pytorch-01
加载mnist数据集
one-hot编码实现
import numpy as np
import torch
x_train = np.load("../dataset/mnist/x_train.npy") # 从网站提前下载数据集,并解压缩
y_train_label = np.load("../dataset/mnist/y_train_label.npy")
x = torch.tensor(y_train_label[:5],dtype=torch.int64) # 获取前5个样本的标签数据
# 定义一个张量输入,因为此时有 5 个数值,且最大值为9,类别数为10
# 所以我们可以得到 y 的输出结果的形状为 shape=(5,10),即5行12列
y = torch.nn.functional.one_hot(x, 10) # 一个参数张量x,10为类别数
print(y)

对于拥有6000个样本的MNIST数据集来说,标签就是一个大小的矩阵张量。
多层感知机模型
#设定的多层感知机网络模型
class NeuralNetwork(torch.nn.Module):def __init__(self):super(NeuralNetwork, self).__init__()self.flatten = torch.nn.Flatten() # 拉平图像矩阵self.linear_relu_stack = torch.nn.Sequential(torch.nn.Linear(28*28,312), # 输入大小为28*28,输出大小为312维的线性变换层torch.nn.ReLU(), # 激活函数层torch.nn.Linear(312, 256),torch.nn.ReLU(),torch.nn.Linear(256, 10) # 最终输出大小为10,对应one-hot标签维度)def forward(self, input): # 构建网络x = self.flatten(input) #拉平矩阵为1维logits = self.linear_relu_stack(x) # 多层感知机return logits
损失函数
优化函数
model = NeuralNetwork()
loss_fu = torch.nn.CrossEntropyLoss() # 交叉熵损失函数,内置了softmax函数,
optimizer = torch.optim.Adam(model.parameters(), lr=2e-5) #设定优化函数loss = loss_fu(pred,label_batch) # 计算损失完整模型
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0' #指定GPU编
import torch
import numpy as npbatch_size = 320 #设定每次训练的批次数
epochs = 1024 #设定训练次数#device = "cpu" #Pytorch的特性,需要指定计算的硬件,如果没有GPU的存在,就使用CPU进行计算
device = "cuda" #在这里读者默认使用GPU,如果读者出现运行问题可以将其改成cpu模式#设定的多层感知机网络模型
class NeuralNetwork(torch.nn.Module):def __init__(self):super(NeuralNetwork, self).__init__()self.flatten = torch.nn.Flatten()self.linear_relu_stack = torch.nn.Sequential(torch.nn.Linear(28*28,312),torch.nn.ReLU(),torch.nn.Linear(312, 256),torch.nn.ReLU(),torch.nn.Linear(256, 10))def forward(self, input):x = self.flatten(input)logits = self.linear_relu_stack(x)return logitsmodel = NeuralNetwork()
model = model.to(device) #将计算模型传入GPU硬件等待计算
torch.save(model, './model.pth')
#model = torch.compile(model) #Pytorch2.0的特性,加速计算速度
loss_fu = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=2e-5) #设定优化函数#载入数据
x_train = np.load("../../dataset/mnist/x_train.npy")
y_train_label = np.load("../../dataset/mnist/y_train_label.npy")train_num = len(x_train)//batch_size#开始计算
for epoch in range(20):train_loss = 0for i in range(train_num):start = i * batch_sizeend = (i + 1) * batch_sizetrain_batch = torch.tensor(x_train[start:end]).to(device)label_batch = torch.tensor(y_train_label[start:end]).to(device)pred = model(train_batch)loss = loss_fu(pred,label_batch)optimizer.zero_grad()loss.backward()optimizer.step()train_loss += loss.item() # 记录每个批次的损失值# 计算并打印损失值train_loss /= train_numaccuracy = (pred.argmax(1) == label_batch).type(torch.float32).sum().item() / batch_sizeprint("epoch:",epoch,"train_loss:", round(train_loss,2),"accuracy:",round(accuracy,2))

可视化模型结构和参数
model = NeuralNetwork()
print(model)
是对模型具体使用的函数及其对应的参数进行打印。
格式化显示:
param = list(model.parameters())
k=0
for i in param:l = 1print('该层结构:'+str(list(i.size())))for j in i.size():l*=jprint('该层参数和:'+str(l))k = k+l
print("总参数量:"+str(k))
模型保存
model = NeuralNetwork()
torch.save(model, './model.pth')netron可视化
安装:pip install netron
运行:命令行输入netron
打开:通过网址http://localhost:8080打开

