cuda 学习笔记4
一 基本函数


在GPU上开辟空间,无论定义的数据是float还是int ,还是****gpu_int,分配空间的函数都是下面固定的形式 (void**)&

1.函数定义,global void 是配套使用的,是在GPU上定义,也就是GPU上执行,CPU上调用的函数,因为CPU不能识别GPU上运算得到的结果,也就是说在CPU上调用这个函数,是不可能存在return的结果的,所以没有返回值

#include "cuda_runtime.h"
#include "device_launch_parameters.h"#include <stdio.h>// __是GOU函数的标识符,加了__标识这个函数是在GPU上被调用的//这个函数在GPU上是无法调用的,所谓在GPU上,就是定义的在GPU上的函数内调用,因为该函数当前是在CPU上
int add_one(int a)
{return a + 1;
}//这个函数是被定义在GPU上,由GPU本身调用的函数,所以加了这个__devide__标识之后,就可以在__global__ void show(int *a)函数里面调用该函数
__device__ int add_one(int a)
{return a + 1;
}//但是加了__devide__标识之后,由于表示只能在GPU上调用该函数,所以在mian函数里面如果想要实现a[i] = add_one(a[i]);是不可以的
//所以需要再加一个标识符
__host__ __device__ int add_one(int a)
{return a + 1;
}__global__ void show(int *a)
{for (int i = 0; i < 10; i++){a[i] = add_one(a[i]);printf(" %d ", a[i]);}printf("\n");
}
#include "cuda_runtime.h"
#include "device_launch_parameters.h"#include <stdio.h>// __是GOU函数的标识符,加了__标识这个函数是在GPU上被调用的//这个函数在GPU上是无法调用的,所谓在GPU上,就是定义的在GPU上的函数内调用,因为该函数当前是在CPU上
//int add_one(int a)
//{
// return a + 1;
//}
//
这个函数是被定义在GPU上,由GPU本身调用的函数,所以加了这个__devide__标识之后,就可以在__global__ void show(int *a)函数里面调用该函数
//__device__ int add_one(int a)
//{
// return a + 1;
//}//但是加了__devide__标识之后,由于表示只能在GPU上调用该函数,所以在mian函数里面如果想要实现a[i] = add_one(a[i]);是不可以的
//所以需要再加一个标识符
__host__ __device__ int add_one(int a)
{return a + 1;
}__global__ void show(int *a)
{for (int i = 0; i < 10; i++){// a[i] = add_one(a[i]);printf(" %d ", a[i]);}printf("\n");
}__global__ void int_gpu(int* a)
{for (int i = 0; i < 10; i++){a[i] = 100;}
}int main()
{int cpu[10] = { 10, 10, 10, 10, 10, 10, 10, 10, 10, 10};//在GPU上分配空间存储CPU上的数据int* gpu_int;cudaMalloc((void**)&gpu_int, 10*sizeof(int)); //将指针指向GPU的一个内存地址,show << <1, 1 >> > (gpu_int);//一个网格里面只有一个block,也就是只有一个线程//GPU上数组初始化cudaMemset(gpu_int, 0, 10 * sizeof(int));// 将CPU上的数据拷贝到GPU上cudaMemcpy(gpu_int, cpu, 10*sizeof(int), cudaMemcpyHostToDevice); //将数据从GPU拷贝到CPU,同时指定拷贝的长度// 在CPU上调用GPU上的函数进行计算,定义在GPU上的函数就是在GPU上进行运算show << <1, 1 >> > (gpu_int);//一个网格里面只有一个block,也就是只有一个线程int_gpu << <1, 1 >> > (gpu_int);show << <1, 1 >> > (gpu_int);// 将GPU上的数据拷贝到cPU上cudaMemcpy(cpu, gpu_int, 10*sizeof(int), cudaMemcpyDeviceToHost); //将数据从GPU拷贝到CPU,同时指定拷贝的长度cudaFree(gpu_int);cudaDeviceSynchronize();printf(" cpu \n");for (int i = 0; i < 10; i++){printf(" %d ", cpu[i]);}return 0;
}
二 gird, block, thread 之间的关系和理解


)
1 同步的使用时机
2 尽量避免直接从globla memory上频繁读写,可以将数据拷贝到share memory再进行对同一数据频繁的读写操作
local memory,数据读取是很快的
global memeory,从这里读取数据是很慢的
share memory, 是block自己共享的,每个block自己可以读自己内部的数据,一个block内部的线程可以访问自己block的share memory
3
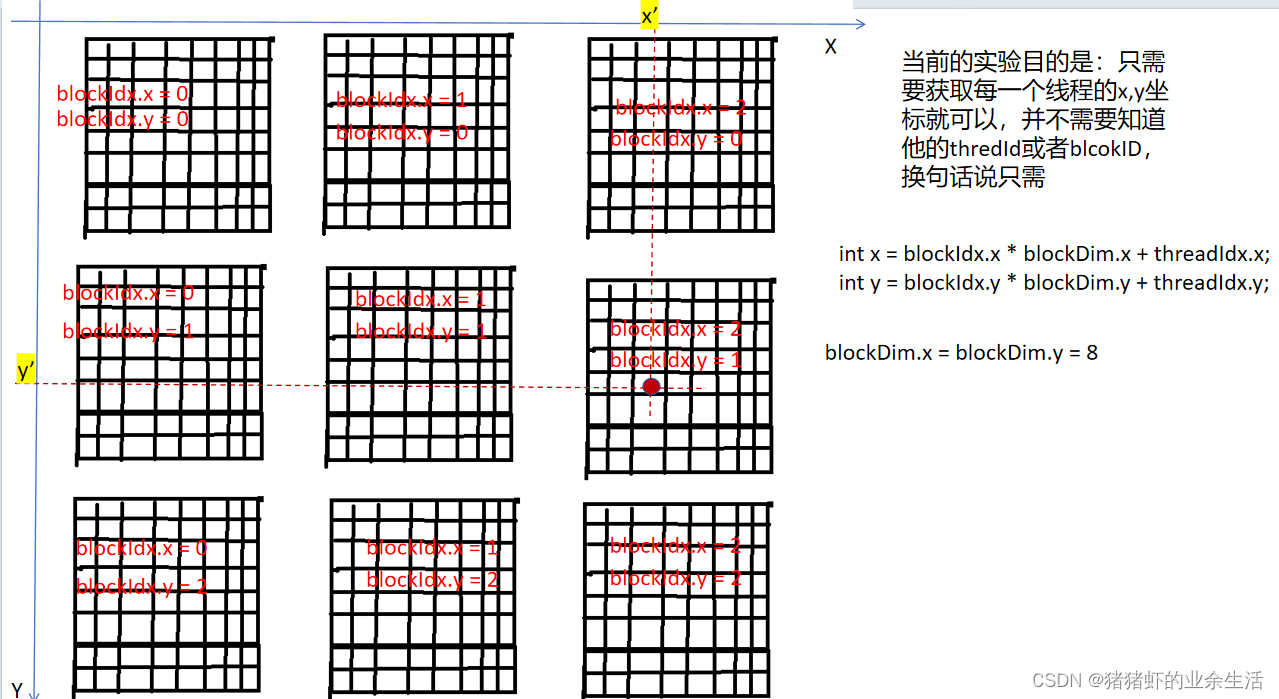
threadIdx是指当前线程在当前线程块里面是排几号,是相对block来说的
blockIdx是当前线程块在当前grid里面,x这个维度是第几个线程块
blockDim是维度的意思


