Python网络爬虫实战6—下一页,模拟用户点击,切换窗口
【前期提要】感兴趣的可以看看往期文章哈~
Python网络爬虫5-实战网页爬取
Python网络爬虫4-实战爬取pdf
Pyhon网络爬虫3-模拟用户点击
Python网络爬虫实战2-下载url下的pdf
Python网络爬虫基础1
1.需求背景
针对长虹美菱电器说明书网页形式,编写爬虫代码,要求获取对应型号的pdf。
网站分析:
第一步:点击一个具体的型号,会打开一个新的pdf的页面,就是目标型号的pdf
第二步:在新的页面点击下载按钮,下载pdf
第三步:切换回原始的型号列表页面
第四步:点击下一页,下载其他型号pdf
2.主要困难与解决方法
上述分析过程有以下需要解决的问题:
问题1. pdf连接不直接暴露。按F12打开开发者模式,我们可以看到,按钮链接时什么也没有的。也就是说不能采用requests获取url的方式,只能通过Selenium模拟用户点击。
解决1:Selenium模拟用户点击,开发者模式下获取向右箭头的位置。发现第一个的Xpath为:
/html/body/div/div[2]/div/div[3]/ul/li[1]/div/div/span-----第一个
/html/body/div/div[2]/div/div[3]/ul/li[2]/div/div/span-----第二个
.....
/html/body/div/div[2]/div/div[3]/ul/li[9]/div/div/span-----第九个个
每一页有九个,可以使用一个for循环用i变量来循环每个位置:
/html/body/div/div[2]/div/div[3]/ul/li[{i}]/div/div/span
同理,我们也可以得到对应的文字说明位置。
/html/body/div/div[2]/div/div[3]/ul/li[{i}]/div/div/text()
问题2:点击箭头打开新的连接页面,通过 self.driver.switch_to.window(handle),切换窗口,pdf_url = self.driver.current_url得到pdf连接,发现此url,无法通过使用download_file_from_url函数下载pdf。
def download_file_from_url(url, save_path, file_name):'''url为以.pdf为结尾的链接'''response = requests.get(url, timeout=10, stream=True, verify=False)if response.status_code == 200:with open(os.path.join(save_path, file_name), 'wb') as f:for chunk in response.iter_content(1024):f.write(chunk)return Trueelse:return False
报错如下:
requests.exceptions.SSLError: HTTPSConnectionPool(host=‘mlmall.meiling.com’, port=443): Max retries exceeded with url
通常表示在尝试通过HTTPS(端口443)连接到指定的主机(mlmall.meiling.com)时发生了SSL/TLS相关的问题
可能是SSL证书问题
总之,是无法从url链接下载pdf。还是只能使用模拟用户点击。
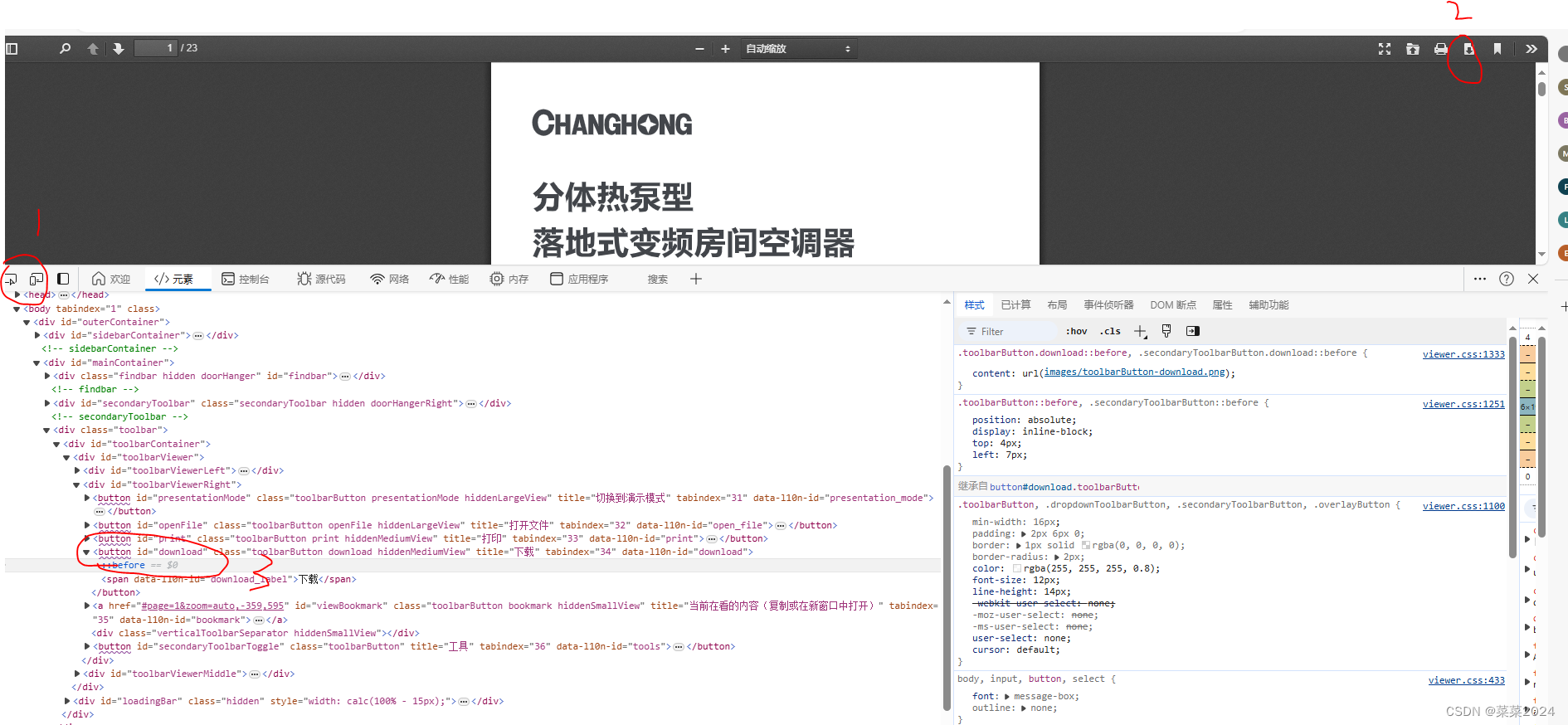
**解决2:**如图所示,找到下载按钮的xapth=//*[@id=“download”] 以此进行定位和点击。
如此便有另一个问题,就是点击此按钮就进行下载pdf了,并不能进行重命名。解决方法只能是将对应的pdf链接和下载的文件及对应的型号信息存储在excel中,爬取完成之后,再根据excel中的信息进行统一的重命名。
问题3:点击下一页
**解决3:**模拟用户点击,获取下一页的按钮,点击它
问题4:如果程序出错停止,如何不重头开始
3.代码实现
1.首先定义一个类,主要是为了更改文件下载的默认地址,和设置全局变量,存储型号文本和pdf链接,以方便存储到excel中
'''
import os
import pandas as pd
import time
import shutilfrom selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Optionsclass MeiLin():def __init__(self,url='https://mlmall.meiling.com/meiling/pages/servicesSupport.html?_v=0.1.0#/instructions',cur_page=1,# 记录当前页面):chrome_options = Options()prefs = {"download.default_directory": "E:\downl", # 下载文件夹路径"download.prompt_for_download": False,"download.directory_upgrade": True,"safebrowsing.enabled": True}chrome_options.add_experimental_option("prefs", prefs)self.res=[]self.driver = webdriver.Chrome(options=chrome_options)self.driver.get(url)2.每一页的主要执行流程