打开保存的模型文件model.pth:

点击颜色块,可以显示详细信息:

相关文章:
pytorch-01
加载mnist数据集 one-hot编码实现 import numpy as np import torch x_train np.load("../dataset/mnist/x_train.npy") # 从网站提前下载数据集,并解压缩 y_train_label np.load("../dataset/mnist/y_train_label.npy") x torch.tensor(y…...
梦想CAD二次开发
1.mxdraw简介 mxdraw是一个HTML5 Canvas JavaScript框架,它在THREE.js的基础上扩展开发,为用户提供了一套在前端绘图更为方便,快捷,高效率的解决方案,mxdraw的实质为一个前端二维绘图平台。你可以使用mxdraw在画布上绘…...

Eureka的介绍与使用
Eureka 是 Netflix 开源的一款服务注册与发现组件,在微服务架构中扮演着重要的角色。 一、Eureka 的介绍 工作原理 服务注册:各个微服务在启动时,会向 Eureka Server 发送注册请求,将自身的服务名、实例名、IP 地址、端口等信息注…...

ChatGPT之母:AI自动化将取代人类,创意性工作或将消失
目录 01 AI取代创意性工作的担忧 1.1 CTO说了啥 02 AI已开始大范围取代人类 01 AI取代创意性工作的担忧 几天前的采访中,OpenAI的CTO直言,AI可能会扼杀一些本来不应该存在的创意性工作。 近来一篇报道更是印证了这一观点。国外科技媒体的老板Miller用…...

【深度学习驱动流体力学】湍流仿真到深度学习湍流预测
目录 一、湍流项目结构二、三个OpenFOAM湍流算例1. motorBike背景和目的文件结构和关键文件使用和应用湍流仿真深度学习湍流预测深度学习湍流预测的挑战和应用结合湍流仿真与深度学习2. pitzDaily背景和目的文件结构和关键文件使用和应用3. pitzDailyMapped背景和目的文件结构和…...

如何从0构建一款类似pytest的工具
Pytest主要模块 Pytest 是一个强大且灵活的测试框架,它通过一系列步骤来发现和运行测试。其核心工作原理包括以下几个方面:测试发现:Pytest 会遍历指定目录下的所有文件,找到以 test_ 开头或 _test.py 结尾的文件,并且…...

