LLM大语言模型-AI大模型全面介绍
简介: 大语言模型(LLM)是深度学习的产物,包含数十亿至数万亿参数,通过大规模数据训练,能处理多种自然语言任务。LLM基于Transformer架构,利用多头注意力机制处理长距离依赖,经过预训练和微调,擅长文本生成、问答等。发展经历了从概率模型到神经网络,再到预训练和大模型的演变。虽然强大,但存在生成不当内容、偏见等问题,需要研究者解决。评估指标包括BLEU、ROUGE和困惑度PPL。
大语言模型 (LLM) 背景
🍹大语言模型 (Large Language Model) 是一种人工智能模型, 它们通常包含数千亿甚至更多的参数,并在大规模数据集上进行训练。大语言模型可以处理多种自然语言任务,如文本分类、问答、翻译、对话等等。
- 自然语言模型的发展经历了从概率模型到神经网络模型,再到大型语言模型的过程。在这个过程中,关键技术的发展推动了模型的演进和性能的提升。
- LLM通常建立在Transformer架构之上,这种架构使用了多头注意力机制,能够处理长距离的依赖关系。这些模型通过堆叠多个注意力层来提高其处理复杂语言任务的能力。
- 随着模型参数数量的增加,LLM展现出了小模型所不具备的特殊能力,如上下文学习能力和逐步推理能力。这些能力的涌现使得LLM在多项任务中取得了显著的效果提升。
- LLM的训练过程通常包括预训练和微调两个阶段。在预训练阶段,模型在大量无标签数据上学习语言的一般性规律;在微调阶段,模型通过有标签数据进行调优,以适应特定的下游任务。
- LLM的应用产生了深远的影响,例如ChatGPT等模型展现出了强大的人机对话能力和任务求解能力,这对整个AI研究社区产生了重大影响。
- 尽管LLM在多方面展现出了强大的能力,但同时也带来了一些风险和挑战,如生成不当内容、偏见放大等问题,这些都需要研究者在模型设计和训练过程中予以重视和解决。
🍹语言模型发展的三个阶段 :
- 第一阶段 :设计一系列的自监督训练目标(MLM、NSP等),设计新颖的模型架构(Transformer),遵循Pre-training和Fine-tuning范式。典型代表是BERT、GPT、XLNet等;
- 第二阶段 :逐步扩大模型参数和训练语料规模,探索不同类型的架构。典型代表是BART、T5、GPT-3等;
- 第三阶段 :走向AIGC(Artificial Intelligent Generated Content)时代,模型参数规模步入千万亿,模型架构为自回归架构,大模型走向对话式、生成式、多模态时代,更加注重与人类交互进行对齐,实现可靠、安全、无毒的模型。典型代表是InstructionGPT、ChatGPT、Bard、GPT-4等。
语言模型通俗理解:用来计算一个句子的概率的模型,也就是判断一句话是否是人话的概率 。
标准定义:对于某个句子序列, 如S = {W1, W2, W3, …, Wn}, 语言模型就是计算该序列发生的概率,如果给定的词序列符合语用习惯, 则给出高概率, 否则给出低概率。
🥂让我们通过一些具体的例子来理解语言模型如何计算句子的概率,并判断一句话是否符合自然语言的语用习惯。
假设有一个非常简单的语言模型,它基于词频来计算句子的概率。这个模型会统计每个单词在大量文本中出现的次数,然后用这些频率来估计概率。例如,如果单词 “the” 在训练集中出现了非常多次,那么 P(the) 就会很高。对于句子 “The quick brown fox jumps over the lazy dog,” 模型会计算每个单词的概率,并将它们相乘得到整个句子的概率 P(S)。
P(S)=P(The)×P(quick)×P(brown)×…timesP(dog)
更复杂的语言模型,如n-gram模型,不仅考虑单个单词的频率,还考虑单词序列的频率。例如,一个bi-gram模型会考虑像 “quick brown” 这样的词对在文本中共同出现的频率。这样,它可以捕捉到一些单词之间的概率依赖关系,比如 “quick” 后面很可能会跟着 “brown”。
P(S)=P(The)×P(quick∣The)×P(brown∣quick)×…×P(dog)
