Robust semi-supervised segmentationwith timestep ensembling diffusion models
时间步合成扩散模型的鲁棒半监督分割
摘要
医学图像分割是一项具有挑战性的任务,由于许多数据集的大小和注释的限制,使得分割更加困难。消噪扩散概率模型(DDPM)最近在模拟自然图像的分布方面显示出前景,并成功地应用于各种医学成像任务。这项工作的重点是使用扩散模型进行半监督图像分割,特别是处理域泛化。首先,我们证明了较小的扩散步长产生的潜在表征对下游任务比较大步长更鲁棒。其次,我们利用这一见解提出了一种改进的相似方案,该方案利用信息密集的小步骤和大步骤的正则化效应来生成预测。我们的模型在领域转移设置中表现出明显更好的性能,同时在领域内保持竞争性能。总的来说,这项工作突出了ddpm在半监督医学图像分割方面的潜力,并提供了在域移位下优化其性能的见解。
1 介绍
去噪扩散概率模型(DDPM) (Sohl-Dickstein等,2015;Ho等人,2020)最近成为自然图像分布建模的一种有前途的方法,在样本真实感和多样性方面优于其他方法。最近,DDPM也成功地应用于各种医学成像任务,如合成图像生成(Kim and Ye, 2022),图像重建(Xie and Li, 2022;Peng et al ., 2022),异常检测(Wolleb et al ., 2022;Pinaya等人,2022),诊断(Aviles-Rivero等人,2022)和分割(Wolleb等人,2022)。
图像分割在医学成像中至关重要,需要准确有效的方法来支持诊断、治疗计划和疾病监测。然而,医学成像数据集通常规模有限,可能缺乏足够的注释,这使得训练准确的分割模型具有挑战性。此外,由于采集参数、扫描仪类型和患者人口统计数据的差异,医学成像数据具有高度可变性的特点。这种现象,也被称为领域转移,对应用于新数据集的分割模型的泛化提出了重大挑战,导致临床环境中潜在的性能不佳。
最近对扩散模型的研究显示了半监督学习的有希望的结果(Baranchuk等人,2021;Deja等人,2023)基于瓶颈网络的发现,瓶颈网络的任务是学习从图像中去除噪声的反向过程,也学习了一种富有表现力的特征表示,可以有利于其他下游分析任务。已经提出了几种技术来利用中间扩散步骤来改善域内下游性能。然而,需要对这些设计选择对模型泛化的影响进行更多的研究。
我们的工作重点是后一个问题。
具体来说,我们研究了如何最优地利用扩散步骤来提高域移位下半监督图像分割的泛化。
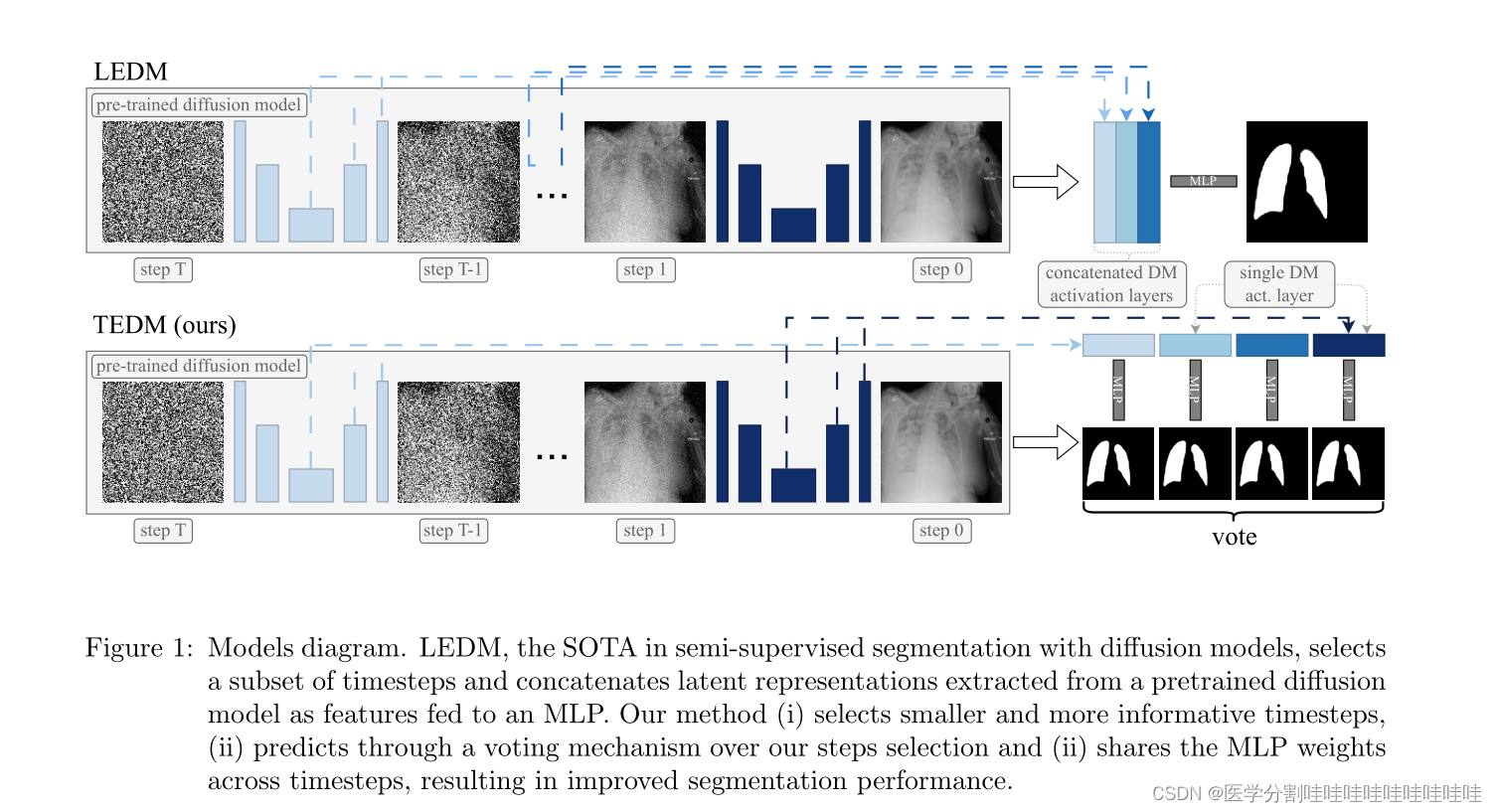
图1:模型图。LEDM是带有扩散模型的半监督分割中的SOTA,它选择一个时间步长子集,并将从预训练的扩散模型中提取的潜在表征连接起来作为特征馈入MLP。我们的方法(i)选择更小和更有信息量的时间步长,(ii)通过投票机制对我们的步骤选择进行预测,(ii)跨时间步长共享MLP权重,从而提高分割性能。
基于对不同成像方式和域转移的数据集的分析,我们的研究结果表明,使用五种不同的数据集,比现有的基线有了显著的改进。我们的主要发现可以总结如下:
①小的扩散步骤对模型泛化至关重要;
②通过步骤串联潜在表示来预测分割图可能会损害泛化;