6.27-6.29 旧c语言
#include<stdio.h> struct stu {int num;float score;struct stu *next; }; void main() {struct stu a,b,c,*head;//静态链表a.num 1;a.score 10;b.num 2;b.score 20;c.num 3;c.score 30;head &a;a.next &b;b.next &c;do{printf("%d,%5.1f\n&…...
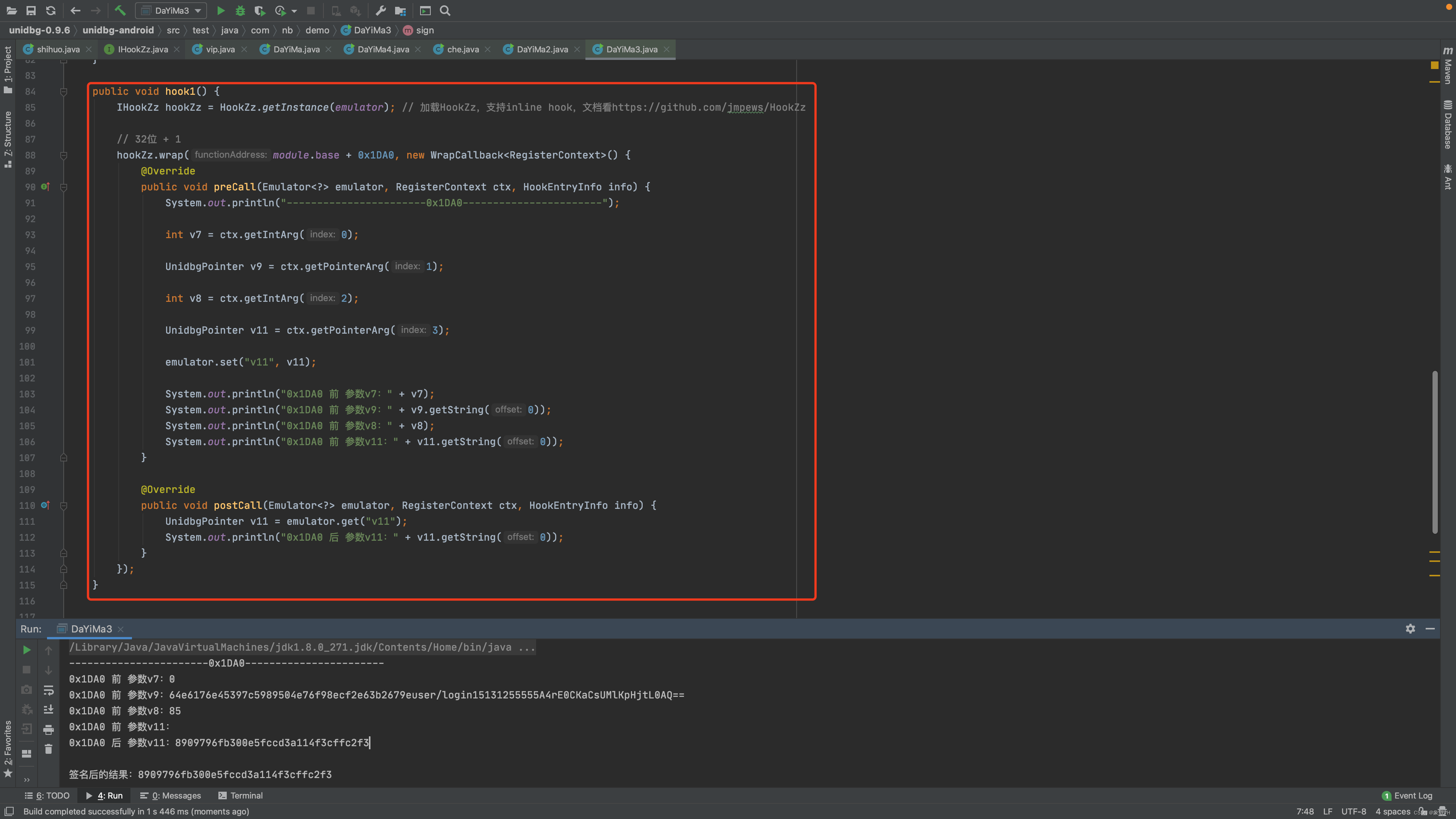
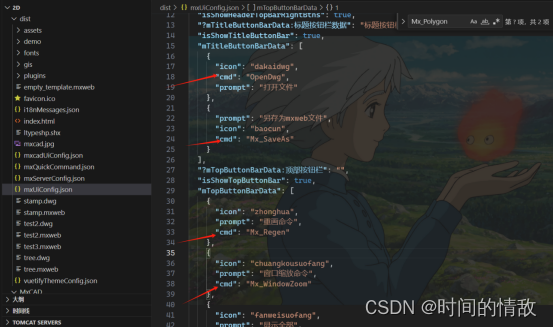
Unidbg调用-补环境V3-Hook
结合IDA和unidbg,可以在so的执行过程进行Hook,这样可以让我们了解并分析具体的执行步骤。 应用场景:基于unidbg调试执行步骤 或 还原算法(以Hookzz为例)。 1.大姨妈 1.1 0x1DA0 public void hook1() {...
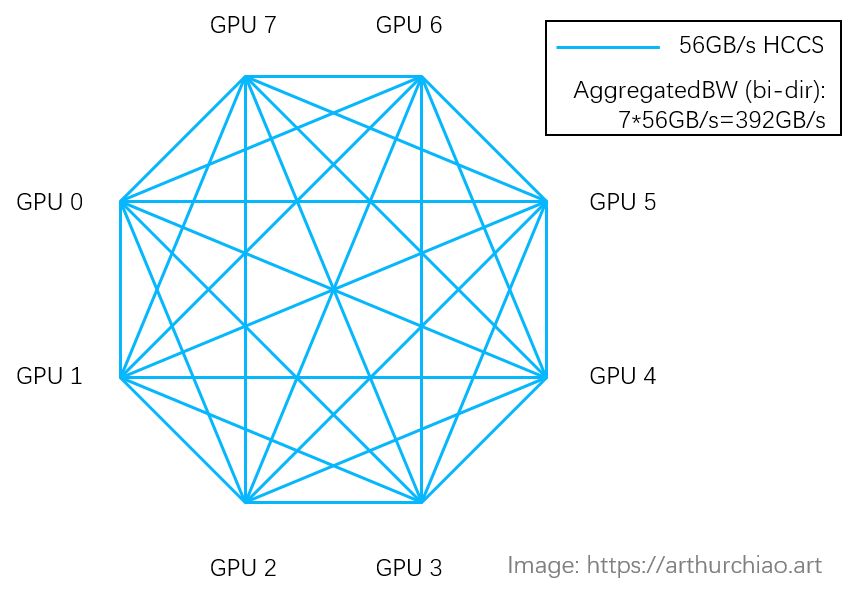