def get_one_page_pdf(self, finish_page=85, page=0):
# finish_page为了指定结束的页面(在实际中发现,到了一定的页面,有的型号不含pdf链接了,新打开的页面结构也不是这样了)
# page 标识正在处理的页面try:while(page<finish_page+1):# 到了指定的页面进行下载# if page>2:# breakpage += 1if page < 4:# 发现前3页,点击下一页的按钮和之后的不一样,所以这里进行分情况,都是实战找出的啊# 为了偷懒就这样吧,实现功能但并不优雅button_xpath = '/html/body/div/div[2]/div/div[3]/nav/ul/li[8]/a'else:button_xpath = '/html/body/div/div[2]/div/div[3]/nav/ul/li[9]/a'# 每页有9个说明书for i in range(1, 10):one_mes = []#if i > 1:# breaktry:# 获取型号文本text_xpath = '/html/body/div/div[2]/div/div[3]/ul/li[{}]/div/div'.format(i)text = self.driver.find_element_by_xpath(text_xpath).textone_mes.append(text)# 点击一个具体的型号,打开了一个新的链接xpath = '/html/body/div/div[2]/div/div[3]/ul/li[{}]/div/div/span'.format(i)click_element = WebDriverWait(self.driver, 5).until(EC.element_to_be_clickable((By.XPATH, xpath)))click_element.click()# 记录当前主要页面的句柄base_window = self.driver.current_window_handleall_handles = self.driver.window_handlesfor handle in all_handles:if handle != self.driver.current_window_handle:# 找到了新打开的页面,切换到新页面,得到urlself.driver.switch_to.window(handle)pdf_url = self.driver.current_url# 有的不是pdf链接,进行后缀判断if '.pdf' in str(pdf_url):one_mes.append(pdf_url)time.sleep(10)# 进行pdf下载try:click_element = WebDriverWait(self.driver, 5).until(EC.element_to_be_clickable((By.XPATH, '//*[@id="download"]')))click_element.click()time.sleep(10)except:print("第{}页的第{}个不是pdf网页,保存失败".format(page, i))passprint("完成第{}页的第{}个".format(page, i))self.res.append(one_mes)self.driver.close()except:print("第{}页的第{}个操作失败".format(page, i))# 如果失败了,还切回去原来的窗口,重新开始self.driver.switch_to.window(base_window)continue# 完成,关闭该页面,切换到原始窗口self.driver.switch_to.window(base_window)print("已经完成第{}页".format(page))# 点击下一页,进行下一页的下载try:click_element = WebDriverWait(self.driver, 5).until(EC.element_to_be_clickable((By.XPATH, button_xpath)))click_element.click()time.sleep(3)except:print("无法点击下一页")breakexcept:print("while 循环终止")3.程序入口:
if __name__=="__main__":meilin = MeiLin()try:meilin.get_one_page_pdf(finish_page=85)except:passfinally:data = meilin.resdf = pd.DataFrame(data, columns=['电器型号', '说明书链接'])save_folder = 'E:\\HWR_files\\Pycharm_files\\HWR\\webcraw\\美菱.xlsx'df.to_excel(save_folder, index=False, sheet_name='匹配结果')print("------------------保存完成------------------")结果图:(只取了两页,每页取一个)

