[机器学习]-3 万字话清从传统神经网络到深度学习
神经网络(Neural Networks, NNs)是机器学习的一种重要方法,灵感来源于生物神经系统,由大量互联的节点(称为神经元或单元)组成,通过调整这些节点间的连接权重来学习和表示复杂的非线性关系。传统神经网络包括感知机、Sigmoid神经元,以及更复杂的多层感知器。深度学习是基于深层次的神经网络,通过多层非线性变换从数据中学习特征和模式,通常由输入层、隐藏层和输出层组成,每一层由若干神经元构成,层与层之间通过权重连接;主流的深度学习有卷积神经网络、循环神经网络、生成对抗网络、Transformer等。
一 基于感知机的传统神经网络
感知机是最简单的也是最早的人工神经网络模型之一,由Frank Rosenblatt在1958年提出,它是一个二分类的线性分类器,可以看作是单层神经网络的基本形式。感知机模型的主要目标是找到一组权重,使得输入数据在这些权重的作用下能够正确分类。
1 模型组成
1)神经元
神经网络的基本构件是神经元。每个神经元接收多个输入信号,进行加权求和,并通过一个激活函数输出结果,即前向传播计算。
数学表达式为: y= f (∑i=1n(wixi+b)),其中xi是输入,wi是权重,b是偏置, f是激活函数,y是输出。
2)激活函数
激活函数用于引入非线性特性,使神经网络能够学习复杂的模式,常用的激活函数有:
- Sigmoid: f(x)=1/{1 + e^{-x}}
- ReLU(Rectified Linear Unit): f(x)=max(0,x)
- Tanh: f(x)=tanh(x)=(ex+e−x)/(ex−e−x)
3)层
神经网络由多个层组成:
- 输入层:输入特征向量 x=[x1,x2,...,xn]
- 权重:与输入特征对应的权重向量 w=[w1,w2,...,wn]
- 偏置:一个常数 b
- 输出层:通过激活函数(通常是符号函数)输出分类结果 y
2 训练过程
1)前向传播
输入数据经过各层网络的处理,最终产生输出。前向传播用于计算网络的预测结果。
2)损失函数
用于衡量预测结果与实际结果之间的差距。常见的损失函数有:
- 均方误差(MSE):用于回归问题。MSE=1/n ∑i=1n(yi−y^i)2
- 交叉熵损失(Cross-Entropy Loss):用于分类问题。 常用二元交叉熵损失函数:L(y,y^)=−(ylog(y^)+(1−y)log(1−y^))
3)反向传播
通过计算损失函数相对于每个权重的梯度,更新网络权重以最小化损失。反向传播步骤:
- 计算梯度:利用链式法则计算损失函数相对于每个权重的梯度。
∂L/∂w =(y^−y)x
∂L/∂b =y^−y
- 更新权重:使用优化算法(如梯度下降)更新权重。
w←w−η(∂L/∂w )
b←b−η(∂L/∂b)
4)优化算法
用于调整网络权重以最小化损失函数。常用的优化算法有:
- 梯度下降:基本的优化算法,通过不断调整权重以最小化损失。
- 随机梯度下降:每次仅使用一个样本计算梯度,适用于大规模数据。
- Adam:结合了动量和自适应学习率,具有更好的收敛性。
二 深度学习
深度学习模型的组成与传统感知机模型类似,每个神经元接收输入信号,通过激活函数进行非线性变换后输出。前向传播就是指从输入层到输出层的计算过程,在每一层输入信号通过权重进行线性变换,然后通过激活函数进行非线性变换。损失函数用于衡量模型预测值与真实值之间的差异,常用的损失函数是均方误差和交叉熵损失函数。反向传播用于计算损失函数相对于每个权重和偏置的梯度,通过优化算法例如梯度下降用于最小化损失函数,从而更新模型参数。
卷积神经网络(CNN)
卷积神经网络是深度学习的一种专门用于处理具有网格拓扑结构(如图像)的数据的神经网络,在计算机视觉和图像处理等领域表现出色,并且广泛应用于诸如图像分类、目标检测和语义分割等任务。
1 网络组成
卷积神经网络由卷积层、池化层和全连接层组成,通过这几种层的组合,CNN能够有效地捕捉图像的空间和局部信息。
1)卷积层
卷积层是CNN的核心组件,用于提取输入数据的局部特征。卷积层通过卷积核(滤波器)在输入数据上滑动,并计算卷积运算的结果,产生特征图。
- 卷积运算:卷积运算是将卷积核与输入数据的每个局部区域进行逐元素相乘并求和,结果作为该区域的特征值。
- 卷积核:卷积核是一个小的权重矩阵,其大小通常远小于输入数据。卷积核的权重是通过训练学习得到的。
- 步幅:步幅决定卷积核在输入数据上滑动的步长。
- 填充:为了保持输出尺寸与输入尺寸一致,可以在输入数据的边缘填充零值。
2)池化层
池化层用于降低特征图的尺寸,从而减少参数数量和计算量,同时保留最重要的特征。池化操作通常有最大池化(Max Pooling)和平均池化(Average Pooling)。
- 最大池化:取池化窗口中的最大值作为特征值。
- 平均池化:取池化窗口中的平均值作为特征值。
3)全连接层
全连接层将前一层输出的特征图展平成一维向量,并与权重矩阵相乘,再加上偏置,最后通过激活函数进行非线性变换。全连接层用于综合高层次特征,并进行分类或回归任务。
2 典型结构示例
1)输入层:输入图像,例如28x28x1的灰度图像。
2)卷积层1:使用32个3x3的卷积核,步幅为1,填充方式为"SAME",输出尺寸为28x28x32。
3)池化层1:使用2x2的最大池化窗口,步幅为2,输出尺寸为14x14x32。
4)卷积层2:使用64个3x3的卷积核,步幅为1,填充方式为"SAME",输出尺寸为14x14x64。
5)池化层2:使用2x2的最大池化窗口,步幅为2,输出尺寸为7x7x64。
6)展平层:将特征图展平成一维向量,尺寸为7x7x64=3136。
7)全连接层1:具有128个神经元,激活函数为ReLU。
8)全连接层2:具有10个神经元,激活函数为Softmax,用于10类分类任务。
3 工作机制
卷积神经网络通过前向传播和反向传播来进行训练和预测。
1)前向传播
前向传播是指将输入数据依次通过卷积层、池化层和全连接层,最终得到输出结果。