现代语言模型,如基于Transformer的模型,使用深度学习来捕捉更加复杂的语言结构。这些模型可以处理长距离的依赖关系,并且能够根据上下文来预测下一个单词。例如,如果你输入了 “The cat is on the”, 模型可能会预测下一个单词是 “mat”,因为它学会了 “on the mat” 是一个常见的短语。
基于语言模型技术的发展,可以将语言模型分为四种类型:
-
基于规则和统计的语言模型
-
神经语言模型
-
预训练语言模型
-
大语言模型
- 基于规则和统计的语言模型:早期的语音识别系统多采用这种语言模型,它通过计算词序列出现的概率来评估句子的合理性。N-gram模型就是一种典型的基于统计的语言模型,它利用大量文本数据来计算单词序列出现的频率。
- 神经语言模型:随着深度学习的发展,神经语言模型(Neural Language Model, NLM)开始兴起。这类模型通常使用神经网络结构,如前馈神经网络(FeedForward Neural Network LM)、循环神经网络(RNN LM)等,能够捕捉到更为复杂的语言模式和上下文信息。
- 预训练语言模型:预训练语言模型(Pre-trained Language Model, PLM)是在大规模数据集上进行无监督预训练的模型,然后再针对特定任务进行微调。BERT(Bidirectional Encoder Representations from Transformers)就是一个著名的预训练语言模型,它通过预训练获得丰富的语义表示,适用于多种自然语言处理任务。
- 大语言模型:大规模语言模型(Large Language Model, LLM)通常拥有数十亿到数万亿个参数,能够处理各种自然语言处理任务,如自然语言生成、文本分类、文本摘要、机器翻译、语音识别等。这些模型基于深度学习技术,使用互联网上的海量文本数据进行训练,具有强大的语言理解和生成能力。
N-gram
N-gram是一种基于统计的语言模型算法,用于预测下一个词或字符出现的概率💡。
N-gram模型的核心思想是将文本分割成连续的n个词(或字符)的序列,这些序列被称为grams。然后,模型统计这些n-grams在文本中出现的频率,以此作为预测下一个词或字符出现概率的依据。这里的n是一个正整数,表示词组中词的个数。例如,在句子“我喜欢学习自然语言处理”中,1-gram(unigram)是单个词,如“我”、“喜欢”、“学习”等;2-gram(bigram)是两个连续的词,如“我喜欢”、“喜欢学习”等;而3-gram(trigram)则是三个连续的词,如“我喜欢学习”、“喜欢学习自然”等。为了解决参数空间过大问题,引入马尔科夫假设:随意一个词出现的概率只与它前面出现的有限的一个或者几个词有关。
- 如果一个词的出现与它周围的词是独立的,那么我们就称之为unigram也就是一元语言模型:P(S) = P(W_1)P(W_2)…*P(W_n)
- 如果一个词的出现仅依赖于它前面出现的一个词,那么我们就称之为bigram:P(S) = P(W_1)*P(W_2|W_1)P(W_3|W_2)…*P(W_n|W_{n-1})
- 如果一个词的出现仅依赖于它前面出现的两个词,那么我们就称之为trigram:P(S) = P(W_1)*P(W_2|W_1)P(W_3|W_2,W_1)…*P(W_n|W_{n-1},W_{n-2})
在实践中用的最多的就是bigram和trigram,接下来以bigram语言模型为例,理解其工作原理:
首先我们准备一个语料库(数据集),为了计算对应的二元模型的参数,即 P ( W i ∣ W i − 1 ) P(W_i|W{i-1}) P(Wi∣Wi−1),我们要先计数即 C ( W i − 1 , W i ) C(W{i-1},W_i) C(Wi−1,Wi),然后计数 C ( W i − 1 ) C(W_{i-1}) C(Wi−1) , 再用除法可得到概率。
根据给定的计数结果,我们可以计算bigram语言模型的参数。首先,我们需要将计数结果转换为概率形式,计算一个句子的概率 :