从AICore到TensorCore:华为910B与NVIDIA A100全面分析
华为NPU 910B与NVIDIA GPU A100性能对比,从AICore到TensorCore,展现各自计算核心优势。 AI 2.0浪潮汹涌而来,若仍将其与区块链等量齐观,视作炒作泡沫,则将错失新时代的巨大机遇。现在,就是把握AI时代的关键…...
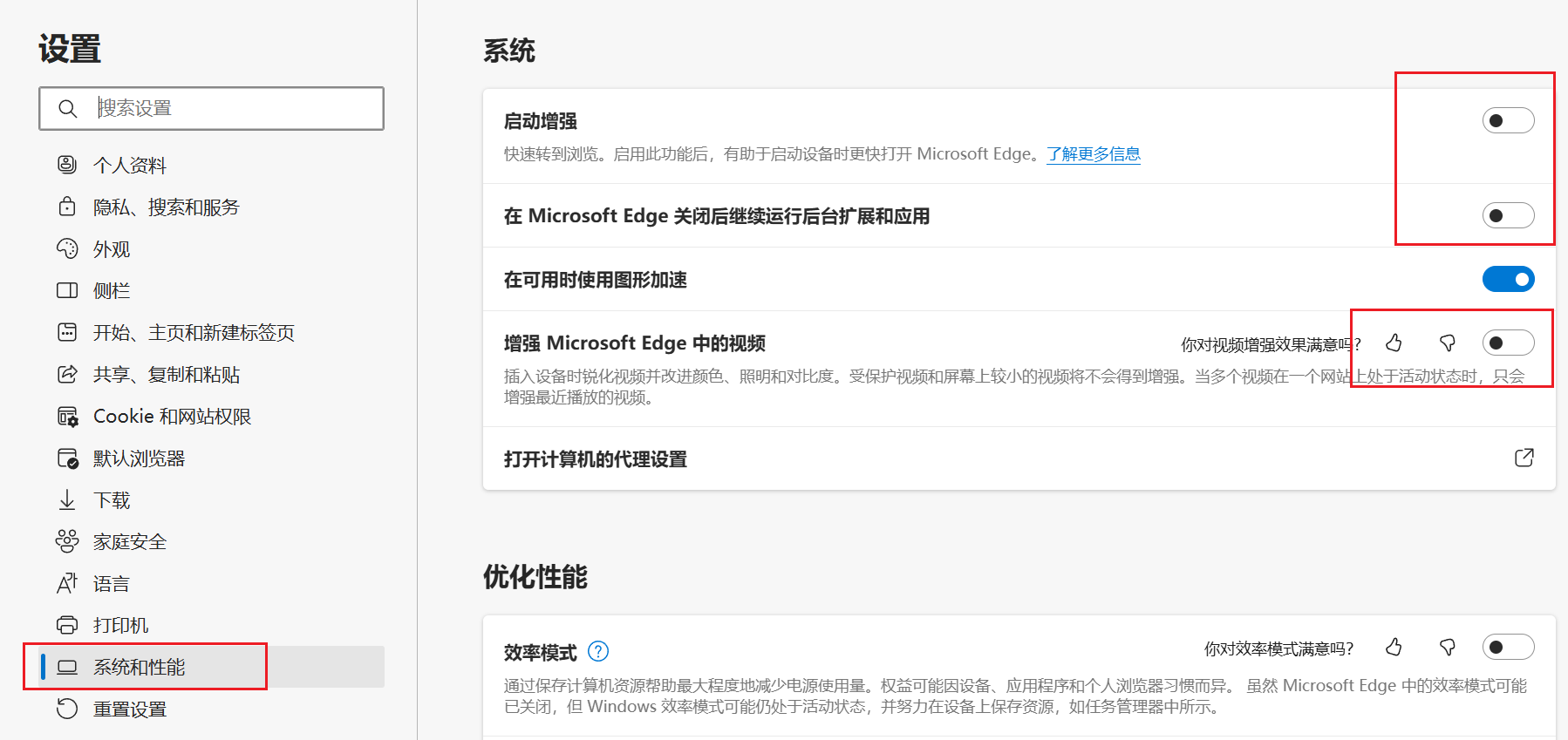
Edge 浏览器退出后,后台占用问题
Edge 浏览器退出后,后台占用问题 环境 windows 11 Microsoft Edge版本 126.0.2592.68 (正式版本) (64 位)详情 在关闭Edge软件后,查看后台,还占用很多系统资源。实在不明白,关了浏览器还不能全关了,微软也学流氓了。…...
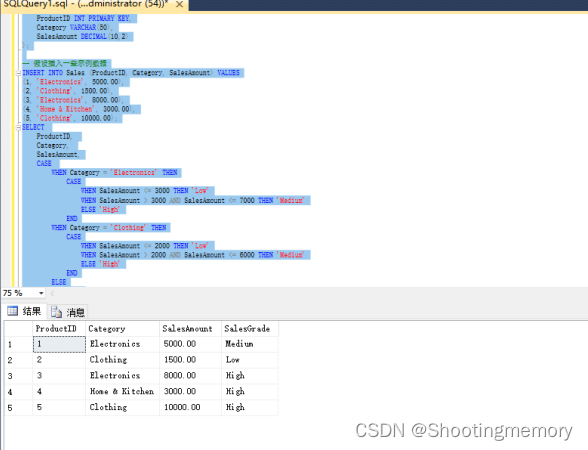
实验八 T_SQL编程
题目 以电子商务系统数据库ecommerce为例 1、在ecommerce数据库,针对会员表member首先创建一个“呼和浩特地区”会员的视图view_hohhot,然后通过该视图查询来自“呼和浩特”地区的会员信息,用批处理命令语句将问题进行分割,并分…...