2)反向传播
反向传播用于训练CNN模型,通过计算损失函数的梯度并更新权重和偏置,以最小化损失函数。反向传播包括以下步骤:
- 计算损失函数:根据预测值和真实值计算损失,例如交叉熵损失或均方误差。
- 梯度计算:使用链式法则计算损失函数对每层参数的梯度。
- 参数更新:使用梯度下降或其变种(如Adam优化算法)更新每层的权重和偏置。
4 典型应用
卷积神经网络在许多领域有广泛的应用,以下是几个主要的应用场景:
图像分类:CNN在图像分类任务中表现出色,例如在著名的ImageNet竞赛中,许多顶级模型都是基于CNN的。通过学习图像的局部特征和全局模式,CNN能够高效地进行图像分类。
目标检测:识别图像中的多个对象并确定它们的位置,Faster R-CNN、YOLO和SSD等基于CNN的模型在目标检测领域取得了显著成果。
语义分割:需要将图像中的每个像素分配给一个类别。U-Net和SegNet等基于CNN的模型在医学图像分割和自动驾驶等领域得到广泛应用。
5 实现示例
以下是一个使用Python和Keras框架实现的简单卷积神经网络,用于MNIST手写数字分类任务:
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
from tensorflow.keras.utils import to_categorical
# 加载MNIST数据集
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 预处理数据
X_train = X_train.reshape(-1, 28, 28, 1).astype('float32') / 255.0
X_test = X_test.reshape(-1, 28, 28, 1).astype('float32') / 255.0
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
# 构建卷积神经网络模型
model = Sequential([
Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1)),
MaxPooling2D(pool_size=(2, 2)),
Conv2D(64, kernel_size=(3, 3), activation='relu'),
MaxPooling2D(pool_size=(2, 2)),
Flatten(),
Dense(128, activation='relu'),
Dense(10, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, batch_size=128, epochs=10, validation_split=0.2)
# 评估模型
loss, accuracy = model.evaluate(X_test, y_test)
print(f'Test accuracy: {accuracy}')
循环神经网络(RNN)
循环神经网络是一种用于处理序列数据的神经网络,具有时间记忆能力能够捕捉输入数据中的时序信息,在自然语言处理、语音识别和时间序列预测等领域有广泛的应用。常见变种包括长短期记忆(LSTM)和门控循环单元(GRU)。
1 网络组成
RNN的核心思想是利用隐藏状态来存储和传递序列信息,与其它神经网络不同的是它在每个时间步都会将前一个时间步的隐藏状态作为当前时间步的输入之一,从而在序列中传递信息。RNN由输入层、隐藏层和输出层组成:
1)输入层:接收当前时间步的输入向量 xt。
2)隐藏层:计算当前时间步的隐藏状态ht,隐藏状态由当前输入向量 xt和前一时间步的隐藏状态 h{t-1} 共同决定。
ht=σ(Whxt+Uh h{t-1} +bh)
3)输出层:计算当前时间步的输出向量 yt。
yt=σ(Wyht+by)
其中Wh、Uh、Wy、bh和by是网络的权重和偏置参数,σ是激活函数。
2 RNN的变种
虽然RNN能够捕捉序列中的时序信息,但它在处理长序列时会遇到梯度消失和梯度爆炸问题。为了解决这些问题,出现了多种RNN的变种,包括长短期记忆网络(LSTM)和门控循环单元(GRU)。
1)长短期记忆网络
LSTM通过引入门控机制来控制信息的流动,从而有效地缓解了梯度消失问题。LSTM包括三个门:输入门、遗忘门和输出门,用于控制信息的存储、更新和输出。
- 遗忘门:控制前一时间步的记忆细胞 c{t-1} 是否保留。
ft=σ(Wf xt+Uf h{t-1} +bf)
- 输入门:控制当前输入 xt是否写入记忆细胞。
it=σ(Wi xt+Ui h{t-1} +bi)
c~t = tanh (Wc xt+Uc h{t-1} +bc)
- 输出门:控制记忆细胞 ct是否输出到隐藏状态ht。
ot =σ(Wo xt+Uo h{t-1} +bo)
ct =ft ⊙ct−1+it ⊙c~t
ht =ot ⊙tanh(ct )
2)门控循环单元(GRU)
GRU是LSTM的简化版,通过合并输入门和遗忘门来减少参数数量,从而提高计算效率。GRU包括两个门:更新门和重置门。
- 更新门:控制隐藏状态ht的更新。
zt =σ(Wz xt+Uzh{t-1} +bz)
- 重置门:控制前一时间步的隐藏状态h{t-1} 是否重置。
rt =σ(Wr xt+Ur h{t-1} +br)
h~t =tanh(Wh xt+Uh (rt ⊙h{t-1} )+bh)
ht =(1−zt )⊙h{t-1} +zt⊙h~t
3 工作机制
RNN通过前向传播和反向传播进行训练和预测。
1)前向传播
前向传播是指将输入序列依次通过RNN的每个时间步,最终得到输出序列。
1.1)初始化隐藏状态:将隐藏状态h0初始化为零或随机值。
1.2)计算隐藏状态和输出:从时间步1到T,依次计算每个时间步的隐藏状态ht和输出 yt。