相关文章:
Python网络爬虫实战6—下一页,模拟用户点击,切换窗口
【前期提要】感兴趣的可以看看往期文章哈~ Python网络爬虫5-实战网页爬取 Python网络爬虫4-实战爬取pdf Pyhon网络爬虫3-模拟用户点击 Python网络爬虫实战2-下载url下的pdf Python网络爬虫基础1 1.需求背景 针对长虹美菱电器说明书网页形式,编写爬虫代码ÿ…...

Notepad++插件 Hex-Edit
Nptepad有个Hex文件查看器,苦于每次打开文件需要手动开插件显示Hex,配置一下插件便可实现打开即调用 关联多个二进制文件,一打开就使用插件的方法,原来是使用空格分割!!!...
Matlab要这样批量读取txt数据!科研效率UpUp第10期
假如我们有多组txt格式的数据: 其数据格式是这样的: 想要批量读取这些数据,并把他们画在一张图上,该怎么操作呢? 之前有分享load函数的版本,本期进一步分享适用性更强的readtable函数的实现方法。 首…...
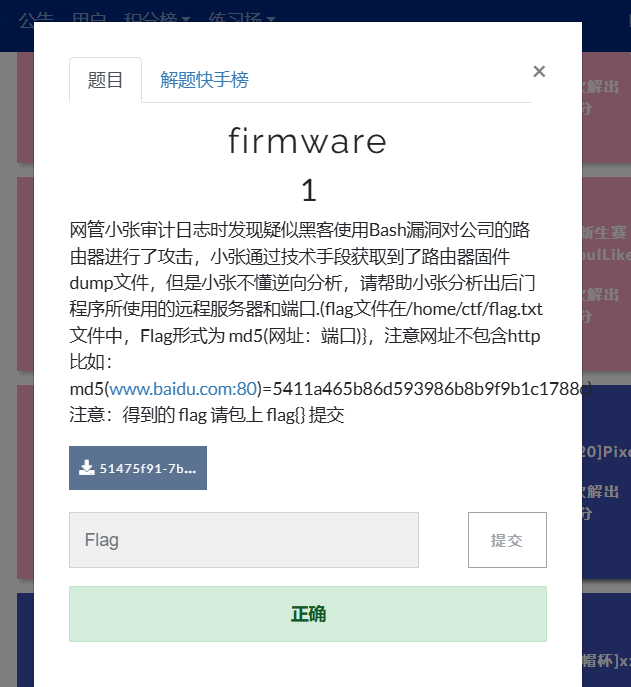
buuctf----firmware
- -一定不能再ubutu22进行,我是在18(血泪教训) binwalk安装 buuctf firmware(binwalk和firmware-mod-kit的使用)_buu firmware-CSDN博客 参考博客 指令 sudo apt-get update sudo apt-get install python3-dev python3-setuptools python3-pip zlib1g-dev libmagic-dev pi…...
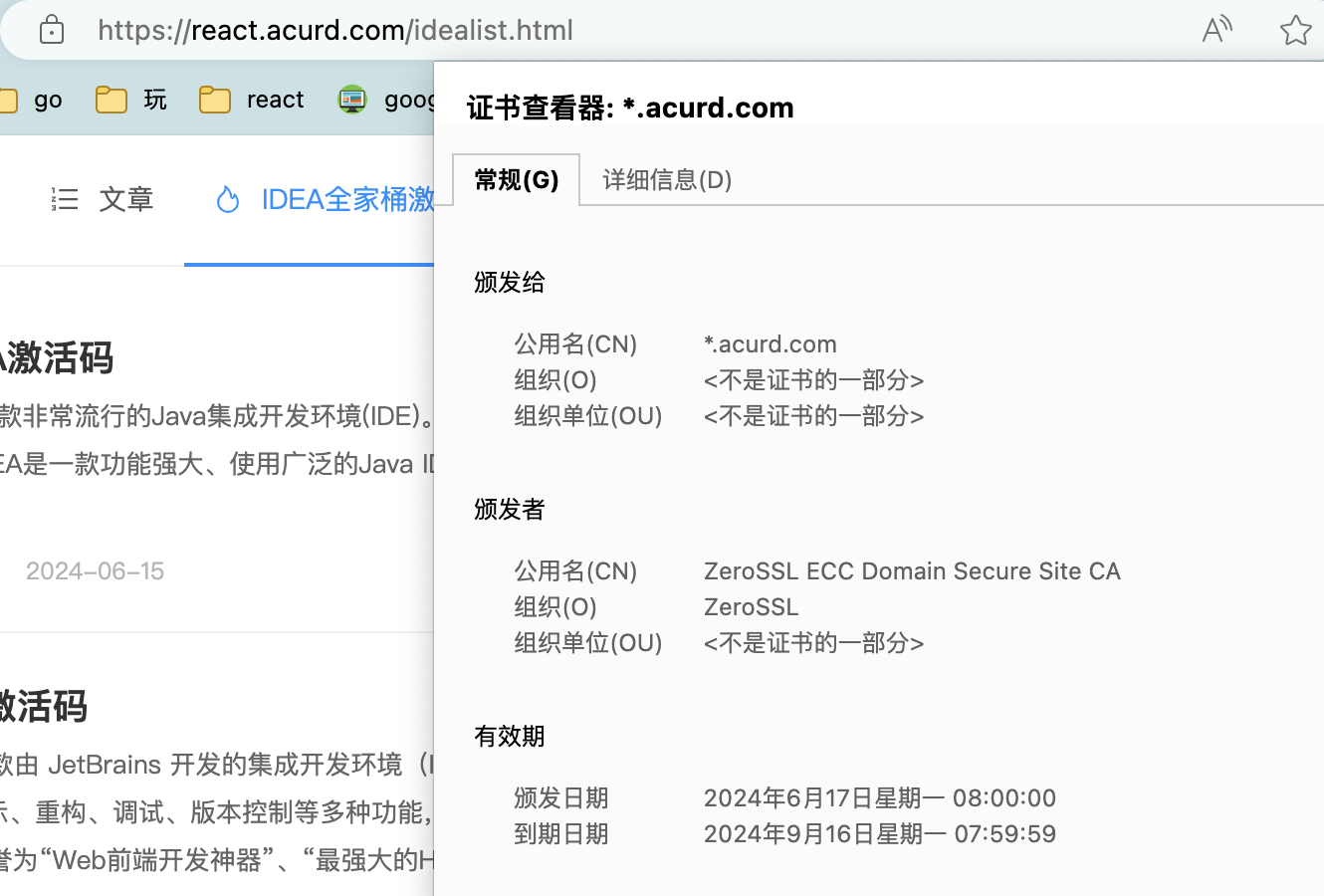
ssl证书90天过期?保姆级教程——使用acme.sh实现证书的自动续期
腾讯云相关文档相关参考-有的点不准确 前言 最近https到期了,想着手动更新一下https证书,结果发现证书现在的有效期只有90天,于是想找到一个自动更新证书的工具,发现了acme.sh,但是网上的文章质量参差不齐࿰…...