【爆肝34万字】从零开始学Python第2天: 判断语句【入门到放弃】
目录 前言判断语句True、False简单使用作用 比较运算符引入比较运算符的分类比较运算符的结果示例代码总结 逻辑运算符引入逻辑运算符的简单使用逻辑运算符与比较运算符一起使用特殊情况下的逻辑运算符 if 判断语句引入基本使用案例演示案例补充随堂练习 else 判断子句引入else…...

React 19 新特性集合
前言:https://juejin.cn/post/7337207433868197915 新 React 版本信息 伴随 React v19 Beta 的发布,React v18.3 也一并发布。 React v18.3相比最后一个 React v18 的版本 v18.2 ,v18.3 添加了一些警告提示,便于尽早发现问题&a…...

耐高温水位传感器有哪些
耐高温水位传感器在现代液位检测技术中扮演着重要角色,特别适用于需要高温环境下稳定工作的应用场合。这类传感器的设计和材质选择对其性能和可靠性至关重要。 一种典型的耐高温水位传感器是FS-IR2016D,它采用了PPSU作为主要材质。PPSU具有优良的耐高温…...

Symfony国际化与本地化:打造多语言应用的秘诀
标题:Symfony国际化与本地化:打造多语言应用的秘诀 摘要 Symfony是一个高度灵活的PHP框架,用于创建Web应用程序。它提供了强大的国际化(i18n)和本地化(l10n)功能,允许开发者轻松创…...

ApolloClient GraphQL 与 ReactNative
要在 React Native 应用程序中设置使用 GraphQL 的简单示例,您需要遵循以下步骤: 设置一个 React Native 项目。安装 GraphQL 必要的依赖项。创建一个基本的 GraphQL 服务器(或使用公共 GraphQL 端点)。从 React Native 应用中的…...

