大数据面试题之Spark(1)
目录
Spark的任务执行流程
Spark的运行流程
Spark的作业运行流程是怎么样的?
Spark的特点
Spark源码中的任务调度
Spark作业调度
Spark的架构
Spark的使用场景
Spark on standalone模型、YARN架构模型(画架构图)
Spark的yarn-cluster涉及的参数有哪些?
Spark提交job的流程
Spark的阶段划分
Spark处理数据的具体流程说下
Sparkjoin的分类
Spark map join的实现原理
Spark的任务执行流程
Apache Spark 的任务执行流程主要分为以下几个阶段:
1. 初始化与作业提交
创建SparkContext:Spark应用程序启动时,首先创建一个SparkContext,这是Spark与集群资源管理器(如YARN或Mesos)交互的入口点。
作业提交:用户编写好Spark应用后,通过SparkContext提交到Spark集群。提交过程包括解析作业、依赖分析等。
2. DAG构建与优化
RDD(弹性分布式数据集)链:Spark应用的核心是通过一系列转换(Transformation)操作构建出RDD链。
DAG(有向无环图)生成:Spark将这些转换操作转化为DAG,每个节点代表一个操作,边表示数据依赖关系。
DAG优化:Spark会对DAG进行优化,比如消除无效操作、重排操作以减少shuffle等,生成优化后的执行计划。
3. 任务调度
Stage划分:根据RDD之间的依赖关系,Spark将DAG划分为多个Stage。宽依赖(如shuffle)处切分,窄依赖则在同一Stage内。
Task生成:每个Stage被进一步划分为多个Task,Task是最小的计算单元,运行在Executor上。
Task调度:Spark的调度器(默认采用FIFO策略,也可以配置为Fair策略)负责将Task分配给各个Worker节点上的Executor执行。
4. 任务执行
Executor执行Task:Executor接收来自Driver的Task,读取或计算所需的数据,执行计算任务。
数据 Shuffle:在有宽依赖的Stage间,数据需要重新分布(Shuffle),这一步通常涉及磁盘I/O和网络传输,是性能瓶颈之一。
结果聚合:每个Stage的输出可能需要进一步聚合,直到最终结果被计算出来。
5. 结果返回与清理
结果收集:最后的Stage计算出的结果会通过网络返回给Driver程序。
SparkContext关闭:当应用程序执行完毕,SparkContext会被关闭,释放所有资源。
日志与监控:Spark提供丰富的日志和Web UI供开发者监控任务执行状态和性能指标。
整个流程体现了Spark的高效执行模型,尤其是其基于内存计算的能力和对迭代式计算的优化,使得Spark在大数据处理场景下表现出色。
Spark的运行流程
Spark的运行流程大致可以概括为以下几个步骤:
启动与初始化:
用户提交Spark应用时,首先会启动一个Driver进程。Driver是Spark应用的主程序,负责管理和协调整个应用的执行。
Driver启动后,会创建一个SparkContext实例,它是Spark与底层集群资源管理器(如YARN、Mesos或Standalone)进行交互的主要接口。SparkContext负责向资源管理器注册应用并请求执行资源。
资源分配与Executor启动:
资源管理器接收到请求后,会为该应用分配必要的资源,如CPU核心和内存。
根据分配的资源,在各个Worker节点上启动Executor进程。Executor是真正执行任务的工作者进程,它们负责运行任务并存储数据。
构建DAG与Stage划分:
Spark会根据用户的代码逻辑构建一个DAG(有向无环图),表示RDD之间的依赖关系。
根据DAG中的宽依赖,DAG会被切分成多个Stage。每个Stage包含一组需要并行执行的Task。
任务调度与执行:
SparkContext中的DAGScheduler将DAG分解成TaskSets(任务集),每个TaskSet对应一个Stage中的所有任务。
TaskScheduler负责将这些TaskSets分配给各个Executor执行。它可以根据不同的调度策略来优化任务的分配。
Executor接收任务后,会执行具体的计算逻辑,包括从内存或磁盘读取数据、执行变换操作、将结果写回存储等。
数据处理与Shuffle:
在处理过程中,如果遇到宽依赖,数据需要进行Shuffle操作,即重新分布数据,以便后续Stage可以并行处理。
Shuffle过程中可能会涉及到数据的序列化、网络传输、磁盘写入和读取等操作,这是Spark计算中的一个潜在瓶颈。
结果收集与应用结束:
最终Stage的计算结果会被收集回Driver节点。
应用程序执行完毕后,SparkContext会向资源管理器注销并释放所有资源,包括Executor和分配的内存、CPU等。
监控与日志:
Spark提供了Web UI,可以实时监控应用的执行状态、资源使用情况、任务进度等信息,便于调试和性能优化。
整个流程展示了Spark如何从应用提交开始,经过资源申请、任务调度与执行,直至最终结果产出并释放资源的全过程,体现了其高度的并行计算能力和资源管理效率。
Spark的作业运行流程是怎么样的?
Spark的作业运行流程可以概括为以下几个关键步骤:
1、启动与初始化:
用户通过编写Spark应用程序并提交至Spark集群。
提交后,首先启动一个Driver进程,该进程负责解析用户代码,创建SparkContext(Spark应用的入口点),并与集群资源管理器(如YARN、Mesos或Standalone)进行通信,申请执行资源。
2、构建执行计划:
SparkContext将用户编写的RDD(弹性分布式数据集)操作转换成DAG(有向无环图),表示RDD间的依赖关系。
DAGScheduler分析DAG,根据RDD之间的依赖关系将DAG切分成多个Stage,每个Stage包含一组可以并行执行的Task。这些Stage按照依赖顺序排列,形成了执行计划。
3、资源分配与Executor准备:
SparkContext根据执行计划的需求向资源管理器请求Executor资源。
Executor在各个Worker节点上启动,准备好执行Task所需的计算资源和环境。
4、任务调度与执行:
TaskScheduler将Stage进一步分解为具体Task,并将这些Task分配给各个Executor执行。
Executor执行Task,处理数据,执行转换操作(如map、reduce等),并在必要时进行数据Shuffle。
Executor之间通过网络交换数据,实现数据的重新分配。
5、结果汇总与输出:
最终Stage的Task执行完成后,它们的结果被收集并汇聚到Driver进程中。
如果是行动(Action)操作,如collect或saveAsTextFile,Driver会处理这些结果,如打印输出或保存到外部存储。
6、资源释放与应用结束:
应用程序执行完毕后,SparkContext会通知资源管理器释放所有资源,包括关闭Executor。
最后,SparkContext自身也会关闭,标志着整个Spark作业的生命周期结束。
在整个过程中,Spark利用内存计算、懒惰求值、DAG执行模型和高效的调度机制,旨在最小化数据读写磁盘的次数,从而提高数据处理的效率和速度。同时,Spark提供了丰富的监控工具,如Web UI,便于跟踪作业的执行状态和性能指标。
Spark的特点
Apache Spark 是一个广泛使用的开源大数据处理框架,它以其高效、易用和灵活的特性,在数据处理领域占据重要地位。以下是Spark的主要特点:
-
高性能:Spark 最显著的特点是它的高性能。它利用内存计算技术,能够在内存中进行数据处理,相比于传统的Hadoop MapReduce,官方数据显示Spark在内存中的运算速度能快100倍以上,即使在需要磁盘IO时也能达到10倍以上的速度提升。这得益于其高效的DAG(有向无环图)执行引擎,能够优化数据处理流程,减少不必要的读写操作。
-
易用性:Spark 提供了高度抽象的API,支持Scala、Java、Python、R等多种编程语言,使得数据处理任务的编写变得更加简单直观。它包括Spark SQL(用于结构化数据处理)、Spark Streaming(处理实时数据流)、MLlib(机器学习)、GraphX(图形处理)等多个库,方便开发者构建复杂的数据处理管道。
-
通用性:Spark 是一个统一的数据处理平台,能够支持批处理、交互式查询(通过Spark SQL)、实时流处理(Spark Streaming)、机器学习和图计算等多种工作负载。这意味着开发者可以使用单一框架解决多样化的数据处理需求,降低了技术栈的复杂度。
-
可扩展性与容错性:Spark 设计为可以轻松部署在从单个计算机到数千台机器的集群上,具备良好的水平扩展能力。它利用Hadoop HDFS或其他分布式文件系统来存储数据,确保数据的高可用性。同时,Spark内部的RDD(弹性分布式数据集)模型支持数据的容错处理,能够在节点故障时自动恢复计算任务。
-
交互式分析:Spark支持交互式查询,允许用户以快速反馈的方式探索数据,这对于数据分析和数据科学应用尤为重要。
-
集成与生态系统:Spark与Hadoop生态系统深度集成,可以无缝读取HDFS、Hive等Hadoop相关组件的数据,并且可以通过Spark SQL与传统关系型数据库和数据仓库进行交互。此外,Spark拥有活跃的社区支持和丰富的第三方工具与库,生态完善。