N-gram语言模型的特点:
-
优点:采用极大似然估计, 参数易训练; 完全包含了前n-1个词的全部信息; 可解释性强, 直观易理解。
-
缺点:缺乏长期以来,只能建模到前n-1个词; 随着n的增大,参数空间呈指数增长。数据稀疏,难免会出现OOV问题; 单纯的基于统计频次,泛化能力差。
神经网络语言模型
伴随着神经网络技术的发展,人们开始尝试使用神经网络来建立语言模型进而解决N-gram语言模型存在的问题。
- 模型的输入: w t − n + 1 , … , w t − 2 , w t − 1 w{t-n+1}, …, w{t-2}, w_{t-1} wt−n+1,…,wt−2,wt−1就是前n-1个词。现在需要根据这已知的n-1个词预测下一个词 w t w_t wt。 C ( w ) C(w) C(w)表示 w w w所对应的词向量。
- 网络的第一层(输入层)是将 C ( w t − n + 1 ) , … , C ( w t − 2 ) , C ( w t − 1 ) C(w{t-n+1}),…,C(w{t-2}), C(w_{t-1}) C(wt−n+1),…,C(wt−2),C(wt−1)这n-1个向量首尾拼接起来形成一个 ( n − 1 ) ∗ m (n-1)*m (n−1)∗m大小的向量,记作 x x x。
- 网络的第二层(隐藏层)就如同普通的神经网络,直接使用一个全连接层, 通过全连接层后再使用 t a n h tanh tanh这个激活函数进行处理。
- 网络的第三层(输出层)一共有 V V V个节点 ( V V V 代表语料的词汇),本质上这个输出层也是一个全连接层。每个输出节点 y i y_i yi表示下一个词语为 i i i 的未归一化log 概率。最后使用 softmax 激活函数将输出值 y y y进行归一化。得到最大概率值,就是我们需要预测的结果。
基于Transformer的预训练语言模型
基于Transformer的预训练语言模型(T-PTLM)是自然语言处理领域的一大创新,它们通过在大量无标注文本数据上进行预训练来学习通用的语言表征,并能够将这些知识迁移到各种下游任务中,以下是一些重要的T-PTLM及其特点:
- GPT(Generative Pre-training Transformer):GPT是一种生成型预训练语言模型,它使用Transformer架构从大规模语料库中学习语言的内在结构和语义信息。GPT的核心思想是自回归建模,即通过逐词预测下一个词的方式来生成整个句子或文本。
- BERT(Bidirectional Encoder Representations from Transformers):BERT是一个双向的Transformer编码器,它通过预训练任务(如遮蔽语言模型和下一句预测)来捕捉文本中的上下文信息。BERT模型在多种NLP任务中取得了显著的性能提升。
- XLNet:XLNet是一种改进的自回归模型,它在GPT的基础上引入了Transformer-XL中的相对位置编码和段级重复机制,旨在克服GPT在长距离依赖学习和复制机制上的不足。
大语言模型
随着对预训练语言模型研究的开展,人们逐渐发现可能存在一种标度定律,随着预训练模型参数的指数级提升,其语言模型性能也会线性上升。2020年,OpenAI发布了参数量高达1750亿的GPT-3,首次展示了大语言模型的性能。
大语言模型的特点💡:
-
优点:具备了能与人类沟通聊天的能力,甚至具备了使用插件进行自动信息检索的能力。
-
缺点:参数量大,算力(进行模型训练和推理所需的计算能力)要求高、生成部分有害的、有偏见的内容等等。
语言模型的评估指标
BLEU
BLEU (Bilingual Evaluation Understudy) 是一种广泛使用的评估机器翻译系统输出质量的指标。它通过比较机器翻译的结果和一组参考翻译(通常由人工翻译或被认为是准确的翻译)来计算翻译的准确性。BLEU算法实际上就是在判断两个句子的相似程度.,BLEU 的分数取值范围是 0~1,分数越接近1,说明翻译的质量越高。
在实际应用中,通常会计算BLEU-1到BLEU-4的值,并对它们进行加权平均以得到一个综合的BLEU分数。这样做的原因是不同的n-gram级别能够捕捉翻译质量的不同方面:BLEU-1更侧重于词汇的准确性,而BLEU-2、BLEU-3和BLEU-4则能够更好地衡量句子的流畅性和结构一致性。
candidate: {it, is, a, nice, day, today}
reference: {today, is, a, nice, day}
☕️
其中{today, is, a, nice, day}匹配,所以匹配度为5/6
candidate: {it is, is a, a nice, nice day, day today}
reference: {today is, is a, a nice, nice day}
☕️
其中{is a, a nice, nice day}匹配,所以匹配度为3/5
candidate: {it is a, is a nice, a nice day, nice day today}
reference: {today is a, is a nice, a nice day}
☕️
其中{is a nice, a nice day}匹配,所以匹配度为2/4
candidate: the the the the
reference: The cat is standing on the ground
如果按照1-gram的方法进行匹配,则匹配度为1,显然是不合理的,所以计算某个词的出现次数进行改进。
ROUGE
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)是一种评估自动文本摘要或机器翻译输出质量的指标,它通过比较生成的摘要与一组参考摘要(通常由人工创建)之间的相似度来衡量。与BLEU类似,ROUGE也使用n-gram的概念,但它们的计算方式和侧重点有所不同。
ROUGE指标通常报告为召回率,因为它更关注生成摘要中包含多少参考摘要的信息,而BLEU则更注重精确率,即生成摘要的准确性。
ROUGE分为四种方法:ROUGE-N, ROUGE-L, ROUGE-W, ROUGE-S。
-
ROUGE-N (ROUGE-n): 计算生成摘要中n-gram(连续的n个单词)在参考摘要中出现的频率。ROUGE-N通常用于计算Unigram(N=1),Bigram(N=2)和Trigram(N=3)。
-
ROUGE-L (ROUGE-L): 基于最长公共子序列(Longest Common Subsequence, LCS)的方法,计算生成摘要与参考摘要之间的LCS长度与参考摘要长度的比例。
-
ROUGE-W (ROUGE-W): 基于最长公共子串(Longest Common Substring, LCS)的方法,计算生成摘要与参考摘要之间的LCS数量与参考摘要中的单词总数之比。
-
ROUGE-S (ROUGE-S): 基于序列的匹配,允许间隔性的词匹配,而不是连续的n-gram匹配。
困惑度PPL
困惑度(Perplexity)是衡量概率模型预测样本的好坏程度的一种指标。在自然语言处理中,它常用于评估语言模型的性能。困惑度越低,表示模型的预测能力越好。
PPL=exp(−fraclog(P(X))N),其中,P(X) 是模型对整个数据集的概率分布的连乘积,N 是数据集中的总词数。困惑度能够衡量语言模型对文本的生成能力,即模型预测单词序列的概率分布的准确性~
相关文章:
LLM大语言模型-AI大模型全面介绍
简介: 大语言模型(LLM)是深度学习的产物,包含数十亿至数万亿参数,通过大规模数据训练,能处理多种自然语言任务。LLM基于Transformer架构,利用多头注意力机制处理长距离依赖,经过预训…...
瑜伽馆管理系统的设计
管理员账户功能包括:系统首页,个人中心,管理员管理,教练管理,用户管理,瑜伽管理,套餐管理,体测报告管理,基础数据管理 前台账户功能包括:系统首页࿰…...

