MetaGPT全面安装与配置指南
文章目录
- MetaGPT环境配置
- 1.1 检查Python版本
- 1.2 拉取MetaGPT仓库
- 1.3 拉取源码本地安装
- 1.4 MetaGPT安装成果全流程展示
- 1.5 尝试简单使用
- MetaGPT的API调用
- 2.1 本地部署大模型尝试
- 安装必要的依赖
- 下载并配置大模型
- 配置API服务
- 2.2 讯飞星火API调用
- 获取API密钥
- 安装讯飞星火SDK
- 调用API
- 安装MetaGPT
- 3.1 安装稳定版本
- 3.2 安装子模块RAG
- 3.3 安装最新的开发版本
- 3.4 以开发模式安装
- 3.5 使用Docker安装
- 3.6 自行构建镜像
- 3.7 安装全部功能
- 使用Mermaid生成图表
- 4.1 通过nodejs直接安装mermaid-cli
- 4.2 使用pyppeteer安装
- 4.3 使用playwright安装
- 4.4 使用ink方法
- 对比Mermaid引擎
- 5.1 安装简易度
- 5.2 平台兼容性
- 5.3 生成png
- 5.4 生成svg
- 5.5 生成pdf
- 5.6 离线运行
- 环境配置
- 6.1 配置MetaGPT
- 6.2 配置大模型api_key
- 6.3 测试demo
- Agent System Overview
- 7.1 智能体概述
- 7.2 多智能体
- 7.3 MetaGPT
- 7.4 其他多智能体框架
- 单智能体入门参考
- 8.1 使用现成的智能体
- 8.2 单动作智能体开发
- 8.3 多动作智能体开发
- 8.4 进阶:编写文档助手参考
- MetaGPT的进一步学习
- 9.1 文章知识点与官方知识档案匹配
- 9.2 如何用MetaGPT帮你写一个贪吃蛇的小游戏项目
- 9.3 MetaGPT初步搭建
- 9.4 多智能体元编程框架:MetaGPT
- 9.5 MetaGPT多智能体小白入门教程
- 9.6 MetaGPT入门(一)
- 9.7 2024.5组队学习——MetaGPT(0.8.1)智能体理论与实战(上)
- 9.8 2024.2DataWhale多智能体实战
- 9.9 最简单的获取配置MetaGPT
- 9.10 MetaGPT前期准备与快速上手
- 9.11 MetGPT实践-安装,配置LLM,跑通一个demo
- 9.12 AIAgent框架——MetaGPT技术详解
- 9.13 大模型到智能体.pdf
- 9.14 一个免费调用gpt4源码
- 9.15 【AI的未来-AIAgent系列】【MetaGPT】4.1细说我在ActionNode实战中踩的那些坑
- 9.16 【AI的未来-AIAgent系列】【MetaGPT】0.你的第一个MetaGPT程序
- 9.17 MetaGPT(TheMulti-AgentFramework):颠覆AI开发的革命性多智能体元编程框架
- 9.18 能当老板的AI大模型多智体框架MetaGPT自动完成项目代码讲故事
- 9.19 MetaGPT-打卡day01
- 9.20 autoconfigbertconfig
MetaGPT环境配置
1.1 检查Python版本
在开始安装MetaGPT之前,首先需要确保你的系统上已经安装了Python 3.9或更高版本。你可以通过以下命令来检查Python版本:
python3 --version
如果显示的版本低于3.9,你需要升级Python。你可以通过官方网站下载最新版本的Python进行安装。
1.2 拉取MetaGPT仓库
为了获取MetaGPT的最新版本,你可以通过GitHub仓库进行拉取。以下是具体步骤:
- 打开终端或命令行工具。
- 使用以下命令克隆MetaGPT仓库:
git clone https://github.com/geekan/MetaGPT.git
- 进入克隆下来的仓库目录:
cd MetaGPT
1.3 拉取源码本地安装
在拉取了MetaGPT仓库之后,你可以通过以下步骤进行本地安装:
- 确保你已经进入了MetaGPT的目录。
- 使用以下命令安装所需的Python包:
pip install -e .
这个命令会安装MetaGPT及其依赖包,并且会创建一个指向本地代码的符号链接,这样你可以在不重新安装的情况下修改代码。
1.4 MetaGPT安装成果全流程展示
为了确保MetaGPT安装成功,我们可以通过一个简单的流程来展示安装成果。以下是一个全流程的展示:
- 打开终端或命令行工具。
- 进入MetaGPT的目录:
cd /path/to/MetaGPT
- 运行一个简单的示例脚本来验证安装:
python examples/simple_example.py
如果一切正常,你应该会看到一些输出,表明MetaGPT已经成功安装并可以正常运行。
1.5 尝试简单使用
在安装并验证了MetaGPT之后,我们可以尝试一些简单的使用示例。以下是一个简单的使用示例:
- 打开终端或命令行工具。
- 进入MetaGPT的目录:
cd /path/to/MetaGPT
- 运行一个简单的示例脚本来生成代码:
python examples/code_generation_example.py
这个示例脚本会使用MetaGPT生成一些代码。你可以根据需要修改脚本中的输入参数来生成不同的代码。
通过以上步骤,你应该已经成功配置并安装了MetaGPT,并且可以开始使用它进行各种任务,如代码生成、文本处理等。
MetaGPT的API调用
2.1 本地部署大模型尝试
在开始使用MetaGPT进行API调用之前,首先需要确保本地环境中已经部署了一个大型语言模型(LLM)。以下是本地部署大模型的基本步骤:
安装必要的依赖
-
检查Python版本:
确保系统中已经安装了Python 3.9+。可以通过以下命令检查Python版本:python3 --version -
安装Transformers库:
使用pip安装Hugging Face的Transformers库,该库提供了许多预训练的大型语言模型。pip install transformers
下载并配置大模型
-
选择并下载模型:
可以从Hugging Face模型库中选择一个合适的模型。例如,下载BERT模型:git clone https://huggingface.co/bert-base-uncased -
加载模型:
使用Transformers库加载模型。以下是一个简单的示例代码,展示如何加载和使用一个预训练的BERT模型:from transformers import BertTokenizer, BertModel import torch# 加载预训练的BERT模型和分词器 tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') model = BertModel.from_pretrained('bert-base-uncased')# 输入文本 inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")# 获取模型输出 outputs = model(**inputs)# 打印最后一层的隐藏状态 last_hidden_states = outputs.last_hidden_state print(last_hidden_states)
配置API服务
-
使用Flask创建API服务:
为了通过API调用本地部署的模型,可以使用Flask框架创建一个简单的API服务。以下是一个示例代码:from flask import Flask, request, jsonify from transformers import BertTokenizer, BertModel import torchapp = Flask(__name__)# 加载预训练的BERT模型和分词器 tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') model = BertModel.from_pretrained('bert-base-uncased')@app.route('/predict', methods=['POST']) def predict():data = request.jsontext = data['text']inputs = tokenizer(text, return_tensors="pt")outputs = model(**inputs)last_hidden_states = outputs.last_hidden_statereturn jsonify({'result': last_hidden_states.tolist()})if __name__ == '__main__':app.run(port=5000) -
测试API服务:
使用curl或其他工具测试API服务是否正常工作:curl -X POST http://127.0.0.1:5000/predict -H "Content-Type: application/json" -d '{"text": "Hello, my dog is cute"}'
2.2 讯飞星火API调用
讯飞星火是科大讯飞推出的一款基于人工智能的智能语音交互平台。通过API调用,可以实现语音识别、语音合成等功能。以下是使用讯飞星火API的基本步骤:
获取API密钥
-
注册并登录讯飞开放平台:
访问讯飞开放平台(https://www.xfyun.cn/),注册并登录账号。 -
创建应用并获取API密钥:
在讯飞开放平台上创建一个应用,并获取相应的API密钥(APPID、APIKey、APISecret)。
安装讯飞星火SDK
- 安装Python SDK:
使用pip安装讯飞星火的Python SDK:pip install iflytek-ai
调用API
-
初始化API客户端:
使用获取的API密钥初始化讯飞星火API客户端。以下是一个示例代码:from iflytek_ai import AIClient# 初始化API客户端 client = AIClient(appid='your_appid', api_key='your_api_key', api_secret='your_api_secret') -
调用语音识别API:
使用API客户端调用语音识别API。以下是一个示例代码:# 读取音频文件 with open('path_to_audio_file.wav', 'rb') as f:audio_data = f.read()# 调用语音识别API result = client.asr(audio_data, 'wav', 16000) print(result) -
处理API响应:
根据API返回的结果进行相应的处理。例如,提取识别的文本内容:if result['code'] == 0:text = result['data']['result']['ws']print('识别结果:', text) else:print('识别失败:', result['message'])
通过以上步骤,您可以在本地部署大模型并调用讯飞星火API,实现文本生成、语音识别等功能。
安装MetaGPT
3.1 安装稳定版本
安装MetaGPT的稳定版本是最简单且推荐的方式。你可以通过以下步骤来完成安装:
-
确保Python版本符合要求:
MetaGPT要求Python 3.9或更高版本。你可以通过以下命令检查当前Python版本:python --version -
使用pip安装:
使用pip安装MetaGPT的稳定版本,命令如下:pip install --upgrade metagpt -
验证安装:
安装完成后,你可以通过以下命令验证MetaGPT是否安装成功:metagpt --version
3.2 安装子模块RAG
RAG(Retrieval-Augmented Generation)是MetaGPT的一个重要子模块。安装RAG可以增强MetaGPT的数据检索和生成能力。以下是安装步骤:
-
安装RAG:
在安装了MetaGPT的基础上,你可以通过以下命令安装RAG:pip install --upgrade metagpt[rag] -
验证安装:
安装完成后,你可以通过以下命令验证RAG是否安装成功:metagpt rag --version
3.3 安装最新的开发版本
如果你需要使用MetaGPT的最新开发版本,可以通过以下步骤进行安装:
-
从GitHub仓库安装:
使用pip从GitHub仓库安装最新的开发版本,命令如下:pip install git+https://github.com/geekan/MetaGPT.git -
验证安装:
安装完成后,你可以通过以下命令验证MetaGPT是否安装成功:metagpt --version
3.4 以开发模式安装
如果你是开发者,希望对MetaGPT进行开发和调试,可以以开发模式进行安装。以下是具体步骤:
-
克隆GitHub仓库:
首先,克隆MetaGPT的GitHub仓库到本地:git clone https://github.com/geekan/MetaGPT.git cd MetaGPT -
以开发模式安装:
使用pip以开发模式安装MetaGPT,命令如下:pip install -e . -
验证安装:
安装完成后,你可以通过以下命令验证MetaGPT是否安装成功:metagpt --version
3.5 使用Docker安装
使用Docker安装MetaGPT可以简化环境配置和部署过程。以下是具体步骤:
-
拉取Docker镜像:
使用Docker拉取MetaGPT的官方镜像,命令如下:docker pull metagpt/metagpt:latest -
运行Docker容器:
使用Docker运行MetaGPT容器,命令如下:docker run -it metagpt/metagpt:latest -
验证安装:
进入容器后,你可以通过以下命令验证MetaGPT是否安装成功:metagpt --version
3.6 自行构建镜像
如果你需要自定义Docker镜像,可以按照以下步骤进行构建:
-
克隆GitHub仓库:
首先,克隆MetaGPT的GitHub仓库到本地:git clone https://github.com/geekan/MetaGPT.git cd MetaGPT -
构建Docker镜像:
使用Docker构建MetaGPT镜像,命令如下:docker build -t metagpt:custom . -
运行Docker容器:
使用Docker运行自定义的MetaGPT容器,命令如下:docker run -it metagpt:custom -
验证安装:
进入容器后,你可以通过以下命令验证MetaGPT是否安装成功:metagpt --version
3.7 安装全部功能
如果你需要安装MetaGPT的所有功能,包括所有子模块和依赖项,可以按照以下步骤进行:
-
安装全部功能:
使用pip安装MetaGPT及其所有依赖,命令如下:pip install metagpt[all] -
验证安装:
安装完成后,你可以通过以下命令验证MetaGPT是否安装成功:metagpt --version
使用Mermaid生成图表
4.1 通过nodejs直接安装mermaid-cli
Mermaid-cli 是一个命令行工具,可以通过 Node.js 直接安装和使用。以下是详细的安装和使用步骤:
-
安装 Node.js:
首先,确保你的系统上已经安装了 Node.js。如果没有安装,可以从 Node.js 官方网站 下载并安装。 -
安装 Mermaid-cli:
打开终端或命令提示符,运行以下命令来全局安装 Mermaid-cli:npm install -g @mermaid-js/mermaid-cli -
验证安装:
安装完成后,可以通过运行以下命令来验证 Mermaid-cli 是否安装成功:mmdc -V如果安装成功,将会显示 Mermaid-cli 的版本号。
-
生成图表:
创建一个包含 Mermaid 图表定义的文件,例如diagram.mmd,内容如下:使用以下命令生成图表:
mmdc -i diagram.mmd -o diagram.png这将生成一个名为