综上所述,Spark凭借其高性能、易用性、通用性、可扩展性以及强大的生态系统支持,成为大数据处理领域的首选工具之一。
Spark源码中的任务调度
Spark的任务调度主要由两大部分组成:DAGScheduler和TaskScheduler。这两个组件协同工作,负责将用户提交的Spark作业转化为可执行的任务,并在集群中高效地调度执行。
DAGScheduler
DAGScheduler位于Spark的Driver端,主要职责如下:
1、构建DAG(有向无环图):根据RDD的依赖关系,构建一个表示整个作业计算流程的DAG。
2、Stage划分:通过对DAG进行分析,识别出那些会产生shuffle的操作(即宽依赖),并据此将DAG切分成多个Stage。Stage之间的边界通常是在shuffle操作的地方,这样可以优化资源的使用和任务的执行。
3、任务集(TaskSet)生成:为每个Stage生成一组Task,这些Task将在Executor上并行执行。每个Task对应RDD的一个分区上的计算操作。
4、任务调度策略:虽然DAGScheduler负责Stage的划分和TaskSet的产生,但它并不直接与Executor交互来分配任务。它会将这些任务集提交给TaskScheduler,由后者负责实际的资源请求和任务调度。
TaskScheduler
TaskScheduler同样位于Driver端,但更侧重于资源管理和任务的实际分配:
1、资源请求与分配:与底层资源管理器(如YARN、Mesos或Kubernetes)交互,请求Executor资源,并接收资源分配的响应。
2、任务分配:根据Executor的资源状况和数据的本地性原则,将DAGScheduler产生的TaskSet中的Task分配给合适的Executor执行。TaskScheduler会尝试将任务分配到数据所在的节点,以减少网络传输,提高执行效率。
3、任务状态跟踪:监控Task的执行状态,包括任务的开始、完成、失败和重试。在Task失败时,TaskScheduler会根据配置的重试策略来决定是否重新调度该任务。
4、Executor管理:管理Executor的生命周期,包括Executor的添加与移除,以及与Executor的通信,以获取任务执行的状态信息。
调度流程总结
1、用户提交作业后,SparkContext创建DAGScheduler和TaskScheduler。
2、DAGScheduler分析作业的RDD依赖,划分Stage并生成TaskSet。
3、TaskScheduler根据资源情况和任务需求,向资源管理器请求Executor资源。
4、TaskScheduler将TaskSet中的Task分配给Executor,并管理任务的执行与失败重试。
5、Executor执行Task,处理数据,并将结果返回给Driver。
这一系列过程确保了Spark能够高效、灵活地在分布式环境中执行复杂的计算任务。
Spark作业调度
Apache Spark作业调度是Spark集群管理中的一个关键部分,它决定了如何在集群的节点上分配和执行任务。Spark提供了几种调度策略和资源管理机制,以确保任务能够有效地被调度和执行。
以下是关于Spark作业调度的一些关键概念和机制:
1、调度器(Scheduler):
Spark提供了几种调度器,如FIFO(先进先出)、Fair(公平)和Capacity(容量)调度器。这些调度器决定了如何为提交的作业分配资源。
FIFO调度器按照作业提交的顺序来调度它们。
Fair调度器尝试在所有作业之间公平地分配资源,允许配置作业池和权重。
Capacity调度器允许用户配置多个队列,并为每个队列分配一定数量的资源。
2、作业(Job):
在Spark中,一个作业通常是由一个行动(Action)触发的,如collect(), count(), saveAsTextFile()等。作业被拆分成多个任务(Tasks)来在集群上并行执行。
3、任务(Task):
每个任务都是作业中的一部分,并在集群的一个节点上执行。任务可以是map任务、reduce任务或shuffle任务等。
4、资源管理器(Resource Manager):
在Spark on YARN这样的环境中,YARN的资源管理器(ResourceManager)负责集群资源的分配。
在Spark Standalone模式下,Spark Master节点负责资源的分配。
5、动态资源分配(Dynamic Resource Allocation):
Spark支持动态资源分配,这意味着它可以根据工作负载自动地增加或减少executor的数量。这有助于更有效地利用集群资源。
6、配置参数:
Spark提供了许多配置参数来控制作业调度和资源管理,如spark.scheduler.mode(设置调度器模式)、spark.dynamicAllocation.enabled(启用动态资源分配)等。
7、任务本地化(Task Locality):
Spark尝试将任务调度到存储了所需数据的节点上,以减少数据传输的开销。这被称为任务本地化。Spark会根据数据的存储位置来决定任务应该在哪里执行。
8、作业调度日志和监控:
Spark提供了Web UI来监控作业的进度、执行时间和资源使用情况。此外,还可以使用Spark的日志和事件日志来分析作业的性能和调度行为。
9、优化调度:
为了优化作业调度,可以采取一些策略,如合并小任务以减少调度开销、优化数据布局以减少数据传输、调整配置参数以适应不同的工作负载等。
10、Spark SQL和DataFrame的调度:
对于使用Spark SQL和DataFrame API编写的作业,Spark会生成一个逻辑执行计划,并将其转换为物理执行计划来执行。这些计划中的操作也会被拆分成任务并在集群上执行。
Spark的架构
Spark的架构是一个基于内存计算的分布式处理框架,其设计旨在高效地处理大规模数据集。以下是Spark架构的主要组件和关键概念的清晰概述:
1、核心组件:
Application:建立在Spark上的用户程序,包括Driver代码和运行在集群各节点的Executor中的代码。
Driver Program:驱动程序,是Application中的main函数,负责创建SparkContext,并作为Spark作业的调度中心。
SparkContext:Spark的上下文对象,是应用与Spark集群的交互接口,用于初始化Spark应用环境,创建RDD、广播变量等。
Executor:Spark应用运行在Worker节点上的一个进程,负责执行Driver分配的任务,并将结果返回给Driver。
Cluster Manager:在集群上获取资源的外部服务,可以是Standalone、YARN、Mesos等。
Worker Node:集群中任何可以运行Application代码的节点,负责启动Executor进程。
2、运行架构:
Spark采用Master-Slave架构模式,其中Driver作为Master节点,负责控制整个集群的运行;Executor作为Slave节点,负责实际执行任务。
Driver负责将用户程序转化为作业(Job),并在Executor之间调度任务(Task)。Executor则负责运行组成Spark应用的任务,并将结果返回给Driver。
3、任务调度与执行:
Spark作业被拆分成多个Task,每个Task处理一个RDD分区。
DAG Scheduler负责根据应用构建基于Stage的DAG(有向无环图),并将Stage提交给Task Scheduler。
Task Scheduler负责将Task分发给Executor执行。
4、资源管理器:
Spark支持多种资源管理器,如YARN、Mesos和Standalone模式。
在YARN模式中,ResourceManager分配资源,NodeManager负责管理Executor进程。
在Standalone模式中,Master节点负责资源的调度和分配,Worker节点负责执行具体的任务。
5、数据核心 - RDD:
RDD(弹性分布式数据集)是Spark的基本计算单元,表示不可变、可分区、里面的元素可并行计算的集合。
RDD支持多种转换操作(如map、filter)和行动操作(如reduce、collect),并且具有容错性,可以在部分数据丢失时重新计算。
6、其他特性:
Spark支持动态资源分配,可以根据工作负载自动增加或减少Executor的数量。
Spark提供了丰富的API,如Spark SQL、MLlib、GraphX等,用于数据查询、机器学习和图计算等任务。
Spark的使用场景
Apache Spark 是一个开源的大数据处理框架,以其高性能的内存计算和易用的API而广受欢迎。以下是Spark的一些典型使用场景:
-
大规模数据处理与分析:Spark非常适合处理PB级别的数据集,常用于数据挖掘、日志分析、用户行为分析等场景。例如,互联网公司可以利用Spark分析用户点击流数据,优化网站布局和推荐算法。
-
实时数据处理:通过Spark Streaming模块,Spark能够实时处理数据流,适用于需要实时数据分析的场景,比如社交媒体趋势分析、实时交通监控、在线广告投放系统等。
-
机器学习与数据科学:Spark包含MLlib机器学习库,支持分类、回归、聚类、推荐等多种算法,适合构建和训练大规模机器学习模型,以及进行特征工程、模型评估等数据科学任务。
