计算预卷积特征
当冻结卷积层和训练模型时,全连接层或dense层(vgg.classifier)的输入始终是相同的。为了更好地理解,让我们将卷积块(在示例中为vgg.features块)视为具有了已学习好的权重且在训练期间不会更改的函数。因此,计算卷积特征并保存下来将有助于我们提高训练速度。训练模型的时间减少了,因为我们只计算一次这些特征而不是每轮都计算。让我们在结合图5.21理解并实现同样的功能。
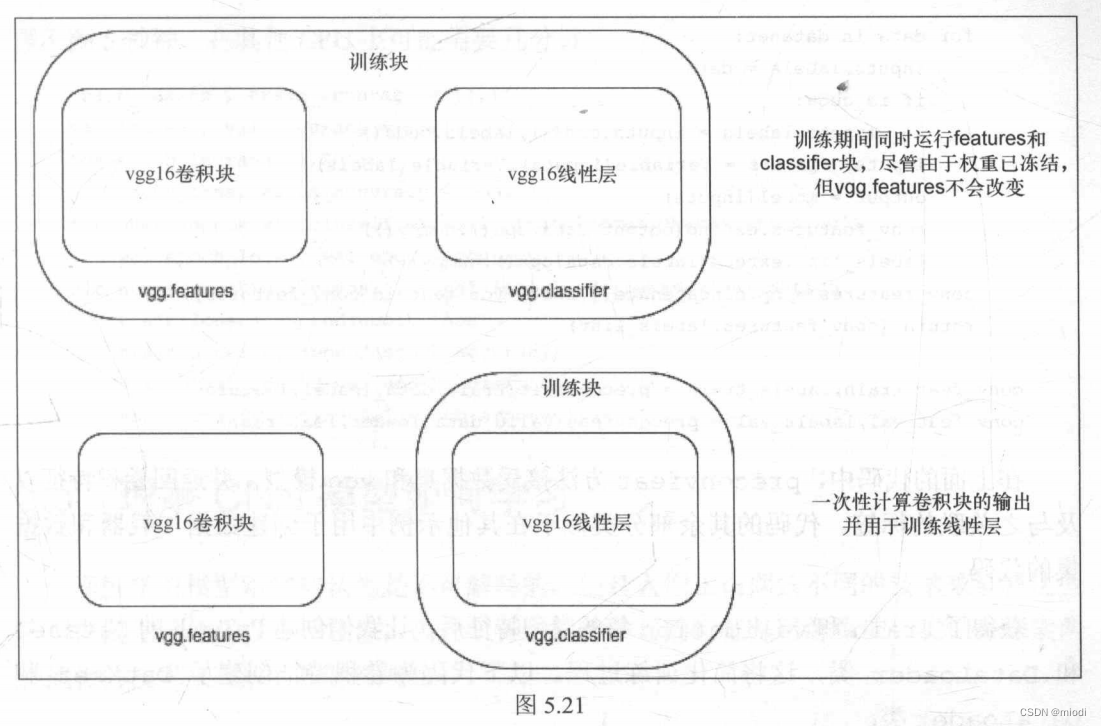
第一个框描述了一般情况下如何进行训练,这可能很慢,因为尽管值不会改变,但仍为每轮计算卷积特征。在底部的框中,一次性计算卷积特征并仅训练线性层。为了计算预卷积特征,我们将所有训练数据传给卷积块并保存它们。为了实现这一点,需要选择 VGG 模型的卷积块。幸运的是,VGG16的PyTorch实现包含了两个序列模型,所以只选择第一个序列模型的特征就可以了。以下代码执行此操作:
vgg = models.vggl6(pretrained=True)
vgg = vgg.cuda()
features = vgg.features
train_data_loader = torch.utils.data.Dataloader(train,batch_size=32,num_workers=3,shuffle=False)
valid_data_loader=
torch.utils,data.Dataloader(valid,batch_size=32,num_workers=3,shuffle=False)
def preconvfeat(dataset,model):conv_features = []labels_list = []for data in dataset:inputs,labels = dataif is_cuda:inputs,labels = inputs.cuda(),labels.cuda()inputs,labels = Variable(inputs),Variable(labels)output = model(inputs)conv_features.extend(output.data.cpu().numpy())labels_list.extend(labels.data.cpu().numpy())conv_features = np.concatenate([[feat] for feat in conv_features])return (conv_features,labels_list)
conv_feat_train,labels_train = preconvfeat(train_data_loader, features)
conv_feat_val,labels_val = preconvfeat (valid_data_loader, features) 在上面的代码中,preconvfeat 方法接受数据集和 vgg 模型,并返回卷积特征以及与之关联的标签。代码的其余部分类似于在其他示例中用于创建数据加载器和数据集的代码。
