小文件过多的解决方法(不同阶段下的治理手段,SQL端、存储端以及计算端)
上一篇介绍了小文件出现的原因以及为什么治理小文件问题迫在眉睫,本篇将为读者讲述在不同阶段下小文件治理的最佳手段以及如何针对性的解决小文件过多的问题。
小文件过多如何解决、治理方法
小文件是特别常见的现象,解决小文件问题迫在眉睫!!!
一般来说,一个任务是由几个步骤组成的,而小文件的产生也来自任务的各个流程和步骤:
上游 => 本地文件系统 => HDFS => Map => Reduce => FileSink
所以解决小文件问题就是需要从最前面的步骤中入手。而且解决小文件的隐患,肯定也是越早越好,就像过滤下推,能尽早做的过滤条件一定是尽早过滤。
因此,能在本地文件系统解决的问题,没必要放到HDFS上解决。就像前面章节的内容所述,HDFS本身就不适合存储大量小文件,小文件过多会导致namenode元数据特别大, 占用太多内存,严重影响HDFS的性能。
当前治理小文件的现有手段主要有以下几种:
1)SQL端规范
治理小文件的最优解一定是从源头(集群规划设计和搭建)开始就进行规范管理。比如在表结构和SQL语句方面进行规范,特别是分桶个数,分区类型的选择,范围分区跨度的选择。如果从初期就开始重视,确保不会出现小文件过多以及合并完成后还是小文件的问题,可以最大程度的减少后续因该问题引发的集群异常、性能下降和宕机的可能,进一步达到治理小文件的目的。
SQL端规范适用于以下原因导致的小文件问题:
- 表结构不合理,设置分桶数过大,数据平均分布,小文件过多;
- 分桶字段不合理,导致数据倾斜,产生大量小文件;
- 单值分区设置不合理,导致单分区数据量小,产生大量小文件;
表结构
分桶表
为了更细粒度地管理和优化数据存储与访问,数据分桶(Bucketing)技术逐渐受到了关注,即对指定列的哈希值将其分配到固定数量的子集中(桶),保障数据的均匀分布,从而为复杂查询提供了更高效的处理方式。
分桶表表结构创建之前需要对表的数据分布情况及数据特征进行大致的分析,一般遵循以下原则:
- 选择离散度高的字段进行分桶,避免选择decimal类型的字段做为分桶键,一般选择表的主键等字段,包括账号,客户号,证件号码等;
- 分桶个数选择非31的质数,减少潜在的哈希冲突;
- 分桶字段在选择时,注意尽量使记录分布均匀,以避免数据倾斜;
- 设计表结构时首先要预估该表的数据量和数据文件的大小,按照每个桶文件100-200M的大小来设置分桶个数;
- 另外,在考虑分桶个数的时候,同时要考虑是否已经分过区。对于已经分过区的表,要按照单分区的大小进行桶数的估计,而不是依照原始表。推荐单个分区中,每个桶文件为 50~100 MB,既可以避免文件过小触发小文件合并,给文件管理带来额外开销,同时也避免了 Block 文件数过多导致查询启动的 task 数过多影响执行和并发效率。
更多有关分桶策略及实践最佳案例可参考:【性能优化】表分桶实践最佳案例
分区表
表分区是一种在数据库中组织和存储数据的技术,其核心思想是将数据按照某个特定的标准分成多个物理块,每个物理块即为一个分区,从而使数据的存储和管理更加高效。
分区表表结构创建之前需要综合分析查询需求,重点关注经常被查询的数据的过滤条件,以选择适当的分区键。建议创建范围分区表,不推荐使用二级分区,分区字段选择上一般选择时间,区域等字段,推荐使用 STRING 或时间类型的列作为分区键,可以帮助在数据均衡和分区数量上取得较好的平衡。
此外,需要权衡分区规模。常规情况下,单个分区的数据量控制在 500GB 内,如果集群的 CPU 核数较多,可适当提升。同时,也需要关注数据的增长趋势,根据每天和每月增量的大小来界定每个分区的范围。如果一个分区数据量太大,可以考虑创建分区分桶表,并合理的设置分桶键和分桶个数。
更多有关分区策略及实践最佳案例可参考:【性能优化】表分区实践最佳案例
不规范表结构改造