【贡献法】2262. 字符串的总引力
本文涉及知识点 贡献法 LeetCode2262. 字符串的总引力 字符串的 引力 定义为:字符串中 不同 字符的数量。 例如,“abbca” 的引力为 3 ,因为其中有 3 个不同字符 ‘a’、‘b’ 和 ‘c’ 。 给你一个字符串 s ,返回 其所有子字符…...
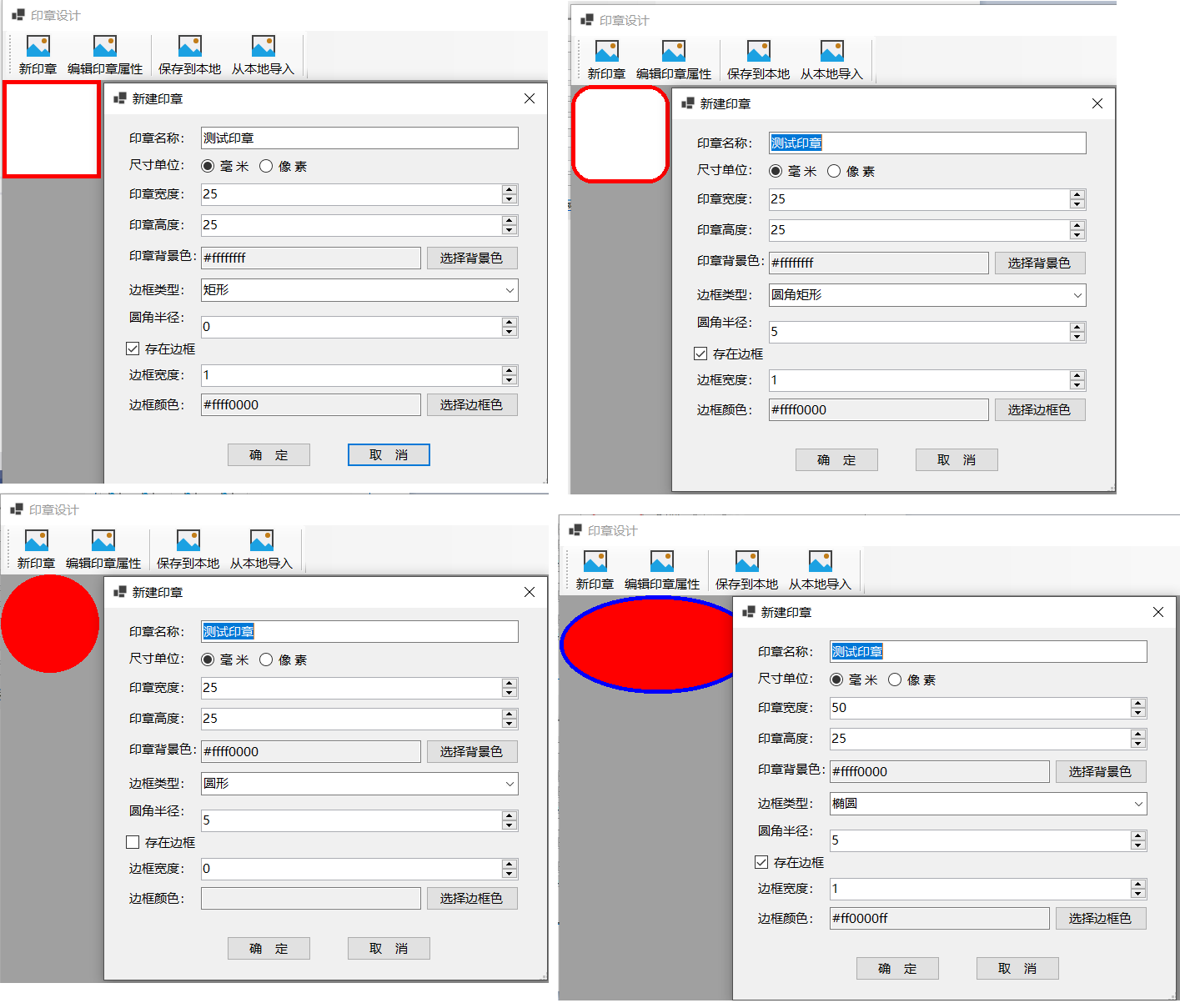
C#基于SkiaSharp实现印章管理(3)
本系列第一篇文章中创建的基本框架限定了印章形状为矩形,但常用的印章有方形、圆形等多种形状,本文调整程序以支持定义并显示矩形、圆角矩形、圆形、椭圆等4种形式的印章背景形状。 定义印章背景形状枚举类型,矩形、圆形、椭圆相关的尺寸…...