-
交互式查询:借助Spark SQL模块,用户可以使用SQL或者DataFrame API对数据进行交互式查询,适用于需要快速响应的BI分析、即席查询等场景。
-
图计算:使用GraphX库,Spark能处理大规模图数据,适合社交网络分析、推荐系统中的关系挖掘、知识图谱构建等应用。
-
批处理:Spark擅长处理批处理任务,包括数据清洗、ETL(提取、转换、加载)、大规模数据聚合等。
-
推荐系统:特别是实时推荐,Spark可以快速处理用户行为数据,即时更新推荐模型,提升用户体验。
-
金融行业应用:在金融领域,Spark被用来处理海量交易数据,进行风险分析、欺诈检测、信用评分等。
-
物联网(IoT)数据处理:随着IoT设备产生的数据量剧增,Spark可用于实时处理和分析这些数据,支持决策制定和预测维护。
-
医疗健康数据分析:在医疗领域,Spark可以用来处理电子病历、基因组学数据,支持疾病预测、患者分群和个性化治疗方案的制定。
综上所述,Spark由于其灵活性和高效性,几乎涵盖了大数据处理的所有关键领域,特别是在需要快速迭代计算、实时处理和复杂数据分析的场景下,Spark展现了其独特的优势。
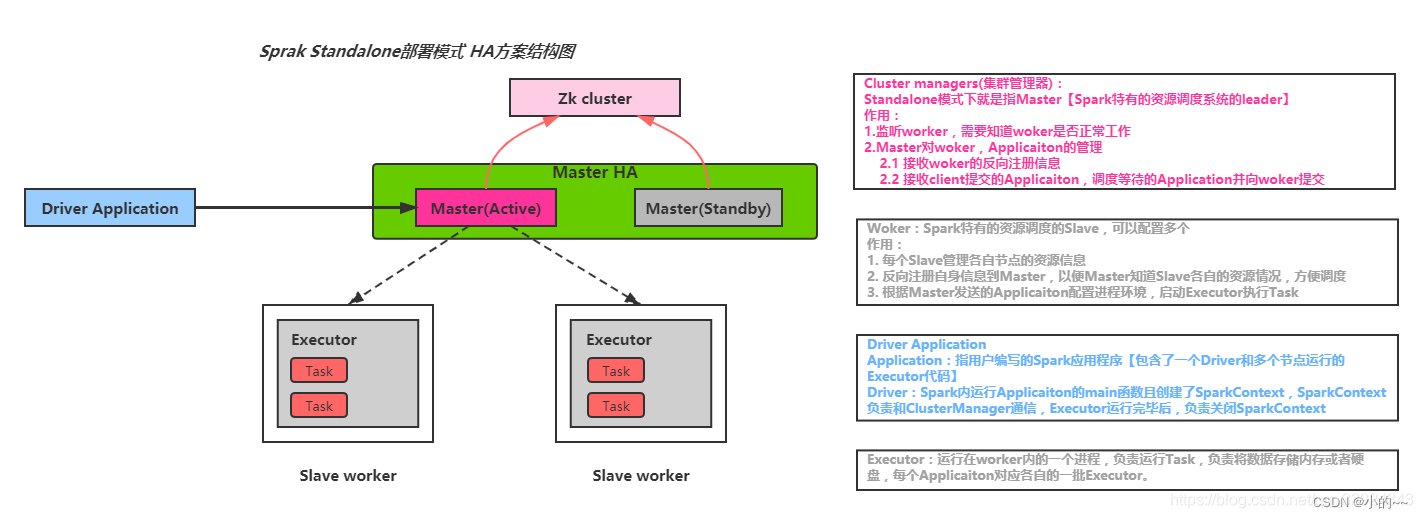
Spark on standalone模型、YARN架构模型(画架构图)
Spark on Standalone模型
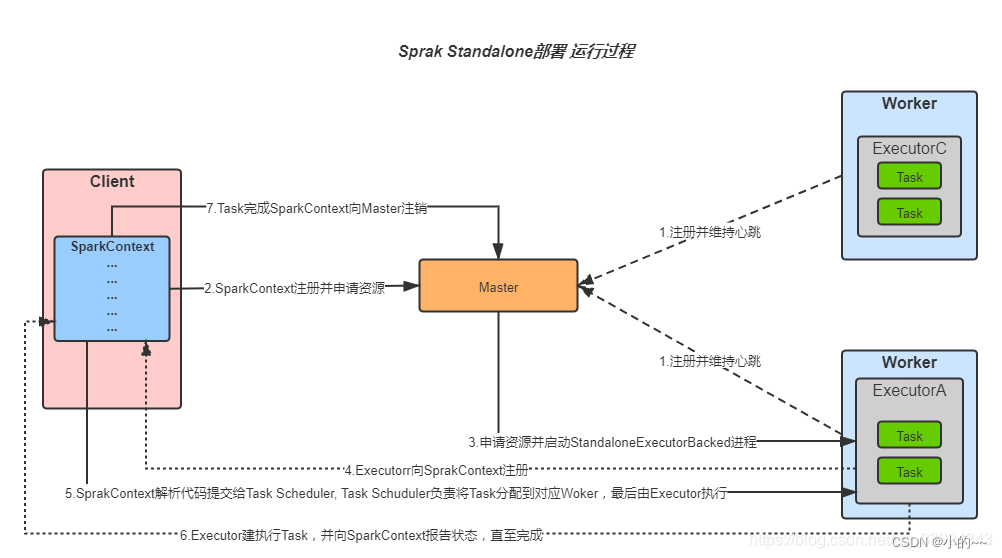
在Spark on Standalone模型中,Spark集群由以下几个主要组件组成:
Driver Program:这是Spark应用程序的入口点,负责创建SparkContext对象,并与集群管理器(在Standalone模式下为Master节点)进行交互。
SparkContext:Spark应用程序的上下文,用于初始化Spark环境,创建RDDs、广播变量等。
Worker Nodes:集群中的工作节点,负责执行Spark任务。每个Worker节点上运行一个Worker进程,负责启动Executor进程。
Executors:运行在Worker节点上的进程,负责执行具体的Spark任务。Executor进程负责读取输入数据、执行计算并将结果返回给Driver。
在Standalone模式下,Master节点负责集群的资源管理和任务调度。当Driver提交作业时,Master节点会分配资源给Executor进程,并监控它们的执行状态。
Standalone模式架构图
Standalone模式运行流程图
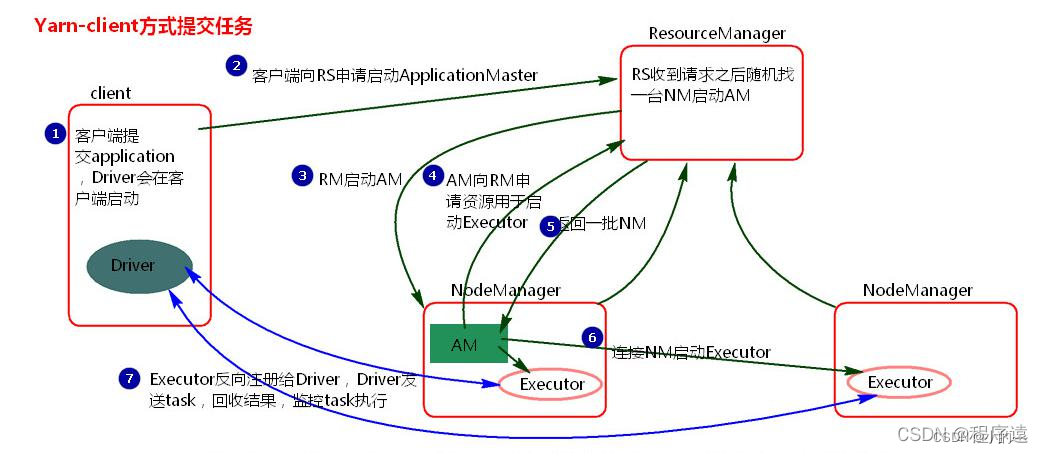
YARN架构模型
在Spark on YARN架构模型中,YARN作为集群的资源管理器,与Spark集群协同工作。主要组件包括:
ResourceManager (RM):YARN集群的资源管理器,负责整个集群的资源管理和调度。RM与NodeManager通信,以分配和管理资源。
NodeManager (NM):YARN集群中的每个节点都运行一个NodeManager进程,负责启动和管理Container。Container是YARN中资源分配的基本单位。
ApplicationMaster (AM):对于每个Spark应用程序,YARN都会在集群中选择一个NodeManager进程启动一个AM。AM负责向RM申请资源,进一步启动Executor进程以运行Task。
Executors:与Standalone模式类似,Executors运行在YARN的Container中,负责执行具体的Spark任务。
在Spark on YARN模式下,有两种提交方式:
Client模式:Driver进程在客户端启动,与AM建立通信。AM负责申请资源并启动Executors。
Cluster模式:Driver进程在YARN集群中启动,作为AM的一部分。AM同时负责申请资源和启动Executors。
在YARN架构中,RM负责资源的全局管理和调度,而AM则负责具体应用程序的资源请求和任务调度。这种架构使得Spark能够充分利用YARN的资源管理和调度功能,实现更高效的资源利用和任务执行。
Spark的yarn-cluster涉及的参数有哪些?
Spark在YARN集群模式(yarn-cluster)下涉及的参数主要包括以下几个方面,这些参数有助于控制应用的资源分配、行为表现及与YARN的集成方式:
1、资源相关参数
spark.executor.memory:每个Executor的内存大小。
spark.executor.cores:每个Executor可以使用的CPU核心数。
spark.executor.instances:Executor实例的数量。
spark.driver.memory:Driver进程的内存大小。
spark.driver.cores:Driver进程可以使用的CPU核心数。
2、网络和序列化参数
spark.serializer:用于RDD序列化的类,默认为org.apache.spark.serializer.JavaSerializer,但推荐使用org.apache.spark.serializer.KryoSerializer以提高性能。
spark.network.timeout:网络超时设置。
spark.rpc.askTimeout 或 spark.rpc.lookupTimeout:RPC通信超时时间。
3、应用名称和队列
spark.app.name:Spark应用的名称。
spark.yarn.queue:YARN队列的名称,用于提交作业。
4、其他重要参数
spark.yarn.maxAppAttempts:应用程序最大重试次数。
spark.yarn.am.attemptFailuresValidityInterval:AM失败有效间隔时间,决定多久内的失败会被计数。
spark.yarn.historyServer.address:Spark历史服务器地址,用于记录和展示应用的历史信息。
spark.yarn.applicationMaster.waitTries:尝试等待Spark Master启动和初始化完成的次数。
spark.yarn.submit.file.replication:Spark应用程序依赖文件上传到HDFS时的备份副本数量。
5、日志和监控
spark.eventLog.enabled:是否启用事件日志记录。
spark.eventLog.dir:事件日志的目录,通常在HDFS上。
6、动态资源分配(可选)
spark.dynamicAllocation.enabled:是否开启动态资源分配。
spark.dynamicAllocation.minExecutors:动态分配时的最小Executor数量。
spark.dynamicAllocation.maxExecutors:动态分配时的最大Executor数量。
这些参数可以通过在提交Spark应用时使用spark-submit命令的--conf选项来设置,或者在Spark应用的配置文件中预先定义。正确配置这些参数对优化Spark作业的性能、资源管理和故障恢复至关重要。
Spark提交job的流程
1、准备阶段:
用户通过spark-submit命令或API提交Spark作业。
如果是基于YARN的集群模式(如YARN-Cluster),ResourceManager(RM)会收到任务提交请求,并进行任务记录,为作业分配一个application_id,并在HDFS上分配一个目录用于存储作业所需的资源(如jar包、配置文件等)。
2、资源分配与初始化:
Spark Client根据application_id上传任务运行所需的依赖到为其分配的HDFS目录,并上传应用代码和其他必要的资源。
ResourceManager(RM)检查资源队列,如果存在可分配的资源(Node Manager, NM),则向这些NM发送请求以创建Container。
NM创建Container成功后,向RM发送响应,RM随后通知Spark Client可以开始运行任务。
3、启动Application Master和Driver进程:
Spark Client发送命令到NM所在的Container中,启动Application Master(AM)。
AM从HDFS中获取上传的jar包、配置文件和依赖包,并创建Spark Driver进程。
4、Executor启动与注册:
Driver根据Spark集群的配置参数,通过RM申请NM容器以启动Executor。
RM调度空闲的NM创建Container,AM获取到NM的Container后,发送启动Executor进程的命令。
Executor启动后,会向Driver进行反向注册,以便进行心跳检测和计算结果返回。
5、任务划分与提交:
Driver进程解析Spark作业并执行main函数,DAGScheduler会进行一系列DAG构建,根据RDD的依赖关系将作业拆分成多个Stage。
每个Stage会被转化为一个或多个TaskSet,由TaskScheduler提交到Cluster Manager(如YARN的ResourceManager)。
6、任务调度与执行:
由于Executor已在Driver注册,Driver会将Task分配到Executor中执行。
Executor执行Task,并将结果返回给Driver。
7、结果聚合与作业结束:
Driver根据Executor返回的结果进行聚合。