由于bug造成truncate table卡住问题
客户反应truncate table卡主,检查awr发现多个truncate在awr报告期内一直没执行完,如下: 检查ash,truncate table表的等待事件都是“enq: RO - fast object reuse”和“local write wait” 查找“enq: RO - fast object reuse”&am…...
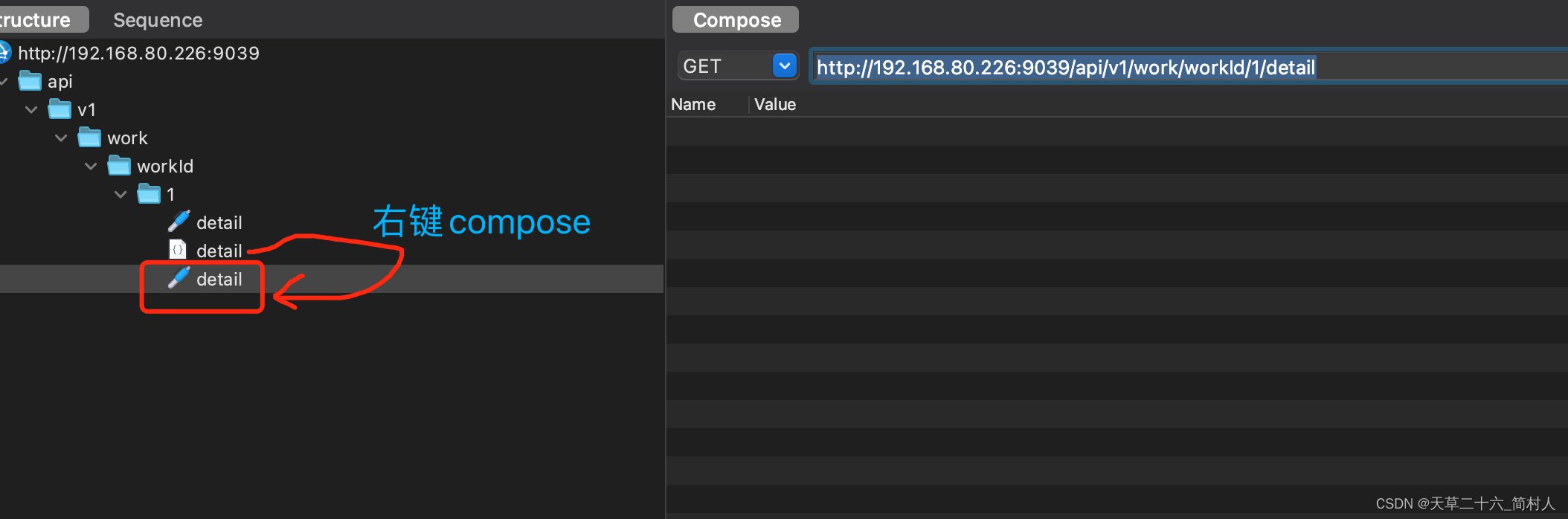
Charles抓包工具系列文章(二)-- Repeat 回放http请求
一、什么是http请求回放 当我们对客户端进行抓包,经常会想要重试http请求,或者改写原有部分进行重新请求,都需要用到回放http请求。 还有一种场景是压力测试,对一个请求进行重复请求多少次,并加上适当的并发度。 这里…...
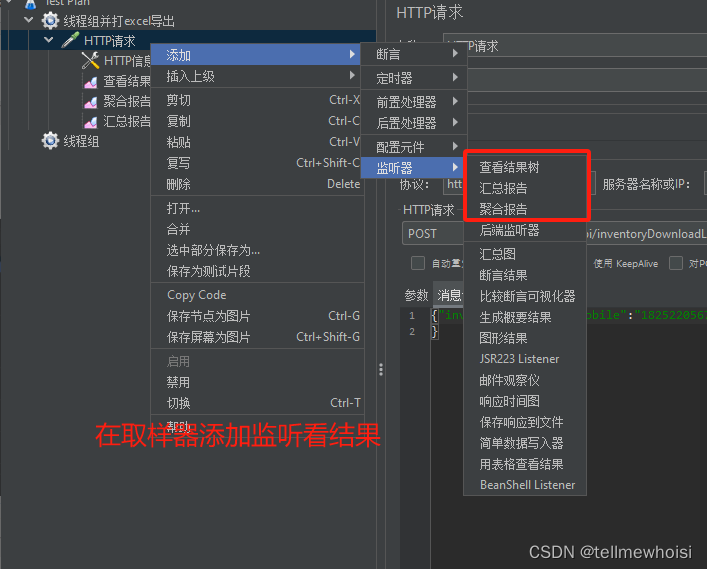
jemeter基本使用
后端关验签,设置请求头编码和token 配置编码和token...