下面这种情况对应的就是grid是2维,block是二维的情况,含有Dim的是对整个grid维度或者blcok维度的定义,也就是有几个


矩阵运算
案例1 矩阵维度为20*20,获取矩阵位置坐标,x,y并返回x+y

#include "cuda_runtime.h"
#include "device_launch_parameters.h"#include <stdio.h>
#include < iostream>using namespace std;//20*20的矩阵, 坐标(x,y)位置赋值x+y__device__ int coord_int(int x, int y)
{return x + y;
}__global__ void Matrix_init(int *a, int m, int n)
{int x = blockIdx.x * blockDim.x + threadIdx.x;int y = blockIdx.y * blockDim.y + threadIdx.y;if (x < m && y < n){a[y * n + x] = coord_int(x, y);}
}void show(int* a, int m, int n)
{for (int i = 0; i < n; i++){for ( int j = 0; j < m; j++){cout << a[i * m + j] << " ";}cout << endl;}
}int main()
{int* gpu_int;cudaMalloc((void**)&gpu_int, 400 * sizeof(int));int cpu_int[400] = { 0 };show(cpu_int, 20, 20);dim3 blockdim(8, 8); //线程数要大于400dim3 griddim(3, 3);//为什么数组要开辟一个新的空间且要用指针,而数据不用,因为数据编译的时候是可以直接读的,不需要开辟空间Matrix_init << <griddim, blockdim >> > (gpu_int, 20, 20);cudaMemcpy(cpu_int, gpu_int, 400 * sizeof(int), cudaMemcpyDeviceToHost);cudaFree(gpu_int);show(cpu_int, 20, 20);return 0;
}
案例2 矩阵乘法和矩阵加法
#include "cuda_runtime.h"
#include "device_launch_parameters.h"#include <stdio.h>
#include <iostream>using namespace std;//矩阵20*20
__host__ __device__ int add_one(int a)
{return a + 1;
}__global__ void Matrix_add(int* a, int* b, int* c, int m, int n)
{int x = blockIdx.x * blockDim.x + threadIdx.x;int y = blockIdx.y * blockDim.y + threadIdx.y;if (x < m && y < n){c[y * n + x] = a[y * n + x] + b[y * n + x];}
}//矩阵乘法:前一个矩阵的行*后一个矩阵的列,然后相加
//只适用与方阵
__global__ void Matrix_multi(int* a, int* b, int* c, int m)
{int x = blockIdx.x * blockDim.x + threadIdx.x;int y = blockIdx.y * blockDim.y + threadIdx.y;int output = 0;//c[y * m + x] = 0; if (x < m && y < m){for (int i = 0; i < m; i++){output += a[y * m + i] + b[i * m + x];//c[y * m + x] += a[y * m + i] + b[i * m + x]; 这里相当于全局内存反复读取c数组,会导致速度慢很多}c[y * m + x] = output;}
}//cpu上的函数
void show(int* a, int m, int n)
{for (int i = 0; i < m; i++){for (int j = 0; j < n; j++){// a[i] = add_one(a[i]);cout << a[i * m + j] << " ";}cout << endl;}}__global__ void int_gpu(int* a,int m, int n)
{for (int i = 0; i < m; i++){for (int j = 0; j < n; j++){a[i * m + j] = 10;}}
}//__global__ void my_gpu_multi(int* a, int* b, int* c, int m)
//{
// __share__ int
//}int main()
{int cpu[400] = { 0 };show(cpu, 20, 20);//在GPU上分配空间存储CPU上的数据int* gpu_int;cudaMalloc((void**)&gpu_int, 400 * sizeof(int)); //将指针指向GPU的一个内存地址,int* gpu_add;cudaMalloc((void**)&gpu_add, 400 * sizeof(int)); //将指针指向GPU的一个内存地址,int* gpu_multi;cudaMalloc((void**)&gpu_multi, 400 * sizeof(int)); //将指针指向GPU的一个内存地址,//GPU上数组初始化cudaMemset(gpu_int, 0, 400 * sizeof(int));cudaMemset(gpu_add, 0, 400 * sizeof(int));cudaMemset(gpu_multi, 0, 400 * sizeof(int));// 将CPU上的数据拷贝到GPU上cudaMemcpy(gpu_int, cpu, 400 * sizeof(int), cudaMemcpyHostToDevice); //将数据从GPU拷贝到CPU,同时指定拷贝的长度cudaMemcpy(gpu_add, cpu, 400 * sizeof(int), cudaMemcpyHostToDevice); //将数据从GPU拷贝到CPU,同时指定拷贝的长度cudaMemcpy(gpu_multi, cpu, 400 * sizeof(int), cudaMemcpyHostToDevice); //将数据从GPU拷贝到CPU,同时指定拷贝的长度// 在CPU上调用GPU上的函数进行计算,定义在GPU上的函数就是在GPU上进行运算dim3 blockdim(8, 8);dim3 griddim(3, 3);int_gpu << <griddim, blockdim >> > (gpu_int, 20, 20);Matrix_add << <griddim, blockdim >> > (gpu_int, gpu_int, gpu_add, 20,20);Matrix_multi << <griddim, blockdim >> > (gpu_int, gpu_int, gpu_multi, 20);// 将GPU上的数据拷贝到cPU上cudaMemcpy(cpu, gpu_int, 400 * sizeof(int), cudaMemcpyDeviceToHost); //将数据从GPU拷贝到CPU,同时指定拷贝的长度show(cpu, 20, 20);//一个网格里面只有一个block,也就是只有一个线程cudaMemcpy(cpu, gpu_add, 400 * sizeof(int), cudaMemcpyDeviceToHost); //将数据从GPU拷贝到CPU,同时指定拷贝的长度show(cpu, 20, 20);//一个网格里面只有一个block,也就是只有一个线程cudaMemcpy(cpu, gpu_multi, 400 * sizeof(int), cudaMemcpyDeviceToHost); //将数据从GPU拷贝到CPU,同时指定拷贝的长度show(cpu, 20, 20);//一个网格里面只有一个block,也就是只有一个线程cudaFree(gpu_int);cudaFree(gpu_add);cudaFree(gpu_multi);cudaDeviceSynchronize();return 0;
}
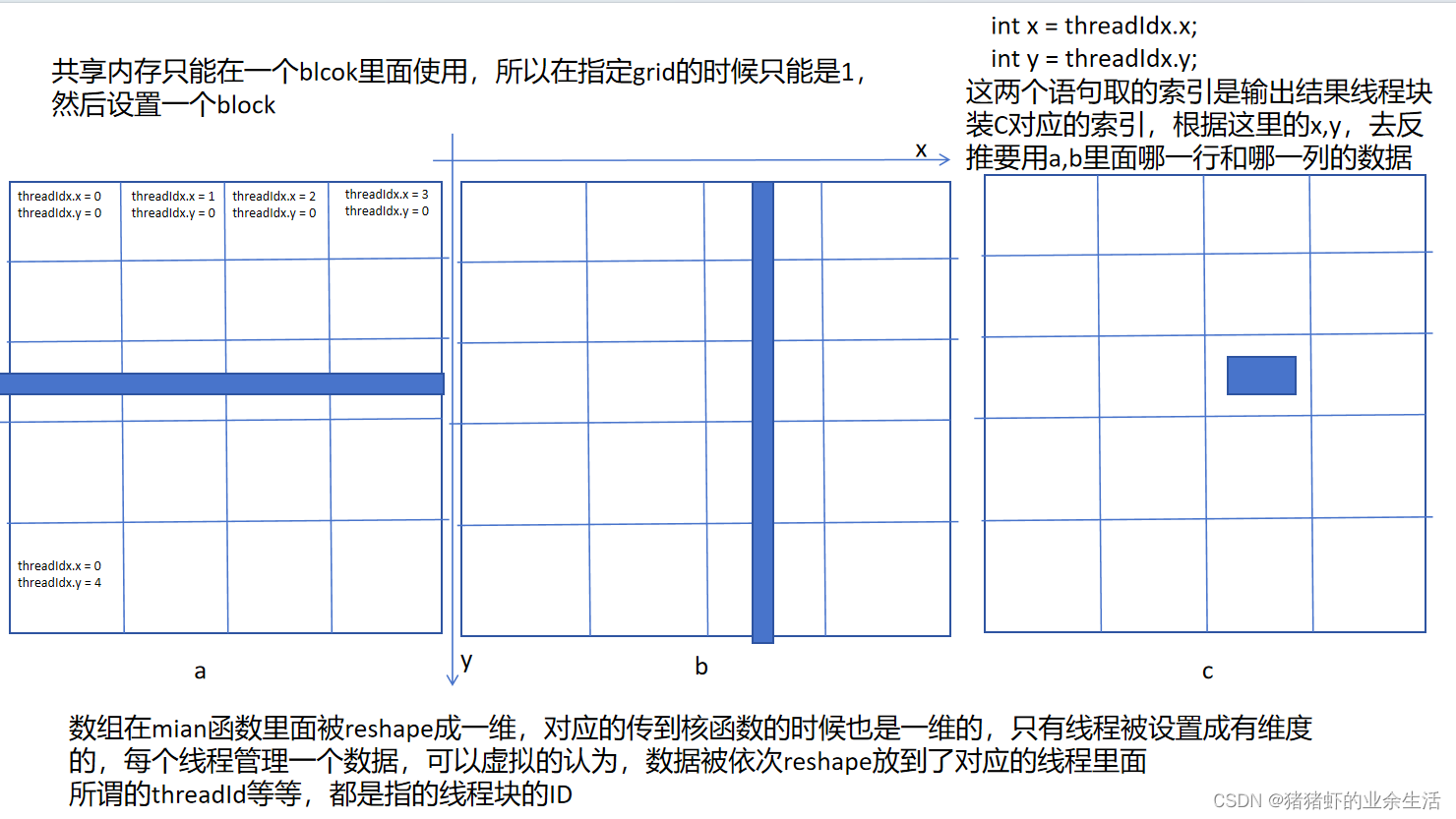
案例3 用共享内存实现矩阵乘法
#include "cuda_runtime.h"
#include "device_launch_parameters.h"#include <stdio.h>
#include <iostream>
#include <curand.h>
#include <curand_kernel.h>using namespace std;
#define ARRAY_SIZE 16
#define ARRAY_LENGTH 256
#define BLOCK_SIZE 16//GPU上初始化,N是
__global__ void gpu_initial(float *a ,int N) {int x = threadIdx.x + blockDim.x * blockIdx.x;curandState state;long seed = N;curand_init(seed, x,0,&state);if (x < N) a[x] = curand_uniform(&state);
}//在CPU上使用随机数初始化,N是要初始化的数组长度
void cpu_initial(float *a, int N)
{curandGenerator_t gen;curandCreateGenerator(&gen, CURAND_RNG_PSEUDO_DEFAULT); //告诉电脑要用什么样的方法生成随机数curandSetPseudoRandomGeneratorSeed(gen, 11ULL); //指定随机数种子curandGenerateUniform(gen, a, N); //curandGenerateUniform, 生成均匀分布的0-1的随机数,让a里面的数据从1-N的数据都进行赋值
}void show(float* a, int m, int n)
{for (int i = 0; i < m; i++){for (int j = 0; j < n; j++){// a[i] = add_one(a[i]);cout << a[i * m + j] << " ";}cout << endl;}}//矩阵乘法:前一个矩阵的行*后一个矩阵的列,然后相加
//只适用与方阵
__global__ void Matrix_multi(float* a, float* b, float* c, int m)
{int x = threadIdx.x;int y = threadIdx.y;int output = 0;if (x < m && y < m){for (int i = 0; i < m; i++){output += a[y * m + i] * b[i * m + x];}c[y * m + x] = output;}
}__global__ void my_gpu_multi(float* a, float* b, float* c, int m)
{int x = threadIdx.x;int y = threadIdx.y;__shared__ float a_share[256];__shared__ float b_share[256];if (x < m && y < m){a_share[y * m + x] = a[y * m + x];b_share[y * m + x] = b[y * m + x];}__syncthreads();float output = 0;if (x < m && y < m){for (int i = 0; i < m; i++){output += a_share[y*m + i] * b_share[i*m + x];}c[y * m + x] = output;}}@fighting
共享内存大小不足:
共享内存的大小由 __shared__ float a_share[256]; 和 __shared__ float b_share[256]; 决定。如果 m 值大于 16,那么共享内存大小可能不足,因为 16x16 = 256。如果 m 大于 16,应该调整共享内存大小。
同步问题:
在 my_gpu_multi 中使用了 __syncthreads() 来确保所有线程都完成了数据拷贝。但如果有些线程的计算还没完成就进入下一步,可能会导致不一致的结果。
线程边界检查:
如果 m 的值较大而 block 尺寸 (m, m) 超出了 GPU 硬件的限制,可能会导致一些线程未能正确启动,导致结果不一致。int main()
{int m = 6;int N = m * m;float* p_d, * p_da, * p_db, * p_h;//cpu上开辟空间p_h = (float*)malloc(N * sizeof(float));//GPU上开辟空间cudaMalloc((void**)&p_d, N * sizeof(float)); //将指针指向GPU的一个内存地址,cudaMalloc((void**)&p_da, N * sizeof(float)); //将指针指向GPU的一个内存地址,cudaMalloc((void**)&p_db, N * sizeof(float)); //将指针指向GPU的一个内存地址,//数组初始化,使用两种不同的方式进行初始化gpu_initial <<<16, 16 >>>(p_da, N); //直接在GPU上初始化cpu_initial(p_db, N); //在CPU上初始化,但是由于是调用的Gpu上的函数进行的初始化,所以最后还是等价于在GPU上初始化的cudaMemcpy(p_h, p_da, N * sizeof(float), cudaMemcpyDeviceToHost); //将数据从GPU拷贝到CPU,同时指定拷贝的长度printf("\n p_da");for (int i = 0; i < N; i++){if (i % m == 0) printf("\n ");cout << p_h[i] << " ";}cudaMemcpy(p_h, p_db, N * sizeof(float), cudaMemcpyDeviceToHost); //将数据从GPU拷贝到CPU,同时指定拷贝的长度printf("\n p_db");for (int i = 0; i < N; i++){if (i % m == 0) printf("\n ");cout << p_h[i] << " ";}printf("\n ");//share memory只能在一个block上使用,所以只能定义一个blockdim3 blockdim(m, m);//Matrix_multi <<<1, blockdim>>> (p_da, p_db, p_d, m); 将GPU上的数据拷贝到cPU上//cudaMemcpy(p_h, p_d, N * sizeof(float), cudaMemcpyDeviceToHost); //将数据从GPU拷贝到CPU,同时指定拷贝的长度//printf("funtuon Matrix_multi: ------------\n ");//show(p_h, m, m);//一个网格里面只有一个block,也就是只有一个线程my_gpu_multi <<<1, blockdim>>> (p_da, p_db, p_d, m);cudaMemcpy(p_h, p_d, N * sizeof(float), cudaMemcpyDeviceToHost); //将数据从GPU拷贝到CPU,同时指定拷贝的长度printf("funtuon my_gpu_multi: ------------\n ");show(p_h, m, m);cudaFree(p_da);cudaFree(p_db);cudaFree(p_d);free(p_h);return 0;
}常用官方库的使用
1. cuda案例
cuda函数说明官网