获得了 train 和 validation 集的卷积特征后,让我们创建 PyTorch 的 Dataset 和 DataLoader 类,这将简化训练过程。以下代码为卷积特征创建了 Dataset 和 DataLoader 类:
class My dataset(Dataset):def _init_(self,feat,labels):self.conv_feat = featself.labels = labelsdef _len_(self):return len(self.conv_feat)def _getitem_(self,idx):return self.conv_feat[idx],self.labels[idx]train_feat_dataset = My_dataset(conv_feat_train,labels_train)
val_feat_dataset = My_dataset(conv_feat_val,labels_val)
train_feat_loader =
DataLoader(train_feat_dataset,batch_size=64,shuffle=True)
val_feat_loader =
DataLoader(val_feat_dataset,batch_size=64,shuffle=True)由于有新的数据加载器可以生成批量的卷积特征以及标签,因此可以使用与另一个例子相同的训练函数。现在将使用 vgg.classifier 作为创建 optimizer 和 fit 方法的模型。下面的代码训练分类器模块来识别狗和猫。在Titan X GPU上,每轮训练只需不到5秒钟,在其他CPU上可能需要几分钟:
train_losses, train_accuracy = [],[]
val_losses, val_accuracy = [],[]
for epoch in range(1,20):epoch_loss, epoch_accuracy =fit_numpy(epoch,vgg.classifier,train_feat_loader,phase='training')val_epoch_loss,val_epoch_accuracy = fit_numpy(epoch,vgg.classifier,val_feat_loader,phase='validation')train_losses.append(epoch_loss)train_accuracy.append(epoch_accuracy)val_losses.append(val_epoch_loss)val_accuracy.append(val_epoch_accuracy)相关文章:
计算预卷积特征
当冻结卷积层和训练模型时,全连接层或dense层(vgg.classifier)的输入始终是相同的。为了更好地理解,让我们将卷积块(在示例中为vgg.features块)视为具有了已学习好的权重且在训练期间不会更改的函数。因此,计算卷积特征并保存下来将有助于我们…...