1.3)保存隐藏状态和输出:将每个时间步的隐藏状态和输出保存下来,用于后续的反向传播。
2)反向传播
反向传播用于计算损失函数的梯度,并更新RNN的参数。由于RNN具有时间步的依赖性,反向传播需要通过时间展开(Unrolling)来计算每个时间步的梯度。
2.1)计算损失函数:根据预测值和真实值计算损失,例如交叉熵损失或均方误差。
2.2)时间展开:将RNN在时间步上的计算展开为一个展开图。
2.3)计算梯度:使用链式法则计算损失函数对每层参数的梯度。
2.4)参数更新:使用梯度下降或其变种(如Adam优化算法)更新每层的权重和偏置。
4 典型应用
RNN在许多领域有广泛的应用,以下是几个主要的应用场景:
自然语言处理(NLP)
- 语言模型:预测句子中下一个词语的概率。
- 机器翻译:将输入语言序列翻译为目标语言序列。
- 文本生成:根据给定的起始文本生成自然语言文本。
语音识别:RNN在语音识别任务中用于将语音信号转换为文本,能够捕捉语音信号中的时序信息,从而提高识别准确率。
时间序列预测:RNN在时间序列预测任务中用于预测未来的数据点,例如使用RNN预测股票价格、天气变化和经济指标等。
5 实现示例
以下是一个使用Python和Keras框架实现的简单RNN,用于文本生成任务:
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import SimpleRNN, Dense
from tensorflow.keras.utils import to_categorical
# 生成示例数据
data = "hello world"
chars = sorted(list(set(data)))
char_to_index = {char: index for index, char in enumerate(chars)}
index_to_char = {index: char for index, char in enumerate(chars)}
X = []
y = []
for i in range(len(data) - 1):
X.append(char_to_index[data[i]])
y.append(char_to_index[data[i + 1]])
X = np.array(X).reshape(-1, 1, 1)
y = to_categorical(y, num_classes=len(chars))
# 构建RNN模型
model = Sequential([
SimpleRNN(50, input_shape=(1, 1), return_sequences=True),
SimpleRNN(50),
Dense(len(chars), activation='softmax')
])
# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(X, y, epochs=100, verbose=2)
# 文本生成函数
def generate_text(model, start_char, num_chars):
generated = start_char
for _ in range(num_chars):
x = np.array([char_to_index[generated[-1]]]).reshape(-1, 1, 1)
pred = model.predict(x, verbose=0)
next_char = index_to_char[np.argmax(pred)]
generated += next_char
return generated
# 生成文本
print(generate_text(model, 'h', 10))
生成对抗网络(GAN)
GAN由Ian Goodfellow等人在2014年提出的深度学习模型,由生成器和判别器两个网络组成,通过博弈过程生成与真实数据分布相似的新数据。GANs在图像生成、视频生成、文本生成等领域有广泛的应用。
1 网络组成
GANs由两个神经网络组成:生成器(Generator)和判别器(Discriminator),生成器试图生成逼真的数据,而判别器则尝试区分生成的数据和真实数据。两个网络通过一个零和博弈相互对抗,最终生成器能够生成与真实数据难以区分的数据。
1)生成器
生成器接受一个随机噪声向量作为输入,通过一系列非线性变换,输出一个与真实数据分布相似的样本。生成器的目标是最大化判别器对生成样本的误判率。
生成器的目标函数:minGV(G,D)=Ez∼pz(z) [log(1−D(G(z)))]
2)判别器
判别器接受一个样本作为输入,输出一个表示样本为真实数据的概率。判别器的目标是最大化对真实数据的正确分类率,同时最小化对生成数据的误分类率。
判别器的目标函数:maxDV(G,D)=Ex∼pdata(x) [logD(x)] + Ez∼pz(z) [log(1−D(G(z)))]
3)GAN的总体目标函数
GAN的总体目标是找到生成器和判别器的纳什均衡点,使得生成器生成的样本与真实数据难以区分。
总体目标函数:minG maxDV(G,D)=Ex∼pdata(x) [logD(x)]+Ez∼pz(z) [log(1−D(G(z)))]
2 典型网络
GAN的基本结构包括生成器和判别器两个部分。生成器通常是一个深度神经网络,接受随机噪声作为输入,生成与真实数据分布相似的样本。判别器也是一个深度神经网络,接受样本作为输入,输出样本为真实数据的概率。
1)生成器的结构
生成器的输入是一个低维的随机噪声向量,通过一系列的全连接层、卷积层或反卷积层,生成高维的样本。例如,生成图像的生成器通常包括反卷积层和批量归一化层。
2)判别器的结构
判别器的输入是一个样本,通过一系列的卷积层、全连接层和激活函数,输出样本为真实数据的概率。判别器通常使用卷积层和最大池化层来提取特征。
3 训练过程
GAN的训练过程是生成器和判别器交替优化的过程。具体步骤如下:
1)初始化生成器和判别器的参数。
2)训练判别器:
- 从真实数据分布中采样一个真实样本。
- 从随机噪声分布中采样一个噪声向量,通过生成器生成一个样本。
- 计算判别器对真实样本和生成样本的分类损失,并更新判别器的参数。
3)训练生成器:
- 从随机噪声分布中采样一个噪声向量,通过生成器生成一个样本。
- 计算判别器对生成样本的分类损失,并更新生成器的参数。
4)重复步骤2和步骤3,直到模型收敛。
4 典型应用
GANs在许多领域都有广泛的应用,包括但不限于以下几个方面:
图像生成:GANs在图像生成方面取得了显著的成功。通过训练GANs,可以生成高质量的图像,如人脸生成、风格迁移(如CycleGAN)、超分辨率图像生成等。
图像修复:GANs可以用于图像修复任务,如去噪、补全缺失部分等。例如使用GANs可以将有缺陷的图像修复为完整的图像。
图像超分辨率:使用GANs可以将低分辨率图像放大为高分辨率图像,同时保持细节和清晰度。例如SRGAN是一种用于超分辨率图像生成的GAN模型。
生成文本:GANs也可以用于文本生成任务,如生成与真实文本相似的句子、段落等。例如TextGAN是一种用于文本生成的GAN模型。
生成视频:GANs可以用于生成连续的视频帧,从而生成与真实视频相似的视频内容。例如MoCoGAN是一种用于生成视频的GAN模型。
5 实现示例
以下是一个使用Python和Keras框架实现的简单GAN,用于生成手写数字图像(MNIST数据集)
import numpy as np
from tensorflow.keras.layers import Input, Dense, Reshape, Flatten, Dropout
from tensorflow.keras.layers import BatchNormalization, Activation, LeakyReLU
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.datasets import mnist
# 定义生成器模型
def build_generator():
model = Sequential()
model.add(Dense(256, input_dim=100))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(1024))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(28 * 28 * 1, activation='tanh'))
model.add(Reshape((28, 28, 1)))
return model
# 定义判别器模型
def build_discriminator():
model = Sequential()
model.add(Flatten(input_shape=(28, 28, 1)))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(256))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(1, activation='sigmoid'))
return model
# 构建并编译GAN模型
optimizer = Adam(0.0002, 0.5)
discriminator = build_discriminator()
discriminator.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy'])
generator = build_generator()
z = Input(shape=(100,))
img = generator(z)
discriminator.trainable = False
valid = discriminator(img)
combined = Model(z, valid)
combined.compile(loss='binary_crossentropy', optimizer=optimizer)
# 训练GAN模型
(X_train, _), (_, _) = mnist.load_data()
X_train = X_train / 127.5 - 1.0
X_train = np.expand_dims(X_train, axis=3)
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs = X_train[idx]
noise = np.random.normal(0, 1, (batch_size, 100))
gen_imgs = generator.predict(noise)
d_loss_real = discriminator.train_on_batch(imgs, valid)
d_loss_fake = discriminator.train_on_batch(gen_imgs, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
noise = np.random.normal(0, 1, (batch_size, 100))
g_loss = combined.train_on_batch(noise, valid)
if epoch % 100 == 0:
print(f"{epoch} [D loss: {d_loss[0]}] [D accuracy: {d_loss[1]}] [G loss: {g_loss}]")
Transformer
Transformer模型基于自注意力机制,其主要组件包括多头自注意力机制和前馈神经网络,广泛应用于自然语言处理任务。由于Transformer目前在AI领域的重要地位,后面将单独成文进行全面介绍。
相关文章:

[机器学习]-3 万字话清从传统神经网络到深度学习
神经网络(Neural Networks, NNs)是机器学习的一种重要方法,灵感来源于生物神经系统,由大量互联的节点(称为神经元或单元)组成,通过调整这些节点间的连接权重来学习和表示复杂的非线性关系。传统…...

网络安全等级保护2.0(等保2.0)全面解析
一、等保2.0的定义和背景 网络安全等级保护2.0(简称“等保2.0”)是我国网络安全领域的基本制度、基本策略、基本方法。它是在《中华人民共和国网络安全法》指导下,对我国网络安全等级保护制度进行的重大升级。等保2.0的发布与实施,…...
用Lobe Chat部署本地化, 搭建AI聊天机器人
Lobe Chat可以关联多个模型,可以调用外部OpenAI, gemini,通义千问等, 也可以关联内部本地大模型Ollama, 可以当作聊天对话框消息框来集成使用 安装方法参考: https://github.com/lobehub/lobe-chat https://lobehub.com/zh/docs/self-hosting/platform/…...
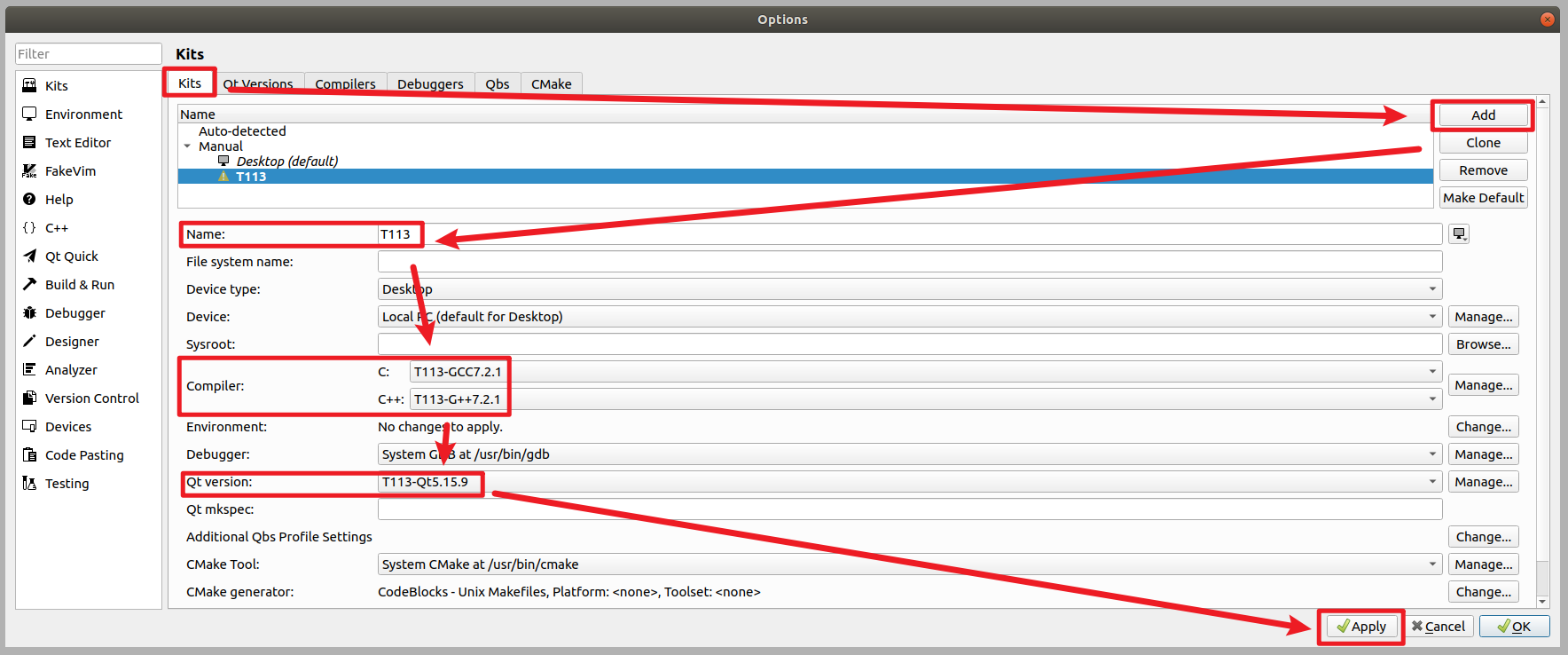
基于ARM的通用的Qt移植思路
文章目录 实验环境介绍一、确认Qt版本二、确认交叉编译工具链三、配置Qt3.1、修改qmake.conf3.2、创建autoConfig.sh配置文件 四、编译安装Qt五、移植Qt安装目录六、配置Qt creator6.1、配置qmake6.2、配置GCC编译器6.3、配置G编译器6.4、配置编译器套件6.5、创建应用 七、总结…...