//Example 1. Application Using C and cuBLAS: 1-based indexing
//-----------------------------------------------------------
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <cuda_runtime.h>
#include "cublas_v2.h"
#define M 6
#define N 5
#define IDX2F(i,j,ld) ((((j)-1)*(ld))+((i)-1))static __inline__ void modify(cublasHandle_t handle, float* m, int ldm, int n, int p, int q, float alpha, float beta) {cublasSscal(handle, n - q + 1, &alpha, &m[IDX2F(p, q, ldm)], ldm);cublasSscal(handle, ldm - p + 1, &beta, &m[IDX2F(p, q, ldm)], 1);
}int main(void) {// cudaError_t可以判断cuda有没有错误,如果定义的cudaStat不是cudaSucess,就会提示错误信息位置cudaError_t cudaStat;cublasStatus_t stat;cublasHandle_t handle;int i, j;float* devPtrA;float* a = 0;a = (float*)malloc(M * N * sizeof(*a));if (!a) {printf("host memory allocation failed");return EXIT_FAILURE;}for (j = 1; j <= N; j++) {for (i = 1; i <= M; i++) {a[IDX2F(i, j, M)] = (float)((i - 1) * N + j);}}cudaStat = cudaMalloc((void**)&devPtrA, M * N * sizeof(*a));if (cudaStat != cudaSuccess) {printf("device memory allocation failed");free(a);return EXIT_FAILURE;}stat = cublasCreate(&handle);if (stat != CUBLAS_STATUS_SUCCESS) {printf("CUBLAS initialization failed\n");free(a);cudaFree(devPtrA);return EXIT_FAILURE;}stat = cublasSetMatrix(M, N, sizeof(*a), a, M, devPtrA, M);if (stat != CUBLAS_STATUS_SUCCESS) {printf("data download failed");free(a);cudaFree(devPtrA);cublasDestroy(handle);return EXIT_FAILURE;}modify(handle, devPtrA, M, N, 2, 3, 16.0f, 12.0f);stat = cublasGetMatrix(M, N, sizeof(*a), devPtrA, M, a, M);if (stat != CUBLAS_STATUS_SUCCESS) {printf("data upload failed");free(a);cudaFree(devPtrA);cublasDestroy(handle);return EXIT_FAILURE;}cudaFree(devPtrA);cublasDestroy(handle);for (j = 1; j <= N; j++) {for (i = 1; i <= M; i++) {printf("%7.0f", a[IDX2F(i, j, M)]);}printf("\n");}free(a);return EXIT_SUCCESS;
}
2.cuda自带函数:实现矩阵乘法运算 cublasSgemm

lad是A的行数,ldb是B的行数

//Example 1. Application Using C and cuBLAS: 1-based indexing
//-----------------------------------------------------------
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <cuda_runtime.h>
#include "cublas_v2.h"
#include <ctime>
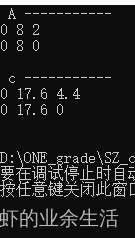
#include <iostream>using namespace std;int main()
{srand(time(0));// C = A*Bint M = 2; //矩阵A的行,矩阵C的行int N = 3; //矩阵A的列,矩阵B的行int K = 4; //矩阵B的列,矩阵C的列float* h_A = (float*)malloc(sizeof(float) * M * N);float* h_B = (float*)malloc(sizeof(float) * N * K);float* h_C = (float*)malloc(sizeof(float) * M * K);//******************************* 矩阵初始化cout << " A ----------- " << endl;for (int i = 0; i < M * N; i++){h_A[i] = rand() % 10;cout << h_A[i] << " ";if ((i + 1) % N == 0)cout << endl;}cout << endl;cout << " B ----------- " << endl;for (int i = 0; i < N * K; i++){h_B[i] = rand() % 10;cout << h_B[i] << " ";if ((i + 1) % K == 0)cout << endl;}cout << endl;//******************************* 在GPU上开辟空间存储数据float *d_A, *d_B, *d_C;cudaMalloc( (void**)&d_A, sizeof(float) * M * N);cudaMalloc((void**)&d_B, sizeof(float) * N * K);cudaMalloc((void**)&d_C, sizeof(float) * M * K);//******************************* 将数据从CPU拷贝到GPUcudaMemcpy(d_A, h_A, sizeof(float) * M * N, cudaMemcpyHostToDevice);cudaMemcpy(d_B, h_B, sizeof(float) * N * K, cudaMemcpyHostToDevice);float alpha = 1;float beta = 0;cublasHandle_t handle;cublasCreate(&handle);cublasSgemm(handle,CUBLAS_OP_N, //数据不转置CUBLAS_OP_N,K, //矩阵B的列M, //矩阵A的行N, //矩阵A的列&alpha,d_B,K,d_A,N,&beta,d_C,K);cudaMemcpy(h_C, d_C, sizeof(float) * M * K, cudaMemcpyDeviceToHost);cout << " c ----------- " << endl;for (int i = 0; i < M * K; i++){cout << h_C[i] << " ";if ((i + 1) % K == 0)cout << endl;}cout << endl;cudaFree(d_A);cudaFree(d_B);cudaFree(d_C);return 0;
}
3.cuda自带函数:实现矩阵每个数的翻倍, cublasSccal
把间隔设置为1,就可以实现把当前矩阵每一个元素都乘以这么一个常量