如果需要,Driver会决定是否进行推测执行(Speculative Execution),即对于运行较慢的Executor,开启新的Executor执行该任务。
所有任务执行完毕后,Executor和Driver进程结束,Application结束,并向RM注销。
8、资源释放:
RM和NM继续接受下一个任务的资源请求,之前为作业分配的资源被释放并回收。
Spark的阶段划分
1. Spark作业的基本组成
Job:一个Spark作业通常是由一个行动(Action)操作触发的,例如collect(), count(), saveAsTextFile()等。每个行动操作都会触发一个或多个Stage的执行。
Stage:Stage是Job的组成单位,一个Job会切分成多个Stage。Stage之间通过依赖关系进行顺序执行,而每个Stage是多个Task的集合。
2. 阶段划分的依据
Shuffle操作:Spark的阶段划分主要基于数据的Shuffle操作。当RDD之间的转换连接线呈现多对多交叉连接时(即涉及Shuffle过程),会产生新的Stage。Shuffle操作是重新组合数据的过程,如将数据按照某个key进行聚合或关联。
窄依赖与宽依赖:Spark中的依赖关系分为窄依赖和宽依赖。窄依赖(如map、filter等)不会导致新的Stage的产生,而宽依赖(如groupBy、join等涉及Shuffle的操作)则会导致新的Stage的产生。
3. 阶段划分的流程
DAG构建:Driver Program根据用户程序构建有向无环图(DAG, Directed Acyclic Graph),表示作业的计算流程。
划分Stage:DAGScheduler遍历DAG,根据宽依赖关系将DAG划分为多个Stage。每个Stage内部是窄依赖的,而Stage之间通过宽依赖连接。
Task生成:在每个Stage中,根据RDD的分区数量生成相应数量的Task。每个Task处理一个RDD分区的数据。
4. 阶段与Task的关系
一个Job至少包含一个Stage,但通常会包含多个Stage。
一个Stage包含多个Task,这些Task在集群的不同节点上并行执行。
5. 优化阶段划分
通过优化Spark代码,减少不必要的Shuffle操作,可以减少Stage的数量,从而提高作业的执行效率。
合理设置RDD的分区数量,确保每个Task能够处理合适大小的数据量,避免资源浪费或任务过载。
Spark处理数据的具体流程说下
1、作业初始化:
驱动程序启动:Spark应用从一个称为驱动程序(Driver Program)的进程中开始执行。驱动程序负责创建SparkContext,这是Spark与集群管理器(如YARN或Mesos)交互的主要接口。
构建逻辑计划:用户通过Spark的API(如RDD、DataFrame或Dataset)定义数据处理任务。驱动程序根据这些操作构建一个执行计划,这个计划是惰性求值的,即直到有动作(action)触发时才会真正执行。
2、任务划分:
DAG构建:Spark会根据用户的转换(transformation)操作构建一个有向无环图(DAG),表示数据处理的各个阶段。
Stage划分:DAG被划分为多个Stage,通常在宽依赖(例如shuffle)的地方切分。每个Stage包含一组任务(Task),这些任务可以在Executor上并行执行。
3、资源申请与任务调度:
向资源管理器申请资源:SparkContext与资源管理器(如YARN或Mesos)沟通,请求Executor资源。
任务分配:一旦资源获得,Spark根据Stage和数据的位置来分配任务给Executor执行。任务调度器确保数据本地性原则,尽可能让任务在数据所在的节点上执行,以减少网络传输。
4、数据处理与计算:
Executor执行任务:每个Executor上的任务负责加载、处理其分配的数据块。数据优先尝试加载到内存中(RDD缓存),以便快速访问和迭代计算。
Shuffle操作:在需要重新分布数据的Stage(如reduceByKey),Spark执行shuffle操作,重新组织数据,确保后续Stage的任务能正确处理分区后的数据。
5、结果汇聚与返回:
任务结果收集:任务完成后,计算结果返回到驱动程序。对于行动(Action)操作,如collect,所有Executor的结果会被汇聚到驱动程序。
结果处理:驱动程序可能对结果进行进一步处理,比如排序、过滤或保存到外部存储系统(如HDFS、数据库)。
6、清理与结束:
资源释放:当应用完成或遇到错误时,Spark会释放所有申请的资源,包括Executor和相关资源。
结果输出:最终结果按照用户需求输出或保存。
Sparkjoin的分类
1、Shuffle Hash Join:
这是最基本的join类型,适用于两个大表的关联。它首先会对参与join的两个数据集使用指定的键进行分区(shuffle过程),然后在每个分区内部使用哈希表来加速匹配过程。Shuffle Hash Join要求数据能够跨节点重新分布,因此可能会产生较大的网络开销。
2、Broadcast Hash Join:
当一个数据集相对较小,可以轻松地复制到所有参与计算的节点上时,Broadcast Hash Join就会非常高效。较小的表会被广播到所有Executor的内存中,形成一个哈希表,然后较大的表的每个分区会在本地与这个哈希表进行匹配。这种方式避免了shuffle过程,减少了网络传输和磁盘I/O,提高了处理速度,但要求“小表”能够适应Executor的内存限制。
3、Sort Merge Join:
如果两个数据集都已经按照join键排序,或者可以接受进行排序的话,Sort Merge Join是一个好的选择。每个数据集先进行局部排序,然后通过合并已排序的部分来进行join操作。这种方法在数据集已经有序或可以经济地排序时,尤其是处理两个大表的情况,能够提供较好的性能。但它涉及到额外的排序步骤,可能增加计算成本。
4、Cartesian Join (Cross Join):
这是一种特殊的join,它返回两个数据集的所有可能组合。在Spark中,通过不指定任何join键直接调用join方法即可实现Cartesian Product。由于其产生的结果集可能非常庞大,因此在实际应用中较少使用。
5、Outer Joins:
Spark还支持各种外连接,包括leftOuterJoin, rightOuterJoin, 和 fullOuterJoin。这些操作在匹配键的同时,还会保留没有匹配项的一方或双方的数据,并用null填充缺失的值。它们可以在上述任何一种join策略的基础上实现。
Spark map join的实现原理
Spark的Map Join实现原理主要依赖于广播小表(Broadcast Join)的策略,这种策略特别适用于一个表(我们称之为“小表”)相对于另一个表(我们称之为“大表”)来说非常小的情况。以下是Map Join实现原理的详细解释:
1、广播小表:
当Spark执行Join操作时,如果它检测到其中一个表(即小表)的大小小于某个阈值(这个阈值在Spark中可以通过spark.sql.autoBroadcastJoinThreshold进行配置,默认上限是10MB,但注意在较新版本的Spark中,这个限制可能已经提高到8GB),它会选择将该小表广播到所有节点上。
广播是指将小表的数据分发到集群中的所有节点,每个节点都会缓存一份小表的完整数据。
2、Map端Join:
在数据已经被广播到所有节点之后,Map Join操作在数据所在的节点上直接进行,而无需通过网络传输大表的数据。
每个节点上的Executor都会使用本地缓存的小表数据和大表数据进行Join操作,这大大减少了网络传输的开销,并提高了Join操作的效率。
3、特点与限制:
只支持等值连接:Map Join主要适用于等值连接的情况,即连接条件是两个表的列之间的等值关系。
内存占用:由于需要将小表广播到所有节点,因此如果小表过大,可能会占用大量的内存,甚至导致内存溢出(OOM)。
广播阈值:如前所述,广播的阈值可以通过配置进行调整。选择合适的阈值对于Map Join的性能至关重要。
4、执行过程:
识别小表:Spark首先会根据表的大小和配置识别出哪个表是小表。
广播小表:将小表的数据广播到集群中的所有节点。
执行Map Join:在每个节点上,使用本地缓存的小表数据和大表数据进行Join操作。
5、优化:
在使用Map Join时,可以考虑对经常用于Join的小表进行缓存,以减少广播的开销。
根据实际的数据分布和大小,合理调整广播的阈值。
总的来说,Spark的Map Join通过广播小表并在Map端直接进行Join操作,减少了网络传输的开销,提高了Join操作的效率。然而,它也有一些限制,如只支持等值连接和可能的内存占用问题。因此,在使用时需要根据实际情况进行合理的配置和优化。
引用:https://www.nowcoder.com/discuss/353159520220291072
通义千问、文心一言
相关文章:
大数据面试题之Spark(1)
目录 Spark的任务执行流程 Spark的运行流程 Spark的作业运行流程是怎么样的? Spark的特点 Spark源码中的任务调度 Spark作业调度 Spark的架构 Spark的使用场景 Spark on standalone模型、YARN架构模型(画架构图) Spark的yarn-cluster涉及的参数有哪些? Spark提交jo…...