【Golang】Steam 创意工坊 Mod 文件夹批量重命名
本文将介绍一个使用Go语言编写的脚本,其主要功能是解析XML文件并基于解析结果重命名文件夹。这个脚本适用于需要对文件夹进行批量重命名,并且重命名规则依赖于XML文件内容的情况。 脚本功能概述 Steam创意工坊下载的Mod文件夹批量重命名为id名称 运行前…...

求职刷题力扣DAY33--贪心算法part04
DAY 33 贪心算法part04 1. 452. 用最少数量的箭引爆气球 有一些球形气球贴在一堵用 XY 平面表示的墙面上。墙面上的气球记录在整数数组 points ,其中points[i] [xstart, xend] 表示水平直径在 xstart 和 xend之间的气球。你不知道气球的确切 y 坐标。 一支弓箭可…...
aws的eks(k8s)ingress+elb部署实践
eks(k8s)版本1.29 ingress 版本1.10.0 负载均衡elb 1. 创建Ingress-Nginx服务 部署项目地址【点我跳转】推荐自定义部署 可绑定acm证书什么的自己属性 这里就是aws上面Certificate Manager产品上面创建证书 导入 创建都行 对应集群版本推荐阵列GitH…...

大数据面试题之YARN
目录 1、介绍下YARN 2、YARN有几个模块 3、YARN工作机制 4、YARN有什么优势,能解决什么问题? 5、YARN容错机制 6、YARN高可用 7、YARN调度器 8、YARN中Container是如何启动的? 9、YARN的改进之处,Hadoop3.x相对于Hadoop 2.x? 10、YARN监控 1…...
)
最小生成树模板(prim,heap-prim,kruskal)
prim 出圈法,时间复杂度 O ( n 2 ) O(n^2) O(n2) #include<iostream> #include<vector> using namespace std; #define MAX_N 5000 #define inf 100000000 struct edge{int v,w; }; vector<edge>e[MAX_N5]; int d[MAX_N5],vis[MAX_N5]; int n,m…...

Centos 7 或 8配置国内yum源及epel源-1
官方教程 Yum工具详解 清理Yum缓存:[rootqfedu.com ~]# yum clean all缓存软件包信息: 提高搜索/安装软件的速度[rootqfedu.com ~]# yum makecache查询yum源信息: [rootqfedu.com ~]# yum repolist 查找软件:[rootqfedu.com ~]# yum search mysql 此命令会搜索到系…...

轻松解决Android复杂数据结构序列化
问题描述 当我编写quickupload库时,因为需要在 Service中进行上传任务,向Service传递时我发现需要传递的数据很多并且结构复杂,如果处理不好就会导致以下几个问题 耗时: 需要更多时间进行开发和测试以确保正确的数据处理。容易出错: 由于手…...

解析PDF文件中的图片为文本
解析PDF文件中的图片为文本 1 介绍 解析PDF文件中的图片,由两种思路,一种是自己读取PDF文件中的图片,然后用OCR解析,例如:使用PyMuPDF读取pdf文件,再用PaddleOCR或者Tesseract-OCR识别文字。另一种使用第…...