JAVA【案例5-2】模拟默认密码自动生成
【模拟默认密码自动生成】 1、案例描述 本案例要求编写一个程序,模拟默认密码的自动生成策略,手动输入用户名,根据用户名自动生成默认密码。在生成密码时,将用户名反转即为默认的密码。 2、案例目的 (1)…...

小区业主管理系统
摘 要 随着城市化进程的加速和人口的不断增加,小区的数量也在不断增加。小区作为城市居民居住的主要场所,其管理工作也变得越来越重要。传统的小区业主管理方式存在诸多问题,如信息传递不畅、业务处理效率低下等。因此,开发一个高…...
vncsever ,window 远程ubuntu远程界面安装方式,VNC Viewer安装教程+ linux配置server 操作
linux 端安装 # 安装VNC 服务器软件 sudo apt install autocutsel # 剪切黏贴操作支持的包 sudo apt-get install tightvncserver # 安装的是 VNC 服务器软件,用于远程桌面访问 # 安装Xfce桌面环境 sudo apt-get install xfce4 xfce4-goodies #安装的是 XFCE 桌…...

java spring boot 单/多文件上传/下载
文章目录 使用版本文件上传服务端客户端(前端)方式一方式二 文件下载服务端客户端(前端) 代码仓库地址 使用版本 后端 spring-boot 3.3.0jdk17 前端 vue “^3.3.11”vite “^5.0.8”axios “^1.7.2” 文件上传 上传文件比较…...

C语言的内存函数
1. memcpy使⽤和模拟实现 1 void * memcpy ( void * destination, const void * source, size_t num ); • 函数memcpy从source的位置开始向后复制num个字节的数据到destination指向的内存位置。 • 这个函数在遇到 \0 的时候并不会停下来。 • 如果source和destination有任…...

【网络通信】计算机网络安全技术总结
一、概述 在数字时代的浪潮下,计算机网络安全技术已成为保护数据完整性和安全性的基石。这项技术不仅是计算机科学的重要组成部分,也是应对各种网络威胁和挑战的关键手段。 二、核心技术和应用 2.1 加密技术 作为网络安全技术的核心,加密技…...
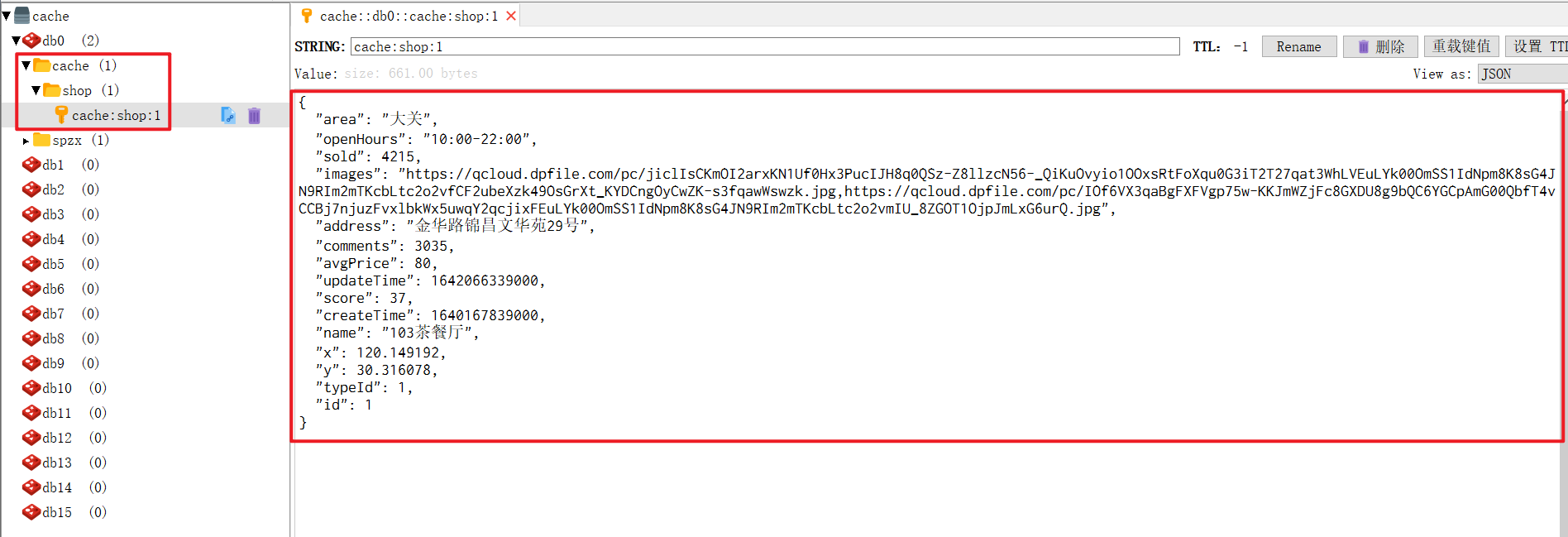
Redis-实战篇-什么是缓存-添加redis缓存
文章目录 1、什么是缓存2、添加商户缓存3、前端接口4、ShopController.java5、ShopServiceImpl.java6、RedisConstants.java7、查看Redis Desktop Manager 1、什么是缓存 缓存就是数据交换的缓冲区(称为Cache),是存贮数据的临时地方ÿ…...