//Example 1. Application Using C and cuBLAS: 1-based indexing
//-----------------------------------------------------------
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <cuda_runtime.h>
#include "cublas_v2.h"
#include <ctime>
#include <iostream>using namespace std;int main()
{srand(time(0));// C = A*Bint M = 2; //矩阵A的行,矩阵C的行int N = 3; //矩阵A的列,矩阵B的行float* h_A = (float*)malloc(sizeof(float) * M * N);//******************************* 矩阵初始化cout << " A ----------- " << endl;for (int i = 0; i < M * N; i++){h_A[i] = rand() % 10;cout << h_A[i] << " ";if ((i + 1) % N == 0)cout << endl;}cout << endl;//******************************* 在GPU上开辟空间存储数据float *d_A, *d_B, *d_C;cudaMalloc( (void**)&d_A, sizeof(float) * M * N);//******************************* 将数据从CPU拷贝到GPUcudaMemcpy(d_A, h_A, sizeof(float) * M * N, cudaMemcpyHostToDevice);float alpha = 2.2;cublasHandle_t handle;cublasStatus_t stat;//函数用于初始化CUBLAS库并创建一个CUBLAS上下文。上下文被表示为一个cublasHandle_t类型的句柄。//handle是一个指向cublasHandle_t类型的指针,cublasCreate函数会将创建的句柄存储在这个位置。//如果初始化成功,stat将返回CUBLAS_STATUS_SUCCESS,否则会返回一个错误码。stat = cublasCreate(&handle); if (stat != CUBLAS_STATUS_SUCCESS) {printf("CUBLAS initialization failed\n");return EXIT_FAILURE;}stat = cublasSscal(handle,6, &alpha, d_A,1);if (stat != CUBLAS_STATUS_SUCCESS) {printf("CUBLAS scaling failed\n");return EXIT_FAILURE;}cudaMemcpy(h_A, d_A, sizeof(float) * M * N, cudaMemcpyDeviceToHost);cout << " c ----------- " << endl;for (int i = 0; i < M * N; i++){cout << h_A[i] << " ";if ((i + 1) % N == 0)cout << endl;}cout << endl;cudaFree(d_A);return 0;
}
4. 傅里叶变换 https://docs.nvidia.com/cuda/cufft/index.html
cufftExecC2C() and cufftExecZ2Z()是一样的,前者是浮点型,后者是double,后者精度更高

//Example 1. Application Using C and cuBLAS: 1-based indexing
//-----------------------------------------------------------
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <cuda_runtime.h>
#include "cublas_v2.h"
#include <ctime>
#include <iostream>
#include <cufft.h>using namespace std;int main()
{const int Nt = 256;const int BACTH = 1;//BACTH 用户霹雳那个处理一批一维的数据,假设数据是512,当BATCH =2,则将0-255,256-512作为两个一维信号做FFT变换//定义cufftDoubleComplex类型的指针,device_in记录输入值,device_out计记录计算结果cufftDoubleComplex *host_in, * host_out, * device_in, * device_out;//这种方式开辟空空间再向GPU传输数据是要快于传统的malloc方式的,两者是等价的/* float* host_in = (float*)malloc(sizeof(float) * Nt);float* host_out = (float*)malloc(sizeof(float) * Nt);*/cudaMallocHost((void**)&host_in, sizeof(cufftDoubleComplex) * Nt);cudaMallocHost((void**)&host_out, sizeof(cufftDoubleComplex) * Nt);for (int i = 0; i < Nt; i++){host_in[i].x = i + 1;host_in[i].y = i + 1;}// ************* 在GPU上开辟空间cudaMalloc((void**)&device_in, sizeof(cufftDoubleComplex) * Nt);cudaMalloc((void**)&device_out, sizeof(cufftDoubleComplex) * Nt);//从CPU上数据拷贝数据到GPU上cudaMemcpy(device_in, host_in, Nt* sizeof(cufftDoubleComplex), cudaMemcpyHostToDevice);//创建cufft句柄cufftHandle cufftForwrdHandle;cufftPlan1d(&cufftForwrdHandle, Nt, CUFFT_Z2Z, BACTH); //传参//CUFFT_Z2Z因为前面定义的数据类型是Double-Complex,所以这里指定的数据类型是这个// typedef enum cufftType_t {// CUFFT_R2C = 0x2a, // Real to Complex (interleaved)// CUFFT_C2R = 0x2c, // Complex (interleaved) to Real// CUFFT_C2C = 0x29, // Complex to Complex, interleaved// CUFFT_D2Z = 0x6a, // Double to Double-Complex// CUFFT_Z2D = 0x6c, // Double-Complex to Double// CUFFT_Z2Z = 0x69 // Double-Complex to Double-Complex//} cufftType;//执行fft正变换cufftExecZ2Z(cufftForwrdHandle, device_in, device_out, CUFFT_FORWARD); //正变换是CUFFT_FORWARD,反变换是CUFFT_INVERSE// 从GPU 上数据拷贝数据到CPU上cudaMemcpy(host_out, device_out, Nt * sizeof(cufftDoubleComplex), cudaMemcpyDeviceToHost);//设置输出精度--输出正变换的结果cout << " 正变换的结果: " << endl;for (int i = 0; i < Nt; i++){cout << host_out[i].x << " + j*" << host_out[i].y << endl;}cudaFree(device_in);cudaFree(device_out);return 0;
}
三 常见的可以采用并行的模式
1, 一对一 ,例如输入x,函数输出y = x*x



#include "cuda_runtime.h"
#include "device_launch_parameters.h"#include <stdio.h>
#include <iostream>
#include <curand.h>
#include <curand_kernel.h>using namespace std;
#define ARRAY_SIZE 16
#define ARRAY_LENGTH 256
#define BLOCK_SIZE 16//GPU上初始化,N是
__global__ void gpu_initial(float *a ,int N) {int x = threadIdx.x + blockDim.x * blockIdx.x;curandState state;long seed = N;curand_init(seed, x,0,&state);if (x < N) a[x] = curand_uniform(&state);
}__global__ void square(float *d_out,int N)
{int myID = threadIdx.x + blockDim.x * blockIdx.x;if (myID < N){float data = d_out[myID];d_out[myID] = data * data;}
}int main()
{int m = 6;int N = m * m;float* d_out, *h_in, *h_out;//cpu上开辟空间h_in = (float*)malloc(N * sizeof(float));h_out = (float*)malloc(N * sizeof(float));//GPU上开辟空间cudaMalloc((void**)&d_out, N * sizeof(float)); //将指针指向GPU的一个内存地址,//数组初始化,使用两种不同的方式进行初始化//直接在GPU上初始化, 4 是 numBlocks,表示启动了 4 个块(block),16 是 numThreadsPerBlock,表示每个块中有 16 个线程(thread)//这种初始化方式适用于一维数组gpu_initial <<<4, 16 >>>(d_out, N); cudaMemcpy(h_in, d_out, N * sizeof(float), cudaMemcpyDeviceToHost);printf("\n h_in");for (int i = 0; i < N; i++){if (i % m == 0) printf("\n ");cout << h_in[i] << " ";}square << <4, 16 >> > (d_out, N);//将数据从GPU拷贝到CPU,同时指定拷贝的长度cudaMemcpy(h_out, d_out, N * sizeof(float), cudaMemcpyDeviceToHost);printf("\n h_out");for (int i = 0; i < N; i++){if (i % m == 0) printf("\n ");cout << h_out[i] << " ";}cudaFree(d_out);free(h_in);free(h_out);return 0;
}2. 卷积操作