Python 入门 —— 描述器
Python 入门 —— 描述器 文章目录 Python 入门 —— 描述器描述器简单示例定制名称只读属性状态交互验证器类自定义验证器验证器的使用 对象关系映射 描述器 前面我们介绍了两种属性拦截的方式:特性(property)以及重载属性访问运算符&#…...

测试驱动开发TDD
如何在后端测试代码,测试一个其前端的请求,能否正常处理 以登录请求为例 package com.example.demo.login;import com.example.demo.login.pojo.User; import com.fasterxml.jackson.databind.ObjectMapper; import org.junit.jupiter.api.Test; import…...
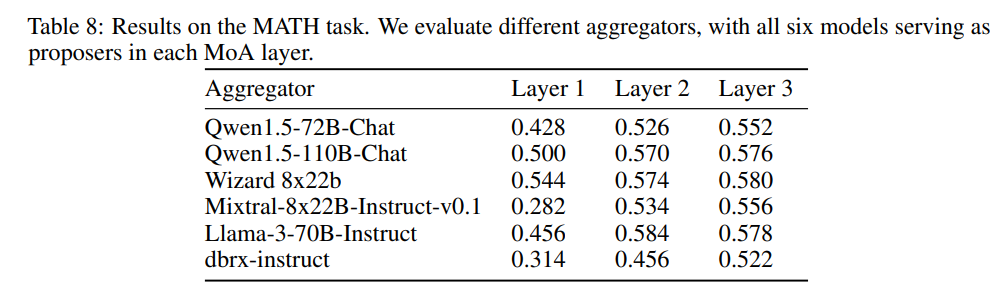
[论文笔记]Mixture-of-Agents Enhances Large Language Model Capabilities
引言 今天带来一篇多智能体的论文笔记,Mixture-of-Agents Enhances Large Language Model Capabilities。 随着LLMs数量的增加,如何利用多个LLMs的集体专业知识是一个令人兴奋的开放方向。为了实现这个目标,作者提出了一种新的方法…...
Redis 7.x 系列【6】数据类型之字符串(String)
有道无术,术尚可求,有术无道,止于术。 本系列Redis 版本 7.2.5 源码地址:https://gitee.com/pearl-organization/study-redis-demo 文章目录 1. 前言2. 常用命令2.1 SET2.2 GET2.3 MSET2.4 MGET2.5 GETSET2.6 STRLEN2.7 SETEX2.8…...
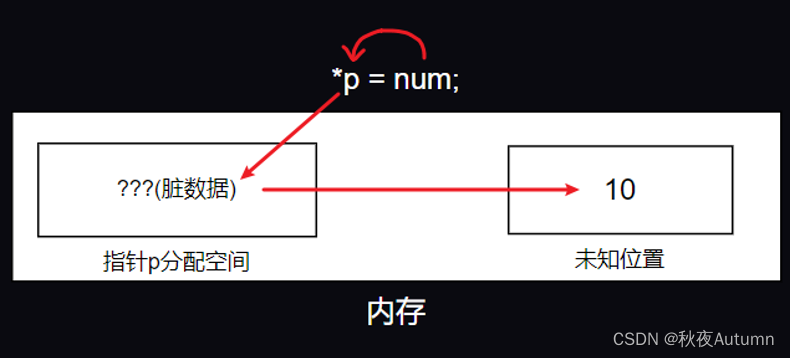
指针(一)
指针基础 在C中,指针是至关重要的组成部分。它是C语言最强大的功能之一,也是最棘手的功能之一。 指针具有强大的能力,其本质是协助程序员完成内存的直接操纵。 指针:特定类型数据在内存中的存储地址,即内存地址。 …...

harmony鸿蒙下实现bc交互的方式和方法
前言 最近在研究harmony操作系统下的交互,因此写一篇文章记录一下。 解决的问题 本篇文章主要是来写解决如果兼容android或者ios的交互,这样子避免h5页面的二次开发,节省资源。 交互的种类 交互对于harmony来说其实只有一种,…...

【MySQL进阶之路 | 高级篇】索引的声明与使用
1. 索引的分类 MySQL的索引包括普通索引,唯一性索引,全文索引,单列索引和空间索引. 从功能逻辑上说,索引主要分为普通索引,唯一索引,主键索引和全文索引.按物理实现方式,索引可以分为聚簇索引…...

探索Java中的设计模式:从单例到工厂模式
探索Java中的设计模式:从单例到工厂模式 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将深入探讨Java中的设计模式,从经典的单…...