③相反,通过(i)优化在测试时使用的时间步长,(ii)使用共享预测器从单个时间步长集成预测,以及(iii)在训练期间使用这些单个预测进行正则化,可以显著改善泛化。
2. 背景及相关工作
2.1. 扩散模型
扩散模型在机器学习社区中引起了极大的兴趣,因为它们具有有效地模拟复杂数据分布的卓越能力。扩散模型利用一系列简单的和可学习变换迭代扩散噪声并从目标分布生成样本。
正式地,DDPM的工作方式如下。给定数据分布p(x0)和正向过程:
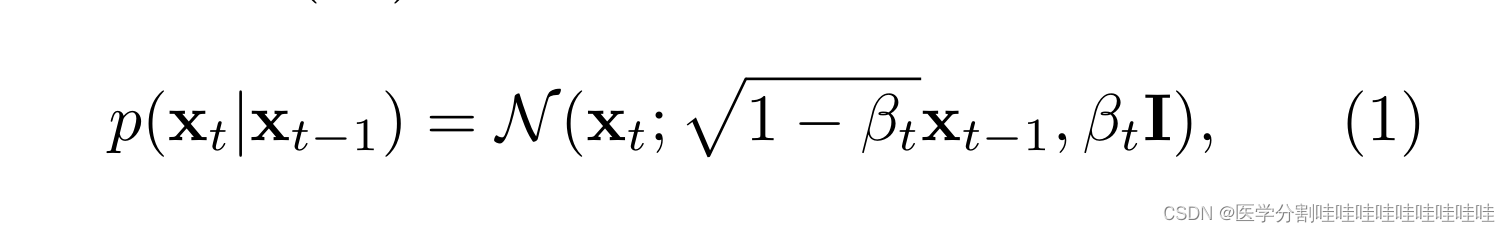
其中βt∈(0,1)为方差计划,t∈[0,t]为马尔可夫链时间步长,DDPM的目标是学习µθ(xt, t)和Σθ(xt, t),它们定义了逆向过程:
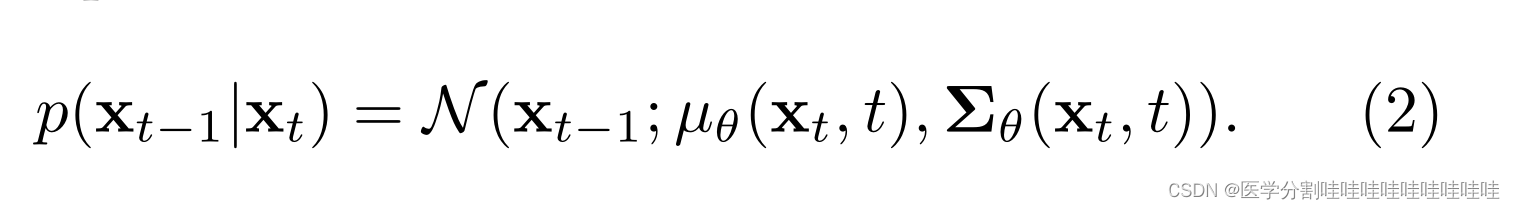
为此,Ho等人(2020)固定方差Σθ(xt, t),将µθ(xt, t)作为噪声ϵθ(xt, t)的函数重新参数化。
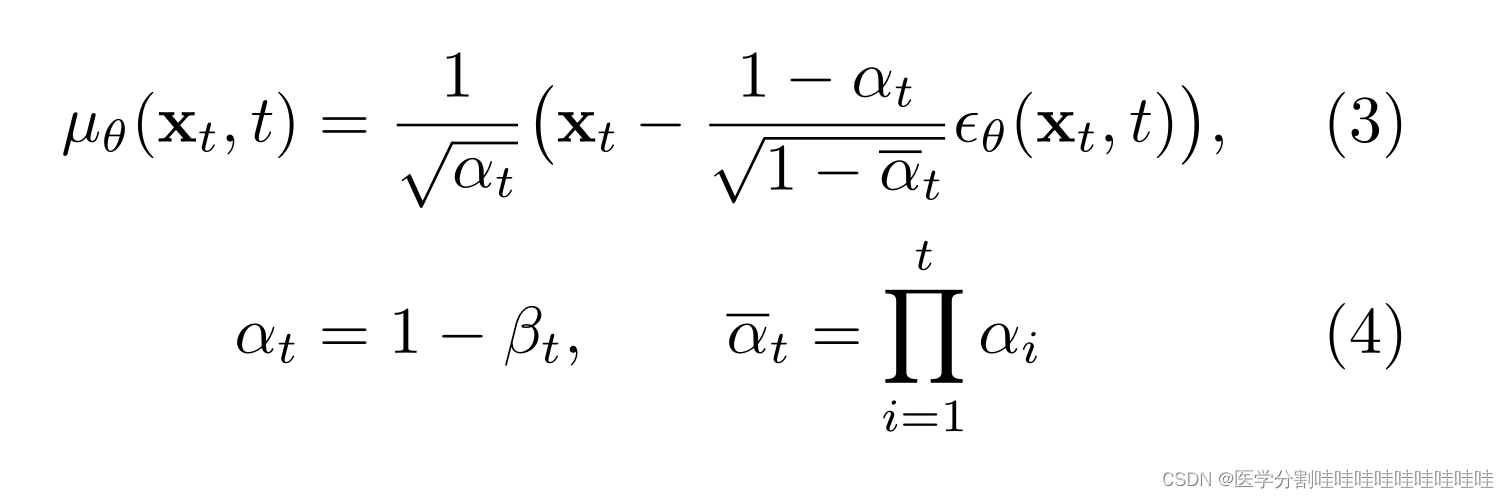
并设计一个基于unet的神经网络架构(Ronneberger et al, 2015)
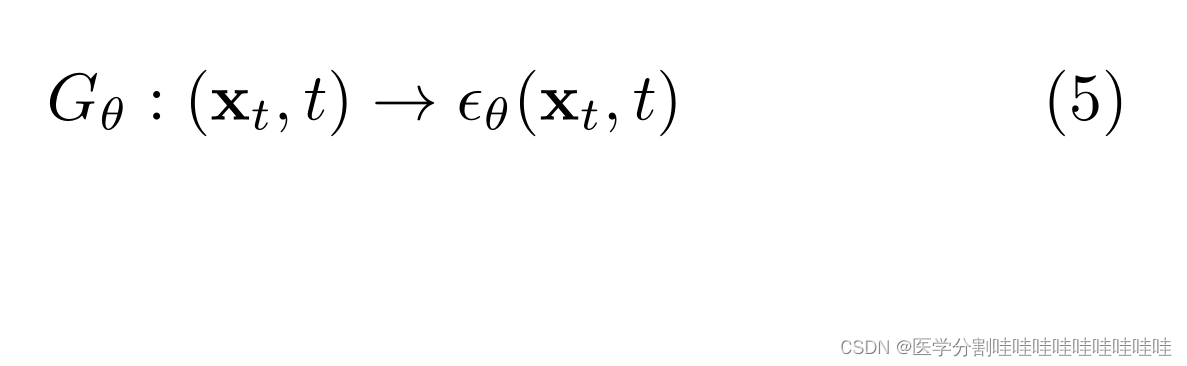
为了学习识别噪音。通过注入噪声和预测噪声之间的交叉熵来训练UNet。
2.2. 标签高效图像分割的扩散模型
Baranchuk等人(2021)将扩散模型应用于半监督分割,方法是在未标记的图像上使用预训练的扩散模型,从UNet的中间层提取潜在表示,并使用它们来训练像素分类器。更具体地说,他们的标签有效扩散模型(LEDM)通过选择一组步长t∈S∧{0,…,提取由预训练的UNet扩散模型生成的潜在表示。T},传递有噪声的输入
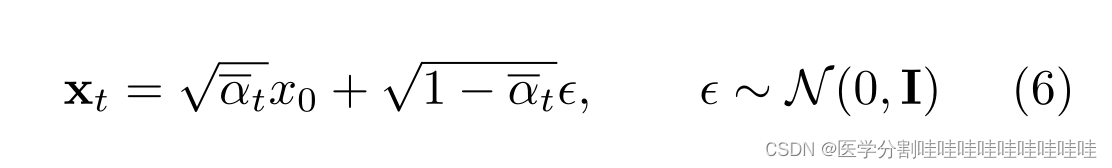
通过UNet。得到的激活图zt∈Rc×h×w然后通过双线性插值上采样到输入大小,并连接到特征图Z∈R(|S|×c)×H×W中。最后,每个逐点预测由轻量级多层感知的集合独立执行
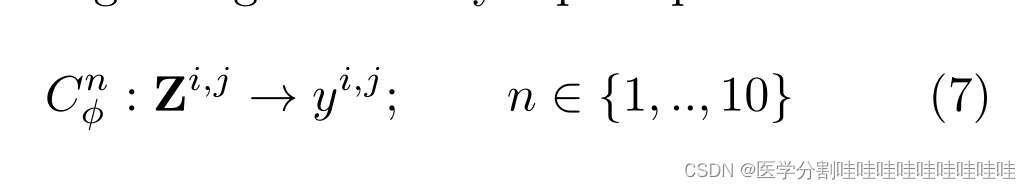
用交叉熵损失训练。作者将扩散步长S ={50,150,250}连接起来,形成这些预测器的输入。
类似地,Deja等人(2023)也使用预训练扩散模型的潜在表示进行分类任务。特别是,他们建议使用所有中间时间步的分类器预测来规范扩散模型的训练。然而,在测试时,他们只使用最后一个扩散步骤t = 1来生成预测。
3. 论扩散步骤对领域推广的重要性
先前的研究结果表明,较大步长中的潜在表征包含粗糙信息,随着扩散步长接近目标数据分布,这些信息变得更加颗粒化(Baranchuk等人,2021;Deja et al, 2023)。在这里,我们感兴趣的是理解当训练数据集大小变化时,每个时间步s∈s中的信息财富如何有助于模型泛化。
我们在特定时间步长t ={1,10,25,50,200,400,600和800}提取的潜在表示上训练基于Ridge逻辑回归的逐像素分类器,以分离每个时间步长的预测能力。我们将这些时间步进预测与LEDM和使用与DDPM骨干相同的UNet骨干的完全监督基线进行比较。