- 我写的
#include "cuda_runtime.h"
#include "device_launch_parameters.h"#include <stdio.h>
#include <iostream>
#include <curand.h>
#include <curand_kernel.h>using namespace std;
#define ARRAY_SIZE 16
#define ARRAY_LENGTH 256
#define BLOCK_SIZE 16//GPU上初始化,N是
__global__ void gpu_initial(float* a, int N) {int x = threadIdx.x + blockDim.x * blockIdx.x;curandState state;long seed = N;curand_init(seed, x, 0, &state);if (x < N) a[x] = curand_uniform(&state);
}void show(float* a, int m, int n)
{for (int i = 0; i < m; i++){for (int j = 0; j < n; j++){// a[i] = add_one(a[i]);cout << a[i * m + j] << " ";}cout << endl;}}//设置n*n大小的block,把对应坐标的矩阵数据读取到共享内存里,然后其中的(n-2)*(n-2)个线程进行卷积运算
__global__ void Conv_method1(float* p_d, float*kernel, int block_size, int kernel_Len)
{int x = threadIdx.x; //现在是一个一维的一个blockint y = threadIdx.y;extern __shared__ float s_pd[];if (x < block_size && y < block_size){s_pd[y * block_size + x] = p_d[y * block_size + x];//printf("s_pd[y * block_size + x] = %f \n" , s_pd[y * block_size + x]);}__syncthreads();//for (int i = 0; i < kernel_Len; i++) {// printf("kernel[%d] = %f", i, kernel[i]);//}float out = 0;if (x > 0 && y >0 && x < block_size-1 && y < block_size-1){out = s_pd[(y-1)* block_size + x - 1] * kernel[0] + s_pd[(y - 1) * block_size + x] * kernel[1] + s_pd[(y - 1) * block_size + x+1] * kernel[2] + s_pd[y * block_size + x - 1] * kernel[3] + s_pd[y * block_size + x] * kernel[4] + s_pd[y * block_size + x + 1] * kernel[5] + s_pd[(y+1)* block_size + x - 1] * kernel[6] + s_pd[(y + 1) * block_size + x] * kernel[7] + s_pd[(y + 1) * block_size + x + 1] * kernel[8];//printf(" x = %d,y = %d,out = %f \n",x,y,out);}p_d[y * block_size + x] = out;__syncthreads();
}int main()
{int m = 6;int N = m*m;int kernelLen = 9;float* p_d, * h_in, * h_out;float *h_kenel, * d_kernel;//cpu上开辟空间h_in = (float*)malloc(N * sizeof(float));h_out = (float*)malloc(N * sizeof(float));h_kenel = (float*)malloc(9 * sizeof(float));//GPU上开辟空间cudaMalloc((void**)&p_d, N * sizeof(float)); //将指针指向GPU的一个内存地址cudaMalloc((void**)&d_kernel, 9 * sizeof(float)); //将指针指向GPU的一个内存地址 使用循环赋值 printf("h_kenel \n ");float values[] = { 1, 1, 1, 1, -8, 1, 1,1,1};for (int i = 0; i < kernelLen; i++) {h_kenel[i] = values[i];cout << h_kenel[i] << " ";}printf(" \n ");cudaMemcpy(d_kernel, h_kenel, kernelLen * sizeof(float), cudaMemcpyHostToDevice);gpu_initial << <16, 16 >> > (p_d, N); //直接在GPU上初始化cudaMemcpy(h_in, p_d, N * sizeof(float), cudaMemcpyDeviceToHost); //将数据从GPU拷贝到CPU,同时指定拷贝的长度printf("h_in \n ");show(h_in, m, m);dim3 griddim(1, 1);dim3 blockdim(m, m);Conv_method1 << <griddim, blockdim, sizeof(float)* N >> > (p_d, d_kernel, m, kernelLen);//将数据从GPU拷贝到CPU,同时指定拷贝的长度cudaMemcpy(h_out, p_d, N * sizeof(float), cudaMemcpyDeviceToHost);printf("\n h_out \n ");show(h_out,m,m);cudaFree(p_d);free(h_in);free(h_out);return 0;
}
- 别人写的
#include "cuda_runtime.h"
#include "device_launch_parameters.h"#include <iostream>
#include <fstream>
#include <iomanip>
#include <time.h>using namespace std;// 调用CUDA函数并检查是否出现错误
#define CUDA_CALL(x) {\const cudaError_t a = (x);\if (a != cudaSuccess) { \fprintf(stderr, "\nCUDA Error: %s (err_num=%d)\nfile %s, line %d\n", cudaGetErrorString(a), a, __FILE__, __LINE__);\cudaDeviceReset(); exit(1);\} \
}// 调用核函数并检查是否出现错误
__host__ void cuda_error_check(const char* kernelName) {if (cudaPeekAtLastError() != cudaSuccess) {printf("\n%s %s\n", kernelName, cudaGetErrorString(cudaGetLastError()));cudaDeviceReset();exit(1);}
}// 设置参数
const int TILE_W = 32; // block的x维大小
const int TILE_H = 32; // block的y维大小
const int DATA_W = 320; // 输入矩阵的x维大小
const int DATA_H = 640; // 输入矩阵的y维大小
const int KERNEL_RADIUS = 1; // 卷积核的半径// 卷积核写入GPU常量内存中
__constant__ int KERNEL[2 * KERNEL_RADIUS + 1][2 * KERNEL_RADIUS + 1] =
{ 1, 1, 1,
1, -8, 1,
1, 1, 1 };// 通过共享内存,进行卷积运算
__global__ void convolution(float* dst, float* src) {// 线程在所在block中的x,y坐标int tidx = threadIdx.x;int tidy = threadIdx.y;// 线程应该读取到shared memory中对应的矩阵元素坐标int readx = (blockDim.x - 2 * KERNEL_RADIUS) * blockIdx.x + (threadIdx.x - KERNEL_RADIUS);int ready = (blockDim.y - 2 * KERNEL_RADIUS) * blockIdx.y + (threadIdx.y - KERNEL_RADIUS);// 除去不需要加载内存的地方if (readx >= DATA_W + KERNEL_RADIUS || ready >= DATA_H + KERNEL_RADIUS)return;// 声明block的共享内存__shared__ float src_s[TILE_H][TILE_W];// 把当前block需要处理的区域读取到shared memory,输入矩阵周围的记为0if (readx >= 0 && readx < DATA_W && ready >= 0 && ready < DATA_H) {src_s[tidy][tidx] = src[ready * DATA_W + readx];}else {src_s[tidy][tidx] = 0;}// 同步block中所有线程,保证共享内存完全读入矩阵__syncthreads();// 卷积计算float output = 0;int kernel_w = 2 * KERNEL_RADIUS + 1;if (tidx < blockDim.x - 2 * KERNEL_RADIUS && readx < DATA_W - KERNEL_RADIUS &&tidy < blockDim.y - 2 * KERNEL_RADIUS && ready < DATA_H - KERNEL_RADIUS) {for (int i = 0; i < kernel_w; i++) {for (int j = 0; j < kernel_w; j++) {output += src_s[tidy + j][tidx + i] * KERNEL[j][i];}}// 写入dst对应坐标dst[(ready + KERNEL_RADIUS) * DATA_W + (readx + KERNEL_RADIUS)] = output;}
}int main() {const int INPUTSIZE = DATA_H * DATA_W;printf("---------- initilizing ----------\n");clock_t tt = clock();// CPU输入输出矩阵的声明float* h_src = (float*)malloc(INPUTSIZE * sizeof(float));float* h_dst = (float*)malloc(INPUTSIZE * sizeof(float));// 输入矩阵中元素全部设为1for (int i = 0; i < DATA_W; i++) {for (int j = 0; j < DATA_H; j++) {h_src[i + j * DATA_W] = (float)1;}}// 将输入矩阵输出ofstream ofs("input_output.txt");for (int j = 0; j < DATA_H; j++) {for (int i = 0; i < DATA_W; i++) {ofs << setw(5) << h_src[i + j * DATA_W];}ofs << '\n';}ofs << '\n';// 设定使用第一个GPUCUDA_CALL(cudaSetDevice(0));// GPU输入输出矩阵的声明float* d_src = 0;float* d_dst = 0;// 初始化CUDA_CALL(cudaMalloc(&d_src, INPUTSIZE * sizeof(float)));CUDA_CALL(cudaMalloc(&d_dst, INPUTSIZE * sizeof(float)));CUDA_CALL(cudaMemcpy(d_src, h_src, INPUTSIZE * sizeof(float), cudaMemcpyHostToDevice));CUDA_CALL(cudaMemcpy(d_dst, h_dst, INPUTSIZE * sizeof(float), cudaMemcpyHostToDevice));// 输出内存初始化所需时间printf("Initializaion time(ms) : %f\n", ((float)clock() - tt) / CLOCKS_PER_SEC);printf("---------- calculating ----------\n");// 设定核函数中grid和block的参数//dim3 gridDim = (11, 22);/*gridDim定义了网格的维度。在这个例子中,网格有两个维度:x 维度有 11 个块y 维度有 22 个块*/dim3 gridDim = { (DATA_W + (TILE_W - 2 * KERNEL_RADIUS - 1)) / (TILE_W - 2 * KERNEL_RADIUS),(DATA_H + (TILE_H - 2 * KERNEL_RADIUS - 1)) / (TILE_H - 2 * KERNEL_RADIUS) };printf("---------- calculating ----(DATA_W + (TILE_W - 2 * KERNEL_RADIUS - 1)) / (TILE_W - 2 * KERNEL_RADIUS) = %d, (DATA_H + (TILE_H - 2 * KERNEL_RADIUS - 1)) / (TILE_H - 2 * KERNEL_RADIUS) = %d--\n", (DATA_W + (TILE_W - 2 * KERNEL_RADIUS - 1)) / (TILE_W - 2 * KERNEL_RADIUS),(DATA_H + (TILE_H - 2 * KERNEL_RADIUS - 1)) / (TILE_H - 2 * KERNEL_RADIUS));dim3 blockDim = { TILE_W, TILE_H };// 调用核函数并计时cudaEvent_t start, stop;cudaEventCreate(&start);cudaEventCreate(&stop);cudaEventRecord(start, 0);convolution << <gridDim, blockDim >> > (d_dst, d_src);// 检查核函数调用是否出现错误cuda_error_check("convolution_shared_memory");// CPU等待GPU完成核函数的计算CUDA_CALL(cudaDeviceSynchronize());// 输出核函数调用时长cudaEventRecord(stop, 0);cudaEventSynchronize(stop);float elapsedTime;cudaEventElapsedTime(&elapsedTime, start, stop);printf("Kernel time(ms) : %f\n", elapsedTime);cudaEventDestroy(start);cudaEventDestroy(stop);// CPU获取GPU核函数计算结果CUDA_CALL(cudaMemcpy(h_dst, d_dst, INPUTSIZE * sizeof(float), cudaMemcpyDeviceToHost));// 输出卷积后的结构for (int j = 0; j < DATA_H; j++) {for (int i = 0; i < DATA_W; i++) {ofs << setw(5) << h_dst[i + j * DATA_W];}ofs << '\n';}ofs.close();// 释放GPU内存cudaFree(d_src);cudaFree(d_dst);//cudaFree(KERNEL);// 释放CPU内存free(h_src);free(h_dst);// 清空重置GPUCUDA_CALL(cudaDeviceReset());printf("Total calculation time(ms) : %f\n", ((float)clock() - tt) / CLOCKS_PER_SEC);}
3.
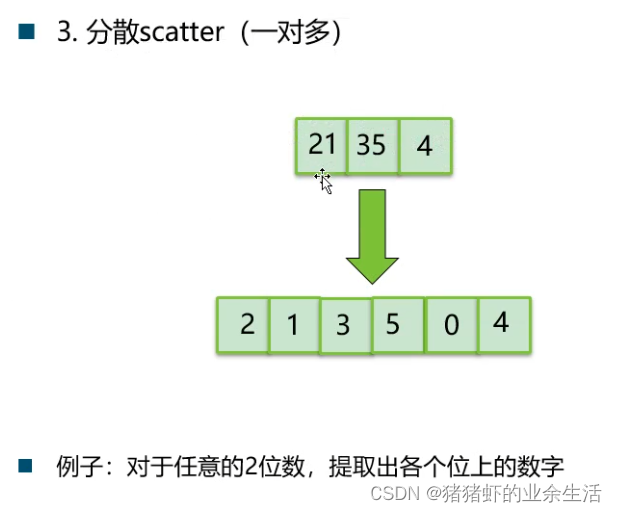
4.
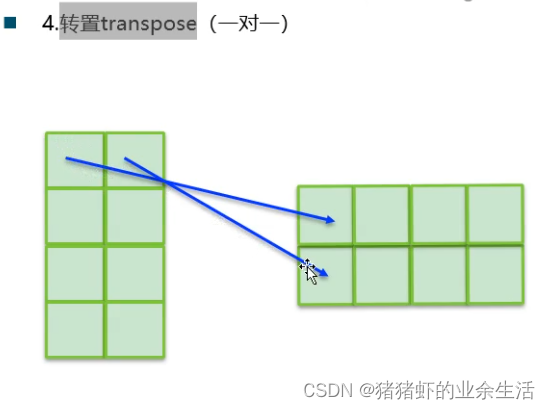
5

