【自然语言处理系列】掌握jieba分词器:从基础到实战,深入文本分析与词云图展示
本文旨在全面介绍jieba分词器的功能与应用,从分词器的基本情况入手,逐步解析全模式与精确模式的不同应用场景。文章进一步指导读者如何通过添加自定义词典优化分词效果,以及如何利用jieba分词器进行关键词抽取和词性标注,为后续的文本分析打下坚实基础。以十九大报告为例,我们将展示如何将分析结果以词云图的形式直观展现,使读者能够更加深入理解和掌握文本分析的实际操作,进而提升处理中文文本数据的能力。此博客适合NLP初学者及对文本分析感兴趣的专业人士。
目录
一、jieba分词器介绍
二、 jieba分词器的全模式和精确模式
三、jieba分词器添加自定义词典
四、 jieba分词器实现关键词抽取
五、jieba分词器进行词性标注
六、文本分析之词云图展示------以十九大报告为例
一、jieba分词器介绍
结巴分词器,全称为jieba分词器,是一个广泛应用于中文自然语言处理的开源库,由Python语言编写。它主要功能是将连续的中文文本切分成单个词语,也就是进行中文词语的词法分析。jieba分词器采用了基于词频统计和HMM(隐马尔可夫模型)的混合算法,能够处理大量的中文文本,支持用户自定义词典,对于网络语言、口语、外来词等有较好的处理能力。它提供了多种分词模式,如精确模式、全模式和搜索引擎模式,以适应不同的应用场景需求。
二、 jieba分词器的全模式和精确模式
下方代码演示了使用jieba分词库对中文文本进行分词的两种主要模式:全模式和精确模式。首先,通过全模式(cut_all=True)对句子‘我来到北京清华大学’进行分词,该模式会尽可能地切分出所有可能的词汇,全模式会生成较多的分词结果,包括一些较短的词汇。接着,使用精确模式(cut_all=False),该模式会尝试将句子最精确地切开,这时的分词更加符合实际的词语使用习惯。最后,对于句子‘他来到了网易杭研大厦’,默认使用精确模式进行分词,得到的结果为‘他/ 来到/ 了/ 网易/ 杭研/ 大厦’,这一结果同样体现了精确模式在中文分词中的有效性。
import jiebaseg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print("全模式: " + "/ ".join(seg_list)) # 全模式seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("精确模式: " + "/ ".join(seg_list)) # 精确模式seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式
print(", ".join(seg_list))
三、jieba分词器添加自定义词典
在自然语言处理领域,分词是基础且关键的一步。为了确保分词的准确性和适应性,jieba分词器不仅提供了内置的词典,还允许用户添加自定义词典,以适应特定的分词需求。自定义词典的用途包括提高分词准确性、增强模型适应性、处理专业术语等。例如,在金融领域,有许多专业术语和名称无法被默认词典所覆盖,此时添加自定义词典可以提高分词的准确率。在文本分析和挖掘中,通过简单的文本文件或数据库等形式来构建自定义词典,并将其导入到jieba分词器中,可以让分词器更好地理解和处理特定的文本内容,从而帮助用户更好地识别和处理实体、事件和情感等语言实体。
text = "故宫的著名景点包括乾清宫、太和殿和黄琉璃瓦等" # 全模式 seg_list = jieba.cut(text, cut_all=True) print(u"[全模式]: ", "/ ".join(seg_list)) # 精确模式 seg_list = jieba.cut(text, cut_all=False) print(u"[精确模式]: ", "/ ".join(seg_list))
在处理句子“故宫的著名景点包括乾清宫、太和殿和黄琉璃瓦等”时,jieba分词器未能将“乾清宫”和“黄琉璃瓦”识别为独立的整体。鉴于这两个词汇实际上应被视作单独的实体,我们考虑通过引入自定义词典来改进分词结果,确保这些专有名词能够被正确分辨和处理。

jieba.load_userdict("./data/mydict.txt") #需UTF-8,可以在另存为里面设置 #这是用户自定义的一个词典#也可以用jieba.add_word("乾清宫") text = "故宫的著名景点包括乾清宫、太和殿和黄琉璃瓦等" # 全模式 seg_list = jieba.cut(text, cut_all=True) print(u"[全模式]: ", "/ ".join(seg_list)) # 精确模式 seg_list = jieba.cut(text, cut_all=False) print(u"[精确模式]: ", "/ ".join(seg_list))
为解决jieba分词器在处理“乾清宫”和“黄琉璃瓦”时的问题,创建了一个包含这两个词汇的自定义词典(txt格式)。通过将此词典导入jieba分词器,同时对句子“故宫的著名景点包括乾清宫、太和殿和黄琉璃瓦等”进行全模式和精确模式下的分词,结果显示“乾清宫”和“黄琉璃瓦”被成功识别为独立的实体。这一改进显著提升了分词的准确性,确保了专有名词的恰当识别。
创建的自定义字典是一个txt格式,如下,主要要将其保存为utf-8格式。