我们评估我们在胸部x线肺分割任务上的工作。胸部x光是临床实践中最常见的放射学检查之一,从解剖区域(如肺)自动提取特征可以帮助临床决策。此外,胸部x射线图像的几个公共数据集的可用性使我们能够在数据集特征发生变化的情况下研究方法的泛化能力。
根据之前在半监督医学图像分割方面的工作(Rosnati等人,2022),我们使用ChestX-ray8 (Wang等人,2017)(n=108k)作为未标记数据集,在T = 1000步上训练DDPM主干,并使用JSRT (Van Ginneken等人,2006)(n=247)标记数据集的子集进行训练(n=197)和验证(n=25)我们的方法。数据集分割、体系结构和代码可以在我们的代码存储库中获得1。
我们保留了剩余的JSRT样本(n=25)以及NIH (Tang等人,2019)(n=95)和Montgomery (Jaeger等人,2014)(n=138)标记的数据集用于最终测试。值得注意的是,NIH数据集是ChestX-ray8数据集的一个注释子集。
这种设置允许我们在以下数据上测试模型:(i)分类器的域内数据(JSRT), (ii)分类器的域外数据,但DDPM的域内数据(ChesX-ray8/NIH)和(iii)两者的域外数据(Montgomery)。
图2显示了在n ={197、49、24、12、6、3和1}个JSRT标记数据点上训练分割模型时的分步实验的Dice系数2,对应于训练数据集的{100、50、25、12、6、3、2和1}%。令人惊讶的是,LEDM并没有明显优于基线在一次设置域移位数据集(NIH, Montgomery)。这表明LEDM可能没有充分利用潜在的表征信息。其次,我们发现
在单个步骤t = 1上训练的预测器在统计上优于LEDM和小训练规模(NIH和Montgomery的1,3,6以及JSRT的一个数据点)的基线。此外,该预测器在所有其他训练数据集大小上都与基线和LEDM具有竞争力。
实验强调,从较小步骤获得的潜在表示比从较大步骤获得的潜在表示更强大,特别是对于领域泛化。特别是,LEDM步骤50、125和250不是分割的最佳选择,因为步长较小的单步方法在分布外数据集上表现更好。在下一节中,我们将研究在正确的选择下,集成不同步骤是否仍然优于单步骤方法的步骤。我们研究了几种集成这些步骤的方法及其对模型泛化的影响。
4. 时间步积扩散模型
在本节中,我们表明,通过在预测和训练时间明智地结合适当的时间步长,可以显著改善低数据区域中基于扩散的分割模型的泛化。
我们假设,在前一节中观察到的LEDM缺乏泛化可以通过更多的模型正则化和减少需要学习的参数数量来缓解。
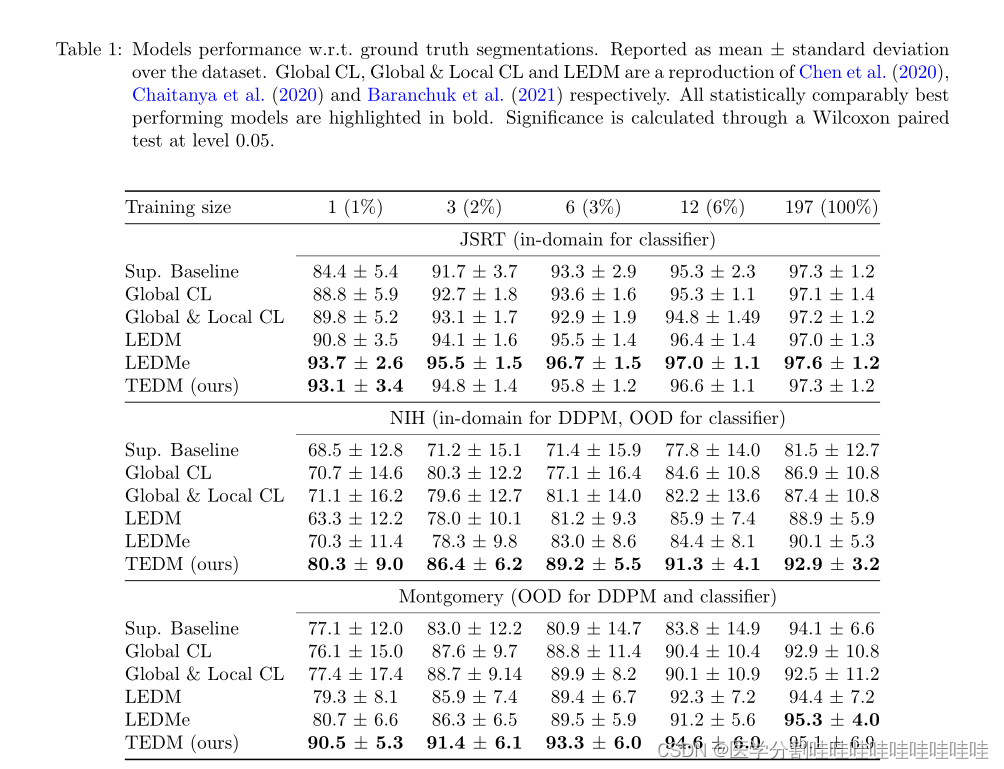
表1:模型性能w.r.t.地面真值分割。以数据集的平均值±标准差报告。Global CL、Global & Local CL和LEDM分别是Chen et al .(2020)、Chaitanya et al .(2020)和Baranchuk et al .(2021)的复制。所有在统计上表现最好的模型都以粗体突出显示。通过Wilcoxon配对检验在0.05水平上计算显著性。
事实上,目前将来自许多时间步长的特征连接到像素级MLP预测器的方法会导致过高的高维输入,从而导致复杂的预测器。为了解决这个问题,我们建议使用经过训练的共享MLP从所考虑的步骤的每个潜在表示生成预测图。
