工作实践:11种API性能优化方法
一、索引优化
接口性能优化时,大家第一个想到的通常是:优化索引。
确实,优化索引的成本是最小的。
你可以通过查看线上日志或监控报告,发现某个接口使用的某条SQL语句耗时较长。
此时,你可能会有以下疑问:
这条SQL语句是否已经加了索引?
加的索引是否生效了?
MySQL是否选择了错误的索引?
1.1 没加索引
在SQL语句中,忘记为WHERE条件的关键字段或ORDER BY后的排序字段加索引是项目中常见的问题。
在项目初期,由于表中的数据量较小,加不加索引对SQL查询性能影响不大。
然而,随着业务的发展,表中的数据量不断增加,这时就必须加索引了。
可以通过以下命令查看/添加索引:
show index from `table_name`
CREATE INDEX index_name ON table_name (column_name);
这种方式能够显著提高查询性能,尤其是在数据量庞大的情况下。
1.2 索引没生效
通过上述命令我们已经确认索引是存在的,但它是否生效呢?
此时,你可能会有这样的疑问。
那么,如何查看索引是否生效呢?
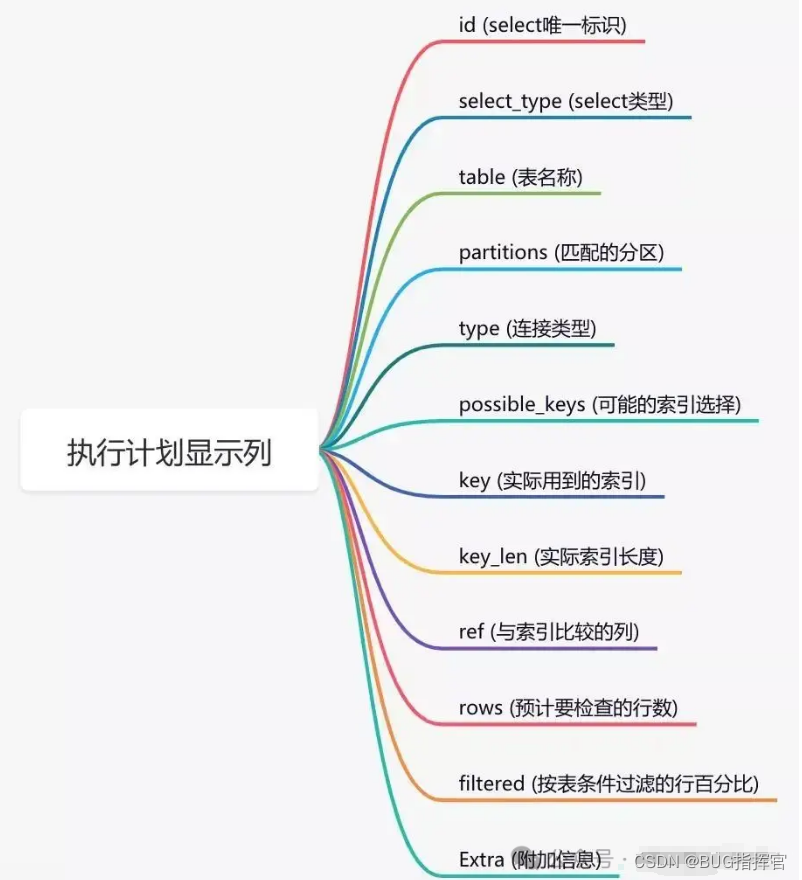
答案是:可以使用 EXPLAIN 命令,查看 MySQL 的执行计划,它会显示索引的使用情况。
例如:
EXPLAIN SELECT * FROM `order` WHERE code='002';
结果:

这个命令将显示查询的执行计划,包括使用了哪些索引。
如果索引生效,你会在输出结果中看到相关的信息。
通过这几列可以判断索引使用情况,执行计划包含列的含义如下图所示:
说实话,SQL语句没有使用索引,除去没有建索引的情况外,最大的可能性是索引失效了。
以下是索引失效的常见原因:
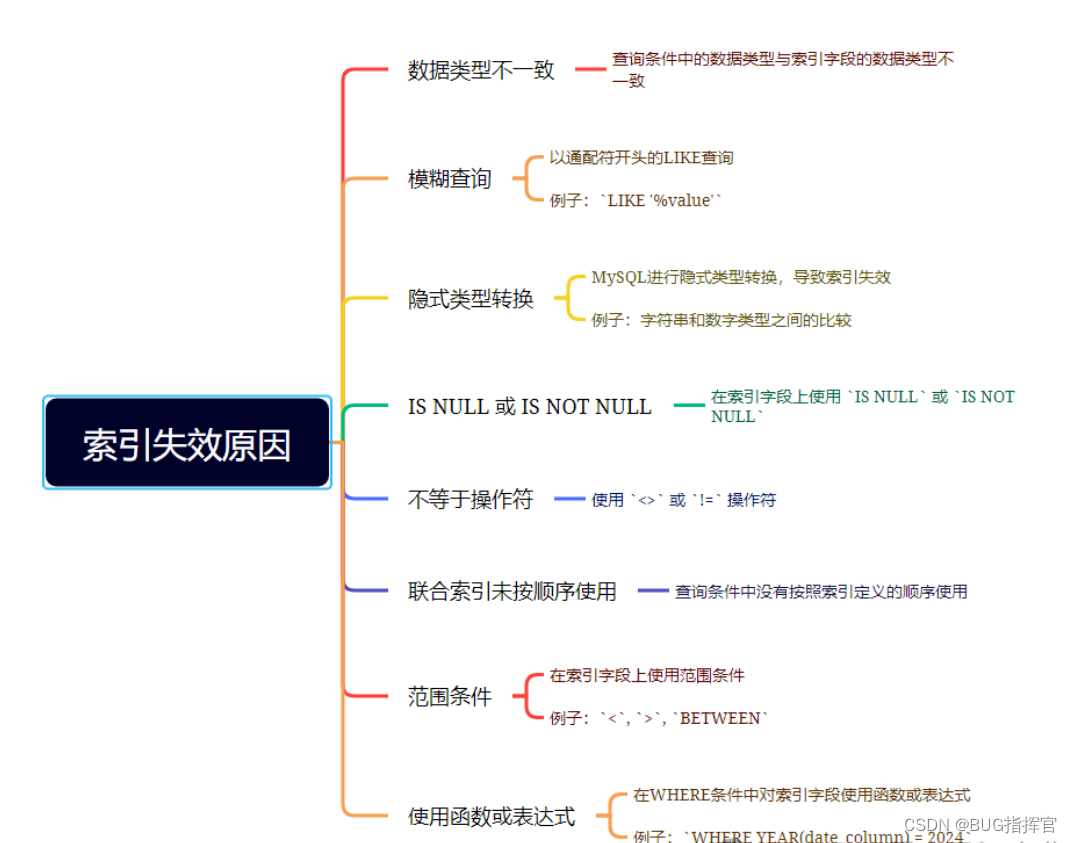
了解这些原因,可以帮助你在查询优化时避免索引失效的问题,确保数据库查询性能保持最佳。
1.3 选错索引
此外,你是否遇到过这样一种情况:明明是同一条SQL语句,只是入参不同。
有时候使用的是索引A,有时候却使用索引B?
没错,有时候MySQL会选错索引。
必要时可以使用 FORCE INDEX 来强制查询SQL使用某个索引。
例如:
SELECT * FROM `order` FORCE INDEX (index_name) WHERE code='002';
至于为什么MySQL会选错索引,原因可能有以下几点:
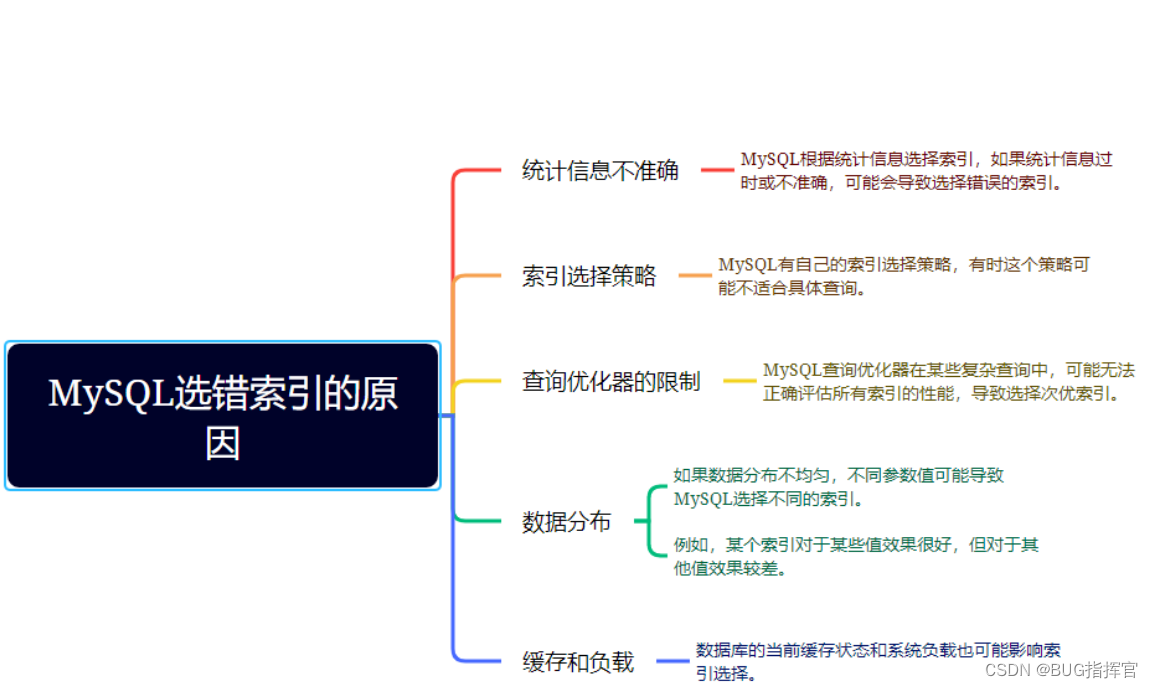
了解这些原因,可以帮助你更好地理解和控制MySQL的索引选择行为,确保查询性能的稳定性。
二、SQL优化
如果优化了索引之后效果不明显,接下来可以尝试优化一下SQL语句,因为相对于修改Java代码来说,改造SQL语句的成本要小得多。
以下是SQL优化的15个小技巧:

三、远程调用
多时候,我们需要在一个接口中调用其他服务的接口。
例如,有这样的业务场景:
在用户信息查询接口中需要返回以下信息:用户名称、性别、等级、头像、积分和成长值。
其中,用户名称、性别、等级和头像存储在用户服务中,积分存储在积分服务中,成长值存储在成长值服务中。为了将这些数据统一返回,我们需要提供一个额外的对外接口服务。
因此,用户信息查询接口需要调用用户查询接口、积分查询接口和成长值查询接口,然后将数据汇总并统一返回。
调用过程如下图所示:
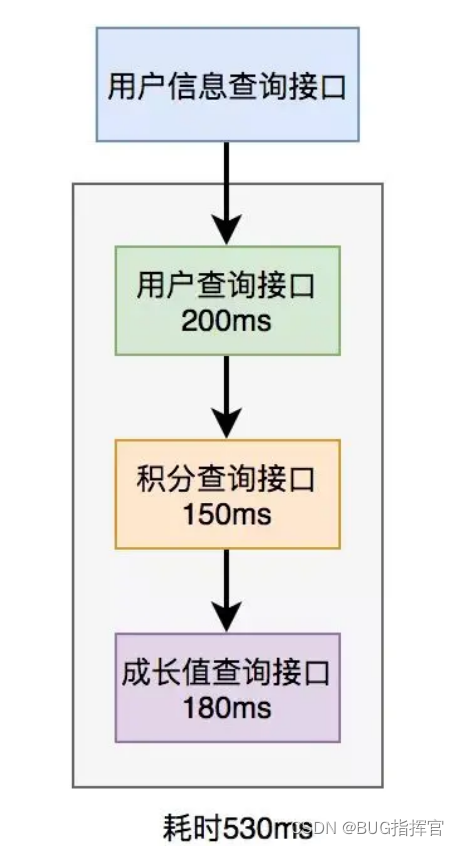
调用远程接口总耗时 530ms = 200ms + 150ms + 180ms
显然这种串行调用远程接口性能是非常不好的,调用远程接口总的耗时为所有的远程接口耗时之和。
3.1 串行改并行
上面说到,既然串行调用多个远程接口性能很差,为什么不改成并行呢?
如下图所示:
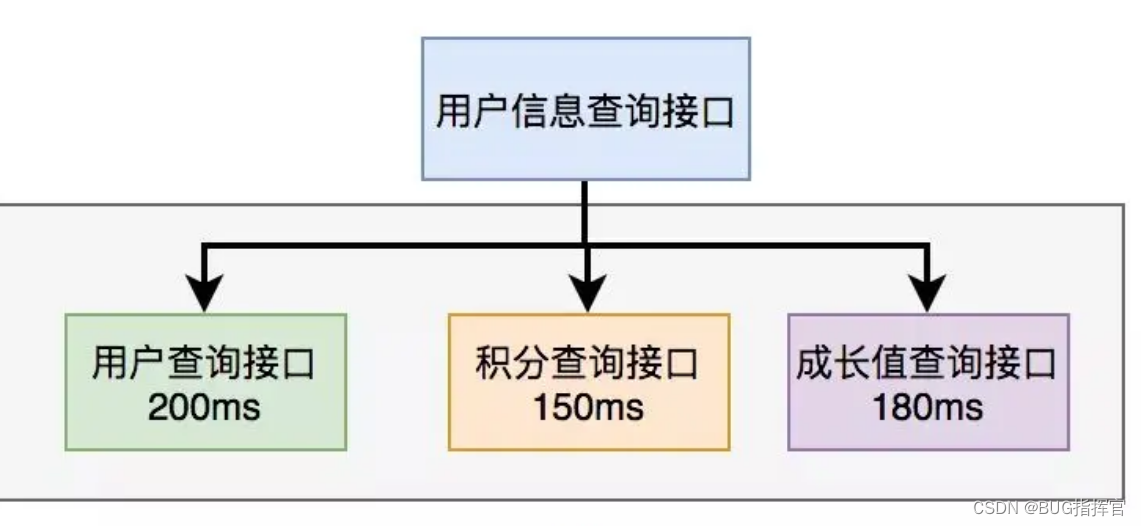
调用远程接口的总耗时为200ms,这等于耗时最长的那次远程接口调用时间。
在Java 8之前,可以通过实现Callable接口来获取线程的返回结果。
在Java 8之后,可以通过CompletableFuture类来实现这一功能。
以下是一个使用CompletableFuture的示例:
public class RemoteServiceExample {public static void main(String[] args) throws ExecutionException, InterruptedException {// 调用用户服务接口CompletableFuture<String> userFuture = CompletableFuture.supplyAsync(() -> {// 模拟远程调用simulateDelay(200);return "User Info";});// 调用积分服务接口CompletableFuture<String> pointsFuture = CompletableFuture.supplyAsync(() -> {// 模拟远程调用simulateDelay(150);return "Points Info";});// 调用成长值服务接口CompletableFuture<String> growthFuture = CompletableFuture.supplyAsync(() -> {// 模拟远程调用simulateDelay(100);return "Growth Info";});// 汇总结果CompletableFuture<Void> allOf = CompletableFuture.allOf(userFuture, pointsFuture, growthFuture);// 等待所有异步操作完成allOf.join();// 获取结果String userInfo = userFuture.get();String pointsInfo = pointsFuture.get();String growthInfo = growthFuture.get();}
}3.2 数据异构
为了提升接口性能,尤其在高并发场景下,可以考虑数据冗余,将用户信息、积分和成长值的数据统一存储在一个地方,比如Redis。
这样,通过用户ID可以直接从Redis中查询所需的数据,从而避免远程接口调用
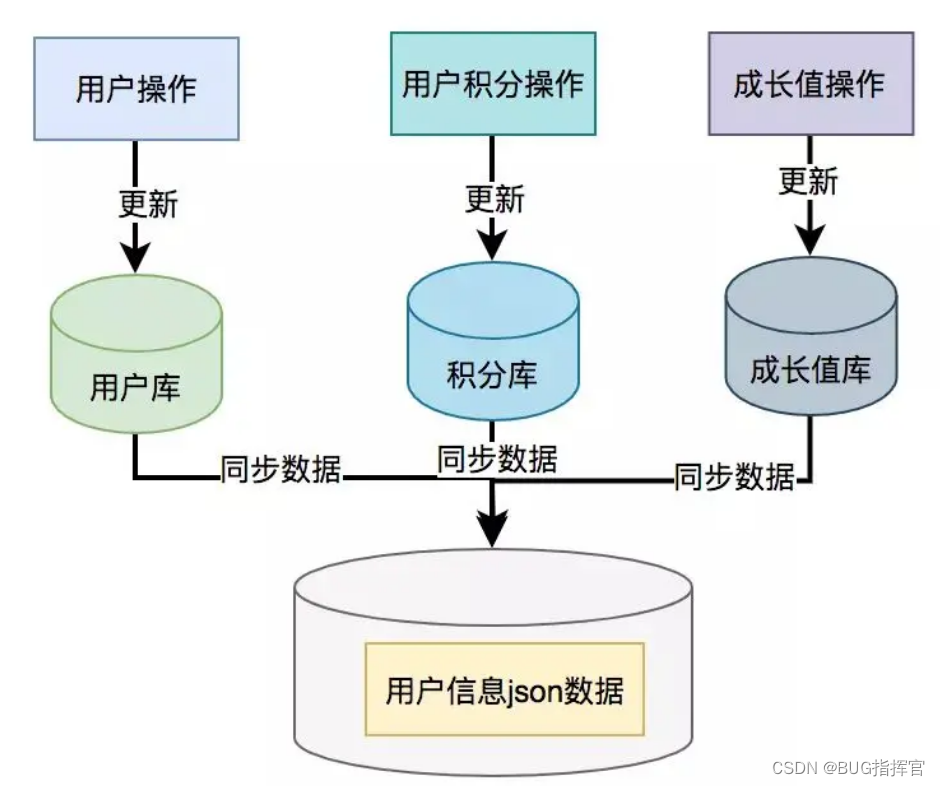
但需要注意的是,如果使用了数据异构方案,就可能会出现数据一致性问题。
用户信息、积分和成长值有更新的话,大部分情况下,会先更新到数据库,然后同步到redis。
但这种跨库的操作,可能会导致两边数据不一致的情况产生。
四、重复调用
在我们的日常工作代码中,重复调用非常常见,但如果没有控制好,会严重影响接口的性能。
让我们一起来看看这个问题。
4.1 循环查数据库 有时候,我们需要从指定的用户集合中查询出哪些用户已经存在于数据库中。
一种实现方式如下:
public List<User> findExistingUsers(List<String> userIds) {List<User> existingUsers = new ArrayList<>();for (String userId : userIds) {User user = userRepository.findById(userId);if (user != null) {existingUsers.add(user);}}return existingUsers;
}上述代码会对每个用户ID执行一次数据库查询,这在用户集合较大时会导致性能问题。
我们可以通过批量查询来优化性能,减少数据库的查询次数。
public List<User> findExistingUsers(List<String> userIds) {// 批量查询数据库List<User> users = userRepository.findByIds(userIds);return users;
}这里有个需要注意的地方是:id集合的大小要做限制,最好一次不要请求太多的数据。要根据实际情况而定,建议控制每次请求的记录条数在500以内。
五、异步处理
在进行接口性能优化时,有时候需要重新梳理业务逻辑,检查是否存在设计不合理的地方。
假设有一个用户请求接口,需要执行以下操作:
-
业务操作
-
发送站内通知
-
记录操作日志 为了实现方便,通常会将这些逻辑放在接口中同步执行,但这会对接口性能造成一定影响。
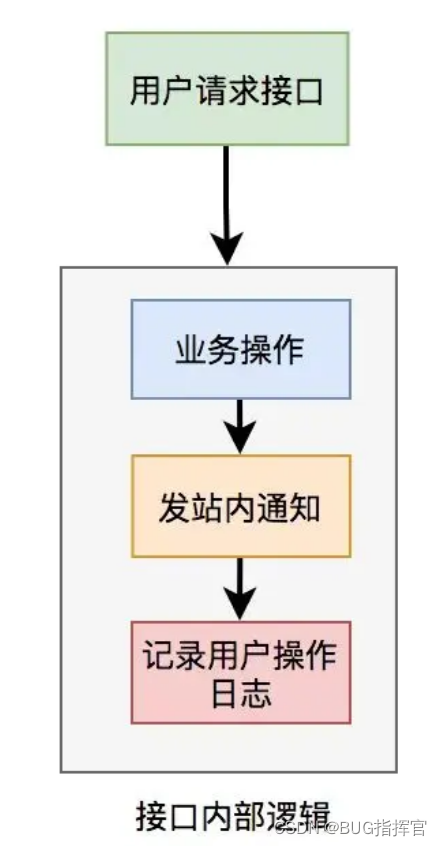
这个接口表面上看起来没有问题,但如果你仔细梳理一下业务逻辑,会发现只有业务操作才是核心逻辑,其他的功能都是非核心逻辑。
在这里有个原则就是:
核心逻辑可以同步执行,同步写库。非核心逻辑,可以异步执行,异步写库。
上面这个例子中,发站内通知和用户操作日志功能,对实时性要求不高,即使晚点写库,用户无非是晚点收到站内通知,或者运营晚点看到用户操作日志,对业务影响不大,所以完全可以异步处理。
异步处理方案
异步处理通常有两种主要方式:多线程和消息队列(MQ)
5.1 线程池异步优化
使用线程池改造之后,接口逻辑如下