diagram.png的图片文件,包含你定义的图表。
4.2 使用pyppeteer安装
Pyppeteer 是一个 Python 版本的 Puppeteer,可以用于自动化浏览器操作。以下是通过 Pyppeteer 安装并生成 Mermaid 图表的步骤:
-
安装 Pyppeteer:
打开终端或命令提示符,运行以下命令来安装 Pyppeteer:pip install pyppeteer -
编写 Python 脚本:
创建一个 Python 脚本文件,例如generate_mermaid.py,内容如下:import asyncio from pyppeteer import launchasync def generate_mermaid():browser = await launch()page = await browser.newPage()await page.goto('https://mermaid-js.github.io/mermaid-live-editor')await page.type('#input', 'graph TD;\n A-->B;\n A-->C;\n B-->D;\n C-->D;')await page.click('#render')await page.screenshot({'path': 'diagram.png'})await browser.close()asyncio.get_event_loop().run_until_complete(generate_mermaid()) -
运行脚本:
在终端或命令提示符中运行以下命令来执行脚本:python generate_mermaid.py这将生成一个名为
diagram.png的图片文件,包含你定义的图表。
4.3 使用playwright安装
Playwright 是一个用于自动化浏览器的库,支持多种浏览器。以下是通过 Playwright 安装并生成 Mermaid 图表的步骤:
-
安装 Playwright:
打开终端或命令提示符,运行以下命令来安装 Playwright:pip install playwright -
编写 Python 脚本:
创建一个 Python 脚本文件,例如generate_mermaid.py,内容如下:from playwright.sync_api import sync_playwrightwith sync_playwright() as p:browser = p.chromium.launch()page = browser.new_page()page.goto('https://mermaid-js.github.io/mermaid-live-editor')page.fill('#input', 'graph TD;\n A-->B;\n A-->C;\n B-->D;\n C-->D;')page.click('#render')page.screenshot(path='diagram.png')browser.close() -
运行脚本:
在终端或命令提示符中运行以下命令来执行脚本:python generate_mermaid.py这将生成一个名为
diagram.png的图片文件,包含你定义的图表。
4.4 使用ink方法
Ink 是一个用于构建命令行界面的 React 组件库。以下是通过 Ink 生成 Mermaid 图表的步骤:
-
安装 Ink 和相关依赖:
打开终端或命令提示符,运行以下命令来安装 Ink 和相关依赖:npm install ink react react-dom -
编写 Ink 脚本:
创建一个 JavaScript 文件,例如generate_mermaid.js,内容如下:const React = require('react'); const { render, Text } = require('ink'); const { Mermaid } = require('ink-mermaid');const App = () => (<Mermaid chart="graph TD;\n A-->B;\n A-->C;\n B-->D;\n C-->D;" /> );render(<App />); -
运行脚本:
在终端或命令提示符中运行以下命令来执行脚本:node generate_mermaid.js这将生成一个包含 Mermaid 图表的命令行界面。
通过以上四种方法,你可以选择最适合你的方式来生成 Mermaid 图表。每种方法都有其独特的优势和适用场景,根据你的需求选择合适的方法即可。
对比Mermaid引擎
5.1 安装简易度
Mermaid是一个用于生成图表和流程图的JavaScript库,它可以通过多种方式进行安装。以下是几种常见的安装方法:
-
通过Node.js安装:
npm install mermaid这种方法需要先安装Node.js,然后使用npm进行安装。虽然步骤稍多,但Node.js和npm的安装过程相对直观,因此整体安装简易度较高。
-
通过CDN引入:
<script src="https://cdn.jsdelivr.net/npm/mermaid/dist/mermaid.min.js"></script>这种方法最为简便,无需任何安装步骤,只需在HTML文件中添加一个script标签即可。
-
通过Python的Mermaid CLI工具安装:
pip install mermaidcli这种方法需要先安装Python,然后使用pip进行安装。虽然步骤稍多,但Python和pip的安装过程相对直观,因此整体安装简易度较高。
5.2 平台兼容性
Mermaid具有很好的平台兼容性,可以在多种环境中使用:
- Web浏览器:Mermaid可以直接在现代Web浏览器中运行,支持Chrome、Firefox、Safari等主流浏览器。
- Node.js:通过npm安装后,可以在Node.js环境中使用Mermaid生成图表。
- Python:通过Mermaid CLI工具,可以在Python环境中生成图表。
5.3 生成png
Mermaid本身不直接支持生成PNG格式的图片,但可以通过以下方法实现:
-
使用Mermaid CLI工具:
mmdc -i input.mmd -o output.png这种方法需要先安装Mermaid CLI工具,然后使用命令行生成PNG格式的图片。
-
使用Puppeteer:
const puppeteer = require('puppeteer'); const fs = require('fs');(async () => {const browser = await puppeteer.launch();const page = await browser.newPage();await page.goto('data:text/html,<script src="https://cdn.jsdelivr.net/npm/mermaid/dist/mermaid.min.js"></script><div class="mermaid">graph TD; A-->B; A-->C; B-->D; C-->D;</div>');await page.waitForSelector('.mermaid');const element = await page.$('.mermaid');await element.screenshot({ path: 'diagram.png' });await browser.close(); })();这种方法需要先安装Puppeteer,然后使用JavaScript代码生成PNG格式的图片。
5.4 生成svg
Mermaid可以直接生成SVG格式的图表:
-
使用Mermaid CLI工具:
mmdc -i input.mmd -o output.svg这种方法需要先安装Mermaid CLI工具,然后使用命令行生成SVG格式的图片。
-
在HTML中使用Mermaid:
<script src="https://cdn.jsdelivr.net/npm/mermaid/dist/mermaid.min.js"></script> <div class="mermaid"> graph TD; A-->B; A-->C; B-->D; C-->D; </div>这种方法无需任何安装步骤,只需在HTML文件中添加Mermaid的script标签和图表代码即可。
5.5 生成pdf
Mermaid本身不直接支持生成PDF格式的文件,但可以通过以下方法实现:
-
使用Mermaid CLI工具和Puppeteer:
mmdc -i input.mmd -o output.pdf这种方法需要先安装Mermaid CLI工具和Puppeteer,然后使用命令行生成PDF格式的文件。
-
使用Puppeteer:
const puppeteer = require('puppeteer'); const fs = require('fs');(async () => {const browser = await puppeteer.launch();const page = await browser.newPage();await page.goto('data:text/html,<script src="https://cdn.jsdelivr.net/npm/mermaid/dist/mermaid.min.js"></script><div class="mermaid">graph TD; A-->B; A-->C; B-->D; C-->D;</div>');await page.waitForSelector('.mermaid');const pdf = await page.pdf({ path: 'diagram.pdf', format: 'A4' });await browser.close(); })();这种方法需要先安装Puppeteer,然后使用JavaScript代码生成PDF格式的文件。
5.6 离线运行
Mermaid可以在离线环境中运行,只需确保所有依赖项都已下载并包含在项目中:
-
本地引入Mermaid库:
<script src="path/to/mermaid.min.js"></script>这种方法需要先将Mermaid的库文件下载到本地,然后在HTML文件中引入本地文件。
-
使用Mermaid CLI工具:
mmdc -i input.mmd -o output.png这种方法需要先安装Mermaid CLI工具,然后使用命令行生成图表。由于Mermaid CLI工具可以在离线环境中运行,因此可以确保在没有网络连接的情况下生成图表。
通过以上方法,Mermaid可以在没有网络连接的环境中生成图表,确保图表的生成和展示不受网络限制。
环境配置
6.1 配置MetaGPT
在安装MetaGPT之后,为了确保其正常运行,需要进行一些基本的配置。以下是配置MetaGPT的步骤:
-
创建配置文件目录:
首先,创建一个目录来存放MetaGPT的配置文件。mkdir -p /opt/metagpt/config -
下载默认配置文件:
使用Docker命令从MetaGPT镜像中下载默认的配置文件config2.yaml。docker pull metagpt/metagpt:latest docker run --rm metagpt/metagpt:latest cat /app/metagpt/config/config2.yaml > /opt/metagpt/config/config2.yaml -
编辑配置文件:
使用文本编辑器打开并编辑配置文件config2.yaml,根据需要修改配置。vim /opt/metagpt/config/config2.yaml -
创建工作目录:
创建一个工作目录来存放MetaGPT的输出文件。mkdir -p /opt/metagpt/workspace
6.2 配置大模型api_key
为了使用MetaGPT与大型语言模型(LLMs)进行交互,需要配置API密钥。以下是配置API密钥的步骤:
-
获取API密钥:
从相应的LLM服务提供商(如OpenAI、讯飞星火等)获取API密钥。 -
编辑配置文件:
打开之前创建的配置文件config2.yaml,添加或修改API密钥配置。api_key: "your_api_key_here" -
保存配置文件:
保存并关闭配置文件。
6.3 测试demo
配置完成后,可以通过运行一个简单的demo来测试MetaGPT是否配置正确。以下是测试demo的步骤:
-
使用Docker运行demo:
使用Docker命令运行MetaGPT并执行一个简单的命令。docker run --rm \--privileged \-v /opt/metagpt/config/config2.yaml:/app/metagpt/config/config2.yaml \-v /opt/metagpt/workspace:/app/metagpt/workspace \metagpt/metagpt:latest \metagpt "Write a cli snake game" -
检查输出:
检查工作目录/opt/metagpt/workspace中是否生成了相应的输出文件,以确认MetaGPT是否正常工作。
通过以上步骤,您可以成功配置MetaGPT并测试其基本功能。如果遇到任何问题,请参考官方文档或社区支持以获取进一步的帮助。
Agent System Overview
7.1 智能体概述
智能体(Agent)是指在计算机系统中能够独立执行任务的实体。智能体通常具备自主性、反应性、主动性和社交性等特征。在人工智能领域,智能体可以是一个软件程序,能够感知环境、做出决策并执行动作。智能体的概念广泛应用于各种领域,如机器人学、多智能体系统、人工智能等。
智能体的核心功能包括:
- 感知:智能体能够从环境中获取信息。
- 决策:基于感知到的信息,智能体能够做出决策。
- 执行:智能体能够执行决策,对环境产生影响。
智能体的应用范围非常广泛,从简单的自动化任务到复杂的人工智能系统,都可以看到智能体的身影。
7.2 多智能体
多智能体系统(Multi-Agent System, MAS)是指由多个智能体组成的系统,这些智能体在同一个环境中相互作用和协作,共同完成任务。多智能体系统的设计和实现涉及到智能体之间的通信、协调、合作和竞争等问题。
多智能体系统的优势在于:
- 分布式处理:多个智能体可以并行处理任务,提高系统的整体效率。
- 鲁棒性:即使某个智能体出现故障,其他智能体仍然可以继续工作。
- 灵活性:智能体可以根据环境变化动态调整策略。
多智能体系统广泛应用于复杂问题的解决,如交通控制、资源分配、智能机器人等。
7.3 MetaGPT
MetaGPT是一个基于大型语言模型(LLMs)的多智能体写作框架。它允许用户通过定义不同的智能体角色和团队,构建自己的智能体来服务各种应用。MetaGPT的核心思想是通过多智能体协作,提高写作和内容生成的效率和质量。
MetaGPT的主要特点包括:
- 多智能体协作:支持多种内置角色和团队,智能体之间可以协同工作。
- 灵活配置:用户可以根据需求自定义智能体的角色和行为。
- 丰富的应用场景:适用于文案助手、摄影师、票据助手等多种应用场景。
通过MetaGPT,用户可以轻松构建复杂的智能体系统,实现自动化内容生成和决策支持。
7.4 其他多智能体框架
除了MetaGPT,还有许多其他的多智能体框架和平台,它们各自具有不同的特点和应用场景。以下是一些知名的多智能体框架:
- JADE:Java Agent Development Framework,是一个用于构建和部署多智能体系统的开源框架。JADE提供了丰富的API和工具,支持智能体之间的通信和协作。
- ROS(Robot Operating System):虽然主要用于机器人开发,但ROS也支持多智能体系统的构建。它提供了丰富的库和工具,用于机器人感知、决策和执行。
- MASON:Multi-Agent Simulator of Networks,是一个用于模拟和研究多智能体系统的框架。MASON支持复杂网络和社交网络的模拟,适用于社会科学和计算机科学的研究。