我们定义损失函数如下:
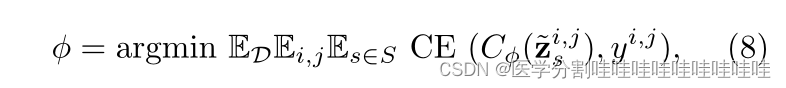
其中i,j是像素索引,yi,j是像素i的真实类,j, ~ zs是步骤s时扩散模型的上采样潜在表示zs, s是所使用的扩散步骤集,Cϕ是像素级MLP预测器,CE代表交叉熵,D是训练集。在测试时,我们使用投票机制集成各种预测图,以获得最终分割图。我们称这种技术为“时间步长集成”,并表明它产生了优越的性能。
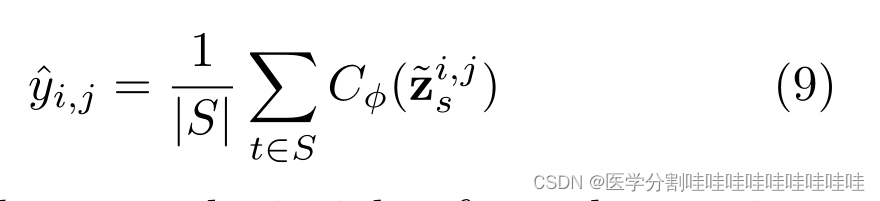
此外,我们利用前一节的见解,并结合扩散步骤S ={1、10、25、50、200、400、600和800}的预测。这种方法使我们受益于小步信息内容和大步正则化效果,不像LEDM,它只使用时间步长{50,125和250。为了更好地理解我们的模型和LEDM之间的区别,请参见图1。关于计算复杂性的讨论可以在附录B部分找到。
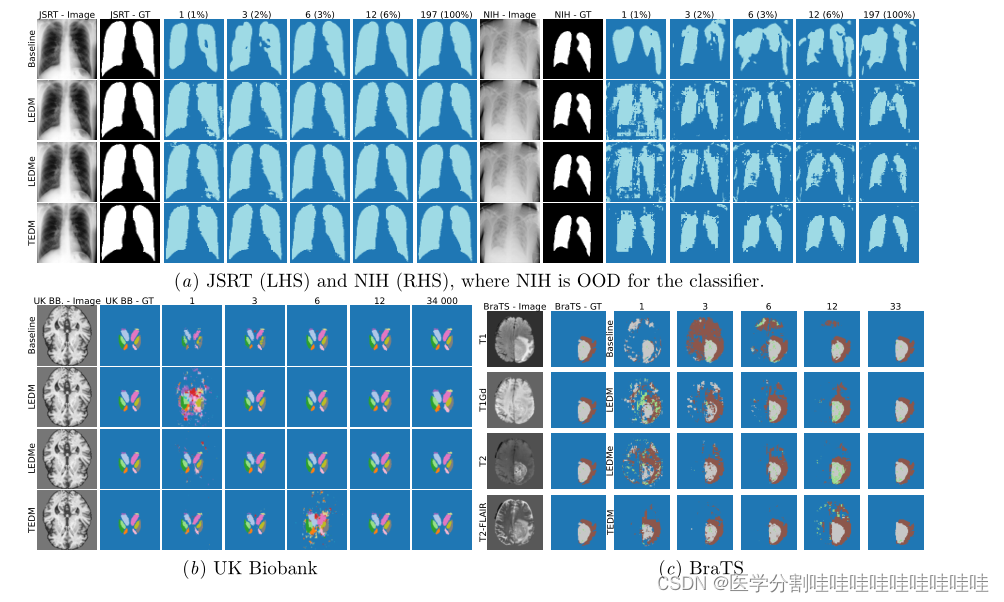
图3:分割示例。Col. 1和Col. 2是图像和地面真值分割。随后的列对应于用n个训练数据点训练的模型(见标题)。第1行对应基线结果,第2、3和4行分别对应LEDM、LEDMe和TEDM(我们的方法)。
5. 实验
我们在JSRT训练数据集的12%、6%、3%、2%和1%的不同百分比上进行了实验,以充分探索我们的半监督方法的潜力。此外,我们在100%的训练集上进行训练,以达到完备性。为了评估我们的时间步集成扩散模型(TEDM)的性能,我们将其与完全监督基线(见第3节)和LEDM进行比较。
LEDM和TEDM具有相同的MLP分类器体系结构。此外,我们将TEDM与另外两种使用对比学习(CL)的半监督方法进行了比较:“全局CL”(Chen等人,2020)和“局部和全局CL”(Chaitanya等人,2020)。
这两种方法都使用与基线和DDPM相同的主干体系结构进行训练。
为了研究我们的TEDM模型中每个组成部分的影响,我们进行了几次消融。
首先,我们将原始LEDM模型与另一个LEDM实例进行比较,这个LEDM实例是用我们的扩散步骤训练的,我们称之为leme。这使我们能够消除扩散步骤选择的影响。
其次,我们通过报告在测试时仅使用步骤1、10或25时的模型性能来测试投票机制。我们使用与第3节相同的评估程序。
最后,为了测试TEDM方法的泛化性,我们将其应用于另外两个数据集:UK Biobank数据集和BraTS数据集(Menze et al, 2014;Bakas et al, 2017,2018)。在英国生物银行数据集中,我们在大脑MRI T1图像的二维切片中分割大脑结构。由于结构和背景之间的低强度变化,该数据集特别具有挑战性。BraTS数据集取脑肿瘤患者的脑MRI (T1, T1Gd, T2和T2- flair),我们将其分解成二维切片和片段。这个数据集更加困难,因为它需要分割不同形状和位置的项目。关于这两个数据集的实验过程的进一步细节可在附录A中找到。
表2:测试时间随时间步长集合的消融研究。每个“步骤i”实验在测试时只使用时间步骤i的预测。所有在统计上表现最好的模型都以粗体突出显示。通过Wilcoxon配对检验在0.05水平上计算显著性。