5.2 MQ异步
使用线程池有个小问题就是:如果服务器重启了,或者是需要被执行的功能出现异常了,无法重试,会丢数据。
为了避免使用线程池处理异步任务时出现数据丢失的问题,可以考虑使用更加健壮和可靠的异步处理方案,如消息队列(MQ)。消息队列不仅可以异步处理任务,还能够保证消息的持久化和可靠性,支持重试机制。
使用mq改造之后,接口逻辑如下:
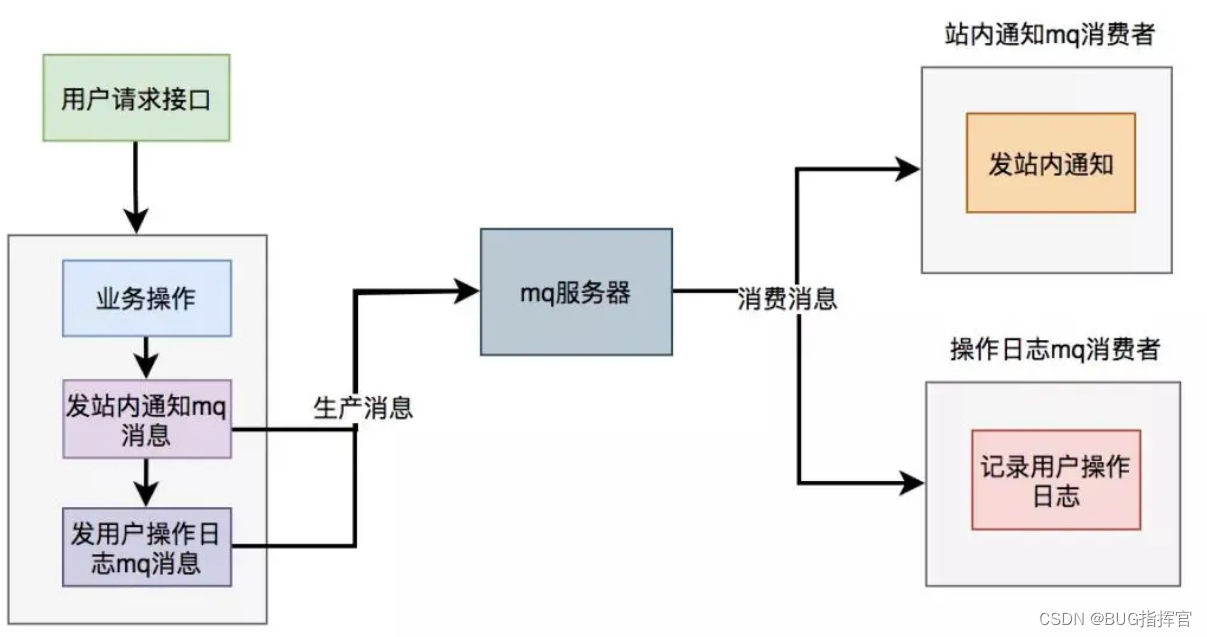
六、避免大事务
很多小伙伴在使用Spring框架开发项目时,为了方便,喜欢使用@Transactional注解提供事务功能。
没错,使用@Transactional注解这种声明式事务的方式提供事务功能,确实能少写很多代码,提升开发效率。
但也容易造成大事务,引发性能的问题。
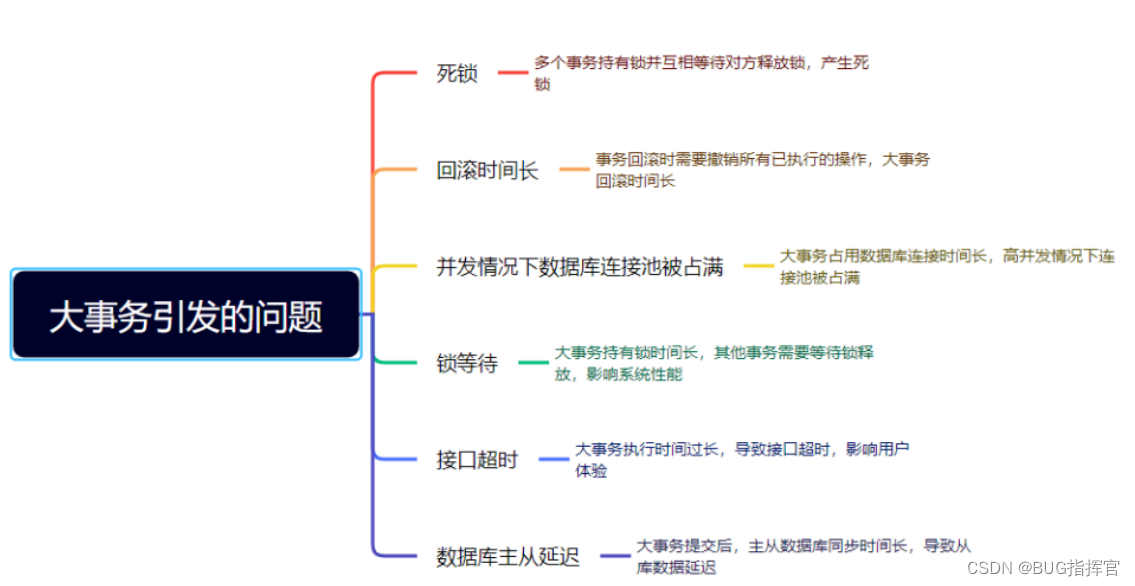
为了避免大事务引发的问题,可以考虑以下优化建议:
-
少用@Transactional注解
-
将查询(select)方法放到事务外
-
事务中避免远程调用
-
事务中避免一次性处理太多数据
-
有些功能可以非事务执行
-
有些功能可以异步处理
七、锁粒度
在一些业务场景中,为了避免多个线程并发修改同一共享数据而引发数据异常,通常我们会使用加锁的方式来解决这个问题。
然而,如果锁的设计不当,导致锁的粒度过粗,也会对接口性能产生显著的负面影响。
7.1 synchronized
在Java中,我们可以使用synchronized关键字来为代码加锁。
通常有两种写法:在方法上加锁和在代码块上加锁。
1. 方法上加锁
public synchronized void doSave(String fileUrl) {mkdir();uploadFile(fileUrl);sendMessage(fileUrl);
}
在方法上加锁的目的是为了防止并发情况下创建相同的目录,避免第二次创建失败而影响业务功能。
但这种直接在方法上加锁的方式,锁的粒度较粗。
因为doSave方法中的文件上传和消息发送并不需要加锁,只有创建目录的方法需要加锁。
我们知道,文件上传操作非常耗时,如果将整个方法加锁,那么需要等到整个方法执行完之后才能释放锁。
显然,这会导致该方法的性能下降,得不偿失。
2. 代码块上加锁我们可以将加锁改在代码块上,从而缩小锁的粒度, 如下:
public void doSave(String path, String fileUrl) {synchronized(this) {if (!exists(path)) {mkdir(path);}}uploadFile(fileUrl);sendMessage(fileUrl);
}
这样改造后,锁的粒度变小了,只有并发创建目录时才加锁。
创建目录是一个非常快的操作,即使加锁对接口性能的影响也不大。
最重要的是,其他的文件上传和消息发送功能仍然可以并发执行。
多节点环境中的问题 在单机版服务中,这种做法没有问题。但在生产环境中,为了保证服务的稳定性,同一个服务通常会部署在多个节点上。如果某个节点挂掉,其他节点的服务仍然可用。
多节点部署避免了某个节点挂掉导致服务不可用的情况,同时也能分摊整个系统的流量,避免系统压力过大。
但这种部署方式也带来了新的问题:synchronized只能保证一个节点加锁有效。
7.2 Redis分布式锁
在分布式系统中,由于Redis分布式锁的实现相对简单且高效,因此它在许多实际业务场景中被广泛采用。
使用Redis分布式锁的伪代码如下:
public boolean doSave(String path, String fileUrl) {try {String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);if ("OK".equals(result)) {if (!exists(path)) {mkdir(path);uploadFile(fileUrl);sendMessage(fileUrl);}return true;}} finally {unlock(lockKey, requestId);}return false;