动态共享内存的初始化和使用

#include "cuda_runtime.h"
#include "device_launch_parameters.h"#include <stdio.h>
#include <iostream>
#include <curand.h>
#include <curand_kernel.h>using namespace std;
#define ARRAY_SIZE 16
#define ARRAY_LENGTH 256
#define BLOCK_SIZE 16//GPU上初始化,N是
__global__ void gpu_initial(float* a, int N) {int x = threadIdx.x + blockDim.x * blockIdx.x;curandState state;long seed = N;curand_init(seed, x, 0, &state);if (x < N) a[x] = curand_uniform(&state);
}//使用共享内存
__global__ void sortFun(float* p_d, int N)
{int x = threadIdx.x; //现在是一个一维的一个block//定义动态内存,动态内存的长度是在初始化的时候 sortFun << <1, N, sizeof(float)*N >> > (d_in, N);sizeof(float)*N 指定共享内存的字节大小extern __shared__ float temp_d[]; temp_d[x] = p_d[x];__syncthreads(); //相当于是把所有数据都加载到temp_d之后才开始后面的排序操作//奇偶排序,长度为N的数组需要排序N次,所以这里的for循环里面的N是对排序次数的循环,而不是数据for (int i = 0; i < N; i++) {int j = i % 2; //先奇偶比,然后下一次才是偶奇比,也就是偶数次是奇偶比,奇数次是偶奇比int idx = 2 * x + j;if (idx + 1 < N && temp_d[idx] < temp_d[idx + 1]){float tep = temp_d[idx];temp_d[idx] = temp_d[idx + 1];temp_d[idx + 1] = tep;}__syncthreads(); //每排序一次,要等所有数据都判断完毕才进行下一轮的排序}p_d[x] = temp_d[x];__syncthreads(); //所有数据都排序完毕且结束,程序结束
}int main()
{int m = 6;int N = m;float* p_d, *h_in, *h_out;//cpu上开辟空间h_in = (float*)malloc(N * sizeof(float));h_out = (float*)malloc(N * sizeof(float));//GPU上开辟空间cudaMalloc((void**)&p_d, N * sizeof(float)); //将指针指向GPU的一个内存地址 使用循环赋值 //int values[] = { 1, 5, 4, 2, 6, 3};//for (int i = 0; i < N; i++) {// h_in[i] = values[i];//}//cudaMemcpy(p_d, h_in, N * sizeof(float), cudaMemcpyHostToDevice);gpu_initial << <16, 16 >> > (p_d, N); //直接在GPU上初始化cudaMemcpy(h_in, p_d, N * sizeof(float), cudaMemcpyDeviceToHost); //将数据从GPU拷贝到CPU,同时指定拷贝的长度printf("h_in \n ");for (int i = 0; i < N; i++){cout << h_in[i] << " ";}sortFun <<<1, N, sizeof(float)*N >>> (p_d, N);// sort << <1, N, N * sizeof(float) >> > (p_d, N);//将数据从GPU拷贝到CPU,同时指定拷贝的长度cudaMemcpy(h_out, p_d, N * sizeof(float), cudaMemcpyDeviceToHost);printf("\n h_out \n ");for (int i = 0; i < N; i++){cout << h_out[i] << " ";}cudaFree(p_d);free(h_in);free(h_out);return 0;
}