6. 结果
胸部x线和脑部MRI表现结果定量见表1和表3,定性见图3。烧蚀结果见表2。进一步的结果可以在附录c中找到。对于所有表,表现最好的模型和所有统计上等效的模型都以粗体突出显示其结果。
使用较小的步长可以提高域内和域外的性能。
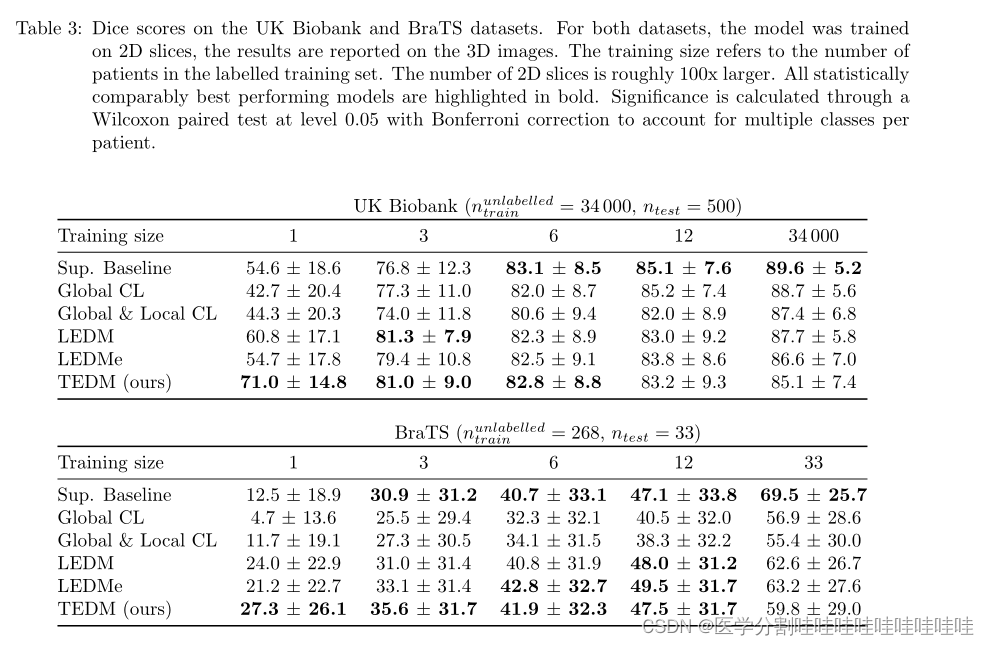
在表1中,我们观察到,在所有情况下,选择较小的扩散步长产生了性能最好的模型:除了两个实验(Montgomery n = 12和NIH n = 12)之外,LEDMe在所有实验中都显著优于LEDM。此外,对于训练规模分别大于3和1的UK Biobank和BraTS数据集,LEDMe优于LEDM(见表3)。
连接潜在表示会损害低数据状态下的通用性。
除了n=197之外,在NIH和Montgomery数据集上,TEDM优于LEDMe(和LEDM)。
我们推断,在LEDM中使用的连接方法导致在标记训练集之外的域上泛化不良。此外,对于JSRT, TEDM的统计性能与LEDM相当,这表明它的泛化属性几乎没有域内性能成本。
时间步长的测试时间集成改进了单步预测的泛化。
表2显示,使用投票机制进行预测(在TEDM中使用)比使用最小步长更有效(在OOD情况下,TEDM优于竞争模型),这意味着不同的步骤产生聚焦于图像稍微不同方面的潜在表征。
TEDM在日益具有挑战性的分割任务中表现稳健。
表3显示,在少于12个数据点的所有情况下,TEDM在统计上优于或等于其竞争对手,这表明我们的方法在更具挑战性的域内低标记数据场景中仍然具有竞争力。
完全监督基线在领域内较难分割的任务中具有竞争力
我们的方法TEDM在非常小的数据集大小(表3中的1、2、3和6)上展示了出色的性能。
然而,对于更大的数据集(6名或更多患者),设计良好的基线模型比任何半监督模型都更有效。这一结果表明,尽管具有自监督预训练的半监督方法在为大型数据集提供特定任务性能方面可能存在局限性,但它们在改善小型数据集的结果方面具有很大的潜力。
7 结论
本文研究了不同扩散步骤对半监督分割模型性能和泛化的影响。我们在多个数据集上的综合实验表明,小的扩散步骤对领域泛化至关重要,只需要少量的训练样本就可以成为强大的像素预测器。此外,我们发现随时间步长集成分割映射显着提高了低数据状态下的模型泛化,同时在域内提供具有竞争力的性能。相反,连接潜在表示可能会损害逐像素分类器的泛化。我们提出的时间步合成扩散模型在胸部x射线上的优越性能证明了这些发现
肺分割和更具挑战性的任务,如大脑结构和肿瘤分割。我们的结果表明,跨不同步骤的潜在表示共享语义,并充当模型正则化器,比竞争方法产生更好的泛化。这一分析强调了彻底研究扩散模型中辅助任务的设计决策的重要性,例如时间步长选择和集成。这些决策会对模型的性能产生重大影响。
我们的发现提供了重要的新见解,并可能为利用强大的扩散模型进行医学成像任务的新方法的发展提供信息。在未来的工作中,应该将TEDM和类似方法的性能与新兴的基础模型技术进行比较,其中预训练比半监督方法执行的规模更大。在这里,扩散模型从大量未标记数据中有效捕获数据分布的能力有望克服医学图像分割中持续存在的数据稀缺性问题。
表3:骰子在UK Biobank和BraTS数据集上的得分。对于这两个数据集,模型都是在二维切片上训练的,结果报告在三维图像上。训练大小是指标记训练集中患者的数量。2D切片的数量大约是原来的100倍。所有在统计上表现最好的模型都以粗体突出显示。通过0.05水平的Wilcoxon配对检验和Bonferroni校正来计算显著性,以解释每个患者的多个类别。
相关文章:
Robust semi-supervised segmentationwith timestep ensembling diffusion models
时间步合成扩散模型的鲁棒半监督分割 摘要 医学图像分割是一项具有挑战性的任务,由于许多数据集的大小和注释的限制,使得分割更加困难。消噪扩散概率模型(DDPM)最近在模拟自然图像的分布方面显示出前景,并成功地应用于各种医学成像任务。这…...