对于由于表结构原因导致小文件过多的表,建议是重建表结构,一般具体流程为:备份表和数据-->重建表结构-->回填表数据-->验证表数据和文件-->删除备份表。
注意:对于分区表、分桶表、分区分桶表,回填数据时,可以sort by备份表的分区键、分桶键来提升表的查询效率。
SQL语句规范
规范的SQL语句可以帮助优化数据查询和处理过程,减少不必要的数据扫描和计算,从而降低小文件的产生。通过合理地设计和优化SQL语句,可以有效地治理小文件问题,提高数据处理的效率和性能。
可以遵循以下规则进行规范:
- 必须尽量避免大表与大表直接JOIN,执行之前要检查分析一下SQL,如果有小表,先用小表或是过滤率较高的表过滤大表,即尽可能先做与小表有关的 JOIN,再使大表参与进来;
- 大表与小表JOIN 时,可以采用MapJoin,减少Shuffle过程;
- 两张大表关联时,使用 Bucketed Join;
- 小表 Join 大表时,使用 Lookup Join;;
- 数据倾斜导致 Join 性能地下时,使用 SKEWJOIN;
- 注意笛卡尔积等数据翻倍情况的出现;
- 减少INNER JOIN的中间量,在多表进行连接时,JOIN之间的连接顺序将极大影响SQL的执行效率。应尽量优先执行过滤高的JOIN,以提高SQL的整体执行速度;
- 先INNER JOIN后OUTER JOIN,当一条语句中的INNER JOIN与OUTER JOIN顺序执行且关联,并都涉及同一张表时,执行顺序通常也可满足交换律。一般情况下,由于带过滤条件的INNER JOIN会减少记录数,而OUTER JOIN不会减少记录数,所以建议用户先执行INNER JOIN;
- 添加手工推导的过滤规则,即在原有SQL的基础上手动的添加额外的过滤条件,这些过滤条件仅仅以优化为目的,不会影响查询返回结果。它们是通过表与表之间的关系推导得到的,是以正确分析两表或多表之间存在的关联信息为前提的,最重要的是能够根据一张表的结果锁定结果所在范围;
- 用GROUP BY实现DISTINCT,在DISTINCT可以用GROUP BY去重表达时,尽量用GROUP BY;
- 尽量返回更少的数据。在编写SQL语句时,通过明确指定查询字段去除不必要的返回字段,以减少不必要的查询时间;
- 多表关联时,使用SQL92标准写法,目的是更能体现表与表之间的关联关系,杜绝使用 Right 连接、非SQL92标准的"(+)左连接";
- 如果业务逻辑允许的情况下,尽量用UNION ALL代替UNION,用UNION ALL代替OR;
- SQL语句的WHERE子句中应尽可能将字段放在等式左边,将计算操作放在等式的右边;
- SQL语句的操作符两边类型应相同,禁止潜在的数据类型转换,建议用户在执行计算前通过类型转换,使各操作数的类型匹配,或者建表时尽可能的把字段安排成相同的数据类型。
2)存储端合并
存储端合并主要是合并已经写入到存储的文件,当表中有小文件或者小文件过多时,可以使用下述存储端合并的方式进行合并以达到减少文件数量、降低存储开销提高数据读写效率的目的。存储端合并的方式主要适用于以下原因导致的小文件问题:
- 频繁的写入数据;
- torc表compact多次合并失败后进入黑名单,导致小文件不再继续合并;
- 历史数据流程导致小文件问题,这些数据一般是从别的数据库迁移过来,后续没有进行治理;
需要注意的是,不同表格式(如.TORC事务表、RCfile/ORC/Text等非事务表、星环自研Holodesk表)的合并方式并不相同。
下一篇将介绍下星环不同表格式的合并方式(即将发布)
归档分区
除了针对上述表实现合并机制外,星环分布式分析型数据库ArgoDB在6.0及后续版本中引入了归档分区的功能,用户可以跨分区进行合并。归档分区的实现手段是用范围分区去表示单值分区,适用于分区字段为离散类型的单值分区,如日期 (暂不支持时间戳类型)、整数的场景。