表单(forms)
自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm1001.2014.3001.5501 在app1文件夹下创建一个forms.py文件,添加如下类代码: from django import forms class PersonForm(forms.Form): first_na…...
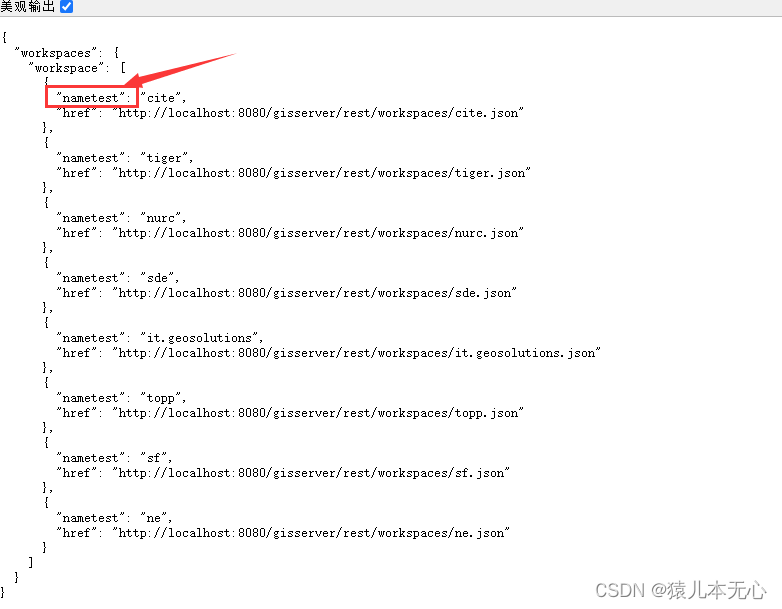
Geoserver源码解读四 REST服务
文章目录 文章目录 一、概要 二、前置知识点-FreeMarker 三、前置知识点-AbstractHttpMessageConverter 3.1 描述 3.2 应用 四、前置知识点-AbstractDecorator 4.1描述 4.2 应用 五、工作空间查询解读 5.1 模板解读 5.2 请求转换器解读 一、概要 关于geoserver的r…...
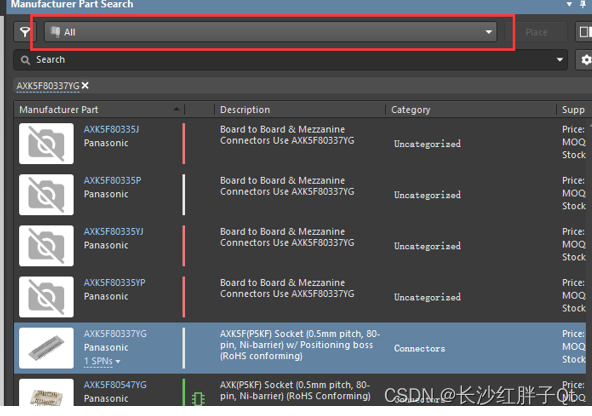
硬件开发笔记(二十一):外部搜索不到的元器件封装可尝试使用AD21软件的“ManufacturerPart Search”功能
若该文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/139869584 长沙红胖子Qt(长沙创微智科)博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、OpenCV…...
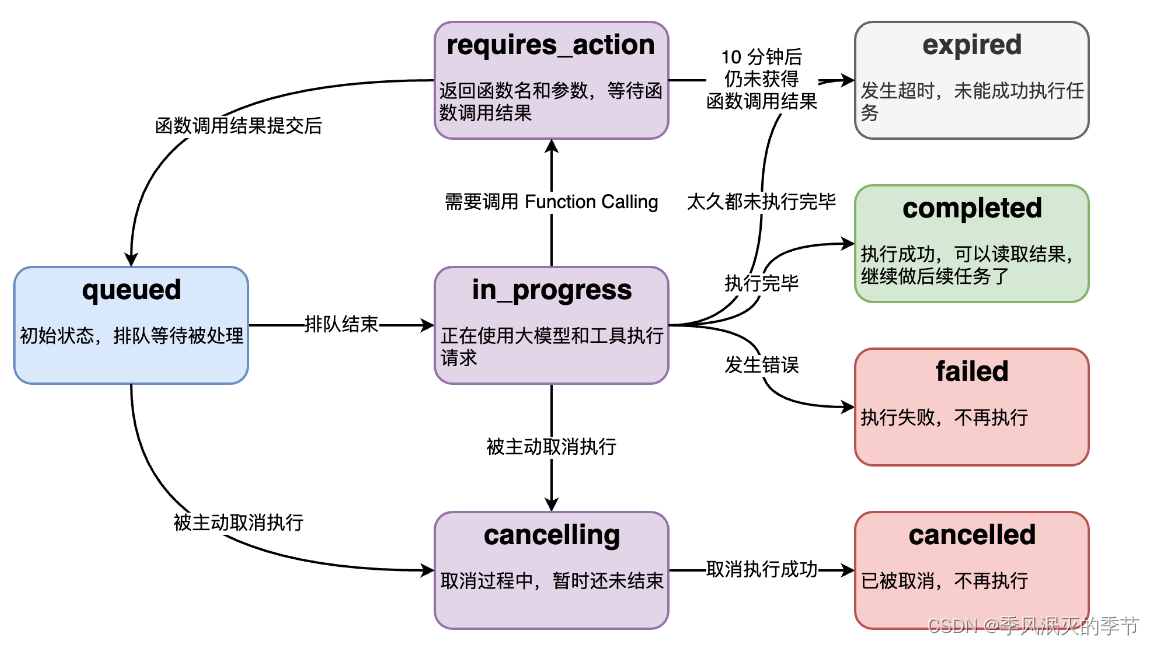
【AI大模型】GPTS 与 Assistants API
前言 2023 年 11 月 6 日,OpenAI DevDay 发表了一系列新能力,其中包括:GPT Store 和 Assistants API。 GPTs 和 Assistants API 本质是降低开发门槛 可操控性和易用性之间的权衡与折中: 更多技术路线选择:原生 API、…...