如何理解泛型的编译期检查
既然说类型变量会在编译的时候擦除掉,那为什么我们往 ArrayList 创建的对象中添加整数会报错呢?不是说泛型变量String会在编译的时候变为Object类型吗?为什么不能存别的类型呢?既然类型擦除了,如何保证我们只能使用泛型…...
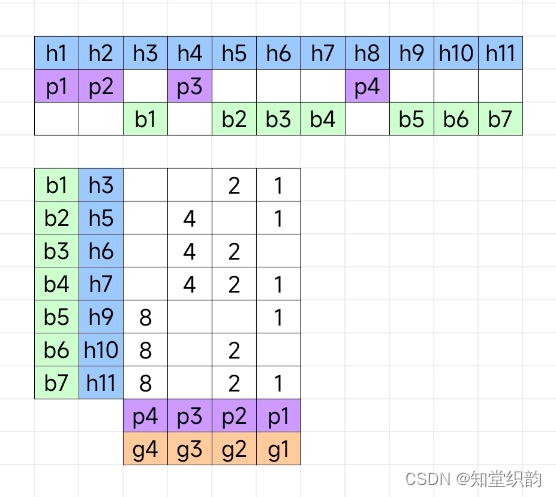
计算机组成原理:海明校验
在上图中,对绿色的7比特数据进行海明校验,需要添加紫色的4比特校验位,总共是蓝色的11比特。紫色的校验位pi分布于蓝色的hi的1, 2, 4, 8, 16, 32, 64位,是2i-1位。绿色的数据位bi分布于剩下的位。 在下图中,b1位于h3&a…...

大数据学习栈记——Neo4j的安装与使用
本文介绍图数据库Neofj的安装与使用,操作系统:Ubuntu24.04,Neofj版本:2025.04.0。 Apt安装 Neofj可以进行官网安装:Neo4j Deployment Center - Graph Database & Analytics 我这里安装是添加软件源的方法 最新版…...

【杂谈】-递归进化:人工智能的自我改进与监管挑战
递归进化:人工智能的自我改进与监管挑战 文章目录 递归进化:人工智能的自我改进与监管挑战1、自我改进型人工智能的崛起2、人工智能如何挑战人类监管?3、确保人工智能受控的策略4、人类在人工智能发展中的角色5、平衡自主性与控制力6、总结与…...
Cesium相机控制)
三维GIS开发cesium智慧地铁教程(5)Cesium相机控制
一、环境搭建 <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"> 关键配置点: 路径验证:确保相对路径.…...

Admin.Net中的消息通信SignalR解释
定义集线器接口 IOnlineUserHub public interface IOnlineUserHub {/// 在线用户列表Task OnlineUserList(OnlineUserList context);/// 强制下线Task ForceOffline(object context);/// 发布站内消息Task PublicNotice(SysNotice context);/// 接收消息Task ReceiveMessage(…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

Python+ZeroMQ实战:智能车辆状态监控与模拟模式自动切换
目录 关键点 技术实现1 技术实现2 摘要: 本文将介绍如何利用Python和ZeroMQ消息队列构建一个智能车辆状态监控系统。系统能够根据时间策略自动切换驾驶模式(自动驾驶、人工驾驶、远程驾驶、主动安全),并通过实时消息推送更新车…...