如何迁移R包
迁移R包涉及将一个或多个R包从一个系统转移到另一个系统。以下是迁移R包的详细步骤: 1. 确定要迁移的R包 首先,列出你在当前系统中安装的所有R包,或仅列出你需要迁移的R包。你可以使用以下代码列出所有安装的R包: installed_pa…...

如何在next14项目中加入favicon
如何在next14项目中加入favicon 第一次碰见这个问题的时候很头疼,直接搜官方文档也没有详细介绍这个,但其实next14提供了很简单的方法: Convention 将 favicon.ico 放置在 app/ 或 public/ 文件夹中,Next.js 将自动生成必要的元…...

【深度学习】基础数据结构+访问
目录 深度学习中的基础数据结构1. N维数组定义特点访问元素 2. 机器学习中常用的数据结构N维数组示例 3. 数学中的访问操作带跳转的子区域访问示例 4. 数学中的访问操作4.1 一维数组(向量)访问一个区间带步长的区间访问 4.2 二维数组(矩阵&am…...

一个产品需求工程师繁忙的一天
早晨:开启新的一天 7:00 AM - 起床 早晨七点准时起床。洗漱、早餐后,查看手机上的邮件和消息,提前了解今天的工作安排和优先事项。 8:00 AM - 前往公司 坐地铁前往公司。在地铁上,习惯性地阅读一些行业资讯和市场报告࿰…...