IT专业入门,高考假期预习指南
七月来临,各省高考分数已揭榜完成。而高考的完结并不意味着学习的结束,而是新旅程的开始。对于有志于踏入IT领域的高考少年们,这个假期是开启探索IT世界的绝佳时机。 一、基础课程预习指南 IT专业是一个广泛的领域,涵盖了从软件开…...

芯片详解——AD7606C
芯片详解——AD7606C AD7607C 是一款由 Analog Devices(模拟器件公司)生产的 6 通道同步采样模数转换器(ADC),适用于高速数据采集系统。 工作原理 AD7607C 的工作原理主要包括以下几个步骤: 模拟信号输入:AD7607C 有六个模拟输入通道,可以同时进行采样。这些模拟信号…...
IDEA 编译单个Java文件
文章目录 一、class文件的生成位置二、编译单个文件编译项目报错Error:java: 无效的源发行版: 8 一、class文件的生成位置 file->project structure->Modules 二、编译单个文件 选中文件,点击recompile 编译项目报错 Error:java: 无效的源发行版: 8 Fi…...

人工智能业务分析
人工智能业务分析的组成图 #mermaid-svg-SKV0WrbMSANzQz4U {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-SKV0WrbMSANzQz4U .error-icon{fill:#552222;}#mermaid-svg-SKV0WrbMSANzQz4U .error-text{fill:#552222;s…...

随机文本生成器
目录 开头程序程序的流程图程序打印的效果(不必细看,因为字符太多)例1例2例3 结尾 开头 大家好,我叫这是我58。看!这下面有一个程序。 程序 #define _CRT_SECURE_NO_WARNINGS 1 #include <stdio.h> #include <random> #includ…...

java中输入输出流的继承关系
在 Java 中,输入输出流的继承关系主要围绕两个抽象基类展开:字节流基类 InputStream 和 OutputStream,以及字符流基类 Reader 和 Writer。这些类形成了 Java I/O 系统的基础,提供了丰富的子类以适应不同的输入输出需求。 字节流 字节流用于处理原始的二进制数据。 Input…...

c++应用网络编程之一基本介绍
一、网络编程介绍 c编程的应用场景在前面分析过,一个重要的方向就是网络编程。一般来说,开发者说的服务端编程在c方向上简单的可以认为是网络编程。首先需要说明的,本系列不对网络编程的相关基础知识展开详细的说明,因为这种知识…...

Web后端开发概述环境搭建项目创建servlet生命周期
Web开发概述 web开发指的就是网页向后再让发送请求,与后端程序进行交互 web后端(javaEE)程序需要运行在服务器中 这样前端才可以对其进行进行访问 什么是服务器? 解释1: 服务器就是一款软件,可以向其发送请求,服务器会做出一个响应.可以在服务器中部署文件,让…...

Java 位运算详解
位运算是一种直接在二进制位上进行操作的方式。位运算符包括按位与 (&)、按位或 (|)、按位异或 (^)、按位非 (~)、左移 (<<)、右移 (>>) 和无符号右移 (>>>)。这些操作符用于操作整型数据类型,如 int 和 long。 一、按位与 (&) 按位…...

智能体实战:开发一个集成国内AI平台的GPTs,自媒体高效智能助手
文章目录 一,什么是GPTs二,开发GPTs1,目标2,开发2.1 打开 GPTS:https://chat.openai.com/gpts2.2 点击 Create 创建一个自己的智能体 2.3 配置GPTs2.4 配置外挂工具2.4.1 配置Authentication-授权2.4.1.1 生成语聚AI的…...

完美世界|单机版合集(共22个版本)
前言 我是研究单机的老罗,今天给大家带来的是完美世界的单机版合集,一共22个版本。本人亲自测试了一个版本,运行视频如下: 完美世界|单机版合集 先看所有的版本的文件,文件比较大,准备好空间,差…...

Jenkins的一些记录
设置环境变量 在 Jenkins 流水线中,取决于使用的是声明式还是脚本式流水线,设置环境变量的方法不同。 声明式流水线支持 environment 指令,而脚本式流水线的使用者必须使用 withEnv 步骤。 pipeline {agent anyenvironment { CC clang}stag…...

