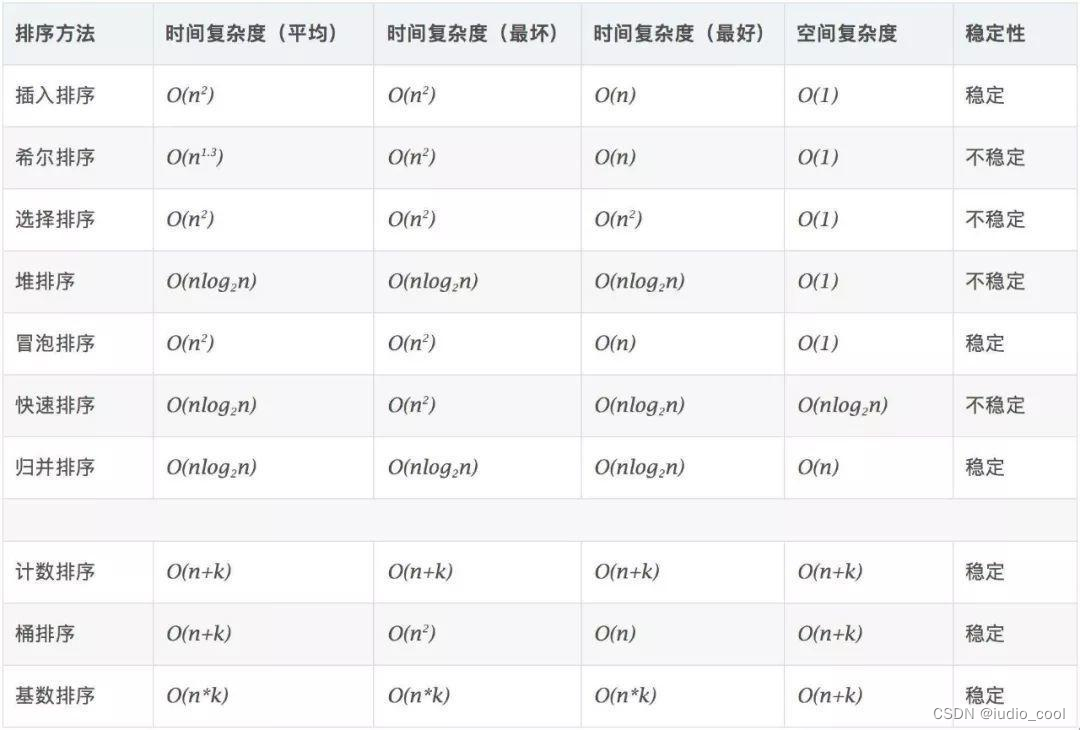
【算法时间复杂度】学习记录
最近开算法课,开几篇文章记录一下算法的学习过程。 关于算法的重要性 学习计算机当程序员的话,在编程过程中是绕不开算法这个大矿山的,需要我们慢慢挖掘宝藏。 算法(Algorithm)是指用来操作数据、解决程序问题的一组…...

汽车车机芯片Linux系统内核编译问题总结
谈到车机,很多人会想到华为问界上装的大屏车机,号称车机的天花板,基于鸿蒙OS的,而今天谈到的车机芯片用的是linux内核Kernel,对于它的编译,很多人一时会觉得头大,的确如果工具不是很齐全,就会遇到这样那样的问题,但是过程都会有错误提示,按照错误提示基本可以解决,而…...