}
与之前使用synchronized关键字加锁时一样,这里的锁的范围也太大了,换句话说,锁的粒度太粗。这会导致整个方法的执行效率很低。
实际上,只有在创建目录时才需要加分布式锁,其余代码不需要加锁。
于是,我们需要优化代码:
public void doSave(String path, String fileUrl) {if (tryLock()) {try {if (!exists(path)) {mkdir(path);}} finally {unlock(lockKey, requestId);}}uploadFile(fileUrl);sendMessage(fileUrl);
}private boolean tryLock() {String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);return "OK".equals(result);
}private void unlock(String lockKey, String requestId) {// 解锁逻辑
}
上面的代码将加锁的范围缩小了,只有在创建目录时才加锁。这样的简单优化后,接口性能可以得到显著提升。
7.3 数据库锁
MySQL数据库中的三种锁
-
表锁:
-
优点:加锁快,不会出现死锁。
-
缺点:锁定粒度大,锁冲突的概率高,并发度最低。
-
-
行锁:
-
优点:锁定粒度最小,锁冲突的概率低,并发度最高。
-
缺点:加锁慢,会出现死锁。
-
-
间隙锁:
-
优点:锁定粒度介于表锁和行锁之间。
-
缺点:开销和加锁时间介于表锁和行锁之间,并发度一般,也会出现死锁。
-
锁与并发度
并发度越高,接口性能越好。因此,数据库锁的优化方向是:
-
优先使用行锁
-
其次使用间隙锁
-
最后使用表锁
八、分页处理
有时候需要调用某个接口来批量查询数据,例如,通过用户ID批量查询用户信息,然后为这些用户赠送积分。
但是,如果一次性查询的用户数量太多,例如一次查询2000个用户的数据,传入2000个用户的ID进行远程调用时,用户查询接口经常会出现超时的情况。
调用代码如下:
List<User> users = remoteCallUser(ids);
众所周知,调用接口从数据库获取数据需要经过网络传输。如果数据量过大,无论是数据获取速度还是网络传输速度都会受到带宽限制,从而导致耗时较长。
优化使用:分页处理。
将一次性获取所有数据的请求,改为分多次获取,每次只获取一部分用户的数据,最后进行合并和汇总。
其实,处理这个问题可以分为两种场景:同步调用和异步调用。
8.1 同步调用
如果在job中需要获取2000个用户的信息,它要求只要能正确获取到数据即可,对获取数据的总耗时要求不高。
但对每一次远程接口调用的耗时有要求,不能大于500ms,否则会有邮件预警。
这时,我们可以同步分页调用批量查询用户信息接口。
具体示例代码如下:
List<List<Long>> allIds = Lists.partition(ids, 200);for (List<Long> batchIds : allIds) {List<User> users = remoteCallUser(batchIds);
}
代码中我使用了Google Guava工具中的Lists.partition方法,用它来做分页简直太好用了,不然要写一大堆分页的代码。 8.2 异步调用 如果是在某个接口中需要获取2000个用户的信息,需要考虑的因素更多。
除了远程调用接口的耗时,还需要考虑该接口本身的总耗时,也不能超过500ms。
这时,使用上面的同步分页请求远程接口的方法肯定是行不通的。
那么,只能使用异步调用了。
代码如下:
List<List<Long>> allIds = Lists.partition(ids, 200);final List<User> result = Lists.newArrayList();
allIds.stream().forEach(batchIds -> {CompletableFuture.supplyAsync(() -> {result.addAll(remoteCallUser(batchIds));return Boolean.TRUE;}, executor);
});使用CompletableFuture类,通过多个线程异步调用远程接口,最后汇总结果统一返回。
九、加缓存
通常情况下,我们最常用的缓存是:Redis和Memcached。
但对于Java应用来说,绝大多数情况下使用的是Redis,所以接下来我们以Redis为例。
在关系型数据库(例如:MySQL)中,菜单通常有上下级关系。某个四级分类是某个三级分类的子分类,三级分类是某个二级分类的子分类,而二级分类又是某个一级分类的子分类。
这种存储结构决定了,想一次性查出整个分类树并非易事。这需要使用程序递归查询,而如果分类很多,这个递归操作会非常耗时。
因此,如果每次都直接从数据库中查询分类树的数据,会是一个非常耗时的操作。
这时我们可以使用缓存。在大多数情况下,接口直接从缓存中获取数据。操作Redis可以使用成熟的框架,比如:Jedis和Redisson等。 使用Jedis的伪代码如下:
String json = jedis.get(key);
if (StringUtils.isNotEmpty(json)) {CategoryTree categoryTree = JsonUtil.toObject(json);return categoryTree;
}
return queryCategoryTreeFromDb();
十、分库分表
有时候,接口性能受限的并不是其他方面,而是数据库。
当系统发展到一定阶段,用户并发量增加,会有大量的数据库请求,这不仅需要占用大量的数据库连接,还会带来磁盘IO的性能瓶颈问题。
此外,随着用户数量的不断增加,产生的数据量也越来越大,一张表可能无法存储所有数据。由于数据量太大,即使SQL语句使用了索引,查询数据时也会非常耗时。
那么,这种情况下该怎么办呢?
答案是:需要进行分库分表。
如下图所示:
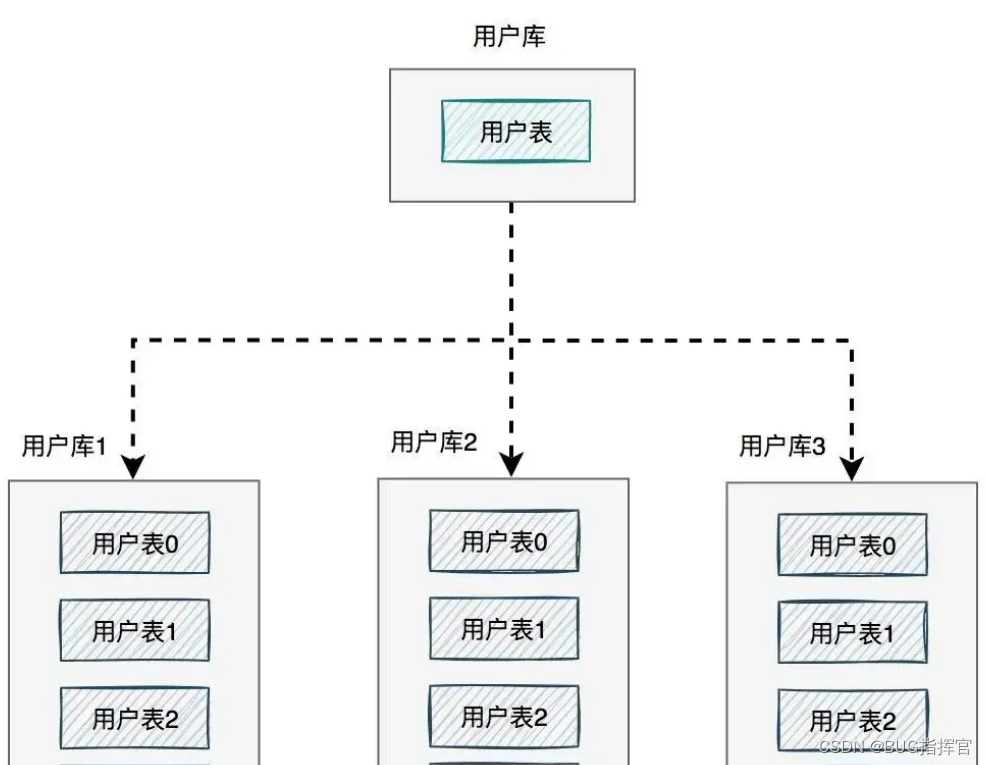
图中将用户库拆分成了三个库,每个库都包含了三张用户表。
如果有用户请求过来,先根据用户ID路由到其中一个用户库,然后再定位到某张表。
路由的算法有很多:
-
根据ID取模:
-
例如:ID=7,有3张表,则
7%3=1,模为1,路由到用户表1。
-
-
给ID指定一个区间范围:
-
例如:ID的值是0-10万,则数据存在用户表0;ID的值是10-20万,则数据存在用户表1。
-
-
一致性Hash算法。 分库分表主要有两个方向:垂直和水平。
1. 垂直分库分表
垂直分库分表(即业务方向)更简单,将不同的业务数据存储在不同的库或表中。
例如,将用户数据和订单数据存储在不同的库中。
2. 水平分库分表
水平分库分表(即数据方向)上,分库和分表的作用有区别,不能混为一谈。
分库
-
目的:解决数据库连接资源不足问题和磁盘IO的性能瓶颈问题。
分表
-
目的:解决单表数据量太大,SQL语句查询数据时,即使走了索引也非常耗时的问题。此外,还可以解决消耗CPU资源的问题。
分库分表
-
目的:综合解决数据库连接资源不足、磁盘IO性能瓶颈、数据检索耗时和CPU资源消耗等问题。
业务场景中的应用
-
只分库:
-
用户并发量大,但需要保存的数据量很少。
-
-
只分表:
-
用户并发量不大,但需要保存的数据量很多。
-
-
分库分表:
-
用户并发量大,并且需要保存的数据量也很多。
-
十一、监控功能
优化接口性能问题,除了上面提到的这些常用方法之外,还需要配合使用一些辅助功能,因为它们真的可以帮我们提升查找问题的效率。
11.1 开启慢查询日志