微信小程序表单
在我们的课程中,我们深入探讨了微信小程序表单的开发和应用。以下是我们课程的主要内容和收获: 一、课程目标 本课程旨在帮助学生掌握微信小程序表单的基本概念、开发流程和最佳实践。学生将学习如何创建和配置表单组件,处理表单数据…...
--学习记录)
Javascript高级程序设计(第四版)--学习记录
var关键字:定义变量同时可以进行赋值 var message"hello" message 10 可以改变保存的值,也可以改变值的类型,但是不推荐这样写。 var声明的变量会成为包含它的函数的局部变量。 function test(){ var message "hello";…...

DVWA-CSRF-samesite分析
拿DVWA的CSRF为例子 接DVWA的分析,发现其实Impossible的PHPSESSID是设置的samesite1. 参数的意思参考Set-Cookie SameSite:控制 cookie 是否随跨站请求一起发送,这样可以在一定程度上防范跨站请求伪造攻击(CSRF)。 下面用DVWA CS…...

代码随想录训练营Day48
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、买卖股票的最佳时机4二、买卖股票的最佳时机含冷冻期三、买卖股票含手续费 前言 提示:这里可以添加本文要记录的大概内容: 今天是…...

JVM垃圾回收机制全解析
Java虚拟机(JVM)中的垃圾收集器(Garbage Collector,简称GC)是用于自动管理内存的机制。它负责识别和清除不再被程序使用的对象,从而释放内存空间,避免内存泄漏和内存溢出等问题。垃圾收集器在Ja…...

全球首个30米分辨率湿地数据集(2000—2022)
数据简介 今天我们分享的数据是全球30米分辨率湿地数据集,包含8种湿地亚类,该数据以0.5X0.5的瓦片存储,我们整理了所有属于中国的瓦片名称与其对应省份,方便大家研究使用。 该数据集作为全球首个30米分辨率、覆盖2000–2022年时间…...

2025盘古石杯决赛【手机取证】
前言 第三届盘古石杯国际电子数据取证大赛决赛 最后一题没有解出来,实在找不到,希望有大佬教一下我。 还有就会议时间,我感觉不是图片时间,因为在电脑看到是其他时间用老会议系统开的会。 手机取证 1、分析鸿蒙手机检材&#x…...

C# SqlSugar:依赖注入与仓储模式实践
C# SqlSugar:依赖注入与仓储模式实践 在 C# 的应用开发中,数据库操作是必不可少的环节。为了让数据访问层更加简洁、高效且易于维护,许多开发者会选择成熟的 ORM(对象关系映射)框架,SqlSugar 就是其中备受…...

鱼香ros docker配置镜像报错:https://registry-1.docker.io/v2/
使用鱼香ros一件安装docker时的https://registry-1.docker.io/v2/问题 一键安装指令 wget http://fishros.com/install -O fishros && . fishros出现问题:docker pull 失败 网络不同,需要使用镜像源 按照如下步骤操作 sudo vi /etc/docker/dae…...

全面解析各类VPN技术:GRE、IPsec、L2TP、SSL与MPLS VPN对比
目录 引言 VPN技术概述 GRE VPN 3.1 GRE封装结构 3.2 GRE的应用场景 GRE over IPsec 4.1 GRE over IPsec封装结构 4.2 为什么使用GRE over IPsec? IPsec VPN 5.1 IPsec传输模式(Transport Mode) 5.2 IPsec隧道模式(Tunne…...

Spring数据访问模块设计
前面我们已经完成了IoC和web模块的设计,聪明的码友立马就知道了,该到数据访问模块了,要不就这俩玩个6啊,查库势在必行,至此,它来了。 一、核心设计理念 1、痛点在哪 应用离不开数据(数据库、No…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

OPenCV CUDA模块图像处理-----对图像执行 均值漂移滤波(Mean Shift Filtering)函数meanShiftFiltering()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 在 GPU 上对图像执行 均值漂移滤波(Mean Shift Filtering),用于图像分割或平滑处理。 该函数将输入图像中的…...

sipsak:SIP瑞士军刀!全参数详细教程!Kali Linux教程!
简介 sipsak 是一个面向会话初始协议 (SIP) 应用程序开发人员和管理员的小型命令行工具。它可以用于对 SIP 应用程序和设备进行一些简单的测试。 sipsak 是一款 SIP 压力和诊断实用程序。它通过 sip-uri 向服务器发送 SIP 请求,并检查收到的响应。它以以下模式之一…...