这些框架和平台为多智能体系统的开发和研究提供了强大的支持,推动了多智能体技术的发展和应用。
单智能体入门参考
8.1 使用现成的智能体
在MetaGPT框架中,使用现成的智能体是最简单快捷的入门方式。这些智能体已经预先配置了各种功能和行为,可以直接用于各种任务。以下是如何使用现成的智能体的步骤:
-
选择智能体:
- 根据任务需求,从MetaGPT提供的智能体库中选择合适的智能体。例如,如果需要进行数据分析,可以选择“DataInterpreter”智能体。
-
配置智能体:
- 使用MetaGPT的配置文件(如
config2.yaml)来配置智能体的参数。这些参数包括智能体的API密钥、行为模式、交互方式等。
- 使用MetaGPT的配置文件(如
-
启动智能体:
- 使用命令行或脚本启动智能体。例如,使用以下命令启动一个数据分析智能体:
metagpt start DataInterpreter --config /path/to/config2.yaml
- 使用命令行或脚本启动智能体。例如,使用以下命令启动一个数据分析智能体:
-
交互与监控:
- 通过MetaGPT提供的交互界面与智能体进行交互,监控其工作状态和输出结果。
8.2 单动作智能体开发
开发单动作智能体是理解MetaGPT框架工作原理的重要步骤。单动作智能体通常只执行一个特定的任务。以下是开发单动作智能体的步骤:
-
定义智能体类:
- 创建一个新的Python类,继承自MetaGPT的
BaseAgent类。例如:from metagpt.base import BaseAgentclass SimpleTaskAgent(BaseAgent):def __init__(self, name):super().__init__(name)
- 创建一个新的Python类,继承自MetaGPT的
-
实现动作方法:
- 在智能体类中定义一个方法,用于执行特定的任务。例如:
class SimpleTaskAgent(BaseAgent):def __init__(self, name):super().__init__(name)def perform_task(self, task_data):# 任务执行逻辑result = process_task_data(task_data)return result
- 在智能体类中定义一个方法,用于执行特定的任务。例如:
-
实例化并使用智能体:
- 创建智能体实例并调用其动作方法。例如:
agent = SimpleTaskAgent("SimpleTaskAgent1") result = agent.perform_task(task_data) print(result)
- 创建智能体实例并调用其动作方法。例如:
8.3 多动作智能体开发
多动作智能体可以执行多个不同的任务,适用于更复杂的应用场景。以下是开发多动作智能体的步骤:
-
定义智能体类:
- 创建一个新的Python类,继承自MetaGPT的
BaseAgent类。例如:from metagpt.base import BaseAgentclass MultiTaskAgent(BaseAgent):def __init__(self, name):super().__init__(name)
- 创建一个新的Python类,继承自MetaGPT的
-
实现多个动作方法:
- 在智能体类中定义多个方法,每个方法用于执行一个不同的任务。例如:
class MultiTaskAgent(BaseAgent):def __init__(self, name):super().__init__(name)def perform_task_one(self, task_data):# 任务一执行逻辑result = process_task_one_data(task_data)return resultdef perform_task_two(self, task_data):# 任务二执行逻辑result = process_task_two_data(task_data)return result
- 在智能体类中定义多个方法,每个方法用于执行一个不同的任务。例如:
-
实例化并使用智能体:
- 创建智能体实例并调用其不同的动作方法。例如:
agent = MultiTaskAgent("MultiTaskAgent1") result_one = agent.perform_task_one(task_data_one) result_two = agent.perform_task_two(task_data_two) print(result_one) print(result_two)
- 创建智能体实例并调用其不同的动作方法。例如:
8.4 进阶:编写文档助手参考
编写文档助手是一个更复杂的任务,涉及到文本处理、自然语言理解等多个方面。以下是编写文档助手的参考步骤:
-
定义智能体类:
- 创建一个新的Python类,继承自MetaGPT的
BaseAgent类。例如:from metagpt.base import BaseAgentclass DocumentAssistant(BaseAgent):def __init__(self, name):super().__init__(name)
- 创建一个新的Python类,继承自MetaGPT的
-
实现文档处理方法:
- 在智能体类中定义多个方法,用于处理文档的不同方面,如摘要生成、关键词提取等。例如:
class DocumentAssistant(BaseAgent):def __init__(self, name):super().__init__(name)def generate_summary(self, document):# 生成文档摘要summary = process_document_summary(document)return summarydef extract_keywords(self, document):# 提取文档关键词keywords = process_document_keywords(document)return keywords
- 在智能体类中定义多个方法,用于处理文档的不同方面,如摘要生成、关键词提取等。例如:
-
实例化并使用智能体:
- 创建智能体实例并调用其文档处理方法。例如:
agent = DocumentAssistant("DocumentAssistant1") summary = agent.generate_summary(document) keywords = agent.extract_keywords(document) print(summary) print(keywords)
- 创建智能体实例并调用其文档处理方法。例如:
通过以上步骤,你可以逐步掌握单智能体的开发和应用,为进一步学习和开发更复杂的智能体打下坚实的基础。
MetaGPT的进一步学习
9.1 文章知识点与官方知识档案匹配
在学习MetaGPT的过程中,了解文章中的知识点与官方知识档案的匹配情况是非常重要的。官方知识档案通常包含了框架的核心概念、使用方法、最佳实践以及常见问题的解答。通过将文章中的知识点与官方知识档案进行匹配,可以确保学习的内容是准确和最新的。
例如,如果你在学习如何配置MetaGPT时,发现文章中提到的配置步骤与官方知识档案中的步骤不一致,那么你应该优先参考官方知识档案中的信息。这样可以避免因为过时的信息而导致配置失败。
9.2 如何用MetaGPT帮你写一个贪吃蛇的小游戏项目
使用MetaGPT来编写一个贪吃蛇的小游戏项目是一个很好的实践机会。以下是一些步骤和建议:
- 定义需求:首先,明确贪吃蛇游戏的基本需求,包括游戏规则、界面设计、玩家操作等。
- 创建团队:使用MetaGPT创建一个多智能体团队,包括产品经理、架构师、项目经理和工程师等角色。
- 初始化团队:
import asyncio from metagpt.roles import Architect, Engineer, ProductManager, ProjectManager from metagpt.team import Teamasync def startup(idea: str):company = Team()company.hire([ProductManager(), Architect(), ProjectManager(), Engineer()])company.invest(investment=3.0)company.run_project(idea=idea)await company.run(n_round=5)await startup(idea="write a cli snake game") - 运行项目:运行上述代码,MetaGPT将根据需求生成贪吃蛇游戏的代码。
9.3 MetaGPT初步搭建
MetaGPT的初步搭建包括以下几个步骤:
- 安装MetaGPT:
pip install metagpt - 配置环境:确保Python版本符合要求,通常建议使用Python 3.7或更高版本。
- 初始化项目:创建一个新的项目目录,并在其中初始化MetaGPT。
9.4 多智能体元编程框架:MetaGPT
MetaGPT是一个多智能体元编程框架,它允许开发者通过定义不同的智能体角色来协作完成复杂的编程任务。以下是一些关键概念:
- 智能体角色:包括产品经理、架构师、项目经理和工程师等。
- 团队协作:智能体之间通过协作来完成项目需求。
- 元编程:通过定义智能体的行为和交互规则,实现自动化的编程任务。
9.5 MetaGPT多智能体小白入门教程
对于初学者来说,了解MetaGPT的基本概念和使用方法是非常重要的。以下是一些入门建议:
- 阅读官方文档:官方文档包含了MetaGPT的基本概念、安装步骤和使用方法。
- 实践项目:尝试使用MetaGPT来完成一个小项目,例如编写一个简单的CLI游戏。
- 参与社区:加入MetaGPT的社区,与其他开发者交流经验和问题。
9.6 MetaGPT入门(一)
MetaGPT入门的第一步是了解其基本概念和安装方法。以下是一些关键点:
- 基本概念:了解MetaGPT的多智能体框架、智能体角色和团队协作等概念。
- 安装步骤:
pip install metagpt - 初始化项目:创建一个新的项目目录,并在其中初始化MetaGPT。
9.7 2024.5组队学习——MetaGPT(0.8.1)智能体理论与实战(上)
在2024年5月的组队学习中,参与者将学习MetaGPT(0.8.1)的智能体理论和实战技巧。以下是一些学习内容:
- 智能体理论:了解智能体的基本概念、角色和协作方式。
- 实战技巧:通过实际项目来学习如何使用MetaGPT来完成编程任务。
9.8 2024.2DataWhale多智能体实战
在2024年2月的DataWhale多智能体实战中,参与者将学习如何使用MetaGPT来完成实际的编程项目。以下是一些实战内容:
- 项目需求分析:学习如何分析项目需求并定义智能体角色。
- 团队协作:通过实际项目来学习智能体之间的协作方式。
9.9 最简单的获取配置MetaGPT
获取和配置MetaGPT的最简单方法是使用pip安装:
pip install metagpt
9.10 MetaGPT前期准备与快速上手
在开始使用MetaGPT之前,需要做一些前期准备工作:
- 安装Python:确保安装了Python 3.7或更高版本。
- 安装MetaGPT:
pip install metagpt - 创建项目目录:创建一个新的项目目录,并在其中初始化MetaGPT。
9.11 MetGPT实践-安装,配置LLM,跑通一个demo
在实践中,安装和配置MetaGPT以及跑通一个demo的步骤如下:
- 安装MetaGPT:
pip install metagpt - 配置LLM:根据需要配置不同的大模型API,例如OpenAI、Azure等。
- 跑通demo:运行一个简单的demo来验证安装和配置是否成功。
9.12 AIAgent框架——MetaGPT技术详解
MetaGPT作为一个AIAgent框架,其技术详解包括以下几个方面:
- 智能体角色:了解不同的智能体角色及其职责。
- 团队协作:学习智能体之间的协作方式和交互规则。
- 元编程:了解如何通过定义智能体的行为和交互规则来实现自动化的编程任务。
9.13 大模型到智能体.pdf
《大模型到智能体》是一份详细介绍如何从大模型过渡到智能体的文档,其中包含了MetaGPT的使用方法和实践案例。
9.14 一个免费调用gpt4源码
在MetaGPT中,可以通过配置来免费调用gpt4的源码。以下是一些步骤:
- 配置API:根据需要配置gpt4的API。
- 调用源码:通过MetaGPT来调用gpt4的源码。
9.15 【AI的未来-AIAgent系列】【MetaGPT】4.1细说我在ActionNode实战中踩的那些坑
在ActionNode实战中,可能会遇到一些坑。以下是一些常见问题和解决方法:
- 配置问题:确保配置文件正确无误。
- 依赖问题:确保所有依赖项都已正确安装。
- 运行问题:确保运行环境正确无误。
9.16 【AI的未来-AIAgent系列】【MetaGPT】0.你的第一个MetaGPT程序
编写你的第一个MetaGPT程序的步骤如下:
- 安装MetaGPT:
pip install metagpt - 创建项目目录:创建一个新的项目目录,并在其中初始化MetaGPT。
- 编写代码:编写一个简单的MetaGPT程序。
9.17 MetaGPT(TheMulti-AgentFramework):颠覆AI开发的革命性多智能体元编程框架
MetaGPT作为一个革命性的多智能体元编程框架,其特点包括:
- 多智能体协作:通过定义不同的智能体角色来协作完成复杂的编程任务。
- 元编程:通过定义智能体的行为和交互规则来实现自动化的编程任务。
- 灵活性:可以根据需求灵活配置和扩展智能体角色。
9.18 能当老板的AI大模型多智体框架MetaGPT自动完成项目代码讲故事
MetaGPT可以自动完成项目代码并讲故事,以下是一些步骤:
- 定义需求:明确项目需求和故事情节。
- 创建团队:使用MetaGPT创建一个多智能体团队。
- 运行项目:运行项目代码并生成故事。
9.19 MetaGPT-打卡day01
在MetaGPT的打卡day01中,参与者将学习如何安装和配置MetaGPT,并运行一个简单的demo。以下是一些步骤:
- 安装MetaGPT:
pip install metagpt - 配置环境:确保Python版本符合要求。
- 运行demo:运行一个简单的demo来验证安装和配置是否成功。
9.20 autoconfigbertconfig
在MetaGPT中,可以使用autoconfigbertconfig来自动配置BERT模型。以下是一些步骤:
- 安装依赖:确保安装了所有必要的依赖项。
- 配置BERT模型:使用autoconfigbertconfig来自动配置BERT模型。
相关文章:

MetaGPT全面安装与配置指南
文章目录 MetaGPT环境配置1.1 检查Python版本1.2 拉取MetaGPT仓库1.3 拉取源码本地安装1.4 MetaGPT安装成果全流程展示1.5 尝试简单使用 MetaGPT的API调用2.1 本地部署大模型尝试安装必要的依赖下载并配置大模型配置API服务 2.2 讯飞星火API调用获取API密钥安装讯飞星火SDK调用…...
云计算期末综合测试题
云计算综合测试题 单选题填空题判断题简答题 单选题 这里选择题,直接以填空题展示,并给出解析 Bigtable是(Google)开发的分布式存储系统 解析:分布式结构化数据表Bigtable是Google基于GFS和Chubby开发的分布式存储系统…...
vue3-cropperjs图片裁剪工具-用户上传图片截取-(含预览视频)
效果图 上传图片弹窗预览 对于这个上传图片样式可以参考 官方原代码 官网传送入口 Upload 上传 | Element Plus (element-plus.org) <template><el-uploadclass"upload-demo"dragaction"https://run.mocky.io/v3/9d059bf9-4660-45f2-925d-ce80ad6…...