讲讲js中的prototype和__proto__
在Javascript中,prototype和__proto__是两个重要的概念,在对象的原型链中扮演重要的角色。 prototype prototype是js函数的内置属性,每个函数都有一个prototype属性,它是一个指针,指向一个对象(原型对象&a…...
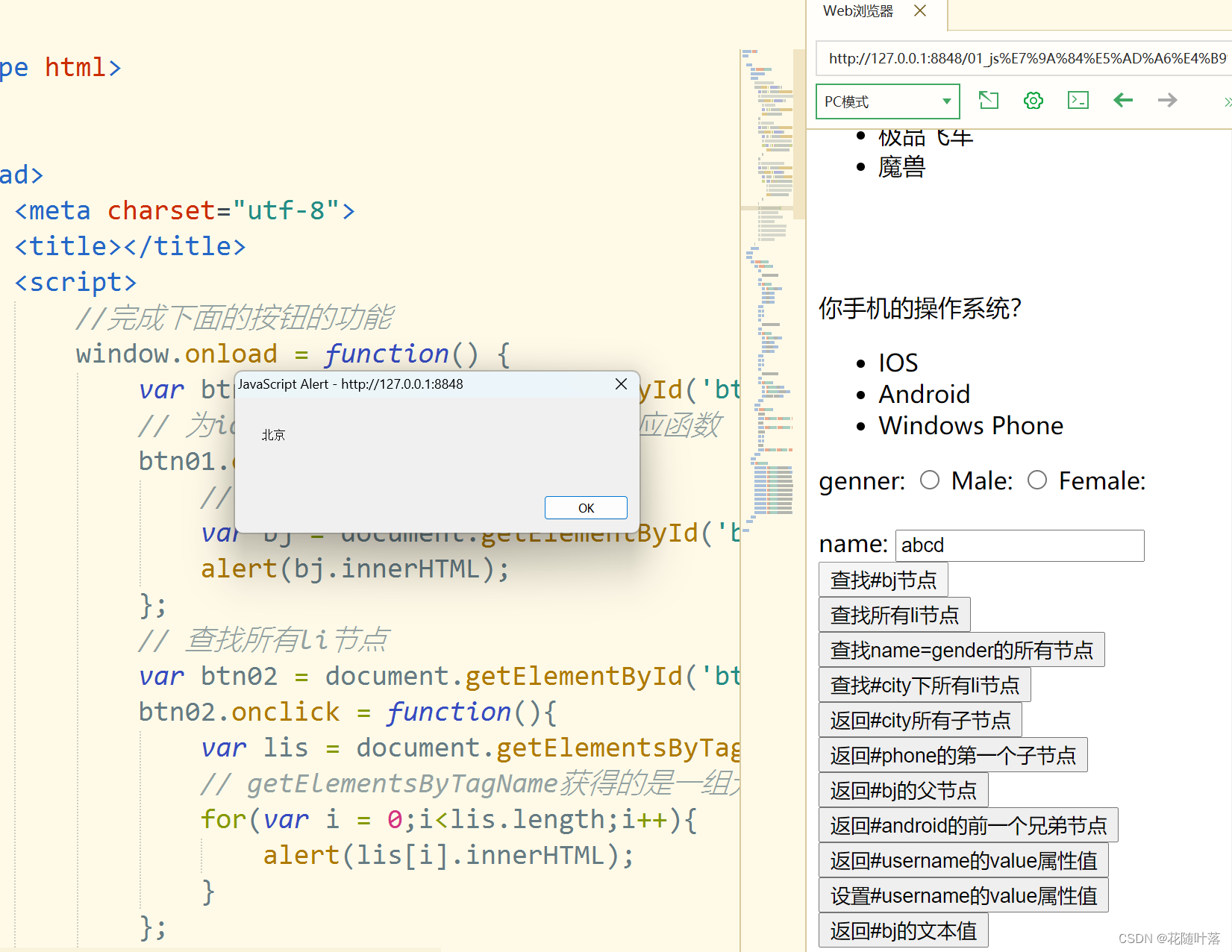
JavaScript的学习之DOM的查询(一)
一、获得元素 通过document对象调用: getElementById():通过id属性获取一个元素节点对象getElementsByTagName():通过标签名获取一组元素节点对象getElementsByName():通过name属性来获取一组元素节点对象 核心学习代码 <scrip…...
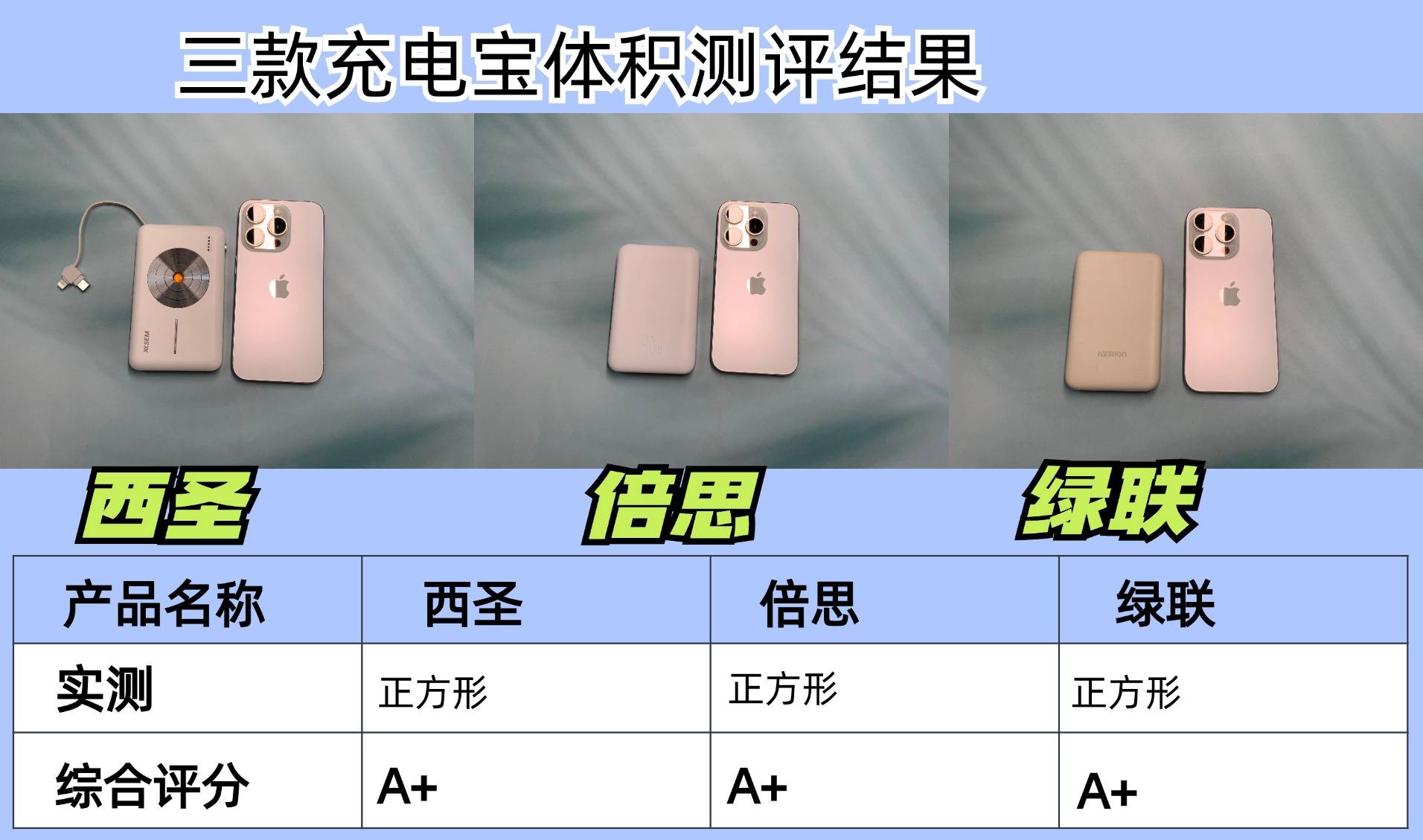
充电宝哪个品牌比较好一点?多维度实测西圣、绿联、倍思充电宝!
在这个快节奏的时代,智能手机已成为我们日常生活不可或缺的一部分,而充电宝作为其能量补给站,重要性不言而喻。面对市场上琳琅满目的充电宝品牌与型号,如何挑选一款既实用又高效的充电伴侣,成为了许多消费者的难题。今…...