攻击者开始使用 XLL 文件进行攻击
近期,研究人员发现使用恶意 Microsoft Excel 加载项(XLL)文件发起攻击的行动有所增加,这项技术的 MITRE ATT&CK 技术项编号为 T1137.006。 这些加载项都是为了使用户能够利用高性能函数,为 Excel 工作表提供 API …...

Why RAG is slower than LLM?
I used RAG with LLAMA3 for AI bot. I find RAG with chromadb is much slower than call LLM itself. Following the test result, with just one simple web page about 1000 words, it takes more than 2 seconds for retrieving: 我使用RAG(可能是指某种特定的…...

Word页码设置,封面无页码,目录摘要阿拉伯数字I,II,III页码,正文开始123为页码
一、背景 使用Word写项目书或论文时,需要正确插入页码,比如封面无页码,目录摘要阿拉伯数字I,II,III为页码,正文开始以123为页码,下面介绍具体实施方法。 所用Word版本:2021 二、W…...
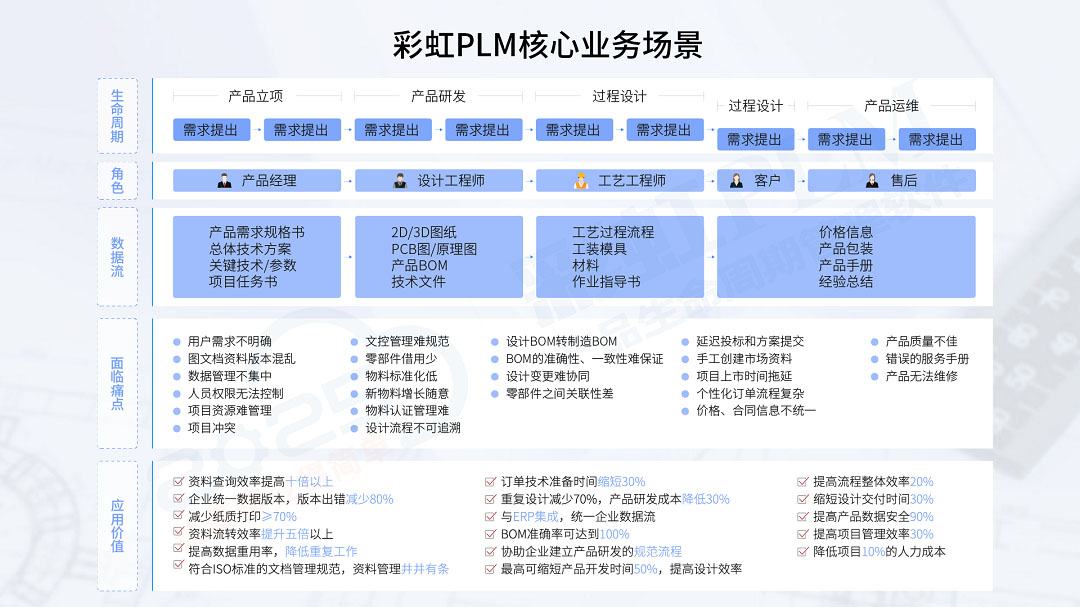
汽车汽配图纸管理、产品研发管理解决方案
汽车汽配图纸管理、产品研发管理解决方案 随着全球汽车市场的快速发展,中国汽车汽配行业迎来了前所未有的发展机遇。然而,在这一过程中,企业也面临着诸多挑战,如研发能力的提升、技术资料管理的复杂性、以及跨部门协作的困难等。为…...