MD5加密接口
签名算法 app_key和app_secret由对方系统提供 MD5_CALCULATE_HASH_FOR_CHAR(中文加密与JAVA不一致) 代码: *获取传输字段名的ASCII码,根据ASCII码对字段名进行排序SELECT * FROM zthr0051WHERE functionid iv_functionidINTO …...

AI大模型日报#0626:首款大模型芯片挑战英伟达、面壁智能李大海专访、大模型测试题爆火LeCun点赞
导读:AI大模型日报,爬虫LLM自动生成,一文览尽每日AI大模型要点资讯!目前采用“文心一言”(ERNIE-4.0-8K-latest)生成了今日要点以及每条资讯的摘要。欢迎阅读!《AI大模型日报》今日要点…...
专业技能篇---计算机网络
文章目录 前言计算机网络基础一、网络分层模型 HTTP一、从输入URL到页面显示发生了什么?二、Http的状态码有哪些?三、 HTTP与HTTPS有什么区别?四、URI 和 URL 的区别是什么?五、Cookie和Session有什么区别?六、GET与POST WebSock…...
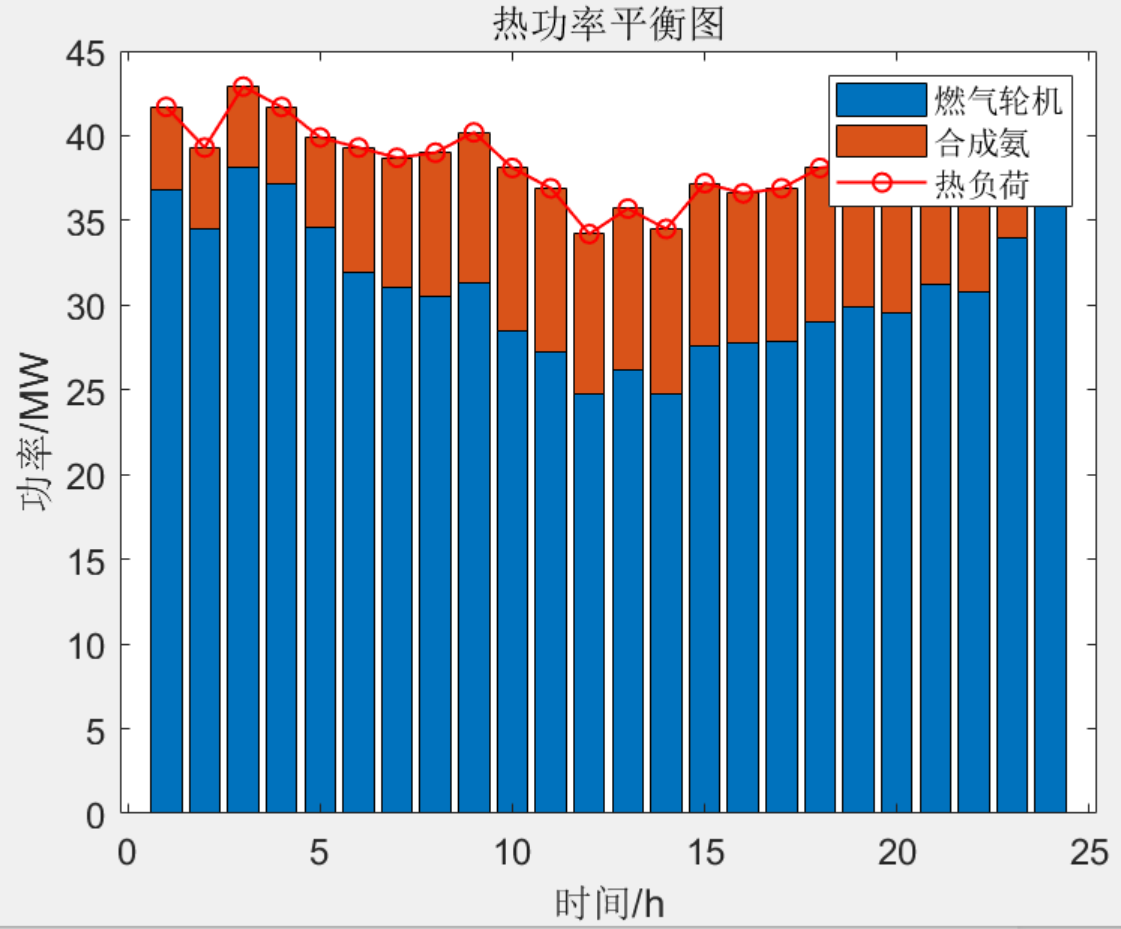
Matlab|【免费】含氢气氨气综合能源系统优化调度
目录 主要内容 部分代码 结果一览 下载链接 主要内容 该程序参考《_基于氨储能技术的电转氨耦合风–光–火综合能源系统双层优化调度》模型,对制氨工厂、风力发电、电制氢、燃气轮机、火电机组等主体进行建模分析,以火电机组启停成本、煤耗…...

python的一些常用的内建函数
内建函数 python中的内建函数是可以被自动加载的,可以随时调用这些函数,不 需要定义。方便的编程。 eval()函数 将字符串当成有效的表达式来求值,并返回计算结果 用于对动态表达式求值,语法格式如下: eval(source&…...
Docker部署常见应用之Oracle数据库
文章目录 安装部署参考文章 安装部署 使用Docker安装Oracle数据库是一个相对简便的过程,可以避免在本地环境中直接安装Oracle数据库的复杂性。 安装Docker环境:确保你的系统上已经安装了Docker,并且Docker服务正在运行。具体的安装方法可以根…...

小程序中echarts的bug
这个文字在手机上显示会有黑的的阴影 textStyle: {fontSize: 12,wrap: true,textShadowColor: "#fff", // 文字本身的阴影颜色textShadowBlur: 10, // 文字本身的阴影长度textShadowOffsetX: 10, // 文字本身的阴影X偏移textShadowOffsetY: 10, //阴影Y偏移}...