四、 jieba分词器实现关键词抽取
下方代码通过使用jieba库的分词功能(jieba.cut)将文本分解成如'故宫'、'著名景点'、'乾清宫'等有意义的词语(分词结果)。然后运用关键词提取技术(jieba.analyse.extract_tags),选取了文本中最具代表性的五个词(关键词),这些关键词有助于读者快速理解文本的主题和关键内容。结果显示,前五个关键词中分为是”著名景点”、”乾清宫”、”黄琉璃瓦”、”太和殿”、”故宫”。同时输出了这五个关键词在文本中的重要程度。
权重的定义:权重在这里指的是每个关键词在文本中的TF-IDF值,即词频-逆文档频率。这是一种统计方法,用以评估一个词语对于一个文件集或一个语料库中的一个文件的重要程度。
权重的计算:TF-IDF值由两部分组成。第一部分是词频(TF),即词语在文本中出现的次数;第二部分是逆文档频率(IDF),这部分衡量的是词语的罕见程度,即如果一个词语在许多文档中都出现,则其IDF值会较低。这两部分的乘积形成了最终的权重值。
权重的应用:通过这种方式计算得出的权重有助于我们了解每个关键词在文本中的重要性。权重越高,表明该词在文本中越重要,这可以用于文本摘要、信息检索等多种NLP任务。
权重的应用场景:关键词提取的结果可以用在很多场景,比如自动摘要、搜索引擎优化、舆情分析等。在这些应用中,准确地了解关键词的重要性是非常关键的一点。
权重的优劣势:虽然TF-IDF是一种有效的关键词权重计算方法,但它也有局限性,比如无法捕捉词语之间的语义关系。因此,在使用这种方法时,通常需要根据具体任务调整或结合其他方法使用。
import jieba.analyse
text = "故宫的著名景点包括乾清宫、太和殿和黄琉璃瓦等"
seg_list = jieba.cut(text, cut_all=False)
# print (u"分词结果:")
# print ("/".join(seg_list))
#获取关键词
tags = jieba.analyse.extract_tags(text, topK=5)
print (u"关键词:")
print (" ".join(tags))
tags = jieba.analyse.extract_tags(text, topK=5, withWeight=True)
for word, weight in tags:print(word, weight)
五、jieba分词器进行词性标注
下方是使用jieba库的posseg模块对中文句子进行分词和词性标注的示例。
import jieba.posseg as pseg
words = pseg.cut("我爱北京天安门")
for word, flag in words:print("%s %s" % (word, flag))
六、文本分析之词云图展示------以十九大报告为例
import jieba
from wordcloud import WordCloud
import imageio
from collections import Counter
import matplotlib.pyplot as pltdata={}#读入数据
text_file = open('./data/19Congress.txt','r',encoding='utf-8')#文本数据是十九大报告
text = text_file.read()
#加载停用词表
with open('./data/stopwords.txt',encoding='utf-8') as file:stopwords = {line.strip() for line in file}#分词
seg_list = jieba.cut(text, cut_all=False)
for word in seg_list:if len(word)>=2:if not data.__contains__(word):data[word]=0data[word]+=1
#这个词在词典之中,每出现一次就加1;如果没有出现在词典中,则置为0
#print(data) my_wordcloud = WordCloud( background_color='white', #设置背景颜色max_words=400, #设置最大实现的字数#font_path=None,font_path=r'./data/SimHei.ttf', #设置字体格式,如不设置显示不了中文mask=imageio.imread('./data/mapofChina.jpg'), #指定在什么图片上画width=1000,height=1000,stopwords = stopwords
).generate_from_frequencies(data)plt.figure(figsize=(18,16))
plt.imshow(my_wordcloud)
plt.axis('off')
plt.show() # 展示词云
# my_wordcloud.to_file('result.jpg')
text_file.close()
上述Python代码实现了基于“十九大报告”文本数据的中文词云可视化。具体而言,步骤如下:step1:从“./data/19Congress.txt”文件中读入文本数据;step2: “./data/stopwords.txt”文件中加载停用词表;step3:对文本数据进行分词,这里使用了jieba分词工具;step4:对分词后的数据进行词频统计,统计每个词在文本数据中出现的次数,并存储在字典data中;step5:基于词频统计数据,使用WordCloud工具生成词云图片,词云图片中单词的大小与其词频成正比;Step6:展示词云:使用matplotlib工具将生成的词云图片展示出来。同时根据实际需求,调整背景图片这个参数,将词云图的背景设为白色,形状为中国地图,以生成更符合需求的词云图片。
相关文章:
【自然语言处理系列】掌握jieba分词器:从基础到实战,深入文本分析与词云图展示
本文旨在全面介绍jieba分词器的功能与应用,从分词器的基本情况入手,逐步解析全模式与精确模式的不同应用场景。文章进一步指导读者如何通过添加自定义词典优化分词效果,以及如何利用jieba分词器进行关键词抽取和词性标注,为后续的…...