Android13 音量曲线调整
Android13 音量曲线调整 Android13 上配置文件的路径: /vendor/sprd/modules/audio/engineconfigurable_apm/工程目录/system/etc/audio_engine_config/audio_policy_engine_stream_volumes.xml /vendor/sprd/modules/audio/engineconfigurable_apm/工程目录/sys…...
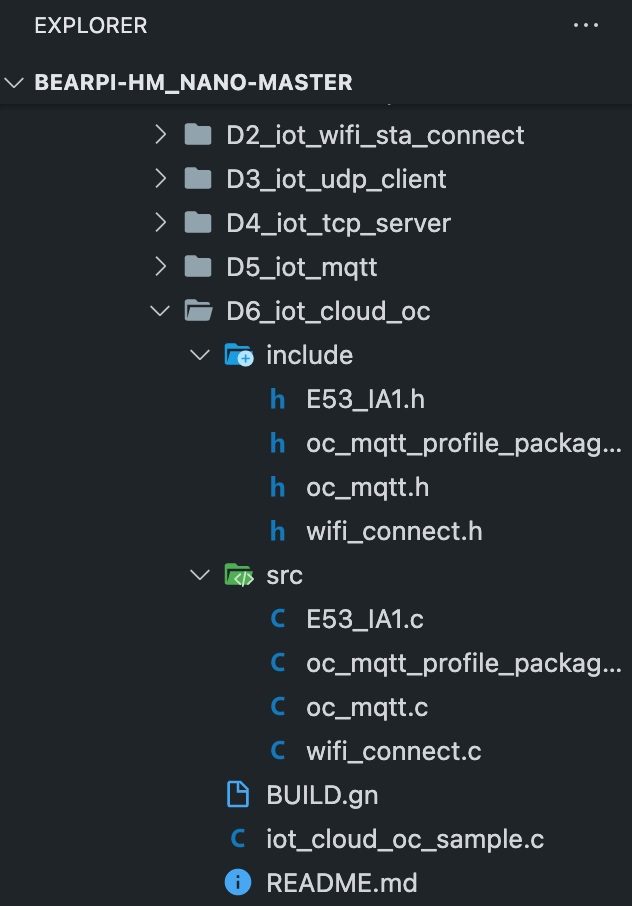
OpenHarmony通过MQTT连接 “改版后的华为IoT平台”
一、前言 本篇文章我们使用的是BearPi-HM_Nano开发板:小熊派的主板+E53_IA1扩展板 源码用的是D6_iot_cloud_oc,点击下载BearPi-HM_Nano全量源码 那么为什么要写这篇呢? 前段时间看到OpenHarmony群里,经常有小伙伴问接入华为IoT平台的问题,他们无法正常连接到华为IoT平台等…...
SQS (Simple Queue Service)简介
mazon Simple Queue Service (SQS)是一种完全托管的消息队列服务,可以让你分离和扩展微服务、分布式系统和无服务应用程序。 在讲解SQS之前,首先让我们了解一下什么是消息队列。 消息队列 还是举一个电商的例子,一个用户在电商网站下单后付…...
)
高速PCB设计指南系列(三)
第一篇 高密度(HD)电路的设计 本文介绍,许多人把芯片规模的BGA封装看作是由便携式电子产品所需的空间限制的一个可行的解决方案,它同时满足这些产品更高功能与性能的要求。为便携式产品的高密度电路设计应该为装配工艺…...

(LeetCode 每日一题) 3442. 奇偶频次间的最大差值 I (哈希、字符串)
题目:3442. 奇偶频次间的最大差值 I 思路 :哈希,时间复杂度0(n)。 用哈希表来记录每个字符串中字符的分布情况,哈希表这里用数组即可实现。 C版本: class Solution { public:int maxDifference(string s) {int a[26]…...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...

中南大学无人机智能体的全面评估!BEDI:用于评估无人机上具身智能体的综合性基准测试
作者:Mingning Guo, Mengwei Wu, Jiarun He, Shaoxian Li, Haifeng Li, Chao Tao单位:中南大学地球科学与信息物理学院论文标题:BEDI: A Comprehensive Benchmark for Evaluating Embodied Agents on UAVs论文链接:https://arxiv.…...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...

ElasticSearch搜索引擎之倒排索引及其底层算法
文章目录 一、搜索引擎1、什么是搜索引擎?2、搜索引擎的分类3、常用的搜索引擎4、搜索引擎的特点二、倒排索引1、简介2、为什么倒排索引不用B+树1.创建时间长,文件大。2.其次,树深,IO次数可怕。3.索引可能会失效。4.精准度差。三. 倒排索引四、算法1、Term Index的算法2、 …...
)
【服务器压力测试】本地PC电脑作为服务器运行时出现卡顿和资源紧张(Windows/Linux)
要让本地PC电脑作为服务器运行时出现卡顿和资源紧张的情况,可以通过以下几种方式模拟或触发: 1. 增加CPU负载 运行大量计算密集型任务,例如: 使用多线程循环执行复杂计算(如数学运算、加密解密等)。运行图…...

基于matlab策略迭代和值迭代法的动态规划
经典的基于策略迭代和值迭代法的动态规划matlab代码,实现机器人的最优运输 Dynamic-Programming-master/Environment.pdf , 104724 Dynamic-Programming-master/README.md , 506 Dynamic-Programming-master/generalizedPolicyIteration.m , 1970 Dynamic-Programm…...

python执行测试用例,allure报乱码且未成功生成报告
allure执行测试用例时显示乱码:‘allure’ �����ڲ����ⲿ���Ҳ���ǿ�&am…...

Qt 事件处理中 return 的深入解析
Qt 事件处理中 return 的深入解析 在 Qt 事件处理中,return 语句的使用是另一个关键概念,它与 event->accept()/event->ignore() 密切相关但作用不同。让我们详细分析一下它们之间的关系和工作原理。 核心区别:不同层级的事件处理 方…...

认识CMake并使用CMake构建自己的第一个项目
1.CMake的作用和优势 跨平台支持:CMake支持多种操作系统和编译器,使用同一份构建配置可以在不同的环境中使用 简化配置:通过CMakeLists.txt文件,用户可以定义项目结构、依赖项、编译选项等,无需手动编写复杂的构建脚本…...