通常情况下,为了定位SQL的性能瓶颈,我们需要开启MySQL的慢查询日志。把超过指定时间的SQL语句单独记录下来,方便以后分析和定位问题。
开启慢查询日志需要重点关注三个参数:
-
slow_query_log:慢查询开关
-
slow_query_log_file:慢查询日志存放的路径
-
long_query_time:超过多少秒才会记录日志
通过MySQL的SET命令可以设置:
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL slow_query_log_file = '/usr/local/mysql/data/slow.log';
SET GLOBAL long_query_time = 2;
设置完之后,如果某条SQL的执行时间超过了2秒,会被自动记录到slow.log文件中。
当然,也可以直接修改配置文件my.cnf:
[mysqld]
slow_query_log = ON
slow_query_log_file = /usr/local/mysql/data/slow.log
long_query_time = 2但这种方式需要重启MySQL服务。
很多公司每天早上都会发一封慢查询日志的邮件,开发人员根据这些信息优化SQL。
11.2 加监控
为了在出现SQL问题时能够及时发现,我们需要对系统做监控。
目前业界使用比较多的开源监控系统是:Prometheus
它提供了监控和预警的功能。
架构图如下:
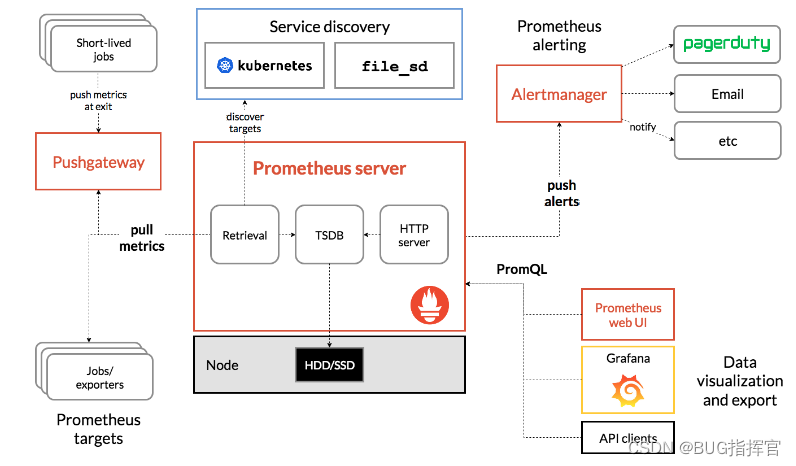
我们可以用它监控如下信息:
-
接口响应时间
-
调用第三方服务耗时
-
慢查询sql耗时
-
cpu使用情况
-
内存使用情况
-
磁盘使用情况
-
数据库使用情况
-
等等。。。
它的界面大概长这样子:
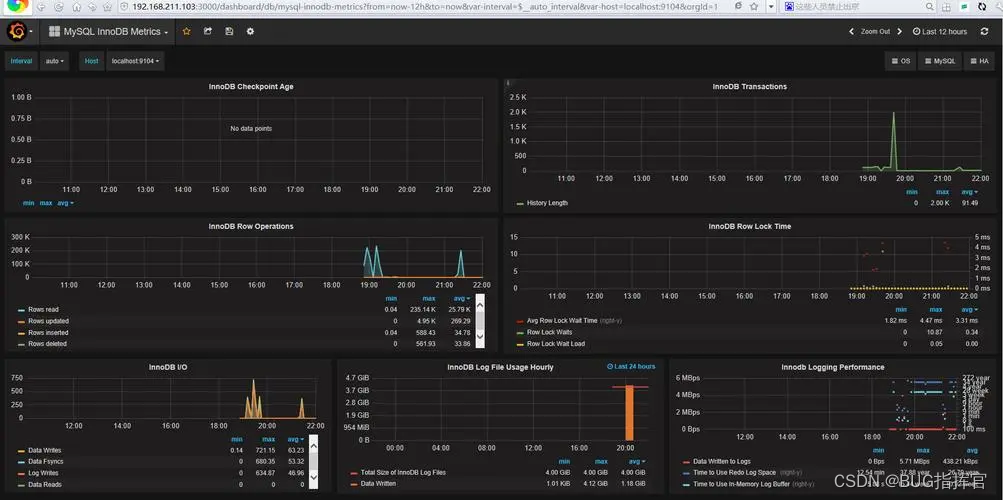
可以看到MySQL的当前QPS、活跃线程数、连接数、缓存池的大小等信息。
如果发现连接池占用的数据量太多,肯定会对接口性能造成影响。
这时可能是由于代码中开启了连接却忘记关闭,或者并发量太大导致的,需要进一步排查和系统优化
11.3链路跟踪
有时候,一个接口涉及的逻辑非常复杂,例如查询数据库、查询Redis、远程调用接口、发送MQ消息以及执行业务代码等等。
这种情况下,接口的一次请求会涉及到非常长的调用链路。如果逐一排查这些问题,会耗费大量时间,此时我们已经无法用传统的方法来定位问题。
有没有办法解决这个问题呢?
答案是使用分布式链路跟踪系统:SkyWalking
SkyWalking的架构图如下:
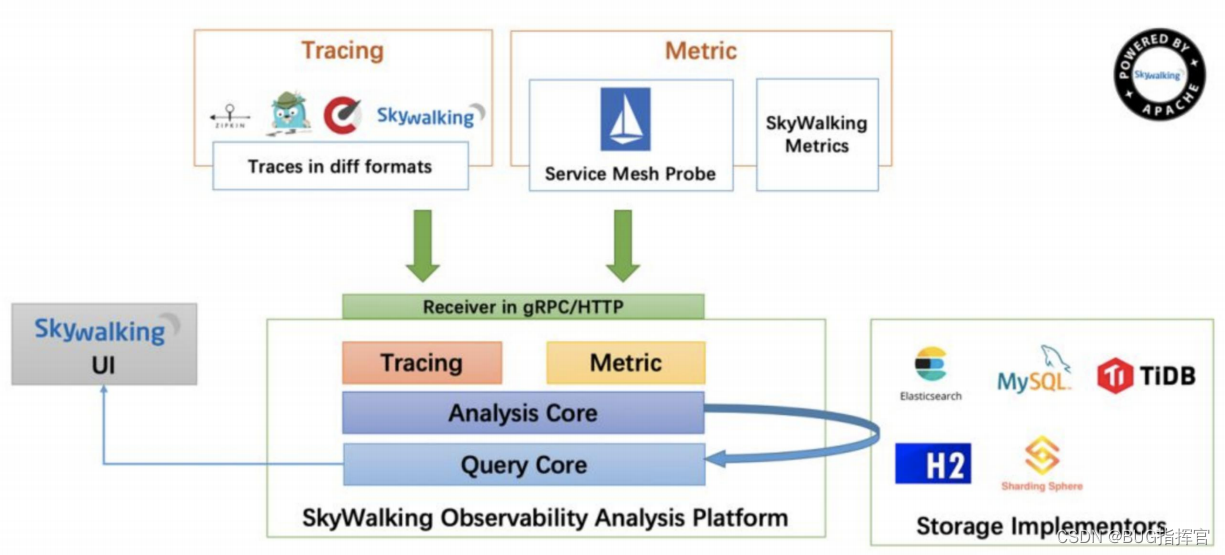
在SkyWalking中,可以通过traceId(全局唯一的ID)来串联一个接口请求的完整链路。你可以看到整个接口的耗时、调用的远程服务的耗时、访问数据库或者Redis的耗时等,功能非常强大。
之前没有这个功能时,为了定位线上接口性能问题,我们需要在代码中加日志,手动打印出链路中各个环节的耗时情况,然后再逐一排查。这种方法不仅费时费力,而且容易遗漏细节。
如果你用过SkyWalking来排查接口性能问题,你会不自觉地爱上它的功能。如果你想了解更多功能,可以访问SkyWalking的官网:www.skywalking.apache.org
相关文章:
工作实践:11种API性能优化方法
一、索引优化 接口性能优化时,大家第一个想到的通常是:优化索引。 确实,优化索引的成本是最小的。 你可以通过查看线上日志或监控报告,发现某个接口使用的某条SQL语句耗时较长。 此时,你可能会有以下疑问ÿ…...
正版软件 | WIFbox:智能化文件管理工具,让效率与隐私并行
在数字化办公日益普及的今天,文件管理成为了提升工作效率的关键。WIFbox 一款智能文件管理工具,利用强大的人工智能技术,帮助您快速对文件进行分类,完成复杂的智能文件分类任务。 智能分类,效率倍增 WIFbox 通过精细化…...