ubuntu安装QT
以QT5.15.14为例 下载地址:Index of /archive/qt 安装步骤: 解压qt-everywhere-src-5.15.14运行: cd qt-everywhere-src-5.15.14 mkdir build cd build ../configure -prefix /opt/qt5.15.14 -opensource -confirm-license make -j16 sudo…...

synchronized 学习
学习源: https://www.bilibili.com/video/BV1aJ411V763?spm_id_from333.788.videopod.episodes&vd_source32e1c41a9370911ab06d12fbc36c4ebc 1.应用场景 不超卖,也要考虑性能问题(场景) 2.常见面试问题: sync出…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

ES6从入门到精通:前言
ES6简介 ES6(ECMAScript 2015)是JavaScript语言的重大更新,引入了许多新特性,包括语法糖、新数据类型、模块化支持等,显著提升了开发效率和代码可维护性。 核心知识点概览 变量声明 let 和 const 取代 var…...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...

【git】把本地更改提交远程新分支feature_g
创建并切换新分支 git checkout -b feature_g 添加并提交更改 git add . git commit -m “实现图片上传功能” 推送到远程 git push -u origin feature_g...

unix/linux,sudo,其发展历程详细时间线、由来、历史背景
sudo 的诞生和演化,本身就是一部 Unix/Linux 系统管理哲学变迁的微缩史。来,让我们拨开时间的迷雾,一同探寻 sudo 那波澜壮阔(也颇为实用主义)的发展历程。 历史背景:su的时代与困境 ( 20 世纪 70 年代 - 80 年代初) 在 sudo 出现之前,Unix 系统管理员和需要特权操作的…...

Java毕业设计:WML信息查询与后端信息发布系统开发
JAVAWML信息查询与后端信息发布系统实现 一、系统概述 本系统基于Java和WML(无线标记语言)技术开发,实现了移动设备上的信息查询与后端信息发布功能。系统采用B/S架构,服务器端使用Java Servlet处理请求,数据库采用MySQL存储信息࿰…...
免费数学几何作图web平台
光锐软件免费数学工具,maths,数学制图,数学作图,几何作图,几何,AR开发,AR教育,增强现实,软件公司,XR,MR,VR,虚拟仿真,虚拟现实,混合现实,教育科技产品,职业模拟培训,高保真VR场景,结构互动课件,元宇宙http://xaglare.c…...

提升移动端网页调试效率:WebDebugX 与常见工具组合实践
在日常移动端开发中,网页调试始终是一个高频但又极具挑战的环节。尤其在面对 iOS 与 Android 的混合技术栈、各种设备差异化行为时,开发者迫切需要一套高效、可靠且跨平台的调试方案。过去,我们或多或少使用过 Chrome DevTools、Remote Debug…...
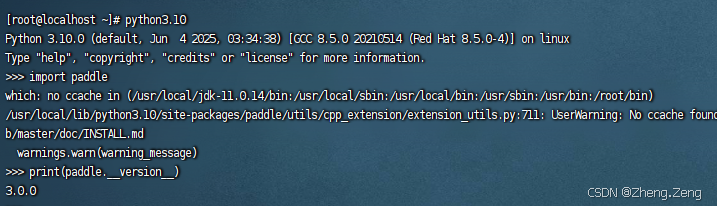
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10+pip3.10)
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10pip3.10) 一:前言二:安装编译依赖二:安装Python3.10三:安装PIP3.10四:安装Paddlepaddle基础框架4.1…...