【WEB前端2024】3D智体编程:乔布斯3D纪念馆-第48课-可视化控制机器人
【WEB前端2024】3D智体编程:乔布斯3D纪念馆-第48课-可视化控制机器人 使用dtns.network德塔世界(开源的智体世界引擎),策划和设计《乔布斯超大型的开源3D纪念馆》的系列教程。dtns.network是一款主要由JavaScript编写的智体世界引…...

Java Stream API揭秘:掌握List流操作,打造高效数据处理流程
序言 Java Stream API是Java 8中引入的一个非常重要的功能组成部分,它提供了一种声明式的处理数据集合的方法。它主要特点是基于函数式编程的理念,允许我们以更加简洁、高效的方式进行集合的处理、转换和过滤。通过Stream API,我们可以灵活地…...
))
最新Java面试题及答案(Java基础、设计模式、Java虚拟机(jvm))
文章目录 前言一、Java基础题1.什么是Java?2.Jdk和Jre和JVM的区别?3.Java语言有哪些特点?4.Java有哪些数据类型?5.switch 是否能作用在 byte 上,是否能作用在 long 上,是否能作用在 String上?6.…...
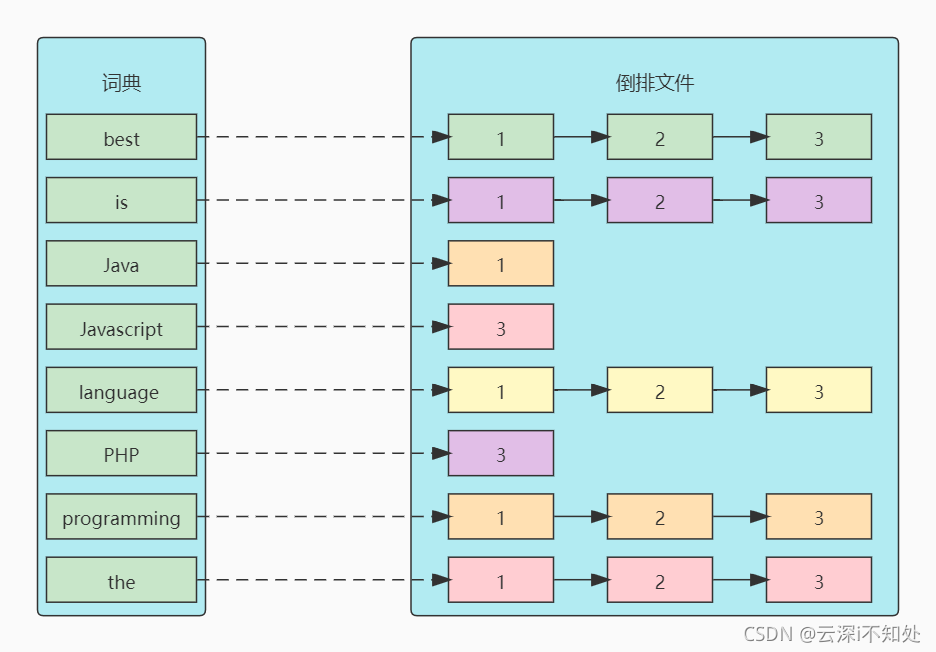
详解Elastic Search高速搜索背后的秘密:倒排索引
🎬 鸽芷咕:个人主页 🔥 个人专栏: 《C干货基地》《粉丝福利》 ⛺️生活的理想,就是为了理想的生活! 引入 全文搜索属于最常见的需求,开源的 Elasticsearch (以下简称 Elastic)是目前全文搜索引…...

数据库操控指南:玩转数据
对于表中数据的基本操作 数据的操作——DML语句(增删改)1.插入数据2.修改数据3.数据删除 数据的查询——DQL语句1.原理:2.查看表结构3.条件查询4.基础的SELECT语法 阅读指南: 本文章讲述了对于数据库中的数据的基本操作࿰…...

前端 CSS 经典:图层放大的 hover 效果
效果 思路 设置 3 层元素,最上层元素使用 clip-path 裁剪成圆,hover 改变圆大小,添加过渡效果。 实现代码 <!DOCTYPE html> <html lang"en"><head><meta charset"utf-8" /><meta http-eq…...

Flutter实现页面间传参
带参跳转 步骤 在router中配置这个路由需要携带的参数,这里的参数是 arguments,注意要用花括号包裹参数名称 在相应组件中实现带参构造函数 在state类中可以直接使用${widget.arguments}来访问到传递的参数 在其他页面中使用Navigator.pushNamed()带参跳转...

如何在Java中实现安全编码
如何在Java中实现安全编码 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 在当今数字化和网络化的时代,安全编码成为软件开发中至关重要的一环。特…...
C#开发-集合使用和技巧(八)集合中的排序Sort、OrderBy、OrderByDescending
C#开发-集合使用和技巧(八)集合中的排序Sort、OrderBy、OrderByDescending List<T>.Sort()方法签名使用场景示例升序实现效果 降序实现效果 IEnumerable<T>.OrderBy()方法签名使用场景示例实现效果 Enumerable<T>.OrderByDescending()…...
仓库管理系统
摘 要 随着电子商务的快速发展和物流行业的蓬勃发展,仓库管理成为了企业重要的一环。仓库管理涉及到商品的入库、出库、库存管理等一系列操作,对于企业的运营效率和成本控制具有重要影响。传统的仓库管理方式往往依赖于人工操作和纸质记录,存…...

AI绘画Stable Diffusion:超级质感真人大模型,逼真青纯!
大家好,我是设计师阿威 今天和大家分享一个具有超级质感的基于SD1.5的真人大模型:极致质感-DgirlV5,该模型追求质感的不断优化,细到发丝,当前最新版本是V5.1,修正了V5版本整体色彩发红的问题。 作者对该模…...

CMake笔记之CMAKE_INSTALL_PREFIX详解以及ROS中可执行文件为什么会在devel_lib中
CMake笔记之CMAKE_INSTALL_PREFIX详解以及ROS中可执行文件为什么会在devel_lib中 code review! 文章目录 CMake笔记之CMAKE_INSTALL_PREFIX详解以及ROS中可执行文件为什么会在devel_lib中1.CMAKE_INSTALL_PREFIX详解变量作用设置 CMAKE_INSTALL_PREFIX示例影响范围常见用法特别…...