《妃梦千年》第十一章:再遇故人
第十一章:再遇故人 宫中的局势暂时平静下来,但林清婉知道,危险随时可能卷土重来。她必须不断提升自己,才能在这复杂的环境中保护自己和皇上。一天,林清婉正在寝宫中读书,忽然收到了一封信。信中只有短短几…...
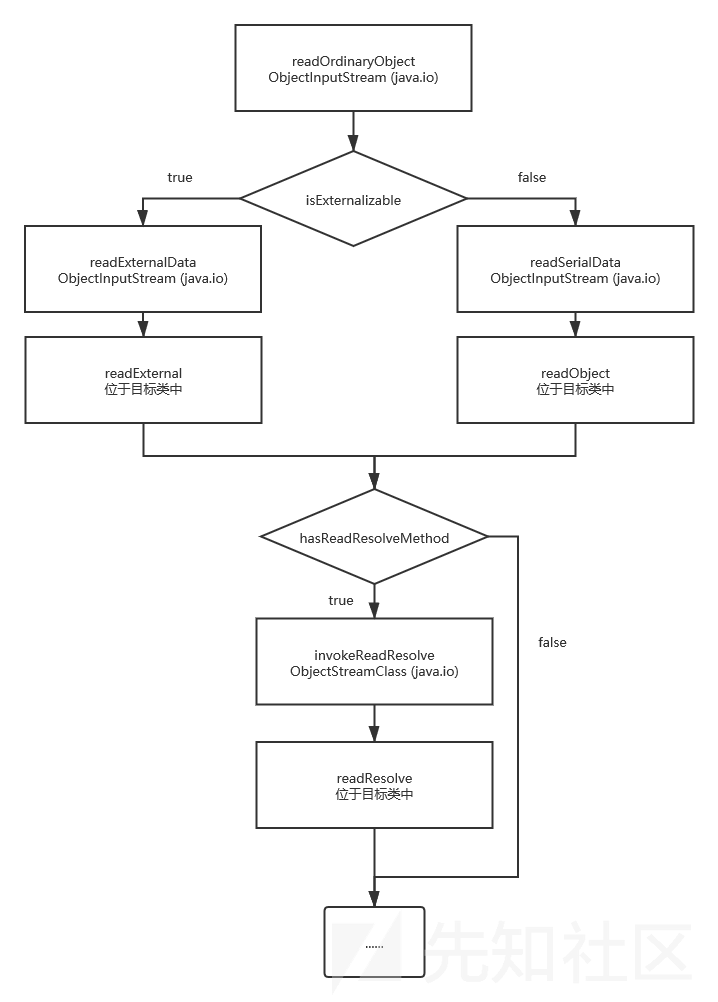
反序列化底层学习
反序列化底层学习 前言 以前也是懒得学,觉得没有必要,学到现在发现好多东西都需要学习java的底层,而且很多漏洞都是通过反序列化底层挖出来的,比如weblogic的一些绕过,我这里也主要是为了学习weblogic来学习的&#…...
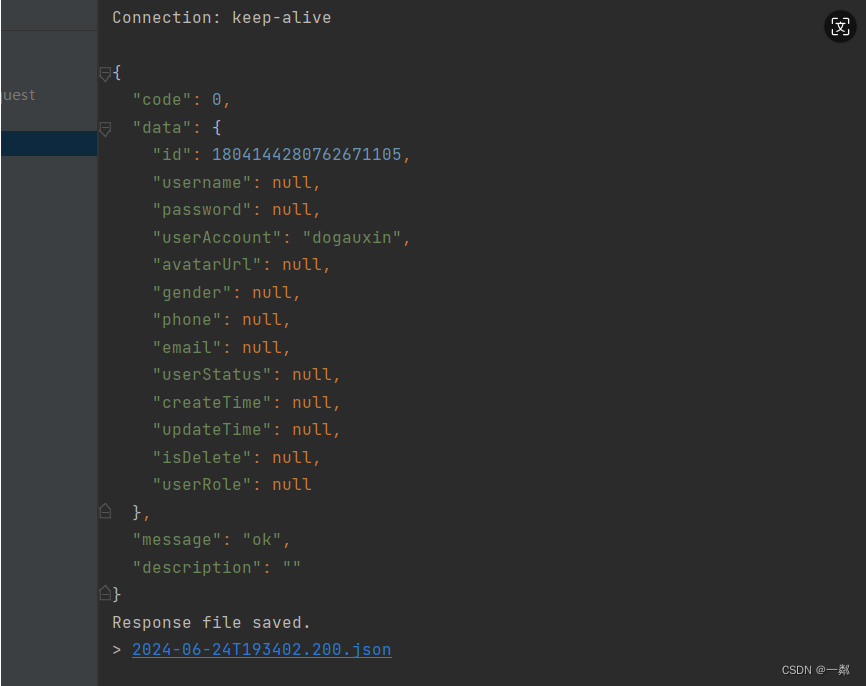
项目训练营第五天
项目训练营第五天 后端代码优化 通用异常处理类编写 Data public class BaseResponse<T> implements Serializable {int code;T data;String message null;String description null;public BaseResponse(int code, T data, String message, String description) {th…...