TikTok短视频矩阵系统
随着数字化时代的到来,短视频已成为人们获取信息、娱乐消遣的重要渠道。TikTok,作为全球最受欢迎的短视频平台之一,其背后的短视频矩阵系统是支撑其成功的关键因素。本文将深入探讨TikTok短视频矩阵系统的构成、功能以及它在新媒体时代中的影…...

码题杯:我会修改图
原题链接:码题集OJ-我会修改图 题目大意:给你一张n个点(编号为1∼n),m条边(编号为1∼m)的无向图,图上每个点都有一个点权,权值分别为a1,a2,…,an&…...

MongoDB Map-Reduce 简介
MongoDB Map-Reduce 简介 MongoDB 是一个流行的 NoSQL 数据库,它使用文档存储数据,这些数据以 JSON 格式存储。MongoDB 提供了多种数据处理方法,其中 Map-Reduce 是一种用于批量处理和聚合数据的功能强大的工具。Map-Reduce 允许用户对大量数…...
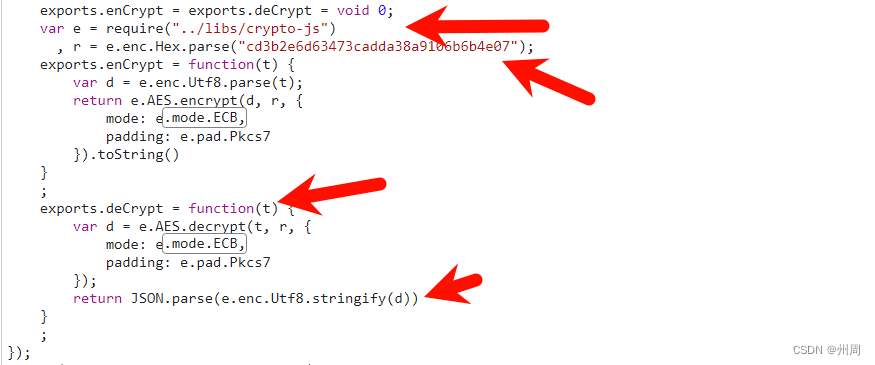
某平台小程序逆向思路整理
一、下载软件 devtools 二、强制打开控制台 根据返回的数据我们得知数据被加密了 找到这个加密的js 发现加密的位置 打断点进入这个加密的方法 之后自定义js。python调用解密即可。...

黑马苍穹外卖6 清理redis缓存+Spring Cache+购物车的增删改查
缓存菜品 后端服务都去查询数据库,对数据库访问压力增大。 解决方式:使用redis来缓存菜品,用内存比磁盘性能更高。 key :dish_分类id String key “dish_” categoryId; RestController("userDishController") RequestMapping…...