Spring Boot 和 Spring Framework 的区别是什么?
SpringFramework和SpringBoot都是为了解决在Java开发过程中遇到的各种问题而出现的。了解它们之间的差异,能够更好的帮助我们使用它们。 SpringFramework SpringFramework是一个开源的Java平台,它提供了一种全面的架构和基础设施来支持Java应用程序的开…...
JVM原理(四):JVM垃圾收集算法与分代收集理论
从如何判定消亡的角度出发,垃圾收集算法可以划分为“引用计数式垃圾收集”和“追踪式垃圾收集”两大类。 本文主要介绍的是追踪式垃圾收集。 1. 分代收集理论 当代垃圾收集器大多遵循“分代收集”的理论进行设计,它建立在两个假说之上: 弱分…...
1961 Springboot自习室预约系统idea开发mysql数据库web结构java编程计算机网页源码maven项目
一、源码特点 springboot 自习室预约管理系统是一套完善的信息系统,结合springboot框架和bootstrap完成本系统,对理解JSP java编程开发语言有帮助系统采用springboot框架(MVC模式开发),系统具有完整的源代码和数据库…...
答案版)
前端面试题(12)答案版
1. H5的新特性? 1) 更加语义化的标签,如<header>、<nav>、<article>等,便于网页结构的表达。 2) 新的多媒体标签,如<video>和<audio>,支持本地视频和音频的播放。 3) 本地存储API,如localStorage和sessionStorage,用于在客户端保存数…...