项目验收测试有必要找第三方软件测试机构吗?
在当今信息技术飞速发展的时代,软件测试成为了确保软件质量的重要环节。而在项目的验收测试中,很多企业都面临一个问题,那就是是否有必要找第三方软件测试机构进行验收测试?今天,我们就来探讨一下这个问题。 第三方软件测试机构…...

【python入门】循环语句
文章目录 1. for 循环2. while 循环3. break 和 continue 语句4. else 子句5. 循环控制语句6. 列表推导式7. 循环中的异常处理8. 循环的高级用法 1. for 循环 for 循环通常用于遍历序列(如列表、元组、字典、集合、字符串)或者迭代器。for 循环可以自动…...

php调用soap, 报错 failed to load external entity‘http://xxxxxxxx?wsdl‘ 解决方法
先说下环境,非当前环境参考思路 服务器 centos 6php版本 5.5.39调用java写的soap服务器开启soap缓存出现的问题是, 运行一段时间后就会随机报异常 PHP Fatal error: SOAP-ERROR: Parsing WSDL: Couldnt load from http://xxxxxxxx?wsdl : failed to l…...

ts可选参数
可选参数 参数后加个问号,代表这个参数是可选的 function bdd(x:number,y?:number){return x y } console.log(bdd(2,3)) function bdd(x:number,y?:number){return x y } console.log(bdd(2))...
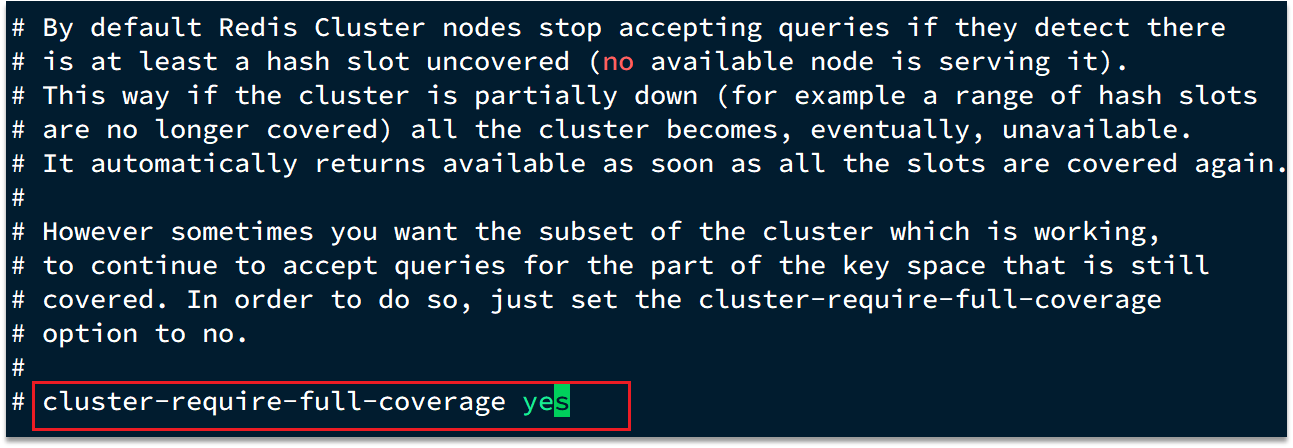
day41--Redis(三)高级篇之最佳实践
Redis高级篇之最佳实践 今日内容 Redis键值设计批处理优化服务端优化集群最佳实践 1、Redis键值设计 1.1、优雅的key结构 Redis的Key虽然可以自定义,但最好遵循下面的几个最佳实践约定: 遵循基本格式:[业务名称]:[数据名]:[id]长度不超过…...

PDF 生成(4)— 目录页
当学习成为了习惯,知识也就变成了常识。 感谢各位的 关注、点赞、收藏和评论。 新视频和文章会第一时间在微信公众号发送,欢迎关注:李永宁lyn 文章已收录到 github 仓库 liyongning/blog,欢迎 Watch 和 Star。 回顾 上一篇 PD…...

黑盒测试用例的四种设计方法
🍅 视频学习:文末有免费的配套视频可观看 🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 一、输入域测试用例设计方法 输入域测试法是一种综合考虑了等价类划分、边界值分析等方法的综合…...

GIT重新提交-恢复到暂存状态
Git重新提交 --git reset --soft HEAD~n 有时候我们提交了commit并且push到分支之后,发现代码有需要修改的地方,想要修改重新提交commit应该怎么办呢 这时候我们只需要使用git reset --soft HEAD~n命令,然后修改代码后强制提交修改提交就可以 示例(修改最近的1个提交):…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

mongodb源码分析session执行handleRequest命令find过程
mongo/transport/service_state_machine.cpp已经分析startSession创建ASIOSession过程,并且验证connection是否超过限制ASIOSession和connection是循环接受客户端命令,把数据流转换成Message,状态转变流程是:State::Created 》 St…...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...

让AI看见世界:MCP协议与服务器的工作原理
让AI看见世界:MCP协议与服务器的工作原理 MCP(Model Context Protocol)是一种创新的通信协议,旨在让大型语言模型能够安全、高效地与外部资源进行交互。在AI技术快速发展的今天,MCP正成为连接AI与现实世界的重要桥梁。…...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...

在Ubuntu24上采用Wine打开SourceInsight
1. 安装wine sudo apt install wine 2. 安装32位库支持,SourceInsight是32位程序 sudo dpkg --add-architecture i386 sudo apt update sudo apt install wine32:i386 3. 验证安装 wine --version 4. 安装必要的字体和库(解决显示问题) sudo apt install fonts-wqy…...

Linux系统部署KES
1、安装准备 1.版本说明V008R006C009B0014 V008:是version产品的大版本。 R006:是release产品特性版本。 C009:是通用版 B0014:是build开发过程中的构建版本2.硬件要求 #安全版和企业版 内存:1GB 以上 硬盘…...

破解路内监管盲区:免布线低位视频桩重塑停车管理新标准
城市路内停车管理常因行道树遮挡、高位设备盲区等问题,导致车牌识别率低、逃费率高,传统模式在复杂路段束手无策。免布线低位视频桩凭借超低视角部署与智能算法,正成为破局关键。该设备安装于车位侧方0.5-0.7米高度,直接规避树枝遮…...