通过分区归档合并功能,可以将大量小文件(归档前的单值分区)合并成较大的文件(归档后的范围分区),从而减少存储开销、元数据管理的开销以及处理时的任务调度开销。
创建归档分区表
归档分区表的本质为范围分区表,所以创建语句与创建范围分区表一致,只需额外设置表参数"archive_partition"="true" 来区分为归档分区表。支持直接创建归档分区表和修改普通范围分区表为归档分区两种方式。
分区合并
命令:ALTER TABLE TBL_NAME MERGE FROM PARTITION (values_start) TO PARTITION (values_end) INTO PARTITION <partition_name>;
3)计算端合并
计算端合并分为两个阶段:map端合并和reduce端合并,适用于因为不规范的sql语句,导致的小文件问题。
正如前面所说,小文件的产生来自任务的各个流程和步骤,越早解决对业务的影响越小。如果在前期无法解决的情况下,可以考虑在以下两个阶段进行合并:
maptask阶段合并
Maptask阶段合并可以使用automerge功能,在map端控制map task的数目,它可以根据每个partition (数据块) 所在的位置及大小将多个partitions交给一个task去完成;
在星环TDH9.3及后续版本中,产品引入了改进后的automergeV2功能,V2版本在性能方面有很大提升,并且解决了有关automerge可能存在的一些问题。
由于篇幅原因,有关automerge功能及优化后的automergeV2功能如何使用,情参考:https://community.transwarp.cn/article/250
Reduce 阶段合并
当小文件过多引起后续reduce任务数量暴增到一定值的情况下,引擎出于自我保护会中断任务并返回一些报错提醒,因此可以设置合理的reduce个数(mapred.reduce.tasks),以保证单reduce处理合适的数据量。
设置mapred.reduce.tasks数可以增加初始化性能,建议 500w数据量设置一个tasks。同时也可以按照文件的大小来设置tasks数据,如果小于500M,则设置为5,如果大于500M,则是文件大小/300M设置,根据hdfs上文件总大小合理控制。也可以将reduce数设定为集群vcore的一半,既保证vcore被充分利用,又不影响其他程序的工作。但是最终的mapred.reduce.tasks尽量小于1000。
总结
总的来说,在生产上小文件一直以来都是很棘手的问题,从上游到下游的各个步骤都有可能产生小文件问题,虽然技术上星环针对此类问题做了很多处理机制,但是如果要彻底预防和根治此类问题,还是需要尽可能从源头开始规范管理。从集群规划搭建,到各个业务系统表的设计,再到日常使用过程中SQL语句的规范编写,每一步都有可能减少后续小文件的产生。
以上就是有关小文件治理系列的全部内容,希望对您针对小文件问题的规避及治理思路有所帮助,有更多想要了解的内容,欢迎随时留言,谢谢阅读。
相关文章:
)
小文件过多的解决方法(不同阶段下的治理手段,SQL端、存储端以及计算端)
上一篇介绍了小文件出现的原因以及为什么治理小文件问题迫在眉睫,本篇将为读者讲述在不同阶段下小文件治理的最佳手段以及如何针对性的解决小文件过多的问题。 小文件过多如何解决、治理方法 小文件是特别常见的现象,解决小文件问题迫在眉睫࿰…...
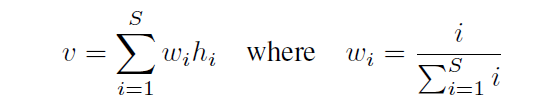
SGPT论文阅读笔记
这是篇想要用GPT来提取sentence embedding的工作,提出了两个框架,一个是SGPT-BE,一个是SGPT-CE,分别代表了Bi-Encoder setting和Cross-Encoder setting。CE的意思是在做阅读理解任务时,document和query是一起送进去&am…...