SpringMVC 域对象共享数据
文章目录 1、使用ServletAPI向request域对象共享数据2、使用ModelAndView向request域对象共享数据3、使用Model向request域对象共享数据4、使用map向request域对象共享数据5、使用ModelMap向request域对象共享数据6、Model、ModelMap、Map的关系7、向session域共享数据8、向app…...
每天五分钟深度学习框架pytorch:tensor向量之间常用的运算操作
本文重点 在数学中经常有加减乘除运算,在tensor中也不例外,也有类似的运算,本节课程我们将学习tensor中的运算 常见运算 加法+或者add import torch import numpy as np a=torch.rand(16,3,28,28) b=torch.rand(1,3,28,28) print(a+b) import torch import numpy as np a…...

【数据结构】(C语言):栈
栈: 线性的集合。后进先出(LIFO,last in first out)。两个指针:指向栈顶和栈底。栈顶指向最后进入且第一个出去的元素。栈底指向第一个进入且最后一个出去的元素。两个操作:入栈(往栈尾添加元素…...
c++类成员指针用法
1)C入门级小知识,分享给将要学习或者正在学习C开发的同学。 2)内容属于原创,若转载,请说明出处。 3)提供相关问题有偿答疑和支持。 c中新增类成员指针操作,为了访问方便,他是指…...