小程序简单版音乐播放器
小程序简单版音乐播放器 结构 先来看看页面结构 <!-- wxml --><!-- 标签页标题 --> <view class"tab"><view class"tab-item {{tab0?active:}}" bindtap"changeItem" data-item"0">音乐推荐</view><…...

驾校预约管理系统
摘 要 随着驾驶技术的普及和交通安全意识的增强,越来越多的人选择参加驾校培训,以获取驾驶执照。然而,驾校管理面临着日益增长的学员数量和繁琐的预约管理工作。为了提高驾校的管理效率和服务质量,驾校预约管理系统成为了必不可少…...
 || 浅拷贝,深拷贝 || 数据类型)
C++ 左值右值 || std::move() || 浅拷贝,深拷贝 || 数据类型
数据类型: 作用:决定变量所占内存空间的字节大小,和布局方式基本数据类型: 算数类型: 整形(bool / char……扩展集 / int / long……)&& 浮点形(float/double……ÿ…...

如何在看板中体现优先级变化
在看板中有效体现优先级变化的关键措施包括:采用颜色或标签标识优先级、设置任务排序规则、使用独立的优先级列或泳道、结合自动化规则同步优先级变化、建立定期的优先级审查流程。其中,设置任务排序规则尤其重要,因为它让看板视觉上直观地体…...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

Springcloud:Eureka 高可用集群搭建实战(服务注册与发现的底层原理与避坑指南)
引言:为什么 Eureka 依然是存量系统的核心? 尽管 Nacos 等新注册中心崛起,但金融、电力等保守行业仍有大量系统运行在 Eureka 上。理解其高可用设计与自我保护机制,是保障分布式系统稳定的必修课。本文将手把手带你搭建生产级 Eur…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...

排序算法总结(C++)
目录 一、稳定性二、排序算法选择、冒泡、插入排序归并排序随机快速排序堆排序基数排序计数排序 三、总结 一、稳定性 排序算法的稳定性是指:同样大小的样本 **(同样大小的数据)**在排序之后不会改变原始的相对次序。 稳定性对基础类型对象…...

08. C#入门系列【类的基本概念】:开启编程世界的奇妙冒险
C#入门系列【类的基本概念】:开启编程世界的奇妙冒险 嘿,各位编程小白探险家!欢迎来到 C# 的奇幻大陆!今天咱们要深入探索这片大陆上至关重要的 “建筑”—— 类!别害怕,跟着我,保准让你轻松搞…...

【JavaSE】多线程基础学习笔记
多线程基础 -线程相关概念 程序(Program) 是为完成特定任务、用某种语言编写的一组指令的集合简单的说:就是我们写的代码 进程 进程是指运行中的程序,比如我们使用QQ,就启动了一个进程,操作系统就会为该进程分配内存…...

【Linux系统】Linux环境变量:系统配置的隐形指挥官
。# Linux系列 文章目录 前言一、环境变量的概念二、常见的环境变量三、环境变量特点及其相关指令3.1 环境变量的全局性3.2、环境变量的生命周期 四、环境变量的组织方式五、C语言对环境变量的操作5.1 设置环境变量:setenv5.2 删除环境变量:unsetenv5.3 遍历所有环境…...

Oracle11g安装包
Oracle 11g安装包 适用于windows系统,64位 下载路径 oracle 11g 安装包...