虚拟机与主机的网络桥接
虚拟机网路桥接是一种网络配置方式,它允许虚拟机与物理网络中的其他设备直接通信。在桥接模式下,虚拟机的网络接口通过主机的物理网卡连接到局域网中,就像主机本身一样,拥有自己的MAC地址和IP地址。这种方式使得虚拟机可以像独立的…...

urfread刷算法题day1|LeetCode2748.美丽下标的数目
题目 题目链接 LeetCode2748.美丽下标对的数目 题目描述 给你一个下标从 0 开始的整数数组 nums 。 如果下标对 i、j 满足 0 ≤ i < j < nums.length , 如果 nums[i] 的 第一个数字 和 nums[j] 的 最后一个数字 互质 , 则认为 nums[i] 和 nums…...

面向对象修炼手册(四)(多态与空间分配)(Java宝典)
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏: 🏀面向对象修炼手册 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 目录 前言 1 多态 1.1 多态的形式&…...
基于UDP的网络聊天室(多线程实现收和发消息)
要求:1.有新用户登录,其他在线的用户可以收到登录信息 2.有用户群聊,其他在线的用户可以收到群聊信息 3.有用户退出,其他在线的用户可以收到退出信息 4.服务器可以发送系统信息 效果图: service.c #include <head…...
)
【脚本工具库】随机抽取数据 - 图像和标签对应(附源码)
在数据处理和机器学习任务中,我们经常需要从大规模数据集中随机抽取一定数量的图像及其对应的标签文件,以便进行模型训练、验证或测试。手动操作不仅耗时,而且容易出错。为了解决这个问题,我们可以编写一个Python脚本,…...
【python】eval函数
1.eval函数的语法及用法 (1)语法:eval(expression) 参数说明: expression:必须为字符串表达式,可为算法,也可为input函数等。 说明:表达式必需是字符串,否则会报错&a…...
实战|记一次java协同办公OA系统源码审计
前言 因为笔者也是代码审计初学者,写得不好的地方请见谅。该文章是以项目实战角度出发,希望能给大家带来启发。 审计过程 审计思路 1、拿到一个项目首先要看它使用了什么技术框架,是使用了ssh框架,还是使用了ssm框架ÿ…...

浅浅谈谈如何利用Javase+多线程+计算机网络的知识做一个爬CSDN阅读量总访问量的程序
目录 我们发现csdn的文章 首先为了印证我们的想法 我们用postman往csdn我们任意一篇文章发起post请求 发送请求 编辑获得响应结果 我们发现我们的阅读量上涨 PostRequestSender类 但是我们经过测试发现 定义一个字符串数组 把URL放进去 然后延迟启动 在线程池里面…...

Vscode 中launch.json与tasks.json文件
Vscode 中launch.json与tasks.json文件 launch.json文件基本结构主要属性示例配置PythonCNode.js 常见配置项1. Python2. C3. Node.js 使用示例 tasks.json基本结构主要属性示例配置C 编译任务Python 运行任务Node.js 运行任务 常见配置项使用示例 tasks.json与launch.json文件…...

C#基于SkiaSharp实现印章管理(2)
上一篇文章最后提到基于System.Text.Json能够序列化SKColor对象,但是反序列化时却无法解析本地json数据。换成Newtonsoft.Json进行序列化和反序列化也是类似的问题。 通过百度及查看微软的帮助文档,上述情况下需自定义转换类以处理SKColor类型数据的…...
)
大二C++期末复习(自用)
一、类 1.定义成员函数 输入年份判断是否是闰年,若是输出年份;若不是,输出NO #include<iostream> #include<cstring> using namespace std; class TDate{private:int month;int day;int year;public:TDate(int y,int m,int d)…...
重大进展!微信支付收款码全场景接入银联网络
据中国银联6月19日消息,近日,银联网络迎来微信支付收款码场景的全面接入,推动条码支付互联互通取得新进展,为境内外广大消费者提供更多支付选择、更好支付体验。 2024年6月,伴随微信支付经营收款码的开放,微…...
msvcr110.dll丢失的解决方法,亲测有效的几种解决方法
最近,我在启动一个程序时,系统突然弹出一个错误提示,告诉我电脑缺失了一个名为msvcr110.dll的文件。这让我感到非常困惑,因为我之前从未遇到过这样的问题。经过一番搜索和尝试,我总结了5种靠谱的解决方法。下面分享给大…...

SUSE Linux 15 sp5上Nginx安装配置升级
1.安装SUSE linux 15 SP5 图形化界面安装很简单,选择最小安装,安装好后,使用vim编辑配置文件,结果提示"bash: vim: command not found"。 最简安装把一些常用命令都整没有了,于是又重新选择了Server Applica…...