鸿蒙开发系统基础能力:【@ohos.systemTime (设置系统时间)】
设置系统时间 本模块用来设置、获取当前系统时间,设置、获取当前系统日期和设置、获取当前系统时区。 说明: 本模块首批接口从API version 7开始支持。后续版本的新增接口,采用上角标单独标记接口的起始版本。 导入模块 import systemTime …...
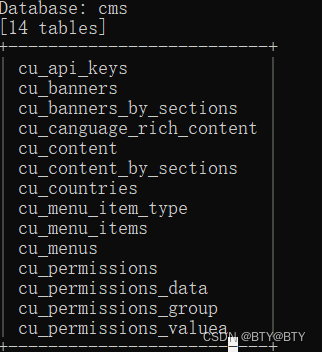
CVE-2020-26048(文件上传+SQL注入)
简介 CuppaCMS是一套内容管理系统(CMS)。 CuppaCMS 2019-11-12之前版本存在安全漏洞,攻击者可利用该漏洞在图像扩展内上传恶意文件,通过使用文件管理器提供的重命名函数的自定义请求,可以将图像扩展修改为PHP…...

【面试题】信息系统安全运维要做什么
信息系统安全运维是确保信息系统稳定、可靠、安全运行的一系列活动和措施。 其主要包括以下几个方面: 1.系统监控: 实时监测信息系统的运行状态,如服务器的性能指标、网络流量、应用程序的运行情况等。通过监控工具,及时发现系统…...
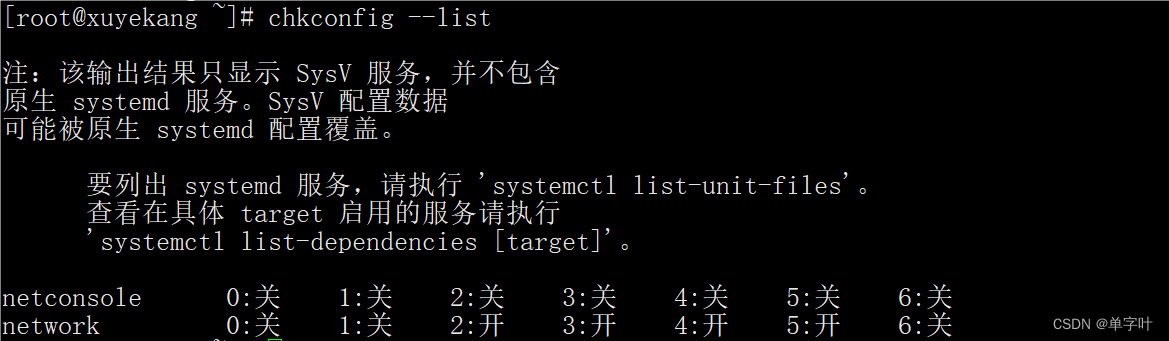
引导过程与服务器控制
一、引导过程 1.开机自检 服务器主机开机以后,将根据主板 BIOS 中的设置对 CPU(Central Processing Unit, 中央处理器)、内存、显卡、键盘等设备进行初步检测,检测成功后根据预设的启动顺序移 交系统控制权,…...

前置章节-熟悉Python、Numpy、SciPy和matplotlib
目录 一、编程环境-使用jupyter notebook 1.下载homebrew包管理工具 2.安装Python环境 3.安装jupyter 4.下载Anaconda使用conda 5.使用conda设置虚拟环境 二、学习Python基础 1.快排的Python实现 (1)列表推导-一种创建列表的简洁方式 (2)列表相加 2.基本数据类型及运…...
的方法)
在Ubuntu上安装和配置配置服务器防火墙(CSF)的方法
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 简介 Config Server Firewall(CSF)是大多数 Linux 发行版和基于 Linux 的 VPS 的免费高级防火墙。除了基本的防…...
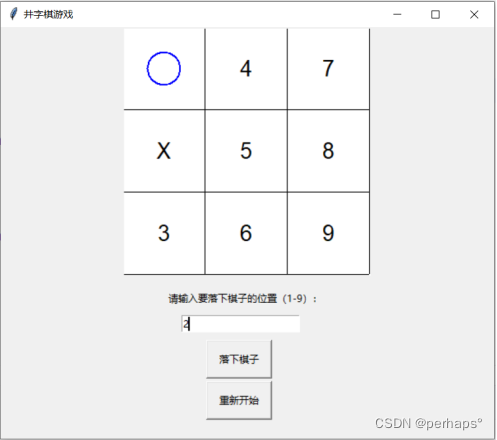
Python-井字棋
井字棋 1.设计登录界面1.1导入需要的工具包1.2窗口显示1.3登录界面图片显示1.6标签按钮输入框显示 2.登录功能实现2.1用户数据存储 2.2登录和注册2.2.1登录功能实现2.2.2注册功能实现 3.井字棋游戏3.1 导入需要的工具包3.2 窗口显示3.2 按钮标签显示3.3 棋盘设置初始状态3.4 游…...