[240625] Continue -- 开源 Copilot | Web-Check 网站分析工具 | Story of EOL
目录 Continue -- 开源 CopilotWeb-Check 网站分析工具Web-Check 提供全面的网站分析功能Web-Check 支持多种部署方式:配置选项开发环境Web-Check 使用多种数据源进行分析 Story of EOLASCII 文本中的换行符问题 Continue – 开源 Copilot 让 Continue 和 Ollama 成…...

【Mac】Auto Mouse Click for Mac(高效、稳定的鼠标连点器软件)软件介绍
软件介绍 Auto Mouse Click for Mac 是一款专为 macOS 平台设计的自动鼠标点击软件,它可以帮助用户自动化重复的鼠标点击操作,从而提高工作效率。以下是这款软件的主要特点和功能: 1.自动化点击操作:Auto Mouse Click 允许用户录…...
javaSE知识点整理总结(下)、MySQL数据库
目录 一、异常 1.常见异常类型 2.异常体系结构 3.异常处理 (1)finally (2)throws 二、JDBC 1.JDBC搭建 2.执行SQL语句两种方法 三、MySQL数据库 1.ddl 2.dml 3.dql (1)字符函数 (…...

Perl入门学习
Perl是一种强大的脚本语言,以其灵活性和文本处理能力而闻名,常用于系统管理、Web开发、生物信息学以及数据处理等领域。以下是Perl语言入门学习的一些关键点: ### 1. Perl简介 - **起源与特点**:Perl由Larry Wall在1987年创建&am…...
)
2024年7月计划(ue5肉鸽视频完成)
试过重点放在独立游戏上,有个indienova独立游戏团队是全职的,由于他们干了几个月,节奏暂时跟不上,紧张焦虑了。五一时也有点自暴自弃了,实在没必要,按照自己的节奏走即可。精力和时间也有限,放在…...