突破Web3红海,DePIN如何构建创新生态系统?
撰文:TinTinLand 本文来源香港Web3媒体Techub News专栏作者TinTinLand 2023 年 DePIN 赛道的火热成为 Web3 行业的重点关注方向,当前如何以可扩展、去中心化、安全方式推动 DePIN 赛道赋能下的 AI 版图建设,寻找更多 Web3 行业创新机遇成为…...

裸机与操做系统区别(RTOS)
声明:该系列笔记是参考韦东山老师的视频,链接放在最后!!! rtos:这种系统只实现了内核功能,比较简单,在嵌入式开发中,某些情况下我们只需要多任务,而不需要文件…...

详解 ClickHouse 的分片集群
一、简介 分片功能依赖于 Distributed 表引擎,Distributed 表引擎本身不存储数据,有点类似于 MyCat 之于 MySql,成为一种中间件,通过分布式逻辑表来写入、分发、路由来操作多台节点不同分片的分布式数据 ClickHouse 进行分片集群的…...

AI问答-医疗:什么是“手术报台”
手术报台并不是传统意义上的医疗工具或设备,而是一个与手术耗材追溯管理相关的系统或工具。以下是对手术报台的详细解释: 一、定义与功能 手术报台系统,如医迈德手术报台系统,是一款面向医院跟台人员的微信小程序。 它通过手术耗…...

测试微信模版消息推送
进入“开发接口管理”--“公众平台测试账号”,无需申请公众账号、可在测试账号中体验并测试微信公众平台所有高级接口。 获取access_token: 自定义模版消息: 关注测试号:扫二维码关注测试号。 发送模版消息: import requests da…...

Docker 离线安装指南
参考文章 1、确认操作系统类型及内核版本 Docker依赖于Linux内核的一些特性,不同版本的Docker对内核版本有不同要求。例如,Docker 17.06及之后的版本通常需要Linux内核3.10及以上版本,Docker17.09及更高版本对应Linux内核4.9.x及更高版本。…...

C++初阶-list的底层
目录 1.std::list实现的所有代码 2.list的简单介绍 2.1实现list的类 2.2_list_iterator的实现 2.2.1_list_iterator实现的原因和好处 2.2.2_list_iterator实现 2.3_list_node的实现 2.3.1. 避免递归的模板依赖 2.3.2. 内存布局一致性 2.3.3. 类型安全的替代方案 2.3.…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...

【JavaEE】-- HTTP
1. HTTP是什么? HTTP(全称为"超文本传输协议")是一种应用非常广泛的应用层协议,HTTP是基于TCP协议的一种应用层协议。 应用层协议:是计算机网络协议栈中最高层的协议,它定义了运行在不同主机上…...

k8s从入门到放弃之Ingress七层负载
k8s从入门到放弃之Ingress七层负载 在Kubernetes(简称K8s)中,Ingress是一个API对象,它允许你定义如何从集群外部访问集群内部的服务。Ingress可以提供负载均衡、SSL终结和基于名称的虚拟主机等功能。通过Ingress,你可…...

PPT|230页| 制造集团企业供应链端到端的数字化解决方案:从需求到结算的全链路业务闭环构建
制造业采购供应链管理是企业运营的核心环节,供应链协同管理在供应链上下游企业之间建立紧密的合作关系,通过信息共享、资源整合、业务协同等方式,实现供应链的全面管理和优化,提高供应链的效率和透明度,降低供应链的成…...

解决Ubuntu22.04 VMware失败的问题 ubuntu入门之二十八
现象1 打开VMware失败 Ubuntu升级之后打开VMware上报需要安装vmmon和vmnet,点击确认后如下提示 最终上报fail 解决方法 内核升级导致,需要在新内核下重新下载编译安装 查看版本 $ vmware -v VMware Workstation 17.5.1 build-23298084$ lsb_release…...

基于服务器使用 apt 安装、配置 Nginx
🧾 一、查看可安装的 Nginx 版本 首先,你可以运行以下命令查看可用版本: apt-cache madison nginx-core输出示例: nginx-core | 1.18.0-6ubuntu14.6 | http://archive.ubuntu.com/ubuntu focal-updates/main amd64 Packages ng…...

华为OD机试-食堂供餐-二分法
import java.util.Arrays; import java.util.Scanner;public class DemoTest3 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseint a in.nextIn…...