Python 训练营打卡 Day 47
注意力热力图可视化 在day 46代码的基础上,对比不同卷积层热力图可视化的结果 import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader import matplotlib.pypl…...
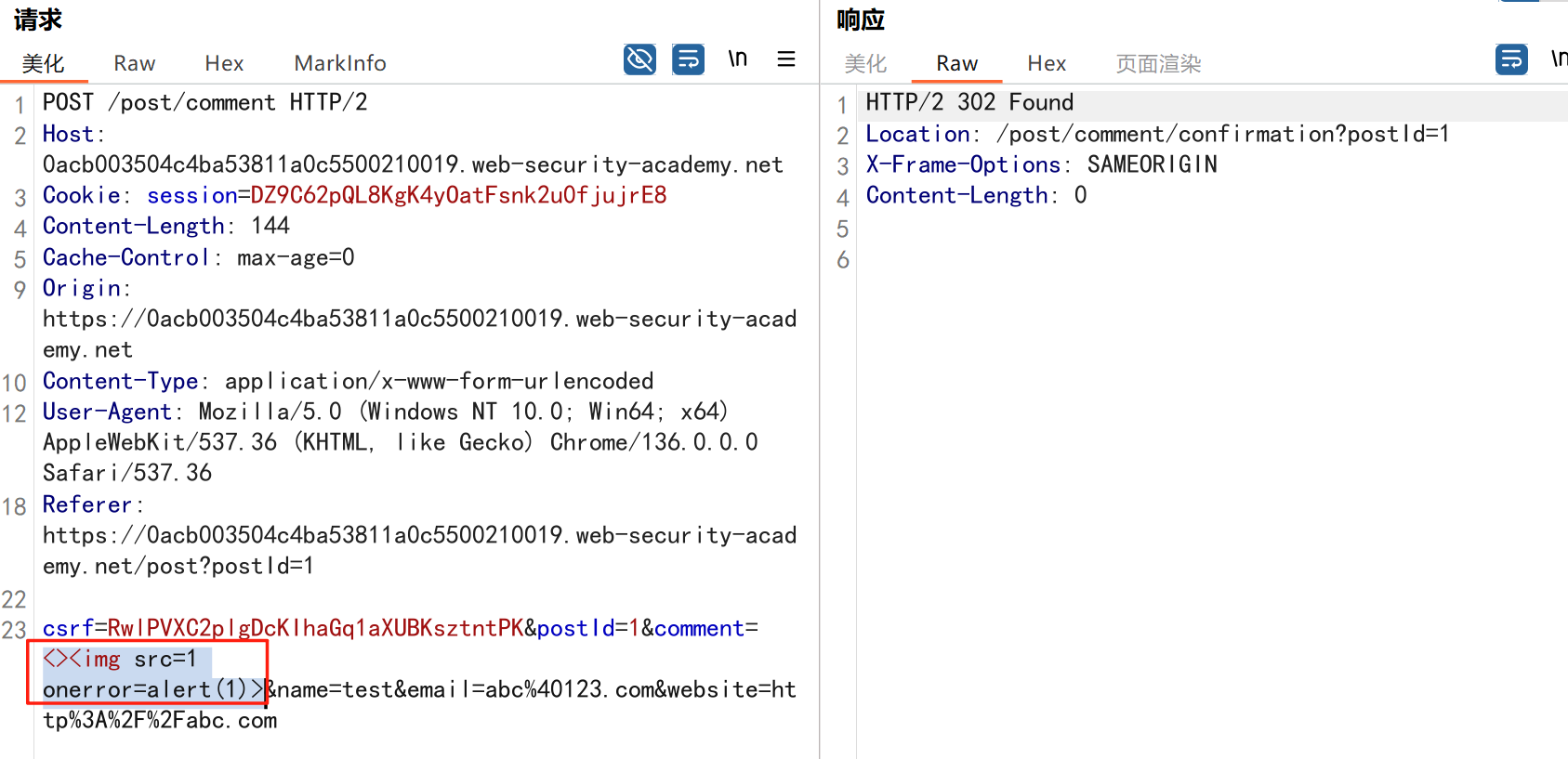
渗透实战PortSwigger靶场:lab13存储型DOM XSS详解
进来是需要留言的,先用做简单的 html 标签测试 发现面的</h1>不见了 数据包中找到了一个loadCommentsWithVulnerableEscapeHtml.js 他是把用户输入的<>进行 html 编码,输入的<>当成字符串处理回显到页面中,看来只是把用户输…...

用 Rust 重写 Linux 内核模块实战:迈向安全内核的新篇章
用 Rust 重写 Linux 内核模块实战:迈向安全内核的新篇章 摘要: 操作系统内核的安全性、稳定性至关重要。传统 Linux 内核模块开发长期依赖于 C 语言,受限于 C 语言本身的内存安全和并发安全问题,开发复杂模块极易引入难以…...
)
2025.6.9总结(利与弊)
凡事都有两面性。在大厂上班也不例外。今天找开发定位问题,从一个接口人不断溯源到另一个 接口人。有时候,不知道是谁的责任填。将工作内容分的很细,每个人负责其中的一小块。我清楚的意识到,自己就是个可以随时替换的螺丝钉&…...