Postman接口工具实战
为了更好地展示Postman接口测试的实战过程,我将以一个简单的实战示例来说明如何使用Postman完成一个API的测试。假设我们要测试一个假想的天气查询API,该API允许用户通过城市名查询天气情况。我们将执行以下步骤: 1. 准备工作 确保已经安装…...
江协科技51单片机学习- p17 定时器
🚀write in front🚀 🔎大家好,我是黄桃罐头,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流 🎁欢迎各位→点赞👍 收藏⭐️ 留言📝…...

【D3.js in Action 3 精译】前言
早在 2017 年,我还是一名渴望迈出职业生涯关键一步的前端开发者。虽然我很热衷于网站开发,但总感觉缺了点什么。我一直希望自己的工程专业背景和对教学的热爱能与新的编程技能相结合。就在这时,搭档建议我学学数据可视化。出于某种原因&#…...
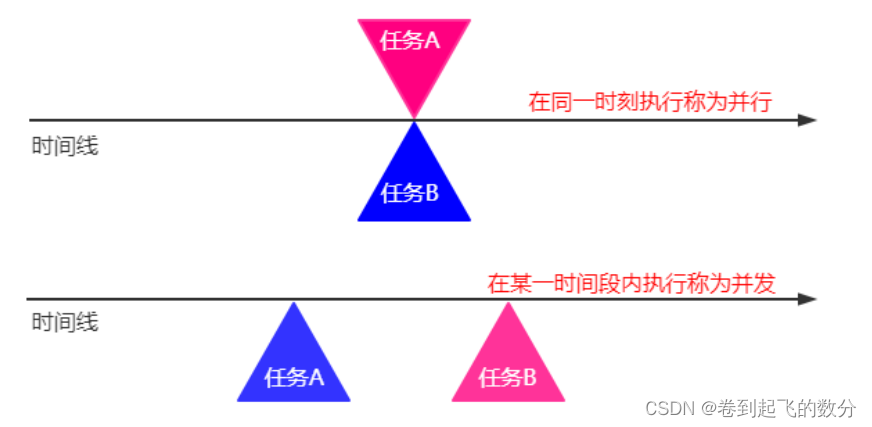
Java SE入门及基础(58) 并发 进程与线程概念
目录 并发 进程和线程 1. 进程和线程 2. 进程 3.线程 总结 并发 并发(Concurrency) Computer users take it for granted that their systems can do more than one thing at a time. They assume that they can continue to work in a word processor, while other app…...