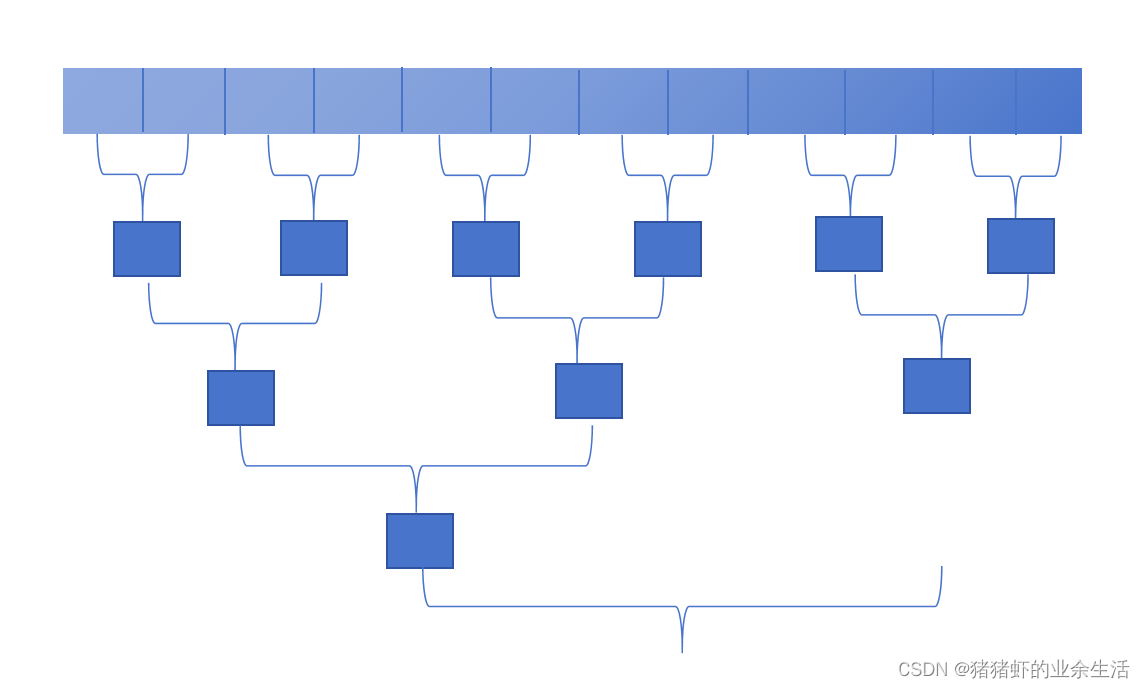
6 !!! 数组求和
#include "cuda_runtime.h"
#include "device_launch_parameters.h"#include <stdio.h>
#include <iostream>
#include <curand.h>
#include <curand_kernel.h>using namespace std;
#define ARRAY_SIZE 16
#define ARRAY_LENGTH 256
#define BLOCK_SIZE 16//GPU上初始化,N是
__global__ void gpu_initial(float* a, int N) {int x = threadIdx.x + blockDim.x * blockIdx.x;curandState state;long seed = N;curand_init(seed, x, 0, &state);if (x < N) a[x] = curand_uniform(&state);
}void show(float* a, int m, int n)
{for (int i = 0; i < m; i++){for (int j = 0; j < n; j++){// a[i] = add_one(a[i]);cout << a[i * m + j] << " ";}cout << endl;}
}__global__ void reduce_kernel (float *data_in, float *data_out)
{//现在是N个1维的blockint threadIDinAllBlock = threadIdx.x + blockDim.x*blockIdx.x; int threadIDinOneBlock = threadIdx.x;int blockID = blockIdx.x;extern __shared__ float s_d[];//共享内存是在一个blcok,但是传入的数据是分散到1024个block上s_d[threadIDinOneBlock] = data_in[threadIDinAllBlock];__syncthreads();//for (int i = 0; i < N; i++)//{// printf("here s_d[%d] = %f \n",i, s_d[i]);//}//printf(" \n");//对半求和,前一半数据的第一位数和后半数据的第一位数相加,。。。//这里是算完一个blockfor (int s = blockDim.x/2; s > 0; s >>= 1) //s >>= 1 是除以2的意思,数据依次是1024,512,256.。。。。{if (threadIDinOneBlock < s){s_d[threadIDinOneBlock] += s_d[threadIDinOneBlock + s];}__syncthreads();}//输出1024个blcok的各自的结果if (threadIDinOneBlock == 0){data_out[blockID] = s_d[0];/*printf("here s_d[0] = %f \n", s_d[0]);*/printf("here data_out[%d] = %f \n", blockID, data_out[blockID]);}
}void cpu_reduce(float *d_in, float* d_mid, float* d_out, int N)
{int threadNum = N;int blocks = N / threadNum;//printf("blocks = %d \n", blocks);reduce_kernel << <blocks, threadNum, threadNum * sizeof(float) >> > (d_in, d_mid);reduce_kernel << <1, threadNum, threadNum * sizeof(float) >> > (d_mid, d_out);
}int main()
{int m = 50;int N = m*m;float* d_in,*d_mid, *d_out, * h_in, * h_out;//cpu上开辟空间h_in = (float*)malloc(N * sizeof(float));h_out = (float*)malloc(N * sizeof(float));//GPU上开辟空间cudaMalloc((void**)&d_in, N * sizeof(float)); //将指针指向GPU的一个内存地址cudaMalloc((void**)&d_mid, m * sizeof(float));//一个block的大小cudaMalloc((void**)&d_out, N * sizeof(float));gpu_initial << <m, m >> > (d_in, N); //直接在GPU上初始化cudaMemcpy(h_in, d_in, N * sizeof(float), cudaMemcpyDeviceToHost); //将数据从GPU拷贝到CPU,同时指定拷贝的长度clock_t t_start_cpu = clock();float sum = 0;printf("in mian \n");for (int i = 0; i < N; i++){sum += h_in[i];//cout << h_in[i] << " ";}cout << " \n";cout << "sum_ cpu = " << sum << endl;cout << " time in cpu = " << (double)(clock() - t_start_cpu) / CLOCKS_PER_SEC << endl;cout << " \n";cout << "----------------------- \n";clock_t t_start_gpu = clock();cpu_reduce(d_in, d_mid,d_out,N);cudaDeviceSynchronize();cudaMemcpy(h_out, d_out,N * sizeof(float), cudaMemcpyDeviceToHost);cout << " SUM gpu : h_out = " << h_out[0] << endl;cout << " time in GPU = " << (double)(clock() - t_start_gpu) / CLOCKS_PER_SEC << endl;cudaFree(d_in);cudaFree(d_out);cudaFree(d_mid);free(h_in);free(h_out);return 0;
}
相关文章:
cuda 学习笔记4
一 基本函数 在GPU上开辟空间,无论定义的数据是float还是int ,还是****gpu_int,分配空间的函数都是下面固定的形式 (void**)& 1.函数定义,global void 是配套使用的,是在GPU上定义,也就是GPU上执行,CPU上调用的函数…...
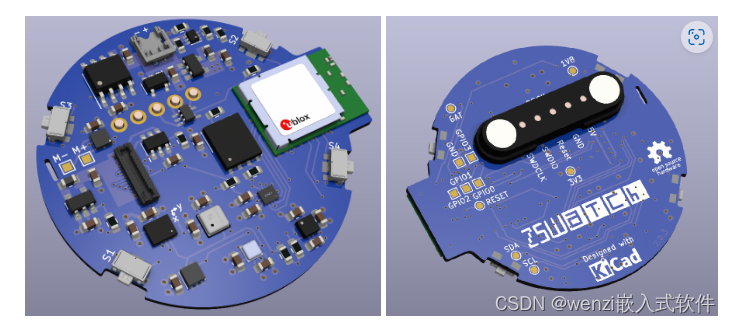
ZSWatch 开源项目介绍
前言 因为时不时逛 GitHub 会发现一些比较不错的开源项目,突发奇想想做一个专题,专门记录开源项目,内容不限于组件、框架以及 DIY 作品,希望能坚持下去,与此同时,也会选取其中的开源项目做专题分析。希望这…...
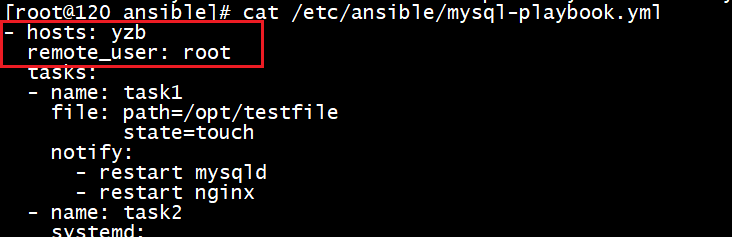
Ansible-综合练习-生产案例
斌的招儿 网上教程大多都是官网模板化的教程和文档,这里小斌用自己实际生产环境使用的例子给大家做一个详解。涉及到一整套ansible的使用,对于roles的使用,也仅涉及到tasks和files目录,方便大家快速上手并规范化管理。 0.环境配置…...

lombok关于构造器的注解的坑【避坑】
文章目录 背景问题问题解决 背景 平时,我们不定义构造器时,会自动创建一个无参的构造器。 当我们提供了任意有参构造器后,将不再自动创建无参构造器。 问题 为了方便创建对象并同时赋值,使用了全参构造器的注解NoArgsConstruct…...

指针并不是用来存储数据的,而是用来存储数据在内存中地址(内存操作/函数指针/指针函数)
推荐:1、4、5号书籍 1. 基本概念 首先,让小明了解指针的基本概念: 指针的定义:指针是一个变量,它存储的是另一个变量的地址。指针的声明:例如,int *p表示一个指向整数的指针变量p。 2. 形象…...

iso21434认证的意义
ISO 21434认证对于汽车行业具有深远的意义,主要体现在以下几个方面: 确保汽车网络安全:ISO 21434认证旨在确保汽车在设计和制造过程中能够抵御潜在的网络威胁和攻击。通过遵循该标准,汽车制造商能够开发出具备可靠网络安全能力的…...
分页处理封装+分页查询题目列表
文章目录 1.sun-club-common封装分页1.com/sunxiansheng/subject/common/eneity/PageInfo.java2.com/sunxiansheng/subject/common/eneity/PageResult.java 2.sun-club-application-controller1.SubjectInfoDTO.java 继承PageInfo并新增字段2.SubjectController.java 3.sun-clu…...

每天一个项目管理概念之WBS
项目管理中的工作分解结构(Work Breakdown Structure,简称WBS)是规划和管理项目的核心工具之一,它通过将复杂的项目任务细分为更小、更易管理的部分来提高项目执行的效率与效果。WBS不仅有助于明确项目范围,还为时间管…...

linux安装mysql8并查看密码
1. **下载RPM包**: wget https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm 2. **安装RPM包**: sudo rpm -ivh mysql80-community-release-el7-3.noarch.rpm 3. **更新YUM缓存**: sudo yum makecache 4. **安装…...

[渗透测试] 任意文件读取漏洞
任意文件读取漏洞 概述 漏洞成因 存在读取文件的功能(Web应用开放了文件读取功能)读取文件的路径客户端可控(完全控制或者影响文件路径)没有对文件路径进行校验或者校验不严格导致被绕过输出文件内容 漏洞危害 下载服务器中的…...

sudo: /etc/init.d/ssh: command not found
在 WSL 中尝试启动 SSH 服务时遇到 sudo: /etc/init.d/ssh: command not found 错误 安装 OpenSSH 服务器 更新软件包列表 sudo apt update安装 OpenSSH 服务器 sudo apt install openssh-server启动 SSH 服务 在 WSL 2 上,服务管理与传统 Linux 系统有所不同。你可以手动启动…...