恢复策略(上)-撤销事务(UNDO)、重做事务(REDO)
一、引言 利用前面所建立的冗余数据,即日志和数据库备份,要将数据库从一个不一致的错误状态恢复到一个一致性状态,还需要相关的恢复策略,不同DBMS的事务处理机制所采用的缓冲区管理策略可能不同,发生故障后的数据库不…...
【鸿蒙学习笔记】位置设置
官方文档:位置设置 目录标题 align:子元素的对齐方式direction:官方文档没懂,看图理解吧 align:子元素的对齐方式 Stack() {Text(TopStart)}.width(90%).height(50).backgroundColor(0xFFE4C4).align(Alignment.TopS…...

41.HOOK引擎设计原理
上一个内容:41.HOOK引擎设计原理 在一个游戏里通过hook来完成各种各样的功能,比如hook点是a、b、c,然后a点会有它自己所需要的hook逻辑,b、c也是有它们自己的hook逻辑(hook逻辑指的是hook之后要做的事)&am…...

STM32启动流程 和 map文件的作用
一,启动流程 1. 复位/上电 2. 根据 BOOT0/BOOT1 确定程序从哪个存储位置执行 3. 初始化 SP 及 PC 指针 将 0X08000000 位置的栈顶地址存放在 SP 指针中 将 0x08000004 位置存放的向量地址装入 PC 程序计数器 4. 初始化系统时钟 5. 初始化用户堆栈 6. 进入main函数 二…...

深度解析华为仓颉语言
什么是华为仓颉语言? 华为仓颉语言(Huawei Cangjie Language,HCL)是华为公司推出的一种新型编程语言,旨在解决大规模分布式系统开发中的复杂性问题。仓颉语言以高效、简洁和易用为设计目标,特别适用于云计…...
Android简介-历史、API等级与体系结构
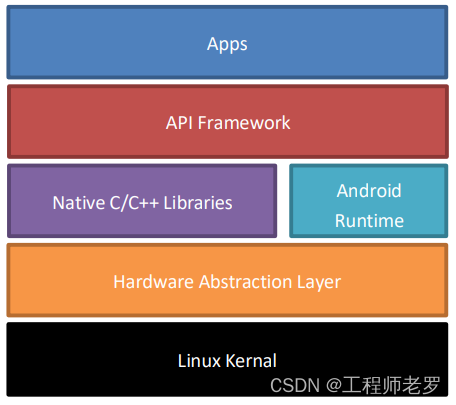
1. Android简介 Android是一种基于Linux内核的自由及开放源代码的操作系统。最初是由安迪鲁宾(Andy Rubin)开发的一款相机操作系统。2005年8月被Google收购。2007年11月,Google与84家硬件制造商、软件开发商及电信营运商组建开放手机联盟共同研发改良Android系统。…...

[特殊字符] 智能合约中的数据是如何在区块链中保持一致的?
🧠 智能合约中的数据是如何在区块链中保持一致的? 为什么所有区块链节点都能得出相同结果?合约调用这么复杂,状态真能保持一致吗?本篇带你从底层视角理解“状态一致性”的真相。 一、智能合约的数据存储在哪里…...

业务系统对接大模型的基础方案:架构设计与关键步骤
业务系统对接大模型:架构设计与关键步骤 在当今数字化转型的浪潮中,大语言模型(LLM)已成为企业提升业务效率和创新能力的关键技术之一。将大模型集成到业务系统中,不仅可以优化用户体验,还能为业务决策提供…...

深入浅出Asp.Net Core MVC应用开发系列-AspNetCore中的日志记录
ASP.NET Core 是一个跨平台的开源框架,用于在 Windows、macOS 或 Linux 上生成基于云的新式 Web 应用。 ASP.NET Core 中的日志记录 .NET 通过 ILogger API 支持高性能结构化日志记录,以帮助监视应用程序行为和诊断问题。 可以通过配置不同的记录提供程…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...

相机Camera日志实例分析之二:相机Camx【专业模式开启直方图拍照】单帧流程日志详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 目录 一、场景操作步骤 二、日志基础关键字分级如下 三、场景日志如下: 一、场景操作步骤 操作步…...

java 实现excel文件转pdf | 无水印 | 无限制
文章目录 目录 文章目录 前言 1.项目远程仓库配置 2.pom文件引入相关依赖 3.代码破解 二、Excel转PDF 1.代码实现 2.Aspose.License.xml 授权文件 总结 前言 java处理excel转pdf一直没找到什么好用的免费jar包工具,自己手写的难度,恐怕高级程序员花费一年的事件,也…...

C++ 基础特性深度解析
目录 引言 一、命名空间(namespace) C 中的命名空间 与 C 语言的对比 二、缺省参数 C 中的缺省参数 与 C 语言的对比 三、引用(reference) C 中的引用 与 C 语言的对比 四、inline(内联函数…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...

Ascend NPU上适配Step-Audio模型
1 概述 1.1 简述 Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤)&#x…...
中关于正整数输入的校验规则)
Element Plus 表单(el-form)中关于正整数输入的校验规则
目录 1 单个正整数输入1.1 模板1.2 校验规则 2 两个正整数输入(联动)2.1 模板2.2 校验规则2.3 CSS 1 单个正整数输入 1.1 模板 <el-formref"formRef":model"formData":rules"formRules"label-width"150px"…...