数据收集和数据分析
数据分析和收集是一个多步骤的过程,涉及到不同的方法和思维构型。 以下是一些常见的数据收集方法和数据分析的思维模式: ### 数据收集方法: 1. **调查问卷**: 通过设计问卷来收集定量或定性数据。(质量互变规律里面…...
从入门到精通系列之十九:Operator模式)
Kubernetes(K8s)从入门到精通系列之十九:Operator模式
Kubernetes K8s从入门到精通系列之十九:Operator模式 一、动机二、Operators in Kubernetes三、Operator示例四、部署Operator五、使用Operator六、编写自己的operator Operator 是 Kubernetes 的软件扩展,它利用自定义资源来管理应用程序及其组件。 Ope…...
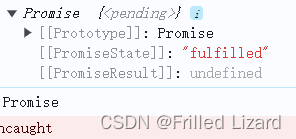
vuex的actions返回结果类型是promise及actions方法互相调用
this.$store.dispatch(‘logout’)返回的结果是Promise类型的 调用成功的情况下,返回状态为fulfilled,值为undefined。 所以可以直接进行.then操作: this.$store.dispatch(logout).then((result) > {console.log(result); });因为 Vuex …...
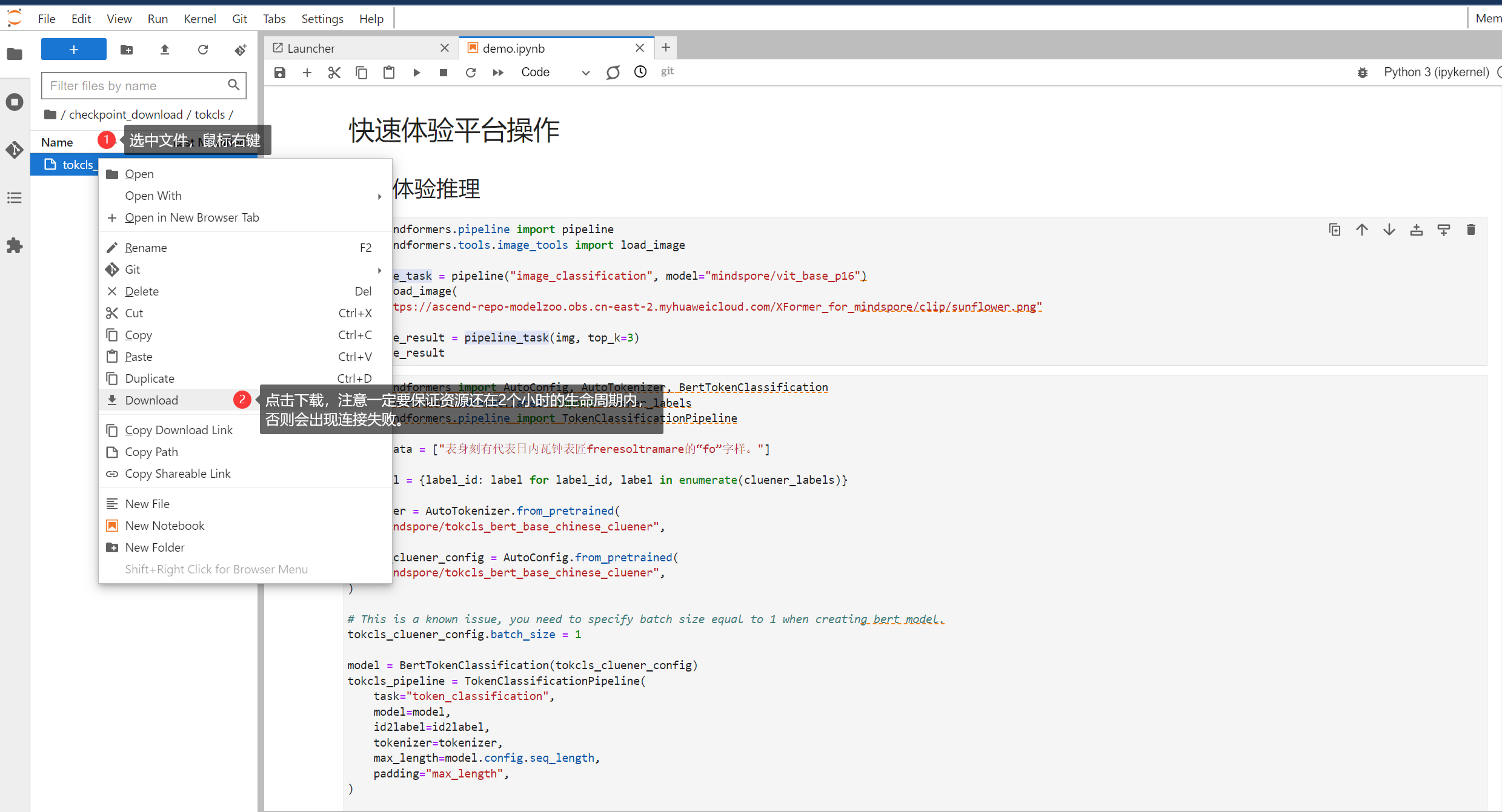
【干货】Jupyter Lab操作文档
Jupyter Lab操作文档1. 使用须知2. 定制化Jupyter设置主题显示代码行数设置语言更多设置 3. 认识Jupyter界面4. 初用Jupyter运行调试格式化查看源码 5. 使用Jupyter Terminal6. 使用Jupyter Markdown7. 上传下载文件(云服务器中的Jupyter Lab)上传文件到…...
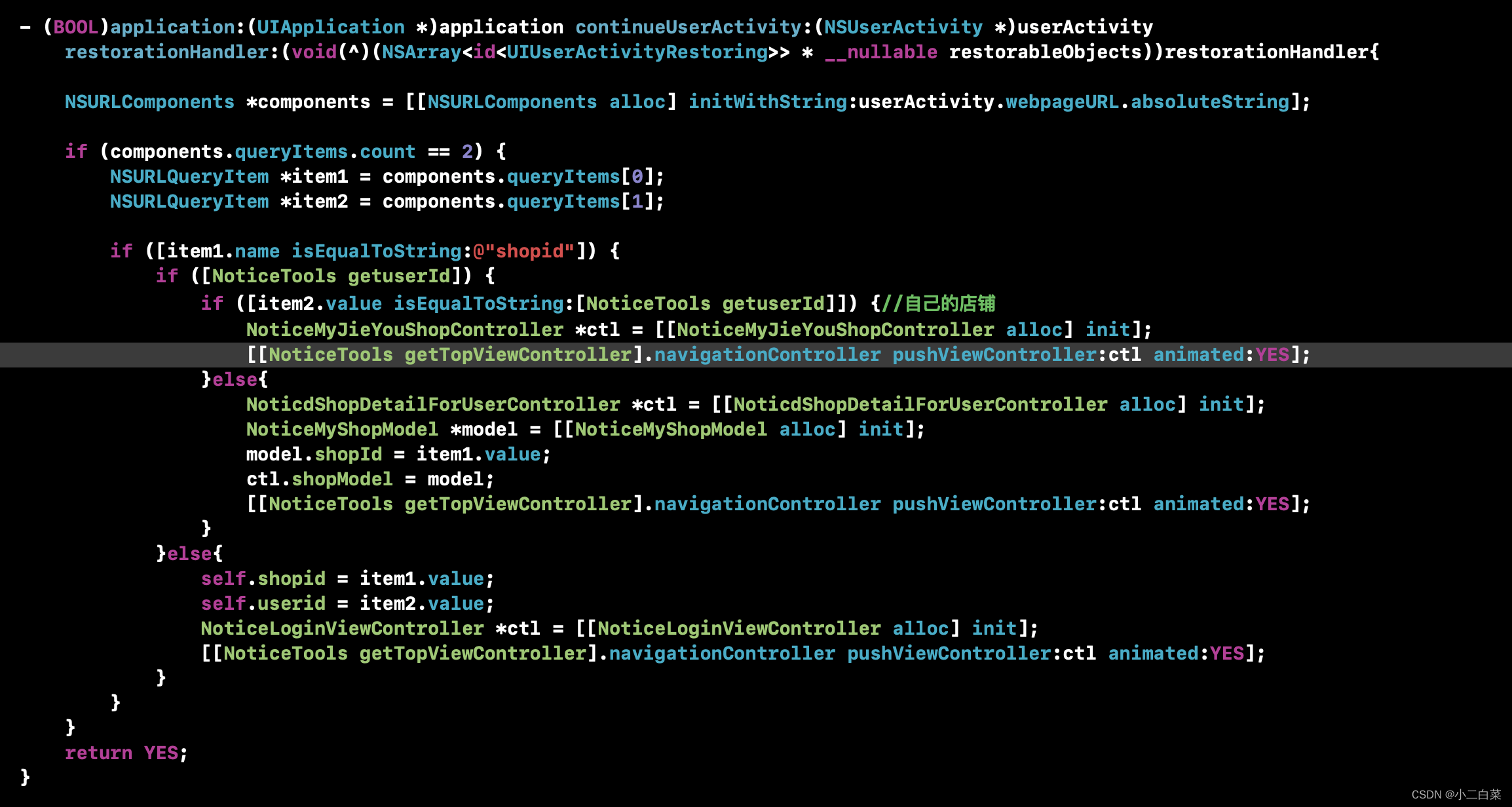
iOS分享到微信,配置Universal Links,并从微信打开app,跳转到指定界面
iOS分享到微信之后,需要从微信浏览器直接打开app,跳转到指定界面,这个时候最主要的就是分以下几步(微信sdk集成就不说了) 1.配置Universal Links Universal Links是iOS新系统出来后通用链接,用于在第三方浏览器直接打开app&…...
基于SSM构建的校园失眠与压力管理系统的设计与实现【附源码】
毕业设计(论文) 题目:基于SSM构建的校园失眠与压力管理系统的设计与实现 二级学院: 专业(方向): 班 级: 学 生: 指导教师&a…...