秋招倒计时?到底需要准备到什么程度?
秋招倒计时?需要准备到什么程度? 秋招,面向全国的毕业生,招聘的激烈程度可想而知!按照往年时间,秋招通常从八月初开始,九月黄金期,十月中后期。距今刚好差不多60天,时间其…...
6.26.4.1 基于交叉视角变换的未配准医学图像多视角分析
1. 介绍 许多医学成像任务使用来自多个视图或模式的数据,但很难有效地将这些数据结合起来。虽然多模态图像通常可以在神经网络中作为多个输入通道进行配准和处理,但来自不同视图的图像可能难以正确配准(例如,[2])。因此,大多数多视…...
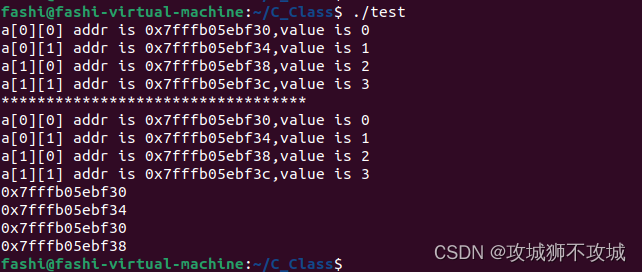
62.指针和二维数组(2)
一.指针和二维数组 1.如a是一个二维数组,则数组中的第i行可以看作是一个一维数组,这个一维数组的数组名是a[i]。 2.a[i]代表二维数组中第i行的首个元素的地址,即a[i][0]的地址。 二.进一步思考 二维数组可以看作是数组的数组,本…...

学生表的DDL和DML
DDL -- 创建学生表 CREATE TABLE students (student_id INT PRIMARY KEY AUTO_INCREMENT,studentname VARCHAR(50),age INT,gender VARCHAR(10) );-- 创建课程表 CREATE TABLE courses (course_id INT PRIMARY KEY AUTO_INCREMENT,course_name VARCHAR(50) );-- 创建教师表 CR…...

视觉灵感的探索和分享平台
做设计没灵感?大脑一片空白?灵感是创作的源泉,也是作品的灵魂所在。工作中缺少灵感,这是每个设计师都会经历的苦恼,那当我们灵感匮乏的时候,该怎么办呢?别急,即时设计、SurfCG、Lapa…...
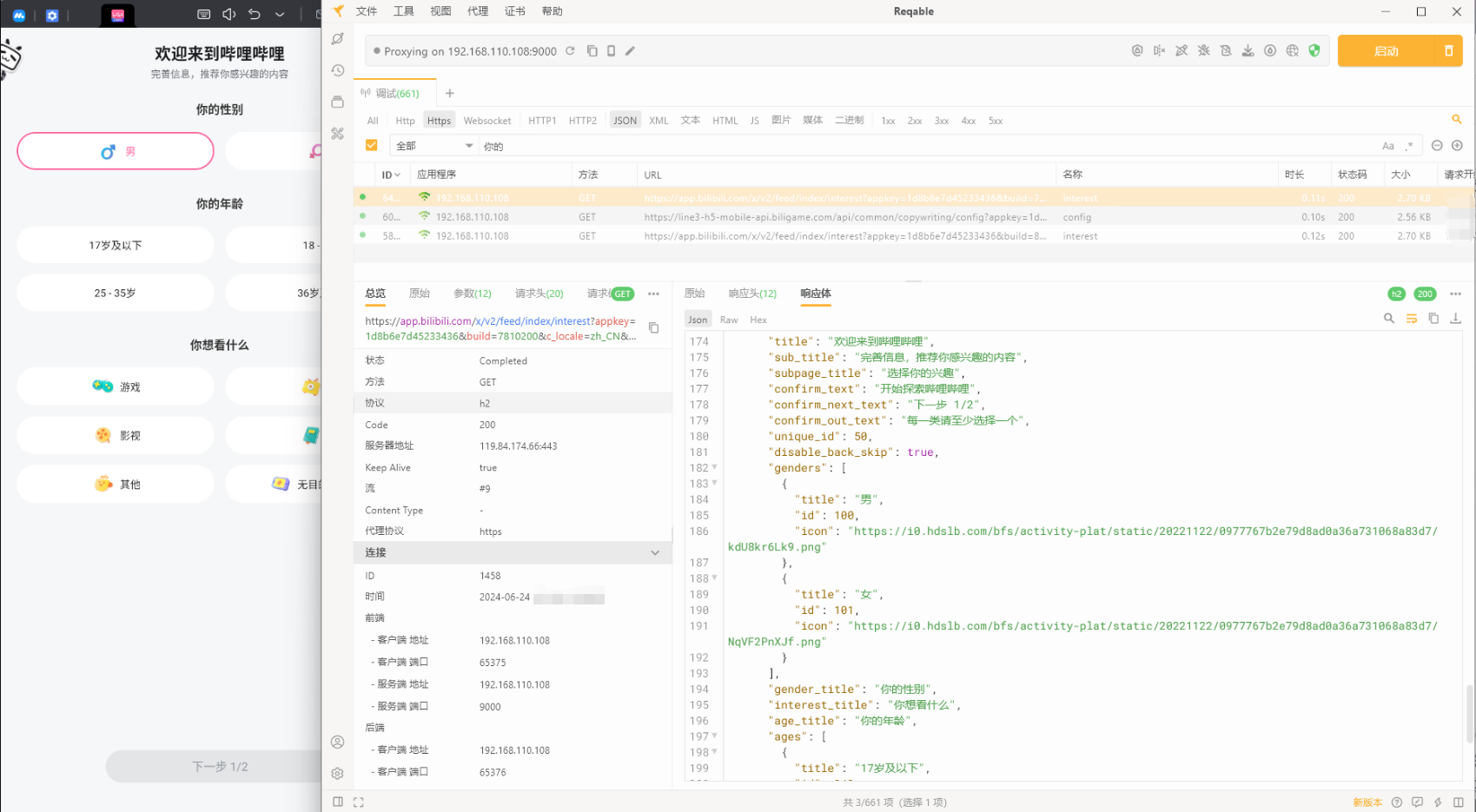
使用 Reqable 在 MuMu 模拟器进行App抓包(https)
1、为什么要抓包? 用开发手机应用时,查看接口数据不能像在浏览器中可以直接通过network查看,只能借助抓包工具来抓包,还有一些线上应用我们也只能通过抓包来排查具体的问题。 2、抓包工具 实现抓包,需要一个抓包工具…...

RedisConnectionException: Unable to connect to localhost/<unresolved>:6379
方法一:删除配置密码选项 一般是因为你在启动redsi服务的时候没有以指定配置文件启动 把application.yml文件中的redis密码注释掉 方法二 以指定配置文件启动 这样就不用删除yml文件中密码的选项了 在redis,windows.conf 中找到requirepass,删除掉前…...

poi word写入图片
直接使用的百度结果,经过测试可行 1.pom增加jar <dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>5.2.3</version></dependency><dependency><groupId>org.apach…...

【监控】2.Grafana的安装
在 macOS 上部署 Grafana 和 Prometheus 来监控 Java 服务是一个非常实用的操作。以下是详细的步骤,包括如何安装和配置 Prometheus、Grafana 以及在 Java 服务中集成 Prometheus 的客户端库来收集指标数据。 1. 安装 Grafana 1.1 使用 Homebrew 安装 Grafana br…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...
)
React Native 开发环境搭建(全平台详解)
React Native 开发环境搭建(全平台详解) 在开始使用 React Native 开发移动应用之前,正确设置开发环境是至关重要的一步。本文将为你提供一份全面的指南,涵盖 macOS 和 Windows 平台的配置步骤,如何在 Android 和 iOS…...

Cesium1.95中高性能加载1500个点
一、基本方式: 图标使用.png比.svg性能要好 <template><div id"cesiumContainer"></div><div class"toolbar"><button id"resetButton">重新生成点</button><span id"countDisplay&qu…...

从深圳崛起的“机器之眼”:赴港乐动机器人的万亿赛道赶考路
进入2025年以来,尽管围绕人形机器人、具身智能等机器人赛道的质疑声不断,但全球市场热度依然高涨,入局者持续增加。 以国内市场为例,天眼查专业版数据显示,截至5月底,我国现存在业、存续状态的机器人相关企…...

第25节 Node.js 断言测试
Node.js的assert模块主要用于编写程序的单元测试时使用,通过断言可以提早发现和排查出错误。 稳定性: 5 - 锁定 这个模块可用于应用的单元测试,通过 require(assert) 可以使用这个模块。 assert.fail(actual, expected, message, operator) 使用参数…...

深入浅出Diffusion模型:从原理到实践的全方位教程
I. 引言:生成式AI的黎明 – Diffusion模型是什么? 近年来,生成式人工智能(Generative AI)领域取得了爆炸性的进展,模型能够根据简单的文本提示创作出逼真的图像、连贯的文本,乃至更多令人惊叹的…...
恶补电源:1.电桥
一、元器件的选择 搜索并选择电桥,再multisim中选择FWB,就有各种型号的电桥: 电桥是用来干嘛的呢? 它是一个由四个二极管搭成的“桥梁”形状的电路,用来把交流电(AC)变成直流电(DC)。…...

加密通信 + 行为分析:运营商行业安全防御体系重构
在数字经济蓬勃发展的时代,运营商作为信息通信网络的核心枢纽,承载着海量用户数据与关键业务传输,其安全防御体系的可靠性直接关乎国家安全、社会稳定与企业发展。随着网络攻击手段的不断升级,传统安全防护体系逐渐暴露出局限性&a…...