放松一下,简简单单了
哈哈哈哈哈...

【智能制造-5】数采和电机
既然可以采集PLC的数据,为什么要采集电机的数据? 采集PLC(可编程逻辑控制器)的数据和采集电机的数据是两个不同的概念和目的。 PLC是用于控制和监控工业自动化过程的设备,它可以接收传感器的输入信号并根据预设的逻辑…...

【软考论文】论信息系统的安全性与保密性设计
目录 一、题目二、论文2.1 摘要2.2 正文三、扩展3.1 信息安全包括5个基本要素3.2 国产秘钥算法3.3 等保(信息安全等级保护)3.4 其他一、题目 在企业信息化推进的过程中,需要建设许多信息系统,这些系统能够实现高效率、低成本的运行,为企业提升竞争力。但在设计和实现这些…...
【图文教程】电脑查看显卡GPU温度方法:小白也能秒懂!
在电脑操作中,显卡是电脑的重要组件之一,其温度控制对于保持系统稳定运行是特别重要的。但是,许多新手用户不知道要怎么操作才能查看电脑显卡CPU的温度?接下来小编给大家介绍三种简单有效的查看显卡温度方法,操作简单&…...
Qt的智能终端项目文档完整版
由于上一篇文章已经把用户端的页面都显示了,这里就不在赘述,就将那个运行在虚拟机上的截图展示下来了,其实这个也就是最后的效果了。目前就是这个,感觉当练手的也还行...

SQL面试题练习 —— 查询最近一笔有效订单
目录 1 题目2 建表语句3 题解 题目来源:字节跳动。 1 题目 现有订单表t_order,包含订单ID,订单时间,下单用户,当前订单是否有效,请查询出每个用户每笔订单的上一笔有效订单 ----------------------------------------…...

分享HTML显示2D/3D粒子时钟
效果截图 实现代码 线上体验:three.jscannon.js Web 3D <!DOCTYPE html> <head> <title>three.jscannon.js Web 3D</title><meta charset"utf-8"><meta name"viewport" content"widthdevice-width,ini…...
Java——IDEA使用
一、IDEA介绍 IntelliJ IDEA 是 JetBrains 公司开发的一款功能强大的集成开发环境(IDE),主要用于 Java 编程语言,但也支持多种其他语言和框架。由于其强大的功能和灵活性,IntelliJ IDEA 被广泛应用于软件开发领域&…...

高性能STL库 EASTL 、高性能JSON库
GitHub - electronicarts/EASTL: EASTL stands for Electronic Arts Standard Template Library. It is an extensive and robust implementation that has an emphasis on high performance. 兄弟们,对STL要求性能高的可以试试这个EASTL库!!…...

多通道采集器采样接口设计[进行中...]
1.技术问题 这是一个非常小的设计,完全不值得把它展示出来。但是因为这个接口设计关系到一些细微的配置和技术限制,仍然有一些细节需要处理,并且很容易出错,我们先把技术问题罗列一下: 多个传感器对应的多个逻辑通道…...

rapidjson使用中crash问题分析
问题 在使用rapidjson时,使用Document的Parse方法解析json字符串,程序crash。 分析 可以参考https://github.com/Tencent/rapidjson/issues/1269,由于rapidjson的内存分配器默认认为内存分配成功,没有对分配后做判空判断&#…...

TCP协议中的三次握手和四次挥手机制
TCP协议中的三次握手和四次挥手机制 TCP(Transmission Control Protocol,传输控制协议)是一种面向连接的、可靠的、基于字节流的通信协议,它的三次握手和四次挥手机制是建立和断开连接的关键步骤。 三次握手: 第一次…...

Linux双网卡默认路由的metric设置不正确,导致SSH连接失败问题定位
测试环境 VMware虚拟机 RockyLinux 9 x86_64 双网卡:eth0(访问外网): 10.206.216.92/24; eth1(访问内网) 192.168.1.4/24 问题描述 虚拟机重启后,SSH连接失败,提示"Connection time out",重启之前SSH连接还是正常的…...

Batch入门学习:从零开始掌握批处理脚本
目录 1. Batch脚本简介 1.1 什么是Batch脚本? 1.2 Batch脚本的历史 1.3 Batch脚本的应用场景 2. Batch脚本基本语法 2.1 注释 2.2 变量 2.3 常用命令 2.3.1 ECHO 2.3.2 PAUSE 2.3.3 CLS 2.3.4 GOTO 2.3.5 IF 2.3.6 FOR 2.4 参数传递 2.5 输入输出重…...

eNSP-Cloud(实现本地电脑与eNSP内设备之间通信)
说明: 想象一下,你正在用eNSP搭建一个虚拟的网络世界,里面有虚拟的路由器、交换机、电脑(PC)等等。这些设备都在你的电脑里面“运行”,它们之间可以互相通信,就像一个封闭的小王国。 但是&#…...

19c补丁后oracle属主变化,导致不能识别磁盘组
补丁后服务器重启,数据库再次无法启动 ORA01017: invalid username/password; logon denied Oracle 19c 在打上 19.23 或以上补丁版本后,存在与用户组权限相关的问题。具体表现为,Oracle 实例的运行用户(oracle)和集…...

【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...

全志A40i android7.1 调试信息打印串口由uart0改为uart3
一,概述 1. 目的 将调试信息打印串口由uart0改为uart3。 2. 版本信息 Uboot版本:2014.07; Kernel版本:Linux-3.10; 二,Uboot 1. sys_config.fex改动 使能uart3(TX:PH00 RX:PH01),并让boo…...

Python ROS2【机器人中间件框架】 简介
销量过万TEEIS德国护膝夏天用薄款 优惠券冠生园 百花蜂蜜428g 挤压瓶纯蜂蜜巨奇严选 鞋子除臭剂360ml 多芬身体磨砂膏280g健70%-75%酒精消毒棉片湿巾1418cm 80片/袋3袋大包清洁食品用消毒 优惠券AIMORNY52朵红玫瑰永生香皂花同城配送非鲜花七夕情人节生日礼物送女友 热卖妙洁棉…...

Mysql中select查询语句的执行过程
目录 1、介绍 1.1、组件介绍 1.2、Sql执行顺序 2、执行流程 2.1. 连接与认证 2.2. 查询缓存 2.3. 语法解析(Parser) 2.4、执行sql 1. 预处理(Preprocessor) 2. 查询优化器(Optimizer) 3. 执行器…...

[免费]微信小程序问卷调查系统(SpringBoot后端+Vue管理端)【论文+源码+SQL脚本】
大家好,我是java1234_小锋老师,看到一个不错的微信小程序问卷调查系统(SpringBoot后端Vue管理端)【论文源码SQL脚本】,分享下哈。 项目视频演示 【免费】微信小程序问卷调查系统(SpringBoot后端Vue管理端) Java毕业设计_哔哩哔哩_bilibili 项…...

如何更改默认 Crontab 编辑器 ?
在 Linux 领域中,crontab 是您可能经常遇到的一个术语。这个实用程序在类 unix 操作系统上可用,用于调度在预定义时间和间隔自动执行的任务。这对管理员和高级用户非常有益,允许他们自动执行各种系统任务。 编辑 Crontab 文件通常使用文本编…...