SAP 初始化库存移动类型561501511区别简介
项目上线初始化库存经常会用到561这个移动类型,同时我们在平时测试的过程中也会用到会进行库存的初始化,用的比较多是就是561和501这两个移动类型,本文将测试移动类型561&501&511这三个移动类型,分析三者之间的区别&#…...

情感搞笑聊天记录视频:AI自动化生成技术,操作简单,教程+软件
在数字化时代,内容创作已成为吸引观众、传递信息的重要手段。随着人工智能技术的飞速发展,AI自动生成视频为创作者提供了新的工具和可能性。本文将介绍如何利用AI技术,通过情感搞笑聊天记录视频,在视频号上实现内容的自动化生成&a…...

AI-调查研究-01-正念冥想有用吗?对健康的影响及科学指南
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

多模态大语言模型arxiv论文略读(108)
CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文标题:CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文作者:Sayna Ebrahimi, Sercan O. Arik, Tejas Nama, Tomas Pfister ➡️ 研究机构: Google Cloud AI Re…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

python执行测试用例,allure报乱码且未成功生成报告
allure执行测试用例时显示乱码:‘allure’ �����ڲ����ⲿ���Ҳ���ǿ�&am…...

08. C#入门系列【类的基本概念】:开启编程世界的奇妙冒险
C#入门系列【类的基本概念】:开启编程世界的奇妙冒险 嘿,各位编程小白探险家!欢迎来到 C# 的奇幻大陆!今天咱们要深入探索这片大陆上至关重要的 “建筑”—— 类!别害怕,跟着我,保准让你轻松搞…...

Linux nano命令的基本使用
参考资料 GNU nanoを使いこなすnano基础 目录 一. 简介二. 文件打开2.1 普通方式打开文件2.2 只读方式打开文件 三. 文件查看3.1 打开文件时,显示行号3.2 翻页查看 四. 文件编辑4.1 Ctrl K 复制 和 Ctrl U 粘贴4.2 Alt/Esc U 撤回 五. 文件保存与退出5.1 Ctrl …...

认识CMake并使用CMake构建自己的第一个项目
1.CMake的作用和优势 跨平台支持:CMake支持多种操作系统和编译器,使用同一份构建配置可以在不同的环境中使用 简化配置:通过CMakeLists.txt文件,用户可以定义项目结构、依赖项、编译选项等,无需手动编写复杂的构建脚本…...

基于江科大stm32屏幕驱动,实现OLED多级菜单(动画效果),结构体链表实现(独创源码)
引言 在嵌入式系统中,用户界面的设计往往直接影响到用户体验。本文将以STM32微控制器和OLED显示屏为例,介绍如何实现一个多级菜单系统。该系统支持用户通过按键导航菜单,执行相应操作,并提供平滑的滚动动画效果。 本文设计了一个…...

如何通过git命令查看项目连接的仓库地址?
要通过 Git 命令查看项目连接的仓库地址,您可以使用以下几种方法: 1. 查看所有远程仓库地址 使用 git remote -v 命令,它会显示项目中配置的所有远程仓库及其对应的 URL: git remote -v输出示例: origin https://…...
2025-05-08-deepseek本地化部署
title: 2025-05-08-deepseek 本地化部署 tags: 深度学习 程序开发 2025-05-08-deepseek 本地化部署 参考博客 本地部署 DeepSeek:小白也能轻松搞定! 如何给本地部署的 DeepSeek 投喂数据,让他更懂你 [实验目的]:理解系统架构与原…...