39.客户端与服务端断开事件handler
客户端与服务端断开有两种情况: 1.正常断开,客户端调用了ctx.channel().close(); 2.异常断开,比如客户端挂掉了 服务端定义handler来处理连接断开情况下要进行的逻辑操作: package com.xkj.server.handler;import com.xkj.ser…...

SSL 之 http只用crt格式证书完成SSL单向认证通信
背景 远程调用第三方服务时,之前都是双向认证,服务器提供jks格式的keystore证书,客户端配置好即可。 今天遇到个奇葩需求,服务器只给根公钥证书(root.crt),还是第三方合法证书,要求单向认证,客户…...

实训作业-人事资源管理系统
er图 模型图 DDL与DML DROP TABLE IF EXISTS departments; CREATE TABLE departments (department_id int(11) NOT NULL AUTO_INCREMENT COMMENT 部门ID,department_name varchar(100) NOT NULL COMMENT 部门名称,PRIMARY KEY (department_id),UNIQUE KEY department_name (de…...

Flink 资源静态调度
本内容是根据 Flink 1.18.0-Scala_2.12 版本源码梳理而来。本文主要讲述任务提交时,为 Task 分配资源的过程。 以下是具体步骤讲解: TaskManager 资源注册 TaskManager 在启动时,会向 ResourceManager 注册资源。ResourceManager 会将 Tas…...

upload-labs第十三关教程
upload-labs第十三关教程 第十三关一、源代码分析代码审计 二、绕过分析1)0x00绕过a.上传eval.pngb.使用burpsuite进行拦截修改之前:修改之后:进入hex模块: c.放包上传成功: d.使用中国蚁剑进行连接 2)%00绕…...
基于springboot实现宠物商城网站管理系统项目【项目源码+论文说明】计算机毕业设计
基于springboot实现宠物商城网站管理系统演示 摘要 传统信息的管理大部分依赖于管理人员的手工登记与管理,然而,随着近些年信息技术的迅猛发展,让许多比较老套的信息管理模式进行了更新迭代,商品信息因为其管理内容繁杂ÿ…...
Fragment与ViewModel(MVVM架构)
简介 在Android应用开发中,Fragment和ViewModel是两个非常重要的概念,它们分别属于架构组件库的一部分,旨在帮助开发者构建更加模块化、健壮且易维护的应用。 Fragment Fragment是Android系统提供的一种可重用的UI组件,它能够作为…...

设计模式和设计原则回顾
设计模式和设计原则回顾 23种设计模式是设计原则的完美体现,设计原则设计原则是设计模式的理论基石, 设计模式 在经典的设计模式分类中(如《设计模式:可复用面向对象软件的基础》一书中),总共有23种设计模式,分为三大类: 一、创建型模式(5种) 1. 单例模式(Sing…...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

golang循环变量捕获问题
在 Go 语言中,当在循环中启动协程(goroutine)时,如果在协程闭包中直接引用循环变量,可能会遇到一个常见的陷阱 - 循环变量捕获问题。让我详细解释一下: 问题背景 看这个代码片段: fo…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

盘古信息PCB行业解决方案:以全域场景重构,激活智造新未来
一、破局:PCB行业的时代之问 在数字经济蓬勃发展的浪潮中,PCB(印制电路板)作为 “电子产品之母”,其重要性愈发凸显。随着 5G、人工智能等新兴技术的加速渗透,PCB行业面临着前所未有的挑战与机遇。产品迭代…...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...

苍穹外卖--缓存菜品
1.问题说明 用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大 2.实现思路 通过Redis来缓存菜品数据,减少数据库查询操作。 缓存逻辑分析: ①每个分类下的菜品保持一份缓存数据…...

【JavaWeb】Docker项目部署
引言 之前学习了Linux操作系统的常见命令,在Linux上安装软件,以及如何在Linux上部署一个单体项目,大多数同学都会有相同的感受,那就是麻烦。 核心体现在三点: 命令太多了,记不住 软件安装包名字复杂&…...

VM虚拟机网络配置(ubuntu24桥接模式):配置静态IP
编辑-虚拟网络编辑器-更改设置 选择桥接模式,然后找到相应的网卡(可以查看自己本机的网络连接) windows连接的网络点击查看属性 编辑虚拟机设置更改网络配置,选择刚才配置的桥接模式 静态ip设置: 我用的ubuntu24桌…...