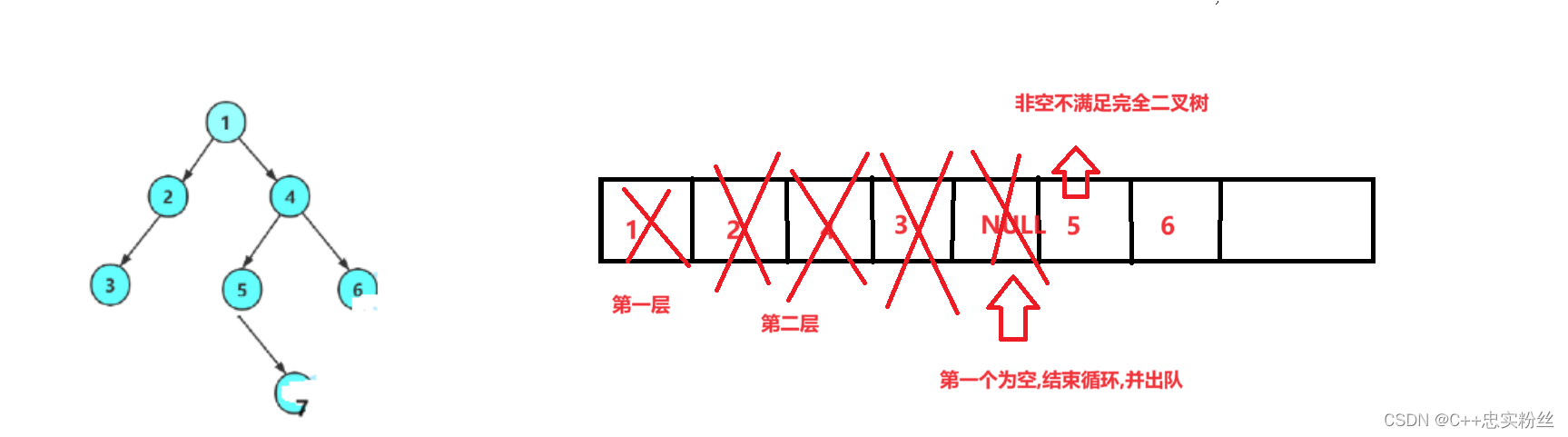
数据结构之二叉树的超详细讲解(3)--(二叉树的遍历和操作)
个人主页:C忠实粉丝 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 C忠实粉丝 原创 数据结构之二叉树的超详细讲解(3)--(二叉树的遍历和操作) 收录于专栏【数据结构初阶】 本专栏旨在分享学习数据结构学习的一点学习笔记,欢迎大家在评…...
Arduino - 旋转编码器 - 伺服电机
Arduino - 旋转编码器 - 伺服电机 Arduino - Rotary Encoder In this tutorial, We are going to learn how to program Arduino to rotate a servo motor according to the rotary encoder’s output value. 在本教程中,我们将学习如何对Arduino进行编程ÿ…...

儿童电动音乐牙刷OTP芯片方案:NV040C,耐温耐压,抗干扰能力强
一:方案背景概述 随着科技的飞速发展,源于对儿童口腔健康深入细致的关怀,以及对现代科技在日常生活用品中应用的不断追求,儿童电动音乐牙刷OTP芯片方案的诞生。 二:芯片简介 NV040C语音芯片是一款性能稳定、适合工厂量…...
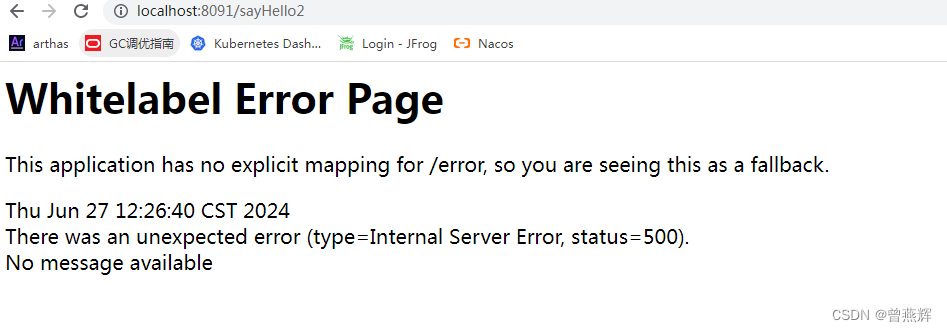
Sentinel链路流控模式失效的解决方法
解决方法 1、在pom.xml中增加sentinel-web-servlet的依赖,我使用的版本是1.7.1 <dependency><groupId>com.alibaba.csp</groupId><artifactId>sentinel-web-servlet</artifactId> </dependency>2、在项目中添加一个FilterCon…...
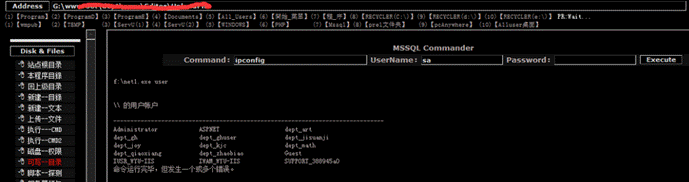
Web应用安全测试-专项漏洞(一)
Web应用安全测试-专项漏洞(一) 专项漏洞部分注重测试方法论,每个专项仅列举一个例子。实际测试过程中,需视情况而定。 文章目录 Web应用安全测试-专项漏洞(一)Web组件(SSL/WebDAV)漏…...
: K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?)
云原生核心技术 (7/12): K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?
大家好,欢迎来到《云原生核心技术》系列的第七篇! 在上一篇,我们成功地使用 Minikube 或 kind 在自己的电脑上搭建起了一个迷你但功能完备的 Kubernetes 集群。现在,我们就像一个拥有了一块崭新数字土地的农场主,是时…...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...

解决本地部署 SmolVLM2 大语言模型运行 flash-attn 报错
出现的问题 安装 flash-attn 会一直卡在 build 那一步或者运行报错 解决办法 是因为你安装的 flash-attn 版本没有对应上,所以报错,到 https://github.com/Dao-AILab/flash-attention/releases 下载对应版本,cu、torch、cp 的版本一定要对…...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...
中的KV缓存压缩与动态稀疏注意力机制设计)
大语言模型(LLM)中的KV缓存压缩与动态稀疏注意力机制设计
随着大语言模型(LLM)参数规模的增长,推理阶段的内存占用和计算复杂度成为核心挑战。传统注意力机制的计算复杂度随序列长度呈二次方增长,而KV缓存的内存消耗可能高达数十GB(例如Llama2-7B处理100K token时需50GB内存&a…...
)
Typeerror: cannot read properties of undefined (reading ‘XXX‘)
最近需要在离线机器上运行软件,所以得把软件用docker打包起来,大部分功能都没问题,出了一个奇怪的事情。同样的代码,在本机上用vscode可以运行起来,但是打包之后在docker里出现了问题。使用的是dialog组件,…...